Desarrollo de nuevos algoritmos de navegación reactiva e híbrida
80
0
0
Texto completo
(2)
(3) Í NDICE GENERAL. Índice general. i. Índice de figuras. iii. Índice de Tablas. v. Acrónimos. vii. Resumen. ix. 1. . . . . . . . .. 1 1 1 1 2 4 5 5 6. 2. 3. Introducción 1.1 Problema con la navegación . . . . . . . . . . . 1.2 Paradigmas . . . . . . . . . . . . . . . . . . . . . 1.2.1 Paradigma deliberativo . . . . . . . . . 1.2.2 Paradigma reactivo . . . . . . . . . . . . 1.2.3 Paradigmo híbrido . . . . . . . . . . . . 1.2.4 Conclusión sobre los paradigmas . . . 1.3 Objetivos del Trabajo de Final de Grado (TFG) 1.4 Estructura del documento . . . . . . . . . . . . Herramientas software utilizadas 2.1 MRPT . . . . . . . . . . . . . . 2.1.1 Idea general . . . . . . 2.1.2 Aplicaciones . . . . . . 2.1.3 Ejemplo de uso . . . . 2.2 SBPL . . . . . . . . . . . . . . . 2.2.1 Idea general . . . . . . 2.2.2 Ejemplo de uso . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. 7 7 7 7 8 8 8 8. Algoritmos utilizados 3.1 Algoritmo reactivos . . . . . . . . 3.1.1 Nearness Diagram (ND) . 3.1.2 Virtual Force Field (VFF) 3.2 Algoritmos de planificación . . . 3.2.1 A* . . . . . . . . . . . . . . 3.2.2 Algoritmos Anytime . . . 3.2.3 ARA* . . . . . . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. 11 11 11 13 14 14 15 16. . . . . . . .. i.
(4) ii. 4. 5. ÍNDICE GENERAL. iND reactivo 4.1 Descripción del método iND . . . . . . . . . . . . . . . . . . . . 4.2 División en regiones del barrido láser . . . . . . . . . . . . . . 4.3 Comportamientos del robot . . . . . . . . . . . . . . . . . . . . 4.4 Memoria a corto plazo . . . . . . . . . . . . . . . . . . . . . . . 4.4.1 Adición de puntos de detección de obstáculos . . . . 4.4.2 Modificación de puntos de detección de obstáculos . 4.4.3 Borrado de puntos de detección de obstáculos . . . . 4.4.4 Estructuración en capas de la memoria . . . . . . . . . 4.5 Filtrado de información . . . . . . . . . . . . . . . . . . . . . . 4.5.1 Detalles de implementación del filtro de información 4.6 Pseudocódigo . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. 19 19 19 21 22 22 23 25 25 26 27 30. iND híbrido 5.1 Estructura del sistema de navegación híbrido . . . . . . . . . . . . . . . . 5.2 Generación del mapa del entorno . . . . . . . . . . . . . . . . . . . . . . . 5.2.1 Estructura del mapa y definición de los sistemas de coordenadas 5.2.2 Construcción del mapa . . . . . . . . . . . . . . . . . . . . . . . . 5.3 Planificación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.3.1 Seguimiento de la trayectoria . . . . . . . . . . . . . . . . . . . . . 5.3.2 Métodos de validación del camino . . . . . . . . . . . . . . . . . 5.3.3 Primer método de validación: Comprobación de la posición de los subgoals . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.3.4 Segundo método de validación: Comprobación de los puntos que representan el camino planificado. . . . . . . . . . . . . . . .. 33 33 34 35 36 38 39 39. Resultados experimentales 6.1 Resultados de iND reactivo . . . . . . . 6.1.1 Entorno sencillo . . . . . . . . 6.1.2 Entorno con un paso estrecho 6.1.3 Entorno en forma de espiral . 6.1.4 Entorno complejo . . . . . . . 6.2 Resultados de iND híbrido . . . . . . . 6.2.1 Entorno simple . . . . . . . . . 6.2.2 Entorno complejo . . . . . . .. . . . . . . . .. 45 45 45 46 48 48 49 49 50. 7. Conclusiones 7.1 Dificultades . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7.2 Trabajos futuros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 53 54 54. 8. Anexos 8.1 ANEXO A . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8.1.1 Artículo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8.1.2 Carta de aceptación del artículo . . . . . . . . . . . . . . . . . . .. 55 55 55 66. 6. Bibliografía. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. 40 41. 67.
(5) Í NDICE DE FIGURAS. 1.1 1.2 1.3. Flujo que sigue el paradigma deliberativo. . . . . . . . . . . . . . . . . . . . . Flujo que sigue el paradigma reactivo. . . . . . . . . . . . . . . . . . . . . . . Flujo que sigue el paradigma híbrido. . . . . . . . . . . . . . . . . . . . . . . .. 2.1. Algoritmos reactivos implementados en la app de Holonomic Navigation Demo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Trayectorias calculadas mediante el algoritmo de planificación ARA*, utilizando las librerías SBPL. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 2.2. 3.1. Diferentes resultados después de la ejecución del planificador ARA* en un mismo entorno, con diferentes valores del factor de inflación ². Para el último caso, se itera con un ² inicial de 10 y un ² final de 1. . . . . . . . . . .. Aspecto del barrido láser dividido en regiones, con región del objetivo libre y ocupada. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.2 Posiciones de R T y R ob j et i vo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.3 Diferentes comportamientos del robot aplicando el algoritmo iND . . . . . 4.4 Diferentes pasos en un entorno que requiere adición de memoria por capas para llegar al objetivo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.5 Ejemplo de punto recordado desde el paso 1 hasta el paso 2. Sus datos relativos al robot han sido modificados desde el paso 1 al paso 2. . . . . . . 4.6 Ejemplos dónde no se muestra la característica de iND del borrado de puntos almacenados y en dónde sí se muestra claramente. . . . . . . . . . . . . 4.7 Comportamiento del robot en un pasillo estrecho . . . . . . . . . . . . . . . 4.8 Comparación entre el sistema angular normal y el utilizado por el sensor láser del robot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.9 Limites del filtro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.10 Direcciones perpendiculares a la dirección que sigue el robot. La flecha de color morado señala la dirección que sigue el robot, y la flecha de color granate señala la perpendicular a la dirección que sigue el robot . . . . . . 4.11 En ambas figuras se ilustra la creación del filtro de información a pesar de haber un límite marcado por el ángulo 0º o 360º. Este límite es tenido en cuenta para evitar que el filtro contenga limitaciones a la hora de su creación. 4.12 El área de color naranja representa el área que cubría el filtro en el ciclo anterior. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 2 3 4. 8 9. 17. 4.1. 5.1. Estructura del sistema de navegación híbrido formada por capas . . . . . . iii. 20 20 21 23 25 26 27 27 28. 29. 30 31 34.
(6) iv 5.2 5.3. Índice de figuras. 5.5 5.6. Ejemplo de creación del mapa del entorno. . . . . . . . . . . . . . . . . . . . Sistema de coordenadas que se utiliza a la hora de ir construyendo el mapa que representa el entorno del robot. . . . . . . . . . . . . . . . . . . . . . . . Sistemas de coordenadas durante la construcción del modelado del entorno en un mapa. El recuadro negro indica la posición del sistema de coordenadas M 0 , el recuadro rojo indica la posición del sistema de coordenadas R 0 y el recuadro morado indica la posición del sistema de coordenadas O 0 . . . . Ejemplo de uso del primer método de validación. . . . . . . . . . . . . . . . Ejemplo de uso del segundo método de validación. . . . . . . . . . . . . . .. 37 40 41. 6.1 6.2 6.3 6.4 6.5 6.6. Entorno con un camino sencillo Entorno con un paso estrecho . Entorno en forma de espira . . . Entorno complejo . . . . . . . . Entorno simple . . . . . . . . . . Entorno complejo . . . . . . . .. 46 47 47 48 49 51. 5.4. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. 34 35.
(7) Í NDICE DE TABLAS. 2.1. Parámetros de planificación para ejemplos de ARA*. . . . . . . . . . . . . . .. 9. 3.1. Coste del camino planificado por ARA* para diferentes valores del factor de inflación ². . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 16. 4.1 4.2. Datos del punto detectado en cada paso . . . . . . . . . . . . . . . . . . . . . Explicación de cada una de las funciones utilizadas. . . . . . . . . . . . . . .. 24 32. 5.1 5.2 5.3. Parámetros utilizados en la figura 5.5 . . . . . . . . . . . . . . . . . . . . . . . Parámetros utilizados en la figura 5.6 . . . . . . . . . . . . . . . . . . . . . . . Explicación de cada una de las funciones utilizadas. . . . . . . . . . . . . . .. 41 42 43. 6.1 6.2 6.3 6.4 6.5 6.6. Datos de cada algoritmo para el entorno con un camino sencillo. Datos de cada algoritmo para el entorno con un paso estrecho. . Datos de cada algoritmo para el entorno con forma de espiral. . . Datos de cada algoritmo para el entorno complejo. . . . . . . . . Datos de cada algoritmo para el entorno complejo. . . . . . . . . Datos de cada algoritmo para el entorno complejo. . . . . . . . .. 45 46 47 48 50 50. v. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . ..
(8)
(9) A CRÓNIMOS TFG Trabajo de Final de Grado MRPT Mobile Robot Programming Toolkit SBPL Search-Based Planning Library VFF Virtual Force Field ND Nearness Diagram iND improved Nearness Diagram ARA* Anytime Repairing A* AD* Anytime Dynamic A* CCIA Catalan Association for Artificial Intelligence. vii.
(10)
(11) R ESUMEN La navegación es una tarea fundamental para cualquier robot móvil. Consiste en guiar autónomamente al robot desde su posición inicial hasta una posición objetivo determinada sorteando todos los obstáculos que encuentre en el camino. En la literatura se han propuesto diferentes formas —paradigmas— de llevar a cabo esa tarea de navegación. Por un lado, tenemos el llamado paradigma reactivo que considera al robot como un ente sin memoria, es decir, como un ente que toma sus decisiones sólo en base a la información que le proporcionan sus sensores en el momento de la toma de la decisión. Por otro lado, tenemos el llamado paradigma deliberativo que dota al robot de una memoria con capacidad suficiente como para poder guardar una representación/mapa del entorno en el que el robot está navegando. Es más, un robot deliberativo toma sus decisiones aplicando un proceso de razonamiento complejo sobre ese mapa. Finalmente, tenemos el paradigma híbrido que es una mezcla de los dos paradigmas anteriores, el reactivo y el deliberativo. En este Trabajo Final de Grado (TFG) se ha desarrollado un nuevo algoritmo de navegación basado en el paradigma reactivo y un nuevo algoritmo de navegación basado en el paradigma híbrido. Para poder llevar a cabo ese desarrollo se ha hecho uso de la librería MRPT (Mobile Robot Programming Toolkit) y de la librería SBPL (Search-Based Planning Library) sobre el sistema operativo UBUNTU. Ambas librerías son de código abierto y escritas en C++ y proveen un conjunto de estructuras de datos y de algoritmos que facilitan el desarrollo de nuevas aplicaciones dentro del campo de la robótica móvil.. ix.
(12)
(13) CAPÍTULO. 1. I NTRODUCCIÓN 1.1 Problema con la navegación Conseguir que un robot móvil sea autónomo requiere la realización de dos tareas básicas: localización y navegación. La primera de estas tareas permite estimar la posición actual del robot dentro de su entorno. La segunda tarea, por otro lado, es la encargada de mover el robot desde su posición actual hasta una posición destino deseada. La tarea de navegación es el objeto del presente TFG y es por ello que en las siguientes líneas describiremos con detalle los diferentes paradigmas que se han seguido para poder abordar esta complicada tarea.. 1.2 Paradigmas A lo largo de los años, la tarea de navegación se ha abordado desde tres diferentes puntos de vista o paradigmas ([1], [2]): el paradigma deliberativo, el paradigma reactivo, y el paradigma híbrido, que es una combinación de los dos anteriores.. 1.2.1 Paradigma deliberativo El paradigma deliberativo es el más antiguo de los tres paradigmas, predominó desde 1967 hasta 1990. Según este paradigma, el robot debe seguir en, cada ciclo, la estructura S-P-A, es decir, sentir, planificar y actuar, o lo que es lo mismo, percepción, razonamiento y ejecución, tal y como se muestra en la figura 1.1. En cada ciclo percibe el entorno, crea un modelo del entorno percibido, y con este modelo planifica la serie de acciones que va a ejecutar para llegar al destino deseado. En el paradigma deliberativo, la información sensorial no provoca de manera directa una acción. Los robot deliberativos modelan el entorno que les rodea construyendo mapas. Es 1.
(14) 1. I NTRODUCCIÓN. Figura 1.1: Flujo que sigue el paradigma deliberativo.. más, toman todas sus decisiones de navegación aplicando complicados procesos de razonamiento sobre dichos mapas. Esto puede ser tanto un punto fuerte del paradigma, como un punto débil. Como se puede adivinar fácilmente, estos robots requieren de mucha memoria y de una alta capacidad de cómputo. Al tener una representación del entorno, el robot puede moverse fácilmente hacia su objetivo sin necesidad de tener una funcionalidad completamente correcta de los sensores. Para poder realizar esto, debe tener una representación exacta y completa del entorno, pero el conocimiento de un entorno no puede ser completo, porque no todas las características del entorno pueden reflejarse en la información que se tiene de él. Por otro lado, no se puede obtener un conocimiento bajo dominio temporal, es decir, que no se puede saber qué ocurrirá en un futuro. Por muy completo que sea el conocimiento del entorno, las condiciones del entorno van cambiando y no se pueden predecir. Al tener una velocidad de reacción reducida, se pueden producir colisiones del robot con algún obstáculo del entorno en alguna situación inesperada. Al no poderse conocer con antelación la dinámica del entorno, no se puede realizar una planificación a largo plazo, dando lugar a constantes replanificaciones durante el camino del robot. Para la aplicación de este paradigma es necesaria la suposición de un mundo cerrado. No existe nada más que lo que se ha modelado.. 1.2.2 Paradigma reactivo El paradigma reactivo surgió en 1986 intentando imitar el comportamiento reactivo de los animales, para así evitar los problemas del paradigma deliberativo. Con la aplicación de este paradigma, el robot debe seguir, en cada ciclo, la estructura S-A, es decir, sentir y actuar, o lo que es lo mismo, percepción y ejecución, tal y como se muestra en la figura 1.2. El paradigma reactivo evita mantener cualquier representación del entorno que rodea al robot — p.e. un mapa. Estos robots toman sus decisiones de navegación de forma local, considerando únicamente la información que, en ese momento, le proporcionan sus sensores. Esto hace que no necesiten procesar grandes cantidades de información. 2.
(15) 1.2. Paradigmas. Figura 1.2: Flujo que sigue el paradigma reactivo.. En definitiva, los robots reactivos requieren de muy pocos recursos, tanto en términos de consumo de memoria como en términos de capacidad de cómputo, y, gracias a ello, estos robots consiguen reaccionar muy rápidamente ante situaciones inesperadas, como ocurre en entornos dinámicos caracterizados por contener obstáculos en movimiento. Con la aplicación de este paradigma, el robot no crea modelos de su entorno, simplemente actúa de acuerdo a sus sensores de manera local, siendo así más predecibles y rápidos, cumpliendo así restricciones estrictas de tiempo real. Tampoco entran en el problema de hipótesis de un mundo cerrado que tiene el paradigma deliberativo, dado a que solamente reaccionan a todo lo que es perceptible a través de la información sensorial. Este paradigma presenta como desventaja la inefectividad que presenta ante tareas complejas al no poseer ningún sistema de razonamiento y no tener ningún modelo interno para poder planificar operaciones de forma eficiente, además de que en algunas ocasiones puede dejar al robot atrapado, como el típico entorno en forma de U. Existen dos tipos de paradigmas reactivos. Que un paradigma reactivo sea de un tipo o de otro depende de si contiene internamente algún modelo del entorno o no. Es decir, si no contiene ningún tipo de modelo del entorno se trata de un sistema reactivo puro y, en caso contrario, se trata de un sistema reactivo no puro. A continuación, se explican ambos tipos de una manera más detallada.. - Los sistemas reactivos puros, deciden qué acción tomar teniendo en cuenta únicamente los datos recogidos por los sensores del robot en aquél mismo momento, es decir, que y actúa en función de lo que percibe en cada momento. - Los sistemas reactivos no puros, deciden sus acciones dependiendo de un modelo interno del entorno. Este modelo interno es, en realidad, una pequeña memoria a corto plazo que va guardando la información recogida por parte de los sensores del robot. Esta información es utilizada para decidir determinadas acciones en un tiempo posterior. Los sistemas reactivos no puros, suelen ser más efectivos que los sistemas reactivos puros, aunque esto tiene un coste de memoria y tiempo computacional. 3.
(16) 1. I NTRODUCCIÓN. 1.2.3 Paradigmo híbrido El paradigma híbrido surgió en 1990 de la intención de aglutinar lo mejor del paradigma reactivo y del paradigma deliberativo. Para ello, el paradigma híbrido propone el uso de dos capas diferenciadas: una capa reactiva que aporta al robot los mecanismos básicos de supervivencia en el entorno, y una capa deliberativa que permite al robot realizar razonamientos complejos para poder así realizar una toma de decisiones más eficaz. El robot, sigue en cada ciclo una estructura de P, S-A. Es decir, planificar, sentir y actuar. En este caso, se realiza primero la planificación y luego actúan continuamente la percepción y la ejecución hasta que sea necesario volver a realizar la planificación. El flujo de este paradigma se ilustra en la figura 1.3.. Figura 1.3: Flujo que sigue el paradigma híbrido.. La parte deliberativa del sistema híbrido puede, en cualquier momento, interrumpir a la parte reactiva, por causa de que la parte deliberativa ha encontrado una planificación más efectiva que la actual. Una desventaja de este paradigma es la dificultad de conseguir un buen compromiso entre la capa reactiva y la capa deliberativa, dado a que el compromiso entre una visión global y una visión local no siempre es fácil de conseguir, dando lugar a que el ajuste de los parámetros que configuran el funcionamiento del sistema híbrido deban ser establecidos de forma empírica por una persona experta. El problema está en que ese ajuste de parámetros del sistema puede consumir mucho tiempo, o podría depender de la ubicación del destino del robot.. Por otro lado, se debe también notar que el uso de una capa deliberativa trae consigo una importante desventaja: la necesidad de abundancia de recursos hardware, imposibilitando su aplicación en cualquier robot, en especial aquellos robots de valor adquisitivo bajo, debido a que suelen estar equipados con microcontroladores. 4.
(17) 1.3. Objetivos del TFG. 1.2.4 Conclusión sobre los paradigmas Cada uno de los paradigmas anteriormente explicados, son efectivos dependiendo del contexto en el que se encuentren. Pero, hoy en día, en los sistemas más modernos de control, se suelen hacer uso del paradigma reactivo y del paradigma híbrido. Esto es debido a que las suposiciones que se hacen al utilizar el paradigma deliberativo, entran en conflicto con la realidad. Aunque el paradigma híbrido ayude al robot a superar entornos más complejos, su diseño e implementación pueden ser difíciles de realizar, por lo tanto, se debe tener en cuenta un equilibrio esfuerzo-resultado. Para ello, se suele utilizar el paradigma reactivo cuando se trata de un entorno simple, y el paradigma híbrido cuando se trata de un entorno complejo con el que la aplicación de un paradigma reactivo no es suficiente para cumplir satisfactoriamente la misión dad del robot. En el transcurso de este TFG, el lector verá que, teniendo en cuenta que el paradigma reactivo requiere un menor esfuerzo de diseño e implementación, como primer paso, se implementará un nuevo sistema de navegación capaz de superar entornos complejos que, hasta ahora, ningún otro sistema de navegación reactiva, puro o no puro, podría superar. Y, finalmente, se le añadirá un planificador convirtiendo así a nuestro sistema de navegación en híbrido. De esta manera, se podrán superar con mayor facilidad entornos más complejos, y el robot podrá alcanzar su destino siguiendo caminos más cortos.. 1.3 Objetivos del TFG Este TFG se ha abordado desde el punto de vista de cada uno de los paradigmas. Especialmente, el paradigma reactivo y el paradigma híbrido. Los objetivos que busca alcanzar este TFG son los que se detallan a continuación. 1. Mejorar un algoritmo de navegación reactiva existente (ND) [3]. Este método es uno de los más populares entre todos aquellos basados en el concepto de hueco. Su popularidad se debe, principalmente, a los siguientes tres factores: (1) permite a un robot navegar por espacios muy estrechos sin que se produzcan colisiones con los obstáculos; (2) ha sido utilizado con éxito sobre robots reales en pruebas muy exigentes como es el DARPA Grand Challenge [4]; y, por último, (3) su código fuente está disponible (a través de la página web de los autores). ND es un método de navegación reactiva pura, es decir, es un método de navegación sin memoria. En este TFG se le añade a ND una memoria a corto plazo, además de otra serie de componentes, con el objetivo de conseguir un nuevo método de navegación reactiva que sea capaz de resolver problemas de navegación de complejidad elevada que, hasta ahora, estaban fuera del alcance del paradigma reactivo. A este nuevo método de navegación se le denominará improved Nearness Diagram (iND). 2. Implementar un algoritmo de navegación híbrida, donde se propone como componente reactivo el algoritmo anterior (iND). Como componente deliberativo se 5.
(18) 1. I NTRODUCCIÓN propone ARA*[5]. ARA* es un algoritmo de tipo any time, por lo tanto, permite establecer un tiempo de planificación y aportando siempre el mejor camino que puede encontrar con el tiempo de planificación establecido. cuanto mayor sea el tiempo, la planificación será más próxima a la óptima. Este tipo de algoritmo permite al robot ajustarse mejor a tiempos de respuesta estrictos, permitiendo así que el robot no pierda su reactividad.. 1.4 Estructura del documento El presente documento de TFG se organiza como se enumera a continuación. - En el capítulo 2 se describirán las distintas herramientas que se han utilizado a la hora de desarrollar este TFG. - En el capítulo 3 se explicarán los algoritmos ND y ARA*. - En el capítulo 4 se explicarán el comportamiento y las características del método reactivo propuesto (improved Nearness Diagram (iND)). - En el capítulo 5 se hablará sobre la adición de una capa deliberativa al método propuesto en el capítulo 4, convirtiendo así ese método en híbrido. - En el capítulo 6 se propondrán varios problemas/entornos de navegación, simularemos el comportamiento que tendría un robot guiado mediante iND (con y sin capa deliberativa) en esos entornos, y compararemos estos resultados con los que se obtendrían aplicando otros métodos de navegación. - En el capítulo 7 se presentan tanto las conclusiones obtenidas en la realización de este TFG, como las dificultades y los posibles trabajos futuros. - En el capítulo 8 se presentan los anexos del presente documento, donde se habla del artículo científico que se ha derivado del trabajo realizado en este TFG, y que ha sido aceptado para su publicación en un libro de la editorial IOS Press [6].. 6.
(19) CAPÍTULO. 2. H ERRAMIENTAS SOFTWARE UTILIZADAS Para el desarrollo de este trabajo de fin de grado se han utilizado principalmente dos herramientas software. Estas dos herramientas son Mobile Robot Programming Toolkit (MRPT)[7] y Search-Based Planning Library (SBPL)[8]. La utilización de estas dos herramientas se ha realizado sobre una máquina virtual con Ubuntu como sistema operativo base.. 2.1 MRPT 2.1.1 Idea general MRPT es una herramienta que contiene un conjunto de librerías, que permiten el uso de algoritmos y estructuras de datos normalmente utilizados en el campo de la investigación de la robótica. El uso de estas librerías portables y bien testeadas permiten partir de puntos avanzados y seguros en el desarrollo de un proyecto, como es en este caso, evitando el gasto innecesario de recursos y tiempo. Además, pueden ser utilizadas sin ningún problema debido a que son de código abierto.. 2.1.2 Aplicaciones Las librerías MRPT llevan implementadas una serie de aplicaciones. Cada una de estas aplicaciones contienen una serie de algoritmos implementados o tienen un uso específico. En el caso de este TFG, se ha dado uso de la aplicación holonomic-navigatordemo. Holonomic Navigator Demo Esta aplicación permite a su usuario testear, aprender y modificar los algoritmos Virtual Force Field (VFF) y Nearness Diagram (ND). Esta aplicación asume que el robot utilizado es un robot holonómico. 7.
(20) 2. H ERRAMIENTAS SOFTWARE UTILIZADAS. 2.1.3 Ejemplo de uso Como ejemplos de uso se pueden observar, en la figura 2.1, los algoritmos nombrados en la sección anterior.. (a) Algoritmo VFF. (b) Algoritmo ND. Figura 2.1: Algoritmos reactivos implementados en la app de Holonomic Navigation Demo.. 2.2 SBPL 2.2.1 Idea general SBPL son un conjunto de librerías que tienen como objetivo principal el desarrollo de planificadores, teniendo en cuenta las búsquedas heurísticas e investigando como combinar la planificación con el aprendizaje de una máquina. Para la planificación de la trayectoria del robot se ha utilizado el algoritmo ARA*[5], uno de los algoritmos que contiene SBPL. Entre el resto de algoritmos de planificación están Anytime Dynamic A* (AD*) [9] y R* [10]. AD* es una versión de ARA* que permite la replanificación incremental, siendo útil en entornos dinámicos. R* es una versión de A* que ejecuta múltiple veces A* de manera simplificada, encontrando soluciones en un corto rango, evitando soluciones complejas que necesiten de mucho computo, y reconstruyendo un camino a partir de estas soluciones.. 2.2.2 Ejemplo de uso Como ejemplo de uso se puede observar en la figura 2.2 la trayectoria planificada por el algoritmo de planificación ARA*. En la figura 2.2.a se le ha asignado al planificador un tiempo lo suficientemente grande para obtener el camino óptimo. Por lo contrario, en la figura 2.2.b se le ha asignado un tiempo bajo, obteniendo así un camino lejano del óptimo. En la tabla 2.1 se pueden observar los parámetros de tiempo utilizados y la longitud del camino obtenida.. 8.
(21) 2.2. SBPL. (a) Planificación óptima. (b) Planificación lejana de la óptima. Figura 2.2: Trayectorias calculadas mediante el algoritmo de planificación ARA*, utilizando las librerías SBPL.. Figura 2.2.a 2.2.b. Tiempo máximo de planificación (s) 100.0 1.0. Longitud del camino (m) 76.7446 88.9401. Tabla 2.1: Parámetros de planificación para ejemplos de ARA*.. 9.
(22)
(23) CAPÍTULO. 3. A LGORITMOS UTILIZADOS Para la realización de este TFG se ha hecho uso de dos algoritmos comentados en el capítulo anterior (capítulo 2). Estos dos algoritmos son ND [3] y Anytime Repairing A* (ARA*) [5].. 3.1 Algoritmo reactivos 3.1.1 Nearness Diagram (ND) ND [3] es un algoritmo de evitación de obstáculos, creado principalmente para entornos en los que es difícil actuar para un robot, como lo puede ser una oficina. Se consideran entornos dificultosos para el movimiento de un robot lugares que presenten las siguientes características. - Obstáculos en forma de U. Un problema bastante frecuente en el campo que estudia la evitación de obstáculos de un robot móvil. - Movimiento oscilante en sitios estrechos. - La difícil obtención de maniobras en dirección hacia los obstáculos y lejos del objetivo. - La difícil identificación de áreas en las que el robot pueda moverse sin colisiones. Con este algoritmo se puede hacer uso de diferentes características del entorno, como pueden ser los diferentes diagramas, la distancia de los obstáculos al robot y las áreas libres de obstáculos. Con estas características se puede decidir qué acciones ejecutar en cada momento, también llamadas leyes de movimiento. Para llevar a cabo la ejecución del algoritmo, se debe identificar la situación del robot y dependiendo de la situación, ejecutar determinadas acciones. En primer lugar, una vez detectados los obstáculos, este algoritmo se encarga de descubrir los huecos (o gaps) disponibles. Una vez obtenidos los gaps, los clasifica en 11.
(24) 3. A LGORITMOS UTILIZADOS diferentes categorías dependiendo de sus tamaños, la dirección en la que se encuentra el objetivo del robot, donde están situados los obstáculos y su estado de seguridad, es decir si hay obstáculos dentro de su zona segura. Estas situaciones son las siguientes. 1. Situaciones con seguridad baja (obstáculos dentro de la zona de seguridad del robot). - Low Safety 1 (LS1): Cuando los obstáculos dentro de la zona de seguridad solo están en uno de los lados del gap más cercano al objetivo, en el área libre de obstáculos. - Low Safety 2 (LS2): Cuando los obstáculos dentro de la zona de seguridad están en ambos lados del gap más cercano al objetivo, en el área libre de obstáculos. 2. Situaciones con seguridad alta (no hay obstáculos dentro de la zona de seguridad del robot). - High Safety Goal in Region (HSGR): Esta situación ocurre cuando el objetivo está en el área libre de obstáculos. - High Safety Wide Region (HSWR): Esta situación se da cuando el área libre de obstáculos más cercana al objetivo es amplia, pero no contiene al objetivo. - High Safety Narrow Region (HSNR): Esta situación se da cuando el área libre de obstáculos más cercana al objetivo es estrecha, pero no contiene al objetivo. En segundo lugar, asociamos unas determinadas acciones a cada situación. Estas acciones pueden ser desde ir directamente hacia el objetivo, hasta tener que esquivar un obstáculo cercano e ir hacia el objetivo o pasar entre dos obstáculos en un espacio muy pequeño. Estas acciones son las siguientes. - Low Safety 1 (LS1): Aleja al robot el obstáculo más cercano, en dirección al gap del área libre de obstáculos más cercano al objetivo. - Low Safety 2 (LS2): Centra el robot entre los dos obstáculos, que están a los dos lados del gap del área libre de obstáculos más cercano al objetivo, y se mueve hacia este gap. - High Safety Goal in Region (HSGR): Mueve el robot directamente hacia el objetivo. - High Safety Wide Region (HSWR): Mueve al robot entorno a los bordes el obstáculo que está entre el robot y el objetivo. - High Safety Narrow Region (HSNR): Mueve al robot a través de la zona central del área libre de obstáculos. Una gran ventaja de este algoritmo es que utiliza el método divide y conquista, teniendo una acción para cada situación y no una única acción para todas las situaciones. De esta manera, se podrían añadir más situaciones con sus respectivas acciones, siendo así más flexible el algoritmo. Además, estas acciones no pueden interferir entre sí. Únicamente puede haber una situación y una respectiva acción en cada momento. 12.
(25) 3.1. Algoritmo reactivos. 3.1.2 Virtual Force Field (VFF) VFF [11], se trata de una combinación entre el algoritmo Potential Field con Certainty Grid. Las lecturas recogidas por el sensor del robot son proyectadas en el algoritmo Centainty Grid, estando el robot dentro de un cuadrado, siendo él su centro y dividiendo este cuadrado en distintas celdas. Estas celdas luego son analizadas, y cada una de las celdas ocupadas aplicará una fuerza repulsiva hacia el robot, alejándolo de esta celda. De esta forma el robot se irá alejando de los obstáculos que se encuentre en su camino. · ¸ F cr C (i , j ) x t − x 0 y t − y0 F (i , j ) = x̂ + ŷ d 2 (i , j ) d (i , j ) d (i , j ). (3.1). Dónde. F cr = Constante de fuerza (repulsiva) d (i , j ) = Distancia entre la celda (i,j) y el robot C (i , j ) = Nivel de certeza de la celda (i,j) x 0 , y 0 = Coordenadas del robot x i , y j = Coordenadas de la celda (i,j) Observando la fórmula de la ecuación 3.1 , se puede comprobar que a medida que el robot está más cerca de un obstáculo, la fuerza repulsiva es más fuerte, es debido a esto que la fuerza está dividida por un d 2 . La fuerza repulsiva resultante es la suma de todas las fuerzas repulsivas causadas por cada una de las celdas ocupadas, tal y como se muestra en la ecuación 3.2.. Fr =. X. F (i , j ). (3.2). i,j. Por otro lado, existe otra fuerza atractiva F t , que atrae al robot hacía su objetivo. Esta fuerza no contiene ninguna dependencia con la distancia absoluta al target. Esta fuerza se expresa en la ecuación 3.3. ·. F (i , j ) = F c t. y t − y0 x t − x0 x̂ + ŷ d (t ) d (t ). ¸. (3.3). Dónde F c t = Constante de fuerza (atracción hacia el target) d (i , j ) = Distancia entre el objetivo y el robot x t , y t = Coordenadas del objetivo (i,j). Con la suma de estas dos fuerzas, obtenemos el vector de fuerza resultante R, así como se muestra en la ecuación 3.4. R = F t + Fr. (3.4) 13.
(26) 3. A LGORITMOS UTILIZADOS La velocidad de giro Ω a la que debe girar el robot en cada momento viene dada por la expresión de la ecuación 3.5.. Ω = K s [θ(−)δ]. (3.5). Dónde K s = Constante proporcional para la dirección(seg −1 ) θ = Dirección actual de navegación (grados) δ = Referencia para la velocidad de giro del robot. δ = R/|R| (En grados). Esta expresión describe que la velocidad de giro a la que debe girar el robot es la mínima rotación entre el ángulo actual y el ángulo marcado por la fuerza resultante, multiplicada por la constate proporcional K s .. 3.2 Algoritmos de planificación 3.2.1 A* Está basado en el algoritmo de Dijkstra [12], que encuentra los caminos a todas las localizaciones, teniendo en cuenta los costes de estos caminos. Pero a diferencia del algoritmo de Dijkstra, A* [13] se trata de un algoritmo best-first search, es decir que encuentra la solución al camino más corto posible teniendo en cuenta todos los posibles caminos, optimizando así la planificación hacia una única localización. Calculo del coste del camino: f(n) = g(n) + h(n) Propiedades:. - Se trata de un algoritmo completo: si existe una posible solución, siempre dará con ella. - Tiene en cuenta los costes de los caminos y busca en cualquier dirección. - Utiliza la heurística para acelerar el proceso de planificación. - Utiliza una cola de prioridades, para comprobar constantemente cual es el camino más corto, eliminando los caminos con mayor coste y añadiendo los de menor coste. - El algoritmo será optimo, siempre y cuando no se sobrepase la estimación de h(n), es decir que h(n) nunca sea mayor que la distancia entre el nodo n y sucesor más la distancia entre su sucesor y el objetivo. Esto se debe aplicar para cualquier nodo n, en caso contrario estaremos hablando de un algoritmo A. 14.
(27) 3.2. Algoritmos de planificación Funcionalidad: - Tiene dos listas: lista abierta y lista cerrada. La lista abierta contiene todos los nodos con menor coste, que guían la trayectoria a seguir. La lista cerrada contiene todos los nodos visitados, que han sido considerados nodos con un coste alto, por lo tanto han sido descartados. Introducimos el nodo de comienzo en la lista abierta, con el valor de f (coste del camino) a 0. - Mientras la lista abierta no esté vacía: a) Se coge el nodo con menor coste de la lista abierta. Lo sacamos de la lista. b) Se encuentran 8 nodos sucesores i. Si alguno es el objetivo, paramos la búsqueda y calculamos su coste. ii. Si alguno de los sucesores coincide en posición con algún nodo que esté en la lista abierta, pero el nodo de la lista abierta tiene menor coste, pasamos al siguiente sucesor (si lo hay). iii. Si alguno de los sucesores coincide en posición con algún nodo que esté en la lista cerrada, pero el nodo de esta lista tiene menor coste, pasamos el nodo sucesor a la lista cerrada, y el nodo que coincide en posición con el nodo sucesor pasa a la lista abierta. - Introducimos el nodo escogido al principio del bucle en la lista cerrada. Aunque el algoritmo A* es bastante efectivo, es necesaria la reducción de su tiempo de cómputo para mejorar la navegación de un robot en movimiento. Una posible solución es la utilización de Anytime A* Algorithm.. 3.2.2 Algoritmos Anytime En la navegación de un robot el tiempo es muy importante. Se prefiere un robot que esté en continuo movimiento y sus movimientos sean lo más eficiente posible para llegar lo antes posible al objetivo. Por lo tanto, para llegar a este objetivo es necesario de un planificador, pero un planificador que no exceda un tiempo determinado calculando la trayectoria del robot. Aquí es donde entran en acción los algoritmos de planificación anytime algorithms [14]. Estos algoritmos evitan los excesivos cálculos que ralentizan la tarea del robot encontrando soluciones sub óptimas, es decir, soluciones no demasiado precisas, pero rápidas de hallar. Concretamente, encuentran una primera solución, bastante aproximada para la más óptima, rápidamente, pero siguen mejorándola hasta que el tiempo fijado para la planificación expira. Un ejemplo de un anytime algorithm es Anytime A* o ARA* [5]. En A* se utiliza el factor de inflación ² para multiplicar su valor por los valores heurísticos obtenidos. En Anytime A* se iría reduciendo el valor de este factor en cada iteración, obteniendo valores cada vez más cercanos al óptimo, pero cada vez más costosos a nivel computacional. Por este motivo utilizamos un algoritmo, que en cada iteración planifica la trayectoria, más óptima cada vez, como Anytime A*, pero a su vez con más eficiencia. 15.
(28) 3. A LGORITMOS UTILIZADOS. 3.2.3 ARA* ARA* [5], funciona ejecutando el algoritmo A* múltiples veces y reduciendo su factor de inflación ² en cada iteración hasta llegar a un valor de ² = 1 o hasta que se termine el tiempo de planificación establecido. Esto sería costoso computacionalmente hablando, pero ARA* reutiliza los resultados obtenidos en las iteraciones anteriores para ahorrar en tiempo de computo. Otras ventajas de ARA* son la posibilidad de decrementar sus límites más rápido y de manera más gradual, y la ventaja de examinar cada estado solamente una vez durante su primera búsqueda, aportándonos una acotación antes de que ARA* comience su planificación. Cuando en ARA* se llega a obtener un valor de ² igual a 1, se considera que actúa como A*, es decir que ARA* aplica sus ventajas sobre A* cuando el tiempo de respuesta debe ser menor al tiempo que llevaría obtener un valor de ² de 1. Ejemplo de ARA* A continuación se puede observar en la figura 3.1 el comportamiento que reproduce ARA* para distintos valores de ² especificados junto con su coste de camino en la tabla 3.1.. Tabla 3.1: Coste del camino planificado por ARA* para diferentes valores del factor de inflación ². Epsilon 10 8 6 4 2 1. Coste del camino 54522 54522 54522 54522 35312 33898. Se ve claramente como el coste del camino se va reduciendo a medida que el valor de ² va acercándose más a 1. Sobre todo se aprecia cuando el valor pasa de 4 a 2. También se puede observar la diferencia de caminos escogidos por el planificador. Formato del mapa Para que el planificador sea capaz de interpretar el mapa que se ha construido, se debe tener en cuenta un determinado formato a la hora de su construcción. Este formato debe seguir la siguiente estructura. - discretization(cells). Indica la cantidad de celdas que contiene el mapa, se debe indicar tanto la cantidad de celdas en el eje X como en el eje Y. 16.
(29) 3.2. Algoritmos de planificación. (b) ² = 10,0. (a) Entorno. (c) ² = 8,0. (d) ² = 6,0. (f) ² = 2,0. (g) ² = 1,0. (e) ² = 4,0. (h) Con iteraciones. Figura 3.1: Diferentes resultados después de la ejecución del planificador ARA* en un mismo entorno, con diferentes valores del factor de inflación ². Para el último caso, se itera con un ² inicial de 10 y un ² final de 1.. - obsthresh. Indica el valor, a partir del cual, una celda es considerada como una celda ocupada, es decir que se ha detectado un obstáculo en su posición. - start(cells). Indica las coordenadas (X, Y) del inicio que debe tener en cuenta el planificador a la hora de planificar el camino hacia el objetivo. - end(cells). Indica las coordenadas (X, Y) del final que debe tener en cuenta el planificador a la hora de planificar el camino, es decir las coordenadas donde se encuentra el destino del robot. - environment. Representa el entorno del robot mediante celdas, conteniendo cada una de las celdas un valor que indica cuan ocupadas está cada una de ellas. Estos 17.
(30) 3. A LGORITMOS UTILIZADOS valores pueden ser cualquiera, teniendo en cuenta que toda celda con valor igual o superior al obsthresh es considerada una celda ocupada. Se pueden observar cada una de la partes en la figura 3.1.a.. 18.
(31) CAPÍTULO. 4. I ND REACTIVO 4.1 Descripción del método iND El método propuesto parte del algoritmo reactivo Nearness Diagram (ND), un algoritmo que permite a un robot móvil llegar hasta su objetivo en entornos problemáticos, como lo es, por ejemplo, una oficina, entorno contenedor de obstáculos de distintas formas y caminos de escasa amplitud. Este método llamado iND pretende reducir las limitaciones que posee el algoritmo ND en entornos con obstáculos muy grandes, que obligan al robot a entrar en un bucle que le imposibilita avanzar y llegar a su objetivo. Estas situaciones de atrapamiento son debido a la mala elección, por parte del algoritmo ND, de la dirección en la que debe moverse el robot. Con iND se pretende añadir un nuevo módulo que selecciona de manera inteligente la dirección de movimiento del robot. A partir de aquí, el robot debe seguir esta dirección, utilizando ND para evitar cualquier tipo de colisión con los obstáculos del entorno. En esta sección se describe el nuevo módulo de selección de movimiento del robot, ya comentado. El lector es remitido a [?] para obtener detalles sobre cómo ND transforma esta dirección de movimiento en comandos de control específicos para el robot. Para la aplicación de este método se debe presuponer que el robot utilizado se encuentra equipado con un sensor láser, el cuál nos proporciona un barrido de 360 grados con información sobre los obstáculos próximos al robot.. 4.2 División en regiones del barrido láser Para facilitar el manejo de la información recogida por el robot, se divide su percepción del entorno en distintas regiones del mismo tamaño. A estas regiones se les pueden asignar diferentes valores: a) Dependiendo de si localmente el sensor del robot detecta o no un obstáculo dentro de una región, esta región puede ser etiquetada como región libre (regiones verdes 19.
(32) 4. I ND REACTIVO. (a). (b). Figura 4.1: Aspecto del barrido láser dividido en regiones, con región del objetivo libre (a) y ocupada (b).. (a). (b) i zq. Figura 4.2: Posiciones de R T y R ob j et i vo : (a) R T es igual a R l i br e y se encuentra en la región posterior a R ob j et i vo , (b) R T es igual a R ldier y se encuentra en la región anterior br e a R ob j et i vo .. de la Figura 4.1) o como ocupada (regiones de color marrón de la Figura 4.1). b) Por otro lado, la recta r ob j et i vo (línea naranja de las Figuras 4.1.a y 4.1.b) es la recta que une el centro del robot con el punto objetivo (estrella roja de las Figuras 4.1.a y 4.1.b), y R ob j et i vo es la región del barrido láser a la que pertenece la recta r ob j et i vo . Esta región puede ser etiquetada como libre (región azul marino que se ilustra en la Figura 4.1.a) o como ocupada (región azul celeste que se ilustra en la Figura 4.1.b). c) Por último, el barrido láser contiene una región R T (región amarilla ilustrada en la Figura 4.1) que indica la dirección en la que debería moverse el robot. Esta región es igual a la región libre más cercana a la región R ob j et i vo . R T puede ser igual a la región i zq. R l i br e en sentido horario (como se ilustra en la Figura 4.2.a), o igual a la región R ldier br e en sentido anti horario (como se ilustra en la Figura 4.2.b). Esta decisión dependerá del mínimo ángulo que haya entre el robot y el punto objetivo en el momento en que el robot topa con un obstáculo. Se ha de tener en cuenta que hay regiones más prioritarias que otras. En función de su prioridad son pintadas o no. La prioridad que se sigue es la siguiente, en orden de prioridad descendente. 1. Región de dirección R T (región amarilla). 20.
(33) 4.3. Comportamientos del robot 2. Región del objetivo R ob j et i vo (Región de color azul celeste si está ocupada o azul marino si está libre). 3. Región ocupada (Regiones de color marrón). 4. Región libre (Regiones de color verde).. 4.3 Comportamientos del robot. (a). (b). (c). (d). (e). Figura 4.3: Diferentes comportamientos del robot aplicando el algoritmo iND: (a) el robot se dirige directamente hacia su objetivo; (b) el robot detecta un obstáculo j −1 (trazo grueso negro) y lo comienza a rodear; (c) R T en el ciclo j − 1, denotado R T ; j. (d) en el ciclo j , R T = R ob j et i vo , y, de acuerdo con la Figura 4.3.c, también se cumple j −1. j. R T = R ob j et i vo+1 ∧ R T = R ldier , de la Ecuación 4.1; (e) vuelta al comportamiento br e inicial. Con el algoritmo iND, el robot ejecutará continuamente, una y otra vez, los comportamientos que vienen a continuación, en el orden explicado, hasta llegar a su objetivo. Cada comportamiento se encuentra ilustrado con la misma enumeración en las distintas subfiguras de la Figura 4.3. 21.
(34) 4. I ND REACTIVO a) Inicialmente, el robot activa su comportamiento Motion To Goal (MTG). De este modo, el robot se dirige directamente hacia su objetivo mientras no se encuentre con ningún obstáculo en su camino. b) Al encontrarse con un obstáculo, el robot rodea este obstáculo por su contorno, siguiendo la dirección indicada por la región R T . c) El tiempo de ejecución del comportamiento anterior se extenderá hasta que se cumpla la siguiente condición: ³. ´ ³³ ´ j j −1 j i zq R T = R ob j et i vo ∧ R T = R ob j et i vo−1 ∧ R T = R l i br e ∨ ³ ´´ j −1 j R T = R ob j et i vo+1 ∧ R T = R ldier , br e. (4.1). siendo j el ciclo en el que se encuentra actualmente el robot. Esta condición se cumplirá en el momento en que la región R T y la región R ob j et i vo coincidan, además de que la región R T del ciclo anterior coincida con la región anterior a la región R ob j et i vo en caso de que el movimiento del robot sea en sentido horario. En caso de que el movimiento del robot sea anti horario, la región R T del ciclo anterior debe coincidir con la región posterior a la región R ob j et i vo . En la Figura 4.2, se puede observar con claridad cuáles son las regiones anteriores y posteriores a la región R ob j et i vo . Por otro lado, en las Figuras 4.3.c y 4.3.d se puede apreciar el cambio de j −1. RT. j. (ciclo j − 1, Figura 4.3.c) a R T (ciclo j , Figura 4.3.d).. d) El robot adopta de nuevo el comportamiento MTG descrito en (a), una vez se cumple la condición (c).. 4.4 Memoria a corto plazo Para poder recordar los obstáculos detectados en un pasado reciente y evitar comportamientos que hagan que el robot se mueva por los mismos lugares una y otra vez, sin que se avance en la consecución del punto objetivo, se ha dotado al robot de una memoria a corto plazo. Los detalles se proporcionan a continuación.. 4.4.1 Adición de puntos de detección de obstáculos Cuando el robot se encuentra siguiendo el contorno de un obstáculo acumula en su memoria a corto plazo las lecturas que le proporciona su sensor láser en cada paso de ejecución. Esas lecturas se corresponden a puntos de detección de obstáculos. Esta característica del algoritmo iND se ve reflejada en la Figura 4.4.a. Como ejemplo, se observa que en el paso 2, las regiones próximas a R ob j et i vo se encuentran coloreadas en marrón, es decir, están ocupadas. En ese momento, el sensor láser no está detectando ningún obstáculo en esas direcciones. Sin embargo, iND, utilizando su memoria a corto plazo, recuerda que, en el paso 1, sí que se detectaron obstáculos en esas direcciones y es por ello que las mantiene etiquetadas como ocupadas. Cada vez que se añade un punto a la memoria a corto plazo del robot, este punto es almacenado en una estructura de datos teniendo una serie de características: 22.
(35) 4.4. Memoria a corto plazo. (a) Capa 1. (b) Capa 2. (c) Capa 1. Figura 4.4: Diferentes pasos en un entorno que requiere adición de memoria por capas para llegar al objetivo.. - Ángulo en el que se encuentra el punto relativo al robot. - Distancia del punto relativa al robot. - Coordenadas del punto relativas al robot. [X, Y] - Coordenadas del punto absolutas al mapa. [X, Y]. 4.4.2 Modificación de puntos de detección de obstáculos Después de la adición de información a la memoria a corto plazo del robot, se debe ir teniendo en cuenta en cada ciclo, que esta información se va actualizando, debido a que el robot efectúa continuamente un desplazamiento, y este desplazamiento afecta a la posición relativa al robot de cada uno de los puntos almacenados en la memoria a corto plazo del robot. Cada una de las partes de esta información se va modificando como se explica a continuación. 23.
(36) 4. I ND REACTIVO - Posición relativa. A partir de la posición absoluta de cada punto se obtiene la posición de cada punto p relativa al robot como se observa en la ecuación 4.2. X pr el = X pabs − X r obot. (4.2). Y pr el = Y pabs − Yr obot. - Distancia. Con las coordenadas relativas del punto al robot, se puede obtener la distancia que existe entre cada punto p y el robot en cada ciclo, aplicando la ecuación 4.3. q p p (4.3) Di st ance p = (X r el )2 + (Yr el )2 - Ángulo. Por último, utilizando las coordenadas relativas y la distancia relativa del punto al robot como referencia, se puede obtener el ángulo que tiene el punto p en referencia al robot.Para obtener este ángulo se deben realizar las siguientes 4 operaciones. X pr el. · Ang 1 = ar ccos( d i st ance p ) Y pr el. · Ang 2 = ar csi n( d i st ance p ) · Ang 3 = −Ang 1 · Ang 4 = π − Ang 2 Estas 4 operaciones se deben calcular debido a que puede haber ángulos complementarios al ángulo que se está buscando. Para solucionar este problema, se deben tener ángulos similares, tanto para el cálculo en el eje X (ángulos Ang 1 y Ang 3 ) como para el cálculo en el eje Y (ángulos Ang 2 y Ang 4 ). Es decir, se debe cumplir la condición 4.4.. Si Ang 1 == Ang 2 ∨ Ang 1 == Ang 4. ent onces Si no. 180 + 180 π 180 Ang l e p = Ang 3 ∗ + 180 π (4.4) Ang l e p = Ang 1 ∗. Tabla 4.1: Datos del punto detectado en cada paso Robot Punto. Posición absoluta (m) Posición absoluta (m) Posición relativa (m) Distancia relativa (m) Ángulo relativo (grados). Paso 1 (2.436, -5.768) (2.727, -6.824) (0.291, -1.056) 1.095 105.414. Paso 2 (2.070, 7.031) (2.727, -6.824) (0.657, -13.855) 13.871 92.710. Ejemplo En la figura 4.5 se puede observar como el punto p añadadido a la memoria a corto plazo en el paso 1, ha seguido almacenado durante todo el recorrido hasta el paso 2. El ángulo representado en esta figura ha sido calculado utilizando las ecuaciones 4.2, 4.3 y 4.4. 24.
(37) 4.4. Memoria a corto plazo. (a) Paso 1. (b) Paso 1. (c) Paso 2. Figura 4.5: Ejemplo de punto recordado desde el paso 1 hasta el paso 2. Sus datos relativos al robot han sido modificados desde el paso 1 al paso 2.. 4.4.3 Borrado de puntos de detección de obstáculos A medida que el robot va detectando obstáculos, va ocupando todas sus regiones. Por esta razón, ha de ir olvidando la información de que dispone sobre obstáculos a medida que dichos recuerdos pasan a ser obsoletos. Si este mantenimiento no se lleva a cabo, el barrido láser del robot puede llegar a constar de únicamente regiones ocupadas, imposibilitando su avance. El proceso de borrado de puntos analiza la región siguiente a la R T , teniendo en cuenta el sentido en el que se mueve en ese momento el robot. Si esa región está libre localmente, es decir, si dicha región es detectada como libre por el sensor del robot, la región es liberada dentro de la memoria a corto plazo, borrando todos los puntos detectados dentro de la misma. En la figura 4.6 se muestra como influye el borrado de puntos durante la navegación del robot. Pudiéndose dar la posibilidad de no llegar a su destino al no realizar un borrado de puntos de detección de obstáculos, tal y como se muestra en la figura 4.6.b. Por otro lado, se puede observar, en las figuras 4.6.c y 4.6.d, figuras dónde se realiza el borrado de puntos, como el robot se dirige sin ningún problema hacia su destino.. 4.4.4 Estructuración en capas de la memoria Aunque la dotación de memoria a corto plazo mejora bastante las habilidades del robot en términos de navegación, el robot aún está afectado por ciertas limitaciones en entornos con una apariencia en espiral, entornos que abarrotan de regiones ocupadas el barrido láser del robot. Estas regiones no pueden ser liberadas con el criterio explicado en la sección anterior, debido a que también son detectadas como ocupadas localmente, de acuerdo con el sensor láser del robot. En estos casos, el robot pierde la posibilidad de moverse. En la Figura 4.4.a se ilustra como el robot avanza hacia un entorno en forma de espiral, almacenando toda la información que va recogiendo con su sensor láser en la primera capa de memoria (capa 1). El robot no se encuentra con ningún problema hasta llegar al paso 4 de la Figura 4.4.a, donde su barrido láser se abarrota de regiones ocupadas. Para solventar este problema, se aplica la condición 4.5, creando así una nueva capa de memoria (capa 2) en el paso 5 (Figura 4.4.b), permitiendo avanzar al 25.
(38) 4. I ND REACTIVO. (a) Posición inicial. (b) Sin borrado de puntos. (c) Borrado de puntos. (d) Borrado de puntos. Figura 4.6: Ejemplos dónde no se muestra la característica de iND del borrado de puntos almacenados (figura b) y en dónde sí se muestra claramente (figuras b y c).. robot. Esto se prolonga hasta llegar al paso 7 (Figura 4.4.c), momento en el que el robot elimina toda la información de la capa 2, aplicando la condición 4.6, recuperando así la capa 1 y toda su información. Crear nueva capa cuando: n X m=0. j. j. R m ∈ S banned , n = Número de regiones. (4.5). Eliminar capa actual cuando: j −1. no se crea una capa nueva en el paso j ∧ R T. j −1. j. j. ∈ S banned ∧ R T ∈ S al l owed. (4.6). 4.5 Filtrado de información El algoritmo iND no almacena toda la información que recibe del sensor láser en su memoria a corto plazo, sino que lleva a cabo un proceso de filtrado. Cuando el robot debe pasar por espacios estrechos puede ser necesario obviar la presencia de ciertos obstáculos. A modo de ejemplo, la Figura 4.7.a muestra una situación donde 26.
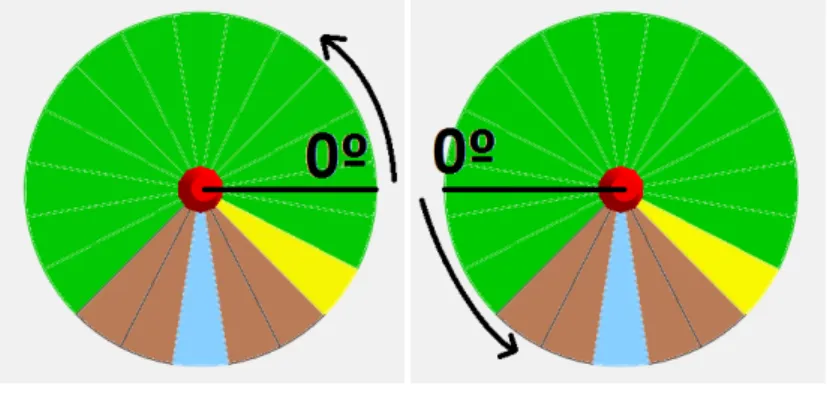
(39) 4.5. Filtrado de información. (a). (b). Figura 4.7: Comportamiento del robot en un pasillo estrecho: (a) el robot no detecta el hueco de entrada al pasillo, (b) el robot filtra los datos que le proporciona el sensor láser y únicamente almacena en la memoria a corto plazo los datos que provienen del obstáculo 1.. el robot detecta tanto el obstáculo 1 como el obstáculo 2. Si ambos obstáculos fuesen memorizados en la memoria a corto plazo, el robot sería incapaz de pasar por el pasillo, ya que todas las regiones que apuntan hacia él aparecen ocupadas. Eso impediría que el robot pudiera alcanzar el punto objetivo. En la Figura 4.7, se ilustra el comportamiento que tendría el robot una vez se aplicara el filtro de información comentado más arriba. Este filtro elimina toda aquella información que no pertenece al obstáculo que el robot está intentando evitar. En el caso de la Figura 4.7.a, eso significaría que el filtro eliminaría la información proveniente del obstáculo 2, ya que el robot se encontraría en ese momento siguiendo el contorno del obstáculo 1. De esta manera, el robot sería capaz de navegar por el pasillo estrecho y de alcanzar el punto objetivo, tal y como muestra la Figura 4.7.b.. 4.5.1 Detalles de implementación del filtro de información. (a) Sistema angular convencional. (b) Sistema angular del robot. Figura 4.8: Comparación entre el sistema angular normal y el utilizado por el sensor láser del robot Esta comparativa es necesaria, debido a que cuando se utilizan funciones matemática trigonométricas, el ángulo calculado forma parte del sistema convencional. Por 27.
(40) 4. I ND REACTIVO lo contrario, el sensor láser del robot hace uso de otro sistema, forzando a convertir este ángulo al sistema angular del sensor láser. Esta transformación se realiza con la ecuación 4.7, siendo Ang l e R el ángulo en el sistema del robot y Ang l e C el ángulo en el sistema convencional. Ang l e R = Ang l e C ∗. (a). 180 + 180 π. (4.7). (b). Figura 4.9: Limites del filtro: (a) El área del robot no está sobre el límite del barrido láser, entonces el ángulo inicial del filtro es menor que el ángulo final del filtro. Ángulo inicial: 62º, ángulo final: 203º (b) El área del robot está sobre el límite del barrido láser, entonces el ángulo inicial del filtro es mayor que el ángulo final del filtro. Ángulo inicial: 292º, ángulo final: 53º Este filtro viene limitado por dos variables que indican el inicio y el final del obstáculo que se está rodeando en el momento. Todos aquellos puntos que se encuentran dentro de los límites del filtro, serán considerados aptos. El filtro tiene la forma que se muestra en la figura 4.9. El considerado límite inferior siempre será el primer ángulo del filtro con una perspectiva en sentido antihorario, teniendo en cuenta que el área del filtro es continua hasta llegar al límite superior del filtro. El ángulo inferior tendrá un valor menor al ángulo superior siempre y cuando el área del filtro no pase por el límite del barrido del sensor. A la hora de la implementación, para saber cuales son los límites del filtro, se deben tener en cuenta los siguientes pasos. 1. Se recogen todos los puntos almacenados hasta el momento y se ordenan en función de su ángulo de manera ascendente, y posteriormente se almacenan en un vector ya ordenados. Este vector se llamará orderedAngles. 2. De este vector con los ángulo ordenados, se parte de un punto a partir del ángulo perpendicular al robot, teniendo en cuenta el sentido que se está siguiendo actualmente. De esta manera se elige un punto perteneciente al obstáculo que el robot está rodeando en el momento.. X p = d i st p ∗ cos(αp ) Y p = d i st p ∗ si n(αp ) 28. (4.8).
(41) 4.5. Filtrado de información. (a) Sentido horario. (b) Sentido anti horario. Figura 4.10: Direcciones perpendiculares a la dirección que sigue el robot. La flecha de color morado señala la dirección que sigue el robot, y la flecha de color granate señala la perpendicular a la dirección que sigue el robot. 3. Desde este punto se comprueba en ambas direcciones donde se encuentra cada uno de los dos límites que representan al filtro. a) Para saber dónde se encuentra cada uno de los límites se debe comprobar lo siguiente. i) Si el sentido es anti horario, para cada punto i se deben realizar las siguientes acciones. • Calcular ángulo para cada punto i y el ángulo de su punto vecino i-1. • Calcular la distancia que hay entre los dos puntos utilizando la ecuación 4.9. Para conseguir las coordenadas de cada punto se debe tener en cuenta la expresión de la ecuación 4.8. d i st ii−1. q (X i − X i −1 )2 + (Yi − Yi −1 )2. (4.9). • ³ ³ ´´ Si (αi − αi −1 < αl i m ) ∧ d i st ii < Di amet er r obot. ent onces si no. i ∈ obst acl e. (4.10). i − 1 ∈ l i mF i l t er. ii) Si el sentido es horario, para cada punto j se deben realizar las siguientes acciones. • Calcular ángulo para cada punto j y el ángulo de su punto vecino j+1. • Calcular la distancia que hay entre los dos puntos utilizando la ecuación 4.11. Para conseguir las coordenadas de cada punto se debe tener en cuenta la expresión de la ecuación 4.8. j +1. d i st j. q (X j +1 − X j )2 + (Y j +1 − Y j )2. (4.11) 29.
(42) 4. I ND REACTIVO • Si. ³¡ ´´ ¢ ³ α j +1 − α j < αl i m ∧ d i st ij +1 < Di amet er r obot. ent onces si no. j ∈ obst acl e. (4.12). j + 1 ∈ l i mF i l t er. b) En caso de no encontrar alguno de los dos límites con los pasos anteriores, sea cual sea el sentido que se está siguiendo en el momento, se debe tomar como límite tanto el último ángulo del vector (en sentido anti horario), como el primer ángulo del vector (en sentido horario). Para realizar esto se debe tener también en cuenta si realmente ese es el limite o si existe otro límite recorriendo el mismo sentido.. (a) Sentido horario. (b) Sentido anti horario. Figura 4.11: En ambas figuras se ilustra la creación del filtro de información a pesar de haber un límite marcado por el ángulo 0º o 360º. Este límite es tenido en cuenta para evitar que el filtro contenga limitaciones a la hora de su creación.. 4. Una vez se obtienen los puntos delimitantes del filtro, se debe ir comprobando si cada uno de los puntos detectados con el sensor láser en el ciclo actual pertenecen al obstáculo que se está rodeando en este momento, aplicando las condiciones del punto anterior descritas en las ecuaciones 4.9 y 4.11. En la figura 4.12 se puede observar el comportamiento que tiene el filtro en la aceptación de puntos captados por el sensor láser.. 4.6 Pseudocódigo A continuación, se presenta el pseudocódigo del algoritmo de navegación reactivo. Las funciones utilizadas vienen explicadas en la tabla 4.2 30.
(43) 4.6. Pseudocódigo. (a) Sentido horario. (b) Sentido anti horario. Figura 4.12: El área de color naranja representa el área que cubría el filtro en el ciclo anterior.. 1: 2: 3: 4: 5: 6: 7: 8: 9: 10: 11: 12: 13: 14:. mientras st at e 6= M T G hacer Obtener limites del filtro → getLocalObstacleBoundary() Obtener datos del sensor láser → getSensorPoints() Obtener ángulos delimitantes de la región que sigue el robot → → getRegionDirectionBoundary() Actualizar los datos de la memoria a corto plazo → updateEnvironment() Obtener valores de cada región Obtener región del target Gestión de capas de la memoria a corto plazo → manageLayers() Obtención de la dirección que debe seguir el robot en el siguiente ciclo → → targetRegion() Obtención del estado de navegación del robot. Puede devolver MTG. → filterState() Representación de las regiones del sensor láser del robot. fin mientras. Función filterState. Parámetros Región de la dirección actual del robot; Región de la dirección del ciclo anterior del robot; Región del destino del robot; Estado del destino; Booleano que indica si hay que dirigirse de manera directa al destino; Booleano que indica si la última capa de la memoria a corto plazo ha sido eliminada.. Explicación Esta función se encarga de actualizar el estado en el que se encuentra actualmente el robot. Puede devolver tres estados: Motion To Goal (MTG), Boundary Following Right (BFR), Boundary Following Left (BFL).. 31.
(44) 4. I ND REACTIVO Tabla 4.2: Explicación de cada una de las funciones utilizadas. Función getLocalObstacleBoundary. Parámetros Datos sensor láser; Posición del robot; Rango máximo del sensor láser; Dirección actual del robot; Región de la dirección que sigue el robot.. getSensorPoints. Datos sensor láser; Estado de las regiones; Posición del robot; Rango máximo del sensor láser.. getRegionDirectionBoundary. Estado de las regiones del sensor láser; Región de la dirección actual del robot.. updateEnvironment. Posición actual del robot; Región de la dirección actual del robot.. manageLayers. Estado de las regiones del sensor láser; Región del destino; Región del destino del ciclo anterior; región de la dirección del robot del ciclo anterior. Región del destino; estado de las regiones del sensor láser.. targetRegion. 32. Explicación Se obtienen los límites del obstáculo que se están siguiendo, para así únicamente aceptar datos provenientes de este obstáculo, ignorando todos los demás que se presenten. Con esta función se recogen los datos de los obstáculos que detecta el sensor láser del robot. Estos datos pasan un filtrado delimitado por los límites obtenidos con la ejecución de la función getLocalObsacleBoundary. Con esta función se obtienen los ángulos de la región que indica la siguiente región donde se encontrará la dirección que seguirá el robot. Esta función actualiza la información guardada en la memoria a corto plazo, tanto actualizando los datos de cada punto, como la distancia al robot, sus coordenadas y su ángulo, como el borrado de los puntos que cumplen el criterio para ser borrados. Esta función se encarga de añadir o de eliminar capas de la memoria a corto plazo.. Esta función devuelve la región en la que se encuentra la dirección que sigue el robot..
(45) CAPÍTULO. 5. I ND HÍBRIDO. En el capítulo anterior se ha explicado el método reactivo iND. Con este método, el robot alcanzará su destino pero a través de un camino que, por lo general, será subóptimo. El comportamiento del robot en términos de navegación puede ser mejorado, aplicando no solamente un algoritmo de navegación reactivo, sino también un algoritmo de navegación deliberativo, convirtiendo el método en un algoritmo de navegación híbrido. Aplicando este algoritmo de navegación híbrido, el robot puede alcanzar su objetivo de una manera más eficiente, siendo guiado por el planificador utilizado, ARA* [5] en este caso.. 5.1 Estructura del sistema de navegación híbrido El sistema de navegación híbrido propuesto sigue la estructura ilustrada en la figura 5.1. En primer lugar, existe una capa que se encarga de la generación del mapa del entorno a través de la información recogida por el sensor láser del robot. Este mapa es transmitido a la capa de planificación, que se encargará de ejecutar la planificación del camino, de la gestión de los subgoal y de la comprobación de que el camino actual continúe siendo válido. Por último, existe una capa reactiva que se encarga de ejecutar el algoritmo de navegación reactivo iND, éste se encarga, además, de controlar las acciones del robot. 33.
(46) 5. I ND HÍBRIDO. Figura 5.1: Estructura del sistema de navegación híbrido formada por capas. (a). (b). (c). Figura 5.2: (a) Ejemplo de la estructura de un mapa. La S indica la posición del robot y la E indica la posición del destino. Por otro lado, el área amarilla indica el radio que tiene el sensor láser, aunque en este caso, el sensor alcanza más allá del lado izquierdo del robot en el mapa. (b) Se muestra la situación actual del robot, mostrando el estado del sensor láser. (c) Se realiza una combinación entre el robot y la información que ha almacenado en el mapa, teniendo en cuenta el rango del sensor láser.. 5.2 Generación del mapa del entorno Para poder realizar una planificación por parte de ARA*, primero de todo se debe crear un mapa del entorno. En este caso, se le transmite el mapa al planificador mediante un archivo de texto. Este archivo de texto tiene un determinado formato mostrado en la 34.
Figure




+7





Documento similar
Lipinski (2018), las herramientas del marketing digital son fuente importante permiten conocer a detalle mejoras en los procesos, con la finalidad de tomar mejores decisiones las
Las conclusiones del trabajo, se refieren a la necesidad de dar mayor impulso en la aplicación de actividades del Programa de Estimulación Temprana, para
e) Existe correlación significativa entre estrategias de lectura en su dimensión anticipación, con la variable comprensión de textos en su dimensión cognitiva en los estudiantes
La Normativa de evaluación del rendimiento académico de los estudiantes y de revisión de calificaciones de la Universidad de Santiago de Compostela, aprobada por el Pleno or-
El presente trabajo de investigación titulado: “Aplicación de materiales didácticos estructurados en el aprendizaje de los estudiantes del segundo grado de primaria en el área
La finalidad de esta investigación fue identificar, conocer y comprender la identidad profesional docente del profesor de educación básica en México, a la luz de la teoría de los
Aunque los trabajos publicados sobre las políticas paisajísticas españolas son numerosos 61 , salvo algunas excepciones (Fernández Rodríguez o Hervás Más), su
Comunicación presentada en las V Jornadas Interdisciplinares: Estudios de Género en el Aula: Historia, Cultura visual e Historia del Arte, Málaga, España.. ¿Qué sería de
