Extensiones al ambiente de aprendizaje automatizado Weka Parallel con distintos algoritmos de aprendizaje en redes bayesianas Aplicaciones Bioinformáticas
82
0
0
Texto completo
(2) Exergo. Primero resuelve el problema, luego escribe el código.. John Johnson. II.
(3) Dedicatoria. A la memoria de mi mamá, Ana María Malboa Maceda. Quien es la razón por la cual hoy realizo este sueño.. A los pobres, esos pobres que nada tienen y lo dan todo. A mis abuelos por estar siempre a mi lado, dándome todo sin pedirme nada a cambio. A mis hermanos, en especial a Edel, por ser además mi mejor amigo, por apoyarme siempre, por confiar en mi. A mi familia. A mi papá, quien junto a mi mamá y mis abuelos supo guiarme por el buen camino de la vida. A los amigos verdaderos. A los que tienen el valor de luchar por sus sueños. III.
(4) Agradecimientos. A mi mamá, quien fue y será siempre mi musa, mi inspiración para hacerme cada día mejor y, aunque ya no está físicamente, su recuerdo y su memoria vivirá siempre en mí. A mi hermano Edel, por ser tan buen hermano, amigo, consejero. A mis abuelos todos, por hacer de mi el hombre que soy, por su dedicación y amor infinito que nunca me han faltado. A mi abuela Anita, por su infinita bondad. A mi abuela María, por su fortaleza para vivir, por cuidar tan bien de mi mamá. A mi abuelo Yindo, por su carácter, por quererme tanto, aunque no me lo diga. A mi abuelo Nengo, que ya no está, pero que no lo olvido, y seguro junto a mi mamá y mi tío El Chino, velan por mi desde el sitio donde habitan las almas buenas. A mi papá por la fortaleza que día a día me brinda, y por su ejemplo. A Maricela por su apoyo en momentos difíciles. A Lili, por ser la hermanita más linda del mundo y tener siempre una sonrisa, un beso y un abrazo para mí. A mis primos, Carmen, Luis Miguel, Yosney. A mis tíos Odalis, ILida, Luis, y Felipe, y a la gran familia del solar de la calle América. A mis tutoras, María del Carmen y Gladita, por su asesoramiento y ayuda durante la realización de este trabajo. A mi novia Yailiset, por hacerme feliz, estar a mi lado y apoyarme en momentos difíciles. A los amigos. A Marisleidys, por ya ser más que una amiga, una hermana. A las chicas de 4to Turismo, por ser mi familia de aquí de la Universidad. A las chicas de 4to Comunicación Social, por agradar aún más esa familia, en especial a la flaca más linda del grupo, a Lisbet, por ayudarme incondicionalmente en momentos que fueran los más difíciles de mi vida.. IV.
(5) Agradecimientos A la gente del cuarto 111B por todo el tiempo que estuvimos juntos. A Roxana y Julito, por hacerme parte de su familia, por quererme como lo hacen, y ser tan buenos padres.. A María Elena y Mendilahaxo por sus sabios consejos, y sobre todo por ser tan buenos amigos, por su ayuda incondicional. A Mario Pupo, o más conocido como Marius Pupus, Vigésimo Quinto Emperador de la Dinastía Chan, por ser un genio, tanto como amigo, como persona. A Karel, por compartir tantas andanzas juntos, por pasarla bien. Por los buenos momentos. A Cira por abrirme las puertas de su casa en un momento tan difícil para mi. Al resto de la tropa de Bioinformática. Abdel por su ayuda precisa en cada momento que lo necesité, a Oscar, a Pepo, Laureano, Isis y en general a todo el team de profes y estudiantes bajo la tutela del Teacher Grau, con los cuales aprendí mucho en todo el tiempo que estuve en el grupo. A todos esos amigos, socios, compañeros que estuvieron en algún momento a mi lado durante estos cinco años que fueron sin dudas los mejores de mi vida, Yadira, Alina, Kike, Ttricho, Yanet, Aimée, entre muchos que forman parte de una lista bien larga de nombres. A Mandy, Yini y Juanito. A Pancho por la impresión. Y a todos los que de una forma u otra han tenido que ver con la realización de este trabajo y con mi formación como profesional y como persona, brindándome su apoyo, tanto material como espiritual.. A todos muchas gracias.. V.
(6) Resumen. RESUMEN. Weka-Parallel es una versión de Weka, el cual es un software de aprendizaje automatizado que permite realizar pruebas y validar algoritmos de la Inteligencia Artificial. Con el presente trabajo se adicionan algoritmos de búsqueda basados en Redes Bayesianas para clasificación usando la clase BayesNet de Weka, dos de ellos implementados anteriormente en otras versiones del Weka, siendo estos el PSO (Particle Swarm Optimization) y el BayesCHAID, además se implementa un tercer método de búsqueda, el BayNet. El primero de estos métodos utiliza la Optimización Basada en Enjambres de Partículas, el segundo usa el método estadístico Chi-cuadrado, y el tercero se basa de igual modo en este estadístico, pero usando árboles de decisión para construir las Redes Bayesianas. Se extiende el Weka-Parallel y no otra versión del software, debido a la facilidad que este nos brinda de paralelizar los k-fold definidos durante la validación cruzada en cada uno de los experimentos. Se hace una comparación del nuevo algoritmo implementado con otros algoritmos para el aprendizaje de redes bayesianas, y por último se hacen experimentos con dos aplicaciones bioinformáticas para probar la eficiencia del Weka-Parallel usando los algoritmos adicionados al mismo.. VI.
(7) Abstract. ABSTRACT Weka-Parallel is a version of Weka, which is a machine learning software developed to test and validate Artificial Intelligence’s algorithms. In this work some searching algorithms based on Bayesian networks for classification using BayesNet class of Weka are added. Two of them were implemented in other versions of this software, these are the PSO (Particle Swarm Optimization) and BayesCHAID. Now a third search method is implemented: BayNet. The first of these methods uses optimization based on swarms of particles, the second uses the statistical method Chi-square, and the third is similarly based in this statistical, but using decision trees to build the Bayesian Networks. This work extends Weka-Parallel, and not other version of this software, because of the facilities that it gives us in parallelization of the k-fold defined during the cross-validation. A comparison of the new algorithm implemented with other algorithms for learning Bayesian networks is made, and finally we show experiments with two bioinformatic applications to test the efficiency of Weka-Parallel using algorithms added to this program.. VII.
(8) Tabla de contenidos. TABLA DE CONTENIDOS INTRODUCCIÓN .........................................................................................................1 Pregunta de investigación. .......................................................................................2 Objetivo General.......................................................................................................3 Objetivos Específicos. ..............................................................................................3 CAPÍTULO I. CONSIDERACIONES TEÓRICAS SOBRE REDES BAYESIANAS, DEPENDENCIA MULTIVARIADA Y WEKA-PARALLEL.............................................5 1.1. Redes bayesianas, definición. ...........................................................................5 1.1.1. Aprendizaje en RB. ....................................................................................6 1.1.1.1. Aprendizaje estructural........................................................................6 1.1.1.2. Aprendizaje paramétrico (Alcance y Limitaciones de las bases de datos, fundamentalmente en BI). ......................................................................7 1.2. Representación de los árboles de decisión. ....................................................8 1.3. Test de independencia de variables Chi-Cuadrado.........................................10 1.4. Métodos de aprendizaje estructural de RB a adicionar e implementar............11 1.4.1. Método I. Algoritmo BayNet. Aprendizaje de redes bayesianas usando la técnica CHAID. ...................................................................................................12 1.4.2. Método II. Algoritmo BayesCHAID. ...........................................................13 1.4.3. Método III. PSO en el aprendizaje de redes bayesianas. ........................13 1.4.3.1. PSO principios básicos.......................................................................14 1.4.3.2. PSO en el aprendizaje de redes bayesianas......................................14 1.5. Conceptos básicos sobre computación paralela. ...........................................15 1.5.1. Arquitectura Cliente-Servidor. ...................................................................16 1.5.2. Llamada a Procedimiento Remoto (RPC). ................................................17 1.6. Ambiente de aprendizaje automatizado Weka. ..............................................17 1.6.1. Entrada de datos......................................................................................17 1.6.2. Algoritmos para el Aprendizaje Automatizado. ........................................18 1.6.3. Validación con un conjunto de datos.........................................................19 1.6.4. Interioridades de Weka. ...........................................................................20 1.6.5. Weka-Parallel............................................................................................21 1.6.5.1. Validación Cruzada (Cross-Validation)...............................................21 1.6.5.2. Filosofía del Weka-Parallel. ................................................................22 1.7. Conclusiones parciales del capítulo. ...............................................................24 CAPÍTULO II. BAYNET, NUEVO ALGORITMO DE APRENDIZAJE AUTOMATIZADO. ADICIÓN DE LOS METODOS BAYESCHAID Y PSO.................25 2.1. Implementación del nuevo algoritmo de búsqueda BayNet.............................25 2.1.1. Metodología seguida para construir el nuevo algoritmo de búsqueda. .....25 2.1.2. Nuevo algoritmo de aprendizaje automatizado de redes bayesianas BayNet. ...............................................................................................................31 2.1.2.1. Complejidad computacional de algoritmo BayNet..................................35 2.2. Adición al Weka-Parallel de dos algoritmos de aprendizaje automatizado basado en redes Bayesianas. ................................................................................35 2.3. Conclusiones parciales del capítulo. ...............................................................36 VIII.
(9) Tabla de contenidos CAPÍTULO III MANUAL DE USUARIO Y APLICACIÓN. ...........................................37 3.1. Requerimientos. ..............................................................................................37 3.2. Instalación del Weka-Parallel ..........................................................................37 3.2.1. Instalar Weka-Parallel ...............................................................................37 3.2.2. Configurar Weka-Parallel. .........................................................................38 3.3. Usar BayNet en Weka-Parallel. .......................................................................39 3.3.1. Ejecutar Weka-Parallel para trabajar desde líneas de comandos.............39 3.3.2. Ejecutar Weka-Parallel con interfaz visual. ...............................................40 3.3.3. Clasificador BayesNet...............................................................................44 3.3.4. Algoritmo de aprendizaje automatizado BayNet. ......................................46 3.3.5. Pasos para realizar la validación Cruzada en Paralelo. ............................47 3.3.6. Visualización del tiempo total de corrida en Weka-Parallel.......................49 3.3.7. Conclusiones parciales del capítulo. .........................................................50 CAPÍTULO IV: ANÁLISIS DE LOS RESULTADOS A PARTIR DE EJEMPLOS DE APLICACIONES BIOINFORMÁTICAS. .....................................................................51 4.1. Planteamiento del problema de localización de splice sites. ...........................51 4.2. Planteamiento del problema de predicción de interacciones de proteínas. .....56 4.2.1. Conjunto de Datos ....................................................................................56 4.2.2. Rasgos del problema ................................................................................56 4.3. Análisis de los resultados obtenidos a partir del procesamiento con el método BayNet....................................................................................................................57 4.3.1. Resultados del BayNet..............................................................................57 4.4. Análisis de resultados obtenidos de experimentos con Weka-Parallel. ...........59 4.4.1. Resultado del experimento usando el algoritmo BayesCHAID. ................59 4.4.2. Resultado del experimento usando el algoritmo PSO...............................60 4.5. Conclusiones parciales del capítulo. ...............................................................62 CONCLUSIONES ......................................................................................................63 RECOMENDACIONES ..............................................................................................64 REFERENCIAS BIBLIOGRÁFICAS...........................................................................65 ANEXOS ....................................................................................................................68 ANEXO 1. Resultados obtenidos usando BayesCHAID, con el Weka-Parallel. ....68 ANEXO 2. “Log” de Weka-Parallel luego de la corrida sin la validación cruzada en paralelo...................................................................................................................69 ANEXO 3. “Log” de Weka-Parallel luego de la corrida con la validación cruzada en paralelo...................................................................................................................70 ANEXO 4. Resultados de los experimentos con el Weka-Parallel usando el algoritmo PSO. .......................................................................................................71 a) Caso 1: Sin validación cruzada en paralelo. ..................................................71 b) Caso 2: 1 cliente y 1 servidor.........................................................................71 c) Caso 3: 1 cliente y 2 servidores. ....................................................................72 d) Caso 4: 1 cliente y 3 servidores.....................................................................72 e) Caso 5: 1 cliente y 4 servidores.....................................................................73. IX.
(10) Introducción. INTRODUCCIÓN En la actualidad los nuevos retos de la Bioinformática están relacionados con el problema técnico que representa el manejo de grandes volúmenes de datos, y con la forma en la que se puede extraer nuevo conocimiento de ellos. (Benson 2005) Un modo consistente de razonar ante la presencia de incertidumbre es la inferencia bayesiana siendo la probabilidad una medida intuitiva de esta. La independencia condicional entre los rasgos de una población, simplifica considerablemente los modelos de dependencia.(Bouckaert 2004) Las Redes Bayesianas (RB), están basadas en dicho modelo, codificando estas un conjunto de aseveraciones de independencia condicional. Estas redes presentan una topología que se puede obtener utilizando métodos de aprendizaje estructural, Una vez que esté definida la estructura, deben calcularse las tablas de probabilidad asociadas. A este paso se le conoce con el nombre de aprendizaje paramétrico. En la tesis que se presenta se pretende usar algoritmos de aprendizaje estructural que utilizan técnicas de segmentación estadística (árboles de decisión basados en Chi-Cuadrado), y métodos de búsqueda de la estructura de la red basados en el algoritmo bioinspirado de optimización en enjambres de partículas (Particle Swarm Optimization, PSO). La calidad de la estructura obtenida se mide usando métricas que miden la información que aporta la estructura de la red bayesiana actual. La plataforma inteligente para aprendizaje automatizado Weka (Waikato Environment for Knowledge Análisis)(Witten 2005) es un ambiente de trabajo para la prueba y validación de algoritmos de la Inteligencia Artificial, además es una aplicación de código abierto, y tiene incorporadas muchas técnicas estadísticas, entre muchas otras que nos brindan la posibilidad de experimentar con ellas para investigar con cuáles se obtienen mejores resultados. Como se había mencionado anteriormente, Weka es de código abierto, por lo tanto puede ser modificada y redistribuida, esto a permitido la aparición de varias versiones para resolver problemas determinados. Una de estas versiones es el Weka-Parallel, la cual permite la realización de la validación cruzada en paralelo. 1.
(11) Introducción usando varias computadoras simultáneamente, es esta la versión del software que nos concierne para el desarrollo de nuestra investigación. El grupo de Bioinformática de nuestra Universidad trabaja en el desarrollo de nuevos modelos en esta temática. Es. importante la validación de estos modelos con. diferentes tipos de conjuntos de datos, así como la comparación de los resultados de su desempeño con otros modelos similares ya existentes reportados en la bibliografía. En particular, resulta de interés la validación de modelos de construcción de redes bayesianas. Una de las características más interesantes de Weka es la posibilidad de modificar su código y obtener versiones adaptadas con otras funcionalidades ampliando así sus posibilidades de uso. En el laboratorio de Bioinformática y en el de Inteligencia Artificial se han implementado y agregado al Weka algunos de los algoritmos para la obtención de la topología de una RB, desde datos, resolviendo (parcialmente) esta tarea, a partir de los problemas que se presentan en el Laboratorio. Se dice parcialmente ya que resultan ineficientes dichas implementaciones cuando las bases de datos cuentan con grandes volúmenes de información, debido a la falta de soporte técnico, es decir, en el grupo no se cuenta con ordenadores con capacidad y velocidad suficiente para procesar dicha información en un tiempo razonable. Por esto se hace necesario adicionar e implementar algoritmos al Weka-Parallel para lograr que la validación cruzada se realice en paralelo, haciendo uso del hardware disponible y aprovechando las ventajas, en cuanto a velocidad y eficiencia, que nos brinda el trabajo en ambiente paralelo de los ordenadores con que se disponen, y así lograr el necesario ahorro de tiempo en cada corrida. Partiendo de esto nos enfrentamos a la siguiente:. Pregunta de investigación. •. ¿Cómo implementar y extender los nuevos algoritmos de aprendizaje estructural de Redes Bayesianas a Weka-Parallel?. Partiendo de lo planteado anteriormente el presente trabajo tiene el siguiente:. 2.
(12) Introducción Objetivo General. Extender Weka-Parallel a través de la implementación de un nuevo método de aprendizaje estructural de Redes Bayesianas desde datos.. Objetivos Específicos. • Implementar un nuevo algoritmo de aprendizaje estructural de Redes Bayesianas a Weka-Parallel. • Incorporar al Weka-Parallel dos algoritmos implementados en otras versiones no paralelas de Weka. • Realizar experimentos con los algoritmos implementados y adicionados al WekaParallel, usando la validación cruzada en paralelo, y ver la eficiencia del mismo en cuanto a disminución de tiempo de corrida. Los experimentos realizados con los algoritmos adicionados al Weka-Parallel constituyen la culminación de la investigación y para ello se utilizan dos problemas de Bioinformática, uno basado en la detección de sitios de splicing en secuencias de ADN para la localización de genes y otro basado en la predicción de interacciones de proteínas en Arabidopsis thaliana. El presente trabajo se estructura en 4 capítulos: El capítulo I describe un análisis teórico de los conceptos fundamentales que son necesarios para la implementación del algoritmo, así como una descripción de cada uno de los otros dos algoritmos incorporados al Weka-Parallel. En el capítulo II se presenta una metodología general para incorporar nuevos algoritmos de aprendizaje de Redes Bayesianas en Weka-Parallel, usando como referencia el nuevo algoritmo a implementar, se presenta el análisis y diseño de dicho algoritmo, analizando además su complejidad computacional. Por último se describe brevemente como se adicionaron los dos algoritmos implementados en otra versión de Weka a Weka-Parallel. El capítulo III lo constituye el Manual de Usuario, en el que se explica el funcionamiento de la herramienta Weka-Parallel, y la forma de acceder y procesar el nuevo algoritmo implementado, así como los otros dos adicionados.. 3.
(13) Introducción En el capítulo IV se plantean los problemas de localización de los genes y predicción de interacciones de proteínas para su posterior uso en los experimentos. Se hace una comparación de los resultados del algoritmo de aprendizaje estructural de Redes Bayesianas propuesto, con otros algoritmos para esta tarea. Además se hacen experimentos, con los otros dos algoritmos adicionados, para comprobar la efectividad, en cuanto a disminución de tiempo de corrida del WekaParallel, respecto a otras versiones del Weka que no tienen implementada la validación cruzada para que funcione de forma paralela, haciendo uso de los problemas mencionados anteriormente. Estos experimentos son realizados en el laboratorio de Bioinformática del CEI, usamos como máximo cinco máquinas conectadas en paralelo.. 4.
(14) Capítulo I. CAPÍTULO. I.. CONSIDERACIONES. REDES BAYESIANAS, DEPENDENCIA. TEÓRICAS. SOBRE. MULTIVARIADA Y. WEKA-PARALLEL. Es mucho más común razonar con incertidumbre que sin ella(Castillo, Gutiérrez et al. 1996). Numerosos son los formalismos que intentan actualmente modelar la incertidumbre, pero sin dudas fue la Teoría de las Probabilidades la primera que lo hizo. Dentro de esta, la Teoría Bayesiana ha alcanzado un desarrollo notable en los últimos años. Las redes bayesianas (RB) constituyen un entorno para realizar razonamiento interesante en condiciones inciertas. Ellas son redes probabilísticas que han probado ser muy útiles en la solución de problemas de diagnóstico médico así como en otros bien diferentes como lo son los problemas de bioinformática, (Kennedy 1998).. 1.1. Redes bayesianas, definición. Las redes bayesianas (RB) son una herramienta poderosa de representación del conocimiento, son conocidas como redes de creencia bayesianas, grafos causales, redes de creencia, modelos recursivos, redes probabilistas, en el trabajo se asume el termino RB (Bouckaert 1995). Múltiples trabajos se pueden referenciar con alusión a la temática, algunas referencias (Pearl 1988),(Heckerman 1996), (Jensen 1996), (Qi 1995), (Castillo 1997), (Minka 2001), interesante resulta la referencia (Buntine 1996), la cual constituye una guía en el estudio de la bibliografía presente sobre la temática. La idea principal de esta teoría consiste en que para describir el mundo real no es necesario utilizar una enorme tabla en la que se listen las probabilidades de todas las combinaciones concebibles de sucesos. La mayoría de los sucesos son condicionalmente independientes de los demás, por lo que no deben considerarse sus interacciones. En lugar de esto, se puede usar una representación más local donde se describan grupos de sucesos que interactúen. Una red bayesiana es un grafo acíclico dirigido (Grau) con una distribución de probabilidad asociada a cada nodo. Los nodos en la red representan las variables, 5.
(15) Capítulo I atributos o rasgos del dominio de aplicación, y los arcos entre los nodos representan las relaciones de dependencia entre las variables(Kennedy 1995b). Una red bayesiana es un par (D,P), donde D es un grafo acíclico dirigido, P = [p(x1|τ1), …, p(xn |τn)] es un conjunto de n distribuciones de probabilidad condicionales, una por cada variable xi (nodos del grafo), y τi es el conjunto de padres del nodo. xi. en D. El conjunto P define la. distribución de probabilidad. conjunta asociada, como muestra la ecuación (1):. p(x) =. n. ∏. i=1. p ( xi τi ). x = ( x 1 , x 2 ,..., x n ). (1). 1.1.1. Aprendizaje en RB. Encontrar un modelo de red bayesiana consta de dos partes fundamentales, determinar la parte estructural de la red (o sea, los enlaces entre los nodos que representan las variables) y la parte paramétrica (las tablas de probabilidades asociadas a cada nodo). 1.1.1.1. Aprendizaje estructural. Las técnicas de aprendizaje estructural dependen del tipo de estructura de red: árboles, poliárboles y redes multiconectadas. Otra alternativa es combinar conocimiento subjetivo del experto con aprendizaje. Para ello se parte de la estructura dada por el experto, la cual se valida y mejora utilizando datos estadísticos. Existen dos clases de métodos para el aprendizaje genérico de redes bayesianas, que incluyen redes multiconectadas. Éstos son: •. Métodos basados en medidas de ajuste y búsqueda.. •. Métodos basados en pruebas de independencia.. Dentro de los métodos basados en ajuste y búsqueda, se generan diferentes estructuras y se evalúan respecto a los datos utilizando alguna medida de ajuste. Estos métodos tienen dos aspectos principales: una medida para evaluar que tan buena es cada estructura respecto a los datos y un método de búsqueda que genere. 6.
(16) Capítulo I diferentes estructuras hasta encontrar la óptima, de acuerdo a la medida seleccionada. La búsqueda de la estructura puede interpretarse como un problema de optimización, se transforma en hallar la red de mejor calidad en el espacio de posibles redes, donde la calidad puede medirse por una métrica que evalúa la red de acuerdo a los datos de partida. Existen varias métricas que evalúan la calidad de las redes, específicamente con enfoque bayesiano, K2, basados en criterios de información o entropía, AIC Akaike Information Criterion, MDL Minimum Description Length (Kennedy 1998). El alto costo en tiempo y recursos que han mostrado los algoritmos exactos de búsqueda, ha conllevado al auge y desarrollo de las heurísticas y metaheurísticas cuyo uso ha arrojado resultados muy alentadores. En el trabajo se adiciona un método basado en el algoritmo de búsqueda heurística PSO (Particle Swarm Optimization). 1.1.1.2. Aprendizaje paramétrico (Alcance y Limitaciones de las bases de datos, fundamentalmente en BI). El aprendizaje paramétrico consiste en encontrar los parámetros asociados a una estructura dada de una red bayesiana. Dichos parámetros consisten en las probabilidades a priori de los nodos raíz y las probabilidades condicionales de las demás variables, dados sus padres. Si se conocen todas las variables, es fácil obtener las probabilidades requeridas. Las probabilidades previas corresponden a las marginales de los nodos raíz, y las condicionales se obtienen de las conjuntas de cada nodo con su(s) padre(s). Para que se actualicen las probabilidades con cada caso observado, éstas se pueden representar como razones enteras, y actualizarse con cada observación. El aprendizaje paramétrico depende de las características de los datos que se utilicen, teniendo en cuenta que estos pueden ser completos o no. En la tesis trabajamos con datos de aplicaciones Bioinformáticas de análisis de secuencias, en los cuales usualmente no hay conocimiento apriori sobre la información de que se. 7.
(17) Capítulo I dispone (precisamente es lo que se busca), y por tanto es necesario aprender desde los datos. Un obstáculo para la aplicación de las redes bayesianas es construir las redes cuando las bases de casos no están completas o cuando existen carencias de conocimiento que dificultan la construcción con ayuda de expertos humanos. Otra limitación consiste en la dificultad para explicar el razonamiento, pues los métodos y modelos que utiliza están aún lejos de ofrecer explicaciones comprensibles y satisfactorias para los expertos que pudieran utilizar las redes desarrolladas actualmente. Para construir una RB se debe poder obtener información del experto en el dominio de la aplicación a realizar, lo cual resulta difícil y costoso o realizar el aprendizaje de la red desde datos, el que esta constituido de las dos partes mencionadas anteriormente, usando el aprendizaje paramétrico para estimar las probabilidades asociadas a la red obtenida mediante el aprendizaje estructural de la red, el cual constituye la parte central de la tesis, pues se desea extender el Weka-Parallel implementándole un nuevo algoritmo de aprendizaje de RB.. 1.2. Representación de los árboles de decisión. Un árbol de decisión es un modelo de predicción utilizado en el ámbito de la inteligencia artificial, dada una base de datos se construyen estos diagramas de construcciones lógicas, muy similares a los sistemas de predicción basados en reglas, que sirven para representar y categorizar una serie de condiciones que suceden de forma sucesiva, para la resolución de un problema. Un árbol de decisión tiene unas entradas las cuales pueden ser un objeto o una situación descrita por medio de un conjunto de atributos y a partir de esto devuelve una respuesta la cual en últimas es una decisión que es tomada a partir de las entradas. Los valores que pueden tomar las entradas y las salidas pueden ser valores discretos o continuos. Se utilizan más los valores discretos por simplicidad, cuando se utilizan valores discretos en las funciones de una aplicación se denomina clasificación y cuando se utilizan los continuos se denomina regresión.. 8.
(18) Capítulo I Un árbol de decisión lleva a cabo un test a medida que este se recorre hacia las hojas para alcanzar así una decisión. El árbol de decisión suele contener nodos internos, nodos de probabilidad, nodos hojas y arcos. Un nodo interno contiene un test sobre algún valor de una de las propiedades. Un nodo de probabilidad indica que debe ocurrir un evento aleatorio de acuerdo a la naturaleza del problema, este tipo de nodos es redondo, los demás son cuadrados. Un nodo hoja representa el valor que devolverá el árbol de decisión. Y finalmente las ramas brindan los posibles caminos que se tienen de acuerdo a la decisión tomada. La figura 1.2.1 muestra un árbol de decisión típico. Cada nodo del árbol está conformado por un atributo y puede verse como la pregunta: ¿Qué valor tiene este atributo en el ejemplar a clasificar? Las ramas que salen de los nodos, corresponden a los posibles valores del atributo correspondiente. Un árbol de decisión clasifica a un ejemplar, filtrándolo de manera descendente, hasta encontrar una hoja, que corresponde a la clasificación buscada. Consideren el proceso de clasificación del siguiente ejemplar, que describe un día en particular: Cielo = soleado, Temperatura = caliente, Humedad = alta, Viento = fuerte. Figura 1.2.1: Un árbol de decisión para el concepto “buen día para jugar tenis”.. Los nodos representan un atributo a ser verificado por el clasificador. Las ramas son los posibles valores para el atributo en cuestión. Los textos en mayúsculas, representan las clases consideradas y los posibles valores del atributo objetivo.. 9.
(19) Capítulo I Cada nodo del árbol de decisión será un atributo y se implementaran diferentes formas de selección de atributos como son: Chi-Cuadrado y Entropía. En nuestro caso solo usaremos el estadístico Chi-Cuadrado.. 1.3. Test de independencia de variables Chi-Cuadrado El test Chi-cuadrado es un ejemplo de los denominados test de ajuste estadístico, cuyo objetivo es evaluar la bondad del ajuste de un conjunto de datos a una determinada distribución candidata. El procedimiento de realización del test ChiCuadrado es el siguiente: 1). Se divide el rango de valores que puede tomar la variable aleatoria de la distribución en K intervalos adyacentes:. [a0 , a1 ), [a1, a2 ),K, [aK −1 , aK ) Pueden ser a0 = −∞ y aK = ∞ . 2). Sea N j el número de valores de los datos que tenemos que pertenecen al. [. intervalo a j −1 , a j ). 3). Se calcula la probabilidad de que la variable aleatoria de la distribución. [. candidata FX ( x ) esté en el intervalo a j −1 , a j ). Por ejemplo, si se trata de una distribución continua, esa probabilidad sería:. pj = ∫. aj. a j −1. f X ( x )dx. Siendo f X ( x ) la función densidad de probabilidad de la distribución candidata. También se puede hacer:. p j = FX (a j ) − FX (a j −1 ). 10.
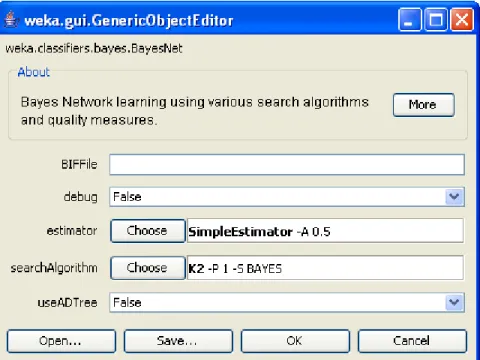
(20) Capítulo I. Nótese que este es un valor teórico, que se calcula de acuerdo a la distribución candidata y a los intervalos fijados. 4). Se forma el siguiente estadístico de prueba:. K. Δ=∑ j =1. (N. − Np j ). 2. j. Np j. Si el ajuste es bueno, Δ tenderá a tomar valores pequeños. Rechazaremos la hipótesis de la distribución candidata si Δ toma valores “demasiado grandes”.. 1.4. Métodos de aprendizaje estructural de RB a adicionar e implementar. En el trabajo que se hace se pretende implementar y adicionar al Weka-Parallel un algoritmo basado en la técnica CHAID(Chi-square Automatic Interaction Detector), para construir árboles de decisión. Además se adicionan dos algoritmos de aprendizaje de Redes Bayesianas, uno basado en la técnica CHAID (Moya 2007), y uno basado en el algoritmo de búsqueda PSO que fueron implementados en otras versiones del Weka. A continuación se explica en que consiste cada uno profundizando fundamentalmente en nuevo algoritmo que se implementa. En el presente trabajo se pretende implementar y adicionar al Weka-Parallel un algoritmo basado en la técnica CHAID para construir árboles de decisión. Además se adicionan dos algoritmos de aprendizaje de Redes Bayesianas, uno basado en la técnica CHAID(Moya 2007), y otro basado en el algoritmo de búsqueda PSO que fueron implementados en otras versiones del Weka. A continuación se explica en que consiste cada uno profundizando fundamentalmente en el algoritmo que se pretende implementar.. 11.
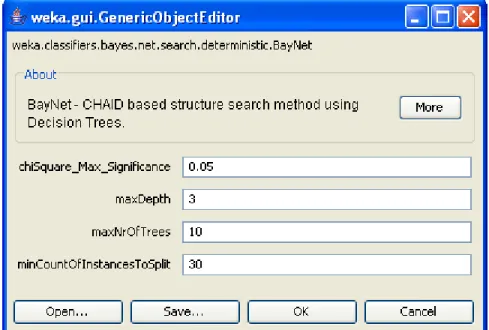
(21) Capítulo I 1.4.1. Método I. Algoritmo BayNet. Aprendizaje de redes bayesianas usando la técnica CHAID. En un estudio real existen frecuentemente múltiples variables (predictivas o independientes) que pueden tener asociación con una variable dependiente y además efectos de interacción entre ellas sobre dicha variable dependiente. La presentación de muchas tablas de contingencia, no siempre refleja las asociaciones esenciales, y usualmente se convierte en un listado inútil de tablas que desinforman en lugar de orientar, aun cuando se utilice la V de Cramer para ordenar la fortaleza de las asociaciones. Un estudio multivariado trata de enfocar el efecto posible de todas las variables conjuntamente incluyendo sus posibles correlaciones; pero puede ser particularmente interesante, si considera además las posibilidades de la interacción entre las variables predictivas sobre la variable dependiente. Cuando el número de variables crece, el conjunto de las posibles interacciones crece en demasía, resulta prácticamente imposible analizarlas y por ello adquiere especial interés una técnica de detección automática de interacciones fundamentales. CHAID hace exactamente esto. Esta técnica está implementada en un programa profesional que puede ejecutarse independiente a partir de un fichero ASCII o desde SPSS para Windows utilizando ficheros de datos de este paquete. Las nuevas versiones del SPSS, tienen el programa incluido dentro de un módulo de elaboración de Árboles de Decisión, que además de CHAID, incluye otros tres algoritmos de construcción de tales árboles El análisis de CHAID surge realmente como una técnica de segmentación. Es particularmente útil en todos aquellos problemas en que se quiera subdividir una población a partir de una variable dependiente y posibles variables predictivas que cambien esencialmente los valores de la variable dependiente en cada una de las subpoblaciones o segmentos. Ejemplos típicos asociados con su origen son por ejemplo, los problemas de estudio de mercado. En estos casos la variable dependiente puede ser la aceptación o no de un producto y las variables predictivas un conjunto de características psico o socio económicas de la población que pueden influir en la aceptación o no. La técnica de CHAID es capaz de segmentar la. 12.
(22) Capítulo I población en grupos de acuerdo con determinados valores de las variables y sus interacciones que distinguen de forma óptima, diferencias esenciales en el comportamiento de la variable dependiente (CHAID, 1994). Un análisis de CHAID automático comienza dividiendo la población total en dos o más subgrupos distintos basado en las categorías del mejor predictor de la variable dependiente (en principio por el estadígrafo Chi-cuadrado de Pearson). Divide cada uno de estos subgrupos en pequeños sub-subgrupos y así sucesivamente. CHAID visualiza los resultados de la segmentación en forma de un diagrama tipo árbol cuyas ramas (nodos) corresponden a los grupos (subgrupos conformados en cada nivel). Entiéndase en este caso que está seleccionando sucesivamente las variables más significativamente asociadas con la clase y las variables que deben ser fuentes de estratificaciones sucesivas.. 1.4.2. Método II. Algoritmo BayesCHAID. El método de aprendizaje utiliza la técnica CHAID para seleccionar las variables significativas en cada paso haciéndolas depender de la clase, e ir repitiendo el proceso en cada paso con las sub-poblaciones obtenidas con los valores de las variables seleccionadas, garantizando de este modo la relación entre las variables significativas, y a su vez con la clase, pero chequeando los distintos parámetros en cada paso (Moya 2007). La adaptación del algoritmo consiste en que hace una búsqueda de las interacciones entre las variables no mediante árboles de decisión, sino que busca a lo ancho y en profundidad en el árbol de interacciones posibles. La búsqueda se acota por un conjunto de parámetros que impone el usuario que serán explicados más adelante, así como su los pasos que resumen dicho algoritmo.. 1.4.3. Método III. PSO en el aprendizaje de redes bayesianas. El método parte de la idea de utilizar el algoritmo evolutivo Optimización de Enjambre de Partículas (PSO, Particle Swarm Optimization) como algoritmo de búsqueda de la estructura, en este caso la búsqueda de la estructura puede interpretarse como un problema de optimización, se transforma en hallar la red de mejor calidad en el. 13.
(23) Capítulo I espacio de posibles redes, donde la calidad puede ser medida por una métrica que evalúa la red de acuerdo a los datos de partida. Existen varias métricas que evalúan la calidad de las redes, específicamente con enfoque bayesiano, K2, basados en criterios de información o entropía, AIC, Akaike Information Criterion, MDL Minimum Description Length (Bouckaert 1995), (Chávez 2005),(Holger H. Hoos 2004). El algoritmo de búsqueda heurística PSO permite seleccionar distintas funciones fitness, la basada en validaciones cruzadas o la basada en el método LOO-CV, ambas ya implementadas en Weka o alternativamente se pueden utilizar otras funciones como la función que tiene en cuenta la dependencia de los atributos con la clase basada en conjuntos aproximados y propuesta por (Wang 2006), y dos medidas utilizadas en (Eitrich 2007) cuando las bases de datos se encuentran desbalanceadas, pero que a su vez se consideran medidas de calidad robustas para clasificación, se trata del coeficiente de correlación de Mattews y una medida de calidad basada en la sensitividad y la precisión de la clasificación (Fawcett 2004). 1.4.3.1. PSO principios básicos PSO es una metaheurística de optimización estocástica basada en una población. Un enjambre se define como una colección estructurada de organismos (agentes) que interactúan. La inteligencia no está en los individuos sino en la acción de todo el colectivo. Cada organismo (partícula) se trata como un punto en un espacio N dimensional el cual ajusta su propio “vuelo” de acuerdo a su propia experiencia y la experiencia del resto de la banda. La banda (swarm) “vuela” por el espacio de búsqueda localizando regiones o partículas prometedoras (Kennedy 1998). 1.4.3.2. PSO en el aprendizaje de redes bayesianas La búsqueda de la estructura de la red puede formularse como un problema de optimización en el espacio de las posibles redes Ω, en otras palabras, determinar Xópt ∈ Ω, H(Xópt) ¥ H(Xi), ∀ Xi ∈ Ω , donde la función objetivo H considerada es una métrica de calidad de las descritas en el capitulo 4 de la tesis de Bouckaert (Bouckaert 1995) para el caso de búsqueda local, o medidas que miden la exactitud en el caso de una búsqueda global cuando se trabajan con validaciones cruzadas de. 14.
(24) Capítulo I los datos según implementaciones en el ambiente Weka (Witten 2005), y otras medidas propuestas en la literatura en el caso de conjuntos de datos con clases desbalanceadas (Beielstein 2002). En la modelación de nuestro problema de búsqueda a partir del algoritmo PSO se define cada partícula como una red bayesiana la cual se representa como una matriz de adyacencias B=bij donde bij =1 si el atributo i es padre del atributo j, (si existe un arco de i a j) y bij =0 en otro caso. Se puede pensar que el espacio de búsqueda Ω 2. tiene cardinal 2 n ; de hecho se puede trabajar con dicho espacio, pero habría que chequear que no existan ciclos. Esto se puede lograr, por ejemplo, eliminando de forma aleatoria arcos que formen parte de ciclos existentes (Chávez 2007). Se propone entonces una forma de generar el espacio de búsqueda garantizando que no existan ciclos, o sea, partiendo de que un grafo dirigido representa un ordenamiento topológico, si y solo sí este no presenta ciclos, es posible a partir de una permutación formar un grafo acíclico dirigido (Chávez 2007).. 1.5. Conceptos básicos sobre computación paralela. La computación paralela es una técnica de programación en la que muchas instrucciones se ejecutan simultáneamente; se basa en el principio de que los problemas grandes se pueden dividir en partes más pequeñas, que pueden resolverse de forma concurrente (en paralelo). Hay varios tipos de computación paralela: paralelismo a nivel de bit, paralelismo a nivel de instrucción, paralelismo de datos y paralelismo de tareas. Durante muchos años, la computación paralela se ha aplicado en la computación de altas prestaciones, pero el interés en ella ha aumentado en los últimos años debido a las restricciones físicas en la prevención del escalado en frecuencia. La computación paralela se ha convertido en el paradigma dominante en la arquitectura de computadores, principalmente en los procesadores multinúcleo. La programación paralela es una técnica de programación basada en la ejecución simultánea, bien sea en un mismo ordenador (con uno o varios procesadores) o en un cluster de ordenadores, en cuyo caso se denomina computación distribuida. Al. 15.
(25) Capítulo I contrario que en la programación concurrente, esta técnica enfatiza la verdadera simultaneidad en el tiempo de la ejecución de las tareas. Los sistemas con multiprocesador y multicomputadores consiguen un aumento del rendimiento si se utilizan estas técnicas. En los sistemas monoprocesador el beneficio en rendimiento no es tan evidente, ya que la CPU es compartida por múltiples. procesos. en. el. tiempo,. lo. que. se. denomina. multiplexación. o. multiprogramación. El mayor problema de la computación paralela radica en la complejidad de sincronizar unas tareas con otras, ya sea mediante secciones críticas, semáforos o paso de mensajes, para garantizar la exclusión mutua en las zonas del código en las que sea necesario.. 1.5.1. Arquitectura Cliente-Servidor. Esta arquitectura consiste básicamente en que un programa (el cliente) realiza peticiones a otro programa (el servidor) que le da respuesta. Aunque esta idea se puede aplicar a programas que se ejecutan sobre una sola computadora es más ventajosa en un sistema operativo multiusuario distribuido a través de una red de computadoras. En esta arquitectura la capacidad de proceso está repartida entre los clientes y los servidores, aunque son más importantes las ventajas de tipo organizativo debido a la centralización de la gestión de la información y la separación de responsabilidades, lo que facilita y clarifica el diseño del sistema. La separación entre cliente y servidor es una separación de tipo lógico, donde el servidor no se ejecuta necesariamente sobre una sola máquina ni es necesariamente un sólo programa. Los tipos específicos de servidores incluyen los servidores web, los servidores de archivo, los servidores del correo, etc. Mientras que sus propósitos varían de unos servicios a otros, la arquitectura básica seguirá siendo la misma. Una disposición muy común son los sistemas multicapa en los que el servidor se descompone en diferentes programas que pueden ser ejecutados por diferentes computadoras aumentando así el grado de distribución del sistema.. 16.
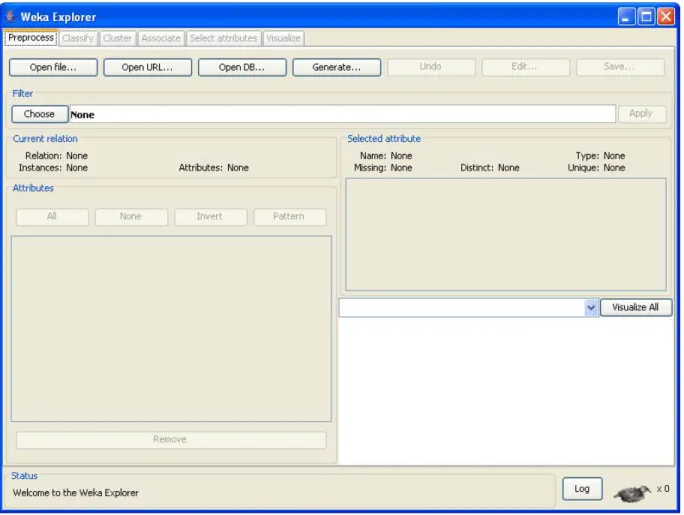
(26) Capítulo I 1.5.2. Llamada a Procedimiento Remoto (RPC). Llamada a Procedimiento Remoto (Remote Procedure Call) es un protocolo que permite a un programa de ordenador ejecutar código en otra máquina remota sin tener que preocuparse por las comunicaciones entre ambos. El protocolo es un gran avance sobre los sockets usados hasta el momento. De esta manera el programador no tiene que estar pendiente de las comunicaciones, estando éstas encapsuladas dentro de las RPC. Las RPC son muy utilizadas dentro del paradigma cliente-servidor. Siendo el cliente el que inicia el proceso solicitando al servidor que ejecute cierto procedimiento o función y enviando éste de vuelta el resultado de dicha operación al cliente. Hay distintos tipos de RPC, muchos de ellos estandarizados como pueden ser el RPC de Sun denominado ONC RPC (RFC 1057), el RPC de OSF denominado DCE/RPC y el Modelo de Objetos de Componentes Distribuidos de Microsoft DCOM. Ninguno de estos es compatible entre sí. La mayoría de ellos utilizan un lenguaje de descripción de interfaz (IDL) que define los métodos exportados por el servidor.. 1.6. Ambiente de aprendizaje automatizado Weka. Weka-Parallel no es más que una modificación del Weka (Waikato 2000), por lo que todo lo que se menciona en los epígrafes del 1.6.1 al 1.6.4 es común para todas las versiones de dicho software.. 1.6.1. Entrada de datos. Weka denomina instancias a cada uno de los casos proporcionados en el conjunto de datos de entrada, las cuales a su vez poseen propiedades o rasgos que las definen. Estos rasgos presentes en cada conjunto de datos se llaman atributos. Se utilizan los ficheros tipo ARFF, acrónimo de Attribute-Relation File Format, como formato de entrada de datos(Witten 2005). Este formato está estructurado en tres partes: Sección de encabezamiento: Se define el nombre de la relación. Sección de declaración de atributos: Se declaran los atributos a utilizar especificando su tipo. Los tipos aceptados por la herramienta son Numérico. 17.
(27) Capítulo I (Numeric), Entero (Integer, Fecha (Date), Cadena ( String 1 ), Enumerado: expresa entre llaves y separados por comas los posibles valores (caracteres o cadenas de caracteres) que puede tomar el atributo. Sección de datos: se declaran los datos que componen la relación. Para ver más sobre la estructura de los archivos .arff se puede consultar (Witten 2005).. 1.6.2. Algoritmos para el Aprendizaje Automatizado. Los algoritmos de Aprendizaje Automatizado implementados al Weka permiten realizar tareas tales como: clasificación, agrupamiento, búsqueda de asociaciones y selección de atributos. El “Explorer”, que es el ambiente gráfico básico de Weka, organiza estos algoritmos de acuerdo a las tareas mencionadas utilizando para su identificación las pestañas: “Classify”, “Cluster”, “Associate” y “Select attributes” respectivamente. La pestaña “Classify” pone a disposición del usuario los algoritmos de clasificación implementados, los cuales se agrupan en paquetes atendiendo a la técnica que empleen. Weka tiene implementado clasificadores basados en redes bayesianas, análisis de regresión, redes neuronales, árboles de decisión, los de tipo perezoso, reglas de producción, y meta-clasificadores. Una vez seleccionado uno de ellos, será aplicado sobre las instancias del conjunto de datos activo. Algunos de los algoritmos para resolver problemas de clasificación ya implementados son: IBk (D. Aha 1991): Perezoso VotedPerceptron (Freund 1998): Redes neuronales NaiveBayesSimple (Duda 1973): Redes bayesianas Id3 (Quinlan 1986), J48 (Quinlan 1993) :Árboles de decisión De igual forma tiene la interfaz de agrupamiento “Cluster” es muy similar a la de los clasificadores. La pestaña “Associate”. permite aplicar métodos orientados a la búsqueda de. asociaciones entre datos.. 1. Tipo string ofrecido por Java.. 18.
(28) Capítulo I Los algoritmos de selección de atributos, mostrados en la pestaña “Select attributes” tienen como objetivo identificar, mediante un conjunto de datos que posee ciertos atributos, aquellos atributos que tienen más peso a la hora de determinar si los datos son de una clase o de otra. La última de las pestañas que se encuentran dentro del modo Explorador es la pestaña “Visualize”. Muestra gráficamente la distribución de todos los atributos mediante gráficas en dos dimensiones, en las que va representando a través de los ejes todos los posibles pares de combinaciones de los atributos. Permite observar correlaciones y asociaciones entre los atributos de forma gráfica.. 1.6.3. Validación con un conjunto de datos. Muchos de los algoritmos disponibles en Weka antes de ser usados necesitan especificar qué datos serán usados como conjunto de entrenamiento y qué datos serán usados como conjunto de prueba. Estos son conjuntos disjuntos, el primero de ellos utilizado por los algoritmos de Aprendizaje Automatizado para realizar el proceso de aprendizaje fijando sus parámetros (ejemplo, los pesos de una RNA), mientras que los ejemplos del conjunto de prueba se utilizan para medir el desempeño del algoritmo. Weka implementa cuatro variantes para la validación:. • Usar los mismos datos como conjunto de entrenamiento y de prueba, conformado con todas las instancias del archivo de datos (Use training set).. • Usar todas las instancias del conjunto de datos solamente como conjunto de entrenamiento, y proporcionar como conjunto de prueba un nuevo archivo de datos (Supplied test set).. • Realizar una validación cruzada estratificada con un número de particiones dado (Folds) (Cross-validation). La validación cruzada (Kohavi, 1995b) parte de dividir los datos en n partes iguales. Luego, se forman n muestras diferentes tomando como conjunto de prueba una de ellas, y como conjunto de entrenamiento las n−1. 19.
(29) Capítulo I partes restantes. Se dice estratificada porque cada una de las partes conserva las propiedades de la muestra original (porcentaje de elementos de cada clase).. 2. • Tomar un porcentaje del conjunto de datos como muestra de entrenamiento y lo restante como muestra de prueba (Percentage split). Estas variantes están disponibles cuando a través del Explorador, explicado en el epígrafe anterior, se definen esquemas individuales para aplicar algoritmos de clasificación, agrupamiento o selección de rasgos. También algunas de ellas se usan desde el modo Experimentador.. 1.6.4. Interioridades de Weka. Weka está implementado en Java, lenguaje de alto nivel multiplataforma, lo que posibilita que sistemas escritos en este lenguaje puedan ejecutarse en cualquier plataforma sobre la que haya una máquina virtual Java disponible. Esta herramienta sigue los preceptos del código abierto (open source), por lo su código fuente está totalmente disponible, permitiendo la modificación del mismo. Una vez modificado se recompila y así es posible agregarle nuevas extensiones al sistema. También es un software de distribución gratuita lo que posibilita su uso, copia, estudio, modificación y redistribución sin restricciones de licencias. Este software demuestra ser una herramienta versátil que funciona a la perfección en la mayoría de las plataformas. Esta versatilidad también hace de Weka una herramienta ideal para las instituciones académicas e investigativas. Las clases de Weka están organizadas en paquetes. Un paquete es la agrupación de clases e interfaces donde lo habitual es que las clases que lo formen estén relacionadas y se ubiquen en un mismo directorio. Esta organización de la estructura de Weka hace que añadir, eliminar o modificar elementos no sea una tarea compleja. Está formado por 10 paquetes globales, y dentro de ellos se agrupan otros paquetes que aunque su contenido se ajusta al paquete padre ayudan a organizar aun mejor la estructura de clases e interfaces.. 2. Ver epígrafe 1.5.5, en este se habla sobre la paralelización del cross-validation en Weka-Parallel.. 20.
(30) Capítulo I Para la implementación del algoritmo concerniente se modificó el paquete “classifiers”: que agrupa todas las clases que implementan algoritmos de clasificación y estas a su vez se organizan en subpaquetes de acuerdo al tipo de clasificador.. 1.6.5. Weka-Parallel. Weka-Parallel es una modificación de Weka, que permite realizar fácilmente el sistema de validación cruzada en ambiente paralelo(Sebastian Celis 2002). Weka-Parallel llena un hueco específico en la comunidad de aprendizaje automatizado. Su objetivo es que el investigador tenga acceso a la capacidad del procesamiento en paralelo, sin necesidad de preocuparse por los detalles de la programación paralela. Java es un lenguaje excelente para utilizar en la implementación de un programa que involucra la computación distribuida, este cuenta con el paquete java.net que además de ser poderoso, es fácil de usar. Weka-Parallel utiliza este paquete para lograr esta capacidad de computación paralela. 1.6.5.1. Validación Cruzada (Cross-Validation). La validación cruzada es una metodología para medir el éxito de algoritmos de aprendizaje automatizado (Kohavi 1995), (Mitchell. 1997). La validación cruzada es de por sí paralelizable, ya que exige dividir en repetidas ocasiones los datos en diferentes segmentos, y la utilización de los datos restantes para poner a prueba los resultados. El deseo de hacer cálculos en paralelo se ha popularizado en los últimos años debido a la caída de los precios de las máquinas multiprocesadores, así como la creciente disponibilidad de redes básicas con máquinas con un solo procesador. Para explicar sobre el funcionamiento de la validación cruzada; asumimos que tenemos un conjunto de datos con m casos y k características, indicadas por la matriz A de orden m x k .También tenemos un vector unidimensional y, de tamaño m, cada uno de los elementos que contienen el valor de la correspondiente fila en A para predecir. Para problemas de clasificación, los elementos de y corresponden a las clases discretas.. 21.
(31) Capítulo I Con el fin de probar la eficacia de un determinado algoritmo de aprendizaje automático, la técnica más común es realizar n-veces la validación cruzada. La matriz A, y los correspondientes elementos de y, son divididos horizontalmente en n grupos separados. Para cada una de las n iteraciones, una partición (o fold) de los datos, es dejado fuera y usado como conjunto de prueba, y el resto de los datos son utilizados como grupo de aprendizaje. El algoritmo de aprendizaje automático se ejecuta sobre el conjunto de entrenamiento y se valida a través del conjunto de prueba. Esto se realiza n veces, dejando cada vez un conjunto diferente como conjunto de prueba, obteniéndose n estimados, hallando el promedio de rendimiento global y la precisión de la validación cruzada. 1.6.5.2. Filosofía del Weka-Parallel. Weka-Parallel se diseñó con el único propósito de disminuir drásticamente la cantidad de tiempo necesario para ejecutar la validación cruzada en un conjunto de datos utilizando cualquier clasificador. Esto es aplicable de manera efectiva cuando se usa un clasificador computacionalmente complejo, así como cuando el número de particiones que se calcula es grande. Como el conocimiento de cada partición se calcula independientemente las n veces usando la validación cruzada, se modificó Weka a fin de que las diferentes particiones se calcularan en diferentes ordenadores. Toda esta información es recuperada en una sola máquina, donde los resultados finales se muestran al usuario. La vía que utiliza Weka-Parallel para conectar a las máquinas que ayudarán con los cálculos es una simple conexión establecida con la clase Socket en el paquete java.net. Cada máquina remota inicia un demonio que se pone a escuchar por un puerto determinado. Una vez establecida la conexión entre la máquina donde se ejecuta Weka y la máquina remota, el Socket es usado para transmitir el flujo de datos en ambas direcciones entre los ordenadores. Esta arquitectura proporciona la capacidad para poner cualquier número de ordenadores escuchando por dicho puerto (servidores) para ejecutar los demonios que escuchan las conexiones entrantes. A continuación, un ordenador que ejecute. 22.
(32) Capítulo I Weka-Parallel (cliente) se puede conectar a estos servidores para comenzar a distribuir el trabajo a través de los hilos. Con el fin de dar al servidor la información necesaria, el cliente envía un primer entero que indica si Weka-Parallel está siendo ejecutado desde la línea de comandos o a través de una interfaz gráfica(GUI). Una vez que el servidor recibe esta información, inmediatamente espera recibir todo lo que necesita con el fin de hacer los cálculos para la validación cruzada. En este caso, el servidor espera recibir una copia de todo el conjunto de datos, el nombre del clasificador que se está utilizando, así como el número total de particiones que deben ser calculados. La última pieza de información enviada al servidor es un entero que representa el índice que indica la partición que el servidor debe analizar. En este punto, el cliente espera a que los servidores terminen de realizar los cálculos y luego envíen los resultados. Cada servidor tiene toda la información que necesita para ejecutar una partición particular. Una vez que un servidor termina de realizar los cálculos y envía los resultados al cliente, este último puede realizar una de dos cosas; si el cliente ve que todas las particiones han sido calculados, cierra la conexión con el servidor, de lo contrario, envía nuevamente al servidor toda la información mencionada, incluyendo el índice de la partición que debe calcular nuevamente, hasta que ya no queden más particiones que calcular. A su vez el cliente funciona como un servidor, calculando particiones a la par con los demás procesadores, con el objetivo de lograr una mayor eficiencia. Es necesario destacar además que el Weka-Parallel puede funcionar y realizar la validación cruzada de igual manera que otras versiones de este software, ya que realizar la validación cruzada en paralelo es opcional. En el capítulo 3 se extenderá y explicará sobre esto. Como resultado de dicha filosofía los autores de Weka-Parallel Sebastian Celis y David Musican obtuvieron los resultados que brinda la figura 1.6.5.2.1, la cual muestra el incremento de la velocidad del cálculo en paralelo de la validación cruzada, usando una cantidad determinada de ordenadores P 4, a 2 GHz. de procesador. La línea roja horizontal indica el tiempo de una corrida, pero usando una versión no modificada del Weka.. 23.
(33) Capítulo I. Figura 1.6.5.2.1 Comportamiento de Weka-Parallel en función del número de la cantidad de máquinas remotas.. 1.7. Conclusiones parciales del capítulo. En este capítulo se abordan conceptos que son importantes para el posterior desarrollo del trabajo, los cuales sirven para una mejor comprensión de las técnicas usadas por el nuevo algoritmo, como son el test Chi-cuadrado o en general el método CHAID. Se describen temas relacionados con redes probabilísticas y redes bayesianas; se comenta sobre los árboles de decisión, forma de construirlos, apoyándonos en ejemplos específicos y reales; también se hace un análisis de algoritmos y modelos, temas generales relacionados con el Weka, así como cuestiones fundamentales para el uso de dicho software. Por último se describe el Weka-Parallel, las modificaciones que este incorpora a partir de la versión original, siendo esta específicamente la paralelización de la validación cruzada. Además se expone de manera detallada cómo funciona el Weka-Parallel.. 24.
(34) Capítulo II. CAPÍTULO. II.. APRENDIZAJE. BAYNET,. NUEVO. AUTOMATIZADO.. ALGORITMO. ADICIÓN. DE. DE LOS. METODOS BAYESCHAID Y PSO. Los diferentes tipos de algoritmos para el aprendizaje automatizado de Redes Bayesianas que usa el clasificador BayesNet en el proceso de clasificación se les denomina algoritmos de búsqueda (search algorithms). Debido a las similitudes que estos algoritmos pudieran presentar entre ellos, pueden ser agrupados en paquetes para reutilizar o compartir rutinas y campos comunes. Estos son especificados mediante uno de sus parámetros de configuración y responden a diferentes estrategias según su concepción. Esta particularidad se pone de manifiesto muy frecuentemente entre algoritmos que siguen ciertos paradigmas o estrategias. Estos algoritmos de búsqueda no hacen más que definir la estructura de la red Bayesiana especificando los arcos entre los nodos con su cardinalidad, lo cual determinará la formación de las tablas de probabilidades condicionales a usar por el mecanismo de propagación de la evidencia o simplemente el clasificador. Exactamente esto es lo que hace el algoritmo BayNet.. 2.1. Implementación del nuevo algoritmo de búsqueda BayNet. Todas las modificaciones, adiciones e implantaciones fueron hechas usando el Eclipse SDK Versión 3.2.0. A continuación mostramos los pasos que se siguieron para implementar el nuevo algoritmo de búsqueda BayNet, quedando conformada una metodología general para implementar nuevos algoritmos de búsqueda.. 2.1.1. Metodología seguida para construir el nuevo algoritmo de búsqueda. 1- Definimos la ubicación dentro del espacio de nombre (deterministic) designado a su agrupación weka.classifiers.bayes.net.search En Weka los paquetes de clases están bien organizados lo que hace muy fácil la implementación de nuevas funcionalidades. Esta característica no solo es una bondad de sus diseñadores sino que es una necesidad ya que gran parte de las. 25.
(35) Capítulo II interfaces de usuarios son inferidas según la ubicación de las clases en el vasto conjunto de nombres de espacio (namespace) en el que Weka organiza sus implementaciones. Esto permite que al añadir nuevos algoritmos o herramientas, no tengamos que cambiar ningún código fuente del sistema (En caso contrario la menor cantidad posible). Esto evita posibles conflictos entre varias adiciones, principalmente de diferentes programadores y/o autores. De esa forma, la clase que contiene el código del nuevo algoritmo queda ubicada en el nombre de espacio anteriormente mencionado. En los correspondientes a los paquetes contenidos directamente de este. Estos paquetes son: ci, fixed, global y local. En el caso que ninguno de estos paquetes satisfacen la ubicación que deseamos para el nuevo algoritmo (esto puede ser por diversos motivos pero el más frecuente es que el nuevo algoritmo no se ajuste a ninguno de estos paradigmas), es posible crear un nuevo paquete con un nombre más conveniente. Para esto le agregamos al weka el paquete deterministic, en la misma ubicación que los paquetes anteriormente mencionados, ya que este contiene las clases necesarias(ChiSquareUtils ) para la implementación del nuevo algoritmo. Para que este paquete y todos los que sean adicionados sean mostrados en el árbol de selección de la interfaz de usuario se debe modificar uno de los recursos de la distribución original, lo que hace que la extensión pueda traer colisiones con alguna otra extensión o versiones posteriores. Este recurso se encuentra dentro del paquete “weka.gui” bajo el nombre “GenericObjectEditor.props”. Allí se debe buscar la cláusula “weka.classifiers.bayes.net.search.SearchAlgorithm=” y agregar el valor del nuevo espacio de nombre. Específicamente en nuestro caso. fue agregada la. siguiente línea: (weka.classifiers.bayes.net.search.deterministic.BayNet, \) 2- Creamos la clase. El nombre de la clase (BayNet) no solo define el nombre de los ficheros con la implementación sino que esta corresponde al nombre mostrado por la interfaz de usuario para referenciar el nuevo algoritmo. Se recomienda que dicho nombre sea. 26.
(36) Capítulo II intuitivo y no demasiado largo aunque el mismo no presenta límite fuera de lo computacionalmente razonable. 3- Se hace uso de los paquetes “weka.core.*”, “weka.classifiers.bayes.BayesNet” y “weka.classifiers.bayes.net.search.*”. Esto es imprescindible hacerlo. Es obligatorio importar al menos estos tres paquetes ya que contienen las especificaciones de las clases usadas por la clase ancestro “searchAlgorithm”. Además de estos se deben agregar los que necesite el desarrollador. 4- Heredamos de alguna clase derivada de “SearchAlgorithm”. La clase de propósito general de la que se hereda se denominada “searchAlgorithm”. Aunque existen otras correspondientes al los paquetes “local” y “global” denominadas. “LocalScoreSearchAlgorithm”. y. “GlobalScoreSearchAlgorithm”. respectivamente. Estas últimas recogen campos y funciones comúnmente usadas por los algoritmos que desarrollan paradigmas correspondientes a los paquetes mencionados. También se tiene la opción de heredar de la clase específica del algoritmo si es que esto facilita el propósito del diseñador. 5- Definimos los nuevos campos. Se definen los nuevos campos o parámetros que se necesitan para el algoritmo. La clase de la que se hereda ya presenta varios campos definidos, pero generalmente no son suficientes. Para nuestro algoritmo se definen como privados, siguiendo con una buena disciplina los siguientes: m_dChiSquare_Max_Significance, m_nMinCountOfInstancesToSplit, m_nMaxDepth, m_nMaxNrOfTrees 6- Definimos las funciones para acceder a los nuevos campos. Uno de los paradigmas adoptados por los creadores de Weka, ha sido su modelo orientado a objeto y más específico, fue usar el Java y su modelo de objetos. En el. 27.
(37) Capítulo II paradigma de la programación orientada a objetos casi la mayoría de los autores que hablan del tema hacen referencia a que los objetos, entiéndase objetos como las instancias de las clases, sean los únicos que puedan acceder a sus campos específicos, ya así sean estos de alcance público o protegido proyectando esta especificidad en las funciones u otro mecanismo destinadas a su manipulación. Así se logra controlar la manera en que estos son usados y ocultar la manera en que estos son representados interiormente. El dúo de funciones, popularmente usado, formado por los prefijos “get” y “set” antes del nombre del campo, es una buena opción para lograr lo anteriormente expuesto. Además esto es usado por el Weka para generar la interfaz de usuario. Debajo se muestra el procedimiento para un parámetro( m_nMaxNrOfTrees), siendo el mismo para todos los otros campos. public int getMaxNrOfTrees() { return m_nMaxNrOfTrees; } public void setMaxNrOfTrees(int MaxNrOfTrees) { m_nMaxNrOfTrees = MaxNrOfTrees; }. 7- Definimos la entrada de parámetros La clase “searchAlgorithm” implementa la interfaz “optionHandler” la cual permite al Weka generar toda la interfaz de usuario correspondiente al algoritmo de forma automática. Esta interfaz define 3 métodos, los cuales deben ser redefinidos siempre que existan variaciones relacionadas con los parámetros, acorde con objetivo del diseñador. Estas funciones son:. •. listOptions: Será el encargado de devolver una lista de instancias de la clase “Options” con las descripciones de los parámetros. La lista debe ser elaborada con la clase “Enumeration” de Java.. •. setOptions: Será el encargado de tomar los valores de las opciones (parámetros de usuario) desde un arreglo de cadenas y guardar los valores en los campos necesarios después de hacer las conversiones necesarias.. 28.
Figure



+7




Documento similar
que hasta que llegue el tiempo en que su regia planta ; | pise el hispano suelo... que hasta que el
por unidad de tiempo (throughput) en estado estacionario de las transiciones.. de una red de Petri
en la secci´ on 2 se presentan las Redes Bayesianas, en cuanto a sus antecedentes, definici´ on, propiedades, tipolog´ıa, aplicaciones y el detalle de las Redes Bayesianas
Como resultado de esta tesis se pudo concluir que los algoritmos evolutivos basados en Redes Bayesianas simplemente conectadas y los algoritmos de optimización basados en colonia de
En este artículo se propone el formalismo de las redes bayesianas como mecanismo de representación del conocimiento en la capa superior de una arquitectura genérica
En cuarto lugar, se establecen unos medios para la actuación de re- fuerzo de la Cohesión (conducción y coordinación de las políticas eco- nómicas nacionales, políticas y acciones
La campaña ha consistido en la revisión del etiquetado e instrucciones de uso de todos los ter- mómetros digitales comunicados, así como de la documentación técnica adicional de
Proposed systems are based on the well known GMM-UBM framework [Reynolds et al., 2000], using duration-equalized DCT-coded temporal trajectories per linguistic unit as
