En esta parte hemos clasificado estas licitaciones como licitaciones con varias unidades logísticas y normalmente se resuelven creando una licitación combinatoria. En este artículo presentamos un ejemplo de licitación de servicios de Internet para escuelas públicas de la ciudad de Buenos Aires, capital de Argentina.
Diseño de la licitación
Licitación basada en unidades territoriales
Luego, las empresas podrían ofertar por combinaciones de distritos escolares, asignando el modelo matemático la división de ciudades que sería más rentable para el estado. Por lo tanto, se descartó esta oportunidad y continuamos analizando el rango donde cada una de las empresas que debían participar en la licitación ya tenían la tecnología instalada.
Una licitación multi-unidades logística
Este último punto no fue finalmente aprobado, pues el gobierno de la ciudad consideró que no era inconveniente asignar todas las escuelas a una misma empresa, si con ello se obtenía el mejor precio para el estado. Es la propia empresa la que define su margen de acción a través de la elección de los centros educativos.

Formulación matemática de la licitación
Formulación exponencial
Las restricciones (1) dictan que cada escuela debe asignarse exactamente a una empresa, y las restricciones (2) exigen que cada empresa debe recibir exactamente un subconjunto de las escuelas por las que presentó su oferta. Este modelo explica explícitamente la naturaleza combinatoria de la licitación, dado que cada empresa recibirá en última instancia un subconjunto de las escuelas por las que licita y cobrará un precio unitario por escuela que depende del número de escuelas adjudicadas.
Formulación polinomial
Por otro lado, este modelo exhibe un alto nivel de simetrías: si para un subconjunto T ⊆ E de escuelas varias empresas han hecho ofertas y T se divide en más de una empresa, entonces cualquier partición de T que preserve el número de escuelas asignadas Será cada empresa una alternativa de solución con la misma función objetivo. Las restricciones (8) obligan a que sit sea al menos el número total de escuelas asignadas a la empresa, siempre que yit = 1 (es decir, siempre que la empresa deba utilizar la banda tarifaria t).
Búsqueda de óptimos múltiples
Es interesante mencionar que las variables z pueden definirse como reales no negativas (es decir, zit ∈ R≥0 para i ∈ C y t ∈ T), ya que en la solución óptima serán números enteros debido a las restricciones. del modelo. Además de consistir en un mayor número de variables y restricciones, esta formulación tendría serios problemas de simetría, y esta última característica afectaría negativamente el procedimiento considerado en la siguiente sección.
Ofertas y resultados
Cabe señalar que en la zona sur de la ciudad había 248 colegios donde solo licitaba la empresa A. Es importante señalar que ni la empresa ni el gobierno de la ciudad sabían antes de las licitaciones que esta empresa sería la única en presentarse. . en la zona sur de la ciudad.

Conclusiones
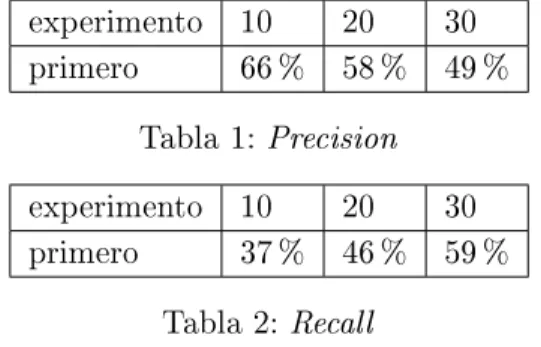
Este porcentaje es relativamente bajo y da una idea de que el diseño de la licitación generó una alta competencia entre las empresas participantes. Este valor se puede calcular ejecutando el modelo del Apartado 3.2 con diferentes valores para la última parte tarifaria de la empresa A (realizamos una búsqueda binaria en el rango de valores posibles para dicho precio, hasta obtener el valor límite deseado ).
Introducción
En la segunda sección de este artículo se presenta el estado del arte en cuanto a técnicas de recuperación de información, modelado de temas en documentos y finalmente algoritmos de minería de opiniones. Para concluir, la quinta sección de este artículo presenta las conclusiones relevantes al trabajo realizado y posibles ramas de investigación futuras.
Trabajo relacionado
Sintaxis: En [12] la relación entre palabras se utiliza como característica en algoritmos de aprendizaje supervisado. Recuento de palabras: las puntuaciones de polaridad de los documentos se obtienen en función de la proporción de palabras que tienen una polaridad dominante.
Detección de Tendencias en la Web
En los últimos años se han adoptado diversos enfoques para detectar tendencias en la Web. A continuación, se dará a conocer la metodología para extraer opiniones de documentos publicados por usuarios de redes sociales y finalmente la metodología utilizada para combinar ambos conjuntos de información para identificar tendencias web.

Aplicación del experimento y análisis de resulta- dos
Por otro lado, al analizar los datos periódicamente, no es posible alertar tempranamente sobre eventos que ocurren diariamente. El modelo es aplicable a los servicios de alimentación en general, pero este desarrollo fue motivado por los requerimientos específicos de un hospital de la provincia de Buenos Aires, Argentina.
Denición del problema
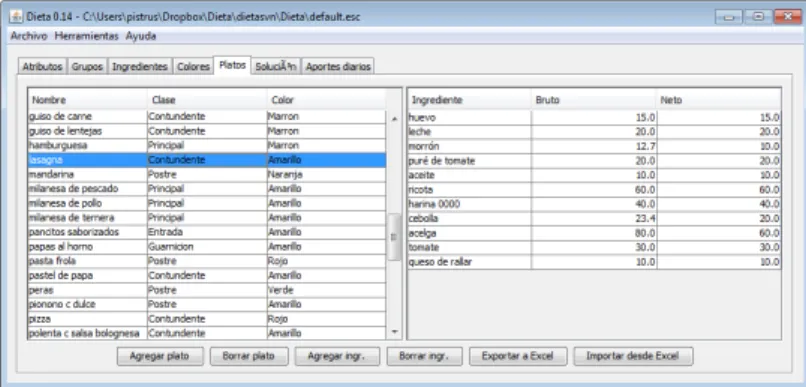
El presente trabajo está organizado de la siguiente manera: la Sección 2 define el problema, los tipos de platos que componen cada snack y una descripción general de las restricciones a incluir en el modelo. Sin embargo, desde el punto de vista de la etnogastronomía, este último conjunto de condiciones da una perspectiva localista al consumo de proteínas de origen animal.
Desarrollo del modelo
En el almuerzo debe haber un plato con no menos de 100 gramos de carne de ave, cordero, ternera o cerdo (excluido el pescado), y en la cena no más de un plato con 40 o más gramos de carne (incluido el pescado cuando sea posible). ). Como máximo un plato de pasta, polenta o arroz (igual o superior a 20 gramos de harina) por merienda.

Resultados
Los impresionantes resultados llevaron a los planificadores de menús de los hospitales a solicitar nuevas funciones de la solución, que se analizan a continuación. Esto se aplicó a una empresa de telecomunicaciones real; donde los resultados fueron utilizados para generar estrategias de retención de clientes y con ello evaluar la calidad de los resultados obtenidos.
Revisión de literatura
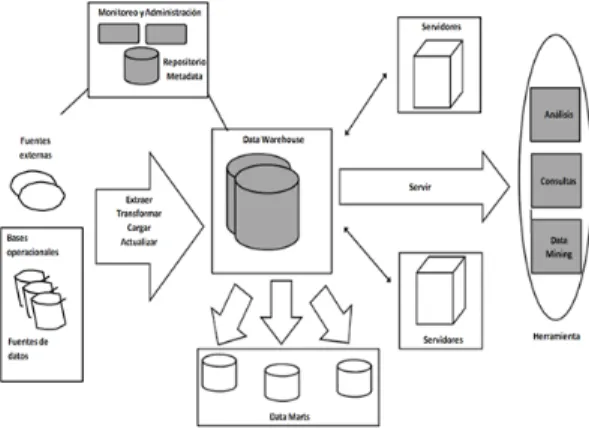
El método del promedio consiste en atribuir los valores desviados en función del promedio de la variable. Otra peculiaridad de este algoritmo es que no requiere información sobre la distribución del conjunto de datos.
Metodología del proceso
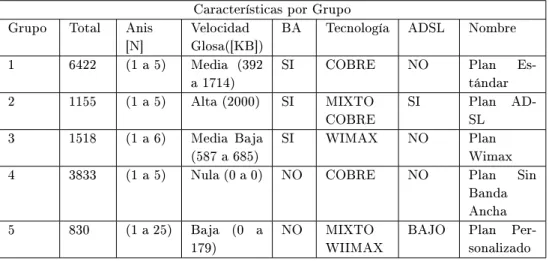
Requisitos Técnicos (RT): Base de datos destinada a generar informes de requisitos desde una perspectiva técnica. BGNN: Esta base de datos únicamente contiene el detalle de los clientes del producto NGN y sus planes correspondientes para cada cliente (con la vigencia respectiva referida a un contrato que puede contener múltiples planes).

Aplicación experimental del proceso
Cabe señalar que la predicción se midió marginalmente para ver la robustez de los modelos de minería de datos en el corto plazo (un mes). Mientras que la segunda muestra se realizó en el experimento final con muestreo estratificado por grupos.
Recomendaciones
Además, sirve como integrador entre bases de datos cuyas relaciones son de 1 a n (por ejemplo, un cliente, muchas suscripciones). Verificar si existe una (base de datos) con los datos del contrato en cada empresa, si existe, validar la veracidad de los campos que contiene, así como su temporalidad, si es explícito sobre una fecha de cambio (válida), se propone utilizar esta base de datos como principal.
Conclusiones
Great DT se inspiró en Fantacalcio [10], un juego de fantasía italiano dedicado a su juego de fútbol Serie A. Según Albini, se inspiró para crear Fantacalcio en el juego de fantasía de la Major League Baseball de EE. UU. [14].
Descripción del juego
La sección 3 presenta dos modelos descriptivos, modelos de programación lineal entera, que encuentran el equipo ideal a lo largo del torneo si pudiera prepararse para cada fecha conociendo los resultados de todo el campeonato. La Sección 4 presenta el modelo prescrito, que incluye un modelo de programación lineal entera que intenta maximizar el puntaje del equipo después de que se hayan estimado los puntajes de cada jugador en cada fecha.
Modelos descriptivos
Equipo jo sólo con titulares: formulación matemáti- ca
Este modelo busca los 11 jugadores habituales que maximizan la puntuación total y cumplen con las restricciones del juego. El resto de las restricciones pueden agregar cierta complejidad a la solución, especialmente las restricciones (4) y (5), que imponen un conjunto de jugadores por posición, pero en general el modelo es una versión algo complicada del problema de la mochila.
Equipo Perfecto: formulación matemática
Las restricciones (10) y (11) especifican los límites del presupuesto total y el número máximo de jugadores por equipo, respectivamente. Las restricciones y (16) relacionan las variables xey con las variables z de modo que zjk = 1 si y sólo si el jugador j se une al equipo (como titular o sustituto) en la fecha.
Resultados
Además, las restricciones (9) requieren exactamente un sustituto por posición, lo que supone, por tanto, los cuatro sustitutos del equipo en total. A su vez, las restricciones (12) y (13) establecen límites superior e inferior al número de jugadores en cada posición dentro del campo de juego.

Modelo prescriptivo
El equipo inicial
Para cada jugador j ∈ J, introducimos una variable binaria xj que tiene el valor xj = 1 si y sólo si el jugador j es titular en el equipo inicial, y una variable binaria yj que tiene el valor yj = 1 si y sólo cuyo jugador j Es suplente en el equipo titular. Las restricciones (20) piden que cada jugador sea titular o suplente, o no en el equipo, mientras que las restricciones (21)-(26) establecen las condiciones que debe cumplir el equipo dadas las reglas del juego.
Cambios y transferencias
La función objetivo busca maximizar el índice global del equipo ponderando a los suplentes en un 10%. El modelo es similar al presentado en la sección anterior y busca maximizar el índice del nuevo equipo (nuevamente ponderando los reemplazos en un 10%) y respetando las limitaciones impuestas por el juego.
Resultados
Una posible explicación de por qué el modelo suele tener un mejor desempeño en el segundo torneo del año que en el primero es la existencia de la Copa Libertadores en el primer semestre de cada año. Esto significa que los mejores jugadores a veces juegan cansados en el torneo local o no juegan en absoluto.

Conclusiones y trabajo futuro
El modelo prescriptivo utiliza datos históricos y características de la próxima fecha jugada para construir un equipo competitivo para el juego. Si tomamos como un único torneo los 6 campeonatos en los que participó el modelo en el juego, nuestro jugador virtual se posiciona en el 2% mejor de la competición.







