Instituto Tecnológico y de Estudios Superiores de Monterrey Campus Monterrey
Monterrey, Nuevo León a
Por medio de la presente hago constar que soy autor y titular de la obra
titulada"
en los sucesivo LA OBRA, en virtud de lo cual autorizo a el Instituto Tecnológico
y de Estudios Superiores de Monterrey (EL INSTITUTO) para que efectúe la divulgación, publicación, comunicación pública, distribución y reproducción, así como la digitalización de la misma, con fines académicos o propios al objeto de
EL INSTITUTO.
El Instituto se compromete a respetar en todo momento mi autoría y a
otorgarme el crédito correspondiente en todas las actividades mencionadas anteriormente de la obra.
De la misma manera, desligo de toda responsabilidad a EL INSTITUTO
por cualquier violación a los derechos de autor y propiedad intelectual que cometa el suscrito frente a terceros.
Nombre y Firma
AUTOR (A)
de 200
Lic. Arturo Azuara Flores:
c
La Relatividad en la Comparación de Algoritmos de
Optimización Ciega: Hacia la Coevolución de Algoritmos y
Problemas-Edición Única
Title La Relatividad en la Comparación de Algoritmos de Optimización Ciega: Hacia la Coevolución de Algoritmos y Problemas-Edición Única
Authors Carlos David Toledo Suárez
Affiliation ITESM-Campus Monterrey
Issue Date 2006-12-01
Item type Tesis
Rights Open Access
Downloaded 19-Jan-2017 10:23:22
La Relatividad en la Comparaci´
on de
Algoritmos de Optimizaci´
on Ciega: Hacia
la Coevoluci´
on de Algoritmos y Problemas
T E S I S
Maestr´ıa en Ciencias en Sistemas Inteligentes
Instituto Tecnol´
ogico y de Estudios Superiores de Monterrey
Por
Ing. Carlos David Toledo Su´
arez
La Relatividad en la Comparaci´
on de
Algoritmos de Optimizaci´
on Ciega: Hacia
la Coevoluci´
on de Algoritmos y Problemas
TESIS
Maestr´ıa en Ciencias en
Sistemas Inteligentes
Instituto Tecnol´
ogico y de Estudios Superiores de Monterrey
Por
Ing. Carlos David Toledo Su´
arez
Instituto Tecnol´
ogico y de Estudios Superiores de
Monterrey
Divisi´
on de Tecnolog´ıas de Informaci´
on y Electr´
onica
Programa de Graduados de la Divisi´on de Tecnolog´ıas de Informaci´on y Electr´onica
Los miembros del comit´e de tesis recomendamos que la presente tesis de Carlos David Toledo Su´arez sea aceptada como requisito parcial para obtener el grado acad´emico
de Maestro en Ciencias en: Sistemas Inteligentes
Comit´
e de tesis:
Dr. Manuel Valenzuela Rend´on
Asesor de la tesis
Dr. Hugo Terashima Mar´ın
Sinodal
Dr. Eduardo Uresti Charre
Sinodal
Dr. Graciano Dieck Assad
Director del Programa de Graduados de la Divisi´on de Tecnolog´ıas de
Informaci´on y Electr´onica
La Relatividad en la Comparaci´
on de
Algoritmos de Optimizaci´
on Ciega: Hacia
la Coevoluci´
on de Algoritmos y Problemas
Por
Ing. Carlos David Toledo Su´
arez
TESIS
Presentada a la Divisi´on de Tecnolog´ıas de Informaci´on y Electr´onica Este trabajo es requisito parcial para obtener el grado acad´emico de Maestro en
Ciencias en Sistemas Inteligentes
Instituto Tecnol´
ogico y de Estudios Superiores de Monterrey
Campus Monterrey
Reconocimientos
Al Consejo Nacional de Ciencia y Tecnolog´ıa y a la c´atedra de Optimizaci´on Evo-lutiva del Instituto Tecnol´ogico y de Estudios Superiores Campus Monterrey por el apoyo en la realizaci´on de mis estudios de maestr´ıa y en la investigaci´on que dio origen a esta tesis.
A mi asesor de tesis y sinodales.
A mi familia. . .
Carlos David Toledo Su´
arez
La Relatividad en la Comparaci´
on de
Algoritmos de Optimizaci´
on Ciega: Hacia
la Coevoluci´
on de Algoritmos y Problemas
Carlos David Toledo Su´arez, M.C.
Instituto Tecnol´ogico y de Estudios Superiores de Monterrey, 2006
Asesor de la tesis: Dr. Manuel Valenzuela Rend´on
Un sue˜no de la computaci´on evolutiva es generar algoritmos que puedan adaptarse a los problemas que enfrentan y a trav´es de estas adaptaciones volverse m´as aptos, an´alogamente a los procesos mediante los cuales las especies biol´ogicas evolucionan en conjunto, coevolucionan. Con esta analog´ıa en mente es que se llama coevoluci´on de
algoritmos y problemas al proceso de adaptaci´on de algoritmos para resolver problemas
sucesivamente m´as dif´ıciles. Saber qu´e es f´acil o dif´ıcil para cierto algoritmo de opti-mizaci´on es un problema de investigaci´on abierto para el que se cree no puede existir un marco te´orico definitivo, por la complejidad de los sistemas implicados.
La tesis descrita en este documento propone que es posible usar a la coevoluci´on de algoritmos y problemas para resolverlo, bas´andose en la hip´otesis de que planteado como problema de optimizaci´on s´olo es posible saber qu´e es f´acil o dif´ıcil para un algoritmo de optimizaci´on ciega tomando en cuenta a otro.
La principal contribuci´on de la tesis es mostrar que asumir la hip´otesis de la re-latividad en la comparaci´on de algoritmos de optimizaci´on ciega hace posible la imple-mentaci´on de la coevoluci´on de algoritmos y problemas, que el problema planteado por dicha coevoluci´on es complementario al de buscar problemas que hagan quedar mejor a un algoritmo frente a otro, a los que se les da el nombre deproblemas tendenciosos.
´Indice general
Reconocimientos VII
Resumen VIII
´Indice de tablas XI
´Indice de figuras XII
Cap´ıtulo 1. Introducci´on 1
1.1. Antecedentes . . . 1
1.2. Definici´on del problema . . . 2
1.3. Preguntas de investigaci´on . . . 2
1.4. Hip´otesis . . . 3
1.5. Objetivo . . . 3
1.6. Contribuci´on de la investigaci´on . . . 3
1.7. Organizaci´on del documento . . . 3
Cap´ıtulo 2. Algoritmos de optimizaci´on ciega y su comparaci´on vista como problema de optimizaci´on 5 2.1. Definiciones . . . 5
2.2. No Free Lunch is No Big Deal . . . 7
2.3. La relatividad en la comparaci´on de algoritmos de optimizaci´on . . . . 8
2.4. Medida de desempe˜no y problemas tendenciosos . . . 9
2.5. Resumen . . . 10
Cap´ıtulo 3. Algoritmo de coevoluci´on incremental 12 3.1. Contras a la b´usqueda de problemas tendenciosos como problema de optimizaci´on . . . 12
3.2. Algoritmo gen´etico generacional simple y coevoluci´on . . . 13
3.3. Algoritmo de coevoluci´on incremental . . . 15
3.4. Coevoluci´on incremental de algoritmos y problemas . . . 16
Cap´ıtulo 4. La arena y los contendientes 20
4.1. Codificaci´on de problemas . . . 20
4.2. Algoritmos a competir y la codificaci´on de sus afinaciones . . . 23
4.2.1. AG generacional simple . . . 23
4.2.2. Recocido simulado . . . 24
4.2.3. B´usqueda aleatoria . . . 26
4.3. Operadores de cruce y mutaci´on . . . 26
4.4. Resumen . . . 27
Cap´ıtulo 5. Experimentos y an´alisis de resultados 29 5.1. AG vence a recocido simulado . . . 30
5.2. Recocido simulado vence a AG . . . 30
5.3. B´usqueda aleatoria vence a AG . . . 31
5.4. B´usqueda aleatoria vence a recocido simulado . . . 31
5.5. An´alisis de resultados y comparaci´on con teor´ıas de dificultad . . . 32
5.5.1. Intermezzo mutacional . . . 35
5.5.2. Teor´ıa de enga˜no . . . 36
5.5.3. Escalamiento y multimodalidad . . . 40
5.5.4. Espacios de aptitudes . . . 41
5.6. Conclusiones del an´alisis . . . 47
5.7. Resumen . . . 48
Cap´ıtulo 6. Conclusiones 50 6.1. Investigaciones futuras . . . 51
6.1.1. Codificaci´on de problemas y algoritmos . . . 51
6.1.2. Medida de desempe˜no y eficiencia . . . 51
6.1.3. Ecuaciones de ajuste y par´ametros del ACI e inclusi´on de m´as poblaciones . . . 52
6.2. Comentarios finales . . . 52
Bibliograf´ıa 53
´Indice de tablas
3.1. Pasos b´asicos de un AG generacional simple . . . 14
3.2. Pasos b´asicos de un ACS . . . 15
3.3. Pasos b´asicos de un ACI . . . 17
4.1. Codificaci´on de la afinaci´on del AG . . . 24
4.2. Pasos b´asicos del recocido simulado . . . 25
4.3. Codificaci´on de la afinaci´on del recocido simulado . . . 25
4.4. Cruce de un punto en un cromosoma binario de 10 bits . . . 27
5.1. Par´ametros del ACI usados en todos los experimentos . . . 29
5.2. Datos sobre ganadores de competencias de 19 bits para el problema de la figura 5.1: (a) Evaluaci´on, (b) diferencia entre miembros que lo forman, (c) n´umero de bits que no coinciden con el ´optimo global, (d) m´axima separaci´on entre bits no coincidentes. El promedio de las evaluaciones es 0.3399. . . 43
5.3. Datos sobre ganadores de competencias de 19 bits para el problema de la figura 5.3: (a) Evaluaci´on, (b) diferencia entre miembros que lo forman, (c) n´umero m´ınimo de bits que no coinciden con uno de los 351 ´optimos globales, (d) m´ınima de las m´aximas separaciones entre bits no coincidentes con alguno de los ´optimos globales. El promedio de las evaluaciones es 0.0214. . . 44
5.4. Datos sobre ganadores de competencias de 19 bits para el problema de la figura 5.5: (a) Evaluaci´on, (b) diferencia entre miembros que lo forman, (c) n´umero m´ınimo de bits que no coinciden con uno de los 2 ´optimos globales, (d) m´ınima de las m´aximas separaciones entre bits no coincidentes con alguno de los ´optimos globales. El promedio de las evaluaciones es 0.1387. . . 45
´Indice de figuras
2.1. Curvas de mejor encontrado para dos algoritmos a1 y a2 (con n grande). 10
3.1. Funci´on tanh(x) . . . 19 4.1. Ejemplo de pasos en la codificaci´on de funciones a usar: (a) la longitud
del segmento ies ri y Pji=1θj es el ´angulo entre los segmentosi−1 e i
, (b) rotaci´on, (c) reordenamiento de dominio y escalamiento. . . 21 4.2. Funci´on con α =π/100 yN = 103 . . . . 22
4.3. Funci´on con α =π/10 yN = 103 . . . . 22
4.4. Ejemplo del efecto del cruce para posibles funciones g o h con N = 103
y α=π/100 . . . 27 5.1. Curvas de mejor encontrado obtenidas usando las afinaciones m´as aptas
y gr´afica del mejor problema tendencioso en el que AG vence a RS . . . 30 5.2. Historia de las mejores aptitudes de las afinaciones en la corrida del ACI
en que se encontr´o el problema de la figura 5.1. . . 31 5.3. Curvas de mejor encontrado obtenidas usando las afinaciones m´as aptas
y gr´afica del mejor problema tendencioso en el que RS vence a AG . . . 32 5.4. Historia de las mejores aptitudes de las afinaciones en la corrida del ACI
en que se encontr´o el problema de la figura 5.3. . . 33 5.5. Curvas de mejor encontrado obtenidas usando las afinaciones m´as aptas
y gr´afica del mejor problema tendencioso en el que BA vence a AG . . 34 5.6. Curvas de mejor encontrado obtenidas usando las afinaciones m´as aptas
y gr´afica del mejor problema tendencioso en el que BA vence a RS . . . 35 5.7. Ejemplos de problemas en los que es derrotado el AG. En los dos
supe-riores fue derrotado por RS y en los infesupe-riores por BA. . . 36 5.8. (a) Distribuci´on de frecuencias de la evaluaci´on de los m´aximos locales,
5.9. (a) Distribuci´on de frecuencias de la evaluaci´on de los m´aximos locales, (b) distribuci´on de las evaluaciones de los m´aximos locales versus su m´ınima distancia de Hamming a uno de los 351 m´aximos globales , (c) distribuci´on de frecuencias de la cantidad de pasos dados antes de encontrar un m´aximo local; todos para el problema de la figura 5.3. . . 38 5.10. (a) Distribuci´on de frecuencias de la evaluaci´on de los m´aximos locales,
(b) distribuci´on de las evaluaciones de los m´aximos locales versus su m´ınima distancia de Hamming a uno de los dos m´aximos globales , (c) distribuci´on de frecuencias de la cantidad de pasos dados antes de en-contrar un m´aximo local; todos para el problema de la figura 5.5. . . . 39 5.11. (a) Distribuci´on de frecuencias de la evaluaci´on de los m´aximos locales,
(b) distribuci´on de las evaluaciones de los m´aximos locales versus su distancia de Hamming al m´aximo global, (c) distribuci´on de frecuencias de la cantidad de pasos dados antes de encontrar un m´aximo local; todos para el problema de la figura 5.6. . . 40 5.12. Curvas de mejor encontrado para el problema de la figura 5.3 asignando
al AG una probabilidad de mutaci´on del 50 %. . . 41 5.13. Curvas de mejor encontrado para el problema de la figura 5.5 asignando
al AG una probabilidad de mutaci´on del 50 %. . . 42 5.14. Gr´afica en la que cada punto blanco situado en (x, y) significa que es
Cap´ıtulo 1
Introducci´
on
1.1.
Antecedentes
Casi cualquier problema de dise˜no ingenieril e incluso cient´ıfico puede traducirse como un proceso de optimizaci´on combinatoria. Teniendo un modelo matem´atico del comportamiento de algo que recibiendo datos de entrada brinda otros de salida, llamado
espacio de b´usqueda, suele resultar ´util encontrar para qu´e valores de entrada los de salida son m´aximos o m´ınimos. Los casos en que pueden encontrarse ´optimos por medios anal´ıticos tradicionales como el c´alculo son escasos en la pr´actica, lo que ha dado origen a la creaci´on de una infinidad de algoritmos de optimizaci´on. Se llama optimizaci´on
ciega a todo aquel caso en que no se cuenta con una forma de saber el valor del ´optimo
a buscar.
A pesar de la existencia del teorema No Free Lunch (NFL) que afirma que, pro-mediados sobre el espacio de todos los problemas posibles, todos los algoritmos de optimizaci´on ciega son igualmente eficientes (Wolpert y Macready, 1995a), se ha man-tenido la sospecha de que algunos son mejores que otros ante algunos problemas. Hasta ahora no se ha dado un nombre propio a este tipo de problemas, por lo que por fines de referencia f´acil en esta tesis se denominanproblemas tendenciosos.
Se llama computaci´on evolutiva al conjunto de t´ecnicas computacionales basadas en la mec´anica de la selecci´on natural y la idea darwiniana de la supervivencia de acuerdo a la aptitud. Un ejemplo caracter´ıstico es el algoritmo gen´etico (Goldberg, 1989), que en su versi´on m´as simple es un m´etodo estoc´astico de b´usqueda en el que las posibles soluciones a un problema son codificadas en forma de tiras de caracteres de un alfabeto que asemejan los cromosomas de seres vivos. Un algoritmo gen´etico evoluciona una poblaci´on de estos individuos aplicando los operadores gen´eticos de selecci´on, cruce y mutaci´on.
sus-tentados en la selecci´on natural mediante los cuales las especies biol´ogicas evolucionan en conjunto, coevolucionan. Con esta analog´ıa en mente es que se llama coevoluci´on de
algoritmos y problemas al proceso de adaptaci´on de algoritmos para resolver problemas
sucesivamente m´as dif´ıciles.
1.2.
Definici´
on del problema
Todo proceso de computaci´on evolutiva requiere que existan caracter´ısticas medi-bles en lo que se desea evolucionar mediante las cuales sea posible distinguir combina-ciones buenas de ellas que valga la pena explotar. El problema de lograr la coevoluci´on de algoritmos y problemas implica resolver tres sub-problemas principales:
1. Encontrar una representaci´on de problemas tal que la aplicaci´on de operadores gen´eticos sobre ellos brinden resultados significativos, que se hereden y recombi-nen a lo largo de las generaciones las caracter´ısticas que los hacen aptos y que sirva para representar muchos espacios diferentes.
2. Encontrar la forma de medir la aptitud de un problema de optimizaci´on frente a un algoritmo haciendo b´usqueda en ´el, es decir, que el hecho de que los m´aximos y m´ınimos de dos espacios sean num´ericamente diferentes esto no afecte en demas´ıa la selecci´on de uno sobre el otro, sino primordialmente c´omo se comporta un algoritmo en ellos.
3. Si lo que se desea evolucionar son las caracter´ısticas que definen el comportamien-to de un algoritmo, eso significa que lograrlo requiere disponer de formas de com-parar el desempe˜no de dicho comportamiento con otros.
Saber qu´e es f´acil o dif´ıcil para cierto algoritmo de optimizaci´on ciega es otro problema de investigaci´on abierto para el que se cree no puede existir un marco te´orico definitivo, por la complejidad de los sistemas implicados.
1.3.
Preguntas de investigaci´
on
Las preguntas que gu´ıan la investigaci´on presentada en esta tesis son:
1.4.
Hip´
otesis
La presente tesis est´a basada en la hip´otesis de que s´olo es posible medir las caracter´ısticas que determinan qu´e es f´acil o dif´ıcil para un algoritmo en t´erminos de otro algoritmo, es decir que si se plantea como problema de optimizaci´on s´olo es posible saber qu´e es f´acil o dif´ıcil para un algoritmo de optimizaci´on ciega tomando en cuenta a otro, que no hay una forma absoluta de evaluar una b´usqueda ciega. Esta es lahip´otesis de la relatividad en la comparaci´on de algoritmos de optimizaci´on ciega. A partir de las caracter´ısticas que un algoritmo debe tener para poder implementar este proceso de optimizaci´on es que aparece como respuesta natural la coevoluci´on de algoritmos y problemas.
1.5.
Objetivo
Esta tesis tiene el objetivo principal de mostrar que asumir la hip´otesis de la relatividad en la comparaci´on de algoritmos de optimizaci´on ciega hace posible la im-plementaci´on de la coevoluci´on de algoritmos y problemas, es decir que el problema planteado por dicha coevoluci´on es complementario al de buscar problemas tenden-ciosos.
1.6.
Contribuci´
on de la investigaci´
on
Son dos las principales contribuciones del trabajo mostrado en esta tesis:
La introducci´on de la hip´otesis de la relatividad en la comparaci´on de algoritmos de optimizaci´on ciega, como un paradigma que resuelve autom´aticamente los sub-problemas 2 y 3 mencionados en la definici´on del problema.
La presentaci´on de una codificaci´on de funciones que hace posible ocuparlas como individuos de un algoritmo gen´etico, suficiente para lidiar con el sub-problema 1 mencionado en la definici´on del problema.
1.7.
Organizaci´
on del documento
Este documento est´a organizado de la siguiente forma:
comunidad de investigadores. Esta exposici´on sirve como marco para introducir la idea de hacer comparaciones de algoritmos mediante la b´usqueda de problemas tendenciosos, basada en la relatividad de dichas comparaciones.
Cap´ıtulo 3 Se presenta al algoritmo de coevoluci´on incremental (ACI) y algunos de los detalles de su implementaci´on (que son complementados en el siguiente cap´ıtulo) para encontrar problemas tendenciosos mediante la coevoluci´on de problemas y afinaciones de algoritmos.
Cap´ıtulo 4 Se presenta la forma en que se codifican los problemas de optimizaci´on que constituyen a la poblaci´on de problemas del ACI, as´ı como los algoritmos —gen´etico generacional simple, recocido simulado y b´usqueda aleatoria— y las codificaciones de sus afinaciones que dan forma a las otras dos poblaciones im-plicadas en ´el, y se explica la forma como se aplican los operadores de cruce y mutaci´on sobre estas codificaciones.
Cap´ıtulo 5 Se presentan los resultados de la implementaci´on exitosa de la coevoluci´on de afinaciones de algoritmos y problemas detallada en los cap´ıtulos anteriores, se muestra el an´alisis de los problemas tendenciosos obtenidos y se compara con teor´ıas de dificultad existentes.
Cap´ıtulo 2
Algoritmos de optimizaci´
on ciega y su comparaci´
on
vista como problema de optimizaci´
on
En este cap´ıtulo se expone en qu´e consiste un problema de optimizaci´on combi-natoria, un algoritmo de optimizaci´on ciega para resolver esta clase de problemas y en qu´e formas puede pensarse que un problema es dif´ıcil, todo en el contexto del teorema
No Free Lunch (NFL) y las reacciones comunes que ha generado entre la comunidad
de investigadores. Esta exposici´on sirve como marco para introducir la idea de hacer comparaciones de algoritmos mediante la b´usqueda de problemas tendenciosos basada en la relatividad de dichas comparaciones.
2.1.
Definiciones
Teniendo el mapeo de un espacio finito X de tama˜no |X | hacia un conjunto de valores num´ericos finitoY de tama˜no|Y|dado por la funci´onf :X → Y, un problema de optimizaci´on combinatoria consiste en encontrar el valor de X que corresponda al valor ´optimo (m´aximo o m´ınimo) dado porf.
Es inagotable la cantidad de problemas ingenieriles y cient´ıficos que pueden ser traducidos a un problema de optimizaci´on de este tipo, puesto que es com´un que se cuente con modelos matem´aticos que describen el dise˜no o el funcionamiento de al-go para lo cual resulta ´util conocer bajo qu´e condiciones ciertas medidas que se le apliquen son m´aximas o m´ınimas. Hallar formas eficientes de encontrar (o por lo menos acercarse) a esos ´optimos resulta vital cuando |X | es tan grande que evaluar opciones exhaustivamente es inviable, a lo que se ha dado por llamarexplosi´on combinatoria y que llev´o al reconocimiento del nuevo campo de investigaci´on de lossistemas complejos. La forma en que los algoritmos lidian con esta explosi´on para una clase de problemas recurrentes en la pr´actica es lo que est´a detr´as de las definiciones de las clases P yN P en la teor´ıa de la complejidad computacional (Garey y Johnson, 1979).
Siguiendo con la notaci´on usada por Wolpert y Macready (1995a, 1995b), sea dm ≡ {(dxm(1), d
y
m(1)), . . . ,(d x
m(m), d y
una muestra de m puntos de X ordenados de acuerdo a como son visitados donde dx
m(i) indica el valor deX ydym(i) el valor deY deli-´esimo elemento de la muestra, con
dx
m ≡ {dxm(1), . . . , dxm(m)}ydym ≡ {dym(1), . . . , dym(m)}. El espacio de todas las muestras
de tama˜nom es Dm = (X × Y) m
tal que dm ∈ Dm y el conjunto de todas las posibles
muestras de tama˜no arbitrario es D ≡ ∪m≥0Dm.
Un algoritmo de optimizaci´on ciega a se define como un mapeo de conjuntos de puntos previamente visitados a uno nuevo en X, es decir
a:d∈ D → {x|x∈ X } (2.1)
esta definici´on de algoritmo incluye a t´ecnicas comunes de b´usqueda ciega (no necesitan un modelo expl´ıcito anal´ıtico def sino que la emplean como una caja negra a la que se le dan datos de entrada y brinda datos de salida sin tener idea de qu´e pasa adentro), de entre las cuales dos de las m´as populares son recocido simulado y algoritmos gen´eticos, t´ecnicas que sirven en cap´ıtulos posteriores para confirmar las hip´otesis de esta tesis.
Dada la definici´on 2.1, ¿qu´e significa decir que un algoritmo es bueno o que es mejor que otro? ¿C´omo hacer comparaciones entre algoritmos? La costumbre extendida entre quienes dise˜nan alg´un algoritmo de optimizaci´on es presentarlo junto con un conjunto de problemas frente a los cuales, mediante una afinaci´on minuciosa de sus par´ametros, suelen dar buenos resultados —como en el caso de as funciones de DeJong para algoritmos gen´eticos (DeJong, 1975). ¿Es posible llegar a una evaluaci´on m´as imparcial?
Tomando aF =YX como el espacio de todos los posibles problemas, cuyo tama˜no
es |Y||X |, y a P(dy
m|f, m, a) como la probabilidad condicional de obtener la muestra
dm bajo las condiciones dadas, Wolpert y Macready llegaron a trav´es de una elegante
demostraci´on anal´ıtica a la pol´emica conclusi´on de que, para cualquier par de algoritmos a1 y a2 con cualquier medida de desempe˜no Φ(dym) que diga qu´e tan buena es una
muestra
X
f
P(dym|f, m, a1) = X
f
P(dym|f, m, a2) (2.2)
para el caso en que a : d ∈ D → {x|x /∈dx}, es decir para algoritmos que no visitan
puntos en X m´as de una vez, lo que significa que para cualquier medida de desempe˜no ninguno de este tipo de algoritmos de optimizaci´on es mejor que otro cuando su de-sempe˜no es promediado sobre todas las posibles funciones discretas F =YX (Wolpert
y Macready, 1997). Wolpert y Macready llamaron a este resultado el teorema No Free
Lunch (NFL).
Una variante del teorema NFL consiste en, dadas las mismas condiciones, siendo Apply(a, f, m) un meta-algoritmo que da como salida el orden en que a visita m ele-mentos deY despu´es dem pasos, para cada par de algoritmosa1 ya2 y para cualquier
Apply(a1, f1, m)≡Apply(a2, f2, m) (2.3)
lo que significa que el comportamiento agregado de cualquier par de algoritmos es equivalente comparado sobre todas las posibles funciones discretas F =YX (Whitley
y Watson, 2004).
El teorema NFL, junto con las reacciones que ha generado, ha sido la aportaci´on te´orica m´as importante de los ´ultimos a˜nos concerniente a la comparaci´on entre al-goritmos de optimizaci´on, por lo que resulta insoslayable usarlo como marco para los objetivos de esta tesis.
2.2.
No Free Lunch is No Big Deal
Las principales reacciones de los investigadores ante el teorema NFL pueden re-sumirse en dos (Whitley y Watson, 2004):
El conjunto de todas las posibles F no es aplicable al mundo real puesto que existen muchas funciones que no son representativas de problemas reales, es in-finitamente grande tal que la mayor´ıa de las funciones son incompresibles en el sentido de que no hay representaciones de ellas que sean significantemente menores que el tama˜no de la funci´on enumerada en su totalidad.
En la pr´actica para mejorar el desempe˜no de los algoritmos acaba incluy´endose conocimiento del problema en espec´ıfico, por lo que el teorema NFL no es m´as que la confirmaci´on de la intuici´on de que la b´usqueda ciega no es una panacea capaz de resolver todos los problemas.
Aunado a estas actitudes la mayor´ıa de quienes utilizan algoritmos de optimizaci´on no se preocupan en modificarlos de forma que se cumpla a : d ∈ D → {x|x /∈dx}.
Asumir que el que cualquier algoritmo pueda modificarse para no visitar el mismo punto m´as de una vez sea una condici´on indispensable —algunos dir´an ad hoc— para poder llegar a una demostraci´on anal´ıtica de la igualdad 2.2, no significa que sea pr´actico en su implementaci´on. Como se puede ver en la definici´on del teoremaNFLqueda excluida cualquier noci´on de la eficiencia de un algoritmo.
tiempo satisfacer la igualdad 2.2, mas no dice algo m´as de las propiedades de estos subcojuntos con respecto a los algoritmos.
Uno de los objetivos principales de esta tesis es el hallar una forma pr´actica de introducir la idea de eficiencia en la comparaci´on de algoritmos, mas lo complejo que resulta anal´ıticamente indica que hacerlo implica abandonar la esperanza de llegar a un resultado tan general del tipo del teorema NFL:
The larger lesson here is the existence of what might be called theNFL
The-orem for TheThe-orems in Complex Systems. This theorem —really a conjecture—
says that there is no free lunch with respect to theorem proving in complex systems science and engineering in the sense that it is not possible to say anything definitive or profound about a complex system without an appro-priately complex proof (Goldberg, 2002, pp. 75,76)
2.3.
La relatividad en la comparaci´
on de algoritmos
de optimizaci´
on
Un algoritmo de optimizaci´on es una forma de usar a la complejidad para encontrar soluciones a problemas. ¿C´omo convertir el problema de no saber qu´e es f´acil o dif´ıcil para un algoritmo en un problema de optimizaci´on?
Para un conjunto finito de valores num´ericos Z de tama˜no |Z| supongamos que hay un mapeow:F → Z que adjudica a cada problemaf una evaluaci´on de su dificul-tad, por lo que visto como problema de optimizaci´on consiste en encontrar problemas f´aciles o dif´ıciles en F. ¿Es posible hallar una medida w que sea independiente de los algoritmos que se empleen para optimizar a miembros de F? ¿Es posible hallar una medida absoluta de la dificultad de un problema? Si hacemos caso a la conjetura NFL
para teoremas en sistemas complejos podemos concluir que el hallar una medida de este tipo ser´ıa una forma simple de hablar de la complejidad de F, por lo que es altamente probable que no exista.
Para corregir el planteamiento anterior se podr´ıa tomar a w como la medida del desempe˜no Φ de un algoritmo a, por lo que optimizando F podr´ıamos responder a la pregunta de qu´e es f´acil o dif´ıcil para dicho algoritmo. Este enfoque se enfrenta a la dificultad de que la comparaci´on de la medida num´erica del desempe˜no de un algoritmo en dos problemas por s´ı sola no nos dice cu´al es m´as dif´ıcil. Supongamos que dm es
una muestra del algoritmo a en el problema f1 cuyo m´aximo global es M1 y em una
muestra de a en el problema f2 cuyo m´aximo global es M2, con Φ(dym) = max(dym)
y Φ(ey
m) = max(eym), entonces es posible que M1 −Φ(dym) < M2 −Φ(eym) y al mismo
tiempo Φ(ey
m)>Φ(dym) si es queM2 > M1, lo que se cumple en el caso en queF incluye
en el teorema NFL pues en el caso de una aut´entica b´usqueda ciega no conocemos el valor deM1 ni deM2. Esta dificultad sugiere que tambi´en es poco probable hallar una
medida absoluta de qu´e es f´acil o dif´ıcil para un algoritmo de b´usqueda ciega.
Las dificultades anteriores sustentan una la principal hip´otesis de esta tesis, que es la de la relatividad en la comparaci´on de algoritmos de optimizaci´on ciega:
Hip´otesis 1 Planteado como problema de optimizaci´on, s´olo es posible saber qu´e es f´acil o dif´ıcil para un algoritmo de optimizaci´on ciega en t´erminos del desempe˜no de otro algoritmo.
Para entender la hip´otesis anterior supogamos que1d
m es una muestra del
algorit-mo a1 y 2dm del algoritmoa2 ambas en el problemaf1, 1em es una muestra del
algorit-mo a1 y 2em del algoritmoa2 ambas en el problema f2. Tomando Φ(1dym) = max(1dym),
Φ(2dy
m) = max(2dym), Φ(1eym) = max(1eym) y Φ(2eym) = max(2eym), si recordamos que
todas las funciones en F tienen como codominios a subconjuntos de Y por lo que la diferencia entre el m´aximo y el m´ınimo global en cada una de ellas est´a acotada, el que se d´e Φ(1dy
m)−Φ(2dym)>Φ(1eym)−Φ(2eym) indica que el problema f1 es m´as f´acil para
el algoritmo a1 que el problema f2 con respecto al algoritmo a2, independientemente
de los valores espec´ıficos de los m´aximos globales de ambos problemas.
La siguiente secci´on y los pr´oximos cap´ıtulos est´an dedicados a los aspectos pr´acti-cos sobre c´omo implementar un algoritmo de optimizaci´on de tipo evolutivo basado en la hip´otesis 1.
2.4.
Medida de desempe˜
no y problemas tendenciosos
El planteamiento mostrado de la comparaci´on de algoritmos como un proceso de optimizaci´on no presenta la pol´emica restricci´on a :d ∈ D → {x|x /∈dx} que sustenta
al teorema NFL, por lo que es posible utilizar una medida de desempe˜no que tome en cuenta la eficiencia con que el algoritmo funciona.
Concentr´andonos de ahora en adelante en el caso de maximizaci´on (sin menoscabar el planteamiento), se define a la curva de mejor encontrado (Valenzuela-Rend´on, 2004) del algoritmoa frente al problema f como
Ωf a(i) =
1 n n X j=1 max
k≤i jdy
m(k) (2.4)
donde i = 1, . . . , m y jdy
m es la j-´esima de n muestras de tama˜no m. La figura 2.1
muestra ejemplos de curvas de mejor encontrado para dos algoritmos. En el caso (a)a1
siempre es mejor que a2 mientras que en (b) qui´en es mejor depende de cu´anto tiempo
(a)
Ωa f
(i)
i−ésimo elemento de las muestras
a1 a
2
(b)
Ωa f
(i)
[image:25.595.131.509.98.274.2]i−ésimo elemento de las muestras
Figura 2.1: Curvas de mejor encontrado para dos algoritmos a1 y a2 (con n grande).
El ´area bajo la curva de mejor encontrado es una medida que adem´as de brindar el m´aximo de una muestra refleja la evoluci´on temporal —la eficiencia— de la b´usqueda y que al ser obtenida empleando varias muestras reduce los efectos fortuitos en la eva-luaci´on del comportamiento de un algoritmo. La medida del desempe˜no del algoritmo a1 con respecto al algoritmo a2 que se buscar´a maximizar explorandoF ser´a:
m
X
i=1
Ωfa1(i)−Ω f a2(i)
, f ∈ F (2.5)
que es la diferencia entre las ´areas de sus curvas de mejor encontrado.
Un problema para el que la medida 2.5 es mayor a cero tiende a beneficiar al algoritmo a1 sobre el algoritmo a2, por lo que por motivos de referencia f´acil se le
denominar´aproblema tendencioso.
El objetivo principal de esta tesis es proponer a la b´usqueda de problemas ten-denciosos como una forma pr´actica de usar a la complejidad para saber qu´e es f´acil o dif´ıcil para un algoritmo, como una forma de suplir a la demostraci´on compleja a la que se refiere Goldberg en su menci´on a la conjetura NFL para teoremas en sistemas complejos.
2.5.
Resumen
Cap´ıtulo 3
Algoritmo de coevoluci´
on incremental
En este cap´ıtulo se presentan los algoritmos gen´etico generacional simple y de coevoluci´on simple, como antecedentes a la presentaci´on del algoritmo de coevoluci´on incremental (ACI), finalizando con algunos de los detalles de la implementaci´on de este ´
ultimo —que son complementados en el siguiente cap´ıtulo— para encontrar problemas tendenciosos mediante la coevoluci´on de problemas y algoritmos.
3.1.
Contras a la b´
usqueda de problemas
tenden-ciosos como problema de optimizaci´
on
El planteamiento te´orico del cap´ıtulo anterior sobre c´omo convertir el problema de saber qu´e es dif´ıcil para un algoritmo en un problema de optimizaci´on enfrenta dos problemas principales, a resolver para ser implementado computacionalmente:
Problema 1 Lo que se plantea es buscar en un espacio de problemas. . . ¿C´omo codi-ficar cadaf de tal forma que se pueda implementar un algoritmo de optimizaci´on para explorarF? Esta pregunta es respondida en el siguiente cap´ıtulo.
Problema 2 Suponiendo que se resolvi´o el problema anterior y se implement´o un algo-ritmo que da como resultado un problema que tiende a beneficiar a un algoalgo-ritmo a1 sobre uno a2, alguien podr´ıa argumentar que no puede objetar el proceso de
b´usqueda mas que la medida de desempe˜no fue sesgada por la forma en que los algoritmos fueron afinados. Ya que en la pr´actica la mayor´ıa de los algoritmos cuentan con un conjunto de par´ametros que determinan su comportamiento, nos enfrentamos ante el problema de optimizaci´on adicional de encontrar aquellas afinaciones de par´ametros que produzcan los mejores comportamientos. ¿Existe alg´un algoritmo que incluya la optimizaci´on de los par´ametros junto a la opti-mizaci´on de la medida de desempe˜no presentada en el cap´ıtulo anterior?
implementando un algoritmo de coevoluci´on incremental (ACI). Para poder entrar a los detalles que explican por qu´e un algoritmo de coevoluci´on resulta una respuesta natural habr´a que dar primero una breve revisi´on a la definici´on de algoritmo gen´etico y coevoluci´on.
3.2.
Algoritmo gen´
etico generacional simple y
co-evoluci´
on
En su forma m´as simple un algoritmo gen´etico (Goldberg, 1989; Whitley, 1994) es un m´etodo estoc´astico de b´usqueda basado en la mec´anica de la selecci´on natural y la idea darwiniana de la supervivencia de acuerdo a la aptitud, en el que un conjunto de puntos en X son codificados en forma de tiras de caracteres de un alfabeto —binario en el caso m´as com´un— que asemejan los cromosomas de seres vivos. Un algoritmo gen´etico (AG) evoluciona a esta poblaci´on realizando las operaciones de selecci´on, cruce y mutaci´on.
La selecci´on consiste en dar un n´umero proporcionalmente mayor de hijos a aque-llos individuos mejor evaluados por la funci´on a optimizar, a fin de que las caracter´ısticas que los hacen aptos predominen en la poblaci´on. La forma en que estas caracter´ısticas son combinadas para generar nuevos individuos es mediante el operador de cruce, que no es m´as que el intercambio de porciones de la cadena de caracteres de dos individuos seleccionados apareados al azar para producir dos nuevos hijos que formar´an parte de la nueva generaci´on. Adicionalmente con una probabilidad muy peque˜na se hacen cambios aleatorios a los caracteres de individuos escogidos al azar, operaci´on llamada mutaci´on. Repitiendo generaci´on tras generaci´on los operadores de selecci´on, cruce y mu-taci´on el algoritmo gen´etico realiza optimizaci´on de funciones a trav´es de la recombi-naci´on de caracter´ısticas ´utiles —selecci´on y cruce— alternando ocasionalmente con b´usqueda aleatoria —mutaci´on. Mientras el cruce contribuye en mayor proporci´on a la b´usqueda de nuevos individuos cuando hay diferencias entre los actuales mutaci´on hace lo propio cuando los individuos de una generaci´on son muy parecidos entre s´ı, apoy´andose uno al otro en casos intermedios (Goldberg, 1989). La tabla 3.1 sintetiza los pasos b´asicos de un AG generacional simple.
Generar poblaci´on inicial al azar
Repetir
Generar nueva poblaci´on mediante (a) Selecci´on de acuerdo a aptitud (b) Crucede parejas
(c) Mutaci´on de hijos
[image:29.595.212.424.83.293.2]Hasta cumplir criterio de terminaci´on
Tabla 3.1: Pasos b´asicos de un AG generacional simple
m´as fuerte, a lo que la planta podr´ıa responder evolucionando para generar veneno, a lo que los insectos podr´ıan responder generando una enzima que los proteja del efecto de este, y as´ı consecutivamente. En la naturaleza resulta com´un que como parte de estas guerras armamentistas una especie realice alg´un tipo de cooperaci´on con una tercera.
Suele pensarse que el tipo de competencia involucrada en un proceso coevoluti-vo llevada al terreno de los algoritmos funciona como un catalizador para lograr un mejor desempe˜no de un algoritmo gen´etico en la b´usqueda de soluciones. La idea de coevoluci´on ha sido empleada para resolver problemas como selecci´on de algoritmos de ordenamiento (Hillis, 1992), buscadores de estrategias de juegos (Pollack, Blair, y Land, 1997; Rosin y Belew, 1995), generaci´on de predictores (Ficici y Pollack, 1998) y b´usqueda de estrategias de persecuci´on y evasi´on (Cliff y Miller, 1995). La tabla 3.2 sintetiza los pasos b´asicos de un algoritmo de coevoluci´on simple (ACS) para el caso competitivo entre una poblaci´on de anfitriones y otra de par´asitos (Palacios-Durazo, 2002).
Un proceso de coevoluci´on resulta una respuesta natural al problema de opti-mizaci´on m´ultiple que se se˜nal´o en la secci´on anterior. En este caso se cuenta con tres poblaciones: 1) una poblaci´on de afinaciones dea1, 2) una poblaci´on de afinaciones de
a2 y 3) una poblaci´on de problemas. En el caso en que busquemos problemas que hagan
quedar bien aa1 la relaci´on entre las poblaciones 1) y 2) as´ı como aquella entre 2) y 3)
Generar al azar poblaciones iniciales de anfitriones y par´asitos
Repetir
Se hace unacompetici´onentre cada posible par anfitri´on-par´asito. La aptitud de cada individuo de ambas poblaciones corresponde al n´umero de competencias que gane
Generar nuevas poblaciones de anfitriones y par´asitos mediante (a) Selecci´on de acuerdo a aptitud
(b) Cruce de parejas (c) Mutaci´on de hijos
Hasta cumplir criterio de terminaci´on
Tabla 3.2: Pasos b´asicos de un ACS
3.3.
Algoritmo de coevoluci´
on incremental
El ACS —tabla 3.2— tiene algunos problemas para hacer efectiva la idea de que un proceso coevolutivo genera individuos m´as aptos que el de un AG simple:
No suele llevar a las poblaciones a un estado estable ya que tienden a oscilar alrededor de zonas del espacio ya visitadas, lo que se ejemplifica con el caso en que una de las poblaciones de deshaga de un “arma” adquirida recientemente, por lo cual la otra ya no necesita la “defensa” que hab´ıa desarrollado para combatirla y al deshacerse de ella ambas regresan a una situaci´on en la que ya hab´ıan estado con anterioridad.
El n´umero de competiciones por hacer en cada generaci´on tiene un costo com-putacional alto. Un ACS conpanfitriones yq par´asitos implica pqcompetencias. Es dif´ıcil medir el progreso del algoritmo puesto que no se cuenta con una funci´on objetivo expl´ıcita con la que medir la aptitud de los individuos, sino impl´ıcita debido a la dependencia de ambas poblaciones, por lo que es dif´ıcil saber cu´ando detenerlo.
con las dificultades pricipales del ACS, como lo demuestra experimentalmente al bus-car con ´exito identidades trigonom´etricas que se acoplen lo mejor posible a una funci´on dada, teniendo una poblaci´on de funciones cuyos genes son operadores trigonom´etricos y otra de par´asitos que busquen concentrarse en las zonas del dominio de la funci´on a igualar cuyas aproximaciones propuestas sean malas.
Las principales caracter´ısticas del ACI para resolver los problemas del ACS son: Es no generacional, es decir se permite que hayan individuos que sobrevivan a los cambios de generaci´on por lo que la poblaci´on funciona como memoria de lo aprendido, ayudando a evitar que oscile alrededor de zonas ya visitadas.
Los individuos de cada poblaci´on compiten con una muestra aleatoria de la poblaci´on oponente.
La aptitud de cada individuo en un tiempot es una medida expl´ıcita cuyo ajuste se inspira en el ajuste de aptitudes del sistema de aprendizaje de un sistema adaptable de clasificadores (J. Holland, 1986; Valenzuela-Rend´on y Uresti-Charre, 1997). SeaS la aptitud de un individuo, su ajuste para un tiempot+ 1 se realiza mediante la siguiente ecuaci´on
S(t+ 1) =S(t) + Recompensa−Costo de competir
la evaluaci´on de la recompensa refleja la comparaci´on con cada individuo con que compita y junto con el costo de competir se calcula de tal forma que est´e acotada y que haga que la aptitud de los mejores individuos tienda a un valor fijo en estado estable conformet crece, es decir que llegue un momento en queS(t+ 1)≈S(t). Lo incremental del algoritmo proviene de aprovechar la coexistencia de indivi-duos en una poblaci´on —al no ser generacional— as´ı como del ajuste paulatino de sus aptitudes. La tabla 3.3 muestra los pasos b´asicos del ACI.
3.4.
Coevoluci´
on incremental de algoritmos y
pro-blemas
Generar al azar poblaciones iniciales de anfitriones y par´asitos
Repetir
Hacer competici´on entre un n´umero fijo de pares anfitri´on-par´asito elegidos al azar. La aptitudS de cada individuo de ambas poblaciones se ajusta de la forma
S(t+ 1) =S(t) + Recompensa−Costo de competir
Eliminar al individuo de menor aptitud de cada poblaci´on Generar nuevos individuos para cada poblaci´on mediante
(a) Selecci´on de acuerdo a aptitud del mejor par de individuos (b) Cruce de la pareja seleccionada generando un s´olo individuo
que se incluye a la poblaci´on, con aptitud tomada como el promedio de la de los padres
(c) Mutaci´on
Hasta cumplir criterio de terminaci´on
Tabla 3.3: Pasos b´asicos de un ACI
1. Se generan tres poblaciones, la P de problemas y lasA yB de afinaciones de los algoritmos a competir (los detalles de la codificaci´on de estos individuos se trata en el cap´ıtulo siguiente). Se inicializan las aptitudes de P enRP/(10CP), las de
A enRA/(10CA) y las de B en (RB/(10CB) dondeRP, RA y RB representan las
m´aximas recompensas a dar a los individuos de cada poblaci´on por su desempe˜no en una competencia yCP, CA y CB los m´aximos costos de participar en ella.
2. Se selecciona a un individuo de cada poblaci´on al azar, se corren a ambos algo-ritmos con las afinaciones dadas por los individuos escogidos sobre el problema elegido y se ajustan de manera incremental las aptitudes de los tres. Se supone que buscamos un problema tendencioso que haga quedar mejor al algoritmo A que al B.
dondeEX es el ´area bajo la curva de mejor encontrado del algoritmoX dividida
entrem, el tama˜no de las muestras.
El ajuste de aptitud para la afinaci´on del algoritmoAse hace mediante la siguiente ecuaci´on:
SA(t+ 1) =SA(t) +RAtanh(2EA) tanh(10CBSB/RB)−CASA(t) (3.2)
dondeSB es la aptitud de la afinaci´on del algoritmoB contra la que se compite.
El ajuste de aptitud para la afinaci´on del algoritmoBse hace mediante la siguiente ecuaci´on:
SB(t+ 1) =SB(t) +RBtanh(2EB) tanh(10CASA/RA)−CBSB(t) (3.3)
dondeSA es la aptitud de la afinaci´on del algoritmo A contra la que se compite.
3. Se repite la competencia entre otros 3 individuos seleccionados al azar un n´umero #c predeterminado de veces.
4. Despu´es de las competencias, se encuentra al individuo con menor aptitud de cada poblaci´on y se elimina.
5. En cada poblaci´on se seleccionan dos individuos de forma proporcional a su apti-tud y con una probabilidad de cruce se cruzan, generando un s´olo individuo —los detalles de la aplicaci´on del operador de cruce para cada poblaci´on se ver´an en el cap´ıtulo siguiente— cuya aptitud es el promedio de la de sus padres. El hijo se agrega a la poblaci´on sustituyendo al individuo con menor aptitud.
6. Se aplica mutaci´on a las poblaciones. Los detalles de c´omo se lleva a cabo esta operaci´on para cada poblaci´on son mostrados en el siguiente cap´ıtulo.
7. Se repite el proceso de competencia.
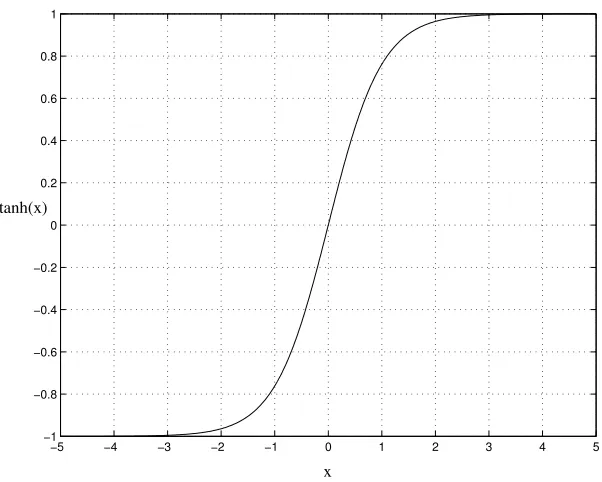
Las funciones compuestas por tangentes hiperb´olicas —v´ease figura 3.1— que multiplican a la m´axima recompensa posible en las ecuaciones de ajuste de aptitudes se encargan de que esta nunca sea rebasada.
−5 −4 −3 −2 −1 0 1 2 3 4 5 −1
−0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1
[image:34.595.169.470.97.338.2]x tanh(x)
Figura 3.1: Funci´on tanh(x)
de la cooperaci´on es algo que tienden a confirmar las mejores estrategias encontradas a la fecha para el famosodilema del prisionero (Dawkins, 1986).
En el siguiente cap´ıtulo se presentan a los algoritmos contendientes para tomar los lugares de A y B y c´omo sus afinaciones son codificadas, cruzadas y mutadas en el ACI, lo mismo para la representaci´on de problemas cuya poblaci´on equivale aP.
3.5.
Resumen
Cap´ıtulo 4
La arena y los contendientes
En este cap´ıtulo se presenta la forma en que se codifican los problemas de op-timizaci´on que constituyen a la poblaci´on P del ACI, as´ı como los algoritmos y las codificaciones de sus afinaciones que dan forma a las poblaciones A y B, los cuales son un AG generacional simple, recocido simulado y b´usqueda aleatoria. Finalmente se explica la forma como se aplican los operadores de cruce y mutaci´on sobre estas codificaciones.
4.1.
Codificaci´
on de problemas
Retomando la pregunta del cap´ıtulo anterior: ¿C´omo codificar cadaf de tal forma que se pueda implementar un algoritmo de optimizaci´on para explorar F?
De acuerdo a las actitudes de la comunidad de investigadores frente al teorema
NFL —cap´ıtulo 2— hay que recordar que una de sus principales posturas es que F
incluye muchas funciones para las que el codificarlas de forma anal´ıtica resulta igual de dif´ıcil que asignar num´ericamente uno por uno valores a sus codominios —son incom-presibles. Por el otro lado el codificar funciones combinando exclusivamente expresiones anal´ıticas a pesar de tener la ventaja de facilitar la compresi´on de informaci´on puede que nos remita a un subconjunto deF demasiado limitado o pobre en el que no encon-tremos problemas tendenciosos, que s´ı necesitemos un poco de aleatoriedad. . . ¿C´omo codificar funciones sin caer en uno de estos extremos?
El problema anterior resulta an´alogo al de decidir c´omo codificar num´ericamente funciones si se quiere hacer minimizaci´on de funcionales en c´alculo variacional utilizan-do un algoritmo gen´etico. La minimizaci´on de funcionales consiste en encontrar una funci´on que minimice una integral aplicada sobre ella (Arfken y Weber, 2001), por lo cual si se quiere encontrarla usando un AG se necesita una forma de codificar a las posibles soluciones de tal forma que aplic´andoles los operadores del AG se pueda llegar a la soluci´on. Toledo (2006) propuso el codificar num´ericamente funciones piecewiese
cada par consecutivo de estos segmentos, codificaci´on con la que pudo resolver satisfac-toriamente algunos problemas variacionales t´ıpicos de la f´ısica como son el de encontrar la curva de m´ınima ´area de revoluci´on y las energ´ıas del ´atomo de hidr´ogeno.
En esta tesis se utiliza una variante de la codificaci´on de Toledo para codificar los problemas que forman aP. Cada problema resulta del producto de dos funcionesg yh, de tal forma que f =g(X1)×h(X2), donde tanto g comoh est´an codificadas cada una
por un par de vectores r y θ, de tal forma que r contiene a las longitudes relativas de los segmentos de la funci´on y Pi
j=1θj es el ´angulo entre los segmentos i−1 ei, como
lo muestra la figura 4.1 (a), posteriormente todo el conjunto de segmentos se rota para que en sus puntos inicial y final la funci´on valga cero —figura 4.1 (b)— y se reordenan los puntos del dominio de forma que al final quede una funci´on 1 a 1 que se escala de forma que la diferencia entre su m´aximo y su m´ınimo sea 1 —figura 4.1 (c).
−0.4 −0.2 0 0.2 0.4
0 0.2 0.4 0.6 0.8 1 (a) θ1 θ1+θ
2
θ1+θ
2+θ3
0 2 4 6
−0.5 0 0.5 1
(b)
0 2 4 6
−0.5 0 0.5 1
(c)
[image:36.595.110.529.315.471.2]θ1+θ2+θ3+θ4
Figura 4.1: Ejemplo de pasos en la codificaci´on de funciones a usar: (a) la longitud del segmento ies ri y Pij=1θj es el ´angulo entre los segmentos i−1 e i, (b) rotaci´on, (c)
reordenamiento de dominio y escalamiento.
Matem´aticamente los pasos anteriores quedan expresados de la siguiente forma:
γ =−tan−1
N
P
i=1
ricos i P j=1 j P l=1 θl ! , N P i=1
risen i P j=1 j P l=1 θl !
, (4.1)
gk =ρ k
X
i=1
risen γ+ i X j=1 j X l=1 θl !
, xk=k (4.2)
donde 0< ri ≤1 y−α ≤θi ≤α (α >0) son vectores de n´umeros reales de tama˜noN
y ρ= 1/(maxg−ming).
que queda decir es que el uso de la codificaci´on presentada basta para lograr los objetivos de esta tesis, como se ve en los cap´ıtulos siguientes.
Para la implementaci´on del ACI del pr´oximo cap´ıtulo se tiene N =|X1|=|X2|=
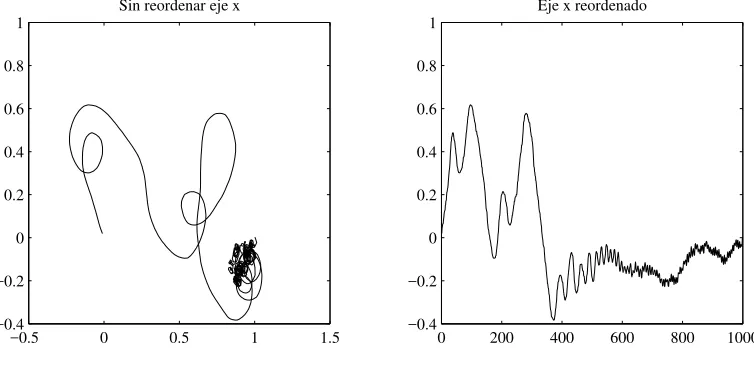
103, es decir f es una superficie con 106 puntos que equivale aproximadamente a un
espacio de b´usqueda de 20 bits, donde los 10 primeros corresponden a una posici´on en
X1 —vista como variable— y los otros 10 a una posici´on en X2. Las figuras 4.2 y 4.3
son ejemplos de la complejidad en la forma de posibles funciones g o h con N = 103 para α=π/100 yα =π/10 respectivamente.
−0.5 0 0.5 1 1.5
−0.4 −0.2 0 0.2 0.4 0.6 0.8 1
Sin reordenar eje x
0 200 400 600 800 1000
−0.4 −0.2 0 0.2 0.4 0.6 0.8 1
[image:37.595.130.507.240.423.2]Eje x reordenado
Figura 4.2: Funci´on con α=π/100 yN = 103
0 0.5 1 1.5
−0.4 −0.2 0 0.2 0.4 0.6 0.8 1
Sin reordenar eje x
0 200 400 600 800 1000
−0.4 −0.2 0 0.2 0.4 0.6 0.8 1
[image:37.595.129.508.479.668.2]Eje x reordenado
Figura 4.3: Funci´on conα=π/10 y N = 103
El tama˜no |X1| × |X2| de los problemas a evolucionar se escogi´o con el fin de
que el ACI sea implementable, por lo que las conclusiones de esta tesis podr´an ser extrapoladas hacia problemas de optimizaci´on en general de dos formas:
Directamente, si se asume que la forma de un problema influye m´as que su ex-tensi´on en determinar si es tendencioso, y por tanto el que 20 bits basten para encontrar problemas tendenciosos es suficiente para extrapolar las conclusiones. Si es posible encontrar problemas tendenciosos queda la opci´on —que no se explo-ra en esta tesis— de estudiar la maneexplo-ra de construir problemas tendenciosos m´as grandes combin´andolos, de forma parecida a como Goldberg (2002) ha construido problemas de 30 bits juntando problemas enga˜nosos de 3 bits —la definici´on de problema enga˜noso se da en el cap´ıtulo siguiente.
4.2.
Algoritmos a competir y la codificaci´
on de sus
afinaciones
Los algoritmos cuyas afinaciones forman las poblacionesAyB son un AG genera-cional simple, recocido simulado y b´usqueda aleatoria. Los dos primeros fueron elegidos debido a su popularidad y por tanto a lo ´util que pueden resultar las conclusiones a que se llegue despu´es de analizar los posibles problemas tendenciosos —beneficiando al AG o beneficiando al recocido simulado— que se obtengan, ya que extrapolar estas conclusiones a problemas reales puede servir en una mejor elecci´on del algoritmo a utilizar.
Otro motivo en espec´ıfico para elegir al AG es que es quiz´as el ´unico algoritmo para el que existen teor´ıas bien desarolladas sobre qu´e es dif´ıcil para ´el, de entre las cuales destacan la teor´ıa de enga˜no (Goldberg, 1989; Whitley, 1991) y NK landscapes (Kauffman, 1993) con las cuales comparar los problemas tendenciosos a obtener. En cuanto a la b´usqueda aleatoria a pesar de que intuitvamente uno pensar´ıa que tanto un AG como recocido simulado deben ser en general mejores que simplemente buscar al azar resulta interesante determinar si es posible encontrar problemas tendenciosos en los que sucede lo contrario.
4.2.1.
AG generacional simple
En cuanto a la forma de hacer la selecci´on de acuerdo a la aptitud de cada indi-viduo, se aplicaselecci´on de torneo. En selecci´on de torneo de tama˜nopse realizan los siguientes pasos (Valenzuela-Rend´on, 2004):
1. La poblaci´on se mezcla en cuanto a la posici´on de cada individuo en el arreglo donde se guarda la poblaci´on.
2. Cada individuo participa en p torneos con los individuos que est´an en posiciones adyascentes a las suya. Los individuos que participan en estos torneos se ob-tienen corriendo una ventana de tama˜nopsobre la poblaci´on considerando que el individuo en la ´ultima posici´on es adyascente al individuo en la primera posici´on. 3. En cada torneo resulta ganador el mejor de los individuos. A este individuo se le asigna una copia para realizar cruce sobre ella apare´andola al azar con otra copia seleccionada.
En el valor esperado, selecci´on de torneo de tama˜no p asigna p copias al mejor individuo,p/2 a la mediana y cero al peor.
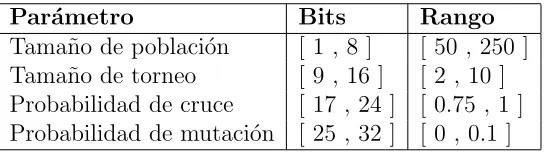
Cada afinaci´on del AG que forma a la poblaci´on A o B del ACI est´a codificada por una cadena de 32 bits. La tabla 4.1 muestra los par´ametros a afinar, los bits que les corresponden y los rangos en que se encuentran sus posibles valores.
Par´ametro Bits Rango
[image:39.595.185.458.406.482.2]Tama˜no de poblaci´on [ 1 , 8 ] [ 50 , 250 ] Tama˜no de torneo [ 9 , 16 ] [ 2 , 10 ] Probabilidad de cruce [ 17 , 24 ] [ 0.75 , 1 ] Probabilidad de mutaci´on [ 25 , 32 ] [ 0 , 0.1 ]
Tabla 4.1: Codificaci´on de la afinaci´on del AG
4.2.2.
Recocido simulado
Recocido simulado es un algoritmo de optimizaci´on de b´usqueda local que se basa en el proceso metal´urgico llamado recocido en el cual se somete a un material a un calentamiento a temperatura muy alta y se despu´es se le deja enfriar lentamente, con lo cual sus mol´eculas se acomodan de tal forma que la energ´ıa potencial es m´ınima, siguiendo en cada temperatura el estado del material la distribuci´on de Boltzman. En el caso de que se busque maximizar una funci´on f partiendo de un punto incial u con energ´ıa f(u) y definiendo un par´ametro de control c(k) que cumple la funci´on de la temperatura, con valor inicial c0, los pasos b´asicos del recocido simulado quedan
sintetizados por la tabla 4.2 (Valenzuela-Rend´on, 2004), en donde Lk es el n´umero de
Inicializar (u0, c0, L0)
k←0 u←u0
repetir
para l ←hasta Lk hacer
Generar vecino v deu sif(v)≥f(u)
entonces u←v si no
sialeatorio[0,1)<exp−f(u)c−f(v)
k
entonces u←v fin-si
fin-si fin-para k ←k+ 1
Calcular longitudLk
Calcular controlck
[image:40.595.196.444.83.359.2]hastaque se cumpla criterio de terminaci´on
Tabla 4.2: Pasos b´asicos del recocido simulado
En la implementaci´on del recocido utilizada cada actualizaci´on del par´ametro de controlckequivale a multiplicarlo por una constante de decremento, mientras que todas
las cadenas de Markov que forman la corrida del algoritmo tienen la misma longitud. Cada afinaci´on del recocido simulado que forma a la poblaci´on A o B del ACI est´a codificada por una cadena de 32 bits. La tabla 4.3 muestra los par´ametros a afinar, los bits que les corresponden y los rangos en que se encuentran sus posibles valores.
Par´ametro Bits Rango
Longitud de cadena de Markov [ 1 , 10 ] [ 5 , 25 ] Valor inicial del par´ametro de control [ 11 , 20 ] [ 103 , 106 ]
Constante de decremento [ 21 , 32 ] [ 0.75 , 0.99 ] Tabla 4.3: Codificaci´on de la afinaci´on del recocido simulado
La peculiaridad del recocido simulado es que es un buscador que, partiendo de un punto en un espacio de b´usqueda, tiene la capacidad de aceptar moverse hacia puntos vecinos peores con la posibilidad de a futuro encontrar vecinos mejores, capacidad que var´ıa de forma proporcional a la temperatura por lo que al final se espera que el comportamiento resulte muy parecido al de una b´usqueda avara.
[image:40.595.146.493.528.590.2]a una cadena de 20 bits, donde los 10 primeros corresponden a una posici´on en X1 y
los otros 10 a una posici´on enX2, en la implementaci´on del recocido simulado usada se
generan vecinos cambiando al azar un bit en la parteX1 y en la X2.
4.2.3.
B´
usqueda aleatoria
La b´usqueda aleatoria utilizada consiste en obtener al azar una cadena de 20 bits generando por separado las partes X1 y X2. Este proceso no requiere afinaci´on, por
lo que cuando se emplea este algoritmo se tiene una poblaci´on virtual de afinaciones donde todas son igualmente buenas. Suponiendo que se tiene la poblaci´on virtualA, el ajuste de la aptitud para cada afinaci´on del algoritmoB despu´es de cada competencia se realiza mediante la ecuaci´on
SB(t+ 1) =SB(t) +RBtanh(2EB)−CBSB(t) (4.3)
4.3.
Operadores de cruce y mutaci´
on
Hasta lo expuesto, los operadores de cruce y mutaci´on (Goldberg, 1989; J. H. Holland, 1975) aparecen en tres formas:
Dentro del ACI en la generaci´on de un nuevo individuo deP. Dentro del ACI en la generaci´on de un nuevo individuo deA y B. Dentro del AG generacional simple.
Llamaremos alelo a cada miembro de los vectores que forman a un individuo, mientras que un cromosoma es aquella cadena de alelos en que se aplica el cruce de un punto de la forma en que se muestra en la tabla 4.4, caso en el que los alelos son binarios, es decir pertenecen a {0,1}. El punto en que se realiza el cruce se escoge al azar. La probabilidad de cruce determina si el cruce se realiza o si los hijos ser´an los padres tal cual fueron seleccionados.
Con esto en mente se define que el cruce de un punto se aplica en cada caso de tal forma que cada individuo de P est´a formado por cuatro cromosomas, dos para la parte r y θ de g y otros dos para las de h con alelos definidos por 0 < ri ≤ 1 y −α ≤ θi ≤ α. Cada individuo de A y B est´a formado por un cromosoma binario de
32 bits mientras que cada individuo del AG generacional simple est´a formado por dos cromosomas binarios de 10 bits, uno paraX1 y otro para X2. La figura 4.4 muestra un
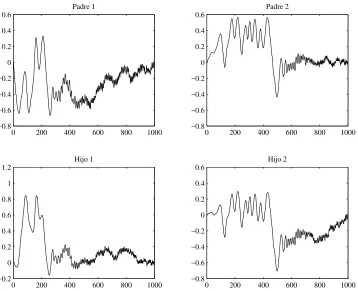
ejemplo del efecto del cruce para posibles funciones g o h con N = 103 y α=π/100.
0 200 400 600 800 1000 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 Padre 1
0 200 400 600 800 1000
−0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 Padre 2
0 200 400 600 800 1000
−0.2 0 0.2 0.4 0.6 0.8 1 1.2 Hijo 1
0 200 400 600 800 1000
−0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 Hijo 2
Figura 4.4: Ejemplo del efecto del cruce para posibles funciones g o h con N = 103 y
α=π/100
Padres Hijos
[image:42.595.142.500.99.390.2]0 1 0 0 0 0 1 1 1 1 0 1 0 0 0 0 1 0 1 0 1 1 0 1 0 1 0 0 1 0 1 1 0 1 0 1 0 1 1 1
Tabla 4.4: Cruce de un punto en un cromosoma binario de 10 bits
si la probabilidad de mutaci´on es mayor que un n´umero al azar en el rango [0,1] el alelo se cambia por su complemento. Para el caso de la poblaci´on de problemas se recorre uno por uno a sus miembros y si su probabilidad de mutaci´on es mayor que un n´umero al azar en el rango [0,1] se ecoge al azar un alelo de cada uno de sus cromosomas para sustituirlo por otro seleccionado al azar dentro del rango definido para cada clase de cromosoma.
4.4.
Resumen
Cap´ıtulo 5
Experimentos y an´
alisis de resultados
En este cap´ıtulo se presentan los resultados de la implementaci´on exitosa de la coevoluci´on de afinaciones de algoritmos y problemas detallada en los cap´ıtulos ante-riores. Posteriormente se muestra el an´alisis de los problemas tendenciosos obtenidos y en el caso espec´ıfico del AG se compara con teor´ıas de dificultad existentes.
La tabla 5.1 muestra los par´ametros del ACI empleados en todos los experimentos.
Par´ametro Descripci´on Valor
m Longitud de las muestras a obtener en cada competici´on 2000 n Cantidad de muestras a obtener para calcular EA y EB 10
#c N´umero de competencias por iteraci´on 50
TP Tama˜no de la poblaci´on de problemas 100
TA =TB Tama˜no de la poblaci´on de afinaciones de algoritmos 25
pcP Probabilidad de cruce de la poblaci´on de problemas 1
pcA =pcB Probabilidad de cruce de las poblaci´ones de afinaciones 1
pmP Probabilidad de mutaci´on de la poblaci´on de problemas 0.05
pmA =pmB Probabilidad de mutaci´on de las poblaci´ones de afinaciones 0.05
CP M´aximo costo por competir para miembros de P 0.01
CA =CB M´aximo costo por competir para miembros de A y B 0.01
RP M´axima recompensa por competir para miembros de P 0.1
[image:44.595.106.540.333.542.2]RA =RB M´axima recompensa por competir para miembros de A y B 1
Tabla 5.1: Par´ametros del ACI usados en todos los experimentos
La longitud de las muestras fue determinada de forma que dividida entre el tama˜no del espacio de b´usqueda da una fracci´on —2×10−3— que es dif´ıcil alcanzar en la
pr´actica, en la que los espacios de b´usqueda suelen ser de tama˜no astron´omico, y que no llevara a un tiempo excesivo en la ejecuci´on del algoritmo.
5.1.
AG vence a recocido simulado
En este caso A corresponde a la poblaci´on de afinaciones del AG y B a la de afinaciones del recocido simulado. La figura 5.1 muestra las curvas de mejor encontrado obtenidas usando las afinaciones m´as aptas y la gr´afica del mejor problema tendencioso en el que el AG vence a recocido simulado. La medida (EA−EB)/Optimoes la fracci´on
[image:45.595.111.512.301.491.2]del ´area bajo el ´optimo que ocupa la diferencia del ´area de la curva del AG menos la del recocido simulado. La figura 5.2 muestra la historia de las mejores aptitudes de las afinaciones en la corrida del ACI en que se encontr´o el mejor problema tendencioso.
Figura 5.1: Curvas de mejor encontrado obtenidas usando las afinaciones m´as aptas y gr´afica del mejor problema tendencioso en el que AG vence a RS
5.2.
Recocido simulado vence a AG
En este caso A corresponde a la poblaci´on de afinaciones del recocido simulado y B a la de afinaciones del AG. La figura 5.3 muestra las curvas de mejor encontrado obtenidas usando las afinaciones m´as aptas y la gr´afica del mejor problema tendencioso en el que recocido simulado vence al AG, que tiene 351 ´optimos globales. La medida (EA−EB)/Optimo es la fracci´on del ´area bajo el ´optimo que ocupa la diferencia del
0 0.5 1 1.5 2 2.5 x 104 10
20 30 40 50 60 70
S
max
Competencia
[image:46.595.166.474.99.337.2]AG RS
Figura 5.2: Historia de las mejores aptitudes de las afinaciones en la corrida del ACI en que se encontr´o el problema de la figura 5.1.
5.3.
B´
usqueda aleatoria vence a AG
En este caso A corresponde a la poblaci´on virtual de afinaciones de b´usqueda aleatoria y B a la de afinaciones del AG. La figura 5.5 muestra las curvas de mejor encontrado obtenidas usando las afinaciones m´as aptas y la gr´afica del mejor problema tendencioso en el que b´usqueda aleatoria vence al AG, que tiene dos ´optimos globales, 11110010011000011111 y 11110010011000100000. La medida (EA−EB)/Optimo es la
fracci´on del ´area bajo el ´optimo que ocupa la diferencia del ´area de la curva de b´usqueda aleatoria menos la del AG.
5.4.
B´
usqueda aleatoria vence a recocido simulado
En este caso A corresponde a la poblaci´on virtual de afinaciones de b´usqueda aleatoria yB a la de afinaciones de recocido simulado. La figura 5.6 muestra las curvas de mejor encontrado obtenidas usando las afinaciones m´as aptas y la gr´afica del mejor problema tendencioso en el que b´usqueda aleatoria vence al recocido simulado. La medida (EA−EB)/Optimoes la fracci´on del ´area bajo el ´optimo que ocupa la diferencia
Figura 5.3: Curvas de mejor encontrado obtenidas usando las afinaciones m´as aptas y gr´afica del mejor problema tendencioso en el que RS vence a AG
5.5.
An´
alisis de resultados y comparaci´
on con teor´ıas
de dificultad
Hay tres caracter´ısticas importantes que saltan a la vista en las gr´aficas de resul-tados mostradas:
Ninguna de las curvas de mejor encontrado alcanz´o el m´aximo global de cada problema, incluyendo a aquellas de los algoritmos vencedores. Esto confirma la idea de que los 20 bits de cada problema bastaron para volverlos lo suficientemente complejos tal que con ninguno de los algoritmos se garantice al 100 % que va a obtenerse el m´aximo global. En la pr´actica suele darse que los problemas de optimizaci´on m´as interesantes son aquellos para los que se tiene desde un inicio la certeza de no poder obtener la mejor soluci´on posible.
0 2000 4000 6000 8000 10000 12000 14000 16000 10
20 30 40 50 60 70
S
max
Competencia
[image:48.595.164.474.99.338.2]RS AG
Figura 5.4: Historia de las mejores aptitudes de las afinaciones en la corrida del ACI en que se encontr´o el problema de la figura 5.3.
que se llega a ´el para dos algoritmos en espec´ıfico de forma experimental y sin asumir la pol´emica restricci´ona :d∈ D → {x|x /∈dx}.
Los casos en que el AG fue derrotado son demasiado planos a diferencia de los dem´as. Resulta sorprendente que el ACI encontr´o la forma de producir esta clase de planicies con mesetas y muros, de hallar la exacta combinaci´on de alelos en r y θ para las funciones que los forman. Esta peculiaridad apareci´o en todas las corridas del ACI en las que el AG fue vencido. Como una muestra de este tipo de problemas est´a la figura 5.7.
Para analizar m´as a fondo la relaci´on de la ´ultima caracter´ıstica con la distribuci´on de los m´aximos locales en los problemas mostrados se utiliz´o un algoritmo de b´usqueda local que, iniciando en un punto del problema escogido al azar escoge al azar un vecino en el eje X1 y en el eje X2 al cual se desplaza s´olo si es mejor que el punto actual.
Cada que la b´usqueda se topa con un punto peor que el actual se reinicia la b´usqueda, proceso que se repite 104 veces. Las figuras 5.8, 5.9, 5.10 y 5.11 muestran cada una: (a)
Figura 5.5: Curvas de mejor encontrado obtenidas usando las afinaciones m´as aptas y gr´afica del mejor problema tendencioso en el que BA vence a AG
Desde el punto de vista del recocido simulado las gr´aficas de tipo (c) revelan que en los casos en que venci´o la cantidad m´axima de pasos que puede dar antes de detenerse pr´acticamente dobla a aquella de los casos en que fue derrotado. Si se recuerda que la probabilidad de seguir adelante va dismuyendo junto con el par´ametro de control el que se pueda avanzar m´as distancia antes de detenerse explica en parte las diferencias de desempe˜no del recocido simulado.
Las gr´aficas de tipo (a) muestran que las evaluaciones de los m´aximos locales para los casos en que recocido simulado fue derrotado est´an distribuidas de manera m´as uniforme alrededor de la evaluaci´on m´as frecuente, mientras que en los otros dos las evaluaciones m´as frecuentes est´an aisladas de manera abrupta. Si pensamos que los algoritmos contra quienes compiti´o el recocido no tienen la limitaci´on de detenerse en un m´aximo local a pensar si seguir o no adelante, sino que continuamente est´an muestreando el espacio sin detenerse, esto explica el que accedan a evaluaciones mejores m´as r´apido que el recocido simulado y por tanto que las ´areas bajo sus curvas de mejor encontrado sean mayores. Esto se confirma observando las gr´aficas de tipo (b) en las que se ve que en los casos en que el AG y la b´usqueda aleatoria ganaron conforme uno se acerca al m´aximo global —en el espacio de Hamming— desde los m´aximos locales m´as distantes sus evaluaciones van volvi´endose uniformemente mejores hasta llegar a valores cercanos al del m´aximo global.