UNIVERSIDAD TÉCNICA PARTICULAR DE LOJA
La Universidad Católica de Loja
TITULACIÓN DE INGENIERO EN SISTEMAS INFORMÁTICOS
Y COMPUTACIÓN
Visualización de redes de colaboración a partir de datos abiertos en
twitter aplicando técnicas de Análisis de Redes Sociales
Trabajo de fin de titulación.
Autor:
Mercy Elizabeth Jiménez Pacheco
Director:
Ing. Nelson Oswaldo Piedra Pullaguari
Loja-Ecuador
CERTIFICACIÓN
Ingeniero.
Nelson Oswaldo Piedra Pullaguari.
DIRECTOR DEL TRABAJO DE FIN DE TITULACIÓN
C E R T I F I C A:
Que el presente trabajo, denominado: “Visualización de redes de colaboración a partir de datos abiertos en twitter aplicando técnicas de Análisis de Redes Sociales” realizado por el profesional en formación: Mercy Elizabeth Jiménez Pacheco; cumple con los requisitos establecidos en las normas generales para la Graduación en la Universidad Técnica Particular de Loja, tanto en el aspecto de forma como de contenido, por lo cual me permito autorizar su presentación para los fines pertinentes.
Loja, Abril de 2013
f) ………..
CESIÓN DE DERECHOS
“Yo, Mercy Elizabeth Jiménez Pacheco, declaro ser autor del presente trabajo y eximo expresamente a la Universidad Técnica Particular de Loja y a sus representantes legales de posibles reclamos o acciones legales.
Adicionalmente declaro conocer y aceptar la disposición del Art. 67 del Estatuto Orgánico de la Universidad Técnica Particular de Loja que su parte pertinente textualmente dice: “Forman parte del patrimonio de la Universidad la propiedad intelectual de investigaciones, trabajos científicos o técnicos y tesis de grado que se realicen a través, o con el apoyo financiero, académico o institucional (operativo) de la universidad”.
DEDICATORIA
El presente trabajo está dedicado de manera especial primeramente a Dios por regalarme la vida y la oportunidad de tomar este camino lleno de expectativas y deseos de triunfar; A mis padres y hermanos por darme su apoyo incondicional y la fortaleza que necesito para seguir adelante.
A todos mis profesores por brindarme sus conocimientos, a mis compañeros y amigas quienes me han ayudado en esta etapa de culminación.
AGRADECIMIENTO
Mi agradecimiento y gratitud a Dios y a mis padres por apoyarme e inculcarme
valores para mi formación como persona, a mis profesores por impartir su conocimiento
y formarme como profesional, en especial al Ing. Nelson Piedra, director de tesis, quién
me ha compartido su conocimiento y guiado durante el desarrollo de esta ardua tarea de
investigación.
A todos los miembros del departamento de investigación de Ciencias de la
Computación y Electrónica, quienes me han brindado su apoyo en esta etapa de
investigación.
Gracias a mis amigos y amigas Iliana, Andrea, María Fernanda, Rodrigo, Cristian,
por dejarme muchos recuerdos felices en mi vida.
INDICE GENERAL DE CONTENIDOS
1 Problemática y Trabajos Relacionados ... 14
1.1 Problemática ... 14
1.2 Justificación ... 14
1.3 Objetivos ... 15
1.4 Resultados obtenidos ... 15
1.5 Hipótesis ... 15
1.6 Trabajos Relacionados en SNA ... 16
1.7 Trabajos relacionados con el estudio de Twitter ... 17
1.8 Trabajos relacionados con Recomendaciones ... 17
Recomendación basada en filtrado colaborativo con Análisis de redes sociales... 17
2 Estado del Arte ... 19
2.1 Análisis de Redes Sociales ... 19
2.2 Tipos de redes sociales ... 19
2.3 Métricas de Análisis de Redes Sociales ... 21
2.3.1 Cohesión ... 21
2.3.2 Centralidad ... 21
2.3.3 Hubs y Autoridades ... 25
2.3.4 Componentes y Comunidades... 26
2.3.5 Algoritmos utilizados por la medidas de SNA ... 28
2.3.6 Page Rank ... 30
2
2.4.1 Muestreo bola de nieve ... 30
2.4.2 Muestreo de nodo ... 31
2.4.3 Muestreo de enlace ... 31
2.5 Medidas de Similitud ... 31
2.5.1 Distancia Euclídea ... 31
2.5.2 Similitud del coseno ... 31
2.5.3 Pearson ... 32
2.5.4 Coeficiente de Jaccard ... 32
2.6 Herramientas de Visualización ... 32
2.6.1 NodelXL ... 34
2.6.2 Ucinet ... 35
2.6.3 Gephi ... 35
2.7 Funcionamiento de Twitter ... 37
2.7.1 Operaciones que se realizan en twitter. ... 38
2.7.2 Metadatos de un Tweet ... 39
2.7.3 Tratamiento de la información ... 41
2.7.4 Identificación de datos dentro del contenido del tweet ... 42
2.7.5 Identificación de datos a partir del enlace (Links) ... 44
2.7.6 Identificación de datos del Usuario de twitter ... 46
2.7.7 Herramientas de Extracción de datos. ... 47
3 Extracción de datos ... 51
3
3.2 Conjunto de datos ... 51
3.3 Arquitectura del agente ... 51
3.3.1 Extracción de datos basado en expresiones regulares ... 52
3.3.2 Extracción de datos mediante Scrapy ... 55
3.4 Almacenamiento de datos ... 57
4 Análisis y Visualización ... 61
4.1 ¿Cuáles son las cuentas más mencionadas en opendata? ... 62
4.1.1 Procesamiento de datos ... 62
4.1.2 Medida de distancia ... 68
4.1.3 Análisis ... 70
4.1.4 Interpretación de resultados ... 73
4.2 ¿A quienes seguir en Twitter en el contexto de opendata?... 74
4.2.1 Procesamiento de Datos ... 74
4.2.2 Análisis ... 82
4.2.3 Interpretación ... 85
4.3 RESULTADOS ... 87
4.3.1 Resultados de la recomendación de usuarios a seguir en opendata ... 87
4.3.2 Resultados de las cuentas más mencionadas ... 88
5 Discusión, Conclusiones, Recomendaciones, Trabajos Futuros ... 89
5.1 DISCUSIÓN ... 89
5.2 CONCLUSIONES ... 91
4
5.4 TRABAJOSFUTUROS ... 94
5.5 REFERENCIAS ... 95
5.6 Anexo A ... 99
5.6.1 Resultados de las cuentas más mencionadas ... 107
5.7 Anexo B ... 110
5.8 Anexo C ... 111
5
ÍNDICE DE FIGURAS
Figura. 1 Interacción de las Universidades asociadas a Universia ... 16
Figura. 2 Red de usuarios de twitter ... 22
Figura. 3 Páginas destacadas como Hubs y Autoridades (CORNELL University)... 26
Figura. 4 Algoritmo de Girvan Newman (Newman) ... 28
Figura. 5 Recorrido primero en anchura (Tsvetovat & Kouznetsov, 2011) ... 28
Figura. 6 Recorrido primero en profundidad (Tsvetovat & Kouznetsov, 2011) ... 29
Figura. 7 Algoritmo de Dijkstra, camino mínimo (Matemáticas, 2010) ... 29
Figura. 8 Recorrido del grafo para encontrar el peso mínimo (Matemáticas, 2010) ... 30
Figura. 9 Funcionamiento del PageRank (Analítica Web, 2011) ... 30
Figura. 10 Herramientas de visualización y sus características (Combe, Largeron, Egyed-Zsigmond&Géry.2010) ... 33
Figura. 11 Visualización de usuarios de twitter en NodeXL ... 34
Figura. 12 Cálculo de medidas de SNA en NodeXL ... 34
Figura. 13 Visualización en Ucinet ... 35
Figura. 14 Visualización en Gephi ... 36
Figura. 15 Funcionamiento de twitter... 37
Figura. 16 Estadísticas del uso de twitter por país (Latorre, febrero 2012) ... 38
Figura. 17 Diferentes formas de estructurar un tweet. ... 39
Figura. 18 Base de datos Crawler ... 40
Figura. 19 Campos seleccionados de la base para el tratamiento de la información. ... 42
6
Figura. 21 Identificación de texto ... 43
Figura. 22 Identificación de la mención. ... 43
Figura. 23 Composición de una URL ... 44
Figura. 24 Identificación de datos ... 45
Figura. 25 Biografía del usuario Open data en twitter.(Twitter, 2012) ... 46
Figura. 26 Arquitectura del agente para la extracción de datos ... 52
Figura. 27 Expresión Regular para extraer la fecha. ... 53
Figura. 28 Identificación del texto que extrae el agente ... 56
Figura. 29 Identificación de la licencia en el código html mediante Scrapy. ... 56
Figura. 30 Scrapy para extraer el titulo de la pagina ... 56
Figura. 31 Detección del idioma del tweet ... 57
Figura. 32 Almacenamiento, datos del contenido del tweet ... 58
Figura. 33 Almacenamiento datos del usuario... 59
Figura. 34 Esquema general para análisis mediante SNA. ... 61
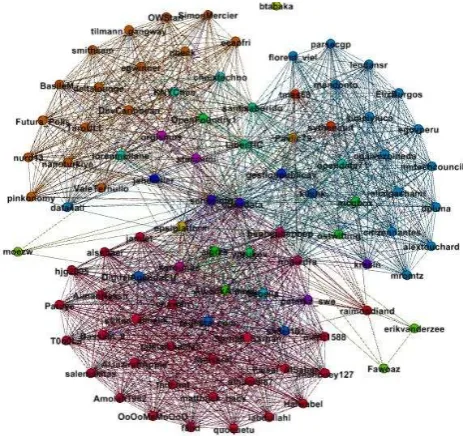
Figura. 35 Topología de usuarios y menciones que interactúan en opendata ... 63
Figura. 36 Identificación de subgrafos dentro de la red ... 63
Figura. 37 Subgrafo de la comunidad 182 ... 63
Figura. 38 Subgrafo de díadas ... 64
Figura. 39 Subgrafo de tríadas ... 64
Figura. 40 Usuarios más destacados por grado de entrada ... 65
Figura. 41 Menciones con un alto nivel de PageRank ... 65
7
Figura. 43 Lista de cuentas más mencionadas por PageRank ... 66
Figura. 44 Matriz de usuarios y menciones (tabla “menciones”)... 68
Figura. 45 Suma de menciones( llamada "menciones")... 68
Figura. 46 Matriz transpuesta de usuarios y menciones “mencion_invert” ... 69
Figura. 47 Matriz de distancias entre menciones (“mencion_cos”) ... 69
Figura. 48 Calculo del percentil sobre la matriz de distancias ... 70
Figura. 49 Red de usuarios clasificada por comunidades ... 71
Figura. 50 Detección de menciones mediante métrica de autoridad ... 71
Figura. 51 Detección de usuarios mediante centralidad de intermediación ... 72
Figura. 52 Detección de usuarios relevantes mediante centralidad de cercanía ... 72
Figura. 53 Red de usuarios vinculados a hashtags ... 74
Figura. 54 Filtro por grado de entrada ... 75
Figura. 55 Clasificación de nodos por grado de entrada ... 75
Figura. 56 Usuarios con cero enlaces ... 76
Figura. 57 Hashtag más utilizados en opendata ... 76
Figura. 58 Diagrama de red por grado de entrada ... 77
Figura. 59 Identificación de usuarios más significativos en opendata ... 77
Figura. 60 Clasificación de hashatg por PageRank ... 78
Figura. 61 Matriz de usuarios clasificados de acuerdo a hashtag ... 79
Figura. 62 Suma de usuarios que tomaron etiquetas... 79
Figura. 63 Matriz transpuesta ... 80
8
Figura. 65 Filtrado de usuarios destacados en opendata. ... 81
Figura. 66 Vecinos más cercanos entre usuarios. ... 81
Figura. 67 Resultados de las métricas de SNA ... 82
Figura. 68 Red de usuarios más destacados en opendata ... 82
Figura. 69 Detección de comunidades en la red de usuarios ... 83
Figura. 70 Usuarios intermediarios en la red de opendata. ... 83
Figura. 71 Usuarios más cercanos a toda la red ... 84
Figura. 72 usuarios centrales por grado ... 84
Figura. 73 Usuarios más significativos mediante PageRank. ... 85
Figura. 74 usuarios destacados para seguir en el tema de opendata ... 87
Figura. 75 menciones destacados para seguir en el tema de opendata ... 88
Figura. 76 usuarios destacados para seguir en el tema de opendata ... 107
9
ÍNDICE DE TABLAS
Tabla 1 Clasificación de usuarios por grado del grafo dirigido de la ... 22
Tabla 2 Cálculo de la centralidad de grado nodal ... 23
Tabla 3 Cálculo de la medida de centralidad de cercanía ... 24
Tabla 4 Cálculo de centralidad de intermediación ... 24
Tabla 5 Nodos puente de la centralidad de intermediación ... 25
Tabla 6 Estructuras de subgrupos Tomado de (Borgatti, 2003) ... 27
Tabla 7 Metadatos de un tweet ... 40
Tabla 8 Selección de los metadatos más relevantes de un tweet... 41
Tabla 9 Tipos de acortadores de URL ... 44
Tabla 10 Parámetros de búsqueda de listas en twitter ... 46
Tabla 11 Métodos para extracción de datos ... 52
Tabla 12 Expresión Regular para URLs ... 54
Tabla 13 Expresión Regular para hashtags ... 54
Tabla 14 Expresión Regular para identificar menciones ... 54
Tabla 15 Expresión Regular para descripción del tweet ... 54
Tabla 16 Expresión regular para extraer licencia ... 55
Tabla 17 Extracción de datos con Scrapy ... 55
Tabla 18 Transformación de formato de fecha ... 57
Tabla 19 Metadatos de los tweets ... 57
Tabla 20 Datos extraídos de la url ... 58
10
Tabla 22 Dataset de experimentación ... 62
Tabla 23 Conjunto de menciones seleccionadas para el análisis matricial ... 67
Tabla 24 Conjunto de usuarios seleccionados para el análisis matricial. ... 67
Tabla 25 Selección de datos para el experimento. ... 67
Tabla 26 Resultados de las métricas de SNA aplicadas a la red de cuentas mencionadas ... 73
Tabla 27 Conjunto de datos ... 74
Tabla 28 Conjunto de datos de Experimento ... 79
Tabla 29 Resultados de las métricas de SNA aplicado a usuarios ... 85
Tabla 30 Usuarios recomendados mediante métricas de SNA en opendata. ... 87
11
RESUMEN EJECUTIVO
12
INTRODUCCIÓN
Las redes sociales han tomado ventaja frente a la necesidad de las personas por comunicar, colaborar, pertenecer a un grupo o comunidad. La web hoy en día facilita la relación mediante el uso de aplicaciones que funcionan como mediadoras en la comunicación donde las personas interactúan entre si aún sin conocerse, comparten recursos que generan gran cantidad de información expuesta en la web que puede ser estudiada con el fin de darle un significado y una plena utilización. El análisis de redes sociales se enfoca al estudio del comportamiento de las personas con el fin de identificar patrones que caractericen a una comunidad. Lin Freeman dice «El análisis de redes se basa en la noción intuitiva de que estos patrones son características importantes de la vida de los individuos que los vean. El análisis de redes sociales utiliza el modelo matemático basado en grafos y de visualización para el estudio de la información.
El objetivo de este proyecto es valorar y visualizar el impacto de las relaciones entre los usuarios de twitter y encontrar patrones sociales que permitan establecer recomendaciones de usuarios a seguir e identificar las cuentas más mencionadas en el contexto de opendata. La solución que se plantea es construir un agente que extraiga información del contenido de los tweets mediante las técnicas de expresiones regulares y Scrapy, una vez de contar con un conjunto de datos, es necesario determinar la rasgos similares entre usuario para poder recomendar, para ello se aplica método de vecindad basado en la cercanía como es la similitud de coseno de acuerdo a los resultados obtenidos se visualiza los datos en Gephi, mediante las métricas de SNA se prioriza la recomendación de usuarios a seguir en el dominio de opendata
La solución se cumple a través de los 4 capítulos que se plantea en este trabajo. En el primer capítulo se establece la problemática, justificación, objetivos y la hipótesis, trabajos relacionados. En el segundo capítulo contiene el marco teórico donde se estudia las métricas de análisis de redes sociales, métodos de similitud, algoritmos de SNA, herramientas de visualización y estructura de twitter. En el capítulo tres se realiza la extracción de datos mediantes la técnica de expresiones regulares aplicada sobre el contenido de los tweet, y la técnica de Scrapy para extraer información web a partir de la url. El cuarto capítulo describe el análisis de los datos extraídos y los patrones estadísticos encontrados en la diagramación de redes, se establece un nivel de recomendación de usuarios y cuentas más populares mediante la aplicación de SNA.
13
14
1
Problemática
y Trabajos Relacionados
1.1
Problemática
El contexto de opendata es una filosofía que abarca diferentes ámbitos de la ciencia por cuanto es un tema que está en auge y se habla mucho en la rede social de twitter; gran cantidad de usuarios en twitter buscan a quien seguir de acuerdo a su afinidad por la información, en base a esta necesidad se plantea aplicar métricas de SNA con la finalidad de encontrar redes de colaboración entre usuarios que expresados mediante patrones estadísticos permitan recomendar cuentas a seguir e identificar las más mencionadas.
1.2
Justificación
15
1.3
Objetivos
General
Valorar y visualizar el impacto de las relaciones sociales extraídas de la red social twitter y establecer recomendaciones de usuarios en base a las medidas de SNA.
Específico
Estudiar las métricas de análisis de redes sociales y de recomendación.
Extracción de información del contenido de los tweets en el contexto de opendata
Obtener patrones e indicadores en opendata para medir impactos y establecer recomendaciones.
1.4
Resultados obtenidos
Los primeros resultados esperados son los datos extraídos por el agente para luego pasar a la fase de análisis donde se aplican las medidas de SNA sobre el conjunto de datos de manera que se pueda encontrar patrones estadísticos y visuales para recomendar usuarios en base a los hashtag usados en los tweets, además se espera encontrar patrones que determinen las cuentas más mencionadas en el contexto de opendata.
1.5
Hipótesis
Twitter se ha convertido en una red social muy difundida y utilizada para publicar temas de interés, mantiene estructurada su información, en este trabajo nos centraremos en el contexto de opendata tomando los tweets que se etiquetan con esta palabra, lo que se pretende es recomendar usuarios a seguir respecto al tema e identificar las cuentas más mencionadas. Mediante la metodología de Análisis de redes sociales se buscará medir el impacto del tema y establecer recomendaciones.
16
1.6
Trabajos Relacionados en SNA
Derntl and Klamma, (2012) En su investigación realizan un estudio de los proyectos financiados por la comisión Europea, los proyectos son FP6 (Framework Programmes), FP7 y eContentplus, La comisión Europea desea conocer el impacto generado por los proyectos, para ello aplicaron análisis de redes sociales sobre los metadatos del proyecto que se han obtenido de diferentes sitios web, incluyendo blogs, bibliografías y hojas informativas del proyecto de un total de 77 proyectos . Las principales conclusiones son que las redes de excelencia y proyectos integrados tienen el mayor impacto en la red del proyecto; eContentplus que era un puente entre la financiación del 6FP y el 7FP, y que la red de colaboración muy unida puede inhibir la asimilación de nuevas organizaciones e ideas en la comunidad TEL.
Otro trabajo de SNA que se realizó es un estudio para medir el nivel de interacción entre las universidades asociadas a Universia y los cursos que brindan, el objetivo es determinar el nivel de colaboración que existe entre las universidades, la visualización se realizó con una base de datos de 1551 nodos y se encontraron 3453 aristas. Se calculó las medidas de centralidad de intermediación con el fin de encontrar los nodos con mejor posicionamiento tienen en la red. Se obtuvo los que pertenecen a la Universidad de Juan Carlos III, Universidad Politécnica de Madrid. La centralidad de cercanía, para identificar grupos que están más expuestos a cierta información que circule por la red de hecho se logró identificar las universidades más aisladas como la UDEM, San Pablo CEU, Politécnica de Catalunya. La densidad encontrada fue de 0.001 comparado con el valor máximo de 1, nos advierte el nivel bajo de comunicación entre las mismas universidades asociadas y los recursos que comparten.
17
1.7
Trabajos relacionados con el estudio de Twitter
Ming, 2012 En este trabajo estudia el contexto de críticas de cine en Twitter y compara la opinión de los usuarios de Twitter con la de la población en línea de IMDb y Rotten Tomatoes. Se introduce una nueva métrica para demostrar que los usuarios de Twitter pueden ser característicamente diferentes de los usuarios en general, tanto en su clasificación y su relación de preferencia por las películas nominadas al Oscar y las no nominadas. Además, se investiga si estos datos pueden realmente predecir la película más taquillera.
1.8
Trabajos relacionados con Recomendaciones
Recomendación basada en filtrado colaborativo con Análisis de redes sociales.
18
19
2
Estado del Arte
2.1
Análisis de Redes Sociales
La teoría de redes sociales surge en base a estudios realizados con fines matemáticos, psicología, sociológica, antropología. Gestalt y Kurtt Lewin estudiaron el comportamiento de los individuos en grupo, así como la estructura del grupo. Moreno y su sociometría contribuyó con el estudio hacia la estructura de los grupos de amigos, por ello se lo considera como el fundador de la teoría de redes.
Las redes sociales brindan un servicio abierto a todo ente y en algunas de ellas la relación está definida por el software, por ejemplo Facebook (Una red social es un conjunto finito de actores como individuos, grupos, organizaciones, comunidades, sociedades, que están vinculados unos a otros a través de una relación o un conjunto de relaciones sociales. (Mitchel, 1969), Twitter (seguidores); la vinculación entre las mismas van formando comunidades.
El análisis de redes sociales, es una metodología de enfoque analítico compuesto por conceptos, métodos descriptivos y predictivos; centrando su idea en lo que la gente siente, piensa y actúa, estas acciones caracterizan a una estructura social, al cual está vinculada, proporcionando información que denote la tendencia por ciertas características en común dentro de la misma red. “Se pueden dar diversas maneras de formalizar y medir datos en el análisis de redes sociales, las dos más importantes son teoría de grafos, matricial.” (Lozares, 1996).
La literatura señala que en las redes sociales existen cuatro niveles de análisis: el primer nivel es la red egocéntrica, que consiste en cada actor individual, todos aquellos con los cuales tiene relación y las relaciones entre ellos; cada actor es un ego. [Granovetter, 1973, Hanneman 2000, Molina 2005, Rodríguez 2005]. El segundo nivel es la red diádica, formada por un par de actores; la cuestión central en este caso es si existe o no una relación directa entre dos actores. El tercer nivel es la red triádica, formada por tres actores. Por último, en la red completa (o sistema) se usa toda la información acerca de pautas de relaciones entre todos los actores, para averiguar la existencia de posiciones y describir las relaciones entre esas posiciones (Lugo, 2009).
2.2
Tipos de redes sociales
20
Redes basadas en su tamaño: dependen del diámetro de la red, dicho valor
dependerá de lo que se quiera representar con la información.
o
Redes a pequeña escala: son analizadas por la mayoría de los sistemas para
visualización de redes y se utilizan para conjunto de datos complejos de
analizar.
o
Redes a gran escala: son más complejas y las mediciones se basan en una
proporción representativa de la red.
Redes basadas en la evolución: depende de los cambios que sufre la red a través del
tiempo, generalmente son redes de cualquier tamaño y forma.
o
Redes estáticas: no sufren alteración al ser estudiadas y mantienen su
estructura.
o
Redes dinámicas: sufren cambios por eliminación e incorporación de actores
y las relaciones entre ellos.
Redes basadas en su origen: depende de los datos fuente.
Redes fuera de línea: (off-line) si las relaciones sociales se establecen sin un medio
electrónico.
Redes en línea: (on-line) dependen altamente de medios electrónicos y están sujetas
a la tecnología de los sistemas.
Redes basadas en su topología: depende de la complejidad de la red.
o
Redes simples: son estructuras que pueden ser analizadas mediante
conceptos básicos de teoría de grafos.
o
Redes complejas: presentan propiedades no triviales, este tipo de redes se
basa en el estudio de redes de mundo real.
o
Redes de mundo real: representan situaciones de la vida cotidiana, modelan
comportamientos de la sociedad y la forma que interactúan en situaciones
reales.
Redes sociales en línea: están en los sitios mas importantes dela web, generan
tráfico en internet.
21
Redes completas: (Complete Network) consiste en la conexión de una sola
comunidad limitada.
Redes egocéntricas: (Ego-Network) son subredes que se conectan a un nodo central
[Tsvetovat & Kouznetsov, 2011].
2.3
Métricas de Análisis de Redes Sociales
Las medias de análisis de redes sociales ayudan a identificar patrones característicos de la vida de las personas mediante su comportamiento en la red a la que pertenece, una relación entre individuos se puede dar tanto a nivel de díadas, tríadas así como grupos y redes complejas Para el cálculo de estas medidas, se derivan algunos algoritmos que facilitan de manera rápida el proceso de la información, las medidas de centralidad buscan encontrar los actores más activos en una red social.
2.3.1
Cohesión
Es una fuerza de atracción entre los individuos, que puede ser medida por el número de intercambios entre dos actores, el promedio de las distancias geodésicas, el tamaño de la red, etc. (Reffay & Chanier, 2003).
Densidad
: La densidad de la red nos muestra la alta y baja conectividad de la red, expresada en porcentaje como el cociente entre el número de relaciones activas con las posibles (Velasquez & Aguilar, 2005).Diámetro de la red
: Es la máxima distancia, el mayor valor de los geodésicos de la red.
Distancia promedio en la red: promedio de las distancias más cortas entre pares de nodos.Número de pares no alcanzables: el número de pares de actores entre los cuales no existen un camino para llegar desde uno hasta el otro. Un número alto indica falta de conexiones en la red. (Navarro & Salazar, 2007).
2.3.2
Centralidad
22
2.3.2.1
Centralidad de Grado
Es el número de enlaces que un nodo tiene con otros nodos, es la suma de sus pesos. (Economo & Keitt, 2009). El grado nodal indica un índice de exposición que está circulando a través de la red.
En la figura 2, se aprecia una red de 10 usuarios que comparten información de su curso de maestría a través de su cuenta de Twitter, mediante esta red se puede demostrar el cálculo de las medidas de análisis de redes sociales como: centralidad de grado, intermediación, cercanía, densidad.
Figura. 2 Red de usuarios de twitter
Elaboración: Mercy Jiménez, Susana Guasha.
Tabla 1 Clasificación de usuarios por grado del grafo dirigido de la
Nodo Grado de Entrada (in degree)
Grado de Salida (out-degree)
Grado Nodal (Degree)
a 3 0 3
b 5 1 6
c 1 1 2
d 1 1 2
e 3 2 5
f 0 2 2
g 1 2 3
h 0 2 2
N k k i iD
p
a
p
p
C
1
,
(1)
23
i 0 1 1
J 0 2 2
En la tabla 1 muestra el grado de entrada y salida para la red de la grafica Tabla 2 Cálculo de la centralidad de grado nodal
Nodo a b c d e f g h i j Grado Nodal (Degree) No dirigido a 0 1 2 1 2 1 2 2 3 2 16
b 1 0 1 2 1 1 1 1 2 1 11
c 2 1 0 2 1 2 2 2 2 3 17
d 1 2 3 0 3 2 2 3 4 1 21
e 2 1 1 3 0 2 1 1 1 2 14
f 1 1 2 2 2 0 2 2 3 3 18
g 2 1 2 2 1 2 0 2 2 1 15
h 2 1 2 3 1 2 2 0 2 3 18
i 3 2 2 4 1 3 2 2 0 3 22
j 2 2 3 1 2 3 1 3 3 0 20
Así la Centralidad de Grado Nodal determina el número de vínculos relacionados con un nodo dado. Al tener más vínculos un actor, mayor será su oportunidad de lograr su propósito debido a su posición ventajosa. [Hanneman, 2005].
2.3.2.2
Centralidad de Cercanía
Es la medida de la posición de un nodo en relación con el resto de la red, generalmente calculado como la distancia media entre un nodo y todos los demás nodos. (Economo & Keitt, 2009). Los actores capaces de alcanzar a otros en longitudes de caminos más cortos calculando la distancia promedio al resto de la red es el más central por lo tanto tienen posiciones favorables. Matemáticamente, se representa como el inverso a la suma de las distancias, o sea, donde di j es la distancia entre el actor i y el actor j.
N k k i i Cp
p
d
N
p
C
1,
1
(2)24
Tabla 3 Cálculo de la medida de centralidad de cercanía Nodos a b c d e f g h i gjk Centralidad
de cercanía a 0 1 2 1 2 1 2 2 3 14 0,61
b 1 0 1 2 1 1 1 1 2 10 0,90
c 2 1 0 3 1 2 2 2 2 15 0,60
d 1 2 3 0 3 2 2 3 4 20 0,45
e 2 1 1 3 0 2 1 1 1 12 0,75
f 1 1 2 2 2 0 2 2 3 15 0,60
g 2 1 2 2 1 2 0 2 2 14 0,64
h 2 1 2 3 1 2 2 0 2 15 0,60
i 3 2 2 4 1 3 2 2 0 19 0,47
j 2 2 3 1 2 3 1 3 3 20 0,45
2.3.2.3
Centralidad de Intermediación
Intermediación es la proporción de las rutas más cortas entre todos los actores en el grupo que van a través de un actor dado, un actor tiene centralidad particularmente alto si es el único puente entre los dos subgrupos. (Sih, Hanser, & McHufh, 2009).
Para calcular los nodos puentes previamente se requiere la centralidad de intermediación de cada nodo como se expresa en la tabla 4.
Tabla 4 Cálculo de centralidad de intermediación
Nodo A b c d e f g h i gjk
1 1 j k jk i jkg
p
g
1 1 1 j k jk i jk N jg
p
g
a 0 1 2 1 2 1 2 2 3 14 11,00 0,82
b 1 0 1 2 1 1 1 1 2 10 15,40 0,58
c 2 1 0 3 1 2 2 2 2 15 10,27 0,88
d 1 2 3 0 3 2 2 3 4 20 7,70 1,17
e 2 1 1 3 0 2 1 1 1 12 12,83 0,70
f 1 1 2 2 2 0 2 2 3 15 10,27 0,88
g 2 1 2 2 1 2 0 2 2 14 11,00 0,82
1 1 1 j k jk i jk N j i Bg
p
g
p
C
(3)25
h 2 1 2 3 1 2 2 0 2 15 10,27 0,88
i 3 2 2 4 1 3 2 2 0 19 8,11 1,11
j 2 2 3 1 2 3 1 3 3 20 7,70 1,17
Total 154
Los nodos puente en la red son los nodos más populares para la transmisión, son los más importantes para la transmisión de la información, a través de ellos se logra transmitir el flujo en la red.
Tabla 5 Nodos puente de la centralidad de intermediación Nodo Es puente para relacionar a:
b (c,a),(e,a),(g,a)
c (e,b)
d (j,a)
e (g,c),(i,b),(i,c),(g,b)
g (j,e)
a,f,h,i,j (ninguno)
2.3.3
Hubs y Autoridades
El concepto de Hub y authorities, fue creado por Jon Kleinberg para clasificar las páginas web de acuerdo a su número de enlaces o concurrencias que tenga. Con esta característica se puede determinar la importancia de una página web a través del análisis de sus enlaces entrantes como los contenidos de los tweets que bien podrían ser una noticia, aviso, pensamiento, respuesta a una mención, etc.
2.3.3.1
Hubs
Son todos aquellos sitios que recibiendo una buena cantidad de links, enlazan, a su vez, a numerosísimas páginas web que consideran importantes. De esta manera los sitios ‘hubs’ determinan la importancia de otros sitios. El exponente más evidente de sitio hub es el directorio DMOZ. (Valverde, 2010)
(4)
26
2.3.3.2
Authorities
Son los web referente en temas concretos. Es decir, aquellos que tienen muchos enlaces entrantes pero que, por su parte apuntan a muy pocos sitios (muy pocos enlaces salientes). (Valverde, 2010)
Los hubs, determinan la importancia de una página como recurso de enlace y los authorities valoran una página como recurso de información.
2.3.3.3
Algoritmo de HITS
Proviene de “Hypertext Induced Topic Selection” que determina dos valores de una página como la autoridad y el valor múltiple. En la autoridad se estima el valor del contenido de la página, y en el valor múltiple estima el valor de sus enlaces a otras páginas
HITS, identifica buenas autoridades y hubs para un tema mediante la asignación de dos números a una página: una autoridad y un peso de hub. Estos pesos se definen de forma recursiva. Un peso autoridad superior se produce si la página es apuntando por páginas con pesos altos hub. Un peso mayor hub se produce si la página apunta a muchas páginas con pesas Alta Autoridad. (CORNELL University)
Figura. 3 Páginas destacadas como Hubs y Autoridades (CORNELL University).
2.3.4
Componentes y Comunidades
27
2.3.4.1
Cliques
Un clique es un sub-grafo completo en que ningún nodo está directamente conectado a ningún otro nodo del sub-grafo.
2.3.4.2
Componentes
Es un grafo máximo conectado, un componente fuerte permite llegar a toda la red, aun cuando exista un solo camino en la red. (Borgatti, 2003).
Tabla 6 Estructuras de subgrupos Tomado de (Borgatti, 2003) Grupos definidos por algoritmos Grupos definidos por acraterísticas
Redes/Teoría de grafos Newman Girvan Distancia: componentes, Clique, n-clique, n-clan, n-club Densidad: Clique, k-core, k-plex, ls-set, lamba set
Proximidad/distancia Clustering Faciones
MDS Nucleo períferico
K-Means Optimización combinacional.
Para las comunidades y agrupamientos se considera los siguientes algoritmos:
2.3.4.3
Algoritmo de Propagación de Etiquetas (LPA)
Es un método rápido para la detección de comunidades en redes complejas, pone de manifiesto las comunidades de la red, identificando a cada nodo con una etiqueta única, en cada interacción, cada nodo adopta una etiqueta compartida por la mayoría de sus vecinos (teniendo en cuenta también pesos de las aristas), los nodos conectados con la misma etiqueta forman una comunidad.
2.3.4.4
Algoritmo de Girvan Newman
28
Figura. 4 Algoritmo de Girvan Newman (Newman)
La Figura. 4 representa la estructura de la comunidad de los delfines reunidos por Lusseauet. Los cuadrados y círculos denotan la división principal de la red en dos grupos y los círculos se subdividen en cuatro grupos más pequeños.
2.3.5
Algoritmos utilizados por la medidas de SNA
2.3.5.1
Primero en anchura
Usa una cola (FIFO), donde los nodos primeros visitados son los primeros expandidos, empieza por el nodo raíz, luego los sucesores del nodo raíz y así sucesivamente. (Russell & Norving, 2004).
Figura. 5 Recorrido primero en anchura (Tsvetovat & Kouznetsov, 2011)
2.3.5.2
Primero en profundidad
29
Figura. 6 Recorrido primero en profundidad (Tsvetovat & Kouznetsov, 2011)
2.3.5.3
Algoritmo Dijkstra
Este algoritmo es aplicado para encontrar las medidas de centralidad dentro de una red o grafo. El algoritmo de Dijkstra proporciona los pesos mínimos desde un vértice dado al resto de los vértices. El algoritmo devuelve solo el peso mínimo y no el camino mínimo propiamente dicho, pero permite obtener fácilmente el camino mínimo (este hecho y su eficiencia, le dan su popularidad). (Matemáticas, 2010)
Figura. 7 Algoritmo de Dijkstra, camino mínimo (Matemáticas, 2010)
30
Figura. 8 Recorrido del grafo para encontrar el peso mínimo (Matemáticas, 2010)
2.3.6
Page Rank
Estudia el flujo del page Rank que determinan la importancia de los enlaces. Y la otra parte es como trabaja page Rank, es decir cómo afectan los enlaces (Adseok Seo, 2007) en términos de grafos se determina que tan influyente es un vértice. (Gao, 2011). Este algoritmo asigna una puntuación a cada página en base a los enlaces que recibe.
Figura. 9 Funcionamiento del PageRank (Analítica Web, 2011)
2.4
Técnicas de Muestreo
Las técnicas más acordes a nuestra investigación tenemos las siguientes:
2.4.1
Muestreo bola de nieve
31
2.4.2
Muestreo de nodo
Este método consiste en seleccionar un número n de nodos de la red original aleatoriamente y posteriormente relacionarlos con los enlaces de la red inicial que existen entre los n nodos seleccionados. (Olivares, 2010)
2.4.3
Muestreo de enlace
Este método difiere del muestreo de nodo, ya que en vez de seleccionar nodos, seleccionan enlaces de manera aleatoria, para este caso no existen nodos o enlaces aislados.
2.5
Medidas de Similitud
La medida de similitud se requiere para determinar la cercanía entre dos actores, etc. Muchas de las medidas de similitud se han derivado para describir la proximidad de dos vectores; entre estas medidas la similitud del coseno es más ampliamente utilizada. En los sistemas de recomendación basados en contenido que dependen tanto del perfil de usuario y de elementos como vectores ponderados.
2.5.1
Distancia Euclídea
Es la distancia clásica como la longitud de la recta que une dos puntos en el espacio Euclídeo. Esta similitud viene de la matriz de adyacencia. Más específicamente, cada nodo se trata como un punto en el espacio euclidiano, cuyas coordenadas son dadas por una fila (o columna) de la matriz de adyacencia. La distancia entre dos puntos en el espacio que es proporcional al número de vecinos comunes compartidos entre los nodos. (Tsvetovat & Kouznetsov, 2011)
2.5.2
Similitud del coseno
Se utiliza a menudo cuando se comparan dos documentos uno contra el otro. Se mide el
ángulo entre los dos vectores. Si el valor es cero, el ángulo entre los dos vectores es de
90 grados y no comparten términos. Si el valor es 1, los dos vectores son iguales,
excepto para las magnitudes. Coseno se utiliza cuando los datos son escasos, asimétrico
y existe una similitud de las características que carecen (Segaran, 2007)
n k k sy
x
y
x
d
1 2)
(
)
,
(
(5)32
2.6
Herramientas de Visualización
La visualización de las redes sociales sirve como método para descubrir propiedades
en las redes, aunque tiene menos peso teórico en el análisis, pero tiene la ventaja de
alimentar rápidamente la intuición del investigador. (Moreno, 2008).
2 2
.
)
,
(
ki k ki k kj ki kw
w
w
w
dj
di
sim
(6)Donde W, es el nodo que representa el grafo; ki recorrido de las filas, Kj Recorrido de las columnas
2.5.3
Pearson
Mide la fuerza y la dirección de la relación lineal entre dos variables. El valor es siempre entre [-1, 1], donde 1 es fuerte relación positiva, 0 hay relación y -1 es una correlación negativa fuerte. Es el coeficiente de correlación más ampliamente utilizado y funciona muy bien cuando todo es lineal, pero no con curvilínea. ( Segaran, 2007) Espinosa y López (1997) afirman que este coeficiente se emplea cuando los objetos que hay que clasificar son variables. Seber (1984) anota que con variables cuantitativas, el coeficiente de correlación es una medida de similitud entre las muestras x y y.
2.5.4
Coeficiente de Jaccard
33
Figura. 10 Herramientas de visualización y sus características (Combe, Largeron, Egyed-Zsigmond&Géry.2010)
De acuerdo a las necesidades que se enfocan los tipos de análisis, se han creado un
sinnúmero de herramientas y librerías que aportan al análisis de redes sociales, frente a
las ventajas descritas en la figura 11 se citan algunas otras herramientas adicionales que
por sus ventajas son estudiadas.
A continuación se citan algunas otras herramientas y algunas de sus características de
cada una de ellas contienen.
34
2.6.1
NodelXL
NodeXL es una herramienta libre de código abierto con plantilla para Microsoft ®
Excel ® 2007 y 2010, que hace que sea fácil de explorar gráficos de redes . Con
NodeXL, se puede introducir una lista de nodos de la red en una hoja de cálculo. Tiene
la característica calcular las medidas de SNA centralidad de grado, centralidad de
intermediación, centralidad de cercanía, centralidad vector propio, PageRank,
coeficiente de agrupamiento, la densidad del grafo, también trabaja identificando
subgrupos (NodeXL, 2011)
Figura. 11 Visualización de usuarios de twitter en NodeXL
Elaboración: Mercy Jiménez y Susana Guasha
Esta herramienta contiene una tabla de aristas y nodos que almacena el cálculo de las
métricas de análisis de redes sociales como centralidad de grado, intermediación,
Eigenvector, PageRank.
Figura. 12 Cálculo de medidas de SNA en NodeXL
35
2.6.2
Ucinet
UCINET es desarrollado por Steve Borgatti, Everett Martin Freeman y Lin. El
programa se distribuye por las tecnologías analíticas. Se trabaja en conjunto con el
programa gratuito llamado Netdraw para visualizar redes, que se instala
automáticamente con UCINET. Este tipo de software puede procesar, leer y escribir una
gran cantidad de archivos de texto con formato diferente, así como archivos de Excel y
manejar un máximo de 32.767 nodos (con algunas excepciones), aunque en términos
prácticos, muchos procedimientos demasiado lentos alrededor de 5.000-10.000 nodos.
Medidas de centralidad, la identificación, el análisis de subgrupos papel, teoría de
grafos permutación elemental, basada en el análisis estadístico, y otras medidas de SNA
se puede realizar en el software. (Furth, 2011)
h Figura. 13 Visualización en Ucinet
Elaboración: Mercy Jiménez y Susana Guasha .
2.6.3
Gephi
36
[image:41.595.185.417.120.338.2]datos; creación de cartografía con el fin de poder visualizar sólo un conjunto de datos que en realidad sea de interés (Meluni, 2011).
Figura. 14 Visualización en Gephi
37
2.7
Funcionamiento de Twitter
La web es rica en información de manera ilimitada, sobre todo si se habla de las redes
sociales que diariamente se están alimentando de información que el usuario
proporciona debido a que está profundamente influido en la compartición de recursos
por sus gustos, la relación con sus amigo o cuestiones de trabajo. Twitter es una de las
redes sociales más destacadas para encontrar patrones sociales, así empezaremos el
estudio. Twitter está basado en microblogin, con millones de usuarios suscritos
denominados seguidores (follow), esta red social publica mensajes con un máximo de
140 caracteres, llamados tweet.
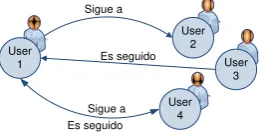
Twitter cuenta con una amplia colaboración para la difusión de información,
mediante sus servicios. La relación entre seguidores es unidireccional se describe en la
siguiente figura.
User 2
User 3
User 4 User
1
Sigue a
Es seguido
Sigue a Es seguido
Figura. 15 Funcionamiento de twitter
Elaboración: Mercy Jiménez y Susana Guasha
[image:42.595.238.368.362.430.2]38
Figura. 16 Estadísticas del uso de twitter por país (Latorre, febrero 2012)
Twitter al igual que otras redes sociales, ha sido tomada como fuente de información
para investigaciones. La información que contiene se basa en análisis del perfil de los
usuarios, y su contenido.
2.7.1
Operaciones que se realizan en twitter.
Existen tweets de estructura simples y complejos; los simples expresan la opinión en
140 caracteres o menos, los complejos incluyen además del texto estructuras
compuestas como enlace acortado, #hashtag, @mención, /via@nombre de usuario
retwitteado. A continuación se indica las principales convenciones en la estructura de un
mensaje:
Interactuar y compartir enlaces:
o
Texto + enlace acortado: comparte enlaces
o
Texto + enlace + #hashtag: compartie enlaces y hashtag
o
@Nombre del usuario + texto: interactua con otro usuario.
Hacer RT a un tweet.
o
RT + @nombre de usuario retwitteado + texto
o
RT + @nombre de usuario retwitteado + texto + enlace + #hashtag
o
texto + RT + @nombre de usuario retwitteado + texto + enlace +
#hashtag.
Otra forma de hacer RT a un tweet.
39
En la figura 15 se ilustra ejemplos de algunas de las operaciones que se puede realizar
en twitter.
Figura. 17 Diferentes formas de estructurar un tweet.
Para medir la interacción social, se toma en cuenta las actividades que realiza cada usuario, twitter almacena esa información, cada tweet es acompañado y cuenta con un conjunto básico de atributos, estos se los puede encontrar en la publicación del contenido de un tweet. Si un tweet se hace en respuesta a otro tweet, tenemos el número de identificación (ID), un 'retweet'("RT") indica si un tweet es una retransmisión de otro tweet, (DM).
2.7.2
Metadatos de un Tweet
40
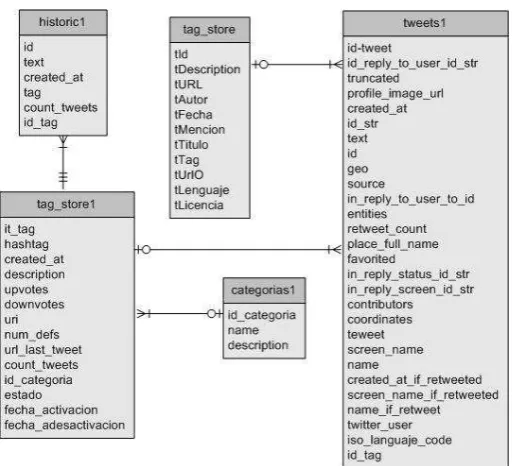
Tabla 7 Metadatos de un tweet
Para el desarrollo de este trabajo se cuenta con una base de datos denominada crawler, la misma que contiene actualmente 80 millones de tweets de diferente propósito. En la figura 18 se puede apreciar el modelo relacional de la base de datos,
su estructura consta de
5 tablas, tweets1 (contiene todos los metadatos de un tweet), categorías (cataloga los tweets de acuerdo al propósito), tag_store (información de los tags), historic (lleva un historial de tweets, como fecha de creación, conteo de tweets), cada campo en las tablas están representadas por los metadatos. [image:45.595.176.435.429.662.2]41
[image:46.595.96.500.192.436.2]Uno de los objetivos de este trabajo es filtrar un conjunto de tweets de esta base de datos con el hashtag #opendata de manera que el análisis vaya orientado a este dominio. Para la obtención de esta información se trabaja con la tabla tweets1, debido a que contiene información del tweet, no todos los campos de la tabla contienen información existen algunos campos nulos, por tanto se realiza una selección de los metadatos más relevantes descritos en la tabla 8.
Tabla 8 Selección de los metadatos más relevantes de un tweet
Metadatos
id-tweet retweet_count iso_languaje_code
id_reply_to_user_id_str place_full_name
id_tag favorited
profile_image_url in_reply_status_id_str
created_at in_reply_screen_id_str
id_str contributors
text coordinates
id teweet
geo screen_name
source name
in_reply_to_user_to_id name_if_retweet
Entities twitter_user
2.7.3
Tratamiento de la información
La información que se obtiene de la base de datos son datos en bruto, por si solos no dicen mucho en el análisis, por esta razón se opta por darle un tratamiento a cada tweet de manera que se pueda identificar y extraer toda la información necesaria para el análisis.
42
Se identifica los campos tomados de la base como: “text”, “languaje” para darle un tratamiento mediante técnicas de extracción de datos.
Figura. 19 Campos seleccionados de la base para el tratamiento de la información.
2.7.4
Identificación de datos dentro del contenido del tweet
La información que se encuentra en el contenido del tweet son hashtag,
2.7.4.1
Hashtag
Debido a que no hay hashtag oficiales en Twitter ni existe un registro # hashtag, los usuarios son libres de crear y utilizar # hashtags. No todos los hashtags # tienen significado o están destinados a ser interpretados en serio. (Weng, Lim, He, & Leung, 2010) (Moulaison and Burns, 2012) La gente usa hashtags para organizar las conversaciones en torno a un tema específico. Al hacer clic en un hashtag te lleva a los resultados de búsqueda de ese término. (Twitter, 2012)
La difusión del hashtag como tema está gobernada por la influencia de aquellos que lo utilizan (Romero, 2011). La ventaja es que ayudan a organizar la información para que pueda ser difundida y buscada de mejor manera.
Figura. 20 Identificación de hashtag
2.7.4.2
Palabras
43
Figura. 21 Identificación de texto
2.7.4.3
Mención
Una mención en un mensaje de twitter incluye la forma @nombre_de_usuario para referir al usuario deseado. Los tweets que incluyen menciones son empleados para informar al destinatario que se ha publicado un mensaje que está dirigido a él, se trata de un mensaje, en principio público y visible por cualquiera, que en el perfil del usuario destinatario irá marcado de forma especial para darle prioridad (Collado, 2011).
Figura. 22 Identificación de la mención.
2.7.4.4
Enlace (Links)
44
Figura. 23 Composición de una URL
2.7.4.5
URL Des-acortada
Un Link-acortado en Twitter característica que le permite pegar un enlace de cualquier longitud en la caja de un tweet y automáticamente se acorta a 19 caracteres. Esto hace que sea más fácil de encajar las URL largas en el límite de 140 caracteres (Twitter, 2012). Entre los servicios gratuitos más populares para acortar URL se describen en la siguiente tabla:
Tabla 9 Tipos de acortadores de URL
*
2.7.4.6
Fecha_tweet
La fecha hace referencia al día, mes y año en que fue creado el tweet, Twitter guarda
la fecha en dos formatos largos, el inconveniente que presenta es que la base de datos
donde se encuentra almacenada la fecha no trabaja con este tipo de formato, de manera
que se considera cambiar a otro formato de fecha, ver figura 24
Formato de fecha del tweet Nuevo Formato
"EEE, dd MMM yyyy HH:mm:ss Z"
"EEE MMM dd HH:mm:ss z yyyy";
DD/MM/YYYY
2.7.5
Identificación de datos a partir del enlace (Links)
La mayoría de los tweets contienen enlaces que referencian al tema que están hablando en la red social, de manera que estos enlaces son útiles para recolectar más información y
Acortador Dominio Ejemplo
Google url shortener goo.gl http://goo.gl/GpbYy Bitly bit.ly http://bit.ly/k0ijFo
TinyURL tinyurl.com http://tinyurl.com/que-es-DirIP Snipurl snurl.com http://cl.lk/que-es-DirIP
45
potenciar los ámbitos de análisis, de este recurso es importante extraer la fecha de publicación, título de la página y la licencia.
2.7.5.1
Fecha _publicación
La fecha de publicación es obtenida de la página web, hace referencia a la creación del artículo de la página, mediante esta fecha se puede determinar si el recurso es actual y el impacto que tiene en el tema. ver figura 24
2.7.5.2
Título
El título es la parte principal de una página web, proporciona un texto que describe el contenido de la página, se define mediante la etiqueta <title>. Su utilidad en el análisis es detectar los temas que más popularidad han tenido. ver figura 24
2.7.5.3
Licencia
La licencia da a conocer los lineamientos al momento de hacer uso de la información
expuesta en la web. ver figura 24
[image:50.595.124.483.402.677.2]46
2.7.6
Identificación de datos del Usuario de twitter
Para extraer información del usuario twitter lo permite a través del consumo de su API REST V1.1 para las peticiones se establece parámetros de búsqueda como ID de usuario ó screen_name.
2.7.6.1
Listas
Las listas es la mejor forma de clasificar las cuentas de acuerdo al tipo de información que publica el usuario, por ejemplo se crea la lista noticias, con las cuentas de todos los diarios de noticas online, otra puede ser trabajo, donde se incluyen las cuentas de los compañeros, tienen una gran utilidad para ahorrar tiempo de lectura permitiendo hacer una revisión selectiva de tweets. Para obtener la información de las listas el API de twitter establece parámetros de búsqueda. ver tabla 9
Tabla 10 Parámetros de búsqueda de listas en twitter
Función Descripción
Parámetros user_idID es útil para verificar si corresponde a una cuenta de usuario válida. : Retorna los resultados para el ID de usuario que se solicita, el screen_name: El nombre de cuenta del usuario, útil para verificar si un usuario válido es también un ID válido.
Petición GET
https://api.twitter.com/1.1/lists/list.json?screen_name=”twitterapi”
2.7.6.2
Bio
Twitter permite un máximo de 160 caracteres para que el usuario se describa a sí mismo, la Bio es parecido a la hoja de vida, es comparado como el identificador de quién eres, si una Bio está vacía limita el seguimiento, porque el usuario antes de seguirlo tendrá que revisar los tweets y definir si mediante la información que publica le interesa seguirlo.
47
2.7.6.3
Ubicación
La ubicación da a conocer la ciudad o país que describe dónde se encuentra el usuario de la cuenta.
2.7.7
Herramientas de Extracción de datos.
En el tratamiento de la información hace referencia a los datos que son importantes dentro del contenido de un tweet, notemos que un enlace ó vínculo dentro de un tweet da mayor puntuación debido al contenido completo que abarca sobre el tema, de manera que también se considera a un vínculo como fuente de extracción de datos, y por último tenemos la información del usuario, un usuario de twitter puede contener en su cuenta listas, biografía, ubicación seguidores, etc. se han considerado 3 formas de extraer la información; una de ellas es la técnica de expresiones regulares, Scrapy y /o consumo del API REST de twitter.
2.7.7.1
Expresiones Regulares
Expresión regular definida en teoría de autómatas es una técnica común para el análisis web, definiendo una expresión regular o patrón para manipular datos que se desea extraer. Aportan como una técnica muy práctica y flexible para el procesamiento de texto, complementando con la programación permiten analizar y realizar funciones de agregar, eliminar, aislar, el contenido que se desea.
2.7.7.2
Web Scrapy
Es una técnica basada en software que rastrea sitios web y analiza la estructura HTML, DOM y CSS, extrae automáticamente información particular de las páginas web, se centra más en la transformación de los datos no estructurados en la web, comparten un objetivo común con la web semántica, es la interacción hombre-máquina en la interacción procesamiento de texto.
Las técnicas de web Scrapy son importantes para encontrar la información pertinente de uso particular como titulo de la página, primeramente se encuentra un patrón para extraer información como:
título
autor
etiqueta
fecha
48
Hay varias herramientas que trabajan de diferentes plataformas en la extracción de datos de la web.
Scrapy (Python)
jsoup (Windows, java)
2.7.7.3
API REST
La información del usuario se puede extraer únicamente consumiendo el servicio de la API REST de twitter, mediante autenticación se puede realizar 350 peticiones caso contrario permitirá 150 peticiones.
Llamadas GET
49
CONCLUSIONES
Durante la investigación de varios métodos que se emplean para determinar la similitud y visualización de objetos se ha llegado a las siguientes conclusiones.
Para lograr el objetivo de recomendar usuarios y detectar las cuentas más mencionadas es preciso encontrar un patrón de similitud entre las variables que se atribuyen al objeto, de manera que es necesario aplicar un método que lo demuestre; El método de similitud de coseno ha sido seleccionado por sus ventajas de trabajar con matrices valoradas a diferencia de otros métodos que para la clasificación de los datos por atributo utilizan valores binarios donde 1 representa la existencia de una relación y 0 no existe relación alguna, este valoración no indica la fuerza de la relación entre los actores de la red. Otra ventaja es que se lo utiliza cuando los datos son escasos y asimétricos.
La visualización es una de las herramientas más fuertes para el investigador de manera que una buena elección de la misma aportaría con buenos resultados. Tomando en cuenta la variedad de herramientas de visualización que existen se ha seleccionado a Gephi, por ser robusta, dinámica y flexible; en su funcionalidad para la navegación, exploración y análisis de grafos, cuenta con varios algoritmos de visualización que permite manipular las estructuras, formas y colores que revelan propiedades ocultas y destaca por la interacción en tiempo real y para ello cuenta con un API Tolkit (Medrano, Ferrocal &Figuerola).
También se ha seleccionado la herramienta de NodeXL, por su ventaja de trabajar con las plantillas de Excel, facilitando el trabajo de forma directa en la transformación de una matriz a tabla de aristas y viceversa de manera que ayuda en el trabajo al momento de aplicar algún otro método u operación sobre la matriz de datos, en este caso se orienta al uso del método de similitud de coseno.
50
51
3
Extracción de datos
3.1
Open Data
El dominio de análisis va orientado al tema de opendata o datos abiertos, es una filosofía que promueve el libre acceso a los datos de manera que puedan ser utilizados, reutilizados y redistribuidos por cualquier persona o sujeto, por tanto son varias áreas de la ciencia que están aplicando esta filosofía, a continuación se citan algunos de sus dominios.
Datos abiertos de gobierno y contenido
Datos abiertos bibliográficos
Datos abiertos de la ciencia
Si varios dominios promueven esta filosofía el nivel de análisis se extiende a ser multidimensional, donde se puede detectar varios temas dentro del contexto de opendata, para ello es importante hacer un seguimiento de cada tweet mediante los atributos que desencadena cada mensaje.
3.2
Conjunto de datos
La selección del conjunto de datos se la realiza de una base de datos ya existente que ha estado extrayendo tweets de la API Search de twitter, actualmente la base de datos denominada “crawler” contiene 75 millones de tweets de todo propósito, de aquí se filtró un conjunto de 25.000 tweets con el hashtag #opendata correspondientes al año 2011-2012.
3.3
Arquitectura del agente
52
Tabla 11 Métodos para extracción de datos Métodos y servicios Datos
API REST Listas, bio, ubicación
Expresiones Regulares, Scrapy Menciones, tags, url, hashtags,fecha, titulo
El agente está creado en la plataforma java, utiliza la librería twitter4j para extraer los datos del usuario mediante el consumo del API REST, para las técnicas de Scrapy y expresiones regulares utiliza las librerías jsoup, httpcommons validator. Consume el API de Microsoft translate para detectar el idioma del tweet. Los datos obtenidos se alojan en la base de datos crawler en la tabla twittertripletas.
Figura. 26 Arquitectura del agente para la extracción de datos
3.3.1
Extracción de datos basado en expresiones regulares
Dentro de java se trabaja con regex, que hace posible manipular las cadenas de acuerdo con un patrón potencialmente muy complejo o simple. [5] Para ejecutar la siguiente expresión regular en java se consideran las siguientes funciones.
Pattern compile (String regex), Compila la expresión regular en un patrón. En java la función
find, se encarga de buscar en todo el texto cadenas que coincidan con el patrón propuesto. Las
funciones start( ) y end( ) de java toman el valor inicial de la cadena que coincide con el patrón y a su vez donde termina, de esta manera retorna la cadena deseada. Para aislar texto que esta demás se consideró usar la función de replace all( ).
find( ),Realiza los intentos para encontrar la próxima subsecuencia de la secuencia de entrada
que coincida con el patrón.
53
end( ), Devuelve el índice del último caracter.
replace all(): Sustituye la cadena determinada por el patrón con la cadena de reemplazo dado.
3.3.1.1
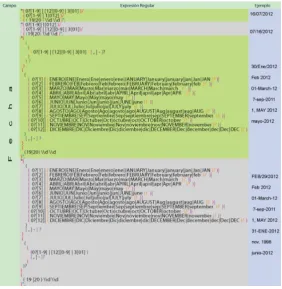
Expresión regular para extraer una fecha.
[image:58.595.157.440.307.597.2]Hay que tomar en cuenta que dentro de un tweet podemos encontrar links que nos llevan a una diversidad de recursos web, donde cada página tiene su propio estilo y formato de fecha, debido a este contexto se han formulado varios formatos de fecha para formular la expresión regular de manera que el agente logre encontrar y extraer todas las fechas coincidentes en los formatos definidos. Para la formulación del patrón se realiza un control de la fecha donde el día opcionalmente puede empezar con 0? y no puede exceder el día 31, en el mes no puede pasar de 12 meses así mismo el año solo contiene cuatro números.
Figura. 27 Expresión Regular para extraer la fecha.