Los sistemas de reconocimiento de voz pueden reducir los costos del call center2. En este proyecto se realizó un prototipo basado en técnicas de reconocimiento de voz para la consulta de una base de datos de Access seleccionada.
PLANTEAMIENTO DEL PROBLEMA Y JUSTIFICACIÓN
ANTECEDENTES
PROYECTOS DE RECONOCIMIENTO DE VOZ
SISTEMAS DE RECONOCIMIENTO DE VOZ
Es un sistema pionero en procesos rápidos de reconocimiento de voz continua y vocabularios de hasta 10.000 palabras. Hay algunos modelos de texto específicos con los que el sistema funciona mejor, pero debe comunicarse con la empresa para ver la disponibilidad. El uso de macros significa que se puede programar un comando vocal para que coincida con una frase completa, por ejemplo, que al pronunciar
ESTADO DEL ARTE
- MÓDULO DE ANÁLISIS FONÉTICO 5
- MÓDULO DE ANÁLISIS MORFOLÓGICO
- MÓDULO DE ANÁLISIS SINTÁCTICO
- MÓDULO DE ANÁLISIS SEMÁNTICO
- AREAS DE APLICACIÓN
El control por voz de una central telefónica o del panel de control de un avión son ejemplos de estas aplicaciones. Las aplicaciones típicas son el control por voz de un ordenador o incluso el control por voz de una máquina herramienta.
MARCO TEORICO
El objetivo del reconocimiento de voz orientado a palabras es comparar dos expresiones vocales aisladas para determinar si corresponden a la misma palabra o no. El oído está orientado a la percepción de la información espectral del sonido más que a su forma de onda. Aunque este enfoque tendría más potencial que la comparación directa de formas de onda, tampoco funciona en la práctica, ya que algunas modificaciones simples del espectro, como un cambio en la frecuencia fundamental, no cambian la identidad de la palabra hablada, pero sí drásticamente. afectan la comparabilidad.
Un examen de los fenómenos acústicos y fonéticos implicados en la emisión vocal nos lleva a la conclusión de que lo realmente característico de la identidad fonética de los sonidos emitidos es la forma en que se distribuyen las resonancias del tracto vocal, es decir, sus formantes. y si el tipo de excitación es tonal (cuasiperiódica) o no tonal (ruido de banda ancha). La comparación de los vectores cepstrales de dos cuadros simultáneos correspondientes a sonidos perceptivamente idénticos (por ejemplo, dos instancias del fonema /a/) se puede realizar mediante la distancia cepstral, es decir, la distancia euclidiana entre los vectores cepstrales.
EL HABLA Y EL LENGUAJE NATURAL
Hablar libremente con un ordenador no es ni muy probable ni necesariamente lo más deseable en un futuro próximo. Hablar con la computadora también puede resultar muy eficaz cuando se combina con otras formas de interacción, como señalar y gesticular. Del mismo modo, otros tipos de audio, no dedicados a la voz, como una alarma, juegan un papel importante en la interacción de los ordenadores, por ejemplo en el control de los procesos fabriles.
A veces, el reconocimiento y la comprensión no son necesariamente necesarios, como en el caso de los contestadores automáticos o un calendario de voz. Un punto importante de este artículo es que la voz no es el único medio de comunicación necesario para interactuar con las máquinas, los gestos juegan un papel importante en este caso, pero ninguno de estos dos elementos debe separarse, juntos es cuando alcanzan su mayor eficiencia.
EL RECONOCIMIENTO DE VOZ O RECONOCIMIENTO DEL HABLA [Web-09]
Después de seleccionar y organizar los sonidos representativos del habla en grupos (ejemplo: /aba, /ata, /apa, /.), se presentan a algoritmos paramétricos y, mediante aprendizaje supervisado, se reconocen las características espectrales de estos sonidos. Se representa internamente en las estructuras internas contenidas en cada modelo [BER00]. Cuanto mayor sea el nivel de características fonéticas proporcionadas, más fácil será reconocer los sonidos representados por ellas [BER00].
LA CONVERSIÓN TEXTO-VOZ
EL RECONOCIMIENTO DE LOCUTORES
LA CODIFICACIÓN DE VOZ
TÉCNICAS DE RECONOCIMIENTO DE PATRONES
Los sistemas de reconocimiento basados en DTW funcionan de la siguiente manera: en primer lugar se parametriza la señal de voz a reconocer; Para ello, se divide en pequeñas ventanas de análisis (de unos 20 mseg), y en cada una de estas ventanas se realiza un proceso de análisis para extraer un conjunto de parámetros (que pueden ser coeficientes acústicos o espectrales). El tipo de funciones estadísticas que se utilizarán para modelar la probabilidad de observar puntos de muestra de cada estado también se establece antes de ingresar a la fase de entrenamiento del modelo. La forma en que las neuronas están conectadas entre sí determina la topología de la red, y podemos decir que el tipo de problemas que una red neuronal en particular resuelve efectivamente depende de la topología de la red, el tipo de neuronas que la conectan. la forma específica en la que se entrena la red.
El algoritmo de entrenamiento particular dependerá de la estructura interna de las neuronas, pero en cualquier caso el entrenamiento se realizará a partir de una base de datos etiquetada, como ocurría con los modelos de Markov, y será un proceso iterativo en el que se modifican los parámetros de la red. Se modifica de manera que dado un conjunto dado de estímulos (preposiciones) se produce una respuesta particular: la palabra verbal representada por esas preposiciones. En la fase de entrenamiento, dada una entrada conocida (por ejemplo, un conjunto de vectores que representan el dígito 1), la salida de la red se compara con la salida esperada (y conocida de antemano) y se calcula el error.
MODELADO DEPENDIENTE DEL ESTILO DE HABLA
La razón por la que estos sistemas avanzados de reconocimiento se denominan sistemas basados en el conocimiento se debe al uso de otras fuentes, otras disciplinas y otros conocimientos para llegar a una comprensión de la expresión. En última instancia, se trata de que una máquina obtenga el conocimiento de un humano y lo utilice para comprender un mensaje. [Web-13].
DEPENDENCIA DEL LOCUTOR
DEPENDENCIA DEL VOCABULARIO
GRAMÁTICAS DE RECONOCIMIENTO
DISCURSO GRABADO
Tradicionalmente, una variación del vocabulario significaba iniciar un proceso largo y costoso de recopilar una nueva base de datos y volver a entrenar los patrones del sistema. Otra idea es tener ambos estilos juntos, notas habladas y escritas. El problema que encontramos es cómo buscar dentro de una nota de voz; en el texto es fácil localizar visualmente un punto deseado. Recientemente se han creado medios que identifican una palabra dentro de una grabación, pero esto tiene sus limitaciones, como que sólo puede ser recuperada por la misma voz que realizó la grabación.
DISEÑO METODOLOGICO
- RECOLECCION Y REFINAMIENTO DE REQUISITOS
- ANALISIS DE LOS REQUISITOS DEL PROTOTIPO
- DISEÑO RAPIDO DEL PROTOTIPO
- ELABORACION DEL CODIGO
- REFINAMIENTO DEL PROTOTIPO
Una vez finalizada la primera titulación se intentará resolver todas las dudas relacionadas con los temas investigados y, paralelamente, el estudio de las técnicas y métodos utilizados para realizar aplicaciones basadas en la tecnología de reconocimiento de voz. En esta etapa del ciclo de vida, el proceso de recopilación y análisis de requisitos se vuelve fundamental para proceder a definir la funcionalidad del prototipo. El diseño de la etapa anterior debe traducirse a una forma comprensible para la máquina, por ello necesitaremos un lenguaje de programación Java o Visual Basic.
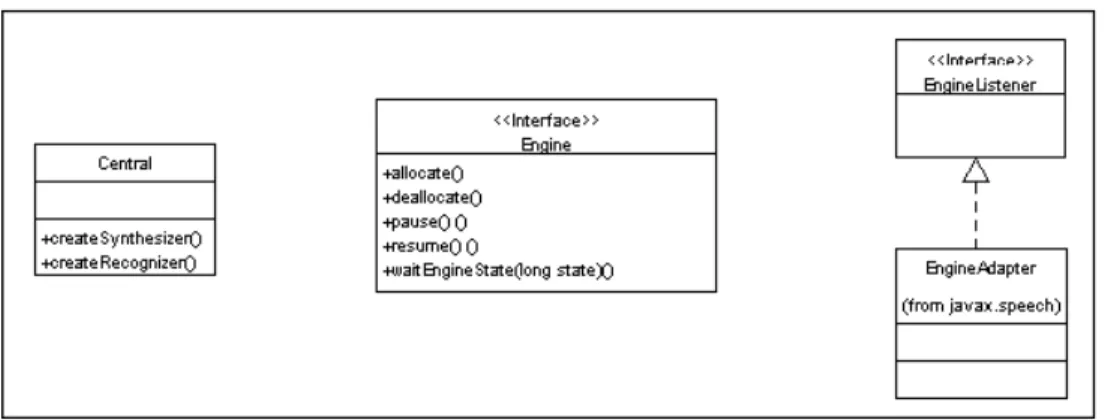
Capacidad para gestionar la voz a través de Java Speech o Microsoft SAPI 5.0. Para el prototipo, se realizarán pruebas en un motor de base de datos específico: (Oracle o Access).
RESULTADOS OBTENIDOS
RESULTADOS EN EL MARCO CONCEPTUAL
Pero este programa de reconocimiento de voz es uno de los más fáciles y prácticos para crear un perfil de voz del usuario. Cuenta con las herramientas e información para el desarrollo de aplicaciones de reconocimiento y síntesis de voz y también se desarrolla el prototipo sobre estas herramientas. IspRecoContext: Esta interfaz habilita el motor de voz para el desarrollo de aplicaciones basadas en reconocimiento de voz.
IspEventSource: Esta interfaz se activa para preparar la aplicación para posibles eventos una vez que se inicia el reconocimiento de voz. La interfaz SpSharedRecoContext es la piedra angular para la creación de aplicaciones basadas en reconocimiento de voz [MIC00].

RESULTADOS EN EL DESARROLLO DE LA APLICACIÓN
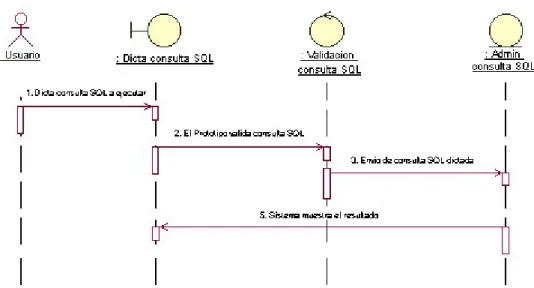
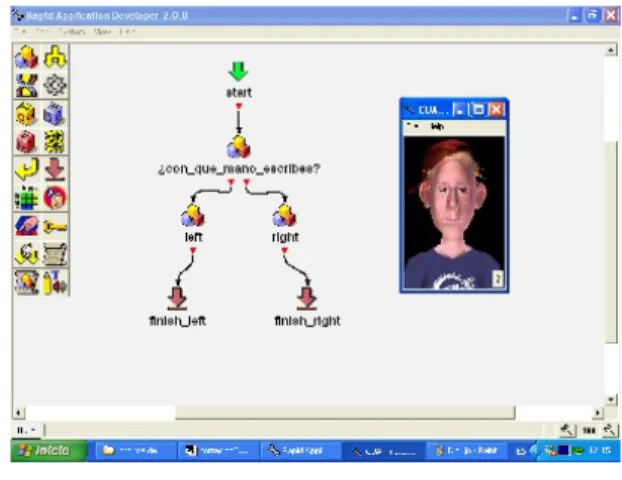
Validación de consultas SQL: Luego de que el usuario ejecuta la consulta SQL con su voz, el prototipo valida la estructura para asegurar su correcto funcionamiento. 2 Parar: reproduce un mensaje de despedida y finaliza el diálogo: esta parte es fundamental para finalizar la aplicación, escribiendo lo que dirá la máquina al final del proceso. Dependiendo de la respuesta del usuario, la interfaz gráfica repite lo dicho (izquierda, derecha).
En esta aplicación, todo lo que tienes que hacer es dictar la estructura de la consulta y ejecutarla para ver los resultados. Segunda aplicación: En esta aplicación intentamos solucionar las deficiencias de la primera aplicación para finalizar el prototipo.

PERSPECTIVA FUTURA DEL RECONOCIMIENTO DE VOZ
El oído es capaz de distinguir entre dos personas que hablan y sintonizar sólo con una de ellas, mientras que la máquina tiene muchos problemas para hacerlo. El oído también es capaz de distinguir el habla del ruido mucho mejor que la máquina. Estos avances se han producido más por el enorme desarrollo de procesadores y memorias que han multiplicado exponencialmente su capacidad de procesamiento y almacenamiento de información sin aumentar significativamente los costes, que por el descubrimiento de nuevos modelos de procesamiento del lenguaje humano.
Es cierto que un método matemático ha ayudado enormemente a mejorar los sistemas de reconocimiento de voz. En el futuro se espera una evolución muy rápida en temas que permitan que los sistemas de reconocimiento de voz se acerquen, e incluso superen, a los humanos en determinadas tareas específicas.
CONCLUSIONES
- GENERALES
- DOCUMENTACIÓN
- HERRAMIENTAS DE RECONOCIMIENTO DE VOZ
- LENGUAJES DE PROGRAMACIÓN
A nivel local, las oportunidades para encontrar desarrolladores de aplicaciones de voz son prácticamente nulas, creando un mercado sin explotar que podría destacarse para futuros ingenieros de sistemas. Debido a que esta tecnología apenas está comenzando a impactar a la sociedad, la creación de aplicaciones de voz se complica por la falta de información explícita sobre la estructura de programación. Java Speech API es un muy buen motor de voz para desarrolladores de aplicaciones en el lenguaje de programación Java, pero es difícil obtener las clases y el soporte técnico necesarios para comenzar a programar aplicaciones basadas en este motor.
SAPI 5.0 de Microsoft es un motor de voz muy potente que brinda todo el soporte necesario para crear aplicaciones de voz, pero una de las mayores desventajas es que no existe un fonema para el idioma español. Aunque programar en Java es interesante desde el punto de vista económico, todavía existen carencias a la hora de crear aplicaciones de voz.
SUGERENCIAS
BIBLIOGRAFÍA
Villarrubia Grande, Módulo de Análisis Pragmático, agosto de 2003, http://2ww.tid.es/presencia/publicaciones/comsid/esp/articulos/vol23/habla/habla.html. Siles Sánchez, Tipos de Aplicaciones, Agosto 2003, http://www.tid.es/presencia/publicaciones/comsid/esp/articulos/vol23/habla/habla.html. Web08] Lenguaje, habla y audición, septiembre de 2003, http://www.angelfire.com/games2/back/Interfaces_Paper.htm].