Desarrollo de una aplicación web de ayuda a la elaboración de exámenes de tipo test
104
0
0
Texto completo
(2)
(3) Me gustaría comenzar agradeciendo a mi familia el haberme apoyado estos últimos meses y haberme animado a que me centrase en lo que debía hacer. En segundo lugar, pero no menos importante, quiero transmitir mi gran agradecimiento a mi tutor Javier Antich, ya que sin su dedicación este proyecto no hubiera salido adelante. Gracias por tu tiempo y paciencia. A mi cotutor Alberto Ortiz también le doy las gracias su tiempo invertido en este proyecto. Por último, quiero agradecerles a mis compañeros el tiempo que hemos compartido juntos en la universidad, el cual siempre recordaré. Y a aquellos que en mitad del camino me dejaron de apoyar, también les doy las gracias..
(4)
(5) Í NDICE GENERAL. Índice general. iii. Índice de figuras. v. Acrónimos. vii. Resumen. ix. 1. Introducción. 1. 2. Especificaciones de la aplicación a desarrollar. 3. 3. Herramientas y software utilizados 3.1 Maria DB . . . . . . . . . . . . . . . . . 3.2 XAMPP . . . . . . . . . . . . . . . . . . 3.3 Grocery CRUD . . . . . . . . . . . . . . 3.4 PHP . . . . . . . . . . . . . . . . . . . . 3.4.1 Declaración de variables PHP 3.4.2 Instrucción echo . . . . . . . .. 4. 5. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. 7 7 8 9 11 11 11. Diseño y creación de la Base de Datos 4.1 Diseño de la base de datos . . . . . . . . . . . . . . . . 4.1.1 Modelo Entidad-Relación . . . . . . . . . . . . 4.1.2 Modelo Relacional . . . . . . . . . . . . . . . . 4.2 MER y MR con GID . . . . . . . . . . . . . . . . . . . . 4.2.1 MER con GID . . . . . . . . . . . . . . . . . . . 4.2.2 MR con GID . . . . . . . . . . . . . . . . . . . . 4.3 Código SQL . . . . . . . . . . . . . . . . . . . . . . . . . 4.4 Otros códigos empleados . . . . . . . . . . . . . . . . . 4.4.1 Creación de Vistas en la base de datos . . . . 4.4.2 Triggers . . . . . . . . . . . . . . . . . . . . . . 4.4.3 Procedure para asignar número de columna . 4.4.4 Procedure para la generación de modelos . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. 13 13 13 18 23 23 25 27 31 31 31 32 34. Grocery CRUD: creamos la interfaz web 5.1 Creación de los formularios . . . . . . . . . . . . . . . . . . . . . . . . . . 5.1.1 Controlador o Controller . . . . . . . . . . . . . . . . . . . . . . . 5.1.2 Vista o View . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 39 39 39 41. iii. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . ..
(6) iv. ÍNDICE GENERAL. 5.2. 5.1.3 Resultado final de Grocery CRUD Formularios creados de la Base de Datos 5.2.1 Asignatura . . . . . . . . . . . . . . 5.2.2 Asignatura seleccionada . . . . . . 5.2.3 Cabecera . . . . . . . . . . . . . . . 5.2.4 Estudios . . . . . . . . . . . . . . . 5.2.5 Profesor . . . . . . . . . . . . . . . 5.2.6 Pregunta . . . . . . . . . . . . . . . 5.2.7 Tipo Pregunta . . . . . . . . . . . . 5.2.8 Imagen . . . . . . . . . . . . . . . . 5.2.9 Examen . . . . . . . . . . . . . . . 5.2.10 Consta Examen-Pregunta . . . . . 5.2.11 Modelo . . . . . . . . . . . . . . . . 5.2.12 Consta Modelo-Pregunta . . . . . 5.2.13 Bitácora . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . .. 42 43 44 45 46 48 48 50 51 51 54 59 60 61 62. 6. Ejemplo de generación de un examen y sus modelos. 65. 7. Conclusiones. 73. A Códigos completos A.1 Fichero .SQL de creación de la Base de Datos . . . . A.2 Procedures . . . . . . . . . . . . . . . . . . . . . . . . A.2.1 Procedimiento para enumerar las columnas A.2.2 Procedimiento para generar los modelos . . Bibliografía. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. 75 75 83 83 84 91.
(7) Í NDICE DE FIGURAS. 2.1 2.2 2.3. Ejemplo de cabecera de un examen . . . . . . . . . . . . . . . . . . . . . . . . Ejemplo de disposición de las preguntas en dos columnas . . . . . . . . . . Esquema del proceso a seguir para la generación del examen y sus modelos. 4 5 6. 3.1 3.2 3.3. Inicio de una sesión en Maria DB . . . . . . . . . . . . . . . . . . . . . . . . . XAMPP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Ficheros de configuración de Grocery CRUD . . . . . . . . . . . . . . . . . .. 8 9 10. 4.1 4.2 4.3 4.4 4.5 4.6 4.7 4.8 4.9 4.10 4.11. Relación 1-N entre Asignatura y Examen . . . . . . . . . . . . . . . . . . . . . Relaciónes 1-N entre Examen y Cabecera, y M-N entre Cabecera e Imagen Relación M-N entre Examen y Pregunta . . . . . . . . . . . . . . . . . . . . . Relación 1-N entre Tipo de Pregunta y Pregunta . . . . . . . . . . . . . . . . Relación 1-N entre Examen y Modelo . . . . . . . . . . . . . . . . . . . . . . . Relación M-N entre Modelo y Pregunta . . . . . . . . . . . . . . . . . . . . . . Entidad Asignatura y todas sus interrelaciones . . . . . . . . . . . . . . . . . Entidad Bitácora . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . MER . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Resultado de una transformación de una entidad a una relación. . . . . . . Ejemplo de transformación de una interrelación M-N que se convierte en una relación. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Ejemplo de relación con herencia 1-N . . . . . . . . . . . . . . . . . . . . . . Ejemplo de relación con PK doble . . . . . . . . . . . . . . . . . . . . . . . . . Ejemplo de relación con atributos propios . . . . . . . . . . . . . . . . . . . . MR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . MER con GID de la Base de Datos . . . . . . . . . . . . . . . . . . . . . . . . . Relaciones que heredan cod_asignatura . . . . . . . . . . . . . . . . . . . . . MR con GID de la Base de Datos . . . . . . . . . . . . . . . . . . . . . . . . . . Ejemplo de sentencias SQL para crear una tabla dentro de una base de datos Creación de la tabla bitácora . . . . . . . . . . . . . . . . . . . . . . . . . . . . Creación de restricciones para las tablas volcadas . . . . . . . . . . . . . . . Disparadores de la tabla Estudios . . . . . . . . . . . . . . . . . . . . . . . . . Creación del procedimiento para asignar columnas y sus variables . . . . . Proceso de asignación de columnas . . . . . . . . . . . . . . . . . . . . . . . . Tabla temporal de Consta_MP . . . . . . . . . . . . . . . . . . . . . . . . . . . Reenumeración de las columnas . . . . . . . . . . . . . . . . . . . . . . . . . Código SQL que da un nuevo orden a las respuestas de una pregunta . . . . Inserción de los valores en Consta_MP y borrado de tablas temporales . . .. 14 14 15 16 16 16 18 19 20 21. 4.12 4.13 4.14 4.15 4.16 4.17 4.18 4.19 4.20 4.21 4.22 4.23 4.24 4.25 4.26 4.27 4.28. v. 21 21 22 22 24 26 27 28 29 30 30 32 33 34 35 36 36 37.
(8) vi. Índice de figuras. 5.1 5.2 5.3 5.4 5.5 5.6 5.7 5.8 5.9 5.10 5.11 5.12 5.13 5.14 5.15 5.16 5.17 5.18 5.19 5.20 5.21 5.22 5.23 5.24 5.25 5.26 5.27 5.28 5.29 5.30 5.31. Fichero controlador . . . . . . . . . . . . . . . . . . . . . . . . . Código HTML y PHP del archivo view . . . . . . . . . . . . . . Resultado de Grocery CRUD . . . . . . . . . . . . . . . . . . . . Función gestion del formulario Asignatura . . . . . . . . . . . Resultado del formulario Asignatura . . . . . . . . . . . . . . . Función gestion del formulario Asignatura Seleccionada . . . Cambios en el fichero vista al filtrar por asignatura . . . . . . . Resultado del formulario Asignatura Seleccionada . . . . . . . Función gestion del formulario Cabecera . . . . . . . . . . . . Resultado del formulario Cabecera . . . . . . . . . . . . . . . . Función gestion del formulario Estudios . . . . . . . . . . . . . Resultado del formulario Estudios . . . . . . . . . . . . . . . . Funciones dentro de la función gestion de Profesor . . . . . . Resultado del formulario Profesor . . . . . . . . . . . . . . . . . Funciones dentro de la función gestion de Profesor . . . . . . Resultado del formulario Pregunta . . . . . . . . . . . . . . . . Función gestion del formulario Tipo de Pregunta . . . . . . . . Resultado del formulario Tipo de pregunta . . . . . . . . . . . Funciones de Imagen . . . . . . . . . . . . . . . . . . . . . . . . Resultado del formulario Imagen . . . . . . . . . . . . . . . . . Resultado del formulario Examen . . . . . . . . . . . . . . . . . Función gestion del formulario Examen . . . . . . . . . . . . . Llamadas a los procedimientos . . . . . . . . . . . . . . . . . . Descarga de los archivos del examen . . . . . . . . . . . . . . . Funciones generadas para descargar los modelos de examen . Formulario Consta Examen - Pregunta . . . . . . . . . . . . . . Obtención de los dos atributos para enviarlos a la Vista . . . . Formulario Modelo . . . . . . . . . . . . . . . . . . . . . . . . . Formulario Consta Modelo - Pregunta . . . . . . . . . . . . . . Resultado del formulario Bitácora . . . . . . . . . . . . . . . . . Funciones del controller de Bitácora . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 40 42 43 44 45 46 46 47 47 48 49 49 50 51 52 53 53 54 54 55 55 56 57 58 59 60 60 61 61 62 63. 6.1 6.2 6.3 6.4 6.5 6.6 6.7 6.8 6.9 6.10 6.11 6.12 6.13. Escoger una asignatura con la acción Seleccionar . . . . . . . . . . . Insertar datos de las distintas tablas desde Asignatura Seleccionada Inserción de una imagen en la base de datos para una asignatura . . Creación de una cabecera . . . . . . . . . . . . . . . . . . . . . . . . . Tipos de pregunta de la asignatura Estructura de Computadores I . . Algunas preguntas de Estructura de computadores I . . . . . . . . . . Generación del Modelo X de un examen . . . . . . . . . . . . . . . . . Examen y sus posibles acciones . . . . . . . . . . . . . . . . . . . . . . Formulario Consta EP y las preguntas ordenadas automáticamente . Formulario Modelo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Formulario Consta Modelo - Pregunta del Modelo 1 . . . . . . . . . . Archivos .tex de las diferentes cabeceras y distintos modelos . . . . . PDF del Modelo 2 y del Modelo 1 . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . .. . . . . . . . . . . . . .. . . . . . . . . . . . . .. . . . . . . . . . . . . .. 65 66 66 67 67 68 68 69 69 70 70 71 72.
(9) A CRÓNIMOS UIB Universitat de les Illes Balears EPS Escola Politècnica Superior TFG Trabajo Final de Grado SGDB Sistema Gestor de Bases de Datos BD Base de Datos GC Grocery CRUD MER Modelo Entidad-Relación MR Modelo Relacional PK Primary Key FK Foreign Key UK Unique Key NN Not Null N Null. vii.
(10)
(11) R ESUMEN Desde el año 2010, cuando se implantó el plan Bolonia en España, tuvo como consecuencia que muchas asignaturas evalúen ciertas competencias y contenidos mediante la realización de exámenes de tipo test. Ante este hecho, se hace necesario el desarrollo de una aplicación que asista a los profesores en la creación de esos exámenes, con el fin de facilitar y agilizar su labor. El siguiente Trabajo Final de Grado (TFG) está planteado como un proyecto de desarrollo de una aplicación web para ayudar a la elaboración de exámenes de tipo test de algunas asignaturas de la Escola Politècnica Superior, ya que el sistema utilizado hasta el momento es lento y está poco automatizado. Dichos exámenes se elaboran siguiendo un formato establecido que se mantendrá cuando se generen con la aplicación web. Para ello, se deben tener ciertos conocimientos sobre el diseño de Bases de Datos Relacionales, conocer sus diferentes etapas y sus reglas básicas. Asímismo, es necesario tener nociones de algún lenguaje relacional. Todos ellos se ampliarán según los requerimientos de la aplicación a lo largo de su desarrollo.. ix.
(12)
(13) CAPÍTULO. 1. I NTRODUCCIÓN Una base de datos es una gran colección de información almacenada pertenecientes a un mismo contexto, de manera estructurada, en la cual se evitan las redundancias de datos y que facilita la comprensión de éstos. Una de las principales ventajas de las bases de datos es que múltiples usuarios pueden acceder a ella simultáneamente, visualizarla, insertar o actualizar datos de acuerdo con el nivel de privilegio que se otorguen. Al ser una base de datos distribuida, y no centralizada, se accede a la información por medio de una red para así poder compartir los datos. Para administrar esta gran cantidad de datos y a sus distintos usuarios es necesario contar con un Sistema Gestor de Bases de Datos (SGBD) o en inglés Database Management System (DBMS). Se trata de un conjunto de programas que facilita la definición de los datos y permite el acceso de los distintos usuarios y la manipulación de los datos que contiene. Se puede entender como interfaz entre la base de datos y las aplicaciones que la utilizan. Por lo tanto, todas las interacciones del usuario con la base de datos se realizan por medio del sistema gestor. Estas interacciones deben realizarse en un lenguaje estándar: Structured Query Language (SQL). Es un lenguaje de alto nivel que cuenta con dos sublenguajes: • Data Definition Language (DDL): permite definir la estructura de la base de datos, es decir, sus entidades, atributos e interrelaciones. Se entendiende por entidad un objeto del mundo real o abstracto, que podemos distinguir del resto de objetos y del que nos interesan algunas propiedades o características de las que guardaremos información, es decir, los atributos. • Data Manipulation Language (DML): permite modificar, insertar, borrar y consultar datos de la base de datos. 1.
(14) 1. I NTRODUCCIÓN Para el presente proyecto se creará una base de datos que generará exámenes tipo test y sus diferentes modelos, que facilitará la tarea de creación y la clasificación de la gran cantidad de preguntas tipo test que contendrá. No solo incluirá la base de datos propiamente dicha, si no que será necesaria además una aplicación que haga de intermediaria entre el usuario y la base de datos, donde se puedan crear visualmente el modelo base, y a partir de éste, generar el número de modelos que se desee. En los siguientes apartados se desarrollará con detalle el proceso de diseño, creación y ejecución tanto de la base de datos como de la citada aplicación, así como todos los elementos requeridos para su elaboración y correcto funcionamiento. En primer lugar, en el capítulo 2, se explicarán los requisitos a cumplir en la creación de la base de datos y en el capítulo 3 se introducirán las herramientas y el software que han hecho posible el desarrollo de la aplicación. A continuación, el capítulo 4 contendrá el diseño de la base de datos y los códigos para generarla. Seguidamente, el capítulo 5 describirá uno a uno los formularios que generan la interfaz web para luego dar un ejemplo de generación de modelos de examen en el capítulo 6. Finalmente, en el Anexo, se adjuntarán los códigos completos que no se hayan podido mostrar a lo largo de la memoria.. 2.
(15) CAPÍTULO. 2. E SPECIFICACIONES DE LA APLICACIÓN A DESARROLLAR. Este trabajo tiene por objetivo el desarrollo de una base de datos con preguntas de exámenes de distintas asignaturas impartidas en la Escola Politècnica Superior (EPS), la cual permite la elaboración de exámenes tipo test y sus diferentes modelos. La interfaz con el usuario se consigue mediante una aplicación web. A través de la aplicación, se podrán llevar a cabo las siguientes operaciones: • Crear, modificar, eliminar y clasificar por asignaturas preguntas de tipo test de respuesta múltiple. • Elaborar un examen de tipo test seleccionando manualmente las preguntas que formarán parte del examen. • Generar los distintos modelos de examen, modificando el orden de las preguntas en cada columna y el de las respuestas dentro de cada pregunta. • Conocer la proporción de aciertos y fallos en cada pregunta. Hasta el momento, el sistema utilizado para la generación de los exámenes tipo test era la creación manual del Modelo X en un archivo .tex, a partir del cual se generan los modelos reales de examen. El Modelo X contiene las preguntas seleccionadas por el o los profesores, dispuestas en dos columnas en cada página. Las preguntas nunca están divididas en dos columnas, es decir, una pregunta debe caber completamente en una columna. Esto se conseguía cuadrando a mano las preguntas y las columnas en el documento .tex. Una vez creado el Modelo X, se procede a la creación de los distintos modelos de examen con ayuda de un programa en C++, de forma automática. El examen tipo test comienza siempre con una cabecera (figura 2.1), que contiene la asignatura, la fecha del examen, el modelo, las reglas a cumplir y las tablas de 3.
(16) 2. E SPECIFICACIONES DE LA APLICACIÓN A DESARROLLAR puntuación según los aciertos. Cada cara del examen, está dividida en dos columnas, dentro de las cuales encontraremos las preguntas de tipo test, como el ejemplo de la figura 2.1. Las preguntas son de respuesta múltiple, teniendo un mínimo de 2 respuestas posibles y un máximo de 5. Solo una será la correcta. El examen creado es el que llamamos Modelo X, que siempre contiene la única respuesta correcta en la opción a), es decir, en la primera opción de respuesta. A partir de él, se generan los modelos de examen, en los cuales el contenido tiene un orden distinto al Modelo X. Todas las partes mencionadas anteriormente están redactadas en formato LATEX. Los modelos se generan en un archivo .tex y con un compilador se genera el documento PDF.. Figura 2.1: Ejemplo de cabecera de un examen La elaboración de los modelos se hace cambiando el orden de las respuestas dentro de una pregunta, cambiando el orden de las preguntas dentro de una columna y cambiando el orden de las columnas dentro del examen. La creación de esta base de datos quiere contribuir a facilitar este proceso sin cambiar la estructura de los exámenes, llevando a cabo el proceso de forma automática o de forma manual, pero consiguiendo el mismo resultado de una manera más sencilla. La figura 2.3 muestra el proceso de generación de un examen y sus modelos por parte de un profesor. Las preguntas deben estar introducidas previamente en la base de datos. Una pregunta se compone de un enunciado y de dos a cinco respuestas, siendo sólo una la correcta. Existe la posibilidad de incluir una imagen en el enunciado, y cada pregunta está catalogada por un tipo de pregunta, además de contener información sobre el número de aciertos y el número de contestaciones que ha tenido. Con estos dos últimos datos se calcula la dificultad de la pregunta, dividiendo el 4.
(17) Figura 2.2: Ejemplo de disposición de las preguntas en dos columnas. primero entre el segundo. También se da la posibilidad de duplicar una pregunta ya existente para modificarla y tener de una forma rápida y sencilla una nueva pregunta. Lo primero que se debe definir es el examen para una asignatura concreta, seleccionada previamente. El examen viene definido por la fecha y la asignatura. En el momento de crear el examen veremos las preguntas insertadas en la base de datos de esa asignatura, ordenadas de más reciente a más antigua con el propósito de hallar antes las nuevas preguntas. Esto se ha pensado de esta manera porque es muy probable que el examen que está siendo creado incluya las preguntas más recientes. Las preguntas que constituyen el examen se pueden ordenar como el usuario desee, arrastrándolas en la ventana de preguntas seleccionadas. Este orden puede usarse para la plantilla Modelo X. Podemos insertar una cabecera que ya esté definida en la base de datos. Si se da el caso que la cabecera no ha sido insertada previamente, creamos el examen con una cabera ya existente y luego la modificamos, o bien cancelamos el proceso para crear primero la cabecera y volver a la definición de exámenes. Es posible incluir más tarde un fichero PDF Modelo X con el resultado final de la creación del examen, con las características explicadas anteriormente. Una vez creado el examen, es posible crear un modelo de examen de dos maneras diferentes. La primera es de forma automática. Este modo, mediante un algoritmo que 5.
(18) 2. E SPECIFICACIONES DE LA APLICACIÓN A DESARROLLAR. Figura 2.3: Esquema del proceso a seguir para la generación del examen y sus modelos. se explicará más adelante, mezcla las columnas, las preguntas y las respuestas, y éste también genera el número de modelos indicado por el usuario. Si, por el contrario, se desea crear los modelos manualmente, se debe acceder a la edición de los atributos para cambiar manualmente el número de columna.. 6.
(19) CAPÍTULO. 3. H ERRAMIENTAS Y SOFTWARE UTILIZADOS A lo largo de este proyecto se han empleado varias herramientas para conseguir el resultado deseado. Éstas se han elegido en base a que cumpliran al máximo nuestras exigencias, según su popularidad de usuarios y su rendimiento.. 3.1 Maria DB MariaDB es nuestro Sistema Gestor de Bases de Datos (SGDB) y es un reemplazo del servidor MySQL, creada a partir de éste por su mismo desarrollador, Monty Widenius, al producirse la compra de Sun Microsystems por Oracle [1]. Nació con el propósito de poder seguir utilizando libremente MySQL ante la posibilidad de que Oracle lo comenzara a distribuir bajo una licencia de pago, además de la gran probabilidad que existía de que se viera perjudicada su funcionalidad al no poder ser actualizada por la comunidad. Por eso su compatibilidad con MySQL es prácticamente del 100 % para que se pueda cambiar de SGDB con poco esfuerzo y sin que se note la diferencia. Todos los comandos, interfaces, librerías y APIs que existen en MySQL también existen en MariaDB. Cuenta con más mecanismos de almacenamiento, mejoras en la velocidad y en las prestaciones, más funcionalidades, mejor rendimiento y con licencia GPL (General Public License) o lo que es lo mismo, de software libre y de código abierto. Las características de MariaDB son las que se presentan a continuación: • Contiene nuevos motores de almacenamiento. Aria es el motor de almacenamiento resistente a caídas del sistema, que reemplaza a MyISAM de MySQL. Implementa el almacenamiento de datos de manera sencilla y robusta, y proporciona una alta velocidad de acceso y un tamaño pequeño de ficheros. XtraDB sustituye al motor InnoDB. Como motor de almacenamiento transaccional encontramos a PBXT, también con nuevas características. 7.
(20) 3. H ERRAMIENTAS Y SOFTWARE UTILIZADOS • La velocidad y el rendimiento son mayores en MariaDB. Cuando se hacen consultas complejas, el rendimiento mejora debido a que Aria examina los datos de tablas temporales en memoria RAM y no hace falta que acceda al disco duro como hace MyISAM. • Se añaden nuevas tablas de sistema para almacenar estadísticas de servicio que nos pueden ayudar a optimizar las bases de datos. Todo esto se almacena en INFORMATION_SCHEMA. • Los comandos ALTER TABLE y LOAD DATA INFILE ahora informan del progreso, sin embargo antes eran opacos. • Se amplían a microsegundos los tipos de datos TIME, DATETIME, y TIMESTAMP.. Figura 3.1: Inicio de una sesión en Maria DB Nuestro interés en utilizar MariaDB se basa no sólo en que es de uso público y en que cada vez cuenta con un mayor número de usuarios, sino que también tiene un gran soporte por parte de los desarrolladores, cosa que consigue que sea potente y más eficiente frente a su primogénito. MariaDB está desbancando a MySQL en número de usuarios, del mismo modo que algunas distribuciones Linux ya lo incluyen por defecto, como por ejemplo OpenSUSE o Fedora [2] y [3]. En la figura 3.1 se ve el inicio de sesión de MariaDB desde el terminal.. 3.2 XAMPP XAMPP es el entorno de desarrollo de PHP más popular entre los usuarios. Contiene el servidor web Apache, MariaDB, software de desarrollo PHP y soporte de Perl, de ahí su nombre formado por los acrónimos por X para designar cualquier sistema operativo más todo lo mencionado anteriormente. Antes de la versión 5.6.15 estaba asociado con MySQL. Es un software libre y gratuito [4]. XAMPP se creó con el objetivo de que fuese una plataforma de desarrollo, para que los desarrolladores fueran comprobando los resultados de su trabajo sin necesidad de conectarse a internet. Sin embargo, hoy en día, se utiliza más como servidor de sitios Web, debido a que es lo suficientemente seguro para serlo. Entre las ventajas de usar XAMPP está su fácil instalación y las mínimas configuraciones que requiere para usarlo. El inicio de los servidores se realiza desde el 8.
(21) 3.3. Grocery CRUD administrador de la figura 3.2.. Figura 3.2: XAMPP. 3.3 Grocery CRUD Grocery CRUD [5] es una librería PHP de alto nivel y de código abierto que nos permite generar interfaces CRUD. CRUD hace referencia a las cuatro sentencias reservadas del lenguaje DML para el almacenamiento de datos: Create, Read, Update and Delete (Crear, Leer, Actualizar y Borrar). Por lo tanto, esta herramienta permite realizar las funciones básicas de una base de datos a través de un interfaz web creado con sencillas líneas de código. La interfaz de usuario es sencilla porque reduce al máximo la documentación necesaria para que el usuario entienda cómo funciona la interfaz, al igual que es posible trabajar con él aunque los conocimientos de PHP del programador sean escasos. Grocery CRUD soporta todos los principales navegadores web y está traducido al Español. Se pueden hacer modificaciones como personalizar columnas, campos y operaciones, y permite las interrelaciones entre entidades. Además, para cualquier consulta que sea necesaria durante el desarrollo, existe una documentación API disponible en la página web. Todas estas razones han sido decisivas a la hora de elegir esta librería para el proyecto. A través de la creación de formularios CRUD para las distintas tablas de la base de datos es como se consigue obtener la interfaz web. Para que ésta funcione, son necesarios dos archivos PHP: un controlador (figura 3.3.a) y una vista (figura 3.3.b). El controlador incluye todas las funciones de un formulario y la vista contiene el código HTML para poder generar la interfaz gráfica del formulario.. 9.
(22) 3. H ERRAMIENTAS Y SOFTWARE UTILIZADOS. (a) Ejemplo de fichero controller. (b) Ejemplo de fichero vista. Figura 3.3: Ficheros de configuración de Grocery CRUD. 10.
(23) 3.4. PHP Para poder utilizar Grocery CRUD, es imprescindible que trabaje conjuntamente con Codeigniter para el desarrollo de aplicaciones web. Codeigniter es un framework, es decir, es un patrón para el desarrollo de una aplicación que proporciona una estructura que tan solo hay que rellenar, haciendo que el proceso de desarrollo sea más rápido, al igual que el mantenimiento. La colaboración con Grocery CRUD se basa en que utiliza internamente las funciones de Codeigniter. Por ejemplo, la declaración de funciones que se hace en Grocery CRUD es propia de Codeigniter.. 3.4 PHP PHP (Hypertext Preprocessor) es un lenguaje de código abierto para el desarrollo web que permite insertarse en código HTML, y es el más popular de los existentes por su gran adecuación. La forma en la que se inserta dentro del código HTML es utilizando una etiqueta al principio y al final del código en PHP. El servidor web es el encargado de procesar el código en PHP, que mostrará las acciones al usuario. Se puede utilizar en todos los sistemas operativos y admite la mayoría de servidores web. Permite trabajar de manera simple a los principiantes y a la vez ofrece un gran número de características avanzadas para gente con gran conocimiento.. 3.4.1 Declaración de variables PHP Las variables en PHP se representan con un signo de dollar $ delante y es sensible a mayúsculas y minúsculas. Los nombres de las variables deben empezar con una letra, o en caso contrario, tendrá que hacerlo con un guión bajo (_), seguido de cualquier otro carácter, sin espacios entre ellos. A diferencia de otros lenguajes, no es necesario indicar el tipo de dato de la variable ya que el mismo intérprete PHP lo establece [6].. 3.4.2 Instrucción echo Es la más utilizada para mostrar textos o variables por pantalla, pero realmente esta no es su finalidad. Su verdadera función es insertar texto dentro de un documento HTML subyacente al código PHP: la instrucción echo hace que el texto se inserte en el documento HTML y, si está entre dos etiquetas de cuerpo (<body> y </body>), será cuando aparecerá en pantalla. Se puede también meter código HTML dentro de la instrucción echo, como por ejemplo poner el texto en formato título con las etiquetas <h1> y </h1>. El resultado será la modificación del tipo de letra sin que éstas se impriman en pantalla. El resultado de la impresión por pantalla será la misma si el texto incluye comillas dobles o simples, al igual que si se pone el texto entre paréntesis o no.. 11.
(24)
(25) CAPÍTULO. 4. D ISEÑO Y CREACIÓN DE LA B ASE DE D ATOS 4.1 Diseño de la base de datos Para crear una Base de Datos (BD), primero se debe realizar el diseño conceptual de ésta, seleccionando las entidades que se desean tener y los atributos de cada una. Algunas entidades estarán interrelacionadas entre sí, lo que quiere decir que compartirán información de algunos atributos porque tienen cierta dependencia o porque están asociadas. Para ello, se debe crear un diagrama: el Modelo Entidad-Relación (MER). El siguiente paso es su transformación al Modelo Relacional (MR) y, por último, la creación del código SQL para la generación de la BD.. 4.1.1 Modelo Entidad-Relación El MER es una herramienta para modelar datos que consigue una representación gráfica de la estructura de la BD con sus entidades e interrelaciones. Antes de comenzar el MER, es necesario conocer ciertas características y restricciones de la BD. En nuestro caso, se pide una base de datos que nos permita modelar la generación de varias versiones de un mismo examen de tipo test. Debemos poder generar tantas versiones como queramos y que todas ellas contengan las mismas preguntas y respuestas pero cambiadas de orden dentro de una columna y de una pregunta respectivamente, y estas columnas también tendrán un orden distinto en cada modelo. La BD podrá tener tantos exámenes como queramos. A continuación explicaremos paso a paso c´omo se ha realizado el MER. Empezaremos por definir el objetivo de la base de datos: la entidad Exámen. La Primary Key (PK) o Clave Primaria de la entidad examen no la definimos en el MER, sino que la definiremos más adelante porque debemos esperar a heredar ciertos atributos de otras entidades. Los otros dos atributos de esta entidad son la fecha de realización del examen como fecha_examen y un documento llamado PDF_ModeloX. 13.
(26) 4. D ISEÑO Y CREACIÓN DE LA B ASE DE D ATOS El primer atributo, será de gran importancia para definir la PK y se debe dar un valor desde el primer momento. El segundo atributo puede ser nulo al principio; primero se debe definir y generar el PDF_ModeloX del examen, y, luego, el fichero .PDF resultante podrá ser guardado en el atributo PDF_ModeloX. De cada examen, se debe poder conocer a qué asignatura corresponde; sólo puede pertenecer a una. Por otro lado, existirán uno o más exámenes de una asignatura. La figura 4.1 muestra la interrelación 1-N que forman las dos entidades, llamada REALIZA. La entidad Asignatura, solo tiene dos atributos: cod_asignatura es el código de asignatura, es decir, un número entero positivo de 5 dígitos que asigna la Universitat de les Illes Balears (UIB), y el nombre, que contiene el nombre completo.. Figura 4.1: Relación 1-N entre Asignatura y Examen Cada examen estará compuesto por una y sólo una cabecera, pero la misma cabecera puede estar en uno o más exámenes, con lo que se trata también de una interrelación 1-N ( TIENE), como podemos observar en la figura 4.2. Los atributos de Cabecera son nom_cabecera como PK y LTX_cabecera que contendrá su código en formato .tex. Las cabeceras pueden contener una o más imágenes, sin ser obligatorio que tengan alguna. De aquí surge la nueva entidad Imagen y la interrelación M-N INCLUYE_CI, también en la figura 4.2. Una imagen puede repetirse en varias cabeceras o puede no estar asignada a ninguna. Imagen no tiene una PK definida en el MER y sus atributos son nom_imagen y BIN_imagen, que contendrá el archivo.. Figura 4.2: Relaciónes 1-N entre Examen y Cabecera, y M-N entre Cabecera e Imagen Lo que es imprescindible en un examen son las preguntas, con lo cual la siguiente interrelación se llama CONSTA_EP y se produce entre las entidades Examen y Pregunta. Se trata de una interrelación M-N porque un examen está compuesto, al menos, 14.
(27) 4.1. Diseño de la base de datos por una pregunta, y las preguntas estarán en, al menos, uno o más exámenes. La PK de pregunta es cod_pregunta, una variable AUTO_INCREMENT que evitará que haya PK’s duplicadas. Los otros atributos de esta entidad son el enunciado de la pregunta LTX_enunciado, las cinco posibles respuestas LTX_respuesta1, LTX_respuesta2, LTX_respuesta3, LTX_respuesta4 y LTX_respuesta5, num_contestaciones y num_aciertos, con el objetivo de calcular la dificultad de la pregunta, y, por último, comentarios, por si se quiere anotar alguna característica de interés.. Figura 4.3: Relación M-N entre Examen y Pregunta Como muestra la figura 4.3, la interrelación M-N CONSTA_EP tiene dos atributos propios, num_pregunta y num_columna. En otros apartados se hablará de estos atributos. La importancia de esta interrelación es que definirá el examen en sí porque contendrá las preguntas elegidas y su orden en el Modelo X. La entidad Tipo Pregunta se ha creado para clasificar las preguntas de la BD en categorías, según el temario al que hacen referencia. De esta manera,n se puede facilitar la búsqueda de preguntas cuando la BD ya cuente con un gran número de ellas. Los atributos de Tipo Pregunta son nom_tipo_pregunta y descripción, con las funciones que claramente indican sus nombres. Es de esperar que esta entidad esté interrelacionada con Pregunta, en una interrelación 1-N llamada SE_CLASIFICA, en la figura 4.4. Cada pregunta será sólo de un tipo, mientras que cada tipo de pregunta tendrá, al menos, una pregunta, pudiendo tener más de una. El paso final de un examen creado en la base de datos es la creación de sus modelos. La interrelación SE_REPARTEN, en la figura 4.5, conecta Examen con la entidad Modelo. Un modelo sólo puede ser de un único examen, y claramente un examen puede tener uno o más modelos. Como atributos encontramos num_modelo, que será un número entero correspondiente al número de modelo, y PDF_modelo, que contendrá el archivo PDF final. Para poder generar los diferentes modelos, es imprescindible que se haga 15.
(28) 4. D ISEÑO Y CREACIÓN DE LA B ASE DE D ATOS. Figura 4.4: Relación 1-N entre Tipo de Pregunta y Pregunta. una interrelación entre las entidades Modelo y Pregunta (Figura 4.6).. Figura 4.5: Relación 1-N entre Examen y Modelo La interrelación CONSTA_MP define un modelo de un examen al que previamente se le han asignado las preguntas. Tendrá, al menos, una pregunta y cada pregunta pertenecerá a, como mínimo, un modelo. Para poder saber en qué orden están las preguntas dentro de un modelo, tenemos que definir atributos dentro de la interrelación: num_pregunta, num_columna, LTXresp1_como, LTXresp2_como, LTXresp3_como, LTXresp4_como y LTXresp5_como. Los dos primeros atributos van a tener la nueva posición de una pregunta dentro del modelo que se está creando, al igual que también se tienen guardadas la nueva posición de las respuestas mediante los demás atributos.. Figura 4.6: Relación M-N entre Modelo y Pregunta La entidad que finalmente ha cobrado mayor importancia una vez diseñada la base de datos es Asignatura, ya mencionada anteriormente. La PK de Asignatura es 16.
(29) 4.1. Diseño de la base de datos cod_asignatura porque nunca se repiten dos asignaturas con el mismo código en la UIB. Para mostrar claramente de qué asignatura se trata, se ha creado el atributo nombre. Asignatura cuenta con muchas interrelaciones que se van a explicar a continuación. Una asignatura estará asociada a uno o más estudios de la EPS con la interrelación M-N IMPARTE_EA, al igual que unos estudios pueden tener más de una asignatura. Para estudios, también existe un código único de cuatro letras que funcionará como PK; al igual que se almacena con el atributo nombre el nombre de los estudios. Una asignatura tendrá asociada uno o más profesores, y un profesor podrá dar una o más asignaturas (interrelación M-N IMPARTE_PA). La entidad profesor requiere bastante información de cada profesor: • La PK es cod_profesor, una cadena de 3 caracteres y 3 números, que utilizan los profesores de la UIB dentro de UIBdigital. • nombre, apellido1 y apellido2. • password. • cambiarpwd, un boolean que, cuando devuelve true, obliga al profesor a cambiar su contraseña cuando se conecta por primera vez a la aplicación. • admin, otro boolean que permitirá que los profesores tengan derechos de administrador o no. Se diseña, al menos, una cabecera para cada asignatura, y una cabecera sólo se emplea para una determinada asignatura; así cuando se inserta una cabecera en el examen, contendrá información de la asignatura. Aquí se crea la interrelación 1-N SE_DISEÑA. Es posible, aunque no obligatorio, asociar imágenes a las asignaturas, pero una imagen no puede estar asociada a más de una asignatura. Por este motivo, se forma la interrelación 1-N HACE_USO. La última interrelación con Asignatura es la 1-N CONTEMPLA, que se produce con Tipo Pregunta. Una asignatura contempla, al menos, un tipo de pregunta, mientras que cada tipo de pregunta sólo será de una asignatura. La figura 4.7 muestra todas las interrelaciones con Asignatura. La última entidad que nos queda por comentar en este MER es algo diferente: la entidad Bitácora. La función de esta tabla es guardar información sobre las modificaciones que sufre la BD: el tipo de modificación (añadir, insertar, editar, eliminar), sobre qué tabla se producen, quién las ha realizado, cuando se han realizado y qué atributos se han modificado. En definitiva, esta entidad es la que nos proporcionará el control de los movimientos dentro de la BD para tener un cierto nivel de seguridad. La primera y más clara diferencia es que no cuenta con ninguna interrelación y tiene una gran lista de atributos, que se muestra en la figura 4.8. Su PK es cod_bitacora, un AUTO_INCREMENT que evitará redundancias. host indica la dirección IP del ordenador desde el que se ha realizado la operación en la BD; 17.
(30) 4. D ISEÑO Y CREACIÓN DE LA B ASE DE D ATOS. Figura 4.7: Entidad Asignatura y todas sus interrelaciones. usuario contendrá el código del profesor que ha realizado un cambio; tipo_operacion guardará el tipo de operación realizada: insert, edit o delete; fecha_operacion registra el día y la hora en que se ha realizado la operación, y detalles_operacion es una cadena de caracteres que mostrará los cambios realizados. Los demás atributos que se ven con un acrónimo al principio, van asociados con las PK de todas las entidades. Por esta razón, se debe añadir esta entidad una vez se ha completado el Modelo Entidad-Relación, explicado en el siguiente apartado, y se conocen las PK de las entidades que no las tienen definidas en el MER y las interrelaciones que se convierten en entidades. Por lo tanto, hay tantos atributos de este tipo como PK’s hay en la base de datos. La tabla 4.1 muestra el significado de los acrónimos de los atributos. Sus nombres utilizan el patrón CÓDIGOTABLA_PKTabla. El resultado final del MER es el de la figura 4.9.. 4.1.2 Modelo Relacional Una vez completado el MER, el siguiente paso es transformarlo al MR [7]. Esta transformación es necesaria porque hay que conseguir un modelo lógico más cercano a lo que será la implementación de la base de datos [8]. Las entidades se convierten en relaciones en el modelo relacional y las interrelaciones de tipo M-N también se convierten en una relación. Las relaciones van en letras mayúsculas, seguidas de un paréntesis en el que se escriben todos sus atributos. La PK aparece subrayada en la 18.
(31) 4.1. Diseño de la base de datos. Figura 4.8: Entidad Bitácora Cuadro 4.1: Leyenda de los atributos de la entidad Bitácora. Código ASIG CAB CEP CMP ES EX IMG IEA IPA INCI INPI MOD PRG PROF TPRG. Entidad Asignatura Cabecera Consta_EP Consta_MP Estudios Examen Imagen Imparte_EA Imparte_PA Incluye_CI Incluye_PI Modelo Pregunta Profesor Tipo Pregunta. lista. En este paso se decide qué atributos pueden ser nulos y cuales no, lo que se indica poniendo Null (N) debajo de los atributos que pueden estar vacíos dentro de la BD y con Not Null (NN) los que no pueden estarlo. Una PK no puede ser nula. Se harán herencias de PK en forma de Foreign Key (FK) o Clave Foránea desde la entidad con 19.
(32) 4. D ISEÑO Y CREACIÓN DE LA B ASE DE D ATOS. Figura 4.9: MER 20.
(33) 4.1. Diseño de la base de datos conectividad 1 a la de conectividad N. Las relaciones Asignatura, Estudios y Profesor se transforman tal cual aparecen en el MER (ver figura 4.10). Todos los atributos son NN excepto apellido2 en profesor, considerando los profesores de fuera de España que solo tengan un apellido.. Figura 4.10: Resultado de una transformación de una entidad a una relación. Imparte_EA e Imparte_PA se convierten en dos relaciones. Cada una hereda las PK de las dos relaciones de las que proviene: cod_estudios y cod_asignatura, cod_profesor y cod_asignatura respectivamente, y todas son PK/FK. El resultado se puede ver en la figura 4.11.. Figura 4.11: Ejemplo de transformación de una interrelación M-N que se convierte en una relación. La relación Cabecera es la primera que vamos a comentar con herencia de PK como FK, que será PK conjuntamente con otro atributo de la entidad. En el MER no se ha indicado la PK de Cabecera porque va a ser compuesta con la FK de Asignatura cod_asignatura y su atributo nom_cabecera. Es la relación Cabecera la que obtiene la herencia porque es la que tiene conectividad N. LTX_Cabecera es N para poder tener un examen sin cabecera, lo que nos posibilita crearla sin necesidad de tener que insertar el texto en ese momento.. Figura 4.12: Ejemplo de relación con herencia 1-N Al igual que Cabecera, la relación Imagen hereda la FK cod_asignatura, que junto con nom_imagen forman la PK. A continuación, volvemos a obtener una relación de una interrelación M-N entre Cabecera e Imagen: Incluye_CI. Los únicos atributos con los que cuenta son las FK cod_asignatura, nom_cabecera y nom_imagen, todos NN y PK.. 21.
(34) 4. D ISEÑO Y CREACIÓN DE LA B ASE DE D ATOS La relación tipo_pregunta en el MR obtiene como FK cod_asignatura, que formará la PK junto a nom_tipo_pregunta. Por lo tanto, sólo descripcion puede ser N. La relación Examen tiene dos herencias: cod_asignatura y nom_cabecera. Formará la PK con cod_asignatura junto a fecha_examen, como muestra la figura 4.13. Se quiere que fecha_examen forme parte de la PK porque será lo que haga único un examen de una asignatura, debido a que se considera que es imposible que una asignatura haga dos exámenes distintos a la vez. PDF_modelo es el único atributo N.. Figura 4.13: Ejemplo de relación con PK doble Pregunta cuenta con un gran número de atributos, donde sólo las tres últimas respuestas LTX_respuesta3, LTX_respuesta4 y LTX_respuesta5, y los comentarios pueden ser N, considerando la opción de examen con sólo dos posibles respuestas. Encontramos dos FK: cod_asignatura y nom_tipo_pregunta, que provienen de Tipo_pregunta. La relación consta_EP (ver figura 4.14), resultado de la interrelación M-N entre Examen y Pregunta, forma su PK con las FK cod_asignatura, fecha_examen y cod_pregunta. Como resultado de las herencias, vemos que esta relación contiene información de Asignatura. Tiene dos atributos más, propios de la interrelación, que son NN: num_pregunta y num_columna. Al elegir las preguntas de un examen, al momento deberán que tener un orden, aunque luego se modifique, por lo tanto se le asignará un valor a num_pregunta.. Figura 4.14: Ejemplo de relación con atributos propios De nuevo como resultado de una interrelación M-N, la relación Incluye_PI hereda de Pregunta y de Imagen las FK, quedando una PK de tres atributos: cod_asignatura, cod_pregunta y nom_imagen. Modelo tampoco había definido su PK en el MER porque la va a formar en esta transformación. De Examen, hereda cod_asignatura y fecha_examen, que junto a num_modelo, un atributo propio, compone la PK. El otro atributo propio PDF_modelo es N porque se subirá a la BD una vez terminada la reorganización de preguntas, respuestas y columnas que se elabora en la relación Consta_MP. Consta_MP es la relación que realmente se encarga de la generación de Modelos. Está fundada por las FK de Pregunta y Modelo que se convierten en PK: cod_asignatura, fecha_examen, num_modelo y cod_pregunta. Como vemos, también le llega información de la relación Asignatura a través de Modelo. Los demás atributos son los de la interrelación, los cuales ninguno de ellos puede ser 22.
(35) 4.2. MER y MR con GID nulo excepto la posición de las respuestas 3, 4 y 5, por el mismo criterio que en Pregunta. Una vez se tienen claras las PK de todas las relaciones, se puede crear la entidad Bitácora en el MER y su transformación al MR. Los atributos que hacen referencia a las relaciones podrán ser nulos, ya que cada vez que se produzca un insert, un edit o un delete se producirá sobre una única tabla, con lo que muchos atributos quedarán vacíos. Los atributos NN serán host, usuario, tipo_operacion y fecha_operacion, además de su PK cod_bitacora. La figura 4.15 muestra el diagrama MR. A continuación, el siguente paso sería la elaboración del código SQL para crear la base de datos. Pero la decisión de utilizar la librería Grocery CRUD retrasará este proceso.. 4.2 MER y MR con GID Al decidir que se utilizaría la librería Grocery CRUD (GC) para aprovechar sus ventajas a la hora de crear la interfaz web, se tuvo que rediseñar el MER y el MR. El motivo de esta remodelación se debe a una limitación del Grocery CRUD (GC), pues éste necesita que cada tabla tenga definida una PK simple (es decir, formada por un único atributo), con lo cual, las tablas cuya PK estaba formada por dos o más atributos no se podían integrar. Además, con el uso de GC, se descubrió que las tablas que no tenían como PK un identificador único de tipo AUTO_INCREMENT, generaban errores en las acciones creadas en los formularios, siendo éstas necesarias para el funcionamiento deseado de la BD.. 4.2.1 MER con GID Como resultado, se ha realizado el diseño de un nuevo MER, basado en el anterior, en el cual, a las tablas que tenían dicho problema, se les ha añadido un nuevo atributo como PK, que siempre sigue la estructura gid_nombreTabla. El acrónimo gid significa Grocery Identifier, y siempre se trata de un AUTO_INCREMENT. A las interrelaciones M-N que generan una nueva relación pero que no tienen interfaz gráfica no se les ha aplicado con esta modificación. Por un lado, en las tablas de Asignatura, Estudios y Profesor se tuvo que reemplazar la PK de los códigos que los identifican dentro de la universidad por un GID de tipo AUTO_INCREMENT, debido a los problemas que generaban los formularios al no tener una PK auto-incremental. Por otro lado, el caso de Cabecera, Consta EP, Consta MP, Examen, Imagen, Modelo y Tipo Pregunta fue que tenían PK compuestas y se les creó el atributo incremental para su correcto funcionamiento. Como resultado, las entidades con este nuevo identificador como PK son las siguientes: • • • •. Asignatura: gid_asignatura Cabecera: gid_cabecera Consta EP: gid_consta_ep Consta MP: gid_consta_mp 23.
(36) 4. D ISEÑO Y CREACIÓN DE LA B ASE DE D ATOS. Figura 4.15: MR 24.
(37) 4.2. MER y MR con GID • • • • • •. Estudios: gid_estudios Examen: gid_examen Imagen: gid_imagen Modelo: gid_modelo Profesor: gid_profesor Tipo Pregunta: gid_tipo_pregunta. Todas las conectividades se conservan del MER original, al igual que todos los otros atributos, excepto en la entidad Imagen. En su caso, se eliminó el atributo BIN_imagen porque GC guarda las imágenes dentro del servidor web, no dentro de la base de datos, por lo que el atributo no ejercía la función para la que había sido creado. Podemos ver el resultado final en la figura 4.16, donde todas las entidades tienen una PK ya definida. Se debe comentar que la PK de Pregunta y de Bitácora no se han cambiado y continúan siendo cod_bitacora y cod_pregunta porque en el MER original ya eran de tipo auto-incremental.. 4.2.2 MR con GID Respecto al nuevo MR, cambian las herencias y las PK de las interrelaciones M-N que se convierten en una nueva relación. Es importante resaltar que la herencia que hace Asignatura no será con su nuevo GID. Al no aportar información significativa, lo que interesa es ver el código de asignatura en las demás tablas, por eso todas las herencias desde Asignatura se hacen con cod_asignatura, las cuales aparecen en la figura 4.17. Las interrelaciones que se convierten en relaciones y heredan los nuevos atributos GID son las siguientes: • • • •. Imparte_EA: gid_estudios, cod_asignatura Imparte_PA: gid_profesor, cod_asignatura Incluye_CI: gid_cabecera, gid_imagen Incluye_PI: gid_pregunta, gid_imagen. Como excepción tenemos Consta_EP y Consta_MP. Las dos relaciones resultantes no van a poder tener como PK los dos atributos GID que han heredado, sino que es necesario crearles los atributos gid_consta_ep y gid_consta_mp como PK, debido a que se usan en formularios de GC. Los atributos de Bitácora se reducen, ya que anteriormente había relaciones que necesitaban tener dos o más atributos como PK y ahora todas tendrán solamente uno. Para que haya concordancia, se cambian los nombres para que todos tengan el GID, a excepción de los casos comentados anteriormente en los que se conserva el nombre del MER original. Las demás interrelaciones se transforman al MR aplicando las reglas generales de transformación sobre el MER con GID. Vemos el resultado completo del MR en la figura 4.18. 25.
(38) 4. D ISEÑO Y CREACIÓN DE LA B ASE DE D ATOS. Figura 4.16: MER con GID de la Base de Datos 26.
(39) 4.3. Código SQL. Figura 4.17: Relaciones que heredan cod_asignatura. 4.3 Código SQL Una vez terminado el diseño en papel, el último paso es crear la BD en el ordenador, traduciendo los diagramas a código SQL. La elección del nombre de la base de datos y de este proyecto nace en este paso. Es necesario darle un nombre a la BD en el momento de su creación. genTUIB es la abreviación de GENerador de Tipos de examen, y se le añade UIB porque es un proyecto para la Universitat de les Illes Balears. Para distinguirla de los MER y MR originales, se le incorpora delante las iniciales GC. La instrucción para crearla es simple: CREATE DATABASE IF NOT EXISTS ’GC_genTUIB’. A continuación, se procede a la creación de las tablas de la base de datos, que son las relaciones del MR. La sentencia SQL para crear una tabla es CREATE TABLE ’nombre’, seguido de un paréntesis que contendrá la lista de atributos de la tabla, separados por comas entre sí. Este es el momento de elegir de qué tipo son los atribitos y de indicar si son N o NN, y de si se trata de una PK, de una FK o de una Clave Única o Unique Key (UK). Una UK sirve para definir una restricción y no permite valores duplicados en una tabla. De hecho, una PK siempre es a la vez una UK, por el contrario, una UK no tiene necesariamente que ser PK, y por tanto puede tener valores nulos y puede existir más de una en la misma tabla. Las UK se utilizan cuando hay atributos que no se pueden repetir pero éste no se quiere utilizar para indexar una tabla. En nuestro caso, encontramos, por ejemplo, las tablas Asignatura, Estudios y Profesor, en las que se tuvo que añadir la PK auto-incremental con un atributo GID para evitar errores en los formularios web; pero lo que en realidad hay que evitar es la coincidencia de códigos de asignatura, de estudios y de profesor para evitar errores y redundancias. En la figura 4.19 aparece la sentencia de creación de estas tres tablas, las cuales siguen la misma estructura que las demás tablas. El motor de almacenamiento escogido es InnoDB porque queremos que se haga la comprobación de integridad para las claves foráneas. Además, nuestra base de datos tendrá un uso más frecuente de inserts, updates y deletes que de consultas, 27.
(40) 4. D ISEÑO Y CREACIÓN DE LA B ASE DE D ATOS. Figura 4.18: MR con GID de la Base de Datos 28.
(41) 4.3. Código SQL. Figura 4.19: Ejemplo de sentencias SQL para crear una tabla dentro de una base de datos. en lo que InnoDB tiene un mayor rendimiento [9]. Para cambiar a este motor de almacenamiento, ya que por defecto se usa MyISAM, se debe indicar con ENGINE = InnoDB, como vemos también en la figura 4.19. Los tipos de variable que usaremos son los más comunes: bigint (número entero de 8 bytes), int (número entero de 4 bytes), tinyint (número entero de 1 byte), varchar (cadena de caracteres), text (bloque de datos), timestamp (para guardar fecha y hora). . . Pero en la tabla bitácora (ver figura 4.20) encontramos otro tipo de variable no tan común: enum. Se trata de una lista de valores, los cuales se enumeran empezando por el índice 1. Se utiliza para el tipo de operación realizada en la BD, y contiene una lista de operaciones posibles: inserción, modificación, borrado, conexión a la base de datos, conexión desde AW (Aplicación Web) y desconexión desde AW. Esto tendrá utilidad cuando se haga el registro de operaciones de la BD con bitácora. Las tablas no presentan ninguna relación entre sí cuando se declaran, por ese motivo hay que indicarle las FK. Por lo tanto, se han de crear las restricciones de las tablas. Primero, se le debe dar un nombre a la FK e indicar a qué atributo hace 29.
(42) 4. D ISEÑO Y CREACIÓN DE LA B ASE DE D ATOS. Figura 4.20: Creación de la tabla bitácora. referencia y a qué tabla, tal y como aparece en la figura 4.21.. Figura 4.21: Creación de restricciones para las tablas volcadas El sistema para darles un nombre a las restricciones sigue el siguiente patrón: TABLA_atrib_FK • La tabla en la que se está añadiendo la restricción se pone en mayúsculas y 30.
(43) 4.4. Otros códigos empleados abreviado de la misma manera que en la tabla bitácora. • La siguiente abreviación hace referencia al atributo que hereda, comenzando por “i“ si es un atributo identificador “gid“ o por “c“ si es un atributo código. • En todos se indica que es una FK.. 4.4 Otros códigos empleados 4.4.1 Creación de Vistas en la base de datos Otra posibilidad que ofrecen las BD es la creación de vistas o views. Una vista es considerada por MariaDB como una tabla virtual que debe cumplir las mismas reglas que una tabla dentro de la BD. Esta tabla virtual se genera haciendo un SELECT de una o varias tablas con los atributos que nos interesan. El interés de crear vistas en nuestra BD se basa en poder mostrar más de un atributo a la vez, guardado con un solo nombre, como se permite hacer en un select. Se han creado dos vistas, una con la tabla Profesor y otra con Pregunta: vw_profesor y vw_pregunta. La vista con Profesor es una consulta muy sencilla, que concatena el nombre, el primer apellido y el segundo apellido como nom_completo: CREATE VIEW vw_profesor AS Select gid_profesor , CONCAT(nombre , ’ ’ , apellido1 , ’ ’ , apellido2 ) AS nom_completo from profesor ;. La vista de Pregunta se crea con el interés de mostrar en un solo campo el código de pregunta, el enunciado y todas las respuestas de la pregunta en un único atributo: texttoshow. Además, en caso de que las respuestas 3, 4 y 5 estén vacías, le añade "NO HAY RESPUESTA". La sentencia que define la vista es la siguiente: CREATE VIEW vw_pregunta AS SELECT cod_pregunta , gid_tipo_pregunta , LTX_enunciado , LTX_respuesta1 , LTX_respuesta2 , LTX_respuesta3 , LTX_respuesta4 , LTX_respuesta5 , num_contestaciones , num_aciertos , comentarios , CONCAT( ’ <h1><b> ’ , cod_pregunta , ’ . </b></h1> ’ , LTX_enunciado , ’ <h3><b>a ) </b></h3> ’ , LTX_respuesta1 , ’ <h3><b>b ) </b></h3> ’ , LTX_respuesta2 , ’ <h3><b>c ) </b></h3> ’ , IFNULL( LTX_respuesta3 , ’NO HAY RESPUESTA<br/><br/> ’ ) , ’ <h3><b>d) </b> </h3> ’ , IFNULL( LTX_respuesta4 , ’NO HAY RESPUESTA<br/><br/> ’ ) , ’ <h3><b>e ) </b></h3> ’ , IFNULL( LTX_respuesta5 , ’NO HAY RESPUESTA<br/><br/> ’ ) ) AS texttoshow FROM pregunta. Las etiquetas HTML insertadas son para encabezados y para saltos de línea.. 4.4.2 Triggers En esta BD los Triggers se crean exclusivamente para el formulario Bitácora. Un disparador o trigger es un evento que se genera automáticamente al realizarse un insert, un edit o un delete [10]. En nuestro caso, son útiles porque es necesario poder obtener un registro de operaciones realizadas. Se han generado triggers por cada tabla 31.
(44) 4. D ISEÑO Y CREACIÓN DE LA B ASE DE D ATOS del MER (a excepción de bitácora), y para cada una hay 3 triggers: el de los insert, el de los update y el de los delete, que generarán mensajes diferentes en la columna detalles_operacion de bitácora. Como ejemplo, se emplea el trigger de Estudios (ver figura 4.22).. Figura 4.22: Disparadores de la tabla Estudios. Cuando se inserta un nuevo dato en la tabla Estudios a través de un CRUD, el trigger BIT_estins_TRIG realiza un INSERT en la tabla bitacora con información del host, del usuario, del tipo de operación, de la fecha y de la PK del estudio que está siendo añadido. En el caso que se modifiquen los datos de un estudio, se dispara el trigger BIT_estupd_TRIG. Guarda en la BD los mismos atributos que en el anterior disparador, además de los detalles de la operación. Mediante un IF, se identifica el atributo o los atributos modificados y se guardan sus valores en detalles_operacion, el cual contiene el valor anterior del atributo, indicado con OLD. al principio y con NEW. el nuevo valor. El último trigger, BIT_estdel_TRIG, asociado a DELETE, inserta en bitacora toda la información del estudio que acaba de ser eliminado. En los detalles de la operación muestra los atributos que contenía con el OLD. delante de cada uno. Los distintos triggers para las distintas tablas se adaptarán según sus atributos, con tantos IF como atributos tenga, y a medida que se vayan realizando operaciones en la base de datos, se guardarán las modificaciones en bitacora, consiguiendo como resultado la lista de operaciones en el formulario de bitácora.. 4.4.3 Procedure para asignar número de columna El procedimiento que se encarga de asignar los números de columna se llama EX_GenNumColumnas_PRC. Se ejecuta en el formulario Examen, en la acción enumerar 32.
(45) 4.4. Otros códigos empleados columnas automáticamente. A este procedure se le pasan por parámetro de entrada dos valores: gid_examen y pmaxnumcar_columna. El primero ya se ha explicado, pero el segundo es un entero que contendrá el número máximo de caracteres que se desean por columna. El procedimiento se basa en un CURSOR, que contiene la longitud – en número de caracteres – de las preguntas – es decir, del enunciado y de sus respuestas – para un gid_examen dado, el cual recorrerá las preguntas una a una haciendo un FETCH para asignarles un número de columna, teniendo en cuenta que la suma de caracteres por columna no puede superar el indicado, ayundándose de un conjunto de variables que llevarán la cuenta de caracteres, de columnas y de preguntas. Estas variables, con la explicación de su papel dentro del procedure, se muestran en la figura 4.23.. Figura 4.23: Creación del procedimiento para asignar columnas y sus variables. Un cursor es un elemento que representará a un conjunto de datos obtenidos por una consulta, que gracias al cursor se podrá leer, recorrer fila a fila y, si se desea, modificar dicho conjunto de resultados. Al declarar el cursor, la consulta no se genera, si no que es necesario abrirlo con un OPEN para que la genere y guarde los datos hallados. Para recorrer los resultados encontrados, se necesita la instrucción FETCH, que “apuntará“ una a una las filas halladas. Para poder guardar el contenido de la fila leída en una variable, se emplea la sentencia INTO a continuación de la sentencia FETCH. Cuando ya no encuentre más resultados y se quiera terminar el cursor, se cerrará con la sentencia CLOSE. Una vez se cierre, ya no se tendrá constancia de los resultados ni se podrán recorrer hasta que sea abierto de nuevo [11]. Se hace un pequeño control de errores antes de empezar. Si se detecta que el examen con el gid_examen dado no existe, terminaremos el procedimiento, al igual que si pmaxnumcar_columna es 0. El cursor de nuestro procedimiento, en la figura 4.24, se inicializa con un OPEN, y todas las filas que encuentra las introduce en la variable vnum_filas. Empezando por la 33.
(46) 4. D ISEÑO Y CREACIÓN DE LA B ASE DE D ATOS. Figura 4.24: Proceso de asignación de columnas. columna número 1, la fila 1 y con el número de caracteres de la columna a 0, entramos en un bucle. Dentro del bucle, el FETCH lee los resultados empezando por la primera fila y guarda el número de pregunta y el número de caracteres que ocupa la pregunta en vnum_pregunta, vnumcar_pregunta con un INTO. Se van sumando los caracteres que ocupa cada pregunta, y mientras no supere el límite de caracteres indicado por el parámetro pmaxnumcar_columna, no se incrementará la columna. Cuando se supera ese límite, al contador de caracteres se le asigna el valor correspondiente a la longitud de la pregunta que acaba de insertar en la nueva columna. Dentro de este mismo bucle, cada vez que se realiza esta comprobación, el atributo num_columna de la tabla Consta_EP se actualiza con un UPDATE y el valor de la columna queda guardado en la base de datos. Cuando se terminen la filas halladas por el cursor, se finaliza el bucle y se hace un CLOSE del cursor.. 4.4.4 Procedure para la generación de modelos Este Procedimiento, llamado EX_GenAleaModelos_PRC, es más complicado que el anterior. Su objetivo es, a partir del Modelo X de un gid_examen, generar tantos modelos como se le pasan por parámetro. Como cada modelo tiene que cambiar el orden de las columnas, de las preguntas en cada columna y de las respuestas de cada pregunta, se generan tres cursores: cnum_columnas: hace un select de las columnas que no han sido reordenadas. Para 34.
(47) 4.4. Otros códigos empleados indexarlas, se utiliza la variable vj. cnum_preguntas: hace un select de las preguntas que no han sido reordenadas. Para indexarlas, se utiliza la variable vk. cnum_respuestas: hace un select de las respuestas que no han sido reordenadas. Para indexarlas, se utiliza la variable vl. En este procedimiento se requieren tablas temporales para cada cursor. Una tabla temporal funciona igual que una tabla común, en la que podemos realizar las mismas operaciones, pero con la diferencia que éstas se eliminarán cuando el procedimiento finalice, y tampoco puede contener una FK, ni puede emplearse en una vista [12]. El primer paso consiste en generar tantos modelos como se haya indicado por parámetro con un while y el índice vi. A continuación, dentro de un bucle que finaliza cuando se han creado todos los modelos, se crea la primera tabla temporal TT_CONSTA_MP. Es una Tabla Temporal de la tabla Consta_MP, y se genera con un select en Consta_EP más unos atributos que contendrán el nuevo orden de la columna, de pregunta y de respuesta para cada columna, pregunta y respuesta del gid_examen introducido. Esta tabla guardará el nuevo orden antes de actualizar la tabla Consta_MP en la BD.. Figura 4.25: Tabla temporal de Consta_MP Para comenzar con las columnas, se guarda el total de columnas y comienza el bucle que renumera las columnas. Dentro del bucle, se abre el cursor y se genera aleatoriamente una nueva posición con select FLOOR(RAND()*vnum_filas) into vnum, que nunca dará un número mayor que el número de columnas del Modelo X. La función FLOOR redondea hacia el número entero inferior más cercano. En este paso, que se puede ver en la figura 4.26, sólo se renumera una columna, porque a continuación se reordenan las preguntas de ésta, no sin antes actualizar la tabla temporal TT_CONSTA_MP con su nuevo valor. Como no sabemos cuántas preguntas hay en la columna que se ha puesto en primer lugar, con un select min(num_pregunta) y select max(num_pregunta) obtenemos esa información. Éstos definirán un while dentro del cual se realiza el mismo proceso de FETCH y de generación de un número aleatorio para, en este caso, reordenar todas las preguntas de la columna. Aquí se actualiza el atributo newnum_pregunta de la tabla temporal TT_CONSTA_MP.. 35.
(48) 4. D ISEÑO Y CREACIÓN DE LA B ASE DE D ATOS. Figura 4.26: Reenumeración de las columnas. Llega el momento de reordenar las respuestas de la primera pregunta que ha sido renumerada. En primer lugar, se debe crear una nueva tabla temporal TT_RESP_COMO para guardar el orden antes de asignarlo a la tabla temporal TT_CONSTA_MP. Se aplica el mismo proceso con el cursor que en los dos casos anteriores es para dar un nuevo orden a las respuestas. Esto se consigue ejecutando un “CASE“, que cambia de posición (del 1 al 5), como se aprecia en la figura 4.27.. Figura 4.27: Código SQL que da un nuevo orden a las respuestas de una pregunta Cuando todas las preguntas y las respuestas tienen un nuevo orden, se renumera la siguiente columna, que repetirá el mismo proceso con sus preguntas y respuestas. Por 36.
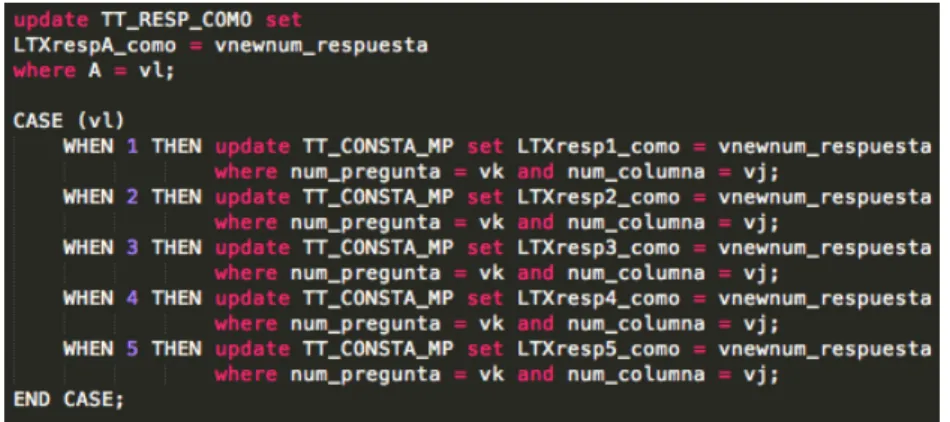
(49) 4.4. Otros códigos empleados último, se han de copiar los valores de la tabla temporal TT_CONSTA_MP a la tabla real de la base de datos Consta_MP. Esto se realiza con un insert, que aparece en la figura 4.28. También es conveniente liberar memoria eliminando las tablas temporales.. Figura 4.28: Inserción de los valores en Consta_MP y borrado de tablas temporales. 37.
(50)
(51) CAPÍTULO. 5. G ROCERY CRUD: CREAMOS LA INTERFAZ WEB. 5.1 Creación de los formularios Después de haber creado la base de datos, el siguiente paso es crear su interfaz gráfica, lo que quiere decir que ha llegado la hora de utilizar Grocery CRUD. Hemos creado un formulario ejemplo, llamado patron, que nos servirá para explicar el proceso hasta obtener la interfaz gráfica. Para llegar a obtener el formulario de una tabla, debemos crear dos archivos: el controlador o controller y la vista o view.. 5.1.1 Controlador o Controller El controlador o controller es el fichero cuya función es definir el CRUD. El CRUD es la parte donde se muestra el contenido de la base de datos, es decir, los atributos y acciones de interés; además, nos permite añadir nuevos datos a una tabla y consultar, modificar y eliminar los que ya existen. GC nos ayuda a implementar todo esto de una forma sencilla, ya que usando simplemente PHP sería mucho más complicado. Las acciones son operaciones extra, diferentes de las que contiene un CRUD por defecto (Añadir, Ver, Editar y Eliminar). Algunos ejemplos de acciones son, por ejemplo, acceder a otro formulario pasando ciertos parámetros de la tabla en la que generamos la acción o duplicar algunos de los datos de la tabla, siempre tomando las medidas necesarias para no duplicar la PK. Explicaremos en dos partes este fichero controlador. La pauta que seguimos para darle nombre a este fichero es el nombre que la tabla tiene dentro de la BD. La primera parte de este fichero, la cual podemos ver en la figura 5.1(a), contiene la definición de clase, que llevará el nombre de la tabla a la que le estamos creando el formulario. A continuación, se crean las instrucciones necesarias para conectarse a la base de datos y cargar la librería del GC. Por último, la función index es una 39.
(52) 5. G ROCERY CRUD: CREAMOS LA INTERFAZ WEB. (a) Creación de la clase y llamadas. (b) Función gestion. Figura 5.1: Fichero controlador. 40.
Figure




+7




Outline
Documento similar
"No porque las dos, que vinieron de Valencia, no merecieran ese favor, pues eran entrambas de tan grande espíritu […] La razón porque no vió Coronas para ellas, sería
(1886-1887) encajarían bien en una antología de textos históricos. Sólo que para él la literatura es la que debe influir en la historia y no a la inversa, pues la verdad litera- ria
entorno algoritmo.
Habiendo organizado un movimiento revolucionario en Valencia a principios de 1929 y persistido en las reuniones conspirativo-constitucionalistas desde entonces —cierto que a aquellas
En este sentido, puede defenderse que, si la Administración está habilitada normativamente para actuar en una determinada materia mediante actuaciones formales, ejerciendo
En la parte central de la línea, entre los planes de gobierno o dirección política, en el extremo izquierdo, y los planes reguladores del uso del suelo (urbanísticos y
Para recibir todos los números de referencia en un solo correo electrónico, es necesario que las solicitudes estén cumplimentadas y sean todos los datos válidos, incluido el
Las actividades ilegales o criminales, sin embargo, cuando faltan víctimas, no tie- nen por qué rendir siempre forzosamente más beneficios. Más bien sucede lo contra- rio. La amenaza
