Detección y marca de los cambios espectrales notorios en voces patológicas
80
0
0
Texto completo
(2) Facultad de Ingeniería Eléctrica Centro de Estudios de Electrónica y Tecnología de la Información. TRABAJO DE DIPLOMA “Detección y marca de los cambios espectrales notorios en voces patológicas .” Autor: Héctor Arturo Kairuz Hernández - Díaz Tutor: Dra. María E. Hernández – Díaz Huici Profesor Titular Centro de Estudios de Electrónica y Tecnología de la Información Facultad de Ingeniería Eléctrica E- mail: [email protected]. Santa Clara 2009 "Año del 50 aniversario del triunfo de la Revolución”. ii.
(3) Hago constar que el presente trabajo de diploma fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de estudios de la especialidad de Ingeniería Biomédica, autorizando a que el mismo sea utilizado por la Institución, para los fines que estime conveniente, tanto de forma parc ial como total y que además no podrá ser presentado en eventos, ni publicados sin autorización de la Universidad.. Firma del Autor Los abajo firmantes certificamos que el presente trabajo ha sido realizado según acuerdo de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. Firma del Tutor. Firma del Jefe de Departamento donde se defiende el trabajo. Firma del Responsable de Información Científico-Técnica. iii.
(4) PENSAMIENTO. Puedes estar cansado de la realidad, pero nunca te cansarás de soñar. L.M. Montgomery. 1.
(5) DEDICATORIA. A mi mamá que contribuyó con sus conocimientos y experiencias, y mi familia por su dedicación, su paciencia y su amor.. 2.
(6) AGRADECIMIENTOS. A mi madre y tutora que desde un principio me ha servido de inspiración y guía en la carrera, desde su selección hasta la culminación, reflejada en este trabajo.. 3.
(7) TAREA TÉCNICA 1. Revisión bibliográfica sobre las medidas acústicas que se realizan en grupos de pacientes disártricos. 2. Programación de un algoritmo para situar marcas en la señal del habla en voces patológicas. 3. Análisis del desempeño del algoritmo en una muestra representativa de pacientes disártricos. 4. Confección del informe final.. Firma del Autor. Firma del Tutor. 4.
(8) RESUMEN. La carencia de medidas objetivas en el habla fluida impone la necesidad de crear las bases para aplicar a una oración o segmento mayor del habla un conjunto de medidas acústicas que se correlacionen con el grado de inteligibilidad del hablante. Por lo anterior, se lleva a cabo un análisis de varios tipos de algoritmos, validados en la literatura, en cuanto a sus características, para realizar la implementación de un algoritmo basado en la propuesta de Liu y orientado a voces patológicas, que permita colocar en la señal de audio marcas en los puntos donde ocurren cambios espectrales de interés. Como aspecto novedoso, se efectúa de forma automática las localizaciones de los puntos en la señal del habla donde ocurren consonantes oclusivas, fricativas, sonoras, silencios y pistas prosódicas. Por último, se ilustran las pruebas realizadas con el algoritmo modificado sobre una muestra de pacientes disártricos donde se destacan los cambios espectrales que ocurren durante el habla fluida y su consideración como puntos de inflexión a tener en cuenta en un análisis multidimensional del habla.. 5.
(9) TABLA DE CONTENIDO TAREA TÉCNICA............................................................................................................4 RESUMEN. .......................................................................................................................5 I.. Capítulo I .................................................................................................................12. Medidas acústicas relacionadas con desordenes del habla. .............................................12 1.1 Disartrias, particularidades de su estudio. .............................................................12 1.2 Necesidad de mediciones objetivas. ......................................................................13 1.3 Aparato fonador, medidas......................................................................................15 1.3.1 Parámetros Relacionados con la Fonación o Calidad del Habla (Sistema Laríngeo)..................................................................................................................15 1.3.2 Parámetros Relacionados con las Funciones del tracto vocal para articulación de vocales: Correlaciones espectrales (Sistema Supra Laríngeo). ...........................15 1.3.3Funciones del Tracto Vocal para la Articulación de Consonantes: (Sistema Supra Laríngeo). ......................................................................................................16 1.3.4 Función velofaríngea. .....................................................................................18 1.3.5 Coordinación de la actividad laríngea y supralaríngea. ..................................18 1.3.6 Asociación de medidas acústicas con aspectos prosódicos y paralingüísticos. .................................................................................................................................20 1.4 Consideraciones finales. ........................................................................................22 II.. Capítulo II Materiales y Métodos. ...........................................................................24 2.1 Algoritmo seleccionado. ........................................................................................24 2.1.1 Detector G (glottis). ........................................................................................27 2.1.2 Detector S (sonorant) ......................................................................................28 2.1.3 Detector B (burst) ...........................................................................................29 2.2 Modificaciones realizadas e implementación ........................................................30 2.2.1 Detector de segmentos con vibración de las cuerdas vocales. Detector g (glottis). ...................................................................................................................31 6.
(10) 2.2.3 Detector de marcas b (burst) plosivas. ...........................................................37 2.2.4 Estimador de el VOT (Voice Onset Time). ....................................................39 2.2.5 Estimador del tiempo de locución. .................................................................39 2.2.6 Detector de intervalos silencio........................................................................40 2.3 Materiales y métodos. ............................................................................................42 2.3.1 El experimento. ...............................................................................................43 III.. Capítulo III Resultados y discusión. .....................................................................45. Correspondencia entre las marcas propuestas y el espectrograma: .............................45 Disartria Atáxica. .........................................................................................................47 Disartria Flácida...........................................................................................................48 Disartria Hipercinética (Corea)....................................................................................50 Disartria Parkinson ......................................................................................................52 Disartria Espástica .......................................................................................................53 Disartria Hipercinética Temblor Orgánico ..................................................................54 Conclusiones y Recomendaciones:..................................................................................56 Conclusiones. ...............................................................................................................56 Recomendaciones. .......................................................................................................56 Referencias Bibliográficas. ..............................................................................................57 Anexo 1: Ejemplo de corrida para un paciente. ...............................................................59 Anexo 2 Resumen de Resultados para cada Paciente.....................................................68 Paciente disartria Atáxica 3 femenino 61 años ................................................................68 Paciente disartria Atáxica 7 masculino 58 años ..............................................................69 Paciente disartria Flácida 3 masculino 20 años ...............................................................69 Paciente disartria Flácida 4 femenino 22 años ................................................................70 Paciente disartria Flácida 5 femenino 26 años ................................................................70 Paciente disartria Corea 2 femenino 42 años...................................................................71 Paciente disartria Corea 6 femenino 34 años...................................................................72 Paciente disartria Corea 7 femenino 65 años...................................................................72 Paciente disartria Parkinson 1 masculino 58 años ...........................................................73 Paciente disartria Parkinson 2 masculino 60 años ...........................................................73 Paciente disartria Parkinson 3 masculino 57 años ...........................................................73 7.
(11) Paciente disartria Espástica 3 femenino 66 años .............................................................74 Paciente disartria Temblor Orgánico 2 femenino 66 años...............................................76 Paciente disartria Temblor Orgánico 5 femenino 70 años...............................................76 Paciente disartria Temblor Orgánico 6 femenino 65 años...............................................77. 8.
(12) INTRODUCCIÓN Desde el siglo XIX aparecen reportados trabajos médicos donde se emplea la voz como medio de diagnóstico. Ya en la década de los sesenta los estudios subjetivos del habla comenzaron a ser formalizados, como colofón de esta etapa aparecen los conocidos trabajos de las Clínicas Mayo, donde se localiza la lesión neurológica a partir de las manifestaciones en el habla y se caracterizan los distintos tipos de disartria. En la segunda mitad del siglo XX se busca que la evaluación esté menos afectada por quien evalúa (disminuir la componente subjetiva), es por ello que se inicia junto con el desarrollo del procesamiento digital de señales, la era de mediciones acústicas. En el libro editado por Kent & Ball en el 2000, aparece un inventario de esta etapa caracterizada por incontables medidas relacionadas con la calidad vocal y pocos intentos asociados a la articulación, la nasalidad y la prosodia, que también se ven afectadas y cuentan para el diagnóstico. En el presente siglo las medidas se concentran en buscar una integración hacia una medida objetiva de la inteligibilidad, lo cual requiere de medidas de articulación, nasalidad y prosodia, que en su mayoría, se han calculado en segmentos cortos debido a la complejidad del análisis del habla fluida. El habla fluida es medio de comunicación natural, empleado para realizar las medidas subjetivas y a él se deben acercar las medidas objetivas, con el propósito de un mejor análisis del fenómeno del habla de forma global. Por ello en la actualidad se buscan algoritmos y técnicas que faciliten el análisis de segmentos con suficiente duración para estudiar la prosodia y en general otras características en el habla fluida. La tarea planteada se enmarca en las investigaciones que lleva a cabo el Laboratorio de Procesamiento de Voz del CEETI con la finalidad de encontrar medidas que apoyen el diagnóstico y evaluación de los pacientes con dificultades en la comunicación oral. Los resultados de este trabajo están encaminados a facilitar la aplicación de las herramientas de análisis, desarrolladas por este colectivo, en el habla fluida. Lo anterior conduce a la siguiente formulación del problema: Existe la necesidad de encontrar una forma de procesar el habla fluida en pacientes disártricos de manera que se obtengan medidas acústicas simultáneas que se relacionen. 9.
(13) con diferentes dimensiones del fenómeno del habla y puedan expresar la afectación que presenta la inteligibilidad del paciente. De este problema se originan las siguientes interrogantes científicas: ¿Puede crearse una etapa de pre-procesamiento acústico que permita, a partir del habla fluida, marcar en el tiempo la ocurrencia de los cambios espectrales notorios y crear las bases para medidas de articulación y prosodia? Para resolver este problema se debe elegir un algoritmo apropiado e implementarlo para su posterior uso. Por lo tanto el objetivo general del presente proyecto es: Seleccionar una herramienta en el dominio del tiempo o la frecuencia que represente las alteraciones prosódicas y articulatorias en pacientes disártricos. De este objetivo general se derivan los objetivos específicos siguientes: Seleccionar el algoritmo adecuado y de ser necesario modificarlo. Programar el algoritmo seleccionado. Evaluar los resultados alcanzados. Con este proyecto se contribuye al desarrollo de procedimientos para un mejor análisis e identificación de variaciones en el habla fluida. La implementación de estas soluciones permitirá a los especialistas e investigadores realizar estudios y análisis comparativos, que contribuirán a una mejor comp rensión del mecanismo de producción y percepción del habla. El informe de la investigación se estructura en introducción, capitulario, conclusiones y recomendaciones, referencias bibliográficas y anexos. En la introducción se deja definida la importancia, actualidad y necesidad del tema que se aborda. El Capítulo 1 se dedica a la caracterización del problema a partir de un análisis de la literatura. Se comentan varios tipos de medidas para el análisis del habla y se realiza una selección de las que serán utilizadas posteriormente. El Capítulo 2 explica el diseño metodológico de la investigación y el algoritmo seleccionado con las modificaciones efectuadas para utilizarlo en voces patológicas. En el Capítulo 3 se realiza la validación de la efectividad del algoritmo modificado ploteando las marcas halladas sobre el espectrograma y mediante un análisis objetivo de. 10.
(14) los resultados con los datos adquiridos y las evaluaciones subjetivas, realizadas por expertos, de la muestra de pacientes seleccionada.. 11.
(15) I.. Capítulo I. Medidas acústicas relacionadas con desordenes del habla. Resumen. El presente capítulo introduce el estado del arte en el estudio de las disartrias y la necesidad de complementar las evaluaciones clínicas subjetivas con medidas acústicas. Se discuten las medidas más frecuentes asociadas a sistemas que componen el aparato fonador, con particular énfasis en la articulación y la prosodia por ser las áreas donde menos medidas se han reportado. Quedando así establecido la necesidad de abordar de forma global y no fragmentada el problema de las medidas acústicas en voces patológicas.. 1.1 Disartrias, particularidades de su estudio. La investigación a largo plazo del laboratorio de voz del CEETI es el desarrollo, basado en sistemas computarizados, de servicios y procesos que integren toda la información relevante en la señal acústica en función de la práctica clínica. Para ello el objeto de análisis son las muestras de voces patológicas procedentes de diferentes grupos y afecciones como son hipoacúsicos, pacientes con trastornos neurológicos, labio paladar hendido, espasmofonías, entre otras. Sin embargo, las manifestaciones que estos grupos presentan, son también recogidas en el habla de los pacientes disártricos. Por ser este un grupo bien descrito desde el punto de vista clínico, se toma como referencia en este trabajo, dado que las medidas desarrolladas a partir de estas muestras serán aplicables a otros grupos de pacientes con similares manifestaciones. Para una mejor comprensión del objeto de estudio, se definen los siguientes términos. Se conoce como Trastornos Motores del Lenguaje al quebrantamiento sobre el control de los movimientos musculares del aparato fonador como consecuencia de una lesión del sistema nervioso central o periférico. Se reconocen dos clases que son: Disartria y Apraxia del lenguaje. Disartria es cualquier combinación de trastornos de la respiración, fonación, articulación, resonancia o prosodia que puede ser causada por incoordinación muscular, debilidad muscular o alteración del tono muscular. Las disartrias son una familia de trastornos motores del lenguaje caracterizadas por rasgos acústicos distintivos. Cada una se origina en una zona motora distinta del sistema nervioso. 12.
(16) Una complicación en el estudio de pacientes con desórdenes del habla es la heterogeneidad en el deterioro en sujetos con la misma clasificación neurológica. Una propiedad acústica común a muchas muestras de pacientes disártricos es la escasez de energía en altas frecuencias. Esta propiedad ayuda a explicar la red ucción en la inteligibilidad porque limita la información para muchas consonantes y reduce la posibilidad de identificar características personales. [1] Apraxia es sinónimo de disartria cortical y desintegración fonética, puede ocurrir aisladamente o asociada a la afasia motora. El control muscular está intacto, hay una pérdida del conocimiento de la articulación de la palabra. En contraste con la disartria no hay distorsión del sonido del lenguaje sino más bien sustituciones fonéticas. [2]. Por ende no se encuentra entre las muestras analizadas en este trabajo. Casi todos los pacientes disártricos están asociados con algún problema de prosodia en acentuación, contornos de entonación, y/o razón del habla y ritmo. Solo recientemente se ha considerado la prosodia como un problema de primera línea en el tratamiento, dado que históricamente los clínicos consideraban la prosodia como un asunto a tratar luego de haber remediado otros trastornos en la producción del habla [3]. Sin embargo Yorkston y sus colegas sugieren una atención temprana a la prosodia basados en: “Usando la prosodia en frases importantes y uniones sintácticas, se provee al auditorio de información importante para decodificar el mensaje… las características prosódicas de los patrones de acentuación y. las fronteras sintácticas mejoran la. inteligibilidad… y la atención a la prosodia puede mejorar la naturalidad del habla y ser importante en la reducción de la minusvalía” [4] El progreso en el estudio de disartrias ha sido lento debido a varios factores como: 1. El modesto esfuerzo en la investigación neurológica de los desordenes del habla. La dificultad para el análisis acústico para personas con discontinuidades en la fonación, hipernasalidad, articulación imprecisa y otras. 2. Las pocas publicaciones sobre análisis acústico de disartrias, que en su mayoría se concentran en un pequeño número de medidas aplicadas a pequeñas muestras.. 1.2 Necesidad de mediciones objetivas. Las evaluaciones subjetivas han sido la herramienta principal para la clasificación y descripción de disartrias, por este motivo han surgido dudas sobre la confiabilidad y la validez de. las evaluaciones subjetivas, especialmente si son hechas por diferentes 13.
(17) jueces con variados entrenamientos y métodos para realizar la evaluación perceptual. También se cuestiona cómo una evaluación perceptual puede discriminar entre dos problemas que ocurren simultáneamente en dos o más componentes del aparato fonador. [5]. La respuesta al problema de la confiabilidad de las medidas subjetivas descansa en la creación de medidas objetivas que surgen a partir del análisis acústico. Este se puede clasificar como: análisis en el dominio del tiempo, en el dominio de la frecuencia, y en el dominio tiempo-frecuencia de la señal de voz. No todos están satisfechos con las medidas objetivas, [6], establecen que las técnicas fisiológicas y acústicas han añadido conocimiento y certeza y medidas objetivas de varios aspectos del aparato fonador; por otra parte no se puede obviar la necesidad de las evaluaciones subjetivas, dado que la voz es el resultado de la interacción de múltiples procesos fisiológicos que no se pueden capturar con una sola técnica de medición. Sin embargo las aplicaciones computarizadas de análisis acústico son más baratas hoy en día y se centran en un acercamiento global al fenómeno del habla. Además la opinión general es que ambos procesos, perceptual y objetivos, deben estar presentes y bien balanceados. Las medidas objetivas para la calidad vocal, articulación y prosodia son componentes esenciales para calcular un índice de inteligibilidad. Hay gran cantidad de trabajos reportados en medidas de calidad vocal, a pesar de las dificultades inherentes al procesamiento digital y la variabilidad de la señal, que se amplifica por los desórdenes del habla; pero por otro lado hay una gran carencia en cuanto a medidas objetivas relacionadas con la articulación y la prosodia debido a la dificultad que acarrea analizar unidades más complejas del lenguaje junto con las dificultades antes mencionadas. [7] La mayoría de las mediciones funcionan en grabaciones de alta fidelidad de voces normales, no se puede suponer que tengan un resultado similar cuando se aplican a muestras de habla patológica, debido al contraste reducido en el habla típica de dichos desórdenes, causados por la nasalidad, la disfonía y otros deterioros. El problema de la precisión es particularmente importante porque el habla de los disártricos incluye nuevos tipos de variabilidad y se debe tener cuidado en distinguir la variabilidad intrínseca del proceso de medición, de la variabilidad que refleja el comportamiento real del habla que se examina. [8]. 14.
(18) 1.3 Aparato fonador, medidas. Se ha hecho costumbre relacionar la medida acústica con un parámetro subjetivo empleado en la evaluación de la voz, o tomar como punto de partida dicho parámetro. [8] Sugiere que la correlación a priori entre evaluaciones perceptuales y la medida acústica debe ser considerada sólo como una hipótesis. En el artículo antes mencionado aparecen relacionadas algunas medidas asociadas a los diferentes subsistemas que se involucran en la producción del habla y en algunos casos, se sugieren medidas posibles. A continuación se hace un análisis crítico de dichos comentarios y otros similares procedentes de otras fuentes.. 1.3.1 Parámetros Relacionados con. la Fonación o Calidad del Habla (Sistema. Laríngeo) Las medidas sugeridas en [8] fueron: Estadísticas y contornos de F0, medidas de perturbación sobre el jitter y/o el shimmer, razón señal a ruido y razones de energía del espectro. Por otra parte, en el libro “Voice Quality Measurement” [9] en las páginas 78 y 79 se encuentran las correlaciones de ronquera y jadeo, con un conjunto de parámetros basados en relaciones señal a ruido, jitter y shimmer. En las mismas puede apreciarse que la mayoría de estas medidas tienen poca especificidad y sensibilidad, aunque son las históricamente más reportadas como se aprecia en el capítulo 9 de dicho libro. Son más promisorias las medidas en segmentos largos, (contornos de F0 y declinación de formantes). Similares medidas han sido usadas para demostrar la decadencia de los pacientes en estudios a largo plazo de Parkinson.. 1.3.2 Parámetros Relacionados con las Funciones del tracto vocal para articulación de vocales: Correlaciones espectrales (Sistema Supra Laríngeo). Las medidas sugeridas en [8] fueron: Valores absolutos de la frecuencia de F1, F2, F3. Diferencias de los valores absolutos de F2-F1, F1-F0. Las medidas sobre frecuencias de los formantes (F1, F2, F3) son representativas dado que varían con la longitud del tracto vocal, la edad y el sexo. Se utilizan para el cuadrilátero vocálico, las líneas isovocálicas y las diferencias de F2-F1, F1-F0. Las. 15.
(19) mismas pueden ser erráticas en algunas muestras de disartria cuando la función de la laringe es altamente variable o existe disfonía. Estas medidas han probado su validez en diferentes aplicaciones como El Triángulo Vocálico que fue aplicado a pacientes con implante coclear para documentar su evolución en [10]. Otras aplicaciones de interés aparecen en [11] Capítulo 9. En cuanto a las fluctuaciones de la frecuencia de los formantes es una de las anomalías más reportadas en producción de vocales en pacientes disártricos ejemplo de esto es la centralización de formantes y frecuencias anómalas para vocales altas y frontales. En consecuencia particular interés debe presentarse en el algoritmo de captura y medición de los formantes, que debe tener en cuenta las características antes mencionadas de las voces patológicas.. 1.3.3Funciones del Tracto Vocal para la Articulación de Consonantes: (Sistema Supra Laríngeo). Las Medidas sugeridas en [8] fueron: Espectro de oclusivas sordas o ruido de fricación. Transiciones de formantes para consonante vocal (CV) y vocal consonante (VC). Como las consonantes son una clase compleja de sonido, no hay una medida que diferencie cada clase; una manera útil de distinguirlas es en sonoras y sordas, basándose en el grado de constricción del tracto vocal. Una consonante sorda está hecha por un cierre completo o un cierre estrecho en la cavidad oral de manera tal que el flujo de aire es de tenido o se produce ruido fricativo. Una consonante sonora es producida por un tracto vocal relativamente abierto por lo tanto ocurre resonancia en la cavidad. Las sordas incluyen fricativas, africadas y oclusivas. Las sonoras incluyen nasales, líquidas y semivocales. Las sonoras pueden describirse por patrones de formantes y antiformantes en estado estable y segmentos de transición. Los datos de estas son similares que para las vocales. Las sordas involucran en si un evento de fricación: Una explosión o ruido de transición para las oclusivas, un breve intervalo de ruido para las africadas y un largo intervalo de ruido para las fricativas. La información publicada sobre disartria enfatiza en el estudio de las consonantes sordas. Las mediciones en el dominio del tiempo están más correlacionadas que las espectrales,. 16.
(20) Aunque no hay medidas que representen en pocos términos el ruido espectral. Algunos trabajos han utilizado los momentos estadísticos. Estos son: Prime r mome nto (media) Da el centro de gravedad para el ruido y parece ser sensible a mala articulación de fricativas. Segundo momento (desviación estándar) representa la distribución de energía alrededor de la media, una medida de los valores esparcidos alrededor de la media, su formula está dada por la siguiente ecuación:. Se calcula encontrando el promedio de la distancia de cada valor de la media. Tercer mome nto (skewness) describe la simetría de la distribución. Su fórmula es la siguiente:. La medida estadística skewness es cuantificada dividiendo el promedio elevado al cubo de las distancias por el cubo de lo la desviación estándar, valores mayores que cero indican skew positivas y menores que cero skew negativa Cuarto mome nto (kurtosis) está relacionado con la distribución de los picos de energía. Su fórmula es la siguiente:. Esta ecuación es casi la misma que la de skewness excepto que las distancias de la media están elevadas a la potencia de cuatro y el promedio de las distancias es dividida por la desviación estándar elevado a la cuarta potencia. En uno de los pocos estudios donde los momentos espectrales fueron aplicados en la disartria, [12] se compararon los espectros fricativos del habla de personas con ALS (Amyotrophic Lateral Sclerosis) con el habla de personas neurológicamente sanas. La diferencia en frecuencia para el primer momento fue correlacionada con evaluaciones perceptuales de la precisión de la consonante. Se demostró que el primer momento 17.
(21) (media espectral) es un índice útil de producción fricativa, particularmente cuando es combinado con la medida de la duración y la energía del segmento de ruido. La kurtosis se correlacionó con problemas articulatorios en varios grupos disártricos en [13] y [14]. La precisión de la producción de las consonantes oclusivas puede ser determinada en parte por medidas de energía durante la fase oclusiva. [15]. Algunos pacientes. disártricos tienden a producir energía durante el silencio. Esta energía tiene regularmente dos formas: ruido turbulento (espirantización) por oclusión incompleta y vocalización que ocurre debido a una pobre coordinación entre las funciones laríngeas y supralaríngeas.. 1.3.4 Función velofaríngea. Acústicamente se caracteriza por cambios en las frecuencias de los formantes, reducción en la amplitud de los formantes, incremento en el ancho de banda de los formantes, presencia de formantes nasales y antiformantes. [16] Estudios de nasalización se han utilizado las medidas de P0, la amplitud de un pico extra y en las bajas frecuencias; P1, la amplitud de un pico extra localizado entre el primer y el segundo formante y A1, la amplitud del primer formante. Los resultados fueron una diferencia de más de 10dB entre la producción de vocales normales y nasalizadas para las diferencias entre A1-P0 y A1-P1. Plante et al. (1993) [17] Demostró que los coeficientes LPC son sensibles a la presencia de nasalización en vocales pronunciadas por niños, si esta sensibilidad se demuestra en adultos sería una medida simple para el estudio de la función velofaríngea en disartria.. 1.3.5 Coordinación de la actividad laríngea y supralaríngea. El VOT (Voice Onset Time) se define como el intervalo entre la oclusión y el comienzo de energía periódica, el intervalo fisiológico entre la liberación de la constricción de la consonante y el comienzo de la vibración de las cuerdas vocales. Es el índice más usado para evaluar la coordinación entre estos subsistemas, aunque debe ser combinado con otras medidas para emitir un criterio, por ejemplo el LGD (laryngeal devoicing gesture) que está compuesto por Tiempo de Oclusión+VOT. Se ha demostrado que el intervalo de VOT cumple las siguientes condiciones: 18.
(22) VOT (/b d g/) <VOT (/p t k/) VOT (/b /) <VOT (/d/) < VOT (/g/) VOT (/p/) <VOT (/t/) < VOT (/k/) La información acústica relevante en la articulación de una plosiva puede estar relacionada con el contexto, el lugar donde ocurre la oclusión, bilabial, alveolar, velar, y la presencia o no de sonoridad. Las pistas relacionadas con el contexto para las plosivas incluyen la presencia de la región de silencio (región de obstrucción), las transiciones rápidas de formantes y particularmente un bajo emplazamiento en frecuencia para el primer formante, cambio rápido de energía, la explosión de liberación y la aspiración. Las pistas relacionadas con el lugar articulatorio incluye la frecuencia central de la explosión (o sea el mayor pico espectral de la turbulencia que ocurre en la liberación), la posición en frecuencia de las transiciones del segundo y tercer formante, el VOT, la presencia de aspiración, la presencia de una transición audible de F1, la intensidad de la explosión y la duración de la vocal precedente. [18] Se ha notado que el espectro de las oclusivas en la liberación aporta datos del lugar de articulación. Otros estudios además han examinado el segundo y tercer formante. Correlaciones acústicas para desórdenes de la fluidez:. Factores que influencian el VOT: Contenido a la izquierda y la derecha de la plosiva. La acentuación, el género, razón del habla, lenguaje y F0 de la vocal. El lenguaje Español tiene VOT negativos para las plosivas sonoras, mientras que en Inglés son mayormente positivos. Las mujeres producen mayores VOT en plosivas sordas y en los niños cambia ligeramente con la edad. Cuando la plosiva es seguida por la vocal /i/ el VOT es mayor que para la vocal /a/ [19]. Un incremento en la razón del habla causa un decremento del VOT para plosivas sordas. Las plosivas sordas producidas con altos valores de F0 producen VOT más cortos que con valores medios o bajos [20] y producen menores tiempos en habla fluida y lectura que en palabras.. 19.
(23) 1.3.6 Asociación de medidas acústicas con aspectos prosódicos y paralingüísticos. Kent et al, 1999 [8] sugiere explorar el área sobre la envolvente de la energía, duración de los sonidos y las pausas, fragmentación y variaciones espectrales, así como varias medidas sobre la frecuencia fundamental, para correlacionar con la prosodia. Las principales correlaciones acústicas son: la ruptura del patrón temporal, que afecta la envolvente de la energía, el contorno de F0 y las propiedades espectrales de las vocales y las consonantes. En disartria sus síntomas son: repetición de silabas o palabras, prolongación de sonidos, bloques de silencios o duda, múltiples oclusiones y liberaciones. La prosodia es el análisis de características suprasegmentales del habla en las que se encuentran: Entonación, tempo, acentuación, uniones y ritmo. Las mismas no pueden ser descritas dentro de un sonido, ellas abarcan de una sílaba a un segmento en el habla. Además se plantea que hallar un proceso sensible y eficiente ha sido un obstáculo dado que existe el problema de la selección del material ya que las características de prosodia difieren para lectura y conversación. El habla es más útil para detectar problemas en prosodia en pacientes disártricos; pero el problema con la conversación es la falta de control sobre propiedades de la pronunciación como longitud, estructura sintáctica y composición fonética. Las medidas que aparecen referenciadas en dicho artículo son análisis basado en consideraciones de unidades de tonos y regulaciones de F0. Donde se ha reportado que individuos con disartria severa tienen unidades cortas de tono y alta media de F0 con respecto a pacientes con disartria leve o individuos sanos. Por otra parte, pacientes con disartrias leves tienen menos variaciones de F0 que pacientes con disartria severa o grupos de control. Leuschel & Docherty (1996) [21] realizaron una aproximación estocástica multidimensional para estudiar prosodia en disartria. Para ello utilizaron las siguientes variables: Razón de articulación, duración media de la pausa, número de pausas, razón de tiempo articulación/pausa, longitud media de la alocución, duración media de la vocal no acentuada, porcentaje de vocales no acentuadas, intervalo de intensidad, envolvente de 20.
(24) intensidad, F0 medio, intervalo de F0, envolvente de F0 y la variación de F0 entre vocales. Para lectura y habla fluida, con mejor resultado en habla fluida. El SPIAP es un evento sobre prosodia en grupos atípicos, en los diferentes trabajos presentados se pueden encontrar un grupo de medidas reportadas para el estudio de la prosodia como son: Caracterización cuantitativa del pitch, Patrones de ruido, Juicio de expertos, Monitores en tiempo real de: rango de F0, núcleo, forma y foco del tono, organización rítmica; esta medida la utilizan como bio-realimentación para los pacientes con tratamiento; Análisis de conversación (con varios métodos como medidas sobre el pitch y la entonación.), Inteligencia artificial: Para predecir parámetros y observar cuanto se desvía el paciente de estos, Mediciones de ritmo y entonación, Longitud de la última sílaba, Duración de la expresión, Palabras por segundo, LTAS (long term average spectrum) y distribución de energía en bandas. Consideran el procesamiento matemático insuficiente para las medidas de prosodia en voces patológicas en gran parte por lo antes mencionado de que no existe una medida cuantitativa para la prosodia. La prosodia también ha sido estudiada con el fin de potenciar los sistemas de reconocimiento. LIU, 1996 [22] planteó que los sistemas de reconocimiento del locutor tienen dos características notables, la primera es escoger la unidad del habla, la cual puede ser las características distintivas. Estas describen el sonido de un lenguaje a nivel de segmento y tienen una relación con la acústica y la articulació n. Otra ventaja de las características distintivas es que son capaces de distinguir muchas de las variaciones contextuales en un segmento; que pueden ser estilos individuales del habla, asimilaciones y fronteras de palabras. Si las unidades fueran los fonemas se necesitaría un modelo aparte para cada modificación de los fonemas; creando una explosión en el número de unidades del habla necesarios para la detección. La segunda característica notable es el sistema de marcas, ellas son una guía para hallar los segmentos subyacentes, estas organizan las características distintivas en grupos. La detección de marcas es solo una manera de organizar la señal del habla. Las marcas definen regiones dentro de una expresión cuando sus correlaciones acústicas son más sobresalientes. Un oyente se concentra en las marcas para conseguir los datos necesarios para obtener pistas acústicas que descifran el mensaje. [23], [24]. Además las mismas permiten concentrarse en porciones relevantes de la señal en vez de tratar toda 21.
(25) la señal. Por otro lado son ligeramente independientes de factores temporales como la razón del habla y la duración de segmentos e incluyen en sí mismas información temporal útil para posteriores procesamientos. La mayor parte de las marcas son acústicamente abruptas, un estimado realizado sobre la base de datos TIMIT muestra que son aproximadamente el 68% del total de las marcas [25] en el habla. Las cuales están relacionadas con cierres y liberaciones.. 1.4 Consideraciones finales. Solo recientemente se ha considerado la prosodia como un problema de primera línea en el tratamiento, dado que históricamente los clínicos consideraban la prosodia como un asunto a tratar luego de haber remediado otros trastornos en la producción del habla [26]. En el procesamiento de señales se han utilizado tanto los algoritmos de procesamiento de señales conocidos, como los métodos heurísticos. La mayoría de los algoritmos utilizados son robustos, (LPC, CEPSTRUM, y las transformadas de HILBERT FOURIER, WAVELET). Ellos se desempeñan bastante bien aun cuando las condiciones en las cuales son aplicables no se cumplen exactamente. Los métodos heurísticos por otra parte involucran recetas ad hoc orientadas a un objetivo. Su limitación es que no se conocen los límites para su aplicación a priori, esto quiere decir que no se garantiza una solución y que cambios pequeños de la señal podrían producir cambios mayores en la salida [7]. A pesar de ello son popularmente utilizados en tareas tales como la estimación del ciclo glotal, la frecuencia instantánea del sonido de la voz, la estimación de los formantes y su ancho de banda [27]. En el presente trabajo se desea combinar ambos métodos teniendo en cuenta la gran variabilidad de la señal ya sea debido al carácter patológico de la misma, como al hecho de que se están tomando segmentos que incluyen las características suprasegmentales del habla. En DeBodt et al 2002 [28] se estableció la vinculación entre la articulación, la calidad vocal, nasalidad y la prosodia con la inteligibilidad en pacientes disártricos. También se estableció la posibilidad de expresar la inteligibilidad como una combinación lineal de las dimensiones mencionadas; podría pensarse que el contar con una medida acústica correlacionada con cada una de las dimensiones permitiría tener una medida indirecta de un parámetro tan complejo como la inteligibilidad. La dificultad en alcanzar este 22.
(26) objetivo es fundamentalmente la falta de especificidad de las medidas acústicas logradas. Por ejemplo medidas relacionadas con la calidad vocal o con la articulación se ven afectadas en su sensibilidad si el paciente además presenta nasalidad [29]. La búsqueda de una medida integral de inteligibilidad es un campo aun abierto a la investigación y dado que estas dimensiones inciden unas en las medidas de otras el presente trabajo busca reportar las afectaciones de forma global y para ello prepara las condiciones para aplicar métodos heurísticos a partir del empleo de la transformada de Fourier y la ubicación temporal de los cambios espectrales más notorios. Conclusiones del capítulo. Luego de una meticulosa búsqueda, que incluyó medidas y características de diferentes subsistemas del sistema fonador y patologías, queda demostrada la necesidad de una herramienta que analice el fenómeno del habla de manera global, para la realización de esta herramienta se considera que las marcas acústicamente abruptas ofrecen un punto de partida dado que son las más representativas y su validez ha sido probada en sistemas de reconocimiento del locutor. Debe destacarse que esas marcas se asocian a eventos que ya se han estudiado con relación a las disartrias como son la sonoridad, las consonantes oclusivas, la intensidad entre otras.. 23.
(27) II.. Capítulo II Materiales y Métodos.. Resumen: En el desarrollo de este capítulo se definen los materiales y métodos utilizados para la realización del presente trabajo. Se explica las características y composición de la muestra de pacientes, así como las distintas herramientas utilizadas. Se realiza una descripción del algoritmo seleccionado, además se llevan a cabo una serie de modificaciones del mismo y se describen las diferentes funciones implementadas para llegar a los resultados esperados.. 2.1 Algoritmo seleccionado. El procesamiento general del algoritmo de Liu [22], consiste en el cálculo de un espectrograma y su división en seis bandas de frecuencia y luego se realizan dos pasos de procesamiento (fino y grueso). En cada paso una forma de onda de energía es construida en cada una de las seis bandas, la derivada de la energía es calculada (ROR, rate of rise) y los picos de las derivadas son detectados. Estos picos representan la posición en el tiempo de cambios espectrales abruptos en cualquiera de las seis bandas. En el procesamiento tipo-específico, los picos localizados son analizados para encontrar tres tipos de marcas: glottis, sonorant, burst. En la Figura II.1 se representa el diagrama en bloques correspondiente.. 24.
(28) F IG URA II.1: Diag rama d e Bloq ues Del A lg o rit mo De Liu , 199 6.. Un espectrograma de banda ancha es calculado con una ventana de Hanning de 6ms cada 1ms. Cada trama de 6ms es rellenada con ceros hasta alcanzar 512 puntos. El espaciamiento entre lo puntos para la transformada discreta de Fourier es de 31.2 Hz para que las amplitudes de los picos espectrales puedan estar bien estimadas. Este espacio de 31.2 Hz entre los puntos se obtiene dividiendo la frecuencia de muestreo entre el número de puntos de la transformada. La alta tasa de segmentos permite que puedan ser monitoreados los cambios acústicos rápidos. Algunos cambios acústicos ocurren muy de prisa, particularmente los asociados con segmentos oclusivos. La pequeña ventana Hanning produce un espectro de banda ancha lo cual da amplia información espectral mientras los detalles armónicos son suprimidos. El espectrograma resultante es dividido en las siguientes bandas de frecuencia: Banda1: 0.0–0.4 kHz; banda2: 0.8–1.5 kHz; banda3: 1.2–2.0 kHz; banda4: 2.0–3.5 kHz; banda5: 3.5–5.0 kHz; banda6: 5.0–8.0 kHz. BANDA 1: Monitorea la presencia o ausencia de vibración glotal. No se extiende por encima de 400 Hz para reducir la oportunidad de recoger ráfagas de energía en las bajas frecuencias pertenecientes a las plosivas. En un cierre de consonantes oclusivas sonoras 25.
(29) o nasales, la energía en esta banda permanece fuerte porque la vibración glo tal es continua. Sin embargo las prominencias espectrales por encima de F1 muestran una marcada disminución en la energía por el incremento de pérdidas acústicas. BANDA 2-5: Cierres y liberaciones para consonantes sonoras. Aproximadamente en estas bandas se encuentran los intervalos de frecuencias para las prominencias espectrales de consonantes sonoras. Los inicios (onset) y los finales (offset) de los ruidos de aspiración y fricación asociados con: consonantes oclusivas, fricativas y africativas también son encontrados en estas bandas. La energía de ruido estará en, al menos, una de estas cuatro bandas. BANDA 2-3: Para segmentos de consonantes sonoras intervocálicas usualmente ocurre un cambio espectral notable en los intervalos de frecuencias de 0.8 a 2 kHz y estos cambios son a menudo debido a la introducción de un cero en la función de transferencia del tracto vocal en ese intervalo. En estas bandas no se garantiza el contenido de una prominencia espectral pero al menos una banda se espera que capture una prominencia espectral. BANDA 6: Esta banda se extiende a lo largo de las frecuencias restantes de 5 kHz hasta 8 kHz y es importante en la detección de silencios. Después del cálculo del espectrograma se buscan los cambios de energía en las seis bandas usando una estrategia de dos pasos. Ambos pasos utilizan el mismo procesamiento, en el caso del procesamiento grueso se realiza para suavizar características indeseadas como ruido o variaciones del pulso glotal con un promedio de 20 ms cada 1ms, el máximo es elegido para representar el valor centrado en el posterior procesamiento. Luego esta curva de energía es llevada a dB. Figura II.2.. amplitud(dB). Energia proc fino. Energia proc grueso. 350. 350. 300. 300. 250. 250. 200. 200. 150. 150. 100. 100. 50. 50. 0. 0. -50. -50 0. 500. 1000. 1500. 2000. 0. 500. 1000. 1500. 2000. tiempo(ms). F IG URA II.2 Gráficas De En erg ía De Los Proc esamien tos Fino Y Gru eso .. 26.
(30) A continuación se calcula el ROR que es la diferencia calculada cada 1ms con un paso de 50 ms, escogido para abarcar transiciones de energía de cierres y liberaciones abruptas. De el ROR se extraen picos con valores mayores que 9 dB y menores que -9 dB, [30] y basado en el conocimiento empírico. En el procesamiento fino se modifican los valores para encontrar los cambios de energía en el tiempo, en este caso se utiliza un suavizado de 10 ms, un paso de 26 ms en el ROR y se cambia el umbral 6 dB en la BANDA1, para tener en cuenta picos más pequeños debido a la reducción del paso (50 ms a 26 ms).. En la Figura II.3 se muestran los resultados obtenidos por Liu para la BANDA1 del espectrograma de la oración The money is coming today.. F IG URA II.3 Resu lt ados Para La Banda1 Según Liu .. Los picos del ROR obtenidos en ambos pasos continúan en el bloque de localización de picos. En él, los picos del paso grueso son utilizados como guía para encontrar los picos del ROR correspondientes al paso fino. Dentro de aproximadamente 30 ms de un pico grueso, el pico más grande en términos absolutos del paso fino es seleccionado como el pico localizado. Los picos localizados son las entradas de la etapa de procesamiento de marcas especificadas por tiempo. 2.1.1 Detector G (glottis). Una marca g define un tiempo de comienzo o fin de vibración de las cuerdas vocales. Los picos localizados en el ROR de la BANDA1 del procesamiento general son todos 27.
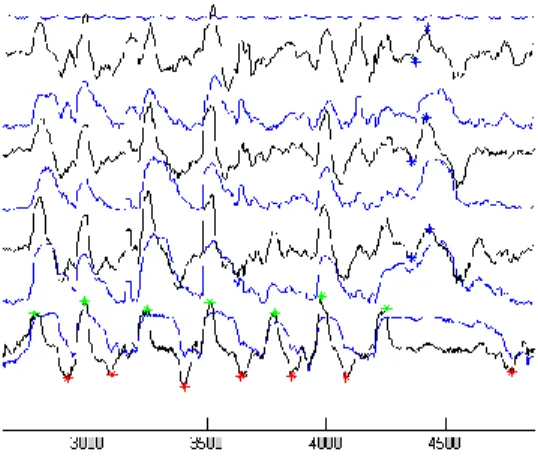
(31) inicialmente candidatos para marcas g. Estos candidatos deben pasar una serie de criterios. Un pico positivo indica el inicio de vibración glotal y un pico ne gativo indica la terminación de vibración glotal. Cuando la vibración glotal comienza debe terminar un tiempo después que debe ser como mínimo 20 ms, que es la duración mínima de una vocal promedio. Así cada pico positivo debería ser seguido por un pico negativo. Los picos son insertados donde sea necesario para satisfacer estas condiciones. El punto de inserción está guiado por la forma del contorno de la energía de la BANDA1 que se rige por un umbral de 20 dB de acuerdo con [31].. 2.1.2 Detector S (sonorant) Una marca s es causada por el cierre o liberación de una consonante nasal o líquida. Un s negativo designa un cierre y uno positivo designa una liberación. Como en el tracto vocal existe una constricción para consonantes sonoras, la energía en el rango de F2 a F4 disminuye y aumenta en una liberación. Si la constricción es lo suficientemente apretada y ocurre de forma rápida, entonces la energía cambiará rápida y simultáneamente en todas las bandas. Durante el intervalo de constricción, para una consonante nasal o líquida, un articulador primario ha hecho un cierre completo, las cuerdas vocales continúan vibrando y la forma del tracto vocal es relativamente constante. Por lo tanto el espectro debería permanecer relativamente estable especialmente en bajas frecuencias. Para encontrar marcas s, solo en regiones donde existe sonoridad, nos ubicamos en aquellas regiones que se encuentran entre un g positivo a la izquierda y un g negativo a la derecha. Dentro de una región sonora, son agrupados cualquier pico con el mismo signo en las bandas de la 2 a la 5. El pico absoluto más grande en cada grupo es el llamado pivot y es un candidato para una marca s. En Figura II.4 se muestra un ejemplo de los resultados alcanzados por el algoritmo de Liu para marcas sonorant.. 28.
(32) F IG URA II.4 Det ecció n De M arcas So no rant Seg ún El A lg o rit mo De Liu .. Generalmente consonantes sonoras oclusivas (e.g., [d, v]) son a menudo difíciles de detectar con el detector de marcas g porque en la energía de la banda1 no ocurren cambios suficientes. Ellos, sin embargo, usualmente muestran cambios de energía más claros en altas frecuencias. Si escapan del detector g, entonces pueden ser detectados por una variación del detector s. En esta variación los pivot son encontrados, sin embargo, la energía en las bajas frecuencias, en medio de un cierre y liberación, no debe estar en un estado estable por lo cual no clasifica como marca s.. 2.1.3 Detector B (burst) Una marca b positiva significa una africación o una ráfaga de fin de aspiración. Los correlativos acústicos para una marca b positiva son un intervalo de silencio seguido por un incremento bien definido de la energía en las altas frecuencias. A partir de que marcas b solo pueden ocurrir durante regiones sin vibración glotal, aquellas regiones delimitadas por un g negativo a la izquierda y un g positivo a la derecha son tomadas por este detector. Primeramente, opivots (para pivot de consonantes oclusivas sordas) son encontrados de una manera análoga a las consonantes sonoras. Después el silencio es medido alrededor de un opivot. Para un opivot positivo, un intervalo de silencio debe existir a la izquierda. Este período de silencio es medido con la energía de las bandas de la 3 a la 6, usando los niveles de energía en cada banda como referencia. Una marca b negativa señala la terminación de una fricación o ruido de aspiración. Los correlativos 29.
(33) acústicos para una marca b negativa son una disminución de energía en las altas frecuencias seguida por un intervalo de silencio. Este silencio es medido usando todas las bandas. En la Figura II.5 se muestra el resultado alcanzado por el detector BURST; las marcas b señaladas definen un intervalo de silencio encontrado en un segmento sordo enmarcado por las marcas g.. F IG URA II.5 Det ecció n De M arcas Bu rst Seg ún El A lgo rit mo De Liu .. 2.2 Modificaciones realizadas e implementación Con el propósito de adaptar el algoritmo para detectar marcas acústicamente abruptas en voces patológicas se realizaron una serie de modificaciones en el procesamiento general, los detectores propuestos y se incluyeron nuevos detectores. Para llevar a cabo esta tarea se utilizó información referenciada e información empírica recogida a lo largo del trabajo con pacientes disártricos. En el procesamiento general se cambió el paso utilizado para dividir las bandas con el fin de poder utilizar grabaciones con diferentes frecuencias de muestreo; esto se realizó modificando la fórmula original, convirtiendo la frecuencia de muestreo en una variable. 2-II-1. 30.
(34) Además la experiencia aportada por el uso del segmentador realizado por Pérez González (2008) [32] mostró que el procesamiento fino era demasiado sensible al ruido y las anomalías de las voces patológicas; por lo tanto en vez de realizar la búsqueda de las marcas con el procesamiento fino, se realizó con el grueso y sólo se cotejaron los resultados finales de los detectores. De esta manera se robusteció el algoritmo y se hizo más eficiente.. 2.2.1 Detector de segmentos con vibración de las cuerdas vocales. Detector g (glottis). Este detector se puede considerar la columna vertebral del resto del algoritmo, ya que los demás detectores utilizan las marcas g como entrada y de fallar este indudablemente fallarán los demás. Para comenzar se buscaron las prominencias en los ROR de la BANDA 1 de los procesamientos fino y grueso; en el primero se buscan las marcas cada 10 ms y con un valor modular mayor de 6 dB, para conseguir mayor precisión temporal, y en el segundo se buscan cada 40 ms para evitar picos espurios; y como modificación se utiliza el mismo umbral de 6 dB del procesamiento fino debido a la pobre variación en intensidad que presentan la mayoría de los casos analizados. El valor de 40 ms está basado en que la duración mínima de un par de marcas g debe ser 20ms y que un silencio o consonante sorda debe durar más que 20 ms por lo tanto un par de marcas del mismo signo deben estar contenidas en un intervalo igual o mayor a este. Utilizando las marcas del procesamiento grueso se comienza la búsqueda de los candidatos a marcas g pareando los picos positivos con los negativos de manera que el resultado sean las marcas más prominentes de ambos signos. A continuación se utilizan las marcas provenientes del procesamiento fino, y se busca en un intervalo de 35 ms antes y después de las marcas pareadas la más prominente, luego se continua la detección de las marcas g en el procesamiento fino apoyándose en dos criterios, tiempo y energía. Como antes se ha mencionado, un intervalo con menos de 20 ms debe ser descartado, lo que significa eliminar un par de marcas. Para concluir, los pares de marcas deben delimitar una región donde la energía de la BANDA 1 debe ser mayor o igual a 10 dB, valor que es menor que el valor propuesto 31.
(35) en el algoritmo original, y que fue seleccionado en este, debido a que uno de los síntomas de los pacientes disártricos es la falta de intensidad en la voz y en más de una ocasión se pudo comprobar que la locución de los pacientes no alcanzaba los 20dB (rojo en la Figura II.6). Sin embargo este valor de 10dB (verde en la Figura II.6) es suficiente para eliminar los pares de marcas introducidos por ruido de fondo o pequeñas aspiraciones.. F IG URA II.6 Oración 1 d el p árrafo d el ab uelo p ronu nciada po r u n p acient e co n Párkins on .. Los pares de marcas que rebasen todas las pruebas serán clasificados como marcas g. como se aprecia en la Figura II.7. La FIGURA II.8 resume en un diagrama de bloques el segmento del algoritmo explicado.. Par. de. marcas. eliminadas. por. tiempo. F igura II.7 ROR de lo s pro cesam iento s f ino ( der echa) y gr ueso con las marcas g en la or ación 1 p ron unciada por el do ctor g m ás (ver de) , g m eno s (ro jo).. 32.
(36) F igura II.8 Diagram a de blo ques del algo ritmo p ara el detector de mar cas g . 10ms 6dB. ROR FINO. ROR GRUESO. 40ms 6dB. Variables Parámetros. Parámetros. Detector de picos.. Marcas +. Marcas finas. Marcas gruesas. BANDA1. BANDA1. Marcas -. Par de marcas +y-. Marcas +. Marcas -. ±35ms. Cotejo. Cotejo. Par de marcas +yfinas. Pares de posibles marcas. ∆t>20m. Desechar par. s NO SI. E>10dB. Desechar par. NO SI. Marcas g+ y g-. 33.
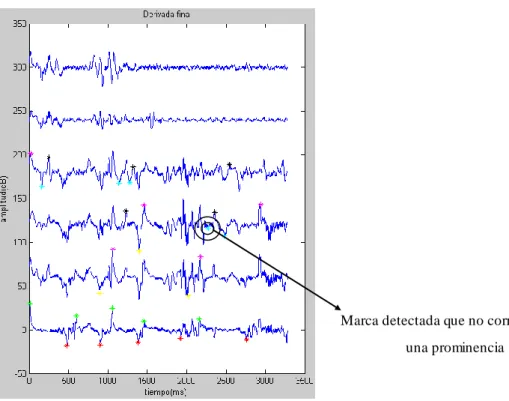
(37) 2.2.2 Detector de consonantes sonoras s (sonorant). Se comienza localizando la posición de las marcas g en el procesamiento grueso, por lo antes mencionado de que la detección es realizada en dicho procesamiento. Las bandas seleccionadas para buscar las prominencias se reducen a la BANDA 4, la BANDA 3 y la BANDA 2 porque para muchos pacientes disártricos la energía en las bandas 5 y 6 es tan pobre que no causa prominencias útiles para la detección; este hecho no afecta el proceso, dado que este algoritmo busca un cero producido en los formantes de F2 a F4 que quedan perfectamente cubiertos por estas tres bandas. A pesar de reducir las bandas debido a los problemas de intensidad encontrados en los pacientes, aún persiste otro problema que son los cierres y liberaciones que en ocasiones son tan débiles que no causan prominencias detectables. De ocurrir en un caso (cierre o liberación) en la misma consonante todavía dejaría una pista detectable; pero de ocurrir en los dos casos causaría un error en la detección. Para suavizar esta situación se organizan todas las marcas por bandas, uniendo las positivas y las negativas, teniendo en cuenta solo el tiempo. Luego se toman las marcas de la BANDA 4 que son las más notables en este caso y se busca meticulosamente su “pareja”, que sería positiva de ser negativo y viceversa. Figura II.9 se muestra el proceso, donde se observan las marcas s siendo las s menos representadas por * azul y s más * negro.. Marca detectada que no corresponde a una prominencia. Figura II.9 Oración 1 paciente 3 de ATF ().. 34.
(38) Esta búsqueda tiene en cuenta la posición del pico con respecto a las marcas g donde está contenido (por ser un detector de consonantes sonoras debe estar entre un g más y un g menos), además del signo y la posición del pico siguiente o anterior. Dicho de otra manera, las consonantes sonoras comienzan con un pico negativo y terminan con uno positivo; por lo tanto si se toma un pico negativo, se comprueba que esté a más de 25 ms de la marca g más para que no se confunda con algún fenómeno relacionado con una plosiva sonora o sonorizada; luego se verifica en qué posición está la marca siguiente, de estar a más de 120 ms no se tiene en cuenta a la hora de buscar la posible marca positiva y de encontrarse a menos de 25 ms, (que es el tiempo mínimo estipulado como promedio para una consonante nasal [11], se descarta la primera marca y se analiza la siguiente; de otra manera se verifica el signo, si es positivo, se toma como la marca positiva buscada y si es negativo debe encontrarse a 45 ms o más, que es el espacio mínimo necesario para la existencia de vocal y otra consonante. Finalmente, se toma la mayor prominencia encontrada para completar el par necesario. Los pares de marcas hallados pasan una prueba de estabilidad que consiste en que el rango dinámico de la energía en la BANDA 1 no debe ser mayor que 5.5 dB, lo cual es una modificación del algoritmo de Liu, ya que se incrementó el rango dinámico debido a las características encontradas en los pacientes que no mantienen una estabilidad en la curva de energía de la BANDA 1. Los pares preclasificados se utilizan para buscar prominencias correspondientes a la consonante en las bandas dos y tres, lo cual se realiza en un intervalo de 35 ms antes y después de la marca encontrada en la BANDA 4 para evitar detectar una prominencia correspondiente a otro fenómeno articulatorio. De no encontrarse, el par de marcas sería desahuciado. Una vez encontrada las marcas en todas las bandas se pasa a su ubicación en el procesamiento fino mediante un cotejo por bandas, cada marca busca su semejante en un rango de 35 ms antes y después, teniendo en cuenta la posición de las otras marcas incluyendo las marcas g donde están contenidas. Figura II.10. 35.
(39) Figura II.10 Procesamiento grueso con los candidatos a marcas s (*azu les). Oración 1 Párkinson 2.. De las marcas posicionadas en el procesamiento fino, se busca la mayor y la menor de todas, y serán finalmente las marcas sonorant positivas y negativas (s más y s menos). Este último paso se realiza con propósitos de detección del tipo de consonante. Figura II.11 y FIGURA II.12. Figura II.11 Marcas s-(cian) y s+ (negro) colocadas en el procesamiento fino.. 36.
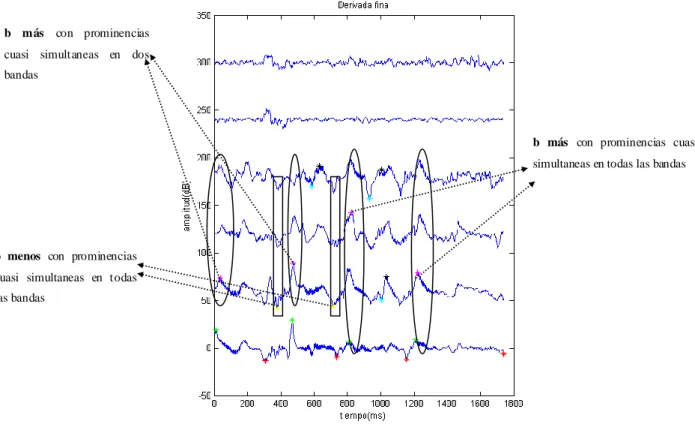
(40) F igura II.12 Marcas S-(Cian ) Y S+ (A zu l) Co lo cad as En El Es p ect ro .. 2.2.3 Detector de marcas b (burst) plosivas. Este detector a diferencia de los anteriores busca las marcas por separado, es decir, no necesita crear pares de marcas positivas y negativas. En este caso las marcas positivas pertenecen a plosivas en inicio de palabra o sílaba y las negativas a ruido en fin de pronunciación asociado con fricativas u oclusivas al final de una palabra. Las principales modificaciones con respecto al detector original consisten en: Asumir que la explosión no causa prominencias simultáneas, ni que necesariamente deben estar presente las mismas en todas las bandas. Aumentar el espectro de búsqueda un poco más allá de las marcas g más y g menos que delimitan el segmento de interés para el algoritmo original, esta última modificación se debe a que muchas veces estas consonantes plosivas son sonorizadas por los pacientes. Además no se tiene en cuenta el silencio alrededor de la marca b ya que puede ocurrir un ruido durante la fase oclusiva debido a la características de las patologías analizadas. Por lo tanto el silencio se mide de forma independiente como una herramienta de diagnóstico. Para detectar las marcas b se comienza organizando todos los segmentos que se encuentran entre una marca g menos y g más. Se rastrean las prominencias desde la BANDA 2 hasta la BANDA 5, tanto positivas como negativas, se toman las mayores modularmente, teniendo en cuenta que las negativas ocurren antes que las positivas y que las marcas deben ser cuasi simultáneas. 37.
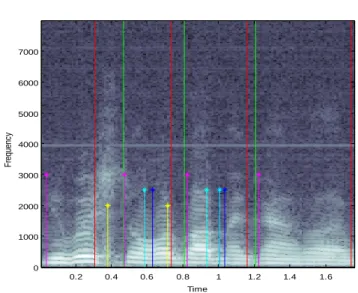
(41) Debido a que las prominencias no siempre ocurren en todas las bandas se toma como un candidato a marca las cuartetas (conjunto de cuatro marcas asociadas a un mismo fenómeno ubicadas en el rango de bandas antes mencionado) que contengan dos o más prominencias en el caso de las positivas y tres o más en el caso de las negativas, el resto queda descartado. En la Figura II.13 se muestran las marcas b menos (amarillas) y b más (magenta). Luego se haya la mayor prominencia de cada cuartetas de marcas y se pasan al procesamiento fino ubicando la marca “fina” dentro de una ventana de 70 ms centrada en la marca b “gruesa”, se busca la mayor prominencia, siempre respetando la frontera de 25 ms después de g más para b más y 25 ms antes de una g menos para b menos. En la Figura II.13 se muestra el Espectrograma de la oración presente en Figura II.14. b más con prominencias cuasi simultaneas en dos bandas. b más con prominencias cuasi simultaneas en todas las bandas. b menos con prominencias cuasi simultaneas en todas las bandas. Figura II.13 Oración 1 paciente AT7M. 38.
(42) 7000. 6000. Frequency. 5000. 4000. 3000. 2000. 1000. 0 0.2. 0.4. 0.6. 0.8. 1. 1.2. 1.4. 1.6. Time. Figura II.14 Espectrograma de la Oración 1 paciente AT7M. 2.2.4 Estimador de el VOT (Voice Onset Time). Dado el concepto de VOT, que es el tiempo que transcurre entre la explosión de la consonante y el comienzo de la vibración de las cuerdas vocales; con los datos adquiridos se puede calcular un estimado de esta variable mediante la fórmula: II-2 Este valor de resultar positivo y, en el caso de pacientes sanos mayor que 20 ms clasifica a la consonante como sorda, de ser negativo la clasifica inmediatamente como sonora, brindando de esta manera un dato adicional para el diagnóstico. 2.2.5 Estimador del tiempo de locución. Esta rutina calcula la posición de la primera y última marca detectada, la diferencia entre estas, que se considera el tiempo de locución. La primera marca podría ser un comienzo de vibración de las cuerdas vocales o una plosiva y la última marca puede resultar un fin de vibración de las cuerdas vocales o una marca b menos. Con la ayuda del valor calculado, se puede estimar la razón del habla de los pacientes dado que el texto utilizado es fijo.. 39.
(43) 2.2.6 Detector de intervalos silencio. El propósito de calcular los silencios se debe a la importancia que se le confiere a estos en medidas reportadas de prosodia y de articulación como es la ausencia de un intervalo de silencio antes de una oclusión, como se explicó en el Capítulo I. Una vez conocida las posiciones en el tiempo de las marcas b y g se localizan los intervalos donde se puede encontrar segmentos sordos, útiles para realizar posteriores medidas. Primero se calcula la energía total del procesamiento fino y se colocan todas las marcas que delimitan los posibles segmentos de silencio. Estas se componen de marcas b y g FIGURA II.15 (en negro las marcas b y g según corresponda).. 30 25 20 15 10 5 0 -5 -10 -15 -20 1000. 2000. 3000. 4000. 5000. 6000. F igura II.15 Oración 3 Pacien te FD3M. Para determinar los valores umbrales de energía requeridos para detectar los intervalos de silencio, es necesario estimar cuál de los intervalos es totalmente sordo o aproximadamente sordo, de manera que el valor medio de la energía por bandas sea semejante a la energía de fondo de la grabación en proceso. Para esto se calcula el valor medio de la energía de todos los segmentos delimitados anteriormente, y a este vector se le halla la mediana. La mediana es una medida resistente a ruidos impulsivos como los que pueden aparecer durante el silencio en una grabación y a valores extremadamente bajos que se encuentran en inicio y fin de la oración. Se busca el segmento que corresponde a la 40.
(44) mediana y este servirá como patrón de silencio. De él se tomarán los valores medios de energía y su desviación estándar de las bandas uno a la cuatro, que han sido las más representativas a lo largo del estudio de la muestra de pacientes. Si se suman los valores medios y las desviaciones estándar de la energía por bandas, se aumenta la sensibilidad del umbral, sin disminuir notablemente su especificidad, debido a que de esta manera se abarca más del 80% de los valores estimados. Con los valores calculados se procede a recorrer todos los posibles segmentos de silencio con un paso de 10 ms y de ser el valor medio de la energía de estos intervalos mayor que el umbral se descartan como un silencio, de lo contrario se añade a un intervalo de silencio o se comienza uno nuevo. En la Figura II.16 se muestra el Espectrograma de la Oración 2 de un paciente con Ataxia, los asteriscos verdes y rojos son inicio y fin de intervalos de silencios, las líneas verdes y rojas marcan el inicio y fin de sonoridad.. 7000. 6000. Frequency. 5000. 4000. 3000. 2000. 1000. 0 1. 2. 3. 4. 5. 6. Time. Figura II.16 Espectrograma de la Oración 2 del Paciente AT3F. 41.
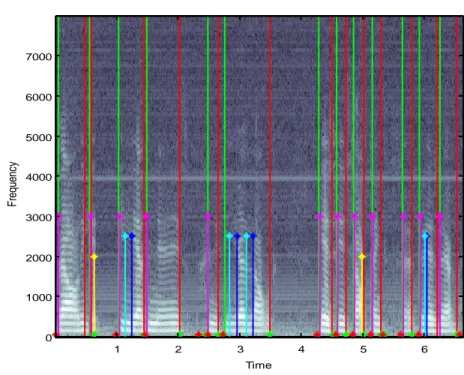
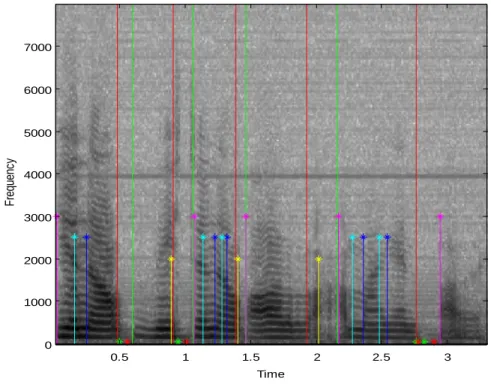
(45) 2.3 Materiales y métodos. El experimento que se reporta está motivado por la inquietud: ¿Es posible tener medidas acústicas simultáneas que se relacionen con diferentes dimensiones del fenómeno del habla y puedan expresar la afectación que presenta la inteligibilidad del paciente? Este tema puede ser objeto de un proyecto con un tiempo mayor a la duración de una tesis de grado, luego el presente trabajo se concentra en la detección de marcas en el tiempo de los fenómenos espectrales trascendentes en una oración. Estas se orientan para que sirvan de base a las medidas deseadas, que como se ha dicho con anterioridad, buscan reflejar la inteligibilidad sin particularizar en cada uno de los subsistemas y la interacción entre los mismos. En otras palabras se detectan efectos simultáneos de calidad vocal, articulación, nasalidad y prosodia, sobre la base de cómo deterioran la señal acústica. La pregunta que aquí se responde es la siguiente: ¿Puede el algoritmo de Liu ser modificado y aplicado a voces patológicas para reportar la ocurrencia de marcas acústicamente abruptas? Para responder esta pregunta científica se seleccionaron los siguientes materiales: Se escogieron 18 pacientes y un individuo sano como referencia de la base de datos de las clínicas Mayo [2]. Estos pacientes se seleccionaron de modo que presentaran desviaciones en las dimensiones subjetivas evaluadas por De Bodt et al, 2002 [28], calidad vocal, articulación, nasalidad y prosodia, y como consecuencia en la inteligibilidad. Al mismo tiempo representan varios grupos disártricos como se aprecia en la Tabla II-1. Sus edades están entre 20 y 70 años aproximadamente.. 42.
(46) Tabla II-1 DISTRIBUCIÓN DE PACIENTES POR SEXO Y GRUPOS DISÁ RTRICOS.. Grupos Disártricos. Pacientes Masculino. Femenino. Total. Atáxicos. 2. 1. 3. Flácidos. 1. 2. 3. Corea. 0. 3. 3. Parkinson. 3. 0. 3. Espástica. 1. 2. 3. Temb lor Orgánico. 0. 3. 3. Control. 1. 0. 1. El programa ECAH fue utilizado para la selección de la muestra de pacientes, atendiendo a que fueran los casos con mayor grado de dificultad para someter el algoritmo propuesto a las situaciones más extremas. El Matlab 7.2 R2006a sobre sistema operativo Windows fue la plataforma sobre la que se desarrolló el algoritmo propuesto en el epígrafe 2.2 Modificaciones realizadas e implementacióny se realizaron las corridas de datos correspondientes al experimento. 2.3.1 El experimento. En la base de datos aparece un párrafo leído por cada paciente (Grandfather Passage), del mismo se seleccionan las tres primeras oraciones: La primera es una interrogación, lo cual facilitará emitir algunos criterios sobre la prosodia, al igual que en la segunda, en la cual aparece una pausa, y en la tercera aparecen además; varias oclusivas sordas, fricativas y múltiples silencios entre palabras que en su totalidad permite n coleccionar elementos sobre la prosodia, la articulación y la calidad vocal. Como se ha mencionado a cada párrafo se le extraen tres oraciones, y se procesan de forma independiente por el algoritmo propuesto en el epígrafe 2.2 Modificaciones realizadas e implementación. 43.
Figure
+3
Documento similar
Las personas solicitantes deberán incluir en la solicitud a un investigador tutor, que deberá formar parte de un grupo de investigación. Se entiende por investigador tutor la
Tal y como se hace constar en el artículo 29 del Real Decreto 412/2014, las solicitudes de plazas de estudiantes con estudios universitarios oficiales españoles parciales que deseen
de se convertir en chaux par la calcination- L a formation de ces pierres nous paroît due, en grande partie , au détritus des coquillages : Tidentité des
Lo más característico es la aparición de feldespatos alcalinos y alcalino térreos de tamaño centimétrico y cristales alotriomorfos de cuarzo, a menudo en agregados policristalinos,
La solución que se ha planteado, es que el paso o bien se hiciese exclusivamente por el adarve de la muralla, o que una escalera diese acceso por la RM evitando la estancia (De
Imparte docencia en el Grado en Historia del Arte (Universidad de Málaga) en las asignaturas: Poéticas del arte español de los siglos XX y XXI, Picasso y el arte español del
Que en la reumon de la Comisión de Gestión Interna, Delegada del Consejo Social, celebrada el día 17 de marzo de 2011 , con quórum bastante para deliberar y
Cuando trabaje en una tabla, haga clic donde desee agregar una fila o columna y, a continuación, haga clic en el signo más.La lectura es más fácil, también, en la nueva vista
