𝑆 =
𝑁 − 1
𝑆
𝑧
2
=
1
𝑁
𝜕𝑧
𝜕𝑥
𝛿𝑥 +
𝜕𝑧
𝜕𝑦
𝛿𝑦
1 Conceptos B´asicos y Organizaci´on de Datos . . . 1
1.1 Aplicaciones e Importancia de la Estad´ıstica . . . 1
1.1.1 Conceptos Basicos . . . 2
1.1.2 Tipos de variables . . . 2
1.1.3 Escalas de medida . . . 3
1.2 Descripci´on de Datos . . . 4
1.2.1 organizaci´on de datos en tablas de frecuencia . . . 4
1.2.2 Gr´aficas Descriptivas . . . 6
1.2.3 Ejercicios . . . 9
2 Medidas de An´alisis descriptivo . . . 11
2.1 Medidas de tendencia central para datos no agrupados . . . 11
2.1.1 media aritm´etica muestral y poblacional . . . 11
2.1.2 Mediana . . . 12
2.1.3 Moda . . . 12
2.2 Medidas de Posici´on relativa para datos no agrupados . . . 12
2.2.1 percentiles, cuartiles y deciles . . . 12
2.3 Medidas de Dispersi´on para datos no agrupados . . . 13
2.3.1 Rango, Rango intercuartilico , varianza y desviaci´on estandar 13 2.4 Medidas de tendencia central para datos agrupados . . . 17
2.4.1 Media, mediana y moda para datos agrupados . . . 17
2.5 Medidas de formas y analisis explaratorio de datos . . . 20
2.5.1 Medidas de formas . . . 20
2.5.2 Analisis exploratorio de datos . . . 20
2.5.3 Diagrama de cajas y bigotes . . . 21
2.5.4 Ejercicios . . . 22
3 Introducci´on a la teoria de probabilidad . . . 25
3.1 Conceptos basicos . . . 25
3.1.1 Experimentos . . . 25
3.1.2 Espacio muestral y eventos . . . 26
3.1.3 Operaciones con eventos . . . 27
3.1.4 Propiedades relacionadas con eventos . . . 31
3.1.5 teoria de probabilidades . . . 32
3.1.6 metodo frecuentista . . . 32
3.1.7 M´etodo cl´asico . . . 33
3.1.8 M´etodo subjetivo . . . 33
3.1.9 Propiedades de la probabilidad . . . 34
Conceptos B´
asicos y Organizaci´
on
de Datos
1.1.
Aplicaciones e Importancia de la Estad´ıstica
Contaduria:Las empresas de contadores p´ublicos al realizar auditor´ıas para sus clientes emplean procedimientos de muestreo estad´ıstico.Por ejemplo, suponga que una empresa de contadores desea determinar si las cantidades en cuentas por cobrar que aparecen en la hoja de balance del cliente representan la verdadera cantidad de cuentas por cobrar. Por lo general,el gran n´umero de cuentas por cobrar hace que su revisi´on tome demasiado tiempo y sea muy costosa. Lo que se hace en estos casos es que el personal encargado de la auditor´ıa selecciona un subconjunto de las cuentas al que le llama muestra.Despu´es de revisar la exactitud de las cuentas tomadas en la muestra (muestreadas) los auditores concluyen si la cantidad de cuentas por cobrar que aparece en la hoja de balance del cliente es aceptable
An´alisis Financiero:Los analistas Financieros emplean una diversidad de informa-ci´on estad´ıstica como gu´ıa para sus recomendaciones de inversi´on.En el caso de accio-nes, el analista revisa diferentes datos financieros como la relaci´on precio/ganancia y el rendimiento de los dividendos.
Mercadeo y Marketing:Escaneres electr´onicos en las cajas de los comercios mi-noristas recogen datos para diversas aplicaciones en la investigaci´on de mercado. por ejemplo proveedores de datos como ACNielsen e Information Research Inc. compran estos datos a las tiendas de abarrotes,los procesan y luego venden los res´umenes estad´ısticos a los fabricantes;quienes gastan cientos de miles de d´olares por producto para obtener este tipo de datos.
1.1.1.
Conceptos Basicos
Definici´on 1.1.1 Poblaci´on: Es la recolecci´on completa de todas las observaciones de inter´es para el investigador. es decir si el director ejecutivo de una gran empresa manofac-turera desea estudiar la producci´on de todas las plantas de propiedad de la firma, entonces la producci´on de todas esas plantas es la poblaci´on.
Definici´on 1.1.2 Par´ametro:Es cualquier caracter´ıstica medible de la poblaci´on. Es de-cir el ingreso promedio de todos los asalariados de colombia.
Definici´on 1.1.3 Muestra:Una muestra es un subconjunto de la poblaci´on; es una parte representativa de la poblaci´on que se selecciona para ser estudiada ya que la poblaci´on es demasiado grande como para analizarla en su totalidad.Es decir si se desea realizar un es-tudio en colombia sobre la proporci´on de embarazos en ni˜nas menores de 14 a˜nos. entonces la region caribe solo ser´ıa una muestra representativa para el estudio.(ver muestreo)
Definici´on 1.1.4 Estad´ıstico:Es cualquier caracter´ıstica medible de una muestra. Es de-cir en el ejemplo anterior la proporci´on de embarazos de ni˜nas en la region caribe repre-sentar´ıa un estad´ıstico.
Definici´on 1.1.5 La mayor parte de la informaci´on estad´ıstica en peri´odicos, revistas, informes de empresas y otras publicaciones consta de datos que se resumen y presentan en una forma f´acil de leer y de entender. A estos res´umenes de datos, que pueden ser tabulares, gr´aficos o num´ericos se les conoce comoestad´ıstica descriptiva.
1.1.2.
Tipos de variables
Definici´on 1.1.6 Una Variable es una caracter´ıstica de la muestra o poblaci´on que se est´a observando.
Ejemplo 1.1.1 Si un asesor estad´ıstico de la empresa de buses alianza sodis de Barran-quilla est´a interesado en saber la velocidad maxima recorrida en una ruta por los buses durante el dia, la variable esvelocidad maxima de la ruta.
Ejemplo 1.1.2 Estatura de los jugadores en el mundial brasil 2014 (cuantitativa conti-nua); el numero de clientes que aprobaron cr´edito en cierto banco durante el mes de diciem-bre(cuantitativa discreta); El estado civil de quienes solicitan un credito(cualitativa)
1.1.3.
Escalas de medida
La recolecci´on de datos requiere alguna de las escalas de medici´on siguientes:Nominal, Ordinal, De intervalo o de Razon. La escala de medicion determina la cantidad de informacion contenidad en el dato e indica la manera m´as apropiada de resumir y de analizarlos estadisticamente.
Definici´on 1.1.8 Una Escala nominal se crea cuando se utilizan palabras letras y nu-meros codificados, etiquetas, para establecer categorias con la condici´on de que cada dato pertenezca ´unica y exclusivamente a una de estas categor´ıas.
Ejemplo 1.1.3 si se tiene una variable llamada ”bolsa de valores”(mercado Bursatil): donde se comercializa (cotiza) la accion: N(bolsa de Nueva York) y NQ ( mercado nacional de Nasdaq). donde observamos que posee datos en escala nominal ya que N y NQ son etiquetas que se usan para indicar d´onde cotiza la acci´on de la empresa.
Definici´on 1.1.9 Una escala de medici´on para una variable esordinalsi los datos mues-tran las propiedades de los datos nominales y adem´as tiene sentido el orden o jerarqu´ıa de los datos.
Ejemplo 1.1.4 Una cajera de un banco quiere que usted le otorge una calificacion so-bre la calidad de su atenci´on, le sugiere clasificar entre excelente, bueno,regular y malo. observamos que es una variable de medida nominal, pero las etiquetas excelente,bueno , regular y malo pueden ser ordenados jerarquizados segun la calidad del servicio; por tanto se consideran de escala ordinal.
Definici´on 1.1.10 Una escala de medici´on para una variable es una escala de intervalo
si los datos tienen las caracteristicas de los datos ordinales y el intervalo entre valores se expresa en terminos de una unidad de medici´on fija. los datos de los intervalos siempre son n´umericos.
Ejemplo 1.1.5 son ejemplos de escalas de intervalo: puntajes en las prubas de aptitudes escolares.
Definici´on 1.1.11 Una variable tiene una escala de raz´on si los datos tiene todas las propiedades de los datos de intervalo y la proporci´on entre dos valores tiene significado.
Ejemplo 1.1.6 Variables como distancia, altura, peso y tiempo usan la escala de raz´on en la medici´on.Esta escala requiere que se tenga el valor cero para indicar que en este punto no existe la variable.En el costo de un par de zapatos, el valor cero para el costo indica que el zapato no cuesta, que es gratis.Adem´as si se compara un par de zapatos de $50000 y$25000 la propiedad de la razon muestra que $50000$25000 = 2,es decir el primer zapato cuesta el doble del segundo.
1.2.
Descripci´
on de Datos
1.2.1.
organizaci´
on de datos en tablas de frecuencia
Cualquier conjunto de datos sean cualitativos o cuantitativos se organizan en tablas o distribuciones de frecuencias, que nos proporciona una herramienta util al momento de describir cualquier estadistico o parametro.Tabla o distribuciones de frecuencias agrupadas (datos cuantitativos)
Ejemplo 1.2.1 Se pide recolectar la informaci´on del gasto en salarios de empleados de una muestra de 50 microempresas en barranquilla registradas ante la camara de comercio, cuyos resultados son los siguientes dados en millones de pesos.
19,5 24,2 19,0 24,1 28,8 32,2 27,3 27,9 25,8 25,8
28,5 26,1 21,5 27,5 19,8 34,3 27,1 27,1 19,2 34,9
28,0 41,8 29,2 18,2 24,5 26,8 18,9 31,6 35,4 19,5
33,6 30,4 27,4 25,1 18,2 26,8 28,4 25,5 31,3 47,0
24,6 19,1 28,9 27,8 25,8 31,5 23,2 29,2 45,5 13,0
una posibilidad de organizar los datos es agruparlos en intervalos (llamadosIntervalos de clase O, simplementeClases)y determinar la llamadaFrecuencia de clase de cada clase, es decir el total de datos que hay en cada clase y se ubican en la tabla de la siguiente forma.
1. N´umero de clases: para aproximar el numero de clases que tendr´a nuestra tabla segun el numero de datos se utlizar´a la Regla de Sturges:
para la situci´on planteada se tiene una muestra de 50 empresas ( n = 50 ) por tanto se concluye seguna la regla de sturges:
c= 1 + 3,3(lg 50) = 6,60≈7
Se aproxima al entero m´as cercano, lo que indica que la tabla de frecuencias tendr´a 7 clases..
2. Se determina el Rango de la distribuci´on de datos que corresponde a la diferencia entre el dato menor y el mayor segun la unidad de medida. es decir:
R=Xmax−Xmin
para la situaci´on ser´ıaR= 47−13 = 34
3. se calcula el tama˜no del intervalo de clase (w): w= Rc. Lo que indica quew= 347 = 4,85≈5.
4. Se determina el punto medio de la unidad de medida (U M), que depende de lo siguiente:
si los datos son eenteros; U M = 12 = 0,5
si los datos contienen una cifra decimal ;U M = 02,1 = 0,05 si los datos contienen dos cifras decimales ;U M = 0,201 = 0,005
5. Se detrmina el Limite real inferior de la primera clase: LRI1 = Xmin −U M =
13−0,05 = 12,95
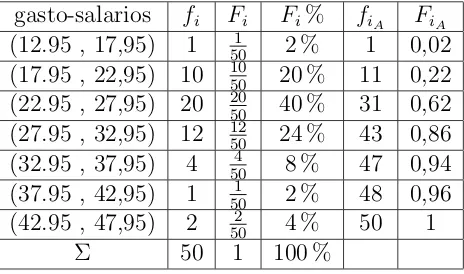
se inicia la organizaci´on de la tabla de frecuencias:
gasto-salarios fi Fi Fi% fiA FiA
(12.95 , 17,95) 1 501 2 % 1 0,02 (17.95 , 22,95) 10 1050 20 % 11 0,22 (22.95 , 27,95) 20 2050 40 % 31 0,62 (27.95 , 32,95) 12 1250 24 % 43 0,86 (32.95 , 37,95) 4 504 8 % 47 0,94 (37.95 , 42,95) 1 1
50 2 % 48 0,96 (42.95 , 47,95) 2 502 4 % 50 1
[image:14.612.197.430.477.615.2]Σ 50 1 100 %
Cuadro 1.1: Tabla o distribucion de frecuencias
siendo:
Fi: frecuencia Relativa de cada clase:=Fi= fni
Fi%: frecuencia relativa porcentual:= Fi×100
fiA: frecuencia Absoluta acumulada: fi+fi+1
FiA: frecuencia relativa acumulada:Fi+Fi+1
1.2.2.
Gr´
aficas Descriptivas
Histograma de frecuencias
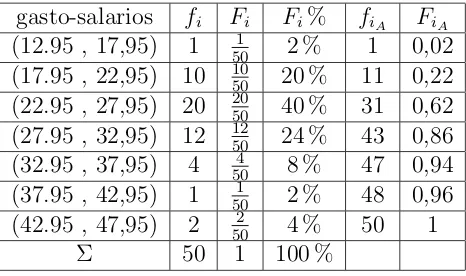
[image:15.612.100.504.328.532.2]Los graficos tambien son metodos utiles para describir conjunto de datos. Un his-tograma coloca las clases de una distribuci´on de frecuencias en el eje horizontal y las frecuencias en el eje vertical.(cualquiera de las frecuencias definidas segun el uso interpretativo).
Figura 1.1: histogramas de frecuencias
poligono de frecuencias
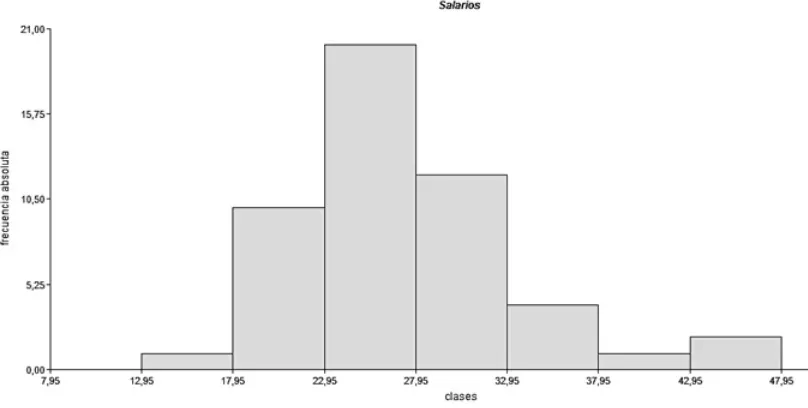
Elpoligono de frecuenciasresulta de la union de los puntos medios de cada clase, llamados marcas de clase.(figura 1.2)
Histograma de frecuencias acumuladas
Figura 1.2: poligono de frecuencias
Figura 1.3: Histograma de frecuencias Absolutas acumuladas
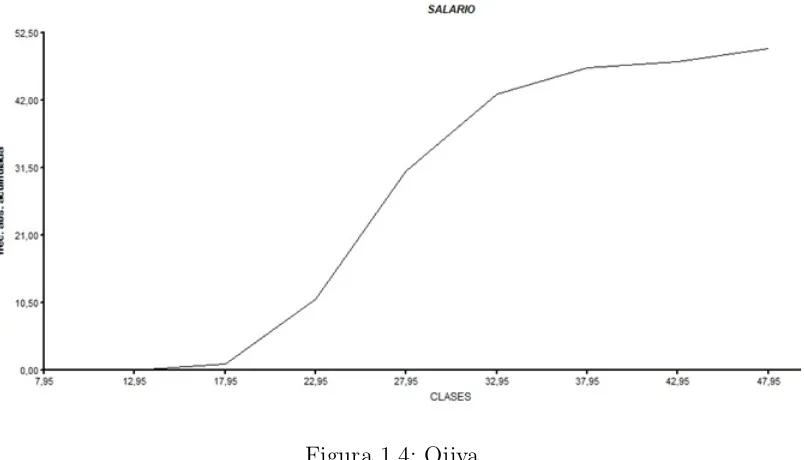
Ojiva
la figura 4 representa el poligono de frecuencias acumuladas conocido tambien como
ojiva, donde se unen los limites reales superiores de cada clase.(figura 1.4)
Diagrama de tallos y hojas
[image:16.612.109.520.93.519.2]Figura 1.4: Ojiva
ofrecen una forma novedosa y rapida de exhibir informaci´on numerica: si un n´umeral tiene dos o m´as digitos, entonces, se puede descomponer en una rama y una hoja. Un
Talloes el primer digito o parte del n´umeral, mientras que una Hojaest´a formada por ´el o los d´ıgitos restantes. es decir para nuestro ejemplo se tiene:
[image:17.612.251.339.408.659.2]1. En una Empresa de fabricaci´on de tuercas, se toma una muestra del diametro 50 de ellas(dadas en mm) para la inspeccion de un control de calidad, segun datos de producci´on la maquina estipula solo el 5 % de defectuosos para diametros menores a 17,95mm y tambien los mayores a 37,95. la muestra es la siguiente:
19,5 24,2 19,0 24,1 28,8 32,2 27,3 27,9 25,8 25,8
28,5 26,1 21,5 27,5 19,8 34,3 27,1 27,1 19,2 34,9
28,0 41,8 29,2 18,2 24,5 26,8 18,9 31,6 35,4 19,5
33,6 30,4 27,4 25,1 18,2 26,8 28,4 25,5 31,3 47,0
24,6 19,1 28,9 27,8 25,8 31,5 23,2 29,2 45,5 13,0
Identificar el tipo de variable; tama˜no de la muestra
Organizar los datos en una tabla de frecuencias
Segun la tabla el hallar el numero de tornillos defectuosos pas´o el control de calidad. Justifique
realizar un diagrama de tallos y hojas
Grafique en escala el histograma y superpuesto el poligono de frecuencias,¿se observa algun comportamiento acampanado del histograma?
2. Un´asesor financiero guarda los registros de las cuentas personales de ahorro. De las 40 nuevas cuentas abiertas el mes anterior, los saldos corrientes son: (dados en dolares US$)
1,150.00 100.00 1,009.10 1,212.43 470.53 780.00 352.00 1,595.10
1,482.00 695.15 952.51 510.52 783.00 793.10 937.01 217.00
890.00 1,200.00 712.10 293.00 415.00 602.00 1,312.52 1,175.00
579.00 287.00 1,112.52 1,394.05 1,101.00 501.01 711.11 1,202
783.00 1,390 666 1555.10 1,422.03 1,273.01 1,112.52 1,394.05
Identifique la variable y clasifiquela.
Realizar una tabla de frecuencias con siete clases.
construya el histograma, poligono de frecuencias y la ojiva
Estaturas en centimetros de 10 jugadores de basket.
los salarios ganados por un coordinador financiero
El dinero que sacan las primeras 50 personas de un cajero automatico.
las temperaturas en barranquilla en grados celcius durante una semana.
las notas de los parciales finales de los estudiantes de estad´ıstica.
la talla de las camisas de las estudiantes mujeres del PCA
la marca de los celulares de todos los estudiantes del PCA
la talla en zapato de los jugadores de la seleccion de football del PCA
Rango militar
Ritmo cardiaco
4. Considere la distribuci´on de frecuencias:
Clase 20–40 40–60 60–80 80—100 100–120 120–140
frecuencia 14 25 15 8 18 24
Medidas de An´
alisis descriptivo
2.1.
Medidas de tendencia central para datos no
agrupados
2.1.1.
media aritm´
etica muestral y poblacional
La medida de tendencia central m´as importante es la media, interpretada como valor promedio, de una variable. la media proporciona una medida de localizaci´on central de los datos, si los datos provienen de una muestra, entonces la medida se denomina media muestral simbolizada x; y si los datos provienen de una poblaci´on entonces la medida se denomina media poblacional, simbolizada con la letra griegaµ. la formula para calcular la media muestral cu´ando se tiene n observaciones es:
¯
x=
P xi
n (2.1)
siendoxi el valor de cada observaci´on desdei= 1,2,3...n.
de igual forma la media aritmetica poblacional:
µ=
P xi
N (2.2)
siendo xi el valor de cada observaci´on desde i = 1,2,3...N. y N el tama˜no de la
poblaci´on.
Ejemplo 2.1.1 se supone una muestra de salarios de 10 trabajadores en millones de pesos de la empresa monomeros colombo venezolana.
2,6 9,1 4,9 3,8 5,8 3,6 4,1 6,9 6,8 0,8
donde:
¯
x= 2,6 + 9,1 + 4,9 + 3,8 + 5,8 + 3,6 + 4,1 + 6,9 + 6,8 + 0,8
10 = 4,84
2.1.2.
Mediana
la mediana tambi´en es llamada una medida de posici´on relativa, ya que es aquella medida que se posiciona en el centro de la distribuci´on de datos, es decir divide en un 50 % por encima y el otro 50 % por debajo.
la mediana se calcula de la siguiente forma.
Si el numero de datos es impar entonces la mediana estar´a en la posici´on i= n+12 . Si el numero de datos es par entonces la mediana estar´a entre las posiciones n2 y
n
2 + 1.
Ejemplo 2.1.2 En el ejemplo anterior se tiene un numero de datos par n = 10 lo que indica que la mediana se encuentra entre la posici´on: 102 = 5 y 6 es importante notar que para el calculo de la mediana los datos deben estar ordenados de menor a mayor. lo que indica en el ejemplo que la mediana est´a entre las posiciones 5 y 6 que corresponde a 4,1 y 4,9 :
mediana= 4,1+42 ,9 = 4,5
0,8 2,6 3,6 3,8 4,1 4,9 5,8 6,8 6,9 9,1
Lo que indica que el 50 % de los trabajadores de la empresa ganan un salario a lo maximo de 4,5 millones de pesos.
2.1.3.
Moda
La moda se define como la observaci´on que ocurre con mayor frecuencia. es decir para los salarios en millones de pesos:
2,6 9,1 4,9 4,8 5,8 3,6 4,8 6,9 6,8 4,8
la moda es 4,8 ya que se observa con frecuencia =3.
2.2.
Medidas de Posici´
on relativa para datos no
agrupados
2.2.1.
percentiles, cuartiles y deciles
Paso 1. Ordenar los datos de mayor a menor valor
Paso 2. Calcular el indiceiposicional.
i=
p
100n
Paso 3. Si i no es un numero entero, se redondea al menor entero mayor a i. Si
i es un numero entero, entonces el percentil p es el promedio de los valores en las posicionesi e i + 1.
Ejemplo 2.2.1 supongamos que se tiene la informaci´on del sueldo mensual( en miles de pesos colombianos) de 12 trabajadores de la empresa ACESCO (aceros de colombia) hallar el percentil 85 e interpretar.
Ordenamos los datos de menor a mayor
3310 3355 3450 3480 3480 3490 3520 3540 3550 3650 3730 3925 luego calculamos la posicion donde se encuentra el percentil 85, i= 10085
12 = 10,2, lo que indica que la es un n´umero Racional la cual se debe redondear al entero siguiente 11. es decir el percentil 85 se encuentra en la posicion 11 de los datos anteriormente ordenados, la cual corresponde al sueldo 3730.
Interpretaci´on En la empresa ACESCO el 85 % de los trabajadores gana a lo sumo
$3.730.000.
Cuartiles y Deciles Al igual que los percentiles;los cuartiles dividen una distribuci´on de datos en 4 partes iguales; y los deciles en 10 partes iguales, es decir hay 3 cuartiles y 9 deciles. Para el calculo se utlizan los pasos anteriores solo que var´ıa el calculo de la posici´on
i=
p
4
n
i= p 10
n
2.3.
Medidas de Dispersi´
on para datos no
agrupa-dos
2.3.1.
Rango, Rango intercuartilico , varianza y desviaci´
on
estandar
Figura 2.1: Localizaci´on de los Percentiles
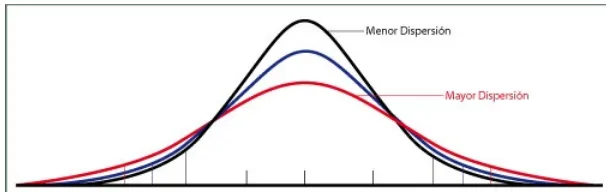
Figura 2.2: Comparaci´on de Dispersion de observaciones
Rango : El rango es la medida de dispersi´on mas simple, como la idea es tener una metrica, se mide la distancia entre la observaci´on menor y mayor de la siguiente forma:
Rango=Xmax−Xmin
la desventaja del rango es que solo tiene en cuenta 2 observaciones.
Rango Intercuartilico : Es la medida de dispersion que elimina la influencia de los datos extremos y se concentra en el 50 % de los datos centrales; es decir el rango intercuartilico ( RI) en la distancia entre el cuartil 1 y el cuartil 3:
RI=Q3−Q1
Ejemplo 2.3.1 En el ejemplo 2.1.3 al calcular Q1 y Q3 como explica el procedimiento se
llega a lo siguiente:
Q1=
3450 + 3480
2 = 3465
Q3=
3550 + 3650
2 = 3600
donde
[image:23.612.146.451.272.368.2]Desviaci´on media : La desviacion media mide la variabilidad de cada observaci´on con respecto a la media aritmetica, ya que el RI omit´ıa el 25 % de los datos por encima y por debajo de la distribuci´on de datos ordenados, la desviaci´on media analiza cada observaci´on sin omitir ningun dato, su calculo es el siguiente:
Di =xi−x¯
lo que implica que esta medida pueder ser un valor positivo,negativo y cero. Si es negativo entonces indica que la observacion est´a en las unidades calculadas por debajo de la media, positivo por encima de la media y cero indica que el valor coincide con la media.
Ejemplo 2.3.2 Sean los siguientes datos que provienen de cualquier variable; 5 1 3 10 6 donde se tiene que x¯= 5 y ademas
D1= 5−5 = 0
D2 = 1−5 =−4
D3 = 3−5 =−2
D4= 10−5 = 5
D5= 6−5 = 1
donde podemos concluir que el dato con mayor dispersion por debajo de la media es el 1, y por encima el 12, y exite un dato que coincide con la media 5.
Teorema 2.3.1 La suma de todas las desviaciones con respecto a la media es igual a cero, es decir:
X
Di = 0
una de las desventajas utiles de las desviaciones es que toca analizar la medida para cada dato; entonces el objetivo ser´ıa una sola medida que indique el promedio de todas las des-viaciones con respecto a la media, pero con el teoerema 2.1.1 estevalor ser´ıa cero, entonces se tiene un problema que va a ser solucionado con la siguiente medida.
Varianza : la varianza es el promedio de todas las desviaciones elevadas al cuadrado.
varianza poblacional σ2 :
σ2=
P
(Di)2
n =
(x1−µ)2+ (x2−µ)2+. . .+ (xN −µ)2
N
varianza muestral s2 :
s2 =
P
(Di)2
n =
(x1−x¯)2+ (x2−x¯)2+. . .+ (xn−x¯)2
n−1
interpretable ya que las unidades de los datos las eleva al cuadrado y se ven modifica-das, como solucion de esto se crea la siguiente medida llamada DESVIACI ´ON TIPICA O ESTANDAR.desviaci´on tipica o estandar poblacional σ :
σ =
√ σ2
desviaci´on tipica o estandar muestral s :
s=
√ s2
Ejemplo 2.3.3 segun el ejemplo xxx, suponiendo que los datos provienen de una muestra:
s2 =
P
(Di)2
5−1 =
02+ (−4)2+ (−2)2+ 52+ 12
4 = 11,5
ahora:
s=
√
s2 =p
11,5 = 3,39
lo que concluye que el promedio de desviaciones de las observaciones con respecto a la media es de 3,39 unidades
Coeficiente de variaci´on de pearson CV :
Definici´on 2.3.2 El coeficiente de variaci´on es una medida relativa de variabilidad que mide la desviaci´on estandar en relacion con la media, ya que es necesario comparar las dispersiones de dos o mas conjunto de datos y por la diferencia de escala puede resultar incoherente, por tal motivo el CV elimina la escala correspondiente de los valores; se calcula de la siguiente forma:
CV =s ¯ x ×100 CV = σ µ ×100
Ejemplo 2.3.4 El gerente de operaciones de servicio de paqueter´ıa desea adquirir una nueva flota de auto. cuando los paquetes se guardan con eficiencia en el interior de los au-tos, se deben considerar dos consideraciones principales, el peso (en libras) y el volumen en (metros c´ubicos) de cada paquete. Ahora en una muestra de 200 paquetes el peso promedio es de 26 libras con una desviac´ıon estandar de 3,9 libras. Ademas el volumen promedio es de 8,8 metros c´ubicos con una desviaci´on estandar de 2,2 metros cubicos ¿ como se puede comparar la variaci´on del peso y el volumen?
utlizando el coeficiente de variacion para comparar la fluctuaciones entre las medidas ,tenemos para el peso se tiene que:
CV =
3,9 26
y para el volumen
CV =
2,2 8,8
×100 = 25 %
entonces podemos concluir que en relaci´on con la media el peso es menos variable que el volumen.
2.4.
Medidas de tendencia central para datos
agru-pados
2.4.1.
Media, mediana y moda para datos agrupados
Media aritmetica para datos agrupados : cuando se tienen datos de variable numerica discreta o continua agrupados en tablas de frecuencias se identifica en cada clase un punto medio llamado ”marca de clase”
xi
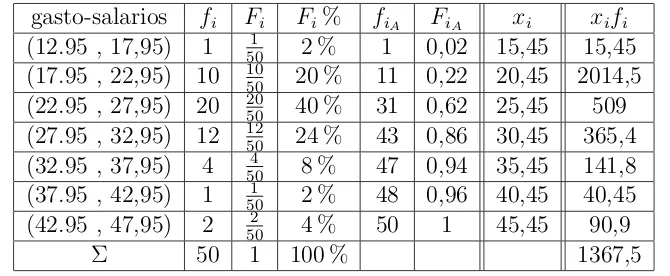
dato que representar´a numericamente a cada clase, suponiendo que los datos se descono-cen.( tambien se conoce como media aritmetica aproximada). En el ejemplo 1.2.1 se lleg´o a la siguiente tabla de frecuencias:
gasto-salarios fi Fi Fi% fiA FiA
(12.95 , 17,95) 1 501 2 % 1 0,02 (17.95 , 22,95) 10 1050 20 % 11 0,22 (22.95 , 27,95) 20 2050 40 % 31 0,62 (27.95 , 32,95) 12 1250 24 % 43 0,86 (32.95 , 37,95) 4 504 8 % 47 0,94 (37.95 , 42,95) 1 1
50 2 % 48 0,96 (42.95 , 47,95) 2 502 4 % 50 1
[image:26.612.198.430.385.522.2]Σ 50 1 100 %
Cuadro 2.1: Tabla o distribucion de frecuencias del ejemplo 1.2.1
ahora se indica una nueva columna con las marcas de cada clase, y otra columna donde est´e la ponderaci´on de cada marca de clase es decir
xifi
. donde se define la media aritmetica como:
¯
xa=
P xifi
n
gasto-salarios fi Fi Fi% fiA FiA xi xifi
(12.95 , 17,95) 1 501 2 % 1 0,02 15,45 15,45 (17.95 , 22,95) 10 1050 20 % 11 0,22 20,45 2014,5 (22.95 , 27,95) 20 20
50 40 % 31 0,62 25,45 509 (27.95 , 32,95) 12 1250 24 % 43 0,86 30,45 365,4 (32.95 , 37,95) 4 504 8 % 47 0,94 35,45 141,8 (37.95 , 42,95) 1 501 2 % 48 0,96 40,45 40,45 (42.95 , 47,95) 2 2
50 4 % 50 1 45,45 90,9
[image:27.612.132.467.86.224.2]Σ 50 1 100 % 1367,5
Cuadro 2.2: Tabla de frecuencias para el calculo de la media aproximada
Ahora se tiene que;
¯
xa=
P xifi
n =
1367,5
50 = 27,35
recordemos que este valor de la media es aproximado suponiendo que no se conocen los datos originales; usted decidir´a si es una buena aproximaci´on.Mediana para datos agru-pados: para el calculo de la mediana aproximada de un conjunto de datos, organizados en una tabla de frecuencias y realiza los siguientes pasos:
1. Se calcula la CLASE MEDIANA como la minima clase cuya frecuencia absoluta acumulada es mayor o igual a n2
2. se identifica elLicm limite o frontera inferior de la clase mediana.
3. se determinaFacm la frecuencia acumulada anterior a la de la clase mediana
4. se identifica lafcm la frecuencia absoluta de la clase mediana
5. se calcula la mediana de la siguiente forma:
M ediana=Licm+
n
2 −Facm
fcm
w
Que en el ejemplo 1.2.1 (cuadro 2.2) se verifica que:
50
2 = 25 donde la clase mediana esta en la clase numero 3 ya el 31 es la minima clase
mayor o igual a 25
Licm= 22,95
Facm = 11
mediana= 22,95 +
25−11 20
5 = 26,45
lo cual es muy familiar con la media aproximada calculada anteriormente.
Moda para datos agrupados :
Para calcular la moda en datos se deben tener en cuenta los siguientes pasos y consi-deraciones:
1. se identifica la clase modal, es decir la clase que tiene la mayor frecuencia absolu-ta.esto uede depender del tipo de forma como se agrupe la tabla.
2. se determina elLicmo, frontera inferior dela clase modal
3. se calcula la Mi−1, es decir la metrica o distancia entre la frecuencia absoluta de la
clase modal y la que antecede.
4. Mi+1, es decir la metrica o distancia entre la frecuencia de la clase modal y la
inmediatamente superior.
5. Se realiza el calculo de la moda
M oda=Licmo+
Mi−1
Mi−1+Mi+1
w
lo que en el ejemplo 1.2.1 ser´ıa:
M oda= 22,95 +
10 10 + 8
= 25,72
Percentiles para datos agrupados : Recordemos que la mediana es considerada una medida de posicion relativa; exactamete el 50 punto percentil, por tanto el procedimiento es igual, solo difiere en la identificacion de la clase percentil,como la minima clase cuya frecuencia absoluta acumulada es mayor o igual a 100np.y los terminos ahora son:
1. Licp: frontera inferior de la clase percentil.
2. Facp: frecuencia absoluta acumulada inmediatamente anterior a la clase percentil.
3. fcp: frecuencia absoluta de la clase percentil. luego se calcula
p− −esimo− −punto− −percentil=Licp+
(p%n)−Facp
fcp
w
Ejemplo 2.4.1 En en ejemplo 1.2.1 se quiere calcular el 85 % percentil lo que indica que la clase percentil se encuentra en la clase cuya frecuencia absoluta es mayor o igual a 85 % de 50 lo cual equivale a 42,5; lo cual se ubica en la cuarta clase, donde:
85 %percentil= 27,95 +
42,5−31 12
2.5.
Medidas de formas y analisis explaratorio de
datos
2.5.1.
Medidas de formas
[image:29.612.92.503.267.348.2]Una medida numerica que determina la forma de la distribuci´on es llamadosesgo, esto indica que una distribucion de datos puede ser simetrica, asimetrica positiva o asimitrica negativa; graficamente podemos interpretalo (figura 2.3). Donde la figura (a) indica una distribuci´on asimitrica positiva donde la moda < mediana < media y la (b) una distri-buci´on asimetrica negativa donde media < mediana < moda y cuando la distribucion es normalmente acampanada se interpreta que la distribuc´ıon de datos tiene una forma sime-trica donde media=mediana=moda. El sesgo de una distribuci´on puede medirse mediante
Figura 2.3: Formas de una distribuci´on
elcoeficiente de sesgo de pearson:
Pa=
3(¯x−mediana)
s
Donde podemos interpretar el resultado de la siguiente forma:
si Pa>0 ; entonces la distribuci´on est´a sesgada a la derecha
si Pa<0 ; entonces la distribuci´on est´a sesgada a la izquierda
si Pa= 0 ; entonces la distribuci´on est´a simetrica y acampanada
2.5.2.
Analisis exploratorio de datos
Cuando se tiene cualquier distribuci´on de datos lo primero que realiza antes de tomar cualquier decisi´on es explorarlos para ello se espera observar solo 5 numeros que son:
1. dato minimo
2. cuartil 1 (Q1).
3. mediana o segundo cuartil (Q2).
4. tercer cuartil (Q3).
5. dato maximo.
2.5.3.
Diagrama de cajas y bigotes
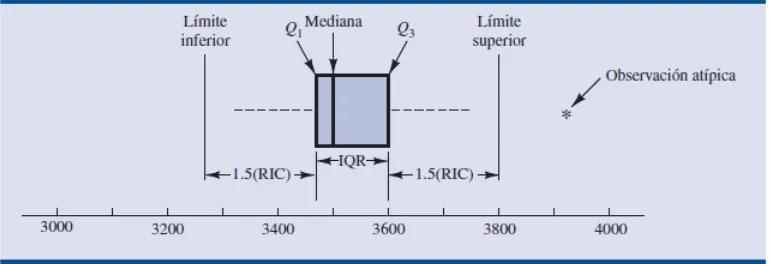
la mejor forma de sacarle provecho al resumen de los 5 numeros es graficarlos en el
diagrama de cajas y bigotes,donde proporciona la estadistica para identificar los valores atipicos de una distribucion de datos. los pasos para elaborar la caja son los siguientes:
1. Se dibuja la caja en cuyos extremos estan el primer y tercer cuartil; lo que indica que la longitud de la caja es el rango intercuatilico (RI)
2. Usando el rango intercuartilico (RI) se determinan los limites de los bigotes, donde se tiene un bigote superior hasta el valor
Q3+1,5RI
, y el bigote inferior hasta el valor
Q1−1,5RI
.
3. Luego de tener los bigotes cuya funcion es darle nombre a algunos datos que pue-den hacer mucho ruido al momento de analizar cualquier estadistico o parametro, entonces se determina que los valores que esten entre 1,5RI y 3RI se denominan va-loresatipicos moderados; ademas los valores mayores a 3RI se denominan atipicos extremos.
[image:30.612.121.506.468.600.2]para el ejemplo 2.2.1 se grafica con los pasos anteriores y los valores calculados an-teriormente para su respectivo diagrama de cajas (figura 2.4). resultando el unico valor atipico el 3925 clasificando como atipico moderado.
2.5.4.
Ejercicios
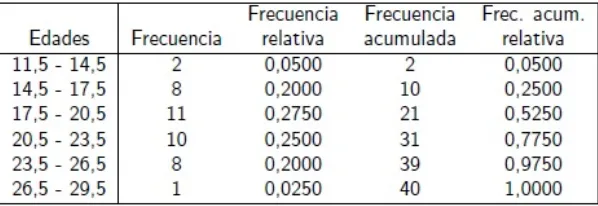
[image:31.612.147.446.167.270.2]1. A continuaci´on se presenta una tabla de frecuencia agrupada, para las edades de un grupo de personas que hay en una sala de concierto, apartir de estos datos responder las preguntas que aparecen a continuaci´on.
Cuadro 2.4: Ejercicio 2
¿Que porcentaje de personas tienen una edad entre 11,5 y 20,5 a˜nos?
¿Que edad tienen el 77,5 % de las personas?
Calcular e interpretar la media, la mediana y la moda de los datos.
2. Una revista publica regularmente las clasificaciones de funcionamiento y de calidad para muchos productos de consumo. se publicaron clsificaciones generales de una muestra de 16 televisores de precio intermedio en una revista. Las marcas y las calificaciones aparecen en la tabla siguiente.
Figura 2.4: Diagrama de venn para el ejemplo 3.1.11
Determine la calificaci´on promedio y forme el resumen de los cinco n´umeros.
¿Hay valores atipicos en los datos de televisores? justifique.
3. El departamento de control de calidad de una embotelladora de refrescos quiere evaluar dos de sus maquinas de llenado. para ello, se mide el proceso de llenado de 20 refrescos en cada una de las maquinas . Si se ofrece al publico refrescos con un contenido de 350 ml, determinar.
¿Cu´al de las dos maquinas cumple mejor, en promedio,con este requisito
Cual de las maquinas tiene mayor regularidad en el llenado. Utilizar la desvia-ci´on standar para justificar la respuesta.
calcular el coeficiente de variaci´on de pearson de cada maquina y realizar la comparaci´on.
calcular el coeficiente de asimetr´ıa de cada maquina e interpretar.
M´aquina 1
365 375 350 352 361
320 361 340 345 349
350 351 353 355 360
357 348 345 351 352
M´aquina 2
380 400 300 389 310
320 361 390 305 369
390 301 353 405 360
302 348 345 351 352
4. Para el ejercicio 1 del capitulo 1 calcular
la media, mediana y la moda e interpretar
coeficiente de variaci´on de pearson
coeficiente de asimetr´ıa o sesgo.
Rango intercuartilico
diagrama de cajas y bigotes e identificar los valores atipicos.
5. millones de estaunidenses trabajan para sus empresas desde sus hogares. A continua-ci´on se presentan una muestra de datos de las edades de las personas que trabajan desde sus hogares:
18 54 20 46 25 48 53 27 26 37
40 36 42 25 27 33 28 40 45 25
calcule e interprete la media y la moda
calcule el primer y el tercer cuartil
calcule e interprete el percentil 12.
calcule el rango intercuartilico.
6. El profesor javier borra accidentalmente una calificaci´on de uno de sus 6 estudiantes; las cinco calificaciones restantes son: 3.8 ; 4.3 ; 2.2 ; 4.5 y 3.3 y la media aritmetica de las 6 calificaciones es 3.5. Encuentre la calificaci´on que borr´o javier.
7. En el ejercicio 4 del capitulo 1 calcular:
la media, la mediana, moda, el rango y el sesgo.
8. Diga si la informaci´on dada es verdadera o falsa. Justifique siempre su respuesta. En caso de que sea falso d´e un contraejemplo.
La suma de los valores con respecto a la media para cualquier conjunto de datos es 1.
Si la desviaci´on estandar de un conjunto de datos es 0, entonces los datos son iguales.
El valor de la desviaci´on estandar es menor que la de la varianza.
No existen datos de tal forma que sean iguales el rango y la desviaci´on estandar.
si el ingreso medio de 25 trabajadores es de $ 2.500.000, entonces el ingreso total es de$10.000.000.
Si 10 calificaciones tienen una media de 2,0 y 27 calificaciones una media de 3,0, entonces,la media del grupo total de 37 calificaciones es 2,5.
Existen datos con desviaci´on estandar negativa.
En una distribuci´on simetrica, la media, la mediana y la moda son iguales.
En una distribuci´on positivamente sesgada, la mediana es mayor que la media.
La desviaci´on estandar est´a dada en la mismas unidades que la media.
Toda informaci´on num´erica proporciona datos cuantitativos.
Cuando todos los datos son categ´oricos, la moda es la ´unica medida de tendencia central que se puede utilizar.
Si el primer cuartil en el primer examen de estadistica fue de 3,0, entonces, este valor indica que el 25 % de los estudiantes ganaron el examen.
Six es un dato de una muestra ys2 es la varianza de esa muestra, entonces la expresi´onx−s2 carece de sentido.
Si un conjunto de datos no es asim´etrico, entonces su coeficiente de sesgo es 1.
Introducci´
on a la teoria de
probabilidad
3.1.
Conceptos basicos
3.1.1.
Experimentos
Definici´on 3.1.1 Un experimento es toda acci´on bien definida que conlleva a un resultado ´
unico bien definido;se clasifican en experimentosdeterminiscos y aleatorios.
Definici´on 3.1.2 Un experimento es determin´ıstico, cuando al repetirse bajo las mis-mas condiciones, genera siempre el mismo resultado
Ejemplo 3.1.1 cualquier experimento que se realiza en un laboratorio bajo las instruccio-nes de una guia y con un objetivo definido, son considerados como deterministicos; como, la caida libre de cuerpos; la ley de la conservaci´on de la energia.
Definici´on 3.1.3 Un experimento es aleatorio o estocastico cuando satisface las si-guientes condiciones:
Todos los resultados del experimento son conocidos antes de ejecutarlo.
El resultado de cualquier ejecuci´on del experimento no se puede conocer de antemano. La presencia de un patr´on de regularidad en los resultados,el cual se manifiesta tras la observaci´on de un gran numero de repeticiones.
Ejemplo 3.1.2 Los juegos de azar como lanzamientos de dados y monedas, modelo de urnas,cartas son considerados experimentos aleatorios. Sin embargo, hay otros tipos de ejemplos de experimentos como los siguientes:
Una bombilla manufacturada en una planta es expuesta a una pueba de vida y el tiempo de duraci´on de una bombilla es registrado.. En este caso no se conoce cual ser´a el tiempo de duraci´on de la bombilla seleccionada, pero claramente se puede conocer de antemano que ser´a un valor entre 0 y ∞ horas
Seleccionar una planta y medir su altura
La duraci´on de vida de las personas, que viven bajo condiciones semejantes, var´ıa y no se puede predecir.
3.1.2.
Espacio muestral y eventos
Definici´on 3.1.4 El conjunto de todos los resultados de un experimento estocastico se denomina, espacio muestral, y se simboliza con la letra griega
Ω
.Los elementos del espacio muestral se denominanpuntos muestrales.
Ejemplo 3.1.3 En el lanzamiento de un dado, el espacio muestral viene dado por
Ω ={1,2,3,4,5,6}
En el lanzamiento de 2 monedas indistinguibles (simultaneamente), el espacio mues-tral
Ω ={(c, s); (s, s); (c, c)}
En el lanzamiento de 2 monedas distinguibles lanzadas al mismo tiempo, el espacio muestral
Ω ={(c, s); (s, c); (s, s); (c, c)}
se instala una computadora nueva en un banco. La computadora controla todas las transferencias bancarias, guardando el valor exacto de cada transacci´on, mas sin embargo no registra transacciones menores a un millon ni mayores 150 millones. se define el experimento aleatorio como los valores que registra la computadora.Aqui el espacio muestral es el conjunto de todos los valores que se encuentren entre 1 millon y 150 millones, ya que el resultado del experimento es el valor de la transaccion que registra la computadora.
Observaci´on 3.1.1 Los eventos comunmente se simbolizan con letras mayusculas A,B ´o C , por ejemplo. Cuando un evento tiene un solo elemento se denomina evento elemental o simple.
Definici´on 3.1.6 como caso particular se tiene que si ∅ y Ω son eventos, es decir son subconjuntos deΩ; el conjunto∅se denomina evento imposible, es decir que nunca puede suceder,y el conjunto Ωse denomina evento seguro, que siempre sucede.
Ejemplo 3.1.4 En el experimento de lanzar un dado dos veces se tiene que
Ω ={(1,1); (1,2); (1,3); (1,4); (1,5); (1,6); (2,1); (2,2);. . .; (6,6)}
son los siguientes ejemplos de eventos aleatorios:
seaA={(5,5); (6,4); (4,6)} ; el evento que la suma de las caras sea 10
seaB ={(1,1); (2,2); (3,3); (4,4); (5,5); (6,6)}; el evento que salgan numeros igua-les.
seaC =∅; la sumas de las caras sea 13.
3.1.3.
Operaciones con eventos
Definici´on 3.1.7 Sean A y B eventos de un espacio muestral Ω; se denomina el evento interseccion de A y B, simbolizado porA∩B; al evento conformado por todos los puntos muestrales que pertenecen a A y B simultaneamente. Es decir:
A∩B={x∈Ω :x∈A∧x∈B}
siendo x un punto muestral.
Definici´on 3.1.8 Sean A y B eventos de un espacio muestral Ω; se denomina el evento Uni´on de A y B, simbolizado por A∪B; al evento conformado por todos los puntos muestrales que pertenecen a por lo menos uno de los dos eventos es decir a A o a B o ambos. Es decir:
A∪B={x∈Ω :x∈A∨x∈B}
Definici´on 3.1.9 Sean A y B eventos de un espacio muestral Ω; se denomina el evento diferencia de A y B, simbolizado porA−B; al evento conformado por todos los puntos muestrales que pertenecen a A y no pertencen a B. Es decir:
A−B ={x∈Ω :x∈A∧x /∈B}
siendo x un punto muestral.
Definici´on 3.1.10 Sean A el eventos de un espacio muestral Ω; se denomina el even-to complemeneven-to de A, simbolizado por A¯; al evento conformado por todos los puntos muestrales que no pertenecen a A . Es decir:
¯
A={x∈Ω :x /∈A}
siendo x un punto muestral.
Ejemplo 3.1.5 se lanza un dado una dos veces; considerar a A:la suma de los resul-tados obtenidos sea 10 y B:los resultados de los dados sean numeros pares. observamos como resulta y se interpreta cada uno de los siguientes eventos.
A∪B ={(2,2); (2,4); (2,6); (4,2); (4,4); (4,6); (6,2); (6,4); (6,6); (5,5)}; lo que sig-nifica que resulte ambos pares o que la suma sea un 10.
A∩B ={(4,6); (6,4)}; lo que significa que resulte ambos pares y la suma sea un 10.
A−B =∅ es decir que es imposible que resulte solamente numeros pares, o mejor que resulten numeros pares y la suma no sea 10.
Definici´on 3.1.11 Sean A y B eventos de un espacio muestral Ω; si los eventos A y B no tienen en comun ningun punto muestral,entonces se denominan mutuamente exclu-yenteso disjuntos; es decir A y B son mutuamente excluyente si
A∩B =∅
.
Definici´on 3.1.12 Sean A y B eventos de un espacio muestral Ω; si los eventos A y B no tienen en comun ningun punto muestral,entonces se denominan mutuamente exclu-yenteso disjuntos; es decir A y B son mutuamente excluyente si
A∩B =∅
Definici´on 3.1.13 Sean A1, A2, . . . , An eventos no vacios de un espacio muestral Ω.
si se cumple que A1 ∪A2 ∪. . . ∪An = Ω entonces los n eventos se denominan
colectivamente exhaustivos.
si A1, A2, . . . , An son colectivamente exhaustivos y adem´as son mutuamente
exclu-yentes dos a dos, entonces estos neventos conforman una partici´on de Ω.
[image:38.612.169.474.293.422.2]Un instrumento util para trabajar las operaciones con eventos son los diagramas de venn euler; en las figuras (3.1);(3.2);(3.3), se representan graficamente las operaciones mencio-nadas anteriormente.
Figura 3.1: Operaciones entre eventos
Figura 3.2: Operaciones entre eventos
Ejemplo 3.1.6 sea Ω = {1,2,3,4,5} el espacio muestral de un experimento aleatorio. sean A={2},B ={1,4},C ={3,5},D={2,3,4,5} , entonces podemos concluir que:
[image:38.612.168.469.490.601.2]Figura 3.3: Operaciones entre eventos
B y D son colectivamente exhaustivos, pero no forman una partici´on de Ω por que
B∩D={4} 6= Ω.
A, C y D no son colectivamente exhaustivos; por que 1∈/ A∪B∪C. Podemos interpretar mejor en la figura 3.4.
Figura 3.4: Diagrama de venn para el ejemplo 3.1.6
Ejemplo 3.1.7 La junta directiva de una empresa productora de cosmeticos quiere lanzar un nuevo producto en la ciudad. para esto la empresa realiza un estudio de mercadeo en el cual se pide establecer: ¿Cu´al es la poblacion de referencia(Ω)? ¿cuales son los posibles consumidores del producto (C)?, Si el producto fue dise˜nado para personas entre 18 y 25 a˜nos,¿Cu´al es la poblaci´on objetivo (B)? ¿Cu´al es la poblaci´on objetivo si se quiere que ´esta tenga la posibilidad de comprar el producto (D)? ¿Que poblaci´on hay que tener en cuenta para realizar las campa˜nas publicitarias (P)?. Con los conjuntos de individuos establecidos anteriormente, ¿ Es posible obtener una partici´on de los consumidores del producto?.
Es necesario tener en cuenta que el producto se va a distribuir por toda la ciudad, luego la poblac´ıon de referencia es:
[image:39.612.188.411.352.493.2]Sin embargo no todos los individuos que transitan por la ciudad son los consumidores potenciales del producto, ya que los menores de edad no son actos para utilizar este cosmetico. entonces los posibles consumidores del producto es:
C = Ω-{los menores de edad}.
De otra parte, si el producto fue dise˜nado para personas entre 18 y 25 a˜nos, como se establece una condici´on inicial para la poblaci´on objetivo, entonces se tiene que ´esta es igual a:
B={ las personas que transitan por la ciudad con una edad entre 18 y 25 a˜nos}. Ahora teniendo en cuenta que no todos los consumidores potenciales tienen la capa-cidad de comprar el producto, en primera instancia se sigue que.
D ={ las personas que tienen el uso libre de capital para la adquisi´on de cosmeticos para su uso}
la poblaci´on que se debe tener en cuenta para realizar las campa˜nas publicitarias es
P =B∩D
.
para establecer si los cojuntos B,D,P conforman una partici´on de A,basta ver que no se cumple al menos una de las condiciones necesarias para tener una partici´on. por ejemplo si se observa que B∩D6=∅ y por lo tanto B,D y P no conforman una partici´on de C.
3.1.4.
Propiedades relacionadas con eventos
Teorema 3.1.1 Sean A y B eventos de un espacio muestral Ω. entonces son validas las siguientes afirmaciones.
1. Ω =¯ ∅
2. ¯∅= Ω
3. A∩ ∅=∅
4. A∪ ∅=A
5. A∩A¯=∅
6. A∪A¯= Ω
7. A∪B = ¯A∩B¯
3.1.5.
teoria de probabilidades
Ahora presentaremos las tres formas iniciales de asignar la probabilidad de ocurrencia de un evento, como lo son el metodo frecuentista, clasico y subjetivo. recordemos que no son definiciones de probabilidad solo es una forma de asiganci´on.
Definici´on 3.1.14 La probabilidad de un evento aleatoria A denotada con P(A) es una medida de la incertidumbre relacionada con la posibilidad de ocurrencia del evento A.
3.1.6.
metodo frecuentista
Definici´on 3.1.15 Se supone que un experimento aleatorio se repite n veces y que un evento A asociado con estos experimentos ocurre exactamente k veces. Entonces la fre-cuencia relativa de A. denotada confn(A), se define como la proporci´on entre la cantidad
de veces que ocurre el evento A y el numero total de repeticiones del experimento aleatorio, es decir:
fn(A) =
k n
Nota 3.1.1 A medida que aumenta el numero de repeticiones de un experimento aleatorio, las frecuencias realtivas son m´as estables, es decir, tiende a ser casi las mismas. en este caso se dice que el experimento muestra Regularidad estadistica ( estabilidad en las frecuencias relativas).
Definici´on 3.1.16 Sea A un evento asociado a un experimento aleatorio,la probabilidad empiricaes igual a la frecuencia relativa de A, al efectuar el experimento cuantas veces sea posible. es decir :
P(A) = l´ım
n→∞fn(A)
considerar las siguientes situaciones:
Ejemplo 3.1.8 una maquina empaca 50 cajas de cereales en 5 minutos, esta maquina empieza su funcionamiento a las 9:00 a.m y termina a las 9:00 p.m., hora en que se toma una muestra de tama˜non del lote, y se revisa el numero de cajas de cereal mal empacadas es decir con defectos. Si el numero de cajas de cereal est´a empacada por encima o por debajo de los limites especificados por el departamento de control de calidad, entonces la produccion del dia se puede distribuir.de otra manera no es posible. Teniendo en cuenta que no hay cambios en el programa de produccion de un dia a otro, se puede determinar la probabilidad de la producci´on del dia no se pueda distribuir mediante:
(no de dias en la que la producci´on no se pudo distribuir)÷ (no de dias en los que se tomaron los registros)
3.1.7.
M´
etodo cl´
asico
Es posible identificar diversos casos en los que se asocie la misma probabilidad a cada evento elemental de un experimento aleatorio. En tales situaciones, se habla de experi-mentos laplacianos o cl´asicos, donde se tienen finitos resultados que suceden con la misma probabilidad ( eventos elementales equiprobables). los juegos de azar hacen parte de este tipo de experimentos.
Definici´on 3.1.17 Sea Ω 6= ∅ un espacio muestral finito asociado con un experimento laplaciano y A un evento aleatorio incluido en Ω. Se define la probabilidad Clasica de A denotada P(A) como el cociente entre el numero de puntos muestrales de A y el nuemro de puntos muestrales deΩ. es decir:
P(A) = #A #Ω
Donde # es el numero de elementos del conjunto dado.
Ejemplo 3.1.9 En el ejemplo 3.1.4 se tiene que
P(A) = 363 = 121
P(B) = 366 = 16
3.1.8.
M´
etodo subjetivo
Existen situaciones donde las probabilidades de ocurrencia del evento se estiman me-diante el grado de credibilidad bas´andose en experiencias pasadas; el metodo que permite asiganar probabilidades a estos eventos se denomina el metodo subjetivo:
Definici´on 3.1.18 La probabilidad subjetiva se define como la probabilidad que expresa un grado de creencia individual sobre la posibilidad de que un evento ocurra.
3.1.9.
Propiedades de la probabilidad
cuando se trabaja con probabilidades sin importar sin importar la forma como se asignen, siempre deben satisfacer las condiciones que se presentan a continuaci´on, pues formalmente son ellas las que definen propiamente una medida de probabilidad.
Teorema 3.1.2 Para eventos A,B y C de un espacio muestral Ω6=∅ se tiene que:
P(∅) = 0
si los eventos A, B y C son mutuamente excluyentes, entonces P(A∪B ∪C) =
P(A) +P(B) +P(C)
P(A= 1−P(A) siendo A el complemento de A.
0≤P(A)≤1
P(A∪B) =P(A) +P(B)−P(A∩B) tambien llamada formula de silvester para la adici´on de dos eventos.
P(A∪B∪C) =P(A)+P(B)+P(C)−P(A∩B)−P(A∩C)−P(B∩C)+P(A∩B∩C)
formula de sivester para la adici´on de tres eventos.
P(A) =P(A∩B) +P(A∩B
Nota 3.1.2 la demostraci´on del teorema anterior no est´a aun destro del proposito de estas notas de clase.
Ejemplo 3.1.11 Sean A, B y C tales que P(A) = 0,5 ; P(B) = 0,26 ; P(C) = 0,55;
P(A∩B) = 0,15 ; P(A∩C) = 0,25 ; P(B∩C) = 0,15 y P(A∩B∩C= 0,05 . calcular las siguientes probabilidades:
P(A∪B)
P(A∩C P(A∪C)
P(A∪B∪C)
solucion :
P(A∪B)P(A) +P(B)−P(A∩B) = 0,50 + 0,26−0,15 = 0,61
P(A∩C=P(A)−P(A∩C) = 0,5−0,25 = 0,25
P(A∪C) = 1−P(A∪C) = 1−P(A∩C) = 1−0,25 = 0,75
P(A∪B∪C) = 0,5 + 0,26 + 0,55−0,15−0,25−0,15 + 0,05 = 0,81
Figura 3.5: Diagrama de venn para el ejemplo 3.1.11
3.1.10.
Ejercicios
1. En el men´u del d´ıa, un restaurante vegetariano ofrece una ensalada especial que contiene tres tipos de verduras distintas que son las preferidas por ciertos habitantes de una ciudad: Esp´arrago (A);Br´ocoli (B); y Coliflor(C). A continuaci´on aparece el porcentaje de clientes del restaurante que pide determinada(s) verdura(s).
70 % A 80 % B 75 % C 85 % A o B 90 % A o C 95 % B o C
98 % A o B o C.
si A significa que un cliente ordena la ensalada de Esparrago. escribir verbalmente lo que significa cada uno de los siguientes eventos y calcular las probabilidades.
A∩B∩C
( ¯A∩B¯)∩C
(A∪B)∩C¯ B∪(C∩A¯)
2. Un grupo de estudiantes del politecnico debe presentar un examen que consta de 5 preguntas;En cada una debe contestarV: verdadero o F: falso
Hallar el espacio muestral Ω del experimento
Calcular la probabilidad del evento que consiste en que por lo menos tres de las 4 preguntas las conteste F.
a. El delincuente cometi´o un delito con arma blanca.
b. El delincuente no sea adicto pero si ejecute sus delitos con arma blanca.
c. El delincuente utilice un arma distinta al arma blanca para sus atracos
d. El delincuente sea adicto a alguna droga o cometa delitos con arma blanca. 4. la probabilidad de que un medico diagnostique correctamente una enfermedad es
0,63. la probabilidad de que el medico sea egresado de una universidad del exterior es de 0,41. Si una persona asiste a una cita medica:
a. ¿Cu´al es la probabilidad de que el medico sea egresado de una universidad nacio-nal?
b. ¿Cu´al es la probabilidad de que el medico diagnostique correctamente la enfer-medad y sea egresado del extranjero si el el 20 % de los medicos son egresados del extranjero y realizan diagnosticos equivocados.
c. ¿Cu´al es la probabilidad de que el medico no se haya graduado en el pais y diagnostique correctamente la enfermedad?
d. ¿cual es la probabilidad de que el medico diagnostique correctamente la enferme-dad o sea egresado de una universienferme-dad nacional.
5. En los ´ultimos a˜nos, las compa˜n´ıas de tarjeta de cr´edito han hecho un gran esfuerzo para lograr nuevas cuentas de estudiantes universitarios. Suponga que una muestra de estudiantes que el polit´ecnico costa atl´antica proporcion´o la siguiente informaci´on sobre si pose´ıa una tarjeta de cr´edito bancaria y/o una tarjeta de cr´edito de viaje. El 50 % posee tarjeta de cr´edito bancaria, el 37 % posee tarjeta de cr´edito de viaje. Si se selecciona un estudiante al azar cual es la probabilidad de que posea tarjeta de cr´edito bancaria o no tenga tarjeta de cr´edito de viaje, si el 21 % de los estudiantes posee ambas.
6. Un comit´e de investigaci´on ha propuesto tres proyectos para la mejora del manejo del capital en una empresa. simbolizados los eventosA1, A2, A3 , donde por ejemplo
,A1 significa .el proyecto 1 fue aceptado”. supongamos que:
P(A1) = 0,30;P(A2) = 0,22;P(A3) = 0,35;P(A1∩A2) = 0,08
P(A1∩A3) = 0,09;P(A2∩A3) = 0,06;P(A1∩A2∩A3) = 0,02
Exprese verbalmente cada uno de los siguientes eventos y determine la probabilidad de que ocurra cada uno de ellos:(tomado de [2])
a. A1∪A2
b. A1∩A2
c. A1∪A2∪A3
d. A1∩A2∩A3
7. Supongamos que los empleados de cierta empresa se tabulan segun los siguientes eventos: tecnicos en gesti´on (T); tecnologos en gesti´on (Tg); administradores (A); y se encontr´o el porcentaje actual de los anteriores eventos:
12 % (T) ; 7 % (Tg) ; 5 % (A) ; 15 % (T ´o Tg) ; 14 % (T ´o A) ; 10 % (Tg ´o A) ; 1 % (T y Tg y A)
si se escoje un trabajador al azar, exprese verbalmente cada uno de los siguientes eventos y determine la probabilidad de que ocurra cada uno de ellos:
a. T
b. T ∩T g∩A
c. T ∪A
d. T ∩T g∩A
[1] Blanco. liliana probabilidad, segunda edicion, Unilibros, colombia 2004.
[2] Webster. Allen Estadistica aplicada a los negocios y la economia, tercera edicion,
MacGraw-Hill, colombia 2001.
[3] LLinas. Humberto y Rojas. carlos Estadistica descriptiva y distribuciones de
probabilidad, primera edicion, Uninorte, colombia 2006.
[4] Anderson. David y Sweeney. Dennis Estadistica aplicada para administraci´on y
economia, decima edicion, Cengage learning, Mexico.D.F 2008.
[5] Christensen. H Estadistica paso a paso, primera edicion, Trillas, colombia 2008.