Asistente Inteligente para Proyectos de Automatización y Sintonización Difusa de PID´S en la Rama del Cemento Edición Única
71
0
0
Texto completo
(2) Instituto Tecnológico y de Estudios Superiores de Monterrey Campus Monterrey Programa de Graduados en Electrónica, Computación, Información y Comunicaciones Los miembros del comité de tesis recomendamos que la presente tesis de Jorge Gerardo Martínez Bortoni sea aceptada como requisito parcial para obtener el grado académico de Maestro en Ciencias especialidad en Sistemas Inteligentes. Comité de Tesis. __________________ Dr. Rogelio Soto R. Asesor Centro de Sistemas Inteligentes __________________ Dr. José de Jesús Rodríguez Sinodal Departamento de Mecatrónica. __________________ Dr. Graciano Dieck Assad Sinodal Departamento de Eléctrica. _________________________ Dr. David Garza S. Director de Investigación y Postgrado DECIC. Mayo 2004. ii.
(3) ASISTENTE INTELIGENTE PARA PROYECTOS DE AUTOMATIZACIÓN Y SINTONIZACIÓN DIFUSA DE PID’S EN LA RAMA DEL CEMENTO. POR: Jorge Gerardo Martínez Bortoni. TESIS. Presentada al Programa de Graduados en Electrónica, Computación, Información y Comunicaciones.. Este trabajo es requisito parcial para obtener el grado de Maestro en Ciencias especialidad en Sistemas Inteligentes. INSTITUTO TECNOLÓGICO Y DE ESTUDIOS SUPERIORES DE MONTERREY. Mayo 2004. iii.
(4) Dedicatoria. A mis padres por impulsar la vida que me otorgaron y ayudarme en todo a lo largo de ella.. Gracias. iv.
(5) Agradecimientos. A Dios, por permitirme todas las aptitudes para seguir su camino.. A mi familia, por acompañarme cada paso y hacerlo más placentero.. A mi comité de tesis por el apoyo que me brindaron para la realización de esta tesis.. Gracias. v.
(6) Resumen. En este documento se explica lo que es un proyecto de automatización en general así como los pasos a seguir en el caso de una planta cementera. Así mismo, se realiza una descripción de los tipos de programas con los que hay que trabajar para lograr una automatización del diseño de la automatización. Más adelante se analiza el problema de tiempo y recurso desperdiciado por cuestiones de programación y se propone la realización de una metodología y un programa inteligente basado en Visual Basic con conexión a otro tipo de aplicaciones como lo son: Excel, Access, LM90, PlantScape y Autocad entre otros. El programa inteligente se encarga de realizar en forma automática una gran parte de la programación manual necesaria para crear un proyecto de automatización y con esto lograr un ahorro de recurso humano y dinero. El modelo propuesto consta de un sistema basado en conocimiento para generar las instrucciones y programación necesaria para crear una lógica escalera para un PLC marca General Electric modelos 9030 y 9070. La base de conocimiento almacena la experiencia del programador de tal manera que se pueda ver reflejada en el sistema inteligente propuesto. Enseguida se procede a identificar los diferentes PID’s que requiere el proceso e identificar el modelo de cada uno de los procesos usando el método estadístico ARX mediante pares de datos experimentales. La sintonía de los controladores PID se hace mediante sistemas difusos en forma heurística. Posteriormente se crea la base de datos necesaria para la buena comunicación con la interfaz. En esta área se manejan las dos marcas más utilizadas que son el PlantScape de Honeywell y el Cimplicity de General Electric. Finalmente se genera la documentación necesaria para el buen mantenimiento de la interfaz, se crea en Excel la base de datos general del sistema y en Autocad R14 los diagramas de alambrado necesarios para la instalación en campo. La implementación del asistente inteligente en proyectos de automatización reducirá el tiempo en recurso humano y como consecuencia obtener un ahorro en la parte de programación, redituando esto en utilidades para la empresa.. vi.
(7) Índice 1. INTRODUCCIÓN. 1. 1.1 Definición del problema. 2. 1.2 Objetivos. 4. 1.3 Hipótesis. 5. 1.4 Modelo de solución 1.4.1 Programación del PLC 1.4.2 Programación de la interfaz Hombre-Máquina 1.4.3 Ingeniería básica 1.4.4 Base de datos. 5 6 8 11 11. 2. FUNDAMENTOS TEÓRICOS. 14. 2.1 Sistemas Basados en Conocimiento. 14. 2.2 Identificación de sistemas 2.2.1 Identificación de señales 2.2.2 Términos Comunes utilizados en identificación de sistemas 2.2.3 Señales 2.2.4 El modelo dinámico básico 2.2.5 Variantes de las descripciones del modelo 2.2.6 Como interpretar la fuente de ruido 2.2.7 Términos para caracterizar las propiedades de un modelo 2.2.8 Pasos básicos para la identificación de un sistema 2.2.9 Procedimiento de identificación. 16 16 16 17 18 19 20 20 21 21. 2.3 Sistemas Difusos 2.3.1 Conceptos básicos 2.3.2 Función de membresía 2.3.3 Operaciones con conjuntos 2.3.4 Conjuntos Difusos 2.3.5 Operaciones con conjuntos difusos 2.3.6 Complemento de un conjunto difuso 2.3.7 Diseño del sistema difuso 2.3.8 Defuzificación. 23 24 25 25 26 27 27 28 29. 3. DISEÑO DEL ASISTENTE INTELIGENTE Y RESULTADOS. 31. 3.1 Metodología de Diseño. 31. 3.2 Sistema Inteligente 3.2.1 Datos requeridos. 31 32. vii.
(8) 3.2.2 Base de datos general 3.2.3 Base de datos interfaz 3.2.4 Lógica escalera. 33 34 36. 3.3 Base de Conocimientos. 37. 3.4 Identificación del Proceso. 40. 3.5 Sintonización de los Controladores PID. 44. 3.6 Diseño del Sistema Difuso. 48. 3.7 Comprobación de Resultados. 55. 4. CONCLUSIONES Y TRABAJOS A FUTURO. 58. 5. BIBLIOGRAFÍA. 60. Vita. 62. viii.
(9) Tabla de Figuras Figura 1.1 Flujo de información en el proceso del cemento. 4. Figura 1.2 Listado de maquinas en orden de flujo. 5. Figura 1.3 Modelo de programa. 6. Figura 1.4 Introducción a la programación de PLC en texto. 7. Figura 1.5 Comandos de programación de PLC en texto. 8. Figura 1.6 Lógica de escalera. 9. Figura 1.7 Mímico de PlantScape de Honeywell. 10. Figura 1.8 Diagrama de Ingeniería Básica. 12. Figura 1.9 Presentación de base de datos. 12. Figura 2.1 Modelo de entrada y salida del sistema. 18. Figura 2.2 Diagrama de Venn. 26. Figura 2.3 Función de membresía y complemento de los conjuntos difusos a y B. 28. Figura 2.4 Diagrama de lógica difusa. 29. Figura 2.5 Grado de pertenencia. 29. Figura 2.6 Defuzificación aritmética. 30. Figura 3.1 Metodología de diseño. 31. Figura 3.2 Pantalla de variables. 32. Figura 3.3 Pantalla de base de datos. 34. Figura 3.4 Pantalla de base de datos PlantScape. 35. Figura 3.5 Pantalla de base de datos Cimplicity. 35. Figura 3.6 Pantalla de lógica escalera. 37. Figura 3.7 Regla para puntos de entrada. 39. Figura 3.8 Datos históricos de entrada al motor de corriente directa. 41. Figura 3.9 Datos históricos de salida al motor de corriente directa. 41. Figura 3.10 Pantalla del Matlab con muestreos insertados y valores estimados. 42. Figura 3.11 Gráfica de salida del sistema ARX, comparación entre real de validación y salidas estimadas del sistema. 42. Figura 3.12 Modelo ARX estimado por Matlab. ix. 43.
(10) Figura 3.13 Comandos para cambio de discreta a continua de función de transferencia 44 Figura 3.14 Modelo del sistema a simular utilizando Simulink. 44. Figura 3.15 Diagrama de bloques de una prueba de retroalimentación tipo relevador 48 Figura 3.16 Diagrama de bloques de auto sintonizador. 49. Figura 3.17 Explicación de variables de sintonización de controlador. 49. Figura 3.18 Diagrama de bloques de la simulación. 50. Figura 3.19 Funciones de membresía de sobre impulso. 51. Figura 3.20 Funciones de membresía de tiempo de elevación. 51. Figura 3.21 Funciones de membresía para las variables de salida Kc y Reset. 52. Figura 3.22 Operación de reglas tipo Sugeno para el diseño propuesto. 54. Figura 3.23 Salida del sistema de control variable: velocidad en RPM. 55. Figura 3.24 Tabla de Gantt proceso realizado en la forma convencional. 56. Figura 3.25 Tabla de Gantt proceso realizado mediante modelo propuesto. 57. x.
(11) 1. INTRODUCCIÓN. En la actualidad los proyectos de modernización en cuanto a la automatización se realizan de manera manual utilizando mucho trabajo de programación que es posible realizar de forma automática. Para lograr este fin se propone una metodología que seguirá un programa inteligente que pueda realizar las funciones del programador y utilizar conocimientos de los expertos en el área para realizar la programación. Normalmente esta programación toma la mayor parte del tiempo del proyecto. Para lograr realizar lo antes descrito se recaba la suficiente información como para empezar y después se programa tanto el PLC como la interfaz. Una vez programado se pasa a la etapa de pruebas en la que se checa que todas las direcciones tanto del PLC como de la interfaz se encuentren correctamente establecidas y con esto toda comunicación se lleve a cabo transparentemente. Una vez realizado se pasa a la implementación para la cual todas las instalaciones físicas deben de estar listas para este punto. Esta parte del diseño se puede realizar mediante el programa inteligente que se propone, para así realizar esta etapa en un intervalo mucho más pequeño de tiempo, y llegar a tener el programa tanto de PLC como de la interfaz, listo en un lapso menor al utilizado en la actualidad. El programa que se trata en esta tesis tiene como mercado final las empresas creadoras de los PLC's o de las interfaces que pueden regalar el servicio de programación en la compra del equipo y de esta forma tener una ventaja competitiva muy grande por encima del resto de las marcas. Esta tesis resuelve el problema de la programación de PLC e interfaz hombre-máquina así como lo es también el hacer la documentación necesaria al realizar un proyecto en la industria como lo es la ingeniería básica y la base de datos. Para lograr llegar al fin deseado se emplean dos diferentes técnicas de inteligencia artificial las cuales son los sistemas basados en conocimiento y los sistemas difusos. La programación de PLC y de la interfaz en la industria es muy amplia debido a la gran variedad de marcas que se manejan en el mercado. En esta tesis se utiliza solamente una de ellas aunque en un futuro es posible utilizar esta misma aplicación como base para llegar a hacer un programa más amplio que maneje una mayor variedad de marcas. La diferencia entre las marcas es debido a que cada una de ellas utiliza un diferente programa. La programación de PLC se realiza a través de su respectivo programa aún y que la mayoría de ellos hacen lo mismo, una programación en tipo escalera. En las interfaces por su parte si son muy amplias las diferencias entre ellas pero primordialmente todas manejan una base de datos en la que se hace relación a una dirección de PLC con un nombre único de manejo interno en ella denominado tag. En la actualidad toda esta programación es realizada manualmente con ninguna ayuda aparte de la ofrecida por el mismo programa que se esté utilizando. Además es necesaria la experiencia del programador en el área para poder realizar la tarea correctamente. En este proceso de programación normalmente se pierde mucho tiempo y dinero en una empresa. Para el caso de esta tesis se va a utilizar el proceso del cemento con el fin de ejemplificar el diseño e implementación. Un proyecto de automatización de un horno o de un molino es una inversión alta llegando a los millones de pesos. De esto una gran parte es en equipo, otra parte es de instalaciones como lo es el cableado necesario para llevar las señales. 1.
(12) de campo hacia el PLC o módulos de I/O y otra gran parte es el de la programación del equipo. Esta programación implica el realizar el diagrama escalera para el PLC, la base de datos para la interfaz, los gráficos de la interfaz, la ingeniería básica que permite realizar cambios futuros y mantener una información de las instalaciones y la documentación de todo lo realizado. Con esta tesis se propone realizar toda la programación y toda la documentación en forma automática, para este proceso en específico y con esto dejar el proyecto en solo equipo e instalaciones. Este documento explica lo que se realiza en un proceso de automatización de una línea de cemento así como lo que se debe de entregar al momento de realizar un trabajo de este tipo. Una vez entendido lo que se quiere eficientizar mediante la implementación de una metodología plasmada en un sistema inteligente, se procede a resolver el problema. En este Capítulo se definen los fundamentos del problema para después especificar los objetivos del diseño de la tesis en la sección 1.3. La sección 1.4 explica el modelo de solución propuesto para el problema estableciendo las diferentes partes del problema a atacar con sus diferentes soluciones. 1.1 Definición del problema En la actualidad cuando se maneja un proyecto de modernización en una planta de cemento se realizan varios pasos dentro del proceso antes de detener la línea de producción para modernizar el equipo. Primero se hace un estudio de qué es lo que más beneficio trae para la empresa para después decidir que equipo es conveniente de entre las diferentes áreas. En el proceso del cemento se consideran más relevantes la molienda de crudo, el sistema del horno rotatorio y la molienda de cemento. Estas son las principales áreas del proceso aunque hay más como lo es el sistema de laboratorio, la extracción de caliza, el empaque, etc. En estos procesos normalmente lo que se hace para realizar una modernización es actualizar el equipo desde la maquinaria en sí hasta lo que es la forma de visualizar y controlar el equipo. En épocas pasadas el sistema de control se llevaba a cabo mediante el uso de relevadores, controlando así su encendido y apagado como protección de otros equipos que pudiesen llegar a tener fallas y afectaran el funcionamiento de los equipos predecesores o siguientes en la línea de flujo del proceso. Cuando se utilizaba el sistema de relevadores se podía observar el funcionamiento de cada una de las maquinas en displays. Un display son dibujos con focos que dan una grafica de flujo del proceso y se muestran las cuatro posiciones que tiene un equipo: apagado, listo para arrancar, dentro o funcionando y falla. Cuando se decide modernizar una parte de la línea de producción se emigra de utilizar relevadores como medio de control a utilizar PLC, y se emigra de utilizar displays como medio de interfaz a utilizar computadoras con algún programa en específico que se denomina interfaz hombre-máquina. La interfaz se encarga de leer los datos de un PLC y transferirlos a gráficos animados que se puedan relacionar con el proceso y el funcionamiento de cada una de las máquinas en campo, así como también llevar historiales y diferentes formas estadísticas de medir el rendimiento del proceso. Una vez decidido que tipo de PLC e interfaz se va a utilizar así como la maquinaria a utilizar en campo se verifica que todo tenga compatibilidad entre sí. Por ejemplo si las señales análogas manejan el mismo rango de amperaje o voltaje para poder comunicarse, en caso de que esto no se de, se utilizan Action Packs, transformadores de 2.
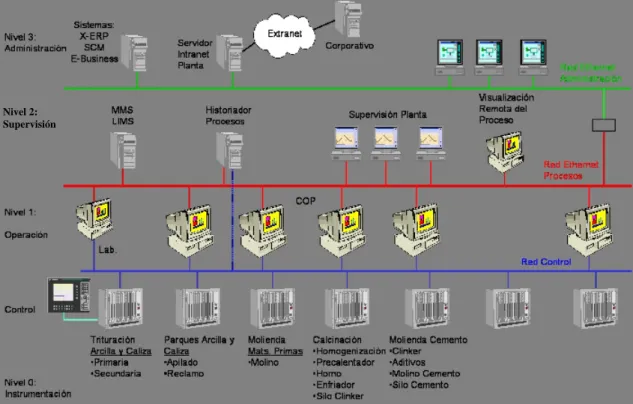
(13) corriente, para que se manejen señales en los mismos rangos y se puedan comunicar satisfactoriamente entre el drive de la máquina en campo y el PLC. Una vez obtenido todo esto se comienza generando el programa del PLC, que es el que controla el encendido y apagado de cada una de las máquinas así como también controla las entradas y salidas de las señales análogas al sistema. Este programa integrador se genera manualmente mediante aplicaciones que se venden por el fabricante del PLC, para el caso de esta tesis se utilizara un PLC marca General Electric Fanuc modelo 90-30 ó 90-70 que son los más comunes. Este programa se desarrolla en una computadora convencional para después ser descargado mediante algún tipo de comunicación al PLC. Las comunicaciones más usuales son: serial RS-232 o RS-425 y la comunicación ethernet que generalmente necesita de una tarjeta adicional en el PLC para funcionar. Este programa realizado en diagramas escalera describe el funcionamiento de las máquinas con relación a las señales de esa misma máquina, a otras máquinas o a comandos provenientes del operador. Estos diagramas describen como se relaciona cada maquinaria entre si y al mismo tiempo permiten al usuario controlar las máquinas desde otra parte mediante algún tipo de comunicación hacia el PLC. Los diagramas escalera solamente manejan ciertos comandos ya reconocidos por el sistema como lo es el -||- que denomina a un contacto normalmente abierto, y otros como un switch normalmente cerrado, una bobina, un contacto sostenido, etc. También estos programas utilizan diferentes tipos de variables para trabajar: %I entrada, %O salida, %T variable temporal, %M variable de memoria, etc. En el árbol de información que se describe en la Figura 1.1 se pueden ver las diferentes partes de bases de datos que se manejan. Se comienza en la parte inferior en la que se encuentran los PLC's (nivel 0) los cuales manejan su programación y bases de datos en lógica escalera. El siguiente nivel es lo que se conoce como la interfaz del proceso. En este nivel se maneja una base de datos diferente a la del nivel inferior manteniendo una relación entre ellas. De esta forma se tiene una relación entre ambas, de tal manera que lo que se muestra en la pantalla aunque tiene una dirección diferente a la del PLC se comunica con ella para lograr mostrar la situación real del proceso en tiempo real. A partir del segundo nivel se tiene una base de datos diferente a los dos niveles inferiores que de igual manera como se mantiene una relación entre los primeros dos niveles, se comunican con niveles inferiores para lograr tener la información actualizada. Una vez que toda la programación se encuentra ya terminada y refinada se pasa a sintonizar los PID’s de las diferentes áreas. En el caso del tema a tratar en esta tesis el cual es una planta cementera se puede tener un gran ahorro económico por medio de una buena sintonización en las diferentes partes del proceso. Un ejemplo de esto es el área de carburación del horno en donde si no se encuentra bien sintonizado el PID cada vez que se tenga que realizar un cambio en la cantidad de combustible a alimentar, ya sea de coque, combustoleo o gas, se puede desperdiciar una gran cantidad de combustible en el tiempo en el que tarda en llegar a su punto de referencia. Este fenómeno se puede disminuir mediante la disminución del tiempo de elevación, así como se puede manejar el sobre impulso de la variable a controlar a lo menos posible de tal forma que se mantenga oscilando el menor tiempo posible y no se le inyecte a la variable manipulada más de lo necesario para llegar a la meta.. 3.
(14) Nivel 2: Supervisión. Figura 1.1 Flujo de información en bases de datos del proceso del cemento. 1.2 Objetivos El objetivo general de esta tesis es el realizar una metodología y plasmarla en un sistema inteligente que facilite el trabajo de un programador en el área de automatización para la industria del cemento. Este sistema inteligente funciona mediante dos métodos inteligentes: sistemas basados en conocimiento y sistemas difusos, para lograr realizar su función. En esta metodología se pueden realizar muchas funciones de forma automática mediante un programa que logre hacer todo lo esencial o la base de la programación que es necesaria en el área de una línea de producción de cemento. Para lograr lo descrito se plasma la metodología en un programa basado en Visual Basic que se encargará de realizar la lógica escalera de un PLC marca General Electric modelos 9030 y 9070. La programación se crea en un archivo texto que se transforma a un archivo base por medio de un programa gratuito de la misma marca que se corre como un ejecutable. Esto concluye la lógica escalera y se procede a realizar la base de datos de la interfaz hombre-máquina donde se tiene la opción de escoger entre dos, el PlantScape de Honeywell y el Cimplicity de General Electric, el PlantScape se maneja en archivos textos y el Cimplicity es una base de datos en Excel. Después de esto se pasa a identificar los diferentes PID’s que se encuentran en el proceso y por medio de modelos de identificación, en este caso se utiliza el modelo ARX (Auto Regresive with Exogeneous Input), se obtiene un modelo del proceso para pasar posteriormente a la sintonización de los PID’s donde se utiliza un sistema difuso. Ya realizada toda la programación se crea la documentación de estos sistemas como lo es la base de datos y la ingeniería básica que son diagramas de alambrado físico.. 4.
(15) Figura 1.2 Listado de maquinas en orden de flujo. 1.3 Hipótesis La hipótesis de esta tesis es que esta metodología y el programa basado en conocimiento a realizar mediante sistemas inteligentes llegara a facilitar en gran medida la función de los programadores dejando más margen de utilidades a las empresas que se dediquen a la programación de sistemas de automatización. 1.4 Modelo de solución Para lograr realizar los objetivos se comienza con un sistema basado en conocimiento que se va a encargar de crear la base de la programación del PLC así como lo relacionado a la base de datos que se requiere para la interfaz en dos sistemas. De igual forma se encargara de crear la documentación de la base de datos tanto del PLC como de la interfaz hombre-máquina y su relación en direcciones entre ambas. Una vez que se tiene esto, el programa utiliza una comunicación con un sistema difuso para lograr sintonizar los PID's que se hayan creado en los pasos anteriores. Como entrada al sistema se va a requerir tener un listado de maquinaria en el que se especifica como están relacionadas las máquinas para tener una especie de diagrama de flujo de forma escrita, se muestra un ejemplo en la Figura 1.2. En esta Figura se puede ver el formato que lleva la lista que se utilizara de entrada para el sistema. Se observan varias máquinas que están ordenadas de acuerdo al flujo del proceso de arriba hacia abajo y en dos columnas. Estas son máquinas estándar de este tipo de procesos que nos servirán para definir cada una dentro del sistema y que este sea capaz de reconocerlas y procesarlas. De aquí se va a ramificar todo el resto de la información necesaria para llegar al resultado final.. 5.
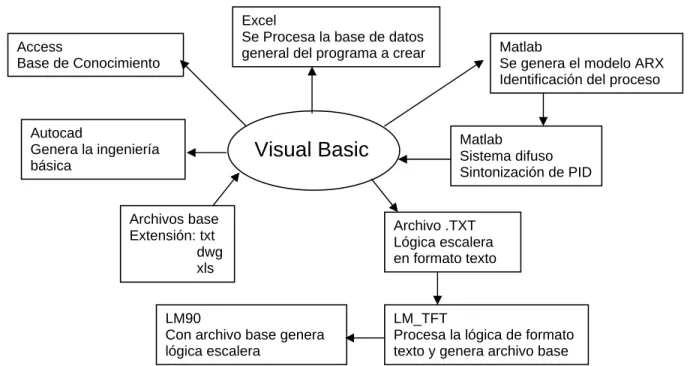
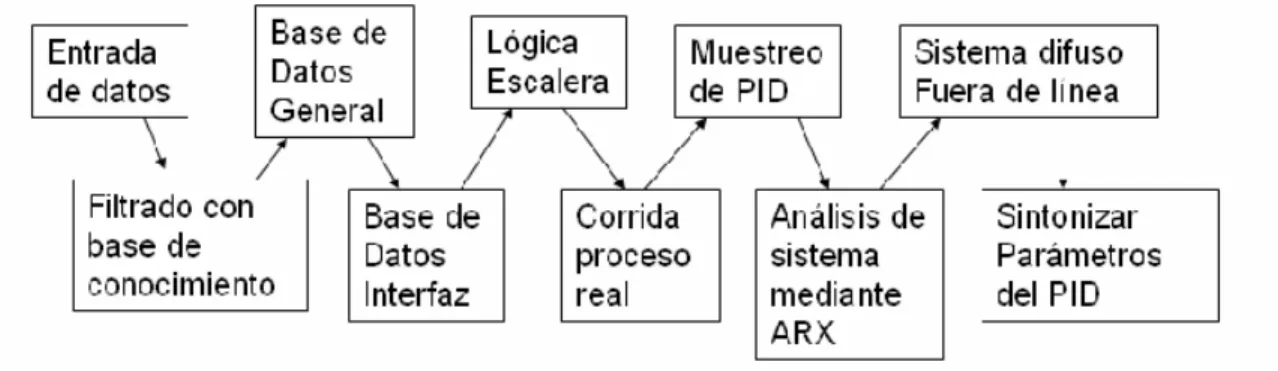
(16) Los diferentes pasos de programación que se van a llevar a cabo para realizar el programa deseado se definen en la Figura 1.3 mediante un modelo en el cual se especifican las diferentes partes y de igual manera se puede observar como se tiene la base en Visual Basic para de aquí comunicarse con los diferentes programas a ser utilizados. En el modelo presentado, las reglas a seguir por el sistema basado en conocimiento se encuentran almacenadas en Access. Por otra parte, estas reglas requieren de varios archivos que contienen la información principal o común a utilizar en el funcionamiento. Estos archivos se encuentran almacenados en diferentes directorios dependiendo de su función y con las extensiones requeridas como lo son: txt, xls y dwg. 1.4.1 Programación del PLC La programación del PLC se creará mediante un teach file que se realiza en un archivo texto con comandos ya especificados por el programa lm_tft.exe. Este programa se encuentra residente en un sistema DOS y se encarga de cambiar los comandos descritos por archivos con extensión .txt como se describe en la Figura 1.3. Los archivos texto son transformados a la entrada necesaria para que sea reconocida por el programa LM90 y se puede convertir a programación de tipo escalera, la cual es utilizada para la programación de PLC’s. El encabezado debe de ser de la manera descrita en la Figura 1.4. En el encabezado es en donde se describe que tipo de programación es y que modelo de PLC es el que se esta utilizando. Los dos modelos de PLC son muy parecidos sólo que el 90-70 es más grande y tiene más capacidad así como también tiene una mayor cantidad de funciones que puede realizar que no los contiene el 90-30 [13].. Excel Se Procesa la base de datos general del programa a crear. Access Base de Conocimiento. Autocad Genera la ingeniería básica. Visual Basic. Archivos base Extensión: txt dwg xls. Matlab Se genera el modelo ARX Identificación del proceso. Matlab Sistema difuso Sintonización de PID. Archivo .TXT Lógica escalera en formato texto. LM90 Con archivo base genera lógica escalera. LM_TFT Procesa la lógica de formato texto y genera archivo base. Figura 1.3 Modelo del programa para la automatización del diseño. 6.
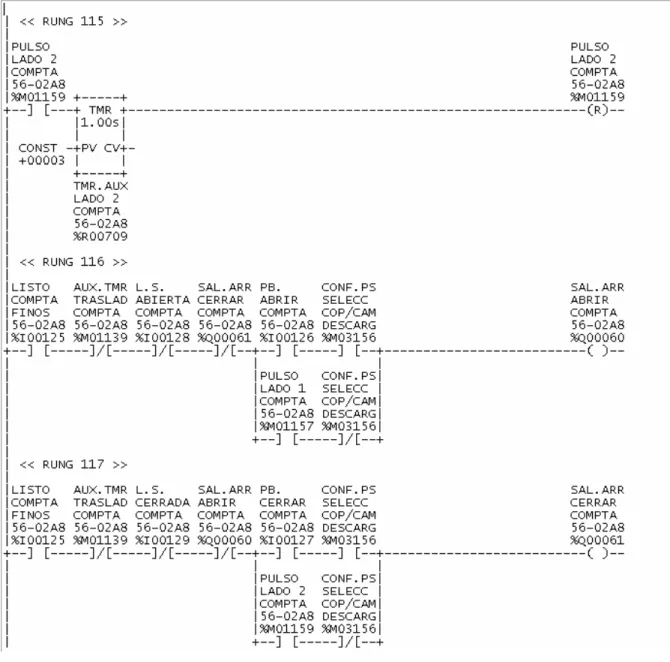
(17) ===== Teach file header info ===== 0 <= sp_byte6 0 header_cksum 0 <= sp_byte7 0 fill_byte 0 <= sp_byte8 1 <= product_code 0 <= sp_byte9 0 <= file_id 0 <= sp_byte10 KH <= subsys_name === 3 bytes of context info; (set each to 255 to 2 <= version_num disable context check) === 0 <= revision_num 0 <= template_id 0 <= release_num 1 <= main_menu_id 0 <= release_minor 1 <= sub_menu_id 0 <= product_origination ===== KH key definition labels and character 0 <= file_map_size input ===== 0 <= sp_byte4 PROGRM -- key value = 4098 0 <= sp_byte5 Figura 1.4 Introducción a la programación de PLC en texto. Al terminar la descripción del encabezado, se comienza con la programación de lo que es en sí el diagrama escalera. Este tiene varios comandos que se deben de introducir para realizar la programación, a continuación se muestran varios ejemplos. Esta línea crea una línea nueva de programación PRG_INSERT -- key value = 4157 Con esta línea se entra al área de comandos del LM90 [12] CONTRL -- key value = 4185 PRG_EXPLN -- key value = 4290 ENTER -- key value = 13 Esta línea especifica que la siguiente dirección es un contacto normalmente abierto "1I" -- ascii text string NO_CONTACT -- key value = 4187 Esta línea especifica que la siguiente dirección es un contacto normalmente cerrado "2I" -- ascii text string NC_CONTACT -- key value = 4188 Al programar en teach file es como si se estuviera programando directo en el LM90, se sigue la misma lógica de empezar en la izquierda y avanzar hacia derecha para después unir las partes paralelas del siguiente renglón. Una vez que se tiene ya toda la programación del diagrama escalera se puede empezar a pensar en hacerla más ordenada mediante bloques de programación. Para finalizar se debe de salir del área de programación mediante un zoom out que es un comando dentro del LM90 para avanzar en directorios hacia arriba. Esta línea se pondría tantas veces como sea necesaria para llegar al directorio raíz. < ZOOM_OUT -- key value = 27 Al terminar la lógica escalera se procede a crear los comentarios de cada una de las variables que se utilizaron para que con esto puedan ser identificadas dentro del programa al momento de hacer una consulta o un cambio de manera eficiente y rápida. Esto es las leyendas que tiene cada una de las variables al estar funcionando. Para crear esto se utiliza otro tipo de comandos como se muestra en la Figura 1.5. Estas líneas se harían para cada una de las entradas, salidas, 7.
(18) variables temporales y variables de memoria que se utilicen en el programa. Se trata que la descripción descrita éste dividida en 4 renglones de 7 caracteres cada uno porque es lo que permite ver el programa al momento de estarse ejecutando. "2000M" -- ascii text string R_CURSOR -- key value = 263 R_CURSOR -- key value = 263 "BIT1 ED x1 PES.CTE" -- ascii text string ENTER -- key value = 13 Figura 1.5 Comandos de programación de PLC en texto. Como resultado final de esta parte de la programación se debe tener un programa en archivo extensión txt el cual se utilizará como entrada para el lm_tft.exe. Este archivo se va a encargar de transformar este archivo en otro con extensión tf, el cual se introduce ya directamente al LM90 como un “teach file” y se encarga de realizar el programa escalera de forma automática. Un ejemplo de las líneas en lógica escalera se muestra en la Figura 1.6 Otra función que hay que tomar en cuenta es la programación de las señales análogas en el PLC. Para esto se requiere de un listado inicial con el equipo con el que se cuenta que tiene como salida una señal análoga. Este listado se analizara para buscar en él palabras claves como lo son potencia, amperaje, peso, etc. Una vez identificadas todas las señales, se le ponen sus rangos, unidades y otras variables que se deben de definir para dar de alta la variable. Una vez que estén las señales análogas dadas de alta se pasa a dar de alta los PID's más comunes para el tipo de señales análogas que se tienen y una vez dadas de alta se procede a utilizar un sistema difuso para sintonizar los PID's. 1.4.2 Programación de la interfaz Hombre-Máquina La base de datos de una interfaz hombre máquina de diferentes marcas contiene información muy parecida por lo que se puede crear un listado de varias de ellas para dar la opción de escoger cuál es la que se va a utilizar. En el caso de esta tesis se describen dos de las más comunes en el mercado hacia el cual va dirigido. Estas marcas son el PlantScape de Honeywell y el Cimplicity de General Electric Fanuc. Ambos programas utilizan gráficos animados para representar el estado de las máquinas. Para esto se utilizan 4 colores básicos que son el gris, amarillo, verde y rojo parpadeante. El gris significa que la máquina esta fuera, esto es que no tiene potencia. El amarillo es que esta lista para ser arrancada, que si. 8.
(19) Figura 1.6 Lógica de Escalera. tiene fuerza; el verde significa que esta funcionando de forma correcta y por último el rojo parpadeante significa que el equipo tuvo alguna falla y se detuvo de su funcionamiento. En la Figura 1.7 se muestra un ejemplo de un mímico del programa PlantScape. En ambas marcas la información que contiene la base de datos es básicamente la necesaria para describir una variable de forma completa: el nombre, la descripción, el tipo de variable (ya sea análoga o digital), sus rangos, sus alarmas, etc. Estos valores normalmente se mantienen constantes dependiendo del tipo de máquina con el que se este trabajando en el momento. Por esta razón se facilita mucho el trabajo ya que se puede hacer un programa basado en reglas que se encargue de sincronizar una base de datos existente ya dividida en partes dependiendo de la máquina en proceso. Con esto ya sus valores predispuestos se encontrarían correctos y sería. 9.
(20) necesario solamente el cambiar la dirección, la descripción y unos pequeños detalles que ya no son tan complicados como lo es el hacer toda la base de datos desde cero. El conocimiento necesario para la generación de las reglas se tomara a partir de programas ya realizados en el pasado y funcionando en la actualidad, tomando como base las técnicas implementadas en éstos. Para crear una base de datos de señales digitales en PlantScape se requiere un formato específico de columnas el cual tiene 99 columnas en un orden específico. Para crear una base de datos de señales digitales en Cimplicity se requiere un formato de 96 columnas con un formato especifico.. Figura 1.7 Mímico de PlantScape de Honeywell. Muchas de estas columnas son de datos fijos o simples variables booleanas que van cambiando dependiendo de la información que se va a manejar con esa variable, ya sea una alarma, una señal para la animación del gráfico, un botón de arranque o paro, una salida o entrada, etc. A simple vista se ven muchas variables que se tienen que cumplir para poder dar de alta una variable en el sistema pero esto incluye muchas cosas que no cambian por lo que se dejaría fijo y solamente se cambiaría lo referente a la variable. Para lograr hacer esto se mantiene una base de datos en Excel que contiene un típico de toda la información que se mantiene constante en las variables que se utilizan para definir una máquina en específico y así para todas las máquinas. Con estos solamente se copiaría esta información de una base de datos a otra cada vez que una máquina de este tipo apareciera y se le cambiarían los datos necesarios. 10.
(21) como direcciones y nombres. De esta manera se puede ir armando toda la base de datos en una página de Excel mediante comunicación hacia este del Visual Basic. 1.4.3 Ingeniería básica La ingeniería básica es un diagrama de alambrado que se entrega como documentación de un proyecto de automatización. En este diagrama se describe el nombre del circuito que conecta cada uno de los componentes de la máquina como lo es el detector de movimiento, el listo o señal de entrada al drive de la máquina, el sello de arrancado, etc. hacia la tarjeta especificada del PLC. En estos diagramas de igual manera se describe el punto, slot y rack del PLC al que va a llegar cada una de las señales así como la dirección que se le va a asignar a cada una de estas señales. Estos diagramas deben de estar creados en Autocad y deben de contar con un formato estándar que se maneja en cada una de las industrias. Estos diagramas varían dependiendo del arreglo físico que se tenga en la maquinaria instalada en campo. Por esta razón es muy difícil dejar un asistente inteligente que pueda sacar estos diagramas al 100%. Sin embargo, si es posible hacer una interfaz que se comunique con el Autocad por medio de Visual Basic, para de esta manera sacar lo necesario de otras bases de datos y hacer posible el llenar un típico de una máquina especifica. En un diagrama de alambrado es reflejada toda la información en cuanto al alambrado como su nombre lo dice. En este diagrama así como en campo, todo cable esta marcado en ambas puntas para su mejor identificación y la función de estas marcas es el encontrar las fallas de cada máquina de una forma más rápida y efectiva. En la Figura 1.8 se puede ver un ejemplo de un diagrama de alambrado. 1.4.4 Base de datos La base de datos es una tabla realizada en Excel la cual se encarga de centralizar toda la información del proyecto en un solo documento. Una base de datos tiene como función la mejor comprensión del cliente sobre el trabajo realizado, así como de referencia rápida en caso de ser necesario el realizar algún cambio en la programación de cualquiera de los componentes ya sea el PLC o la interfaz o incluso un cambio físico en el alambrado en campo. Ya que esta dividido por máquina y más ampliamente por señal, se puede observar como avanza una señal desde el drive que la genera hasta el PLC, como es procesada y adquirida hacia la interfaz que se encarga de reflejarla. Una base de datos depende mucho de la información que se quiere poner en ella así como de que programas se utilizaron para hacer el proyecto. Esto porque se maneja la información diferente en cada caso, así que de igual manera que en las partes anteriores se tienen típicos de cada uno de los que se van a trabajar como lo es el PLC y la interfaz para lograr realizarla sin importar cual combinación se escoja. En la Figura 1.9 se muestra un ejemplo de una base de datos para un PLC 9070 con interfaz PlantScape.. 11.
(22) Figura 1.8 Diagrama de Ingeniería Básica. Figura 1.9 Presentación de base de datos. 12.
(23) El resto de al tesis se divide como sigue: en el capitulo 2 de este documento se explican los fundamentos teóricos que sustentan el trabajo de esta tesis. El capitulo 3 muestra el diseño del asistente inteligente dividido por partes desde la entrada que se requiere de información hasta la salida final. Por último en el capítulo 4 se dan las conclusiones de los trabajos realizados, así como también los trabajos que se recomiendan a futuro relacionados con este documento.. 13.
(24) 2. FUNDAMENTOS TEÓRICOS. En esta sección se explican los elementos tecnológicos utilizados en el sistema inteligente propuesto. 2.1 Sistemas Basados en Conocimiento Un sistema experto o sistema basado en conocimiento se puede definir como un sistema que resuelve problemas utilizando una representación simbólica del conocimiento humano. Los sistemas basados en conocimiento tienen las siguientes características: 1. 2. 3. 4. 5. 6.. Representación explícita del conocimiento Capacidad de razonamiento independiente de la aplicación especifica Capacidad de explicar sus conclusiones y el proceso de razonamiento Alto rendimiento en un dominio especifico Uso de heurísticas vs. modelos matemáticos Uso de inferencia simbólica vs. algoritmo numérico. Los sistemas expertos basan su rendimiento en la cantidad y calidad del conocimiento de un dominio específico y no tanto en las técnicas de solución de problemas. Los sistemas basados en conocimiento tienen los siguientes componentes básicos: 1. Base de Conocimiento (BdeC): Representación del conocimiento del dominio para la solución de problemas específicos, normalmente dicho conocimiento se estructura en forma modular en forma declarativa. 2. Maquina de Inferencia: Proceso que efectúa el razonamiento a partir de los datos y utilizando el conocimiento de la BdeC. Es "genérica", es decir, que se puede aplicar a diferentes dominios solo cambiando la BdeC. 3. Memoria de Trabajo: Lugar donde se almacenan los datos de entrada y conclusiones intermedias que se van generando durante el proceso de razonamiento. 4. Interfaz de Usuario: Entrada/Salida al usuario del sistema, incluyendo, normalmente, mecanismos de pregunta (por que) y de explicación (como). 5. Interfaz de Adquisición: Interfaz para la adquisición del conocimiento del dominio, puede incluir mecanismos para facilitar su adquisición y depuramiento interactivo y para automatizar la adquisición (aprendizaje).. Los sistemas basados en conocimiento tienen varias ventajas, entre las más importante se encuentra el hecho de que es capaz de resolver problemas para los cuales no existe un modelo matemático adecuado o su solución es muy compleja. Por otra parte, también tiene la gran ventaja de que es capaz de preservar el conocimiento de expertos en ciertos dominios y hacerlo accesible a otras personas, así como también tiene la capacidad de explicar al usuario el. 14.
(25) proceso de razonamiento para llegar a los resultados. Los sistemas basados en conocimiento cuentan con la siguiente clasificación jerárquica. [4]. Clasificación jerárquica: Análisis (interpretación) o Identificación Monitoreo Diagnostico o Predicción o Control Síntesis (construcción) o Especificación o Diseño Configuración Planeación o Ensamble Modificación Análisis: identificación --> predicción --> control Síntesis: especificación --> diseño --> ensamble. Existen varias formas de representar un sistema basado en conocimiento y cada una de ellas consta de diferentes partes que la forman. Representaciones básicas: Reglas de producción Redes semánticas Prototipos o marcos Lógica de predicados Representaciones avanzadas: Modelos cualitativos Modelos Temporales Sistemas de pizarrón Sistemas híbridos Representación de incertidumbre:. 15.
(26) Técnicas no-numéricas Factores de certidumbre Lógica difusa Redes probabilísticas 2.2 Identificación de sistemas Para poder identificar los sistemas que controlan los PID’s en el proceso se va a utilizar una modelación ARX. Esto con el fin de llegar a una ecuación diferencial lineal la cual sea capaz de representar al sistema de una manera eficiente y poder utilizarlo en la siguiente parte que es la sintonización en un sistema difuso a través de una simulación computacional antes de su implementación. Para hacer la identificación se requiere una base de datos del proceso en la cual se pueda observar las variables de entrada y salida del sistema en diferentes tiempos. Un sistema de identificación permite el construir modelos matemáticos de un sistema dinámico basado en información medida del sistema. Esto es mediante el ajuste de parámetros dentro de un modelo dado hasta que las salidas del modelo se aproximen en la mayor cantidad posible a las salidas medidas del sistema. Una buena prueba del modelo es tomar la salida del modelo y compararla contra la salida medida en un juego de datos que no fue utilizado para la creación del modelo llamado “Datos de Validación”. La calidad del modelo se puede medir también mediante la observación en la salida de modelo y ver cuales son las condiciones bajo las cuales el modelo no fue capaz de reproducir la salida del sistema, llamado “residuos”, esto no debe de tener relación alguna con otras variables de entrada al sistema [17]. Estas técnicas se aplican a modelos muy generales. La mayoría de los modelos comunes tienen diferentes descripciones en las ecuaciones diferenciales, tales como los modelos ARX y el ARMAX así como todos los modelos de estado, espacios lineales. El modelo ARX es una opción para poder obtener la ecuación diferencial del proceso a ser modelado, que a su vez se necesita para utilizarse como entrada en las simulaciones del sistema que se propone. 2.2.1 Identificación de señales A continuación se mencionan las diferentes partes que constituyen el obtener una función para una serie de datos de entrada y de salida. Para lograr esto en este trabajo se utilizo el método ARX. 2.2.2 Términos Comunes utilizados en identificación de sistemas Esta sección define los términos más frecuentes utilizados en el área de identificación de sistemas [14]:. 16.
(27) Dato de estimación es la información que es utilizada para crear un modelo que concuerde con el muestreo. Dato de validación es la información que es utilizada con el propósito de validar el modelo creado. Esto incluye la simulación del modelo para estos datos y compilar los residuos del modelo al aplicarse a estos datos. Las percepciones del modelo son diferentes formas de inspeccionar las propiedades de un modelo. Estas incluyen el ver los polos y ceros, respuestas de frecuencia y transitorias, etc. Los datos constan con diferentes maneras de inspeccionar las propiedades de las bases de datos. La manera más común es simplemente el graficar la información y escudriñarla. Juegos o estructuras de modelos son familias de modelos con parámetros ajustables. La estimación de los parámetros se utiliza para buscar los mejores valores para estos parámetros. El problema de identificación de sistemas se adjunta tanto en buscar un buen modelo como en buscar los parámetros óptimos para este. Los Métodos de identificación paramétrica son técnicas de estimar el comportamiento del modelo. Básicamente es cuestión de encontrar por búsqueda numérica los valores de los parámetros que dan el mejor resultado en el modelo de tal forma que el valor de respuesta estimado sea el más cercano posible al valor real de salida. Los métodos de identificación no paramétrica son técnicas de estimación de comportamiento de modelos sin utilizar parámetros. Los métodos típicos de este tipo son análisis de correlación, el cual estima la respuesta de un sistema a la entrada, y el análisis espectral el cual estima la respuesta en la frecuencia del sistema. La Validación del modelo es el proceso de adquirir confianza en él. Básicamente esto se consigue mediante pruebas con el modelo hasta tomar en cuenta todos los aspectos del sistema. De mucha importancia en esta parte es la capacidad del modelo de reproducir el comportamiento del sistema en los datos de validación. Así como también es importante tomar en cuenta el comportamiento de las propiedades al ver los residuos del modelo al aplicarlo a los datos de validación. 2.2.3 Señales Los modelos describen relaciones entre señales medidas. Es necesario distinguir entre señales de entrada y de salida. Después las salidas son parcialmente determinadas por las entradas. En la mayoría de los casos las salidas son afectadas por más variables que las señales medidas a lo que se le llama señales de disturbios o ruido. En una caja negra con entradas y salidas y teniendo la entrada medida “e”, el ruido “u” y la salida “y” se vería de la siguiente manera.. 17.
(28) Figura 2.1 Modelo de entrada y salida del sistema. Todas estas señales son funciones del tiempo y el valor de la entrada en un tiempo t se denota por u (t). Normalmente el proceso de identificación solamente utiliza puntos discretos debido a que los sistemas de medición normalmente solo reportan valores de medición en tiempos discretos o instantes. A estos lapsos de tiempo entre una muestra y la siguiente, que normalmente es constante, se le denota intervalo de muestreo con T unidades de tiempo. El problema de modelado es el describir como las tres señales se relacionan entre si [10]. 2.2.4 El modelo dinámico básico La relación básica es la ecuación de diferencia lineal. Un ejemplo de esta ecuación es la siguiente:. y (t ) 1.5 y (t T ) 0.7 y (t 2T ) (2.1). 0.9u (t. 2T ) 0.5u (t 3T ). (ARX). La ecuación de diferencia lineal nos dice como compilar la salida y(t) si la entrada es conocida y el ruido se puede despreciar.. y (t ) 1.5 y (t T ) 0.7 y (t (2.2). 2T ) 0.9u (t. 2T ) 0.5u (t 3T ). La salida en un tiempo t es compilada dependiendo de las entradas y salidas pasadas. De aquí se puede concluir que la salida en un tiempo t depende directamente de las señales de salida y entrada en muchos tiempos antes. A esto es a lo que se refiere la palabra dinámico. El problema en este tipo de sistemas se define en identificar los coeficientes de la ecuación, cuantos tiempos o intervalos de tiempo pasados utilizar en la ecuación, el intervalo de tiempo a utilizar (2T en la ecuación descrita anteriormente, esto debido a que toma 2T unidades de. 18.
(29) tiempo en afectar un cambio en la entrada a la salida) y en calcular cuantas entradas retrasadas se van a utilizar, a esto se le conoce como el orden de la ecuación. 2.2.5 Variantes de las descripciones del modelo El modelo descrito en la sección anterior se llama modelo ARX. Existen muchas variantes de este modelo como el Output-Error (OE), ARMAX, FIR y Box-Jenkins (BJ). Estas variantes del modelo ARX manejan una caracterización de las propiedades de disturbios e [9]. Los modelos lineales espacio-estado son también fáciles de utilizar. La estructura de las variables es escalar, el orden del modelo. Los modelos generales lineales se pueden representar simbólicamente por: y = Gu + He. (2.3). Donde se describe que la salida medida y(t) es una suma de la entrada medida u(t) y el ruido He. El símbolo G denota las propiedades dinámicas del sistema, esto es como la salida es formada por la entrada. Para sistemas lineales es llamada la función de transferencia de entrada a salida. El símbolo H se refiere a las propiedades del ruido y es llamado el modelo de disturbios. Esta describe como los disturbios en la salida son formados de ruidos estandarizados e (t). Los modelos de espacio-estado son representaciones comunes de modelos dinámicos. Describen los mismos tipos de relaciones de diferencia lineal entre las entradas y las salidas como en el modelo ARX, pero se encuentran arregladas de tal forma que solamente un retraso es utilizado en la expresión. Para lograr esto, se introducen variables extras, las variables de estado. No son variables medidas pero pueden ser reconstruidas de las variables de entrada y salida medidas. Esto es muy útil cuando se tienen varias variables de salida o y (t) es un vector. La representación espacio-estado es de la siguiente manera:. x(t 1) Ax(t ) Bu (t ) Ke(t ) y (t ) Cx (t ) Du (t ) e(t ). (2.4) (2.5). En estas ecuaciones x (t) es el vector de variables de estado y el orden de la ecuación es la dimensión de este vector. La matriz k determina las propiedades de los disturbios. Cuando k = 0, e (t) solamente afecta a la salida y no se construye ningún modelo especifico del ruido. Esto corresponde a cuando H = 1 en la descripción general y es llamado modelo de salida-error. Cuando D = 0 significa que no hay influencia directa de u (t) a y (t), aunque el efecto de la entrada en la salida todo pasa por x (t) y va a tener un retraso de al menos una unidad de tiempo o un muestro. El primer valor del vector de la variable de estado x (0) refleja las condiciones iniciales del sistema al principio de los datos recolectados.. 19.
(30) 2.2.6 Como interpretar la fuente de ruido En muchos casos los efectos del ruido en la salida son insignificantes a comparación a los de la entrada. Con buenos cocientes de señal a ruido (SNR) es menos importante el tener un modelo de disturbios exacto. Como quiera es importante el entender el rol de los disturbios y la fuente de ruido e (t). Hay tres aspectos de los disturbios que se deben de tomar en cuenta: el ruido blanco, la interpretación de las fuentes de sonido y la forma en la que se utiliza la fuente de ruido cuando se trabaja con el modelo [15]. Desde un punto de vista formal la fuente de ruido e normalmente se observa como ruido blanco. Esto significa que es completamente impredecible. En otras palabras, es imposible el tratar de adivinar el valor de e (t). La contribución actual de los disturbios a la salida He que se observa en la ecuación (2.3), tiene mucho significado. Esta contiene todas las influencias en la medida y que no están contempladas en la entrada u. Explica y captura la verdad que aunque un experimento sea repetido con las mismas entradas, la señal de salida será normalmente diferente en alguna medida. Como quiera, la fuente de ruido e debe de tener algún significado físico [16]. 2.2.7 Términos para caracterizar las propiedades de un modelo Las propiedades de una relación entrada-salida como un modelo ARX siguen los valores numéricos de los coeficientes, y el número de retrasos utilizados. Existen varios términos para describir estas propiedades. Respuesta al impulso El impulso de respuesta de un modelo dinámico es la señal de salida que resulta cuando la entrada es un impulso. Respuesta de escalón Es la señal de salida que resulta de un escalón en la entrada. Respuesta transitoria Es la señal resultante de la respuesta de impulso y escalón juntos Respuesta de frecuencia Describe como reacciona el modelo a entradas senoidales. Si la entrada u (t) es una función senoidal de frecuencia f, la salida y (t) también será senoidal de frecuencia f pero variara en la amplitud y la fase. Esta respuesta normalmente se muestra en dos graficas, una que muestra los cambios de la amplitud como función de la frecuencia de la función senoidal y otra grafica que muestra el cambio de fase como función de la frecuencia, esta grafica se conoce como grafica de Bode. Polos y ceros Los ceros y polos son formas equivalentes de describir los coeficientes de una ecuación de diferencia lineal como el modelo ARX. Los polos se relacionan con la salida y los ceros se relacionan con la entrada de la ecuación. El número de polos o ceros es equivalente al número de muestras entre el mayor y el menor retraso en la entrada o salida [16].. 20.
(31) 2.2.8 Pasos básicos para la identificación de un sistema El problema de identificación de sistemas es el estimar un modelo de un sistema basado en los datos de entrada y salida observados. Existen varias formas de describir un sistema y de estimar sus descripciones. El procedimiento para determinar un modelo de un sistema dinámico a partir de datos observados de entrada y salida consta de tres elementos básicos: Los datos de entrada salida Un conjunto de modelos candidatos Un criterio para seleccionar un cierto modelo en el conjunto basado en la información recolectada El proceso de identificación se resume en seleccionar una estructura del modelo, compilar el mejor modelo en la estructura y evaluar las propiedades del modelo para ver si son lo suficientemente satisfactorias. El ciclo se puede resumir en los siguientes pasos: 1. Diseñar un experimento y recolecta los datos de entrada y salida del proceso a ser identificado. 2. Examinar los datos y pulirlos para remover los trazos y seleccionar porciones útiles de la información original. Posiblemente aplicar filtros para darle más importancia a las frecuencias y rangos. 3. Seleccionar y definir una estructura de modelo. 4. Compilar el mejor modelo en la estructura que mejor se adapte dependiendo de la información de entrada – salida. 5. Examinar las propiedades del modelo obtenidas. 6. Si el modelo es lo suficientemente bueno aquí termina de lo contrario regresar al paso número 3 para tratar con otro modelo y posiblemente incluso con otro método de estimación, paso 4 [16]. 2.2.9 Procedimiento de identificación No existen estándares para un buen modelo de identificación de sistemas. A continuación se describe una metodología que normalmente se utiliza para una satisfactoria identificación de un sistema. Paso 1. Observación y clasificación de los datos Se grafican y se observan los datos para tratar de entender la dinámica del proceso a simple vista. En esta parte se busca identificar que es lo que pasa a la salida dependiendo de la entrada. Con esto se refiere a si tiene efectos no lineales, diferentes respuestas para diferentes niveles, o diferente respuesta para un escalón hacia arriba y hacia abajo. Algunas veces sucede que existen porciones de datos que no contienen información. Con estos criterios se separan los datos con propósitos de estimación de los de validación. Si no hay niveles físicos que jueguen un rol importante en el modelo se quitan las tendencias en este mediante la remoción de los valores agresivos. Los modelos ahora describen como los cambios en la entrada hacen cambios en la salida, pero no explican los niveles actuales de las señales. Esto es una situación normal.. 21.
(32) La situación mas común es el remover las tendencias y tomar la primera mitad para estimación y la segunda mitad para validación del modelo. Paso 2. Prueba del modelo ARX de cuarto orden Compilar y desplegar los análisis espectrales estimados y el análisis correlacional estimado con un modelo de cuarto orden ARX con un retraso estimado del análisis de correlación. De estos datos arrojados por estos análisis se debe observar: El modelo de frecuencia del estimado del análisis espectral y del ARX. Las respuestas transitorias del estimado del análisis de correlación y del ARX. La salida simulada del modelo ARX y las salidas medidas de los datos de validación. Si estos valores son razonables, entonces el problema no es tan difícil y un modelo lineal simple arroja valores de respuesta correctos. Aun es necesario hacer ajustes en los valores del orden del modelo y los modelos de ruido. Paso 3. Razones de error Pueden existir varias razones por las cuales los valores arrojados por el paso 2 no son tan satisfactorios. Modelo inestable o El modelo ARX puede resultar ser inestable pero seguir siendo útil para cuestiones de control. Para solucionar esto hay que cambiar de 5 a 10 pasos adelante en la predicción en vez de simulación en la vista de la salida del modelo. Retroalimentación en los datos o Si existe una retroalimentación de la salida a la entrada debido a algún regulador en el proceso los datos de los análisis correlacional y espectral no son confiables. Se deben descartar las discrepancias entre los estimados y el modelo ARX. En la vista residual del modelo de los modelos paramétricos también se puede observar la retroalimentación en los datos mediante una correlación entre residuales y entradas para retrasos negativos. Modelo de Perturbaciones o Si el modelo de espacio – estado es mejor que el modelo ARX en la reproducción de la salida medida, esto es una indicación que los disturbios tienen una influencia substancial en la salida y será necesario el modelarlos muy cuidadosamente. Orden del Modelo o Si un modelo de cuarto orden no da como resultado una grafica de salidas modeladas satisfactoria, es necesario aumentar el orden para ver si se mejora. En caso de que si se mejore el modelo obedece a mayores ordenes. Entradas Adicionales o Si el modelo de la salida del sistema no se ha mejorado con los pasos anteriores es necesario pensar en la física del proceso. Hay que ver si existen mas señales de las que se han tomado en cuenta que puedan ser medidas que puedan influenciar sobre la salida del sistema. Si, si existen es necesario tomarlas en cuenta y volver a intentarlo con un modelo de cuarto orden.. 22.
(33) Efectos no lineales o Si el trecho entre las salidas medidas y modeladas aun es muy amplio hay que considerar la física de la aplicación. Se debe de ver si existen efectos no lineales en el sistema. En caso de que si existen es necesario agregar esas no linealidades como datos de entrada. Si aun persisten problemas o Si ninguno de los pasos anteriores pudo resolver el problema o ninguno a llevado a un modelo que pueda reproducir los datos del sistema de datos de validación, la conclusión puede ser que no se puede crear un buen modelo con los datos de entrada actuales. Esto puede llegar a suceder debido a varias razones como son el que los datos contienen grandes no linealidades que no se pueden realizar físicamente. Para estos casos un sistema de caja negra no lineal puede ser una buena opción, el más utilizado en estos casos es un sistema artificial de redes neuronales, también se puede realizar un sistema difuso. Otra buena razón para que no se haya podido completar el problema es que los datos no contienen suficiente información debido a poca cantidad o a grandes medidas de ruido. Paso 4. Estructuras de modelos Para datos reales no existe una estructura de modelo correcta. Sin embargo, diferentes estructuras pueden dar muy diferentes calidades de modelos. La única manera de saber esto es mediante pruebas de diferentes modelos y comparar las propiedades de los modelos resultantes. Ajuste entre la salida simulada y medida o En la salida simulada y la salida modelada se puede observar cual es el mejor modelo, aunque a veces es bueno tomar en cuenta también la complejidad del modelo a comparación de la ganancia en respuesta. Prueba de análisis residual o Se requiere un modelo en el cual la función de correlación entre los residuos y las entradas no salgan de los rangos de confianza. De lo contrario existe algo en los residuos que se origina de las entradas y no se ha tomado en cuenta. Un gran pico en la k muestra que el efecto de una entrada u (t-k) en y (t) aún no se a descrito correctamente. Cancelación de polos y ceros o Si la grafica de los polos y ceros indica cancelaciones en al dinámica, quiere decir que se pueden utilizar modelos de menor orden [14]. 2.3 Sistemas Difusos La vida real está llena de situaciones que requieren del razonamiento aproximado para manipular información cualitativa más que cuantitativa. Un sistema difuso puede resolver problemas tal como lo haría un experto humano, problemas tales como controlar la presión y temperatura de una caldera en la industria,. 23.
(34) procesar y reconocer imágenes o controlar una lavadora de ropa son situaciones que tienen en común el ser complejas y dinámicas y también que son más fácilmente caracterizadas por palabras que por expresiones matemáticas. Mientras que los sistemas de lógica clásica no pueden actuar en problemas de este tipo: Representación de proposiciones en lenguaje natural cuando el significado es impreciso. Mecanismos de evaluación. En la década de los años veinte de este siglo, J. Lukasiewicz desarrolló los principios de la lógica multivaluada, cuyos enunciados pueden tener valores de verdad comprendidos entre el 0 (falso) y el 1 (cierto) de la lógica binaria clásica. En 1965 Lofti A. Zadeh, aplicó la lógica multivaluada a la teoría de conjuntos, estableciendo la posibilidad de que los elementos pudieran tener diferentes grados de pertenencia a un conjunto. Zadeh introdujo el término fuzzy (difuso) y desarrollo un álgebra completa para los conjuntos difusos. Desde sus inicios la teoría de conjuntos difusos causó controversias y debates, por lo que sus primeras aplicaciones prácticas surgieron hasta mediados de los años setenta. Gracias a que la lógica difusa se enfrenta con éxito a situaciones del mundo real, ha encontrado aplicaciones en una gran variedad de campos, de las cuales las más trascendentales se han dado en el área de control con el diseño e implementación de controladores difusos (Fuzzy Logic Control), iniciado por los trabajos de Mamdami y Assilian en los años setenta. Ejemplos de sistemas de control y productos comerciales cuyo funcionamiento se basa en un razonamiento aproximado (difuso), son: Control de un horno de cemento. Estabilización de imágenes en cámaras de video. Lava trastes y lavadoras de ropa. Conducción automática de trenes metropolitanos. Control de aire acondicionado. Pero ¿Cuándo utilizar lógica difusa? Lógica difusa tiene la habilidad de proporcionar un control inteligente en aplicaciones difíciles, especialmente aquellas que requieren de la optimización de muchas variables o el control de sistemas no lineales difíciles de modelar. 2.3.1 Conceptos básicos Un conjunto es un concepto bastante primitivo, análogo al concepto de punto o de recta. Un conjunto se utiliza como algo que puede o no tener elementos, pero con la propiedad de que se puede decir si un objeto dado cualquiera es o no elemento del conjunto en cuestión.. 24.
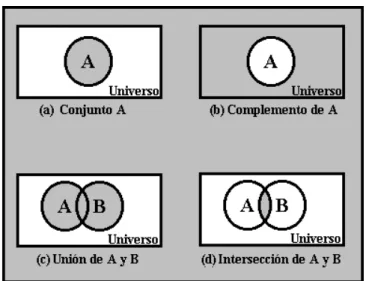
(35) A los objetos (si los hay) que forman un conjunto, se les llama elementos de dicho conjunto. En la teoría de conjuntos que se va a utilizar, se trabajara a veces con varios conjuntos cuyos elementos son todos del mismo tipo, es decir, pertenecen todos a un mismo conglomerado de cosas al que podremos llamar conjunto universal [4]. Sí A es un conjunto, la proposición x es un elemento de A se denotará por x A. La negación de esta proposición es decir x no es un elemento de A se denotará por x neg ( ) A. Sí enumeramos todos los elementos de un conjunto, decimos que los hemos representado por extensión mientras que si enunciamos una propiedad definitoria de los elementos del conjunto, se dice que está representado por comprensión. 2.3.2 Función de membresía La pertenencia o membresía es una relación que vincula a cada elemento con un conjunto. En otras palabras, en un conjunto bien definido (lógica clásica), la pertenencia o no pertenencia de un elemento x a un conjunto A se describe mediante la función característica µA(x) donde:. (2.6) Dicha función es llamada función de membresía ó función característica de A y esta definida para todos los elementos del universo. La función de membresía hace un mapeo de todo el universo U a su conjunto de evaluación de dos elementos {0,1}, esto se escribe: A(x). : U{ 0, 1}. (2.7). Con una identificación de {0,1} y {verdadero, falso}, esta función característica puede jugar un papel importante en la asignación de valores de verdad a proposiciones referentes al conjunto A. 2.3.3 Operaciones con conjuntos. Es posible construir conjuntos a partir de dos o más conjuntos dados, aplicando para ello las operaciones básicas: complemento, unión e intersección de conjuntos. Es común usar diagramas de Venn para representar al conjunto universal U y a los conjuntos formados con elementos de U. La siguiente figura ilustra las operaciones mencionadas anteriormente utilizando diagramas de Venn.. 25.
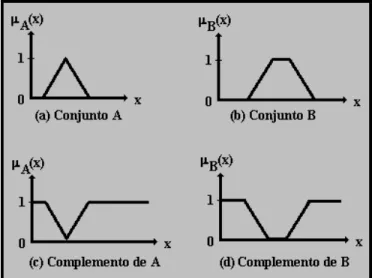
(36) Figura 2.2 diagrama de Venn. 2.3.4 Conjuntos Difusos La lógica difusa trabaja con conjuntos a los cuales llamamos conjuntos difusos, estos conjuntos están definidos por sus funciones de pertenencia, la cual expresa la distribución de verdad de una variable. Teóricamente un conjunto difuso A de un universo de discurso X={x} se define como un mapeo A(x): X [0, a ] donde cada x es asignada a un número en el rango comprendido entre [0, a ] el cual indica que tanto del atributo A tiene x. Cuando se normaliza la función de membresía (a =1), se tiene A(x) : X[0, 1]. Para los casos extremos, donde la distribución de verdad es "cero", la función de membresía se reduce a singularidades, en otras palabras, la lógica difusa pasa a ser lógica clásica. Por ejemplo, si las singularidades tienen dos posibilidades, entonces hablamos de lógica binaria [11]. La normalización del conjunto difuso A se expresa: sup x. A. ( x) 1. (2.8). X. Para un conjunto difuso el conjunto de evaluación es un intervalo real: A(x). : U [0, 1]. (2.9). La función característica de un conjunto difuso permite una continuidad de opciones posibles. El grado de membresía no es probabilidad. Básicamente es una medida de la compatibilidad de un objeto con el concepto representado por un conjunto difuso. 26.
(37) Un conjunto difuso D en un universo U puede ser definido como un conjunto de pares ordenados; cada par formado por un elemento y su grado de membresía al conjunto D: D = {(x. D(x)). | x U}. (2.10). Para el caso de universos discretos U = {x1, x2,…, xn}, una notación más conveniente es:. (2.11). (2.12) La sumatoria anterior se transforma en una integral para un universo U continuo:. (2.13) 2.3.5 Operaciones con conjuntos difusos En lógica booleana la función de los operadores booleanos (o compuertas) es bien conocida. En lógica difusa los valores no están definidos y su defusificación exhibe una distribución descrita por su función de membresía. Como ya se dijo, en lógica difusa se emplean conjuntos así que aquí también contamos con operaciones de complemento, unión e intersección. Cuando a dos variables difusas se les aplica una operación de unión (que en lógica binaria es equivalente a una operación OR), el resultado se obtiene tomando el valor más grande de entre las variables de entrada, max(x1, x2,…, xn). Para el caso de la intersección (que equivale a la operación AND) el valor resultante de la operación corresponde al mínimo valor de alguna de las entradas: min(x1, x2, …, xn). En la operación "complemento" (equivale a una operación NOT), se toma el valor que complemente a 1, de esta forma: x’= 1-x. (2.14). 2.3.6 Complemento de un conjunto difuso. 27.
(38) Sea A un conjunto difuso en el universo U con una función de membresía µA(x), el complemento del conjunto A es el conjunto A definido por: 1 A ( x) (2.15) A x U x La función de membresía del conjunto A es: A( x) 1 A( x). (2.16). La Figura 2.3 muestra las gráficas de la función de membresía de dos conjuntos difusos y sus conjuntos complementos.. Figura 2.3 Función de membresía y complemento de los conjuntos difusos a y B. 2.3.7 Diseño del sistema difuso Para generar el sistema difuso necesario para el funcionamiento requerido en esta tesis se utilizaran los siguientes pasos [1]: 1. 2. 3. 4. 5. 6.. Identificación de variables de entrada y salida Determinación de conjuntos difusos Elección de método para difusificación y desdifusificación Creación de base de conocimiento utilizando reglas del tipo si-entonces Diseño de mecanismo de inferencia Evaluación y uso del sistema. Los elementos fundamentales de la teoría de sistemas difusos son los conjuntos difusos. Sobre ellos se puede realizar operaciones, algunas de ellas semejantes a las que se realizan con. 28.
(39) los conjuntos clásicos. Finalmente, la lógica difusa, esta basada en las combinaciones de conjuntos difusos mediante las mencionadas operaciones.. Figura 2.4 Diagrama de lógica difusa Dados dos conjuntos difusos A y B se definen otros conjuntos difusos a través de sus funciones de pertenencia respectivas. Para la reunión de A y B con el máximo y para la intersección de A y B con el mínimo. Finalmente la operación de complemento se define por medio de la siguiente ecuación: x A. ( x) 1. A. ( x). (2.17). En la figura 2.5 se muestra como se va viendo el grado de pertenencia en cada uno de los casos [11].. AyB. intersección A y B unión AB Figura 2.5 Grado de pertenencia. 2.3.8 Defuzificación La salida de una regla difusa es un conjunto difuso. Debido a esto en una gran parte de las aplicaciones es necesario el transformar esta salida. Para realizar esta transformación hay dos formas [18]: 1. Aproximación lingüística: se transforma en una descripción verbal 2. Defuzificación aritmética: se extrae un valor escalar que represente al conjunto difuso En este caso se utiliza la defuzificación aritmética que a su vez tiene varias formas de realizarse. Las dos más comunes son: 1. Valor máximo 2. Centro de área (o de momentos). 29.
(40) Figura 2.6 Defuzificación aritmética En la Figura 2.6 se muestra en color rojo el resultado del valor máximo y en color rosa el resultado del centro de área.. 30.
(41) 3. DISEÑO DEL ASISTENTE INTELIGENTE Y RESULTADOS. En esta sección se describen los resultados obtenidos en el área de programación así como en la parte técnica de la tesis. 3.1 Metodología de diseño El área de la creación de las partes del sistema de automatización y el área de el sintonizado de PID’s son dos partes distintas de este proceso cada una con su diferente interfaz. Primero se debe de realizar todo lo referente a la base de datos general del proceso, después se pasa a realizar la base de datos de la interfaz, la lógica escalera y la ingeniería básica. Una vez que se tiene todo esto y ya se introdujo todo el sistema se pasa a ponerlo a funcionar de tal manera que se saque un muestreo del proceso en tiempo real para hacer un trabajo fuera de línea utilizando la herramienta de Matlab para obtener los parámetros de sintonización que después se deben de introducir manualmente al PLC con el fin de lograr sintonizar el PID y obtener un sistema funcionando en mejores condiciones.. Figura 3.1 Metodología de Diseño. 3.2 Sistema Inteligente. En esta área se describe el programa creado utilizando un sistema basado en conocimiento. Se describe parte por parte cada una de las áreas del sistema y su funcionamiento básico. Este programa creado en Visual Basic versión 6 se encarga de realizar toda la labor de arreglar datos para su uso en el campo. La primera parte es decirle al programa en donde se va a almacenar toda la información creada por el sistema para lo cual se creo la pantalla de bienvenida en donde se pide un directorio a crear. A continuación de esto se requiere leer un archivo en Excel como el mostrado en la Figura 1.2 de donde se obtendrán todas las máquinas a procesar separadas por. 31.
Figure

+7



Documento similar
The notified body that issued the AIMDD or MDD certificate may confirm in writing (after having reviewed manufacturer’s description of the (proposed) change) that the
En estos últimos años, he tenido el privilegio, durante varias prolongadas visitas al extranjero, de hacer investigaciones sobre el teatro, y muchas veces he tenido la ocasión
que hasta que llegue el tiempo en que su regia planta ; | pise el hispano suelo... que hasta que el
Para ello, trabajaremos con una colección de cartas redactadas desde allí, impresa en Évora en 1598 y otros documentos jesuitas: el Sumario de las cosas de Japón (1583),
E Clamades andaua sienpre sobre el caua- 11o de madera, y en poco tienpo fue tan lexos, que el no sabia en donde estaña; pero el tomo muy gran esfuergo en si, y pensó yendo assi
Sanz (Universidad Carlos III-IUNE): "El papel de las fuentes de datos en los ranking nacionales de universidades".. Reuniones científicas 75 Los días 12 y 13 de noviembre
(Banco de España) Mancebo, Pascual (U. de Alicante) Marco, Mariluz (U. de València) Marhuenda, Francisco (U. de Alicante) Marhuenda, Joaquín (U. de Alicante) Marquerie,
Proporcione esta nota de seguridad y las copias de la versión para pacientes junto con el documento Preguntas frecuentes sobre contraindicaciones y
