Integración de herramientas de ayuda al diseño de bases de datos en ambientes distribuidos
64
0
0
Texto completo
(2) “Es preciso conocer el fin hacia el que debemos dirigir nuestras acciones. En cuanto conozcamos la esencia de todas las cosas, habremos alcanzado el estado de perfección que nos habíamos propuesto.” Confucio.
(3) Dedicatoria. A mis padres y a mi hermano pues sin su presencia nada de esto hubiera sido posible..
(4) Agradecimientos A mi familia: Mi papá, mi mamá y mi hermano. por su apoyo, cariño y confianza, por la. orientación que siempre me han dado, por su amor. A mi tutor, Abel por sus consejos y enseñanzas, por darme la ayuda profesional que necesitaba y brindarme parte de su tiempo. A Dayli y Lyanet por apoyarme durante todo este trabajo. A todos mis compañeros de estudio por compartir grandes momentos durante estos años. A todos aquellos que al término de esta etapa de mi vida han brindado su ayuda, apoyo y comprensión para lograr cumplir este ansiado sueño. Muchas Gracias..
(5) Resumen Captar toda la información que se requiere para diseñar una base de datos distribuida es una tarea difícil que requiere tiempo, experiencia y esfuerzo. Lo cual se facilita con el uso de una herramienta de ayuda al diseño de base de datos distribuida, capaz mantener la gran cantidad de información estructurada referente a los datos, las aplicaciones que corresponden a los casos de uso o solicitudes, los sitios donde residirán los datos y el procesamiento de las solicitudes; también sobre la red que soporta la conexión entre sitios y el intercambio de datos entre estos. Como resultado de este trabajo se obtuvo una nueva versión de la herramienta de ayuda al diseño de base de datos distribuidas (SIADBDD) constituida por las herramientas: ERECASE que sistematiza resolución de problemas de modelación de esquemas conceptuales globales, NETWIZARD que capta la información necesaria para la caracterización de la red y los sitios de procesamiento, APPWIZARD que captura información sobre las aplicaciones del universo de discurso, FRAGMENTER que realiza la fragmentación de esquemas globales en esquemas lógicos, y ALLOCATOR que lleva acabo la asignación lógica y física de los fragmentos a los correspondientes sitios de procesamiento. Además, se creó un sistema de ayudas para SIADBDD y un instalador personalizable con dos opciones excluyentes permitiendo instalar SIADBDD para diseñar BDD o solamente ERECASE para diseñar BD centralizadas..
(6) Abstract To capture all information needed to design a distributed database is a difficult task that requires time, effort and experience. This is facilitated by the use of a tool that aids the design of a distributed database and is capable of maintaining large amounts of structured information concerning data, the applications that correspond to use cases or requests, the sites where the data will reside and the processing of such requests; also the network that supports the connection between sites and data exchange between them. As a result of this work, a new version of the tool to help the design of distributed database (SIADBDD) was presented, it is composed of tools like: ERECASE that systematize modeling problem solving global conceptual schema, NETWIZARD that captures the information needed for characterization of the network and processing sites, APPWIZARD that captures information about the applications of the universe of discourse, FRAGMENTER that performs the fragmentation of global logical schema diagrams and ALLOCATOR that performs the logical and physical mapping of the fragments to corresponding processing sites. Additionally, a support system for SIADBDD and an installer customizable with two mutually exclusive options to install SIADBDD to design BDD or ERECASE to design centralized BD was created..
(7) Tabla de Contenidos INTRODUCCIÓN .................................................................................................................... 1 CAPÍTULO. 1. GENERALIDADES. DEL. DISEÑO. DE. BASES. DE. DATOS. DISTRIBUIDAS ....................................................................................................................... 4 1.1 ACERCA DEL DISEÑO DE BASES DE DATOS DISTRIBUIDAS ................................................... 4 1.2 MODELACIÓN CONCEPTUAL ............................................................................................... 5 1.2.1 Caracterización del esquema conceptual................................................................... 5 1.2.2 Caracterización de las aplicaciones .......................................................................... 7 1.2.3 Caracterización de los sitios de procesamiento ......................................................... 7 1.2.4 Caracterización de la red de comunicación............................................................... 8 1.3 MODELACIÓN LÓGICA ........................................................................................................ 9 1.3.1 Fragmentación de esquemas ...................................................................................... 9 1.3.2 Asignación de fragmentos ........................................................................................ 11 1.4 MODELACIÓN FÍSICA ........................................................................................................ 13 1.5 CONSIDERACIONES FINALES ............................................................................................. 14 CAPÍTULO. 2. REVISIÓN. DE LAS. HERRAMIENTAS. DE AYUDA A LA. MODELACIÓN DE BASES DE DATOS DISTRIBUIDAS .............................................. 16 2.1 DIAGRAMA DE CASOS DE USO ........................................................................................... 16 2.2 DISEÑO DE CLASES ........................................................................................................... 17 2.3 ARQUITECTURA DE LAS HERRAMIENTAS DE AYUDA AL DISEÑO DE BDD ......................... 18 2.3.1 Nivel conceptual ....................................................................................................... 20 2.3.2 Nivel lógico............................................................................................................... 23 2.3.3 Nivel Físico............................................................................................................... 24 2.4 CATÁLOGO DEL DISEÑO ................................................................................................... 25 2.5 CONCLUSIONES PARCIALES .............................................................................................. 26 CAPÍTULO 3 MANTENIMIENTO A LAS HERRAMIENTAS DE AYUDA AL DISEÑO DE BASES DE DATOS DISTRIBUIDAS............................................................ 27 3.1 PREPARACIÓN DEL MANTENIMIENTO ................................................................................ 27 3.2 CREACIÓN Y PERSONALIZACIÓN DE LA INSTALACIÓN DE LAS HERRAMIENTAS ................. 29 3.2.1 Creación del instalador ............................................................................................ 32 3.2.2 Personalización del instalador ................................................................................. 34 3.2.3 Configuración de la interfaz del instalador. ............................................................ 35 3.2.4 Requerimientos técnicos del instalador.................................................................... 37.
(8) 3.3 DOCUM ENTACIÓN PARA EL USUARIO DE SIADBDD ........................................................ 38 CONCLUSIONES PARCIALES .................................................................................................... 45 CONCLUSIONES .................................................................................................................. 46 REFERENCIAS BIBLIOGRÁFICAS.................................................................................. 48.
(9) Introducción. Introducción. Los sistemas de bases de datos distribuidas (SBDD) permiten compartir los datos, ofrecen mayor fiabilidad y disponibilidad, y agilizan el procesamiento de las consultas. Por otra parte, su desarrollo es más costoso, existe mayor posibilidad de errores y se incurre en costos extras de procesamiento. Los beneficios de la modelación conceptual son ampliamente reconocidos como una ayuda para mejorar la comprensión de un universo de discurso; con el desarrollo de la tecnología y la información, dicho universo de discurso puede corresponderse con un área concreta de la realidad o puede tener un alcance global para reflejar la estructura de alguna entidad más compleja desde una perspectiva integrada. La modelación de datos convencional centra sus esfuerzos en aspectos estáticos de la realidad; no obstante, para entornos distribuidos en que los. requerimientos. interacciones. de. datos pueden responder a necesidades departamentales con. complejas. es. necesario. tener. en. cuenta. requerimientos. estructurales,. operacionales e incluso de ubicación física, como un medio para una modelación más completa de esa realidad. Los primeros modelos para describir una base de datos distribuida (BDD) fueron presentados en la década de 1970; aunque un verdadero intento de formalización del problema de distribución de datos se reporta en la década de 1980 con los trabajos de Stefano Ceri y colaboradores (Ceri et al., 1982a, Ceri et al., 1983, Ceri et al., 1982b, Ceri and Pelagatti, 1984, Ceri and Pernici, 1985, Ceri et al., 1987), en que se caracteriza el problema y se brindan soluciones mediante complejos modelos matemáticos que constituyen el núcleo de los desarrollos posteriores en el área de las BDD. A pesar del indudable valor de dichos modelos, la mayoría tenían una complejidad inherentemente exponencial y no presentaban un enfoque integrador,. pues. el. propósito. inicial. no. estaba. dirigido. hacia. su. implementación. computacional (Őzsu and Valduriez, 1999). Tanto para bases de datos (BD) centralizadas como distribuidas, había una gran dispersión de enfoques, extensiones, consideraciones parciales, notaciones, construcciones; que en la medida que buscan mayor riqueza semántica en la modelación de datos y soluciones a fases aisladas de este proceso, hacían difícil su comprensión y sobre todo, su incorporación a herramientas de ayuda al proceso del diseño de una BD.. 1.
(10) Introducción. Como antecedentes de este trabajo se tiene que en el Laboratorio de Bases de Datos del Centro de Estudios de Informática de la Universidad Central “Marta Abreu” de Las Villas se desarrollaron herramientas de ayuda al diseño de bases de datos distribuidas que poseen un determinado nivel de integración entre ellas a través del Sistema Integrado de Ayuda al Diseño de Bases de Datos Distribuidas(SIADBDD)(Rodríguez, 2007). Desde el punto de vista metodológico se enfocan los resultados siguiendo los tres niveles de modelación de la arquitectura de referencia para las bases de datos: conceptual, lógico y físico. Este sistema está formado por las herramientas que se listan a continuación cuyo nombre aparece en letras mayúsculas sostenidas. ERECASE ayuda a la caracterización del esquema conceptual global; APPWIZARD se encarga de la caracterización de las aplicaciones; NETWIZARD recopila información sobre la red de comunicación y los sitios de procesamiento donde residirá la BDD objeto de diseño; FRAGMENTER realiza la fragmentación y ALLOCATOR obtiene tanto la ubicación de los fragmentos a nivel lógico como su correspondiente creación a nivel físico. Posterior a la creación de SIADBDD se obtuvo una nueva versión de ALLOCATOR que no se encuentra debidamente integrada. Algunas características de la versión obtenida de este sistema deben ser perfeccionadas. Concretamente, el problema a resolver en este trabajo consiste en dar mantenimiento a SIADBDD lo que supone: •. Concentrar los accesos al catálogo que mejore la gestión de los accesos al mismo.. •. Permitir la personalización de la instalación de las herramientas individualmente.. •. Disponer de ayuda para llevar a cabo flujos de trabajo de diseño.. •. Obtener informes individualizados sobre el avance en los proyectos de diseño.. En correspondencia con el problema planteado anteriormente y derivado de la construcción del marco teórico–referencial de esta tesis, se tienen las siguientes preguntas de investigación: •. ¿Qué elementos de las herramientas individuales obtenidas deben ser mantenidas para que sea posible integrarlas armónicamente en una nueva versión de SIADBDD?. •. ¿Cómo lograr la creación de instaladores personalizables en un ambiente de integración de herramientas?. El objetivo general de esta tesis consiste en crear una aplicación que integre armónicamente las herramientas de ayuda al diseño de BDD obtenidas en el Laboratorio de Bases de Datos y erradique las dificultades identificadas en la versión anterior de SIADBDD. Para lograr este objetivo general se plantean los siguientes objetivos específicos: 2.
(11) Introducción. •. Modificar la forma de activación de las herramientas que componen SIADBDD de modo que se les puedan indicar los datos relevantes del proyecto en curso y la ubicación física del mismo.. •. Homogeneizar los accesos de las diferentes herramientas al catálogo y proveer un catálogo en blanco con las nuevas características para el inicio de cada proyecto de diseño.. •. Integrar la última versión de la herramienta ALLOCATOR a SIADBDD.. •. Eliminar los errores presentes en los reportes emitidos por SIADBDD.. •. Elaborar el sistema de ayudas como manual de usuario para las herramientas que componen SIADBDD y así asistir a los diseñadores al llevar a cabo flujo de trabajos de diseño.. •. Crear una aplicación de instalación personalizable con dos opciones excluyentes permitiendo instalar SIADBDD para diseñar BDD o solamente ERECASE para diseñar BD centralizadas.. Relacionado con los antecedentes antes planteados, se puede decir que este estudio se justifica por su importancia desde el punto de vista práctico que tendrán los resultados esperados en una nueva versión de herramienta de ayuda al diseño de BDD. Además, en el laboratorio de Bases de Datos existen posibilidades de realización de esta investigación porque se cuenta con recursos materiales para ello, expertos para la consulta y oportunidades de utilización de los resultados en proyectos reales de diseño.. 3.
(12) Capítulo 1. Generalidades del diseño de Bases de Datos Distribuidas. Capítulo 1 Generalidades del diseño de Bases de Datos Distribuidas. En el diseño de BDD se debe considerar el problema de cómo distribuir los datos entre los diferentes sitios de procesamiento. Existen razones organizacionales las cuales determinan en gran medida lo anterior. Sin embargo, cuando se busca eficiencia en el acceso a la información, se deben abordar dos problemas relacionados. Primero, cómo fragmentar los datos. Segundo, cómo asignar cada fragmento entre los diferentes sitios de la red. En el diseño de BDD también es importante considerar si la información está replicada, es decir, si existen copias múltiples del mismo dato y, en este caso, cómo mantener la consistencia de los mismos. Finalmente, una parte importante en el diseño de una BDD se refiere al manejo del directorio. Si existen únicamente usuarios globales, se debe manejar un solo directorio global, sin embargo, si existen también usuarios locales, el directorio combina información local con información global. En este Capítulo se tratan aspectos generales relacionados con el diseño de BDD que sirven de marco teórico referencial a este trabajo. 1.1 Acerca del diseño de bases de datos distribuidas A la hora de abordar el problema de diseño de BDD existen dos enfoques básicos, el enfoque descendente (top-down) y el ascendente (bottom-up). El primero es más apropiado para aplicaciones nuevas y para sistemas homogéneos y consiste en partir desde el análisis de requerimientos para definir el diseño conceptual y las vistas de usuario. A partir de ellas se define un esquema conceptual global y los esquemas externos necesarios. Se prosigue con el diseño de la fragmentación de la BD, y de aquí se continúa con la localización de los fragmentos en los sitios, creando las imágenes físicas. Esta aproximación se completa ejecutando, en cada sitio, el diseño físico de los datos que se localizan en este. El segundo enfoque se utiliza específicamente cuando se parte de BD existentes para obtener BDD integradas. En forma resumida este diseño ascendente de BDD requiere de la selección de un modelo de bases de datos común para describir el esquema global de la base de datos. La tarea de lograr todas las funcionalidades en los SBDD tiene una alta complejidad, pero encontrar soluciones óptimas es aún más complejo. Considerar el diseño de la distribución de SBDD, decidir cómo fragmentar y distribuir los datos sobre los diferentes sitios y cuáles de estos datos deben ser replicados son grandes retos que existen. Desde el punto de vista metodológico se enfocan los aspectos teóricos siguiendo los tres niveles de modelación de la arquitectura de referencia para las bases de datos: conceptual, lógico y físico. 4.
(13) Capítulo 1. Generalidades del diseño de Bases de Datos Distribuidas. 1.2 Modelación conceptual La modelación conceptual (Nelson et al., 2001, Oaks et al., 2003, Olivé, 2002, Olivé, 2004, Poels, 2003, Poels et al., 2002) es el proceso de creación de representaciones abstractas de un dominio de aplicación en términos de conceptos familiares a los actores de ese dominio y no en términos técnicos. Esta requiere de notaciones, herramientas y técnicas para representar procesos e información. En la modelación conceptual el usuario necesita especificar información sobre los datos, las aplicaciones, la red de comunicación y los sitios de procesamiento donde residirá la BDD. Obtener o estimar toda la información requiere de esfuerzo y experiencia. El modelo Entidad-Relación (ER) (Chen, 1976) es un modelo semántico de datos ampliamente aceptado para el diseño del Esquema Conceptual Global (ECG). El modelo ER extendido (ERE) usa los conceptos de entidad, propiedad, interrelación y subtipo para incorporar información semántica importante acerca del mundo real (Elmasri and Navathe, 2004, Salter, 2001, Silberschatz et al., 2006, Teorey et al., 1986). Este modelo ha trascendido como la técnica de modelación conceptual reconocida como ayuda al diseño de BD relacionales. Cualquier herramienta de ayuda a la caracterización del ECG que se integre al proceso de diseño de BDD debe ofrecer una amplia variedad de construcciones del modelo ERE de forma que se facilite el diseño de la distribución, y se realicen validaciones a los diagramas para obtener esquemas correctos. Existen varias herramientas comerciales para la creación de diagramas ERE pero no capturan información adicional requerida para el diseño de BDD. En la bibliografía consultada se emplea el modelo ERE para la caracterización del ECG (Schewe, 2001, Teorey, 1989, van Bommel, 1995), al que se le añaden determinados parámetros sobre las aplicaciones globales para realizar el diseño de la distribución. Gran parte de las decisiones de diseño están fundamentadas en el buen juicio del diseñador de la BD. 1.2.1 Caracterización del esquema conceptual Lo realmente interesante de una base de datos y lo que determina en gran medida su funcionalidad es su esquema conceptual. Para la obtención de esquemas globales, una tarea importante es la modelación conceptual que, a partir del análisis de requisitos, siguiendo una metodología de diseño, genera el esquema global que más tarde será objeto de distribución, obteniendo los esquemas lógicos locales que posteriormente serán ubicados físicamente en los sitios de procesamiento. 5.
(14) Capítulo 1. Generalidades del diseño de Bases de Datos Distribuidas. La mayoría de los SGBD comerciales están enfocados al modelo relacional, debido en gran parte a que cuenta con sólidas bases matemáticas; de hecho, el modelo relacional sigue representando la tendencia dominante en el mercado actual de estos sistemas. La importancia del modelo relacional también está dada por las técnicas y herramientas que se han desarrollado para ayudar a la fase de diseño, existe un conjunto de reglas de transformación bien definidas para obtener esquemas relacionales a partir de diagramas ERE (Elmasri and Navathe, 2004). Para dar solución a la problemática de obtención del esquema conceptual global, en el Laboratorio de Bases de Datos se desarrolló la herramienta de diseño ERECASE (García et al., 2005, Rodríguez et al., 2002), que cumple con los requisitos que debe tener una herramienta para esta función; y se integra coherentemente al proceso general de diseño de BDD emprendido conjuntamente por las herramientas referidas en la Introducción de este trabajo La herramienta ERECASE posee una interfaz gráfica de usuario que apoya la creación de diagramas ERE y la transformación automática a esquemas del modelo relacional; no sin antes someter el diagrama ERE a una exhaustiva validación estructural. La arquitectura interna de esta herramienta consta de tres módulos fundamentales: el editor gráfico, el módulo de validación y el de generación de esquemas. Los dos primeros módulos interactúan entre si durante todo el proceso de diseño y el último sólo interactúa con los demás en el proceso de búsqueda de los esquemas para la generación del código SQL asociado al modelo ERE planteado en el editor gráfico activo. Las construcciones del diagrama ERE en ERECASE están estrechamente relacionadas desde el punto de vista interno y visual, ya que muchos de los errores que se comenten al diseñar se pueden detectar en tiempo de diseño gráfico, y así no es necesario aplicar algoritmos de alta complejidad para detectar dichos errores. La generación de esquemas relacionales se efectúa hacia el catálogo como elemento de integración entre las herramientas que conforman SIADBDD y también se hace mediante código en el lenguaje SQL a través de llamadas sucesivas a operaciones CREATE/ALTER TABLE, que podrá ser ejecutado en el SGBD específico en caso de diagramas libres de errores. Toda la información de entrada y de salida del ERECASE es manejada a través del catálogo, que se crea cuando se inicia un proyecto de diseño, y se actualiza en los pasos posteriores.. 6.
(15) Capítulo 1. Generalidades del diseño de Bases de Datos Distribuidas. 1.2.2 Caracterización de las aplicaciones En el proceso de caracterización de las aplicaciones es necesario captar la información sobre los patrones de acceso y uso de las aplicaciones sobre la BD, de utilidad en el diseño de la distribución. El diseñador, bien por su experiencia o estudios realizados, determina qué caracteriza a las aplicaciones activadas con mayor frecuencia. En realidad no siempre se pueden caracterizar todas las aplicaciones que operan sobre la BD, pero al menos se caracteriza el 20 por ciento de las aplicaciones más frecuentes o que realizan las aplicaciones más críticas en cuanto a volúmenes de accesos a datos. En el proceso de caracterización de las aplicaciones se solicita al diseñador la entrada de toda la información requerida según el método de diseño planteado en (Rodríguez, 2007). Los datos de entrada a la herramienta APPWIZARD son obtenidos por ERECASE y NETWIZARD y depositados en el catálogo. Las salidas se guardan en el mismo, quedando disponibles para las herramientas que continúan con el proceso de diseño, o ejecuciones posteriores de este asistente. 1.2.3 Caracterización de los sitios de procesamiento Los sitios constituyen el área de almacenamiento de múltiples bases de datos lógicamente relacionadas, interconectados por una red de comunicaciones. Estos sitios tienen un sistema de procesamiento de datos completo que incluye una base de datos local, un SGBD y facilidades de comunicaciones.. Si los diferentes sitios pueden estar geográficamente. dispersos, entonces, ellos están interconectados por una red de tipo WAN. Por otro lado, si los sitios están localizados en diferentes edificios o departamentos de una misma organización pero geográficamente en la misma ubicación, entonces, están conectados por una red local LAN. La caracterización de los sitios de procesamiento está, por tanto, ligada indisolublemente a la caracterización de la red donde estos se encuentran interconectados. Existen parámetros que caracterizan a los sitios de procesamiento que son de gran importancia en el proceso de diseño de BDD los cuales se captan por la herramienta NETWIZARD. Dada la combinación de estos factores, un sitio es más conveniente que otro para recibir determinado fragmento, y asociado a esto un determinado tiempo de respuesta a transacciones que le involucren.. 7.
(16) Capítulo 1. Generalidades del diseño de Bases de Datos Distribuidas. 1.2.4 Caracterización de la red de comunicación La más simple de las redes conecta dos sitios, permitiéndoles compartir archivos y otros recursos. Una red mucho más compleja conecta todas las computadoras de una empresa o compañía en el mundo. El objetivo fundamental de conectar sitios es el de poder compartir recursos. Una red es el conjunto de dispositivos físicos o hardware y de programas o software mediante el cual se pueden comunicar sitios para compartir recursos así como trabajo. A cada uno de los sitios conectado a la red también se les denomina nodos. Un SBDD consiste en un conjunto de sitios, cada uno de los cuales mantiene un SBD local. Cada sitio puede procesar transacciones locales, o bien transacciones globales entre varios sitios, requiriendo para ello comunicación entre ellos. Los sitios pueden conectarse físicamente de diversas formas, las principales son: Red totalmente conectada Red prácticamente conectada Red con estructura de árbol Red de estrella Red de anillo Las diferencias principales entre estas configuraciones son: Costo de instalación: El costo de conectar físicamente los sitios del sistema. Costo de comunicación: El costo en tiempo y dinero que implica enviar un mensaje entre dos sitios. Para los objetivos de este trabajo solo tiene interés considerar los costos relacionados con el tiempo invertido en el envío de mensajes y datos entre sitios. Fiabilidad: La frecuencia con que falla una línea de comunicación o un sitio. Disponibilidad: La posibilidad de acceder a información a pesar de fallos en algunos sitios o líneas de comunicación. Los sitios pueden estar dispersos, ya sea por un área geográfica extensa, llamadas redes de larga distancia; o en un área reducida, llamadas redes de área local. Para la comunicación en los primeros se utilizan líneas telefónicas, conexiones de microondas y canales de satélites; mientras que para los segundos se utilizan cables coaxiales de banda base o banda ancha y fibra óptica. En el proceso de diseño de BDD existen características de la red de comunicación que no deben faltar como el promedio del costo de envío de un frame de un sitio a otro, que unidas a 8.
(17) Capítulo 1. Generalidades del diseño de Bases de Datos Distribuidas. las características de los sitios completan la caracterización de la red. Toda la información relevante para el diseño de BDD es captada u obtenida automáticamente por NETWIZARD. 1.3 Modelación Lógica Los sistemas distribuidos más recientes son construidos en redes LAN en las que cada sitio es una sola computadora que mantiene una sola BD local. La siguiente generación será diseñada de manera distinta por el desarrollo de la tecnología, especialmente el surgimiento de multiprocesadores de bajo costo y redes de alta velocidad. El diseño de un sistema también se verá afectado por el aumento del uso de la tecnología de BD en la aplicación dentro de dominios que son más complejos que el procesamiento de datos comerciales y por la adopción amplia del modelo cliente-servidor, junto con la estandarización de la interfaz cliente-servidor.. Así,. los. SGBD. distribuidas. incluirán. servidores. de. BD. con. multiprocesadores conectados a redes de alta velocidad que los una a las máquinas de los clientes que ejecutan aplicaciones y participan en la ejecución de los requerimientos de las BD. Por tanto, en su contexto más moderno, el modelo cliente-servidor del que se habla aquí se refiere a máquinas reales, no a procesos. Así, bajo el modelo cliente-servidor se pueden tener arquitecturas como son la de “un servidor-varios clientes” o la más sofisticada de “varios clientes-varios servidores”. Bajo la perspectiva de la lógica de los datos, los SGBD cliente-servidor proporcionan la misma visión de una BD lógicamente única que dan los sistemas no jerárquicos o también conocidos como “punto a punto” (peer to peer) (Androutsellis-Theotokis and Spinellis, 2004, Pentaris and Ioannidis, 2006), la distribución real se da a nivel físico. Las diferencias sólo se dan a nivel del paradigma de arquitectura empleado para llegar al nivel de transparencia, no en la transparencia a nivel de usuario. 1.3.1 Fragmentación de esquemas La fragmentación, como proceso de división o descomposición presenta ventajas e inconvenientes. Se ha comentado la conveniencia de descomponer las relaciones de la BD en pequeños fragmentos, pero no se ha justificado el hecho ni se han aportado razones para efectuarlo. Por ello, desde este punto de vista existen razones para llevar a cabo esa descomposición o fragmentación. La fragmentación refleja el criterio de mantener los datos locales en los sitios donde frecuentemente son accedidos por las aplicaciones, es por ello que constituyen una unidad apropiada de asignación. Su principal dificultad se refiere al particionamiento de la información para distribuir cada parte a los diferentes sitios de la red. Inmediatamente aparece la siguiente pregunta: ¿cuál es la unidad razonable de distribución? Se puede considerar que una relación completa es lo 9.
(18) Capítulo 1. Generalidades del diseño de Bases de Datos Distribuidas. adecuado ya que las vistas de usuario son subconjuntos de las relaciones. Sin embargo, el uso completo de relaciones no favorece las cuestiones de eficiencia sobre todo aquella relacionadas con el procesamiento de consultas. La otra posibilidad es usar fragmentos de relaciones (sub-relaciones) lo cual favorece la ejecución concurrente de varias transacciones que accedan a porciones diferentes de una relación. Sin embargo, el uso de sub-relaciones también presenta inconvenientes. Por ejemplo, las vistas de usuario que no se pueden definir sobre un solo fragmento necesitarán un procesamiento adicional a fin de localizar todos los fragmentos de una vista. Unido a esto, el control semántico de datos es mucho más complejo ya que, por ejemplo, el manejo de llaves únicas requiere considerar todos los fragmentos en los que se distribuyen todos los registros de la relación. En resumen, el objetivo de la fragmentación es encontrar un nivel de particionamiento adecuado en el rango que va desde tuplas o atributos hasta relaciones completas. El diseño de fragmentación se determina por la forma en que las relaciones globales se subdividen en fragmentos. Para su realización se hace necesario proporcionar información que ayude a desarrollar una fragmentación adecuada. Esta información normalmente debe ser suministrada por el usuario y tiene que ver con cuatro tipos: Información sobre el significado de los datos. Información sobre las aplicaciones que los usan. Información acerca de la red de comunicaciones. Información acerca de los sistemas de cómputo. Una vez concentrada esta información se puede seleccionar de entre tres tipos de fragmentación: Fragmentación horizontal: Consiste del particionamiento en tuplas de una relación global en subconjuntos, donde cada subconjunto puede contener datos que tienen propiedades comunes y se puede definir expresando cada fragmento como una operación de selección sobre la relación global. Fragmentación vertical: es la subdivisión de atributos en grupos. Los fragmentos se obtienen proyectando la relación global sobre cada grupo. Fragmentación mixta o híbrida: esta consiste en aplicar la fragmentación vertical seguida de la fragmentación horizontal o viceversa. Un fragmento puede ser definido por una expresión en un lenguaje relacional como el álgebra relacional y debe cumplir con las siguientes reglas: 10.
(19) Capítulo 1. Generalidades del diseño de Bases de Datos Distribuidas. Completitud: Todos los datos deben estar mapeados en los fragmentos. Reconstrucción: Se debe poder reconstruir la relación global a partir de los fragmentos. Disyunción: Los fragmentos deben ser disyuntos, aunque fundamentalmente esto se debe cumplir con los tipos de fragmentación horizontal y horizontal derivada, los cuales se verán en las siguientes secciones. Para la fragmentación vertical esta condición es definida solamente para los atributos que no forman parte de la llave primaria pues ésta es repetida en todos los fragmentos. Este requisito puede tener excepciones, y es el caso en el que se asignan identificadores de tuplas en la relación global y esos identificadores se mantienen para todos los fragmentos. En la creación de la herramienta FRAGMENTER, que guía el proceso de diseño de la fragmentación de los esquemas globales, fueron implementados algoritmos usando los referentes teóricos de (Őzsu and Valduriez, 1999) y (Rodríguez, 2007). Esta herramienta permite que el diseñador elija qué tipos de fragmentación aplicará a cada esquema. Después de concluida una alternativa de fragmentación, se pueda realizar otra alternativa obteniendo una fragmentación mixta. 1.3.2 Asignación de fragmentos La asignación de los datos a los sitios en un ambiente distribuido afecta notablemente el desempeño de un sistema, ya que el tiempo y el costo requeridos para el procesamiento de las solicitudes dependen en gran parte del lugar donde se encuentren almacenados, ya sea en un solo nodo o que estén distribuidos en varios sitios de la red. La asignación de recursos entre los sitios de una red de computadoras es un problema que se ha estudiado de manera extensa (Apers, 1988, Bellatreche et al., 1998, Brahmadathan and Ramarao, 1992, Chang and Liu, 1982, Chaturvedi and Roan, 1994, Chiu and Raghavendra, 1990, Daudpota, 1998, Gu et al., 2006, Hababeh et al., 2004, Huang and Chen, 2001, Karlapalem and Pun, 1997, Lee and Baik, 2004, Lim and Ng, 1997, Lin and Orlowska, 1995, Ma et al., 2006, March and Rho, 1995, Mei et al., 2003, Pérez et al., 2003, Pérez et al., 2004b, Pérez et al., 2000, Raghuram et al., 1989, Ram and Marsten, 1991, Rodríguez et al., 2007a, Rodríguez et al., 2007b, Savsar and Al-Anzi, 2006, Sheng, 1989, Shepherd et al., 1995, Sun et al., 2004, Tamhankar and Ram, 1998, Wolfson and Jajodia, 1995). En general se supone un conjunto de fragmentos y una red que consiste de un conjunto de sitios en los cuales se va a ejecutar un conjunto de consultas. El problema de asignación determina la distribución óptima de fragmentos en sitios. La optimalidad puede ser definida de acuerdo a dos medidas: 11.
(20) Capítulo 1. Generalidades del diseño de Bases de Datos Distribuidas. Costo mínimo: Consiste del costo de comunicación de datos, del costo de almacenamiento, y del costo de procesamiento (lecturas y actualizaciones a cada fragmento). El problema de asignación, entonces, pretende encontrar un esquema de asignación que minimiza una función de costo combinada. Rendimiento: La estrategia de asignación se diseña para mantener una métrica de rendimiento. Las dos métricas más utilizadas son el tiempo de respuesta y el desempeño (número de trabajos procesados por unidad de tiempo). En cualquier problema de optimización existen restricciones que se deben satisfacer. El caso de distribución de fragmentos, las restricciones se establecen sobre las capacidades de almacenamiento y procesamiento de cada nodo en la red. En la fase de asignación se necesita conocer información cuantitativa relativa a la base de datos, las aplicaciones que se utilizan, la red de comunicaciones, las capacidades de procesamiento y de almacenamiento de cada nodo en la red. La herramienta ALLOCATOR implementa tres métodos basados en metaheurísticas para solucionar el problema de asignación de fragmentos en el diseño de BDD según el modelo matemático general planteado por Özsu y Valduriez(Őzsu and Valduriez, 1999). El primer método se basa en un algoritmo genético generacional(Águila, 2001, Alander, 1992, Cheng et al., 2002, Davis, 1991, Du et al., 2006, Goldberg, 1989, Pérez et al., 2004a, Pérez et al., 2004b, Pettinger and Everson, 2002, Rodríguez et al., 2005); el segundo se basa en el método Q-Learning de aprendizaje reforzado y el tercero usa el método de aprendizaje reforzado (Abe et al., 2003, Choi et al., 2004, Iida et al., 2004, Kaelbling et al., 1996, Mariano and Morales, 2001, Martin, 1998, Morales and Sammut, 2004, O et al., 2004, Paul and Iba, 2003, Pettinger and Everson, 2002, Rodríguez et al., 2007b, Sutton and Barto, 1998)para generar una solución que es entregada como población inicial para el algoritmo genético. Este modelo general pertenece a la clase NP-Hard, cuyo problema de decisión asociado es NP-Completo(Ceri et al., 1982b, Lee and Baik, 2004, Papadimitriou, 1997, Pérez et al., 2005). El problema de asignación resuelto tiene como objetivo minimizar el costo total de procesamiento y almacenamiento,. sujeto. a. restricciones de tiempo. de respuesta,. de capacidad. de. almacenamiento y de tiempo de procesamiento. Los métodos propuestos en esta herramienta son desarrollados en forma de agentes que usan los datos almacenados en el catálogo para obtener esquemas lógicos locales que serán objeto de ubicación física. ALLOCATOR brinda al diseñador la facilidad de elegir el método mediante el cual pretende dar solución al problema de asignación, se lleva a cabo el proceso de optimización y finalmente se muestra la 12.
(21) Capítulo 1. Generalidades del diseño de Bases de Datos Distribuidas. asignación alcanzada o un mensaje en caso de que no se haya encontrado una solución que cumpla con las restricciones del modelo matemático. 1.4 Modelación física La modelación hasta el nivel físico no puede ofrecer soluciones generales por su fuerte dependencia de los SGBD. Por esta razón, en los trabajos desarrollados en el Laboratorio de Bases de Datos referidos como antecedentes en la Introducción, se ofrece una solución propia de este nivel para Microsoft SQL Server, de gran popularidad en Cuba. Otras soluciones para otros SGBD se han considerado como trabajos futuros de este laboratorio. La replicación de datos permite tratar algunos de los problemas que se presentan en sistemas distribuidos, permitiendo a los usuarios que manejen localmente los datos, en lugar de acceder a grandes BD centralizadas a través de redes. También permite duplicar un servidor local de bases de datos a un servidor remoto, y si uno falla las aplicaciones pueden continuar accediendo a copias en el otro. Por su parte, el campo de la réplica de datos y la experimentación de métodos de replicación y su aplicación sistemática, también necesita de futuras investigaciones. La experimentación es requerida para evaluar los argumentos de los diseñadores de algoritmos y sistemas. Una de las dificultades de la evaluación cuantitativa de las técnicas de replicación es la ausencia de modelos comúnmente aceptados de fallos. La replicación de datos de SQL Server es un conjunto de tecnologías destinadas a la copia y distribución de datos a diferentes ubicaciones, y para mejorar el rendimiento de las aplicaciones, separando físicamente los datos en función de cómo se utilicen estos o cómo se distribuye el procesamiento entre varios servidores. Este SGBD utiliza la metáfora de publicación/suscripción (Schewe, 2002, Eugster et al., 2003, Belokosztolszki et al., 2003, Miklós, 2002, Chen et al., 2003, Ulusoy, 2001a, Ulusoy, 2001b, Chakravarthy and Vontella, 2004, Aekaterinidis and Triantafillou, 2005, Jiménez-Peris et al., 2003, Gray, 2004) en su modelo de replicación. Las fases de la replicación son (Hotek, 2002): configuración, generación y aplicación de la instantánea inicial, modificación de los datos replicados y sincronización, y propagación de los datos. SQL Server tiene tres métodos de replicación: instantánea, transaccional y mezcla. La tercera permite obtener copias diferidas de los datos y es probablemente la de más potencialidades para materializar un diseño distribuido de una BD. Entre sus características más relevantes están el permitir que varios sitios funcionen en línea o desconectados de manera autónoma, y mezclar más adelante las modificaciones de datos realizadas en un resultado único y uniforme. Este tipo de replicación es especialmente fuerte en el filtrado de opciones, lo que 13.
(22) Capítulo 1. Generalidades del diseño de Bases de Datos Distribuidas. adquiere relevancia en el proceso de materialización de la distribución, permitiendo la creación de los fragmentos que se ubican en los sitios de procesamiento según los esquemas de asignación obtenidos por los algoritmos implementados. El principio de la distribución de datos es alcanzar máxima localidad de datos y aplicaciones, ubicando los datos tan cerca como sea posible de las aplicaciones que los utiliza, lo que permite reducir el tráfico de comunicaciones en la red. En un sistema bien diseñado el 90 % de los datos deben ser ubicados localmente y solo el 10 % debe ser accedido remotamente (Ceri et al., 1989). En los trabajos referidos en los antecedentes de este trabajo, la asignación física se lleva a cabo por la herramienta ALLOCATOR. Actualmente se desarrollan otros dos trabajos de diploma, en paralelo con el presente, que tiene como propósito fundamental liberar a esta herramienta de los detalles de implementación de la asignación física y en su lugar obtener, por una parte, una solución genérica a través de métodos que crean archivos XML portables conteniendo el resultado del proceso de asignación, y por otra un método que usa los archivos XML obtenidos para generar la BDD físicamente en el SGBD elegido. Por ahora se trabaja en una salida para Microsoft SQL Server. 1.5 Consideraciones finales Aunque muchos investigadores han propuesto modelos y han diseñado algoritmos para el diseño de distribución, la mayoría de los modelos tienen una alta complejidad computacional y es difícil usarlos en un ambiente real. Tradicionalmente, el trabajo de diseño de la distribución ha sido realizado manualmente por el diseñador de la BD basado en su experiencia y en heurísticas. Sin embargo, las dimensiones de las aplicaciones actuales exceden normalmente las capacidades del diseñador para realizar un diseño de distribución adecuado en forma manual. Debido a una aparente ausencia de métodos para llevar los esquemas lógicos locales a esquemas físicos locales, así como la toma de decisiones respecto a cuánto replicar y cuáles relaciones fragmentar se han desarrollo herramientas de ayuda al proceso de diseño en el Laboratorio de Bases de Datos de esta universidad. Estas herramientas han aislado la fragmentación de la asignación, simplificando la formulación del problema de distribución, reduciendo el espacio de decisión, aunque un análisis cuidadoso revela que aislar los dos pasos contribuye a la complejidad de los modelos de ubicación. En estas herramientas se han detectado algunos elementos que pueden ser mejorados para obtener una herramienta integrada que homogenice los accesos de las diferentes herramientas al catálogo y provea un catálogo en blanco con las nuevas características para el inicio de cada proyecto de diseño. 14.
(23) Capítulo 1. Generalidades del diseño de Bases de Datos Distribuidas. También existen errores en los reportes emitidos por SIADBDD que deben ser corregidos. Adicionalmente se requieren ayudas o manuales para poder asistir a los diseñadores al llevar a cabo tareas de diseño. Otro aspecto deseable es poder contar con una aplicación de instalación personalizable que permita instalar SIADBDD para diseñar BDD o solamente ERECASE para diseñar BD centralizadas.. 15.
(24) Capítulo 2. Revisión de las herramientas de ayuda a la modelación de Bases de Datos Distribuidas. Capítulo 2 Revisión de las herramientas de ayuda a la modelación de Bases de Datos Distribuidas El diseño de BDD involucra varias tareas integradas en un proceso para obtener diseños correctos con el menor tiempo posible. SIADBDD fue desarrollado con este fin, integrando un conjunto de herramientas que se explican en este Capítulo. A continuación se muestran algunos elementos generales de ingeniería de requisitos que han sido abordados en este trabajo. Los resultados se enfocan siguiendo los tres niveles de modelación de la arquitectura de referencia para las bases de datos: conceptual, lógico y físico. 2.1 Diagrama de casos de uso La Figura 1 muestra el diagrama de casos de usos de SIADBDD. Esta herramienta tiene como actor principal y único al diseñador de BDD, que es el encargado de modelar el esquema conceptual, caracterizar los sitios de procesamiento, caracterizar la red, caracterizar las aplicaciones, fragmentar y ubicar con ayuda de los casos de uso.. Figura 1. Diagrama de casos de uso y actores.. 16.
(25) Capítulo 2. Revisión de las herramientas de ayuda a la modelación de Bases de Datos Distribuidas. El primer caso de uso le permite al diseñador crear o editar diagramas Entidad-Relación para la construcción de una BD. El segundo caso de uso tiene la funcionalidad de captar las características físicas de cada uno de los sitios de procesamiento que elija el diseñador, y el tercero capta los tiempos de comunicación entre sitios, también previamente elegidos. El cuarto caso de uso capta la información sobre los patrones de acceso y uso de las aplicaciones sobre la BD de utilidad en el diseño de la distribución, los datos que el diseñador, bien por su experiencia o estudios realizados, determina que caracterizan a las aplicaciones activadas con mayor frecuencia. El quinto caso realiza el proceso de fragmentación que se refiere a la división del esquema de una BDD de acuerdo con algún criterio, de forma tal que se minimice el costo de acceso a los datos durante el procesamiento de las transacciones, mejorando los tiempos de respuesta y el paralelismo del sistema. El sexto caso brinda al diseñador la facilidad de elegir el método mediante el cual pretende dar solución al problema de asignación, se lleva a cabo el proceso de optimización y finalmente se muestra la asignación lógica alcanzada o un mensaje en caso de que no se haya encontrado una solución que cumpla con las restricciones del modelo de asignación. En este mismo caso de uso se puede obtener una ubicación física mediante la generación de scripts para el SGBD elegido. Cada caso de uso debe ser capaz de tomar los datos de entrada desde la interfaz con el usuario o desde el catálogo, elemento integrador del diseño entre todas las herramientas, e introducir los datos de salida en el mismo para que sirvan de entrada a otros procesos que los necesiten. 2.2 Diseño de clases Los diagramas de clases se utilizan generalmente para mostrar clases y sus relaciones, pero también pueden utilizarse para mostrar subsistemas e interfaces. La Figura 2 muestra el diagrama de clases de SIADBDD. La clase principal Forma Principal se encarga de responder a los eventos de la aplicación, realiza la llamada a las herramientas de ayuda al diseño de BDD pasándole como parámetro el camino del proyecto. Esta utiliza la clase DalOleDB para lograr la generación de los informes relacionados con los avances del proyecto, además gestionar los accesos al catálogo y la generación de esquemas XML como fuente de datos para los informes.. 17.
(26) Capítulo 2. Revisión de las herramientas de ayuda a la modelación de Bases de Datos Distribuidas. Figura 2. Diagrama de clases de SIADBDD. 2.3 Arquitectura de las herramientas de ayuda al diseño de BDD Una herramienta de ayuda al diseño de BDD debe mantener una gran cantidad de información estructurada referente a los esquemas que conforman cada BD objeto de diseño, sobre las aplicaciones que dan solución a los casos de uso o solicitudes, sobre los sitios donde residirán los datos y el procesamiento de las solicitudes, y sobre la red que soporta la conexión entre sitios y el intercambio entre estos a fin de efectuar sus funciones. Toda esta variedad de información es almacenada usualmente en un catálogo que mantiene SIADBDD para sus propios fines internos. A través de este catálogo se establece la interoperabilidad entre las herramientas, permitiendo las funciones de búsqueda, obtención, transferencia y evaluación de la información almacenada para llevar a término un proyecto de diseño de BDD. Para la descripción arquitectónica de SIADBDD se toma en consideración la práctica recomendada por la IEEE para sistemas intensivos de software, estándar 1471-2000 (IEEE, 2000). Según este estándar, el paradigma arquitectónico debe ser flexible como para contemplar las funciones relevantes y la especificación de cada punto de vista seleccionado para organizar la vista arquitectónica y las motivaciones para ello. El mejor modelo que se amolda a este requisito es el que integre los distintos niveles de la arquitectura de referencia de las BDD integrada al proceso de diseño (Véase la Figura 3). La implementación de las herramientas fue realizada en Visual C# como parte de Visual Studio (Vitter and Templeman, 2002, Rammer, 2002).SIADBDD integra las siguientes herramientas: Nivel conceptual: o ERECASE para la caracterización del esquema conceptual global. o APPWIZARD para la caracterización de las aplicaciones. o NETWIZARD para recopilar información sobre la red de comunicación y los sitios de procesamiento donde residirá la BDD objeto de diseño. Nivel lógico: o FRAGMENTER para hallar la fragmentación. 18.
(27) Capítulo 2. Revisión de las herramientas de ayuda a la modelación de Bases de Datos Distribuidas. o ALLOCATOR contiene un módulo para obtener la ubicación de los fragmentos a nivel lógico. Nivel físico: o ALLOCATOR contiene un módulo para obtener la ubicación física de los fragmentos.. Figura 3. Vista arquitectónica general de la herramienta de ayuda al diseño de BDD. Adaptado de (Rodríguez, 2007) Una suposición básica de este trabajo es que el diseñador de la BD es capaz de predecir las propiedades lógicas que caracterizan la localidad de los datos con respecto a las aplicaciones y la información cuantitativa que mide la carga de aplicaciones en términos de frecuencia de ejecución de las peticiones en cada sitio. De hecho, la dificultad del diseño de la distribución de la BD reside en la interferencia de consideraciones lógicas (cualitativas) y cuantitativas. Durante la experimentación con estas herramientas se han detectado elementos que deben ser mejorados o modificados como se expresó en la introducción. Estas modificaciones suponen concentrar los accesos al catálogo de modo que se mejore la gestión de los accesos al mismo, permitir la personalización de la instalación de las herramientas individualmente, disponer de ayuda para llevar a cabo flujos de trabajo de diseño y obtener informes individualizados sobre el avance en los proyectos de diseño. A continuación se detallan los principales elementos de ingeniería de requisitos que han sido abordados en este trabajo. 19.
(28) Capítulo 2. Revisión de las herramientas de ayuda a la modelación de Bases de Datos Distribuidas. 2.3.1 Nivel conceptual El nivel conceptual es abordado con las herramientas ERECASE, APPWIZARD y NETWIZARD. Herramienta ERECASE La herramienta ERECASE permite la caracterización del esquema conceptual global mediante diagramas ERE. La arquitectura interna de ERECASE consta de tres módulos fundamentales (Véase la Figura 4): el editor gráfico, el módulo de validación y el de generación de esquemas. Los dos primeros módulos interactúan entre si durante todo el proceso de diseño y el último sólo interactúa con los demás en el proceso de búsqueda de los esquemas para la generación del código SQL asociado al modelo ERE planteado en el editor gráfico activo.. Figura 4. Vista arquitectónica de ERECASE. Tomado de (Rodríguez, 2007) ERECASE está concebida como una aplicación MDI (del inglés MultiDocument Interface) que le permite al diseñador trabajar con varios diagramas simultáneamente. No es objetivo de este trabajo realizar modificaciones a esta herramienta.. Herramienta APPWIZARD Esta herramienta capta la información sobre los patrones de acceso y uso de las aplicaciones sobre la BD, de utilidad en el diseño de la distribución. APPWIZARD tiene forma de asistente capaz de introducir en el catálogo, elemento integrador de diseño, los datos que el diseñador, bien por su experiencia o estudios realizados, determina que caracterizan a las aplicaciones.. 20.
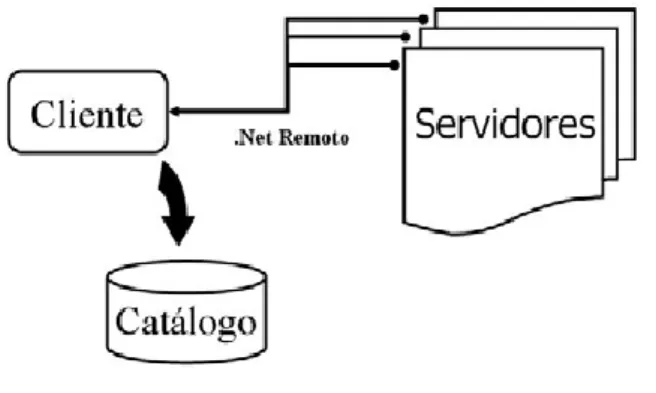
(29) Capítulo 2. Revisión de las herramientas de ayuda a la modelación de Bases de Datos Distribuidas. La información que la herramienta permite captar puede dividirse en grupos o categorías. Estas son: nombre que identifique la aplicación, esquemas y atributos usados así como el tipo de acceso de lectura y/o escritura que realiza, selectividad de cada esquema, sitios donde se activa y la frecuencia de activación en cada sitio. También se solicitan los predicados simples que indican localidad de procesamiento. La captura de estos predicados simples se realiza mediante un constructor de expresiones, que a la vez que permite la edición, realiza la validación de los predicados. Los datos de entrada al asistente son obtenidos por ERECASE y NETWIZARD y depositados en el catálogo. Las salidas se guardan en el mismo, quedando disponibles para las herramientas que continúan con el proceso de diseño, o ejecuciones posteriores de este asistente. Herramienta NETWIZARD La herramienta NETWIZARD presenta una arquitectura cliente-servidor como se muestra en la Figura 5, que usa la tecnología de comunicación .Net Remoto (Rammer, 2002, Richter, 2002, Vitter and Templeman, 2002)basada en los estándares opensource.. Figura 5. Arquitectura de NETWIZARD.. En cada sitio reside un objeto servidor que usa un canal HTTP para escuchar las peticiones de los objetos cliente. Esta herramienta realiza la caracterización de los sitios de procesamiento mediante la captura del nombre que identifica a cada sitio, su dirección IP, la velocidad del procesador, el espacio total en disco y el espacio libre, los tiempos de lectura de disco y de escritura hacia disco. En cuanto a las redes, la herramienta almacena en el catálogo las mediciones de tiempos de respuesta al enviar un frame de un sitio a otro como medida de costo de comunicación entre sitios. Cada vez que se mide un tiempo de respuesta entre dos sitios, se promedia con el ya almacenado, y se reemplaza en el catálogo. La realización de las actividades de caracterización de los sitios y la red no tienen un orden predefinido, el diseñador puede comenzar por una u otra indistintamente. El diagrama que se muestra en la Figura 6, representa el flujo del proceso de NETWIZARD. 21.
(30) Capítulo 2. Revisión de las herramientas de ayuda a la modelación de Bases de Datos Distribuidas. Figura 6. Diagrama de actividad de NETWIZARD.. En la actividad de autentificación, la cuenta de usuario debe ser una de administración en cada uno de los sitios donde se quieran instalar los servicios. La prueba de que el servicio fue instalado correctamente se puede apreciar en la aplicación o en la tarea de “Buscar información de los sitios”. El objeto servidor del la herramienta se instala como un servicio Windows y es el encargado de escuchar las peticiones de los objetos clientes. Será necesario instalar el servicio en cada uno de los sitios que se desee tomar como servidor para la BD. Se seleccionó el canal HTTP para la comunicación cliente-servidor, unido al uso del puerto 80, asegurando así la comunicación entre objetos que estén protegidos por firewalls, necesarios en las redes de acceso telefónico. Este canal disminuye la velocidad de la comunicación pero es necesario debido al formato de los mensajes del canal TCP. Al usar el canal HTTP se sitúa el mensaje en un envoltorio SOAP, basado en XML, preparándolo para la transmisión entre redes protegidas.. 22.
(31) Capítulo 2. Revisión de las herramientas de ayuda a la modelación de Bases de Datos Distribuidas. La herramienta de software que permite captar información acerca de un conjunto de sitios o estaciones previamente escogido dentro de una red local, e incluso de estaciones a las que se pueda acceder mediante conexiones por módem. El Asistente se implementó usando la tecnología .Net de Microsoft, específicamente el framework 2.0 de .Net. Se trabajó con el IDE Visual Studio 2005 de Microsoft. Estos asistentes conocen la estructura del objeto remoto, y todas las especificaciones de configuración del mismo, una vez que se sepa el nombre o el número IP de un sitio, se crea una instancia del objeto remoto y se registra para obtener una referencia al proxy que atenderá todas las peticiones del cliente. Posteriormente, todos estos parámetros capturados por NETWIZARD sirven de entrada para el modelo de asignación implementado en ALLOCATOR. 2.3.2 Nivel lógico El nivel lógico es abordado con las herramientas FRAGMENTER y ALLOCATOR. Herramienta FRAGMENTER. El problema de fragmentación en el diseño de BDD consiste en dividir esquemas globales en fragmentos de datos que sean unidades lógicas de asignación más apropiadas para ubicar en los sitios de procesamiento en aras de potenciar el procesamiento local y minimizar los costos totales de operación. El objetivo de esta herramienta es guiar al diseñador de BDD en el proceso de fragmentación. En cada etapa del proceso se brinda información suficiente y orienta al diseñador, incluso para cuando no sea un experto. La herramienta FRAGMENTER guía el proceso de diseño de la fragmentación y permite que, independientemente de la alternativa aplicada (horizontal o vertical), después se pueda realizar la alternativa contraria lográndose así una fragmentación mixta. FRAGMENTER designa como fragmentos a todos los esquemas relacionales obtenidos en la modelación conceptual y luego procede a la fragmentación, garantizando que cada esquema será objeto de asignación aunque no sea fragmentado; lo cual puede conducir, como condición extrema, a que la BD no sea distribuida sino centralizada. Cuando se decida realizar la fragmentación vertical, primeramente se seleccionan los esquemas que serán fragmentados y luego se visualizan los fragmentos resultantes; para terminar debe pasar a la siguiente etapa donde se guardan los resultados en el catálogo y se le brinda la posibilidad de terminar o volver al inicio para tomar otra decisión. De seleccionar la fragmentación horizontal se visualizan los minterms de cada relación primaria y debe eliminar aquellos que considere semánticamente contradictorios.. 23.
(32) Capítulo 2. Revisión de las herramientas de ayuda a la modelación de Bases de Datos Distribuidas. Herramienta ALLOCATOR La distribución de los datos es un problema crítico que afecta de manera considerable el desempeño global de los sistemas distribuidos, debido a que influye directamente en la eficiencia del procesamiento de las consultas. Debido a la complejidad del problema, las diferentes propuestas de solución presentadas hasta la fecha, han coincidido en dividir el proceso de diseño de la distribución en dos fases seriadas: la fragmentación y la ubicación de los fragmentos en los sitios de la red. El problema de ubicación en el diseño de BDD, también conocido como problema de asignación, consiste en asignar fragmentos de datos a sitios de procesamiento en aras de minimizar los costos totales de operación. La herramienta ALLOCATOR brinda al diseñador la facilidad de elegir el método mediante el cual desee solucionar el problema de asignación. Se proponen tres métodos para solucionar el problema de asignación según el modelo matemático general planteado en la literatura. Se tiene como objetivo minimizar el costo total, sujeto a restricciones de tiempo de respuesta, capacidad de almacenamiento y tiempo de procesamiento. El primer método se basa en un algoritmo genético generacional, y el segundo en Q-Learning, un método de Aprendizaje Reforzado. El tercer método consiste en una hibridación donde se usa el segundo método para generar una solución inicial sin replicación como entrada para el primer método. Para instancias pequeñas y medianas del problema ambos métodos se comportan de manera similar en cuanto a la calidad de la solución. El método basado en Q-Learning consume un menor tiempo de ejecución independientemente del tamaño del problema, pero a medida que este aumenta, va perdiendo calidad en las soluciones; no así el Algoritmo Genético que mantiene cierta estabilidad en el error relativo del costo promedio de encontrar la solución óptima. El método híbrido muestra los mejores resultados de las tres soluciones planteadas. Un aspecto novedoso en estos métodos es considerar la replicación o asignación redundante no considerada en los algoritmos clásicos. 2.3.3 Nivel Físico La herramienta ALLOCATOR también aborda el nivel físico mediante la creación y posterior ejecución de un conjunto de scripts, uno para cada sitio caracterizado por NETWIZARD y en los sitios elegidos por las aplicaciones identificadas por APPWIZARD. Por esta razón se ofrece una solución genérica para ser adaptada al nivel físico soportado por cualquier SGBD y se ofrece una solución personalizada para Microsoft SQL Server, de gran popularidad en Cuba, que utiliza la metáfora de publicación/suscripción en su modelo de replicación. Se prevé desarrollar opciones de salida para otros SGBD. 24.
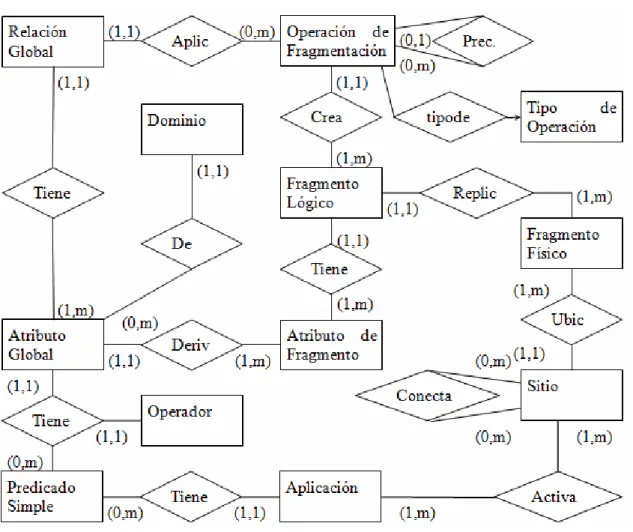
(33) Capítulo 2. Revisión de las herramientas de ayuda a la modelación de Bases de Datos Distribuidas. Para implementar el diseño de la distribución mediante replicación se crean scripts con llamadas a procedimientos almacenados de Transact-SQL, donde se recrea el entorno de replicación y usa la directiva de resolución de conflictos asíncrona; se reconocen los servidores involucrados en la distribución; se crea la BD fragmentada y vistas asociadas; se configuran las publicaciones y las suscripciones (siempre se elige la suscripción de tipo Pull porque da mayor autonomía a los suscriptores). Se elige la mezcla como tipo de replicación por ser la que mayor autonomía da a los sitios y porque es fuerte en el filtrado de opciones. Los filtros horizontales permiten realizar la fragmentación horizontal primaria; los filtros verticales, por su parte, ayudan a obtener la fragmentación vertical; mientras que los filtros combinados facilitan la fragmentación horizontal derivada. Si el diseñador lo desea, puede modificar la secuencia de comandos una vez generada. 2.4 Catálogo del diseño. Figura 7. Esquema conceptual del catálogo. El catálogo es una BD relacional, autodescriptiva por naturaleza (Kutter et al., 2002, NISO, 2004, Özel et al., 2004, Parankusham and Madupu, 2006, Pierson et al., 2004), a la cual se accede indirectamente a través de las herramientas. El mismo almacena toda la información 25.
(34) Capítulo 2. Revisión de las herramientas de ayuda a la modelación de Bases de Datos Distribuidas. que interviene en el proceso de diseño de BDD emprendido por las herramientas reseñadas anteriormente en este Capítulo. A través de este catálogo se reporta y obtiene la información necesaria para lograr completar procesos de diseño. En el uso del catálogo se emplean métodos y lógica de acceso propios para almacenar y recuperar rápida y eficientemente la información que se necesita en la realización de las tareas para las cuales han sido concebidas las herramientas. Las tablas que componen dicho catálogo sólo son usadas internamente por las herramientas, tanto para guardar sus datos como para obtener sus valores de entrada, compartiendo por esta vía toda la información relevante para el proceso de diseño de BDD, de esta forma no son de interés para los diseñadores de BDD; como usuarios de las herramientas. En la Figura 7 aparece el diagrama ER del catálogo. A la hora de lograr una integración de las herramientas se detecta la necesidad de hacer modificaciones en algunas tablas del catálogo, de forma tal que todos los datos se utilicen de forma correcta y no existan conflictos entre tipos de datos. 2.5 Conclusiones parciales Durante la experimentación con estas herramientas se realizó un análisis de cada herramienta por separado, se reseñó cada una y se procedió a su integración. En este paso se detectaron dificultades que fueron sometidas a mantenimiento. Específicamente, se concentraron los accesos al catálogo de modo que se mejorara la gestión de los accesos al mismo; en la llamada a cada herramienta se le suministró la descripción del proyecto de diseño en curso y el camino de ubicación del catálogo correspondiente a ese diseño. En cada herramienta se modificó la forma en que se accedía al catálogo considerando la nueva entrada que se recibe como parámetro.. 26.
(35) Capítulo 3. Mantenimiento a las herramientas de ayuda al diseño de Bases de Datos Distribuidas. Capítulo 3 Mantenimiento a las herramientas de ayuda al diseño de Bases de Datos Distribuidas. Según el estándar IEEE 1219, el mantenimiento del software es la modificación de un software después de la entrega para corregir fallos, para mejorar el rendimiento u otros atributos, o para adaptar el producto a un entorno modificado. En este Capítulo se tratan los elementos relacionados con actividades de mantenimiento que fueron identificadas durante la experimentación con SIADBDD. 3.1 Preparación del mantenimiento Cualquier esfuerzo de ingeniería del software – si termina con éxito – acaba por producir un determinado. producto. software,. orientado. a satisfacer ciertos requisitos previamente. establecidos. El mantenimiento en este contexto se entiende de manera general como las actividades de cambio de ese producto. Dentro de la ingeniería del software se proporcionan soluciones técnicas que permiten abordar el mantenimiento. Estas pueden ser de tres tipos: 1. Ingeniería inversa: Análisis de un sistema para identificar sus componentes y las relaciones entre ellos, así como para crear representaciones del sistema en otra forma o en un nivel de abstracción más elevado. 2. Reingeniería: Modificación de un producto software, o de ciertos componentes, usando para el análisis del sistema existente técnicas de ingeniería inversa y, para la etapa de reconstrucción, herramientas de ingeniería directa, de tal manera que se oriente este cambio hacia mayores niveles de facilidad en cuanto a mantenimiento, reutilización, comprensión o evolución. 3. Reestructuración del software: Cambio de representación de un producto software, pero dentro del mismo nivel de abstracción. El objetivos de estas técnicas es proporcionar métodos para reconstruir el software, ya sea reprogramándolo, redocumentándolo, rediseñándolo, o rehaciendo algunas características del producto. La diferencia entre las soluciones descritas radica en cuál es el origen y cuál es el destino de las mismas (producto inicial y/o producto final).. 27.
(36) Capítulo 3. Mantenimiento a las herramientas de ayuda al diseño de Bases de Datos Distribuidas. Gráficamente, estas tres soluciones técnicas se enmarcan en el ciclo de vida de la siguiente forma:. Figura 8. Relaciones entre los términos asociados con la reingeniería. Tomado de (Sicilia, 2009) La ingeniería directa corresponde al desarrollo del software tradicional. La ingeniería inversa es el proceso de análisis de un sistema para identificar sus componentes e interrelaciones y crear representaciones del sistema en otra forma o a un nivel más alto de abstracción. La reingeniería es el examen y la alteración de un sistema para reconstruirlo de una nueva forma y la subsiguiente implementación de esta nueva forma. La reestructuración es la modificación del software para hacerlo más fácil de entender y cambiar (Sicilia, 2009). La reingeniería hace referencia a un ciclo, esto es, se aplican técnicas de ingeniería inversa para conseguir representaciones de mayor abstracción del producto y sobre ellas se aplican técnicas de ingeniería directa para rediseñar o reimplementar el producto. Cualquiera de estas técnicas se puede aplicar a lo largo de todas las fases del ciclo de vida o bien entre algunas de sus fases. También existen otras tecnologías, como por ejemplo: La remodularización: consiste en cambiar la estructura modular de un sistema de forma que se obtenga una nueva estructura siguiendo los principios del diseño estructurado. Análisis de la facilidad. de mantenimiento: normalmente la mayor parte del. mantenimiento se centra relativamente en unos pocos módulos del sistema. Visualización: el proceso más antiguo para la comprensión del software.. 28.
Figure



+7




Documento similar
Debido al riesgo de producir malformaciones congénitas graves, en la Unión Europea se han establecido una serie de requisitos para su prescripción y dispensación con un Plan
Como medida de precaución, puesto que talidomida se encuentra en el semen, todos los pacientes varones deben usar preservativos durante el tratamiento, durante la interrupción
Memorias de ultratumba de F.-R. de Chateaubriand, en traducción anónima (1849-1850) Marta Giné Janer
Además de aparecer en forma de volumen, las Memorias conocieron una primera difusión, a los tres meses de la muerte del autor, en las páginas de La Presse en forma de folletín,
Abstract: This paper reviews the dialogue and controversies between the paratexts of a corpus of collections of short novels –and romances– publi- shed from 1624 to 1637:
Y tendiendo ellos la vista vieron cuanto en el mundo había y dieron las gracias al Criador diciendo: Repetidas gracias os damos porque nos habéis criado hombres, nos
Después de una descripción muy rápida de la optimización así como los problemas en los sistemas de fabricación, se presenta la integración de dos herramientas existentes
por unidad de tiempo (throughput) en estado estacionario de las transiciones.. de una red de Petri
Habiendo organizado un movimiento revolucionario en Valencia a principios de 1929 y persistido en las reuniones conspirativo-constitucionalistas desde entonces —cierto que a aquellas
