UNIVERSIDAD
AUTONOMA METROPOLITANA
DIVISION DE CIENCIAS BASICAS E
INGENERIA
/-
L,
c , Cob4PdTRao3GXRCÍA
PÉREZ
ADOLFO.
96320902GONZALEZ
P A Y R ~
ARTURO.
96321363MONROY
MINO
ERIKA ALMA
M.
9431 7619SANCHEZ
JUAREZ TERESA. 943053 78BIENVENIDOS A LA PAGINA
DE
LOS
ALUMNOS
DE LA UAM DE IZTAPALAPA.
Cesa
Abierta
ai
Tiempo
UNIVERSIDAD AUTONOMA
METROPOLITANA
PAGINA REALIZADA POR :
GARCÍA PkREZ
ADOLFO
G O N Z ~ E Z P A Y R ~ ARTURO
MONROY MINO
ERIKA
ALMA.SANCHEZ JUAREZ TERESA.
Bajo la supe coordinador de proyecto.
INTRODUCCI~N :
En el presente trabajo se rebisaran diferentes tecnicas para la clwicación de datos destacando varios como es el denominado de Ins K-MEONS, Mineria de datos, Clustering,
Escalamiento Muitidimensional, entre otros, se comenzara con una brebe intruduccón 8 lo que
es un patrón ya que en la mayoria de las teenicas explicadas en este trabajo se basa en la
clasificaci6n de patrones o datos, despn& se rebisoran Ins tecnicas antes mencionadas de una
forma muy compacta por esta razón ai íinPlLePr dkho trabajo se damn algunas referencias por si el usuario esta interesado en conocer más sobre dichas tecnicas, esperamos que el material públicado
sirva
para estimalir a que el lector quiera conocer un poco más sobre estaa tecnicas.TECNICAS DE CLASIFICACI~N DE DATOS.
1.1 ¿Qué es un patrón? Siguiendo la definialón de Watanabe [WatsS], un patrón es
una entidad a la que se le puede dar un nombre y que está representada por un
conjunto de propiedades medidas y las relaaiones entre ellas (vector de
características). Por ejemplo, un patrón puede ser una seiial sonora y su vector de características el conjunto de coeficientes espectrales extraídos de ella
(espectrograma).
El reconocimiento automático, descripción, clasificación y agrupamiento de patrones son actividades importantes en una gran variedad de disciplinas
cientificas, como biología, sicolog6a, medicina, visión por computador, inteligencia artificial, teledetección, etc.
Un
sistema de reconocimiento de patrones tiene uno de los siguientes objetivos:8.- Identificar el patrón como miembro de una clase ya deñaida (clasificación
supervisada).
b.- Asignar el patrón a una clase todavía no definida (clasificación no supervisada,
agrupamiento o clustering).
El diseño de un sistema de reconocimiento
de
patrones se lleva a cabo normalmente en tres fases:i.- Adquisición y preproceso de datos.
3.- Extracción de características.
iii.- Toma de decisiones o agrupamiento.
El universo del discurso, o dominio del problema, gobierna la elección de las
diferentes alternativas en cada paso: tipo de sensores, técnicas de preprocesamiento, modelo de toma de decisiones, etc. Este conocimiento específico del problema está implícito en el diseño y no se representa como un módulo separado como sucede, por ejemplo, en los sistemas expertos.
Tradicionalmente, el reconocimiento de patrones se ha abordado desde un punto de vista estadístico, dando lugar al llamado reconocimiento estadístico de patrones
(REP). como muy prometedora en algunos casos en que el
REP
no funcionasatisfactoriamente. Dicha alternativa son las Redes Neuronales Artificiales (RNA)
1.2.- Reconocimiento Estadístico de Patrones (REP).
El REP es una disciplina relativamente madura hasta el punto de que existen ya en el mercado un cierto número de sistemas comerciales de reconocimiento de patrones que emplean esta técnica. En REP, un patrón se representa por un vector numérico de dimensión n. De esta forma, un patrón es un punto en un espacio n-dimensional (de características).
Un
REP funciona en dos modos diferentes:file ://A:ündex.htm 01/01/88
Página 3 de 24
ni
c
entrenamiento y reconocimiento. En modo de entrenamiento, se diseña el extractor de características para representar los patrones de entrada y se entrena al clasificador con un conjunto de datos de entrenamiento de forma que el número de patrones mal identificados se minimice. En el modo de reconocimiento, elclasificador ya entrenado toma como entrada el vector de características de un patrón desconocido y lo asigna a una de las clases o categohs.
c-
IC
c
El proceso de toma de decisiones en un REP se puede resumir como sigue. Dado un patrón representado por un vector de características
Asignarlo a una de las c clases o categorías, C1, CZ, ..Cc
.
Dependiendo del tipo de información disponible sobre las densidades condicionales de las clases, se pueden diseñar varias estrategias de clasifleacióli. Si todas las densidades condicionales p(x1
Ci ), i=1,2,
...
c se conocen, la regla de decisión es la de Bayes que establece los límites entre las diferentes clases. Sin embargo, en la práctica las densidades condicionales no se conocen y deben ser estimadas (aprendidas) partiendo de los patrones de entrada. Si se conoce la forma funcional de estas densidades pero no susparámetros, el problema se llama de toma de decisión paramétrico. En caso contrario, estamos ante un problema de toma de decisión no paramétrico.
El algoritmo kmeuns
El problema de k-means es determinar k medias de distribitiones Normales.
Debemos de derivar una expresión para
si
entonces:El tener la sumatoria sobre las 2.. se justifica porque solamente una de ellas puede
iJ
tener el valor de 1 para un ejemplo y las demás deben de ser cero.
Finalmente debemos de tomar el valor esperado de esta probabilidad. En general para cualquier función lineal de
z,
E n z ) ]
-fiE[z]). Como tenemos una función lineal de las z's:donde:
El primer paso define Q en términos de los valores estimados de 2.- El segundo paso
encuentra los valores m u emaximizan la función
e.
YPor
lo que la hipótesis de máxima verosimilitud es la que minimiza la suma pesada de los errores al cuadrado. Esta cantidad se minimiza haciendo cada media como la media pesada de la muestra:A continuación veremos un ejemplo del algoritmo para ello se utilizara la explicación con una red neuranal.
Redes de Función de Base Radial
Con el fin de comprender mejor la forma de realizar las simulaciones, en este
apartado se pretende dar una visión panorámica de la arquitectura de una RBF y de su algoritmo de aprendizaje. Asimismo, se comentará la elección de ciertos
parámetros, que hay que fijar antes de comenzar el proceso de entrenamiento; su
validez se comprobará a posteriori.
Arquitectura de la RBF
Este tipo de red como paradigma de clasificación y de aproximación funcional fue desarrollado originariamente por M.J.D. Powell (1985). Los nodos se disponen en
dos capas: oculta y salida. AI igual que en el
MLP,
existe una capa de entrada, peroen ella no se lleva a cabo procesamiento alguno.
Con esta red se pretendía, que ante una muestra de entrada, una de las neuronas de la capa oculta alcance una respuesta signifiaativa respecto al resto. L a neurona concreta, y, por tanto, el valor de su salida, debía ser función del grado de
pertenencia de la muestra a un dominio dentro del espacio de las entradas. Estos dominios responden a un subespacio formado en torno a un punto llamado centro, donde el grado de pertenencia de una determinada muestra vendría dado por su distancia a dicho centro. Así pues, la función de activación de las neuronas de la capa oculta debería ser de base radial, como ocurre, por ejemplo, con el campo gravitatorio o electrostático. Sin embargo, a diferencia con estos campos, la salida de la cada neurona tiene que estar acotada entre cero y uno. Por este motivo, una de las funciones de base radial más utilizada es una gausiana:
F ( r ) = e - ( ? /202)
Obsérvese que en esta función aparece el factor s, cuyo signifEado viene a ser el alcance del dominio, ya que cuanto mayor es su valor, la "campana" de Gaus se ensancha más. Por su parte, la variable res la distancia de la muestra al centro del dominio:
r
=11
w
-
rll
En esta expresión, la entrada vendría denotada por la letra x y el centro por w. Esto último junto con CJ son dos parámetros que se determinarán en el proceso de
aprendizaje. Por analogía con el resto de redes neuronales artificiales, a las coordenadas del centro se las sigue llamado pesos.
A la vista de lo que representa cada neurona de la capa oculta, el procesamiento asignado a cada una de ellas difiere del propuesto en el modelo de McCullot- Pitts. Esta circunstancia, como se verá más adelante, es motivo suficiente para descartar ciertas estrategias de paralelización, que en otros tipos de redes sí tienen
consideración.
Para concluir con esta breve descripción de la arquitectura, resta relatar el funcionamiento de la capa de salida. Considerada ésta de forma aislada, podría tratarse como un perceptrón simple con varios nodos, cuyas entradas y salidas son continuas. Por tanto, cada uno de estas neuronas se ajusta al modelo de McCullot- Pitts con función de activación F(x)-a, porque se considera, que tras la el
agrupamiento en dominios efectuado en la capa oculta, un separador lineal es sufiiente para alcanzar resultados satisfactorios. Esto último, como es lógico, es algo que hay que corroborar experimentalmente.
Algoritmo de aprendizaje
El entrenamiento de esta red se reaüza por etapas.En la primera se efectúa el ajuste de pesos de las neuronas ocultas. A continuación, se lleva a cabo el aprendizaje de la capa de salida. En la capa oculta, cada uno de los nodos representa a uno de los
dominios en que se pretende dividir el espacio de las entradas. En particular, sus pesos no son más que las coordenadas del centro. A priori, esta agrupación en dominios depende del número de ellos y de las propias entradas, ya que con esta división se tiene que cubrir todo el espacio ocupado
por
las muestras.De acuerdo con estos requisitos, el problema puede ser tratado por cualquiera de los algoritmos de agrupamiento no supervisado, donde el número de dominios se fija de antemano, que en este caso particular, vendría dado por el tamaño de la capa
oculta.Así pues, se procederá a aplicar uno de los métodos más conocidos de agrupamiento no supervisado (clustering) denominado de las k-medias (/¿-mean). Brevemente, su funcionamiento se puede resumir en cuatro pasos:
1) Se eligen los k centros de partida iguales a k
muestras cualesquiera, como por ejemplo, las k primeras.
2) En cada iteración se produce un agrupamiento de una o más entradas a un único dominio. Para ello, se calcula la distancia de
la
muestra a todos y cada uno de los centros. Aquella que resulte más pequeña, determinará la asignación de dicha entrada al correspondiente dominio.3) Del agrupamiento realizado en el paso anterior, se pasa a obtener los centros de
los nuevos dominios. Esta operación es similar al cálculo de un centro de masas de un sólido rígido con masas puntuales, todas ellas, de igual peao. En este caso, dichas masas puntuales vendrían a ser las diferentes entradas que conforman el dominio.
4) Si los "centros de masa" coinciden con los centros obtenidos en la iteración anterior, concluiría el algoritmo. En caso contrario, se tomarían como nuevos centros los calculados en el paso 3) y se volvería al paso 2).
Para finalizar el aprendizaje de la capa oculta, faltaría por determinar el factor de escala s.
En
principio, debe alcanzar una cantidad mínima, para que todos lospuntos del dominio queden dentro un intervalo, en el cual la función gausiana dé como resultado una cantidad significativa. Para conseguir esto, bastaria con hallar la distancia del punto más alejado del dominio respecto a su centro. Sin embargo, la experiencia demuestra que este valor no es lo suficientemente grande, porque con él,
en el fondo, lo que se consigue es polarizar los pesos entorno a las muestras de
entrenamiento, de tal manera, que entradas diferentes, como son las empleadas en la fase de recuperación, están siendo agrupadas incorrectamente o, al menos, con demasiada rigidez. El efecto observado es el de una mala generalización, que podría
ser comparable a un sobre
-
entrenamiento (overfruining) en otros tipos de RNA. Asimismo, esta manera de fijar (5 presenta otro inconveniente cuando el dominoestá formado por un punto aislado. En esta situación, al ser (5 igual a cero, se
estaría prácticamente inutilizado la correspondiente neurona, porque su salida será cero, salvo que se introduzca una muestra igual a su centro. Esto no ocurrirá en un caso real, si las muestras empleadas en la recuperación son diferentes de las
utilizadas para aprendizaje.
Teniendo en cuenta las consideraciones del párrafo previo, se recurre a fijar el factor s de forma un tanto heurística. Las técnicas empleadas para ello, se reducen
en la práctica a dos. Hay autores que prefieren calcular este parámetro como la distancia del centro al más cercano (Wassermann 1993). Sin embargo, otros optan por hacerlo igual a la distancia media del centro con el resto (Hush 1993).
En
estetrabajo, solamente se ha ensayado el primer método por su sencillez de cákulo.
Con respecto a la capa de salida, al tratarse de un perceptrón con varias neuronas con entradas y salidas continuas, existen varias alternativas para su entrenamiento, pero solamente se han ensayado dos:
a) Algoritmo de mínimos cuadrados.
b) Regia delta.
Desde un punto de vista geométrico, fijar los pesos de una determinada neurona de salida, equivale a hallar la ecuación de un hiperplano en el espacio de las entradas (Ec. 1: salida de la neurona i ante la muestra p). Pam elb, podría imponerse la condición de que la suma extendida a todas las muestras de la distancia de cada una de éstas ai hiperplano sea mínima. Formulado el problema en estos términos, se reduce a una mera regresión tineal pero en un espacio de más de dos dimensiones.
N-l
wij
xP.
+
ej
Ec.1 Y p = c i = o 3
El algoritmo de mínimos cuadrados
(LMS)
ofrece una solución a este problema, quepasa por resolver un sistema tineal de tantas ecuaciones como incógnitas (pesos).
Ciertamente el hiperplano bailado corresponde a uno de distancia mínima con respecto a las entradas. Sin embargo, de todos es sabido, que en reaüdrd lo que se obtiene es un hiperplano correspondiente a un mínimo de la función distancia; este punto extremo no tiene por qué ser global.
En
la práctica se constata, que con lospesos así calculados se reconocen muy pocas muestras, porque la red no trata de clasificar el mayor número de patrones posible, si no de repartir lo m4s
equitativamente posible ese error mínimo.
Para mayor información sobre este ejemplo visitar la siguiente dirección :
http://www.otilio.dcs.fi.uva.es/ai~ne/dne AntofaeastaIColange Antof
Sitios
W E B
de interés:MINERfA DE DATOS.
¿Qué es la minería de datos?
Las técnicas de minería de datos se emplean para mejorar el rendimiento de procesos de negocio o industriales en I& que se manejan grandes volúmenes de información estructurada y almacenada en bases de datos.
Por
ejemplo, se usan conéxito en aplicaciones de control de procesos productivos, como herramienta de ayuda a la planificación y a la decWi6n en marketing, finanzas, etc.
Asimismo, la minería de datos es fundamental en In investigación científica y
técnica, como herramienta de análisis y descubrimiento de conocimiento a partir de datos de observación o de resultados de experimentos.
La minería de datos consiste en la "explotación" de datos en bruto. Su objetivo, perseguido mediante la manipulación (stmi-)automática de los datos, es la obtención de información clave para conseguir bencficios--información más relevante y útil que los propios datos de partida. El término minería podría inducir al error de restringir este objetivo a la búsqueda y extracción de fragmentos útiles de
información ya almacenada explícitamente. En cambio, la minería de datos se ocupa principalmente de la construcción de información no representada explícitamente en los datos.
La minería de datos se fundamenta en la intersección de diversas áreas de estudio,
entre las que cabe destacar: análisis estadístico, bases de datos, inteligencia artificial y visualización gráfica
Proceso de minería de datos.
Los pasos a seguir para la realición de un proyecto de mineria de datos son
siempre los mismos, independientemente de la técnica específica de extracción de conocimiento usada.
I
Y
I V
El proceso de minería de datos pasa por los siguientes estadios:
.~~uu&eprocesado de los datos. *no&eiección de característicg.
01 I I 1&0 de un algoritmo de extracción de conocimiento.
.uriodnterpretacióó y evaluación.
Nadie duda que la experiencia es elemento crucial del Conocimiento y la sabiduría. L a asimilación de hechos pasados permite enfrentar al futuro con más posibilidades de éxito, sin tener que recordar todos los detalles del pasado. Esto es claro en las personas, pero, jcómo puede aplicarse a las corporaciones?
jQUÉ PROMETE
LA
MINERfA DEDATOS?
La tecnología informática es infraestructura fundamental de las grandes organizaciones y permite, hoy en día, registrar con lujo de detalle, los elementos de todas las actividades con asombrosa facilidad. La tecnología de bases de datos permite almacenar cada transacción, y muchos otros elementos que reflejan la interacción de la organización con todos sus interloeutores, ya sean otras organizaciones, sus clientes, o internamente, sus divisiones, sus empleados, etcétera. Tenemos pues, un registro bastante completo del comportamiento de la organización. Pero, ¿cómo traducir ese voluminoso acervo en experiencia, conocimiento y sabiduría corporativa que apoye efectivamente la toma de decisiones, especialmente al nivel gerencia1 que dirige el destino de las grandes organizaciones? ¿Cómo comprender el fenómeno, tomando en cuenta grandes volúmenes de datos?
La Minería de Datos es una herramienta explorativa y no explicativa. Es decir, explora los datos para sugerir hipótesis. Es incorrecto aceptar dichas hipótesis como explicaciones o relaciones causa-efecto. Es necesario coleccionar nuevos datos y validar las hipótesis generadas ante los nuevos datos, y después descartar aquellas que no son confirmadas por los nuevos datos.
Pero la Minería de Datos no puede ser experimental. En muchas circunstancias, no es posible reproducir las condiciones que generaron los datos (especialmente si son datos del pasado, y una variable es el tiempo).
Afortunadamente, existen algunas técnicas para resolverlo, pero se requiere cierta madurez estadística para su comprensión.
Sitios WEB de interés:
httD://www.ati.es/not¡c¡as/doc/datam¡m-clm.htm~
htt~://www.lania.m~sDanish~actividades/n~slette~/l997-otono-
inyierno/minieria. html
http://www.lania.m~s~anis~actividades/n~slette~/l999-otono-
-
invierno/retos mineria.htm1
http://www.daedalus.es/miner¡a/auees.asp
http://~.lafacu.com/apuntes/informatica/datamin~n~/default. htm
CLASIFICACI~N DE INFORMACI~N
Para poder utilizar o reutilizar información de un modo óptimo e inteligente es necesario primero clasificar esta información, de tal modo que se establezcan relaciones entre los componentes que describen y deñnen la información. Las relaciones son muy importantes para poder seleccionar posteriormente, de forma inteligente, la información que contiene la base de conocimiento. Existen numerosos
y variados enfoques para realizar este proceso. Se presentan en este trabajo alternativas relativas a campos de investigación, muy distintos entre sí en algunos casos. Principalmente se ha trabajado con tres tipos de clasificadores:
Ciencioméiricos: Co-wording.
Estadikticos: Max-min, K-vecinos, K-vecinos incremental, Isodata.
Clasijicadores cienciométricos: Co-wording
El análisis de concurrencia de palabras estudia el uso de grupos de palabras que aparecen simultáneamente en varios documentos. Las palabras pueden pertenecer a un lenguaje controlado o a texto libre. L a metodolqia de co-wording fue desarrollada por el Centre de Sociologie de I'Innovation (CSI) en París.
El método de concurrencias [Call, 831 capaz de avaluar la relación entre dos
descriptores; se considera, por tanto, un método de clasificación. Su propósito es establecer un peso a la relación que existe entre dos descriptores. Para aplicar tal método se deben haber identircado los descriptores, y posteriormente se debe proceder a r e a l i r el análisis de las concurrencias para todos los documentos que componen la definición de un proyecto software. Se calcula un peso para cada término basado en el modelo de espacio vectorial [Salt, 891 y en una función de
semejanza asimétrica [Chen, 921.
El método a utilizar para realizar la clasificación de términos utilizando esta técnica contiene los siguientes pasos:
1 , Cálculo de las frecuencias terminal y documental. Se comienza calculando:
la frecuencia terminal: representa el número de entradas de un término j en un documento i.
a la frecuencia documental: representa el número de documentos de un conjunto de n documentos en los que se encuentra el término j.
1 . Obtención de los pesos combinados. A los términos formados por múltiples palabras se les asigna pesos mayores que a los términos formados por palabras simples ya que los términos formados por varias palabras suelen aportar mayor contenido semántico.
2. Análisis concurrente. Se genera una tabla de términos co-ocurrentes basada en la "función cluster" desarrollada por [Chen 921.
3. Aplicación de los umbrales. Cada término puede tener miles de conceptos relacionados. Pero toda esta cantidad de relaciones no tiene por qué tenerse en
cuenta, ya que a medida que se va realizando se pueden ir escogiendo los más significativos. Para un sistema de interacción productivo, sólo se deben mencionar las relaciones más significativas.
Se ha estimado como 100 el número máximo de enlaces para cada nodo. Con esto puede desecharse el
60%
de los pares menos significativos [Vela, 981.Algoritmos estadísticos de agrupación en clases
L a agrupación en clases o clustering puede definirse como el proceso de clasificación no supervisada de objetos. Si se le indican ai proceso el número de clases diferentes en que se puede clasificar se le facilita el trabajo, pero en algunos casos esto no es necesario y en el caso en el que se indican, a veces es meramente informativo.
No se conoce la distribución de los objetos en las distintas clases. Se dispone de
un conjunto de vectores {xl,
...,
x } que representan a los objetos y a partir de él se desea obtener el conjunto de clases {a 1,...,
a n} que los engloban. El problema consiste en que a priori no se sabe cómo se distribuyen los vectores en las clases, ni siquiera cuántas clases habrá. En cambio, sí se tiene definida la estructura del vector de características.P
Por lo tanto, el problema consiste en, a partir del conjunto de vectores de características dado, conseguir realizar agrupaciones de estos vectores en clases en función de las similitudes encontradas.
¿Cuándo interesa aplicar estas técnicas de agrupación? [Vela, 981
En áreas de trabajo en las que apenas exista información acerca de la distribución en clases. En aplicaciones con conocimiento prácticamente nulo son imprescindibles.
En áreas de trabajo en las que exista conocimiento incluso completo, porque tienen interés para probar la calidad de las características escogidas. En aplicaciones con conocimiento previo son importantes para poder realizar pruebas.
Han de tenerse en cuenta dos parámetros:
Compactación.
Separación.
El agrupamiento se efectúa en función de la similitud o diferencia de patrones, basadas en las distancias que se utiümn, principalmente la euclídea, aunque existen otras, como la distancia angular, o las normas
L1
y L2.Este tipo de algoritmos son heurísticos y se suelen basar en la minimización de algún índice, por ejemplo, índices cuadráticos basrdos en distancias.
No existe una medida cuantitativa de la calidad del proceso de clustering. ¿Cómo dependen entonces los resultados de los datos? Pueden establecerse dos correlaciones [Vela,
981:
Búsqueda de las modas: con el valor máximo de la función de densidad de probabilidad local, si el número de clases es conocido.
Cuando el número de clases es desconocido puede estimarse el número y la situación de las modas, con la búsqueda de los agrupamientos naturales de los patrones.
Los algoritmos de clustering pueden dividirse de varias formas:
Directos (constructivos), que tienen una aproximación heurística.
Indirectos (optimizados), que utiliznn una función criterio para optimizar la clasificación.
Otra clasificación posible es:
Unión (Bottom-Up).
División (top-Down).
CLUSTERING.
Hoy en día, las soluciones I,clustei-ig de NT resuehren uno de los problemas de la informática empresarial: la disponibilidad. Con el duplicado de datos, aplicaciones,
e incluso sistemas enteros, el clustering permite a dos o más sistemas vigilarse y en caso de que el sistema caiga, hacerse cargo del trabajo del otro (conexiones de usuarios, aplicaciones, y servicios). En este artículo repasaremos los distintos tipos de soluciones clustering que están disponibles, clasifícaremos las soluciones de clustering, e ilustraremos los tipos de problemas de la informática empresarial que
el clustering puede ayudar a solucionar.
Pero, ¿qué es un Cluster?
Un cluster es un grupo de todo, ordenadores estándar que trabajan juntos como un
recurso unificado y que pueden crear la ilusión de ser una sola máquina, un solo sistema imagen. (Con clusters NT, el término ordenador total, qua es sinónimo de nodo, significa que un sistema puede correr por si solo, separado del cluster. Si usted no está familiarizado con la terminología de clustering, puede consultar
«Terminología y Tecnología de Clustering», en la página 20). Estos recursos
unificados aseguran la disponibilidad dado que cualquier
nodo
puede hacerse cargo del trabajo de cualquier otro nodo que está a punto de caer.Los clusters se presentan tres tipos de configuración: activo/activo, activo/standby, y tolerante a fallos. Examinemos cada una de las tres configuraciones:
Activo/activo: Todos los nodos en el cluster realizan un trabajo significativo. Si algún nodo cae, el nodo restante (o nodos restantes) continúan realizando su trabajo y además el trabajo del nodo que ha caído. El tiempo de recuperación está entre 15 y 90 segundos.
Activo/standby:
Un
nodo (el nodo primario) realiza trabajo, y el otroII
c
If
t
U
o
espera a que suceda una caída del nodo primario. Si el primer nodo falla, la solución clustering transfiere el trabajo del nodo primario al nodo standby y finaliza la sesión de los usuarios o cualquier trabajo en el nodo standby. El tiempo de recuperación está entre los 15 y los 90 segundos.
Tolerante a Fallos:
Un
cluster tolerante a fallos es un sistemacompletamente redundante (disco y CPU) cuyo objetivo es estar
disponible el 99'999% del tiempo. Este objetivo se traduce en menos de 6 minutos fuera de servicio por año. Ambos nodos del cluster tolerante a fallos realizan simultáneamente tareas idénticas; el trabajo de los nodos es redundante. El tiempo de recuperación es menos de 1 segundo.
EJEMPLO 1: Expansión de su servidor de ficheros y impresoras
Problema: Su compañía tiene un servidor N T en un Pentium de un solo procesador que se utilizs como servidor de ficheros e impresoras, que está sacando humo. Sus aplicaciones incluyen una base de datos multiusuario Access97 constantemente en uso y Office97. Usted tiene que reducir el tiempo de downtime, especialmente con la base de datos Access97, que está empezando a ser crítica.
Solución: Si usted compra un servidor adicional, puede utilizar una solución basada en mirroring como Octopus para conectar los dos servidores en un cluster. Puede disminuir la capacidad de caída
poniendo los ficheros de Office97 en uno de los servidores y Access97 en
el otro. A la vez, puede replicar los datos críticos entre los servidores y crear un entorno elástico a fallos.
¿Podría utilizar Wolfpack en esta situación? Podría, sólo si su nueva configuración se encuentra en la WHCL, que por ahora es bastante reducida. Además Wolfpack necesita un subsistema de disco SCSI que siempre representa un gasto extra.
EJEMPLO 2: Configuración de una tienda en la Web utilizando Merchant Server
Problema: Su compañía ha decido recibir pedidos y pagos a través de Internet. Para un rendimiento óptimo, usted decide utilizar Merchant Server y Internet Information Server @IS) en un servidor y SQL Server en otro. Ambos servidores tendrán usuarios activos, por lo que necesita una solución de clustering activdactiva.
Un
retraso de 30 segundos esaceptable durante una recuperación, porque usted tiene 30 días para servir el pedido.
Solución: Wolfpack todavía no está a la venta, de manera que puede empezar con LifeKeeper o Firstwatch. Como no tiene todavía el equipo, puede comprar una solución basada en SCSI (dos servidores y
un subsistema de disco), Una solución posible es
NT
Cluster-in-a-Box de Data General, que viene preconfigurada de fábrica. (Información sobre esta solución, ver«NT
Cluster-in-a-Box», en el próximo número deWindows
NT
Magazine). Si lo desea, puede esperar a Wolfpack, que también resolverá su problema.Similaridad entre patrones. La tarea fundamental de un sistema de reconocimiento de patrones (clasificador) es la de asignar a cada patrón de entrada una etiqueta.
Dos patrones diferentes deberían asignarse a una misma clase si son similares y a clases diferentes si no lo son. La cuestión que se plantea ahora es la definición de una medida de similaridad entre patrones. A lo largo de este manual descubriremos varias maneras de expresar la similaridad entre patrones, aunque debemos adelantar que estas medidas son mug dependientes del problema a resolver.
Supongamos un sistema de adquisición perfecto (sin ruido). Podemos asegurar que:
1.La adquisición repetida del mismo patrón debería proporcionar la misma representación en el espacio de patrones. Por ejemplo, una cámara debería proporcionar siempre la misma imagen de la misma escena si las c'ondiciones externas no cambiaran.
2.Dos patrones diferentes deberían proporcionar dos representaciones diferentes.
3.Una iigera distorsión aplicada sobre un patrón debería proporcionar una pequeña distorsión de su representación.
En definitiva, se supone que el proceso de adquisición es biunívoco y continuo. Esta consideraciones sugieren que si las representaciones de dos patrones están muy cercanas en el espacio de representación, entonces los patrones deben tener un alto grado de similaridad.
No
obstante, no puede afirmarse tajantemente que a mayor distancia mayor disimilaridad ya que la medida (absoluta) de distancia depende de la escala en la que se cuantifiquen las variables asociadas al patrón.Variabilidad entre patrones. La suposición de un sistema de adquisición perfecto no deja de ser eso, un suposición. Los sistemas de adquisición introducen,
indefectiblemente, cierta distorsión o ruido, lo que produce una Variabilidad en la representación de los patrones. Aunque es posible controlar eficientemente en muchos casos esta distorsión mediante el calibrado de los sistemas de adquisición aparece otra fuente de variabilidad por la propia naturaleza de los patrones.
Con mucha frecuencia, patrones de una misma clase difieren, incluso
significativamente. Un ejemplo sencillo es el de los sistemas de reconocimiento de caracteres
OCR
que pueden interpretar diversos tipos de letra, incluso caracteresescritos (bajo fuertes restrucciones). Bien, en el caso más simple, en el que se trata un solo tipo de letra, la variabilidad de los patrones se debe a factorec: tales como el
granulado, color y calidad del papel o el tipo de tinta empleado.
Supongamos una imagen de Teledetección captada por el sensor T M (7 bandas). La imagen registra una escena en la que se distinguen tres clases: agua (azul),
vegetación (verde) y suelo (marrón). En la figura .A mostramos la distribución espacial de las tres clases en la escena. Sin embargo, no todos los patrones de una clase son iguales: la incidencia de la luz solar (sombras), la distribución no uniforme de la vegetación, la presencia de distintos tipos de rocas y minerales, La profundidad del agua, etc. hace que en realidad una imagen cualquiera de las 7 disponibles (la banda 5, P.e.) ésta sea algo parecido a lo que mostramos en la figura
.B.
'ideal".
A
B
Si mostráramos otra de las 7 imágenes disponibles (la bada 7, P.e.), ésta no sería exactamente igual a la anterior, aunque sí muy "parecida". Esto se debe a que el sensor que registra la imagen es sensible a la radiación electromagnética en un rango del espectro diferente (ver
feun
1.A). Si representamos cada patrón (cada pixel) en el espacio bibimensional formndo porlos
valores registrados en las bandas7 y 5, el resultado será el mostrado en la figura 1.B.
Figure 1: A) Curvas de reflectividad. B) Representación e s p &
granulado, color y calidad del papel o el tipo de tinta empleado.
Supongamos una imagen de Teledetección captada por el sensor TM (7
bandas).
L a imagen registra una escena en la que se distinguen tres clases: agua (azul),vegetación (verde) y suelo (marrón). En la figura .A mostramos la distribución espacial de las tres clases en la escena. Sin embargo, no todos los patrones de una clase son iguales: la incidencia de la luz solar (sombras), la distribución no uniforme de la vegetación, la presencia de distintos tipos de rocas y minerales, la profundidad del agua, etc. hace que en realidad una imagen cualquiera de las 7 disponibles (la banda 5, P.e.) ésta sea algo parecido a lo que mostramos en la figura .B.
figura : A) Imagen "ideal". B) Una de las 7 bandas
A
B
Si mostráramos otra de las 7 imágenes disponibles (la bada 7, P.e.), ésta no sena exactamente igual a la anterior, aunque sí muy "parecida". Esto se debe a que el sensor que registra la imagen es sensible a la radiación electromagn6tiea en un rango del espectro diferente (ver iigura l.A). Si'representamos cada patr6n (cada pixel) en el espacio bibimensional formado por los valores registrados en las bandas
7 y 5, el resultado será el mostrado en la figura l.B.
Figure 1: A) Curvas de reflectividad. B) Representación espectral
L a variabilidad intrínseca de los patrones hace que las representaciones tengan la forma de nubes de puntos en lugar de puntos individuales. Esta Última
representación sería la de darse el caso de que no existiera variabilidad entre los patrones. Estas nubes de puntos sugieren que patrones de una misma clase
(similares) se representan cercanos (relativamente) en el espacio de representación mientras que patrones de diferentes clases (diferentes) se representan lejanos (relativamente) en ese espacio.
Selección
y
extracción
de características
El problema que se trata de resolver es el de extraer la información relevante para la clasificación entre la suministrada por los sensores (datos en bruto). De forma general este problema puede plantearse camo sigue. Dado un conjunto de patrones n-dimensionales
se trata de obtener un nuevo conjunto (características) d-dimensionales
donde d <= n.
Este objetivo puede abordarse de dos formas:
1.Reduciendo la dimensionalidad de los datos. Si los patrones son de alta
dimensionalidad, el coste computacional asociado a la clasificación puede ser muy
alto. Como veremos en capítulos posteriores, muchos clasificadores están basados en
cálculos de distancias y estos cálculos pueden depender de forma cuadrática respecto a la dimensionalidad de los patrones. Como otra consideración
computacional hay que considerar el espacio de almacenamiento adicional que supone guardar los valores de nuevas variables. Además, algunas de las variables pueden ser redundantes con otras y no aportar información adicional.
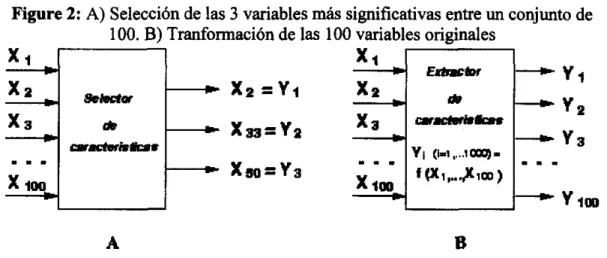
Las técnicas dedicadas a seleccionar las variables más relevantes se dicen de selección de características y reducen la dimensionalidad de los patrones. Este proceso puede esquematizarse como se indica en la figura 2.A, en el que un módulo selector recibe patrones n-dimensionales (en el ejemplo, n = 100) y proporciona como resultado las d variables más significativas (en el ejemplo, d = 3) de acuerdo a algún criterio a optimizar. En este caso d
seleccionadas es un subconjunto del conjunto original de variables.
2.Cambiando el espacio de representación. El objetivo es obtener una nueva representación de los patrones en la que los agrupamientos aparezcan bien separados si son de diferente clase y que haya un agrupamiento por clase. Esto puede conseguirse aplicando alguna transformación sobre los datos originales. Estas transformaciones suelen ser transformaciones lineales y el objetivo suele ser
maximizar la varianza.
n y el conjunto de las d variables
Estas técnicas reciben el nombre de extracción de características y producen un nuevo conjunto de variables. Este proceso puede esquematizarse como se indica en la figura 2.B, en el que un módulo extractor recibe patrones n-dimensionales (en el ejemplo, n = 100) y proporciona como resultado nuevos patrones n-dimensionales de acuerdo a algún criterio a optimizar. Es posible que las nuevas variables estén
implícitamente ordenadas, por lo que proporcionan, adicionalmente un
procedimiento de selección. En este caso d = n y las variables seleccionadas no forman un subconjunto del conjunto original de variables.
Figure 2: A) Selección de las 3 variables más significativas entre un conjunto de 100. B) Tranformación de las 100 variables originales
y2
-
Y 3-
V1mar8dmbb.r
Y1 (i-1
...
imq- Crrc(air#ur. . I 1 . 1 I . .
f VI,
...
$103)A B
Los vectores resultantes del proceso de selección o extracción se denominan características, aunque nosotros utiliaremos el término patrón a no ser que queramos resaltar explícitamente que se ha producido un proceso de
selección/extracción de características.
Aprendizaje. Aprendizaje supervisado
Se suele utilizar indistintamente los términos aprendizaje y entrenamiento para referirse al proceso de construcción del ciasidicador. El aprendizaje puede realizarse de dos maneras muy diferentes.
1.Aprendizaje supervisado.
Un
aprendizaje supervisado requiere disponer de un conjunto de patrones de los cuales se conoce su clase cierta. A este coniunto se le denomina coniunto deentrenamiento. Este tipo de entrenamiento se denomina entrenaminto supervisado
y los clasificadores así obtenidos clasificadores supervisados. Disponer de un conjunto de entrenamiento supone que alguien se ha preocupado de etiquetar los patrones de ese conjunto. Esta tarea la suele realizar un experto en el campo en el que se va a realizar el reconocimiento y generalmente viene impuesto.
2.Apreiidizaje no siipervisada.
El aprendhje no supervisado se realiza a partir de un conjunto de patrones del que no se conoce su clase cierta. Bbsicamente, se traduce en encontrar agrupamientos.
El
objetivo suele ser el de verificar la validez d d conjunto de clases informacionaies para una clasificación supervisada. Las técnicas utilizadas suelen denominarse métodos de agrupamiento o clustering.
Aprendizaje supervisado paramétrico y no paramétrico
Si consideramos que en un caso ideal cada agrupamiento representa a una clase y
cada clase tiene asociado un agrupamiento bien diferenciado de los demás, un problema de clasificación supervisada puede plantearse como la búsqueda de las
superficies que separan los diferentes agrupamientos. Estas superficies se denominan superficies de decisión.
Las superficies de decisión determinan regiones de decisión de forma que cada clase tiene asociada una región en
P
y la decisión sobre la clase a asignar a un nuevo patrón se hará en base a la región en la que &te se encuentra enP.
La búsqueda de estas superficies (an4logamente, regiones) de decisión se puede abordar de dos maneras, dependiendo de si se conoce o supone un determinado modelo estadístico para las clases.
1.Si se supone un completo conocimiento a priori de la estructura estadística de las clases, el aprendizaje se reduce
a
la estimación de los parámetros que determinan las funciones de densidad de probabiliad de Las clases. Los clasificadores construidos bajo esta suposición se conocen como clasificadores paramétricos y se discuten con profundidad en el tema 2.2.Si no se supone un determinado modelo estadístico,
bien
por desconocimiento o por la imposibilidad de asumir un modelo paramétrico adecuado, el problema resulta más complejo y se puede abordar desde diferentes perspectivas. Los clasificadores construidos sin esta suposición se conocen como clasificadores no paramétricos.ESCALAMIENTO MULTIDIMENSIONAL.
Simplificando la Complejidad:
El Análisis Multivariado (Ordenación y ClasiCicación):
La ordenación y clasificación son métodos analiticos para identificar similitud entre entidades (sitios de muestreo, comunidades, dietas, etc). En ecología, el término ordenación abarca una serie de métodos estadísticos que permiten organizar entidades (a menudo, sitios de muestreo) a lo largo de ejes cuantitativos en base a sus atributos, tales como la composición de especies. L a ordenación se puede hacer con datos cuantitativos (abundancia o densidad) o con datos de presencia
-
ausencia.Uno
de los resultados importantes de estos análisis es un diagrama, generalmentecon dos o tres ejes en donde las entidades (representadas por puntos) que se encuentran cercanos tienen una composición similar.
Existe una gran variedad de técnicas de análisis multivariado disponibles con diferentes suposiciones. Entre las principales suposiciones se encuentra la de si las especies responden de manera lineal a los gradientes (respuesta beal) o si
responden a un Óptimo ambiental (respuesta unimodal).
Los
métodos lineales yunimodales enfatizan los patrones en términos de abundancia absoluta y relativa respectivamente. Si los datos de especies contienen muchos ceros es mejor
analizarlos
con
un método unimodal.¿Quieres entender la distribución de entidades en gradientes continuos?.
.. .
.
..
Usa ordenación0
¿Quieres separar entidades en clases distintas (categorías)?.
.. . . . .. .
..
. . ...
Usa clasificación @I)I. Ordenación
Clave para seleccionar métodos de ordenación
1. ¿Quieres analizar la respuesta de una especie a las variables ambientales?
...
Si (ve a 3).2. ¿Quieres analizar la respuesta de varias especies a las variables ambientales?
...
Si (ve a 4)3. Modelos de una sola especie..
...
Modelos Lineales Generales (a)4. ¿La ordenación sólo utilizará datos de las
especies?
...
Si (sigue a 5)...
No (sigue a 6)5. Métodos indirectos (b)
Lineal..
...
Análisis de Componentes Principales (PCA)Unimodal..
...
Análisis de Correspondencia (CA) o Promedios Recíprocos (RA)Unimodal Rectificado..
...
Análisis de Correspondencia Rectificado OCA)Ordenación de minima distorsión espacial (Non Metric Multidimensional Scaling)
(c)
6. ¿Tienes datos de especies y datos
ambientales?
...
.Si (sigue a 7) ¿Tienes datos de especies, datos ambientales ycovariables?
...
Si (sigue a 8)7. Métodos Directos
Lineal..
...
Análisis de Redundancia (RDA)Unimodal..
...
Análisis de Correspondencia Canónica (CCA)Unimodal Rectifwado..
...
Análisis de Correspondencia Canónica Rectificado8. Métodos Parciales (d)
Lineal
...
Análisis de Redundancia Parcial (PRDA)Unimodal...
...
Análisis de Correspondencia Canónka ParcialUnimodal Rectificado..
...
..Análisis de Correspondencia Canónica Rectificado Parcial(a) El objetivo del estudio puede ser la modelación de las distribución de una sola especie en relación a las variables ambientales. Los Modelos Lineales Generales (GLM), extensión de la regresión lineal múltiple, proporcionan un marco robusto en
donde las funciones lineales y no-lineales de las variables ambientales pueden ser
utilizadas para "predecir" cuantitativamente la abundancia de las poblaciones. La información de presencia-ausencia también puede ser modelada utilizando la
regresión logística en GLM. El resultado es la probabilidad de ocurrencia (un valor entre O y 1), en vez de un valor de abundancia.
(b) Los métodos indirectos también pueden ser utilizados para relacionarlos a las variables ambientales utilizando regresión múltiple de las mismas variables ambientales con los ejes de la ordenación. Este método puede confirmar la interpretación cualitativa de los ejes de ordenación. L a comparación de los
resultados de la ordenación/regresión indirecta con métodos canónicos @ D A y CCA ver más abajo) puede ayudar a identificar variables ambientales faltantes.
(c) Non-Metric Multidimensional Scaling
(NMDS)
es otro método indirecto queacomoda los sitios de manera que se represente la similitud de composición entre ellos eficazmente y en pocas dimensiones. Se escoge una medida de similitud
(ejemplos: Jaccard, Distancia Euclideana, Bray-Curtis), y los datos de la matriz son las medidas de similitud. Este método, relacianado al análisis de agrupamientos (cluster analysis), proporciona una visión multidimensional de las similitudes con las que se puede hacer una regresión con las variables ambientales.
(d) Los métodos parciales primero extraen los efectos de las covariables (éstas a menudo son variables ambientales) y después extraen uno o más ejes basados en la información residual de las especies.
11. Clasificación
Los análisis de clasificación (cluster) son utilizados para acomodar sitios, especies o variables de acuerdo a su similitud. Pueden ser utilidos con datos cuantitativos o de presencia-ausencia.
Métodos divisorios
Se inicia con todos los objetos (sitios, especies, variables) y se va dividiendo en grupos menores. Estos métodos enfatizrin las diferencias grandes sobre las
pequeñas.
Uno
de los métodos divisorios más utilizados es el Análisis de especies indicadoras de dos vías (Two-way Indicator Species Analyses, TWINSPAN).Métodos aglomerativos
Se inicia con los objetos individuales y se van uniendo en grupos de mayor tamaño. La similitud local prevalece sobre las diferencias grandes. Los métodos
aglomerativos requieren de dos decisiones: escoger una medida de similitud, y
escoger un método de aglomeración.
Algunas medidas comunes de similitud
Cualitativas (Presencia / Ausencia)
Coeficiente de Jaccard Coeficiente de Sorensen Coeficiente de pares simples
Coeficiente de Baronyi-Urbani y Buser
Cuantitativas (de distancia)
Distancia Euclideana Medida de Bray-Curtis Métrico de Canberra
Cuantitativas (de correlación)
Coeficiente de correlación de Pearson Coeficiente de correlación de Spearman
Otros
Porcentaje de Similitud
Indice de similitud de Morisita Indice de similitud de Horn
Algunos métodos de aglomeración
Agrupación de un solo enlace (Single Linkage Clustering) o del vecino más cercano (Nearest-neighbour Clustering)
Agrupación de enlaces completos (Complete Linkage Clustering) o del vecino más lejano (Furthest-neighbour Clustering)
Agrupación con promedios de enlaces (Average Linkage Clustering): Unweighted pair-group arithmetic averages (UPGMA)
Agrupación con centroides (Centroid Clustering)
Agrupación con el método de Ward o de varianza mínima (Minimum Variance Clustering)
Sitios W E B de interés:
Cavalcanti, M. Taxonomía
v
ecoloeía digitalMicheloud,
F.X.
Correswndence analysisc
II
ICL
Multivariate Statistics: AnIntmduction
Palmer, M. Métodos de ordenación para ecólogos. Oklahoma State University
Ter Braak, C.J.F. and P. Smilauer. Canoco for Wi-ows 4.0
Wulder. M. Estadística Multivariada: guía práctica. University of Waterloo, Canada
Ecological Data Analysis : Exploratory and Euclidean methods in Environmental sciences
http://wyw.stanford.eddgroup/~/Eco/multivar,htm
http://~.~va.es/psicolonia/mds.htm
Preprocesado de los datos
El formato de los datos contenidos en la fuente de datos (base de datos, Data Warehouse ...) nunca es
el idóneo, y la mayoría de las veces no es posible ni siquiera utilizar ningún algoritmo de minería
sobre los datos "en bruto". Mediante el preprocesado, se filtran los datos (de forma que se eliminan valores incorrectos, no válidos, desconocidos
...
según las necesidades y el algoritmo a usar), seobtienen muestras de los mismos (en busca de una mayor velocidad de respuesta del proceso), o se
reducen el número de valores posibles (mediante redondeo, clustering,...).
Selección de características.
Aún después de haber sido preprocesados, en la mayoría de los casos se tiene una cantidad ingente de
datos. La selección de características reduce el tamaño de los datos eligiendo las variables más influyentes en el problema, sin apenas sacrificar la calidad del modelo de conocimiento obtenido del proceso de minería.
Los métodos para la selección de características son básicamente dos:
.r,io&pellos basados en la elección de los mejores atributos del problema,
WII &aquellos que buscan variables independientes mediante tests de sensibilidad, algoritmos de
distancia o heurísticos.
Algoritmos de aprendizaje.
Mediante una técnica de minería de datos, se obtiene un modelo de conocimiento, que representa
patrones de comportamiento observados en los valores de las variables del problema o relaciones de
asociación entre dichas variables. También pueden usarse varias técnicas a la vez para generar distintos modelos, aunque generalmente cada técnica obliga a un preprocesado diferente de los datos.
Interpretación y evaluación
I
V
I
v
Una vez obtenido el modelo, se debe proceder a su validación, comprobando que las conclusiones que arroja son váíidas y suficientemente satisfactorias. En el caso de haber obtenido varios modelos
mediante el uso de distintas técnicas, se deben comparar los modelos en busca de aquel que se ajuste
mejor al problema. Si ninguno de los modelos alcanza los resultados esperados, debe alterarse alguno
de los pasos anteriores para generar nuevos modelos.