ESCUELA SUPERIOR DE INGENIERÍA MECÁNICA Y ELÉCTRICA UNIDAD ZACATENCO
Ingeniería en Comunicaciones y Electrónica Academia de Acústica
“
RECONOCEDOR AUTOMÁTICO DE COMANDOS POR
MEDIO DEL HABLA PARA LAS FUNCIONES DE UN
AUTOMÓVIL
”
TESIS
QUE PARA OBTENER EL TÍTULO DE
INGENIERO EN COMUNICACIONES Y ELECTRÓNICA
PRESENTAN
ALFONSO JORGE BONNET FUENTES
JOSÉ ALFONSO GUTIÉRREZ OSORIO
HÉCTOR ALONSO HERNÁNDEZ BENÍTEZ
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil II
Resumen
La presente tesis muestra el diseño y desarrollo de un programa de reconocimiento
de voz orientado a la implementación de un sistema de control de funciones
dentro de un automóvil. Cabe destacar que el alcance de esta tesis abarcara sólo el
desarrollo del software y no su implementación, por lo que este trabajo puede ser
consultado para futuras referencias.
El método utilizado para la obtención de datos de las señales de voz se le conoce
como Codificación por Predicción Lineal (LPC – por las siglas en inglés Linear Prediction Coding), el cual junto con la implementación de ventanas obtiene información característica de una señal de voz haciendo más sencilla y rápida la
comparación entre la señal ingresada y la base de datos. Dicha base está conformada por seis comandos ( “A”, “Afuera”, “Usuario”, “Llamada”, “Cajuela “ y “Luces”), cada uno grabado veinte veces, formando así un total de ciento veinte archivos en formato “.wav”, audio monofónico, una tasa de 16 bits y una frecuencia de muestreo de 22050 Hz. Todos los archivos fueron normalizados y
segmentados.
Se utilizó la plataforma de MATLAB (Matrix Laboratory) y la herramienta “GUIDE” (Graphical User Interface Development Enviroment – incluida dentro de MATLAB), para crear una interfaz gráfica capaz de reconocer los diferentes comandos dichos
por el usuario, y a su vez, este pueda visualizar la forma de onda, los LPC y la
transformada rápida de Fourier (FFT por sus siglas en inglés Fast Fourier Transform), además de darle la oportunidad de trabajar con la señal de voz.
El software obtiene los LPC de la señal del usuario y los compara con los de la
base de datos por medio del error cuadrático medio, y así, se determina qué
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil III
Agradecimientos
Quiero dedicar y agradecer esta tesis a mis padres Crispina y Alfonso por
brindarme todo su apoyo y cariño para lograr esta meta que sin su ayuda hubiera
sido muy difícil cumplirla, ustedes me dieron las herramientas necesarias para
enfrentarme a la vida, los amo, a mi hermana Adriana por su ayuda y por ser un
modelo a seguir, la amo, a todos mis amigos por animarme en los tiempos más
difíciles y estresantes, a mis profesores de toda la carrera por sus conocimientos y
dedicación, a mis asesores porque sin su orientación este trabajo no hubiera sido
posible y finalmente a mis amigos y compañeros Héctor y José Alfonso por
compartir este trabajo y llevarlo hasta el final, ¡sí se pudo!, les deseo éxito en todo
lo que hagan.
Bonnet Fuentes Alfonso Jorge
Agradezco el apoyo y asesoría que nos brindaron los profesores Mario de la
academia de física, Patricia de la academia de acústica, para el desarrollo de este
proyecto, así como la dedicación y esfuerzo de mis compañeros y amigos Héctor
Alonso y Alfonso Jorge en la realización de tal, por las desmañadas y desveladas,
por nunca rendirse y les agradezco por todas las cosas que aprendí y que por
ustedes seguiré aprendiendo. A los compañeros de clases por la motivación que
nos brindaron. Finalmente a mi familia, por el apoyo incondicional para cualquier
cosa a lo largo no solo del desarrollo de este proyecto, si no a lo largo de toda la
carrera.
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil IV A mi hermosa familia, que en todo momento estuvo ahí para apoyarme y
sustentarme cuando más lo necesitaba, en especial a mis padres, que fueron el pilar
y el motor de todo lo que he realizado como estudiante. A mis compañeros, a los
que siempre supieron hacerme sonreír aún cuando las adversidades estuvieron
presentes, a los que con humildad me brindaron de su conocimiento, a los que tuve
que confrontarme pues de ellos aprendí a escuchar nuevas ideas, a ser más
tolerante y a crecer como persona, y a todos aquellos que en gran o pequeña
medida dejaron una huella en mi vida. A mis profesores, que me ofrecieron la
herramienta del conocimiento para con ellas construir mi futuro, pero sobre todo, a
aquellos que más que conocimiento me compartieron de sus experiencias y
vivencias.
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil V
Índice de contenido
Introducción
XIIObjetivo
XIIIHipótesis
XIIIJustificación
XIV
Capítulo 1: Antecedentes históricos
1Capítulo 2: Marco teórico
52.1.- Teoría de la producción del habla 5
2.1.1.- Producción anatómica del habla 5
2.1.2.- La fonética 7
2.1.2.1.- Clasificación por su modo de excitación 7
2.1.3.- Fonemas 7
2.2.- Modelo acústico del habla 9
2.2.1.- La producción del habla 9
2.2.2.- Filtrado del tracto vocal 10
2.2.3.- Radiación en los labios 12
2.3.- Modelo digital de la producción del habla 13
2.3.1.- Excitación 13
2.3.2.- Filtrado 15
2.3.3.- Radiación 16
2.3.4.- Modelo completo 17
2.4.- Análisis en el dominio del tiempo 17
2.4.1.- Transducción, muestreo y cuantización del habla 18
2.4.2.- Análisis en tiempo corto 19
2.4.2.1.- Energía 21
2.4.2.2.- Función de autocorrelación 22
2.5.- Análisis de Fourier en tiempo corto 24
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil VI
2.6.- Análisis predictivo lineal 26
2.6.1.- Análisis de la señal del habla 27
2.6.2.- Método de autocorrelación 28
2.6.3.- Algoritmo de Levinson-Durbin 29
2.7.- Sistema de verificación de usuario 30
Capítulo 3: Desarrollo del proyecto
323.1.- Interfaz grafica de usuario (GUI) 33
3.1.1.- Partes de la GUI 36
3.1.1.1.- Texto estático (static text) 37
3.1.1.2.- Botón (push button) 38
3.1.1.3.- Texto editable (edit text) 39
3.1.1.4.- Ejes (axes) 40
3.1.1.5.- Panel (panel) 41
3.1.2.- Funcionamiento de una GUI 42
3.1.3.- Interfaz del reconocedor de voz 42
3.2.- Base de datos 43
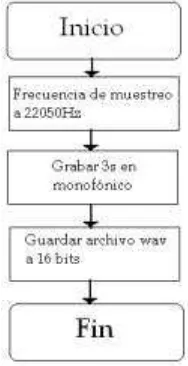
3.2.1.- Grabación 43
3.2.2.- Normalización 45
3.2.3.- Segmentación 47
3.3.- Programación del reconocedor de comandos 49
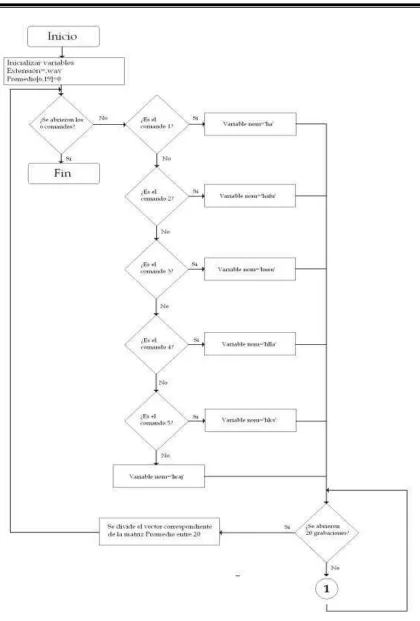
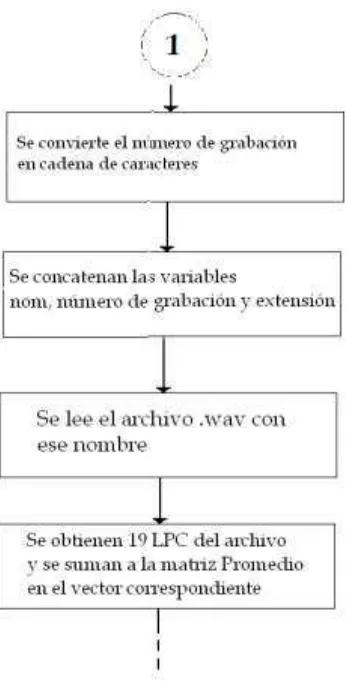
3.3.1.- Caracterizar 49
3.3.2.- Reconocer 55
3.3.2.1.- Petición y grabación del comando 56
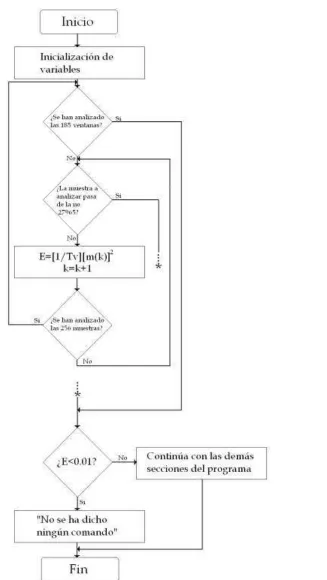
3.3.2.2.- Cálculo de la energía 58
3.3.2.3.- Normalización y cálculo de los LPC 63 3.3.2.4.- Cálculo del error cuadrático medio 67
3.3.2.5.- Determinación del comando 68
Capítulo 4: Pruebas y resultados
784.1.- Prueba con automóvil apagado en un ambiente silencioso 79
4.2.- Prueba con el motor encendido en diferentes vehículos 84
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil VII
Conclusiones
94Bibliografía y referencias
96Anexo A
97Anexo B
107Reconocedor automático de comandos por medio del habla para las funciones de un automóvil VIII
Índice de imágenes
Capítulo 2: Marco teórico
Fig. 2.1.- Corte sagital del tracto vocal. 6
Fig. 2.2.- Velocidad – volumen glotal: a) forma de onda (tren de impulsos 9 – línea segmentada), b) magnitud de espectro. Fig. 2.3.- Tubo uniforme sin perdidas de longitud “l” y una abertura con
área “A”. 10
Fig. 2.4.- Respuesta en frecuencia de un tubo uniforme sin perdidas. 11 Fig. 2.5.- Modelo de tubos concatenados (seis secciones). 12 Fig. 2.6.- Radiación de los labios: a) Bafle plano infinito, b) Respuesta en
frecuencia del bafle plano infinito. 13 Fig. 2.7.- Modelo de excitación para sonidos vocálicos. 14 Fig. 2.8.- Modelo de excitación para sonidos sordos. 14
Fig. 2.9.- Modelo completo de la excitación. 15
Fig. 2.10.- Modelo digital de la producción del habla completo. 17 Fig. 2.11.- Implementación de ventana rectangular. 20 Fig. 2.12.- Cálculo de la energía (gráfica azul) de la grabación de la palabra”
hipotenusa” (gráfica negra). 21 Fig. 2.13.- Cálculo de la función de autocorrelación (abajo) para una señal
periódica (arriba). 23
Fig. 2.14.- Cálculo de la función de autocorrelación (abajo) para una señal no
periódica (arriba). 23
Fig.2.15.- Transformada de Fourier de segmentos de señales de voz de diferentes longitudes. (A) Segmento de señal de 5ms. (B) Transformada de Fourier de (A). (C) Segmento de señal de voz
de 37.5ms. (D) Transformada de Fourier de (C). 24
Fig.2.16.- Espectro digital utilizando FFT. 25
Capítulo 3: Desarrollo del proyecto
Fig. 3.1.- Primer modo de acceso a la herramienta GUIDE de MATLAB. 34 Fig. 3.2.- Segundo modo de acceso a la herramienta GUIDE de MATLAB. 34
Fig. 3.3.- Ventana de inicio rápido de GUIDE. 35
Fig. 3.4.- Espacio de trabajo para crear una interfaz 35 Fig. 3.5.- Desglose de la paleta de componentes. 36 Fig. 3.6.- Inserción de un texto estático; a) Ícono de texto estático,
b) Texto estático en la interfaz gráfica. 37
Fig. 3.7.- Edición del texto estático en el inspector de propiedades. 38 Fig. 3.8.- Inserción de un botón; a) Ícono de botón, b) Ejemplo de botones en la
interfaz gráfica. 38
Fig. 3.9.- Inserción de un texto editable; a) Ícono de texto editable,
b) Ejemplo de texto editable en la interfaz gráfica. 40 Fig. 3.10.- Inserción de un eje; a) Ícono de ejes, b) Ejemplo de un eje en la interfaz
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil IX Fig. 3.11.- Inserción de un panel; a) Ícono del panel, b) Ejemplo de panel en la
interfaz gráfica. 42
Fig. 3.12- Interfaz del reconocedor de comandos. 43 Fig. 3.13.- Diagrama de flujo para programa de grabación. 44 Fig. 3.14.- Diagrama de flujo para programa de normalización. 45 Fig. 3.15.- Modo de abrir un archivo en Audacity. 47 Fig. 3.16.- Forma de onda dentro de la interfaz de Audacity. 47 Fig. 3.17.- Selección de una parte de la señal de onda. 48 Fig. 3.18.- Forma de onda después de ser segmentada. 48 Fig. 3.19.- a) Diagrama de flujo sección caracterizar. 54 Fig. 3.19.- b) Complemento del diagrama de flujo sección caracterizar. 55
Fig. 3.20.- Menú de opciones en forma de árbol. 56
Fig. 3.21.- Estructura general del proceso de reconocimiento. 56 Fig. 3.22.- Diagrama de flujo para la sección de petición y grabación
del comando. 57
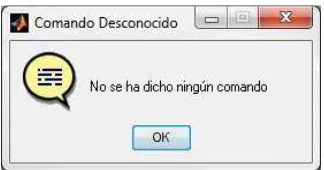
Fig. 3.23.- Diagrama de flujo para el cálculo de la energía. 60 Fig. 3.24.- Ventana con el mensaje “No se ha dicho ningún comando”. 62 Fig. 3.25.- Despliegue de información y señal en la sección de GUI
denominada “Dominio en el Tiempo”. 63
Fig. 3.26.- Gráfica de los LPC de la señal y despliegue de los valores de error en la sección de la GUI denominada “Procesamiento
de la señal”. 63
Fig. 3.27.- Diagrama de flujo para la normalización y cálculo de los LPC. 66 Fig. 3.28.- Diagrama de flujo para el cálculo del error cuadrático medio. 67 Fig. 3.29.- a) Diagrama general de la sección determinación de comando. 70 Fig. 3.29.- b) Parte 1 del diagrama general de la sección determinación de
comando; c) Parte 2 del diagrama general de la sección determinación de comando; d) Parte 3 del diagrama general
de la sección determinación de comando. 71
Fig. 3.30.- Mensaje de reconocimiento del comando “A”. 73 Fig. 3.31.- Mensaje de reconocimiento del comando “Afuera”. 74 Fig. 3.32.- Mensaje de reconocimiento del comando “Usuario”. 74 Fig. 3.33.- Mensaje de reconocimiento del comando “Llamada”. 75 Fig. 3.34.- Mensaje de reconocimiento del comando “Luces”. 75 Fig. 3.35.- Mensaje de reconocimiento del comando “Cajuela”. 76
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil X Capítulo 4: Pruebas y resultados
Fig. 4.1.- Posicionamiento del individuo y la computadora para pruebas
dentro del automóvil. 78
Fig. 4.2.-Respuesta del programa de reconocimiento de voz en porcentaje
de cada comando para el sujeto 1 en la prueba 1. 81 Fig. 4.3.- Respuesta del programa de reconocimiento de voz en porcentaje
de cada comando para el sujeto 2 en la prueba 1. 82 Fig. 4.4.- Respuesta del programa de reconocimiento de voz en porcentaje
de cada comando para el sujeto 3 en la prueba 1. 83 Fig. 4.5.- Comparación de la respuesta del programa de reconocimiento
de voz en porcentaje de cada uno de los sujetos. 84 Fig. 4.6.- Respuesta del programa de reconocimiento de voz en porcentaje
de cada comando para el sujeto 1 en el vehículo 2 de la prueba2. 86 Fig. 4.7.- Respuesta del programa de reconocimiento de voz en porcentaje
de cada comando para el sujeto 1 en el vehículo 1 de la prueba 2. 88 Fig. 4.8.- Señales obtenidas en el vehículo 2 de a) voz y b) su respectivo
espectros de frecuencia. 88
Fig. 4.8.- Señales obtenidas en el vehículo 2 de c) ruido de auto, e) ruido más voz y su respectivo espectros de frecuencia: d) ruido de auto,
f) ruido más voz. 89
Fig. 4.9.- Señal obtenida en el vehículo 1 de a) voz, c) ruido de auto y e) ruido más voz y los espectros de frecuencia b) voz, d) ruido auto,
f) ruido más voz. 91
Fig. 4.10.- Respuesta del programa de reconocimiento de voz en porcentaje
de cada comando para el sujeto 1 en la prueba 3. 93
Anexo B
Fig. B.1.- Descripción física del sonómetro. 108
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil XI
Índice de tablas
Capítulo 2: Marco teórico
Tabla 2.1.- Fonemas del español. 8
Capítulo 4: Pruebas y resultados
Tabla 4.1.- Mediciones del nivel de ruido en la prueba 1. 79 Tabla 4.2.- Resultados del sujeto 1 en la prueba 1. 80 Tabla 4.3.- Resultados del sujeto 2 en la prueba 1. 81 Tabla 4.4.- Resultados del sujeto 3 en la prueba 1. 82 Tabla 4.5.- Mediciones del nivel de ruido en vehículo 2 de la prueba2. 84 Tabla 4.6.- Resultados del sujeto 1 en el vehículo 2 en la prueba 2. 85 Tabla 4.7.- Mediciones del nivel de ruido en el vehículo 1 de la prueba 2. 86 Tabla 4.8.- Resultados del sujeto 1 con el motor encendido en el vehículo 1
en la prueba 2. 87
Tabla 4.9.- Mediciones del nivel de ruido en la prueba 3. 92 Tabla 4.10.- Resultados del sujeto 1 en el tránsito de la prueba 3. 92
Anexo B
Tabla B.1.- Especificaciones del instrumento de medición. 107
Anexo C
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil XII
Introducción
La presente tesis está dividida en cuatro capítulos que tienen como finalidad
explicar de manera detallada e ingenieril, las bases teóricas y el proceso que se
llevó a cabo para el diseño de un programa que se podría implementar en el
desarrollo de un sistema con el cual el usuario de un automóvil tenga control de
funciones básicas de este.
El capítulo uno se enfoca en los precedentes históricos y tecnológicos, de los
reconocedores de voz, su importancia y la forma en la que desde su concepción
han ido evolucionando.
El segundo capítulo desarrolla y explica las bases teóricas implementadas en el
diseño del reconocedor de voz que aquí se expone. La primera sección de este
capítulo se enfoca en la producción anatómica de la voz y el estudio del habla. La
segunda sección expone el desarrollo de modelos acústicos que simulen la
producción del habla, su estudio y los modelos matemáticos. Partiendo de lo
anterior, en la sección tres se elabora un modelo digital del habla que servirá como
base para la implementación de los LPC. La sección cuatro expone los procesos en
el tiempo que sufre la señal de voz, desde su conversión a energía eléctrica hasta la
obtención de algunos parámetros de ella, como la energía. La quinta sección
expone el tratamiento de la señal en el dominio de la frecuencia, proceso necesario
para la realización de cálculos expresados en la última sección del capítulo.
Finalmente se presentan las ecuaciones que son relevantes en el método
implementado en el reconocimiento de comandos, así como la manera en que se
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil XIII El tercer capítulo comprende el desarrollo del proyecto, en el que se explica a
detalle los pasos realizados para construir el software del reconocedor de voz. El
capítulo está dividido en tres secciones, la primera expone los elementos y
características necesarios para la creación de la interfaz gráfica con la que
interactuará el usuario. La segunda sección se enfoca en la grabación y edición de
la base de datos necesaria para el sistema de reconocimiento de voz. Por último la
tercera sección desarrolla los elementos principales del reconocedor de comandos
que son caracterizar y reconocer, los cuales se enfocan en la obtención y
comparación de los LPC de la base de datos y la señal de entrada.
En el cuarto capítulo se presentan las diferentes pruebas realizadas para cuantificar
la eficiencia del software de reconocimiento así como los resultados de estas.
Objetivo
Diseñar un programa de reconocimiento de voz orientado a la implementación en
un sistema de control de funciones básicas en un automóvil.
Hipótesis
A través del método de reconocimiento de voz LPC y las herramientas que
MATLAB proporciona para el tratamiento de señales, se busca crear un programa
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil XIV
Justificación
Hoy en día la industria automovilística, al igual que muchas otras, está invirtiendo
en tecnología que haga de sus automóviles espacios más cómodos, seguros y
acordes a la tecnología que sus clientes estén usando. Ahora los automóviles
cuentan con interfaces de pantallas táctiles para el control del radio o la
calefacción, servicio de GPS (por sus siglas en inglés Global Positioning System) y control por voz de algunos de los dispositivos del automóvil. Sin embargo son
sólo los autos de alto valor, los que cuentan con la mayoría de estos servicios, por
lo que un grupo muy limitado de personas tiene acceso a este tipo de beneficios
dentro de sus vehículos. La creación de un programa de reconocimiento de voz,
como el que se propone en esta tesis, puede dar pie al desarrollo de un sistema de
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 1
Capítulo 1: Antecedentes históricos
El habla y el lenguaje son las herramientas que los seres humanos usan para
comunicar o intercambiar pensamientos, ideas y emociones. Las condiciones
básicas de la vida social son comprender y expresar. La primera es apropiarse de la
realidad, clasificándola ordenadamente según las palabras comunicadas. La
segunda es hacer eficaz la voluntad del ser humano, actuando sobre los demás
para dejar constancia de su presencia. En sí el habla es la conversación, una de las
formas de expresar el idioma a lo que se denomina fonación.
Los seres humanos han demostrado un gran interés no sólo por comunicarse entre
sí mismos, sino por crear dispositivos que analicen e incluso que compartan
ciertas similitudes con los humanos. En la actualidad es un tema de investigación y
desarrollo que aún sigue vigente, sin embargo se han tenido muchos avances
dentro de todo este ámbito.
En el año 1930, el científico húngaro, Tihamér Nemes quiso patentar el desarrollo
de una máquina de transcripción automática de voz, lamentablemente su iniciativa
fue considerada como poco realista y no progresó. En el año 1936, Bell Laboratories
creó el primer analizador y el primer sintetizador de voz a los que llamaron
Vocoder y Voder respectivamente. Homer Dudley, su creador, reconoció la
naturaleza de la portadora de la voz, observó que la señal de voz se forma
modulando el espectro del sonido producido por la fuente vocal. Estas fuentes
pueden ser periódicas, producto de las vibraciones de las cuerdas vocales, o
aperiódicas, producto de turbulencias del flujo de aire en una constricción. Las
modulaciones en la forma del espectro de voz pudieron ser medidas en términos
de energía en sucesivos filtros de bandas; y las fuentes periódicas y aperiódicas
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 2 toma los datos del análisis, los entrega a una serie de filtros excitados por una señal
de pulsos periódicos o una fuente de ruido y crea finalmente una señal audible.
Este sistema era operado por sólo una persona, un operador entrenado podía hacer
que el sistema “hable” con una pronunciación razonablemente entendible. El
sistema tenía la habilidad de asombrar y entretener mientras se demostraban sus
principios científicos.
En 1952, los investigadores de Bell Laboratories: K. H. Davis, R. Biddulph y S.
Balashek, construyeron un sistema dependiente del locutor y capaz de reconocer
dígitos del 0 al 9 basándose en las características del espectro de cada número. En
1953, Walter Lawrence creó el primer sintetizador de voz basado en frecuencias
formantes, al que denominó PAT (Por sus siglas en inglés Parametric Artificial Talker). En 1956, en los laboratorios RCA, los investigadores Harry Olson y Herbert Belar intentaron reconocer 10 sílabas distintas con un método dependiente del
locutor. El sistema se basó nuevamente en el análisis espectral.
George Rosen, creó en 1958 el primer sintetizador articulatorio: DAVO (Por sus
siglas en inglés Dynamic Analog Vocal tract). Este modelo era controlado por una grabación de señales de control hechas manualmente.
En 1959, la University College London con sus investigadores Dennis B. Fry y
Peter Denes, crearon un sistema capaz de reconocer cuatro vocales y nueve
consonantes. Emplearon el análisis espectral y comparación de patrones, aunque
en realidad el aspecto innovador fue el uso de información estadística, con ello
determinaron secuencias posibles de fonemas en inglés.
Durante la década de 1960 las técnicas de reconocimiento de voz dieron un nuevo
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 3 vocabularios pequeños, dependientes del locutor y con un flujo discreto. La
tecnología digital irrumpió en esta década.
En 1962, el físico Lawrence Kersta de los Bell Laboratories, realizó el primer gran
paso en la identificación de locutores al introducir el término “voiceprint” para un
espectrograma generado por un complejo dispositivo electromecánico.
Paralelamente, IBM y Carnegie Mellon University, investigaban en reconocimiento
de voz continua.
Los años 70 fueron testigos de esfuerzos por mejorar los sistemas dependientes del
locutor con entrada de voz discreta y vocabularios reducidos. ARPA (Por sus siglas
en inglés Advanced Research Projects Agency) de la sección americana de defensa, comienza a interesarse en el reconocimiento de voz e inicia sus propias
investigaciones. Nacieron técnicas como “time warping”, “modelado
probabilístico” que son aplicaciones de los modelos ocultos de Markov, y el
“algoritmo de retropropagación”.
En 1980, los costos reducidos de las aplicaciones, el fuerte comienzo de desarrollo
de los PC y el apoyo de ARPA beneficiaron el desarrollo del reconocimiento de
habla. Se trabajó en el tamaño del vocabulario, algunos casos llegaron hasta 20,000
palabras y se cambió el enfoque trasladándose desde las técnicas de
reconocimiento según patrones a técnicas probabilísticas como son las cadenas de
Markov. Durante los años 90 se siguió trabajando con vocabularios amplios. Los
costos siguieron disminuyendo y se hicieron más comunes las aplicaciones
independientes del locutor y flujo continuo.
Los primeros modelos neuronales (como por ejemplo el perceptrón), inicialmente
propuesto en los años 50, volvieron a aparecer a finales de esta década gracias al
desarrollo de algoritmos de aprendizaje mucho más eficaces, un ejemplo de su
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 4 matrix laboratory (en español laboratorio de matrices), creado en 1970 para proporcionar un sencillo acceso al software de matrices LINPACK y EISPACK sin
tener que usar FORTRAN (por su abreviatura en inglés The IBM Mathematical Formula Translating System) con el que trabajó inicialmente. Desde la primera versión muchas otras personas han contribuido al desarrollo de MATLAB. Este
lenguaje de alto nivel fue implementado para realizar cálculos técnicos. Por su
capacidad es un sistema interactivo ideal para aplicaciones de ingeniería. En la
actualidad dispone de una amplia cantidad de programas de apoyo especializados,
denominados “toolboxes”, estos extienden significativamente el número de
funciones incorporadas en el programa principal. Estos cubren prácticamente casi
todas las áreas principales en el mundo de la ingeniería y la simulación, por
ejemplo existen para el proceso de imágenes, procesamiento digital de señales,
control robusto, estadística, análisis financiero, matemáticas simbólicas, redes
neuronales, lógica difusa, entre otros. Integra todos los requisitos claves de un
sistema de computación técnico: cálculo numérico, gráficos, herramientas para
aplicaciones específicas y capacidad de ejecución en múltiples plataformas como
Windows 95/98/XP/NT, Macintosh, Unix y Linux. Todas estas herramientas
proporcionadas por MATLAB permitieron analizar, simular y crear sistemas de
reconocimientos de voz de una manera más sencilla, referente a los gráficos de
señales utilizadas en el proceso y operaciones automáticas de matrices, sin
embargo se sigue trabajando para poder hacer más eficaz las aplicaciones que se le
dan a estos sistemas de programación, debido a que tienden a trabajar con lentitud
a medida que se realizan base de datos más extensos y completos en los
reconocedores. Los sistemas del presente y presumiblemente los que puedan venir
en el futuro se basarán al menos en parte, en modelos y técnicas que aparecieron
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 5
Capítulo 2: Marco teórico
El objetivo del habla siempre ha sido el de la comunicación. Este siempre se ha utilizado para comunicarse acústicamente entre un humano y otro. A lo largo del último siglo se han logrado desarrollar tecnologías que permiten transformar esas señales acústicas en señales eléctricas lo que se ha logrado, entre otras cosas, que el hombre pueda interactuar con las máquinas por medio de la voz.
A partir de esta conversión de las señales de la voz (analógicas) al formato digital, ha sido posible analizar y procesar las señales a través de medios digitales, dando pie a lo que se conoce como procesamiento digital de señales, herramienta con la cual se desarrollaron los métodos (LPC y la transformada rápida de Fourier) para el reconocimiento de voz que se usará en el prototipo reconocedor de comandos que expone esta tesis. Con estas dos bases, el habla y el tratamiento de señales digitales, se establecerá el marco teórico que comprenderá esta tesis.
Se dividirá el capitulo en dos secciones. La primera sección está comprendida por tres temas que se enfocan en: la producción del habla, el modelo acústico y el digital del mismo. La siguiente sección comprende las herramientas matemáticas que se utilizan para el desarrollo del reconocedor de comandos.
2.1.- Teoría de la producción del habla
2.1.1.- Producción anatómica del habla
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 6
[image:21.612.165.406.428.709.2]Los mecanismos utilizados en la producción del habla son: las componentes subglotales, la laringe, el tracto vocal y los articuladores (ver Fig. 2.1). Los componentes subglotales son los pulmones y la tráquea. Los primeros son los encargados de suministrar la energía, en forma de aire, necesaria para producir el sonido. El segundo canaliza este aire y lo dirige hacia la laringe. Estos dos órganos juntos son los que ajustan el tono, el volumen y la calidad de la voz. Dentro de la laringe se encuentran las cuerdas vocales, que son tejidos conformados por músculos y membranas mucosas, que se extienden a lo ancho de toda la cavidad. Estas cuerdas sirven como moduladores del aire que pasa a través de la laringe para así, formar los sonidos. El tracto vocal, compuesto por la faringe y la cavidad oral, actúa como un tubo resonador que filtra los sonidos. Para producir los sonidos nasales (consonantes), el velo del paladar baja y el tracto vocal se acopla acústicamente con la cavidad nasal. Los articuladores, que incluyen al velo del paladar, lengua, quijada y labios, configuran al tracto vocal para determinar que frecuencias de sonidos son las que pasan para así, producir los diferentes sonidos, que serán radiados por los labios o por la ventana de la nariz.
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 7 2.1.2.- La fonética
La fonética es el estudio acerca de los sonidos de uno o varios idiomas, sea en su fisiología y acústica. Estos sonidos pueden ser clasificados por su modo de excitación o por características especificas como los fonemas.
2.1.2.1.- Clasificación por su modo de excitación
Para el análisis de señales esta clasificación es de mucha ayuda debido a que separa las características de la fuente del sonido de las que produce el tracto vocal. Existen tres clases de sonidos dentro de esta clasificación:
Sonidos sonoros: son creados por vibraciones en las cuerdas vocales que producen pulsos de aire cuasi-periódicos (vocales) a través de la laringe.
Sonidos sordos: son producidos por una excitación turbulenta en el tracto vocal. Por ejemplo la “s” y la “f”.
Sonidos explosivos: son producidos por una explosión de energía acústica originada por el escape de la acumulación de presión de aire en el tracto vocal. Por ejemplo la “t” y la “p”.
2.1.3.- Fonemas
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 8
Tabla 2.1 Fonemas del español
fonema grafía ejemplos
/a/ a
/b/ b, v vaso, bote, cava / / c, z cena, caza /k/ c, qu, k casa, queso, kilo /t∫/ ch chico, muchacho /d/ d dado
/e/ e
/f/ f fama, café /g/ g, gu gama, guiso /i/ i
/x/ j, g paja, gitano /l/ l ala, mal
/λ/ ll llave, calle /m/ m mamá /n/ n nana /η/ ñ caña /o/ o
/p/ p piedra, capa /r/ r para
/ / rr, r perro, remo /s/ s soy, dos
/t/ t tapa, atar /u/ u
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 9
2.2.- Modelo acústico del habla
Teniendo conocimiento del sistema que se ocupa de producir el habla, es posible producir un modelo acústico que realice las mismas funciones. Este sistema está dividido en tres partes: la fuente, el filtrado y la radiación del sonido.
2.2.1.- La producción del habla
La fuente del sonido es lo que genera la energía acústica necesaria para la producción del habla y es visto como la excitación aplicada al sistema. Esta excitación puede ser vocálica o fricativa.
Los sonidos vocálicos son producidos por la vibración de las cuerdas vocales (que se encuentran en la laringe). Esta oscilación, que se produce por la liberación de presión de aire en la glotis, se repite a una frecuencia fundamental que depende de la presión de aire detrás de las cuerdas, la masa de las cuerdas y la tensión aplicada a ellas. El resultado es que la corriente de aire que es modulada por la glotis (junto con las cuerdas vocales), es liberada como una serie de pulsos (ver Fig. 2.2a). La frecuencia fundamental a la que oscilan estos pulsos es conocido como el “tono de voz” de la persona. En la figura 2.2b, se grafica el espectro de una señal donde pueden verse la frecuencia fundamental y sus armónicos (conocidos también como “armónicos del tono de voz”).
a) b)
Fig. 2.2.- Velocidad – volumen glotal: a)forma de onda (tren de impulsos – línea segmentada), b)
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 10 2.2.2.- Filtrado del tracto vocal
El tracto vocal filtra acústicamente los pulsos generados y permite que algunas frecuencias pasen, mientas que a otras las atenúa. La manera más sencilla de explicar el modelo del tracto vocal es con el “tubo sin perdidas uniforme” (ver fig. 2.3).
Fig. 2.3.- Tubo uniforme sin perdidas de longitud “l” y una abertura con area “A”.
Este es un cilindro de paredes duras, con un área transversal A constante y una longitud l, y que en uno de sus extremos tiene un pistón que genera un flujo ideal de presión de aire. Si se asume que en él no hay pérdidas por viscosidad o por la conducción térmica y que sólo se producen ondas planas, el sonido dentro del tubo cumple con el siguiente par de ecuaciones de diferenciales parciales (Ec. 2.1).
(Ec. 2.1)
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 11
frecuencia, se obtiene la relación de volumen-velocidad que hay en la abertura del tubo y la que se produce en la fuente de excitación . Ver Ec. 2.2.
(Ec. 2.2)
Esta respuesta en frecuencia está ilustrada en la Fig 2.4, para l = 17.5 cm y c = 35000 cm/seg. Estos polos de (en los que el denominador vale cero) son las frecuencias de resonancia del tubo acústico. En el habla a estas frecuencias de resonancia del tracto vocal se llaman formantes.
Fig. 2.4.- Respuesta en frecuencia de un tubo uniforme sin perdidas.
Un modelo más realista puede obtenerse al concatenar varios tubos acústicos de diferentes áreas transversales como se muestra en la Fig. 2.5. Hay que asumir en este diseño, que las longitudes de los tubos deben de ser las mismas, y tener en cuenta que la señal es parcialmente propagada y reflejada en cada conjunción. Para calcular el coeficiente de reflexión de la n-ésima conjunción se utiliza la Ec. 2.3.
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 12
Donde representa la cantidad de la onda que se reflejó en esa unión. De esta manera la respuesta en frecuencia del tracto vocal queda determinada por los coeficientes de reflexión, el área de empalme de los tubos y los polos de la función de transferencia.
Fig. 2.5.- Modelo de tubos concatenados (seis secciones).
2.2.3.- Radiación en los labios
La relación entre el volumen-velocidad y la presión en los labios puede ser modelado por un bafle plano con una abertura de área A (Fig. 2.6.a), está dado por la Ec 2.4.
(Ec. 2.4)
Donde la impedancia de radiación está dada por la Ec. 2.5.
(Ec. 2.5)
En la Fig 2.6.b., se observa la radiación que se obtendría al tener una resistencia
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 13
a) b)
Fig. 2.6.- Radiación de los labios: a) Bafle plano infinito, b) Respuesta en frecuencia del bafle plano infinito.
2.3.- Modelo digital de la producción del habla
En la sección anterior, se vio con detalle la producción del habla desde el punto de vista fisiológico, para así desarrollar un modelo acústico que facilite la comprensión del fenómeno físico. A partir de dicho modelo se procederá a crear una representación digital, con el propósito de hacer un análisis de las señales del habla, las cuales se manejan en tiempo discreto y limitadas a una frecuencia de Nyquist, cabe destacar que el modelo digital se considerará como un sistema lineal. A continuación se analizará por separado cada sección del modelo acústico para crear su versión digital. Éste se divide básicamente en tres secciones: excitación, filtrado y radiación, en donde al final del capítulo se unirán para así obtener por completo el modelo digital de la producción del habla.
2.3.1.- Excitación
Como se vio en la sección 2.2.1, los sonidos vocálicos son de tipo cuasi periódicos por lo que la representación digital de estos se modela de la siguiente manera: primero un tren de impulsos separados por el periodo de la fundamental es generado, donde posteriormente son filtrados por un modelo de la glotis llamado
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 14
modelo biológico o acústico (ver Fig. 2.2). Por último, el resultado es multiplicado por un controlador de amplitud denominado A. La Fig. 2.7, ilustra de una manera sencilla lo descrito anteriormente. El modelo de la glotis , es un filtro que tiene una respuesta al impulso infinito con dos polos (es decir un filtro IIR – por sus siglas en inglés Infinite Impulse Response), el cual es descrito por la Ec. 2.6, en donde
y son reales o complejos conjugados.
Fig. 2.7.- Modelo de excitación para sonidos vocálicos.
(Ec. 2.6)
Para el caso de los sonidos sordos, el modelo de excitación se basa en la implementación de un generador de ruido Gaussiano. Fonemas como /f/ o /s/ al ser producidos por el sistema biológico tienen una forma de onda similar a este tipo de ruido. Al igual que en el modelo de sonidos vocálicos, después del generador de ruido existe un controlador de ganancia denominado A. La Fig. 2.8, muestra el modelo de excitación para los sonidos sordos.
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 15
La producción del habla es una combinación de ambos tipos de sonidos, por lo que el modelo completo de excitación se ilustra en la Fig. 2.9. Si se desea producir un sonido de tipo vocálico uno sordo, un switch elegirá el modelo correspondiente.
Fig. 2.9.- Modelo completo de la excitación.
2.3.2.- Filtrado
Esta sección del modelo digital comprende lo que es el tracto vocal, en donde se producen sonidos nasales y no nasales; y también donde se generan las formantes para cada fonema.
De acuerdo al sistema acústico de tubos concatenados, en lo que respecta a los sonidos no nasales, la función de transferencia está determinada por los coeficientes de reflexión y contiene sólo polos. Por lo tanto, el modelo digital se representa por la Ec. 2.7, donde es el número de polos y estos últimos son las raíces de la función .
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 16
Debido a que la forma de onda que ha sido filtrada es real, los polos complejos aparecerán en pares simétricos los cuales corresponden a las formantes de la señal. Así que, la función puede ser encontrada por el conjunto de coeficientes de reflexión de la siguiente manera:
Para el caso de la producción de sonidos nasales, es necesario agregar ceros a la Ec. 2.7, pero se sabe que esto puede ser sustituido agregando un número infinito de polos a . Evidentemente, esta solución no es factible, ya que se requieren de más parámetros para caracterizar el filtro, por lo que sólo es suficiente implementar la Ec. 2.7.
2.3.3.- Radiación
En esta sección se incluye el efecto de presión de los labios que se ejerce a la hora de producir un sonido. Como se vio anteriormente, la respuesta en frecuencia de la radiación en los labios (Fig. 2.6.b) se comporta como un filtro pasa altas. La Ec. 2.8 representa dicho modelo de radiación, el cual es un diferenciador digital con un cero en corriente directa.
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 17 2.3.4.- Modelo completo
Una vez analizadas las secciones 2.3.1, 2.3.2 y 2.3.3 se procede a formar el sistema digital de la producción del habla, el cual se ilustra en la Fig. 2.10. En este un switch
es el encargado de elegir el modo de excitación deseado, para así pasar por el filtro
el cual se describe en la Ec. 2.9, para al final producir una señal . Este modelo digital es la base para el diseño de los sintetizadores de voz comerciales.
Fig. 2. 10.- Modelo digital de la producción del habla completo.
(Ec. 2.9)
2.4.- Análisis en el dominio del tiempo
En los apartados 2.2 y 2.3 se expusieron dos modelos de producción del habla (acústico y digital), sin embargo no se ha contemplado como sería posible que un sistema electrónico o computacional pudiese entender lo que se le dice. Para lograr esto, es necesario convertir las señales acústicas en digitales y realizar un análisis en tiempo corto sobre ellas, con el fin de poder cuantificar parámetros como la energía o la autocorrelación, elementos clave en el procedimiento de reconocimiento de voz.
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 18
La sección se divide en dos partes: digitalización de la señal (transducción, muestreo y cuantización del habla) y análisis en tiempo corto.
2.4.1.- Transducción, muestreo y cuantización del habla
Todos los sonidos, incluyendo los producidos por el habla, se deben a los cambios de presión en el aire. El oído humano es sensible a estos cambios, debido a que la membrana timpánica responde a ellos, convirtiendo dicha energía acústica en energía mecánica, que después es convertida en energía eléctrica por las células ciliadas que se encuentran en el oído interno. Una vez convertido el sonido en señales eléctricas, el cerebro las procesa.
Algo similar se requiere para que un sistema electrónico o computacional entienda y procese una señal sonora. Para ello se requiere utilizar un micrófono, el cual es un transductor acústico-mecánico-eléctrico, que simularía el funcionamiento del oído humano. Este dispositivo convierte el sonido en señales eléctricas, las cuales son continuas en amplitud y tiempo, siendo esto un impedimento para los sistemas digitales ya que sólo pueden procesar señales discretas en amplitud y tiempo. Por ello, las señales continuas deben pasar por dos procesos: muestreo y cuantización.
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 19
Algunos estándares importantes en la industria son: La telefonía digital utiliza una frecuencia de muestreo de 8KHz por lo que la frecuencia de Nyquist es 4KHz, siendo esto lo suficiente para poder transmitir voz. Los discos compactos utilizan una frecuencia de muestreo aproximada de 44KHz, teniendo una frecuencia Nyquist o máxima de 22KHz, así garantizando que se reproducirá todo el ancho de banda audible del ser humano.
Una vez discretizada la señal en el tiempo, es necesario hacerlo en amplitud. Para ello existe el proceso de cuantización que funciona de la siguiente manera: se toman los valores continuos de amplitud de la señal muestreada y se representan por una serie de valores finitos de amplitud de un formato digital de bits, en otras palabras, los valores de amplitud de la señal muestreada son redondeados o aproximados a unos valores finitos ya establecidos de acuerdo al número de bits que se utilicen en el formato digital. Entre mayor número de bits se utilicen, menor error o ruido de cuantización existirá, esto se puede apreciar en la Ec. 2.10, que muestra la relación señal a ruido expresada en dB.
(Ec. 2.10)
2.4.2.- Análisis en tiempo corto
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 20
la suficiente información y caracterizar las propiedades a estudiar (energía y función de autocorrelación). A esto se le conoce como ventaneo y se representa con la función . Se recomienda que en cada ventana se encuentren al menos dos periodos de la frecuencia fundamental. Por lo regular se utiliza un ancho de ventana de 30ms y un desplazamiento cada 10ms. Dentro de las ventanas más utilizadas se encuentran las rectangulares, las de Hamming, las de Hanning y las de Blackman, pero en el desarrollo de esta tesis sólo se implementará la rectangular (Ec. 2.11), la cual vale 1 en todo el ancho de ventana y 0 para el resto. La Fig. 2.11 muestra como se utiliza .
(Ec. 2.11)
Fig. 2.11.- Implementación de ventana rectangular.
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 21 2.4.2.1.- Energía
La energía se obtiene de la suma de los cuadrados de los valores de la señal ponderados por la ventana elegida, donde lo anterior se describe en la Ec. 2.12.
(Ec. 2.12)
Si el tamaño de la ventana es muy grande no se apreciarán los cambios en las propiedades energéticas de la señal, mientras que al elegir un tamaño muy pequeño existirán demasiados cambios en tales propiedades.
Esta medición permite identificar si en una grabación existe silencio, siempre y cuando los niveles de ruido sean muy bajos, es decir, la SNR sea alta. En la Fig. 2.12 se ilustra el cálculo de la energía de la palabra “hipotenusa”. En ella se observa cómo los máximos existen en los segmentos vocálicos, mientras que para los segmentos sordos o silenciosos, la energía decae.
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 22 2.4.2.2.- Función de autocorrelación
Dicha medición permite saber que tan parecida es una muestra de otra, he de ahí su nombre. La función de autocorrelación se define en la Ec. 2.13, donde es el retraso de la señal.
(Ec. 2.13)
Cuando una muestra pasada es similar a la presente, el valor que se obtiene en la función es máximo, por lo tanto es evidente que las periodicidades que se encuentran en la señal cumplen con lo anterior, por ejemplo si la señal tiene un periodo , entonces en la función de autocorrelación se puede decir que
Como se mencionó en la introducción de este tema, es necesario implementar el concepto de ventaneo, por lo que la función de autocorrelación finalmente se expresa en la Ec. 2.14.
(Ec. 2.14)
Independientemente de que la señal sea periódica o no lo sea, cuando la función de autocorrelación es máxima y corresponde al cálculo de la energía, esto es .
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 23
Fig. 2.13.- Cálculo de la función de autocorrelación (abajo) para una señal periódica (arriba).
De manera contraria, si la señal no es periódica, en la función de autocorrelación se puede observar que no existe ninguna similitud en todos los valores de , por lo que se dice que no hay una correlación en la señal, tal como puede ser apreciado en la Fig. 2.14.
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 24
2.5.- Análisis de Fourier en tiempo corto
La transformada de Fourier es una técnica implementada para pasar una señal del dominio del tiempo al dominio de la frecuencia o viceversa. De igual manera esto permite identificar las frecuencias en las cuales una señal produce energía. La transformada de Fourier está dada por la Ec. 2.15:
(Ec. 2.15)
La Fig. 2.15 (A) y Fig. 2.15(C) son segmentos de señales de voz de diferentes longitudes, la Fig. 2.15 (B) y Fig. 2.15 (D) son sus respectivas transformadas de Fourier, notando que la estructura armónica en la transformada de la señal de 35.5ms es más notoria que en la de 5 ms, al igual que la estructura de formantes.
Fig.2.15.- Transformada de Fourier de segmentos de señales de voz de diferentes longitudes (A) Segmento de señal de 5ms. (B) Transformada de Fourier de (A). (C) Segmento de señal de voz
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 25 2.5.1.- Transformada rápida de Fourier
Es un eficiente algoritmo matemático que permite calcular la transformada de Fourier discreta (DFT – por sus siglas en inglés Discrete Fourier Transform) y su inversa. La DFT es el proceso matemático con el cual se obtiene la transformada de Fourier para señales discretas. Las siglas FFT son la abreviatura usual del inglés para Fast Fourier Transform. Este algoritmo es de gran importancia en una amplia variedad de aplicaciones, desde el procesamiento digital de señales hasta en diseños de filtros digitales. En general su función es la de resolver ecuaciones diferenciales, ecuaciones diferenciales parciales o algoritmos de multiplicación rápida de grandes enteros.
La Fig. 2.16 ilustra el espectro digital en tres dimensiones (x para la frecuencia, y
para la magnitud y z para el tiempo). La transformada de Fourier en tiempo corto se utiliza también para las técnicas de codificación de la voz (como el canal de codificación de voz), donde los parámetros de dominio de frecuencia se codifican y se transmiten, y para la mejora del habla y la modificación de la señal.
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 26
2.6.- Análisis predictivo lineal
Comúnmente llamada coeficientes de predicción lineal LPC (por sus siglas en inglés Linear Predictive Coding), es considerada una de las mejores herramientas para las señales de voz debido a que se adapta al modelo de producción del habla digital que se presentó en la sección 2.3, y es muy conocida por su velocidad de cálculo.
La idea básica de predicción lineal es que una muestra se predice a partir de la suma de muestras anteriores, ponderadas linealmente, como se muestra en la Ec. 2.16.
(Ec. 2.16)
El conjunto son los coeficientes de predicción lineal, este está determinado por minimizar la diferencia media cuadrática entre las muestras de habla y las predichas. La ecuación anterior puede ser escrita de manera alternativa como se muestra en la Ec. 2.17.
(Ec. 2.17)
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 27
(Ec. 2.18)
Si se pasa la Ec. 2.18 al dominio del tiempo, se obtiene la ecuación del modelo de producción del habla en su forma diferencial (Ec. 2.19).
(Ec. 2.19)
Como se puede apreciar la Ec. 2.19 es similar a la Ec. 2.17. Por esta razón es que se considera el método de LPC como apto para la implementación en el reconocimiento de voz ya que con este se obtienen los coeficientes del filtro inverso
.
2.6.1.- Análisis de la señal del habla
El error que se estima entre las señales predichas y las reales viene dado por la Ec. 2.20. Donde los parámetros son las estimaciones de los coeficientes del filtro LPC.
(Ec. 2.20)
Es posible determinar esas estimaciones de los coeficientes del filtro, minimizando el error cuadrático medio sobre una sección de la señal (Ec. 2.21).
(Ec. 2.21)
Para minimizar el error cuadrático medio se calcula la derivada parcial
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 28
(Ec. 2.22)
Dos diferentes formulaciones son posibles, dependiendo del intervalo de y de la minimización que se produzca, los cuales son: el método de autocorrelación y de covarianza. De estos dos métodos, sólo se usará el de autocorrelación para la solución de la matriz expuesta en la Ec. 2.22.
2.6.2.- Método de autocorrelación
En este método se asume que y la forma de onda se ventanea, de modo que todo lo que está fuera de esta ventana toma el valor de cero, esto es: , donde es una ventana de longitud finita (de N puntos) que cubre el intervalo deseado.
Debido a que este método intenta predecir las primeras muestras de la señal que se encuentran fuera de la ventana, puede que el error resultante sea muy grande, para evitar esto es preferible usar la ventana de Hamming debido a que esta reduce suavemente los extremos de la señal a cero. Por lo que la ecuaciones normales (Ec. 2.22) se rescriben:
(Ec. 2.13)
Donde
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 29
muy eficiente llamado la recursión de Levinson puede utilizarse para resolver este sistema de ecuaciones.
2.6.3.- Algoritmo de Levinson-Durbin
La matriz de la Ec. 2.13 puede ser resuelta por un método muy eficiente, el cual fue inventado por Levinson y reformulado por Durbin, de ahí su nombre.
El algoritmo de Levinson-Durbin se muestra en el conjunto de ecuaciones Ec. 2.14. Dicho proceso de resolución de la matriz es de forma cíclica, donde i es el número de iteración y es indicado en los índices entre paréntesis, k es el orden del filtro predictor, R(i) el valor de autocorrelación, ai(i) son los elementos de pivotaje, aj(i) son
los coeficientes LPC; y E es el error de predicción. La ecuación Ec. 2.14a sólo es la inicialización del ciclo, por lo que las iteraciones serían desde Ec. 2.14b hasta Ec. 2.14d. Para una iteración, una vez inicializado el error de predicción, se calculan los coeficientes de pivotaje y con ellos se obtienen los coeficientes LPC. Al final de la iteración se calcula el error de predicción con los elementos de pivotaje.
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 30
Este método comparado con otros es más eficiente en los procesos computacionales debido a que el número de las operaciones que realiza es proporcional a k2 mientras que para otros es de k3, también es que el orden del
predictor puede ser de cualquier valor y si se desea, es posible colocar un umbral para el error predictivo para que así al momento de llegar a este el cálculo cese.
2.7.- Sistema de verificación de usuario
Una aplicación que ha implementado toda la teoría expuesta anteriormente y también hace uso de más técnicas de reconocimiento de voz, fue desarrollada por Rosenberg y compañía. A esta aplicación se le conoce como sistema de verificación de usuario, y consiste en una computadora que hace una petición para que la persona por reconocer diga una expresión, la cual habilitará alguna función específica (como si fuera una contraseña).
El sistema funciona realizando tres procesos. El primero es el del tratamiento de la señal, es decir, eliminar las partes de la grabación donde no se grabó el mensaje para sólo quedarse con la señal de voz. El segundo es para que se obtengan los parámetros necesarios (para esta aplicación son detector de pitch, energía, LPC y analisis de formantes) los cuales serán ocupados en el tercer proceso, el cual trata sobre una comparación de una referencia, almacenada previamente, con la expresión. De acuerdo al resultado de esta comparación, el sistema tomará la decisión si la persona ha sido reconocida o no.
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 31
la referencia. Esta distorsión es muy importante y ha sido aplicada en varios procesos que involucran el procesamiento del habla.
Lo único que hace falta para concluir el tercer proceso es el de obtener la medición de la distancia entre la referencia y la expresión, la cual puede ser obtenida por la Ec. 2.15, donde ajs(i) es el valor de la j-ésima medición del contorno en el tiempo i,
ajr(i) es el valor de la j-ésima medición del contorno de referencia en el tiempo i,
aj(i) es la desviación estándar de la j-ésima medición en el tiempo i.
(Ec. 2.15)
Este sistema previamente descrito ha sido muchas veces un caso de estudio y puesto en práctica debido a su eficiencia. Para el desarrollo de esta tesis, parte de esta se ha basado en este procedimiento, sólo que la distancia que se usará se expresa en la Ec. 2.16. la cual es el error cuadrático medio.
(Ec. 2.16)
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 32
Capítulo 3: Desarrollo del proyecto
El objetivo de este capítulo es explicar de manera detallada el proceso de
elaboración del programa que se encargará del reconocimiento de voz, desde la
presentación (interfaz gráfica) hasta las entrañas del mismo (programación y base
de datos). Esta sección está comprendida por tres partes. La primera se refiere al
aspecto visual del proyecto, en este caso, la creación de una interfaz grafica en
MATLAB con la que el usuario interactuará. En esta primera parte se explicará a
detalle el proceso para la creación de la interfaz, los componentes que la integran y
la implementación de estos. La segunda parte de este capítulo comprende lo
relacionado con la grabación y edición de la base datos, parte fundamental del
programa de reconocimiento de voz utilizando dos programas auxiliares
desarrollados de igual manera en MATLAB (“Grabadora” y “Normalizador”) y el
software Audacity. En esta se desarrolla cómo fueron grabados los comandos “A”,
“Afuera”, “Llamada”, “Usuario”, “Cajuela” y “Luces”, las características de estas grabaciones y la edición que se aplicó a las mismas para evitar problemas a la hora
de implementar la base de datos. Se utilizaron estos comandos con la intención de
cumplir con las siguientes tareas que normalmente se llevan a cabo al utilizar un
automóvil.
Comando “A”: Habilita las funciones que se realizarán dentro del vehículo.
Comando “Afuera”: Habilita las funciones que se realizan al exterior del
vehículo.
Comando “Llamada”: Permite contestar una llamada telefónica entrante.
Comando “Usuario”: Enciende el automóvil.
Comando “Cajuela”: Abre la cajuela del auto.
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 33 En la última parte se explican las secciones centrales del programa que son:
caracterizar y reconocer. La primera obtiene los promedios de los LPC de cada
comando y la segunda hace una comparación entre dichos promedios y la señal
producida por el usuario. Estas secciones son la esencia del programa pero no lo
conforman del todo, por ello en el anexo A se ha agregado el programa completo
para un análisis a mayor detalle.
3.1.- Interfaz gráfica de usuario (GUI)
El ambiente de desarrollo de interfaz gráfica de usuario (GUIDE, por sus siglas en
inglés Graphical User Interfase Development Environment) es una serie de
herramientas que se extienden por completo en el software de MATLAB,
diseñadas para crear interfaces graficas de usuario (GUI´s, por sus siglas en inglés
Graphical User Interfaces) de manera fácil, pues no existe la necesidad de que el
programador tenga que agregar código para el desarrollo de la misma, debido a
que MATLAB automáticamente realiza esta acción, y rápida, ya que presta ayuda
en el diseño y presentación de los elementos de la interfaz, reduciendo la labor al
grado de seleccionar, tirar, arrastrar y personalizar propiedades. Los elementos
que se usan son: botones (push buttons), ejes (axes), texto estático (static text), panel
(panel) texto editable (edit text), que serán explicados más adelante.
Una vez que los elementos están en posición se editan las funciones de llamada
“callback” de cada uno de ellos, escribiendo el código de MATLAB que se ejecutará
cuando el elemento sea utilizado. Cabe destacar que el orden del programa con el
que trabaja la GUI, está determinado por el usuario, pues no existe un flujo
establecido como en el caso de un programa común de MATLAB, dándole al
usuario la opción de elegir qué elementos y en qué momento usarlos, sin ser esto
motivo para que la GUI termine su funcionamiento, a menos de que el usuario así
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 34
El desarrollo de la GUI se realiza en dos etapas:
Diseño de los componentes (botones, textos, paneles y ejes) que la
formarán.
Programación de cada uno de los componentes ante la interacción del
usuario.
A la herramienta GUIDE se accede de varias maneras, la primera de ellas es
tecleando “guide” en la ventana de comando, como se muestra en la Fig. 3.1.
Fig. 3.1.- Primer modo de acceso a la herramienta GUIDE de MATLAB.
Otra manera de acceder, es a través del menú “File” “New” “GUI”, como se
muestra en la Fig. 3.2.
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 35 Una vez que es llamada la función GUIDE, aparecerá la ventana de inicio rápido
de GUIDE (GUIDE Quick start), como se muestra en la Fig. 3.3.
Fig. 3.3.- Ventana de inicio rápido de GUIDE.
Donde se presentan diferentes modalidades para la creación de una GUI. En este
caso se utilizará la opción “Blank GUI (Default)”, la cual creará una interfaz en
blanco predeterminada, en la que se diseñará la interfaz conforme a las
necesidades. Al seleccionar esta opción se generará el siguiente espacio de trabajo
donde se crea esta. Tal y como se muestra en la Fig. 3.4.
Reconocedor automático de comandos por medio del habla para las funciones de un automóvil 36 Los componentes principales de la GUIDE son:
Barra de menús: Aquí se encuentran las funciones elementales de edición de
las GUI.
Paleta de componentes (component palette): Aquí se encuentran los
componentes que formarán parte de la interfaz gráfica (botones, textos
editables, etc.).
La Barra de Herramientas: En ella se encuentran botones que ayudan a la
edición de una GUI. En el desarrollo de esta tesis sólo se utilizaron los
siguientes botones.
o Botón de ejecución (run button): Al presionarse ejecuta el código referido
a la GUI y crea la figura de la interfaz diseñada en el espacio de trabajo
(layout area).
o Alineación de Componentes (alignment tool): Esta opción permite alinear
los componentes que se encuentra en el área de trabajo (layout area) de
manera personalizada.
3.1.1.- Partes de la GUI
Las partes que pueden componer una GUI son las siguientes (Fig. 3.5):
Fig. 3.5.- Desglose de la paleta de componentes.