Codificación de video de alta eficiencia en un clúster de computadoras para implementarse en la televisión digital de ultra alta definición
88
0
0
Texto completo
(2)
(3) i. PENSAMIENTO. “Solo quien quiere hacer algo encuentra la vía, el que no quiere hacer nada encuentra una excusa”. Anónimo.
(4) ii. DEDICATORIA. A mis padres, mi novia y mi suegra..
(5) iii. AGRADECIMIENTOS. A mi familia que siempre me apoya y me ayuda a realizar mis metas. A Melissa y su madre que son parte de mi familia también. A mis amigos que me acompañan en todo momento. A mi tutora Irina y su esposo por su apoyo. A mi otro tutor Carlos Lester por su ayuda incondicional. A todas las personas que me apoyaron para que la realización de esta tesis de pre grado fuera posible..
(6) iv. TAREA TÉCNICA. 1. Análisis de los principales formatos de compresión de video utilizados para la transmisión de los mismos. 2. Análisis de las características y ventajas de un clúster para la codificación de video de Ultra Alta Definición. 3. Realización de la codificación con formatos de compresión H.265 y H.264 variando sus configuraciones y los nodos en los que se realizarán las codificaciones para obtener diversas muestras de video codificado. 4. Comparación la eficiencia de codificación en términos de calidad de imagen, razón de bit y tiempo de codificación de los formatos de compresión H.265 y H.264. 5. Determinación de los valores óptimos de los parámetros de codificación para codificar eficientemente videos de Ultra Alta Definición en un clúster de computadoras para la televisión digital..
(7) v. RESUMEN. El avance de la televisión digital mundialmente ha impuesto retos a los desarrolladores de formatos de compresión de video pues los formatos Ultra Alta Definición requieren una buena calidad de imagen y de razones de bit elevadas pero que se ajusten a la razón de transmisión establecida para el canal. H.264 es uno de los códec más populares para la codificación de video, sin embargo, no es capaz de reducir la razón de bit de los videos en Ultra Alta Definición por lo cual surge consecuentemente H.265. Este trabajo aborda la problemática de la eficiencia del códec H.265 para la codificación de video. En la investigación se ha hecho un análisis de los principales parámetros en los que se basa la compresión para medir la calidad del codificador. También se realiza un estudio de las herramientas usadas para la codificación como un clúster de computadoras y el software ffmpeg con las correspondientes librerías. El análisis de los resultados permite arribar a conclusiones acerca de la eficiencia de codificación del codec H.265 sobre H.264 en cuanto a calidad de imagen, razón de bit y tiempo de codificación, y permite seleccionar los parámetros óptimos de codificación para codificar los videos..
(8) vi. ÍNDICE PENSAMIENTO ....................................................................................................................................... i DEDICATORIA ....................................................................................................................................... ii AGRADECIMIENTOS .......................................................................................................................... iii RESUMEN ................................................................................................................................................ v INTRODUCCIÓN .................................................................................................................................... 1 Organización del informe .................................................................................................................... 4 CAPÍTULO 1. 1.1. Principales formatos de compresión de video para la TVD. ................................... 5. Compresión de la señal de video ............................................................................................. 5. 1.1.1. Submuestreo de la señal de video ................................................................................... 7. 1.1.2. Técnicas de compresión de video ................................................................................... 8. 1.2. Estándares de compresión de video para la televisión digital ............................................ 12. 1.2.1. Formato de compresión de video H.261 ...................................................................... 13. 1.2.2. Formato de compresión de video H.262 ...................................................................... 14. 1.2.3. Formato de compresión de video H.263 ...................................................................... 14. 1.2.4. Formato de compresión de video H.264 ...................................................................... 15. 1.3. Formato de compresión de video H.265 ............................................................................... 17. 1.3.1. Nueva unidad básica...................................................................................................... 17. 1.3.2. Compensación de movimiento ...................................................................................... 19. 1.3.3. Intrapredicción de imágenes......................................................................................... 20. 1.3.4. Bloque de transformada................................................................................................ 20. 1.3.5. Codificación de entropía ............................................................................................... 21. 1.3.6. Filtrado antibloques y sao ............................................................................................. 21. 1.3.7. Herramienta de procesamiento en paralelo ................................................................ 22. 1.4. Conclusiones del capítulo ...................................................................................................... 24. CAPÍTULO 2. Definición 2.1. Computación de Alto Rendimiento para la codificación de video de Ultra Alta 25. Ventajas de la utilización de un clúster de computadoras para la codificación de video. 25.
(9) vii 2.2. Clúster de la Universidad Central de las Villas ................................................................... 27. 2.3. Clúster de la Universidad de Oriente.................................................................................... 28. 2.4. Acceso al clúster ..................................................................................................................... 29. 2.4.1 2.5. Envío de trabajos al clúster ........................................................................................... 29. La herramienta de software ffmpeg...................................................................................... 31. 2.5.1. Codificador x264............................................................................................................ 32. 2.5.2. Codificador x265............................................................................................................ 33. 2.5.3. Ficheros de entrada ....................................................................................................... 35. 2.6. Descripción de los experimentos ........................................................................................... 36. 2.7. Secuencias de prueba ............................................................................................................. 39. 2.8. Mediciones de los parámetros de calidad ............................................................................ 41. 2.9. Conclusiones del capítulo ...................................................................................................... 43. CAPÍTULO 3.. Análisis de los resultados .......................................................................................... 44. 3.1. Análisis de los resultados de la secuencia Foreman_ProRes .............................................. 44. 3.2. Análisis de los resultados de la secuencia Coastguard_ProRes........................................... 47. 3.3 Influencia de la cantidad de núcleos de procesamiento para la codificación de video con H.265 y H.264. .................................................................................................................................... 50 3.4. Determinación los parámetros óptimos para una codificación eficiente .......................... 53. 3.5. Conclusiones del capítulo ...................................................................................................... 54. CONCLUSIONES Y RECOMENDACIONES ................................................................................... 55 Conclusiones ....................................................................................................................................... 55 Recomendaciones ............................................................................................................................... 56 REFERENCIAS BIBLIOGRÁFICAS.................................................................................................. 57 Glosario ................................................................................................................................................... 61 ANEXOS ................................................................................................................................................. 63 Anexo I: Comandos usados para la interacción con el clúster y sus colas. ................................... 63 Anexo II: Comandos usados para la interacción con la herramienta ffmpeg .............................. 63 Anexo III: Comandos y parámetros para la configuración de la librería libx265 ....................... 64.
(10) viii Anexo VI: Valores pre establecidos en las opciones que brinda el comando preset ..................... 72 Anexo V: Ejemplo de reporte de informe de codificación H.264 enviado por el clúster.............. 72 Anexo VI: Ejemplo de reporte de informe de codificación H.265 enviado por el clúster en nodos de 4 y 12 CPU. .................................................................................................................................... 74 Anexo VII: Ejemplo de reporte de informe de codificación H.265 enviado por el clúster en nodos de 64 CPU. ............................................................................................................................... 75 Anexo VIII: Gráficas del tiempo de codificación de la secuencia Coastguard_ProRes usando nodos de 4, 12 y 64 CPU. ................................................................................................................... 77.
(11) INTRODUCCIÓN. 1. INTRODUCCIÓN. La televisión digital (TVD) se basa en la transmisión de imágenes en movimiento, audio y datos correspondientes mediante una codificación binaria, lo cual hace posible la creación de vías de retorno entre consumidor y productor de contenidos posibilitando el uso de aplicaciones interactivas. Las ventajas que brinda la Televisión digital Terrestre (DTT, del inglés Digital Television Terrestrial) con respecto a la televisión analógica son formidables ya que permite un mejor aprovechamiento del espectro radioeléctrico permitiendo acomodar varios programas de televisión en un mismo (Sjöberg et al., abril 2013). El desarrollo de la transmisión de la televisión digital en Cuba comenzó con el anuncio, en el 2011 de que Cuba utilizaría la norma china Transmisión de Multimedia Digital Terrestre (DTMB, del inglés Digital Terrestrial Multimedia Broadcast), para la difusión de la televisión digital. De acuerdo a esta norma quedaron establecidos para la compresión de audio el uso del formato MPEG-1 Capa2 y para la compresión de video los formatos AVS y H.264/AVC. Los formatos de imágenes transmitidos actualmente tienen una resolución de 640x480 (definición estándar). Para la alta definición implementó el formato de imagen 720p (720 líneas horizontales de resolución con barrido progresivo) y 1080i (1080 líneas en resolución horizontal entrelazada) utilizando el formato de compresión H.264 y se utilizará la misma compresión de audio (LACETEL, 2014). El formato de compresión H.264 es uno de los estándares más populares en la actualidad para la codificación de video, el cual logra bajas razones de transmisión con buena calidad de imagen gracias a la compresión que se realiza mediante el uso de la información redundante y las limitaciones psicovisuales sin incrementar demasiado la complejidad del diseño de codificación (Sze, 2013). Sin embargo, la creciente demanda de tecnología de alta y ultra alta definición requiere una calidad de imagen superior que permita explotar las.
(12) INTRODUCCIÓN. 2. cualidades que poseen los equipos de reproducción multimedia con estas resoluciones. Se hace necesario, entonces, la transmisión de videos en formatos de alta y ultra alta definición lo cual, a su vez, implica una mayor tasa de transmisión. Basados en la idea anterior el ISO/IEC MPEG (Grupo de Expertos de Imágenes en Movimiento) y ITU-T VCEG (Grupo de Expertos de Codificación de Video) crearon el formato de compresión de video H.265 o HEVC (Codificación de Video de Alta Eficiencia) que, según (UIT-T, abril 2015), permite reducir la razón de bit con respecto al formato de compresión H.264 (Martínez, enero 2016). No obstante, llevar a cabo el proceso de compresión del video de alta definición empleando codificación H.265 es una tarea que requiere un alto nivel de procesamiento. En este sentido las técnicas de procesamiento en paralelo contribuyen a la implementación más eficiente del proceso (Pourazad et al., julio 2012). La presencia en la Universidad de Oriente (UO) y en la Universidad Central de las Villas (UCLV) de un centro de Clúster de computadoras propicia que el mismo pueda ser empleado para tareas de altos requerimientos computacionales, tales como la codificación de video de Ultra Alta Definición (UHD, del inglés Ultra High Definition) para la televisión digital. Otras grandes ventajas de la utilización de un Clúster de Alto rendimiento (HPC, del inglés High Performance Cluster) son que lo convierten en una opción atractiva son: el buen rendimiento, bajas latencias, comunicaciones de gran ancho de banda, redes escalables y accesos rápidos a archivos. No obstante, todo no está resuelto con esta herramienta se hace necesario conocer las configuraciones óptimas para lograr una codificación eficiente que garantice una alta compresión, buena calidad de imagen y bajos requerimientos de tiempo para el proceso. En este trabajo se hace un estudio en base a la codificación de video usando los formatos de compresión desarrollados haciendo énfasis en la codificación de video de UHD para la transmisión de televisión digital. Tomando en consideración lo expuesto anteriormente se plantea la siguiente situación problemática: . ¿Cómo contribuir en el desarrollo de la codificación de servicios de video en formato de Ultra Alta Definición para la televisión digital en Cuba?.
(13) INTRODUCCIÓN. 3. El objetivo general es: . Codificar eficientemente videos de Ultra Alta Definición en un clúster de computadoras para el servicio de video de la televisión digital. A partir del objetivo general se plantean los siguientes objetivos específicos 1. Analizar los principales formatos de compresión de video utilizados para la transmisión de señales audiovisuales. 2. Analizar las ventajas de la utilización de un clúster de computadoras para la codificación de video de Ultra Alta Definición. 3. Comparar la eficiencia de codificación en términos de calidad de imagen, razón de bit y tiempo de codificación de los formatos de compresión H.265 y H.264. 4. Determinar los valores óptimos de los parámetros de codificación para codificar eficientemente videos de Ultra Alta Definición en un clúster de computadoras para la televisión digital. De los objetivos se generan las siguientes interrogantes científicas a las cuales se les dan. respuesta en el desarrollo de la investigación: 1. ¿Cuáles son los principales formatos de compresión de video utilizados para la transmisión de las señales audiovisuales? 2. ¿Qué ventajas tiene la utilización de un clúster para la codificación de video usando la herramienta ffmpeg para codificar videos en Ultra Alta Definición? 3. ¿Qué resultados ofrece la codificación de video, en términos de calidad de imagen, razón de bit y tiempo de codificación, utilizando el formato de compresión H.265 con respecto al H.264 en un clúster de computadoras? 4. ¿Cuáles son los valores óptimos de los parámetros de codificación para codificar eficientemente videos de Ultra Alta Definición en un clúster de computadoras para la televisión digital? Con la realización de este trabajo se espera demostrar la eficiencia del formato de compresión H.265 sobre los demás métodos utilizados para la codificación de videos de la TVD, principalmente H.264. Los resultados que se obtendrán deberán contribuir al desarrollo de la TVD en Cuba y al finalizar la investigación se contará con un codificador H.265.
(14) INTRODUCCIÓN. 4. implementado en un clúster de alto rendimiento y con las configuraciones óptimas para la codificación con H.265. El presente proyecto es viable puesto que se cuenta con el Clúster de Alto Rendimiento de la UCLV y la UO que sería la parte más costosa de esta investigación; desde el punto de vista de implementación práctica, y tomando en consideración el hecho indudable de la tendencia a UHD, las soluciones de mercado en vez de cambiar el equipamiento existente totalmente, solo sería necesario actualizar el software/hardware tanto del codificador como del decodificador.. Organización del informe El informe consta de tres capítulos que conforman el cuerpo de la tesis. En el capítulo 1 se exponen los conceptos básicos que abarca la compresión de video. También se caracterizan los principales estándares de compresión de video que se han utilizado para la transmisión de video perteneciente a la familia H.26x haciendo énfasis en el H.265 como el nuevo estándar para la codificación de video de alta eficiencia. En el capítulo 2 se hace una descripción de las herramientas que se utilizarán para la codificación, así como del clúster de alto rendimiento utilizado, haciendo énfasis en las ventajas que ofrece para la codificación de video de Ultra Alta Definición. También se caracteriza el software ffmpeg el cual es la herramienta que permite la codificación en las diferentes normas usando las librerías que descifran la forma de realizarla según el estándar que se vaya a utilizar, en este caso H.264 y H.265. Posteriormente se hace la descripción de los experimentos, se analizan los parámetros que calidad que se medirán y se detallan las secuencias de prueba que se utilizarán en las codificaciones. En el capítulo 3 se exponen los resultados y se prosigue con la comparación de los resultados alcanzados por ambos formatos de compresión en diferentes ambientes como la calidad de imagen, la razón de bits y el tiempo de codificación. Seguidamente se analizan las ventajas de utilizar nodos multinúcleos y se determinan los parámetros óptimos de codificación para codificar videos UHD..
(15) CAPÍTULO 1. PRINCIPALES FORMATOS DE COMPRESIÓN DE VIDEO PARA LA TVD. 5. CAPÍTULO 1. PRINCIPALES FORMATOS DE COMPRESIÓN DE VIDEO PARA LA TVD.. En este capítulo se tratan los principios básicos de la compresión de vídeo, orientados principalmente a los estándares adoptados para televisión digital, particularmente la familia H.26x. Se enfatizará en el formato de compresión H.265/HEVC como el formato de compresión emergente más eficiente en la codificación de video de Ultra Alta Definición. 1.1. Compresión de la señal de video. Según (UIT-T, febrero 2000, UIT-T, mayo 2003, UIT-T, UIT-T, febrero 1998, UIT-T, abril 2015, UIT-T, marzo 1993) la compresión de video y audio pueden definirse como métodos de codificación de fuente con los que se pretende obtener la máxima eficiencia en la codificación de la señal analógica original. La compresión de video tiene sus bases en los siguientes conceptos: . Compresión sin pérdida: los que conservan los datos originales y aseguran que las imágenes sean las mismas después de la compresión y posterior descompresión. En estos sistemas, se intenta que el codificador extraiga la redundancia de la señal y envíe solo la entropía al decodificador. Sin embargo, las técnicas de compresión sin perdida no son, en general, muy efectivas con el video digital, ya que éste tiene pocas áreas de color continuo y está formado por numerosas variaciones de color (Vicens, 2011).. . Compresión con pérdidas: intenta eliminar información de las imágenes de forma que sea lo más inapreciable posible para el espectador. Se intenta eliminar la información irrelevante o no tan crítica para el observador antes de analizar los componentes importantes en la señal. Solo la entropía es almacenada o transmitida y el decodificador calcula la redundancia con la señal recibida. Esa información eliminada no puede ser recuperada (Mitchel, 2000). La cantidad de información.
(16) CAPÍTULO 1. PRINCIPALES FORMATOS DE COMPRESIÓN DE VIDEO PARA LA TVD. 6. perdida depende del grado de compresión y es proporcional a la disminución de calidad, en la figura 1.1 se muestra un ejemplo de una compresión con pérdidas.. Figura 1.1: A. Imagen original, B. Repercusiones en los bordes por una excesiva compresión, C. Detalles en los bordes de 8x8 pixeles. Fuente (Vicens, 2011). El proceso de compresión con pérdidas es irreversible, es decir que no es posible recuperar la información original a partir de la información comprimida. Tal irreversibilidad da lugar a una rápida degradación de la calidad de señal si la compresión se aplica de forma concatenada, es decir, la realización de compresiones sucesivas sobre señales decodificadas (Vicens, 2011). La compresión de video está basada en varios parámetros que miden la calidad del proceso de codificación tales como: . Relación de compresión: Se define como: 𝑐𝑟 =. . 𝑓𝑙𝑢𝑗𝑜 𝑏𝑖𝑛𝑎𝑟𝑖𝑜 𝑎 𝑙𝑎 𝑒𝑛𝑡𝑟𝑎𝑑𝑎 𝑑𝑒𝑙 𝑐𝑜𝑑𝑖𝑓𝑖𝑐𝑎𝑑𝑜𝑟 𝑓𝑙𝑢𝑗𝑜 𝑏𝑖𝑛𝑎𝑟𝑖𝑜 𝑎 𝑙𝑎 𝑠𝑎𝑙𝑖𝑑𝑎 𝑑𝑒𝑙 𝑐𝑜𝑑𝑖𝑓𝑖𝑐𝑎𝑑𝑜𝑟. (1.1). Eficiencia de codificación: por lo general, se expresa en bits por muestra o en bits por segundo está limitada por el contenido de información o entropía de la fuente. Cuanto mayor sea ésta, más difícil y compleja será la compresión (Mitchel et al., 2000).. . Complejidad de codificación: la complejidad del proceso de compresión tiene que ver directamente con la carga o esfuerzo de cómputo para implementar las funciones de codificación y decodificación. Esto afecta tanto al hardware como al software y, por lo general, se mide en función de los requerimientos de memoria y de la cantidad de operaciones aritméticas necesarias, expresada en Millones de Operaciones Por Segundo (MOPS, del inglés Million Operations Per Second) o bien de Millones de Instrucciones Por Segundo (MIPS del inglés Million Instructions Per Second). La complejidad de codificación también está relacionada con el consumo de potencia del.
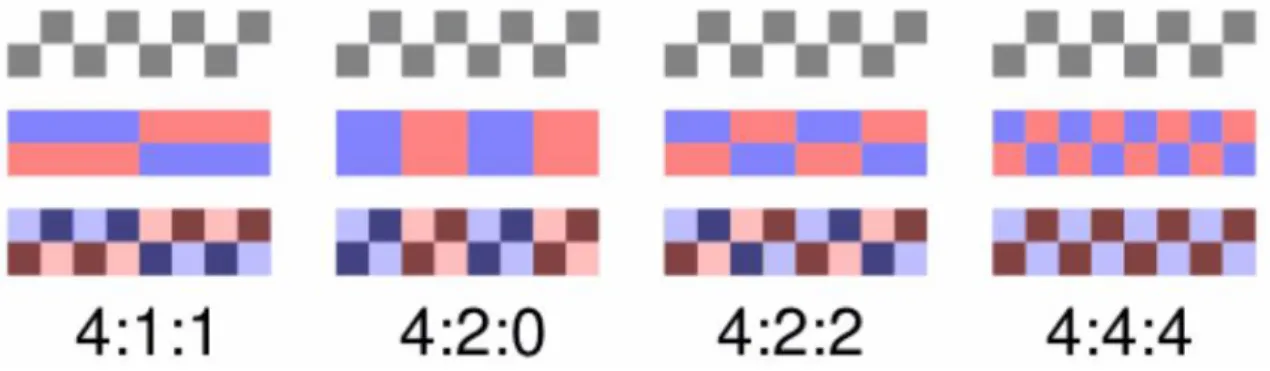
(17) CAPÍTULO 1. PRINCIPALES FORMATOS DE COMPRESIÓN DE VIDEO PARA LA TVD. 7. codificador y con el tiempo requerido para realizar el proceso de compresión, al que se designa como retardo de codificación (Vicens, 2011, Mitchel et al., 2000). . Retardo de codificación: todo proceso de compresión requiere de un cierto tiempo que, dependiendo de la aplicación, puede resultar o no, crítico. Hay aplicaciones de compresión que pueden llevarse a cabo “fuera de línea”, es decir en tiempo no real, como el procesado de imágenes médicas o las que generan algunos sistemas de percepción remota. Esto no es posible en televisión, donde todo el procesado debe hacerse en tiempo real o cuasi-real de modo que el retardo introducido por los procesos de codificación y decodificación no sea perceptivo al observador.. . Calidad de señal: en general, este concepto se aplica a la señal de salida del decodificador y, en realidad, no hay un criterio cuantitativo aceptado universalmente para definirlo. En la mayoría de la literatura, se define mediante una Relación Señal a Ruido Pico (PSNR, del inglés Peak Signal to Noise Ratio) dada por: 𝑃𝑆𝑁𝑅 = 10 log (. . 𝑒𝑛𝑒𝑟𝑔í𝑎 𝑑𝑒 𝑙𝑎 𝑠𝑒ñ𝑎𝑙 𝑎 𝑙𝑎 𝑒𝑛𝑡𝑟𝑎𝑑𝑎 𝑑𝑒𝑙 𝑐𝑜𝑑𝑖𝑓𝑖𝑐𝑎𝑑𝑜𝑟 𝑒𝑛𝑒𝑟𝑔í𝑎 𝑑𝑒 𝑟𝑢𝑖𝑑𝑜 𝑑𝑒 𝑙𝑎 𝑠𝑒ñ𝑎𝑙. ). (1.2). Caudal binario a la salida del codificador: se refiere al número de bits que se transmiten por unidad de tiempo a través de un sistema de transmisión digital o entre dos dispositivos digitales. Es la velocidad de transferencia de datos.. 1.1.1 Submuestreo de la señal de video El submuestreo de crominancia es la práctica de codificar el componente de crominancia de la señal de video, mediante su muestreo a menor frecuencia que para el componente de luminancia, aprovechando la inferior agudeza del sistema visual humano para diferencias de color que para la luminancia. Se utiliza en muchos esquemas de codificación de vídeo, tanto analógicos como digitales. Existen varias formas de submuestreo y dentro de las más usadas se encuentran las siguientes: . 4:4:4 mantiene intacta tanto la información de la luminosidad (primer "4") como la del color (los otros dos "4"s), o sea, indica que no se ha aplicado submuestreo, es decir, que las tres componentes tienen la misma resolución. Se utiliza en postproducción cinematográfica..
(18) CAPÍTULO 1. PRINCIPALES FORMATOS DE COMPRESIÓN DE VIDEO PARA LA TVD. . 8. 4:2:2 reduce el muestreo del color a la mitad, este tipo de submuestreo es utilizado en estudios de televisión, sistemas profesionales DV50 y por el formato MPEG-2, y se trata del esquema de submuestreo recomendado por la Recomendación UIT-R BT.6017 (UIT-T, 1980).. . 4:1:1 reduce el muestreo de color a la cuarta parte.. . 4:2:0 elimina uno de los valores de color dejando el otro valor en la mitad. Este sistema es utilizado por los formatos JPEG y JFIF a nivel de imagen, por el formato H.261 para videoconferencia (UIT-T, marzo 1993), por el formato MPEG-1 y algunas variantes del formato MPEG-2. El significado de cada uno de los tres números de los tipos de submuestreo es la cantidad. de muestras que se debe tomar para representar cuatro píxeles; es decir, por píxel se tomará una muestra de cada parámetro del espacio de color Y, Cb y Cr (luminancia, crominancia roja y crominancia azul respectivamente). En la siguiente figura se expone un ejemplo de los anteriores tipos de submuestreos:. Figura 1.2: Ejemplo de los distintos niveles de submuestreo. Fuente (Hanhart and Rerabek, 2013). 1.1.2 Técnicas de compresión de video Las técnicas de compresión de video se basan en una serie de algoritmos que permiten reducir la cantidad de información sin que el resultado se vea afectado. Estas técnicas además de recurrir a los procedimientos generales de compresión de datos, aprovechando además la redundancia espacial de una imagen (áreas uniformes), la correlación entre puntos cercanos, la menor sensibilidad del ojo a los detalles finos de las imágenes (Mitchel et al., 2000). En todo material real ya sea de audio o video, hay dos tipos de componentes de señal: aquellos componentes que son nuevos o impredecibles y aquellos que pueden ser anticipados..
(19) CAPÍTULO 1. PRINCIPALES FORMATOS DE COMPRESIÓN DE VIDEO PARA LA TVD. 9. Los componentes nuevos son llamados entrópicos y corresponden a la verdadera información en la señal. Los restantes son llamados redundancia ya que no son esenciales. La redundancia puede ser espacial tal como un área plana de una imagen, donde los píxeles cercanos tienen el mismo valor, o temporal, donde se explota la similitud de imágenes sucesivas (Mitchel et al., 2000). Primero se decodifica la imagen en sus componentes originales, RGB (Rojo, Verde, Azul), Y (Luminancia) o cualquier método de almacenamiento de video digital. Tras esto se le aplican los algoritmos que permiten la compresión (Gil and Santos, 2006). Algunas de estas técnicas son las siguientes: . Truncamiento, reducción del número de bits por cada componente, pixel, o resolución. Esta técnica es la más simple de todas, y su ventaja es que la complejidad de procesamiento es mínima.. . RLC (del inglés Run Length Coding), son las regiones que no cambian de una escena a otra, se almacenan y se les da un número, en la siguiente escena, si la región no cambia, se almacena el número de región y no sus píxeles constituyentes.. . CAVLC (Codificación Adaptativa Según el Contexto de Longitud Variable), permite procesar la información que se quiere transmitir o almacenar en un dispositivo de forma que ocupe el mínimo espacio posible. De esta manera será posible transmitir una imagen en menos tiempo o hacer que ocupe menos espacio en el dispositivo de almacenamiento. Una característica importante de esta codificación es que no tiene pérdidas y, por lo tanto, se podrá recuperar la información original al aplicar el proceso inverso (USACH MOLINA, 2016).. . CABAC (del inglés Context Adaptative Binary Arithmetic Code), tiene la misma funcionalidad que CAVLC con la particularidad que reduce el número de bits a transmitir en un 10% con respecto CAVLC (Marpe, 2002).. . Código de Longitud Variable Universal (UVLC, del inglés Universal Variable Length Code), es un método que elimina la redundancia estadística en el algoritmo de compresión CAVLC, y se encuentra generalmente en la última etapa en el algoritmo de compresión de vídeo H.264. Es un método de codificación de fuente que codifica la entropía. Sustituye las palabras de código de una fuente, por una longitud.
(20) CAPÍTULO 1. PRINCIPALES FORMATOS DE COMPRESIÓN DE VIDEO PARA LA TVD. 10. proporcional a la frecuencia de salida de dicha palabra. De esta forma se reduce las palabras que salen con mayor frecuencia a una palabra clave menor, reduciendo así la cantidad de datos a transmitir o almacenar (Chen, 2013). . Interpolación de regiones, similar al anterior, pero permite que la región tenga cambios, así se almacena la región la primera vez, y mediante técnicas de interpolación, se reconstruye la siguiente con ciertos cambios que también se almacenan (Hermosilla, 2006).. . Predicción de valores, DPCM y ADPCM (del inglés Differential Pulse Code Modulation y Adaptive DPCM respectivamente) se usan para almacenar píxeles o regiones y reducir los posibles cambios que pueda haber a un rango menor.. . Transformación de regiones, básicamente, se cambia la información de una región por otra que nos devuelva un resultado visual similar. Algunos de los algoritmos usados para esta transformación son la Transformada Discreta del Coseno (DCT, del inglés Discrete Cosine Transform).. . Compensación de Movimiento, usa varias de las técnicas anteriores, decidiendo qué partes sufren cambios menores, divide la imagen en bloques y realiza cambios en los posibles valores obtenidos. Si los cambios entre regiones son mínimos, trata de no hacer cambio ninguno o predecir los valores.. . Detección de bordes con precisión de subpíxel (interpolación), se basa en la obtención de nuevos puntos partiendo del conocimiento de un conjunto discreto de puntos. Este es un procedimiento para incrementar la resolución en la detección de bordes en imágenes digitales. En el cual se aplica la interpolación en la imagen, con el objetivo de obtener los valores en una malla más fina. Sobre la imagen interpolada se aplican los algoritmos de detección de bordes de Prewitt, Sobel y de Canny. Pretendiéndose así aumentar la resolución de los bordes detectados por encima de los límites impuestos por el tamaño del píxel de la imagen. Algunos de los problemas que ocasionan estas técnicas son la pérdida apreciable de información del color, contraste/brillo erróneo o degradación de la señal que se da por errores en los.
(21) CAPÍTULO 1. PRINCIPALES FORMATOS DE COMPRESIÓN DE VIDEO PARA LA TVD. 11. codificadores o decodificadores teniendo como resultado cuadros corruptos (Hermosilla et al., 2006). . DCT, es una implementación específica de la transformada de Fourier donde la imagen es transformada de su representación espacial a su frecuencia equivalente. Cada elemento de la imagen se representa por ciertos coeficientes de frecuencia. Las zonas con colores similares se representan con coeficientes de baja frecuencia y las imágenes con mucho detalle con coeficientes de alta frecuencia. Tiene una buena capacidad de compactación de la energía al dominio transformado, es decir, que concentrar la mayor parte de la información en pocos coeficientes transformados. La transformada es independiente de los datos que recibe y el algoritmo aplicado no varía con estos datos recibidos. Produce pocos errores en los límites de los bloques imagen. La minimización de los errores a los bloques imagen permite reducir el efecto de bloque en las imágenes reconstruidas. La capacidad de interpretar los coeficientes en el punto de vista frecuencial permite aprovechar al máximo la capacidad de compresión (Gonzáles, 2012).. Codificación intra o espacial, hace referencia a la compresión de las imágenes sin referencia a las demás. Se vale de las similitudes entre píxeles adyacentes en zonas de la imagen lisas, y de las frecuencias espaciales dominantes en zonas de color muy variado. Esta codificación puede dividirse en codificación por predicción y codificación de la transformada, usando la transformada del coseno (Vegas, 2011). Codificación inter o temporal, la codificación inter aprovecha la ventaja que existe cuando las imágenes sucesivas son similares. En lugar de enviar la información de cada imagen por separado, el codificador inter envía la diferencia existente entre la imagen previa y la actual en forma de codificación diferencial. De esta forma, se elimina la redundancia temporal, usando información de las imágenes ya enviadas y enviando únicamente las zonas de la imagen que han cambiado de un fotograma a otro. El codificador necesita de una imagen, la cual fue almacenada con anterioridad (key frame) para luego ser comparada con imágenes sucesivas y, de forma similar, se requiere de una imagen previamente almacenada para que el decodificador desarrolle las imágenes siguientes (Mitchel et al., 2000)..
(22) CAPÍTULO 1. PRINCIPALES FORMATOS DE COMPRESIÓN DE VIDEO PARA LA TVD. 12. Codificación bidireccional, esta codificación deja información para ser tomada de imágenes anteriores y posteriores a la imagen observada. Si el fondo ya ha sido revelado, y este será presentado en una imagen posterior, la información puede ser movida hacia atrás en el tiempo, creando parte de la imagen con anticipación (Álvarez, 1998). Con esta codificación el factor de compresión global se ve favorecido ya que son las imágenes que más frecuentes en una secuencia, sin embargo, esto se paga con un tiempo de codificación/decodificación más largo, un aumento en el tamaño de la memoria necesaria tanto en el codificador como en el decodificador y una relación de compromiso Otra desventaja de la codificación bidireccional es que un uso excesivo de ella provoca una disminución en la calidad de la imagen (Mollat, 2011). A modo general todas estas técnicas de compresión implican eliminación de información visual para lograr una mayor compresión de la señal lo cual trae consigo efectos negativos a la hora de la reproducción de la multimedia. Uno de estos típicos problemas es el efecto Gibbs, que se da en recuadros con alto contraste o cambio brusco de color o textura. Se da por el error relativo en la transformación trigonométrica de la información de color/luminancia (U.N.S, 2011). Pero el fallo más característico y apreciable es el "Blockiness" (este efecto tiene lugar cuando se comprime una imagen y luego se reproduce en resoluciones mayores, es conocido también como efecto pixeleado), haciendo que los cuadros o regiones en que se ha dividido la imagen aparezcan perfectamente visibles debido a la gran diferencia de calidad con respecto a la imagen original. Se debe a la baja razón de bits para esa secuencia (Gil and Santos, 2006). 1.2. Estándares de compresión de video para la televisión digital. Los formatos de compresión de video para la televisión digital han de cumplir una serie de requisitos relacionados con la transmisión de información de video por una red con retrasos y pérdidas. Estos formatos deben conseguir una gran escalabilidad, una complejidad computacional baja, una gran capacidad de recuperación ante pérdidas en la red y una gran agilidad en la codificación/decodificación. A la vez, deben conseguir altas tasas de cuadros por segundo y la mejor calidad de imagen posible. Existen dos familias principales de compresión de video:.
(23) CAPÍTULO 1. PRINCIPALES FORMATOS DE COMPRESIÓN DE VIDEO PARA LA TVD. . 13. MPEG: es un Grupo de Expertos de Imágenes en Movimiento que se formó por la Organización Internacional de Normalización (ISO, del inglés International Organization for Standardization) y la Comisión Electrotécnica Internacional (IEC, del inglés International Electrotechnical Commission) para establecer estándares para el audio y la transmisión video. La metodología de compresión MPEG se considera “asimétrica” ya que el codificador es más complejo que el decodificador. El codificador tiene que ser algorítmico o adaptativo, mientras que el decodificador lleva a cabo acciones fijas esto se considera una ventaja en aplicaciones tales como la radiodifusión, donde el número de codificadores costosos y complejos es pequeño, pero el número de descodificadores simples y de bajo costo es grande. El enfoque de la estandarización de MPEG es novedoso, porque no es el codificador el que está estandarizado, pero si la forma que un decodificador interpreta la cadena de bits (Mitchel et al., 2000).. . H.26x: familia de formatos de compresión desarrollada por la Unión Internacional de Telecomunicaciones (ITU-T, del inglés International Telecommunication Union) y VCEG desde la década de los 80 hasta la actualidad, la cual abarca formatos para la transmisión de video por cualquier medio con mejoras de calidad en cada una de las actualizaciones de dicha familia.. En los siguientes subepígrafes y epígrafe se hace alusión a cada una de ellas haciendo énfasis en las renovaciones con respecto a la anterior. 1.2.1 Formato de compresión de video H.261 El formato H.261 es un estándar de codificación de video de la UIT, diseñado originalmente para la transmisión a través de líneas Red Digital de Servicios Integrados (ISDN, del inglés Integrated Services Digital Network) (UIT-T, marzo 1993). Es estándar adopta una combinación de predicción inter imágenes para utilizar redundancia temporal y codificación de la transformada de la señal restante para reducir la redundancia espacial. El decodificador tiene la capacidad de compensación de movimiento, permitiendo la incorporación facultativa de esta técnica en el codificador. El estándar está orientado fundamentalmente hacia la utilización de velocidades binarias entre unos 40 kbit/s y 2 Mbit/s. El tren de bits transmitido contiene un código BCH (del inglés.
(24) CAPÍTULO 1. PRINCIPALES FORMATOS DE COMPRESIÓN DE VIDEO PARA LA TVD. 14. Bose Chaudhuri Hocquengham) de corrección de errores sin canal de retorno. Su utilización en el decodificador es facultativa (UIT-T, marzo 1993). 1.2.2 Formato de compresión de video H.262 El estándar se elabora con el fin de codificación genérica de imágenes en movimiento y sonido asociado para diversas aplicaciones, tales como medios de almacenamiento digital, radiodifusión de televisión y comunicación (UIT-T, febrero 2000). Define tres tipos de imágenes principales: . Intracodificadas (imágenes I), se codifican sin referencia a otras imágenes, proporcionan puntos de acceso a la secuencia codificada donde la decodificación puede comenzar.. . Predictivas (imágenes P), se codifican más eficazmente utilizando la predicción con compensación de movimiento a partir de una imagen pasada intracodificada o con codificación predictiva y se utilizan generalmente como una referencia para la predicción posterior.. . Bidireccionales (imágenes B), proporcionan el más alto grado de compresión, pero requieren imágenes de referencia pasadas y futuras para la compensación del movimiento.. La organización de los tres tipos de imágenes en una secuencia es muy flexible. La elección se deja al codificador y dependerá de los requisitos de la aplicación. La redundancia espacial se sigue tratando con la DCT en bloques de 8x8 donde son ponderados antes de ser cuantificados. 1.2.3 Formato de compresión de video H.263 Es un estándar de la ITU-T diseñado para comunicaciones con bajo ancho de banda (UITT, febrero 1998). La Recomendación H.263 no restringe la tasa binaria. Sin embargo, su objetivo es hasta velocidades de 64 Kb/s. En aplicaciones sobre redes telefónicas conmutadas, mediante modems de 28.8 Kbit/s, la máxima velocidad de transmisión de video puede ser alrededor de 20 Kbit/s, ya que el ancho de banda restante debe reservarse para voz, datos y señales de control (Aarhus and Regnesentral, 2003). Se adopta un híbrido de predicción entre imágenes para utilizar redundancia temporal y codificación de la transformada de la señal restante para reducir la redundancia espacial. El.
(25) CAPÍTULO 1. PRINCIPALES FORMATOS DE COMPRESIÓN DE VIDEO PARA LA TVD. 15. decodificador tiene capacidad de compensación de movimiento, lo que permite la incorporación opcional de esta técnica en el codificador. Se utiliza una precisión de mitad de píxel para la compensación de movimiento, en vez de la precisión de píxel entero y filtro de bucle de la Recomendación H.261. En la transmisión de los símbolos se emplea la codificación de longitud variable (UIT-T, febrero 1998). Tiene un modo opcional de escalabilidad temporal, espacial y SNR. La escalabilidad significa que un tren de bits se compone de una capa básica y de una o más capas de mejora asociadas. La capa básica es un tren de bits decodificable separadamente. Las capas de mejora se pueden decodificar junto con la capa básica para aumentar la calidad percibida incrementando el periodo de transmisión, la calidad o el tamaño de la imagen. La escalabilidad SNR se refiere a la información de mejora para aumentar la calidad de la imagen sin incrementar resolución de la imagen. La escalabilidad espacial se refiere a la información de mejora para aumentar la calidad de la imagen incrementando la resolución de la imagen en la dirección horizontal, en la dirección vertical, o en ambas (UIT-T, febrero 1998). 1.2.4 Formato de compresión de video H.264 La intención del proyecto H.264/AVC (Codificación de Video Avanzado) fue la de crear un estándar capaz de proporcionar una buena calidad de imagen con tasas binarias notablemente inferiores a los estándares previos, además de no incrementar la complejidad de su diseño (UIT-T, mayo 2003). El uso inicial del AVC estuvo enfocado hacia el video de baja calidad para videoconferencia y aplicaciones por Internet, basado en 8 bits/muestra y con un muestreo ortogonal de 4:2:0. Esto no daba salida al uso de este formato de compresión en ambientes profesionales que exigen resoluciones más elevadas, necesitan más de 8 bits/muestra y un muestreo de 4:4:4 o 4:2:2, funciones para la mezcla de escenas, tasas binarias más elevadas, poder representar algunas partes de video sin pérdidas y utilizar el sistema de color por componentes RGB. Por este motivo surgió la necesidad de programar extensiones que soportasen esta demanda (UIT-T, mayo 2003). Este conjunto de extensiones denominadas de "perfil alto" son: . La extensión High que soporta 4:2:0 hasta 8 bits/muestra..
(26) CAPÍTULO 1. PRINCIPALES FORMATOS DE COMPRESIÓN DE VIDEO PARA LA TVD. 16. . La extensión High-10 que soporta 4:2:0 hasta 10 bits/muestra.. . La extensión High 4:2:2 que soporta hasta 10 bits/muestra.. . La extensión High 4:4:4 que soporta hasta 4:4:4 y 12 bits/muestra y la codificación de regiones sin pérdidas.. Se encuentran las mismas imágenes que en las normas precedentes (Imágenes I, P y B) y dos nuevas, la SP y la SI (del inglés Switching P y Switching I respectivamente) que sirven para codificar la transición entre dos flujos de video. Permiten pasar de un video a otro utilizando predicción temporal o espacial como antes, pero con la ventaja de que la reconstrucción de valores específicos exactos de la muestra, aunque se utilicen imágenes de referencia diferentes o un número diferente de imágenes de referencia en el proceso de predicción. En el estándar el proceso de compensación de movimiento propone una gran variedad de formas y de particiones de bloques. Cada macrobloque, aparte del tamaño original (16x16 píxeles), puede ser descompuesto en subbloques de 16x8, 8x16 u 8x8 píxeles. En este último caso, es posible descomponer a su vez cada subbloque de 8x8 píxeles en particiones de 8x4, 4x8 o 4x4 píxeles. Antes, el estándar más novedoso introducía particiones de 8x8. Esta variedad de particiones proporciona una mayor exactitud en la estimación, a lo que se suma una precisión que puede llegar hasta un cuarto de píxel (UIT-T, mayo 2003). H.264 también integra un filtro antibloques que mejora la eficacia de compresión y la calidad visual de las secuencias de vídeo eliminando efectos indeseables de la codificación como por ejemplo el efecto de bloques y para la codificación de la entropía el estándar lo realiza de tres formas diferentes: UVLC, CAVLC y CABAC (UIT-T, mayo 2003). H.264 tiene una Capa de Abstracción de Red (NAL, del inglés Network Abstraction Layer) cuyo principal objetivo es facilitar una representación del contenido, adaptada al soporte de almacenamiento o de transmisión. Dicha representación se puede realizar tanto para aplicaciones de video telefonía como para aplicaciones de almacenamiento, difusión, o flujo. Gracias a la NAL, se ha conseguido una significante mejora en términos de eficiencia de tasa de transmisión y distorsión (UIT-T, mayo 2003)..
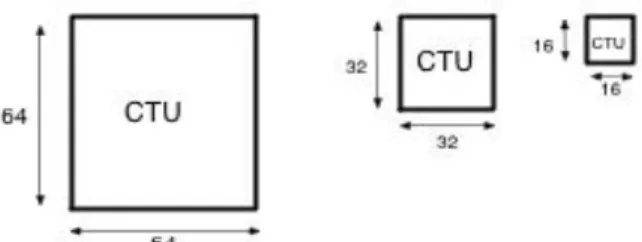
(27) CAPÍTULO 1. PRINCIPALES FORMATOS DE COMPRESIÓN DE VIDEO PARA LA TVD. 17. El formato de compresión H.264 posee cuatro algoritmos fundamentales de prevención de pérdidas de datos: . La ordenación flexible de macrobloques y la ordenación arbitraria de slices son técnicas para reestructurar la representación de las regiones fundamentales (macrobloques) aunque también pueden ser utilizadas para otros objetivos.. . La partición de datos proporciona la capacidad de separar los elementos de sintaxis más importantes de los menos importantes en paquetes de datos diferentes, permitiendo el uso de protección de error desigual.. . El algoritmo de slices redundantes permite a un codificador enviar una representación suplementaria de una región de imagen que puede ser usada si la representación primaria es corrompida o perdida.. 1.3. Formato de compresión de video H.265. El estándar H.265 o HEVC para la codificación de video de alta eficiencia, fue aprobado en enero del 2013. Es una norma que define un formato de compresión de video, sucesor de H.264/AVC desarrollado conjuntamente por la ISO/IEC MPEG y la ITU-T VCEG (UIT-T, abril 2015). El formato H.265 soporta video con una mayor resolución. Mejora además los métodos de procesamiento paralelo y tiene la capacidad de duplicar la tasa de compresión, comparado con los mismos parámetros del actual H.264, lo que lo hace definitivamente superior ya que puede soportar video 8K Ultra Alta definición y resoluciones de hasta (8192 x 4320) (Pourazad et al., julio 2012). 1.3.1 Nueva unidad básica En los estándares previos el macrobloque fue el núcleo de la capa de codificación, conteniendo bloques de muestras de luminancia de 16×16, en el caso habitual de muestreo de color de 4:2:0, con dos bloques correspondientes a las muestras de croma de 8×8. En HEVC la estructura análoga es la Unidad de Codificación en Árbol (CTU, del inglés Coding Tree Unit) que tiene un tamaño seleccionado por el codificador. Dicho tamaño puede ser mayor que un macrobloque tradicional y constituye una unidad lógica, o sea, una partición.
(28) CAPÍTULO 1. PRINCIPALES FORMATOS DE COMPRESIÓN DE VIDEO PARA LA TVD. 18. lógica de la imagen de video. Estos CTU tiene dimensiones de 16x16, 32x32 y 64x64 pixeles según se observa en la figura 1.3 (Hernández et al., noviembre 2014).. Figura 1.3: Dimensiones de una CTU. Fuente (Hernández et al., noviembre 2014). Cada CTU está conformada por tres Bloques de Codificación en Árbol (CTB, del inglés Coding Tree Block) de los cuales dos pertenecen a las muestras de crominancia y uno a las de luminancia. Cada CTB sigue teniendo el mismo tamaño de la CTU. En dependencia de la parte de la imagen de video la CTB será del tamaño que decida la predicción inter o intra imagen (Bassen and Bross, 2013, Sze et al., 2015). Un CTB puede contener solo una Unidad de Codificación (CU, del inglés Coding Unit) o puede ser separado en múltiples CUs, y esta, a su vez, está constituida por un Bloque de Codificación (CB, del inglés Coding Blocks) de luminancia y dos de crominancia. La decisión para codificar un área de la imagen ya sea usando inter o intrapredicción de imagen se hace a nivel de la CU. Dependiendo de la decisión que se tome para el tipo de predicción básica, los CBs de luminancia y de croma se pueden dividir aún más en cuanto a tamaño, y ser predichos a partir de Bloques de Predicción (PBs, del inglés Prediction Blocks) de luminancia y de croma. HEVC soporta tamaños variables de PB que van desde muestras de 64×64 hasta 4×4 (Hernández et al., noviembre 2014). El residuo del CB de luminancia puede ser idéntico al Bloque de Transformada (TB, del inglés Transform Block) de luminancia o puede dividirse en TBs de luminancia aún más pequeños. De forma similar este principio se aplica a los TBs de croma. Para los tamaños de TB cuadrados de 4×4, 8×8, 16×16, y 32×32, se definen funciones base enteras similares a la DCT. En la figura 1.6 se muestra un esquema completo de las unidades de codificación mencionadas (UIT-T, abril 2015)..
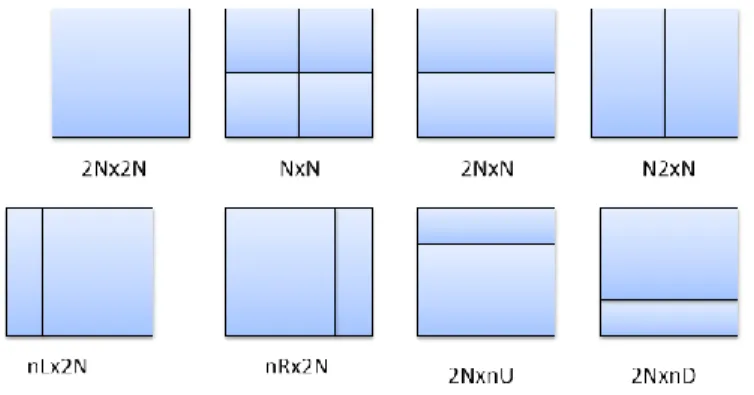
(29) CAPÍTULO 1. PRINCIPALES FORMATOS DE COMPRESIÓN DE VIDEO PARA LA TVD. 19. 1.3.2 Compensación de movimiento Comparado con los CBs intra-codificados, HEVC soporta más formas de división de PBs para los CBs inter-codificados. Los modos de división PARTE 2Nx2N, PARTE 2NxN y PARTE Nx2N indican los casos en que el CB no está dividido, dividido horizontalmente en dos PBs iguales y dividido verticalmente en dos PBs iguales, respectivamente. PARTE NxN especifica que el CB está dividido en cuatro PBs de igual tamaño, pero este modo solo se acepta cuando el tamaño del CB es el menor permitido. Además, existen cuatro tipos de división que soportan la separación del CB en dos PBs que tienen diferentes tamaños: PARTE 2NxnU, PARTE 2NxnD, PARTE nLx2N y PARTE nRx2N. Estos últimos tipos son conocidos como divisiones de movimiento asimétricas(Hanhart and Rerabek, 2013, Velasco, 2000). Estas divisiones pueden observarse en la figura 1.4.. Figura 1.4: División de bloques para la compensación de movimiento. Fuente (Hernández et al., noviembre 2014). Para los vectores de movimiento se sigue utilizando una precisión de ¼ de muestra. Esto contrasta con el proceso utilizado en AVC, el cual aplicaba un proceso de dos interpolaciones, generando primero los valores de una o dos muestras vecinas en posiciones de media muestra usando filtrado 6- tap, redondeando el resultado intermedio, y entonces promediando dos valores en posiciones enteras o de media muestra. HEVC en su lugar, usa un proceso sencillo de interpolación separable y consistente para generar todas las posiciones fraccionarias sin operaciones de redondeo intermedias el cual mejora la precisión y simplifica la arquitectura de la interpolación fraccionaria de muestras. Por cada PB pueden transmitirse tanto uno como dos vectores de movimiento, dando como resultado una codificación de unipredicción o de bi-predicción respectivamente (Schiskiuy, 2010)..
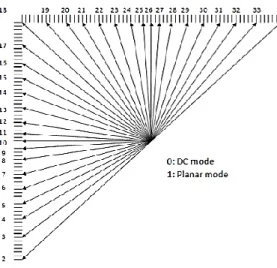
(30) CAPÍTULO 1. PRINCIPALES FORMATOS DE COMPRESIÓN DE VIDEO PARA LA TVD. 20. 1.3.3 Intrapredicción de imágenes Cuando no se realiza compensación de movimiento las muestras decodificadas de los bordes de los bloques adyacentes se utilizan como datos de referencia para la predicción espacial en regiones PB. La intra-predicción soporta 33 modos direccionales (en AVC solo se soportaban 8 modos direccionales), modos de predicción plana (adecuación de superficie) y de DC, ver figura 1.5. Los modos de intra-predicción seleccionados se codifican obteniendo los más probables (por ejemplo, las direcciones de predicción) basados en los PBs vecinos previamente decodificados. La predicción direccional soporta tamaños de bloques de predicción que van desde 4×4 hasta 32×32, para los otros dos modos de predicción se soportan tamaños de 64×64. La partición de bloques en el caso de la intra-predicción soporta las divisiones PARTE 2N×2N y PARTE N×N, similar a la compensación de movimiento estas divisiones significan que no habrá división o que se dividirá en cuatro bloques de predicción, esta última sólo se permite para los tamaños de bloques mínimos.. Figura 1.5: Modos de intra-predicción de HEVC. Fuente (Pourazad et al., julio 2012). 1.3.4 Bloque de transformada Para lograr sencillez, se especifica sólo una matriz entera para la longitud de 32 puntos, y se usan para otros tamaños versiones sub-muestreada de la misma. Para la transformada de 4×4 de los residuos de la intra-predicción de imagen, se especifica de manera alternativa una transformada entera que se deriva de una forma de Transformada de Seno Discreto (DST, del inglés Discrete Sine Transform), en términos de complejidad, la transformada del tipo DST de 4x4 no demanda muchos más recursos que la transformada del.
(31) CAPÍTULO 1. PRINCIPALES FORMATOS DE COMPRESIÓN DE VIDEO PARA LA TVD. 21. tipo DCT de 4x4, y provee aproximadamente una reducción del flujo de bits de un 1% en codificación intra-predictiva. 1.3.5 Codificación de entropía El CABAC se utiliza para realizar la codificación por entropía. Este es similar al esquema de CABAC utilizado en AVC, pero tiene varias mejoras experimentales que aumentan la velocidad del procesamiento total (especialmente para arquitecturas de procesamiento en paralelo), el rendimiento de compresión, además reducen sus requerimientos de memoria. El primer proceso que realiza el CABAC es el de la binarización, ya que la estrategia de codificación de CABAC se basa en encontrar un método de codificación eficiente utilizando un esquema binario como un tipo de pre-procesado para los pasos posteriores. En el proceso de binarización, cuando entra un elemento no binario, éste se pone en una secuencia binaria de longitud variable (bin-string), este nuevo dígito se llama bin. Con este paso se consigue la conversión a binario del elemento. Entonces cuando entra un valor binario no se necesita ningún tipo de conversión y, por lo tanto, se puede saltar el paso de binarización. De esta manera, los símbolos de entrada para el codificador aritmético son siempre valores binarios (Hernández et al., noviembre 2014). 1.3.6 Filtrado antibloques y sao En el lazo de inter-predicción de imagen se opera un filtro de antibloques similar al usado en AVC. Sin embargo, el diseño se simplifica en interés de los procesos de filtrado y de toma de decisiones, y se hace más compatible con el procesamiento en paralelo. El filtro antibloques se aplica a todas las muestras adyacentes a un límite de un PU o al de un TU (del inglés Unit prediction y Unit Transform respetivamente) excepto en el caso cuando este límite también es el límite de la imagen. A diferencia de AVC, donde el filtro antibloques se aplica en una base de la rejilla de muestras de 4x4, en HEVC sólo se aplica a los bordes alineados en una rejilla de muestras de 8x8, tanto para las muestras de luminancia como para las de croma. Esta restricción es de mucha ayuda para reducir la complejidad computacional del peor caso, sin provocar una notable degradación de la calidad visual de la imagen. Esto también mejora las operaciones de procesamiento en paralelo previniendo interacciones en cascada entre operaciones de filtrado cercanas. En HEVC, el orden de procesamiento del filtro antibloques está definido de la siguiente manera: primero se realiza el filtrado horizontal.
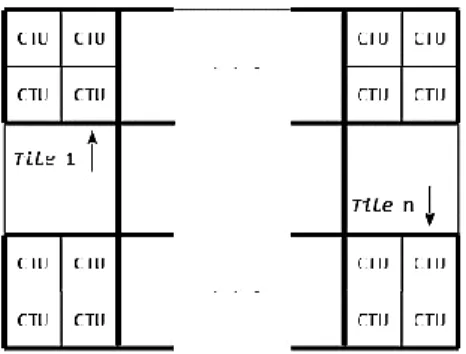
(32) CAPÍTULO 1. PRINCIPALES FORMATOS DE COMPRESIÓN DE VIDEO PARA LA TVD. 22. para los bordes verticales para toda la imagen, luego tiene lugar el filtrado vertical para los bordes horizontales. Este orden específico posibilita que tanto uno como otro, (los procesos múltiples de filtrado horizontal o vertical) puedan aplicarse en paralelo (UIT-T, abril 2015). El SAO (del inglés Sample Adaptive Offset) reduce los artefactos en el interior de las CBs, que se producen con transformadas de mayor tamaño (16x16 y 32x32). El SAO reduce su complejidad al trabajar a nivel de CTU. Esta mejora de la calidad perceptual, pero en ocasiones empeora los valores de la calidad objetiva, en la figura 1.6 se muestra un ejemplo de aplicación de SAO (Hernández et al., noviembre 2014).. Figura 1.6: Ejemplo de aplicación de SAO (A), sin SAO (B). Fuente (Bassen and Bross, 2013). 1.3.7 Herramienta de procesamiento en paralelo En HEVC se introducen nuevas características para mejorar la capacidad de procesamiento en paralelo o modificar la estructura de los datos de los slices para los propósitos del empaquetamiento. Cada uno de ellos puede tener beneficios en contextos de aplicaciones en particular, y depende usualmente del que implementa un codificador o un decodificador si se toma ventajas de esas características y cómo hacerlo. La primera de estas herramientas son las losas (tiles) las cuales son regiones rectangulares con las que se dividen las imágenes, ver figura 1.7. El objetivo principal de las losas es incrementar la capacidad del procesamiento en paralelo antes que de proveer adaptabilidad a los errores. Las tiles son regiones de una imagen que son independientemente decodificables y se codifican con alguna información de cabecera compartida. Por consiguiente, se pueden utilizar adicionalmente para el propósito de acceso aleatorio a regiones locales en las imágenes de video. Una configuración típica de las losas de una imagen consiste en la.
(33) CAPÍTULO 1. PRINCIPALES FORMATOS DE COMPRESIÓN DE VIDEO PARA LA TVD. 23. segmentación de la imagen en regiones rectangulares con aproximadamente igual número de CTUs en cada losa. Las losas proveen paralelismo a un nivel más grueso (imagen/subimagen) de granularidad y no es necesaria ninguna sincronización refinada para su uso (Velasco, 2000).. Figura 1.7: Subdivisión de una imagen en tiles. Fuente (Hernández et al., noviembre 2014) Otra herramienta para el procesamiento en paralelo es el Procesamiento en paralelo de frente de onda. Cuando se activa el Procesamiento Paralelo de Frente de Onda (WPP, del inglés Wavefront Parallel Processing), un slice se divide en filas de CTUs. La primera fila se procesa de forma ordinaria, la segunda fila puede comenzar a procesarse después de solo unas pocas decisiones tomadas en la primera fila, la tercera fila puede comenzar a ser procesada después de solo unas pocas decisiones tomadas en la segunda fila y este mismo procedimiento continúa con las demás filas, tal como se muestra en la figura 1.8. Los modelos de contexto del codificador por entropía en cada fila se deducen de las filas precedentes con pequeñas demoras de procesamiento fijas. El WPP provee una forma de procesamiento en paralelo para niveles más bien finos de granularidad, es decir, dentro de un slice. El WPP puede a menudo ofrecer un mejor rendimiento de compresión que las losas (y evitar algunos efectos visuales que pueden ser inducidos por las losas). Por último, se define una estructura conocida como “slices dependientes”, que permite a los datos asociados con un punto de entrada particular de un frente de onda o con una losa, que se transporten en una unidad NAL separada y de este modo se logra que los datos disponibles al sistema para el empaquetamiento fragmentado tengan menor latencia que si hubiesen sido codificados todos juntos en un slice. Un slice dependiente para un punto de entrada de un frente de onda se puede decodificar solo después de que al menos una parte del proceso de decodificación de otro slice se haya realizado. Los slices dependientes son principalmente útiles en la.
(34) CAPÍTULO 1. PRINCIPALES FORMATOS DE COMPRESIÓN DE VIDEO PARA LA TVD. 24. codificación de bajo retardo, donde otras herramientas en paralelo pueden afectar el rendimiento de la compresión (Velasco, 2000).. Figura 1.8: Procesamiento de una imagen con WPP habilitado. Fuente (Hernández et al., noviembre 2014). 1.4 . Conclusiones del capítulo La compresión de video es un tema que se desarrolla en base a las exigencias de calidad o transmisión de la señal, según las prestaciones. Para ello se han desarrollado varios estándares que permiten la transmisión y reproducción de la señal de video en distintos tipos de medios y condiciones. Todos estos estándares responden a técnicas de compresión con pérdidas, las cuales logran reducir significativamente el caudal binario a cambio de una reducción en la calidad de la imagen, perceptible o no para el espectador, en dependencia del propósito.. . Los principales parámetros que miden la compresión de video son la calidad de imagen en valores de PSNR, caudal binario de salida, complejidad y retardo de codificación.. . Las nuevas tecnologías demandan un caudal binario pequeño y una calidad de imagen muy buena con mucho detalle, dos factores inversamente proporcionales, lo cual se hace una tarea difícil. Sin embargo, el nuevo formato de compresión H.265 logra reducir grandemente la razón de bit gracias a las nuevas técnicas de codificación que implementa, así como las nuevas unidades de codificación diferentes al macrobloque, nuevos filtros que mejoran la calidad de imagen (SAO), nuevas herramientas para la codificación en paralelo que hace el procesamiento más rápido y eficiente, solo por citar algunos..
(35) CAPÍTULO 2. COMPUTACIÓN DE ALTO RENDIMIENTO PARA LA CODIFICACIÓN DE VIDEO DE ULTRA ALTA DEFINICIÓN. 25. CAPÍTULO 2. COMPUTACIÓN DE ALTO RENDIMIENTO PARA LA CODIFICACIÓN DE VIDEO DE ULTRA ALTA DEFINICIÓN. El presente capítulo está encausado en describir los materiales, métodos y herramientas para lograr la implementación de codificaciones de video mediante computación de alto rendimiento. Con tal fin, se parte de una breve reseña de las características de un clúster y su principio de funcionamiento. De modo adicional, se describirá el manejo de la herramienta de software ffmpeg y las librerías necesarias para la codificación de video H.264 y H.265. Por último, se hará una descripción de las secuencias de pruebas empleadas, los parámetros de calidad que se medirán en dichas secuencias y la configuración de las codificaciones que se efectuarán para lograr estos parámetros. 2.1. Ventajas de la utilización de un clúster de computadoras para la codificación de video.. La codificación de video es un proceso minucioso ya que las técnicas de compresión implementadas analizan todas las imágenes de una secuencia de video y los elementos de cada imagen (píxeles) para realizar una compresión lo más estricta posible. A medida que el video tenga una mayor resolución y más exigencias de calidad de imagen, mayor serán los requerimientos de procesamiento para lograr una codificación con dichos términos. El potencial de cómputo requerido para los casos anteriormente definidos no se encuentra en computadoras convencionales, sin embargo, si varias computadoras se interconectaran para realizar una misma tarea el proceso sería más eficiente, la herramienta a la que se hace referencia es un clúster de computadoras. Un clúster es una solución computacional estructurada a partir de un conjunto de sistemas computacionales muy similares entre sí (grupo de computadoras). Interconectados mediante alguna tecnología de red de alta velocidad y configurados de forma coordinada para dar la ilusión de un único recurso, cada uno de estos sistemas estará proveyendo un mismo servicio.
(36) CAPÍTULO 2. COMPUTACIÓN DE ALTO RENDIMIENTO PARA LA CODIFICACIÓN DE VIDEO DE ULTRA ALTA DEFINICIÓN. 26. o ejecutando una (o parte de una) misma aplicación paralela. Un clúster debe tener como característica inherente la compartición de recursos: ciclos de la Unidad Central de Procesamiento (CPU del inglés Central Processing Unit), memoria, datos y servicios (Iván et al., 2006). El problema que se intenta resolver con estos clústeres es el de disponer de capacidad computacional equivalente al encontrado en poderosas y costosas supercomputadoras paralelas tradicionales (Cray/SGI T3E) según (Gordon and J., 2001), pero empleando componentes de bajo costo y ampliamente disponibles (commodities). Los altos requerimientos computacionales a los que se hace mención, son típicos en aplicaciones como algoritmos genéticos, simulación de líneas de fabricación, aplicaciones militares, bases de datos, síntesis de imágenes, recuperación de imágenes por contenido, simulación de modelos para clima, análisis de sismos, algoritmos para solución a problemas de electromagnetismo, dinámica de fluidos, química cuántica, biomedicina, entre otras (Buyya, 1999). Un clúster de computadoras está enfocado a resolver una de las tres metas siguientes: Alto rendimiento Para tareas que requieren gran poder computacional, grandes cantidades de memoria, o ambos a la vez. Las tareas podrían comprometer los recursos por largos períodos de tiempo. Alta disponibilidad Máxima disponibilidad de los servicios. Rendimiento sostenido. Alta razón de transferencia . Independencia de datos entre las tareas individuales.. . El retardo entre los nodos del clúster no es considerado un gran problema.. . La meta es el completar el mayor número de tareas en el tiempo más corto posible.. Las grandes prestaciones del clúster son posible gracias a la disposición de los elementos que lo conforman, de forma general son:.
(37) CAPÍTULO 2. COMPUTACIÓN DE ALTO RENDIMIENTO PARA LA CODIFICACIÓN DE VIDEO DE ULTRA ALTA DEFINICIÓN. . 27. Nodo Maestro, utilizado para proveer al usuario el acceso a los recursos de cómputo, planificación de tareas o espacio para almacenamiento. Esconde los recursos, dando al mundo externo la visión de un único recurso.. . Nodos de Cómputo, realizan las porciones asignadas de los cálculos o cómputos de la aplicación paralela, o una unidad de un servicio escalable (si se habla de disponibilidad, por ejemplo).. . Nodo Administrativo, provee servicios administrativos como monitoreo del rendimiento y generación de eventos para los administradores del clúster.. . Nodo de Infraestructura, provee servicios esenciales para el clúster, tales como servicios de licenciamiento, servicios de autenticación, planificación de tareas y balanceo de carga.. . Nodo de I/O o Servidor de Archivos, provee acceso a los recursos de almacenamiento del clúster para los usuarios y las aplicaciones.. . Varias Redes, de administración del clúster, de acceso a datos, de consolas de administración de los nodos de cómputo.. 2.2. Clúster de la Universidad Central de las Villas. La UCLV cuenta con el servicio de nuevo clúster el cual es el servicio más atractivo para la comunidad científica tanto en la UCLV como en el país. La anterior aseveración se basa en que este permite realizar cálculos de alto procesamiento en menor tiempo, hacer simulaciones de eventos discretos, entre otras tareas que demanden alta capacidad de cómputo. Muchos profesores, estudiantes de pregrado y posgrado, tesiantes y egresados del departamento no solo han realizado sus trabajos investigativos, sino que han contribuido a la implementación y desarrollo de nuevos procesos y servicios que se están implementado en la actualidad. El HPC se extiende a usuarios de otros centros universitarios del país y se establecen lazos de colaboración con los encargados de instalar este tipo de tecnología en la Universidad de Santiago de Cuba. El Centro de Datos actualmente cuenta con el clúster más grande instalado en el país, que posee 36 nodos con los siguientes recursos:.
Figure

+7

Documento similar
Debido al riesgo de producir malformaciones congénitas graves, en la Unión Europea se han establecido una serie de requisitos para su prescripción y dispensación con un Plan
Como medida de precaución, puesto que talidomida se encuentra en el semen, todos los pacientes varones deben usar preservativos durante el tratamiento, durante la interrupción
Memorias de ultratumba de F.-R. de Chateaubriand, en traducción anónima (1849-1850) Marta Giné Janer
Además de aparecer en forma de volumen, las Memorias conocieron una primera difusión, a los tres meses de la muerte del autor, en las páginas de La Presse en forma de folletín,
Abstract: This paper reviews the dialogue and controversies between the paratexts of a corpus of collections of short novels –and romances– publi- shed from 1624 to 1637:
Después de una descripción muy rápida de la optimización así como los problemas en los sistemas de fabricación, se presenta la integración de dos herramientas existentes
por unidad de tiempo (throughput) en estado estacionario de las transiciones.. de una red de Petri
o Si dispone en su establecimiento de alguna silla de ruedas Jazz S50 o 708D cuyo nº de serie figura en el anexo 1 de esta nota informativa, consulte la nota de aviso de la
La siguiente y última ampliación en la Sala de Millones fue a finales de los años sesenta cuando Carlos III habilitó la sexta plaza para las ciudades con voto en Cortes de
