Muestreo progresivo : NSC
85
0
0
Texto completo
(2) Desc11brimie11ro de C'onocimienro en Bases de Daros. Resumen. En la actualidad es indispensable el análisis progresivo e incremental de datos (muestreo progresivo) debido a los grandes volúmenes de información que se tienen ; esto con la finalidad. de reducir. costos. computacionales. en. la. aplicación. del. proceso. de. descubrimiento de conocimiento en bases de datos. El muestreo progresivo de datos forma parte del proceso inicial de descubrimiento de conocimiento, y constituye, en general, una mejor opción que el análisis del total de información . Se busca procesar un subconjunto de datos, cuya medida de calidad del análisis se asemeje a la obtenida a partir del total de información. La adecuada selección de elatos permitirá que la extracción de conocimiento genere eficientemente buenos re!iUltados. En la tesis se diseñó un novedoso algoritmo de muestreo progresivo, el cual toma en cuenta los tres puntos fundamentales que intervienen en el muestreo progresivo : tamaño de muestra inicial, esquema de muestreo, y detección de la convergencia . Es1a técnica de muestreo progresivo demostró, según las pruebas realizadas , ser consist,~ntemente superior al muestreo progresivo aritmético y geométrico.. 2.
(3) Desc11bri111ie1110 d<' Co11oci111ie11/0. ('11. Bases de Dalos. Índice. Capítulo 1. Introducción. 4. 1. 1. Objetivo 1.2. Retos computacionales 1.3. Contenido del documento. 8 8 9. Capítulo 2. Antecedentes y marco teórico. 10. 2.1. Descubrimiento de conocimiento en bases de datos 2.1.1. Las fases del proceso de KDD 2.1.2. Tareas y técnicas en KDD 2.2. Muestreo Progresivo 2.2.1. Programación de muestreo 2.2.2. Detección de la convergencia 2.3. Muestreo adaptativo. 10 14 16 21. Capítulo 3. NSC: Un algoritmo de muestreo progresivo. 32. 3.1. Descripción General 3.2. Selección de tamaño de muestra inicial 3.3 Esquema de muestreo 3.4. Detección de la convergencia por número de iteraciones y medida de precisión 3.5. Análisis del algoritmo. 33 35. 46. Capítulo 4. Pruebas y resultados obtenidos. 48. 4. 1. Datos empleados 4.2. Descripción general del proceso de pruebas 4.3. Selección de tamai'io de muestra inicial 4.4. Esquema de muestreo 4.5. Detección de la convergencia por número de iteraciones y medida de precisión 4.6. Comparación entre métodos 4.6.1. Precisión y tamaño de muestra 4.6.2. Tiempo de ejecución. 24 27. 29. 38 39. ........................... 49 51. 52 54 55 56 57. 60. Capítulo 5. Conclusiones. 63. 5. 1 Trabajo futuro. 65. Fuentes de información. 67. Anexos A. Código fuente principal B. Base de datos de transacciones empleada. 71. 78. 3.
(4) DC'sc11bri111iC'11to de Co11ocimie1110 en BasC's de Datos. Capítulo 1. Introducción En las últimas déccidas, el poder de almacenamiento y proceso de diversos dispositivos de cómputo se ha incrementado considerablemente. Por otro lado la velocidad de análisis de la información es cada vez mayor [ l]. Esto nos brinda grandes oportunidodes para procesar y explotar datos, y convertirlos en información valiosa según el área de aplicación. Sin embarqo, a pesar de que la información es un recurso muy importante para toda industria, el desarrollo y aplicación de las técnicas de análisis de información no ha crecido al mismo ritmo que el almacenamiento de datos. Debido a esto, e>:iste la necesidad de generar y emplear nuevas técnicas y herramientas [6] de cómputo que permitan al usuario obtener mayor información de la que ya pos::;e, al aprovechar y explotar al máximo los recursos computacionales. El descubrimiento de conocimiento en bases de datos (KDD por sus siglas en Inglés Knowledge Discovery in Databases) constituye un procedimiento para generar información útil a partir de datos. La aplicación de los algoritmos para la extracción de patrones 1 corresponde a una fase primordial del proceso de KDD, y es conocido en sí corno minería de datos. Se debe alcanzar el objetivo de que a partir de datos se ~1enere conocimiento relevante, lo que implica poder procesar automáticamente grandes cantidades de datos para hallar dicha información útil y novedosa. Se requiere que las técnicas de análisis de datos interactúen adecuadamente para generar los mejores resultados. Dado que la mayoría de las técnicas de minería de datos son aún muy recientes, se requiere de investigación al respecto, todavía existen varias áreas de oportunidad siguiendo o generando líneas de invesi·igación. Hasta hace unos años, el proceso de KDD era hasta cierto punto suplantado por la actividad de los gerentes, planificadores y administradores. Sin embargo, actualmente en un buen proceso de KDD es más provechoso que un experto o investigador realice esta labor al apoyarse en herramientas diseñadas para ese 1. Representan conocimiento siempre y cuando su medida de interés rebase un determinado umbral. 4.
(5) Desc11bri111ie1110 de Co11oci111ien111 en Bases de Dalos. fin, y al generar un procedimiento a seguir con base en la experiencia. El experto o investigador debe- interactuar constantemente durante los etapas del proceso, con el objetivo de que la información generada sea efectivamente un resultado valioso. La importancia y necesidad actual de un proceso de descubrimiento de conocimiento en bases de datos, ya no se pone en discusión.. El empleo de KDD va en aumento, a pesar de que cada ·1ez es más claro que este proceso involucra un mayor esfuerzo del que inicialmente se habría pensado. Por mencionar algunos casos: es necesario preparar los dalos a examinar, varias veces; se requieren numerosas pruebas de extracción para verificar el proceso; se hace un gran (en ocasiones incierto) uso de recursos computacionales y humanos. En efecto se estima que el 80% del tiempo empleado en KDD, está destinado en la preparación de los datos, y el 20% restante es en sí el proceso de minería. Esto parte ele la noción de que sin los datos adecuados, existen muy pocas posibilidades de encontrar información útil, novedosa y relevante.. El tener grandes cantidades de datos no implica que se deban emplear en su totalidad para la extracción de conocimiento, de hecho el volumen de información almacenada hace a veces imposible el proceso de extracción. Actualmente el incremento desmesurado en el tamaño de las bases de datos constituye un problema grave para el proceso de KDD, dado que los algoritmos de extracción no escalan adecuadamente; la complejidad de éstos es peor que lineal.. Una técnica que tiene el objetivo de eliminar este problema, es el muestreo progresivo. La idea fundamental es obtener un subconjunto de datos a partir del cual se pueda generar un modelo donde, con base en una medida de evaluación (como la precisión - ejemplos correctamente evaluados), se pueda determinar la equivalencia de éste con respecto al modelo 9enerado a partir del total de datos . Aquí se contraponen dos conceptos fundamentales para el muestreo: la precisión y la eficiencia . La precisión permite :letectar estructuras complejas en la generación de modelos lo cual demanda ~Jeneralmente el uso. 5.
(6) Desc11hri111ie11to de Co11oci111ie1110 e11 Bases de Datos. de una gran cantidad de datos. Por el otro lado si se persigue una buena eficiencia, es necesario emplear pocos datos dada la complejidad de los algoritmos de extracción, los cuales normalmente, en el mejor de los casos, son de forma polinomial con el número de datos.. Los algoritmos de extracción requieren de una adecuado cantidad de datos para generar buenos resultados a partir de una base de da-·os, pero ¿cuál es esa cantidad?, ¿cómo saber que son datos adecuados?, ¿cómo saber que otra cantidad de datos no es mejor? Éstas son algunas de k:is preguntas que el muestreo progresivo de datos aborda, pero en si ¿cuál es la necesidad de realizar el muestreo progresivo? Para responder este cuestionamierto debemos retomar el hecho de que las bases de datos almacenan diariamente grandes cantidades de datos a tal grado que es muy difícil, y en algunos casos imposible, procesar esos volúmenes de información. El problema se enfoca en dos puntos: el tiempo que demanda el manejo de tanta información y las limitaciones del hardwaresoftware de poder analizarla adecuadamente.. En realidad estos problemas están fuertemente relacionados a costos para una organización, debido a que los recursos tiempo y uso de hardware no son baratos. En los inicios de la minería de datos la ejecución de los algoritmos se llevaba a cabo con la totalidad de los datos 2, pero en la actualidad esto ya no es factible en muchos casos, tanto por costos (uso de recursos) como por posibilidades (capacidades del hardware). Por citar algunos casos, WalMart realiza más de 20 millones de transacciones diarias y tiene una base de datos de 11 terabytes; AT&T tiene 100 millones de clientes y realiza del orden de 300 millones de llamadas al día de larga distancia; y el telescopio Hubble genera diariamente entre 1O y 15 gigabytes de datos para los astrónomos de todo el mundo (http://www.centennialofflight.gov/essay/Dictionary/HST /DI 19.S.htm). Por tal razón es que surge el muestreo progresivo cuyo objetivo a grandes -asgos es ir tomando muestras incrementales de datos siguiendo un determinado esquema de muestreo hasta que se satisfaga una condición de paro. 2. En algunos casos aplica: 2/3 de los datos para aprendizaje y 1/3 para comprobación. 6.
(7) Desc11bri111ie1110 de Co11oci111ie1110 en Bases de Dalos. Mediante el muestreo progresivo se busca realizar el proce:;o de descubrimiento de conocimiento, de forma más eficiente al no consumir ··iempo analizando la totalidad de los datos, sino solamente una porción del total. Se espera que el modelo de KDD resultante tenga una evaluación similar, en cierto rango, a la alcanzada con la totalidad de los datos.. En si con el muestreo progresivo se. desea hallar un tamaño de muestra que brinde la mayor precisión posible, al menor costo (tiempo y uso de recursos).. Hoy en día existen diversas alternativas para realizar muestreo progresivo. Unas de los más importantes son el muestreo aritmético y el geométrico [7], pero cada uno de estas técnicas presenta problemas que deben ser corregidos . Así mismo existen otros métodos que intentan resolver los problemas del muestreo progresivo atacando los puntos principales de éste : selección del tamar"lo de muestra inicial, esquema de muestreo, y detección del criterio de paro ó convergencia. Sin embargo, en genero!, estos algoritmos tienen una complejidad que los hace deficientes (poco competitivos, baja eficiencia) con respecto al aritmético y el geométrico. Ejemplos de estos métodos, que en sí no realizan muestreo progresivo como tal, son los que tratan de determinar el tamaño de muestra inicial para el muestreo al analizar los datos previamente; o bien evitan el muestreo al procesar los datos una sola vez y obtener así la información necesaria . En efecto la defensa de estos algoritmos, basados en información de los datos, no exponen una adecuada documentación y comparación con el muestreo aritmético y el geométrico; y ademós, en muchos de los casos , terminan por emplear a estos últimos para finalizar su ejecución [2] . Entonces, como se puede ver, es necesario el desarrollo de nuevas técnicas de muestreo progresivo, que aborden los problemas inherentes a este proceso.. 7.
(8) Desrnbrimie1110 de Co11oci111ie1110 en Bases de Datos. 1.1 Objetivo. El objetivo que en esta tesis se planteó, con la meta de impactar o mejorar finalmente el proceso y resultados de KDD , es:. ',. Diseñar un nuevo algoritmo de muestreo progresivo, que considere: o. la selección del tamaño de muestra inicial,. o. el esquema de muestreo,. o. y la detección de la convergencia. Y que sea más eficiente y efectivo que los esquemas actuales; con lo cual se espera resolver, en buena medida, el problema de la cantidad de datos que debe ser procesada por los algoritmos de extracción para la minería de datos, donde (como ya se mencionó) en ocasiones la ejecución de los mismos es imposible (o extremadamente lenta-ineficiente) dados los gr::mdes volúmenes de información.. 1.2 Retos computacionales. Es importante señalar que el muestreo progresivo tiene retos actuales e importantes, que se abordaron en esta investigación: selección del tamaño de muestra inicial. selección de esquema de muestreo, y detección de la convergencia. Se diseñó un algoritmo consistentemente superior (en lo que se refiere a estos conceptos) al esquema aritmético y geométrico. Esta superioridad será demostrada y detallada a lo largo de esta tesis.. El algoritmo planteado tiene, en el mejor de los casos, el mismo costo que la ejecución del proceso de extracción al utilizar el tamaño óotimo N. oráculo. (caso. menos costoso). Así mismo, en el peor de los casos, el costo de ejecución es a lo más semejante al costo del proceso de extracción con el total de datos. El algoritmo de muestreo que se desarrolló, es el NSC, cuyas siglas simbolizan la completa cobertura de los puntos importantes del muestreo progresivo: N inic ~ min -. 8.
(9) Desrnbrimiento de Co11oci1111e1110 en Bases de Datos. tamaño inicial, Sampling - muestreo empleado, y Co1vergence - criterio de terminación .. 1.3 Contenido del documento. En el capítulo dos se plantean los antecedentes y marce teórico necesarios para un buen entendimiento de la tesis, lo que básicamente consiste en situar al lector en el contexto de KDD y el muestreo progresivo. En el copítulo tres se presenta el algoritmo de muestreo progresivo NSC, y las características que lo definen. En el capítulo cuatro de pruebas y resultados, se describen los datos usados para corroborar lo planteado en el capítulo tres, así como los pruebas propiamente hechas. Finalmente el capítulo cinco presenta las principales conclusiones del trabajo realizado y se retoman los puntos que pueden dar paso a líneas de investigación para un trabajo futuro .. 9.
(10) Desc11bri111ie11to de Co11oci111ie11to en Bases de Datos. Capítulo 2. Antecedentes y marco teórico. 2.1 Descubrimiento de conocimiento en bases de datos. Es impresionante si comenzamos a pensar en la canticad de información que manejamos diariomente de manera individual, como códigos de barras, diversos archivos de datos, números telefónicos, cuentas bancarias, etc . Y es aún mayor nuestro asombro cuando escuchamos que la última película de Pixar consumió varios terabytes de datos en su elaboración. Si trasladamos este escenario a un ambiente productivo, fuera del entretenimiento, comenzamos a caer en cuenta de los grandes retos y oportunidades que se nos presenten, en una base de datos de "Cuentas Por Cobrar", por mencionar alguna. Estas oportunidades, a las que hago mención, son por ejemplo el saber qué tipo de clientes requieren de ser avisados con uno semana de antelación del pago que deben realizar dado el perfil que presentan, o bien qué tipo de plan de pago es preferible ofrecer a nuevos prospectos, etc.. Otra aplicación c'e KDD es en la industria farmacéutica, aue se caracteriza por sus grandes costos en investigación y desarrollo. Globalme1te la industria gasta 13 billones de dólares al año en investigación y desarrollo de fármacos. El proceso de desarrollo de un fármaco involucra millones de compuestos químicos de los cuales solo unos cuantos son seguros y utilizables. Est:Js compañías emplean sofisticadas técnicas de predicción para determinar que químicos producirán fármacos usables . Al enfocar la investigación y desarrollo en los químicos apropiados, las compañías ahorran millones y millones de dólares .. Estos son algunos beneficios que puede brindar la minerío de datos, por lo que es fácil entender que las empresas comiencen a llevar a cabo procesos de KDD, siempre y cuando se cumplan ciertos criterios prácticos (existe potencialmente un impacto significativo, no hay métodos alternativos, existe soporte del cliente para el desarrollo, y no existen problemas de legalidad con los datos) y técnicos (existen suficientes datos, atributos relevantes, poco ruido en los datos, y. 10.
(11) D1?srnbri111ie11to de Co11ocimiento en Bases de Datos. conocimiento del dominio) superando por mucho lo inversión de recursos (tiempo, dinero, recursos humanos, maquinaria, etc.) que KDD demanda.. En general, el proceso de KDD es complejo de realizar, sin embargo, numerosas empresas generan continuamente herramientas comerciales para determinadas actividades. Tal es el caso de Clementine (de Integral Solutions), lntelligent Miner (de IBM) , y 4Thought (de Liningstones) . Pero cuando las condiciones de la aplicación de KDD se vuelven más demandantes, el proceso debe aplicarse particularmente.. A pesar de la necesidad que se tiene en el descubrimiento de conocimiento en los grandes volúmenes de datos que se manejan diariamente, existen problemas adicionales, inherentes al proceso que deben ser tratados según la aplicación en cuestión. Esto se debe a que las técnicas empleadas en la minería de datos no siempre se adapton o ajustan adecuadamente al proble-na, o bien los resultados que proporcionan difieren por mucho a lo esperado . En algunos casos los algoritmos empleodos requieren de mayor información, la cual no siempre esta disponible, para poder generar resultados satisfactorios o bien viene con datos corruptos que provocan un mal funcionamiento . En otros casos el proceso que se ejecuta brinda como resultado demasiada información. difícil de tratar; lo que puede deberse a un empleo inadecuado de las herramientas o técnicas . Además de esto, debemos considerar que no siempre e'.; fácil aplicar el proceso de KDD, ya que se depende del dominio de aplicación y en ocasiones los datos pueden presentm una alta complejidad , o bien cambies drásticos en el tiempo (lo que imposibilitd un buen tratamiento).. El descubrimiento de conocimiento en bases de datos es un proceso mediante el cual se puede generar información aplicable a partir de volúmenes de datos almacenados. en. una. base. de. datos.. La. historia. de. KDD. se. remonta. concretamente hasta hace unas pocas décadas, sin embargo, la necesidad de análisis e interpretación de información, es algo inherente al mismo desarrollo humano. Siguiendo la huella que el hombre ha dejado desde su estancia en la. 11.
(12) Desc11brimie1110 de Co11ocimie1110 en Bases de Dolos. Tierra, podemos hacer un resumen de los medios físicos que se han empleado para hacer permanente dicha trayectoria. El ser humano ha plasmado su estancia a través de pinturas rupestres, artesanías, lienzos, pergaminos, hojas, libros, audio, vídeo, medios electrónicos (como las bases de datos), etc. Sin embargo, conforme estos medios nos han permitido almacenar mayores cantidades de datos, estos a su vez han aumentado la complejidad de su estructura; tanto lo que representan, así como la que los constituye.. En la actualidad los grandes volúmenes de datos representan una gran oportunidad desperdiciada. Las bases de datos son comúnmente empleadas como enormes bodegas de datos, sin mayores beneficios que un historial que permita trazar la 'vida" de un evento determinado por ciar un ejemplo. Por ello, actualmente, dada la demanda acelerada de informoción que. presenta la. sociedad, se ha provocado que el ritmo con que se puecen analizar los datos ya no sea suficiente para cubrir los requerimientos diarios. Si bien es cierto que las pequeñas 3 bases de datos que anteriormente se manejaban no significaban gran reto para las ciencias computacionales, también es cierto que hoy en día es necesario, en lo posible, el análisis automático e inteligente de datos. Digo en lo posible debido a los problemas que surgen durante el proceso, los cuales se pueden resumir en:. •. Disponibilidod de información.. •. Naturaleza, comportamiento, características, y volumen de los datos.. •. Interacción o dependencia con el experto o investi9ador.. •. Entendimiento del dominio del problema, y de los resultados generados.. •. Naturaleza incremental del proceso, dados los ajustes derivados del análisis.. El descubrimiento de conocimiento en bases de datos es en si un reto; el entendimiento del dominio del problema !dominio de aplicación) es un punto crítico para todo el proceso, y de hecho es la fase que consume mayor tiempo. 3. En comparación con las bases de datos actuales, las que fácilmente almacenan varios millones de registros.. 12.
(13) Desc11bri111ie11/o de Co11ocimie1110 e11 Bases de Datos. Esto se debe a que el investigador debe ser un experto en técnicas de minería de datos, así como. U'l. experto en el dominio del problema. Dada esta necesidad, el. proceso de KDD es por naturaleza muy interactivo e iterativo; el investigador debe estar constantemente interpretando los resultados del proceso, para que de esta forma , pueda ajustar adecuadamente el mismo y obtener un mejor análisis posterior.. Hoy en día el proceso de descubrimiento de conocimiento no es una tarea exclusiva de las bmes de datos, sino que se ha extendido hacia otros rumbos tales como el descubrimiento de conocimiento en texto, en vídeo, en audio, y en imagen [6] . Sin embargo, las mayores investigaciones :;e han realizado en el análisis de bases de datos.. En nuestros días existe una gran cantidad de aplicaciones de la minería de datos en diversas áreas que incluyen, entre otras muchas,. a la astronomía, biología. molecular, aspectos climáticos y medicina [6]. KDD es un proceso que ya está siendo puesto en marcha. Grandes organizaciones corno American Express y AT&T emplean KDD para analizar sus archivos de clientes [6] . En el Reino Unido, la BBC ha aplicado técnicas de minería de datos para analizar figuras de despliegue, y en lo mayoría de los países europeos muchos de sus bancos han comenzado a realizar experimentos con KDD .. KDD es un proceso que involucra un conjunto de técnica, que el ser humano ha desarrollado y perfeccionado. La minería de datos es una respuesta a las necesidades que se tienen en cuanto al proceso no trivial para identificar patrones que sean válidos, novedosos, potencialmente útiles y entendibles a partir de datos [6]. Se considera que KDD es un proceso debido a que se constituye de una serie de pasos de manera iterativa, con el fin de que ol hallar información útil se puedan realizar ajustes que mejoren los resultados obtenidos. Los patrones que son descubiertos mediante este proceso deben ser válidos, en el sentido que puedan ser aplicodos posteriormente. Adicionalmente estos patrones deben cumplir las características de ser novedosos y útiles; la mzón es que no tendría. 13.
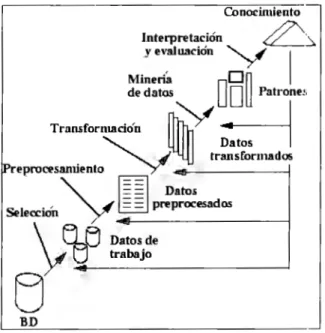
(14) Desrnbrimie11to de Conocimie11to en Bases de Datos. sentido ejecutar un proceso de descubrimiento de conocimiento en bases de datos si los resultados obtenidos fueran información corocída por el usuario, o bien no aplicable al dominio del problema. En efecto los resultados que se generen no deben ser complejos de interpretar, e~to con el fin de no comprometer la utilidad que éstos puedan tener. Hay que señalar que el dominio de aplicación es en sí el mayor trabajo del proceso de KCD ; además los datos no siempre son adecuados (tipos, valores faltantes , muchos datos, etc.) para la extracción de conocimiento.. 2.1.1 Las fases del proceso de KDD. El procesar automáticamente grandes cantidades de datos para encontrar conocimiento útil para un usuario y satisfacerle sus metas, es el objetivo principal de la minería de datos. El proceso de KDD se compone en general de las siguientes 3 fases, con diversas tareas cada una (ver figura 2.1 .1. 1) :. •. Preprocesarniento.. •. Extracción de conocimiento.. •. Postprocesamiento, evaluación o Análisis.. Conocimiento. ~~. Interpretación y e,:aluación Mineria de datos. ~y. Traruform.adón. y oºn DUPatroneii 1. _u u. _J. 1. ~. transformados. .,.---------1. IPreprocesamiento . ,. ~ ~~ 1. 1 Pr!';::esados. ~~\;~::;:· BD. Figura 2. 1.1 . 1. Proceso general de KDD. 14.
(15) Desc11brimic11to de Co11ocimie11to en Bases de Datos. En el preprocesamiento se realizan las siguientes tareas:. •. Entendimiento del dominio de aplicación, selección del conocimiento relevante a emplear, y definición de las metas del usuario.. •. Selección de un conjunto o subconjunto de bases de datos; seleccionar y enfocar la búsqueda en subconjuntos de variables, y seleccionar muestras o instancias de datos para realizar el proceso de descubrimiento. Hasta hoy en día los datos han sido tradicionalmente tablas ASCII y la tendencia es utilizar manejadores de bases de datos y almacenes de datos que estén optimizados para realizar un proceso analítico.. •. Limpieza. y. preprocesamiento. de datos,. diseiiando. una. estrategia. adecuada para manejar, entre otras cosas, ruido4, valores incompletos, secuencias de tiempo, casos extremos, etc . •. Selección de la tarea de descubrimiento a realiza-; lo que puede ser, por mencionar olgunas, clasificación , agrupamiento, e1c.. •. Selección de los algoritmos a ejecutar.. •. Transformación de los datos al formato requerido por el algoritmo específico de minería de datos .. La extracción de conocimiento es básicamente:. •. Llevar a cabo el proceso de extracción. Se buscan patrones que pueden expresarse como un modelo, o que simplemente expresen dependencias de los datos. El modelo encontrado depende de su función (tarea de descubrimiento) y de su forma de representación (depende del algoritmo seleccionaclo). Se tiene que especificar un criterio de preferencia para seleccionar un modelo dentro de un conjunto posible de modelos .. 4. Valores incorrectos (ya ,ea precisión o tipo de datos). 15.
(16) Descubrimiento de Co11oci111irnto en Bases de Datos. En el postprocesamiento se efectúan los siguientes pasos:. •. Interpretación de resultados y posiblemente regreso a los pasos anteriores. Esto puede involucrar repetir el proceso, quizás con otros datos, otros algoritmos, otras metas y otras estrategias . Este es tc1mbién un paso crucial, en el cual se requiere tener conocimiento del dominio de aplicación. La interpretación puede beneficiarse de procesos d-3 visualización, y sirve también para eliminar patrones redundantes o irrelevantes.. •. Incorporación del conocimiento descubierto al proceso para mejorarlo, lo cual puede incluir resolver conflictos potenciales con el conocimiento existente.. •. El conocimiento se obtiene para realizar acciones; ya sea incorporándolo dentro de un sistema de desempeño, o simplemente para almacenarlo y reportarlo a lm personas in teresadas.. 2.1.2. Tareas y técnicas en KDD. Dado que la minería de datos explora y analiza grandes volúmenes de datos, para descubrir patrones y reglas interesantes, entonces es necesario saber el motivo por el cual se buscan esos patrones y reglas. La minería de datos se enfoca a un conjunto específico de tareas, de las cuale:; todas involucran la extracción de nuevo conocimiento significativo a partir ele los datos. Las seis actividades principales de KDD [4] son las siguientes :. •. Clasificación.. •. Estimación.. •. Predicción.. •. Reglas de asociación.. •. Clustering.. •. Descripción y Visualización.. 16.
(17) Desc11brimie11/o de Co11ocimie11to en Bases de Datus. Las primeras tres toreas se consideran instancias de minería de datos dirigida, en la cual el objetivo es emplear los datos disponibles para construir un modelo que describa un atributo de interés particular, en términos de los demás datos. Las siguientes tres tareas son ejemplos de minería de datos no-dirigida, en la cual ningún atributo es considerado como objetivo, sino que se busca establecer alguna relación entre todos los datos.. Clasificación: Consiste en examinar las características de un nuevo objeto presentado y asignarlo a una clase predefinida . Los objetos por clasificar son generalmente registros (ejemplos) en una base de datos. La tarea de clasificación es entonces actualizar cada registro con su clase correspondiente. Esta tarea se caracteriza por uno buena definición de clases, y un conjunto de datos de prueba formado por ejemplos preclasificados . Algunos ejemplos de clasificación son : asignar palabrm clave a textos; clasificar aplicacione'.; de crédito como de riesgo bajo, medio. o alto;. determinar que líneas telel'ónicas de casa son. empleadas para acceso a Internet; asignar clientes a segmentos de clientes predefinidos, etc .. Estimación: La clasificación trabaja con valores discretos : SÍ, NO, REPARAR; TARJETA_DEBITO, TARJETA_CRÉDITO. continuos.. Pero la estimación. maneja los valores. Dada una entrada de datos, se usa la estimación para obtener un. valor de una variable desconocida continua; como lo puede ser por ejemplo: el ingreso familiar, o un balance de tarjeta de crédito. En lo práctica se usa la estimación para realizar tareas de clasificación. Por ejemplo un banco intentando decidir a quien debe ofrecer una hipoteca, implica la toreo de que un modelo base califique a sus clientes con valores entre O y 1; esto es en realidad una estimación de la probabilidad de repuesta positiva de una persona hacia la oferta . Este proceso presenta la ventaja de que los registros se ordenan de mayor a menor (o viceversa) , según el grado de respuesta hacia esa oferta. Comúnmente la clasificación y estimación son empleadas en conjunto; por dar un caso , cuando se emplea la minería de datos para predecir quien es propenso. 17.
(18) Desc11bri111iento de Co11oci111ie11to en Bases de Dalos. a responder a una oferta de transferencia de balance de tarjeta de crédito, y también para estimar el tamaño del balance a ser transferido.. Predicción: No debería existir un apartado para predicción debido a que cualquier predicción puede pensarse como una clasificación o estimación; la diferencia es el énfasis. Cuando la minería de datos es usada para clasificar una línea telefónica de acceso a Internet uno no espera poder dar marcha atrás. posteriormente para averiguar si la clasificación fue correcta . La clasificación quizás sea correcta o incorrecta pero la incertidumbre queda sujeta solo al conocimiento incompleto; afuera en el mundo real las acciones relevantes ya han tomado su lugar: la línea de teléfono es o no empleada para una conexión loca/ a ISP . Con suficiente esfuerzo es posible corroborar . Las tareas predictivas son entonces diferentes dado que los registros son clasificados de acuerdo a un comportamiento futuro predicho, o a un valor futuro estimado. Con la predicción, la única forma de verificar que la clasificación sea ccrrecta, es esperar y ver. Algunos ejemplos de predicción son: determinar que clientes se irán durante los próximos seis meses y que subscriptores de teléfono ordenarán un servicio de valor agregado como llamadas de tres vías o correo de voz. Cualquiera de las técnicas usadas para clasificación o estimación pueden ser adaptadas para usarse en la predicción al emplear ejemplos de prueba en los cuales el valor de la variable a ser predicha ya es conocido; esto en conjunto con dotos históricos. Los datos históricos se utilizon para elaborar un modelo que corresponda a una predicción del comportamiento futuro .. Reglas de asocioción: la tarea es determinar "que cosm van juntas". El ejemplo prototípico es determinar que cosas van juntas en un carrito de compras en el supermercado. Se pueden usar las reglas de asociación para planear la organización de productos es los estantes de una tiendo en la cual los productos que comúnmente se compran a la misma vez sean colocados en el mismo lugar. Las reglas de osociación también pueden ser empleadas para identificar oportunidades de ventas cruzadas y para diseñar paquetes atractivos de productos o serv:cios.. 18.
(19) Desrnbrimiento de Co11ocimie11to e11 Bases de Datos. Clustering (Agrupoción): Es la tarea de segmentar un grupo diverso en un número mayor de subgrupos similares o clusters (grupos) . Lo que diferencia a clustering de clasificación es que clustering no se basa en clases predefinidas y ejemplos. Los registros son agrupados con el principio de auto similaridad. Es decisión del algoritmo determinar que significados otorgar a los clusters resultantes. Un cluster particular de síntomas quizás indique una enfermedad específica. Clustering es comúnmente llevoda a cabo como paso anterior a alguna otra forma de minería de datos o modelado. Por ejemplo, esta tarea quizás sea el primer paso en un esfuerzo de segmentación de mercado . En lugar de intentar generar una regla de un-tamaño-abarca-todo para ver "a que tipo de promoción responderán mejor los clientes", es mejor primero dividir la base de clientes en clusters o personas con hábitos de compra similares, y después preguntar qué tipo de promoción funciona mejor poro cada cluster.. Descripción y Visualización: En algunas ocasiones el propósito de la minería de datos es simplemente describir lo que sucede con una base de datos compleja de tal forma que se mejore el entendimiento de la gente, productos y procesos que generan los datos . Una buena descripción d,9 un comportamiento frecuentemente sugiere una explicación del mismo, o al menos establece los pasos para comenzar a buscarla. El famoso eslogan de género en los políticos americanos es un ejemplo de cómo una simple descripción: "las mujeres aceptan a los demócratas en mayor número que los hombres". puede provocar gran interés y trabajo futuro en sociólogos, economistas, y políticos. La visualización de datos es una forma poderosa de minería de datos descriptiva . No es fácil generar visualizaciones si~Jnificativas, pero la imagen adecuado realmente puede ser mejor que miles de reglas de asociación debido a que para el ser humano le es más sencillo extraer conocimiento de escenarios visuales.. KDD es un proceso complejo e interdisciplinario por lo que involucra y requiere de áreas tales como :. 19.
(20) Desc11brimie1110 de Conoci111io1/o en Bnses de Dntos. •. Tecnologías de bases de datos y bodegas de da .. os. Se buscan maneras eficientes de almacenar, acceder y manipular datos.. •. Aprendizaje. computacional,. estadística,. computación. suave. neuronales,. lógica. algoritmos. genéticos,. razonamiento. probabilístico):. difusa,. Constituye. el. desarrollo. de. y. técnicas. para. (redes. extraer. conocimiento a partir de datos . •. Reconocimiento detección. •. de. patrones.. Desarrollo. de. herramientas. para. la. v reconocimiento de patrones.. Visualización : Se busca mejorar las interfaces en1re humanos y datos, y entre humanos y patrones.. •. Cómputo de alto desempeño: Es la mejora de desempeño de algoritmos debido a su complejidad y a la cantidad de datos.. Como se puede ver, el. proceso de KDD implica relaciones complejas entre. actividades hete ogéneas que se aplican en cada fase. Por lo cual a 0. continuación se presenta una tabla con algunas técnicas empleadas en el proceso, de acuerdo a cada etapa del mismo:. Tabla 2.1.2.1. Algunas técnicas de KDD en cada etapa del proceso. 20.
(21) Descubrimiento de Co11oci111il·11to en Bases de Datos. KDD busca hallar patrones, tendencias y anomalías que presentan las bases de datos, donde los avances tecnológicos y el abaratami,:;nto de dispositivos de cómputo han permitido el surgimiento de grandes colecciones de datos. De hecho se ha estimado que la cantidad de datos almacenados en el mundo en las bases de dato5. se duplica cada 20 meses [6]. Sin emborgo, aún son necesarias nuevas técnicas y herramientas que den solución al interés comercial que existe por explotar los volúmenes de información almacenados. La velocidad a la que se almacenan los datos es muy superior a la velocidad en que se analizan .. El muestreo progresivo de datos es indispensable hoy en día debido a la complejidad y altos costos que demanda el análisis de grandes volúmenes de información. En realidad el muestreo progresivo es en mJchas ocasiones mejor5 que el análisis de todas las instancias en una base de da -ros, lo que no ocurre así en los casos donde el aplicar muestreo progresivo supero el costo de analizar la totalidad de datos en primera instancia. El resultado finol esperado de ejecutar muestreo progresivo es hallar un tamaño óptimo de muestra (N. oráculo). tal, que. muestreos de mayor tamaño no involucran mejores precisiones. Si este tamaño es previamente conocido; al ejecutar muestreo progresivo ele datos, en el mejor de los casos, solo se i~Jualará el costo resultante de analizar inicialmente la N oráculo.. 2.2 Muestreo progresivo. El objetivo principol de los métodos de muestreo progresivo de datos es maximizar la precisión lo más eficientemente posible. La idea genero! es iniciar con muestras pequeñas e ir aumentando el tamaño de éstas hasta que la precisión del modelo generado no mejore. El muestreo progresivo requiere. entonces de una. programación de muestreo la cual se sigue hasta que se cumple un criterio de paro. En este punto surgen preguntas importantes: ¿qué programación de muestreo es eficiente?, ¿cómo se puede detectar la convergencia efectiva y. 5. En cuanto a costo: menor tiempo de ejecución, menor uso de recursos . Sin embargo la precisión alcanzada con muestras menores al total de los datos es en general menor bajo un cierto umbral aceptable. 21.
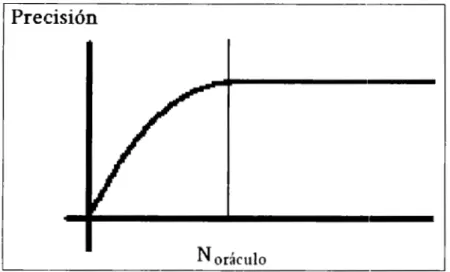
(22) Descubrimiento de Co11ocimiento en Bases de Datos. eficientemente? , y ¿se puede ajustar la programación :::le muestreo conforme avanza el muestreo?. Aquí comienza a ser evidente la necesidad de buenos métodos de muestreo; es indispensable detectar que programación de muestreo es mejor dada una expectativa de convergencia con base en una medida de evaluación del algoritmo de extrocción . Es importante indicar el hecho de que existe una interacción estrecha entre la programación de muestreo y el método de detección de la convergencia, debido a que en ocasiones la programación de muestreo no se cubre totalmente, si es que se converge (se alcanza el criterio de paro) antes de evaluar la muestra final. El objetivo en sí es generar una programación de muestreo adaptativa, la cual surja al tomar en consideración tanto la convergencia del método, como la complejidad-tiempo de ejecución de los algoritmos de extracción. Esto permitirá tener una programación dinámica (ver sección 2.3) cuyas muestras presenten una variación en tamaño acorde al comportamiento ~~eneral del método, y no con base en algún esquema comúnmente fijo.. Para el muestreo progresivo es necesario establecer una re 'ación entre el tamaño de muestra y la precisión del modelo, obtenida a partir del análisis de la muestra en cuestión. Esto da como resultado las curvas de precisión mediante las cuales es más sencillo visualizar la finalidad de los métodos de muestreo progresivo (ver figura 2.2.1) .. 22.
(23) Desc11brimie1110 de Conocimiento e11 Bases de Datos. Precisión. N oráculo figura 2.2.1. Curva de precisión. Lo que una curva ce precisión indica es que al iniciar el muestreo la precisión del modelo va mejorando conforme aumenta el tamaño de muestra. Pero llega un punto a partir del cual la curva comienza a ser horizontal (indica convergencia), lo que se logra en el momento en el cual al emplear más instancias de datos, la precisión no mejore. En esto existe una suposición fuerte: IGs curvas de precisión presentan un buen comportamiento como el mostrado en la figura 2.2. l, sin embargo en la práctica el comportamiento de estas curvas tiende a ser oscilatorio antes de converger.. La N. oráculo. entonces se define como: dado un. conjunto de datos, un. procedimiento de muestreo, y un algoritmo de extracción, N. orá c ulo. o N. min. es el. tamaño del más pequeño pero suficiente subconjunto de datos que cumple la siguiente condición :. (precisión con N < N min) < (precisión con N min). En algunos casos N. min. :::::. (precisión con N total). es imposible de determinar teóricamente , sin embargo,. ésta puede ser ap roximada empíricamente mediante un procedimiento de muestreo progresivo .. 23.
(24) Descubrimiento ,te Co11oci111ie11to en Bases de Datos. Aquí se hacen evidentes los problemas del muestreo progresivo, los cuales se tratarán con detalle posteriormente y que en general son : el establecimiento de una buena programación de muestreo a partir de un buen tamaño de muestra inicial, y con base en un adecuado esquema de muestreo; la detección de la convergencia; y el lograr una programación adaptativa (sección 2.3).. 2.2.1 Programación de muestreo. El problema de de1"erminar una programación de muestreo eficiente no es trivial, involucra dos cuestionamientos importantes del muesireo progresivo : ¿qué tamaño de muestm inicial es adecuada?, y ¿qué esquema de muestreo seguir? Para dar solución a estas preguntas existen actualmente d versas técnicas, de las cuales las más destocadas [7] son los siguientes .. Muestreo aritmético 6 . Sigue una programación de muestreo acorde a: tamaño de. muestra = tamaño base + (# del muestreo ó iteración * delta ó factor de crecimiento). Por dar ·un ejemplo, este tipo de muestr,30 puede dar como resultado programociones de muestreo tales como: 100, '.LOO, 300, 400, etc. Si se toma el tamaño bme. = 100 y. el delta de crecimiento. = 100,. lo que significa n =. 100 + (iteración * 100). Sin embargo, no se ha determinado un buen tamaño de. muestra inicial al emplear este tipo de muestreo, lo cual puede provocar que el número de iteraciones necesarias para alcanzar la precisión buscada hagan que el costo de este método sea elevado. A continuación se presenta el algoritmo de muestreo progresivo aritmético.. 6. Arithmetic Sampling. 24.
(25) Descubrimic1110 de Conocimie11to en Bases de Datos. 1. Generar programación de muestreo S = {no, n1, n2, n3 ... nk} con base en la fórmula : n = tam_base + (iteración* factor_crec miento). Siempre que n <= 50% del total de datos (criterio de paro empleado en la tesis).. 2. n. ~. no. 3. M ~ modelo inducido a partir de n instancias. 4. Mientras que no se converja (considerando S y la precisión de M) a. n b. M. ~. siguiente elemento de S. ~. modelo inducido a partir de n instancim. 5. Regresar M. Tabla 2.2.1.1. Alg oritmo para muestreo progresivo aritmé tico. Como puede apreciarse este algoritmo es muy sencillo de implementar, sin embargo presenta el problema de realizar muchos muestreos (afecta el tiempo de ejecución) antes de converger si la programación de muestreo no es adecuada, lo que se refiere a una mala elección del tamaño base ó del factor de crecimiento. Por tal motivo es importante estimar odecuadamente estos valores , a pesar que este algoritmo no contempla dicha situación en su totalidad.. Muestreo estático 7 . Intenta estimar N. submuestreos. de. similaridad. min. sin muestreo progresivo. Se basa en. estadística. a. la. muestra. completa. donde. generalmente se obtiene información (por dar un ejemplo: se emplean algoritmos pesados que usan la medida de información de Kullback [3]) acerca de los datos . Pero, como ya se mencionó es difícil estimar N. min,. o bien los algoritmos. empleados para dicho fin hacen que este tipo de muestreo este en desventaja respecto a los otros (en cuanto a eficiencia; orden-complejidad del algoritmo) . De hecho el muestreo estático corresponde a una degeneración del muestreo progresivo debido a que consiste en un intento por "adivinar" N. min,. más que. realizar muestreo p rogresivo .. 7. Static Sampling. 25.
(26) Desc11bri111iento de Conocimi.~1110 en Bases de Datos. Muestreo geométrico 8 . Este método genera mejores modelos que el muestreo estático y en general que el aritmético si consideramos boses de datos grandes. El muestreo geométrico sigue una programación de muestreo acorde a: tamaño de muestra = (factor AJ /\ (# del muestreo ó iteración) * tamaño base. Por dar un ejemplo este tipo de muestreo puede dar como resultodo programaciones de muestreo tales como : l 00, 200, 400, 800, etc. Si se toma el tamaño base = 100 y el factor A base. =2. = 400. [n y. = (2 ileraciónJ* 100]. un factor A = 2. En la práctica se ha estimado que un tamaño son buenos parámetros (estos parámetros sin. embargo pueden ser adaptados) para una planeaciór de default para minar grandes bases de datos empleando este tipo de muestreo, sin embargo, las muestras crecen aceleradamente, lo que inevitablemente impacta en el costo del método y la precisión alcanzada. Además en este método se tiene una dependencia con los datos y el algoritmo de extracción de conocimiento. A continuación se presenta el algoritmo de muestreo progresivo geométrico .. 1. Generar programación de muestreo S = {no, n1, n2, n3 ... nk} con base en la fórmulo: n = (factor_A iteración) * tam_base . Siempre que n <= 40% del total de datos (criterio de paro reportado en la literatura) .. 2. n f- no. 3. M f- modelo inducido a partir de n instancias 4. Mientras que no se converja (considerando S y la precisión de M) a. n ~- siguiente elemento de S b . M f- modelo inducido a partir de n instancias 5. Regresar M. Tabla 2.2.1 .2 . Algoritmo para muestreo progresivo geométrico. Al igual que en el esquema aritmético, este algoritmo es muy sencillo de implementar, sin embargo presenta el problema de estimar adecuadamente el tamaño base, así como el factor_A. Una mala elección de ambos valores 8. Geometric Sampling. 26.
(27) Desrnbrimiento de Conocimirnto en Bases de Datos. provoca una pro,;;iramación de muestreo agresiva, la que en ocasiones queda muy lejos de alcanzar N min ya sea sub ó sobre estimando este tamaño.. El muestreo progresivo de datos en general no es peor (en cuanto a costo) que la ejecución única con la N. 10101.. De los esquemas antes descritos destaca el. muestreo geométrico por ser simple y converger en pocos muestreos. Para el muestreo progresivo,. N oróc uio. y. N 10101. representan los límites de los posibles valores a. los que puede llegar finalmente la N del muestreo; entre mejor (más próxima a Noracuio ). sea esta t-..J, más bajos serán los costos esperados de las programaciones. obtenidas . Existen otros métodos que emplean programación dinámica 9 para generar la progmmación de muestreo, lo que en realidad es generar la misma adaptativamente,. no. usando. fuerza. bruta. parci. explorar. todas. las. programaciones posibles . El resultado es un algoritmo de tiempo polinomial, a partir del cual aún se realiza investigación para mejorarlo.. 2.2.2. Detección de la convergencia. Este punto continúa siendo un problema abierto. Se persique la detección precisa y eficiente de la convergencia del método, lo que frecuentemente se relaciona con el algoritmo de extracción. La detección de la convergencia es entonces generalmente un juicio estadístico que involucra algún procedimiento para estimar la precisión tomando en cuenta las tres secciones de la curva de aprendizaje: pendiente en creciente (positiva), pendiente en descenso (positiva pero menor a lo anterior), pendiente horizontal (casi cero). Donde se debe establecer un acotamiento para cada segmento.. Un problema de las estimaciones estadísticas de la convergencia es el hecho de que compiten nuevamente la precisión y la eficiencia . Si se desea una buena medida de la precisión se requiere que la programación de muestreo tenga un mayor número de puntos, sin embargo, esto se contrapone a los objetivos del muestreo progresivo (por eficiencia) . Otro problema es que las medidas de 9. Muestreo Progresivo Dinámico. 27.
(28) Descubrimiento de Conocim;ento en Bases de Datos. calidad empleadas (por ejemplo la precisión) presentan altibajos que deben ser asimilados por el algoritmo de muestreo. El objetivo es poder analizar el comportamiento general de la curva de aprendizaje si esta comienza por ejemplo a oscilar, por mencionar un caso: puede presentarse una oscilación (alternación de pendientes negativas y positivas) mínima con los últimos cinco puntos de una curva de precisión, pero en conjunto al ccnsiderar diez de éstos, es posible apreciar que se ha convergido (ver figura 2.2.2. l).. Precisión Pendiente casi cero l~. N oráculo Figura 2.2.2.1. Oscilaciones en una curva de precisión. Hasta el momento el método más prometedor es el LRLS 10 [7] que toma cada punto de la programación de muestreo y examina los k vecinos para realizar una regresión lineal. Se considera que la pendiente de las líneos tangentes a las curvas de aprendizaje siempre disminuye hasta que se alcanza un determinado criterio de convergencia. Pero este criterio debe ser definido y el método LRLS aumenta la complejidad del muestreo progresivo en un factcr constante dado que requiere k vecinos por cada punto de la programoción para efectuar la estimación estadística.. 'º Linear Regression with Local Sampling 28.
(29) DC'sc11brimie11to de Co11ocimie11to e11 Bases de Datos. 2.3. Muestreo adaptativo. Un. objetivo. importante. del. muestreo. progresivo. es. construir. modelos. adaptativamente tomando como experiencia el muestreo progresivo dinámico (sección 2.2.1) qJe requiere la definición de un modelo de probabilidad de convergencia, y lo definición de un modelo de complejidad de ejecución ; ambos posiblemente ob1enidos a partir del algoritmo de extracción . Un algoritmo de muestreo podría entonces. generar (de manera. ne. costosa). información. substancial al incluir estas evaluaciones en su programación .. Al modelar la probabilidad de convergencia y el costo o complejidad actual de ejecutar el algoritmo de extracción [7), se puede permitir a un procedimiento de muestreo. progresivo. incrementar. la. eficiencia. ele. su. programación. adaptativamente durante la ejecución, esto al tener la posibilidad de ajustar la programación de muestreo según el comportamiento que se presente. Sin embargo, esto no es siempre sencillo y eficiente de obtener a pesar de que el muestreo progresivo puede permitirlo dinámicamente en ejecución . Pero, como ya se mencionó, en esta línea de investigación faltan por definirse aún muchos puntos abiertos pero críticos, que le den fortaleza a este tipo de muestreo. Por ejemplo: ¿cómo realizar el ajuste de la programación de muestreo? , ¿en qué medida?, y ¿acora e a que variación en la precisión y la complejidad? Hasta el momento el muestreo progresivo adaptativo no ha demostrado ser más eficiente que el muestreo geométrico, por dar un caso.. En general el real:zar muestreo progresivo de datos e~: menos costoso que emplear el total de los datos cuando la convergencia del método no se prolonga [7]. De todas formas si esto sucede, el aplicar el método 110 es por mucho más caro que el análisis de toda la base de datos, pero sí se debe considerar el hecho de que la mejor ejecución posible es saber de antemano N. oráculo. (como ya se. explicó esto difícilmente es posible). Un punto importante es que las técnicas de muestreo progresivo a vencer son principalmente el esquema aritmético y el. 29.
(30) Desrnbrimiento de Co11ocimie11to en Bases de Datos. geométrico; y dcido que ambos presentan las desventajas descritas entonces es necesario diseñar nuevos algoritmos que los superen.. En cuanto a la selección de tamaño de muestra iricial tanto el esquema geométrico corro el aritmético no presentan una buena elección, y ambos esquemas de muestreo arrastran inconvenientes deb dos este problema. En cuanto al esquema aritmético, una mala elección del tcrmaño de muestra inicial puede provocar que el número de muestreos sea muy costoso (muchos muestreos, muchos accesos a base de datos), y además este esquema de muestreo debe ser adaptado particularmente a la aplicación sin considerar algún criterio adaptativo.. Si bien es cierto que el muestreo geométrico puede iniciar con un tamaño de muestra pequeño (la sugerencia es 400), también es cierto que el crecimiento que lo caracterizo es muy acelerado dando grandes saltos en la programación de muestreo. Esto puede provocar que difícilmente se alcance la N. oráculo. ya sea. sobrepasándola por mucho, o quedando muy lejos de ella. Ambos casos se ven reflejados en costos debido a que por un lado se pierde eficiencia, y por el otro precisión. Este tipo de muestreo, al igual que el aritmético, no es adaptativo.. En lo referente al criterio de paro ambos esquemas tienen deficiencias. No se ha definido para ninguno de los casos un buen método para detectar la convergencia. Hmta el momento solo han surgido técnicas particulares a la aplicación del muestreo en las cuales se define un criterio de paro específico. Pero además de poder detectar la convergencia con base en la precisión, también es posible hacerlo con base en el tamaño del muestreo. En el caso del esquema geométrico este criterio de paro se alcanza cuando el tamaño del muestreo corresponde al 40% del total de los datos. Esto es evidente dado que el siguiente muestreo a partir del 40% de los datos es prácticamente el total de la base de datos, y peor aún si se consideran todos los muestreos que se han realizado previamente a este tamaño. Con respecto al esquema aritmético, no se ha definido un criterio de paro general con base en el tcrmaño de muestra, sino. 30.
(31) Desrnbrimiento de Co11oci111ie1110 en Bases de Datos. más bien este tipo de muestreo se adapta particularmente a la aplicación en cuestión.. Por tales motivos -problemas, en el siguiente capítulo se presenta un novedoso método de muestreo progresivo de datos denominodo NSC; del cual se comprobarán las ventajas que tiene sobre los otros métodos (muestreo aritmético, geométrico, ejecución con todos los datos, y ejecución con N orócu10).. 31.
(32) Descubrimie1110 de Conocimienro en Bases de Datos. Capítulo 3. NSC: Un algoritmo de muestreo progresivo. Como puede verse, existe la necesidad de un algoritmo que de inicio comience con un buen tamaño de muestra, y que ésta crezca grodualmente permitiendo un buen análisis del comportamiento del muestreo. Esto permitirá que, con base en un buen método de detección de la convergencia, y tomando en cuenta la precisión. y. el. tamaño. del. muestreo;. el. criterio. de. paro. se. alcance. adecuadamente. A continuación se presenta de manera general el algoritmo NSC el cual cubre las deficiencias que tienen las otras técnicas de muestreo progresivo haciendo énfasis principalmente en: el tamaño de muestra inicial, un buen esquema de muestreo (todo muestreo se hace aleotoriamente a partir del total de datos con el objetivo de tener una selección justa y sin tendencias), y una buena detección de la convergencia considerando la precisión y el tamaño del muestreo.. 1. Sea N el número de instancias, M el número de atr:butos, A el algoritmo de aprendizaje, y CA la complejidad del algoritmo con base en A N, y M.. 2. Sea S = {SO, Sl, S2, ... , Sk} (- generaPlaneaciónNSC '.N, CA) 3. Sea conta = O;. 4. Mientras que halla elementos en S a. precision = ejecutaAlgoritmoExtracción(A S[conta]) b. Si evaluaPrecision(precision) es igual a CONVERGE, i. Entonces fin de ciclo,. ii. de lo contrario conta = conta + l. 5. END. Tabla 3.1 . Algoritmo para muestreo progresivo NSC. Si se desea analizar en mayor detalle el algoritmo NSC, en E·I anexo A se brinda el listado completo del código fuente principal (el algoritmo, por reflejar un. 32.
(33) Desc11bri111ie11/o de Co11oci111ien10 en Bnses de Dnlos. panorama globo!, difiere un poco del código fuente). El entendimiento del algoritmo se complementa con la descripción que se da en la sección 3.2.. 3.1. Descripción general. El algoritmo NSC genera la planeación de muestreo tomando en cuenta los siguientes límites: inferior. = tamaño de muestra inicial; superior = número máximo. de iteraciones o muestreos. La planeación de muestreo sigue el siguiente esquema de muestreo: tamaño de muestra actual = 1.1 * tamaño de muestra anterior (ver sección 3.3). La evaluación de la convergencia, en lo que se refiere a precisión, se rea 'iza con base en pendientes de precisión (en la sección: detección de la convergencia, se explicarán a detolle las pendientes de precisión; corresponden a las pendientes de las regresiones lineales empleadas). A continuación se describirán brevemente las etapas principales del algoritmo. presentado, para oosteriormente analizar a profundidad los puntos principales del mismo.. En generaPlaneaciónNSC se involucran tres aspectos funcamentales: la selección del tamaño de muestra inicial, la selección del número máximo de muestreos (parte del criterio de paro), y la generación de la programación de muestreo con base en el esquema de muestreo (factor de crecimiento 11 = 1.1) . En seguida se proporciona el algoritmo correspondiente .. 11. Tamaño de muestra actual = 1.1 * tamaño de muestra anterior. 33.
(34) Descubrimiento de Conoci111iento en Bases de Datos. generaPlaneaciónNSC(N, CA) 1. Sea Nmin = calculaNmin(N) 2. Sea Max_lt = calculaMaxlteraciones(N, CA) 3. Sea factorCrecimiento = 1.1 4. Sea S f- arreglo[Max_lt+ 1] S. Sea conto = O 6. Sean= Nmin 7. Mientras que conta sea menor o igual a Maxlt a. S[conta] = n b. n = n * factorCrecimiento 8. Regresa S. Tabla 3.1.1. Extensión de rutina del algoritmo para muestreo progresivo NSC. El ciclo que sigue a continuación de generaPlaneación~JSC lleva el control que relaciona el muestreo NSC con el proceso de extracción de patrones. Este ciclo valida la convergencia con base en dos criterios: la precis ón, y el número máximo de iteraciones. Es importante señalar que estos controles no se llevan a cabo propiamente dentro del ciclo, sino más bien son validaciones de resultados que devuelven. otrm. rutinas. del. algoritmo. NSC,. como. lo. son:. ejecutaAlgoritmoExtraccion y evaluaPrecision. Esto se debe a que en cuanto a la precisión, evaluaF'recisión() se encarga de verificar el cri1erio de paro y da fin al ciclo o permite la siguiente iteración. En cuantQ al número de iteraciones, como éstas ya fueron previamente definidas en el paso anterior y si el ciclo no finaliza por el criterio de precisión, entonces éste se realiza hasta el número de iteraciones permitidas.. El paso ejecutaAl~JoritmoExtracción ejecuta el algoritmo de extracción con base en el muestreo actual y devuelve una medida de la evaluación del proceso. 34.
(35) Desc11brimie1110 de Co11ocimie1110 en Bases de Daros. efectuado, que en este caso es la precisión (precisión= porcentaje de ejemplos correctamente evaluados, sin embargo se puede emplear otra medida como lo es recall,. medida F, etc.). Esta medida posteriormente es analizada en. evaluaPrecisión donde se toma en cuenta el posible corrportamiento de la curva de precisión y se determina cuando el método ha alcanzado el criterio de paro. En este algoritmo intervienen varios aspectos que son importantes para un completo entendimiento del mismo, por tal motivo en lm siguientes secciones se detalla cada uno de estos puntos cruciales.. 3.2. Selección del tamaño de muestra inicial y esquema de muestreo. Como se mencionó anteriormente los métodos de muestreo deben partir de un tamaño de muestra inicial adecuado para evitar que los olgoritmos de extracción se ejecuten demasiadas veces, agregando así ineficiencia al método. Existen métodos que traton de estimar un buen tamaño de muestra inicial mediante un análisis estadístico a partir del total de la base de datos [3]. Buscan hallar una muestra cuyo anólisis sea lo suficientemente semejante al análisis del total de datos, sin embargo, no se ha demostrado aún que estos métodos sean en general más eficientes y menos costosos que los esquemas aritmético y geométrico.. En la tesis se propone un método que más que basado en información estadística a partir del análisis de los datos, obtiene un tamaño inicial adecuado a partir del tamaño total. Esto se basa en el hecho de que es posible determinar el número de observaciones necesarias para estimar una media poblacional tomando en consideración que existe un límite para el error de la estimoción.. La suposición es que si se tiene una muestra de datos de un atributo, ésta permite calcular con un morgen pequeño de error la media del atributo. La consideración se extendió entonces para el cálculo de N. min. tomando en cuenta todos los. atributos. Se toma una muestra de datos que aproxime con un alto grado de confianza la media de una variable aleatoria. En las pruebas realizadas se. 35.
(36) Desrnbri111ie11to de Conoci111ie11to en Bases de Datos. observó que éste es en general un buen estimador, y por consiguiente en el capítulo cuatro se presentan los resultados comparativos entre la N min calculada y la real (N. orácu10).. La fórmula estadística [5] que se adecuó, y que a continuación se presenta, aplica sobre el total de ejemplos más que sobre la información que se pueda generar con base en los atributos de la base de datos. Esto hace que el estimador resultante sea muy eficiente debido a que es en sí un cálculo directo.. _ Tamano de muestra incial. Don d e D =. y cr. =. Total. -. de Datos* a- 1. -. ,. . . ... (3.2.1). Total de Datos* D +:J -. límite error estimación 2. -. -. 4. = Total_ de_ Datos 4. Cabe señalar que existe una estrecha relación entre límite para el error de estimación y el total de datos.. En efecto el límite para el error de estimación. corresponde a un porcentaje 12 del total de datos, sin embargo, en lugar de fijar un porcentaje se determinó información a partir de varias bases de datos, para obtener así una proporción adecuada según el tamaño total.. Esto se realizó calculando el N. min. de las bases de datos (capítulo cuatro), al. aumentar gradualmente el tamaño de muestra, y repitiendo el proceso 1O veces. Con estos datos, se calculó un valor de porcentaje de confianza que diera como resultado un tamaño equivalente al N min, y acorde al total de datos.. Límite error - estimación. 12. = Total -. de - Datos* C. Esto implica que en las fórmulas 3.2.2 y 3.2.3, C = C/100 para que quede expresado como porcentaje. 36.
(37) Desc11brimiento de Conocimie1110 en Bases de Datos. En t onces D =. Donde C. .D. = (Total - de - datos* C). 2. 4. = 41.468 * Total de Datos-º·479 + 0.05. El cálculo de C se realizó con base en una regresión lineal a partir de las pruebas realizadas sobre diversas colecciones de datos; lo que se detalla en el capítulo cuatro. El valor obtenido del límite, expresado como porcentaje, para el error de estimación es la mejor relación entre éste y el total de datos .. · Entonces,. para. Total_de_Datos. simplificar. la. fórmula. 3.2. l. primero. consideremos. que. = N, y que Tamaño_de_muestra_inicial = n:. 11. N•(:)'. =. 2. N*. (NC) + (. N). 4. . .... (3.2.2). 2. 4. Ahora al simplificar la fórmula 3.2.2 se obtiene la "fórmula para estimar el tamaño de muestra inicial" que aquí se propone:. n=. N. 4NC 1 +l. . . . .. (3.2.3). Al realizar este cálculo se tiene como resultado una buena estimación 13 del tamaño de muestra inicial con base en la media poblacionol y un posible error en la estimación a partir del total de datos. Al emplear este vclor en el muestreo se puede lograr una buena programación de muestreo, lo cual se explica a continuación.. 13. En el capítulo: Pruebas y resultados obtenidos, se muestra que n. N 0 ,áculo. 37.
(38) Desc11bri111iento de Conocimiento en Bnses de Dntos. 3.3. Esquema de muestreo. La programación de muestreo NSC es en sí un cálculo muy sencillo (lo que se mostrará posteriormente), sin embargo, es un punto importante debido a que ésta programación es la que establecerá los tamaños de muestra que serán proporcionados ol algoritmo de extracción. Adicionalmente aquí es donde comienza a intervenir uno de los dos criterios de paro el cual se trata en la siguiente sección: máximo número de iteraciones.. Esto se debe a que la programación de muestreo NSC se rige en realidad por la fórmula 3.2.3, a partir del tamaño de muestra inicial (límite inferior), y hasta que se alcanza el máximo número de iteraciones (límite superior). El esquema de muestreo, para el olgoritmo NSC, se incrementa entonces de la siguiente forma:. Tamaiio actual. = 1.1 * Tama,10 anterior. ..... (3.3.1). La justificación-elección del valor 1. 1 es resultado de las pruebas efectuadas, y que se presentan en el capítulo cuatro; en esta sección solo se detallan las características que tiene una programación de muestreo derivada de la fórmula 3.3.1. Este esquema de muestreo genera programaciores de muestreo más eficientes que las aritméticas y geométricas. Al comenzar el muestreo a partir de un buen tamaño de muestra inicial el muestreo progresivo NSC convergerá en pocas iteraciones o diferencia del muestreo aritmético. El valor de 1. 1 evita realizar numerosos muestreos como en el esquema aritmético. De igual manera no sucede lo mismo que con el muestreo geométrico, con el cual en ocasiones el muestreo sobrepasa por mucho el tamaño de muestra Nmin, o bien se queda muy lejos de éste. Este problema se debe a las características del, hasta cierto punto agresivo, esquema de muestreo geométrico, sin embargo, el esquema de muestreo NSC genera una programación de muestreo ade::uado al tamaño de muestra inicial. No crece desmesuradamente ni a pasos cortos. sino trata de mediar el crecimiento apoyándose en la ventaja de iniciar con un buen tamaño de muestra inicial.. 38.
(39) Desc11bri111ie11to de Co11ocimie1110 en Bases de Datos. El algoritmo NSC genera inicialmente la programación de muestreo con el objetivo de mejorar la eficiencia del mismo y sobre todo simplificar el entendimiento del muestreo. Esto se debe a que el únic:i control adicional que debe realizarse en el muestreo es la detección de la convergencia con base en la precisión. 3.4. Detección de la convergencia por número de iteraciones y medida de precisión. La detección de lo convergencia es un problema abierto. No existen muchos métodos propiamente y en efecto los esquemas aritmético y geométrico no detallan en gran medida el proceso que siguen al respecto. Lo que si se menciona es que emplean el método LRLS, abordado en el capítulo dos. La propuesta que aquí se presenta en cuanto a la detección :le la convergencia es una técnica doble que considere:. l. Un número máximo de iteraciones con base en el costo de realizar el muestreo. 2. Una medida de la precisión con base en una técnica similar al método LRLS.. Primero analicemos el criterio de paro con base en un máximo de iteraciones, lo cual no es contemplado por los esquemas aritmético y geométrico. Para entender que significa el máximo de iteraciones debemos estar consientes de que este límite se relaciona con el costo de ejecución del algoritmo de minería de datos que se emplee. No tiene caso realizar el muestreo progresivo si es más costoso que ejecutar el proceso de extracción con el total de datos. Por tal motivo este límite se define con la siguiente relación:. Costo con Total de Datos 2: Costo usando Muestreo NSC. 39.
(40) Desc11brimien10 de Conocimienlo en Bases de Daios. Donde Costo_con_Total_de_Datos se refiere al costo computacional de analizar todos. los. dotos. con. un. cierto. algoritmo. de. minería,. y. Costo_usando_Muestreo_NSC se refiere al costo computc1cional total al emplear muestreo progresivo NSC y el mismo algoritmo de minería.. Como el costo de la generación de conocimiento radica ,3n sí en el algoritmo de extracción, entonces en la relación anterior el costo corresponde al orden de dicho. algoritmo.. Este. orden. depende completamente. del. algoritmo. de. extracción aplicado y por tal motivo las siguientes fórmulas se expresan de manera genérica mostrando que el algoritmo de muestreo progresivo NSC no depende estrechamente del algoritmo de extracción empleado. La gama de costos que se rigen con las siguientes fórmulas corresponden al O(n. co st0 u 0rd en¡.. Otro punto a señolar es que el ~, queda sustituido por un = dado que analizaremos el caso límite de la relación:. Costo_ Total== (N 101a, )º. rd "". = Costo _usando _Muestreo _NSC. ..... (3.4.1). Donde el costo de aplicar el muestreo progresivo NSC, con base en el orden del algoritmo de extracción y el esquema de muestreo NSC, se obtiene de la siguiente manera (tomando en consideración que Nmin = n ele las fórmulas 3.2.2 y 3.2.3):. Costo_ con_ NSC. = N, ¡ + 1.1 * N 1 11. ¡. 111 11. + 1.1(1.1 * N min) + 1.1(1.1(1.1 * Nmin )) + .... Costo _con _NSC = Nmin (1.1° + l. 11 + 1. 12 + 1.1 3 + ... ) Costo _con_NSC = N Dondel4. ""x L,i=O. 1.1;. ¡. 111 11. ¿;~ 1.1; 0. = 1.1>+1 _1 Ü.1. De tal manera que la fórmula 3.4.1 queda expresada como:. 14. Fórmula deducida con ayuda del Dr. Antonio Acosta. Departamento de Matemátic:1.s, ITESM CCM.. 40.
Figure


+7






Documento similar
"No porque las dos, que vinieron de Valencia, no merecieran ese favor, pues eran entrambas de tan grande espíritu […] La razón porque no vió Coronas para ellas, sería
Primeros ecos de la Revolución griega en España: Alberto Lista y el filohelenismo liberal conservador español 369 Dimitris Miguel Morfakidis Motos.. Palabras de clausura
Volviendo a la jurisprudencia del Tribunal de Justicia, conviene recor- dar que, con el tiempo, este órgano se vio en la necesidad de determinar si los actos de los Estados
(29) Cfr. MUÑOZ MACHADO: Derecho público de las Comunidades Autóno- mas, cit., vol. Es necesario advertir que en la doctrina clásica este tipo de competencias suele reconducirse
Observando los grabados y los dibujos de Jacques Moulinier, Francois Ligier, Constant Bourgeois, Dutailly y Alexandre de Laborde, es fácil comprobar que todos ellos
b) El Tribunal Constitucional se encuadra dentro de una organiza- ción jurídico constitucional que asume la supremacía de los dere- chos fundamentales y que reconoce la separación
H1) La presencia en Internet (PI) influye positivamente en el e-listening. A efectos de nuestro estudio, consideramos que una empresa está en el primer nivel cuando usa
