Módulo de visualización científica para Weka
82
0
0
Texto completo
(2) Hago constar que el presente trabajo fue realizado en la Universidad Central Marta Abreu de Las Villas como parte de la culminación de los estudios de la especialidad de Ciencias de la Computación, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad. ________________ Firma del autor Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. ______________. ________________________. Firma del tutor. Firma del jefe del Seminario. II.
(3) A mi madre y a mi padre. A todos los que contribuyeron a formar mi carácter. A los que me quieren y aceptan.. III.
(4) Agradecimientos A mi tutor Carlos Pérez Risquet por su valiosa ayuda. A Mabel por su colaboración durante todo este trabajo y su apoyo en otras muchas circunstancias. A mi madre por sus múltiples consejos metodológicos y su disposición. A mi padre y mi hermana Lorna por encargarse de algunos importantes temas logísticos. A todas las personas, compañeros de estudio y profesores, que con pequeños aportes contribuyeron con este trabajo.. Inti González Herrera.. IV.
(5) ﻦ اﻟﺣﻴاة اﻠﺪﻧﻴا ﻋﺑارﻩ ﻋن ﺤﻘل ﺤﻴث ﻴﺰﺮع ﻔﻴﻪ ﻠﻠﺤﻴاﻩ اﻻﺧﺮى " "إﱠ ﻣﺤﻣﺪ. Este mundo es el campo en que se siembra para el otro. Mahoma. V.
(6) Resumen. Resumen. La visualización científica es una herramienta útil durante el proceso de extracción de conocimiento. Weka es un poderoso sistema de aprendizaje automático, que en cambio ofrece pocas alternativas en el área de la visualización. En este proyecto se adiciona un módulo de visualización científica a Weka. Al módulo se han incorporado las siguientes técnicas de visualización para datos multiparamétricos: Coordenadas Paralelas, iconos con StarField, Gráfico de Andrews, Proyecciones con Escalado Multidimensional y Segmentos de Círculo. Se ha agregado además una valiosa técnica para la visualización de conglomerados, a partir de partículas afectadas por la gravedad. El módulo tiene gran flexibilidad, por lo que en futuros trabajos se podrán adicionar otras técnicas o modificar las existentes. Fue creado como un paquete independiente de Weka, que permite incorporarlo a otros sistemas.. VI.
(7) Abstract. Abstract. The scientific visualization is a useful tool during the process of discovery of knowledge. Weka is a powerful machine learning system, which in return offers very few alternatives in the visualization area. In this project, a module of scientific visualization is added to Weka. The following visualization techniques have been added to the module for multiparametric data: parallel coordinates, Starfield icons, Andrews graph, multidimensional scaling project and circle segments. A very valuable technique has been added to the cluster from gravity affected particles. The module has great flexibility, so that in future papers, other techniques can be added or the present ones modification. It was developed as an independent package, which permits its involment in other systems.. VII.
(8) Índice.. Introducción. ................................................................................................. 1 Capítulo 1. Técnicas de Visualización Científica. ...................................... 4 1.1 Introducción a las técnicas de visualización científica....................................... 5 1.2 Técnicas de visualización para volúmenes.......................................................... 6 1.3 Técnicas de visualización para datos de fluidos. ................................................ 8 1.4 Visualización de información. .............................................................................. 9 1.5 Técnicas de visualización para datos multiparamétricos. ............................... 13 1.5.1 Técnicas geométricas. .................................................................................... 14 1.5.2 Técnicas basadas en iconos. .......................................................................... 18 1.5.3 Técnicas orientadas a píxel. .......................................................................... 21 1.5.4 Proyecciones. .................................................................................................. 23 1.6 Visualización como apoyo a los métodos automáticos de extracción de conocimiento. ............................................................................................................. 24 Búsqueda de conglomerados. ................................................................................. 25 1.7 Descripción general de WEKA (Waikato Environment for Knowledge Analysis) ..................................................................................................................... 28 Técnicas de Visualización implementadas en Weka ............................................ 28 1.8 Conclusiones parciales. ....................................................................................... 29. Capítulo 2. Diseño e Implementación de la extensión. ............................ 30 2.1 Análisis del problema. Selección de las técnicas a incluir en la extensión. .... 30 2.2 Diseño de la extensión realizada al sistema Weka. .......................................... 31 2.3 Consideraciones acerca de las técnicas implementadas. ................................. 40 2.3.1 Implementación de la técnica de visualización basada en Iconos.............. 40 2.3.2 Implementación de la técnica Gráfico de Andrews. ................................... 41 2.3.3 Implementación de la técnica de visualización de proyecciones ................ 42 2.3.4 Método de Coordenadas Paralelas ............................................................... 43 2.3.5 Método de Segmentos de Círculo ................................................................. 43 2.3.6 Visualización de conglomerados como partículas afectadas por la gravedad................................................................................................................... 44 2.4 Metodología para la adición de una técnica para visualización de datos multiparamétricos. .................................................................................................... 45 2.4.1 Creación de la subclase de MultiParametricVisualizationPanel. ................ 45 2.4.2 Creación de la subclase de VisualizationConfigPanel. ................................ 46 2.4.3 Creación de la subclase de ExploratoryVisualization. ................................. 46 2.5 Metodología para la adición de la visualización de conglomerados a un método de búsqueda de conglomerados.................................................................. 47 2.6 Implementación de la extensión......................................................................... 48 2.7 Conclusiones parciales. ....................................................................................... 50. Capítulo 3. Manual de Usuario.................................................................. 51 3.1 Requerimientos del sistema................................................................................ 51 3.2 Nuevas facilidades del sistema. .......................................................................... 51 3.3 Manual de usuario .............................................................................................. 51 3.3.1 Coordenadas Paralelas. ................................................................................. 53 VIII.
(9) Índice. 3.3.2 Gráfico de Andrews. ...................................................................................... 56 3.3.3 Iconos basados en Campo de Estrellas......................................................... 58 3.3.4 Segmentos de Círculo. ................................................................................... 60 3.3.5 Proyecciones. .................................................................................................. 62 3.3.6 Partículas Afectadas por Gravedad. ............................................................ 64 3.4 Conclusiones Parciales........................................................................................ 66. Conclusiones. ............................................................................................... 67 Recomendaciones. ....................................................................................... 68 Referencias Bibliográficas.......................................................................... 69 Anexos. ......................................................................................................... 71. IX.
(10) Introducción.. Introducción. Weka es un sistema para la extracción de conocimiento que implementa varias técnicas de aprendizaje automático, supervisado y no supervisado. Como corresponde a esta clase de sistema él manipula considerables volúmenes de datos, algunos son entrados al sistema y otros son producidos por métodos de aprendizaje automático. La visualización científica, por otro lado, es una herramienta útil para la exploración de datos y el análisis de resultados. El sistema Weka, que es utilizado en áreas como la minería de datos, presenta un módulo de visualización científica muy pobre, con tan solo unas pocas opciones. Adicionarle a este sistema un módulo de visualización científica incrementaría las potencialidades del mismo permitiendo a los usuarios ser parte del proceso de extracción de conocimiento, mediante un método tan interactivo y natural como la visualización.. Objetivo General. Desarrollar un módulo de visualización científica para el sistema Weka que facilite la exploración y análisis de los datos iniciales y apoye la visualización de resultados de métodos de aprendizaje automático.. Objetivos Específicos. •. Implementar un paquete para la exploración y análisis visual de los datos iniciales.. •. Implementar un paquete para visualizar los resultados de algunos métodos de búsqueda de conglomerados que contiene Weka.. Justificación de la investigación. La adición de un módulo de visualización científica a Weka aportaría valiosas herramientas a los usuarios del sistema. La representación de los datos iniciales permitiría a los usuarios conocer con facilidad características de los mismos, que podrían ser desde 1.
(11) Introducción. informaciones estadísticas básicas hasta importantes conclusiones sobre un problema. Los resultados producidos por los métodos de aprendizaje automático del sistema serían más fáciles de estudiar permitiendo investigaciones más profundas y análisis más detallados. Los usuarios del sistema con menos experiencia asimilarían más fácilmente los resultados. Por otro lado la graficación de los datos iniciales podría servir de ayuda a los usuarios en la tarea de elegir o configurar los métodos de aprendizaje automáticos a utilizar sobre ellos. Dada la gran cantidad de técnicas existentes y teniendo en cuenta la estructura de Weka ¿Cuales técnicas de visualización seria apropiado añadir a la extensión? Y además: ¿Qué estructura específica se adoptaría para la adición a Weka de cada una de ellas? Por otra parte ¿Cómo enfrentar el reto de agregar técnicas de visualización científica a un sistema que no está específicamente diseñado para ello? Viabilidad de la investigación. El estado actual de las técnicas de visualización científica ofrece una amplia gama de ideas a desarrollar en este trabajo. Por otro lado se cuenta con el apoyo del grupo de Computación Gráfica del Centro de Estudios Informáticos que tiene suficiente experiencia en el área. Existe más de una biblioteca gráfica que ya ha sido estudiada y por tanto puede ser empleada en la elaboración de este proyecto. La herramienta WEKA ha sido utilizada a lo largo de la carrera, así como el lenguaje Java. Estructura general de la tesis. Este trabajo está dividido en tres capítulos. En el primer capítulo se realiza una introducción a la visualización científica. Se describen los tipos de datos que utilizan las técnicas de visualización y en base a este criterio se efectúa una clasificación de las mismas. Posteriormente se realiza una explicación de las técnicas fundamentales. 2.
(12) Introducción. profundizando en las usadas para representar datos multiparamétricos. Se abordan también las técnicas de visualización como apoyo a la búsqueda de conglomerados. Finalmente se realiza un resumen de las principales características y funcionalidades de Weka, especialmente las opciones de visualización En el segundo capítulo se describen los datos usados por el sistema Weka y se eligen las técnicas que se adicionarán al módulo de visualización. Para cada una de estas técnicas se seleccionan los detalles específicos de la implementación. A continuación se realiza el proceso de diseño del software y se muestra la metodología para extender el módulo. En el capítulo 3 se presenta el manual de usuario del módulo y se dan algunos consejos para su utilización.. 3.
(13) Capítulo 1.. Capítulo 1. Técnicas de Visualización Científica. Las computadoras son hoy una herramienta de uso cotidiano en las más diversas áreas. Son utilizadas en el comercio, la medicina, la industria y en general en cualquier rama de la ciencia. El desarrollo tecnológico actual está basado en gran medida en el uso de la computación y una característica fundamental de las modernas tecnologías es la producción de grandes volúmenes de datos. Las fuentes de datos en la actualidad son en extremo variadas. Los datos pueden ser registros de clientes de una compañía, registros climáticos en una determinada localidad, historias clínicas de pacientes con determinada enfermedad en una ciudad, la monitorización de la velocidad de las corrientes de aire alrededor de las alas de un avión o los parámetros que definen un determinado fenómeno físico. La recolección de datos se realiza con motivos bien definidos, pues evidentemente los datos son susceptibles a contener información relevante para un determinado problema. La extracción de información a partir de los datos puede convertirse en un reto para los investigadores, producto del volumen de los datos primarios o de la complejidad de los mismos[1]. La ciencia ha desarrollado diversos métodos para la obtención de información, y uno de ellos se basa en la creación de imágenes a partir de los datos. Este método, conocido como visualización, ha sido utilizado como vía natural para mostrar información[1]. Recientes investigaciones han impulsado en gran medida este campo mediante el uso de la computación. La visualización de datos puede en general perseguir diferentes metas. La naturaleza del objetivo que se persigue está en relación directa al conocimiento que se tenga sobre los datos iniciales. Los objetivos pueden ser los siguientes [2]: •. Análisis Exploratorio.. •. Análisis confirmativo.. 4.
(14) Capítulo 1. •. Presentación de información.. El Análisis Exploratorio en la visualización parte de un conjunto de datos sobre el que no se tiene hipótesis y a partir de un proceso interactivo usando una búsqueda no dirigida se llega a la obtención de una imagen que aporta una hipótesis sobre los datos. El Análisis Confirmativo comienza con datos sobre los que se tiene a priori una hipótesis. El proceso consiste en la búsqueda de la confirmación de la hipótesis. La Presentación de Información parte de hechos que son fijos a priori y que se desean enfatizar y mostrar con extrema calidad.. Producto del desarrollo de esta área es necesario realizar un breve estudio para determinar la dirección a seguir en el proyecto. En este estudio debe analizarse las posibilidades que ofrecen las técnicas de visualización y las facilidades de Weka en este aspecto.. 1.1 Introducción a las técnicas de visualización científica. Son muchas las técnicas de visualización científica existentes. Diversos enfoques se han empleado para agruparlas y clasificarlas. Un enfoque establecido para clasificar las técnicas es a través del tipo de dato sobre los que operan. Por el tipo de datos nos referimos al tipo al que pertenecen los atributos o variables. Según este criterio podemos encontrar las siguientes categorías [1, 2]: •. Técnicas de visualización para datos volumétricos.. •. Técnicas de visualización para fluidos.. •. Técnicas de visualización para datos multiparamétricos.. •. Técnicas de visualización de la información.. Existen diversos enfoques para especificar los datos[3]. Estos enfoques permiten definir una amplia variedad de característica de los datos como son la dimensionalidad, el nivel. 5.
(15) Capítulo 1. de medición y la estructura. En este trabajo utilizaremos un enfoque simple para definir los datos [1-3]. Los datos volumétricos representan una malla de tres dimensiones donde cada punto tiene asociado un valor. En general los datos se definen como un conjunto S de muestras, donde cada elemento s Є S es un vector de la forma (x, y, z, v) que contiene las coordenadas espaciales y un elemento que es un escalar [1-4]. Los campos vectoriales representan una malla de dimensión menor o igual que tres donde cada punto está relacionado con un vector. Una de las áreas de mayor uso de los campos vectoriales es para representar datos de fluidos [1, 4]. Los datos multiparamétricos son aquellos en que el número de variables relacionadas con cada observación es mayor o igual que dos. Estas variables pueden ser cuantitativas o cualitativas y a su vez ordinales o nominales [1, 3]. En algunas aplicaciones los datos presentan una estructura que no concuerda con ninguna de las anteriores o que sencillamente no puede ser definida con exactitud. A estos datos se le suele llamar información y entre las principales se identifican estructuras como árboles, grafos e hipertexto [1, 2, 5]. A continuación se relacionan las principales técnicas de visualización de acuerdo al tipo de dato con que operan. Este trabajo se centró en la implementación de técnicas de visualización para datos multiparamétricos. Es por ello que se hace mayor énfasis en este tipo de técnicas, las cuales son descritas detalladamente en el epígrafe 1.5. 1.2 Técnicas de visualización para volúmenes. La visualización de volúmenes permite la obtención de información a partir de datos espaciales. La estructura de los datos volumétricos quedó definida anteriormente pero en aplicaciones específicas pueden representarse mediante funciones, imágenes o sencillamente mediante observaciones individuales [1, 4].. 6.
(16) Capítulo 1.. Las técnicas de visualización de datos volumétricos pueden clasificarse como técnicas de representación de superficies o de representación directa de volúmenes [1], a continuación se analizan cada una de ellas con mayor detalle. Representación de superficies. En la representación de volúmenes a través de superficies, solo se muestra la parte exterior de los datos del volumen, de forma tal que las superficies creadas se colorean según el valor v. La técnica fundamental de extracción de superficies a partir de datos volumétricos, se conoce como contorneado, que en dos dimensiones se llama isolíneas y en tres isosuperficies [1, 2, 4]. En la figura 1-1 se observa la técnica de isosuperficie.. Figura 1-1: Isosuperficies.. Representación Directa de Volúmenes. La visualización de volúmenes de forma directa es capaz de mostrar mayor cantidad de información que las técnicas de superficie para datos volumétricos, pero esta efectividad es a costa de una mayor complejidad computacional. Existen dos técnicas básicas para el dibujado de volúmenes, estas son Raycasting y la Proyección de Elementos del Volumen [1, 2].. 7.
(17) Capítulo 1. 1.3 Técnicas de visualización para datos de fluidos. La utilización de estos algoritmos requiere que los atributos sean de naturaleza vectorial. Los vectores tienen la capacidad de representar datos como fuerza y velocidad. Estos conjuntos de datos generalmente resultan del estudio de fluidos[1, 2]. Un método sencillo para representar campos vectoriales es conocido con el nombre de erizo.[1] (cita) Este método consiste en dibujar una línea orientada para cada punto del conjunto de datos. Cada línea comenzará en el punto asociado al vector. El mayor inconveniente de esta técnica se hace palpable cuando el conjunto de datos crece, ya que en estas circunstancias se pierden los detalles. La técnica de Alteración (en Inglés Warping), ver en figura 1-2, se basa en que los campos vectoriales generalmente se asocian con acción. En este caso se procederá a deformar la geometría representada por los datos, la deformación estará basada en los vectores asociados. La imagen creada consistirá en la geometría sin deformar y la deformada, lo que permitirá observar a través de la comparación el efecto provocado por los vectores. En caso de que la magnitud de algunos vectores sea muy pequeña el efecto de los mismos no se notará por lo que la técnica perderá efectividad[1].. Figura 1-2: Warping. La geometría original puede verse de forma alambrada. El cuerpo sólido esta deformado por la acción del campo vectorial.. La visualización de fluidos es un caso particular de la visualización de atributos vectoriales. Este campo ha sido estudiado en profundidad y existen un buen número de técnicas que pueden usarse. Algunas de ellas son las flechas (en Inglés arrows) y las líneas de flujo (en Inglés StreamLines)[2]. 8.
(18) Capítulo 1.. La técnica de las líneas de flujo es usada para mostrar el movimiento de partículas producto de la acción de un campo vectorial. Los vectores son usados para construir una línea que representa el recorrido de una partícula en un espacio de tiempo[2]. Un ejemplo puede observarse en la figura 1-3.. Figura 1-3: StreamLines.. 1.4 Visualización de información. La visualización de la información contempla la presentación de datos jerárquicos, de textos y grafos. Estos datos suelen tener características estructurales especiales, que los diferencian de otros tipos y que pueden y deben ser utilizadas en el proceso de visualización[1, 2, 5, 6]. A continuación se relacionan algunas de las técnicas de visualización fundamentales en esta área. Visualización de datos jerárquicos. La jerarquía es una forma común de representar ciertos datos, en muchos casos ellos son intrínsicamente jerárquicos. La jerarquía describe la topología de los datos, no el tipo de las dimensiones[6, 7]. Los ejemplos de uso de esta clase de información son muy. 9.
(19) Capítulo 1. disímiles y uno clásico lo constituye la estructura de directorios de los sistemas de archivo. Prácticamente todos los objetos pueden ser descritos jerárquicamente. Para ello basta con observar que los objetos suelen estar formados por múltiples componentes que a su vez están formados por subcomponentes. Cada uno de estos componentes representa un elemento en la jerarquía y está descrito por diferentes rasgos. Otro de los ejemplos comunes de jerarquía es la relación que existe entre clases de la programación orientada a objetos. La representación tradicional o puede decirse universal, de los datos jerárquicos es el árbol[1, 7, 8]. Un árbol es una estructura jerárquica por naturaleza. La raíz del árbol representa la mayor jerarquía y cada rama representa un nuevo nivel de jerarquía. Este esquema permite que niveles de la misma jerarquía estén a la misma “distancia” de la raíz. Los árboles han sido utilizados tradicionalmente en diversas esferas que van desde la creación de genealogías hasta la representación del curso evolutivo. Otra variante muy popular de imagen que muestra jerarquías es la pirámide[6]. En la pirámide el triangulo superior representa la máxima jerarquía y el descenso de nivel significa descender en la jerarquía. La visualización de una jerarquía persigue fundamentalmente dos metas [2]: •. Mostrar las relaciones jerárquicas entre los objetos.. •. Mostrar los rasgos que describen los objetos.. La representación jerárquica en forma de árbol, es la base de varias técnicas de visualización que han sido desarrolladas. Entre las más importantes están [2, 6, 9]: •. Cone Tree.. •. Hiperbolic browser.. •. Tree View.. 10.
(20) Capítulo 1.. Figura 1-4: Cone Tree.. Una de las técnicas usadas es Cone Tree que se muestra en la figura 1-4. Algunas representaciones se han creado basándose en la proyección de una jerarquía en un espacio dado. El espacio a utilizar es por lo general 2D pero no está excluida la utilización de 1D o 3D. En este tipo de visualización el espacio es dividido en partes según los niveles de jerarquía. Como ejemplo tenemos las técnicas de TreeMap, un ejemplo puede verse en la figura 1-5.. Figura 1-5: TreeMap. Muestra el uso de un disco.. Visualización de Redes y Grafos. Gran cantidad de problemas se pueden representar como redes y por tanto pueden ser analizados usando este tipo de visualización. Entre las problemáticas que por su. 11.
(21) Capítulo 1. naturaleza se expresan como redes, se encuentran los mapas conceptuales y los problemas de tráfico. Las redes son en esencia nodos y enlaces entre nodos. Tanto los nodos como los enlaces pueden contener información variada[1]. La representación de redes puede utilizarse en áreas como la comprensión de estructuras y el flujo de tráfico, haciendo posible la identificación de nodos importantes y de enlaces claves[1]. La visualización de una red persigue en un amplio sentido los siguientes objetivos[1, 2]: •. Mostrar la estructura de la red y las conexiones entre nodos.. •. Mostrar características de los enlaces.. •. Mostrar datos de los nodos.. Es fácil encontrar una representación de una red pues el nombre de la estructura de datos sugiere la misma, pero esta representación puede mostrar deficiencias en muchas aplicaciones. El motivo es que al representar una red puede producirse desorden en la imagen. La probabilidad de surgimiento del desorden se incrementa con el crecimiento de la red. El origen del desorden es la gran cantidad de líneas que representan los enlaces y que suelen cruzar el grafo en todas direcciones. Otra de las deficiencias del método tradicional es que variaciones en la posición de los nodos pueden tener un fuerte impacto en la percepción de la representación[1, 8]. Con el objetivo de combatir estas deficiencias se crearon un número de técnicas de visualización de los grafos. La característica fundamental de estas es la obtención de una matriz como resultado de la visualización, dicha matriz representa el grafo. Este diseño minimiza el desorden pero en cambio impacta la percepción de la estructura y limita el tamaño de la red[1].. 12.
(22) Capítulo 1. Existen metodologías para minimizar el desorden que se basa en el filtrado de los datos. Al filtrar los datos se reduce el volumen tanto de nodos como de enlaces. Esta variante es aceptable cuando no es grande la pérdida de información o cuando el desorden es intratable por otras vías[7, 8]. 1.5 Técnicas de visualización para datos multiparamétricos. Existe una multitud de problemas en que cada punto de dato contiene más de un atributo, estos atributos pueden ser fechas, lugares, precios o valores descriptivos. Algunos de estos atributos son espaciales mientras que otros no. A este tipo de datos se les llama multiparamétricos y se encuentran generalmente en aplicaciones de minería de datos, estadística e inteligencia artificial[5]. Los datos multiparamétricos son un reto para los investigadores. No pueden ser visualizados con las técnicas tradicionales para 1D, 2D y 3D. Los datos de 1D y 2D pueden mostrarse directamente en un plano e incluso pueden representarse datos de 3D aplicando proyecciones a un plano, aunque con cierta pérdida de información. Los datos multiparamétricos en cambio requieren de una transformación en la cantidad de dimensiones que suele ignorar demasiado conocimiento, por ejemplo la proyección en el espacio de dos dimensiones. Sin embargo muchos de los conjuntos de datos no son susceptibles a ser proyectados, sencillamente porque ninguno de sus rasgos es espacial[10]. Los campos escalares y los campos vectoriales son casos especiales de datos multiparamétricos. Varias técnicas de visualización de datos multiparamétricos pueden utilizarse para visualizarlos pero los resultados son pobres en comparación con los obtenidos al usar técnicas de visualización de volúmenes o de fluidos. El objetivo fundamental de los métodos de visualización para datos multiparamétricos es lograr que las representaciones revelen correlaciones o patrones entre los atributos[2, 5, 11]. Con este fin existen actualmente una amplia gama de técnicas de visualización para. 13.
(23) Capítulo 1. las cuales se han creado además diversas mejoras. Las técnicas pueden ser clasificadas en geométricas, basadas en iconos, basadas en píxel y proyecciones[2, 5, 9]. 1.5.1 Técnicas geométricas. Las técnicas geométricas son aquellas que utilizan elementos como líneas, puntos o curvas como propiedades visuales para representar los datos [2, 5]. Existe gran número de ellas, pero hay dos que sobresalen por su generalidad y amplio uso. Estas son los diagramas de dispersión y las coordenadas paralelas. Diagramas de dispersión (en inglés ScatterPlot). El Diagrama de dispersión es una técnica simple muy utilizada. Su forma más sencilla se manifiesta cuando los datos tienen solo dos dimensiones. Con dos dimensiones la técnica consiste en trazar un eje de coordenadas y utilizar los valores de las dimensiones como punto (x,y) de R2 resultando un gráfico donde se observan dispersos los puntos de datos. Por otro lado, visualizar datos de más de dos dimensiones no es obvio, para lograrlo pueden utilizarse proyecciones, que provocan pérdida de información debido a la reducción de la dimensión[1, 2, 5]. Para datos multiparamétricos es muy frecuente utilizar matrices de diagramas de dispersión. Las matrices resultantes son cuadradas y el elemento (i,j) de la matriz es un diagrama de dispersión de la dimensión i y la j. El diseño evita la pérdida de información pero en cambio son engorrosos los análisis complejos. Una deficiencia adicional es que la diagonal principal de la matriz es subutilizada. Algunos trabajo actuales están encaminados a aprovechar mejor esta región de la representación[12]. Ver figura 1-6.. 14.
(24) Capítulo 1.. Figura 1-6: Matrice de diagramas de dispersión con la diagonal principal con histogramas.. Coordenadas Paralelas. La técnica de las coordenadas paralelas es un esquema simple de gran generalidad que permite visualizar conjuntos de datos multidimensionales. Esta técnica geométrica es una de las más utilizadas debido a su fácil implementación y los buenos resultados que se obtienen al aplicarla[5]. Obsérvese la figura 1-7. Esta técnica usa un sistema de coordenadas como base y consiste en crear un eje de coordenadas para cada atributo colocándolos paralelamente. El valor de cada dimensión en un determinado punto de datos es marcado en el eje correspondiente. La representación final para un objeto es una línea que recorre las posiciones marcadas en cada dimensión[2, 5].. Figura 1-7: Coordenadas paralelas. Este ejemplo muestra un conjunto de datos con tres atributos.. 15.
(25) Capítulo 1. La técnica anteriormente descrita es especialmente útil para mostrar patrones en los datos o para percibir relaciones entre los atributos, ya que el resultado es muy intuitivo[2]. El color de las líneas que representan los objetos puede ser elegido por varios criterios. El más simple es utilizar un color constante para todos los objetos. Un criterio que maximiza la calidad de la imagen es seleccionar una dimensión para que sea el color del objeto, de tal forma que puntos con diferentes valores en el atributo de color serán mostrados con diferentes tonos y los similares serán mostrados con tonos equivalentes[2, 5]. Existen limitaciones en el número de dimensiones que puede mostrar ya que al crecer no pueden presentarse todos los ejes en una simple imagen. Para enfrentar esta falta puede permitirse al usuario interactuar con la visualización para que filtre las dimensiones de tal forma que pueda enfocar su atención en las de mayor interés. La implementación de esta técnica suele trasformar los valores de una dimensión al intervalo real [0,1]. Esto se hace debido a que generalmente los máximos y mínimos de las diferentes dimensiones varían considerablemente[2, 5, 9]. Las coordenadas paralelas tienen fundamentalmente dos deficiencias. La primera se evidencia cuando el volumen de datos crece. Bajo estas condiciones la gran cantidad de líneas que se solapan tiende a formar una superficie de la que no puede extraerse ninguna conclusión. El principal problema del solapado es que dejan de ser visibles segmentos de las líneas con la consiguiente pérdida de información. Una solución es utilizar colores semitransparentes, con lo que se logra disminuir el número de líneas ocultas por superposición. Otra salida más radical es realizar un filtrado del conjunto de datos para disminuir el total de entradas[1, 2, 10]. La segunda y mayor deficiencia de la técnica tiene relación con los atributos nominales. Los rasgos nominales pueden ser representados en un eje. Para ello se crea una tabla donde se le asigna valores enteros igualmente espaciados a cada valor del dominio. Los valores numéricos asignados se utilizan en el algoritmo de visualización y se añaden los. 16.
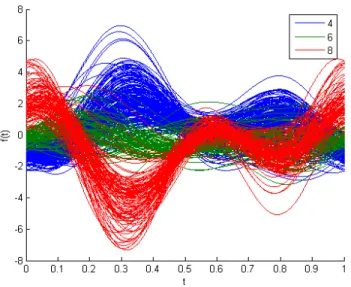
(26) Capítulo 1. verdaderos valores como etiquetas visuales, de forma que el usuario no se percate del subterfugio. El problema con los rasgos nominales es que tienden a formar en la imagen segmentos de líneas por los que pasan muchos puntos del conjunto de datos. Estos segmentos eliminan la posibilidad de percibir patrones y relaciones entre los atributos, pero además eliminan la posibilidad de mostrar información estadística básica como la frecuencia de aparición de un valor en un atributo. Una vía para aminorar esta dificultad es transformar el eje de un atributo nominal en un arreglo vertical de gráficos que muestran la frecuencia absoluta de los valores. Así, aunque no se logra obtener todo el conocimiento deseado, se incrementa la expresividad visual[2]. Gráfico de Andrews. Una idea similar para representar datos multiparamétricos es el gráfico de Andrews. En esta técnica cada observación es representada por una función f(t) que se evalúa en el intervalo [0,1]. Cada función es una serie de Fourier, cuyos coeficientes se igualan a los valores de las dimensiones para cada observación[13].. Figura 1-8: Gráfico de Andrews.. Esta técnica, puede verse en la figura 1-8, permite identificar con facilidad diferencias entre grupos de observación ya que por lo general observaciones pertenecientes a un. 17.
(27) Capítulo 1. mismo grupo presentan una forma de la función similar. Los análisis sobre variables individuales resultan en cambio mucho más engorrosos[13]. El principal parámetro que puede ajustarse es la forma de la función utilizada, que al variar puede incrementar o disminuir la expresividad de la imagen. Debe considerarse, ya que puede maximizar los resultados, el color que se utilizará para representar cada observación. Además pueden efectuarse transformaciones sobre los datos como la estandarización[13]. La virtud fundamental de la técnica es que puede representar conjuntos de datos de un tamaño relativamente grande y además con un número de dimensiones elevado. 1.5.2 Técnicas basadas en iconos. Estas técnicas no sufren de pérdida de información. Se logra evitar la perdida de información al realizar una proyección de las dimensiones a diferentes atributos de un icono[2, 9]. Al crear una imagen a partir de un conjunto de datos el resultado es un conjunto de figuras con diferentes características visuales. Las técnicas basadas en iconos tiene dos parámetros que la caracterizan: el primero es el tipo de figura que representará cada observación, o sea, la forma del icono; el segundo parámetro es la forma en que se definirá la posición de cada icono en la imagen[2, 14]. Existen diversas formas de seleccionar cada uno de estos parámetros, las soluciones puede combinarse entre si con el fin de conseguir mejores resultados. Entre los métodos para crear iconos están los rostros de Chernoff (Chernoff Face) y los campos de Estrellas (StarField). Además suelen crearse editores de iconos para aplicaciones específicas[2, 6, 9]. Por otro lado, la solución más popular para la colocación de los iconos en la imagen esta basada en el uso de proyecciones[14]. Esta familia de técnicas, que resulta tan útil en el análisis de datos multiparamétricos, falla ante determinadas condiciones. La primera deficiencia es que algunas características. 18.
(28) Capítulo 1. de un icono son más perceptibles que otras, por lo que los iconos mostrarán mejor algunas dimensiones selectas. Por otro lado existen limitaciones en el número de características que pueden presentar los iconos, lo que restringe el número de dimensiones. Estas dos deficiencias no son un gran inconveniente para aplicaciones de dominio específico, donde las dimensiones del conjunto de datos no cambian y donde los iconos son específicamente diseñados. En cambio para aplicaciones más generales donde pueden usarse diferentes conjuntos de datos no relacionados,. las deficiencias se. convierten en un problema considerable [15]. Una aproximación a la solución de estas deficiencias son los iconos procedurales. Este tipo de iconos produce una imagen de un punto de datos usando un algoritmo que recibe como entrada los atributos del punto. Estos algoritmos realizan el trabajo de relacionar cada dimensión de los datos con una característica visual de la figura. Este esquema permite variabilidad en el número de dimensiones y además usa características visuales similares para las diferentes dimensiones[2, 5]. Campo de estrellas (en inglés Starfield). La técnica de campo de estrellas utiliza un método procedural para representar cada icono y permite elegir entre varias opciones para colocar los mismos. Tiene el potencial para mostrar datos de múltiples dimensiones sin pérdida de información y es habitualmente usada por los especialistas[2, 6]. El campo de estrellas utiliza un algoritmo para componer los iconos, lo que le confiere cierta generalidad. En la forma básica el método utiliza dos dimensiones como coordenadas de posición en un eje imaginario. El resto de las dimensiones deben poder ser normalizadas al intervalo [0,1]. Estas coordenadas serán el punto de inicio en el dibujado del icono. Las dimensiones restantes se expresarán a partir de líneas que parten del punto inicial y cuya longitud estará determinada por el valor del atributo. Estas líneas o rayos que representan las diferentes dimensiones estarán dispuestos entre si con igual distancia angular lo que genera una figura de estrella. Frecuentemente los extremos de las líneas son conectados entre sí. Esta variación elimina la silueta de estrella y crea una. 19.
(29) Capítulo 1. figura cerrada que suele presentar más claramente las características del objeto[11]. En la figura 1-9 puede observarse un ejemplo.. Figura 1-9: StarField.. Todos los puntos del conjunto de datos pueden mostrarse con el mismo color pero resulta muy conveniente utilizar esta característica para codificar algún atributo de interés. Igualmente pueden usarse otros rasgos de la figura para codificar otras informaciones, por ejemplo: la calidad de los datos[16]. La técnica de Campo de estrellas también sufre de limitaciones a pesar de sus ventajas. Una de ellas es que no todos los atributos visuales se perciben con igual intensidad. Esta dificultad influye directamente en el número de dimensiones que pueden ser representadas. Además, al crecer el conjunto de rayos de un icono aumenta la complejidad del análisis puesto que los diferentes puntos de datos comienzan a lucir similares. La conclusión es que esta técnica solo debe usarse cuando el número de dimensiones es relativamente pequeño[11]. Una cuestión de particular importancia en la técnica es la estrategia de posicionamiento del icono. En el proceso de posicionamiento de los iconos pueden usarse los datos de ciertas dimensiones, que en el caso más simple utiliza dos dimensiones y en caso de un número mayor de dimensiones requiere el uso de proyecciones[14].. 20.
(30) Capítulo 1. Una problemática adicional surge con el incremento del conjunto de datos pues las estrategias de posicionamiento del icono usualmente producen desorden. Una solución a esto es el filtrado del conjunto de datos o alternativamente el agrupamiento de puntos de datos[15]. 1.5.3 Técnicas orientadas a píxel. Se ha mencionado que la visualización de un conjunto de datos de gran tamaño resulta un reto para técnicas geométricas y basadas en iconos. Al graficarlos suele surgir desorden que esta originado por el tamaño de la figura que representa una observación simple. A partir de esta idea resulta lógico concluir que minimizando el espacio que ocupa un solo punto de datos en la imagen se mejoraría la percepción visual[1, 6, 17]. Las técnicas basadas en píxel son las más eficientes cuando el número de dimensiones es grande y cuando crece el número de registros. Esto se debe a que utilizan un píxel para representar cada atributo de una observación. Los retos fundamentales en estos métodos son la elección del color para cada elemento y el modo de posicionamiento de los píxeles[5]. El procedimiento en las técnicas basadas en pixel consiste en relacionar cada valor de una dimensión a un color y agrupar los píxeles de cada dimensión en áreas adyacentes. Puesto que este método utiliza un píxel simple por cada valor de dato, la técnica permite mostrar hasta más de 1.000.000 de valores[5]. En este esquema el asunto principal es como colocar los píxeles en la imagen. Este tipo de técnicas utilizan diferentes modos de posicionamiento para lograr diferentes objetivos. Colocar los píxeles en la forma apropiada ofrece la posibilidad de observar información sobre correlaciones, dependencias y regiones trascendentales. Dos de los modos de posicionamiento de los píxeles son: los Patrones Recursivos y los Segmentos Circulares[1].. 21.
(31) Capítulo 1. La técnica de los patrones recursivos se basa en un posicionamiento recursivo general de atrás hacia delante de los píxeles. Está particularmente dirigida a representar conjunto de datos con un orden natural de acuerdo a un atributo, propiedad que la convierte en una opción para problemas de series de tiempo[2, 5]. Ver figura 1-10.. Figura 1-10: La técnica de patrones recursivos.. Los segmentos de círculo utilizan como imagen base un círculo que es dividido en segmentos iguales a partir del origen. Puede verse un ejemplo en la figura 1-11. Cada segmento corresponde a un atributo del conjunto de datos. Dentro de cada segmento el valor del atributo para cada registro de datos se representa con un píxel simple. La colocación de los píxeles comienza en el centro de la circunferencia y continúa hacia fuera dibujando sobre una línea ortogonal al segmento[1, 18].. Figura 1-11: Píxel compacto usando posicionamiento basado en segmentos de círculo.. 22.
(32) Capítulo 1. Debe observarse que los únicos atributos visuales de estas técnicas son la localización de los píxeles y la intensidad del color. De ello resulta que la elección del color sea un proceso de vital importancia, que requiere escalas de colores elegidas cuidadosamente para cada uno de los atributos[5, 18]. La deficiencia fundamental de esta clase de representación es la poca cantidad de atributos visuales, que convierte la tarea de codificar información adicional en un trabajo prácticamente imposible[5, 19]. 1.5.4 Proyecciones. La proyección de datos multidimensionales es una técnica utilizada para reducir el número de dimensiones de un conjunto de datos[20]. Un número menor de dimensiones permite realizar análisis con mayor facilidad y éxito sobre los datos. Los métodos de proyección de datos multidimensionales no pertenecen al área de la visualización científica. Entre las disciplinas que se han enfrentado a esta problemática se encuentran la estadística y la inteligencia artificial. Sin embargo, resulta natural utilizar estos procedimientos con el objetivo de visualizar un conjunto de datos. Esto se debe a que, si el número de dimensiones se reduce a tres o menos, las observaciones pueden ser visualizadas con técnicas tradicionales de 1D, 2D y 3D. De esta forma la representación visual muestra los resultados de los métodos de proyección[20]. Los métodos de proyección siempre producen pérdida de información. Sin embargo existen soluciones que permiten preservar gran parte de la información relevante. Entre estos métodos pueden mencionarse el Análisis de Componentes Principales, el Escalado Multidimensional y los Mapas Auto Organizados[20, 21]. Escalado Multidimensional. Este es un método de proyección no lineal. El escalado multidimensional trata de proyectar las observaciones de forma tal que se preserven las métricas interobservaciones. El problema fundamental de este algoritmo es que la proyección realizada. 23.
(33) Capítulo 1. es punto a punto por lo que no existe una función de proyección. Este inconveniente provoca que al adicionar una observación deba recalcularse la proyección para todas las observaciones[20]. El método utiliza una matriz D con las métricas Inter-observaciones donde la métrica puede ser de similaridad o disimilaridad. Además de esto es necesario conocer el número de dimensiones (m) deseadas en el espacio generado E[20]. El Escalado Multidimensional puede formularse como sigue: Dada una matriz D encontrar la proyección de las observaciones de forma que al construir una nueva matriz M, esta se asemeje a D. Donde Mi,j es el valor de una métrica (usualmente la distancia euclidiana) en el espacio E entre las observaciones i y j[20]. El punto clave es como comparar la diferencia entre estas matrices, M y D. Para ello se define una función que indica la diferencia entre las dos matrices. A esta se le llama función de Stress y el método de Escalado Multidimensional consiste en optimizarla[20]. Existe gran cantidad de trabajos dirigidos a decidir formas para la función de Stress, al igual que a definir los métodos de optimización a utilizar[20]. 1.6 Visualización como apoyo a los métodos automáticos de extracción de conocimiento. Los métodos de aprendizaje automático tratan de extraer conocimiento de un conjunto de datos. Los procesos de extracción de conocimiento pueden tener variados objetivos, entre ellos [22] •. Extracción de conocimientos para construir un modelo de clasificación.. •. Selección de rasgos significativos de un conjunto de datos.. •. Extracción de dependencias entre atributos.. •. Agrupamiento de observaciones del conjunto de datos.. 24.
(34) Capítulo 1. Para cada uno de estos objetivos los investigadores han desarrollado diversos métodos. Los procedimientos ideados tienen como base, esencialmente, la estadística y la inteligencia artificial. Los métodos de aprendizaje automático se dividen en dos categorías esenciales [22]: el aprendizaje supervisado y el aprendizaje no supervisado. Se han desarrollado técnicas para apoyar diferentes procesos de extracción de conocimiento, o sencillamente algunas se han adaptado para mostrar información. Entre estas técnicas destacan aquellas que permiten mostrar reglas, conglomerados y árboles de clasificación [1, 23]. Búsqueda de conglomerados. La búsqueda de conglomerados es el proceso de dividir el conjunto de datos en subconjuntos homogéneos[1, 24, 25]. Por subconjuntos homogéneos se entiende aquellos en los que todos sus elementos sean parecidos. Como puede observarse es necesario definir una función que indique cuando dos elementos del conjunto de datos son similares, que es igual a decir que la distancia entre ellos es pequeña. La búsqueda de conglomerados es un método de aprendizaje no supervisado [22]. Se han propuesto una gran variedad de métodos de búsqueda de conglomerados con buenos resultados, incluyendo el algoritmo EM y el K-Means [1, 24, 25]. La mayor parte de los algoritmos requiere de algunos parámetros que influyen en el resultado del proceso. Los parámetros incluyen en algunos métodos hasta el número de conglomerados a formar. Este es un proceso en el que no se conoce a priori el resultado y como para diferentes parámetros el resultado será diferente, no puede identificarse fácilmente la mejor solución. La visualización de los resultados de una búsqueda de conglomerados puede usarse para verificar el resultado del proceso y repetir el mismo si es necesario. Permite además comparar el impacto de aplicar a un conjunto de datos, diferentes algoritmos. También brinda la posibilidad de observar con facilidad la asignación de las observaciones a los conglomerados[24, 26].. 25.
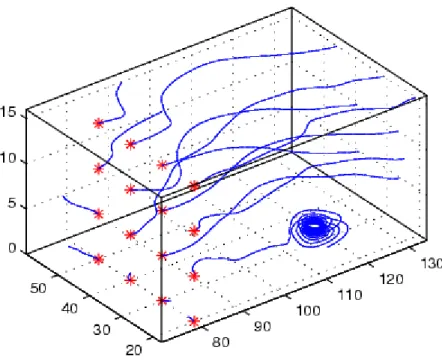
(35) Capítulo 1.. Cuando las observaciones pertenecen al espacio 2D y 3D es fácil mostrar el resultado de la asignación de conglomerado, basta con representar cada observación mediante un punto y establecer un mapa de colores para los conglomerados encontrados de manera que cada observación sea mostrada con el color de su conglomerado. En espacios con mayor número de dimensiones la representación requiere de mayor esfuerzo. Un procedimiento que se utiliza en estos casos es realizar una proyección de las observaciones hacia 2D o 3D tratando de mantener la información del proceso en el espacio multidimensional. La información más importante que debe mantenerse durante la proyección es la distancia entre los elementos de cada conglomerado[1, 24]. Esta variante funciona bien para datos con un número mediano de dimensiones, pero se torna impracticable cuando crece la cantidad de dimensiones y el tamaño del conjunto de datos. Sistemas como el OPTICS y HD-EYE implementan técnicas que pueden enfrentar el desafío, de datos con gran cantidad de dimensiones[1]. Un algoritmo de visualización basado en partículas. El algoritmo realiza una representación 3D del resultado de la búsqueda de conglomerados donde cada observación es una partícula afectada por la fuerza de gravitación. Se coloca el centro de cada conglomerado en un lugar del espacio 3D de forma tal que los conglomerados similares estén en posiciones cercanas y los diferentes se encuentren alejados. Cada una de las partículas (observaciones) es colocada alrededor de los centros de conglomerado de acuerdo al grado de atracción que ejercen los centros sobre la partícula. La fuerza gravitatoria esta dada por el grado de membresía de la observación al conglomerado[24, 26]. El algoritmo utiliza como entrada una matriz de distancia entre conglomerados Ckxk y una matriz de membresía de cada observación a cada conglomerado Pkxn donde k es el número de conglomerados y n el número de observaciones. En la matriz C cada miembro c(i,j) denota la distancia entre el centroide del conglomerado i y el centroide del conglomerado j. En la matriz P cada elemento p(i,j) denota la probabilidad de que el. 26.
(36) Capítulo 1. observación j sea miembro del conglomerado i [24]. La matriz de distancia C puede estar formada por Kullback-Leibler (del algoritmo EM) o por las distancias Euclidianas (del algoritmo K-Means)[26]. La matriz de membresía puede calcularse en prácticamente todo algoritmo de búsqueda de conglomerados, pero siempre debe cumplir que Sumatoriai(p(i,j)) = 1 [24, 26]. El procedimiento primero calcula la posición de los centroides utilizando la matriz de distancia C. Si el conjunto de datos es multidimensional se realiza una proyección que preserva la información de distancia entre los conglomerados. Se procede entonces a colocar cada observación alrededor del centroide más cercano de acuerdo al grado de membresía, a una distancia del centroide definida por:. r = f ( p) = c *. 3 *π * 3 1 − p 4. donde c es una constante utilizada para escalar la imagen. La posición final de la partícula en la esfera se obtiene por el grado de membresía. del registro a los demás. conglomerados[24, 26].. Figura 1-12: Visualización de conglomerados de un conjunto de datos con el algoritmo K-Means. (K = 3). Este método de visualización, puede verse un ejemplo en la figura 1-12, permite realizar comparación entre resultados con diferentes parámetros y entre la búsqueda de conglomerados realizada por distintos algoritmos[26].. 27.
(37) Capítulo 1. 1.7 Descripción general de WEKA (Waikato Environment for Knowledge Analysis) Weka es una herramienta de aprendizaje automatizado, fue Ian Witten, profesor del Departamento. de Ciencias de la Computación de la Universidad de Waikato, Nueva. Zelanda (1992) quien la creó. Desde este momento se le comenzaron a hacer mejoras y se le agregaron nuevas facilidades apareciendo así diferentes versiones. Weka superó los límites del lugar de creación y hoy día en varios lugares del mundo diferentes personas se esfuerzan en la ampliación y perfeccionamiento de esta herramienta. La herramienta Weka. es un ambiente de trabajo para la prueba y validación de. algoritmos de la IA. Tiene implementada una colección de algoritmos conocidos, varias maneras para preprocesar los archivos de datos a utilizar por dichos algoritmos; así como facilidades para validar los mismos. Posee interfaces graficas de usuario (GUI: Graphical User Interface) y cuenta con herramientas para realizar tareas de regresión, clasificación, agrupamiento, asociación y visualización[27]. Entre los métodos de aprendizaje automático que contiene se encuentran los de clasificación, búsqueda de conglomerados y selección de rasgos. Además, brinda gran potencialidad para la transformación de los datos a través de numerosos filtros. Técnicas de Visualización implementadas en Weka El sistema Weka contiene pocas técnicas de visualización científica. Para la exploración de datos solo tiene implementada histogramas y las matrices de diagramas de dispersión. La otra técnica que contiene es la visualización de conglomerados basada en árboles. Además de esto permite mostrar algunos diagramas de dispersión en técnicas de clasificación y búsqueda de conglomerados. Esto hace de Weka una herramienta realmente pobre en el área de las visualizaciones, donde brinda muy pocas opciones a los usuarios. De esta forma se hace prácticamente imposible realizar una verdadera exploración de los datos, constituyendo una real limitante para los usuarios de este sistema. Sin embargo, hemos visto en el desarrollo del. 28.
(38) Capítulo 1. capítulo la forma en que algunas técnicas sencillas, tales como las coordenadas paralelas o los segmentos de círculo, pueden mejorar la exploración y análisis de los datos. 1.8 Conclusiones parciales. Después de esta revisión podemos concluir que: •. Las técnicas de visualización pueden ser clasificadas entre otras formas por el tipo de dato que utilizan. Este criterio es particularmente útil al desarrollar aplicaciones específicas ya que permite seleccionar las técnicas a emplear.. •. Las diversas técnicas de visualización para datos multiparamétricos suelen ser útiles para diferentes conjuntos de datos. Por ello es conveniente utilizar varias simultáneamente.. •. Weka presenta serias deficiencias en el área de la visualización científica. Existe un número considerable de técnicas que pueden incluírsele para aumentar su potencial.. 29.
(39) Capitulo 2. Diseño e Implementación.. Capítulo 2. Diseño e Implementación de la extensión. En este capítulo se pretenden definir las técnicas que se incluirán en el módulo de visualización para el sistema Weka, así como realizar el proceso de diseño del nuevo módulo definiendo las características específicas que se utilizarán en la implementación. Además se presenta una metodología para la realización de futuras extensiones al módulo de visualización. 2.1 Análisis del problema. Selección de las técnicas a incluir en la extensión. El proceso de desarrollo de técnicas de visualización para algún sistema tiene como punto de partida natural el tipo de datos que utiliza el sistema. Esto es producto del modelo de clasificación de las técnicas que se describió anteriormente. La correcta descripción de los datos usados por Weka permite identificar las técnicas que pueden aportar más al software. Descripción de los datos. Weka utiliza una fuente de datos multiparamétricos que consiste en un conjunto C de cardinalidad m en que cada elemento Oi=<V1,…Vn>, i=1…m es una n-upla. A cada elemento de C se le conoce como instancia u observación y cada componente de una observación es una dimensión o variable [2, 3]. En estos datos, cada variable puede tener nivel de medición continua o nominal. Adicionalmente se ha podido constatar que los conjuntos de datos suelen tener un número relativamente mediano de dimensiones y el número de observación en los datos varía considerablemente. Elección de las técnicas. Después de estudiar los objetivos del proyecto, así como las funcionalidades actuales del sistema Weka se decidió desarrollar dos paquetes: el primero tendrá como objetivo la visualización de datos multiparamétricos y el segundo será usado para visualizar resultados de búsquedas de conglomerados.. 30.
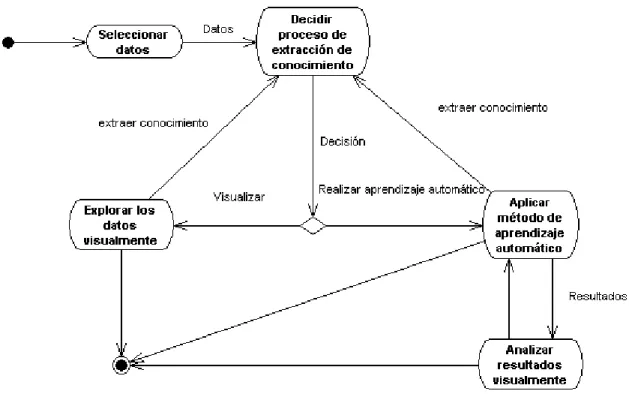
(40) Capitulo 2. Diseño e Implementación.. Las técnicas que se decidieron incluir en el módulo de visualización de datos multiparamétricos son: •. Coordenadas Paralelas.. •. Gráfico de Andrews.. •. Iconos basados en Campo de Estrellas (StarField).. •. Segmentos de Círculo.. •. Proyección basada en Escalado Multidimensional.. En la visualización de conglomerados se decidió incluir la técnica de Partículas Afectadas por Gravedad. Las técnicas seleccionadas ofrecen un amplio número de beneficios y generalidad ya que se incluyen las más tradicionales que permiten mostrar conjuntos de datos con disímiles características en cuanto a la cantidad de observación, dimensiones y el tipo de las mismas. 2.2 Diseño de la extensión realizada al sistema Weka. Para el desarrollo y extensión de cualquier sistema computacional se tiene como necesidad inicial lograr un diseño apropiado del problema a tratar. Con este objetivo debemos hacer un adecuado modelado del negocio, identificando los actores y caso de uso que intervienen en el mismo. Para ello se tendrá en cuenta el diseño ya establecido del sistema que se está extendiendo y las características de los módulos que se pretenden añadir. Se analizarán las clases que surgen en la solución del problema así como otras con las cuales se interactúa y que ya estaban presentes. Logrando de esta forma una mejor comprensión del problema y de la solución que se propone. Se efectuó un análisis detallado de las facilidades que el sistema Weka brindaba al usuario, específicamente en cuanto a las visualizaciones científicas, determinándose así los procesos claves por los que transita cualquier tipo de visualización. Se confeccionó un diagrama de actividad en el que se visualiza el flujo de dichos procesos.. 31.
(41) Capitulo 2. Diseño e Implementación.. Figura 2-1: Diagrama de actividad. Análisis de actores y casos de uso Teniendo en cuenta que se va ha realizar una extensión a un sistema ya implementado podemos pasar directamente al análisis de los casos de uso y los actores del sistema. A partir del planteamiento del problema podemos extraer al único actor que tiene el sistema al cual llamaremos especialista y es el encargado de interactuar con el mismo con múltiples objetivos. A su vez los casos de uso del sistema son muchos por los que analizaremos los que surgen como consecuencia de la inclusión de los nuevos módulos. El diagrama que analizaremos a continuación ilustra lo anterior.. 32.
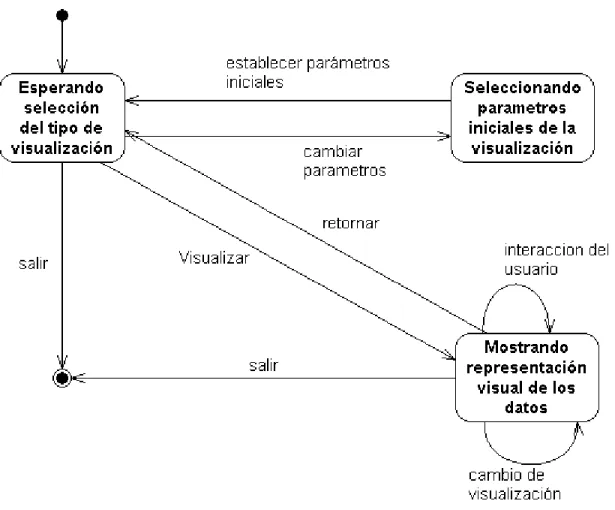
(42) Capitulo 2. Diseño e Implementación.. Figura 2-2: Actores y casos de uso.. Como casos de uso principales se consideraron: la exploración de un conjunto de datos y la visualización del resultado de un algoritmo previamente obtenido. Como instancias del primer caso de uso tenemos la exploración usando coordenadas paralelas, MDS, exploración basada en íconos, en segmentos de círculo y análisis con gráfico de Andrews. La instancia del segundo caso de uso es específicamente la visualización del resultado de una determinada búsqueda de conglomerados mediante el uso de partículas. Diagrama de estado En el proceso de obtención de una visualización exploratoria de los datos el sistema pasa por una serie de estados los cuales se muestran en el siguiente diagrama. Consideramos. 33.
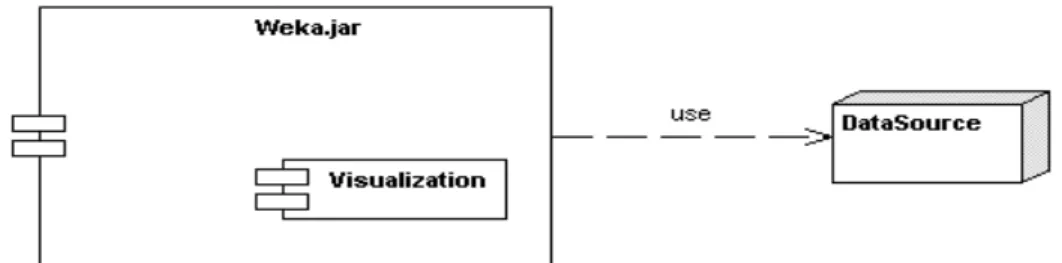
(43) Capitulo 2. Diseño e Implementación. un estado inicial en el que ya se captaron los datos y el usuario está listo para elegir una visualización.. Figura 2-3: Diagrama de transición de estado para el proceso de exploración visual de datos.. Componentes del sistema El sistema cuenta con dos componentes principales: una fuente de datos y un paquete Weka que contiene todas las implementaciones de este sistema. Dentro de este último paquete podemos identificar como un tercer componente el módulo de visualización Visualization donde se encuentran los nuevos algoritmos implementados. Podemos considerarlo una componente más, ya que su implementación no lo hace dependiente del sistema Weka. Ver Figura 2.4.. 34.
(44) Capitulo 2. Diseño e Implementación.. Figura 2-4: Diagrama de componentes del sistema. Diagrama de clases El módulo de visualización está dividido en dos paquetes: el de visualización de conglomerados y el de visualización de datos multiparamétricos. A continuación se muestran las clases que conforman el paquete de visualización de datos multiparamétricos (figura 2-5).. Figura 2-5: Diagrama de clases del paquete de visualización de datos multiparamétricos. 35.
(45) Capitulo 2. Diseño e Implementación. El próximo diagrama (figura 2-6) muestra las clases que están presentes en el paquete de visualización de resultados de búsqueda de conglomerados.. Figura 2-6: Diagrama de clases. El. diagrama. muestra. dos. paquetes.. Las. clases. ParticleVisualization. y. ParticleVisualizationPanel son utilizadas por el paquete weka a través de la interfaz de usuario. Como esas relaciones no son de particular interés para el proyecto no se muestran en el diagrama. Para lograr la integración del Weka con el nuevo paquete de visualización de datos multiparamétricos se procede a la creación de un paquete que cumpla con esta responsabilidad. El diagrama de clases que aparece a continuación describe dicho paquete.. Figura 2-7: Diagrama de clases del paquete de enlace. 36.
(46) Capitulo 2. Diseño e Implementación. El siguiente diagrama de clases muestra las relaciones entre los diferentes paneles de configuración para las técnicas (figura 2-8).. Figura 2-8: Diagrama de clases de configuración.. Los dos diagramas de clases que aparecen en figura 2-9 y 2-10 muestran las relaciones entre las clases del paquete de visualización de datos multiparamétricos y Weka.. Figura 2-9: Diagrama de clases que muestra las relaciones entre clases de dos paquetes.. 37.
(47) Capitulo 2. Diseño e Implementación.. Figura. 2-10:. Diagrama. de. clases. de. interacción. del. paquete. weka.VisualizationEx. y. weka.VisualizationEx.config. Para una mejor comprensión de los diagramas de clases presentados, ver el anexo 2. Diagramas de Colaboración. Uno de los objetivos es que el paquete de visualización de datos multiparamétricos sea independiente de Weka y que además sea fácilmente extensible. El siguiente diagrama de colaboración muestra como debe usarse la jerarquía de clases para conseguir estos objetivos (figura 2-11).. 38.
(48) Capitulo 2. Diseño e Implementación.. Figura 2-11: Diagrama de colaboración de las clases del paquete de Visualización de datos Multiparamétricos y del paquete de Integración con Weka.. Como puede observarse en este diagrama se utilizan las clases abstractas ExploratoryVisualization y MultiParametricVisualizationPanel. El diagrama muestra la integración entre el paquete de visualización el paquete de integración que se basa en la utilización. de. subclases. de. ExploratoryVisualization. y. MultiParametricVisualizationPanel. El diagrama de colaboración que aparece en la figura 2-12 muestra como se realiza la comunicación entre las clases de visualización de resultados de búsqueda de conglomerados y el paquete de búsqueda de conglomerados de Weka. En esta versión solo se utiliza el método de búsqueda de conglomerados SimplekMeans.. 39.
(49) Capitulo 2. Diseño e Implementación.. Figura 2-12: Diagrama de Colaboración de clases del paquete de visualización de conglomerados con Weka.. 2.3 Consideraciones acerca de las técnicas implementadas. Las técnicas seleccionadas presentan una estructura general, la cual contiene parámetros que pueden variar de una implementación a otra. A continuación se establecen las consideraciones realizadas en cada método para esta versión en particular. 2.3.1 Implementación de la técnica de visualización basada en Iconos. La técnica de visualización basada en iconos se diseñó maximizando la flexibilidad. La implementación permite cambiar dos parámetros fundamentales que son el modo de colocar los iconos en la imagen y el tipo de icono a utilizar. De esta forma tenemos en realidad la base para construir una familia de métodos de visualización basados en iconos. Esta técnica, que está implementada en la clase IconPanel, utiliza para permitir el cambio del modo de posicionamiento de iconos un parámetro que es un objeto de una subclase de. 40.
(50) Capitulo 2. Diseño e Implementación. LocatingMethod. Para modificar el tipo de icono se utiliza un parámetro de una instancia de IconShape. En el proyecto se implementaron dos métodos de colocación de iconos. El primero se implementó en la clase LocateByOrder y coloca los iconos en filas consecutivas según el orden de aparición en la fuente de datos. El segundo método está implementado en la clase LocateWithMDS y coloca los iconos proyectándolos hacia dos dimensiones utilizando el método de escalado multidimensional. Se incluyó en el proyecto un solo tipo de icono que está implementado en la clase StarShape. Este es un tipo de icono procedural que se basa en la técnica StarField. 2.3.2 Implementación de la técnica Gráfico de Andrews. Como se analizó en el capítulo anterior, la técnica utiliza una función para representar cada observación. La implementación realizada utiliza una serie de Fourier de la forma: D. f i (t ) = X i ,1 + ∑ ( X i , 2 n ∗ sin(2n *π * t ) + X i , 2 n+1 ∗ cos(2n *π * t )) n=1. Esta función es evaluada para cada instancia i con t Є [0,1]. X es una matriz que contiene los datos sobre las observaciones. Cada fila de la matriz corresponde a una observación y cada columna es una variable o dimensión de la observación. El valor D que se utiliza en la sumatoria se obtiene a partir de la expresión d/2 - 1, donde d es el número de dimensiones que poseen las instancias. Un aspecto a destacar es que aquellas observaciones con valores perdidos son desestimadas por la implementación. Por lo tanto la técnica no es recomendable para conjuntos de datos con gran cantidad de datos perdidos. En la implementación cada función que representa una observación es aproximada a través de segmentos de líneas. El número de segmentos de líneas puede influir en la calidad de la imagen resultante por lo que se ha incluido un número alto de los mismos.. 41.
Figure


+7
![figura cerrada que suele presentar más claramente las características del objeto[11]. En la figura 1-9 puede observarse un ejemplo](https://thumb-us.123doks.com/thumbv2/123dok_es/7364091.461909/29.918.137.451.202.441/figura-cerrada-presentar-claramente-características-objeto-observarse-ejemplo.webp)


Documento similar
Estas instrucciones de seguridad se aplican para el módulo de visualización y configuración PLICS- COM según la certificación de examen de tipo CE TÜV 15 ATEX 161127 U (Número
La primera parte de cualquier trabajo de visualización de datos es la recogida y el análisis es por ello que en este módulo se trabajará la búsqueda de fuentes, los
Se busca analizar las funciones de MongoDB por medio del diseño de un clúster para el almacenamiento de datos distribuidos para la visualización de datos y
Simplificar los datos, darle forma visual (no textual). Software para tratamiento, análisis y visualización de datos.. Herramientas de visualización. Importar datos
Programa de Doctorado Comunicación Facultad de Humanidades y Ciencias de la Comunicación Curso 2011-2012.. Módulo Metodología de Investigación Científica
Se selecciona Visual Paradigm como herramienta para el modelado del módulo visualización de objetos geológicos del proyecto Minería, porque posibilita la
El contar con una semántica rigurosa para el modelo de datos de la visualización, las transformaciones, estados intermedios y las diferentes técnicas aplicables también
11 Secretaría de Investigaciones | FADU | UBA VISUALIZACIÓN DE MACRO DATOS: HERRAMIENTAS DE EXPLORACIÓN Y COMUNICACIÓN GROISMAN, Martín; GUTMAN, Margarita
