INSTITUTO POLITÉCNICO NACIONAL
ESCUELA SUPERIOR DE INGENIERÍA
MECÁNICA Y ELÉCTRICA
ANÁLISIS DE ENRUTAMIENTO EN LA ARQUITECTURA MPLS
TESIS
QUE PARA OBTENER EL TÍTULO DE INGENIERO
EN COMUNICACIONES Y ELECTRÓNICA
PRESENTAN
JULIO CÉSAR GONZÁLEZ ORTÍZ
MARCO ALONSO JIMÉNEZ JIMÉNEZ
KAREN ROMERO CRUZ
ASESORES TÉCNICOS:
PEDRO GUSTAVO MAGAÑA DEL RÍO
CÍRILO GABINO LEÓN VEGA
ASESOR METODOLÓGICO:
ÍNDICE DE CONTENIDO.
_______________________________________________________________
Objetivo………...4
Introducción……….... 6
Capítulo 1: Capa de Red y Protocolos de enrutamiento……….8
1.1 Algoritmos de enrutamiento………...12
1.1.1 Algoritmo de camino más corto………...13
1.1.2 Inundación de red. ………13
1.1.3 Enrutamiento de vector de distancia………..13
1.1.4 Enrutamiento de estado de enlace……….14
1.2 Protocolos de enrutamiento………...14
1.3 Protocolos de pasarela interior………..15
1.3.1 Protocolo de información de enrutamiento………15
1.3.2 Protocolo de enrutamiento de pasarela de internet……….15
1.3.3 Protocolo primero el camino abierto más corto………16
1.3.4 Protocolo mejorado de enrutamiento de pasarela de internet…………...19
1.3.5 Protocolo de sistemas intermedios……….19
1.4 Protocolos de pasarela exterior……….21
1.4.1 Protocolo de pasarela exterior……….21
1.4.2 Protocolo de pasarela de frontera………..21
Capítulo 2: Antecedentes de MPLS………...24
2.1 Definición de MPLS……….25
2.2 Uso de una infraestructura de red unificada………...26
2.3 Mejor integración IP en ATM……….26
2.4 ATM………27
2.5 Formato de datos de las celdas ATM………..28
2.7 Señalización ATM………33
Capítulo 3: Arquitectura de la Conmutación de Etiquetas Multiprotocolo.………..34
3.1 Etiquetas MPLS………...35
3.2 Apilado de etiquetas………36
3.3 Codificación de MPLS……….…36
3.4 Enrutador conmutador de etiquetas……….37
3.5 Camino conmutado de etiquetas………..38
3.6 Clases de equivalencia de reenvío (FECs)……….39
3.7 Distribución de etiquetas………40
3.8 IP sobre ATM………42
3.9 Conmutación de paquetes……….43
Capítulo 4: Descripción funcional de MPLS……….………...….46
4.1 Paquetes etiquetados reenviados……….47
4.1.1 Reenvío de paquetes etiquetados……….47
4.1.1.1 Operación de etiquetas………47
4.1.1.2 Etiquetas desconocidas………...48
4.2 Protocolo de distribución de etiquetas……….48
4.3 Control de la información en MPLS………..49
4.4 Funcionamiento global MPLS………...50
Capítulo 5: Aplicaciones de MPLS……….53
5.1 Red Privada Virtual MPLS……….54
5.2 Clase de Servicio……….58
5.3 Ingeniería de tráfico……….59
5.3.1 Ingeniería de tráfico con MPLS………...60
OBJETIVO.
_______________________________________________________________
INTRODUCCIÓN.
_______________________________________________________________
En las comunicaciones y tecnologías de la información se brindan soluciones para la demanda de servicio de Internet. Algunas de ellas se centran en el desarrollo de dispositivos electrónicos, así como software e interfaces que mejoren el rendimiento de las redes informáticas.
Una red está compuesta por “routers” o “enrutadores”, que son los encargados de
desplazar paquetes de información de una fuente a un destino. Estos paquetes deben realizar una serie de saltos a través de varios enrutadores que pueden pertenecer a una misma red o una red diferente.
En la primera década del funcionamiento de la Internet y debido al uso puramente de
paquetes, a las redes que componen la Internet se les denominó “redes de paquetes o datagramas”. Más adelante, se fue agregando tráfico de voz y video. Para cubrir está
necesidad se requirió la implementación de una “red de circuitos”. Concepto que se
basa en las redes conmutadas empleadas en la telefonía.
El uso de una red de circuitos permitió fijar una ruta por la cual se desplazan los paquetes para tener un mayor control de estos, además de brindar servicios para la corrección de errores.
CAPÍTULO 1: CAPA
DE RED Y
CAPÍTULO 1: CAPA DE RED Y PROTOCOLOS DE ENRUTAMIENTO.
_______________________________________________________________
La mayor parte de las redes se organizan como una pila de capas o niveles. Estas capas se comunican entre sí utilizando protocolos de red. El número de capas o niveles puede variar dependiendo de cada red. El conjunto de capas y protocolos se conoce como arquitectura de red.
En una red existen dos capas fundamentales en intercambio de información: una es la capa de enlace y la otra es la capa de red. En la primera capa existe una diferenciación en el flujo de bits que se le denomina tramas. En la capa de red se mueven mensajes de una fuente a un destino. Estos mensajes reciben el nombre de paquetes.
Para que los paquetes lleguen al destino, antes tienen que realizar una serie de saltos a través de dispositivos que reciben el nombre de “routers” o “enrutadores”. Al encaminar paquetes se producen problemas como sobrecarga en algunas líneas de comunicación, así como la inactividad de enrutadores. Para resolver esta situación, en la capa de red se deben contar con características funcionales que mejoren el encaminamiento de paquetes.
Debido a que la capa de red es considerada como una capa superior y la capa de enlace es considerada inferior. En el proceso de comunicación, la capa de enlace debe de brindar servicios a la capa de red. Estos servicios se ven reflejados en un encabezado (o header) que es colocado junto a un paquete. Este proceso es conocido como encapsulamiento.
“Enrutamiento” es el proceso de mover uno o más paquetes desde una fuente a un destino de red. El enrutamiento es fundamental dentro de de las redes de la Internet, debido a que se realiza en varias ocasiones de una máquina o varias máquinas a uno o varios puntos destino dentro de una red de datos. En este proceso existen dos tipos: Enrutamiento estático. Utiliza registros fijos que son definidos por el administrador de la red. Cuando la red es de gran tamaño, es difícil escalar y mantener los registros de enrutamiento.
Enrutamiento dinámico. Es establecido por los diferentes protocolos de enrutamiento de datos. Es muy común y el más usado.
Un host de red es un dispositivo conectado a una red, el cuál proporciona información, de fuentes, servicios y aplicaciones. Un host es un nodo que se le es asignado un número de identificación. Éste número de identificación es una porción de una dirección IP.
Una característica de IPv4 son sus direcciones de 32 bits. Cada host y enrutador en la Internet tiene una dirección IP que puede ser usada en los campos de dirección de los paquetes IP de la fuente y destino.
[image:11.612.104.548.354.557.2]Cuando un paquete se envía de un host para transmitirse al enrutador más cercano, sea a través de una Red de Área Local o un enlace punto a punto a un Proveedor de servicio de Internet (ISP - Internet Service Provider). El paquete es almacenado en dicho enrutador hasta que el proceso de transmisión esté completo y el enlace haya finalizado un proceso de verificación. Después es enviado al siguiente enrutador hasta alcanzar el host destino. Este mecanismo se conoce como conmutación de paquetes y reenvío. (Ver Figura 1.1).
Figura 1.1 Proceso de conmutación de paquetes y reenvío: el host 1 envía un paquete al enrutador más cercano y posteriormente a otro enrutador, así sucesivamente hasta
llegar al destino (host 2).
arreglos encargados de listar las rutas para destinos de red particulares. Estos arreglos se conocen como tablas de enrutamiento.
Las redes pueden proveer dos tipos de servicio: orientado a la conexión, como es el caso de las redes de circuitos y no orientado a la conexión, como en las redes de paquetes. El tipo de servicio empleado depende del tipo de información. En el envío de datos no es indispensable la calidad de servicio, por lo tanto, la mejor opción es el uso de servicio no orientado a la conexión. En el caso de voz y video, la calidad de servicio es fundamental, por ello, la opción más recomendable es el servicio orientado a la conexión.
Para el servicio orientado a la conexión, es necesario establecer una ruta del host fuente al host destino. Así, los paquetes tendrán que seguir un mismo camino. Caso contrario al servicio no orientado a la conexión, donde cada paquete elige la ruta más conveniente.
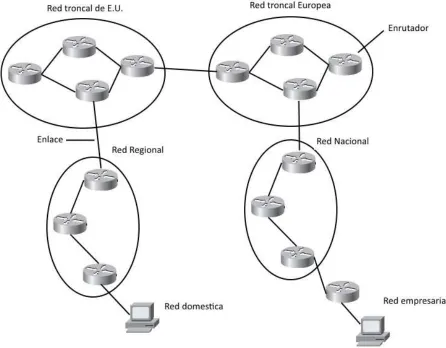
La Internet es un conjunto de redes o subredes, dónde dependiendo el tamaño de la red o el tipo de operación, requiere manejar sus propias políticas de enrutamiento. Sin embargo para que pueda existir un intercambio de tráfico, es importante el manejo de determinados protocolos para el manejo de las políticas entre redes.
Figura 1.2 La internet está compuesta de distintas redes.
1.1. ALGORITMOS DE ENRUTAMIENTO.
Los algoritmos de enrutamiento forman parte del software de la capa de red. Tienen la responsabilidad de decidir sobre cual línea de salida, los paquetes entrantes deben ser transmitidos. Si la red usa datagramas internamente, la decisión debe hacerse nuevamente para cada paquete de datos entrante. La ruta más adecuada puede cambiar desde la última vez, por esto se requieren nuevas decisiones. Por otro lado, si la red utiliza circuitos virtuales internamente, las decisiones de enrutamiento deben hacerse cada vez que un nuevo circuito virtual sea establecido.
1.1.1 ALGORITMO DE CAMINO MÁS CORTO.
El algoritmo de camino más corto es una técnica para calcular los caminos más óptimos en una red o conjunto de redes. Para ello proporcionan una representación de la red o conjunto de redes.
El propósito de obtener una representación de red o conjunto de redes es para elegir una ruta entre un par de enrutadores determinados. La ruta debe ser la más corta entre un conjunto de rutas analizadas. Para hacer esto posible se requiere una representación de red con cada nodo representando a un enrutador y cada límite de dicha representación, simbolizando una línea o enlace.
1.1.2 INUNDACIÓN DE RED.
Después de la implementación de un algoritmo, cada enrutador debe tomar decisiones respecto al conocimiento local, no necesariamente sobre la representación completa de la red. Para ello, se requiere una técnica local denominada Inundación de red. Esta técnica consiste en que cada paquete entrante es enviado en cada línea de salida excepto el paquete recién llegado.
La inundación de red genera un vasto número de paquetes duplicados. Incluso, se podría generar un número infinito de paquetes duplicados, a no ser que se tomen medidas para abortar el proceso, si es el caso. Una medida es tener un contador de saltos. Este contador tendría que estar contenido en el encabezado de cada paquete, por lo tanto, tendría que ir disminuyendo en cada salto hasta que el paquete sea descartado cuando el contador llegue a cero.
Una técnica más óptima para evitar el duplicado de paquetes. Es tener un conjunto de enrutadores que mantengan registro de los paquetes que han sido inundados, para evitar que sean enviados por segunda vez.
1.1.3 ENRUTAMIENTO DE VECTOR DE DISTANCIA.
Usualmente las redes utilizan algoritmos de enrutamiento dinámicos que son más complejos que el algoritmo de inundación de red. Estos algoritmos son más eficientes debido a que localizan el camino más corto en la topología en que son implementados. El algoritmo de vector de distancia de enrutamiento opera haciendo que cada enrutador mantenga una tabla que proporcione la mejor distancia conocida para cada destino, que el enlace va a usar para llegar ahí. Las tablas son actualizadas debido al intercambio de información entre enrutadores vecinos. Eventualmente, cada enrutador conocerá el enlace más óptimo para alcanzar el destino.
enrutador de la red. Esta entrada está compuesta de dos partes: la línea de salida preferida para ser usada para cada llegar al destino que se desea y un estimado de la distancia para llegar a tal destino. La distancia puede ser medida como un número de saltos o utilizar una métrica similar al algoritmo de camino más corto.
Se asume que los enrutadores conocen la distancia de cada enrutador vecino. Si se determina que la métrica son saltos, la distancia es un solo salto. Si se decide que la métrica es la propagación de retraso, el enrutador debe medir la distancia directamente con paquetes especiales que el receptor detenga momentáneamente y que posteriormente reenvíe lo más pronto posible.
1.1.4 ENRUTAMIENTO DE ESTADO DE ENLACE.
El enrutamiento de vector de distancia solía ser muy utilizado, posteriormente fue remplazado por el enrutamiento de estado de enlace. El principal problema del enrutamiento utilizando los algoritmos de vector de distancia, fue el largo tiempo para converger después que la topología cambiara.
El concepto del enrutamiento de estado de enlace está divido en cinco partes:
1 El descubrimiento de cada vecino y el conocimiento de sus respectivas direcciones.
2 El establecimiento de la métrica de distancia o costo de cada uno de sus enrutadores vecinos.
3 La construcción de un paquete con información sobre las direcciones y la métrica. 4 El envío del paquete construido y la recepción de paquetes de información de
otros enrutadores.
5 El registro del camino más corto para cada enrutador.
1.2. PROTOCOLOS DE ENRUTAMIENTO.
Los protocolos de enrutamiento se encargan de mantener las tablas de enrutamiento de manera exacta a pesar de que la red sobre la cual estén operando cambie constantemente debido a equipo o fallas al agregar nuevos segmentos de red.
La operación de un protocolo de enrutamiento tiene dos partes: la primera parte se encarga de enviar avisos o actualizaciones de enrutamiento desde un enrutador con respecto a números de red conocidos; la segunda parte recibe y procesa estas actualizaciones o avisos de manera que las tablas de enrutamiento mantengan un tráfico eficiente.
1.3. PROTOCOLOS DE PASARELA INTERIOR.
La Internet está compuesta por un largo número de redes independientes o Sistemas Autónomos que son operadas por distintas organizaciones, puede ser una compañía, una escuela o un proveedor de servicio de internet. Una organización puede utilizar su propio algoritmo de enrutamiento para el enrutamiento interno de su propia red. No obstante, existen protocolos estándar para realizar esa tarea.
1.3.1 PROTOCOLO DE INFORMACIÓN DE ENRUTAMIENTO (RIP).
El primer Protocolo de Pasarela Interior fue el Protocolo de Información de Enrutamiento (RIP - Routing Information Protocol). Este protocolo fue diseñado para un ambiente compuesto de sólo unos cuantos aparatos que están conectados a enlaces de características similares.
El Protocolo de Información de Enrutamiento pertenece a la clase de algoritmos conocidos como Vector de Distancia. El propósito de RIP es para el uso de la Internet basado en IP. La Internet está organizada dentro de un número de redes conectadas a través de Puertas de enlace. Los hosts y puertas de enlace son presentados con datagramas IP y direccionados a algún host. RIP es destinado para permitir que hosts y puertas de enlace intercambien información para rutas a través de redes basadas en IP. Los paquetes realizan saltos por distintos enrutadores hasta llegar a su destino, para ello, RIP usa el conteo de saltos de enrutadores como métrica. Existen dos versiones: RIP versión 1 o RIPv1 y RIP versión 2 o RIPv1.
1.3.2. PROTOCOLO DE ENRUTAMIENTO DE PASARELA DE INTERNET (IGRP).
El Protocolo de Enrutamiento de Pasarela de Internet (IGRP - Internet Gateway Routing Protocol) es un protocolo del tipo de vector de distancia. Fue desarrollado por los sistemas Cisco para redes complejas de gran tamaño basadas en los protocolos IP.
El propósito del desarrollo de IGRP fue para resolver problemas que limitan a RIP. La métrica de IGRP se basa en parámetros de tiempo real de la red como: retardo, ancho de banda, Máxima Unidad de Transmisión (MTU - Maximum Transmission Unit), confiabilidad y carga de los recursos de la red. La métrica puede ser configurada de acuerdo a las necesidades y requerimientos por el administrador de la red.
IGRP incluye tres tipos de paquetes de actualizaciones que permiten ampliar la estabilidad de este protocolo: mantenimiento (Hold-down), horizonte dividido (Split-horizon) e inversa envenenada (Poison-reverse).
Los mensajes de mantenimiento previenen reinserciones inapropiadas de rutas no óptimas durante cierto periodo de tiempo. Las actualizaciones de horizonte dividido trabajan bajo la regla de no enviar información innecesaria de determinadas subredes al enrutador origen. Los mensajes de tipo de inversa envenenada tienen por finalidad evitar grandes lazos de enrutamiento. El propósito de los mensajes es para eliminar la ruta afectada.
1.3.3. PROTOCOLO EL CAMINO MÁS CORTO PRIMERO (OSPF).
La Fuerza Especial de Ingeniería en Internet (IETF - Internet Engineering Task Force) empezó a trabajar en un nuevo protocolo estándar para sustituir al RIP. El resultado fue el Protocolo de Pasarela Interior Primero el Camino Abierto más Corto (OSPF – Open Shortest Path First). Este protocolo es una tecnología pública sin propietario.
Este es un protocolo de enrutamiento con estructura "jerárquica", basado en una primera versión del Protocolo de Enrutamiento de Sistemas Intermedios (IS-IS – Intermediate System to Intermediate System). Y que trabaja basándose en el algoritmo del camino más corto, así como en algoritmos de estado de enlace. OSPF es un protocolo importante porque posee un número de ventajas que no se encuentran en ningún otro protocolo de pasarela interior. Lo que lo hace la opción preferida en las nuevas redes IP, especialmente en grandes redes.
Sus actualizaciones incluyen información referente a interfaces conectadas y métricas usadas, entre otras variables. Estas actualizaciones son enviadas a los enrutadores dentro del "área común de enrutamiento" cuando existe algún cambio en el estado de los enlaces. La métrica se calcula basándose en el estado de los enlaces, y la misma permite al enrutador determinar cuál es el camino más corto hacia uno o varios nodos.
Este protocolo tiene como características adicionales el enrutamiento basado en múltiples caminos con igualdad de costos, y el enrutamiento basado en requerimientos de Tipos de Servicios (TOS - Type of Service) de las capas de alto nivel; este tipo de enrutamiento soporta aquellos protocolos que puedan especificar ciertos tipos de servicios. Por ejemplo, una aplicación puede requerir que ciertos datos sean enviados urgentemente, y esto es posible si el OSPF tiene disponibilidad de enlaces de alta prioridad.
es usado a través del uso de una métrica aparte (y por consiguiente, utilizándose una tabla de enrutamiento separada) para cada una de las ocho combinaciones creadas por los tres bits IP del TOS (a saber: el retardo, la eficiencia y la disponibilidad).
En la Figura 1.3 se muestra un ejemplo de lo que puede ser una red basada en OSPF. En la misma se observan que las redes basadas en OSPF están organizadas en áreas. Las áreas pueden ser definidas basándose en la ubicación o a una región, o pueden estar basadas en límites administrativos. Todas las redes OSPF están formadas al menos por un área, una red dorsal y tantas áreas adicionales como sean necesarias.
[image:18.612.172.466.324.570.2]Dentro de un área OSPF todos los enrutadores mantienen la topología de base de datos, intercambiando información de estado de enlace para mantener su sincronización. Esto asegura que los enrutadores pueden calcular el mismo mapa de red para una misma área.
Figura 1.3 Ejemplo de Red Dorsal OSPF (Primero el Camino Abierto más Corto)
Además de las áreas, una red OSPF está compuesta por otras entidades, las cuales se listan a continuación.
Enrutadores de Intra-Área (IA), límite de área (AB) y de frontera (ASB). A continuación se detalla su funcionamiento.
Enrutadores de Intra-Área (IAR - Intra-Area Routers). Estos enrutadores se encuentran situados dentro del área OSPF. Todos estos enrutadores entregan avisos de enlaces de enrutadores en esta área para definir los enlaces a los cuales se encuentran conectados.
Enrutadores de límite de Área (ABR - Area Border Routers). A los enrutadores que se encuentren conectados a más de dos áreas se les denomina Enrutadores de límite de área. Se encargan de mantener la topología de base de datos para cada una de las áreas a las que están “conectados”.
Enrutadores de Frontera (BR - Boundary Routers). Estos son los enrutadores que se encuentran ubicados en la periferia de una red OSPF e intercambian información con los enrutadores en otros Sistemas Autónomos usando protocolos de pasarela exterior.
Los mensajes de OSPF se transmiten directamente en datagramas IP. Todos los mensajes OSPF comparten una cabecera común, la cual se muestra en la Fig. 1.5. Cabecera común de OSPF. Esta cabecera contiene información general, como por ejemplo: el identificador de área (ID del área) y el identificador de enrutador origen (ID del enrutador o router), entre otros. Un campo define cada paquete OSPF como una de los siguientes cinco tipos posibles:
Saludo (Hello). Se usa para identificar a los vecinos, elegir un enrutador designado para una red de multienvío, para encontrar a un enrutador designado existente y para enviar señales de “estoy vivo”.
Descripción de la base de datos (Database description). Durante el inicio, se usa para intercambiar información de manera que un enrutador pueda descubrir los datos que le faltan en la base de datos.
Petición del estado de enlace (Link state request). Se usa para pedir datos que un enrutador se ha dado cuenta que le faltan en su base de datos o que están obsoletos. Actualización del estado de enlace (Link state update). Se usa como respuesta a los mensajes de Petición del estado de enlace y también para informar dinámicamente de los cambios en la topología de la red.
Reconocimiento de estado de enlace (Link state acknowledgement). Se usa para confirmar la recepción de una Actualización del estado de enlace. El emisor retransmitirá hasta que se confirme.
1.3.4. PROTOCOLO MEJORADO DE ENRUTAMIENTO DE PASARELA DE INTERNET
El Protocolo Mejorado de Enrutamiento de Pasarela de Internet (EIGRP- Enhanced Internet Gateway Routing Protocol) desarrollado por S i s t e m a s Cisco, combina la facilidad del uso de los protocolos tradicionales con las ventajas del rápido re-enrutamiento de los protocolos con algoritmos de estado de enlace, suministrando así capacidades avanzadas en la convergencia rápida y las actualizaciones parciales. Se usan mensajes simples periódicos de saludo para descubrir a los vecinos y para comprobar que aún están activos. Otra mejora importante de este protocolo es el uso del Algoritmo de Actualización por Difusión (DUAL – Diffusing Update Algorithm). La idea básica de DUAL es simple. Se basa en la siguiente observación: Si una ruta consistente te lleva más directo a un destino, la ruta no puede ser un bucle.
Cuando ocurre un cambio en la topología de la red el algoritmo de difusión, realiza la convergencia en menos de 5 segundos en la mayoría de los casos; esto equivale a la convergencia ejecutada por protocolos de enlace de estado tales como OSPF y por IS- IS. Adicionalmente, EIGRP sólo envía actualizaciones de re-enrutamiento cuando ocurren cambios a los enrutadores directamente afectados.
Por otra parte, EIGRP soporta enmascaramiento de rede de longitud variable (VLSM - Variable-Length Subnet Mask). El protocolo EIGRP soporta actualizaciones increméntales en el Protocolo de Servicio de Aviso (SAP - Service Advertisement Protocol), elimina la limitación de RIP en el número máximo de saltos, y provee uso de caminos óptimos. Un enrutador ejecutando EIGRP realiza actualizaciones parciales y limitadas de enrutamiento y provee balanceo de cargas y uso de caminos óptimos.
1.3.5. PROTOCOLO DE SISTEMAS INTERMEDIOS.
El Protocolo de Enrutamiento de entre Sistemas Intermedios (IS-IS – Intermediate System to Intermediate System), inicialmente, fue definido para los enrutadores pero se ha extendido a redes IP. Al igual que OSPF, IS-IS es un protocolo de estado de enlace que dispone de enrutamiento jerárquico, enrutamiento por tipo de servicio, división del tráfico por varias rutas y autenticación.
IS-IS tiene dos tipos de Rutas: enrutamiento de nivel 1 dentro de un área y enrutamiento de nivel 2 para destinos fuera del área.
están accesibles a través de un enrutador de nivel 2. Sin embargo, los enrutadores de nivel 2 no necesitan conocer la topología dentro de cualquier área de nivel 1, excepto aquellas en las que un enrutador de nivel 2 sea un enrutador de nivel 1 dentro de una sola área. Sólo los enrutadores de nivel 2 pueden intercambiar paquetes de datos o información de enrutamiento directamente con enrutadores externos localizados fuera del dominio de enrutamiento. En pocas palabras, los enrutadores de nivel 1 se podrían ver de forma análoga a los enrutadores de la red dorsal en OSPF. Un enrutador de un Sistema intermedio de nivel 1 reenvía el tráfico a destinos fuera del área a su enrutador de nivel más cercano.
Las direcciones están subdivididas en: parte del domino inicial (IDP-Initial Domain Part), y la parte del dominio específico (DSP-Domain Specific Part). El IDP está estandarizado por la Organización Internacional para la Estandarización (ISO – International Organization for Standarization), y específica el formato y la autoridad responsable para asignar el resto de las direcciones. El DSP es asignado por cualquier autoridad de direccionamiento especificada por el IDP. El DSP está subdividido en: a l t o o r d e n ( HO-DSP - High Order of DSP), un identificador de sistema (ID), y un selector de (SEL). El IDP junto al HO-DSP (también denominada dirección de área) identifican el dominio de enrutamiento y el área dentro del dominio de enrutamiento. (Ver figura 1.4).
Una ventaja del uso de IS-IS integrado tiene que ver con el esfuerzo en la gestión de redes. Ya que el IS-IS integrado provee un protocolo de enrutamiento simple, dentro de un dominio de enrutamiento coordinado que utiliza una sola red dorsal, existe menos información que configurar.
[image:21.612.205.432.513.615.2]Otra ventaja del IS-IS integrado es que utiliza menos recursos. Esto es, menos recursos de implantación (ya que sólo se utiliza un protocolo), menos recursos de CPU y memoria son usados por el enrutador, y menos recursos de red.
1.4. PROTOCOLOS DE PASARELA EXTERIOR.
Los protocolos de pasarela exterior son usados para intercambiar información de enrutamiento entre redes que no comparten una administración común. Estos protocolos requieren la siguiente información antes de iniciar las tareas de enrutamiento: una lista de enrutadores vecinos con los cuales se intercambia información de enrutamiento, una lista de redes de acceso directo, un número de sistemas autónomos del enrutador local.
1.4.1. PROTOCOLO DE PASARELA EXTERIOR.
El Protocolo de Pasarela Exterior (EGP - Exterior Gateway Protocol) es el primer protocolo de enrutamiento al nivel de interdominios usado entre los enrutadores de la red dorsal principal de la Internet.
A pesar de ser un protocolo de enrutamiento dinámico, no usa métricas ni realiza decisiones inteligentes de enrutamiento, sino que sus actualizaciones contienen la disponibilidad de redes, asumiendo que las mismas son alcanzables a través de determinados enrutadores. Éstas se efectúan entre determinados enrutadores vecinos por intervalos regulares de tiempo, indicando cada enrutador las subredes directamente conectadas al mismo.
A pesar de que EGP tuvo buen desempeño por algunos años, ya había comenzado a mostrar ciertas fallas. EGP no tenía manera de tratar con los lazos de enrutamiento que ocurrían en redes con múltiples caminos, también las actualizaciones frecuentemente eran muy largas. Además, el EGP no podía realizar decisiones de enrutamiento inteligente porque no soportaba métricas de enlaces, esto se logra con el protocolo de pasarela de frontera.
1.4.2. PROTOCOLO DE PASARELA DE FRONTERA.
El Protocolo de Pasarela de Frontera (BGP - Border Gateway Protocol) es un protocolo de enrutamiento externo (o entre sistemas autónomos) diseñado para corregir las fallas presentadas por el EGP, ya que detecta los lazos de enrutamiento y usa una métrica con el fin de realizar decisiones de enrutamiento inteligente.
Este protocolo puede ser utilizado dentro de los sistemas autónomos, y sus actualizaciones consisten en direcciones IP de las subredes y en caminos hacia distintos sistemas autónomos. Estos caminos contienen información de sistemas autónomos a través de los cuales ciertas subredes pueden ser alcanzadas. Estas actualizaciones son enviadas usando los mecanismos de transporte.
enviadas cuando cambian las tablas de enrutamiento. A diferencia de otros protocolos de enrutamiento de datos, éste no requiere renovaciones periódicas y completas de las tablas de enrutamiento. En su lugar, estos enrutadores retienen la última versión de las tablas de enrutamiento de los enrutadores vecinos con los cuales se estén ejecutando sesiones BGP. Aunque el BGP mantiene una tabla de enrutamiento con todos los posibles caminos hacia una subred en particular solamente anuncia el camino óptimo.
BGP usa una métrica simple para determinar el mejor camino hacia una o varias redes en particular. Esta métrica consiste en un número arbitrario que especifica el grado de preferencia de un enlace en particular. Comúnmente esta métrica es asignada sobre cada enlace por el administrador de la red, y este valor puede ser basado en ciertos parámetros, incluyendo el número de sistemas autónomos a través de los cuales se enrutan los datos (los caminos con el menor número de sistemas autónomos son generalmente los mejores), la estabilidad, velocidad, el retardo o el costo.
El protocolo BGP está compuesto por cuatro pasos principales: apertura y confirmación de una conexión BGP con un enrutador vecino, mantenimiento de la conexión BGP, envío de información de rutas óptimas y notificación de condición de error.
Apertura y confirmación de una conexión BGP con un enrutador vecino. La comunicación BGP entre dos enrutadores se inicia con el establecimiento de la conexión del protocolo de control de transmisión (TCP – Transmission Control Protocol). Una vez que esta conexión se establece, cada enrutador puede enviar un mensaje abierto a su vecino.
El mensaje abierto de BGP consiste de una cabecera estándar más contenidos específicos de tipo paquete. La cabecera estándar consta de un campo de 16 octetos, los cuales se ponen en todos uno cuando la el código de autenticación es 0, la longitud del mensaje de BGP (el formato de la cabecera de BGP se muestra en la figura 1.7), y el campo de tipo que especifica si el mensaje puede ser de uno de los siguientes tipos: OPEN. UPDATE. NOTIFICATION y KEEPALIVE.
El mensaje abierto define el número de AS del enrutador originador, su identificador de enrutador BGP y el tiempo de mantenimiento para la conexión. Si no se reciben mensajes keepalive, update o notification, el enrutador originador asume que existe un error y envía un mensaje de notificación y corta la conexión. El formato del mensaje abierto se muestra a continuación.
entre vecinos. Estos mensajes KEEPALIVE consisten de un mensaje BGP solamente, no posee datos.
CAPÍTULO 2:
CAPITULO 2: ANTECEDENTES DE MPLS.
____________________________________________________________
Para lograr que la capa de red haga que los paquetes de información lleguen de una fuente a un destino. Ésta debe conocer la topología de la red para el elegir el camino apropiado. Debido a que esta acción tiene que realizarse de manera óptima, se deben elegir rutas que eviten la sobre carga de algunas líneas de comunicación mientras algunos routers permanezcan inactivos.
La red puede proveer a los usuarios dos clases de servicio. Para ello existen dos tipos de organizaciones posibles dependiendo el tipo de servicio ofrecido. El primer tipo de organización provee servicio no orientado a la conexión, los paquetes son inyectados dentro de la red de manera individual y enrutados de manera independiente. Este tipo de red es llamada Red de datagramas. El segundo tipo de organización provee servicio orientado a la conexión, en este caso, se establece una trayectoria desde el enrutador fuente hasta el enrutador destino. Esta conexión es conocida como Circuito Virtual (VC – Virtual Circuit). A la arquitectura de red que provee este tipo de servicio se conoce como Red de circuitos virtuales. En algunos contextos, este proceso se llamado conmutación de etiquetas. Un ejemplo de servicio de red orientado a la conexión es Conmutación de Etiquetas Multiprotocolo o MPLS (MPLS – Multiprotocol Label Swtiching), el cuál es utilizado en la redes de los Proveedores de Servicio de Internet o ISP (ISP – Internet Service Provider), con paquetes IP envueltos en una encabezado MPLS teniendo un identificador de conexión de 20 bits, también llamado etiqueta. MPLS es usualmente oculto de los clientes, con el ISP estableciendo conexiones a largo plazo para grandes cantidades de tráfico. Es muy usado cuando se requiere Calidad de Servicio (QoS – Quality of Service) y también para tareas de manejo de tráfico proveniente de otro ISP.
2.1 DEFINICIÓN DE MPLS.
Las etiquetas MPLS son anunciadas entre los enrutadores para que éstos puedan construir un mapeo de etiqueta a etiqueta. Estas etiquetas están adjuntas a los paquetes IP. Lo que permite reenviar el tráfico de red basándose en la información proporcionada en las etiquetas y no en la dirección IP. De esta forma, se habla de conmutación de etiquetas y no conmutación IP.
trama reside. La similitud entre ATM y Frame Relay es que en cada salto o intercambio de router a través de la red, el valor de la etiqueta en el encabezado cambia. Esto difiere del reenvío de paquetes IP. Cuando un router reenvía un paquete IP, no cambia el valor que pertenece al destino del paquete, es decir, no cambia la dirección IP del paquete. El hecho qye las etiquetas MPLS son usadas para reenviar los paquetes y no la dirección IP destino es algo que ha acrecentado el uso del conjunto de protocolos MPLS.
2.2 USO DE UNA INFRAESTRUCTURA DE RED UNIFICADA.
La idea de MPLS es etiquetar paquetes entrantes basados en su dirección destino u otro criterio de configuración y conmutar todo el tráfico en una infraestructura común. Una de las razones que hizo a IP el protocolo dominante en el mundo de las redes es su habilidad de transportar diversas tecnologías. No sólo datos, también telefonía. Al usar MPLS con IP, se pueden extender las posibilidades de lo que se puede transportar. Agregar etiquetas en los paquetes permite llevar otros protocolos a parte de IP en una dorsal capa 3 IP habilitada MPLS.
MPLS puede transportar IPv4, IPv6, Ethernet, control de enlace de datos de alto nivel y otras tecnologías de la capa de enlace.
La característica por la cual cualquier trama de capa 2 es llevada a través de una dorsal MPLS es conocida como AToM (AToM – Any Transport over MPLS). Los routers que conmutan el tráfico AToM no necesitan estar consientes de la carga útil MPLS, sólo necesitan tener permitido la conmutación de tráfico etiquetado al inspeccionar la etiqueta en la parte superior del paquete. En esencia, la conmutación de etiquetas MPLS es un método para conmutar múltiples protocolos en una red. AToM permite al ISP proveer el mismo servicio de capa 2 hacia el cliente como cualquier específica red sin MPLS. Al mismo tiempo, el proveedor de servicio necesita una infraestructura de red unificada para llevar todos los tipos de tráfico del cliente.
2.3 MEJOR INTEGRACIÓN IP EN ATM.
Hace dos décadas, el protocolo IP prevaleció sobre todos los protocolos de red. Es relativamente simple y omnipresente. Un protocolo de capa de enlace muy publicitado en ese momento fue ATM.
Una solución fue la implementación IP sobre ATM de acuerdo con la “Encapsulación
Multiprotocolo sobre la Capa 5 de Adaptación ATM (AAL – ATM Adaptation Layer)”, que específica como encapsular múltiples protocolos enrutados y puenteados sobre AAL5. Para hacer esto posible, todos los circuitos ATM tuvieron que ser establecidos manualmente, y todos los mapeos entre saltos siguientes IP y puntos finales ATM tuvieron que ser manualmente configurados en cada router con ATM adjunto en la red. Una mejor solución para la integración de IP sobre ATM fue una de las razones para la invención de MPLS. Los prerrequisitos para MPLS en conmutadores ATM fueron que los conmutadores ATM tuvieron que volverse más inteligentes. Los conmutatores ATM tuvieron que ejecutar un protocolo de enrutamiento IP e implementar un protocolo de distribución de etiquetas.
2.4 ATM.
El Modo de Transferencia Asíncrono o ATM es una tecnología de conmutación de paquetes para alta velocidad con una serie de características muy particulares: Los paquetes son de tamaño pequeño y constante (53 bytes); es una tecnología de naturaleza conmutada y orientada a conexión; los nodos que componen la red no tienen mecanismos para el control de errores de flujo; el encabezado de las celdas tiene una funcionalidad limitada.
En ATM el flujo de información está organizado en celdas constituidas por un campo de información y un encabezado que se transmiten en un circuito virtual y el enrutamiento se realiza basándose en un Identificador de Circuito Virtual (VCI – Virtual Circuit Identifier) y a un Identificador de Camino Virtual (VPI – Virtual path Identifier) contenidos en el encabezado.
Cada conexión virtual es identificada por un número, cuyo significado es sólo local, es decir está asociado a cada enlace. Esta función de identificación es ejecutada por dos subcampos del encabezamiento de la celda: el VPI y el VCI. El VCI identifica a un Circuito Virtual (VC – Virtual Circuit) específico en un Camino Virtual (VP – Virtual Path) dado. Un VC es un concepto usado para describir un transporte unidireccional de celdas ATM y un VP es un concepto usado para describir un transporte unidireccional de celdas ATM pertenecientes VCs.
Un VC es análogo a una conexión Frame Relay. Un camino virtual es un conjunto de VCs que tienen los mismos puntos finales. Este concepto fue desarrollado para las redes de alta velocidad con el fin de disminuir el costo del manejo de las señales de control.
Las conexiones virtuales ATM pueden proporcionarse utilizando gestión de red. Estas conexiones se denominan canales virtuales permanentes (PVC-Permanent Virtual Channels). Así mismo, los canales virtuales pueden establecerse dinámicamente utilizando procedimientos de señalización ATM. Estos canales virtuales se denominan canales virtuales conmutados (SVCs- Switched Virtual Channels).
En ATM no se asignan ranuras de tiempo específico periódicas al canal. La capacidad disponible es segmentada en las unidades de información de tamaño fijo (celdas), por tanto ATM se comporta de forma asíncrona porque transmite celdas que no necesitan ser periódicas. Se considera que ATM es un modo de transferencia eficiente y flexible, ya que al asignar ranuras según la demanda, se pueden acomodar fácilmente servicios de velocidad variable. ATM puede ganar también eficiencia en el manejo del ancho de banda multicanalizando estadísticamente fuentes de tráfico de tipo ráfaga, donde aparecen celdas a una velocidad muy alta por un período de tiempo muy corto. Este tipo de fuente no requiere una asignación continua de ancho de banda a su velocidad máxima y un gran número de estas fuentes puede compartir el mismo ancho de banda
ATM es capaz de soportar todo tipo de servicio (con y sin conexión), inclusive emulación de redes de área local y de circuitos, Frame Relay. Además puede soportar todo tipo de tráfico (voz, video, dato y combinaciones).
2.5. FORMATO DE DATOS DE LAS CELDAS ATM.
Una celda ATM está formada por 53 bytes, de los cuales 5 bytes son de encabezado y 48 bytes de información (ó carga útil). Los bytes son enviados en orden creciente, empezando con el primer byte del encabezado. Dentro de un byte, los bits son enviados en forma decreciente, comenzando por el bit 8. Para todos los campos de una celda ATM, el primer bit enviado es también el bit más significativo (MSB).
El encabezado está dividido en diferentes campos ( Ver figura 2.2). El campo más importante es el campo de dirección, ya que identifica el circuito y provee una dirección de enlace único entre dos nodos de red, a través de los VPI y VCI.
misma conexión y el valor del bit CLP puede ser asignado tanto por el usuario como por la red, en el caso de que no exista espacio suficiente para todas las celdas.
El último campo del encabezado contiene un control de código cíclico (HEC –
Header Error Control) que permite detectar y corregir un error aislado en un bit del encabezamiento y además detectar un número de errores superior o igual a dos, en cuyo caso se desecha la celda. Este último campo desempeña un papel muy importante, ya que el enrutamiento de las celdas y la propia integridad de las conexiones dependen de la interpretación del encabezamiento.
En la interfaz entre el usuario y la red (UNI – User-Network Interface), cuatro bits del campo VPI son reemplazados por el campo de control de flujo genérico (GFC –
[image:30.612.132.508.345.568.2]Generic Flow Interface), el cual se emplea para controlar el uso de la capacidad de la red entre el terminal y la red. Esto es, permite implementaciones básicas de multiplexaje, es decir, puede ser utilizado por la red para controlar, en la instalación del usuario, el flujo de algunas conexiones y arbitrar el acceso a la red de varios terminales.
Figura 2.2 Estructura de una celda ATM
En la interfaz entre el usuario y la red (UNI – User-Network Interface), cuatro bits del campo VPI son reemplazados por el campo de control de flujo genérico (GFC –
del usuario, el flujo de algunas conexiones y arbitrar el acceso a la red de varios terminales.
2.6. CLASIFICACIÓN DE SERVICIOS.
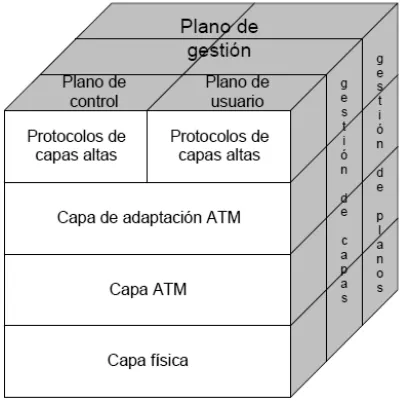
El modelo de capas de ATM se encuentra en la figura 2.3. Las tres capas más bajas son:
Capa 1, la capa física, la cual transporta información (bits/celdas). ATM no prescribe un conjunto de reglas en particular, pero en cambio dice que las celdas ATM se pueden enviar por sí solas por un cable o fibra o bien se pueden empacar dentro de la carga útil de otros sistemas portadores. En otras, palabras, ATM se diseñó para que fuera independiente del medio de transmisión.
Capa 2, la capa ATM, la cual principalmente ejecuta conmutación/enrutamiento y multiplexación. Define la organización de las celdas y dice lo que significan los campos del encabezado. Esta capa también tiene que ver con el establecimiento y la liberación de circuitos virtuales. En esta capa se localiza el control y la congestión. Capa 3, la capa de adaptación de ATM (AAL – ATM Adaptation Layer), la cual principalmente es responsable de la adaptación de los servicios de información de las celdas ATM. Esta capa permite a los usuarios enviar paquetes mayores a una celda porque la mayor parte de las aplicaciones no quieren trabajar de manera directa en celdas. Por lo que esta capa segmenta estos paquetes, transmite las celdas en forma individual y las reensambla en el otro extremo.
El modelo que presenta ATM es un modelo tridimensional (Ver Fig. 2.3). El plano de usuario se encarga del transporte de los datos, el control de flujo, la corrección de errores y otras funciones de usuario. Mientras que el plano de control tiene que ver con la administración de la conexión. Las funciones de gestión de capas y planos se relacionan con la administración de recursos y la coordinación intercapas.
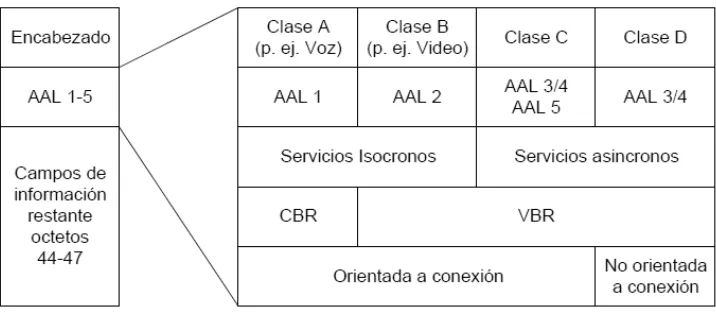
Para permitir la transferencia de datos y servicios isócronos, la información debe ser adaptada a la red en diferentes maneras. Por esta razón, ATM ha sido dividida en cuatro clases de servicios (A, B, C y D) basándose en tres parámetros:
Servicios sincronos y asíncronos.
Proporción de bit variable (VBR) y proporción de bit constante (CBR). Orientado a conexión y no orientado a conexión.
Además se pueden mencionar cuatro protocolos: AAL 1, AAL 2, AAL 3/4 y AAL 5 (Ver Fig. 2.4).
una gama de parámetros de calidad de servicio. Estos parámetros de calidad de servicio pueden definir los niveles mínimos de ancho de banda requeridos y los límites en el retardo de las celdas y la tasa de pérdida de celdas. A continuación se detalla brevemente éstas clases de servicio.
Figura 2.3 Modelo de Capas ATM.
Proporción de Bit Constante (CBR - Constant Bit Rate): Es el tipo más sencillo de las clases de servicio ATM. Cuando una aplicación negocia el establecimiento de una conexión CBR, la red garantiza una proporción de celda de cresta (PCR - Peak Cell Rate), la cual es la máxima velocidad de datos que la conexión ATM puede soportar sin riesgos de pérdida de celdas. No existen límites para la velocidad de datos que se puede negociar en una conexión CBR, pero cualquier tipo de tráfico por encima de la velocidad negociada puede ser descartado por la red.
Figura 2.4. Descripción de los servicios de la capa AAL de ATM
Real-Time Variable Bit Rate (rt-VBR): Se parece a la clase de servicio CBR en el sentido que deseamos un retardo por bajo tránsito pero el tráfico puede variar su velocidad. Los datos pueden ser video comprimido, voz comprimida con supresión de silencio, o emulación de enlaces DIC.
Non-Real-Time Variable Bit Rate (nrt-VBR): Este es un servicio de entrega garantizado, donde el retardo de tránsito y el “jitter” son quizás menos importantes que el caso de rt-VBR. Un ejemplo de su aplicación puede ser la distribución de video codificado MPEG-2. En este caso, la información proviene de un disco y su distribución de la señal TV es de una vía. Un retardo de tránsito en la red de unos cuantos segundos no representa un problema aquí. Pero lo que sí deseamos es un servicio garantizado ya que la pérdida de algunas celdas en video comprimido tiene un efecto severo en la calidad de la conexión.
Unspecified Bit Rate (UBR): No provee garantías sobre la velocidad de bits especificada, ni sobre los parámetros de tráfico ni sobre la calidad de servicio. La clase de servicio UBR ofrece una solución parcial para aquellas aplicaciones de ráfagas imposibles de predecir que no se ajustan realmente a los parámetros del contrato de tráfico. Cuando la red se congestiona, las conexiones UBR continúan su transmisión.
Las conexiones UBR no tienen contrato de gestión con la red y por lo tanto las primeras celdas que se pierden son las suyas. El caudal de tráfico exitoso puede caer a niveles inaceptables, menos del 50%. Este tipo de servicio se puede aplicar a conexiones que puedan enviar datos a través de la red sin requerir garantía de cómo y cuándo estos datos lleguen a su destino. Desde el punto de vista de la red, la clase UBR utiliza excedentes de ancho de banda que de otro modo no se emplearían.
Cuando una aplicación solicita una conexión ABR, la misma negocia con la red una velocidad de celda de cresta, sin embargo no negocia los parámetros específicos de tolerancia de variación de retardo de celda o de tolerancia de ráfaga. En realidad la aplicación y la red negocian un requerimiento de velocidad mínima, el cual garantiza a la aplicación un pequeño ancho de banda (la mínima requerida para mantener la aplicación establecida y funcionando). El usuario ABR acuerda no transmitir a velocidades superiores a la PCR y la red acuerda siempre proveer por lo menos la velocidad mínima (Minimum Cell Rate= MCR).
Dado que la clase ABR provee garantías mínimas de ancho de banda para mantener las aplicaciones en funcionamiento (pero no garantiza el retardo de la celda), ella es apta para aplicaciones en tiempo no real en las cuales los datos no son demasiado sensibles al retardo.
2.7. Señalización ATM.
CAPÍTULO 3:
ARQUITECTURA
DE LA
CONMUTACIÓN DE
ETIQUETAS
CAPÍTULO 3: ARQUITECTURA DE LA CONMUTACIÓN DE
ETIQUETAS MULTIPROTOCOLO.
_______________________________________________________________
Al principio el IPv4 fue el único protocolo en ser conmutado por medio de etiquetas.
Después, se unió IPv6. Posteriormente, con AToM o “Cualquier trasporte sobre MPLS”
fue el comienzo para etiquetar y transportar tramas de capa 2 sobre una dorsal MPLS. Así es como se llenó el aspecto multiprotocolo de MPLS.
La conmutación de etiquetas indica que los paquetes conmutados ya no son paquetes IPv4, paquetes IPv6 o tramas de capa 2 cuando son conmutados, pero son etiquetados. La parte más importante para MPLS es la etiqueta.
3.1 ETIQUETAS MPLS.
[image:36.612.131.506.386.451.2]Una etiqueta MPLS es un campo de 32 bits con una estructura determinada. La figura 3.1 muestra la constitución de una etiqueta.
Figura 3.1 Constitución de una etiqueta o label MPLS.
Los primeros 20 bits son los valores de la Label o etiqueta. Este valor puede estar entre 0 y 2²º-1 o 1,048,575. Por otro lado. Los primeros 16 valores fueron exentados de uso normal. Los bits de 20 a 22 son los tres bits experimentales o EXP. Estos tres bits son usados para la calidad de servicio o QoS (QoS - Quality of Service).
El bit 23 es la parte trasera de la pila o BoS (BoS – Bottom of Stack). Éste es 0 menos que sea la etiqueta trasera o la última de etiqueta en la cola. Si es así, el bit BoS es puesto como 1. La pila es una colección de etiquetas que son encontradas en la parte superior del paquete. La pila puede consistir de una o más etiquetas. El número de etiquetas que se puede encontrar en la pila no tiene límite.
es evitar que un paquete se atore en un bucle “enrutado”. Si un bucle enrutado ocurre
y no hay un TTL presente, el paquete puede enlazarse eternamente. SI el TTL de una etiqueta alcanza el valor 0, el paquete es descartado.
3.2 APILADO DE ETIQUETAS.
Un enrutador con la capacidad de usar MPLS puede necesitar más de una etiqueta en
la parte superior de un paquete para “enrutar” dicho paquete a través de la red MPLS.
[image:37.612.132.503.294.464.2]Esto es pasible si empaquetan las etiquetas en una pila. La primera etiqueta en la pila se denomina top label o etiqueta superior, y la última etiqueta es llamada etiqueta bottom label o última etiqueta. Entre estas etiquetas se puede tener cualquier número de etiquetas. La figura 3.2 muestra la estructura de una pila de etiquetas.
Figura 3.2 Estructura de una pila de etiquetas MPLS.
3.3 CODIFICACIÓN DE MPLS.
[image:37.612.115.523.622.676.2]La pila de etiquetas o MPLS Label Stack se coloca en enfrente del paquete de capa 3, es decir, antes del encabezado del Protocolo Transportado o Transported Protocol pero después del Encabezado de Capa 2 o Layer 2 Header. En la figura 3.3 se puede visualizar la colocación de la pila de etiquetas para paquetes etiquetados.
El encapsulado del enlace puede ser casi cualquier tipo encapsulado suportado por el sistema operativo de un determinado router.
3.4 ENRUTADOR CONMUTADOR DE ETIQUETAS.
Un enrutador conmutador de etiquetas o label switch router es un enrutador que soporta MPLS. Es capaz de entender etiquetas MPLS; y de recibir y transmitir un paquete etiquetado en un enlace de datos. En una red MPLS, existen tres clases de enrutadores:
-LSRs de ingreso o Ingress LSRs.
Estos enrutadores reciben un paquete que aún no es etiquetado, insertan una etiqueta enfrente del paquete, después es enviado en el enlace de datos.
-LSRs de egreso o Egress LSRs.
Estos enrutadores reciben paquetes ya etiquetados, su función es remover las etiquetas y enviar estos paquetes en un enlace de datos. Los Ingress LSRs y Egress LSRs también son conocidos como LSRs de borde o Edge LSRs.
-LSRs intermediarios o Intermediate LSRs.
Este tipo de enrutadores reciben un paquete etiquetado, realizan alguna operación en él, conmutan el paquete y posteriormente envían el paquete al enlace de datos correcto.
Un LSR es capaz de remover una o más etiquetas de la parte superior de la pila de etiquetas antes de conmutar el paquete a la salida. Un LSR debe ser capaz de empujar una o más etiquetas en el paquete recibido. Si el paquete recibido ya ha sido etiquetado, el LSR empuja una o más etiquetas en la pila de etiquetas y conmuta el paquete a la salida. Si el paquete no ha sido etiquetado, el LSR crea una pila de etiquetas y la empuja en el paquete. Un LSR también debe ser capaz de intercambiar una etiqueta. Esto significa que cuando un paquete etiquetado es recibido, la etiqueta superior de la pila de etiquetas es intercambiada por una nueva etiqueta y el paquete es conmutado en la salida del enlace de datos.
3.5 CAMINO CONMUTADO DE ETIQUETAS.
Un camino conmutado de etiquetas (LSP – Label Switched Path) es una secuencia de LSRs que conmutan paquetes etiquetados a través de una red MPLS. Básicamente, el LSP es el camino a través de la red MPLS o parte de ella que los paquetes toman. El primer LSR de una LSP es el ingress LSR para ese LSP, mientras que el último LSR del LSP es el egress LSR. Todos los LSRs entre los ingress y egress LSRs son los intermédiate LSRs.
[image:39.612.123.509.273.433.2]En la figura 3.4, la flecha en la parte superior indica la dirección porque un LSP es unidireccional. El flujo de paquetes etiquetados en otra dirección, de derecha a izquierda entre los mismos edge LSRs puede ser otro LSP.
Figura 3.4 Red MPLS.
Figura 3.5 Red MPLS con LSPs anidados.
3.6 CLASES DE EQUIVALENCIA DE REENVÍO (FECs)
Una clase de equivalencia de reenvío (FEC – Forwarding Equivalence Class) es un grupo o flujo de paquetes que son reenviados en el mismo camino y son tratados con la misma consideración de reenvío. Todos los paquetes pertenecientes al mismo FEC tienen la misma etiqueta. No obstante, no todos los paquetes que tienen la misma etiqueta pertenecen al mismo FEC porque su valor EXP puede ser diferente; así que el tratamiento de reenvío puede ser diferente y pueden pertenecer a un FEC diferente. El enrutador que decide que paquete pertenece a que FEC es el ingress LSR. Es lógico porque el ingress LSR clasifica y etiqueta los paquetes.
Algunos ejemplos de FECs son:
-Paquetes con direcciones de destinos IP igualando un prefijo determinado. -Paquetes multicast perteneciendo un determinado grupo.
-Paquetes con un mismo tratamiento de reenvío.
-Tramas de capa 2 llevadas a través de una red MPLS recibidas en un VC o subinterface en el ingress LSR y transmitido en un VC o subinterface en el egress LSR.
-Paquetes con direcciones IP destino de Capa 3 que pertenecen a un conjunto de prefijos de protocolos de pasarela de borde (BGP), todo con el mismo siguiente salto BGP.
Figura 3.6 Una red MPLS con LSR corriendo BGP o iBGP.
La dirección IP destino de todos los paquetes IP entrando al ingress LSR serán buscadas en la tabla de reenvío IP. Todas estas direcciones pertenece a un conjunto de prefijos que son conocidos en la tabla de enrutamiento como prefijos BGP. Varios de los prefijos BGP en la tabla de enrutamiento tienen la misma dirección del salto siguiente BGP, a saber esto un egress LSR. Todos los paquetes con una dirección IP destino para los cuales la búsqueda IP en los recursos de la tabla de enrutamiento a la misma dirección de siguiente salto BGP serán mapeados al mismo FEC. Todos los paquetes que pertenecen al mismo FEC obtienen la misma etiqueta impuesta por el ingress LSR.
3.7 DISTRIBUCIÓN DE ETIQUETAS.
La primera etiqueta es impuesta por el ingress LSR y la etiqueta pertenece a un LSP. El camino del paquete a través de la red MPLS es ligado a ese LSP. Todo lo que cambia es que esa etiqueta superior en la pila de etiquetas es intercambiada en cada salto. El ingress LSR impone una o más etiquetas en el paquete. Los intermediate LSRs intercambian la etiqueta superior (la etiqueta entrante) del paquete recibido etiquetado con otra etiqueta (la etiqueta saliente) y transmite el paquete en el enlace saliente. El egress LSR del LSP desmonta las etiquetas de este LSP y reenvía el paquete.
sistema intermedio [IS-IS] y protocolo de enrutamiento de pasarela interior mejorado [EIGRP]). El ingress LSR busca la dirección IPv4 destino de el paquete, impone una etiqueta y reenvía el paquete. El siguiente LSR recibe el paquete etiquetado, intercambia la etiqueta entrante por una etiqueta saliente y reenvía el paquete. El egress LSR remueve la etiqueta y reenvía el paquete IPv4 sin etiquetas en el enlace saliente. Para que esto funcione correctamente los LSRs adyacentes debe estar de acuerdo en que etiqueta debe usarse para cada prefijo IGP. Por lo tanto, cada intermediate LSR debe tener la capacidad de figurar que etiqueta saliente, la etiqueta entrante debe ser intercambiada. Esto significa, que se requiere un mecanismo que indique a los enrutadores que etiquetas se deben usar cuando se reenvíe un paquete. Etiquetas son locales para cada par de enrutadores adyacentes. Las etiquetas no tienen significado global a través de la red. Para cada enrutador adyacente esté de acuerdo en que etiqueta usar para que prefijo, estos necesitan alguna forma de comunicación entre ellos; de otra forma, los enrutadores no reconocen que etiqueta saliente es necesaria para igualar que etiqueta entrante. Por lo que es necesario un protocolo de distribución de etiquetas.
Se pueden distribuir etiquetas en dos maneras:
-Recargar las etiquetas en un protocolo de enrutamiento IP existente. -Tener un protocolo separado que distribuya las etiquetas.
El primer método tiene la ventaja que un nuevo protocolo no es necesario para correr en los LSRs pero cada protocolo de enrutamiento IP necesita ser entendido para llevar las etiquetas. La gran ventaja de tener un protocolo de enrutamiento que lleve las etiquetas es que el enrutamiento y la distribución de etiquetas siempre están en sincronía. Lo que significa que no se puede tener una etiqueta si el prefijo se encuentra perdido y viceversa. También elimina la necesidad de otro protocolo para la distribución de etiquetas. La implementación para protocolos de enrutamiento vector de distancia (como EIGRP) es completamente plana, ya que cada enrutador origina un prefijo de su tabla de enrutamiento.
Los protocolos de enrutamiento de estado de enlace (como IS-IS y OSPF) no funcionan de esa forma. Cada enrutador origina actualizaciones de estado del enlace que después son reenviadas y sin alteraciones por todos los enrutadores dentro de un área.
El segundo método, que es correr un protocolo separado para distribución de etiquetas tiene la ventaja de ser protocolo de enrutamiento independiente. De la forma que sea el protocolo de enrutamiento, si es capaz de distribuir etiquetas o no, un protocolo separado distribuye las etiquetas y permite a los protocolos de enrutamiento distribuir los prefijos.
3.8 IP SOBRE ATM.
El protocolo IP fue conquistando terreno como protocolo de red ante otras arquitecturas que se encontraban en uso. El gran auge de la Internet y su explosivo crecimiento generó un déficit de ancho de banda, ya que las redes dorsales IP de los proveedores de servicio estaban construidos con enrutadores conectados por líneas dedicadas, lo que ocasionaba congestión y saturación de las redes. Por lo que se requirieron otras alternativas de ingeniería de tráfico.
La respuesta de los proveedores de servicio de Internet o ISPs fue el incremento del número y de la capacidad de los enlaces. Del mismo modo, se plantearon la necesidad de aprovechar mejor los recursos de red existentes, sobre todo la utilización eficaz del ancho de banda de todos los enlaces. Con los protocolos habituales de encaminamiento (basados en métricas del menor número de saltos), ese aprovechamiento del ancho de banda global no resultaba efectivo.
Por lo tanto, los esfuerzos se centraron en aumentar el rendimiento de los enrutadores tradicionales, tratando de combinar de diversas maneras, la eficacia y rentabilidad de los conmutadores ATM con las capacidades de control de IP.
A favor de integrar conmutación y enrutamiento, estaban las infraestructuras de redes ATM que comenzaban a desplegar los operadores de telecomunicación. Estas redes ofrecían entonces una buena solución a los problemas de crecimiento de los ISPs. Por un lado, proporcionaba mayores velocidades y además, las características de respuesta determinanticas de los circuitos virtuales ATM posibilitaban la implantación de soluciones de ingeniería de tráfico. El modelo de red "IP sobre ATM" (IP/ATM) pronto ganó adeptos entre la comunidad de ISPs, a la vez que facilitó la entrada de los operadores telefónicos en la provisión de servicios IP y de conexión a la Internet al por mayor.
El funcionamiento IP/ATM supone la superposición de una topología virtual de enrutadores IP sobre una topología real de conmutadores ATM. Cada enrutador se comunica con el resto mediante los circuitos virtuales permanentes (PVC) que se establecen sobre la topología física de la red ATM, desconociendo la topología real de la infraestructura ATM que sustenta los PVC.
La base del modelo IP/ATM está en la funcionalidad proporcionada por el nivel ATM, es decir, los controles de software (señalización y enrutamiento) y el envío de las celdas por hardware (conmutación). En realidad los circuitos (PVCs) se establecen a base de intercambiar etiquetas en cada conmutador de la red, por lo tanto asociando etiquetas entre todos los elementos ATM se determinan los PVCs.
de los 90, tenían una calidad cuestionable, al estar basados en funcionamiento por software.
La solución de superponer IP sobre ATM permite aprovechar la infraestructura ATM existente. Las ventajas inmediatas son el ancho de banda disponible a precios competitivos y la rapidez de transporte de datos que proporcionan los conmutadores. En los casos de ISPs de primer nivel que poseen y operan la red dorsal ATM para ofrecer el servicio de sus redes IP, los caminos físicos de los PVCs se calculan a partir de la necesidades del tráfico IP, utilizando la clase de servicio ATM UBR (UBR - Unspecified Bit Rate), ya que en este caso el ATM se utiliza solamente como infraestructura de transporte de alta velocidad (no hay necesidad de apoyarse en los mecanismos inherentes de ATM para control de la congestión y clases de servicio). La ingeniería de tráfico se hace a base de proporcionar a los enrutadores los PVCs necesarios con una topología lógica entre enrutadores totalmente superpuestos. El "punto de encuentro" entre la red IP y a ATM está en el acoplamiento de las subinterfaces en los enrutadores con los PVCs, a través de los cuales se intercambian los enrutadores la información de enrutamiento correspondiente al protocolo interno IGP. Lo habitual es que, entre cada par de enrutadores, haya un PVC principal y otro de respaldo, que entra automáticamente en funcionamiento cuando falla el principal.
El modelo IP/ATM tiene también sus inconvenientes: se debe gestionar dos redes diferentes, una infraestructura ATM y una red lógica IP superpuesta, lo que supone a los proveedores de servicio unos mayores costos de gestión global de sus redes. Existe, además, lo que se llama la "tasa impuesta por la celda", una cabecera aproximada del 20% que causa el transporte de datagramas IP sobre las celdas ATM y que reduce en ese mismo porcentaje el ancho de banda disponible. Por otro lado, la solución IP/ATM presenta los típicos problemas de crecimiento exponencial n x (n-1) al aumentar el número de nodos IP sobre una topología completamente superpuestas. Debido al crecimiento exponencial de rutas el protocolo de pasarela interior debe realizar un mayor esfuerzo.
3.9 CONMUTACIÓN DE PAQUETES
Es la respuesta a los requerimientos de mantener una convergencia entre el enrutamiento de IP y la conmutación ATM. El nombre de conmutación de IP (IP switching) engloba dos términos antagónicos. IP: un protocolo no orientado a conexión, basado en enrutamiento, y Conmutación: método empleado por las redes ATM, gracias a la cual son posibles todas sus funcionalidades. Se basa en un mecanismo de intercambio de etiquetas al igual que Tag Switching.