Módulo QtNLP Wordnet para la aplicación QtNLP
71
0
0
Texto completo
(2) Declaración de autoría: Título del documento: Módulo QtNLP-Wordnet para la aplicación QtNLP Dado a los 25 días del mes de junio de 2016 Versión 1.0 publicada en junio del 2016 Copyright © 2016 UCLV, Abel Meneses Abad y Alexander Avello Silverio Licencia. Esta obra se publica bajo la licencia Creative Commons 3.0 BY-NC-SA que establece las siguientes condiciones: Atribución: Debes reconocer y citar la obra de la forma especificada por el autor y el licenciante.. No Comercial: No se puede utilizar esta obra para fines comerciales.. Licenciar igual: Si se altera o transforma esta obra, o se genera una obra derivada, sólo se puede distribuir la obra generada bajo una licencia idéntica a esta.. Para. ver. una. copia. de. esta. licencia. visitar. la. siguiente. dirección. en. internet:. http://creativecommons.org/licenses/by-nc-sa/3.0/legalcode. Marcas comerciales y marcas de servicios. Todas las marcas comerciales, marcas de servicios, logotipos y nombres de compañías mencionadas en esta obra son propiedad de sus respectivos dueños. Las mismas están protegidas bajo la ley de marcas comerciales y la ley de competencia desleal. Derechos comerciales. Los derechos comerciales para exportación de esta obra son concedidos a la UCLV y los autores de forma exclusiva. En territorio cubano la utilización comercial de esta obra no debe interferir con el uso social de la misma. En caso de conflictos primará el derecho social sobre el comercial. Autores: Ing. Abel Meneses Abad, Alexander Avello Silverio En caso de muerte los derechos morales de esta obra, su preservación, ejecución o modificación, quedarán bajo la responsabilidad moral y jurídica de: Yanet Conde González, y Jane Meneses Conde.
(3) PENSAMIENTO. “El que con poco se conforma es porque poco se merece” AL-D-A. ii.
(4) DEDICATORIA. A la persona que más admiro y quiero en el mundo, a mi hermano Livi.. iii.
(5) AGRADECIMIENTOS. Agradezco al equipo de producción Verborrea S.A. en especial a la directora mi tía tula, también a la editora principal mi prima Liane y al ingeniero de la arquitectura del documento Carly.. Agradezco a mi familia, por siempre estar hay para mí, sin ustedes no lo hubiera logrado.. Agradezco a todas las personas que, aunque no pudieron ayudarme, me demostraron que puedo contar con ellos para lo que sea.. Agradezco a mi tutor, Abel por todo lo que me enseño y por la ayuda que me brindo.. Agradezco a todas las personas que aportaron un grano de arena para la creación de este proyecto, que dará paso a mi vida laboral.. iv.
(6) RESUMEN. Los recursos semánticos relacionados con el procesamiento del lenguaje natural han sido motivo de varias investigaciones como disciplina dentro de la lingüística computacional. Entre los recursos semánticos más utilizados se encuentra la base de datos léxica “WordNet”. Esta investigación tiene como objetivo desarrollar un módulo que permita a la herramienta “QtNLP”, agregar palabras a la base de datos léxica “WordNet”, utilizando Python y Qt. Para ello se diseña el módulo “QtNLP-Wordnet” y posteriormente se adiciona a la aplicación “QtNLP”. Para su desarrollo se utiliza la metodología ágil SXP y el Modelo-VistaControlador (MVC de sus siglas en inglés) como patrón de diseño. La aplicación terminada se valida mediante pruebas de caja negra.. v.
(7) ABSTRACT. The semantic resources related to the processing of the natural language have been subject of several investigations as a discipline inside computational linguistics. WordNet data base it is one of the semantic resources commonly used. This research aims to develop a module that allows to "QtNLP" tool, add words to the lexical database "WordNet", using Python and Qt. To reach this, the "QtNLP-Wordnet" module is designed and subsequently added to "QtNLP" application. To develop this project the agile methodology SXP and the ModelView-Controller are used design pattern. The completed application is validated through black box tests.. vi.
(8) TABLA DE CONTENIDOS. Declaración de autoría: ............................................................................................................i PENSAMIENTO ....................................................................................................................ii DEDICATORIA ................................................................................................................... iii AGRADECIMIENTOS .........................................................................................................iv RESUMEN ............................................................................................................................. v ABSTRACT...........................................................................................................................vi INTRODUCCIÓN .................................................................................................................. 1 Organización del informe ................................................................................................... 3 CAPÍTULO 1.. CARACTERIZACIÓN DE LAS TECNOLOGÍAS PARA LA GESTIÓN. DE LA BASE DE DATOS LÉXICA WORDNET ................................................................ 4 1.1. Conceptos básicos .................................................................................................... 4. 1.1.1. Módulo para un programa................................................................................. 4. 1.1.2. Aplicación informática ..................................................................................... 5. 1.1.3. Interfaz gráfica de usuario ................................................................................ 5. 1.1.4. Procesamiento del lenguaje natural español ..................................................... 5. 1.1.5. Similitud semántica........................................................................................... 5. 1.1.6. Base de datos léxica .......................................................................................... 6. 1.1.7. WordNet............................................................................................................ 6. Synsets ........................................................................................................................ 9 vii.
(9) 1.2. Estado actual de las tecnologías de WordNet ........................................................ 10. 1.3. Navegadores y editores de WordNet...................................................................... 11. 1.3.1. StarDict ........................................................................................................... 11. 1.3.2. GoldenDict ...................................................................................................... 11. 1.3.3. Open Wordnet ................................................................................................. 11. 1.3.4. Artha ............................................................................................................... 12. 1.3.5. ToNgueLP (QtNLP) ....................................................................................... 12. 1.4. Valoración personal del estado actual de las tecnologías de “WordNet” .............. 12. 1.5. Herramientas, lenguajes y tecnologías a utilizar .................................................... 13. Conclusiones del capítulo. ................................................................................................ 13 CAPÍTULO 2.. ANÁLISIS DEL SISTEMA .................................................................... 14. 2.1. Metodología de desarrollo ágil: SXP ..................................................................... 14. 2.2. Principales roles (integrantes del equipo) .............................................................. 16. 2.3. Método del negocio utilizado IDEF ....................................................................... 17. 2.3.1. As-Is ................................................................................................................ 17. 2.3.2. To-Be .............................................................................................................. 18. 2.4. Pila del Producto .................................................................................................... 19. 2.5. Plan de Iteraciones ................................................................................................. 20. 2.6. Historias de usuario ................................................................................................ 21. 2.7. Requisitos no funcionales ...................................................................................... 25. Conclusiones del capítulo ................................................................................................. 26 CAPÍTULO 3. 3.1. ARQUITECTURA DE SOFTWARE ..................................................... 27. Lista de Reserva del Producto «LRP» ................................................................... 27. viii.
(10) 3.2. Herramientas asociadas al desarrollo del sistema .................................................. 27. 3.2.1. Entornos integrados de desarrollo «IDE» ....................................................... 28. 3.2.2. Marcos de trabajos que soportarán el desarrollo «Framework de desarrollo»29. 3.2.3. Gestores de bases de datos .............................................................................. 29. 3.2.4. Lenguajes de programación ............................................................................ 30. 3.2.5. Ingeniería del Software asistida por computadoras «CASE» ......................... 31. 3.2.6. Sistemas de Control de Versiones «CVS» ...................................................... 31. 3.2.7. Otras herramientas .......................................................................................... 32. 3.3. Estándar de codificación ........................................................................................ 32. 3.4. Estructuración de los componentes ........................................................................ 34. 3.4.1. Fundamentación de patrones .......................................................................... 34. 3.4.2. Diagramas utilizados para el desarrollo del módulo ...................................... 34. 3.5. Esquema del Modelo de Datos ............................................................................... 37. 3.6. Definición de la Arquitectura de Información ....................................................... 43. Conclusiones del capítulo ................................................................................................. 48 CAPÍTULO 4. 4.1. VALIDACIÓN DE LA SOLUCIÓN DEL SOFTWARE ....................... 49. Pruebas de caja negra ............................................................................................. 49. CONCLUSIONES Y RECOMENDACIONES ................................................................... 54 Conclusiones ..................................................................................................................... 54 Recomendaciones ............................................................................................................. 54 REFERENCIAS BIBLIOGRÁFICAS ................................................................................. 55 ANEXOS .............................................................................................................................. 59 Anexo 1 ............................................................................................................................. 59. ix.
(11) INDICE DE TABLAS. Tabla 2.1 Pila del producto ................................................................................................... 19 Tabla 2.2 Plan de iteraciones ................................................................................................ 20 Tabla 2.3 Mostrar atributos de la palabra ............................................................................. 21 Tabla 2.4 Mostrar relaciones entre palabras ......................................................................... 22 ´Tabla 2.5 Gestionar atributos de la palabra ......................................................................... 22 Tabla 2.6 Gestionar relaciones de la palabra ........................................................................ 23 Tabla 2.7 Busqueda de palabras en libros en formato TXT ................................................. 23 Tabla 2.8 Editar excepciones ................................................................................................ 24 Tabla 2.9 Requisitos no funcionales ..................................................................................... 25 Tabla 3.1 Atributos index_sense ........................................................................................... 38 Tabla 3.2 Atributos exceptions ............................................................................................. 38 Tabla 3.3 Atributos max_synset_offset ................................................................................ 39 Tabla 3.4 Atributos data_verb .............................................................................................. 39 Tabla 3.5 Atributos data_verb_ptr ........................................................................................ 40 Tabla 3.6 Atributos data_verb_word_lex_id ........................................................................ 40 Tabla 3.7 Atributos data_verb_frames.................................................................................. 41 Tabla 3.8 Atributos index_verb ............................................................................................ 41 x.
(12) Tabla 3.9 Atributos verb_exc................................................................................................ 42 Tabla 3.10 Atributos index_verb_ptr_symbol ...................................................................... 42 Tabla 3.11 Atributos index_verb_synset_offset ................................................................... 42 Tabla 3.12 Explicación de los elementos de Figura 3.5 ....................................................... 43 Tabla 3.13 Explicación de los elementos de Figura 3.8 ....................................................... 45 Tabla 4.1 Caso de prueba mostrar atributos de la palabra .................................................... 49 Tabla 4.2 Caso de prueba mostrar relaciones de la palabra .................................................. 50 Tabla 4.3 Caso de prueba insertar atributos de la palabra .................................................... 50 Tabla 4.4 Caso de prueba modificar atributos de la palabra ................................................. 51 Tabla 4.5 Caso de prueba insertar nueva relación a la palabra ............................................. 51 Tabla 4.6 Caso de prueba Búsqueda de palabras en libros.txt .............................................. 52 Tabla 4.7 Caso de prueba Insertar excepción ....................................................................... 52 Tabla 4.8 Caso de prueba Eliminar excepción ..................................................................... 53. xi.
(13) INTRODUCCIÓN. INTRODUCCIÓN. Los estudios realizados sobre los recursos semánticos han abarcado temas relacionados con en el Procesamiento del Lenguaje Natural (NLP, de sus siglas en inglés), como disciplina dentro de la lingüística computacional. “WordNet” constituye un recurso semántico que ha sido motivo de varias investigaciones. El objetivo fundamental de las mismas es el de realizar adaptaciones de “WordNet” a otros idiomas diferentes al inglés (Fellbaum, 1998). Las herramientas que visualizan “WordNet” son liberadas bajo licencia BSD (acrónimo en inglés de Berkeley Software Distribution) y pueden ser descargadas y usadas libremente. Sin embargo, no existen herramientas de libre acceso que permitan la edición de este recurso léxico. El Centro de Estudios de Informática (CEI) de la Universidad Central "Marta Abreu" de Las Villas (UCLV), realiza trabajos de investigación y desarrollo. En este centro existe una investigación de conjunto con la Universidad de Camagüey sobre el procesamiento del lenguaje natural español. En el marco de dicho convenio se creó la aplicación “QtNLP”, la cual se utiliza para el trabajo con corpus lingüísticos, y tiene como objetivo la creación, edición y análisis de corpus en español para tareas de Procesamiento de Lenguaje Natural. Es una aplicación fácil de usar por lingüistas con poco conocimiento de informática y también por especialistas informáticos que investigan en el área de NLP (Meneses Abad & Salazar Videaux, 2015). Por tanto, se desea realizar una aplicación que permita visualizar y editar, lo mismo en inglés que en español la base de datos léxica de “WordNet”. Por lo que se plantea el siguiente problema científico: La aplicación “QtNLP” no implementa la edición de la base de datos léxica “WordNet”. 1.
(14) INTRODUCCIÓN. Objetivo General Desarrollar un módulo de “QtNLP”, con la base de datos léxica “WordNet”, utilizando una estructura editable, “Python” y “Qt”, que permita adicionar palabras nuevas en inglés y español. Objetivos específicos: . Sistematizar el estado actual y las tendencias de las herramientas para la edición de la base de datos léxica “WordNet”.. . Diseñar el módulo “QtNLP-Wordnet” para la aplicación “QtNLP”.. . Implementar el módulo “QtNLP-Wordnet” en la aplicación “QtNLP”.. . Validar la solución implementada a través de pruebas del software.. Preguntas de investigación: ¿Qué elementos de usabilidad aportan las tecnologías actuales de “WordNet” para la gestión de esta base de datos léxica? ¿Cómo diseñar la consulta y edición de “WordNet” para usuarios de pocos conocimientos informáticos? ¿Cómo implementa “QtNLP-Wordnet” el negocio de la consulta y edición del diccionario léxico “WordNet”? Justificación La detección de similitud en textos escritos en lenguas naturales es un área de investigación actual. Mayoritariamente los trabajos existentes se realizan sobre el idioma inglés. Los recursos disponibles como corpus o lexicones están personalizados para la lengua inglesa. Dentro de estos recursos, uno de los más utilizados es la base de datos léxica “WordNet”, con más de 30 años de desarrollo. “WordNet” en inglés posee más de 100 mil términos, y es libre, mientras que el “WordNet” en español solo posee unos 20 mil y es comercial. Las herramientas para la edición de estos diccionarios son tecnologías privadas de instituciones científicas que solo divulgan su resultado. Se desea aplicar a los algoritmos de detección de 2.
(15) INTRODUCCIÓN. similitud en español similares recursos a los existentes para idioma inglés. Una dificultad con la generalización de estos recursos es que el trabajo de los investigadores de la lingüística debe hacerse sobre herramientas libres y de fácil uso. Hipótesis La implementación de la edición de la base de datos léxica “WordNet”, en la aplicación “QtNLP” permitirá mejorar este recurso léxico. Organización del informe El presente trabajo estará estructurado de acuerdo a la siguiente secuencia lógica: introducción, cuatro capítulos, conclusiones, recomendaciones, bibliografía y anexos. Capítulo 1: Se brindan conceptos básicos y se describe en detalle la base de datos léxica “WordNet”. Se analizan diferentes investigaciones referentes a este tema. También se describen algunos navegadores y editores de esta base de datos. Capítulo 2: Se desarrolla la gestión y planificación del proyecto utilizando la metodología ágil SXP. Capítulo 3: Se realiza el diseño del proyecto y se explica la arquitectura del sistema para el manejo de este módulo. Se hace un resumen sobre las herramientas y tecnologías necesarias para el desarrollo de la aplicación. También se muestran los diagramas de paquetes y de componentes, luego son descritas las interfaces de la aplicación. Capítulo 4: Se valida el módulo “QtNLP-Wordnet” mediante la realización de pruebas de caja negra a las interfaces y procesos implementados.. 3.
(16) CAPÍTULO 1. CARACTERIZACIÓN DE LAS TECNOLOGÍAS PARA LA GESTIÓN DE BASES DE DATOS LÉXICA DE WORDNET. CAPÍTULO 1. CARACTERIZACIÓN DE LAS TECNOLOGÍAS PARA LA GESTIÓN DE LA BASE DE DATOS LÉXICA WORDNET. En este capítulo se abordan descriptivamente los sustentos teóricos de este trabajo. Para su elaboración, se brindan conceptos básicos sobre el proceso de desarrollo de software y relativos a “WordNet”. Se describe en detalle la base de datos léxica “WordNet” y su estructura estándar en formato TXT. También se resumen las características de los principales proyectos que existen en el mundo relacionados con esta tecnología y se expone brevemente algunos navegadores y editores de esta base de datos léxica. Haciendo una valoración final del estado actual de las tecnologías estudiadas y la necesidad de una nueva aplicación para los investigadores cubanos de la lengua española. 1.1. Conceptos básicos. Los conceptos básicos listados forman parte de los fundamentos requeridos por los clientes de “QtNLP”. Constituyen además las premisas para el análisis de las tecnologías estudiadas, y puede utilizarse para orientar a usuarios de pocos conocimientos de informática durante la capacitación en los procesos descritos a lo largo del documento. 1.1.1. Módulo para un programa. En programación un módulo es una porción de un programa. Entre las diferentes tareas que debe realizar un programa para cumplir con su función u objetivo, un módulo realiza, una o varias de dichas tareas. Suelen estar (no necesariamente) organizados jerárquicamente en niveles, de forma que hay un módulo principal que realiza las llamadas oportunas a los 4.
(17) CAPÍTULO 1. CARACTERIZACIÓN DE LAS TECNOLOGÍAS PARA LA GESTIÓN DE BASES DE DATOS LÉXICA DE WORDNET. módulos de nivel inferior (Moreira, 2006). En el caso específico de este trabajo el módulo principal seria “QtNLP” encargado de llamar al módulo en desarrollo. 1.1.2. Aplicación informática. En informática, una aplicación es un tipo de programa informático diseñado como herramienta para permitir al usuario realizar una o varias acciones en el ordenador, esto, lo diferencia de otros programas, como son: los sistemas operativos (que hacen funcionar la computadora), los utilitarios (que realizan tareas de mantenimiento o de uso general), y los lenguajes de programación (para crear programas informáticos) (Prieto et al., 1995; Cabero Almenara, 1992). 1.1.3. Interfaz gráfica de usuario. La interfaz gráfica de usuario, conocida también como GUI (acrónimo en inglés de Graphical User Interface) es un programa informático que actúa como interfaz, utilizando un conjunto de imágenes y objetos gráficos para representar la información. Su principal uso consiste en proporcionar un entorno visual sencillo, que permita la comunicación con el sistema operativo de una máquina (Insfrán et al., 2001). 1.1.4. Procesamiento del lenguaje natural español. El procesamiento del lenguaje natural o lingüística computacional, tiene como objetivo conseguir que los ordenadores realicen tareas útiles que utilicen el lenguaje humano, tareas tales como la comunicación entre hombre-máquina, mejorando la comunicación entre personas, o simplemente haciendo procesamiento útil de texto o de voz (Jurafsky & Martin, 2009). 1.1.5. Similitud semántica. “La similitud semántica en el área de procesamiento de lenguajes naturales, es la medida de la interrelación existente entre dos palabras cualesquiera en un texto” (Rada et al., 1989). La medida de la similitud semántica entre palabras se realiza mediante la relación existente entre los conceptos de la red semántica. La relación existente entre las palabras y su discurso coherente forma parte de la propiedad natural del lenguaje humano y al mismo tiempo la base 5.
(18) CAPÍTULO 1. CARACTERIZACIÓN DE LAS TECNOLOGÍAS PARA LA GESTIÓN DE BASES DE DATOS LÉXICA DE WORDNET. para el desarrollo de los sistemas de desambiguación automáticos. Se puede afirmar, por tanto, que las palabras que comparten un contexto similar están generalmente relacionadas, y por consiguiente, se pueden seleccionar sus sentidos a partir de la distancia semántica (Rada et al., 1989). 1.1.6. Base de datos léxica. Cuando se habla de una base de datos léxica, nos referimos a aquellos repositorios de información léxica elaborados con el objeto de servir de soporte representacional a diversas aplicaciones en el ámbito de las tecnologías del lenguaje humano HLT (acrónimo en inglés de Human Language Technologies), así como al trabajo lexicográfico tradicional, es decir, a la elaboración de diccionarios destinados a la consulta por un usuario humano (Moreno, 2000). 1.1.7. WordNet. “WordNet” es una base de datos léxica diseñada sobre la base de las teorías psicolingüísticas del lexicón mental (Miller et al., 1990) con el objetivo de agilizar las búsquedas en los diccionarios en línea de la lengua inglesa. Posteriormente, con el proyecto “EuroWordNet” (Verdejo Maillo, 1996) se logró ampliar la base de datos léxica a otros lenguajes, tales como: español, alemán, etc. Esta base de datos léxica se construye sobre la base de las categorías sintácticas de sustantivo, verbo, adjetivo, adverbio y las relaciones semánticas de hiponimia, hiperonimia, meronimia, holonimia, sinonimia, antonimia, términos coordinados, y troponimia. El equivalente a las relaciones de sinonimia y antonimia en el lenguaje natural se expresa mediante los sinónimos y antónimos de las palabras, respectivamente. Las relaciones de hiponimia e hiperonimia expresan relaciones “tipo de”, es decir, dados dos términos: árbol y Pino; Pino es un “tipo de” árbol, por lo que Pino es hipónimo de árbol, mientras que árbol es hiperónimo de Pino. Los términos coordinados se basan en la hiperonimia; se dice que dos términos son coordinados siempre que compartan un hiperónimo común, por ejemplo, Pino y Ceiba que comparten árbol como hiperónimo común. Las relaciones de meronimia y holonimia expresan relaciones “parte de”, es decir, dados dos términos: carro y rueda; rueda es “parte 6.
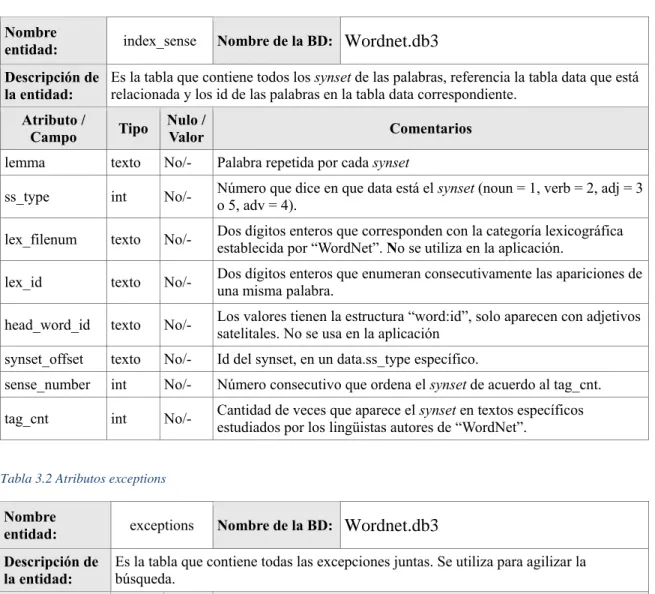
(19) CAPÍTULO 1. CARACTERIZACIÓN DE LAS TECNOLOGÍAS PARA LA GESTIÓN DE BASES DE DATOS LÉXICA DE WORDNET. de” carro, por lo que rueda es merónimo de carro, mientras que carro es holónimo de rueda. La troponimia es una relación que se observa sobre verbos, se dice que dos verbos son tropónimos si uno de ellos se activa dentro del otro de alguna manera, por ejemplo, susurrar y hablar. “WordNet” combina las características de varios recursos lingüísticos ya que incluye definiciones o glosas de términos en cada uno de sus sentidos, tal y como lo hace un diccionario y define conjuntos de palabras sinónimas, con diferentes relaciones semánticas entre ellas, de la misma forma que lo hace un tesauro. Además, constituye un recurso de amplia utilización por parte de los algoritmos de desambiguación semántica y su distribución se realiza de forma libre (Porrata et al., 2004). WordNet se basa en el supuesto teórico de matriz léxica, integrada por los elementos palabra y significado. En la matriz léxica las columnas corresponden a palabras de un idioma y las filas a conceptos o significados. Los conceptos son representados por la lista de palabras que pueden ser usadas para expresarlo, es decir, por todos los elementos que pertenecen a una misma fila, los cuales constituyen sinónimos. Estas listas de palabras son llamadas “synsets” (término que proviene de conjunto de sinónimos) (Fernández Reyes et al., 2011). Descripción de los ficheros: A continuación se realiza la descripción de los ficheros txt de “WordNet” 3.0.(Princeton University, 2016d) index.sense: El archivo index.sense contiene una lista de todos los senses (se entiende por sense: cada tupla palabra – id del significado) de la base de datos “WordNet”, cada línea representa un sense. Está en orden alfabético y los campos están separados por. espacio.(Princeton. University, 2016a) Contiene la siguiente estructura: sense_key synset_offset sense_number tag_cnt sense_key es representado como: lemma % lex_sense 7.
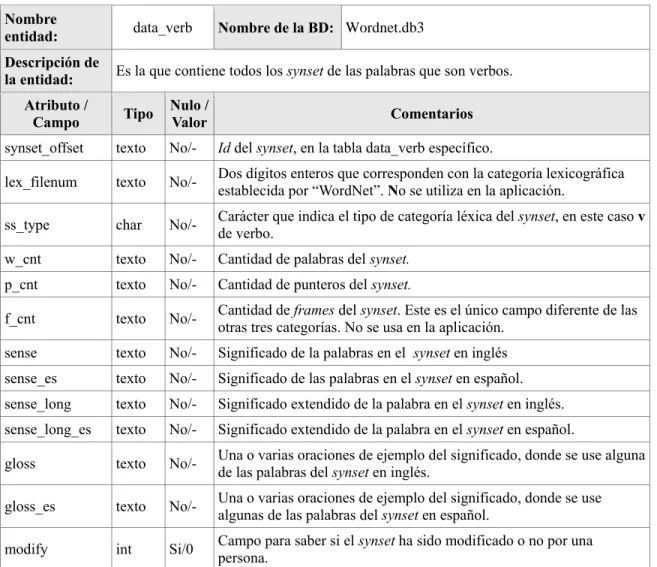
(20) CAPÍTULO 1. CARACTERIZACIÓN DE LAS TECNOLOGÍAS PARA LA GESTIÓN DE BASES DE DATOS LÉXICA DE WORDNET. lex_sense es codificado como: ss_type:lex_filenum:lex_id:head_word:head_id Ejemplo: kid%1:05:00:: 02416820 5 0 kid%1:18:00:: 09917593 1 53 kid%1:18:01:: 09918248 4 0 kid%1:18:02:: 11113489 3 0 kid%1:27:00:: 14762846 2 0 kid%2:32:00:: 00855295 2 2 Para cada categoría sintáctica, son necesarios tres archivos: index.pos y data.pos para representar los contenidos de la base de datos “WordNet”, y pos.exc utilizado para ayudar en el proceso de descubrimiento morfológico de las formas bases de inflexiones irregulares, donde pos puede ser: noun, verb, adj y adv. (Princeton University, 2016c) index.pos: Cada archivo index.pos es una lista en orden alfabético de todas las palabras encontradas en WordNet en la categoría gramatical correspondiente |sustantivo (noun), verbo (verb), adjetivo (adj), adverbio (adv)| con los datos que le corresponden (Princeton University 2016c). Contiene la siguiente estructura: lemma pos synset_cnt p_cnt [ptr_symbol...] sense_cnt tagsense_cnt [synset_offset...] Ejemplo: kid n 5 4 @ ~ #m %p 5 1 09917593 14762846 11113489 09918248 02416820 data.pos El fichero data.pos para una categoría sintáctica, contiene información correspondiente a los synsets que se especifican en los archivos lexicógrafos, con punteros de relaciones hacia otros synsets (Princeton University, 2016c). Contiene la siguiente estructura: synset_offset lex_filenum ss_type w_cnt [word lex_id...] p_cnt [ptr...] [frames...] | gloss 8.
(21) CAPÍTULO 1. CARACTERIZACIÓN DE LAS TECNOLOGÍAS PARA LA GESTIÓN DE BASES DE DATOS LÉXICA DE WORDNET. ptr es representado como: pointer_symbol synset_offset pos source/target El campo frames solo se utiliza en el data.verb y se representa de esta forma: f_cnt [ + f_num w_num...] Ejemplo: 00003133 29 v 01 hyperventilate 1 003 $ 00002942 v 0000 @ 00078760 v 0000 + 00833870 n 0101 01 + 09 00 | produce hyperventilation in; "The nurses had to hyperventilate the patient" pos.exc Los ficheros pos.exc contienen la palabra flexional y su forma base (Princeton University, 2016c). Contiene la siguiente estructura: word_inflected base_form Ejemplo: best good.. Synsets El concepto de synset fue expresado por primera vez en una conferencia impartida por Fellbaum en la Universidad de Waterloo Centre en el año 1998. En esta explica la idea de usar conjuntos de sinónimos (synsets) para representar conceptos léxicos y describir la matriz léxica que existe entre formas de palabras y sus significados (Fellbaum, 1998). En (Fellbaum, 1998; Miller et al., 1990), synset es definido como conjuntos de palabras sinónimas que se presentan relacionadas entre sí a través de la hiperonimia, por lo que el resultado final es una red semántica. Para cada synset se aporta la definición compartida por los diferentes miembros del grupo de sinónimos, y en algunos casos, también se presentan ejemplos del uso de algunos de ellos (Fernández Montraveta & Vázquez, 1998).. 9.
(22) CAPÍTULO 1. CARACTERIZACIÓN DE LAS TECNOLOGÍAS PARA LA GESTIÓN DE BASES DE DATOS LÉXICA DE WORDNET. 1.2. Estado actual de las tecnologías de WordNet. A continuación, se menciona los diferentes proyectos e investigaciones que existen en la. actualidad sobre las tecnologías de “WordNet”: 1. WordNetPojos: Este proyecto intenta proveer transparencia SQL para la base de datos. de “WordNet” SQL (mediante el marco de trabajo Hibernate) creando una biblioteca que tiene clases de Java encapsuladas en identidades de “WordNet” (word, sense, synset…), garantizando la interacción con la base de datos sin la complicación de manejar consultas SQL (Princeton University, 2016f). 2. WordNetTrans: En este proyecto se pretende aumentar la probabilidad de portabilidad. de la base de datos de “WordNet” a través del marco de trabajo Hibernate (Princeton University, 2016h). 3. WordNet SQL Builder: Aplicación java para generar la base de dato SQLUNET. desde “WordNet” y otras bases de datos “XNet”. Se mezcla wnsqlbuilder con sqlunetbuilder (Princeton University, 2016b). 4. WordNet EJB: Este es un proyecto que aspira a proveer escalabilidad para el uso. distribuido de la base de datos “WordNet”, garantizando tolerancia a las fallas en un contexto empresarial (Princeton University, 2016e). 5. WordNetDatabases: En este proyecto se intenta proveer base de datos de “WordNet” SQL en varios idiomas (Princeton University, 2016g). 6. Construcción del “WordNet” 3.0 en español: Es el resultado de un proyecto, en el cual se ha creado un nuevo recurso léxico para el español a partir de la adaptación de la base de datos léxica “WordNet”, ya existente para la lengua inglesa, en su versión 3.0. Actualmente el proyecto ha finalizado y se han traducido aproximadamente unas 15.000 glosas, lo cual quiere decir que están disponibles para el español aproximadamente unas 30.000 entradas léxicas (nominales y verbales)(Montraveta & Vázquez, 2010).. 10.
(23) CAPÍTULO 1. CARACTERIZACIÓN DE LAS TECNOLOGÍAS PARA LA GESTIÓN DE BASES DE DATOS LÉXICA DE WORDNET. 7. Browsers de “WordNet”: Son un conjunto de herramientas con interfaces gráficas sencillas para usuarios no experimentados en informática, con el objetivo de gestionar dentro de la base de datos, recuperar palabras, significados y relaciones. Entre ellas encontramos: WordNet Web App WordNetScope Stardict Goldendict 1.3. Navegadores y editores de WordNet. Los navegadores y editores de “WordNet” pueden utilizar la base de datos léxica de “WordNet”, gestionando datos dentro de la misma y mostrándolo en interfaces sencillas. A continuación, se realiza una breve descripción de los navegadores más utilizados en la actualidad. 1.3.1. StarDict. Es un programa libre y gratuito donde se accede a los archivos del diccionario StarDict. Mientras está en modo de escaneo, muestra los resultados en un mensaje descriptivo (en inglés Tooltip), permitiendo una búsqueda fácil en el diccionario. Los diccionarios son gratuitos y se instalan a elección del usuario luego de instalar el programa (AITOC n.d.). 1.3.2. GoldenDict. Es un programa de código abierto con función de diccionario de computadora. El mismo brinda traducciones de palabras y frases en lenguajes diferentes. Permite el uso de múltiples formatos de diccionarios electrónicos, entre ellos “WordNet” (Konstantin Isakov, 2013). 1.3.3. Open Wordnet. Es un operador que carga un diccionario de “WordNet” para encontrar sinónimos, hipónimos e hiperónimos. Este diccionario puede ser cargado con un directorio en el sistema o una carpeta en el repositorio(GitHub, 2016). 11.
(24) CAPÍTULO 1. CARACTERIZACIÓN DE LAS TECNOLOGÍAS PARA LA GESTIÓN DE BASES DE DATOS LÉXICA DE WORDNET. 1.3.4. Artha. Es un diccionario en inglés auspiciado por la universidad de Princeton. Dispone de una base léxica muy completa que incluye significados, ejemplos, antónimos y sinónimos. Este diccionario es ideal para aprender o mejorar el inglés, o en trabajos de traducción (Canonical Ltd, 2016). 1.3.5. ToNgueLP (QtNLP). “QtNLP” es una aplicación de escritorio del tipo Front-End para el trabajo con corpus lingüísticos. Está desarrollada en “Qt” y “Python”. Tiene como objetivo la creación, edición y análisis de corpus en español para tareas de Procesamiento de Lenguaje Natural (NLP), fáciles de usar por lingüistas con poco conocimiento de informática; y también por especialistas informáticos que investigan en el área de NLP. Entre sus referencias de requisitos se encuentra la edición de “WordNet” aunque todavía no está implementado (Meneses Abad & Salazar Videaux, 2015). 1.4. Valoración personal del estado actual de las tecnologías de “WordNet”. Existen diferentes proyectos encaminados al mejoramiento del recurso léxico “WordNet”, sin embargo, la información publicada en internet es escasa, lo que impide que se utilicen como base para otros proyectos, o en investigaciones relacionadas. Los usos u operaciones que se pueden realizar con navegadores de “WordNet” son numerosas, desafortunadamente, las implementaciones de estas funcionalidades, se encuentran divididas en distintas aplicaciones. El desarrollo y divulgación de nuevos proyectos de “WordNet” para el idioma español, ayudaría a los usuarios de habla hispana ya que existen pocos recursos en esta lengua. Esta situación hace que se dificulte el trabajo en NLP para dicho idioma. Las entidades que elaboran este recurso léxico, no publican sus herramientas de edición, aunque la disponibilidad de la descripción de los archivos de “WordNet” brindada por la Universidad de Princeton puede facilitar la creación de componentes de edición, como es el caso de este proyecto, el cual pretende mejorar las investigaciones en el campo de NLP para el idioma español en Cuba. 12.
(25) CAPÍTULO 1. CARACTERIZACIÓN DE LAS TECNOLOGÍAS PARA LA GESTIÓN DE BASES DE DATOS LÉXICA DE WORDNET. 1.5. Herramientas, lenguajes y tecnologías a utilizar. Para desarrollar este trabajo se utilizan las herramientas, lenguajes y tecnologías de “QtNLP” y otras específicas como “WordNet”, necesarias para lograr un óptimo desempeño de la aplicación. Estos recursos conforman una parte importante de la arquitectura de software. La descripción de componentes específicos utilizados en el desarrollo de “QtNLP-Wordnet” pueden leerse en detalle en la sección 3.2. Conclusiones del capítulo. La revisión bibliográfica realizada en este capítulo, permitió llegar a las siguientes conclusiones: No se encontró ningún editor del cual se pudiera reutilizar su código fuente para el desarrollo de “QtNLP-Wordnet”. Además, no existen aplicaciones de escritorio que utilicen “WordNet” implementadas en “Python” y “Qt”. A pesar de que existen proyectos que trabajan con bases de datos relacionales, ninguno utiliza “SQLite”, la cual está incluida en el core de “Python”, de ahí, que se escoja para facilitar el proceso de integración con “QtNLP” y la instalación en los ordenadores de los usuarios finales. Por otra parte, las interfaces GUI encontradas aportan elementos para el diseño de la aplicación centrado en los usuarios con pocos conocimientos de informática (Ej. los lingüistas).. 13.
(26) CAPÍTULO 2. ANÁLISIS DEL SISTEMA. CAPÍTULO 2. ANÁLISIS DEL SISTEMA. Este capítulo explica el modelo de negocio y requisitos para el desarrollo de la aplicación. Se exponen los diagramas de los procesos de negocios en su forma As-Is y To-be, así como las características de la metodología SXP necesarias para la gestión y planificación del proyecto. 2.1. Metodología de desarrollo ágil: SXP. El desarrollo ágil de software se refiere a métodos de ingeniería del software basados en el desarrollo iterativo e incremental, donde los requisitos y soluciones evolucionan mediante la colaboración de grupos auto organizados y multidisciplinarios. Existen muchos métodos de desarrollo ágil; la mayoría minimiza riesgos desarrollando software en lapsos cortos. El software desarrollado en una unidad de tiempo es llamado una iteración, la cual debe durar de una a cuatro semanas. Cada iteración del ciclo de vida incluye: planificación, análisis de requisitos, diseño, codificación, revisión y documentación. Una iteración no debe agregar demasiada funcionalidad para justificar el lanzamiento del producto al mercado, sino que la meta es tener un «demo»1 (sin errores) al final de cada iteración. Al llegar este momento el equipo vuelve a evaluar las prioridades del proyecto (Canós et al., 2003; Unkasoft, 2007). Algunas de las metodologías ágiles más conocidas son: XP (Extreme Programming), SCRUM, Dynamic Systems Development Method (DSDM), Adaptive Software Development (ASD) y Feature-Driven Development (FDD).. 1. Aplicación parcial que sirve para demostrar.. 14.
(27) CAPÍTULO 2. ANÁLISIS DEL SISTEMA. Principios de la metodología ágil: Según (Beck et al., 2001) los principios de las metodologías ágiles son los siguientes: . Entregas periódicas y frecuentes que funcionen.. . Los clientes forman parte del equipo de desarrollo.. . Equipo con individuos motivados. Darles para ello el ambiente, apoyo y confianza.. . La comunicación directa, método más eficiente y efectivo para comunicar información dentro de un equipo de desarrollo.. . La medida principal de progreso es un software que funcione.. . Desarrollo sostenible. Es indispensable que exista paz y armonía en el equipo para que el proyecto tenga éxito.. . Buen diseño y calidad técnica.. . La simplicidad es algo básico.. . Equipos auto-organizados.. . El equipo debe realizar reflexiones periódicamente para plantearse cómo llegar a ser más efectivo.. SXP (híbrido cubano): Metodología compuesta por las metodologías SCRUM y XP. Ofrece una estrategia tecnológica a partir de la introducción de procedimientos ágiles, que permitan actualizar los procesos de software para el mejoramiento de la actividad productiva, fomentando el desarrollo de la creatividad, aumentando el nivel de preocupación y responsabilidad de los miembros del equipo y ayudando al líder del proyecto a tener un mejor control del mismo. SCRUM es una forma de gestionar un equipo de manera que trabaje de forma eficiente y de tener siempre medidos los progresos, tal que sepamos por dónde andamos. XP más bien es una metodología encaminada para el desarrollo; consiste en una programación rápida o extrema, cuya particularidad es tener como parte del equipo al usuario final, este es uno de los requisitos para tener éxito en el proyecto (Peñalver Romero & Meneses Abad, 2008).. 15.
(28) CAPÍTULO 2. ANÁLISIS DEL SISTEMA. Esta metodología consta de 5 fases principales: . Investigación: revisión de tecnologías existentes y proyectos similares.. . Planificación-Definición: donde se establece la visión, se fijan las expectativas y se realiza el aseguramiento del financiamiento del proyecto.. . Desarrollo: es donde se realiza la implementación del sistema hasta que esté listo para ser entregado.. . Entrega: entrega del producto y despliegue en el entorno real, incluye la capacitación.. . Mantenimiento, donde se realiza el soporte para el cliente.. De cada una de estas fases se realizan numerosas actividades tales como el levantamiento de requisitos, la priorización de la Lista de Reserva del Producto, definición de las Historias de Usuario, diseño, implementación, pruebas, entre otras; de donde se generan artefactos para documentar todo el proceso. Las entregas son frecuentes, y existe una refactorización continua, lo que permite mejorar el diseño cada vez que se le añada una nueva funcionalidad (Peñalver Romero & Meneses Abad, 2008). 2.2. Principales roles (integrantes del equipo). En un equipo de desarrollo, los integrantes del mismo desempeñan diferentes roles que juegan un papel importante para la realización del producto final. El equipo conformado para el desarrollo de la aplicación “QtNLP-Wordnet” queda estructurado de la siguiente forma: . ProductOwner (Jefe de Proyecto): Alexander Avello Silverio. . Interesados (Clientes): Ing. Abel Meneses Abád y Lic. Manuel Llanes. . Scrum Master (Instructor del Scrum): Ing. Abel Meneses Abád. . Equipo de Desarrollo: Alexander Avello Silverio, Javier Sardiñas Morales, Ing. Abel Meneses Abád y Lic. Manuel Llanes. 16.
(29) CAPÍTULO 2. ANÁLISIS DEL SISTEMA. 2.3. Método del negocio utilizado IDEF. Métodos de definición integrado (IDEF, de sus siglas inglés), es una familia de técnicas de modelado que ofrecen una perspectiva integrada para representar procesos, información, datos, cambios de estados, e incluso, clases de software. Todos los métodos son iterativos, contienen un lenguaje de modelado, procedimientos y técnicas para desarrollar e interpretar los diagramas, incluyendo la obtención de información, construcción de diagramas, ciclos de revisión y documentación (Mayer et al., 1992). Para la modelación del negocio de esta aplicación se utiliza IDEF0, a continuación, se conceptualiza este método: IDEF0: Modelado funcional. Es un método diseñado para modelar decisiones, acciones y actividades de un sistema. Dicho sistema puede ser o no un sistema informático. Como lenguaje de modelado permite la representación gráfica de una variedad de sistemas y la comunicación entre analistas, desarrolladores y usuarios, haciendo énfasis en la exposición jerárquica de los detalles. Es coherente y simple. Como metodología describe las siguientes técnicas: revisión documental, entrevistas, observación, cuestionarios, reuniones grupales, redacción y desarrollo de descripciones hipotéticas que los lectores deben ir acercando a la realidad (Dorador & Young, 2000; Kim & Jang, 2002). 2.3.1. As-Is. El usuario después de haber instalado la aplicación que utiliza “WordNet”, busca en él la palabra deseada. Al buscarla, se muestran sus atributos (sense, gloss, etc.), y se muestran las palabras relacionadas destacando el tipo de relación existente (Figura 2.1).. Figura 2.1 Diagrama del proceso de negocio As-Is. 17.
(30) CAPÍTULO 2. ANÁLISIS DEL SISTEMA. 2.3.2. To-Be. La Figura 2.2 muestra el diagrama del proceso de negocio To-Be, el cual permite realizar las mismas acciones que el modelo As-Is y además incorpora otras acciones. Primeramente, se convierten los TXT de “WordNet” a una base de datos en “SQLite”, aumentando campos como sense_es, gloss_es, entre otros, los mismos se inicializan en “not”. De esta base de datos se exportan los atributos en inglés de cada tabla, línea a línea en formato TXT para luego ser traducido al español. Posteriormente, se insertan las traducciones en los campos correspondientes al idioma español. Al mismo tiempo este módulo permite los synsets de una palabra existente en la base de datos, o insertar una nueva palabra y luego agregar sus synsets. Si el usuario desea puede convertir la base de datos editada hacia el formato inicial de “WordNet” en TXT.. Figura 2.2 Diagrama del proceso de negocio To-Be. 18.
(31) CAPÍTULO 2. ANÁLISIS DEL SISTEMA. 2.4. Pila del Producto. Es una lista priorizada que define el trabajo que se va a realizar en el proyecto. Cuando un proyecto comienza es muy difícil conocer claramente todos los requerimientos sobre el producto. Sin embargo, los más importantes se describen primero por el cliente, y casi siempre son suficientes para el primer Sprint (Iteración). Las siguiente tabla es una versión mejorada de la LRP de (Céspedes Fernández et al., 2008). Tabla 2.1 Pila del producto. Asignado a. Ítem. Descripción. Estimación. Estimado por. HU. Estad o. 01_HU. ok. 02_HU. ok. 03_HU. ok. 04_HU. ok. 05_HU. ok. 06_HU. ok. 14_HU. ok. 07_HU. ok. 08_HU. ok. 12_HU. ok. 09_HU 10_HU. ok ok. 11_HU. ok. 13_HU 14 HU. ok ok. Prioridad Muy Alta Alex. 1. Alex. 2. Alex. 3. Alex. 4. Alex. 5. Alex. 6. Alex. 7. Alex. 8. Alex. 9. Alex. 10. Alex Alex. 11 12. Alex. 13. Alex Alex. 14 15. Diseño e implementación de la BD wordnet.db3 en SQLite. Parser de los XMLs de WordNet-ES a SQLite para QtNLP-Wordnet. Parser de los TXT de WordNetING a SQLite para QtNLPWordnet.. Prioridad Alta Gestionar atributos de la palabra en QtNLP-Wordnet. Gestionar relaciones de la palabra en QtNLP-Wordnet. Gestionar palabras en QtNLPWordnet. Parser de la BD SQLite a ficheros estándar de WordNet.. Prioridad Media Mostrar atributos de las palabras (definición, glosa). Mostrar relaciones entre palabras (sinónimos, etc). Búsqueda de palabras en libros en formato txt.. Prioridad Baja Filtrar atributos Generar TXT mediante wordnet.db3 para traducir. Inyectar traducciones en wordnet.db3. Editar excepciones. Parsers para generar WordNetENG-ES, o WordNet-ES-ENG. 19.
(32) CAPÍTULO 2. ANÁLISIS DEL SISTEMA. Leyenda. Ítem: Número de la funcionalidad Estimación: Duración de la funcionalidad por semanas HU: Historia de Usuario. 2.5. Plan de Iteraciones. En la Tabla 2.2 se recogen las iteraciones a realizar con sus características, además del orden de las historias de usuario a implementar y la duración total de la iteración. La siguiente tabla fue obtenida de (Céspedes Fernández et al., 2008). Tabla 2.2 Plan de iteraciones. Release. Descripción de la iteración. Orden de la HU a implementar. Duración total. Ninguna. Artefacto solo el capítulo 1 de la tesis.. 15/10 – 15/12. 1. Investigación del tema de WordNet y herramientas para visualizar y editar la base de datos de WordNet3.0-ENG.. 2. Iteración de capacitación. Refactorizar la investigación. Los documentos del diseño del sistema en SXP.. 3. Parsear los xmls de WordNet-ES. Además comenzar los diseños de los GUI en Qt.. HU1. 1/2 – 29/2. 4. Diseño de la base de datos SQLite de WordNet-ENG. Parsers para el llenado de wordnet.db3 desde los ficheros de WordNet-ENG.. HU2, HU3. 1/3 – 31/3. 1. 2. 3. 4.. HU7, HU8 HU10 ... HU11. 1/4 – 30/4. 1. 2. 3.. HU4, HU5, HU6 HU12 HU13. 1/5 – 30/5. 1. 2.. HU09 HU14. 1. 2. 5 3. 4.. 1. 6. 2. 3.. 7. 1. 2.. Terminar GUI de visualizar (buscar, atributos, relación synset). Parser de generar palabra, glosa, significado para traducir. Traducir. Parser para inyectar en wordnet.db3 las traducciones (Ej. Los significados largos) Terminar GUI de gestionar (relaciones, atributos, y palabra). Búsqueda de palabras en libros en formato txt. Editar excepciones. Filtrar atributos Parsers para generar WordNet-ENG-ES, o WordNet-ES-ENG.. 1/1 – 31/1. ninguna. 1/6-15/6. 20.
(33) CAPÍTULO 2. ANÁLISIS DEL SISTEMA. 2.6. Historias de usuario. Las historias de usuario son la técnica utilizada en SXP para especificar los requisitos del software. Las mismas son escritas por los clientes como las tareas que el sistema debe hacer. Su construcción depende principalmente del trabajo conjunto del cliente y el desarrollador para definirlas. Son utilizadas como el único documento de requisito que se genera en SXP. También son escritas en lenguaje natural, sin un formato predeterminado, no excediendo su tamaño de unas pocas líneas de texto. El modelo de esta plantilla es una versión actualizada de (Céspedes Fernández et al., 2008). Este proyecto consta de catorce historias de usuario. A continuación, se exponen las más significativas.. Tabla 2.3 Mostrar atributos de la palabra. Historia de Usuario Número: 7 Nombre Historia de Usuario: Mostrar atributos de la palabra. Modificación de Historia de Usuario Número: 0 Usuario: Lingüista computacional Iteración Asignada: 5 Programador responsable: Alexander Avello Silverio Prioridad en Negocio: Media Puntos Estimados: 1 Riesgo en Desarrollo: bajo Puntos Reales: 2 Descripción: Mostrar al usuario los atributos de la palabra (definición, glosa, etc.).Poner todos los atributos, su nombre y descripción. Observaciones: Los atributos se muestran en una tabla. Se decidió entre el tutor y el lingüista adicionar los atributos: (sense_es, sense_long, sense_long_es, gloss_es). El objetivo es utilizar esto en asignaturas de traducción para generar “WordNets” multilingües. Ej: (kid, niño) (a young person of either sex, una persona joven de cualquier sexo) (she writes books for children) (ella escribe libros para niños). Tareas de Ingeniería: 1. Se estudió los métodos del TableWidget para mostrar los atributos de la palabra (sense, gloss, etc.). 2. Se implementó la función para mostrar (word, translated, ss_type, sense, sense_es, sense_long, sense_long_es, gloss, gloss_es) de una palabra específica.. 21.
(34) CAPÍTULO 2. ANÁLISIS DEL SISTEMA Tabla 2.4 Mostrar relaciones entre palabras. Historia de Usuario Número: 8 Nombre Historia de Usuario: Mostrar relaciones entre palabras. Modificación de Historia de Usuario Número: 2 Usuario: Lingüista computacional Iteración Asignada: 5 Programador responsable: Alexander Avello Silverio Prioridad en Negocio: Media Puntos Estimados: 1 Riesgo en Desarrollo: bajo Puntos Reales: 3 Descripción: Mostrar al usuario las relaciones que existen entre palabras como son: sinónimos, antónimos, derivados, relacionado con, atributo, similar, dominio, causa, implica, tipo de, tipo y parte de. Observaciones: Los sinónimos se muestran siempre. Se muestra en un ListWidget. Dos palabras en un mismo synset no tienen las mismas relaciones. Ejemplo el synset(child,kid) tiene el antónimo “parent”, sin embargo el index.noun especifica que este antónimo es para “child” solamente. Tareas de Ingeniería: 1. Realizar consulta de todas las palabras que se relacionan mediante la tabla index_sense, eliminando las palabras repetidas. 2. Poner las palabras en minúscula, eliminar la palabra buscada y mostrar las demás palabras que se encuentran en la relación seleccionada. ´Tabla 2.5 Gestionar atributos de la palabra. Historia de Usuario Número: 4 Nombre Historia de Usuario: Gestionar atributos de la palabra. Modificación de Historia de Usuario Número: 3 Usuario: Lingüista computacional Iteración Asignada: 6 Programador responsable: Alexander Avello Silverio Prioridad en Negocio: Alta Puntos Estimados: 3 Riesgo en Desarrollo: medio Puntos Reales: 3 Descripción: El usuario busca la palabra y rellena o cambia los campos de los atributos. Observaciones: Al buscar la palabra, te salen los atributos de la misma por synset, si no se encuentra, se toma como la inserción de una palabra nueva. Se puede agregar un synset nuevo en blanco y llenarlo posteriormente. Tareas de Ingeniería: 1. Reusar los métodos de buscar los atributos e insertar en la tabla. 2. Implementar un método para pasar atributos de otra palabra buscada en la tabla inferior para la que se está editando en la tabla superior. 3. Guardar la información de los mismos en arreglos para su posterior inserción o modificación en la base de datos.. 22.
(35) CAPÍTULO 2. ANÁLISIS DEL SISTEMA Tabla 2.6 Gestionar relaciones de la palabra. Historia de Usuario Número: 5 Nombre Historia de Usuario: Gestionar relaciones de la palabra. Modificación de Historia de Usuario Número: 5 Usuario: Lingüista computacional Iteración Asignada: 6 Programador responsable: Alexander Avello Silverio Prioridad en Negocio: Alta Puntos Estimados: 3 Riesgo en Desarrollo: medio Puntos Reales: 4 Descripción: El usuario busca la palabra y rellena o cambia los campos de los atributos. Observaciones: Al buscar la palabra te salen las relaciones de la misma, si no se encuentra hay que llenarlos de 0, se puede buscar otra palabra para tomar de sus relaciones y aumentarlas en la relación seleccionada de la palabra en edición. Tareas de Ingeniería: 1. Reusar los métodos de buscar las relaciones e insertar en la tabla. 2. Implementar un método para pasar relaciones de otra palabra buscada en la tabla inferior para la que se está editando en la tabla superior. 3. Guardar la información de los mismos en arreglos para su posterior inserción o modificación en la base de datos. Tabla 2.7 Busqueda de palabras en libros en formato TXT. Historia de Usuario Número: 12 Nombre Historia de Usuario: Búsqueda de palabras en libros en formato TXT. Modificación de Historia de Usuario Número: 3 Usuario: Lingüista computacional Iteración Asignada: 6 Programador responsable: Alexander Avello Silverio Prioridad en Negocio: Media Puntos Estimados: 2 Riesgo en Desarrollo: bajo Puntos Reales: 1 Descripción: Buscar palabras en libros otorgados por el lingüista para mejor edición de palabras. Observaciones: Cada vez que se agregue algún libro nuevo al programa se debe copiar en este formato: 1. El nombre del libro se debe poner en el primer renglón del txt de esta forma [nombre del libro autor]. 2. Al archivo se le debe cambiar el nombre y ponerle el número consecutivo del último que se encuentre en la carpeta data/book. Tareas de Ingeniería: 1. Poner los libros en el formato descrito en las observaciones y copiarlos en la carpeta data/book. 2. Implementar método para buscar la palabra en todos los textos y agregar en el Qlistwirdget el nombre del texto donde lo encontró y la dimensión del mismo. 3. Implementar método para seleccionar los párrafos de la palabra buscada y guardarlo en un arreglo para que el usuario pueda leer el que necesite. 4. Implementar método para pintar la palabra en el texto.. 23.
(36) CAPÍTULO 2. ANÁLISIS DEL SISTEMA Tabla 2.8 Editar excepciones. Historia de Usuario Número: 13. Nombre Historia de Usuario: Editar excepciones.. Modificación de Historia de Usuario Número: 2 Usuario: Lingüista computacional. Iteración Asignada: 6. Programador responsable: Alexander Avello Silverio Prioridad en Negocio: Baja. Puntos Estimados: 1. Riesgo en Desarrollo: Bajo. Puntos Reales: 1. Descripción: El usuario puede editar las excepciones de una palabra ya sea insertar, modificar o eliminar la mismas. Observaciones: Solo puede haber una excepción para cada tabla exc (noun_exc, verb_exc, adj_exc, adv_exc). Lo que se edita son base form de la palabra. Tareas de Ingeniería: 1.. Implementar método para insertar una nueva excepción.. 2.. Implementar método para modificar o eliminar una excepción.. Las historias de usuario que no se expusieron fueron las siguientes: . 01_HU “Diseño e implementación de la BD wordnet.db3 en SQLite”. . 02_HU “Parser de los XMLs de WordNet-ES a SQLite para QtNLP-Wordnet”. . 03_HU “Parser de los TXT de WordNet-ING a SQLite para QtNLP-Wordnet”. . 06_HU “Gestionar palabras en QtNLP-Wordnet”. . 09_HU “Filtrar atributos”. . 10_HU “Generar TXT mediante wordnet.db3”. . 11_HU “Inyectar traducciones en wordnet.db3”. . 13_HU “Editar excepciones”. 24.
(37) CAPÍTULO 2. ANÁLISIS DEL SISTEMA. 2.7. Requisitos no funcionales. Como su nombre indica, son requisitos que no tienen que ver directamente con las funciones específicas entregadas por el sistema. Pueden referirse a las propiedades emergentes del sistema, como la fiabilidad, tiempo de respuesta y la memoria que ocupa. Alternativamente, pueden definir restricciones en el sistema, tales como las capacidades de los dispositivos de E/S y las representaciones de datos utilizadas en las interfaces del sistema. Tabla 2.9 Requisitos no funcionales. RNF1 Descripción. RNF2 Descripción. Usabilidad El sistema podrá ser usado por cualquier persona con conocimientos básicos de informática. El número de clicks consecutivos para lograr un resultado será de 2 o 3. Software Las estaciones de trabajo deberán contar con soporte para python y Qt.. RNF3. Hardware. Descripción. Para la aplicación servidora es necesaria una PC con microprocesador Pentium 4 3.0GHz, 512MB de RAM y una capacidad de 1GB en disco duro.. RNF4. Soporte. Descripción. Debe poder ser mantenido por el equipo creador.. Descripción. Multiplataforma, que sea ejecutable en Windows, Linux y Mac.. RNF5. Rendimiento. Descripción. El tiempo de respuesta no debe exceder los treinta segundos ante las solicitudes del usuario.. RNF6. Entrega. Descripción. Debe contar con un manual de desarrollo. Ejecutable.pyc. Código fuente. Documentación en plantillas SXP del proyecto. Documento de tesis.. RNF6. Éticos. Descripción. Los datos y tecnologías utilizadas deben tener licencias de uso que permitan utilizarse libremente en entornos académicos.. 25.
(38) CAPÍTULO 2. ANÁLISIS DEL SISTEMA. Conclusiones del capítulo En este capítulo se ha realizado un análisis del sistema que se utilizará para la implementación del módulo “QtNLP-Wordnet” en el desarrollo de los próximos capítulos, Para ello se conformó el. equipo de desarrollo basado en 4 roles. Luego fueron realizados los diagramas As-Is y ToBe utilizando IDEF0 para la modelación. Los artefactos de SXP utilizados: la pila del producto, el plan de iteraciones, los requisitos no funcionales, las historias de usuarios y el código fuente, fueron cambiando durante las iteraciones de desarrollo, acorde a lo descrito en la metodología utilizada. Además, durante el proceso de desarrollo se cumplieron todos los principios ágiles.. 26.
(39) CAPÍTULO 3. ARQUITECTURA DEL SOFTWARE. CAPÍTULO 3. ARQUITECTURA DE SOFTWARE. En este capítulo se diseña e implementa la base de datos de “QtNLP-Wordnet” y se explica la arquitectura del sistema para el manejo de este módulo. Se realiza un resumen sobre las herramientas y tecnologías utilizadas durante el desarrollo de la aplicación. Además se ejemplifican, con códigos, los principales elementos utilizados del estándar de codificación PEP8. También se explica los patrones utilizados en la aplicación, el diagrama de paquetes y de componentes. Posteriormente se muestra el modelo de datos SQL con campos basados en el estándar de “WordNet”. Por último, se describen las interfaces de la historia de usuario correspondientes. 3.1. Lista de Reserva del Producto «LRP». La Lista de Reservas del Producto y el Plan de iteraciones, constituyen elementos esenciales en la arquitectura de la aplicación. La descripción detallada de los mismos se encuentra en los sub-epígrafes 2.4 y 2.5. 3.2. Herramientas asociadas al desarrollo del sistema. La Figura 3.1 representa las diferentes herramientas para el desarrollo de la aplicación “QtNLP-Wordnet”, y la forma en que se utilizan cada una de ellas. Primeramente, se revisa analiza la estructura de “WordNet” y los campos que desea agregar el cliente a la misma. Luego se realiza el modelo relacional de la base de datos utilizando el software “Embarcadero ERStudio” que da paso a la creación del modelo físico en “SQLite Expert Personal” mediante el gestor “SQLite3”. Por otra parte, se utiliza “Qt-Designer” para el diseño visual de las interfaces de usuario del módulo. Se programa mediante el IDE “PyCharm” utilizando.
(40) CAPÍTULO 3. ARQUITECTURA DE SOFTWARE. 28. “Python” como lenguaje de programación e importando la biblioteca “PyQt”, quedando de esta forma elaborada la aplicación “QtNLP-Wordnet”.. Figura 3.1 Herramientas asociadas al desarrollo del sistema. 3.2.1. Entornos integrados de desarrollo «IDE». A continuación, se describen los IDE de desarrollo utilizado en el proyecto proporcionando el nombre, la licencia del producto, la versión y la descripción de su uso. PyCharm(JetBrains s.r.o, 2016) Licencia del producto: Dual (Proprietary, Apache License) Versión: 4.5.3 Descripción de su uso: Se utilizó para la programación del módulo. Fue de mucha ayuda debido a las facilidades que brinda el mismo, como son: el auto-completamiento y que contiene implícito el estándar de codificación PEP8 (Van Rossum et al. 2013) utilizados en la edición. También, permite cambiar los nombres de variables y funciones en el código entero. Contiene integrado un controlador de versiones, entre otras facilidades.. 28.
(41) CAPÍTULO 3. ARQUITECTURA DE SOFTWARE. 29. Qt Designer (The Qt Company, 2016a) Licencia del producto: LGPL Versión: 4.7.0 Descripción de su uso: Se utilizó para la creación de las interfaces (GUI) de “QtNLPWordnet”. SQLite Expert Personal (Coral Creek Software, 2016) Licencia del producto: Freeware Versión: 3.5.92.2512 Descripción de su uso: Es un programa que se utilizó para la creación de la base de datos o modelo físico, desde el modelo lógico realizado en “ERStudio”. 3.2.2. Marcos de trabajos que soportarán el desarrollo «Framework de desarrollo». Seguidamente se describe el Framework de desarrollo utilizado en el proyecto. Se proporciona el nombre, la licencia del producto, la versión y la descripción de su uso. Qt (The Qt Company, 2016b) Licencia del producto: LGPL-2.1 (Qt versión de código abierto) Qt Commercial License (Qt versión comercial) Versión: 4.7.0 Descripción de su uso: Qt es ampliamente usado para desarrollar aplicaciones con interfaz gráfica de usuario, también se utiliza para el desarrollo de programas sin interfaz gráfica y como herramientas de consolas para servidores. Qt es desarrollado como un software libre y de código abierto a través de Qt Project, donde participa tanto la comunidad, como los desarrolladores de empresas. 3.2.3. Gestores de bases de datos. El gestor utilizado en el desarrollo de la aplicación se describe a continuación. Se proporciona el nombre, la licencia del producto, la versión y la descripción de su uso.. 29.
(42) CAPÍTULO 3. ARQUITECTURA DE SOFTWARE. 30. SQLite (Granado, 2004) Licencia del producto: Public domain Versión: 3.x Descripción de su uso: se utilizó como sistema gestor para la base de datos con la API (acrónimo en inglés de Application Program Interface) de “python” _sqlite3 versión 2.6.0. 3.2.4. Lenguajes de programación. A continuación, se describe el lenguaje de programación Python y la biblioteca “PyQt” que se utilizaron en el proyecto. Se proporciona el nombre, la licencia del producto, la versión y la descripción de uso de cada uno de ellos. Python (Bahit, 2010) Licencia del producto: Python Software, Foundation License Versión: 2.7 Descripción de su uso: Python es un lenguaje de programación multiparadigma. Permite varios estilos: programación orientada a objetos, programación imperativa y programación funcional. Para el trabajo con el mismo se importaron módulos como sqlite3 orientadas a la gestión con la base de datos y algunas funciones internas (builtins) para el trabajo con cadenas de texto como lower y unicode para la conversión. PyQt (Summerfield, 2007) Licencia del producto: GPL 3.0 Versión: 4.11.4 Descripción de su uso: Es la unión de la biblioteca gráfica Qt para el lenguaje de programación Python. La misma está desarrollada por la firma británica Riverbank Computing y está disponible para Windows, GNU/Linux y MacOSX bajo diferentes licencias.. 30.
(43) CAPÍTULO 3. ARQUITECTURA DE SOFTWARE. 3.2.5. 31. Ingeniería del Software asistida por computadoras «CASE». Las herramientas CASE utilizadas para el desarrollo de la aplicación se describen a continuación. Se proporciona el nombre, la licencia del producto, la versión y la descripción de su uso. Embarcadero ERStudio (IDERA, 2016) Licencia del producto: Comercial, Academic Versión: 8.0.3 Descripción de su uso: Esta herramienta fue utilizada para la confección del diagrama del modelo lógico de la base de datos wordnet.db3. Dia (The GNOME Proyect, 2016) Licencia del producto: GPL2 Versión: 0.97.2 Descripción de su uso: Esta herramienta fue utilizada para realizar los diagramas As-Is y ToBe debido a las facilidades que brinda la misma para la confección de diagramas. Visual Paradigm (Visual Paradigm, 2013) Licencia del producto: Proprietary with Free Community Edition Versión: 6.0 Descripción de su uso: Mediante el uso de esta herramienta se desarrollaron los diagramas de paquete y de componente. 3.2.6. Sistemas de Control de Versiones «CVS». El sistema de control de versiones utilizado es el Bazaar Explorer usando Bazaar como servidor. A continuación, se describen ambos. Se proporciona el nombre, la licencia del producto, la versión y la descripción de su uso.. 31.
(44) CAPÍTULO 3. ARQUITECTURA DE SOFTWARE. 32. Bazaar (Canonical Ltd, 2011) Licencia del producto: GPLv2 o mayor Versión: 2.5.1 Descripción de su uso: Servidor de control de versiones utilizado para este proyecto. Bazaar Explorer (Canonical Ltd, 2010) Licencia del producto: Versión: 1.2.2 Descripción de su uso: GUI encargado de trabajar con Bazaar, se utilizó en el desarrollo del proyecto, debido a que proporciona copias de seguridad de versiones anteriores del proyecto en desarrollo. Permite comparar los cambios producidos entre diferentes versiones. Además, sirve como métrica para medir la cantidad de código que se produce por día, entre otras funcionalidades. 3.2.7. Otras herramientas. No se utilizaron herramientas adicionales. 3.3. Estándar de codificación. Se utiliza el estándar de codificación PEP8 de “python”, a continuación, se exponen los elementos esenciales. Para ver el resto estudiar (Van Rossum et al., 2013). Dejar 4 espacios de sangría por nivel, exceptuando cuando se abre y cierra paréntesis, o corchetes. Ejemplo: for id in self.__allsynset_offset: if(self.__tablesynset[cont][0] == "noun"): ss_type = 1 arrayrela = [self.__antonyms, self.__derivatives, self.__relatesto, self.__attributes, self.__similar, self.__domain, self.__causes, self.__entails, self.__kindof, self.__kinds, self.__partof, self.__parts]. 32.
Figure




+7


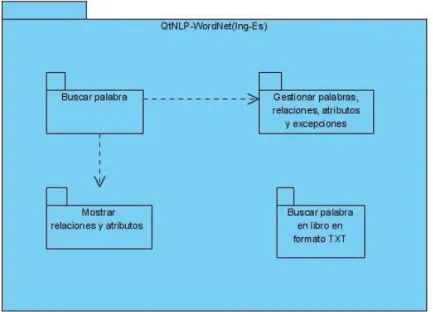

Documento similar
La moral especial (o institucional, la M de G ARZÓN ) parece ofrecer de- masiados pretextos; terminaría por justificar cualquier tipo de acción requerida por ra- zones
Proporcione esta nota de seguridad y las copias de la versión para pacientes junto con el documento Preguntas frecuentes sobre contraindicaciones y
[r]
Sanz (Universidad Carlos III-IUNE): "El papel de las fuentes de datos en los ranking nacionales de universidades".. Reuniones científicas 75 Los días 12 y 13 de noviembre
(Banco de España) Mancebo, Pascual (U. de Alicante) Marco, Mariluz (U. de València) Marhuenda, Francisco (U. de Alicante) Marhuenda, Joaquín (U. de Alicante) Marquerie,
Tejidos de origen humano o sus derivados que sean inviables o hayan sido transformados en inviables con una función accesoria.. Células de origen humano o sus derivados que
d) que haya «identidad de órgano» (con identidad de Sala y Sección); e) que haya alteridad, es decir, que las sentencias aportadas sean de persona distinta a la recurrente, e) que
De hecho, este sometimiento periódico al voto, esta decisión periódica de los electores sobre la gestión ha sido uno de los componentes teóricos más interesantes de la
