33 Figura 5: Código de programación utilizando el marco Scrapy para recuperar información sobre vacantes de empleo de sitios web. 40 Figura 7: Código de programación NLTK para limpieza de datos en currículums y ofertas de empleo. Cómo estructurar un modelo de minería de datos utilizando técnicas de minería de texto para recomendar ofertas de trabajo a partir de currículums y ofertas de trabajo de sitios web.
Cómo aplicar técnicas de minería de textos en el procesamiento de currículums y ofertas de trabajo de sitios web para construir un modelo de minería de datos para recomendar ofertas de trabajo. Proponer un modelo de minería de datos basado en currículums y ofertas de trabajo de sitios web para recomendar ofertas de trabajo. Aplique técnicas de minería de textos para procesar CV y ofertas de trabajo de sitios web para crear un modelo de minería de datos para recomendar ofertas de trabajo.
Sí, es posible construir un modelo de minería de datos utilizando técnicas de minería de datos para recomendar ofertas de trabajo a partir de currículums y ofertas de trabajo de sitios web. La aplicabilidad de técnicas de minería de textos para procesar currículums y ofertas de empleo de sitios web es eficiente para construir un modelo de minería de datos para la recomendación de empleo. Y por otro lado, el modelo de datos de recomendación laboral se considera como variable dependiente.

Segundo documento
Descripción del Currículum: Considerado como el primer documento, consta de información que describe ampliamente tu visión, misión, objetivos, etc. La información revelada por el candidato sobre sí mismo como se muestra en la figura no. 11.
Tercer documento
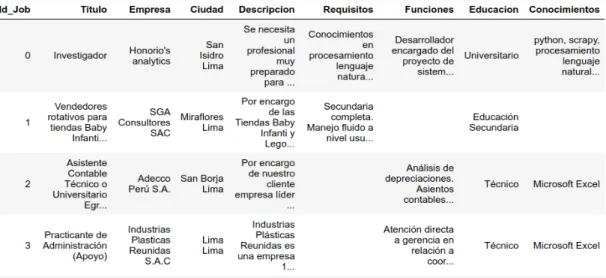
La información de la oferta de trabajo se divide en cinco documentos, los cuales se consideran como: Título, como primer documento, descripción, como segundo documento, requisitos, como tercer documento, funciones como cuarto documento y conocimientos como quinto documento de la oferta de trabajo. ofertas de empleo, como se puede observar en el cuadro nº 6.
Primer documento
Descripción de la oferta de trabajo: Cuando existe un contenido de términos que describen el contexto de la oferta de trabajo, dicha información es homogénea con la información de descripción de los CV, donde también describe generalmente el contexto del candidato. Requisitos de la oferta de trabajo: Donde exista un contenido de términos que describan las especificaciones y requisitos mínimos que deben cumplir los candidatos, que sea homogéneo con la información que se encuentra en el apartado de experiencia y habilidades de los candidatos en su CV.
Cuarto documento
Luego, teniendo en cuenta la homogeneidad de la información contenida en los documentos CV de los candidatos y las ofertas de empleo, se calcula el valor tf-idf de cada uno de los términos. Considerando la distribución de la información encontrada en los documentos en el punto anterior, a continuación se explica el desarrollo de la técnica de frecuencia de términos – frecuencia inversa de documentos, para encontrar el valor de relevancia de cada uno de los términos CV en relación con todo el corpus de datos de cada uno. vacante. El algoritmo consta de una serie de vectores que contienen listas de términos de CV y ofertas de empleo como datos de entrada, que se distinguen por una clave primaria; es decir, los cinco documentos de oferta de trabajo distribuidos en.
V1: es el vector principal de ofertas de trabajo, cuyos elementos son un conjunto de ofertas de trabajo (JOB1, JOB2...JOBN), y los subvectores tienen como elementos las condiciones de cada uno de los documentos de oferta de trabajo fusionados en uno solo. lista (T1, T2…TN). Y este último trámite se repite tres veces, las condiciones de las hojas de vida ya están distribuidas en tres documentos. Las listas de términos del CV son las que nos permiten encontrar el valor numérico real de relevancia en relación con todas las ofertas de trabajo.
El primer grupo de términos corresponde a los términos reunidos en una lista única de los cinco documentos de oferta de trabajo. El segundo grupo de listas corresponde a listas de términos de los tres documentos CV separados. El cual se detalla en la Tabla No. 9, donde se muestra el proceso de procesamiento de los términos para obtener los valores: término frecuencia (tf), frecuencia inversa del documento (idf) y finalmente el término frecuencia valor – frecuencia inversa del documento (tfidf) para cada uno de los documentos del CV.
Finalmente, muestra inmediatamente el valor del Promedio General, que es el promedio general de los promedios tf-idf de sus respectivos documentos. El mayor problema a la hora de recomendar empleo es disponer de información que evalúe las hojas de vida y esté escrita en lenguaje humano. En el proceso anterior se obtuvieron promedios tf-idf para cada documento de las hojas de vida. En resumen, se extrae el dato promedio del tfidf en detalle por documentos (tabla no. 10) y otro en general (tabla no. 11), que para este trabajo se considera una revisión de las hojas de vida relacionadas con las vacantes. que puede utilizarse como valor de evaluación al recomendar vacantes.
El modelo permite una visualización mucho más detallada de los datos, como en las imágenes no. 24 y 25 en el primero se ve la diferencia en los valores de relevancia de los currículums según las 10 primeras ofertas de trabajo. Calificación global: Es el valor de relevancia de los currículums en relación a las ofertas de trabajo. El uso de técnicas de minería de textos y procesamiento de lenguaje natural para construir un modelo de minería de datos para recomendar ofertas de trabajo a partir de datos de currículums no estructurados y ofertas de trabajo de sitios web es muy útil para la recuperación de información, el procesamiento de textos escritos en lenguaje humano, la extracción de información relevante y su análisis.
Frecuencia de términos: se ha demostrado que la frecuencia inversa de documentos (tf-idf) es eficaz para identificar la información más importante de un corpus de datos de currículums y ofertas de trabajo basados en términos escritos palabra por palabra y en lenguaje humano, finalmente promedios generales. -idf se proponen como puntaje crediticio de currículums para recomendar ofertas de trabajo.

1 Extracción de datos de los currículums vitae
2 Recuperación de información de las ofertas laborales
Exportación de datos de las Ofertas Laborales
El siguiente código le permite exportar los datos extraídos del formato HTML al formato CSV para su uso posterior en el procesamiento del lenguaje natural.
1 Procesamiento Lenguaje Natural
- Importación de librerias NLTK
- Funciones de limpieza de datos con NLTK
- Importación de datos de los currículums vitae Se importa datos de currículums vitaes
- Lectura de documentos
- Limpieza de datos de los currículums vitae
- Importación de los Ofertas laborales
- Lectura de documentos de ofertas laborales
- limpieza de datos de las ofertas laborales
- Concatenación de documentos de currículums vitae
- Calculando valor de relevancia de cada CV respecto a cada Oferta laboral con TFIDF
- Ejecución de función anterior TFIDFCV
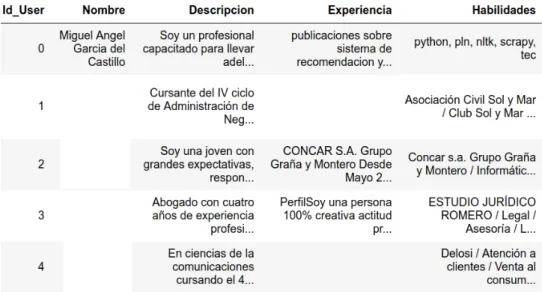
Descripción, experiencia y habilidades son los campos que se importan para el procesamiento de la información. Estos campos contienen una serie de términos escritos y referenciados en forma de texto. Cada campo de datos se importa en tres listas diferentes por candidato, es decir, cada uno de los términos se lee como elementos en tres listas por candidato (descripción, experiencia y habilidades). CV_Descripcion = CV_Data.Descripcion.str.split(' ') CV_Experience = CV_Data.Experiencia.str.split(' ') CV_Skills = CV_Data.Skills.str.split('.
Cada una de las listas generadas en el punto anterior (descripción, experiencia y habilidades) pasa por las funciones de limpieza de datos de NLTK sin excepción. A continuación, primero se leen las listas de términos por separado y luego se ejecuta la función leanWords, a la cual se vinculan las listas de términos a la variable Words, se vincula la clave primaria del usuario a la variable usuario y finalmente una variable vectorial vacía Clean_Words se envía que devuelve los términos limpios. En este punto se importan datos de los campos: Título, Descripción, Requisitos, Funciones y Conocimientos, los cuales se denominarán: documento A, documento B, documento C, documento D y documento E, respectivamente.
Job_Description = Job_Data.Descripcion.str.split(' ') Job_Requisitos = Job_Data.Requisitos.str.split(' ') Job_Funciones = Job_Data.Funciones.str.split('. Toda la información de la oferta de trabajo convertida en cinco listas diferentes se pasa por La programación de la función CleanWOrds para la limpieza de datos con NLTK. Todo lo demás es igual que el proceso de limpieza de datos CV.
Luego, todos los documentos por vacante se fusionan en una lista, con el objetivo de reducir el tiempo de procesamiento y la redundancia de datos en las listas. El siguiente código proviene del algoritmo TF-IDF, que nos permite calcular la relevancia de los términos de un CV con respecto a las ofertas de trabajo. Está diseñado y programado según el caso, permitiéndonos tener valores promedio tf-idf en detalle para cada documento CV (Descripción, Experiencia y Habilidades) y otro documento general, este último se exporta como el valor de calificación de un CV relacionado con las vacantes. Incluso puede solicitar una lista de términos relevantes para cada uno de estos documentos.
CV_Description_list,CV_Experience_list,CV_Abilities_list: estas son listas de requisitos de ingreso al currículum. OfferList: Esta es la variable en la que devuelve listas de términos if-idf y sus valores sugeridos.
2 Extracción de datos
1 Importación de datos
Luego extraemos una muestra de los 10 primeros CV y las 10 primeras ofertas de trabajo para una visualización clara de los resultados y el análisis.
2 Visualización de datos
La relevancia de los primeros 10 CV y vacantes se puede mostrar gráficamente.
1 Preparación de datos para recomendación de ofertas laborales
En el siguiente punto se muestran los datos importados de las ofertas de empleo, los datos son originales y con los campos de información pertinentes. Luego, se agregan los datos sobre las ofertas de trabajo (dfjob) y la calificación de importancia de los términos de cada CV (df_scores) con respecto a todas las ofertas de trabajo. Estos se asocian a través de sus claves primarias, el Job_Id de las ofertas de trabajo. y "Job_Id" de la evaluación del CV.