UNIVERSIDAD
AUTONOMA CHAPINGO
DEPARTAMENTO DE ZNGENZEMA AGROZNDUSTRIAL Tesis donada a la UAM por la
JURADO
EXAMINADOR
ESTA TESIS FUE REALIZADA BAJO LA DlRECClON Y ASESORIA DEL M.C. PEDRO PONCE HERNANDEZ Y HA SIDO REVISADA Y APROBADA POR EL JURADO EXAMINADOR COMO REQUISITO PARCIAL PARA OBTENER EL TITULO DE:
INGENIERO AGROINDUSTRIAL
I
PRESIDENTE:
SECRETARIO:
VOCAL:
SUPLENTE:
SUPLENTE:
JURADO EXAMINADOR:
/1
\
-
M.C. SA- E GUADARRAMA
AGRADECIMIENTO
AI C. M.C. Pedro Pon- Hernandez por su orientación y dirección del presente trabajo.
A los CC. M.C. Salvador Valle Guadarrama. Dr. Arturo Hernández Montes, Dr. Joel E. Corrales Garcia e Ing. Marco V. Bañuelos Gudiño por su gran ayuda en la revisión de este trabajo.
AI C. Abogado José Carlos Guerra Aguilera y Lic. Santiago López Acosta por su apoyo y compresión para la elaboración del presente trabajo.
DEDICATORIA
A mi Alma Mater
que me dio la oportunidad y me formó profesionalmente.
A mi padre y hermanos, en especial a Ma. Elena, como prueba de gratitud por todos sus sacrificios.
A mi esposa Silvia y mis hijos Mayra Cristina, Jorge Luis y Jazmín Cintya por la paciencia que mostraron ante la falta de atención y el tiempo no dedicado a su compailia. Tesis donada a la UAM por la
TABLA DE CONTENIDO
Lista de cuadros Lista de gráficas Clave de símbolos Clave de abreviaturas Resumen
Introducción
Revisión de literatura
Regresión lineal simple
El modelo de regresión lineal Simple
Suposiciones del modelo de regresión lineal simple
Estimación de la recta de regresión por mínimos cuadrados
Interpretación de la ecuación de regresión estimada Análisis de varianza de la regresión
Interpretación de las inferencias sobre
pi
Análisis del error puro y falta de ajusteComparación de las medias de dos poblaciones usando técnicas paramétricas y muestras apareadas
Medidas de asociación entre dos variables o características de una población
Materiales y métodos
Análisis de regresión lineal simple entre la edad promedio del electorado y la proporción de la votación de cada partido político en la elección de presidente de la República
Partido Acción Nacional (PAN)
Partido Revolucionario lnstitucional (PRI) Partido Popular Sosialista (PPS)
Partido de la Revolución Democrática (PRD)
PAGINA
7
8
9
1 1
13
15
19
19
20
21
23
24
24
26
27
29
31
33
33
3540
44
47
Partido del Frente Cardenista de Reconstrucción Nacional (PFCRN)
Partido Auténtico de la Revolución Mexicana (PARM) Partido Demócrata Mexicano (PDM)
Partido del Trabajo (PT)
Partido Verde Ecologista de México (PVEM)
Análisis de regresión lineal simple entre la edad promedio del electorado y la proporción del abstencionismo
Análisis de regresión lineal simple entre la proporción de electores del sexo femenino y la proporción de la votación
obtenida por el Partido del Trabajo en la elección de presidente de la República
Comparación de las medias de la votación obtenida por el Partido del Trabajo en las elecciones de presidente de la República, diputados de mayoría relativa y senadores
Comparación de la media de la votación en la elección de presidente de la República y diputados de mayoría relativa
Comparación de la media de la votación en la elección de senadores y diputados de mayoría relativa
Prueba de correlación entre la edad promedio y la proporción de electores del sexo femenino
Resultados y discusión
De los análisis de regresión De la comparación de las medias
De la prueba de correlación entre la edad promedio y la proporción de electores del sexo femenino
Concluciones Literatura citada
,
Apéndice 106
53
56 61 67 70 7782
86
89
91
93
95
95
99
101103
105CUADRO PAGINA 1 2 3 4 5 6 7 8 9 10 11 12
Tabla del análisis de varianza para el modelo Yi =
00
+
pixi
+
ci.
Ho: = O en oposición a Ha:bi f OTabla del análisis de varianza para el modelo Y~0.691 93
-
0.011 gqXi.Ho:01
= O en oposición a Ha:p1# O
Tabla del análisis de varianza para el modelo Y~0.364 29
+ 0.006 4oxi, Ho:
Tabla del análisis de varianza para el modelo Yi=O.O19 27
-
o.ooo
3 4 ~ ~ . Ho:PI
= O en oposición a Ha:p1 f OTabla del análisis de varianza para el modelo Yi=-0.218 69
+
0.008lexi.
Ho:PI
= O en oposición a Ha:Bi f OTabla del análisis de varianza para el modelo Yi=O.l12 63
-
0.002
42xi.Ho:
pi
= O en oposición a Ha:Pi # OTabla del análisis de varianza para el modelo Y¡=-0.015 08
+
0.000
54x1. Ho:pi
= O en oposición a Ha:bi f OTabla del análisis de varianza para el modelo Yi=0.029 07
-
0.000
51Xi. Ho:01
= O en oposición a Ha:81 # OTabla del análisis de varianza para el modelo Yi=-O.O06 66
+
0.000
51xi. Ho:0,
= O en oposición a Ha:pi Z OTabla del análisis de varianza para el modelo Yi=O.O19 18
-
o.000
%xi.
Ho:01
= O en oposición a Ha:pi Z OResultados obtenidos en las pruebas de hipótesis de los análisis de regresión lineal simple
Resultados de las pruebas de hipótesis en la comparación de las medias de dos pares de poblaciones
= O en oposición a Ha:
01
Z OLISTA DE GRAFICAS
GRAFICAS PAGINA
1 2 3 4
5
6 7 8 9 10 11 12Diagrama de dispersión de la proporción de la votación del PAN
Diagrama de dispersión de la proporción de la votación del PRI
Diagrama de dispersión de la proporción de la votación del PPS
Diagrama de dispersión de la proporción de
la
votación del PRDDiagrama de dispersión de la proporción de la votación del PFCRN
Diagrama de dispersión de la proporción de la votación del PARM
Diagrama de dispersión de la proporción de la votación del PDM
Diagrama de dispersión de la proporción de la votación del PT
Diagrama de dispersión de la proporción de la votación del PVEM
Diagrama de dispersión de la proporción del abstencionismo según la edad del electorado
Diagrama de dispersión de la proporción de la votación del PT en función de la proporción de electores del sexo femenino
Diagrama de dispersión de la prueba de correlación edad vs sexo
39
43
48 5257
62 66 71 76 81 871 02
SIMBOLO
Ho
Ha B OPI
P OB l
Yi Xi Yi ,. A,.
Ei # Yo YlXi A
2
o2
i
¡=I- Y X t - Se2 Fo 1
-
-
r
FCO aCLAVE
DE
SIMBOLOS
SIGNIFICADO Hipótesis nula Hipótesis alternativa
Ordenada al origen de la recta Pendiente de la recta
Ordenada al origen de la recta estimada Pendiente de la recta estimada
Valor de la variable Y en la i-ésima casilla Valor de la variable X en la i-ésima casilla
Valor estimado de la variable Y en la i-ésima casilla Variable aleatoria no observable
Diferente
Variable Y estimada Varianza de Y dado X, Varianza de la variable Y
Sumatoria desde i=l hasta n
Media estimada de la variable Y
Media estimada de la variable X
Variable de la distribución t de Student o número de valores diferentes de la variable independiente
Varianza estimada de la variable
Y
Estadístico de prueba usando la distribución F Mayor o igual que
Menor o igual que
Valor de la distribución F con m grados de libertad en el numerador, n en el denominador y un nivel de significancia a
SIGNIFICADO
Valor de la variable aleatoria D en el i-ésimo par de datos Media de la variable
D
Varianza de la variable D Mayor que
Menor que
Normal con media
Media estimada de la variable D Varianza estimada de la variable D
Se distribuye
Estadístico de prueba usando la distribución t de Student Desviación estándar estimada de la variable D
Valor de la diferencia entre las medias de dos poblaciones
Valor de la distribución t, con un nivel de significancia a y n-I grados de libertad
Valor de la distribución normal estándar
Valor de la variable Y para el partido j-ésimo en la i-ésima casilla Votación obtenida por el j-ésimo partido político en la i-ésima casilla Votación válida en la i-ésima casilla
Número de unidades experimentales o número de datos
Estimador insesgado de la varianza poblacional en el nivel i-ésimo de la variable X
Número de datos de la variable Y en el nivel i-ésimo de la variable X Diferentes valores de la variable Y en el i-ésimo nivel
Suma de los valores de Y para el nivel i-ésimo de X Media de los valores de Y para el nivel i-ésimo de X
Estimador ponderado (insesgado) de O', independientemente del
modelo pylx Función de X Media de Y dado X
y varianza
02
. - ..,.. ~
ABREVIATURA PAN PRI PPS PRD PFCRN PARM PDM PT PVEM EXP Prod XX
Prod XY Prod W
SPXX SPXY SPW S.C. Error S.C. Total S.C. Regresión S.C.E.P. S.C.F.A. C.M.E.P. C.M.F.A. INDEP. Dep. Prop./Proporc.
CLAVE DE ABREVIATURAS
SIGNIFICADO
Partido Acción Nacional
Partido Revolucionario Istitucional Partido Popular Socialista
Partido de la Revolución Democrática
Partido del Frente Cardenista de Reconstrucción Nacional Partido Auténtico de la Revolución Mexicana
Partido Demócrata Mexicano Partido del Trabajo
Pantido Verde Ecologista de México Exponencial
Productos X, X Productos X, Y Productos Y, Y
Sumatoria de productos X, X Sumatoria de productos X, Y Sumatoria de productos Y, Y Suma de Cuadrados del Error Suma de Cuadrados Total
Suma de Cuadrados de Regresión Suma de Cuadrados de Error Puro Suma de cuadrados de Falta de Ajuste Cuadrado Medio de Error Puro
Cuadrado Medio de Falta de Ajuste Independiente
Dependiente Proporción
ABREVIATURA Vot. Abstenc. Elec. Sew. L.N. Ubic. Masc. Fem./Femen. Presid. Diput. Senad. NReg SIGNIFICADO Votación Abstencionismo Electores Sección Lista Nominal Ubicación Masculino Femenino Presidente Diputados Senadores
ANALISIS OF ELECTORAL RESULTS IN THE DISTRICT Xlll OF THE IFE IN GUANAJUATO
I
SUMMARY
In the present job we have done a statistical analysis of the election results obtained by the rival political parties in the 1994’s federal election, trying to
accurately define the electorate‘s preferences, such as the degree of non- participation depending on the electorate‘s age and the number of votes the Worker’s Party (Partido del Trabajo) recieved, the same votes that allowed them to keep their party’s legal register. For this study, a simple lineal regression analysis has been used for the measures of comparison beiwwen
two
populations, using statistical test calculation and the spreadsheet Lotus 1-2-3. The application of this method presents data for the eight legal political parties, the electorate‘s age included in the results, the significance levels, ages for non-participation and the elections won by the Worker‘s Party where female candidates were in contetion. In conclusion, the electorate’s age does affect the electorial preference and the degree on non-participation. The candidates‘ sex for the Worker’s Party showed an influence.Political Parties, Electing, Votings
RESUMEN
En el presente trabajo se hace un análisis de los resultados electorales obtenidos por los nueve partidos politicos que participaron en las elecciones federales de 1994. Se pretende establecer si hay alguna relación entre la proporción de la votación obtenida por cada partido y la edad promedio del electorado inscrito en Lista Nominal de cada una de las casillas electorales. Además, para el caso del Partido del Trabajo se analiza si existe relación entre la proporción de electores del sexo femenino de cada una de las casillas instaladas y la proporción de la votación obtenida por el mismo; y, finalmente, se analiza la posible relación entre la edad promedio del electorado y la
proporción del abstencionismo que se manifestó en ésta elección.
Todos estos análisis se abordan haciendo uso de las técnicas del análisis de regresión lineal simple, para establecer si existe relación entre las variables
y
verificar si el modelo de linea recta es adecuado para explicar esa relación.
Además de los análisis anteriores, se hace la comparación de las medias de dos poblaciones usando técnicas paramétricas y muestras apareadas. Se comparan los resultados obtenidos por el Partido del Trabajo en la elección de presidente de la República y diputados de mayoria relativa; y los resultados de la elección de senadores y diputados de mayoria relativa. Pretendemos, con estas comparaciones, establecer si existió alguna influencia del sexo de los
candidatos que postuló el Partido en tos resultados obtenidos en las diferentes elecciones de 1994.
Aplicados los procedimientos estadísticos antes invocados, encontramos que para niveles de significancia de 0.01 a 0.10 la proporción de la votación del Partido de la Revolución Democrática (PRD) y del Partido Auténtico de la Revolución Mexicana (PARM) se incrementa al aumentar la edad promedio del electorado; con niveles de significancia de 0.025 a 0.10 también se incrementa la proporción de la votación del Partido Revolucionario lnstitucional (PRI) a mayor edad promedio del electorado; igual tendencia presenta la proporción de la votación del Partido del Trabajo (PT), solo que para niveles de significancia de 0.05 a 0.10. Se encontró también que cuando se incrementa la edad promedio del electorado disminuye la proporción de la votación para los partidos: Acción Nacional (PAN), del Frente Cardenista de Reconstrucción Nacional (PFCRN) y Partido Verde Ecologista de México (PVEM), para niveles de significancia de 0.01 a 0.10; y Partido Popular Socialista con niveles de significancia de 0.05 a 0.10.
No
se encontró relación entre las variables, para esos niveles de significancia, en el caso de la proporción de la votación del Partido Demócrata Mexicano (PDM) y la edad promedio del electorado, ni en el caso de la proporción de electores del sexo femenino y la proporción de la votación del Partido del Trabajo enla
elección de presidente de la Republica.Se encontró que para niveles de significancia de 0.01 a 0.10 se incrementa la proporción del abstencionismo de los electores cuando se incrementa su edad promedio.
INTRODUCCION
Desde la epoca de estudiantes, tal vez de educación media superior, hasta
la
fecha, normalmente todas las personas escuchamos opiniones sobre cuestiones político-electorales tendientes a explicar la preferencia electoral o el grado de participación de la población en los procesos electorales, tanto federales, locales
o
regionales.Las opiniones escuchadas han tratado de explicar la preferencia politics en función de la edad del electorado, pretendiendo establecer que las generaciones jóvenes apoyan a los partidos de oposición y no al partido que ha gobernado al país casi de manera hegemónica durante mas de 60 años y que por el contrario, prefiere a los partidos de oposición y mas especificamente a aquellos de tesis izquierdistas. Otros manifiestan que las generaciones jóvenes son mas participativas que las generaciones maduras o de edad avanzada, es decir que son menos abstencionistas debido a que poseen una cultura politice mas elevada.
la elección de diputados (tanto de mayoría relativa como de representación proporcional) y el 0.22% para la elección de senadores. En la elección de 1994 el mismo partido político obtuvo a &el distrital el 1.37% de la votación emitida para la elección de Presidente de la República, el 0.96% para la elección de diputados de representación proporcional y el 1.07% para la de senadores.
Si tomamos en cuenta que a nivel distrital el
53.7%
de la población es del sexo femenino (muy similar a la proporción a nivel nacional) y que el Partido del Trabajo participó en la elección de Presidente de la Republica con un candidato del sexo femenino, entonces el haber logrado la obtención del registro definitivo por alcanzar un porcentaje de la votación emitida a nivel nacional de entre el 2.58% y el 2.77% para las distintas elecciones (Diario Oficial de la Federación del 19 de diciembre de 1994) puede debersea
la inclinación del electorado del sexo femenino a votar por un candidato de su mismo sexo o a que la oferta politica de ese Instituto Politico mejoró sustancialmente o, en último término, al perfil personal del Candidato independientemente de su sexo.Si por otro lado observamos la votacion obtenida para las distintas elecciones en el Distrito en 1994, encontramos que la mas alta fue la de Presidente de la República y senadores, precisamente en los rubros donde el Patido del Trabajo tuvo candidatos del sexo femenino.
Según lo anterior, podemos intuir que el sexo del electorado puede jugar
un
papel importante en las preferencias de la ciudadanía en la elección de Presidente de la República y senadores para este partido político.
de Guanajuato, que tiene como obligación, entre otras compredidas en
los
programas anuales de actividades y sustentadas en el Código Federal de Instituciones y Procedimientos Electorales, el proporcionar la información necesaria para la elaboración de la estadística electoral del Distrito. Tambíen comprende la elaboración de diversos analisis estadisticos de datos del Proceso Electoral proximo pasado.
No obstante, en el ámbito de competencia del Distrito no se han efectuado trabajos de similar rigor en el análisis y métodos empleados, ni se han analizado aspectos que tengan estrecha relación con las variables que aqui se pretende estudiar.
Este trabajo se circunscribe
al
ambito de competencia del Xlll DistritoElectoral
Federal en el Estado de Guanajuato del Instituto Federal Electoral (IFE) y para su desarrollo usa los resultados electorales del 21 de agosto de 1994, dado que no se tienen resultados de eleccciones de otros años y que pertenezcan a los mismos ámbitos territoriales, debido a que de una elección a otra normalmente cambia el número de casillas instaladas, as¡ como los limites de cada sección.
Se ha mencionado anteriormente que en acasiones se trata de dar respuesta apriori a la relación que puede haber entre las variables edad del electoradp y las preferencias por tal o cual partido politico y el grado de participación o abstencionismo electoral.
De igual manera sería interesante et conocer si existe alguna relación entre
los
Pretendemos establecer mediante el empleo de una metodologia con rigor científico si existe alguna relación entre las variables edad promedio
del
electorado y resultados electorales de cada partido político; la proporción de electores del sexo femenino y los resultados electorales del Partido del Trabajo (PT); la edad promedio del electorado y el abstencionismo; y si hay diferencia entre la votación del Partido del Trabajo en las diferentes elecciones que pudiera atribuirse al sexo de los candidatos que postuló. Estas técnicas son las del análisis de regresión lineal simple y la comparación de las medias de dos poblaciones usando muestras apareadas y técnicas paramétricas.
Mediante el empleo de estas técnicas nos hemos propuesto, en el transcurso del presente trabajo, cumplir con los siguientes objetivos:
1. Establecer la influencia de la edad del electorado en el abstencionismo y las preferencias electorales.
REVISION DE LITERATURA
Rearesión lineal simDle
Con los métodos de regresión lineal simple se pretende, ademas de medir el grado de asociación entre dos variables, investigar la naturaleza de la relación y construir módelos que la describan, fundamentalmente con el propósito de predecir el comportamiento de una de ellas a partir de los valores de la otra, aunque en general podemos decir que el objetivo global es hacer mejores inferencias sobre la variable que nos interesa primordialmente.
Puede darse que las situaciones prácticas en que es importante investigar la naturaleza de la relación entre las variables pertenecen a todos los aspectos del quehacer humano. As¡, por ejemplo, el grado de participación p o l k a de.un individuo y su nivel de educación aparecen frecuentemente relacionados. La dependencia entre las cantidades gastadas en la publicidad de un producto y las ventas del mismo es preocupación fundamental de los gerentes de ventas.
Y podriamos continuar citando ejemplos de aplicación.
El modelo de rearesión lineal simple
En el análisis de regresión lineal es necesario elaborar un diagrama de dispersión de los datos, ya que este puede ayudar en la búsqueda de
un
modelo que describa la relación entre las variables involucradas. También es necesario definir cual es la ecuación matemática apropiada para describir SU
relación: si es de linea recta, logaritmica, de parábola, etc. Una vez decidido ésto permanece el problema de encontrar las constantes que identifiquen a la ecuación del caso y posteriormente el de interpretar la ecuación resultante.
Algunas de las formas, entre la infinidad de posibilidades, que puede tener la relación de las variables en una regresión simple son:
Todos estos modelos son de regresión simple, puesto que solo involucran a una variable independiente.
En cambio solo los cuatro primeros son lineales, mientras que los dos Últimos son no-lineales. Por lineal entenderemos cualquier modelo en el cual k m es de la forma:
Donde
f
(X) es cualquier función de X.Debemos notar que el hecho de usar un modelo de regresión lineal simple de ninguna manera implica que la relación entre Y y X puede representarse por una línea recta, aunque esto es sierto cuando PYN =
po
+
pix. En los otroscasos la relación de línea recta se da entre Y y una función de X.
A h X
=
PII
+
PIX se le conoce como recta de regresiónAA partir de una muestra (Xi, Vi), (Xz, Y2),,.., (Xn, Yn) de las variables X y Y, se trata de obtener una ecuación que represente la relación entre dichas variables. El modelo supuesto es:
Y,=~Y/X+&,=PO+ piX,+&,; ¡ = I ,
...,
n,. ,.
El problema es obtener estimadores Po y
Pi
depo
ypi
para estimar adecuadamente la recta de regrecion P y N . El estimador de PYN lo denotamospor? y será de la forma Y
=
Po
+Pi
X.A,. h
Suposiciones del modelo de rearesión lineal simple
En todo modelo de regresión lineal simple tendremos cinco suposiciones:
1 .- Y es una variable aleatoria cuya distribución probabilistica depende de
X
2.- Modelo de linea recta
Esta suposición requiere que la ecuación para
h m
sea una linea recta, esdecir, que
PYN
=
PO
+
PIX y, por lo tanto, que la ecuación de dependencia seaY =
p,,
+
p,x
+ E.3.- Homogeneidad de varianzas
Una suposición muy importante en el análisis de regresión es que las varianzas
de las distribuciones de
Y
son idénticas para todoslos
valores de X:Esto equivale a soponer que la media de Y se modifica con el valor de
X,
perola varianza se mantiene constante.
4.- Independencia
Implica que
los
valores de Y deberán ser estadisticamente independientes.5.- Normalidad
La distribución de Y para cualquier val de X c normal.
Esto
equivale asuponer que la variable aleatoria no observable E es normal, ya que X se toma
como una variable no aleatoria susceptible de ser manipulada por el
Estimación de la recta oor rninirnos cuadrados
h A
El método más usado para encontrar
BO
yPi,
estimadores de Po y P i es elllamado
método de mínimos cuadrados,
usado ya por Carl Gauss (I 777-1 855) y que en resumen establece:A,.
El
método de minimos cuadrados
consiste en encontrarPo
yPi,
estimadores dePo
ypi,
tales que minimicen la S.C.Error, la cual tiene por expresión:2 - 2
- 6S.C.Error= i=i (Yi
-
Y ) *=
i=i (Vi-
Po-
Pi
X)’.
Los estimadores producidos por el método son:
303 303
es igual a SPXX.
z
V . - R
(Y.-?)1
(X,-
% 2Donde i=i I I es igual a SPXY y i-i
h
A A
,.
Interpretación de la ecuación de rear.t?sion estimada
h
1.- Interpretación de la estimación de la ordenada al origen
(Po)
,,
PO
es el valor de la predicción para Y cuando la variable independiente toma el valor cero. Dado lo anterior es importante señalar que este estimador no tiene interpretación practica en muchos problemas. Para que pueda haber una interpretación práctica deben existir dos condiciones importantes: a) debe ser físicamente posible que X tome el valor cero, y b) deben tenerse suficientes datos alrededor del valor X=
O. ~h
De otro modo el valor de
PO
solo es necesario para representar la tendencia que muestran los datos en el espacio de valores observados para la variable independiente.h
2.- Interpretación del estimador de la pendiente o coeficiente de regresión
(Bi)
El estimador de la pendiente nos indica la forma en que están relacionadas X y
Y , en el sentido que mide cuanto y en qué dirección se modifican los valores de
Y cuando cambia X.
Pi
estima la pendiente de la recta, o sea el número de unidades que cambiaY
por cada unidad de cambio en X.h
Análisis de varianza de la reqresión
La técnica de análisis de varianza se utiliza como alternativa de la prueba de t
para el juego de hipótesis HO:
P i
=O
en
Oposición a H a : h f 0 y nos permite.
A continuación presentamos un resumen del análisis de varianza para un modelo de regresión lineal simple:
La variabilidad de la variable dependiente puede separarse en dos componentes: una es consecuencia del error que se comete al ajustar una recta a puntos que no están exactamente sobre ella. La otra es resultado de
la
pendiente
(Pi)
de la recta ajustada. La partición, expresada en términos de sumas de cuadrados es:h
S.C.Total = S.C.Regresión + S.C.Error
donde
S.C.Total = S P W
S.C.Regresión =
fii
SPXYS.C.Error
=
SPYY-
131 SPXY.Puesto que la S.C.Total es la misma independientemente del modelo que se ajuste, es claro que existe una interdependencia entre las sumas de cuadrados
de regresión y del error, y consecuentemente entre
pi
y S.C.Error. A mayorvalor de
Pi
menor S.C.Error.h
*
Estas sumas de cuadrados pueden usarse para realizar una prueba de hipótesis sobre
PI
mediante la distribuciónF.
Esto es por que sus distribuciones están relacionadas con la de Ji-cuadrada.-
Puede demostrarse que para probar HO:
Pi
=
0 en oposición a Ha:pi f O sepuede usar el estadistico
Fa
= S.C.Regresión/Sez; donde:FO tiene una distribución F con 1 y n-2 grados de libertad. Una prueba de tamaño a para Ho:
pi
= O en oposición a Ha:Pl #O
se obtiene mediante laregla de decisión: "rechazar Ho si Fo F n-2, a. Estos resultados se
acostumbran presentar en la tabla del análisis de varianza.
1
[image:27.628.106.546.236.357.2]FUENTE DE GRADOS DE SUMA DE CUADRADOS
Cuadro
No.
1. Tabla del análisis de varianza para el modelo Yi= Po
+
pixi
+ Ei.Ho:
P
1 = O en oposición a Ha:p
1 fO
Fo VARlAClON
REGRESION
LIBERTAD CUADRADOS MEDIOS
A A
1
P
I SPXY'Pi
sPxy/i PIsPxY/ se2ERROR
TOTAL
Donde Se2 = (SPYY-fii SPXY)/(n-2) A
n-2 SPW-Pi SPXY Se2
n-I S P W
Interpretación de las inferencias sobre Dl
Cuando en la prueba de hipótesis del análisis de varianza no se rechaza
Ho:
p,=O, si solo atendemos al resultado de la prueba nos llevaría a concluir que X no contribuye a predecir a Y. Sin embargo, los diagramas de dispersión pueden sugerir explicaciones muy distintas para dos situaciones:a) Que el modelo de linea recta puede ser adecuado solo que con pl=O. Es decir, que
7
es tan buena como el modelo de línea recta estimado para predecir a Y.Si en la prueba de hipótesis se rechaza Ho: pi=O, concluiriamos que
x
contribuye a predecir aY.
Esta aseveración la debemos tomar con precaución, ya que en algunos casos, aún cuando el modelo de linea recta es mejor que uno que incluya a X, quizá el modelo propuesto solo proporciona una aproximación al verdadero, que puede incluir funciones de X más complejas. En estas circunstancias debemos optar por buscar un modelo alternativo que explique mejor la tendencia de la variable dependiente. El diagrama de dispersión puede ser de utilidad para sugerirnos algún tipo de relación entre las variables.En la comparación de dos modelos diferentes aceptaremos como mejor aquel que tenga menor cuadrado medio del error (que es un estimador de la varianza de Y).
Análisis del error Duro
v
falta de aiusteCon el objeto de verificar que Se2 (cuadrado medio del error) es un estimador insesgado de
0';
y por lo tanto que nuestras inferencias basadas en esteestimador (como la prueba de hipótesis sobre
Pi)
no caracen de sentido, haremos una prueba para mostrar que el modelo de línea recta es correcto para el conjunto de datos que tenemos.,.
Esta prueba parte del hecho de que el numerador de la varianza estimada de
Se2
=
1
(Y,-y,
) 2que puede reducirse usando un modelo alternativo y se le llama Suma de Cuadrados de Falta de Ajuste (S.C.F.A.).
S.C. Error = S.C.E.P. + S.C.F.A.
Como en nuestro caso tenemos 303 datos y solo 253 niveles de la variable independiente X, para cada uno de los valores de X donde hay más de una observación los diferentes valores de Y son una muestra aleatoria de una distribución normal con varianza IS2, de manera que podemos obtener:
ni ni
,...
In i - I ni
-
1donde Y¡. es la suma de los valores de Y para el nivel i-ésimo de X, y
vi.
es la media delos
mismos.Cada Si2 es un estimador insesgado de su varianza poblacional, pero
como
para el modelo de linea recta se supone homogeneidad de varianzas, se genera el estimador ponderado:
que es un estimador insesgado de IS2 independientemente de la forma del modelo PYn, que es precisamente el Cuadrado Medio de Error Puro (C.M.E.P.) para destacar que no depende del modelo ajustado. El numerador es precisamente la S.C.E.P.
Para probar que el modelo es adecuado usaremos el estadístico
I .
Fo=C.M.F.AíC.M.E.P, el cual bajo Ho: pym=po+plX es oposición a Ha: PYM
po+piX, tiene una distribución F‘ñ-:, por lo que la regla de decision para una Ho si FogFk3,0í,
ComDaracion de
las
medias &&!Q s poblaciones usando técnicas paramétricas v-muestras aDareadasEntre las técnicas paramétricas para la comparación de las medias de dos poblaciones tenemos dos opciones: hacer la comparación mediante dos muestras aleatorias independientes o usar muestras apareadas.
En el primer caso se usa la aleatorización irrestricta, consistente en asignar tratamientos al azar al total de las unidades experimentales que se tienen para la realización de la investigación.
Las muestras apareadas consisten en formar pares de unidades experimentales, de tal forma que las unidades que integran cada par sean tan semejantes entre si como sea posible, mientras que los pares pueden ser muy diferentes entre ellos. En estas condiciones tenemos dos fuentes de variabilidad: la que hay dentro de los pares y la que hay entre los mismos pares.
La variabilidad que se busca minimizar con esta opción es la que existe dentro de los pares, de modo que las diferencias que se pudieran encontrar entre los tratamientos se obtienen en condiciones presumiblemente más homogeneas que en el caso del uso de muestras aleatorias independientes.
respecto a la soposición de independencia (pues
su
importancia es 'capital), cosa que no sucede con la suposición del modelo probabilistico normal pues en este sentido son más robustas, y además, siempre existe la posibilidad de usar una aproximación a la distribución normal cuando tenemos muestras grandes en virtud del Teorema Central del Limite.La estructura de nuestro método estadístico de análisis es la siguiente:
Si se tienen n pares de unidades experimentales para comparar dos tratamientos, y se asignan los dos tratamientos aleatoriamente, uno a cada miembro del par, se obtienen dos muestras relacionadas. La información resultante la denotamos por (Xi, Yi), (X2, Y2), ..., (X.
,
Y"), donde Xi es la respuesta al primer primer tratamiento en el par i-esimo, y Yi es la respuesta al segundo tratamiento (¡=I, 2, . _ _ , n). Se tiene una muestra aleatoria de unavariable aleatoria bidimencional, es decir que
los
pares (X,, Y,) son independientes. Para el análisis estadístico definamos las variables aleatorias:Di= Xi - Yi ; ¡=I, 2, .._, n
La independencia entre los pares garantiza que Dt, Dz,
...,
D, es una muestra aleatoria de una variable que identificaremos por D. La esperanza y la varianza de cada Di las denotaremos por 1iD y o:.De lo antes expuesto es claro que pD = O implica que las medias de
los
tratamientos son iguales; po > O indica que la media del primer tratamiento es mayor que la del segundo, y pD O que la media del segundo es mayor.
2
Cuando
Di,
DZ,...,
D, es una muestra aleatoria que se distribuye N(pD, o D )sabemos, de la teoria sobre pruebas de hipótesis, que las inferencias sobre
los
n
-
i
1.1 Di 2(Di-6)'
D = S
D=
;Y n-1
El juego de hipótesis de interés es:
Ho:
PO O en oposición a Ha: po > 0Si suponemos que las Di son una muestra aleatoria de N(~i0, a:), entonces se tiene que
D
N N(pD, oD 2 ).Por lo tanto, la prueba adecuada es una prueba t usando la estadística:
112 -
to = (n) (D-K)/So ; donde K toma el valor cero para nuestro juego de hipótesis.
Este estadistico tiene una distribución t de Student con n-1 grados de libertad. Por lo tanto la regla de decisión es "rechazar Ho si 1, t,,(".,)n.
Si
el
tarnario de muestra es grande, puede evitarse suponer que la distribución de D, es normal. En este caso, apoyados en el Teorema Central del Limite, podemos usar la misma estadística to y realizar una prueba de Z (usando las tablas de la distribución normal estandar).Medidas de asociación entre dos variables o características de una población
Cuando se estudian dos características, una pregunta que surge es si existe alguna relación entre ellas. Esta relación o asociación se puede evaluar a traves de dos madidas o parámetros: la covarianza y la correlación.
Una desventaja de la covarianza como medida de asociación es que su Valor depende de las unidades en que se miden las variables de interés. Para evitar esta propiedad indeseable, se ha ideado una medida de asociación que es independiente de las unidades de medición, que recibe el nombre de correlación.
Definición de correlación (rxy). Sean (XI, Y,), (XZ, Yz), ..., (Xn, Yn); n observaciones hechas en dos caracteristicas. Sean Sxy ,Sx y Sv la covarianza entre ellas y las desviaciones estándar corespondientes. El coeficiente de correlación (rxy), o simplemente la correlación, tiene como expresión: -
rXY= Sxy I SX Sy
-
De manera más explicita, la acuación para la correlación puede escribirse:
La correlación es una medida de la asociación entre dos variables, que tiene las siguientes propiedades:
a) Es independiente de las unidades de medida utilizadas en las variables y toma exclusivamente valores entre -1 y 1.
MATERIALES Y METODOS
Análisis de rearesión lineal sirnDie entre la edad Rromedio del electorado
presidente de la Republica
J f f
Para el desarrollo de las tecnicas estadísticas que nos permitan desahogar el presente título, partiremos de los datos de los cuadros del anexo 11 y 12, que contienen la información de edad promedio del electorado y el numero de votos obtenidos por cada partido político en las elecciones federales realizadas el pasado 21 de agosto de 1994, a nivel de cada una de las casillas instaladas en ese Distrito
La razón de usar proporciones de 18 votación obtenida por cada partido politico
como datos de nuestra variable dependiente Y, es en razón de que en cada casilla votó un número diferente de electores; por lo que la diferencia de la votación absoluta de una casilla a otra puede no ser atribuida a la preferencia electoral, sino a que en una casilla habia más votantes potenciales que en otra.
Por otra parte, se omiten los datos de las casillas especiales porque en ellas vota cualquier elector en tránsito que ande fuera de su sección, por lo que no es representativo de la población del Distrito y, además, no se cuenta con los datos de la edad promedio de los electores que votaron en ellas por no haber listados nominales. Los datos de las casillas extraordinarias se suman a las básicas porque téoricamente la población de la sección se divide para ir a votar o a la casilla básica, o bien a la casilla extraordinaria; y ambas tienen la misma Lista Nominal.
Las proporciones de la votación para cada partido politico se calculará de los datos del cuadro del anexo número 11, dividiendo la votación obtenida por el partido politico j-ésimo en la casilla i-ésima, entre votos válidos de la i-esima casilla:
Y,, =
vji
Nu, ;j = PAN, PRI, PPS, PRD, PFCRN, PARM, PDM, PT, PVEM
i = 1, 2, 3,
...,
303donde Yji= proporción de la votación obtenida por el j-ésimo partido politico en la i-ésima casilla.
Vji = votación obtenida por el j-ésimo partido politico en la i-ésima casilla.
Wi = votación válida de la i-esirna casilla.
Partido Acción Nacional (PAN)
Los datos de la variable independiente (X) se toman del cuadro del anexo número
12
y los de la variable dependiente (Y) se calculan mediante programacomputacional a partir del cuadro del anexo número
1 1 .
Tenemos entonces dosgrupos de datos
Xi, XI, X3,
...,
XW para la variable independiente; yY1, Y,, Y3,
...,
YJo3 para la variable dependiente.Mediante el empleo del método de estimación de la recta de regresion por mínimos cuadrados obtenemos los siguientes estadísticos:
303
(Xi
-
x)’=
SPXX =1 839.793
20
i l l
303
(xi
-
X)
(Vi-
Y )
= SPXY =-21.908
67
i=1
y
(Vi-
v)2=
SPYY =3.279
73
x
=
38.432
87
Y
=0.234
26
~ i-1 303 SPXY SPXX -
h
1
i=1 (Xi-X) (Vi- Y )
-
1’1
=
303( X i - X Y
is1
=
-0,011
91
h
-
21.908
67
=
1839.793
20
h A _
Do
= V - D l X hDo
=0.234
26
-
(-0.011 91)(38.432
87)
Po
=
0.691
93
A
El modelo de línea recta estimado es Yi
=
0.691 93-
0.01 1 91 Xi.FUENTE DE GRADOS DE SUMA DE VARl AC ION LIBERTAD CUADRADOS
REGRESION 1 0.260 89
ERROR 301 3.018 83
TOTAL 302
Prueba de hipótesis
CUADRADOS Fo MEDIOS
0.260 89 26.013
O0
0.010 03
Nuestro interés fundamental es tratar de establecer
si
existe relación entre las variables X e Y , porlo
que debemos probar la hipótesis:Ho:
pi
= O en oposición a Ha:P1*
0 [image:37.629.105.553.365.480.2]Para ello construiremos la siguiente tabla de análisis de varianza.
CUADRO No. 2. Tabla de análisis de varianza para el modelo Yi=0.691 93- 0,011 gqxi, Ho:
p1
= O en oposición a Ha:Pi f OUna prueba de tamaño Q para Ho:
p i
=0
en OPosición a Ha:pi #0
se obtienemediante la regla de decision "rechazar Ho si Fo F ~ c I " . 1
1
De tablas de la distribución F, tenemos que para F 3 0 i 3 o.ro=2.725 95;
F 301, 1 o.oid.878 58; F 301, 1 0.025=5.084 52;
F
301. 1 o.oi=6.737 08.En el caso particular de este estudio wrece de importancia el tratar de darle
una explicación al estimador
Po,
dado que no tiene interpretación practica. Esto se afirma por dos razones:A
a)
No
es posible que X tome el valor cero, dado que las personas que tienen derecho al voto deben tener al menos 18 años.b)
No
se tiene dato alguno alrededor del valor X = OA
En estas condiciones, el valor del estimador Po solo es necesario para representar la tendencia que muestran los datos en el espacio de valores observados para la variable independiente X.
A
Por otro lado, el estimador
Pi
nos indica que la proporción dela
votación obtenida por el Partido Acción Nacional disminuye en 0.01 1 91 al aumentar en un año la edad promedio del electorado. O a la inversa, que la proporcion de la votación aumenta en 0.011 91 al disminuir en un año la edad promedio del electorado.Análisis del error puro y falta de ajuste
Nuestra hipótesis a probar es Ho: P Y n : = Po
+
pix
en oposición a Ha: P Y M*
po+pix.
Como en nuestro caso tenemos 303 datos y solo 253 niveles de la variable independiente X, para cada uno de los valores de X donde hay mas de una observación los diferentes valores de Y son una muestra aleatoria de una distribución normal con varianza
ü2,
de manera que podemos obtener unCalculando los estadisticos necesarios para esta prueba mediante el empleo de un sistema computacional similar al del anexo 5 y 8, tenemos los siguientes resultados:
253 j=l
S ~ P
-
501
(ni- 1) S:= 0.574 722
-
0.57472 = 0.011 49S.C.Error = S.C.E.P.
+
S.C.F.A.Del cuadro del análisis de varianza sabemos que S.C. Error es 3.018 83 y del resultado anterior la S.C.E.P. es 0.574 72. Entonces:
S.C.F.A. =S.C. Error-S.C.E.P.
S.C.F.A. = 3.018 83
-
0.574 72 = 2.444 11C.M.E.P. = 0.01 1 49
C.M.F.A. = S.C.F.A. / (1-2)= 2.444 11/ (253-2) = 0,009 74
Fo = C.M.F.A./C.M.E.P. =0.00974/0.011 49=0.84769
251
Consultando en las tablas de la distribución F tenemos que F5o ,0.10=1.365 56; Fso 251 ,o.os=1.492 38; Fso ,0.025=í.614 251 87; Fso 251 ,o.oi=1.771 98.
Dado que 0.847 694.365 56, 1.492 38, 1.614 87 y 1.771 98; no se rechaza
Ho
para ningún nivel de significancia razonable. Ademas que el diagrama de dispersión de los datos que se muestra en la gráfica numero 1 indican que el modelo razonable debe ser el lineal.
Conclusión
Los
datos muestran evidencia con un nivel de significancia desde 0.10 a 0.01 de que la edad promedio del electorado si contribuye a predecir la proporción de la votación obtenida por el Partido Acción Nacional (PAN) y que el modelo.. . .... . . _. ~ . .. . .. . . .~ I
-
-----.I--- 1
N. 9
'4
N013ViOA Q l 3 0 N013üOdOtld
O O
O
(9
O
39
de linea recta es adecuado para
mostrar
la relación existente entre lasvariables.
Partido Revolucionario lnstitucional (PRA
De la aplicación de la técnica de mínimos cuadrados obtenemos los siguientes parámetros, tal como se muestran en el anexo número 1:
SPXX = 1 839.793 20 SPXY = 11.774 63
S P W = 4.494 08
X
=
38.432 87I
= 0.610 26De ahí que los estimadores de p ~ y
pi
serin:h
Pi
=
SPXYISPXX=
11.774 6311 839.793 20Pi
=
0.006 40h
h
- -
P o =
v
-
P I Xh
Po
= 0.610 26-
(0.006 40) (38.432 87)Po
= 0.364 29-
El modelo de linea recta estimado es
91
=
0.364 29-
0.006 40x1.41
Por su lado el estimador de
pi
nos-indica que la proporción de la votación obtenida por el Partido Revolucionario lnstitucional se incrementa en 0.006 40al aumentar en un año la edad promedio del electorado en las casillas.
FUENTE DE VARl AC ION
REGRESION ERROR
TOTAL
Prueba de hipótesis
GRADOS DE SUMA DE CUADRADOS Fo LIBERTAD CUADRADOS MEDIOS
1 0.075 36 0.075 36 5.133 28
301 4.41 8 72 0.014 68
302 4.494 08
[image:42.631.100.557.344.464.2]A continuación se muestra la tabla de análisis de varianza
CUADRO No. 3. Tabla de análisis de varianza para el modelo Yi
=
0.364 29 +0.006 4oxi. Ho: 81 = O en oposición a Ha:P1 f O
Consultando las tablas de la distribución F, encontramos que la hipotesis nula se rechaza para niveles de significancia de 0.025 a 0.10 por ser Fo mayor que
los
valores criticos (F=2.725 95, 3.878 58 y 5.084 52); pero no para uno menor, es decir para 0.01 (F=6.737 08).Análisis del error puro y falta de ajuste
Nuestra hipotesis a probar es Ho: p y m
=
po +pix
en oposición a Ha: p y f i =kpoipix.
AI igual que para el caso del Partido Acción Nacional, tenemos 303 datos y 253 niveles de la variable independiente X. Por lo tanto, procesando losdatos en computadora nos arrojan
los
siguientes datos (mismosque
estánregistrados en el anexo número
2).
n - t = 5 0
entonces Sep' =
0.663 48/50
=0.013 27
De la tabla del análisis de varianza del cuadro número
3
tenemos queS.C.Error=4.418
72
y como sabemos que S.C. Error = S.C.E.P.+
S.C.F.A,entonces:
S.C.F.A=S.C. Error-S.C.E.P.
S.C.F.A. =
4.418
72-
0.663 48
S.C.F.A. =
3.755 24
C.M.F.A= S.C.F.A.l(t-2)=3.75524/251
C.M.F.A
=
0.014 96
Fo
=
C.M.F.A.IC.M.E.P.Fo
=
0.014 96í0.013 27
=
1.127 35
Dado que
1.127 35 1.365 65, 1.492 38, 1.614 87
y1.771 98;
no se rechazaHo para ningún nivel de significancia razonable. Además, el diagrama de
dispersion de los datos de la gráfica número
2
muestra que el modelo linealpuede ser el adecuado.
Conclusión
Los datos muestran evidencia con un nivel de significancia de
0.10
a 0.05 deque la edad promedio del electorado si contribuye a predecir la proporción de
I ! I
2
<4 o
N013VlOA-Vl30 N013t10dOtld
z
O Olado, el modelo de línea recta es adecuado para mostrar la relación de las variables para niveles de significancia desde
0.01
a0.10.
Partido PoDular Socialista (PPSI
En el anexo numero
1
tenemos el resumen de .JS parámetros resultar..s de laaplicación del método de mínimos cuadrados a los datos correspondientes al
PPS: ~
SPXX =
1 839.793
20
SPXY
=
-0.628
72
SPYY =
0.014
93
x
=38.432
87
v
=0.006
14
El cálculo de los estimadores de
DO
y01,
aun cuando se hizo directamente en la computadora, se ilustra a continuación:h
Pi
=
SPXYISPXX =-0.628
7211 839.793
20
h
PI
=-0.000
34
hP o =
Y
-E,
x
h
P o
=
0.006
14
-
(-0.000
34)
(38.432
87)
130
=
0.019
27
h
El modelo de linea recta estimado es ?i
=
0.019
27
-
0.000
34x1./
A
Como se ha dicho anteriormente, no tiene caso tratar de interpretar Po.
edad promedio de
los
electores de las casillas, hay una disminución de 0.000 34 en la proporción de su votación.SUMA DE CUADRADOS CUADRADOS MEDIOS
0.000 21 0.000 21 0.014 71 0.000 05
-
0.01493Prueba de hipótesis
Nuestra hipótesis a probar es HO:
P i
=0
en OpOSiC¡Ón a H a : h #o.
[image:46.623.96.546.339.462.2]Para ello construyamos la tabla de análisis de varianza.
CUADRO No. 4. Tabla de análisis de varianza para el modelo Yi
=
0.019 27-
0,000
34xi.
Ho:PI
= O en oposición a Ha:Pi Z OFo
4.395 50 FUENTE DE GRADOS DE
VARlAClON LIBERTAD REGRESION
ERROR
TOTAL 302
De las tablas de la distribución F, con 1 grado de libertad en el numerador y 301 grados de libertad en el denominador, encontramos que Ho se rechaza para niveles de significancia de O. 1 O a 0.05, pero no a menores valores de alfa.
Análisis del error puro y falta de ajuste
Para este análisis nuestra hipótesis es H o : k K
=
po
+
pix
en oposición aPara todos
los
casos de este titulo tenemos 303 datosy
253 niveles de la variable independiente X. Bajo esta condición, del anexo numero 2 tenemos que la aplicación de la técnica en sistema de cómputo nos arroja los siguientesparámetros:
-
n-t
=
50Sep2 = C.M.E.P. = 0.001 41/50
=
0.000
03En la tabla del análisis de varianza calculamos S.C.Error = 0.014 71, por lo
tanto:
S.C.F.A.=S.C.Error-S.C.E.P. S.C.F.A.
=
0.014 71-
0.001
41S.C.F.A.
=
0.013 30y, C.M.F.A.=S.C.F.A./(t-2) C.M.F.A. = 0.013 30/251
C.M.F.A. = 0.000 05
Entonces nuestro estadístico de prueba será:
Fo = C.M.F.A./C.M.E.P.
Fo = 0.000 05/0.000 03
Fo
=
1.666 67siendo esta cierta, encontramos que Ho no se rechaza (se acepta) dado que 1.666 67 < 1.771 98.
Por otro lado, en la gráfica número 3 encontramos que el diagrama
de
dispersión de los datos no sugiere la necesidad de otro modelo que no sea el lineal para mostrar la relación entre las variables.
Conclusión
Los datos muestran evidencia, con un nivel de significancia 0.10 a 0.05, de que la edad promedio del electorado sí contribuye a predecir la proporción de la votación obtenida por el Partido Popular Socialista.
Por otro lado, encontramos que el modelo de linea recta no es adecuado
para
mostrar la relación de las variables con niveles de significancia superiores O
iguales a 0.025. Esto nos llevaria a concluir que debiamos buscar un modelo alternativo, pues nuestra conclución anterior no tendría validez por estar fundada en el hecho de suponer que Se2 es un estimador insesgado de
d,
cosa que no ocurriria. Sin embargo, si disminuimos la probabilidad de cometer el error tipo I ( rechazar Ho siendo cierta ), encontramos que para un nivel de significancia de 0.01, la hipótesis nula no es rechazada, lo cual nos indica que los datos muestran evidencia de adaptarse al modelo de linea recta.
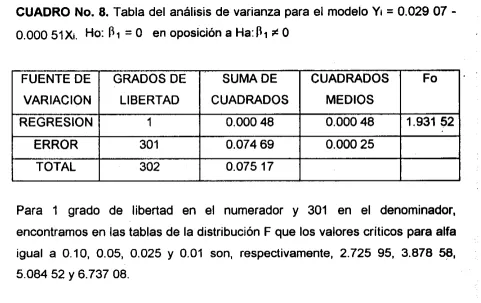
Partido de la Revolución Dernócratica fPRD)
En el cuadro del anexo número 1 se muestra el resumen de los resultados de la aplicación del método de minimos cuadrados para obtener el modelo de regresión lineal simple, que son:
N
O 0.
9
O
O
_ll_l.l-...--....- ". .
-.--
SPXY =
15.006
43
SPYY =
1.804
03
x
=38.432
87
v
=0.094
79
Ilustrando las operaciones para el cálculo de los estimadores de Doy pi:
,.
P I
=
SPXYISPXXh
Pi
=15.006
4311 839.793
20
Pi
=
0.008
16A
A h
P o =
v
-BlM
A
130 =
0.094
79
-
(0.008
16)
(38.432
87)
n o
=
-0.218
69
A
El modelo de línea recta estimado es ?i
=
-0.218
69
+
0.008
16
Xi.No
trataremos de interpretar el estimador depo
por carecer de sentido práctico. En cambio el estimador depi
nos indica que por cada año que aumente la edad promedio del electorado en las casillas, aumentará en0.008
16
la proporciónde su votación con respecto al total de votos válidos en la casilla.
Prueba de hipótesis
Nuestro juego de hipótesis para esta prueba está integrado
por
Ho:
Pi
= O en oposicion a Ha:Pl f O.FUENTE DE GRADOS DE SUMA DE CUADRADOS VARlClON LIBERTAD CUADRADOS MEDIOS REGRESION 1 O. 122
40
O.
12240
ERROR 301 1.681 63 0.005 59
[image:51.636.101.558.128.242.2]TOTAL 302 1.804 03
CUADRO No.
5. Tabla del análisisde
varianza para el modelo Yr=
-0.218 69+
0.008
j6xi,Ho:
Pi = O en oposición a Ha:PI
ZO
Fo
21.908
94
En las tablas de distribución F, con 1 grado de libertad en el numerador y 301 en el denominador encontramos que para alfa igual a 0.10, 0.05, 0.025
y 0.01,
tenemos respectivamente los valores críticos 2.725 95, 3.878
58,
5.084 52y
6.737 08.
Dado que Fo es mayor que cualquier F de tablas, se rechaza Ho para esos niveles de significancia.
Análisis del error puro y falta de ajuste
Nuestro juego de hipótesis a probar es Ho:PYM
=
Po+
PIX en oposición aHa:
P Y M 2 i
po
+
prx.
Tenemos 303 datos y 253 niveles de la variable independiente X. Procesando estos datos en equipo de cómputo, nos arrojan los resultados que se resumen en el anexo numero 2 y que son:
253
E
(ni- 1)S.'
j=l
'
= 0.312 96n-t
= 50
De la tabla de análisis de varianza antericPr (cuadro número 5), sabemos que la S.C. Error
=
1.681 63. Calculemos la S.C.F.A:S.C.F.A. = S.C. Error
-
S.C.E.P.S.C.F.A. = 1.681 63
-
0.312 96S.C.F.A.
=
1.368 67Entonces el C.M.F.A. Será:
I
C.M.F.A.
=
S.C.F.A/(t-2) C.M.F.A.=
1.368 67/(253-2) C.M.F.A.=
0.005 45Entonces nuestro estadístico de prueba Fo es:
Fo
=
C.M.F.A./C.M.E.P.Fo = 0.005 45l0.006 26
Fo
=
0.870 61De tablas de la distribución F tenemos que para niveles de significancia de 0.10, 0.05, 0.025, 0.01; y con 251 grados de libertad en el numerador y 50 en el denominador, F toma respectivamente los valores 1.36556, 1.49238, 1.61487 y 1.77198.
Dado que Fo
ningún nivel de significancia razonable.
1.36556, 1.49238. 1.61487 y 1.771 98, no se rechaza
Ho
paraEn la gráfica número 4 se muestra el diagrama de dispersión de
los
datos, que no sugieren la necesidad de otro modelo para explicar la relacion de las variables que no sea el de linea recta.-
0.
O
7
0- N.
9
O
a
OI
Conclusi6n
Los datos muestran evidencia con
un
nivel de significancia desde 0.01 hasta 0.10, de que la edad promedio del electorado sí contribuye a predecir I8 proporción de la votación del Partido de la Revolución Democrática. Además se acepta con el mismo nivel de significancia que el modelo lineal es adecuado para mostrar la relación existente entre las variables.Partido del Frente Cardenista de Reconstrucción Nacional íPFCRNi
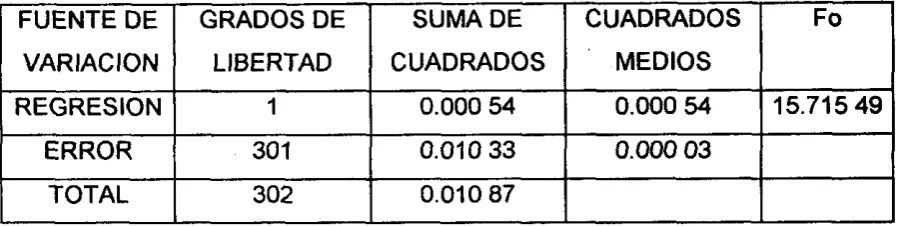
Del anexo número 1, tenemos que
los
resultados de aplicar el método de minimos cuadrados a los datos de nuestras variables son:SPXX = 1 839.793 20
SPXY = -4.447 36
S P W = 0.169 79
x
=38.432 87v=
0.019 73Con estos resultados calculamos nuestros estimadores:
1
h
P*
= SPXYISPXXPi
=-
4.447 3611 839.793 20 hPi=
- 0.0024 17 hP o =
I
- P I Xh
P o
=
0.019 73-
(-
0.0024 17) (38.432 87)FUENTE DE
VARl AC ION
REGRESION
ERROR
TOTAL
54
El modelo de linea recta estimado es
?I
=
0.1 126 31-
0.0024 17Xi.GRADOS DE SUMA DE CUADRADOS Fo
LIBERTAD CUADRADOS MEDIOS
1 0.010 75 0.010 75 20.346 38
301 O. 159 04 0.000 53
302 -0.169 79
No es de ninguna utilidad el interpretar el estimador de
PO;
en cambio,el
estimador de
DI
nos indica que por cada año que aumente la edad promediodel
electorado en las casillas, la proporción de la votación se reducirá en
0.0024 17 para el Partido del Frente Cardenista de Reconstrucción Nacional (PFCRN).
Prueba de hipótesis
El juego de hipótesis que a nosotros nos interesa probar
es
Ho:
p
1=
O en oposición a Ha:P
1 f O. [image:55.634.105.565.457.570.2]Para probarla construiremos la tabla del análisis de varianza.
CUADRO No. 6. Tabla del análisis de varianza para el modelo Yi
=
0.1126 31-
0.0024 17Xi.Ho:
Pi
=
O en oposición a Ha:Pl Z ODe las tablas de distribución F, con 1 y 301 grados de libertad (en el numerador
y denominador) y con un alfa de 0.10, 0.05, 0.025 y 0.01, tenemos
respectivamente para F los valores 2.725 95, 3.878 58, 5.084 52 y 6.737 08.
,
-
55
Como
nuestra regla de decisiónes
rechazarHo
siFo
es mayor o igualal valor
F de tablas, encontramos que
Ho
se rechaza para cualquier alfa razonable, dado que Fo es mayor que cualquiera de los valores de tablas.Análisis del
error
puro y falta de ajustePara hacerlo probaremos la hipótesis H o : h X
=
po+
pix
en opOS¡C¡tm a Ha:pyK&p.
+
pix.
Para estos casos tenemos 303 datos repartidos en 253 niveles de la variable independiente X. AI procesarlos en equipo de cómputo nos arroja
los
resultados del anexo número 2:
n-t = 50
Sep' = C.M.E.P. = 0.000 52
Sabemos del cuadro número 6 que la S.C. Error
=
0.159 04, por lo que laS.C.F.A. será:
S.C.F.A.=S.C.Error-S.C.E.P. S.C.F.A.
=
0.159 04-
0.026 16 S.C.F.A. = 0.132 88Por ello el C.M.F.A. será: C.M.F.A. = S.C.F.N(t-2)
C.M.F.A. = 0.132 88/(253-2)
C.M.F.A. = 0.000 53