ESCUELA SUPERIOR DE INGENIERÍA MECÁNICA Y ELÉCTRICA
CONTROL DE UN MOTOR DE CD MEDIANTE EL USO DE CONTROL
INTELIGENTE
TESIS
Que para obtener el título de
INGENIERO EN COMUNICACIONES Y ELECTRÓNICA
PRESENTAN:
JULIETA AGUILERA MUÑOZ
DAVID HERNÁNDEZ PÉREZ
ASESORES:
DR. JULIO CESAR TOVAR RODRÍGUEZ DR. CARLOS ROMÁN MARIACA GASPAR
DR. RODRIGO LÓPEZ CÁRDENAS
AGRADECIMIENTOS
JULIETA AGUILERA MUÑOZ
Son tantos los sentimientos encontrados al ver concluida mi meta, que echando un vistazo para
atrás me doy cuenta que llegar hasta aquí no fue fácil, hubo desvelos, preocupaciones, tristezas,
enojos; pero también hubo alegrías, amor, aprendizaje, nuevos amigos, y sobre todo, ese apoyo
de las personas que sé que siempre estarán a mi lado.
A mis padres,
Por ser orgullosamente su hija, que me guiaron y motivaron en todo momento, que estuvieron
conmigo en cada desvelo, que me inculcaron todos los valores necesarios y por todo el apoyo que
me han brindado.
A mi hermano,
Por su preocupación, consejos y estar siempre al pendiente de mi madurez.
A mi novio,
Por estar conmigo en todo momento, apoyar mis decisiones, perdonar mis errores, aguantar mis
altibajos y sobre todo por darme tanto amor para seguir adelante superando los obstáculos.
A mis amigos,
Que siempre me han apoyado en las buenas y malas decisiones que he tomado, pero sobre todo
por todo el cariño y amor recibido.
A mis asesores,
Por su tiempo, paciencia, dedicación y comprensión.
Al IPN,
DAVID HERNÁNDEZ PÉREZ
Reír a menudo y mucho; ganar el respeto de gente inteligente y el cariño de los niños, conseguir el aprecio de críticos honestos y aguantar la traición de falsos amigos; apreciar la belleza, encontrar lo mejor en los demás; dejar el mundo un poco mejor, sea con un niño saludable, una huerta, un libro o una condición social remitida; saber que por lo menos una vida ha respirado mejor porque tú has vivido. Eso es tener éxito Ralph Waldo Emerson
El que este trabajo haya sido iniciado y culminado es resultado de todos mis esfuerzos, desvelos y sacrificios realizados. Pero es gracias a que nunca estuve solo y por tanto este trabajo se lo dedico a toda la gente que me ha brindado su apoyo incondicional (Familiares, Amigos y Profesores, tanto los presentes como a los que por una u otra circunstancia han quedado atrás más jamás en el olvido), ya que sin este, esta meta nunca podría haber sido alcanzada Este logro es de ustedes!!!
Gracias a todos
A mi mamá,
Marisela, a quien debo todo incluyendo lo más valioso que tengo la vida. Por tu infinito amor, paciencia, comprensión, dedicación, ternura, por sacrificar tu vida en mí, por hacer de mi tu mejor creación, por llenarme de orgullo y motivación así como por ser un modelo a seguir, por mostrarme el camino hacia la superación en base al conocimiento, por tu amistad y confianza, por tu apoyo incondicional, en fin, absolutamente todo te lo debo a ti y tu sola existencia se la agradezco a Dios pues tenerte como madre ha sido su mejor regalo.
A mi familia,
Quiero agradecer profunda y sinceramente a todos: Agüe, Moña, Tio Rani, Tio George, Citlali; por inspirarme y hacer de mí un hombre de bien con su apoyo moral que desde siempre me han brindado y con el cual he logrado terminar una carrera profesional que junto con sus enseñanzas, amor y existencia son para mí las mejores de las herencias.
A Dios y mi Niña,
A mi novia,
July, por abrirme tu corazón y permitirme compartir a tu lado una de las mejores etapas de mi vida, por apoyarme y estar conmigo en las buenas y en las malas, por impulsarme a ser mejor y superarme, por tu gran amor y paciencia, por comprenderme, tolerar mis arranques, por festejar mis aciertos y sufrir mis derrotas, por llenar de bellos momentos mi vida y mi paso por esta institución Este es el primero de nuestros logros y sueños realizados juntos mi vida!!!
A mis amigos,
En especial a Charly y a Arturo (Cheyenne), por su cariño, por estar ahí cuando más he necesitado de ustedes, por compartir momentos de alegría, coraje y tristeza, por tolerar mis arranques, disculpar mis errores y aceptarme tal como soy y por impulsarme a ser mejor día a día.
A mis profesores,
Por aportarme nuevos y valiosos conocimientos. En especial a nuestros directores de tesis los Doctores Julio Tovar, Carlos Mariaca y Rodrigo López, por brindarnos el material necesario para la realización de este trabajo y aún más, por su tiempo, apoyo, dedicación y amistad.
Al IPN y a la ESIME,
Por abrirme las puertas, darme una oportunidad en esta gran institución y brindarme los espacios para concluir mis estudios de ingeniería y así superarme para servir a los demás.
Gracias a todos ustedes, pues son gente de éxito y con su ayuda también yo lo soy
Los AMO!!!
Dicen que toda gloria es efímera, sin embargo he aprendido de todos ustedes que para trascender no solo basta con un solo logro, hay que luchar día a día para ser mejores y conseguir éxitos diarios.
Por último, a todos aquellos que lean este trabajo y pudieran encontrar una inspiración en él o bien su contenido les sea de ayuda, de igual manera gracias pues habré cumplido mi cometido, recuerden que:
Índice General
Objetivo. . . 11
Justificación. . . 11
Planteamiento del problema. . . 11
1 Introducción a las redes neuronales artificiales. . . 12
1.1 Elementos de una red neuronal artificial. . . 13
1.2 Función de salida o de transferencia . . . 14
1.3 Topología de las redes neuronales. . . 16
1.3.1 Redes mono capa . . . 16
1.3.2 Redes multicapa. . . 17
3.4 Mecanismo de aprendizaje. . . 18
1.4.1 Aprendizaje corrección por error . . . 19
1.4.2 Aprendizaje Hebbiano . . . 20
1.4.3 Aprendizaje competitivo y cooperativo. . . 21
1.4.4 Aprendizaje supervisado . . . 21
1.4.5 Aprendizaje no supervisado. . . 22
1.5 El perceptrón . . . 23
1.5.1 Ley de aprendizaje del perceptrón. . . 24
1.6 El perceptrón multicapa . . . 25
1.6.1 Aprendizaje del PMC- . . . 26
1.6.1.1 Pasos para el cálculo del algoritmo BP . . . 26
1.6.2 Algoritmo BP . . . 27
1.7 Método diagramático y red adjunta . . . 32
1.7.1 Representación en diagramas de bloques de la RN . . . 33
1.7.2 La red adjunta. . . 34
1.7.3 Deducción del algoritmo BP utilizando el método diagramático. . . 36
1.8 Teorema universal de aproximación. . . 37
2 Redes Neuronales Recurrentes. . . 38
2.1 Red de Hopfield. . . 38
2.2 Red Neuronal Recurrente Entrenable . . . 40
2.2.1 Propiedad de Observabilidad de la RNRE . . . 42
2.2.2 Propiedad de Controlabilidad de la RNRE . . . 46
2.2.3 Aprendizaje de la RNRE . . . 47
2.2.4 Estabilidad de la RNRE. . . 52
3 Identificación y control de sistemas utilizando RN. . . 56
3.1 Identificación de sistemas utilizando RN . . . 56
3.1.1 Identificación de sistemas . . . 56
3.1.2 Identificación con Redes Neuronales. . . 58
3.1.3 Identificación con Redes Neuronales Recurrentes . . . 61
3.2 Control de un motor utilizando RNRE. . . 62
3.2.1 Sistemas de control . . . 62
3.2.1.1 Sistemas de control en el espacio de estados . . . 63
3.2.1.2 Sistemas de control adaptable . . . 63
3.2.2 Control adaptable usando redes neuronales recurrentes entrenables. . . 67
3.2.2.1 Control adaptable directo . . . 68
4 Simulaciones y Resultados. . . 71
4.1 Motor. . . 71
4.1.1 Cálculo de los parámetros del motor. . . 71
4.1.2 Modelo matemático del motor. . . 73
4.1.3 Representación de la F.T. en Espacio de Estados. . . 73
4.1.4 Controlabilidad y Observabilidad. . . 76
4.1.5 Error en estado estacionario. . . 77
4.1.6 Cambio de polos del sistema . . . 78
4.2 Control de velocidad del motor con PID (Simulación). . . 80
4.3 Control de velocidad del motor con Control Inteligente RNRE (Simulación). . . 84
4.4 Control de velocidad del motor con PID (Pruebas físicas). . . 92
4.5 Control de velocidad del motor con Control Inteligente RNRE (Pruebas físicas). . . 94
5 Conclusiones. . . 101
Trabajos futuros. . . 103
Bibliografía. . . 104
Apéndice A Motor . . . i
A.1 Definición . . . i
A.2 Motor de Corriente Directa (C.D.). . . i
A.3 Funcionamiento de un motor de C.D. con escobillas. . . ii
Apéndice B Sensor .. . . iii
B.1 Definición . . . iii
B.2 Sensores de desplazamiento y rotación . . . iii
B.2.1 Sensores basados en efecto Hall. . . iii
Apéndice C PWM . . . v
C.1 Definición . . . v
C.2 Funcionamiento del PWM . . . v
Apéndice D Control PID . . . vi
D.1 Control Proporcional (P) . . . vi
D.2 Control Proporcional Integral (PI) . . . vi
D.3 Control Proporcional Derivativo (PD) . . . vii
D.4 Control Proporcional Integral Derivativo (PID) . . . viii
Apéndice E Imágenes del sistema físico utilizado . . . ix
Apéndice F Diagramas de flujo de los programas en los microcontroladores . . . xi
Índice de Figuras
1.1 Modelo no lineal de una j-ésima neurona . . . 14
1.2 Funciones de activación: (a) identidad, (b) escalón, (c) saturación, (d) sigmoide, (e) tangente hiperbólica, (f) gaussiana. . . 16
1.3 Red neuronal Mono capa conectada completamente . . . 16
1.4 Diferentes Topologías Multicapa de Redes Neuronales Artificiales. (a) Un perceptrón multicapa (MLP) conectado completamente. (b) Un MLP modular. (c) Una red recurrente conectada completamente. (d) Una red recurrente conectada parcialmente. . . 18
1.5 Diagrama a bloques del aprendizaje supervisado. . . 23
1.6 Diagrama a bloques del aprendizaje no supervisado. . . 23
1.7 Diferentes arquitecturas de un PMC . . . 25
1.8 Detalles de una neurona j de la capa de salida. . . 28
1.9 Propagación del error . . . 30
1.10 Gráfica de la conexión entre dos neuronas. La i-ésima neurona de la capa oculta conectada a la j-ésima neurona de la capa de salida . . . 31
1.11 Descripción gráfica de las partes de una red neuronal . . . 33
1.12 Diagrama de una RN de tres capas. . . 34
1.13 Red Adjunta deducida a partir de la Red Neuronal . . . 36
1.14 Diagrama representativo de una RN y el esquema de la RA. . . 37
2.1 RN de Hopfield en tiempo discreto . . . 40
2.2 Ejemplo de RNRE con tres entradas, tres salidas y tres nodos en la capa oculta. . . 42
2.3 (a) Diagrama a bloques de una RNRE. (b) Diagrama a bloques de la red adjunta de una RNRE . . . 50
3.1 Modelos de Identificación. (a) Modelo I. (b) Modelo II. (c) Modelo III. (d) Modelo IV . . 60
3.2 Identificación dinámica de una planta . . . 61
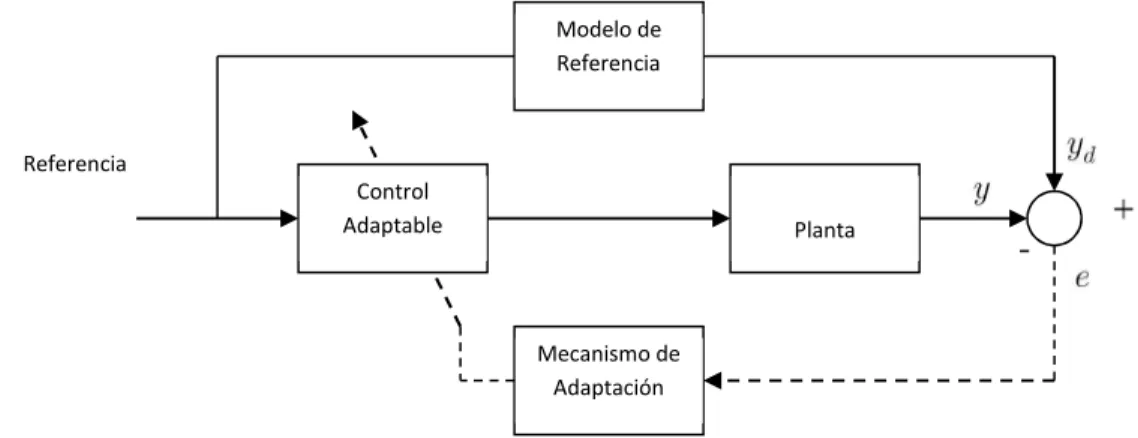
3.3 Esquema básico de un sistema de control adaptable. . . 64
3.4 Esquema de Control Adaptable Directo por Modelo de Referencia. . . 66
3.5 Diagrama a bloques para un sistema de control directo adaptable de seguimiento de trayectoria. . . 68
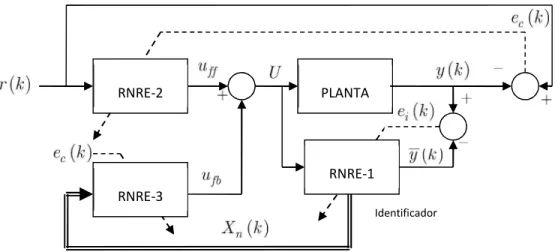
3.6 Diagrama de bloques para un sistema de control adaptable directo utilizando tres RNRE. . . 70
4.1 Motorreductor metálico con relación de engranaje 131:1. . . 71
4.2 Dimensiones del motor. . . 72
4.4 Función de transferencia del motor. . . 75
4.5 Retroalimentación de estado. . . 79
4.6 Control PID: (a), (b) comparación entre la señal de referencia y la señal de entrada . . . 81
4.7 Control PID: Señal de control. . . 82
4.8 Control PID: (a) Error en estado estacionario, (b) Error cuadrático medio (RMS). . . 83
4.9 Control directo adaptable con tres RNRE´s: (a), (b) Comparación entre la señal de referencia y la señal de salida de la planta. . . 85
4.10 Control directo adaptable con tres RNRE´s: (a) Señal de Control ff, (b) Señal de control fb. (c) Señal de control total. . . 87
4.11 Control directo adaptable con tres RNRE´s: Error instantáneo de Control. . . 87
4.12 Control directo adaptable con tres RNRE´s: Error Cuadrático Medio de control. . . 88
4.13 Control directo adaptable con tres RNRE´s: (a), (b) Comparación entre la señal de salida de la planta y la señal de identificación de la planta controlada. . . 89
4.14 Control directo adaptable con tres RNRE´s: (a) y (b) Estados identificados de la planta. 90 4.15 Control directo adaptable con tres RNRE´s: Error instantáneo de Identificación. . . 90
4.16 Control directo adaptable con tres RNRE´s: Error Cuadrático Medio de identificación. . 91
4.17 Control PID: (a), (b) comparación entre la señal de referencia y la señal de entrada . . . 93
4.18 Control PID: Error cuadrático medio (RMS). . . 93
4.19 Control directo adaptable con tres RNRE´s: (a), (b) Comparación entre la señal de referencia y la señal de salida de la planta. . . 95
4.20 Control directo adaptable con tres RNRE´s: (a) Señal de Control ff, (b) Señal de control fb. (c) Señal de control total. . . 97
4.21 Control directo adaptable con tres RNRE´s: Error Cuadrático Medio de control. . . 97
4.22 Control directo adaptable con tres RNRE´s: (a), (b) Comparación entre la señal de salida de la planta y la señal de identificación de la planta controlada. . . 98
4.23 Control directo adaptable con tres RNRE´s: (a) y (b) Estados identificados de la planta. 99 4.24 Control directo adaptable con tres RNRE´s: Error instantáneo de Identificación. . . 100
4.25 Control directo adaptable con tres RNRE´s: Error Cuadrático Medio de identificación. . 100
A.1 Principio básico de funcionamiento de un motor de C.D . . . ii
A.2 Motor de cuatro polos, el campo magnético es producido por la corriente que fluye en las bobinas . . . ii
B.1 Efecto Hall en un semiconductor tipo n . . . iv
C.1 Regulación de Ancho de Pulsos . . . v
D.1 Sistema de control PID. . . viii
E.1 Sistema físico en reposo y ubicación de sus partes. . . ix
OBJETIVO
Controlar la velocidad de un motor de corriente directa utilizando redes neuronales recurrentes entrenables para el desarrollo de plataformas de enseñanza para las materias de la especialidad de control de la Ingeniería en Comunicaciones y Electrónica (ICE).
JUSTIFICACIÓN
Se realizará el control de un motor de Corriente Directa con redes neuronales recurrentes para compararlos con los de un sistema de control clásico (PID), esto, para observar las diferencias y similitudes en cuanto a su funcionalidad y estabilidad. Además al tenerlo realizado físicamente se le podrá dar utilidad en alguna aplicación de la vida cotidiana, así como para el desarrollo de plataformas educativas que coadyuven en la enseñanza de las distintas materias de la especialidad de control.
PLANTEAMIENTO DEL PROBLEMA
En la actualidad, todo el entorno está ligado plenamente en cualquier aspecto al uso de motores (de cualquier tipo), por lo que como estudiantes de ingeniería y con los conocimientos ya adquiridos y por aprender, se quiere hacer una mejora en alguna aplicación.
Así, en un principio, se desea controlar la velocidad de un motor de Corriente Directa por medio de un PID, se observará y se comprenderá su funcionamiento el cual será remplazado por un control inteligente del tipo Red Neuronal Recurrente Entrenable.
Capítulo 1, [25]
Introducción a las redes neuronales artificiales
En los últimos años de exploración en inteligencia artificial, los investigadores se han intrigado por las redes neuronales. El concepto se basa vagamente en cómo pensamos que funciona el cerebro de un animal. Un cerebro consiste en un sistema de células interconectadas, las cuales son, aparentemente, responsables de los pensamientos, la memoria y la conciencia. Una red neuronal artificial puede verse como una máquina diseñada originalmente para modelar la forma en que el sistema nervioso de un ser vivo realiza una determinada tarea. Para lograr este objetivo, una red neuronal artificial está formada por un conjunto de unidades de procesamiento interconectadas llamadas neuronas.
Cada neurona recibe como entrada un conjunto de señales discretas o continuas, las pondera e integra, y transmite el resultado a las neuronas conectadas a ella. Cada conexión entre dos neuronas tiene una determinada importancia asociada denominada peso sináptico o, simplemente, peso. En los pesos se suele guardar la mayor parte del conocimiento que la red neuronal tiene sobre la tarea en cuestión. El proceso mediante el cual se ajustan estos pesos para lograr un determinado objetivo se denomina aprendizaje o entrenamiento y el procedimiento concreto utilizado para ello se conoce como algoritmo de aprendizaje o algoritmo de entrenamiento. El ajuste de pesos es la principal forma de aprendizaje de las redes neuronales. Las neuronas demuestran plasticidad: una habilidad de cambiar su respuesta a los estímulos en el tiempo, o aprender; en una red neuronal artificial, se imitan estas habilidades por software, [16].
Las redes neuronales destacan por su estructura fácilmente paralelizable y por su elevada capacidad de generalización (capacidad de producir salidas correctas para entradas no vistas durante el entrenamiento). Otras propiedades interesantes son:
Adaptabilidad. Las redes neuronales son capaces de reajustar sus pesos para adaptarse a cambios en el entorno. Esto es especialmente útil cuando el entorno que suministra los datos de entrada es no estacionario, es decir, algunas de sus propiedades varían con el tiempo.
Tolerancia ante fallos. Una red neuronal es tolerante ante fallos en el sentido de que los posibles fallos operacionales en partes de la red solo afectan débilmente al rendimiento de ésta. Esta propiedad es debida a la naturaleza distribuida de la información almacenada o procesada en la red neuronal.
Capacidad para aproximar mapeados no lineales mejor que otros esquemas (polinomios, etc.) Capacidad para operar con datos numéricos y simbólicos simultáneamente.
Son aplicables a sistemas MIMO.
1.1 Elementos de una red neuronal artificial
Cualquier modelo de red neuronal consta de dispositivos elementales de proceso: las neuronas. A partir de ellas, se puede generar representaciones específicas de tal forma que un estado conjunto de ellas pueda significar una letra, un número o cualquier otro objeto. La neurona artificial pretende mimetizar las características más importantes de las neuronas biológicas.
En el modelo más habitual de neurona se identifican cinco elementos básicos para la j-ésima neurona de una red de tiempo discreto:
Un conjunto de n señales de entrada,xi (t ) , i = 1,2,....,n ,que suministran a la neurona los datos del
entorno; estos datos pueden ser externos a la red neuronal, pertenecientes a la salida de otras neuronas de la red, o bien correspondientes a la salida anterior de la propia neurona.
Un conjunto de sinapsis, caracterizada cada una por un peso propiowij,i =1,2,....,n . El pesowij
está asociado a la sinapsis que conecta la unidad i-ésima con la neuronaj-ésima.
Un valor constante llamado polarización o bias representado por b cuya presencia aumenta la capacidad de procesamiento de la neurona y que eleva o reduce la entrada a la neurona, según sea su valor positivo o negativo.
Un sumador o integrador que suma las señales de entrada, ponderadas con sus respectivos pesos, y el bias.
Una función de activaciónfque suele limitar la amplitud de la salida de la neurona.
Cadaj-ésima neurona está caracterizada en cualquier instante por un valor numérico denominado valor o estado de activación vj(t). Las señales moduladas que han llegado a la i-ésima unidad se combinan entre ellas, generando así el estado actual de activación como lo muestra la siguiente ecuación:
1
( ) ( )
m j ij i
i
v t w x t b
(1.1)
( )
( ( ))
j i j
La figura 1.1 nos muestra el modelo no lineal de una neurona artificial, en base a los elementos descritos anteriormente. La dinámica que rige la actualización de los estados de las unidades (evolución de la red neuronal) suele ser de dos tipos: modo asíncrono y modo síncrono. En el primer caso, cada neurona evalúa su estado continuamente, según les va llegando la información, y lo hacen de forma independiente. En el caso síncrono, la información también llega de forma continua, pero los cambios se realizan de forma simultánea, como si existiera un reloj interno que decidiera cuando deben cambiar su estado. Los sistemas biológicos quedan probablemente entre ambas posibilidades.
Figura 1.1. Modelo no lineal de unaj-ésima neurona.
1. 2 Función de salida o transferencia
La función de activación es la que define finalmente la salida de la neurona. Entre las unidades o neuronas que forman una red neuronal artificial estas funciones de activación o transferencia forman un conjunto de conexiones que unen unas neuronas con otras. Las funciones de activación más utilizadas habitualmente son las siguientes:
1. Función identidad. Tiene la forma f (v) = vy se utiliza cuando no se desea acotar la salida de la neurona, la figura 1.2 (a) nos representa esta función.
2. Función escalón. La figura 1.2 (b) nos presenta la gráfica de una función escalón. Esta función adopta la forma
1
0
( )
1
0
si v
f v
si v
(1.3)y proporciona una salida con dos posibles valores. Es habitual encontrársela con el nombre de función de
Función
3. Función saturación. La figura 1.2 (c) muestra la gráfica de una función de activación saturación, cuya representación matemática se presenta a continuación:
1
( ) 1
si v c
f v si v c
av en otro caso
(1.4)
4. Función sigmoide. Las funciones sigmoideas son un conjunto de funciones crecientes, monótonas y acotadas que provocan una transformación no lineal de su argumento. Una de las más utilizadas es la función sigmoide definida por la siguiente ecuación, dondepes la pendiente de la función de activación:
1 f(v) =
1+exp(-pv) (1.5)
La función sigmoide está acotada entre 0 y 1, en la figura 1.2 (d) se muestra su representación. 5. Otra función sigmoidea es la función tangente hiperbólica:
1 exp(
)
( )
1 exp(
)
pv
f v
pv
(1.6)La figura 1.2 (e) representa la gráfica de la función de activación tangente hiperbólica.
6. Función de base radial. La figura 1.2 (f) nos muestra un ejemplo de este tipo de funciones de activación. Las más habituales son funciones gaussianas no monótonas del tipo
2
2 ( ) exp
2
v
f v (1.7)
donde define la anchura. La función alcanza su valor máximo cuando la entrada es cero.
(d) (e) (f)
Figura 1.2. Funciones de activación: (a) identidad, (b) escalón, (c) saturación, (d) sigmoide, (e) tangente hiperbólica, (f) gaussiana.
1.3 Topología de las redes neuronales
La topología o arquitectura de las redes neuronales consiste en la organización y disposición de las neuronas en la red formando capas o agrupaciones de neuronas más o menos alejadas de la entrada y salida de la red. En este sentido, los parámetros fundamentales de la red son: el número de capas, el número de neuronas por capa, el grado de conectividad y el tipo de conexiones entre neuronas.
1.3.1 Redes mono-capa
En su forma más simple, una red neuronal tiene una capa de entrada y una capa de salida.
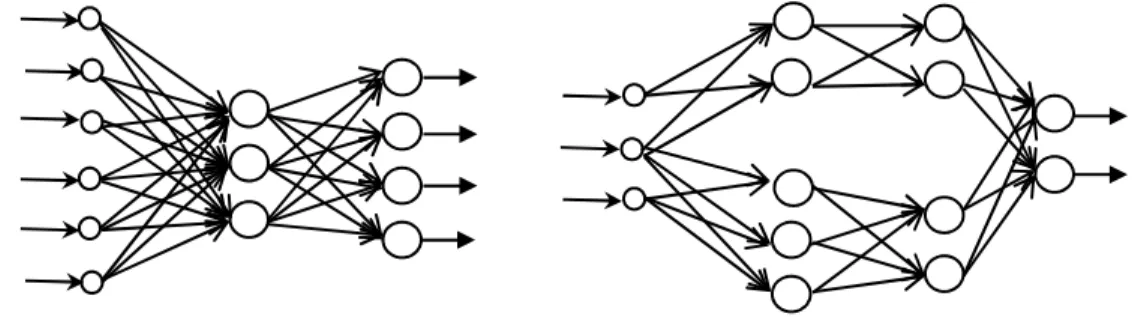
En las redes mono capa (1 capa) se establecen conexiones laterales entre las neuronas que pertenecen a la única capa que constituye la red. También pueden existir conexiones auto-recurrentes (salida de una neurona conectada a su propia entrada). Las redes de una sola capa se utilizan típicamente en tareas relacionadas con auto-asociación; por ejemplo para regenerar informaciones de entrada que se presentan a a red incompletas o distorsionadas. La figura 1.3 nos ilustra un ejemplo de esta topología con 5 nodos en la capa de entrada y cuatro en la capa de salida.
1.3.2 Redes multicapa
Las redes multicapa son aquellas que disponen de conjuntos de neuronas agrupadas en varios niveles o capas. Normalmente, todas las neuronas de una capa reciben señales de entrada de otra capa anterior, más cercana a las entradas de la red, y envían señales de salida a una capa posterior, más cercana a la salida de la red; a estas conexiones se les denomina conexiones hacia adelante o feed forward. Sin embargo, en un gran número de estas redes también existe la posibilidad de conectar las salidas de las neuronas de capas posteriores a las entradas de las capas anteriores, a estas conexiones se las denomina conexiones hacia atrás o feed back.
Redes con conexiones hacia delante (
feed forward
)
En las redes feed forward, todas las señales neuronales se propagan hacia delante a través de las capas de la red, no existen conexiones hacia atrás (ninguna salida de neuronas de una capa ise aplica a la entrada de neuronas de la capa i 1, i 2 ) y normalmente tampoco auto-recurrentes (salida de una neurona aplicada a su propia entrada), ni laterales (salida de una neurona aplicada a neuronas de la misma capa). Las redes feed forward más conocidas son: Perceptrón, Adaline, Madaline, Drive-Reinforcement, Back propagation. Todas ellas son especialmente útiles en aplicación de reconocimiento o clasificación de patrones.
Redes con conexiones hacia atrás
En este tipo de redes circula información tanto adelante (forward), como hacia atrás (backward), durante el funcionamiento de la red. En general en este tipo de conexiones, existen dos conjuntos de pesos: los correspondientes a las conexiones feed forward de la primera capa (capa de entrada), hacia la segunda (capa de salida), y los de las conexiones feed back de la segunda a la primera.
Los dos modelos de red feed forward/feed back de dos capas más conocidos son la red ART (Adaptive Resonante Theory) y la red BAM (Bidirectional Associative Memory). Para ilustrar las diferentes formas de conectividad presentamos la figura 1.4 en la que podemos visualizar 4 topologías de redes diferentes: (a) Un Perceptrón multicapa (MLP) conectado completamente. (b) Un MLP modular. (c) Una red recurrente conectada completamente. (d) Una red recurrente conectada parcialmente.
a) b)
c) d)
Figura 1.4Diferentes Topologías Multicapa de Redes Neuronales Artificiales. (a) Un Perceptrón multicapa (MLP) conectado completamente. (b) Un MLP modular. (c) Una red recurrente conectada completamente. (d) Una red recurrente conectada
parcialmente.
1.4 Mecanismo de aprendizaje
El aprendizaje es el proceso por el cual una red neuronal modifica sus pesos en respuesta a una información de entrada. Los cambios que se producen durante el proceso de aprendizaje se reducen a la destrucción, modificación y creación de conexiones. En los modelos de redes neuronales artificiales, la creación de una nueva conexión implica que el peso de la misma pasa a tener un valor distinto de cero.
asignado a las conexiones cuando se pretende que la red aprenda una nueva información.
Estos criterios determinan lo que se conoce como la regla de aprendizaje de la red. Otro factor que debe ser considerado es la manera en la cual una red neuronal adopta un conjunto interconectado de neuronas. En este último contexto se habla de un paradigma de aprendizaje, el cual se refiere a un modelo del entorno en el que la red neuronal funciona. Los dos tipos de paradigmas que habitualmente se conocen son: aprendizaje supervisado y aprendizaje no supervisado. La diferencia fundamental entre ambos tipos de aprendizaje está en la existencia o no de un agente externo (supervisor) que controle el proceso de aprendizaje de la red.
Otro criterio que se puede utilizar para diferenciar las reglas de aprendizaje se basa en considerar si la red puede aprender durante su funcionamiento habitual o si el aprendizaje supone la desconexión de la red; es decir su inhabilitación hasta que el proceso termine. En el primer caso, se trata de un aprendizaje ON LINE, mientras que el segundo es lo que se conoce como aprendizajeOFF LINE.
En las redes con aprendizajeON LINEno se distingue entre fase de entrenamiento y de operación, de tal forma que los pesos varían dinámicamente siempre que se presente una nueva información al sistema.
Cuando el aprendizaje esOFF LINE, se distingue entre una fase de aprendizaje o entrenamiento y una fase de operación o funcionamiento, existiendo un conjunto de datos de entrenamiento y un conjunto de datos de test o prueba que serán utilizados en la correspondiente fase. En estas redes, los pesos de las conexiones permanecen fijos después que termina la etapa de entrenamiento de la red.
A continuación se presentan tres de las reglas de aprendizaje más populares: aprendizaje corrección por error , aprendizaje Hebbiano, y, aprendizaje competitivo y cooperativo. Al final de estas reglas, se exponen los dos fundamentales paradigmas de aprendizaje mencionados anteriormente: aprendizaje supervisado, y aprendizaje no supervisado.
1.4.1 Aprendizaje corrección por error
Consiste en ajustar los pesos de las conexiones de la red en función de la diferencia entre los valores deseados y los obtenidos den la salida de la red; es decir, en función del error cometido en la salida.
Una regla o algoritmo simple de aprendizaje por corrección de error podría ser el siguiente:
( )
( )
( )
donde
( )
( )
( )
k k k
e n
d n
y n
(1.9)siendo wij la variación en el peso de la conexión entre las neuronasi y j ; y i(n)es la salida de lai
-ésima neurona, correspondiente a la entrada de la neurona j; dk (n) es el valor deseado para la j -ésima neurona; yk (n) es la salida de laj-ésima neurona; es el factor de aprendizaje(0 < 1)que regula la
velocidad del aprendizaje.
Existen varios algoritmos de aprendizaje por corrección de error, por ejemplo la denominadaregla delta generalizadao algoritmo de retro propagación del error (error back propagation), también conocido como regla LMS (Least-Mean-Square Error) multicapa. Se trata de una generalización de la regla delta para poder aplicarla a redes con conexiones hacia adelante (feed forward) con capas o niveles internos u ocultos de neuronas que no tienen relación con el exterior, [15].
1.4.2 Aprendizaje Hebbiano
Este tipo de aprendizaje se basa en el siguiente postulado formulado por Donald O. Hebb en 1949: Cuando un axón de una celda A está suficientemente cerca cómo conseguir excitar una celda B y repetida o persistentemente toma parte en su activación, algún proceso de crecimiento o cambio metabólico tiene lugar en una o ambas celdas, de tal forma que la diferencia de A, cuando la celda a activar es B, aumenta. Por celda, Hebb entiende un conjunto de neuronas fuertemente conexionadas a través de una intensidad o magnitud de la conexión; es decir, el peso.
Se puede decir, por tanto, que el aprendizaje Hebbiano consiste básicamente en el ajuste de los pesos de las conexiones de acuerdo con la correlación (multiplicación en el caso de valores binarios +1 y -1) de los valores de activación (salidas) de las dos neuronas conectadas:
w
ij
y y
i j (1.10)1.4.3 Aprendizaje competitivo y cooperativo
En las redes con aprendizaje competitivo (y cooperativo), suele decirse que las neuronas compiten (y cooperan), unas con otras con el fin de llevar a cabo una tarea dada. Con este tipo de aprendizaje, se pretende que cuando se presente a la red cierta información de entrada, solo una de las neuronas de salida de la red, o una por cierto grupo de neuronas, se active (alcance su valor de respuesta máximo). Por tanto, las neuronas compiten por activarse, quedando finalmente una, o una por grupo, como neurona vencedora (winner-take-all unit), quedando anuladas el resto, que son forzadas a sus valores de respuesta mínimos.
El objetivo de este aprendizaje es categorizar los datos que se introducen en la red. De esta forma, las informaciones similares son clasificadas formando parte de la misma categoría, y por tanto deben activar la misma neurona de salida. Las clases o categorías deben ser creadas por la propia red, puesto que se trata de un aprendizaje no supervisado, a través de las correlaciones entre los datos de entrada, [16].
1.4.4 Aprendizaje supervisado
La técnica mayormente utilizada para realizar un aprendizaje supervisado consiste en ajustar los pesos de la red en función de la diferencia entre los valores deseados y los obtenidos en la salida de la red; es decir, una función de error cometido en la salida.
Existen varias formas de calcular el error y luego adaptar los pesos con la corrección correspondiente. Una de las más implementadas utiliza una función que permite cuantificar el error global cometido en cualquier momento durante el proceso de entrenamiento de la red, lo cual es importante, ya que cuanto más información se tenga del error cometido, más rápido se puede aprender [Widrow & Hoff, 1960]. El error medio se expresa por la ecuación:
P N (k) (k)global j j
k=1 j=1
1
Error
=
y d
2P
(1.11)dónde:
N = Número de neuronas de salida.
P= Número de informaciones que debe aprender la red. dj= Valor de salida deseado para la neurona j.
yj= Valor de salida obtenido para la neurona j.
Por lo tanto, de lo que se trata es de encontrar unos pesos para las conexiones de la red que minimicen esta función de error. Para ello, el ajuste de los pesos de las conexiones de la red se puede hacer de forma proporcional a la variación relativa del error que se obtiene al variar el peso correspondiente:
global ji
ji
Error
w k
w (1.12)
dónde:
wji= Variación en el peso de la conexión entre las neuronasiyj.
Mediante este procedimiento, se llegan a obtener un conjunto de pesos con los que se consigue minimizar el error medio, con la presentación de cada nuevo patrón de entrenamiento a la red.
1.4.5 Aprendizaje no supervisado
Las redes con aprendizaje no supervisado no requieren influencia externa para ajustar los pesos de las conexiones entre sus neuronas. La red no recibe ninguna información por parte del entorno que le indique si la salida generada en respuesta a una determinada entrada es o no es correcta; por ello, suele decirse que estas redes son capaces de auto-organizarse. Estas redes deben encontrar las características, regularidades, correlaciones o categorías que se puedan establecer entre los datos que se presentan en su entrada.
En algunos casos, la salida representa el grado de familiaridad o similitud entre la información que se le está presentando en la entrada y las informaciones que se le han mostrado hasta entonces (en el pasado). En otro caso podría realizar una clusterización o establecimiento de patrones o categorías, indicando la red a la salida a qué categoría pertenece la información presentada a la entrada, siendo la propia red quien debe encontrar las categorías apropiadas a partir de las correlaciones entre las informaciones presentadas. Una variación de esta categorización es el prototipado. En este caso, la red obtiene ejemplares o prototipos representantes de las clases a las que pertenecen las informaciones de entrada.
Figura 1.5Diagrama a bloques del aprendizaje supervisado
Figura 1.6Diagrama a bloques del aprendizaje no supervisado.
1.5 El Perceptrón
El perceptrón es en realidad una neurona artificial conformada por los 5 elementos básicos descritos en el apartado 1.1; esto es: un conjunto de señales de entrada, sinapsis, bias, un sumador o integrador y, una función de activación. El modelo del perceptrón como lo conocemos es atribuido a Rosenblatt [16]. Este modelo está dado por la siguiente expresión:
1
( )
( )
n
i i
i
y
f
w k u k
(1.13)donde y , w , u , y kson definidos como se hizo anteriormente, para el caso del perceptrón f ( ) es la función escalón unitario.
El perceptrón fue desarrollado para ejecutar tareas de clasificación de patrones, esto lo hace definiendo fronteras de decisión lineales, es decir, resuelve problemas de separabilidad de conjuntos convexos.
Vector que describe el estado
del entorno
Respuesta deseada Supervisor
Entorno
Sistema de Aprendizaje
Respuesta actual
Salida de error
Vector que describe el estado
del entorno
1.5.1 Ley de aprendizaje del perceptrón
La ley de aprendizaje del perceptrón es un algoritmo conocido comúnmente como Algoritmo LMS (Least Mean Square, por sus siglas en inglés), y es del tipo de aprendizaje corrección por error descrito anteriormente. Para evaluar el desempeño de las RN se evalúa una función de costo que, para el caso del perceptrón es:
2
1
( )
( )
2
J k
e k
(1.14)dondee(k )es el error en la k-ésima iteración generado por la diferencia en la salida de la RN y la salida deseada. Por lo tanto en el aprendizaje lo que se desea es minimizar esta función con respecto a los pesos w, dado que en el ajuste de los pesos interviene el error diremos que el perceptrón es una RN con aprendizaje supervisado. Veamos ahora como es que se obtiene esa ley de aprendizaje.
Derivemos Jcon respecto a cada uno de los pesos w i, i =1,2,...,m; donde mes el número de
entradas; el error ese= d y, dondeyes la salida del perceptrón y des la salida deseada; f ´( ) , es la primera derivada de la función de activación.
Entonces:
´( )
ii i
e
y
f
u
w
w
(1.15)(
)
( )
´( )
ii i
J W
e
g k
e
ef
u
(1.16)El método del Gradiente Descendente o regla Delta, [5] nos dice que:
(
1)
( )
( )
ik
ik
g k
(1.17)dondeg(k) es el gradiente deJcon respecto awi(k), es decir,g (k)= J / wi; multiplicando por 1 nos da la dirección de descenso y es una constante positiva llamada tasa de aprendizaje. Entonces la actualización de los pesos del perceptrón es:
(
1)
( )
( ) `( ) ( )
ik
ik
e k f
u k
i (1.18)Tabla 1.1Resumen del algoritmo LMS
1.- Se selecciona un vector de entrenamiento
u
(
k
)
y una respuesta deseadad
(
k
)
2.- Seleccionamos un parámetro de aprendizaje
0 <
<1
3.- Inicialización de los pesos
w
i(0)
=valores aleatorios pequeños uniformemente distribuidos.4.- Calculamos. Para
k
= 1,2,...,
n
tenemos que(
1)
( )
( ) `( ) ( )
i
k
ik
e k f
u k
i
Donde
( ) ( ) ( ) e k d k y k
1.6 El perceptrón multicapa
El perceptrón multicapa (PMC), [15], [16], [50] es un elemento muy importante en la evolución de las RN, debido a que es una de las primeras RN s propiamente dichas, su importancia queda manifiesta en [19]. Un PMC es un arreglo de neuronas (perceptrones) en capas. Una capa es un conjunto de neuronas que están conectadas al mismo vector de entradas y generan un vector de salida. Cuando la salida. Cuando la salida de una capa es la entrada de otra capa entonces decimos que el arreglo obtenido es un PMC, a diferencia del perceptrón, el PMC puede tener múltiples salidas.
La diferencia entre un perceptrón y un PMC radica precisamente en que un perceptrón es una red de una sola capa, con su respectiva entrada y salida, que contrasta con la arquitectura del PMC, el cual, es una red de al menos 2 capas, una de entrada y una salida. Cuando en un PMC se tienen más de dos capas es decir,n+2 capas, decimos que el perceptrón tiene una capa de entrada, una de salida y un número nde capas a las que llamaremos ocultas . La figura 1.7 muestra a dos perceptrones, el primero con una capa oculta y el segundo con dos.
La estructura del PMC es una RN del tipo Feed Forward (RNFF), esto es, que el patrón de la entrada se propaga hacia delante hasta la salida.Para aclarar este punto supóngase un elemento de entrada ui(k)y un elemento de la matriz de pesos wij (k) entonces la propagación consiste en realizar el producto
ui(k)wiJ (k)y sumarlo a los demás productosuJ wkl (k); i k , j l , de la misma capa obteniendo una
señalzm(k), la cual, después es introducida como argumento de la función f ( ) formando una señalzm
(k), es decir, f (vm (k)) = zm (k) ; donde, f ( ) es la función de activación y zm(k) es la m-ésima
componente del vector de entrada de la siguiente capa;este proceso continúa neurona por neurona, capa por capa hasta obtener el vector de salidaY(k).
1.6.1 Aprendizaje del PMC
En el apartado 1.6.1 asentamos que el perceptrón tiene una ley de aprendizaje basada en el algoritmo LMS.El algoritmo para el ajuste de los pesos del PMC es una derivación del LMS y se conoce como algoritmo de retro-propagación o Back propagation (BP). Este algoritmo, como su nombre lo indica, es una propagación hacia atrás de la señal de error, la cual se forma de la diferencia entre la señal deseada y la salida de la RN;el(k) =dl(k) yl(k).Recordemos que cuando se tenía un perceptrón simple se
tomaba el error e(k) y se implementaba en la ecuación (1.19) para actualizar los pesos. En este caso es más complicado pues se tiene al menos dos vectores de pesos.
1.6.1.1 Pasos para el cálculo del algoritmo BP
En la aplicación del algoritmo BP, se distinguen dos pasos en el cálculo. El primero es llamado paso hacia adelante, mientras que el segundo es llamado paso hacia atrás.
Paso hacia adelante
En el paso hacia delante los pesos sinápticos permanecen sin alteración a través de toda la red, y las funciones de activación de la red son evaluadas neurona por neurona. La función de activación que aparece a la salida de la neuronajes evaluada de la siguiente forma:
( ) ( )
j j j
y k f k (1.19)
donde
vj
(
k
)
es el estado de activación de la neuronaj
definido por:( )
( )
( )
mdonde m es el número total de entradas aplicadas a la neurona j y wji(k) es el peso sináptico entre la
neurona jy la neuronai , yyi(k ) es la señal de entrada a la neuronajo bien, visto de otra manera es el
valor de la función de salida de la neuronai . Si la neurona jpertenece a la primera capada la red, la cual queda expresada de la siguiente forma:
( )
( )
i i
y k
u k
(1.21)donde ui(k) es el i-ésimo elemento del vector de entrada. Por otro lado, si la neurona j pertenece a la
capa de salida de la red,m = mjy el índice jseñala la j-ésima señal de salida de la red, la cual, queda
expresada de la siguiente forma:
( )
( )
J J
y k
o k
(1.22)donde oJ(k) es el j-ésimo elemento del vector de salida. Esta salida es comparada con la respuesta
deseada dJ(k), obteniendo así, el error de salida eJ(k) para la j-ésima neurona de salida. En la fase del
paso hacia delante el cálculo comienza con la primera capa oculta que presenta el vector de entrada, y termina con la capa de salida calculando la señal del error para cada neurona de esta capa.
Paso hacia atrás
El paso hacia atrás, por otro lado, comienza en la capa de salida pasando a las señales del error hacia la izquierda a través de la red, capa por capa, y recursivamente calculando el gradiente local para cada neurona. Para una neurona localizada en la capa de salida, es simplemente igual a la señal de error multiplicada por la primera derivada de la función de activación de esta neurona. El cálculo recursivo es continuado, capa por capa, propagando los cambios para todos los pesos sinápticos de la red.
1.6.2 Algoritmo BP
Las redes neuronales entrenadas por medio del algoritmo BP son poderosas herramientas para reconocimiento de patrones, memoria asociativa y filtros adaptables [31], pero también se ha descubierto que cualquier tipo de RN puede ser entrenada por este algoritmo y realizar tareas como identificación y control, [18],[29], describamos ahora el algoritmo.
La señal de error de laj-ésima neurona de salida en lak-ésima iteración es definida por:
( )
( )
( )
J J J
e k
d k
y k
(1.23)El error cuadrático de la j-ésima neurona de salida en la k-ésima iteración es ½e2
J(k), el error
2
1
( )
( )
2
JJ C
J k
e k
(1.24)donde C es el conjunto de todas las neuronas de salida. Sea N el número total de iteraciones; el error medio cuadrático medio es obtenido sumando todos losJ(k) y normalizando con respecto aN, es decir:
1
1
( )
PROM k
J
J k
N
(1.25)JPROM yJ(k)son funciones de los pesos de la red.JPROMrepresenta la función de costo total, por lo tanto nuestro objetivo en el aprendizaje es ajustar los pesos tal queJPROMsea mínima. Para el ajuste de los pesos se utiliza el error instantáneo Ec. (1.24), que nos ayudará a crear una corrección que es proporcional al gradiente descendente de la funciónJ(k).
La figura 1.8 describe la j-ésima neurona de una RN alimentada por la señal de salida yi(k)de la i-ésima neurona de la capa anterior. El estado de activación vJ(k) asociado con la j-ésima neurona es
definido en la Ec. (1.21), donde m es el número total de entradas, y0= 1 es la entrada al umbral J
aplicado a la neurona j; ywijes el peso de la j-ésima neurona de la capa anterior. Por lo tanto, la salida de
laj-ésima neurona en la iteraciónkes:
y ( )j k fj j( )k (1.26)
donde
f
es la función de activación.j-esima neurona
Figura 1.8Detalles de una neuronajde la capa de salida.
El método BP aplica la corrección wij(k)a los pesos sinápticos que es proporcional a la derivada
parcial J(k)/ wij(k)Ec. (1.18). De acuerdo a la regla de la cadena tenemos:
wJi(k)
Y0=
yi(k)
J(k)
vJ(k) yJ(k)
dJ(k)
( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( )
j j j
ij j j j ij
J k e k y k k
J k
w K e k y k y k w k (1.27)
haciendo los cálculos pertinentes tenemos que:
( )
( )
( )
1
( )
( )
( )
( )
´
( )
( )
( )
( )
j j j j j jj j i
j ij
e k
J k
e k
e k
y k
y k
k
f
k
y k
y k
w k
donde f J()es la derivada de laj-ésima función de activación con respecto a su argumento.
Por lo tanto:
( )
( ) ´
( )
( )
( )
j j j iij
J k
e k f
k y k
w k
(1.28)La corrección wij(k)es definida como, [5]:
( )
( )
( )
ij ijJ k
w k
w k
(1.29)donde es la tasa de aprendizaje, el signo ( ) es debido a que se desea tener la dirección de máximo descenso para que el cambio de pesos reduzca el valor deJ (k).
Si J(k)es el gradiente local de la neurona de salidaj, tenemos que:
( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( )
j j jj j j j
e k y k
J k J k
k
k e k y k k (1.30)
entonces
( ) ( ) ´ ( )
j k e k fj j j k (1.31)por lo tanto
( )
( ) ( )
w k
ij
jk y k
i (1.32)con lo que la actualización de los pesos de la capa de salida está dada por:
(
1)
( )
(
1)
ij ij ij
donde es la tasa del término momento de aprendizaje que es usado para eliminar oscilaciones en el error.
La figura 1.9 muestra el comportamiento del BP con respecto a las señales que intervienen.
Figura 1.9Propagación del error.
Para los pesos de la capa de salida se utiliza la señal deseada y la salida de la red para generar el erroreJ(k)y obtener el gradiente local que nos ayude a actualizar los pesos. Cuando queremos actualizar
los pesos de las capas que no son de salida, el problema radica en que no contamos con una señal deseada, en consecuencia es imposible generar un error ei(k) y obtener el gradiente local en esa capa, entonces
utilizaremos el error de salida para retro propagarlo y obtener un estimado del error en las capas anteriores a la salida y así proporcionar un gradiente local que nos de la capacidad de actualizar los pesos de esas capas. Considere la situación descrita en la figura 1.10, la cual bosqueja una neurona j como un nodo oculto en red.
De la ecuación (1.31) podemos definir el gradiente local i(k)para una neurona ocultaicomo:
( )
( )
( )
( )
( )
( )
´
( )
( )
i i
i i
i i
y k
J k
k
y k
k
J k
f
k
y k
(1.34)
donde i(k) es el gradiente de la i-ésima neurona; yi(k) es la salida de la i ésima neurona; vi(k) es el
estado de activación de lai-ésima neurona; fi( ) es la derivada de lai -ésima función de activación con
j j j C i ie
J
e
y
y
(1.35)aplicando la regla de la cadena:
j i j j Ci i i
e
J
e
y
y
(1.36)tomando las ecuaciones (1.24) y (1.27) se tiene ej= dj- fj(vj)con lo que:
´( ) j j j j e f (1.37)
Figura 1.10Gráfica de la conexión entre dos neuronas. Lai-ésima neurona de la capa oculta conectada a laj ésima neurona de la capa de salida.
derivando parcialmente la ecuación (1.21) con respecto ai yse obtiene:
ij i
J
w
y
(1.38)sustituyendo (1.37) y (1.38) en (1.39) se tiene
´ (
)
j j j ij ji
J
e f
w
y
(1.39)de (1.32) se sigue:
j ij j i
J
w
y
(1.40)j-esima neurona i-esima neurona
i(k)
wij(k) vi(k) yi(k)
j(k)
wij(k) vj(k) yj(k)
sustituyendo en la ecuación (1.35) se tiene que:
´( )
i i i
j ijj
f w (1.41)
que es el gradiente local de una neurona que no es la capa de salida.
Por último se obtiene que la actualización de los pesos sinápticos para una neurona que no pertenece a la capa de salida es:
w
li
i ly
(1.42)donde yles la entrada a la i-ésima neurona de la capa que no es de salida y a su vez es la salida de la
l-ésima neurona de la capa anterior.
Una restricción para el uso de este algoritmo es que f ( ) sea una función diferenciable, por ejemplo en el caso de quef(v) = tanh (v)entoncesf´(v) = 1 y2, dondey =f (v).
A pesar de que el uso del algoritmo BP es bastante difundido a veces, sin embargo, la deducción de éste para algunas topologías de redes puede llegar a ser bastante compleja por el cálculo de las numerosas derivadas parciales. En el siguiente apartado se presenta un método gráfico más directo y sencillo para obtener las expresiones para actualizar los pesos de las redes.
1.7 Método diagramático y red adjunta, [49]
En varias ocasiones puede resultar muy tedioso o realmente difícil trabajar con redes neuronales dependientes del tiempo porque pueden requerir numerosas expansiones en cadena y cuidadosas manipulaciones de los términos, pues todo ello nos conduce a resultados erróneos. Este es un método alternativo que pretende disminuir todos esos problemas mediante un conjunto de simples reglas de manipulación de diagramas de bloques. Este método provee una manera bastante sencilla para derivar algoritmos tan populares como el back propagation.
En el BP se busca encontrar el conjunto de pesos que minimicen la función de costoJ , es decir, encontrar J / wjisi tomamos en cuenta que j
( )
ji i( )
i
v k
w u k
entonces:
j
ji j ji
d
J J
w w (1.43)
para fines prácticos redefinimos
j jJ
(1.44) y ji j N w ji G w (1.45) donde ji N wG
es el jacobiano del vectorv; entonces:
ji N j w jiJ
G
w
(1.46)1.7.1 Representación en diagramas de bloques de la RN.
Una RN puede ser representada en forma arbitraria como un diagrama de bloques cuyos elementos esenciales son: sumador, puntos de bifurcación, funciones univaluadas como los pesos y las funciones de activación, funciones multivaluadas y operadores de retardo. Un peso sináptico por ejemplo puede ser visto como una línea de transmitancia. La neurona básica es una simple suma de transmitancias lineales seguidas por una función sigmoidal. La figura 1.11 presenta una descripción gráfica detallada de las partes de una RN.
Figura 1.11Descripción gráfica de las partes de una red neuronal. Señal de entrada wij Sumador Función de una variable (pesos)
A partir de esta relación es fácil representar cualquier RN gráficamente, por ejemplo sea la RN de tres capas descrita por la siguiente ecuación.
3 3 3
2 2 2
1 1 1
( )
( ) ;
( )
( )
( )
( ) ;
( )
( )
( )
( ) ;
( )
( )
Y k
F N k
N k
W Z k
Z k
F N k
N k
W X k
X k
F N k
N k
WU k
(1.47)
donde Y (k ) es la salida; F ( )es el vector de funciones de activación f ( );Ni (k) son los estados de
activación en la neurona de entrada, oculta y de salida;Wi i=1, 2, 3 son las matrices de pesos de la capa
de entrada, oculta y de salida; Z(k ) es el vector de salida de la capa oculta; X(k ) es la salida de la neurona de capa oculta; U(k ) es el vector de entrada a la RN. La gráfica que describe esta RN es la mostrada en la mostrada en la figura 1.12.
1.7.2 La red adjunta
Dada la representación gráfica de la RN y el objetivo de determinar el gradiente local, es decir la Ec. (1.45), sólo necesitamos aplicar un conjunto de reglas simples para construir la RA y determinar el gradiente en cuestión.
Figura 1.12Diagrama de una RN de tres capas.
Reglas para la construcción de la red adjunta
1.-Puntos suma son reemplazados por puntos bifurcación
W1 N1
f f f f f f f f f
W2 N2 W3 N3
2.-Puntos de bifurcación son reemplazados por puntos suma
3.-Funciones de una variable son reemplazadas por sus derivadas
Por ejemplo. Funciones de activación: yj = tanh (xi). En este caso, f´´(yj) = 1-x2, ó si yj = sigm (xi)
entoncesf´(yj) = xi(1-xi).
4.-Las funciones Multivaluadas son reemplazadas por sus jacobianos.
Casos especiales
- Productos: yj=xixl en cuyo caso
T F
a l i
G x x
- Redes neuronales: Una función multivaluada puede representar una red multicapa. En este caso, el producto
i
F x y
G
puede ser obtenido por retro propagación de y a través de la red sin lanecesidad de calcular i
F x
G
5.-Operadores de retardo son reemplazados por operadores de avance
6.-Los nodosan=ynsalida en la red original se transforman en nodos de entrada en la red adjunta, donde
la entrada es generalmente el erroren
wl yi yj yi Yj xl yj
xi wi yi
y0 yq yp xj wj xn y0 yq yp xi xj xn yq ui uj
y0 -ej
-ei
Red original
Este conjunto de reglas son un elemento importante para la construcción de la Red Adjunta, la cual propaga la señale (k) que corresponde al error de salida generado por la diferencia entre la salida de la RN y la señal deseada, entonces obtenemos el gradiente j(k)necesario para la adaptación de los pesos. En la figura 1.13 se muestra la RA obtenida a partir de las reglas anteriores.
La RN y la RA en base a estas reglas son topológicamente equivalentes. La justificación teórica de las reglas está dada en [49]. A modo de ejemplo mostramos la deducción de la regla BP por este método.
Figura 1.13Red Adjunta deducida a partir de la Red Neuronal.
1.7.3 Deducción del algoritmo BP utilizando el método diagramático
En la figura 1.14 (a) es mostrada una neurona de capa oculta conectada a otras neuronas y también se muestra una neurona de salida de una red multicapa. Sea vil la función de activación en la i-ésima
neurona de lal-ésima capa de la RN,1 l L ; L es el número total de capas. El término(k)se omite por simplicidad.
En la figura 1.8 (b) podemos observar la red adjunta construida a partir de las reglas descritas anteriormente. Las ecuaciones para el cálculo del gradiente local il pueden ahora ser deducidas inmediatamente a partir de dicha figura.
f
f f
f
W1 W2
f
f
f f
f f v1
v2
v3 z3
z2
z1
y3
y2
y1
e3
e2
e1
d1
d2
d3
u1
u2
u3
e1
e2
e3
f
f
1 1 ´( )
´( ) 1 1
l i ll l l
i
i j ij
j
ef l L
f w l L (1.48)
el cual es el término deducido matemáticamente en la sección anterior. Como pudimos observar este método es una alternativa bastante confiable y efectiva para encontrar los gradientes en RN de arquitectura más complicada.
(a)
(b)
Figura 1.14Diagrama representativo de una RN y el esquema de la RA
1.8 Teorema universal de aproximación
Este teorema nos proporciona la justificación teórica para el uso de RN en la aproximación de funciones.
Teorema 1.1:
Seaf ( )una función continua, no constante, acotada y monótona creciente. Sea Imo un hipercubo unitario de dimensión mo. El espacio de funciones continuas en Imo es denotado porC(Imo). Entonces, dada cualquier función f ∈C(I mo) y > 0 , existe un entero M y conjuntos de
constantes reales i , i y wij dondei = 1,...,m1y j,...,motal que definimos
0 1 0 1 1 1 ( , , )
m mm i ij j i
i i
F X X f w x
como una realización aproximada de la funciónf ( ) ; esto es,
0 0
1 1
( ,, m ) ( ,, m )
F X X f X X