Detección de Regiones de Interés en imágenes de la prueba de Papanicolaou
58
0
0
Texto completo
(2) Universidad Central “Marta Abreu” de Las Villas. Facultad de Ingeniería Eléctrica. Trabajo de Diploma. Detección de Regiones de Interés en imágenes de la prueba de Papanicolaou. Autor: Reinier Rodríguez Guillén. Tutor: Maykel Orozco Monteagudo Máster en Ciencias de la Computación, Profesor Auxiliar, CEETI, Facultad de Ingeniería Eléctrica, Universidad Central de Las Villas [email protected]. Santa Clara 2014 "Año 56 de la Revolución".
(3) Hago constar que el presente trabajo de diploma fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de estudios de la especialidad de Ingeniería en Automática, autorizando a que el mismo sea utilizado por la Institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos, ni publicados sin autorización de la Universidad.. Firma del Autor. Los abajo firmantes certificamos que el presente trabajo ha sido realizado según acuerdo de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. Firma del Tutor. Firma del Jefe de Departamento donde se defiende el trabajo. Firma del Responsable de Información Científico-Técnica.
(4) PENSAMIENTO. “Escuchamos lo que nadie ha dicho; miramos lo que nadie ve”.. KakuzoO kakura. i.
(5) DEDICATORIA Dedico este trabajo a mi mamá la cual se ha sacrificado mucho por mí y lo sigue haciendo, a mi papá y a mi abuela Marta que siempre han estado presentes. A mi abuelo fallecido Papi que siempre me apoyó. Una dedicatoria especial a mi niña Emily y a mi novia Yainet, por ser las personas que más quiero. A mi familia.. ii.
(6) AGRADECIMIENTOS Son muchas personas las personas a las que agradecerles. Si algunas no están, que me disculpen, es por mi falta de memoria. A mi esposa y bebe que me han impulsado a terminar la tesis. A mi tutor que me ha ayudado enormemente todo este tiempo, y sin el cual no habría podido terminarla. A mi oponente que me ha ayudado tanto a mi como a mi novia en las tesis .A mi mamá, papá, abuela Marta, tío Sergio, en fin, a mi familia. A mis compañeros de cuarto Supervia, Joisel, Yusniel, Damaris que me han alimentado todo este tiempo. A mis compañeros de aula Linet, Vlaky, Oto, Aniel, Patricia, Primo, Darién, Osniel, Jonay, Yayo, los animalitos, Alexander. A mis compañeros del pre Ramses, Víctor, Javier David. En fin a todas las personas que de una forma u otra me ha apoyado todo este tiempo.. iii.
(7) TAREA TÉCNICA 1. Realizar un estudio del estado del arte en técnicas de detección de anomalías en imágenes médicas. 2. Realizar un estudio de técnicas supervisadas y no supervisadas de clasificación, siempre incluyendo: Análisis discriminante. K Vecinos más cercanos. Máquinas de soporte vectorial. K-Medias. 3. Realizar una revisión bibliográfica relacionada con los descriptores de células en imágenes de la prueba de Papanicolaou. 4. Diseñar e implementar un algoritmo que determine regiones de interés en imágenes de la prueba de Papanicolaou. 5. Comparar los resultados obtenidos con otros reportados en la literatura.. Firma del Autor. Firma del Tutor. iv.
(8) RESUMEN Las Regiones de Interés son ampliamente usadas en el procesamiento digital de imágenes para la detección de anomalías u otros tipos de procesamiento. Las anomalías son pequeños objetos que son diferentes de la gran mayoría. En el presente trabajo se obtienen ROI en la prueba de Papanicolaou para su uso posterior, de detección de anomalías. Se diseñó e implementó un algoritmo con clasificadores basados en histogramas y rasgos para la detección de regiones de interés en imágenes de la prueba de Papanicolaou. Este algoritmo se probó con 40 imágenes, 20 que sólo contenían células normales y 20 con células anómalas. El 100% de las imágenes con células anómalas presentó regiones de interés. De las 20 imágenes con sólo células normales, sólo 9 contuvieron regiones de interés. Por otro lado, el método propuesto incluyó en las regiones de interés al 92.43% de las células anómalas.. v.
(9) ÍNDICE Pensamiento .................................................................................................................. i Dedicatoria ................................................................................................................... ii Agradecimientos ...........................................................................................................iii Tarea Técnica .............................................................................................................. iv Resumen ...................................................................................................................... v Índice ............................................................................................................................ 1 Introducción .................................................................................................................. 3 Capítulo I. Detección de Anomalías en Imágenes Médicas........................................... 6 1.1. Detección de anomalías en imágenes médicas .............................................. 6. 1.1.1. Detección de anomalías en imágenes de tomografía computarizada. ..... 9. 1.1.1.1. Colección de datos y etapa preliminar.................................................. 9. 1.1.1.2. Clasificación basada en histograma. .................................................. 11. 1.1.1.3. Clasificación basada rasgos. .............................................................. 11. 1.2. Procesamiento de imágenes a color ............................................................. 14. Capítulo II. Detección de Regiones de Interés en Imágenes de la Prueba dePapanicolaou .......................................................................................................... 19 2.1. Cáncer Cervicouterino y la Prueba de Papanicolaou .................................... 19. 2.2. Descriptores utilizados en la detección de regiones de interés ..................... 21. 2.2.1. Rasgos de color. .................................................................................... 22. 2.2.2. Rasgos de bordes. ................................................................................ 23. 2.2.3. Rasgos de textura.................................................................................. 23. 2.3. Histogramas en imágenes a color ................................................................. 26. 2.3.1 2.4. Medidas de similitud entre histogramas. ................................................ 27. Método propuesto para la detección de regiones de interés en imágenes de la. pruebas de Papanicolaou ........................................................................................ 27 Capítulo III: Resultados y Discusión ............................................................................ 32 Página 1.
(10) 3.1. Experimentos realizados............................................................................... 32. 3.1.1 3.2. Medición de la calidad de los resultados de los clasificadores. .............. 32. Selección de los clasificadores ..................................................................... 33. 3.2.1. Clasificación basada en histogramas. .................................................... 33. 3.2.2. Clasificación basada en rasgos. ............................................................ 34. 3.3. Selección del umbral T para la determinación de las regiones de interés ..... 35. Conclusiones y recomendaciones............................................................................... 40 Bibliografía .................................................................................................................. 41 Anexo1. Rasgos Evaluados en Imágenes CT de Cerebro .......................................... 45 Anexo 2.Medidas de Similitud entre Histogramas ....................................................... 48 Anexo 3. Rasgos seleccionados para la clasificación basada en rasgos .................... 50. Página 2.
(11) INTRODUCCIÓN El análisis de anomalías en imágenes médicas ha sido ampliamente abordado en la literatura científica [1-5]. Debido a que las anomalías son diferentes de la gran mayoría de los datos, estas técnicas de procesamiento de imágenes posibilitan la detección y el monitoreo de enfermedades en un nivel pre-sintomático y pre-fenotípico, abriendo el camino a pronósticos tempranos de enfermedades, tratamientos, monitoreos y desarrollo de regímenes personalizados de tratamiento [3, 4] . La Prueba de Papanicolaou también llamada citología de cérvix o citología vaginal, se realiza para diagnosticar el cáncer Cervicouterino, para conocer el estado funcional de las hormonas y para identificar las alteraciones inflamatorias a través del análisis de las células descamadas que se acumulan en un plazo de 28 días. Esta es una prueba que debe practicarse a todas las mujeres desde que inician su actividad sexual hasta los 65 años de edad. La detección temprana de anomalías en la prueba de Papanicolaou es un gran avance en el mejoramiento de la calidad de vida de las mujeres que pudieran presentar cáncer Cervicouterino. Según el Instituto Nacional del Cáncer, alrededor del 6 por ciento de las 55 millones de pruebas de Papanicolaou realizadas anualmente en los EEUU indican anomalías. Anualmente se dan 490,000 casos de esta enfermedad en el mundo. Aproximadamente el 85% de las mujeres que fallecen por este tipo de cáncer viven en países en vías de desarrollo. La concentración más elevada está en el centro de América del Sur, con aproximadamente 71.000 casos por año [6] . El cáncer de cuello uterino solía ser la primera causa de muerte por cáncer en las mujeres en Estados Unidos. Sin embargo, en los últimos 40 años, el número de casos de cáncer de cuello uterino y las muertes relacionadas con este cáncer han disminuido significativamente. Esta disminución se debe en gran parte a que muchas mujeres están haciéndose pruebas de Papanicolaou periódicamente, lo que permite identificar células precancerosas en el cuello uterino antes de que se conviertan en cáncer. En el año 2010 un total de 11,818 mujeres en los Estados Unidos recibieron un diagnóstico de cáncer de cuello uterino y 3,939 murieron por esta enfermedad [7]. Dado que la prueba de Papanicolaou es revisada por especialistas humanos, el cansancio y la gran cantidad de muestras que estos tienen que diagnosticar ha dado lugar a equivocaciones tanto positivamente como negativamente, lo que ha abierto el camino al aparecimiento de técnicas del aprendizaje automatizado capaces de resolver estos problemas [5, 8-10]. Página 3.
(12) Por todo lo anterior el problema de nuestro trabajo será la ubicación de regiones de interés en la prueba de Papanicolaou para la detección de anomalías. A partir del problema antes mencionado, nos hacemos la siguiente pregunta de investigación: Pregunta de Investigación: ¿Es posible obtener un método con buenas prestaciones que sea capaz de determinar, en poco tiempo, las regiones de interés con fines de detectar anomalías, en una imagen de la prueba de Papanicolaou? La hipótesis de esta investigación es la siguiente: Hipótesis de Investigación: Existe un algoritmo, basado en el método de los K vecinos más cercanos, que es capaz de determinar, en un tiempo aceptable, las regiones sobresalientes en una imagen de la prueba de Papanicolaou. A partir de lo que se expone anteriormente, en el presente trabajo tiene como objetivo general y objetivos específicos los siguientes: Objetivo General: . Diseñar e implementar un algoritmo, basado en el método de los K vecinos más cercanos, para la determinación de regiones de interés en imágenes de la prueba de Papanicolaou.. Objetivos Específicos: . Diseñar e implementar un algoritmo basado en rasgos, usando el método de los K vecinos más cercanos, para la detección de anomalías en imágenes de la prueba de Papanicolaou.. . Diseñar e implementar un algoritmo basado en histogramas, usando el método de los K vecinos más cercanos, para la detección de anomalías en imágenes de la prueba de Papanicolaou.. . Construir mapas que representen las regiones de interés para la detección de anomalías en imágenes de la prueba de Papanicolaou.. . Probar el método propuesto con imágenes reales.. El trabajo está estructurado de la siguiente forma: introducción, capitulario, conclusiones y recomendaciones, referencias bibliográficas y anexos. El capítulo 1 realiza un estudio sobre el tema de detección de anomalías en imágenes médicas. El segundo capítulo expone el método propuesto sobre la Detección de Regiones de Página 4.
(13) Interés en Imágenes de la Prueba de Papanicolaou. En el tercer capítulo se realiza un análisis de los resultados obtenidos para los experimentos.. Página 5.
(14) CAPÍTULO I. DETECCIÓN DE ANOMALÍAS EN IMÁGENES MÉDICAS 1.1. Detección de anomalías en imágenes médicas. En años recientes, las imágenes moleculares han emergido como una herramienta promisoria para entender los mecanismos moleculares de las enfermedades. Estas se pueden utilizar para la detección temprana de cáncer, el monitoreo de la efectividad de terapias, y para la comprensión de la biología de organismos vivos en diversos niveles de detalle [1, 2]. La importancia de este campo desciende de que los síntomas de enfermedades como cáncer, Parkinson, y Alzheimer es precedido por cambios moleculares en células y tejido fino [3, 4]. En el análisis de imágenes, se entiende por anomalía un objeto desconocido, con baja probabilidad de ocurrencia, como pude ser los tumores en las imágenes médicas [11]. La detección de anomalías (AD) es el proceso de detectar una pequeña fracción de datos que son diferentes de la mayoría o de un modelo definido por un conjunto de datos. El objetivo de un detector de anomalías es la identificación de las diferencias en una serie de datos, sin tener ninguna información previa de sus propiedades. Muchos estudios se basan en una definición negativa del problema: anomalías son porciones de datos que no se ajustan a la norma o al modelo de normalidad, los datos que se rigen por esta descripción son normales; aquellos que no se rigen al modelo son considerados anómalos. Las regiones anómalas son difíciles de detectar por lo que se utilizan una gran cantidad de rasgos [5]. Se han utilizado muchos tipos de imágenes médicas para el desarrollo de algoritmos encaminados a su análisis. La Figura 1 muestra la diversidad de tipos de imágenes en las cuales se ha usado la AD. Los diferentes avances de AD en imágenes dependen del tipo de imagen que se trabaje: escala de grises, color, espectral, etc., o como se trabaje: completamente o parcialmente automatizado. Se distinguen también por si los detectores de anomalías son locales o globales. Esto depende del tamaño del área usada para construir el modelo de fondo. Acorde a la exploración se pueden identificar con algoritmos de correlación espectral y/o espacial [12].. Página 6.
(15) Figura 1.1. Tipos de imágenes usadas en AD. Muchos estudios se han ocupado en la AD en imágenes médicas: -. Detección de tumores en mamografía digital [8, 10]. Los principales problemas de su detección: la separación pobre de “distribuciones cruzadas” en las clasificaciones correctas dependiendo del valor de cada rasgo y el solapamiento de las distribuciones de rasgos normales y anormales [8, 10]. En [10] se introduce la utilización de máquinas de soporte vectorial (SVM) basadas en el mapeo no cruzado y en la diferencia local de probabilidad (LDP). Otros problemas que se han introducidos son que la utilización de equipos convencionales y el cansancio de técnicos debido a la cantidad de imágenes puede provocar que se dejen de observar malformaciones. Se ha utilizado el detector de borde Canny para encontrar dichas anomalías [8].. -. Imágenes de tomografía computarizada de pulmón e imágenes de resonancia magnética (MR) de cerebro [13].. -. Imágenes citométricas en patología donde se utiliza la patología quirúrgica para tomar contenido de ADN nuclear para analizarlo y dictar un pronóstico. Dentro de estos estudios están los del pulmón, esófago, ovario, endometrio, próstata, vejiga urinaria y papilar tiroideo [9].. -. Selección de características en la clasificación de los espectros de masas para la Página 7.
(16) detección del cáncer de ovario [14]. En la cual se utiliza la proteómica para la detección temprana de patologías, ya que estas modifican las proteínas induciendo procesos como glucosilación, fosforilación, metilación o cualquier otra adición de un grupo molecular a las proteínas. En [14] se utilizaron las SVM para la clasificación. -. La extracción automática de melanoma en imágenes demoscópicas. En [15] se introduce un nuevo método computacional basado en la utilización de regiones crecientes por parte de dermatólogos para dar resultados. Después se construyen dos clasificadores lineales para la extracción de tumores y son evaluados por la curva operativa del receptor (ROC).. Muchos estudios médicos se enfocan en órganos que pueden presentar diversos tipos de cáncer como el de pulmón, cerebro o mama. También existen algunos que se aplican a imágenes de células. Algunos se han dedicado al cuerpo entero donde se ha aplicado una segmentación Watershed para detectar tumores [16]. Para localizar anomalías se han implementado diversas técnicas médicas como: . Fotografía convencional [15]: la utilización de un endoscopio o un microscopio es un método utilizado para la detección de células cancerígenas en sangre, la cual es una importante herramienta para el diagnóstico y monitoreo de tumores en etapas tempranas [17].. . Tomografía de impedancia eléctrica [18].. . Ultrasonido: utilizado para la detección de masas en el pecho [8, 16] .. . Rayos X [19].. . Tomografía computarizada (CT) [20].. . Resonancia magnética (MRI): en [21] se describe una forma automática de segmentar tumores cerebrales basadas en detecciones de forma atípicas. Esta segmentación está compuesta por tres etapas. Primeramente se detectan regiones anormales usando un atlas de cerebro como modelo. Se usó un estimador robusto para la localización y dispersión, para determinar la intensidad normal de tejidos cerebrales. En la segunda etapa se determinó la intensidad de las regiones que aparecían junto con los tumores. Finalmente se aplicaron restricciones espaciales y geométricas para la detección de tumores y edemas cerebrales.. . Tomografía por emisión de fotones simples (SPECT) y Tomografía de Emisión de Positrones (PET): en [22] se desarrolla una detección automática de imágenes PET usando modelos estadísticos y multiescala. Página 8.
(17) 1.1.1 Detección de anomalías en imágenes de tomografía computarizada. En esta sección explicaremos detalladamente el método propuesto en [5] para la detección de anomalías en imágenes de cabeza utilizando tomografía computarizada.. 1.1.1.1. Colección de datos y etapa preliminar.. Primeramente se coleccionaron 27 estudios de CT, con 33 cortes axiales cada uno (en total fueron 890 cortes de tamaño 512x512 vóxeles y 12 bits de resolución, con 4096 niveles de gris).. Figura 1.2. Parches de 16x16 tomados de regiones de clases normales en imágenes de cerebro de CT. En la etapa preliminar, un grupo de radiólogos y neurólogos seleccionaron las regiones que representan las clases normales (Figura 1.2): huesos de alta densidad (High Density Bones, HDB), fluido cerebro-espinal (Cerebro-spinal Fluid, CSF), materia cerebral (Brain Matter, BM) dividido en materia blanca (White Matter, WM) y materia gris (Gray Matter, GM) respectivamente y fondo o aire (Background, BG). Se hizo una segmentación bruta, donde se extrajeron miles de parches de 16x16 para cada clase. Se sacaron los valores de los niveles de gris de los histogramas de los vóxeles (bins1de 0 a 4095, con anchura =2) en cada parche. Luego se hizo un promedio, bin a bin, de todos los histogramas de la misma clase obteniendo un histograma prototipo por clase. Estos fueron normalizados dividiendo la frecuencia de conteo de cada bin por el número de vóxeles por parche (16x16=256) obteniéndose un estimado. 1. Llamaremos “bin” (bins, en plural) a cada uno de los intervalos que componen un histograma.. Página 9.
(18) probabilístico de niveles de gris por clase. Los histogramas de las clases más externas son fácilmente reconocidos del resto. Los parches correspondientes a esas clases fueron clasificados usando un simple rasgo, como la media de los valores de niveles de grises, y un umbral (especificado como, si la media de los niveles de grises < 500, entonces los parches son de BG; si la media de los niveles de grises > 1250, entonces los parches son de HDB). Se utilizó un clase que reuniera a WM y GM como BM porque los histogramas de estos se superponían, el prototipo de histograma se hizo calculando un promedio bin a bin de los histogramas de WM y GM. Anomalías en la región cerebral como hemorragias, infartos, tumores y calcificaciones fueron consideradas como tejidos atenuados (con la excepción de ciertas calcificaciones). Se propuso tamaño de bin variable para el histograma, acorde con el tradicional ajuste de nivel/ventana usado para analizar/visualizar imágenes CT de materia cerebral y cráneo. Se utilizó la combinación del histograma y clasificación basada en rasgos como se muestra en la Figura 1.3.. Figura 1.3. Propuesta de sistema de AD en imágenes de CT: diagrama en bloque de las etapas de prueba y entrenamiento. Se realizó una etapa de entrenamiento donde se calcularon los histogramas y un conjunto de rasgos que representan las clases normales, nombradas CSF y BM. Se verificó la pre-clasificación de los parches usando los prototipos obtenidos en la etapa Página 10.
(19) de entrenamiento. Se usaron rasgos en imágenes médicas que han sido utilizados en otros trabajos [16, 19, 23-27]. Los rasgos pueden ser estimados usando procesamiento estadístico, estructural y por modelos. Se utilizaron dentro de los métodos estadísticos: el histograma, métodos de primer orden y métodos basado en la matriz de co-ocurrencia [5].. 1.1.1.2. Clasificación basada en histograma.. Los histogramas de las clases CSF y BM (. y. ) fueron utilizadas como. histogramas de referencias. Para la evaluación de resultados intermedios asociados con el conjunto de entrenamiento y el de prueba se utilizaron varias distancias basadas en histogramas. [25, 28]. Después de haber calculado todas las distancias. de los parches, el parche i-ésimo es pre-asignado a la clase que tiene el valor de distancia. menor. Se valoraron medidas diferentes con las tasa de clasificación. en el entrenamiento y en los casos de prueba. Se propuso una medida S, para cuantificar la habilidad de medir la separación de las distancias entre clases. Se calculó la suma de las distancias bajo valoración. Se normalizo la amplitud, con relación a cada histograma menos dos veces la distancia con respecto al histograma prototipo de cada clase esperada. Las distancias erróneas (esperadas como las mayores) contribuyen positivamente a estas medidas, mientras las distancias acertadas (esperadas como las menores) contribuyen negativamente. Por ejemplo para clase BM la medida ( ) es computada para el parche i-ésimo (con histograma. ) usando la medida Dh como se muestra a continuación: (. donde. ). es el histograma del parche y. ( y. ). (1.1). son histogramas prototipos de las. clases CSF y BM respectivamente. La tasa de clasificación y la medida de separación ( ) permite ordenar por rango las medidas de distancias. . Los histogramas de las distancias. y. son los dos. mejores para la etapa de clasificación [5].. 1.1.1.3. Clasificación basada rasgos.. Se utilizaron rasgos reportados en [16, 19, 23, 24, 26-28]. Además se usaron medidas de textura basadas en la matriz de co-ocurrencia de niveles de grises (Gray Levels Coocurrence Matrix, GLCM). Solamente se usó la orientación (θ) este y sur y distancia o escala d = 1. Se aplicó una selección de rasgos para reducir la dimensionalidad del problema. Para Página 11.
(20) realizar esta selección de rasgos se usó la función FSV implementada en el paquete de programas de Matlab, Spider2 versión 1.71. El objetivo era encontrar un subconjunto de tamaño M entre los 42 rasgos (ver Anexo1) originales (M<42) que maximizara el desempeño de la clasificación basada en rasgos. Después de la selección de rasgos, se obtuvo para cada clase un vector prototipo de rasgos, denotado. y VBM para la clase CSF y BM respectivamente. Los vectores fueron. caracterizados por sus centros (. y. para las clases CSF y BM. respectivamente) y sus matrices de covarianza (CCSF y CBM, para CSF y BM, respectivamente). Las distancias inspiradas en Mahalanobis [28, 29], entre el rasgo del vector del parche i-ésimo,. , y el prototipo de vector de rasgo,. y VBM, fueron. calculadas como:. (. ). √∑(. ). (. ) (1.2). (. ). √∑(. ). (. ). Después de haber calculado esas distancias para todos los parches bajo clasificación el parche i-ésimo es pre-asignado a la clase que tiene un valor mínimo de distancia . Etapa de clasificación El diagrama en bloque de la etapa de clasificación se muestra en la Figura 1.4. Ésta muestra los pasos seguidos para el procesamiento de las imágenes. Después de cargar un estudio de CT una imagen o un conjunto de imágenes con cortes (de tamaño 512x512 cada una), con una ventana deslizante de 16x16 vóxeles, relacionado con la detección de la anomalía más pequeña, se generó un conjunto de parches con un solapamiento del 50% (en total (2(512/16)-1)2=3969 por corte) [28]. Una importante parte (Ne) de esos parches fueron inmediatamente pre-clasificados como fondo (BG), o hueso de alta densidad (HDB). El resto de los parches (Nr = 3969 – Ne) fueron clasificados usando el algoritmo antes descrito.. 2. th. The Spider for Matlab, versión 1.71 released on July 24 , 2006. (http://www.kyb.tuebingen.mpg.de/bs/people/spider/main.html).. Página 12.
(21) Figura 1.4 Propuesta del sistema de AD: Diagrama en bloque de la etapa de clasificación. Para la clasificación basada en histograma, se aplicó el modelo de hacer corresponder la cercanía de los vecinos cercanos, usando la primera mejor distancia barrida de y. :. minDh(i)=min(Dh1(hi,hCSF),Dh1(hi,hBM)), 1<i<Nr, if minDh(i)=Dh1(hi,hCSF), then hclass(i)=CSF, 1<i<Nr , if minDh(i)=Dh1(hi,hBM), then hclass(i)=BM, 1<i<Nr . minDh2(i)=min(Dh2(hi,hCSF),Dh2(hi,hBM)),1<i<Nr , if minDh2(i)=Dh2(hi,hCSF),thenh2class(i)=CSF,1<i<Nr , if minDh2(i)=Dh2(hi,hBM),thenh2class(i)=BM,1<i<Nr . Para la clasificación basada en rasgos, se llegó a: minDM(i)=min(DM(Vi,VCSF),DM(Vi,VBM)) ,1<i<Nr , if minDM(i)=DM(Vi,VCSF),then Mclass(i) = CSF,1<i<Nr , ifminDM(i)=DM(Vi,VBM), then Mclass(i) = BM,1<i<Nr . La clasificación final es la siguiente: ifhclass(i)=Mclass(i),thenclass(i)=hclass(i) , Página 13.
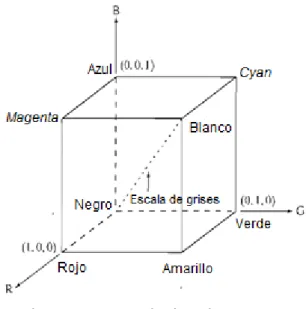
(22) elseif h2class(i)=Mclass(i)orh2class(i)=hclass(i), thenclass(i) = h2class(i) ,otherwiseclass(i) = Anomaly. Realmente, como solamente en esta etapa existían dos clases normales (CSF y BM), el parche bajo clasificación estará clasificado como una de ellas (CSF o BM), de acuerdo a la ecuación previa, y la última línea de la clasificación final no se aplica. Sin embargo, se incluye explícitamente ya que podría ser útil para un fondo complejo normal. Después de esas etapas, puede pasar que algunas anomalías fueran inadvertidamente pre-clasificadas como clases normales (CSF o BM), pueden dar falsos negativos. Para mejorar el desempeño del detector de anomalías, se calculó la distancia robusta entre todos los vectores de rasgos (V) que caracterizan los parches pre-clasificados en la misma clase normal, ( ). √(. ). (. (1.3). ). Entonces se clasifica como parches anómalos aquellos con valores grandes de Esta distancia robusta. es muy similar a. .. , pero a diferencia del centro clásico. (media), el método robusto utiliza el Determinante de Covarianza Mínima (Minimum Covariance Determinant, MCD), posición. En adición,. , como una estimación multivariable de la. usa matriz de dispersión,. , en vez de la matriz de. covarianza de (1.3) y no es afectada por el efecto de enmascaramiento. El MCD es un método robusto en el sentido de que las estimaciones no sean influenciadas grandemente por anomalías en los datos, aún si hay bastantes de ellas [30].. 1.2. Procesamiento de imágenes a color. El color es usado en procesamiento de imágenes ya que es un descriptor poderoso que simplifica la identificación de objetos y a la vez su extracción de una escena. Los humanos pueden percibir miles de colores e intensidades, en comparación con solo dos docenas de niveles de grises, este último factor muy usado en las imágenes [31]. La visión humana se divide fisiológicamente en la visión monocromática (niveles de gris), debida a la respuesta de los bastones, y la visión polícroma, que se debe a la respuesta de los conos [32]. El ojo humano cuenta aproximadamente entre 6 o 7 millones de conos, los cuales son los encargados de percibir los colores rojo, verde y azul, de los cuales el 65% de los conos son sensibles al rojo el 33% al verde y el 2% al azul. Estos son llamados los colores primarios. Los modelos de colores (espacios de colores o sistemas de colores) tienen como objetivo facilitar la normalización del color en un estándar, generalmente aceptado. Un Página 14.
(23) modelo de color es una especificación de un sistema de coordenadas y un subespacio, donde dentro del sistema cada color es representado por un simple punto [31]. En la práctica se emplean dos tipos diferentes de definición de sistemas en color: el sistema RGB y el sistema TLS [32]. El modelo de color RGB se basa en el sistema cartesiano de coordenadas. El subespacio de color de interés es un cubo con los valores de rojo, verde y azul en las esquinas. La Figura 1.5 muestra el espacio de color RGB.. Figura 1.5. Espacio de color RGB Las imágenes que están en RGB, están formadas por tres componentes uno por cada color primario (uno por el rojo, verde y azul respectivamente). La profundidad de pixel (pixel depht) es llamado al número de bits necesarios para representar un pixel en cada color del espacio RGB. Cada imagen de rojo, verde y azul son de 8 bits, lo cual quiere decir que cada pixel de color RGB es de 24 bits (son tres planos de imágenes con 8 bits por plano). El término full-color se usa para identificar imágenes de color RGB de 24 bits. El número total de colores en una imagen full-color es de (28)3 = 16, 777,216. La Figura 1.6 muestra una imagen a color con sus niveles de rojo, verde y azul. Note como los mayores niveles de rojo se encuentran en el platillo volador, los mayores niveles de verde en el agua y los mayores niveles de azul en el cielo o la trusa de la muchacha.. Página 15.
(24) (a). (b). (c). (d). Fig. 1.6. Espacio de color RGB. (a) Imagen original. (b) Canal rojo. (c) Canal verde. (d) Canal azul. Otro espacio de color ampliamente usado en la comunidad científica es el espacio de color Lab. El CIE L*a*b* (CIE-Lab) [33] es el modelo cromático usado normalmente para describir todos los colores que puede percibir el ojo humano. Los tres parámetros en el modelo representan la luminosidad de color (L, L = 0 indica negro y L=100 indica blanco), su posición entre magenta y verde (a, valores negativos indican verde mientras valores positivos indican magenta) y su posición entre amarillo y azul (b, valores negativos indican azul y valores positivos indican amarillo). La faceta más importante del espacio de color CIE-Lab es que éste pretende emular la forma en la que los humanos percibimos el color [34]. El espacio de color CIE-Lab está basado en los colores primarios imaginarios XYZ (Figura 1.7).. Página 16.
(25) Figura 1.7. Espacio de color CIE-Lab. Las imágenes en el espacio RGB se pasan al espacio XYZ de la siguiente manera: ⌊ ⌋. [. ][ ]. (1.4). Al obtenerse X, Y y Z con la matriz de transformación (1.5) se pasa al espacio CIE-Lab con las ecuaciones de transformación: √. ( ) (1.5a). {. ( ) [ (. ). [ ( ) en donde. ,. y. ( )]. (1.5b). (. (1.5c). )]. son los valores tri-estímulo tomando como referencia el color. blanco definidos como: (1.6) Por último, el otro espacio de color utilizado en este trabajo es el espacio de color Página 17.
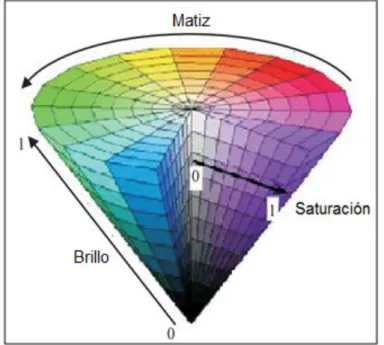
(26) Matiz-Saturación-Brillo (Hue-Saturation-Value, HSV). El espacio de color HSV fue creado para poder manejar el color de manera intuitiva y fue diseñado en base a la manera en que los humanos percibimos e interpretamos el color. El matiz (H) representa el color, la saturación (S) es la cantidad de blanco que es mezclado con el color y V indica el brillo (Figura 1.8).. Figura 1.8. Espacio de color HSV. El modelo HSV fue creado en 1978 por Alvy Ray Smith [35]. Dado un pixel en el espacio de color RGB (R, G, B) definimos el matiz (H), saturación (S) y brillo (V) como:. (1.7a). { {. (1.7b). (1.7c) Donde. *. +y. *. +. La saturación, el tono y la luminosidad son características diferenciables en este espacio de color [36]. Página 18.
(27) CAPÍTULO II. DETECCIÓN DE REGIONES DE INTERÉS EN IMÁGENES DE LA PRUEBA DEPAPANICOLAOU 2.1. Cáncer Cervicouterino y la Prueba de Papanicolaou. El cáncer Cervicouterino (CaCu) es la segunda causa de muerte por neoplasia en mujeres a nivel mundial y la primera en países en vías de desarrollo. En México, el CaCu ha sido la neoplasia más común en las mujeres en las últimas décadas y es la principal causa de muerte por cáncer entre mujeres mayores de 35 años [37]. La lenta evolución de la enfermedad y la accesibilidad de células del cérvix para su estudio, permite tener tiempo y herramientas para detectar y erradicar la enfermedad, si el diagnóstico se hace oportunamente, lo que hace que el CaCu sea una neoplasia 100% prevenible. Anualmente aparecen 490.000 nuevos casos de esta enfermedad en el mundo. Cada año fallecen 230,000 personas [38]. Uno de los avances más importantes en el tratamiento de la neoplasia de cérvix ha sido la identificación de las lesiones precursoras, las cuales han sido objeto de diferentes clasificaciones. La primera clasificación se realizó en 1930 y se designó con el término de displasia. En 1968 se acuñó el concepto de Neoplasia Cervical Intraepitelial (NIC), con diferentes grados: NIC I, NIC II, NIC III o carcinoma in situ [37]. La cérvix es la porción más baja del útero, está cubierta por una capa delgada de células llamada epitelio, las células del epitelio tienen dos formas diferentes (escamosa y columnar) y están localizadas en áreas separadas: área escamosa y área columnar (Figura 2.1). El área escamosa se localiza al fondo del canal de la cérvix (Figura 2.2) y aquí las células se dividen en cuatro capas: basal, parabasal, intermedia y superficial.. Página 19.
(28) Figura 2.1. Células escamosas y columnares. El área columnar [39, 40], se localiza más arriba, en el canal de la cérvix (Figura 2.2). Las células columnares solo existen en la capa basal, tienen forma de columnas como su propio nombre lo indica con un citoplasma oblongo y un núcleo largo localizado en un extremo. La unión entre estas dos áreas se denomina unión escamo columnar, y puede estar localizada dentro o fuera de la cérvix. La unión escamo columnar es llamada también como zona de transición porque las células se transforman de una forma a otra.. Figura 2.2. Detalles del útero y localización de las células escamosas y columnares. Los exámenes selectivos de detección de cáncer de cérvix constituyen una parte importante del cuidado médico regular de la mujer. Es una forma de detectar células del cérvix anormales, incluso lesiones precancerosas del cérvix, así como también cánceres cervicales en etapa temprana. Tanto las lesiones precancerosas como los cánceres de cérvix en etapa temprana se pueden tratar con mucho éxito. Se ha comprobado que los exámenes selectivos de detección rutinarios de cáncer de cérvix reducen considerablemente tanto el número de cánceres nuevos de cérvix que son diagnosticados cada año como las muertes por esta enfermedad.. Página 20.
(29) Los exámenes selectivos de detección de cáncer de cérvix incluyen dos tipos de pruebas de detección: la prueba citológica, conocida como prueba de Papanicolaou o frotis de Pap y la prueba de VPH. El propósito principal de hacer exámenes selectivos de detección con la prueba de Papanicolaou es detectar células anormales que pueden convertirse en cáncer si no son tratadas. La prueba de Papanicolaou puede también encontrar estados no cancerosos, como infecciones e inflamación. Puede también encontrar células cancerosas. En las poblaciones que se hacen exámenes de detección con regularidad, la prueba de Papanicolaou identifica la mayoría de las células anormales antes de que se conviertan en cáncer. Las muestras utilizadas para esta prueba se toman de tres sitios: 1. Endocérvix, que es el orificio que comunica con el útero. 2. Cérvix, que es la parte más externa del útero, y que comunica directamente con la vagina. 3. Tercio superior de la vagina, que es la región que rodea el cuello del útero. Mientras la mujer se acuesta en una mesa de exámenes, un profesional al cuidado de la salud introduce un instrumento llamado espéculo en su vagina para ensancharla a fin de poder ver la parte superior de la vagina y del cérvix. Este procedimiento permite también que el profesional al cuidado de la salud tome una muestra de las células del cérvix. Las células se toman con un raspador de madera o de plástico o con un cepillo cervical y se preparan luego para el análisis en una de dos formas. En una prueba convencional de Papanicolaou, la muestra (o frotis) se pone en un portaobjetos de vidrio para microscopio y se añade un fijador. En una prueba de Papanicolaou citológica líquida automatizada, las células del cérvix colectadas con un cepillo o con otro instrumento se colocan en un frasco que contiene líquido de conservación. Luego se envía el portaobjetos o el frasco a un laboratorio para su análisis [41].. 2.2. Descriptores utilizados en la detección de regiones de interés. En el presente trabajo se utilizaron tres tipos de rasgos para caracterizar a los parches de una imagen de la prueba de Papanicolaou. Estos fueron: . Rasgos de color: 72 rasgos3 que se corresponden con las 8 medidas. 3. Ocho estadísticos sobre 9 canales de los distintos espacios de color dan los 72 rasgos de color por parche.. Página 21.
(30) estadísticas descritas en la sección 2.2.1 calculadas sobre los canales R, G y B del espacio de color RGB; los canales H, S y V del espacio de color HSV; y los canales L, a y b del espacio de color Lab. . Rasgos de bordes: 5 rasgos que se describen en la sección 2.2.2.. . Rasgos de Textura: 78 rasgos de textura4 correspondientes a 13 rasgos basados en la matriz de co-ocurrencia calculada para los valores de escala 2, 4 y 8 y las orientaciones 0º y 90º.. En total se calcularon 155 rasgos por parche de la imagen. A continuación se describe como se calculan estos rasgos. Asumamos que un parche S viene dado en un espacio de color C. Supongamos que un parche está compuesto por N píxeles *. +. Para cada S se calculan medidas o un grupo. de rasgos que se describen a continuación.. 2.2.1 Rasgos de color. 1- Media: valor promedio de la muestra: ̅. (2.1). ∑. 2- Desviación estándar: desviación estándar de la muestra.. √. ∑(. ̅). (2.2). 3- Rango intercuantil: es una estimación robusta de la difusión de los datos, en donde los cambios del 25% en la parte superior e inferior de los datos no la afectan. (2.3) donde. y. son el primer y tercer cuantil, respectivamente.. 4- Mediana: la mitad de los elementos de la muestra es inferior o igual a la mediana y la otra mitad superior. 5- Mínimo: valor mínimo de la muestra. 6- Máximo: valor máximo de la muestra. 7- Asimetría: medida de los datos alrededor de la media de la muestra. Si la asimetría es negativa, los datos se extienden más a la izquierda de la media,. 4. 13 rasgos x 3 escalas x 2 orientaciones dan los 78 rasgos de textura.. Página 22.
(31) de lo contrario se extiende a la derecha. La asimetría de la distribución normal(o cualquier distribución perfectamente simétrica) es cero. ∑ ( (√ ∑ (. ̅) (2.4). ̅) ). 8- Curtosis: medida del achatamiento de una distribución. La curtosis de una distribución normal es tres. Distribuciones que son más propensas a valores atípicos con respecto a la distribución normal tienen valores superiores a tres, de lo contrario son menores de tres. ∑ ( ( ∑ (. ̅) (2.5). ̅) ). 2.2.2 Rasgos de bordes. Los rasgos de borde se calculan a partir del resultado del método de Canny para la detección de bordes [42]. Los cinco rasgos son los mismos que se usan en [43]. 1. Cantidad de pixeles borde en la región que están por encima de cierto umbral. 2. Medida de la homogeneidad de la intensidad de los pixeles en los bordes. 3. Dos medidas de la homogeneidad de la dirección de los pixeles en los bordes. 4. Medida de la diferencia de la dirección de los pixeles en los bordes.. 2.2.3 Rasgos de textura. Se llama a textura a la característica visual o táctil de la superficie de un objeto [44]. Otra definición de textura es que son características físico-estructurales dadas a un objeto por el tamaño, forma, arreglo y proporciones de sus partes [45]. En las imágenes digitales, la textura visual se representa como variaciones de los valores de las intensidades de los píxeles que forman ciertos patrones repetitivos. La textura es una propiedad que está presente en la superficie de los objetos reales y contiene información importante acerca de su estructura. Es extremadamente difícil definirla de forma precisa y realizar su análisis mediante cálculos. La formación de textura se describe a partir de las propiedades estadísticas de las intensidades y posiciones de los píxeles [44]. La descripción de la textura de una región puede determinarse con distintos modelos teóricos, los principales utilizados en el procesamiento digital de imágenes (PDI) son: el Estadístico, el Espectral y el de Multi-Resolución [45]. Se han hecho investigaciones sobre la diferencia de histogramas y la matriz de Página 23.
(32) ocurrencia de niveles de gris. Para el análisis de textura se han usado medidas basadas en la matriz de ocurrencia de niveles de gris, también llamada matriz de dependencia espacial de tonos de gris (Gray Level Co-occurrence Matrix, GLCM, o Gray Tone Spatial Dependency Matrix, GTSDM, por sus siglas en inglés) [46]. La ocurrencia espacial de niveles de gris proporciona un estimado de las propiedades de la imagen que está relacionado con los estadísticos de segundo orden. Las medidas de segundo orden o más consideran la relación que existe entre dos o más píxeles, usualmente vecinos, de la imagen original. En [46] se proponen 13 rasgos basados en la GLCM que describen algunas de las características de la textura: Notación: (). ∑ (. ). (2.6a). Donde Ng es la cantidad de niveles de gris. ∑. ∑. (2.6b). ∑. ∑. (2.6c). (). ( ). ( ). ∑∑ (. ∑∑ (. ∑ (. ). ). ) |. (2.6d). (2.6e). |. (2.6f). 1. Segundo Momento Angular (ASM): ∑ ∑* (. )+. (2.7). 2. Contraste:. Página 24.
(33) (∑ ∑ (. ∑. ) |. |. ). (2.8). 3. Correlación: ∑ ∑(. donde. ,. ). (. ). (2.9). son las medias y las desviaciones estándar de. .. 4. Suma de cuadrados (varianza): ∑∑. (. ). (. ). (2.10). 5. Diferencia de momento inverso: ∑∑. (. (. ). ). (2.11). 6. Suma de promedio: ∑. ( ). (2.12). 7. Suma de la varianza: ∑(. ). ( ). ∑. ( ). ( (. )). (2.14). ). ( (. )). (2.15). (2.13). 8. Suma de entropía:. 9. Entropía: ∑∑ (. 10. Diferencia de varianza: (2.16) 11. Diferencia de entropía: Página 25.
(34) ∑. ( ). (. (2.17). (i)). 12. Información del coeficiente de correlación: ∑ ∑. (. ). ( (. )). ( ∑ ∑. (. ). (. (. (). ( )). ). (2.18). 13. Información del coeficiente de correlación: (. (. ( ∑∑ (. ). (. (). ( ))) (2.19). ( ∑∑ (. 2.3. ). ( (. )))). Histogramas en imágenes a color. (a). (b). (c). (d). Página 26.
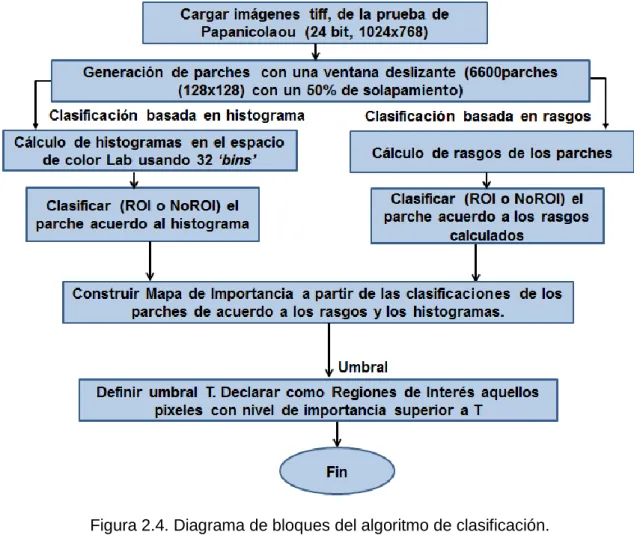
(35) Figura 2.3. Histogramas de los canales de color .a) Imagen original. b) Histograma del canal rojo. c) Histograma del canal azul. d) Histograma del canal verde. El histograma es una distribución de probabilidades P(b) de las diferentes amplitudes o niveles de gris de la imagen [47]. Para imágenes a dada en el espacio RGB histograma está formado por la composición de tres canales de color RGB (componentes roja, verde y azul) (Figura 2.3).. 2.3.1 Medidas de similitud entre histogramas. En muchos trabajos se han utilizado diferentes medidas de similitud entre histogramas [28, 48, 49] (ver Anexo2), ya que éstas pueden determinar eficientemente diferencias a la hora de la clasificación. En este trabajo se utilizaron las distancias Matusita y Bhattacharyya [5] ya que con estas se obtuvieron la mejor tasa de clasificación. *. Dados dos histogramas de. bins. que cumplir que ∑. y ∑. +y. *. , además de. +, estos tienen . Entonces las. distancias Matusita y Bhattacharyya entre estos dos histogramas se definen por: 1-Distancia de Matusita: (. ). |. |. (2.20). 2-Distancia de Bhattacharyya: (. 2.4. ). ∑√. (2.21). Método propuesto para la detección de regiones de interés en imágenes de la pruebas de Papanicolaou. La Figura 2.4 muestra el diagrama en bloque del algoritmo de detección de regiones de interés en imágenes de la prueba de Papanicolaou. Éste está compuesto por los pasos o etapas que se muestran en la Figura 2.5. A continuación se explican en detalle los pasos del algoritmo anterior. Paso 1. Cargar imagen. Las pruebas se realizaron utilizando imágenes full-color de 0.78 Megapíxeles (1024x768) en formato TIFF (Tagged Image File Format). Paso 2. Generar parches de la imagen. Página 27.
(36) Los parches se tomaron de tamaño 128x128 píxeles de forma tal que dentro de un parche cupiera una célula anómala. La ventana deslizante utilizada para generar los parches se realizó con un solapamiento del 50% (Figura 2.6). Para cada imagen se obtuvo 165 parches.. Figura 2.4. Diagrama de bloques del algoritmo de clasificación.. Página 28.
(37) 1. Cargar imagen. 2. Generar parches de la imagen. 3. Para cada parche de la imagen hacer: 3.1. Calcular histograma en espacio de color Lab. 3.2. Clasificar (ROI o NoROI) el parche de acuerdo al histograma. 3.3. Calcular rasgos del parche. 3.4. Clasificar (ROI o NoROI) de acuerdo a los rasgos calculados. 4. Construir Mapa de Importancia a partir de las clasificaciones de los parches de acuerdo a los rasgos y los histogramas. 5. Definir umbral T. Declarar como pixeles de Regiones de Interés aquellos pixeles con nivel de importancia superior a T.. Figura 2.5. Algoritmo de clasificación.. 128 8 128 8. 128 8 128 8. Figura 2.6. Parches de 128x128 con un 50% de solapamiento. Paso 3.1 Calcular histograma en espacio de color Lab. Para cada parche se calculan histogramas de 32 bins para los canales L, a y b. Se realizaron experimentos para elegir entre los espacios de colores Lab y RGB para el cálculo de los histogramas. Los mejores resultados se obtuvieron para el espacio de Página 29.
(38) color Lab como se explica en el capítulo 3 de este informe. Paso 3.2 Clasificar (ROI o NoROI) el parche de acuerdo al histograma. Cada parche se clasifica en ROI (Región de Interés) o NoROI (No Región de Interés) usando los histogramas en el espacio de color Lab y el método de los K Vecinos más Cercanos (K Nearest Neigbours, KNN). Para la determinación de los valores de K y la distancia a usar se realizaron varios experimentos cuyos resultados se exponen en el capítulo 3 de este informe. Los mejores resultados se obtuvieron para. y la. distancia Bhattacharyya. Para el cálculo de la distancia entre los histogramas de dos parches se promedia la distancia de acuerdo a cada canal, o sea: ( donde *. y. ). (. (. son dos parches y. ). (. ). (. es el histograma del parche. )) *. (2.22). + en el canal. +.. Paso 3.3. Calcular rasgos del parche. A partir de los 155 rasgos descritos en la sección anterior, se realizó una selección secuencial de rasgos. Los 12 rasgos significativos o relevantes se muestran en el anexo 4. Paso 3.4. Clasificar (ROI o NoROI) de acuerdo a los rasgos calculados. Cada parche se clasifica en ROI (Región de Interés) o NoROI (No Región de Interés) usando los 12 rasgos y el método KNN. Para la determinación de los valores de K y la distancia a usar se realizaron varios experimentos cuyos resultados se exponen en el capítulo 3 de este informe. Los mejores resultados se obtuvieron para distancia cityblock. La distancia cityblock entre dos vectores *. + , de tamaño. *. y la + y. se define como: (. ). |. ∑|. (2.23). Paso 4. Construir Mapa de Importancia a partir de las clasificaciones de los parches de acuerdo a los rasgos y los histogramas. El mapa de importancia. de la imagen. se calcula a partir de las clasificaciones de. acuerdo a histograma y rasgos de cada uno de los parches en los cuales se dividió la imagen. (. ). (2.24) Página 30.
(39) donde. y. son los mapas de importancia de acuerdo a la clasificación de los. parches en rasgos e histogramas respectivamente. La importancia de un pixel de acuerdo a la clasificación de basada en rasgos se define como:. ( (. donde. (. ). (. ). ) (. (2.25). ). ) es la cantidad de parches clasificados como ROI (de acuerdo a los )y. rasgos) que contienen al pixel(. (. ) es la cantidad de parches clasificados. como NoROI (de acuerdo a los rasgos) que contienen al pixel ( Del mismo modo se define. ).. .. 5. Definir umbral T. Declarar como Regiones de Interés aquellos pixeles con nivel de importancia superior a o igual T. Definimos un umbral . En nuestro trabajo, los mejores resultados se obtuvieron para . Los experimentos (ver capítulo 3) se realizaron para los valores de conjunto * pixeles (. +. Al final, la región de interés de la imagen ) que cumplen que. (. ). en el son los. .. Página 31.
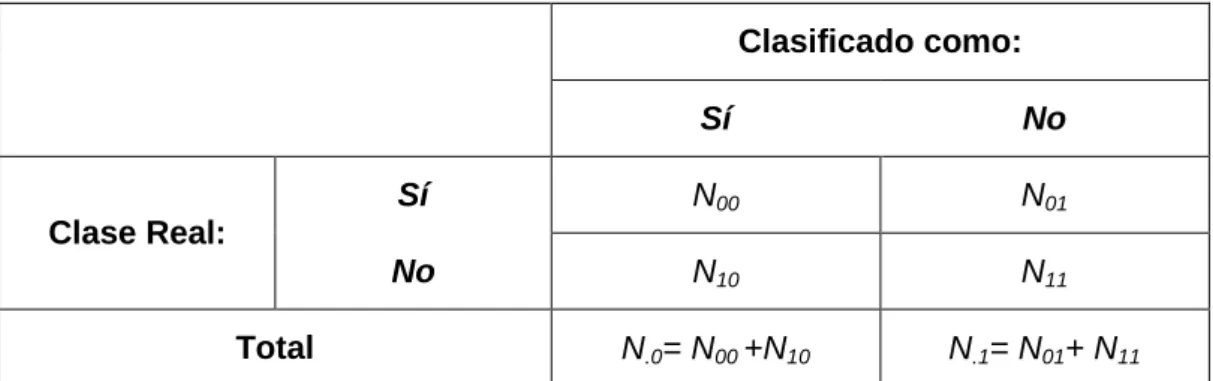
(40) CAPÍTULO III: RESULTADOS Y DISCUSIÓN 3.1. Experimentos realizados. Para la realización de los experimentos se utilizaron 40 imágenes de la prueba de Papanicolaou. Estas imágenes provienen de muestras del departamento de patología del Hospital Ginecobstétrico “Mariana Grajales”, en Santa Clara. Las imágenes se tomaron usando una cámara digital 319CU. De estas 40 imágenes, 20 contenían células anómalas mientras que las 20 restantes sólo contenían células normales. En total, estas imágenes de prueba contenían un total de 687 células anómalas.. 3.1.1 Medición de la calidad de los resultados de los clasificadores. En muchos trabajos se han reportado la utilización de medidas para la evaluación de la calidad de la clasificación [50]. Para la evaluación de la clasificación se usó la matriz de confusión, la cual deriva de una prueba que se la hace al clasificador en un conjunto de datos que no intervienen en el entrenamiento [51]. La siguiente (Tabla 3.1) muestra la matriz de confusión de un problema de dos clases: Tabla 3.1. Matriz de Confusión de un problema de dos Clases. Clasificado como: Sí. No. Sí. N00. N01. No. N10. N11. N.0= N00 +N10. N.1= N01+ N11. Clase Real:. Total. Al valor N00 se le denomina verdaderos positivos, N01 falsos negativos, N10 falsos positivos y N11 verdaderos negativos. A partir de estos valores se definen la Cantidad de Casos ( ), la Tasa de Clasificación (. ) y la Tasa de Error ( ) en las ecuaciones. (3.1) – (3.3), respectivamente. (3.1). (3.2). Página 32.
(41) (3.3). 3.2. Selección de los clasificadores. 3.2.1 Clasificación basada en histogramas. Para la clasificación basada en histogramas se utilizó el método KNN. Los espacios de colores que se probaron para la clasificación basada en histogramas fueron RGB y Lab. En la clasificación basada en histogramas se probaron las siguientes distancias entre histogramas (ver Sección 2.3.1 y Anexo 2): . Distancia Bhattacharyya.. . Distancia Chi-Cuadrado.. . Distancia Intersección de histogramas.. . Distancia Kullback-Leibler,. . Media armónica de la distancia Kullback-Leibler.. . Distancia Matusita.. Se probaron, además, distintos valores de K: 1, 11, 21 y 31.. 0,07 k=1. k = 11. k = 21. 0,0629. k = 31. 0,06. Tasa de Error. 0,05 0,0400 0,04. 0,0423. 0,0462 0,0467. 0,0501. 0,0350 0,0358. 0,03 0,02 0,01 0,00 Bhattacharyya. Matusita Distancia. Figura 3.1. Tasas de error obtenidas para las distancias Bhattacharyya y Matusita para K = 1, 11, 21 y 31, usando histogramas en el espacio Lab. Los mejores resultados se obtuvieron usando las distancias Bhattacharyya y Matusita. Los resultados para estas dos distancias y los distintos valores de K para los espacios de color Lab y RGB, respectivamente se muestran en la Figura 3.1 y 3.2. Estas tasas Página 33.
(42) de error se calcularon usando los histogramas de los 6600 parches con una validación cruzada con 10 grupos. Los mejores resultados se obtuvieron usando los rasgos que se muestran en el anexo 3 y el método KNN con K = 1 y la distancia Bhattacharyya entre histogramas calculados en el espacio Lab. La Figura 3.4 muestra un ejemplo de mapa de importancia según la clasificación basada en histogramas. 0,07 k=1. k = 11. k = 21. 0,06. 0,0527. Tasa de Error. 0,05 0,04. 0,0629. k = 31. 0,0591. 0,052. 0,0432 0,0367. 0,0394 0,0353. 0,03 0,02 0,01 0 Bhattacharyya. Matusita Distancia. Figura 3.2. Tasas de error obtenidas para las distancias Bhattacharyya y Matusita para K = 1, 11, 21 y 31, usando histogramas en el espacio RGB.. 3.2.2 Clasificación basada en rasgos. Con respecto a la clasificación basada en rasgos se calcularon 155 rasgos de color, textura y borde. La clasificación se realizó utilizando el método KNN con las siguientes medidas de distancia (ver Anexo 4): . Distancia Chebychev.. . Distancia Cityblock.. . Distancia Coseno.. . Distancia Euclidiana.. . Distancia Euclidiana Estandarizada.. Página 34.
(43) 0,119. 0,140 0,120. 0,020 0,000 Chebychev. Cityblock k=1. Cosine k = 11. k = 21. Euclidean. Seuclidean. k = 31. Figura 3.3. Tasas de error obtenidas para las distintas medidas de distancias para K = 1, 11, 21 y 31, usando clasificación basada en rasgos.. Se probaron, además, distintos valores de K: 1, 11, 21 y 31. Para cada distancia y valor de K se realizó una selección secuencial de rasgos usando el algoritmo KNN y una validación cruzada con 10 grupos. Los mejores resultados se obtuvieron para la distancia Cityblock con K=11 como se muestra en la figura 3.3. La Figura 3.4 muestra un ejemplo de mapa de importancia según la clasificación basada en rasgos.. 3.3. Selección del umbral T para la determinación de las regiones de interés. La Figura 3.4d muestra el mapa de importancia de una imagen, calculado según la ecuación (2.22). A partir de este mapa de importancia se determinan las regiones de interés. Se consideran píxeles de regiones de interés aquellos con importancia superior a un umbral T. La Figura 3.5 muestra las regiones de interés de la imagen de la Figura 3.4a según la selección de distintos valores de T.. Página 35. 0,035. 0,031. 0,032. 0,067 0,034. 0,031. 0,035. 0,032. 0,032. 0,036. 0,034. 0,027. 0,037. 0,037. 0,040. 0,033. 0,060. 0,038. 0,067. 0,065. 0,080. 0,071. Tasa de Error. 0,100.
(44) (a). (b). (c). (d). Figura 3.4. Mapas de importancia. (a) Imagen original. (b) Mapa de importancia según la clasificación basada en histogramas. (c) Mapa de importancia según la clasificación basada en rasgos. (d) Mapa de importancia de la imagen.. La calidad de las regiones de interés obtenidas para los distintos valores de T se muestra en la Figura 3.6. Haciendo una comparación con todos los valores del umbral T analizados (T = 0.25, T = 0.5, T = 0.75, T = 1) se puede observar que la cantidad de pixeles en la ROI disminuye significativamente de 14.33% para T = 0,25 a 1.77% para T = 1, tomando el 100% como todos los pixeles de las imágenes usadas.. Página 36.
(45) (a). (b). (c). (d). (e). (f). Figura 3.5. Regiones de Interés. (a) Imagen original. (b) Mapa de importancia. (c) Región de interés para T = 0.25. (d) Región de interés para T = 0.50. (e) Región de interés para T = 0.75. (f) Región de interés para T = 1.. Página 37.
(46) 100,00%. Anomalías completamente fuera de la ROI. 80,00% 60,00%. Anomalías con más de la mitad de su área fuera de la ROI. 40,00%. Anomalías con más de la mitad de su área dentro de la ROI. 20,00%. Anomalías completamente dentro de la ROI Píxeles en la ROI. 0,00% T = 0.25. T = 0.5. T = 0.75. T=1. Figura 3.6. Calidad de las regiones de interés obtenidas para los distintos valores de T. Desde el punto de vista de las anomalías detectadas dentro de la ROI, las anomalías completamente fuera de las ROI aumentan significativamente de 5,24% para T = 0.25 a 52,4% para T = 1. Lo mismo sucede con las anomalías parcialmente descartadas por la ROI (aquellas con más de la mitad de su área fuera de la ROI).. Área detectada como ROI. 25,00%. 20,00%. 15,00%. 10,00%. 5,00%. 0,00% Imágenes normales. Imágenes anómalas. Figura 3.7. Área detectada como ROI, para imágenes normales y anormales, tomando T= 0.25. Por otro lado, las anomalías completamente (completamente dentro de la ROI) y parcialmente (más de la mitad de su área dentro de la ROI) incluidas en la ROI, disminuyen drásticamente a medida que aumentamos el valor del umbral T. Por esta razón, elegimos un valor de compromiso para T (T = 0.25), de forma tal que incluyera la mayor cantidad de anomalías pero que también hiciera una reducción considerable de las regiones de interés. Además, para T = 0.25, el algoritmo demostró su eficacia ya que encontró ROIs en Página 38.
(47) todas las imágenes donde había células anómalas. En 11 de las 20 imágenes normales (donde no había células anómalas) no se encontraron ROIs. En las 20 imágenes donde no había células anómalas, solo se seleccionó como ROI el 5.47% de su área (Figura 3.6).. Página 39.
(48) CONCLUSIONES Y RECOMENDACIONES A partir de los resultados alcanzados en esta investigación se llegó a las siguientes conclusiones: 1. Se diseñó e implementó un algoritmo basado en rasgos, usando el método de los K vecinos más cercanos, para la detección de regiones de interés para la detección de anomalías en imágenes de la prueba de Papanicolaou. La distancia Cityblock y K=11, así como los rasgos del Anexo 4, dieron los mejores resultados. 2. Se diseñó e implementó un algoritmo basado en histogramas, usando el método de los K vecinos más cercanos, para la detección de regiones de interés para la detección de anomalías en imágenes de la prueba de Papanicolaou. La distancia Bhattacharyya y K= 11 dieron los mejores resultados. 3. Se construyeron mapas, a partir de las clasificaciones basadas en rasgos e histogramas, que representan las regiones de interés para la detección de anomalías en imágenes de la prueba de Papanicolaou. 4. Se probó el método propuesto con imágenes reales: . El 100% de las imágenes con anomalías mostró regiones de interés acorde al algoritmo propuesto.. . El 55% de las imágenes sin anomalías no mostró regiones de interés según el método propuesto.. . El método propuesto redujo el área de interés en un 85.67% del total.. . El método propuesto excluyó de la región de interés a solo el 5.24% de las células anómalas.. Al presente trabajo le realizamos las siguientes recomendaciones con el objetivo de darle continuidad: 1. Implementar otros algoritmos para la clasificación basada en rasgos. 2. Implementar otros algoritmos para la clasificación basada en histogramas. 3. Implementar otro método para que la generación de mapas de importancia se puedan combinar con el método propuesto.. Página 40.
(49) BIBLIOGRAFÍA 1.. Weissleder, R., Molecular imaging:Exploring the next frontier1. Radiology., 1999.. 2.. Herschman, H.R., Molecular imaging:Looking at problems, seeing solutions. . Science., 2003.. 3.. Petricoin, E., Molecular profiling of human cancer. Nat.Rev.Genet, 2000. 1: p. 48-56.. 4.. Contag, C.H., Using in vivo bioluminescence imaging to sheld light on cancer biology. IEEE, 2005. 93: p. 750-762.. 5.. Taboada Crispi Alberto, S.H., Orozco Monteagudo Maykel, Hernández Pacheco Denis, Falcón Ruiz Alexander. , Anomaly Detection in Medical Image Analysis ,2009: IGI Global. 21.. 6.. Chirenje M, El impacto global del cáncer de cuello uterino, 2014: Universidad de Zimbabue.. 7.. UU, G.d.T.s.E.d.C.d.l.E. Estadísticas de cáncer en los Estados Unidos. Informe electrónico sobre incidencia y mortalidad 1999–2010. 2013 [cited 2014 9 de junio]; Available from: http://www.cdc.gov/uscs.. 8.. Ikedo, Y., et al., Development of a fully automatic scheme for detection of masses in whole breast ultrasound images. Medical physics, 2007. 34(11): p. 4378-4388.. 9.. Cohen, C., Image cytometric analysis in pathology. Human Pathology, 1996. 27(5): p. 482-493.. 10.. Chiracharit, W., et al., Normal mammogram detection based on local probability difference transforms and support vector machines. IEICE TRANSACTIONS on Information and Systems, 2007. 90(1): p. 258-270.. 11.. Ginori, V.L.J., Procesamineto Digital de Imágenes Avanzado., in Detección de anomalías en imágenes,2013.. 12.. Hodge, V.J. and J. Austin, A survey of outlier detection methodologies. Artificial Intelligence Review, 2004. 22(2): p. 85-126.. 13.. Salgado P. and Vendrell P., La imagen por resonancia magnética en el estudio de la esquizofrenia. Anales de psicología, 2004. vol. 20: p. p.261-272. 14.. Ceccarelli, M., d.A. A., and A. Facchiano, A scale space approach for unsupervised feature selection in mass spectra classification for ovarian cancer detection. BMC Bioinformatics, 2009. 10.. 15.. Iyatomi, H., et al., Quantitative assessment of tumour extraction from dermoscopy images and evaluation of computer-based extraction methods for an automatic melanoma diagnostic system. Melanoma Research, 2006. 16(2): p. 183-190.. 16.. Huang, Y.-L. and D.-R. Chen, Watershed segmentation for breast tumor in 2-D sonography. Ultrasound in medicine & biology, 2004. 30(5): p. 625-632.. 17.. Krivacic, R.T., et al., A rare-cell detector for cancer. Proceedings of the National Academy of Sciences of the United States of America, 2004. 101(29): p. 10501Página 41.
(50) 10504. 18.. Zapata A., et al., Proyecto de tomografía por el método de impedancia eléctrica. Avances actuales. Salud Mental, 2000. 23(2): p. 8-15.. 19.. Müller, H., et al., A review of content-based image retrieval systems in medical applications—clinical benefits and future directions. International journal of medical informatics, 2004. 73(1): p. 1-23.. 20.. Gallego P., et al., Actualización en técnicas de imagen cardiaca. Ecocardiografía, resonancia magnética y tomografía computarizada. Rev Esp Cardiol, 2008. 61: p. 109-131.. 21.. Prastawa, M., et al., A brain tumor segmentation framework based on outlier detection. Medical Image Analysis, 2004. 8(3): p. 275-283.. 22.. Montgomery, D.W., A. Amira, and H. Zaidi, Fully automated segmentation of oncological PET volumes using a combined multiscale and statistical model. Medical physics, 2007. 34(2): p. 722-736.. 23.. Astley, S.M., Computer-based detection and prompting of mammographic abnormalities. The British Journal of Radiology, 2004. 77: p. 194-S20.. 24.. Radke, R.J., et al., Image change detection algorithms: a systematic survey. Image Processing, IEEE Transactions on, 2005. 14(3): p. 294-307.. 25.. Lehmann, T.M., et al., Automatic categorization of medical images for contentbased retrieval and data mining. Computerized Medical Imaging and Graphics, 2005. 29(2): p. 143-155.. 26.. Xu, R., et al., Target Detection with Improved Image Texture Feature Coding Method and Support Vector Machine. International Journal of Intelligent Technology, 2006. 1(1).. 27.. Duncan, J.S. and N. Ayache, Medical image analysis: Progress over two decades and the challenges ahead. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 2000. 22(1): p. 85-106.. 28.. Crispi, A.T. and H. Sahli, Experimental System for Image Anomaly Detection Based on Features and Distances. 2008.. 29.. Daszykowski, M., et al., Robust statistics in data analysis—a review: basic concepts. Chemometrics and intelligent laboratory systems, 2007. 85(2): p. 203-219.. 30.. Rousseeuw, P.J., et al., Robustness and outlier detection in chemometrics. Critical reviews in analytical chemistry, 2006. 36(3-4): p. 221-242.. 31.. Gonzalez, R.C. and R.E. Woods, Digital image processing,. Vol. Second Edition. 2002, New Jersey: Prentice-Hall, Englewood Cliffs, NJ.. 32.. Joaquín., A.L., M.B. Verónica., and L. Jean-Francois., Procesamiento de imágenes biomédicas 2000, México, D.F.: UNIVERSIDAD AUTÓNOMA METROPOLITANA.. 33.. Ramírez J., et al., Segmentación de imágenes a color para la Identificación automática de rostros utilizando FCM. Synthesis, 2010. Aventuras del pensamiento.. 34.. Cervantes G., Etiquetado Automático de Imágenes Usando Múltiples Segmentaciones Basándose en Modelos Probabilistas, in Instituto Nacional de Astrofísica,Optica Y Electrónica2010, Universidad Autónoma de la Ciudad de México: México. DF. Página 42.
(51) 35.. Smith, A.R., Color gamut transform pairs. Computer Graphics (SIG-GRAPH'78 Proceedings), 1978. 12(3):12{19.. 36.. MANRIQUEZ J., Microscopía óptica y ánalisis de imágenes en la caracterización del tiempo de cargado de discos de pulido, in Centro de investigación en ciencia aplicada y tecnología avanzada.2009, Instituto politécnico nacional: México.. 37.. Karla R. Dzul-Rosado, M.P.-S., María del R. González-Losa., Cáncer cervicouterino: méto-dos actuales para su detección. Rev Biomed, 2004.. 38.. Peter, L., A system for automated screening for cervical cancer. Medicinsk Visiondag, 2003: p. 36.. 39.. A. Meisels, C.M., D. Giri, and R. S. Hoda, Cytopathology of the uterus. International Journal of Gynecologic Pathology, 1998. 17: p. p. 286.. 40.. Landwehr, D., Web based pap-smear classification., in Dept. of Automation.2001, Technical University of Denmark (DTU) Lyngby.: Denmark.. 41.. Instituto Nacional del Cáncer, d.l.I.N.d.l.S.d.E.U. Pruebas de Papanicolaou y del virus del papiloma humano (VPH). 2012; Available from: http://www.cancer.gov/espanol.. 42.. Canny, J., A computational approach to edge detection. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 1986(6): p. 679-698.. 43.. Murphy, R.F., M.Velliste,et al., "Robust numerical features for description and classification of subcellular location patterns in fluorescence microscope images.". The Journal of VLSI Signal Processing, 2003. 35: p. 311-321.. 44.. Díaz R., Mezcla de regiones en imágenes sobresegmentadas usando rasgos de textura, in Facultad de Ingienería Eléctrica, 2013, Universidad Central de las Villas: Villa Clara.. 45.. Huergo S., Desarrollo de herramientas de cálculo de rasgos para la clasificación de imágenes en microscopía celular, in Facultad de Ingienería Eléctrica, 2013, Universidad Central de las Villas: Villa Clara.. 46.. Robert M. Haralick, K.S., Hak Dinstein, Textural Features for image classification. IEEE, 1973.. 47.. Orozco R., Realce de imágenes in Modificación de la intensidad y transformación del color, 2013.. 48.. Webb, A.R., Statistical pattern recognition. Second Edition ed2002, UK: John Wiley & Sons,Malvern.. 49.. Stoitsis, J., S. Golemati, and K.S. Nikita, A modular software system to assist interpretation of medical images—application to vascular ultrasound images. Instrumentation and Measurement, IEEE Transactions on, 2006. 55(6): p. 19441952.. 50.. Joshi, M.V. On evaluating performance of classifiers for rare classes. in Data Mining, 2002. ICDM 2003. Proceedings. 2002 IEEE International Conference on. 2002. IEEE.. 51.. Zhang, H., J.E. Fritts, and S.A. Goldman, Image segmentation evaluation: A survey of unsupervised methods. computer vision and image understanding, 2008. 110(2): p. 260-280.. Página 43.
(52) Página 44.
Figure



+7



Documento similar
Cedulario se inicia a mediados del siglo XVIL, por sus propias cédulas puede advertirse que no estaba totalmente conquistada la Nueva Gali- cia, ya que a fines del siglo xvn y en
6 Para la pervivencia de la tradición clásica y la mitología en la poesía machadiana, véase: Lasso de la Vega, José, “El mito clásico en la literatura española
d) que haya «identidad de órgano» (con identidad de Sala y Sección); e) que haya alteridad, es decir, que las sentencias aportadas sean de persona distinta a la recurrente, e) que
La siguiente y última ampliación en la Sala de Millones fue a finales de los años sesenta cuando Carlos III habilitó la sexta plaza para las ciudades con voto en Cortes de
La campaña ha consistido en la revisión del etiquetado e instrucciones de uso de todos los ter- mómetros digitales comunicados, así como de la documentación técnica adicional de
You may wish to take a note of your Organisation ID, which, in addition to the organisation name, can be used to search for an organisation you will need to affiliate with when you
Products Management Services (PMS) - Implementation of International Organization for Standardization (ISO) standards for the identification of medicinal products (IDMP) in
This section provides guidance with examples on encoding medicinal product packaging information, together with the relationship between Pack Size, Package Item (container)
