1
UNIVERSIDAD TÉCNICA PARTICULAR DE LOJA
ESCUELA DE CIENCIAS DE LA COMPUTACIÓN
TEMA:
"ESTUDIO DE LA MINERIA DE CONTENIDO WEB Y LA WEB SEMÁNTICA APLICADA A LA BÚSQUEDA DE INFORMACIÓN EN LA WEB".
Memoria de Tesis previa a la obtención
de! Título de Ingeniera en Sistemas
Informáticos y Computación.
AUTOR: Carmiña Maga¡¡ Quezada Maldonado
DIRECTOR: Ing. Janneth Chicaiza
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información en la Web
CERTIFICACIÓN
Ingeniera
Janneth Chicaiza DIRECTOR DE TESIS
C E R T 1 F 1 C A:
Que el presente trabajo de investigación ha sido dirigido, supervisado y revisado en todas sus partes, quedando autorizada su presentación.
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información en la Web
AUTORÍA
El presente proyecto de tesis con cada una de sus observaciones, conceptos, ideas,
opiniones, conclusiones y recomendaciones vertidas, son de absoluta responsabilidad
de la autora.
Además, es necesario indicar que la información de otros autores empleada en el
presente trabajo está debidamente especificada en fuentes de referencia y apartados
bibliográficos.
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información en la Web
CESIÓN DE DERECHOS
Yo, Carmiña Magali Quezada Maldonado, declaro conocer y aceptar la disposición del Art. 67 del Estatuto Orgánico de la Universidad Técnica Particular de Loja que en su parte pertinente textualmente dice: "Forman parte del patrimonio de la Universidad la propiedad intelectual de investigaciones, trabajos científicos o técnicos y tesis de grado que se realicen a través, o con el apoyo financiero, académico o institucional (operativo) de la Universidad".
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información en la Web
AGRADECIMIENTO
Resulta para mí una inmensa satisfacción, agradecer en primer lugar a Dios por la
oportunidad de crecer, aprender, mejorar junto a personas que nos supieron guiar.
A la Universidad Técnica Particular de Loja por ser una entidad educativa forjadora y de apoyo durante nuestra vida universitaria, al personal docente de la Escuela de Ciencias de la Computación, por la dedicación, entrega y el apoyo necesario para mi formación profesional, y de manera especial al Ing. Nelson Piedra por los conocimientos impartidos y sus sabios consejos que ayudaron a culminar este proyecto.
A mis familiares que con su ayuda incondicional, supieron brindarme el cariño y afecto necesario en la elaboración del proyecto.
Y para finalizar quiero resaltar mi agradecimiento a mi directora de tesis lng. Janneth Chicaiza que con su amistad, paciencia, asesoramiento, y sabias sugerencias supieron establecer en mi claridad nitidez de expresión y redacción del texto en cada una de las fases del proyecto.
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información en la Web
DEDICATORIA
A Dios que siempre estuvo ahí en mis momentos más difíciles, para brindarme fortaleza y guía. A mis padres que fueron el pilar para el desarrollo de mi vida profesional, su constante apoyo, sacrificio, y entrega. A mi hijo por ser la fuente de inspiración y alegría dándome ánimo para seguir adelante. A mis amigos que me dieron la mano, que con su alegría, su consejo, me supieron ayudar cuando lo necesité, y a quienes les debo sus sabios consejos para la culminación del presente trabajo.
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información en la Web
CONTENIDO
Índice
CERTIFICACIÓN
... . ...
II AUTORÍA... Hl AGRADECIMIENTO... IV DEDICATORIA... VICONTENIDO
...
vi¡ÍNDICE ... VII INDICEDE ANEXOS ... IX INTRODUCCIÓN... . ... X OBJETIVOS
...
XI OBJETIVO GENERAL...
XI OBJETIVO ESPECÍFICOS...
XIFA SE 1
ESTADO DEL ARTE DE LA MINERÍA DE CONTENIDO WEB PARA LA BÚSQUEDA DE INFORMACIÓN EN LA WEB. 13 1.2. FASES GENERALES . ... 161.3. TAREAS DE LA MINERÍA DE CONTENIDO WEB
...
161.4. ESTRATEGIAS DE LA MINERÍA CONTENIDO WEB
...
181.4.1. MINERÍA DE PÁGINAS WEB. ... 18
1.4.2. MINERÍA DE LOS RESULTADOS DE LAS BÚSQUEDA
...
211.4.2.1. TÉCNICAS PARA MINERÍA DE RESULTADOS DE LAS BÚSQUEDAS. ... 25
1.5. ARGUMENTOS DE LA MINERÍA DE CONTENIDO WEB . ... . ... 33
1.6. APLICACIONES . ... . ... 35
1.7. PUNTUALIZACIONES. ... 36
FA SE II
LA WEB SEMÁNTICA: ESTADO DEL ARTE...
402.1. INTRODUCCIÓN ... 40
2.2. EVOLUCIÓN DE LA WEB
...
41Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información en la Web
2.3. DE LA WEB 1.0 A LA WEB SEMÁNTICA... 43
2.4. LA WEB SEMÁNTICA UN NUEVO ENFOQUE PARA LA ORGANIZACIÓN Y RECUPERACIÓN DE LA INFORMACIÓN... 46
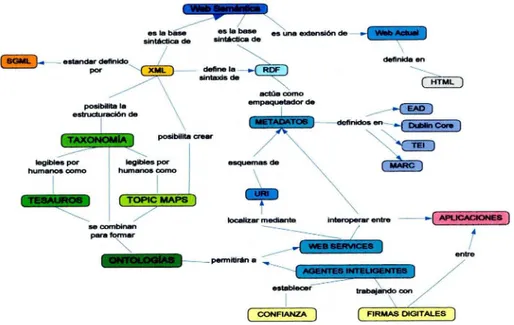
2.4.1. COMPONENTES DE LA WEB SEMÁNTICA ... 47
2.5. AGENTES DE LA WEB SEMÁNTICA ... 54
2.6. APLICACIONES ... 55
2.7. PUNTIJALIZACIONES ... . ... 60
Fase III RECUPERACIÓN DE INFORMACIÓN Y BÚSQUEDA WEB ... 63
3.1. INTRODUCCION
...
633.2. LA RECUPERACIÓN DE INFORMACIÓN EN LA ACTUALIDAD
...
643.3. LA RECUPERACION DE INFORMACIÓN EN LA MINERIA DE CONTENIDO WEB . ... 68
3.4. LA WEB SEMANTICA EN LA MINERIA DE CONTENIDO WEB. ... 69
3.5. MINERÍA DE CONTENIDO CON HERRAMIENTAS DE BÚSQUEDA
...
703.5.1. CONOCIMIENTO Y DIAGNOSTICO DE LA HERRAMIENTA "EZ MINER"
...
703.6. BUSQUEDA SEMÁNTICA: RECUPERACION DE INFORMACION SEMANTICA
... . ...
743.7. RECUPERACIÓN DE INFORMACIÓN DESDE RECURSOS WEB 2.0
...
753.8. HERRAMIENTAS SEMANTICAS
...
763.8.1. WIKIPEDIA... 76
3.8.2. WIKIMEDIA SEMANTICO ... 77
3.9. HERRAMIENTAS DE EVALUACION DE LOS RESULTADOS DE LAS BUSQUEDAS ... 78
3.10. PUNTUALIZACIONES ... .. ... .. ... .. ... 79
Fase IV APLICACIÓN Y EXPERIMENTACIÓN DE LAS HERRAMIENTAS ANALIZADAS ... . ... 82
4.1. INTRODUCCIÓN ... .. ... 82
4.2. DEFINICIONES... 83
4.3. PLAN DE PRUEBAS... 84
4.3.1. CRITERIOS DE EVALUACIÓN ... . ... 85
4.4. EJECUCION DE LA PROPUESTA DE EVALUACIÓN ... 85
4.4.1. EVALUACIÓN DE EZ MINER FRENTE A G000LE ... 86
4.4.2. EVALUACIÓN DE LA WIKIPEDIA FRENTE A LA SEMANTIC MEDIAWIKI ...89
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de
Información en la Web
CONCLUSIONES Y RECOMENDACIONES
ONUUSIONES
...
102RECOMENDACIONES
... . ...
106BIBLIOGRAFÍA... ... ... ... ... ... ... 108
Índice de anexos ANEXO 1.1: METODOS TECNICAS YALGORITMOS DE LA MINERIA DE CONTENIDO WEB.... 126
ANEXO 2.1 LENGUAJES DE CONSULTA PARA DATOS SEMI-ESTRUCTURADOS .... . .... ... . ... 129
ANEXO 3.1: FUNCIONAMIENTO DEL AGENTE COPERNIC ... . ... .. ... . ... 132
ANEXO 4.1: RESULTADOS DE LA EVALUACION DEL SISTEMA "EZ MINER ... ... . ... 143
ANEXO4.2: ARCHIVOS CSV ...... ... ... . ... ... 144
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información en la Web
INTRODUCCIÓN
El surgimiento de la Web ha propiciado un cambio radical en cuanto a la facilidad de acceso y difusión de la información, por lo que es indiscutible que la eficiente recuperación de información y la obtención de conocimiento desde la Web se hayan convertido en un tema importante, para quienes utilizan este dominio virtual. La información almacenada en distintos sitios origina información abundante, imprecisa, ambigua y heterogénea, debido a que no existe una estructuración lógica, lo que origina una serie de complicaciones en la recuperación de información en la Web. Actualmente los buscadores basados en indización humana e indización automática no ofrecen resultados realmente aceptables. El problema de la precisión en la recuperación de información puede ser visto como consecuencia de la falta de significado o semántica que tienen los documentos Web, en su mayoría formateados mediante HTML - lenguaje de etiquetado que expresa únicamente la forma de presentación de los contenidos.
De acuerdo a lo anteriormente expuesto, hoy en día, la mayoría de organismos y entidades educativas mantienen uno o varios sitios web, los cuales son cada día más sofisticados y ofrecen una interacción más detallada y compleja con los usuarios, así mismo la información que se presenta a los usuarios debe ser conocimiento útil. Los sitios web son fuentes valiosas a la hora de evaluar para mejorar la calidad del servicio ofrecido. Por lo tanto, el presente estudio se enfoca en la minería del contenido web y web semántica para la búsqueda de información usando grandes volúmenes de datos cuyo proceso genera información válida acerca del sitio y sus usuarios.
Debido a esto, se vio la necesidad de realizar el presente trabajo de investigación cuyo título es ESTADO DEL ARTE DE LA MINERIA DE CONTENIDO WEB Y LA WEB
SEMANTICA ORIENTADA A LA BUSQUEDA DE INFORMACION EN LA WEB",
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información en la Web
OBJETIVOS
OBJETIVO GENERAL
Presentar el análisis y comparación de las herramientas para Minería de Contenido en la web y Web Semántica para la búsqueda de información.
OBJETIVO ESPECÍFICOS
1. Analizar e investigar el estado del arte de la web semántica.
2. Aplicar las estrategias de Minería de Contenido Web.
3. Investigar, seleccionar y comparar herramientas de contenido web, técnicas o algoritmos para el descubrimiento de información relevante usando la web semántica.
4. Examinar Minería de Contenido Web basado en Agentes-Web.
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información
en la Web
Fase 1
Fase 1
ESTADO DEL ARTE DE LA MINERÍA DE CONTENIDO WEB PARA LA BÚSQUEDA DE INFORMACIÓN EN LA WEB
Resumen
Como punto de partida para el desarrollo del presente proyecto se ha realizado un estudio de los aspectos teóricos y de investigación sobre Minería de Contenido Web; Un análisis y síntesis de lo estudiado se ha condensado en esta fase: Estado del Arte de la Minería de Contenido Web y su aplicación en la búsqueda de la información. En primer lugar se menciona los factores que han dado origen a este componente del Proceso de Descubrimiento del Conocimiento
(KD, Know!edge Discovery)
a partir de contenido web. Como una parte introductoria, se da una visión general de las diferentes técnicas y aproximaciones desarrolladas y la aplicación directa sobre datos provenientes de la web. Luego en la fase 3 se describe cómo éste tipo de minería puede mejorar la recuperación de información desde la web, lo cual puede aportar básicamente a organizaciones y entes particulares que las apliquen.1.1.
INTRODUCCIÓN.El erario valioso de la humanidad es el conocimiento; parte de este conocimiento se encuentra en lenguaje natural: libros, periódicos, artículos y hoy más que nunca, en páginas Web. La posesión real de todo este conocimiento depende de nuestra capacidad para hacer ciertas operaciones con la información, por ejemplo: buscar información interesante, comparar fuentes de información diferentes y traducir textos a diferentes lenguajes. Sin embargo, y a pesar de todas estas bondades, la Web tiene varios aspectos negativos, así; su información es muy heterogénea, desorganizada y se multiplica día a día, existe mucha información irrelevante, la información esta etiquetada de diferentes formas dificultando su procesamiento, y finalmente y no menos importante, la información en un alto porcentaje no es validada para el usuario. [Montes, M]
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información
en la Web
Fase
1
como en el desarrollo de métodos relacionados con el acceso y análisis de información textual, es decir, con tareas relacionadas a la minería de datos (MD).
La Minería de Datos o Data Mining, se basa en la idea de que los datos contienen más información de la que se ve a simple vista. Su propósito es extraer información implícita, previamente desconocida y potencialmente útil a partir de los datos. La combinación de técnicas de PLN y MD para el análisis de grandes conjuntos de información textual se conoce como Minería de Texto (MT) y éste tipo de minería aplicada al análisis de conjuntos de páginas Web se denomina Minería de Contenido de la Web. [Guzmán]
Diversos autores han propuesto, que la minería de texto se puede aplicar en Internet, constituyéndose así la minería web
(Web Mining).
En el ámbito de la minería web, la minería de contenido es esencialmente una técnica análoga de minería que se aplica a bases de datos relacionales y a la información no estructurada que reside en los documentos web. La forma en que se aplica la minería web se puede conceptualizar en tres grandes aéreas o dimensiones. En la figura1
se muestran las categorías de la Minería Web y las operaciones que realizan cada una de ellas, en función de la parte que minan (contenido, enlaces, Iog del servidor) [De Gyves, F]:Minería de contenido de la Web—Web Content Mining (WCM): Es el proceso que
consiste en la extracción de conocimiento del contenido de documentos web o de sus descripciones. Además, la localización de patrones en el texto de los documentos, el descubrimiento de recursos basados en conceptos de indexación y la tecnología basada en agentes también forma parte de esta categoría.
Minería de estructura de la Web—Web Structure Mining (WSM): Se encarga de
explorar los enlaces en los sitios web, generar grafos a partir de los enlaces y realizar búsqueda en los grafos resultantes con el fin de obtener información que pueda resultar relevante para el usuario.
Minería de uso de la Web—Web Usage Mining (WUM): Aquí lo que se intenta es
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información
en la Web
Fase 1
Minena b Recaeçación de intomación
Minería de la Minena de Uso de Minada de Cont~
Esiludura b la vveb de la Wob
Negados inteligentes Ard,ivo de dientes uso de preercilvos
Si~ Recomendación
Comendo Detección de
Páalna de aoentes
Ant0
Asoc. de reglas Pinas asmma Páginas de contenidos
8Crsqueda de Resultados - Mirsog
Minarle Textos Minada Imagen Miring XML
(DTS) esquema
Mnng
HTML
Documentos
Navegación
Consultas Anexos Evaluación
Figura 1. Taxonomía de la Minería Web
Fuente: Sushmita Mitra, Tinku Acharya (2003)
Siendo todas estas aéreas de gran importancia y que específicamente requieren de meticulosas investigaciones. Ha sido exactamente el motivo para llevar a cabo el presente trabajo de tesis enfocándose específicamente en la minería de contenido web, pero si dejar de lado el estudio de las aéreas restantes. Por ello, al respecto se ha realizado un estudio y aplicación de la Minería de Uso Web, enfocado a explorar la información registrada en el servidor proxy de la Universidad Técnica Particular de Loja (UTPL), para determinar patrones generales y específicos de los usuarios de estos servidores. [Figueroa, R]
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información
en la Web
Fase
1
En las siguientes secciones se hablara exclusivamente de este tipo de minería web, considerando aspectos como tareas que realiza, taxonomía, estrategias que utiliza en el proceso de minería, herramientas existentes en este campo, así mismo sus aplicaciones para finalmente hacer algunas puntualizaciones referentes a esta fase.
1.2. FASES GENERALES.
En los últimos años, ha ocurrido una lenta expansión en el área de la minería de contenido Web, debido al crecimiento acelerado de la Web, sumado a su naturaleza dinámica. Si se considera que, los sistemas de recuperación de información realizan una función primaria al recuperar un grupo de documentos con cierta relevancia y realizar un determinado procesamiento sobre éstos. Sin embargo, el descubrimiento automático del conocimiento y la información cambiante, presenta todavía muchos desafíos para la investigación.
La minería de contenido se presenta como un proceso, que hace uso de técnicas de minería de datos y descubrimiento de conocimientos, para poder encontrar información muy específica. Por lo que considera procesos de recuperación de información, extracción de información, minería de textos y minería de estructura de la web. En el Anexo A.1 se recoge los diferentes métodos automáticos que utiliza la minería de contenido web; así como las técnicas, procesos y algoritmos.
Por consiguiente, se puede definir, el objetivo de la minería de contenido Web, como la recolección de los datos e identificación de patrones relativos a los contenidos de la Web (audio, video, símbolos, datos, meta-datos, link, hiperlink, texto y otros) y a las búsquedas que se realizan sobre los mismos, y que pueda ayudar a clasificar y aumentar la organización del contenido, así permita mejorar la relevancia del sitio, para posteriormente mejorar el acceso y la recuperación de la información. [Benítez, J]
1.3. Tareas de la minería de contenido web
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información
en la Web
Fase
1
Tabla 1.1. Tareas de la Minería de Contenido Web
Extracción de datos/información Recuperación en BDs Proporcionanservicios de valor Técnicas de aprendizajeautomático o extracción
estructurada desde la web agregado automático.
Integración de interfaz de consulta Integración de información de la Emparejar datos similares Meta-búsqueda " (formas de búsqueda)
Integración de ontologías
web y emparejamiento de semánticamente Meta-consulta
esquemas (taxonomía)
Integración de información textual Evaluar productos Clasificación supervisada y no Extracción de opinión desde Minería de opiniones, en sitios supervisada
fuentes on-line evaluaciones comerciales, foros, Extracción de patrones
blogs, etc. Machine Leaming Patrones sintácticos Sintetizar y organizar la Información de la Minería de datos Síntesis del conocimiento información en la web web orientada al Jerarquía de conceptos u
usuario ontologías
Segmentación Algoritmo CST (árbol de estructura
Segmentación de páginas web y Evitar ruido de bloques automática de comprimida)
detección de ruidos (anuncios, servicios, etc.) páginas web Machina Leaming, segmentación, PageRank.
Considerando los problemas citados y las tareas que la Minería de Contenido Web realizada para contrarrestarlos. Según esto, la tarea de
Síntesis del Conocimiento
se trata con mayor énfasis en este estudio, el cual se basa en el problema de la búsqueda en la web, dada una consulta o algunas palabras a un motor de búsqueda el cual retorna una lista clasificada de páginas, el usuario entonces mira y lee las páginas para encontrar lo que requiere. Pero este conjunto de páginas a menudo contienen información desordenada y redundante.Siendo la aplicación principal de esta tarea, sintetizar y organizar la información en la Web, dándole un cuadro coherente del dominio del tema al usuario. Para explotar la información redundante en la web se usa patrones sintácticos (encontrar relaciones de conceptos), organización de páginas existentes, minería de datos, Jerarquías de conceptos u ontologías, estas incluyen métodos que exploran la redundancia de la información en la Web. Apoyadas en técnicas de clustenng, para producir una taxonomía que organice los resultados. Algunos buscadores ya categorizan sus resultados como: vivísimo.com .
1.4. ESTRATEGIAS DE LA MINERÍA CONTENIDO WEB.
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información
en la Web
Fase 1
rapidez a los usuarios, pero no permiten categorizar apropiadamente la información, ni filtrarla e interpretar los documentos localizados. La problemática anterior, es la que ha propiciado el inicio de investigaciones para desarrollar herramientas inteligentes para la recuperación de información (agentes Web inteligentes, técnicas de bases de datos y minería de datos). [Mobaster, 8]
La figura2. Muestra la clasificación de la minería de contenido web, conceptualizada en dos áreas o enfoques.
Minería Web
Minería de Contenidos Web
Enfoque basado nfoque basado en agentes 11-1n bases de datos
• Agentes de búsqueda inteligentes • Bases de datos multinivel • Filtrado y Clasificación de información • Sistemas de consulta web • Agentes de Web Personalizados
Figura 2. Clasificación de la Minería de Contenido Web
Fuente: Fayyad, Shapiro, & Smyth, CACM 96. Modificado
El proceso de minería de contenido se centra en la recogida de datos e identificación patrones relativos a los contenidos de la web, existiendo dos estrategias para la extracción del conocimiento:
1.4.1. Minería de Páginas Web.
Extrae patrones directamente de los contenidos existentes en las páginas. Estos documentos pueden ser: texto libre, información procedente de bases de datos generadas en páginas con formato HTML, páginas escritas en XML, elementos multimedia y cualquier otro tipo de contenido presente en la web. La principal técnica de inteligencia artificial que se utiliza para realizar esta tarea es la utilización de técnicas de recuperación de información.
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información
en la Web
Fase 1
TEXT MINING: La minería de texto, es el resultado de la combinación de dos
grandes ciencias; la lingüística que estudia las leyes del lenguaje humano y, la
inteligencia artificial que investiga los métodos computacionales para el manejo de sistemas complejos. Esta minería resultante permite descubrir conocimientos
desde grandes colecciones de texto no estructurado. Existen dos tipos de
aplicaciones para minería de texto: text categorization 1 y text clustering2 . El proceso de minería de texto se realiza en tres fases:
. Selección de documentos y filtración (técnicas de IR) Píe-procesamiento de documentos (técnicas de PLN)
. Procesamiento de documentos (técnicas de PLN, ML, estadísticas)
Y realizar las siguientes tareas:
• Extraer información relevante de un documento • Agregar y comparar información automáticamente
• Análisis de tendencias y construcción de resúmenes
• Organizar depósitos para búsqueda y recuperación • Clasificar textos según su contenido e indizarlos en la web
HIPERTEXT MINING: Se refiere a enlaces entre documentos e intra-documentos, mediante un grafo de referencias. La estructura del hipertexto se compone de tres elementos esenciales: nodos (unidades básicas que contienen la información), enlaces (conectan los nodos) y anclajes (marcan el inicio y destino de cada enlace). Estos elementos básicos y simples dan lugar al desarrollo de estructuras heterogéneas y complejas que permiten acceder a la información mediante la
llamada navegación o recorrido a grandes colecciones de hipertexto o hipermedia3.
Para mejorar la recuperación de la información en la web se debe tomar en cuenta los hiperenlaces y el contenido de la página web.
1 Text categonzation: clasifica un documento en uno ó más
categorías mediante una
taxonomía predeterminada, para realizar búsqueda por clases y no por documento.
2 Text clustering: Divide una colección de documentos
extraídos de un motor de búsqueda en
clúster.
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información
en la Web
Fase
1
> MARKUP MINING: En un documento existen diferentes niveles de información: por un lado, los datos que conforman el contenido de un documento, y por otro, una información superpuesta al contenido, que constituye el etiquetado, marcado o "markup" [Lamarca, M]. La minería de marcado, trabaja sobre la información que aportan las marcas HTML (secciones, tablas, negritas, cursivas) y las marcas XML (si los documentos son estructurados con marcas). Estos lenguajes de marcado están orientados a definir la estructura y semántica de un documento, son metalenguajes o sistemas formales mediante los cuales se añade información o codificación a la forma digital, bien para controlar su procesamiento o para representar su significado. En un documento HTML sus elementos dan información sobre su estructura física o presentación, a diferencia de XML en el que los elementos que lo componen dan información sobre lo que contienen el documento.
> MULTIMEDIA MINING: Se dedica a la minería de información de alto nivel, desde grandes fuentes multimedia. El aprendizaje multimedia es realmente un desafío, que surge en disponer de métodos de búsqueda sobre nuevos contenidos que se están imponiendo en la red (videos, imágenes, sonidos, numéricos, gráficos, datos temporales, relacionales y categóricos). En general, realizar búsquedas sobre éstos medios implica el uso de metadatos, los cuales aportan información de manera externa a cada documento almacenado, así como la gran cantidad de solicitudes de consulta, búsqueda y recuperación de información en estos dominios, requiere de un sistema de procesamiento de filtrado distribuido necesario para calcular, filtrar, comprimir y analizar datos multimedia. [TH ESESTOPICS]
Resumen. Con objetivo de dar una visión general de las características de los
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información
en la Web
Fase 1
(P.D).
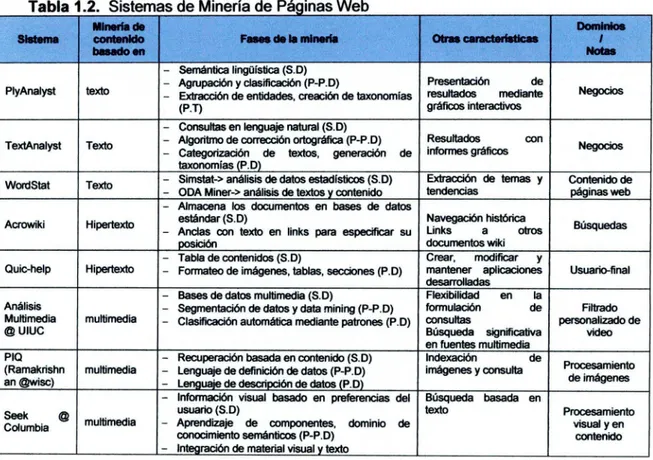
En la cuarta columna se indican algunas características relevantes del sistema. En la última columna se indica el dominio de aplicación del sistema.Tabla 1.2.Sistemas de Minería de Páginas Web
MInería de DOmInIOS
Sistema contenido Fases deis minería Otras característIcas
basado en Notas
- Semántica lingüística (S.D)
Agrupación y clasificación (P-P.D) Presentación de
PlyAnalyst texto Extracción de entidades, creación de taxonomías resultados mediante Negocios
(P.T) gráficos interactivos
- Consultas en lenguaje natural (S. D)
TextAnalyst Texto -Algoritmo de corrección ortográfica (P-P.D)Categonzación de textos, generación de informes gráficosResultados con Negocios taxonomías (P.D)
WordStat Texto - Simstat-> análisis de datos estadísticos (SO)- ODA Miner-> análisis de textos y contenido tendenciasExtracción de temas y Contenido depáginas web - Almacena los documentos en bases de datos
Acrowki - Anclas con texto en links para especificar su Linksestándar (SO) Navegación históricaa otros Búsquedas
posición documentos wiki
- Tabla de contenidos (S. D) Crear, modificar y
Quic-help Hipertexto - Formateo de imágenes, tablas, secciones (PD) mantener aplicaciones Usuario-final desarrolladas
- Bases de datos multimedia (S. D) Flexibilidad en la
Análisis - Segmentación de datos y data mining (P-P. D) formulación de Filtrado
Multimedia multimedia - Clasificación automática mediante patrones (P.D) consultas personalizado de
© UIUC Búsqueda significativa video
en fuentes multimedia
P10 - Recuperación basada en contenido (S.D) Indexación de
(Ramaknshn multimedia - Lenguaje de definición de datos (P-P.D) imágenes y consulta Procesamiento
an ©wisc) - Lenguaje de descripción de datos (PD) de imágenes
- Información visual basado en preferencias del Búsqueda basada en
usuario (S. D) texto Procesamiento
Seek © multimedia -Aprendizaje de componentes, dominio de visual yen
Columbia conocimiento semánticos (P-P.D) contenido
- Integración de material visual y texto
1.4.2. MINERÍA DE LOS RESULTADOS DE LAS BÚSQUEDA
Consiste en identificar patrones de comportamiento y características comunes en los
archivos de sucesos de los servidores web. Esta estrategia tiene dos aproximaciones:
basada en agentes y la base de datos. La aproximación basada en agentes comprende el desarrollo de sofisticados sistemas de Inteligencia Artificial, que actúan
de manera autónoma o semi-autónoma guiados por un usuario en particular, con el
propósito de organizar y descubrir información en la Web. [Divan, J] Además esta aproximación se organiza en tres categorías:
> Agentes de búsqueda inteligente: Este tipo de agentes recuperan información específica y de dominio sobre tipos particulares de documentos en servidores de
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información
en la Web
Fase 1
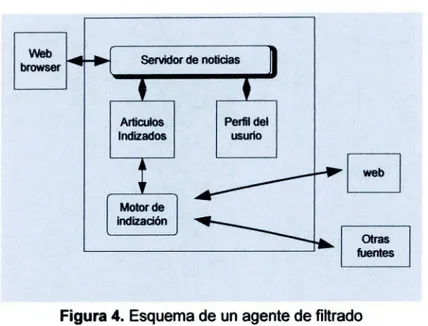
En la figura 3. Muestra un esquema de un agente de búsqueda, el proceso de búsqueda que realiza este tipo de agente.
Figura 3. Esquema de agente de búsqueda
Fuente: Juan José Puello, Amaury Cabarcas,
Silvia Baldiris. Modificado.
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información
en la Web
Fase 1
VVeb [4
+
Servidorde noticias browserArticulos Perfil del Indizados 1 1 usuno
web
Motor de 1
indizaJ '---._L. Otras fuentes
Figura 4. Esquema de un agente de filtrado
Fuente. Agentes de Información
Agentes Web Personalizados: Obtienen o aprenden las preferencias del usuario
y descubren fuentes de información en la Web que se correspondan con las mismas o posiblemente con preferencias de otros usuarios con intereses similares. Algunos ejemplos de tales agentes son WebWatcher, Syskill y Webert. [Liu,B]
Estos agentes tienen como objetivo formular consultas automáticamente y buscar documentos similares, organizar bookmarks o construir un perfil de usuario, pudiendo anticiparse a la obtención de la información solicitada por el usuario y hacer recomendaciones dinámicas a un usuario Web, en base a su perfil y a los patrones de uso obtenidos. Para construir el perfil de un usuario el agente realiza el análisis de las interacciones del usuario con el sistema, es decir minería web con agentes inteligentes, para ello considera dos formas: Directa, cuando el usuario determina su perfil a través de una interfaz en el que especifica, por medio de palabras clave, los temas de interés. Indirecta, el control efectuado por el propio agente de los enlaces seguidos por el usuario en una sesión concreta.
lndexador Web, música, multir Buscador propio
Representación conceptual propia. Negocios
Técnicas de recuperación de información
Reducir sobreabun-de información
Agrupación jerárquica. financieras
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información en la Web
Tabla 1.3. Agentes para Minería de Contenido Web
AGENTES PARA
DOMINIOS! FUNCION DEL
MINERIA DE AGENTE PARAMETROS OTRAS CARACTERISTICAS COMPONENTES
CONTENIDO NOTAS
WEB
Búsqueda inteligente
Búsqueda inteligente
Filtrado y categorización
BO(bookmar Filtrado y
organizador) categorización
Características de un dominio dado Buscar información. Agentes de internet.
Estructura de fuentes de información Refinar búsquedas. Solo para UNIX
Utiliza información semántica Filtrar, clasificar.
incrustada en la estructura de Iinks. Jerarquía de grupos de documentos de hipertexto.
Hipertexto. Organiza colección de documentos
Colección de documentos. basado en información conceptual
Copernic
ShopBot, ILA
Hypursuit
Forma un historial para determinar Sumario de páginas. Tasas de interés c
Syskill & Web Recoge evaluaciones del usuario
que otras páginas pueden interesarle páginas web
Webert personalizados al usuario Clasificación bayesiana simple
Web Watcher personalizadosWeb
rormuia un camino ae enlaces para Nealimentación basada en Agente guía de la w
dirigir al usuario por los enlaces que recorridos anteriores.
Consulta dada por el usuario cree son de interés
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información Fase 1 en la Web
La aproximación basada en bases de datos tiene como objetivo integrar y organizar los datos heterogéneos y semi-estructurados de la Web para transformarlos en bases de datos estándar, mediante de consulta a bases de datos y técnicas de minería de datos. [Mobasher, B] Esta aproximación tiene dos categorías:
> Bases de datos multinivel: La idea principal de esta técnica es organizar la información de tal manera que: El nivel más bajo contiene información primitiva semi-estructurada como documentos de hipertexto. Y en el nivel más alto, extraer metadatos o generalizaciones de niveles más bajos los cuales se organizan en conjuntos estructurados como las bases de datos relacionales u orientadas a objetos
Sistemas de consulta web: Estos sistemas utilizan tanto lenguajes estándar
(SQL), como el procesamiento del lenguaje natural.
1.4.2.1. TÉCNICAS PARA MINERÍA DE RESULTADOS DE LAS BÚSQUEDAS.
Esta segunda estrategia de minería sobre los resultados de las búsquedas, considera algunas técnicas de minería de contenido web, dependiendo del formato de los datos; no estructurado, semi-estructurado y estructurado 4 [Buddhinath, G]:
Si bien la primera estrategia del proceso de Minería de Contenido Web es igualmente importante que esta segunda estrategia. En adelante se enfocará como mayor detalle la minería de los resultados de las búsquedas (Search Result Mining), se trata de técnicas que mejoran los resultados de las búsquedas, para luego extraer conocimiento significativo de estos resultados:
a) Extracción de contenido con herramientas de búsqueda para fuentes de datos
no-estructurados,
para este formato de datos existen dos técnicas:• KNOWLEDGE DISCOVERY IN TEXT: El sistema KDT [Fe1d95] fue uno de los
primeros intentos para descubrir conocimientos desde grandes colecciones de texto, descubrir y explotar nuevos patrones de texto a partir de un estudio estadístico de la distribución de conceptos en una base de datos textual, capaz de realizar clasificación, clustering, recuperación y reutilización de información de la
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información
en la Web
Fase 1
Web. Con la adquisición de conocimientos y de técnicas de representación de Razonamiento Basado en Casos (CBR) ayudar a transformar los patrones en estructuras de nuevos conocimientos. Además de compartir muchas características y algoritmos con la minería de datos como los árboles de decisión o valores de predicción. [Gordon, R]
Dentro de esta técnica un ejemplo que se puede citar es, System Knowledge
discovery from text based web sites. Este proyecto busca agregar inteligencia a
un sitio web estándar. Mediante la minería web identifica las necesidades de los usuarios, la información de fuentes textuales, el uso de los datos de secuencias click, y la estructura de la página. La minería de datos por su parte, identifica caminos a través de la web, con el objetivo de construir automáticamente bases de conocimiento para la extracción de conocimiento desde páginas web basadas en texto flexible.
. CONCEPT BASED KNOWLEDGE DISCOVERY FROM WEB TEXT: La minería de
texto está basada en términos o palabras, presentando dificultades para distinguir sinónimos, polisemia, etc. El enfoque propuesto por Stanley Loh propone aplicar minería sobre conceptos5 y no sobre palabras o términos. Para ello se construye un modelo de recuperación en base al conjunto de palabras, nombres, frases sustantivas, términos etc. Y mediante una estructura conceptual, describir los objetos de información usados en una consulta. La estructura conceptual puede ser general o de dominio específico, ser creada manual o automáticamente. Este método consta de tres pasos, los que usan tres técnicas diferentes:
- Identificar los conceptos en el texto - Usa un algoritmo PLN estadístico - Adquirir definiciones de los conceptos - Usa machine learning
(clasificación)
- Encontrando nuevos patrones basados en conceptos - Usa métodos estadísticos.
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información
en la Web
Fase 1
Los tipos de estructuras conceptuales que se utilizan en esta técnica son:
taxonomía6 conceptual
(es el enlace a su más específico padre o superconcepto y asu más general hijo o subconcepto),
Ontología de dominio
(sirven como una fuente de descripción y puede ser usada para formular consultas),Red lingüística
semántica de concepto
(usada para la creación de una estructura conceptual enuna red semántica), tesauros (su construcción es manual y consume mucho tiempo),
Modelo predictivo,
similar a las redes neuronales, usado para recuperación de información basada en conceptos.Fases del Concept Based Knowledge Discovery from Web Text: Como
identificar conceptos en un texto (categorización). Consiste en que mediante el
procesamiento de lenguaje natural analiza la sintaxis y semántica de los textos [Loh, S] y clasificar los conceptos significativos encontrados de acuerdo a la estructura conceptual dada. Como adquirir las definiciones de concepto
(clasificación), Después que los conceptos son categorizados, la clasificación
determina donde en la estructura conceptual un nuevo concepto pertenece, entonces se elige los conceptos y la descripción de cada concepto. Para este propósito, se puede usar o una estructura conceptual existente (semejante a diccionario, tesauros u ontologías) o generar uno automáticamente por procesos de; aprendizaje supervisado (datos de afta calidad disponibles, encontrados en un ambiente como la web) y no supervisado (utiliza técnicas clustering). Usando
técnicas estadísticas en conceptos (minería), Este es semejante al paradigma
lE+KDD, donde lE extrae atributos del texto y las técnicas KDD son usadas sobre esos atributos. La tarea de minería, no considera el grado de relación entre un texto y un concepto, solo importa conocer si un concepto está presente o no en un texto y contar el número de textos al cual el concepto es asignado.
Un ejemplo Un enfoque basado en conceptos para KDT: En este enfoque se representan conceptos como una red o una lista ordenada de términos. Los términos en un concepto podrían incluir sinónimos, variaciones léxicas, palabras relacionadas semánticamente, etc. En resumen, la estrategia KDT es opuesto a las fases del KDD [Loh et al]. Aquí se explica cada paso de este enfoque:
6TaXOnOmÍa Es una organización jerárquica de descripciones de conceptos.
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información
en la Web
Fase
1
a) El usuario define que conceptos son interesantes (1 parte de la fase de clasificación);
b) Seleccionar un conjunto de datos objetivo: El texto se reúne, usando herramientas de recuperación de información o en forma manual;
c) Integrando y verificando conjuntos de datos.
d) Limpiando datos, Pre-procesamiento y transformación: aquí los conceptos son descritos (2 parte de la fase de clasificación);
e) Desarrollar el modelo y construir la hipótesis: identificando conceptos en la colección (tarea de categorización);
f) Elegir el algoritmo de minería de datos apropiado: la aplicación de técnicas estadísticas (tarea de minería);
g) Interpretación de resultados y visualización (usuario);
h) prueba de resultados y verificación: rehacer los procesos o algunas etapas para validar el descubrimiento del conocimiento.
b) Existen tres técnicas que se aplican a
datos semi-estructurados
detalladas acontinuación;
• EXTRACTING SYMBOLIC KNOWLEDGE FROM WEB: El objetivo de esta
técnica, propuesta por Craven, es desarrollar métodos automáticos para construir y mantener grandes bases de conocimiento, que reflejen el contenido de la web, para ello utiliza una estructura de grafo de la web. Así como, métodos para extraer y mantener bases de ontologías. Esta técnica indica si una página pertenece a una ontología o no y está habilitada para desarrollar automáticamente la ontología.
En cuanto a la extracción de información se tiene 2 entradas:
(1)
una ontología y sus relaciones y (2) un conjunto de datos que representan instancias de clases y relaciones, para extraer información de otras páginas y enlaces de la web. [STORMING MEDIA]Integración simbólico neural, se presenta como un ejemplo dentro de esta
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información
en la Web
Fase 1
se enfoca especialmente en extraer conocimiento simbólico desde redes entrenadas en términos de exactitud, eficiencia, comprensibilidad de reglas y solidez [Hitzler et al].
• LEARNING PAGE-INDEPENDENT HEURISTIC: El método propuesto por Cohen,
describe árboles que aprenden heurísticas de páginas independientes, para la extracción de datos desde documentos HTML. La entrada al sistema es un conjunto de programas wrapper. La salida es un procedimiento general para extraer datos independientes del formato y número de páginas. La ventaja de este sistema es su habilidad para clasificar y su desventaja es que los datos extraídos por los wrappers están codificados en HTML, debido a que las páginas frecuentemente cambian de formato, y por ello construir y mantener los wrappers a menudo consume tiempo y son tediosos. Sin embargo, los wrappers convierten las páginas web en un formato adecuado para ser almacenadas en la base del conocimiento.
Como ejemplos de esta técnica se presenta el Sistema de aprendizaje flexible,
que consiste en un sistema de aprendizaje de wrappers, para explotar diferentes representaciones de un documento. El sistema es modular y se puede adaptar fácilmente a nuevos dominios y tareas. [Cohen, W]. Y ANDES, software que combina la tecnología de un rastreador con la tecnología de extracción de datos basados en XML, es similar a otros sistemas de extracción en el sentido de que define un wrapper para cada sitio web. ANDES, es sólido y produce wrappers robustos, esto se logra confiando menos en la estructura HTML y más en el contenido.
• AUTOMATIC FEATURE EXTRACTION FROM THE WEB: Consiste en extraer
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información
en la Web
Fase 1
Se presenta como un ejemplo de esta técnica Automatic Feature Extraction of
Search Sites, utiliza el término Search Sities, para referirse a motores de
búsqueda propios de ciertas compañías a diferencia de los motores de búsqueda como Google que actúa en toda la web. El sistema se basa en probar palabras claves e indexación de semántica latente, extrae contenido de los resultados de las búsquedas mediante un wrapper de esta manera poder integrar sitios de búsqueda.
c)
Extracción de contenido con herramientas de búsqueda para fuentes de datosestructuradas:
• Bases de Datos Orientadas al modelado de la web: Esta principalmente
relacionado con la administración de los datos en la web similar a las bases de datos convencionales. Se trata de una "Vista de la BD" de la web, que consiste en un capa abstracta que esconde la web bajo una vista de una BD virtual. Existen tres clases de tareas hechas sobre una vista de una BD de la web:
- Modelado y Consulta de la web
- Extracción de Información e Integración - Construcción del sitio web y mantenimiento.
Los trabajos hechos en el área de vistas de BD. Están principalmente relacionados con 2 objetivos:
-
Extracción de esquema desde datos semi-estructurados:
Para formular unavista de una BD de datos semi-estructurada, se necesita descubrir la estructura de los datos. Este es llamado: "schema discovery or schema extraction". Debido a la naturaleza semi-estructurada del contenido de la web esta no es una tarea trivial.
-
Lenguajes de consulta para datos semi-estructurados:
Son lenguajes deEstudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información
en la Web
Fase 1
conocimientos, sigue la perspectiva de la minería de contenido web. Estableciendo una diferencia con WebSQL y WebOQL que no proveen ningún significado al conocimiento descubierto. En estos lenguajes siguen la sintaxis de la consulta estándar SOL. Una explicación más detallada de estos tres lenguajes se da en el anexo A.2.
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información
en la Web Fase 1
Tabla 1.4. Sistemas para Minería de los Resultados de las Búsquedas
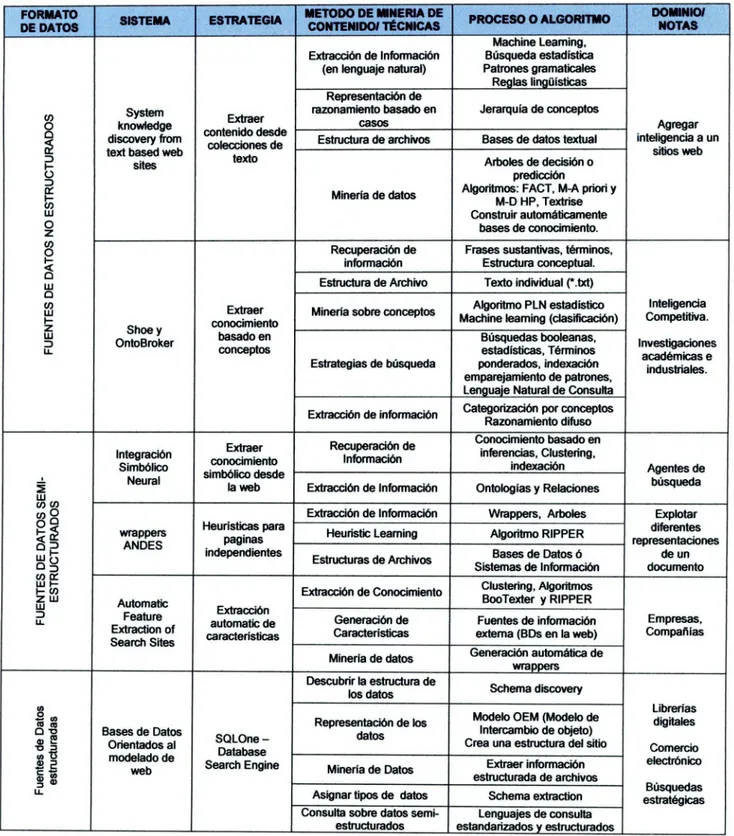
FORMATO SISTEMA ESTRATEGIA METODO DE MNERIA DE PROCESO O ALGORITMO DOMINIO!
DE DATOS CONTENIDO! TÉCNICAS NOTAS
Machine Leaming, Extracción de Información Búsqueda estadística
(en lenguaje natural) Patrones gramaticales Reglas lingüísticas Representación de
System Extraer razonamiento basado en Jerarquía de conceptos
casos Agregar
O knowledge contenido desde
Estructura de archivos Bases de datos textual inteligencia a un
text based webdiscovery from colecciones detexto sitios web
sites Arboles de decisión o
O predicción
Minería de datos Algoritmos: M-D HP, TextnseFACT, M-A priori y
Lii Construir automáticamente
bases de conocimiento.
Z
U) Recuperación de Frases sustantivas, términos,
información Estructura conceptual.
C)
w Estructura de Archivo Texto individual (*.lxt)
Q U,
Extraer Minería sobre conceptos Algoritmo PLN estadístico Inteligencia
conocimiento Machine leaming (clasificación) Competitiva.
Z Shoev
w OntoBroker basado en Búsquedas booleanas,
conceptos estadísticas, Términos Investigacionesacadémicas e
Estrategias de búsqueda ponderados, indexación industriales. emparejamiento de patrones,
Lenguaje Natural de Consulta Extracción de información Categorización por conceptosRazonamiento difuso
Extraer Recuperación de Conocimiento basado en
Integración conocimiento Información inferencias, Clustenng,
Simbólico simbólico desde ________________ _________________________________________ indexación Agentes de
Neural la web Extracción de Información Ontologías y Relaciones búsqueda
Lii 0)0)
0) 0 Extracción de Información Wrappers, Arboles Explotar
O wrappers Heurísticas para Heunstic Learning Algoritmo RIPPER diferentes
ANDES independientespaginas representaciones
Bases de Datos ó de un
Estructuras de Archivos
o Sistemas de Información documento
1- II) Extracción de Conocimiento Clustenng, Algoritmos
Z W Automatic BooTexter y RIPPER
w
Feature Extracción
LL
Extraction of automatic de Generación de Fuentes de información Empresas,
Search Sites características Características externa (BD5 en la web) Compañías Minería de datos Generación automática dewrappers
Descubrir la estructura de
los datos Schema discovery
Librerías Representación de los Modelo OEM (Modelo de digitales
Bases de Datos Intercambio de objeto)
O
Orientados al SOLOne - datos Crea una estructura del sitio Comercio
modelado de Database
. web Search Engine Minería de Datos estructurada de archivosExtraer información electrónico
LL Asignar tipos de datos Schema extraction Búsquedas
estratégicas Consulta sobre datos semi- Lenguajes de consulta
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información
en la Web
Fase 1
1.5. ARGUMENTOS DE LA MINERÍA DE CONTENIDO WEB.
Existen varios elementos que intervienen en la minería de contenido web nombrados anteriormente, por ello se precisa establecer diferencias claras con términos que comúnmente se confunden estos elementos. El primero que se considera son los agentes inteligentes estos son relacionados similarmente con los índices temáticos/directorios y los motores de búsqueda.
Existen diferentes imprecisiones terminológicas a este respecto. Por un lado, a los motores de búsqueda se les ha denominado con otros términos sinónimos, tales como: buscadores, rastreadores, webcrawlers, agentes, índices, directorios. Y por otro, durante cierto tiempo, se han confundido tres tecnologías que ahora tienen autonomía propia: los índices temáticos/directorios, los motores de búsqueda y los agentes inteligentes. La diferencia radica en que los índices temáticos, son sistemas de búsqueda por temas o categorías jerarquizadas (aunque también suelen incluir sistemas de búsqueda por palabras clave). Se trata de bases de datos que contienen direcciones que son recopiladas, organizadas y clasificadas manualmente. Los
motores de búsqueda son sistemas de búsqueda por palabras clave, bases de datos
que incorporan automáticamente páginas web mediante "robots' de búsqueda por la red. Y los agentes inteligentes pueden realizar una serie de tareas sin que los humanos u otros agentes les tengan que decir que hacer a cada paso que dan en su camino. [Fernández, R]
Otro elemento de singular importancia son los documentos recuperados en el proceso de minería de contenido web. La mayoría de las herramientas de búsqueda en la Web se basan solamente en la información textual de los documentos ignorando la información implícita que contienen los links o los analizan sin tomar en cuenta el tipo de link, tratando al documento como un documento de hipertexto típico. Para aclarar las deficiencias de este enfoque se analiza las diferencias existentes entre un documento de Web y un documento hipertexto clásico ([Spertus,
1997]).
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información
en la Web
Fase
1
diferencia de la web que es redundante y en constante cambio creando el problema de poder encontrar información que no se encuentra todavía indexada.
Finalmente considerar como elemento importante a la hora de realizar minería de los resultados de las búsquedas intervienen directamente los motores buscadores por ello a continuación se detalla las características de los buscadores más importantes de aquellos buscadores que tienen una mayor aceptación por parte del usuario.
Si se tiene en cuenta que las búsquedas son la segunda tarea que más se hace en Internet después del correo electrónico, entonces se requiere, ver nuevos productos de búsqueda perfectos que comprendan exactamente lo que quiere decir el usuario y le ofrece exactamente lo que desea, teniendo en cuenta el estado actual de las tecnologías de búsqueda, búsquedas previas e incluso pensar en nuevas maneras de agrupar la información (los
mapeadores).
Como ya se ha visto, Google hace realmente minería Web. Google ofrece buenos resultados porque confía en la valoración que millones de personas que publican sitios web, hacen del contenido de los demás sitios. En lugar de basarse en la opinión de un grupo de editores o únicamente en la frecuencia con la que aparecen ciertos términos, Google clasifica las páginas web mediante una técnica innovadora denominada
PageRank. Se trata de evaluar todos los sitios que se enlazan con una página web y
asignarles un valor.
Cuando Google hubo indexado más páginas HTML que ningún otro servicio de búsqueda en Internet, centrándose en datos a los que no se podía acceder fácilmente. En algunos casos se trataba únicamente de integrar nuevas bases de datos. En otros casos, permitir las búsquedas en más de 880 millones de imágenes o visualizar páginas creadas originalmente como archivos PDF, precisaron más creatividad. Google ha creado un método exclusivo para transformar archivos HTML a un formato que puede visualizarse en dispositivos móviles, lo que resulta muy útiles a usuarios de tecnología inalámbrica.
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información
en la Web
Fase 1
De momento Google es el líder, pero nuevos buscadores con nuevas prestaciones empiezan a salir al mercado. [Vicente, M]
(www.vivisimo.com): este buscador agrupa los resultados con el fin de que el usuario pueda encontrar la información más rápidamente.
•
1
)N'LA (www.teoma.com):
devuelve información en función de larelevancia que le otorgan otros sitios Web
(peer-sites).
WiseNut
(www.wisenut.com): es un buscador sensible al contexto.(www.starpond.com ): es un motor de búsqueda de uso colaborativo.
Los buscadores que incorporan visualización gráfica de sus resultados van saliendo poco a poco al mercado.
M(search.mapstan.net): este buscador capitaliza el conocimiento, tiene
la capacidad de aprovechar la información de las búsquedas anteriores.
1.6. APLICACIONES
El área de aplicabilidad de la minería de contenido web es promisoria, existen algunos trabajos realizados hasta la actualidad que los citaremos a continuación:
La Solución de Monitoreo de Imagen Pública se basa en WebSphere lnformation Integrator OminiFind Edition [IBM], la primera plataforma comercial para implementar soluciones de analítica de textos basadas en Unstructured Information Management Architecture (UIMA). WebSphere Information Integrator OminiFind Edition proporciona avanzadas capacidades de búsqueda inteligente, facilitando a las empresas acceder a información de negocios crítica y mejorando en gran medida la relevancia de sus resultados de búsqueda. "Esta solución, está muy comprometida con el mercado emergente de minería de contenido en busca de inteligencia de valor agregado.
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información
en la Web
Fase 1
Dentro de las aplicaciones industriales distribuidas, las que se encargan de: Control
de procesos: gestión autónoma de edificios inteligentes en cuanto a su seguridad y
consumo de recursos, gestión del transporte de electricidad, en plantas industriales. En otros campos se han desarrollado aplicaciones para el control del tráfico aéreo en aeropuertos como el de Sidney en Australia.
Producción: aspectos como la planificación, producción o fabricación de productos
son tratados desde la perspectiva de agencia. Algunos ejemplos: ABACUS, CORTES, MASCOT, Sensible Agents, YAMS, etc.
En aplicaciones comerciales, sobre todo a nivel de red, tanto en Internet como en
redes corporativas existen avances en cuanto a:
Gestión de información: como por ejemplo el filtrado inteligente de correo electrónico
(Agentware e lnfoMagnet), de grupos de noticias o la recopilación automática de información disponible en la red (Letizia, ATI, BullsEye, Go-Get-It, Got-It, Surfbot y WebCompass). Tareas para las cuales el agente necesita ser capaz de almacenar, aprender y manipular las preferencias y gustos de cada usuario, así como sus cambios. La imposibilidad en ocasiones de gestionar todo tipo de información suministrada por la red ha provocado que el agente se especialice en la búsqueda de determinados tipos de documentos (CiteSeer). Otra posible línea sería la planificación de la agenda personal, en otras palabras, disponer de una secretaría virtual o asistente personal.
Comercio electrónico: proporciona un entorno virtual donde realizar posibles
operaciones comerciales (compra-venta de productos) o también para realizar tareas de búsqueda de productos, todo ello de manera automatizada (Jango, BargainFinder, Kasbah).
1.7. PUNTUALIZACIONES
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información
en la Web
Fase
1
+ La minería web, engloba tres tipos de datos principales. El más importante y difícil de procesar es el contenido, que es multimedial, en el cual el texto juega un rol dominante. El segundo proviene de la estructura no lineal de la web: sus hiper-enlaces. Finalmente, el último procede del uso reflejado a través de los logs o bitácoras de los servidores Web.
+ La Minería de Contenido Web utiliza las ideas y los principios de la minería de datos y del descubrimiento de la información para obtener datos más específicos. El uso del Web como abastecedor de la información es desafortunadamente más complejo que trabajar con las bases de datos estáticas. Debido a su naturaleza muy dinámica y su número extenso de documentos, hay una necesidad de nuevas soluciones que no dependen de tener acceso a los datos completos. Otro aspecto importante es la presentación de los resultados de las búsquedas. Debido a su enorme tamaño, una pregunta puede recuperar millares de páginas Web como resultado. Así la necesidad de métodos significativos para presentar estos grandes resultados necesarios para ayudar al usuario a seleccionar el contenido más interesante.
+ La necesidad de obtener información relevante y pertinente en la inmensidad del web hace necesario que la información esté, de alguna manera, organizada y que sea posible procesarla de forma automática. Hoy por hoy, el web está hecho pensando que lo leerán personas y no máquinas. Es necesario disponer de una categorización de la información del web que sea procesable por máquinas. Ello se consigue con las ontologías, que es el fundamento del Web Semántica. Muchos de los artículos publicados durante el pasado año 2001 hacen referencia a la minería de web Semántica.
+ Las tecnologías que son la infraestructura de mineros web, también van cambiando. Se empieza a detectar un cambio de paradigma en el desarrollo del software: se paso de programación orientada a objetos a la otra orientada a tareas o roles utilizando agentes. Este cambio es inminente.
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de Información
en la Web
Fase 1
+ La Minería de Contenido Web utiliza los datos reales o primarios de la Web. El objetivo de la minería es encontrar información con el fin de extraer información y conocimiento valioso de la Web.
+ Los desafíos dentro del área de minería de contenido web están principalmente en la naturaleza de los datos disponibles en la Web, y que además, más y más nuevos formatos son abiertos continuamente. Convirtiéndose en una técnica eficaz que permite descubrir conocimientos en el mundo heterogéneo y dinámico de la Web.
En esta tesis se analizara algunas herramientas existentes para minería de contenido web. Se propondrá una mejora a la
evaluación pertinente,
que busque mejorar los resultados de las búsquedas. Y las ventajas de aplicar dichas herramientas en una web más estructurada como lo es la web semántica.Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de
Fase II
Información en la Web
Fase II
LA WEB SEMÁNTICA: ESTADO DEL ARTE
2.1. INTRODUCCIÓN
En la fase anterior se presentó un estudio de los aspectos fundamentales de la Minería de Contenido Web como una de las aéreas de la minería web. Cómo, ésta tecnología ayuda a mejorar los resultados de las búsquedas dándole al usuario conocimientos útiles que satisfagan sus inquietudes permanentes. En esta fase se enfocará en el estudio de una web que surge de la necesidad de información relevante frente a la información poco estructurada e irrelevante a la que nos enfrentamos en estos días. Se trata de la web semántica, para poder tener una visión más amplia de cuáles son sus implicaciones, componentes, tecnologías. A continuación se presenta un estudio que se centra en sus características más importantes que permitan determinar en qué manera la web semántica mejora la recuperación de información.
La búsqueda semántica ha sido uno de los beneficios esperados de la Web Semántica. Una forma de entender un motor de búsqueda semántica es como una herramienta que recibe consultas basadas en ontologías (p.e. en RDQL, RQL, SPARQL, etc.), las ejecuta contra una base de conocimiento, y devuelve tupias que satisfacen la consulta. La web semántica representa un escenario ideal para realizar búsquedas de contenidos, ya que implica conocer perfectamente el significado de los recursos disponibles. Lamentablemente, el contenido semántico en la web actual representa una muy pequeña porción del total, lo que hace que hoy en día no tenga mucha utilidad basarse en este recurso.
Estado del Arte de la Minería de Contenido Web y la Web Semántica Orientada a la Búsqueda de
Fe II
Información en la WebWeb 1 0
sef-deScnpon
Web 2 0
2
s.eIt-de*crption + bloggirig
,e.d kwf1e
Sernant,C Web
- 4 semnhcs
«,re teques + act'.e ser."
reaø •
taffi VVebj,k rtad • • •
sei-descnp.on' res
• bO99fl9 • semanttcs * actNe serv.c
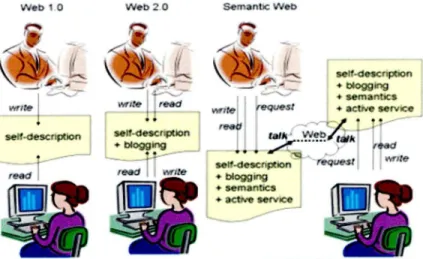
Figura 5. Evolución de la web
Fuente: Yihong-Ding, 2007
En la década de los 80 Tim Berners-Lee presentó su proyecto de gestión de la información "Word Wide Web", que era un espacio donde únicamente se podía publicar
páginas estáticas con texto estático esperando a que algún usuario diera con él y lo
leyera, la gente podía contentarse con ver las letras en negro sobre un fondo blanco. Es cuando se definió un lenguaje de programación llamado HTML y posteriormente XHTML, facilitando la navegación por el contenido web. Tecnologías como imágenes y colores en los textos, ahora son cosas normales y habituales para nosotros. La Web tuvo que ir creciendo y adaptándose a nuevas exigencias. Siempre intentando seguir un estándar para que sean compatibles con otros indexadores y navegadores que iban saliendo.
La conexión fácilmente a otras páginas o servicios se hace posible con el surgimiento de
los Iinks elementos básicos que permiten enlazar dos páginas web, de manera tal que el
usuario puede navegar desde un sitio a otro haciendo clic en uno de ellos.
Estudio de la Minería de Contenido Web y la Web Semántica Aplicada a la Búsqueda de
Fase II
Información en la Web
por estas arañas que leían código y ordenaban texto. Sin embargo, estos buscadores recorrían el texto basándose en palabras claves, y por ello era complicado dar resultados óptimos sin comprender el texto. Se trata de sistemas de recuperación de información tradicionales y que hoy en día no son efectivos ni suficientes para localizar y recuperar recursos en la web actual.
Para la década de los 90 surge la web 2.0 que se presenta como una actitud, más no como una tecnología. Considerada la transición que se ha dado de aplicaciones que funcionan en la web, enfocadas al usuario final, contrario al entorno estático con páginas HTML que sufrían pocas actualizaciones y no tenían interacción con el usuario. En el proceso de información en la web 2.0, presenta una evolución gradual, permite incluir más variables de matching (coincidencia) entre queries y metadatos, y un contexto semántico más cercano al usuario, puesto que los metadatos usados para describir los objetos de interacción (imágenes, videos, etc) son aportados por los propios usuarios, lo que implica la aportación de modelos de usuario en el proceso de recuperación de información.
Con el surgimiento de la web 2.0 y toda su filosofía ha propiciado un presunto
enriquecimiento colectivo provocando el crecimiento exponencial de contenidos repetitivos, vacíos de ideas y creatividad [Cobo, 2007]
Presentando este escenario, es poco viable automatizar tareas mediante software en substitución del humano. Un programa puede generar, transportar, transformar y ofrecer la información a las personas, pero la máquina sencillamente no sabe lo que esta información significa, y por tanto se limita su capacidad de actuación autónoma. Esta limitación hace que la noción de semántica que manejan los buscadores web se limite a palabras clave con pesos, pero planas e inconexas, lo que no permite reconocer ni solicitar significados más elaborados. [Castells, Pl