Fastest: Automatizando el testing de software
151
0
0
Texto completo
(2) Resumen Aún con el uso creciente de los métodos formales en el desarrollo de software, el testing de software continúa siendo una técnica dominante para verificar y validar sistemas. Con el testing basado en especificaciones, la precisión de las especificaciones formales hace del testing una actividad mucho más sistemática. Este trabajo describe el primer prototipo de Fastest, una herramienta que facilita la derivación de casos de prueba a partir de especificaciones en el lenguaje Z..
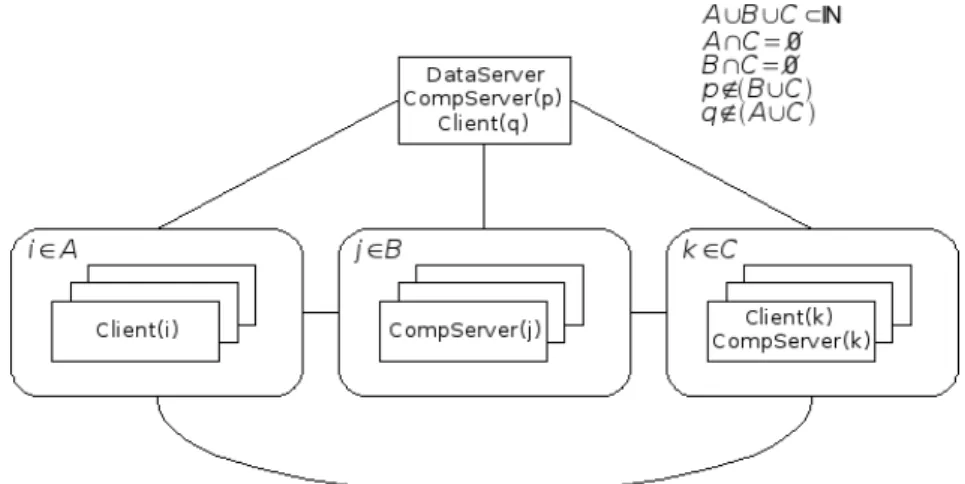
(3) Índice general 1. Introducción 2. La técnica de testing 2.1. ¿Qué se entiende por testing? 2.2. Objetivos del testing . . . . . 2.3. Testing no es debugging . . . 2.4. Testing estructural vs. testing 2.5. Testing in the Large . . . . .. 5. . . . . . . . . . . . . . . . . . . funcional . . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. 3. El testing basado en especificaciones formales Z 3.1. El lenguaje de especificación Z . . . . . . . . . . . . . . . . 3.2. Formalizando el testing funcional basado en especificaciones 3.3. Las etapas del testing funcional . . . . . . . . . . . . . . . . 3.4. Generando casos de prueba abstractos . . . . . . . . . . . . 3.5. Construcción de árboles de pruebas . . . . . . . . . . . . . . 3.5.1. Tácticas de testing . . . . . . . . . . . . . . . . . . . 3.5.1.1. Obteniendo el VIS de la operación . . . . . 3.5.1.2. Forma Normal Disyuntiva (DNF) . . . . . 3.5.1.3. Particiones Estándar (SP) . . . . . . . . . 3.5.1.4. Tipos Libres (FT) . . . . . . . . . . . . . . 3.6. Selección de casos de prueba abstractos . . . . . . . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. 9 9 10 11 11 12. . . . . . formales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. 14 14 15 17 19 20 20 24 25 28 31 32. . . . . .. . . . . .. . . . . .. . . . . .. 4. Estudio del estado del arte. 35. 5. Descripción de Fastest 5.1. Visión general . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.2. Arquitectura . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.2.1. Introducción . . . . . . . . . . . . . . . . . . . . . . . 5.2.2. Arquitectura de Fastest . . . . . . . . . . . . . . . . . 5.2.2.1. Estilos arquitectónicos empleados . . . . . . 5.2.2.2. Diagrama canónico . . . . . . . . . . . . . . 5.2.2.3. Estructura de Hardware y Estructura Fı́sica 5.2.3. Implementación actual de la arquitectura de Fastest . 5.3. Tecnologı́a utilizada . . . . . . . . . . . . . . . . . . . . . . . 1. . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. 38 38 40 40 41 41 44 45 48 48.
(4) ÍNDICE GENERAL. 2. 5.3.1. Java . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.3.2. CZT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.3.2.1. Introducción a CZT . . . . . . . . . . . . . . . . . . 5.3.2.2. CZT Parser y Árboles de Sintaxis Abstracta (AST) 5.3.2.3. CZT Typechecker . . . . . . . . . . . . . . . . . . . 5.3.2.4. CZT ZLive . . . . . . . . . . . . . . . . . . . . . . . 5.4. Implementando el testing funcional en Fastest . . . . . . . . . . . . . 5.4.1. Preprocesando la especificación . . . . . . . . . . . . . . . . . 5.4.2. Generando los árboles de prueba . . . . . . . . . . . . . . . . 5.4.3. Generación de casos de prueba abstractos . . . . . . . . . . . 5.4.3.1. Tipos básicos . . . . . . . . . . . . . . . . . . . . . . 5.4.3.2. Tipos libres . . . . . . . . . . . . . . . . . . . . . . . 5.4.3.3. Números naturales (N) . . . . . . . . . . . . . . . . 5.4.3.4. Números enteros (Z) . . . . . . . . . . . . . . . . . . 5.4.3.5. Conjuntos por extensión . . . . . . . . . . . . . . . 5.4.3.6. Rango de valores . . . . . . . . . . . . . . . . . . . . 5.4.3.7. Conjunto de partes . . . . . . . . . . . . . . . . . . 5.4.3.8. Producto cartesiano . . . . . . . . . . . . . . . . . . 5.4.3.9. Relaciones binarias . . . . . . . . . . . . . . . . . . 5.4.3.10. Funciones totales . . . . . . . . . . . . . . . . . . . . 5.4.3.11. Funciones parciales . . . . . . . . . . . . . . . . . . 5.4.3.12. Secuencias . . . . . . . . . . . . . . . . . . . . . . . 5.4.3.13. Tipos no soportados en la versión actual . . . . . . 5.5. Diseño de Fastest . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.5.1. Patrones de diseño . . . . . . . . . . . . . . . . . . . . . . . . 5.5.2. El subsistema de Invocación Implı́cita . . . . . . . . . . . . . 5.5.3. Aplicando el patrón de diseño Visitor a los AST . . . . . . . 5.5.4. Los módulos del lado del servidor . . . . . . . . . . . . . . . . 5.6. Guı́a para introducir cambios en la herramienta . . . . . . . . . . . . 5.6.1. Agregando nuevos eventos y componentes en los clientes . . . 5.6.2. Agregando nuevas tácticas de testing . . . . . . . . . . . . . . 5.6.3. Agregando comandos del lado del cliente . . . . . . . . . . . . 6. Utilizando Fastest 6.1. Requerimientos . . . . . . . . . . . . . . . . . . . 6.2. Distribución . . . . . . . . . . . . . . . . . . . . . 6.3. Manual de usuario . . . . . . . . . . . . . . . . . 6.3.1. Instalar y ejecutar Fastest . . . . . . . . . 6.3.2. Cargar una especificación . . . . . . . . . 6.3.3. Visualizar la especificación cargada . . . . 6.3.4. Seleccionar operaciones para testear . . . 6.3.5. Agregar tácticas de testing . . . . . . . . 6.3.5.1. Configurar particiones estándar 6.3.6. Generar el árbol de pruebas . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 48 49 49 49 50 50 50 50 52 53 54 55 55 55 55 55 55 56 56 56 56 56 56 57 57 58 60 63 66 66 67 67. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. 69 69 69 70 70 71 71 72 73 74 75.
(5) ÍNDICE GENERAL 6.3.7. 6.3.8. 6.3.9. 6.3.10.. 3. Generar casos de prueba abstractos . . . . . . . . Presentar los resultados . . . . . . . . . . . . . . Otros comandos . . . . . . . . . . . . . . . . . . Ejecutando Fastest como un sistema distribuido. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. 7. Caso de Estudio: Protocolo de Comunicación 7.1. La especificación Z . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7.1.1. Tipos básicos y tipos libres . . . . . . . . . . . . . . . . . . . . . . . . 7.1.2. El espacio de estado del Sistema, sus estados iniciales y sus invariantes 7.1.3. Operaciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7.1.3.1. Operaciones relacionadas a aspectos temporales . . . . . . . 7.1.3.2. Inicio de comando, tipo de comando y fin de comando . . . . 7.1.3.3. Adquisición de datos . . . . . . . . . . . . . . . . . . . . . . 7.1.3.4. Comandos OBDH simples . . . . . . . . . . . . . . . . . . . . 7.1.3.5. Transmisión de datos . . . . . . . . . . . . . . . . . . . . . . 7.2. Resultados de testing basado en especificaciones formales Z . . . . . . . . . . 7.2.1. Poniendo a prueba la operación MemoryLoad . . . . . . . . . . . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. 75 75 76 76. 78 . . . . . 78 . . . . . 79 de estado 80 . . . . . 81 . . . . . 82 . . . . . 83 . . . . . 85 . . . . . 86 . . . . . 91 . . . . . 93 . . . . . 93. 8. Conclusiones y trabajo futuro 103 8.1. Trabajos futuros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103 A. Glosario de Z A.1. Tipos básicos, definiciones y declaraciones A.2. Definiciones axiomáticas . . . . . . . . . . A.3. Tipos libres . . . . . . . . . . . . . . . . . A.4. Operadores aritméticos y relacionales . . . A.5. Cálculo de predicados . . . . . . . . . . . A.6. Expresiones, conjuntos y relaciones . . . . A.7. Relaciones binarias, funciones y secuencias A.8. Definición de esquemas . . . . . . . . . . . A.9. Operadores del cálculo de esquemas . . . A.10.Esquemas de operación . . . . . . . . . . . A.11.Otros operadores del cálculo de esquemas. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. 106 106 107 107 108 108 108 110 112 112 115 116. B. Clases de prueba resultantes del Caso de Estudio. 118. C. Casos de prueba resultantes del Caso de Estudio. 130.
(6) Agradecimientos A mi familia, porque han sido mi sustento principal durante la carrera. Desde lo económico y lo afectivo me han apoyado incondicionalmente a lo largo de todos estos años. Siempre confiaron en mı́; siempre me dieron total libertad y aliento para tomar decisiones académicas, profesionales y de la vida misma. Muchas gracias, sin ustedes esto no hubiese sido posible. A las dos personas con las cuales inicié este camino hace ocho años, Federico Olmedo y Diego Llarrull. Dos tipos increı́blemente capaces, pero fundamentalmente, personas de una enorme calidad humana. Les agradezco muchı́simo por todo lo que compartimos juntos. Al ambiente académico de LCC en general: a todos los compañeros, a todos los profesores, a todos los alumnos que he tenido. Gracias, porque sin duda aprender fue mucho más fácil con ustedes. A mi director Maximiliano Cristiá, por haberme dado la oportunidad de trabajar con él y por haber estado siempre que lo he necesitado. No puedo dejar de mencionar al resto de mis amigos. Con ellos compartı́ experiencias y momentos inolvidables que nos han unido y que han contribuido en mi formación como persona. A todos, muchı́simas gracias!. 4.
(7) Capı́tulo 1. Introducción La verificación y la validación del software (V & V) se ha vuelto esencial a medida que la complejidad de los sistemas informáticos ha ido en aumento, y es necesario que ésta se planifique desde el comienzo del ciclo de vida del desarrollo de software. En los últimos 30 a 40 años, el proceso de desarrollo fue evolucionando desde tareas muy sencillas, que involucraban pocas personas, hasta actividades más complejas, llevadas a cabo por recursos humanos mucho más numerosos. Debido a este cambio, la V & V también ha sufrido modificaciones. Previamente, la verificación y validación era un proceso informal, puesto en práctica por el propio programador. Sin embargo, con el crecimiento de la complejidad de los sistemas, se hizo evidente que continuar con este tipo de práctica iba a resultar en la obtención de productos poco confiables. Es ası́ que se volvió necesario mirar a la V & V como una actividad separada en el marco del ciclo de vida del software. La verificación y validación de hoy en dı́a, es considerablemente diferente a la del pasado, y se aplica sobre todo el proceso de desarrollo1 . En general, la V & V agrupa a todas aquellas actividades necesarias para asegurar que un programa satisfaga su especificación y los requerimientos del usuario. El sistema debe ser verificado y validado en cada etapa del proceso de desarrollo, usando documentos producidos en etapas previas. Como los conceptos de verificación y validación suelen ser confundidos e incluso usados inconsistentemente [1], vale la pena apreciar la diferencia entre ellos de la siguiente manera: Validación: ¿se está construyendo el producto correcto? Verificación: ¿se está construyendo el producto correctamente? Es decir, la verificación consiste en chequear que un programa satisface su especificación, mientras que la validación consiste en asegurar que el programa cumpla con lo que se espera de él, lo cual puede no estar reflejado apropiadamente en la especificación. Normalmente, se desea que a la validación la dirija el usuario y a la verificación algún encargado de la parte técnica del desarrollo del software. Aunque en principio uno puede suponer que el proceso de V & V debe solamente comprobar la corrección del software analizado, en verdad, las cualidades no-funcionales y aquellas que son implı́citas, 1. Lamentablemente, esto es ası́ sólo en la teorı́a. En la práctica industrial concreta, es usual que el testing no sea realizado como una actividad rigurosa.. 5.
(8) CAPÍTULO 1. INTRODUCCIÓN. 6. también deben ser cubiertas por la validación y verificación del sistema en cuestión. Ejemplos de cualidades no-funcionales son el desempeño y la mantenibilidad. Es bastante frecuente que este tipo de caracterı́sticas deban validarse y verificarse en relación a un nivel de aceptación previamente definido y no esperando una respuesta binaria, una respuesta “si o no”, en los análisis aplicados [1]. Para satisfacer los objetivos del proceso de V & V, normalmente se sugiere utilizar técnicas de análisis tanto estáticas como dinámicas. Las técnicas estáticas tienen que ver con el análisis del producto o cualquier documentación de diseño relacionada con él, para evaluar su correcto funcionamiento como consecuencia lógica de haber tomado ciertas decisiones de diseño, de representación o de codificación. Éstas técnicas pueden aplicarse en cualquier momento del ciclo de vida del desarrollo. Sin embargo, al no requerir la ejecución del sistema, no pueden asegurar la utilidad operacional del producto. Por otro lado, las técnicas de tipo dinámico, como el testing, se basan en correr el programa para observar su comportamiento y, obviamente, sólo pueden ponerse en práctica si se cuenta con un prototipo o con un ejecutable del sistema de interés. Los dos enfoques son complementarios [1] [2]. Este trabajo se enfocará exclusivamente en la tarea de verificar programas, dejando de lado la actividad de validación de los mismos. En particular, se hará un estudio sobre todo lo concerniente al testing. Sin embargo, quiere dejarse claro que el testing no es el único medio para encontrar errores en el software, y en verdad, se cuenta con diversas técnicas como: Prototipado. Es un mecanismo que permite presentar un modelo del producto final, implementando un subconjunto de los requerimientos. Éste modelo será lo que se llama “prototipo” y deberá crearse rápidamente y de manera económica. El prototipo deberá ser evaluado por el cliente del sistema final, para confirmar o proponer cambios en los requerimientos o en el diseño. Revisiones o inspecciones. Las revisiones consisten en efectuar lecturas de las distintas representaciones del sistema que fueron confeccionándose en el desarrollo de software. Entre éstas se consideran especificaciones de requerimientos, diagramas de diseño, código fuente, planes de testing, casos de prueba, guı́as de usuario, etc. Si bien las revisiones pueden hacerse como una actividad manual, para la mayorı́a de los items que pueden analizarse, existe la posibilidad de automatizar éstas evaluaciones a través de herramientas apropiadas. Verificación formal de programas. Es un conjunto de técnicas formales de comprobación en las que partiendo de un conjunto axiomático, reglas de inferencia y algún lenguaje lógico (como la lógica de primer orden, por ejemplo), se puede encontrar una demostración o prueba de corrección de un programa. Model checking. Es un método de verificación de sistemas concurrentes de estados finitos, tales como los protocolos de comunicación. Como ventaja sobre los enfoques anteriormente mencionados, se destaca el hecho de que el model checking es automático y usualmente muy rápido. En contrapartida, muchas de las herramientas actuales, basadas en técnicas combinatorias, exploran completamente el espacio de estados posibles del problema, lo que puede conducir a una inmanejable explosión de estados. A fines de la década del ’80, ya se habı́an difundido los métodos formales como técnicas para especificar y diseñar sistemas de software. En particular, aunque el rol principal de las especifica-.
(9) CAPÍTULO 1. INTRODUCCIÓN. 7. ciones formales era ser la base de pruebas de correctitud y metodologı́as de transformación rigurosas, comenzó a destacarse la posibilidad y conveniencia de usarlas en el testing de software. Esto se debió a la concientización de que las especificaciones informales tenı́an cierta utilidad, requerida pero limitada, en el proceso de testing, pero que los beneficios reales se obtenı́an desde las especificaciones formales, las que estaban alcanzando cierto grado de maduración y estabilidad. Patrick A. Hall, un precursor del testing basado en especificaciones, mostró en [3] y [4] cómo derivar tests desde especificaciones formales Z. Conceptualmente, la idea se basaba en que la especificación de un programa define precisamente los aspectos fundamentales del software, mientras omite la información más detallada y estructural. Su propuesta consistı́a en realizar particiones simples del espacio de entrada, examinando las divisiones obvias de la entrada definida por los predicados de las operaciones. El análisis de casos que Hall realizaba era altamente estructurado, aunque no riguroso. Dick y Faivre, en [5], usaron la forma normal disyuntiva (DNF), como la táctica base para dividir el espacio de entrada de operaciones a testear, partiendo de especificaciones VDM. En su tesis de doctorado [6], Philip Stocks introdujo un marco formal para dirigir el testing basado en especificaciones formales Z, incluyendo un mecanismo que permitı́a definir y estructurar, de manera bastante rigurosa, los casos de prueba abstractos. Stocks también extendió el trabajo existente acerca de las tácticas de testing, desarrollando dos tácticas nuevas basadas en algunas anteriores. Las tácticas de testing son los mecanismos que permiten dividir el espacio de entrada en clases de prueba, construyendo lo que se conoce como árbol de pruebas. Hans-Martin Hörcher y Jan Peleska mostraron en [7] cómo la especificación de una operación puede ser usada para derivar sistemáticamente casos de prueba abstractos y evaluar automáticamente los resultados que resultan de testear con ellos, al programa que supuestamente implementa la operación. Este enfoque, al igual que los de Stocks y de Hall, fue puesto en práctica con especificaciones escritas en el lenguaje de especificación Z. Los autores recién mencionados han contribuido notablemente a la causa de automatizar la actividad de testing. En la práctica industrial, el testing suele hacerse de manera prácticamente artesanal, teniendo personal dedicado a la selección manual de casos de prueba, lo cual resulta ser una tarea tediosa y metódica que desaprovecha el potencial humano. Esta tesina presenta el primer prototipo de una herramienta, a la que se ha dado el nombre de Fastest, y que implementa las ideas de Stocks, Hörcher y Peleska para poder generar casos de prueba abstractos de operaciones especificadas en Z. Fastest ha sido desarrollado como parte del Proyecto Flowx, en las instalaciones de la empresa Flowgate Security Consulting2 . El Proyecto Flowx, el cual fue financiado en conjunto por Flowgate y FONTAR (Fondo Tecnológico Argentino) tiene como principal objetivo el implementar polı́ticas de seguridad multinivel en el núcleo del sistema operativo Linux, y es una de las aplicaciones pensadas para Fastest la verificación de tal implementación. 2. http://www.flowgate.net.
(10) CAPÍTULO 1. INTRODUCCIÓN. 8. El resto de este informe se divide en siete capı́tulos, donde se desarrollan los conceptos necesarios para comprender por completo todos los aspectos del prototipo de Fastest. El capı́tulo 2 presentará las ideas generales de la actividad de testing, como una etapa fundamental del ciclo de vida del software. El capı́tulo 3 explicará, en particular, los conceptos relacionados al testing funcional basado en especificaciones formales Z. A continuación, el capı́tulo 4, hará un resumen del estado del arte de las herramientas que automatizan de alguna manera este tipo de actividad. Al pasar al capı́tulo 5, el lector se encontrará con una descripción de Fastest, incluyendo detalles de su arquitectura, diseño y tecnologı́a empleada en su desarrollo. El capı́tulo 6 presenta la distribución del prototipo que acompaña a este informe y un manual de usuario para la correcta utilización del mismo. Un caso de estudio es mostrado en el capı́tulo 7 y, por último, el capı́tulo 8 contiene la conclusión de esta tesina y sugiere trabajos futuros a realizar en el área..
(11) Capı́tulo 2. La técnica de testing El presente capı́tulo presentará un repaso breve y general sobre algunos aspectos del testing de programas. Se hará un recorrido sobre su significado, sus caracterı́sticas más salientes, cualidades esperadas y otras cuestiones relacionadas.. 2.1.. ¿Qué se entiende por testing?. Una forma muy natural de verificar que algo funciona es simplemente ponerlo en operación en algunas situaciones representativas y comprobar si su comportamiento es el esperado [1]. En general, será imposible realizar esto en todas las condiciones de funcionamiento posibles1 con lo cual es necesario encontrar casos de prueba o casos de test que aporten evidencia suficiente para suponer, en forma razonable, que el comportamiento en todas las demás condiciones de funcionamiento será el requerido. Entonces, se puede considerar ahora la siguiente definición, dada en [9]: El testing es la verificación dinámica del comportamiento de un programa contra el comportamiento esperado de ese mismo programa, utilizando un conjunto finito de casos de prueba, seleccionados apropiadamente del dominio de ejecución, usualmente infinito. Como ya se vio en la introducción de esta tesina, la caracterı́stica dinámica del testing significa que al sistema bajo prueba hay que analizarlo al ponerlo en funcionamiento, al ejecutarlo con argumentos o datos de entrada especı́ficos que permitan encontrar fallas en su comportamiento. El procedimiento de testing, a grandes rasgos, consistirá en tomar elementos del dominio de entrada de un programa, ejecutar el programa en estos casos de prueba y comparar la salida o estado final con la salida o estado final esperados. En la literatura sobre testing se presupone la existencia de lo que se llama un oráculo, que es algún tipo de método para determinar que una salida dada es la salida esperada. Éste oráculo puede ser incluso un humano; por ejemplo, el futuro usuario del sistema. En general, el oráculo más confiable lo constituirá una especificación formal de sistema a testear, como se verá en el capı́tulo 3. 1. A esta tarea de realizar pruebas en todos los casos posibles se la denomina testing exhaustivo.. 9.
(12) CAPÍTULO 2. LA TÉCNICA DE TESTING. 10. Dado que usualmente se tiene un conjunto muy grande, o incluso infinito, de posibles casos de prueba, pero sólo se puede ejecutar una fracción muy pequeña de ellos, una cuestión fundamental del testing radica en la elección de los casos que tengan más posibilidades de exponer las fallas del sistema. Es aquı́ donde se pone de manifiesto la importancia que tienen la experiencia y las habilidades del encargado de testing: en el aprovechamiento de lo que conoce sobre el sistema para identificar los conjuntos de casos de prueba que producen el mismo comportamiento y los que producen distinto comportamiento. Antes de continuar, vale la pena aclarar algunos términos básicos: Una falla (failure) es una situación que manifiesta un comportamiento no deseado y, tı́picamente, ocurre cuando el sistema a testear se pone en ejecución. Un defecto (fault) es una porción de software incorrecto2 que causa una falla. Si el sistema no puede fallar, entonces no tiene defectos. Por el contrario, si uno observa una falla, lo que debe hacer es intentar encontrar el defecto que produjo la falla y tratar de corregirlo. De todas maneras, nunca se puede probar que un sistema no puede fallar, sólo se puede probar que contiene defectos. Un error (error, mistake) es una acción humana que resulta en un software con algún defecto. Un error puede llevar a incluir un defecto en el sistema, haciéndolo fallar. Entonces, el testing es la actividad de ejecutar un sistema con el fin de encontrar defectos. Es por esto, porque intenta mostrar que algo es incorrecto, que es un enfoque apropiado el considerar al testing como un proceso destructivo. El encargado de testing debe adoptar una actitud destructiva hacia el programa, debe querer que falle, debe esperar que falle y debe concentrarse en encontrar casos de prueba que muestren sus fallas.. 2.2.. Objetivos del testing. Un aspecto que hay que tener muy en cuenta a la hora de hablar de esta tarea es que, como bien reza la frase de Dijkstra, el testing puede ser usado para mostrar la presencia de defectos en el software, pero nunca para mostrar su ausencia. Esta idea busca sintetizar los objetivos de la actividad: ası́ como se puede asegurar que un sistema no es correcto sólo con encontrar un caso en que el resultado no sea el esperado, no basta con tener un correcto funcionamiento del sistema en un número finito de casos para afirmar su corrección en cualquier situación. De esta manera, es que hay que apreciar al testing como sólo uno de los medios que existen (aunque sea el más popular, y de hecho uno muy útil) para verificar software, pero nunca como un proceso que ofrezca garantı́a absoluta de detección de errores. Además de mostrar la presencia de defectos, el testing debe ayudar a localizarlos. No bastará con testear una pieza de software y obtener la respuesta binaria que indica si la pieza contiene un error o no. Es decir, ante el hallazgo de un error, el proceso de testing debe brindar información útil sobre 2. Puede encontrarse en la especificación, en el diseño, o el código del sistema..
(13) CAPÍTULO 2. LA TÉCNICA DE TESTING. 11. la localización del mismo, para que después pueda ser utilizada por el proceso de debugging, el que intentará corregir el software. En definitiva, el testing tendrá verdadero sentido sólo si después de haberse realizado y de haber detectado un error, hay alguna posibilidad de reparar la situación [1].. 2.3.. Testing no es debugging. Como se vio en la sección anterior, el testing de sofware debe interactuar con el debugging del mismo. Sin embargo, aunque suelen considerarse parte del mismo proceso, vale remarcar que el testing y el debugging son actividades bien distintas. Mientras que el testing establece la existencia de defectos, el debugging está centrado en identificar y corregir esos defectos. Es decir, el testing y el debugging no son lo mismo, pero es claro que están ı́ntimamente relacionados. Otra diferencia entre el testing y el debugging es que es conveniente que la primera actividad sea realizada por una persona, o grupo, externo a la organización de desarrollo, mientras que la segunda debe ser realizada necesariamente por alguien interno, que conozca la arquitectura, el diseño y la implementación con mayor profundidad. Que se recomiende que el testing sea llevado a cabo por personas de otra organización se debe principalmente a cuestiones psicológicas y tiene relación con la caracterı́stica destructiva del testing, ya mencionada anteriormente. Más precisamente, el autor de un programa o sistema tiende a cometer los mismos errores al ponerlo a prueba, es decir, debido a que es SU programa, inconcientemente tiende a hacer casos de prueba que no hagan fallar al mismo. Además, puede llegar a comparar mal el resultado esperado con el resultado obtenido debido al deseo de que el programa pase las pruebas. En base a esto, se pueden considerar cuatro niveles de independencia entre el testing y el desarrollo de un sistema: Tests diseñados por las personas que codificaron el software a testear. Tests diseñados por personas distintas pero del equipo de desarrollo. Tests diseñados por personas de otro grupo de la organización (área de testing) Tests diseñados por personas de otra organización (tercerización). 2.4.. Testing estructural vs. testing funcional. Estos son los dos enfoques que se pueden encontrar si se intenta clasificar a la actividad de testing de acuerdo al tipo de información utilizada para guiarla. Por un lado, el testing funcional o también llamado de caja negra (black-box testing) realiza el testeo de una pieza de software ignorando por completo cómo está construida internamente y sólo mirando su especificación. Se puede pensar que ve al software bajo prueba como si fuera una función, pasándole argumentos o datos de entrada y observando los valores devueltos, sin detenerse a analizar cómo computa dichos valores (de allı́ la denominación de funcional)..
(14) CAPÍTULO 2. LA TÉCNICA DE TESTING. 12. Por otro lado, el testing estructural o de caja blanca (white-box testing) sı́ utiliza información acerca de la estructura interna del programa (de su código fuente), pudiendo incluso ignorar su especificación. Se dice que el testing estructural comprueba lo que el programa hace, mientras que el testing funcional comprueba lo que se supone que hace (lo que deberı́a hacer de acuerdo a la especificación) [1]. Algunas caracterı́sticas del testing estructural Requiere que haya finalizado la fase de codificación para que pueda empezarse a testear. Si se cambia la estructura del código, deben recalcularse los casos de prueba. Algunas caracterı́sticas del testing funcional No hace falta que haya comenzado la fase de implementación para poder empezar con la fase de testing. Si el programa es modificado, gran parte del esfuerzo de testing sigue siendo útil. Aunque parezca que poner en práctica el testing funcional sea más conveniente que hacerlo con el testing estructural, lo cierto es que ambos enfoques son útiles y complementarios. Es bastante común que se utilicen técnicas de testing funcional para encontrar pruebas funcionales y de robustez. Luego se pueden utilizar métricas del testing estructural para chequear qué partes de la implementación no han sido evaluadas correctamente y ası́ obtener nuevas pruebas a partir de esos casos. Este trabajo se enfocará en un tipo particular de testing funcional, que es el testing funcional basado en especificaciones formales. Como su nombre lo indica, esta actividad se basa en utilizar una especificación formal del sistema bajo prueba, y es el próximo capı́tulo donde se describe más en detalle.. 2.5.. Testing in the Large. En la sección anterior se mencionaron dos grandes enfoques que existen para llevar a cabo el proceso de testing. Sin embargo, no puede dejar de mencionarse que los dos son de aplicación práctica sólo en el testing de módulos individuales, es decir, son aplicables para hacer lo que se denomina Testing in the Small. Pero al someter a prueba a un sistema de software completo, se requerirá realizar el proceso de testing de todo un programa o de una serie de programas que deben verificar, en conjunto, un cierto comportamiento esperado. Es lo que se llama Testing in the Large. En ese caso, las técnicas mencionadas podrı́an sufrir de una explosión combinatoria que las volverı́an inaplicables [1]. De todas maneras, los mecanismos de testing estructural y de testing funcional continúan siendo útiles en sistemas complejos. La clave es organizar la actividad de testing de la misma manera que se organiza la actividad de diseño del software en cuestión: dividiendo el problema a tratar en problemas más pequeños. La posibilidad más natural de poner en práctica esta idea es guiar el proceso de testing a partir de la estructura modular del sistema. De esta forma, se podrı́an ir testeando los módulos separadamente, uno por uno, hasta eventualmente poder testear el sistema completo [1]..
(15) CAPÍTULO 2. LA TÉCNICA DE TESTING. 13. En general, el proceso de testing se separa en tres etapas: el testing de unidad, el testing de integración y el testing de sistema. A medida que se van encontrando errores en una etapa, se va a requerir modificar el programa para corregir estos errores, lo que probablemente va a necesitar que se repitan algunas de las etapas ya realizadas. Ası́, puede apreciarse que el proceso de testing raramente es secuencial; lo normal es que sea iterativo. Testing de unidad. El testing de unidad consiste en poner a prueba las menores unidades (módulos) separables de un sistema. Cuando se dice que sea separable, se entenderá que esa unidad pueda ser ejecutada en forma aislada del resto del sistema. Esto no significa que la unidad no interactúe con otras, sino que ésta pueda ser testeada, siempre que sus interfaces estén correctamente definidas, aún cuando aquellas no estén implementadas completamente. Si bien parece imposible hacer uso de módulos para los cuales no se ha terminado su codificación, el hecho de que tengan sus secretos bien ocultos detrás de una interfaz, permite utilizarlos con una implementación básica, que provea un comportamiento altamente simplificado. A este tipo de módulos se los llama normalmente stubs. Testing de integración Esta fase consiste en el testeo de colecciones de módulos que han sido integrados en subsistemas. Para llevarla a cabo, hay distintas estrategias, como por ejemplo, top-down y bottom-up. La primera de ellas testea los componentes más abstractos antes de testear los más especı́ficos mientras que la segunda es la contraria, primero se comienza testeando los módulos del nivel más bajo de la jerarquı́a y se va trabajando hacia arriba por esta jerarquı́a hasta testear el módulo más general. Sin embargo, sea cual sea la estrategia que se adopte, lo más conveniente es utilizar un enfoque incremental, donde se vayan realizando las pruebas agregando los módulos de a uno, siempre testeando cada incremento antes que se agregue un nuevo incremento al sistema. Esto hace posible encontrar errores con mayor facilidad y no tener que esperar a que todos los módulos hayan sido implementados para comenzar a testear el sistema. Testing de sistema Pretende verificar si el conjunto completo de módulos de un sistema consigue el comportamiento adecuado del mismo, posiblemente asumiendo que sus módulos constituyentes proveen la funcionalidad esperada. El presente trabajo no hace un aporte directo a las técnicas de testing de integración y de sistema, y solo se concentra en el testing de unidad de programas. Sin embargo, es cierto que podrı́a interpretarse como un aporte indirecto a esas áreas. Esto es en un sentido mencionado anteriormente, cuando se lleve a cabo el Testing in the Large mediante una división en módulos y una subsecuente aplicación, en esos módulos, de las técnicas aquı́ desarrolladas..
(16) Capı́tulo 3. El testing basado en especificaciones formales Z Como se vio en el capı́tulo anterior, un programa es correcto si verifica su especificación. La especificación puede ser formal, semi-formal, informal, o incluso puede no estar escrita y que sólo la conozca el programador o el usuario. El resto de este trabajo asumirá que existe una especificación formal Z del sistema a ser verificado y el presente capı́tulo explicará las caracterı́sticas del testing funcional bajo tal hipótesis, no sin antes hacer una breve introducción al lenguaje de especificación Z.. 3.1.. El lenguaje de especificación Z. En esta tesina se utilizará la notación Z, un lenguaje de especificación formal usado para describir y modelar sistemas de software [10]. Z fue desarrollado en 1974 por J. R. Abrial y el Programming Research Group de la Universidad de Oxford. Está basado en la teorı́a de conjuntos, la lógica de primer orden y el cálculo lambda. Todas las expresiones en Z son tipadas, por lo que se evitan algunas paradojas de la teorı́a de conjuntos simple. El lenguaje contiene un catálogo estandarizado (llamado mathematical toolkit) con las funciones matemáticas y predicados usados frecuentemente. Un modelo Z permite especificar máquinas de estados, las cuales son representaciones idénticas a las máquinas de estados finitos, con la salvedad de que la cantidad de estados en cada una de ellas puede ser infinita. Para lograr definir una de estas máquinas, Z debe especificar su conjunto de estados y sus operaciones, las cuales determinan las transiciones posibles entre los distintos estados. La descripción de los estados se realiza a través de la definición de los llamados esquemas de estado, los cuales contienen las declaraciones de las variables de estado de la máquina. Por otro lado, con el objeto de definir las operaciones existentes, deben darse uno o varios esquemas de operación para cada una de ellas. En estos esquemas se especifican las transiciones de estados posibles en la máquina, a través de predicados que relacionan las variables de estado con variables de entrada y de salida propias de la operación. [11] En el resto de la tesina se asumirá que el lector está familiarizado con los conceptos de conjuntos, relaciones y cálculo de predicados. En el Apéndice A se hace un repaso de las caracterı́sticas más 14.
(17) CAPÍTULO 3.. EL TESTING BASADO EN ESPECIFICACIONES FORMALES Z. 15. importantes del lenguaje Z. Allı́ también se remarcan aquellos elementos sintácticos que aún no están soportadas en la versión de la herramienta que se presenta en esta tesina.. 3.2.. Formalizando el testing funcional basado en especificaciones formales. Para explicar algunos conceptos generales del testing funcional basado en especificaciones formales, en esta sección se formalizarán algunas ideas relacionadas a él. Sencillamente, se tomará parte de la formalización dada en [1] y en [12]. En lo sucesivo, se verá a un programa o subrutina como una función P : ID → OD donde a ID se lo llamará dominio de entrada del programa y a OD dominio de salida. El dominio de entrada estará dado por el producto cartesiano de los tipos1 de las variables de entrada del programa y el dominio de salida por lo análogo para las variables de salida. Vale la pena observar que la definición podrı́a no ser la más adecuada para tratar con cierto tipo de software. Por ejemplo, en el testing de interfaces gráficas de usuario, GUI testing, el concepto de variables de entrada no resulta del todo claro. De todas formas, en el caso general, con “variables de entrada del programa” se entenderá a todas aquellas entradas que aparecen explı́citamente en el código del mismo (dejando de lado otra información abstracta que pueda estar relacionada), lo que incluye a archivos, parámetros recibidos, datos leı́dos desde el entorno, etc. Análogamente, con “variables de salida” se hará referencia a todas aquellas salidas explı́citas del programa, como ser salidas por cualquier dispositivo, parámetros o valores de retorno e incluso errores tales como no terminación, etc. De esta manera, dado un programa P con dominio de entrada ID, un caso de prueba para P será un elemento x ∈ ID, y testear P con x se hará simplemente calculando P (x ) y comparando su valor con el resultado esperado. En el mismo sentido, un conjunto de prueba T para P será cualquier conjunto de casos de prueba que sea subconjunto finito de D. Testear P con T significa comprobar que P (x ) es el esperado para cada x ∈ T . En particular, se dirá que un caso de prueba para P es exitoso si al testear P con x no se obtiene el resultado esperado, con lo cual el caso de prueba estarı́a descubriendo un error en el programa. Pero para poder juzgar si el comportamiento del programa es el adecuado o no, se deberá contar con una especificación del mismo, la cual lo describirá de una manera diferente. Es la especificación del programa la que tendrá que vincular los casos de prueba con los resultados obtenidos y esperados, para concluir si existe una correspondencia entre los primeros y los últimos. De esta forma, se verá a la especificación Z de un programa2 , también como una función, que va desde el espacio definido por 1. Con “tipo” no se hace referencia a un tipo de un lenguaje de programación, ya que un programa a ser verificado podrı́a estar escrito en un lenguaje no tipado y aún ası́ poder ser testeado. 2 En verdad, a un esquema de operación contenido en una especificación Z de un programa..
(18) CAPÍTULO 3.. EL TESTING BASADO EN ESPECIFICACIONES FORMALES Z. 16. la declaración de las variables de entrada y de estado hasta el espacio dado por las variables de salida y de estado de la operación. Es decir, una especificación Op será vista como una función de IS en OS , donde IS se llama espacio de entrada y OS se llama espacio de salida y se definen de la siguiente manera: IS == [v ?1 : T1 , ..., v ?a : Ta , s1 : Ta+1 , ..., sb : Ta+b ] OS == [v !1 : U1 , ..., v !c : Tc , s1 : Ta+1 , ..., sb : Ta+b ] donde v ?i son las variables de entrada, si las variables de estado y v !i las de salida utilizadas en Op. Pero aunque el estado y cierta entrada sean parte del espacio de entrada de una operación, puede que para ellos no esté especificado el comportamiento de una operación. En otras palabras, una operación puede no relacionar cada elemento de su espacio de entrada con algún elemento de su espacio de salida. Por ejemplo, dado el siguiente esquema de operación: Decrement n:N n0 : N n0 = n − 1 y al verlo como una función de IS == [n : N] en OS == [n : N], se puede apreciar que la misma no está definida cuando n = 0. Es por esto que se introduce la noción de espacio válido de entrada (VIS ) como el subconjunto del espacio de entrada para el cual la operación está definida. Más formalmente, se puede definir al espacio válido de entrada de la especificación Op, VISOp , como el subconjunto de IS que satisface la precondición de Op: VISOp == [IS | pre Op] y de esta manera ver a Op como la siguiente función total: Op : VISOp → OS Para poder formalizar lo que se entiende por caso de prueba exitoso será necesario relacionar de alguna manera un programa con su especificación. Es decir, habrá que establecer una forma de vincular los elementos de ID con los VIS y los de OD con los de OS , Para tal fin se introducen las siguientes funciones: refPOp : VISOp → IDP absPOp : ODP → 7 OSOp donde ref y abs son las abreviaturas de función de refinamiento y función de abstracción, respectivamente. Se puede decir que la primera de ellas refina un elemento a nivel de especificación en un elemento a nivel de implementación mientras que la segunda hace la transformación inversa: dado un.
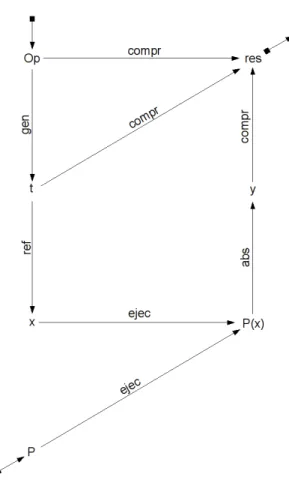
(19) CAPÍTULO 3.. EL TESTING BASADO EN ESPECIFICACIONES FORMALES Z. 17. elemento a nivel de implementación, permite obtener su correspondiente elemento a nivel de especificación. La razón por la que se formaliza la función de abstracción como una de tipo parcial es que no es siempre posible encontrar un elemento abstracto para cada salida de un programa. Este es el caso de una terminación abrupta e inesperada, donde por lo general no se puede realizar una abstracción de este resultado a nivel de especificación, ya que no es algo que se suela especificar. De cualquier manera, que en situaciones como esas no pueda aplicarse la función abs no resulta ser un inconveniente ya que, en definitiva, en ellas se ha alcanzado el objetivo principal del testing: encontrar errores en el programa. Sea P : ID → OD un programa tal que su especificación Z es Op : VISOp → OS y sean t ∈ VISOp y x = refPOp (t). Se dirá que x es un caso de prueba exitoso para P sı́ y sólo si Op(t) 6= absPOp (P (x )), lo que intuitivamente describe lo expuesto anteriormente: que la salida obtenida de ejecutar el caso de prueba no coincide con lo que la especificación esperaba.. 3.3.. Las etapas del testing funcional. Para poner a prueba un programa P , teniendo su especificación Op, se deberá entonces aplicar iterativamente el proceso de testing que consta de las siguientes etapas: Generación de un caso de prueba (gen) Refinamiento del caso de prueba (ref ) Ejecución del caso de prueba (ejec) Abstracción de la salida (abs) Comprobación (compr ) y que se ilustra en la Figura 3.1. En el diagrama se puede observar que partiendo de un programa P y de la especificación Op de P , y mediante las etapas antes mencionadas, se puede alcanzar un resultado, res, que indica si el proceso en cuestión fue exitoso o no, es decir, si encontró un error en P o no. La primer etapa, gen, es la que genera, a partir de la especificación Op, un caso de prueba a nivel de especificación (que será llamado caso de prueba abstracto), t. La segunda etapa, ref , es la que se encarga de transformar ese caso de prueba abstracto en un caso de prueba a nivel de implementación (que será llamado caso de prueba concreto), x . A continuación es necesario ejecutar x en P , con lo cual el paso ejec, representado en la figura por dos flechas, permite obtener la salida P (x ) a nivel de implementación, llamada salida concreta. La etapa siguiente, abs, es la que hace posible abstraer esta salida al nivel de especificación (que como es de esperar, se llamará salida abstracta), resultando en y. Por último, a través de compr y utilizando Op, el caso de prueba abstracto t y la salida abstracta y, se comprueba si y se corresponde con t según Op, obteniendo el resultado res. res es una respuesta binaria que indica si existe o no tal correspondencia. Si no existe, significa que se ha encontrado un error en P . La mayorı́a de las etapas del proceso de testing recién mostradas son automatizables en gran medida. El objetivo de esta tesina es, justamente, mostrar cómo es posible hacer esto principalmente.
(20) CAPÍTULO 3.. EL TESTING BASADO EN ESPECIFICACIONES FORMALES Z. Figura 3.1: El proceso de testing funcional basado en especificaciones formales.. 18.
(21) CAPÍTULO 3.. EL TESTING BASADO EN ESPECIFICACIONES FORMALES Z. 19. con la etapa denominada gen, es decir, cómo pueden generarse de forma automática casos de prueba abstractos partiendo de una especificación Z.. 3.4.. Generando casos de prueba abstractos. En esta sección, y en las que siguen en este capı́tulo, se describirá con más detalle cómo puede llevarse a cabo la generación de casos de prueba abstractos. Para esto, se tendrán en cuenta los trabajos de Hall [3] [4], Stocks [6], Hörcher y Peleska [7] y Stocks y Carrington [8], que mostraron que las especificaciones formales Z pueden ser usadas para derivar sistemáticamente casos de prueba abstractos. Conceptualmente, la idea se basa en que una especificación define precisamente los aspectos fundamentales del software que describe, omitiendo información más detallada, estructural, y de implementación. Estos aspectos fundamentales son, más precisamente, las alternativas funcionales del software que se tuvieron, o mejor dicho, debieron tenerse en cuenta a la hora de implementarlo. En general, el diseñar casos de prueba para testing, lo que puede considerarse un arte, es justamente identificar estas alternativas funcionales para después poder testear el programa sobre ellas. Las alternativas funcionales de un sistema pueden expresarse como restricciones sobre las variables de entrada y de estado definidas en su especificación. Las técnicas propuestas por los autores anteriormente mencionados, entonces, sugieren modelar estas alternativas como esquemas Z a los que se les denominará clases de prueba. Por ejemplo, ClaseDePrueba == [a, b : Z | a < b] define una clase de prueba con dos valores, a y b, tales que a es menor que b. En este contexto, puede apreciarse que ClaseDePrueba no es más que un conjunto (infinito) de casos de prueba definido por comprensión. [a, b : Z | a = 4 ∧ b = 10] y [a, b : Z | a = −10 ∧ b = 5] son ejemplos de casos de prueba pertenecientes a ClaseDePrueba. El proceso a través del cual se generan casos de prueba abstractos, partiendo de la especificación Z de una operación Op, se dividirá en los dos siguientes pasos: Generación de un árbol de pruebas para Op Selección de casos de prueba El primer paso consiste en construir una jerarquı́a entre clases de prueba, que relacionará a las mismas y que se llamará árbol de pruebas. Para tal fin, la propuesta es dividir iterativamente a las clases de prueba en clases de prueba menores usando mecanismos que se denominarán tácticas de testing 3 . El segundo paso, por su parte, consiste en elegir uno o más casos de prueba para cada una de las clases de prueba que se hayan generado en el paso anterior, que no contengan a ninguna de las otras clases de prueba, y que no tengan su predicado equivalente a false. Se explicará la generación de árboles de pruebas en la Sección 3.5 y la selección de casos de prueba en la Sección 3.6. 3 En la bibliografı́a donde se expone esta metodologı́a se utiliza el término estrategia en lugar de táctica. En este trabajo, al igual que se hace en [12], se empleará el segundo de ellos..
(22) CAPÍTULO 3.. 3.5.. EL TESTING BASADO EN ESPECIFICACIONES FORMALES Z. 20. Construcción de árboles de pruebas. Dado que todos los casos de prueba de una operación deben ser tomados del espacio válido de entrada de la misma, éste es un buen punto de partida para construir el árbol de pruebas. Una vez determinado el VIS , hay que dividirlo, aplicando alguna táctica de testing, en una cantidad de nuevas clases de prueba, que posiblemente constituyan una partición de él4 . Estas clases conformarán el primer nivel de nodos del árbol de pruebas. El objetivo es derivar conjuntos de casos de prueba que sean clases de equivalencia respecto a la posibilidad de encontrar un error en la unidad funcional analizada, y que además cubran el VIS . En otras palabras, se pretende encontrar clases tales que cada elemento en ellas, tenga la misma posibilidad de encontrar un error que los demás elementos de la misma clase. Es por esto que la aplicación de tácticas de testing debe realizarse repetidamente, obteniendo nuevas y nuevas clases de prueba que completen el árbol, hasta que se considere que las clases de prueba “hoja” (es decir, aquellas que no tengan nodos hijos en el árbol) representen todas las alternativas funcionales importantes de la operación en cuestión. El árbol de pruebas asociado a una operación queda entonces representado como un grafo, donde los nodos son las clases de prueba (en particular, la raı́z es el espacio válido de entrada de la operación) y las aristas son las tácticas de testing aplicadas en las derivaciones de nuevas clases de prueba. Tı́picamente, un árbol de pruebas se ve como el mostrado en la Figura 3.2. En ella se muestra cómo, en primer lugar, a partir de la aplicación de una táctica Tac1 al VIS de la operación Op, VISOp , se obtienen las n clases de prueba OpiTac1 , para i entre 1 y n. Luego se utiliza la táctica Tac2 sobre la clase de prueba Op1Tac1 para obtener las r clases de prueba OpiTac2 , para i entre 1 y r . De la misma forma la táctica Tac3 permite dividir a la clase de prueba OpnTac1 en OpiTac3 , para i entre 1 y q. Por último, la táctica Tac4 genera las s clases de prueba OpiTac4 con i entre 1 y s, cuando es aplicada a OprTac2 . Es importante remarcar que el proceso de generación de clases de prueba no es exclusivo del lenguaje Z. El mismo puede aplicarse sobre cualquier lenguaje de especificación basado en lógica, como TLA o B, y puede modificarse apropiadamente, según [13] y [14], para ser usado en Statecharts y CSP, respectivamente. A continuación se describirá una serie de tácticas de testing y se presentará la manera en que estas pueden aplicarse sucesivamente para poder construir árboles de pruebas.. 3.5.1.. Tácticas de testing. Esta subsección muestra a través de un ejemplo algunas de las tácticas de testing que se conocen y que fueron propuestas en [6] y en [8]. En particular, se explicarán aquellas que fueron implementadas por el prototipo de Fastest que se describe en esta tesina. Justamente, es notable que tanto la aplicación de éstas como de otras tácticas puede ser automatizada en gran medida, no dependiendo en absoluto de la intervención manual de un encargado de testing. Para realizar la presentación de las tácticas de testing se introduce la siguiente especificación Z, la cual describe una versión simplificada de la lectura de archivos en UNIX. El contenido de los archivos 4 La división de una clase de prueba en otras clases de prueba, a través de la aplicación de una táctica de testing, podrı́a resultar en clases con algunas de ellas solapadas entre sı́, por lo que no formarı́an una partición de la original..
(23) CAPÍTULO 3.. EL TESTING BASADO EN ESPECIFICACIONES FORMALES Z. Figura 3.2: Estructura tı́pica de un árbol de pruebas.. 21.
(24) CAPÍTULO 3.. EL TESTING BASADO EN ESPECIFICACIONES FORMALES Z. 22. se modelará como una secuencia de bytes. A su vez, los bytes serán introducidos con el siguiente tipo básico, sin mayores detalles internos: [BYTE ] Cada archivo tendrá asociado un permiso de acceso, que podrá ser prohibido (si es un archivo sobre el que no se puede leer ni escribir), de sólo lectura, o de lectura y escritura. Los mismos se representan a través del siguiente tipo enumerado: PERMISO ::= prohibido | solo lectura | lectura escritura Archivo datos : seq BYTE permiso : PERMISO El invariante de estado de un archivo se describe en el siguiente esquema: InvarianteArchivo Archivo #datos ≤ 255 La operación de lectura toma el valor de una longitud como entrada y lee esa cantidad de caracteres desde el comienzo del archivo. Se distinguirán cuatro posibles situaciones respecto a la operación de lectura, Leer : Una lectura exitosa, donde también se incluye el caso, teniendo o no permiso de lectura, de solicitar la lectura de 0 bytes del archivo. En el caso general es necesario tener al menos permiso de lectura. Un intento de lectura fallido por querer hacerse sobre un archivo vacı́o. Un intento de lectura fallido por querer hacerse hasta más allá del final del archivo. Un intento de lectura fallido por querer hacerse sobre un archivo cuyo permiso de acceso es prohibido. las que al ejecutar la operación serán reportadas, según corresponda, con los siguientes mensajes: REPORTE ::= ok | error vacio | error fin archivo | error acceso En un primer esquema se captura la situación de una lectura con éxito. Puede notarse que el predicado de LeerOk contiene al operador ⇒, el cual no es muy habitual a la hora de escribir predicados de esquemas Z. Sin embargo, se lo ha incluido por cuestiones didácticas, para favorecer más adelante la presentación de una de las tácticas de testing..
(25) CAPÍTULO 3.. EL TESTING BASADO EN ESPECIFICACIONES FORMALES Z. LeerOk ΞArchivo longitud ? : N lectura! : seq BYTE rep! : REPORTE #datos > 0 longitud ? ≤ #datos longitud 6= 0 ⇒ permiso 6= prohibido lectura! = (1..longitud ?) C datos rep! = ok Los tres esquemas que siguen definen las situaciones erróneas anteriormente mencionadas. ArchivoVacio ΞArchivo lectura! : seq BYTE rep! : REPORTE #datos = 0 lectura! = hi rep! = error vacio. FinDeArchivoEncontrado ΞArchivo longitud ? : N lectura! : seq BYTE rep! : REPORTE longitud ? > #datos lectura! = hi rep! = error fin archivo. ArchivoProhibido ΞArchivo longitud ? : N lectura! : seq BYTE rep! : REPORTE ¬ (longitud ? 6= 0 ⇒ permiso 6= prohibido) lectura! = hi rep! = error acceso. 23.
(26) CAPÍTULO 3.. EL TESTING BASADO EN ESPECIFICACIONES FORMALES Z. 24. La operación cuya implementación se quiere testear, Leer , no altera el contenido de los archivos, lo que se ve expresado por la inclusión de ΞArchivo en los cuatro esquemas presentados. Finalmente, se define Leer como la disyunción de tales esquemas: Leer == LeerOk ∨ ArchivoVacio ∨ FinDeArchivoEncontrado ∨ ArchivoProhibido Para ilustrar el significado de esta combinación de esquemas, se muestra el esquema Leer expandido completamente. Esta expansión no es más que una manipulación sintáctica de los esquemas que conforman a Leer . Si bien el predicado resultante podrı́a contener información redundante o bien podrı́a simplificarse, no es algo que resulte de interés en este momento. La versión completamente expandida de Leer es: Leer datos, datos 0 : seq BYTE permiso, permiso 0 : PERMISO longitud ? : N lectura! : seq BYTE rep! : REPORTE datos 0 = datos permiso 0 = permiso (#datos > 0 ∧ longitud ? ≤ #datos ∧ (longitud 6= 0 ⇒ permiso 6= prohibido) ∧ lectura! = (1..longitud ?) C datos ∧ rep! = ok ) ∨ (#datos = 0 ∧ lectura! = hi ∧ rep! = error vacio) ∨ (longitud ? > #datos ∧ lectura! = hi ∧ rep! = error fin archivo) ∨ (¬ (longitud ? 6= 0 ⇒ permiso 6= prohibido) ∧ lectura! = hi ∧ rep! = error acceso) 3.5.1.1.. Obteniendo el VIS de la operación. Como ya se vio al comienzo de la Sección 3.5, el primer paso para generar casos de prueba para una operación es identificar su espacio válido de entrada. En el caso de Leer , puede probarse que su precondición es equivalente a true, por lo que su VIS define el mismo espacio que su IS , el que a su vez está dado por: ISLeer == [datos : seq BYTE ; permiso : PERMISO; longitud ? : N] En consecuencia, VISLeer es simplemente el esquema formado por la declaración de variables de entrada y de estado iniciales que aparecen en el esquema de operación Leer . Como ejemplo de una operación donde su IS y su VIS no coinciden, se tiene a LeerOk . En tal caso se tendrı́an: ISLeerOk == [datos : seq BYTE ; permiso : PERMISO; longitud ? : N].
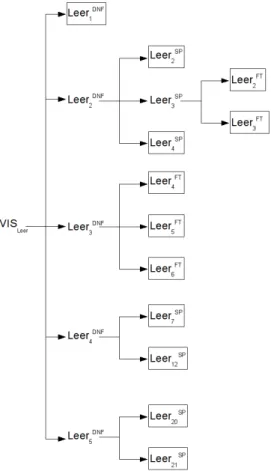
(27) CAPÍTULO 3.. EL TESTING BASADO EN ESPECIFICACIONES FORMALES Z. 25. VISLeerOk datos : seq BYTE permiso : PERMISO longitud ? : N #datos > 0 longitud ? ≤ #datos (longitud 6= 0 ⇒ permiso 6= prohibido) Volviendo a la operación Leer , y habiendo obtenido su VIS , ya puede comenzarse con la aplicación de tácticas de testing. Las mismas serán explicadas, una por una, a continuación. 3.5.1.2.. Forma Normal Disyuntiva (DNF). La táctica de Forma Normal Disyuntiva (cuya abreviatura será DNF, por Disjunctive Normal Form), es la más conocida de las tácticas de testing y por lo general es la primera que se aplica. La misma se basa en el concepto que proviene de la lógica, con el mismo nombre, y que asegura que un predicado está escrito en DNF si es una disyunción de una o más conjunciones de uno o más literales. Un literal es un predicado atómico (indivisible) o la negación de un predicado atómico. Para llevar cualquier predicado a DNF se pueden aplicar los siguientes cuatro pasos: 1. Se transforman todas las equivalencias a ⇔ b contenidas en el predicado en (a ⇒ b) ∧ (b ⇒ a) . 2. Se transforman todas las implicaciones a ⇒ b contenidas en el predicado en ¬ a ∨ b. 3. Se distribuyen todos los conectivos de negación (¬ ) de forma tal que siempre queden junto a predicados atómicos. Para esto se deben utilizar las siguientes reglas: ¬ (a ∨ b) ⇔ ¬ a ∧ ¬ b ¬ (a ∧ b) ⇔ ¬ a ∨ ¬ b ¬¬a⇔a 4. Se distribuyen todas las conjunciones sobre las disyunciones. Ahora bien, para poder aplicar la táctica DNF a una clase de prueba ClaseDePrueba del árbol de una operación Op, se deben realizar los siguientes dos pasos: Expresar el esquema Op como una disyunción de uno o más esquemas, Op1 , Op2 , ..., Opn , donde cada Opi verifique tener como predicado una conjunción de literales. Dividir ClaseDePrueba utilizando las precondiciones de los esquemas Opi , para i de 1 a n. Esto significa, por un lado, que hay una nueva clase de prueba por cada uno de estos esquemas. Y por otro lado, que cada clase de prueba tiene como predicado la conjunción del predicado de la clase de prueba original, ClaseDePrueba, con la precondición del esquema que le corresponde entre Op1 , Op2 , ..., Opn ..
(28) CAPÍTULO 3.. EL TESTING BASADO EN ESPECIFICACIONES FORMALES Z. 26. Para mostrar el procedimiento en la práctica, se lo aplicará al VIS de la operación Leer del ejemplo de lectura de archivos. El primer paso es entonces expresar a la operación como una disyunción de esquemas que cumplan con la condición de tener como predicado una conjunción de literales. Como Leer ya está definida como una disyunción de esquemas, habrá que analizar cuáles de estos esquemas tienen que subdividirse en más esquemas, a través de más disyunciones, de tal manera que cada uno cumpla con la recién mencionada condición. Por empezar, observando que el esquema LeerOk no tiene esta estructura por contener un ⇒ en su predicado, es evidente que habrá que transformarlo, y quizás subdividirlo. La manera de realizar esta subdivisión es reescribiendo su predicado en Forma Normal Disyuntiva y derivando un esquema por cada término de la disyunción, de tal forma que cada término sea el predicado del esquema correspondiente. En el caso de LeerOk , teniendo en cuenta que a ⇒ b es equivalente a ¬ a ∨ b y que la conjunción puede distribuirse respecto a la disyunción, es posible dividir al esquema Leer en los dos siguientes esquemas de operación: LeerOk 1 ΞArchivo longitud ? : N lectura! : seq BYTE rep! : REPORTE. LeerOk 2 ΞArchivo longitud ? : N lectura! : seq BYTE rep! : REPORTE. #datos > 0 longitud ? ≤ #datos longitud = 0 lectura! = (1..longitud ?) C datos rep! = ok. #datos > 0 longitud ? ≤ #datos permiso 6= prohibido lectura! = (1..longitud ?) C datos rep! = ok. los cuales verifican tener predicados que son conjunciones de literales, como se pretendı́a. En el caso de los esquemas de operación ArchivoVacio y FinDeArchivoEncontrado, puede verse que cumplen con esto desde un principio, por lo que no será necesario modificarlos ni subdividirlos. Por último, habrá que transformar el predicado de ArchivoProhibido, que al igual que el de LeerOk , también contiene un ⇒. Como en este caso la implicación está negada, el esquema se reescribe pero no es necesario subdividirlo..
(29) CAPÍTULO 3.. EL TESTING BASADO EN ESPECIFICACIONES FORMALES Z. 27. ArchivoProhibido ΞArchivo longitud ? : N lectura! : seq BYTE rep! : REPORTE longitud ? 6= 0 permiso = prohibido lectura! = hi rep! = error acceso Después de todo esto, la operación Leer queda expresada de la siguiente forma: Leer == LeerOk 1 ∨ LeerOk 2 ∨ ArchivoVacio ∨ FinDeArchivoEncontrado ∨ ArchivoProhibido Para finalizar la aplicación de la táctica DNF, se debe dividir VISLeer con la precondición de cada uno de los esquemas que conforman Leer , lo que resulta en el siguiente conjunto de esquemas: Leer1DNF == [VISLeer | #datos > 0 ∧ longitud ≤ #datos ∧ longitud = 0] Leer2DNF == [VISLeer | #datos > 0 ∧ longitud ? ≤ #datos ∧ permiso 6= prohibido] Leer3DNF == [VISLeer | #datos = 0] Leer4DNF == [VISLeer | longitud ? > #datos] Leer5DNF == [VISLeer | longitud ? 6= 0 ∧ permiso = prohibido] En primer lugar, es importante notar que no se ha obtenido una partición de VISLeer pues no se cumple con que todas las particiones sean disjuntas entre sı́. Por ejemplo, Leer1DNF y Leer2DNF no son disjuntas. Sin embargo, esta división en clases de prueba sı́ realiza un cubrimiento del VIS de Leer . Se puede notar que a partir de estas clases pueden elegirse casos de prueba que hagan posible testear al sistema en las situaciones más importantes, las que se listan a continuación: 1. Se quiere leer una cantidad nula de bytes (y que no sobrepasa el tamaño) del archivo, el cual no está vacı́o. 2. Se quiere leer una cantidad de bytes que no sobrepasa el tamaño del archivo, el cual no está vacı́o y no tiene permiso de acceso prohibido. 3. Se quiere leer un archivo vacı́o. 4. Se quiere leer del archivo una cantidad de bytes que sobrepasa el tamaño del mismo. 5. Se quiere leer una cantidad no nula de bytes del archivo, el cual tiene permiso de acceso prohibido. Como aparte de éstas hay otras pruebas que también puede ser interesante realizar, habrı́a que encontrar la manera de generarlas a partir de alguna o algunas otras tácticas de testing. Ası́, se podrı́a combinar las pruebas nuevas con las anteriores a través del árbol de pruebas de la operación. La siguiente táctica muestra como agregar nuevas clases de prueba al árbol actual, el cual contiene al VIS de Leer como raı́z y a las cinco clases recién listadas como nodos hijos de la raı́z..
(30) CAPÍTULO 3. 3.5.1.3.. EL TESTING BASADO EN ESPECIFICACIONES FORMALES Z. 28. Particiones Estándar (SP). La táctica de Particiones Estándar (SP, por Standard Partitions) fue desarrollada por Stocks y Carrington [6, 8] y consiste en utilizar los operadores matemáticos que aparecen en la operación para generar nuevas clases de prueba. Una metodologı́a tradicional en el testing basado en especificaciones es reducir una especificación a Forma Normal Disyuntiva, como se vio en la sección anterior, y elegir entradas que satisfagan las precondiciones de cada término de la disyunción obtenida. Sin embargo, esto tiende a ser muy simplista porque, por lo general, los lenguajes de especificación tienen operadores matemáticos poderosos donde la complejidad de sus dominios de entrada no se hace evidente en una transformación a DNF. Es esta complejidad a nivel de especificación la que normalmente se ve reflejada en la implementación de los propios operadores, y por lo que omitir su análisis puede impedir que se revelen algunos errores existentes en el programa. Esta táctica, por lo tanto, divide los dominios de estos operadores de acuerdo a la partición estándar de cada uno ellos. Una partición estándar es una partición del dominio del operador en conjuntos llamados sub-dominios, los cuales pueden definirse como condiciones expresadas en función de los operandos del operador. Es la condición que define cada subdominio la que determinará cada nueva clase de prueba. A modo de ilustración, se aplicará esta táctica a las clases de prueba obtenidas en la sección anterior. Para esto, en primer lugar, hay que seleccionar una ocurrencia de un operador en el esquema de operación Leer . Se eligirá el operador C de la expresión: (1..longitud ?) C datos y se tendrá en cuenta que para la restricción de dominio de un conjunto S y una relación R, S C R , una partición estándar podrı́a ser: 1. R = {} 2. R 6= {} ∧ S = {} 3. R 6= {} ∧ S = dom R 4. R 6= {} ∧ S 6= {} ∧ S ⊂ dom R 5. R 6= {} ∧ S 6= {} ∧ S ∩ dom R = {} 6. R 6= {} ∧ S ∩ dom R 6= {} ∧ ¬ (S ⊆ dom R) Ası́, lo que sigue es reemplazar los parámetros formales que aparecen en el listado de sub-dominios de la partición (S y R) por los parámetros reales que aparecen en la expresión original (1..longitud ? y datos), para de esta forma obtener la partición en términos de éstos últimos. El último paso es considerar la clase de prueba sobre la que se quiere aplicar la táctica y generar otras nuevas a partir de los sub-dominios de la partición resultante. En este caso se aplicará sobre Leer2DNF y Leer4DNF . De esta forma, se obtienen nuevas clases de prueba, que están contenidas en las anteriores y que se representan en el árbol de pruebas como las primeras “colgando” de las últimas. En los esquemas.
(31) CAPÍTULO 3.. EL TESTING BASADO EN ESPECIFICACIONES FORMALES Z. 29. correspondientes, deben incluirse unas dentro de otras, como se verá en el siguiente listado, que presenta todas las clases de prueba obtenidas hasta el momento: Leer1SP == [Leer2DNF | datos = {}] Leer2SP == [Leer2DNF | datos 6= {} ∧ 1..longitud ? = {}] Leer3SP == [Leer2DNF | datos 6= {} ∧ 1..longitud ? = dom datos] Leer4SP == [Leer2DNF | datos 6= {} ∧ 1..longitud ? 6= {} ∧ 1..longitud ? ⊂ dom datos] Leer5SP == [Leer2DNF | datos 6= {} ∧ 1..longitud ? 6= {} ∧ 1..longitud ? ∩ dom datos = {}] Leer6SP == [Leer2DNF | datos 6= {} ∧ 1..longitud ? ∩ dom datos 6= {} ∧ ¬ (1..longitud ? ⊆ dom datos)] Leer7SP == [Leer4DNF | datos = {}] Leer8SP == [Leer4DNF | datos 6= {} ∧ 1..longitud ? = {}] Leer9SP == [Leer4DNF | datos 6= {} ∧ 1..longitud ? = dom datos] SP == [Leer DNF | datos 6= {} ∧ 1..longitud ? 6= {} ∧ 1..longitud ? ⊂ dom datos] Leer10 4 SP == [Leer DNF | datos 6= {} ∧ 1..longitud ? 6= {} ∧ 1..longitud ? ∩ dom datos = {}] Leer11 4 SP == [Leer DNF | datos 6= {} ∧ 1..longitud ? ∩ dom datos 6= {} Leer12 4 ∧ ¬ (1..longitud ? ⊆ dom datos)] Análogamente, se considerará el operador ≤ de la expresión: longitud ? ≤ #datos con la siguiente partición estándar para a ≤ b (que también vale para a < b, a > b, a ≥ b y a = b): 1. a < 0 ∧ b < 0. 4. a = 0 ∧ b < 0. 7. a > 0 ∧ b < 0. 2. a < 0 ∧ b = 0. 5. a = 0 ∧ b = 0. 8. a > 0 ∧ b = 0. 3. a < 0 ∧ b > 0. 6. a = 0 ∧ b > 0. 9. a > 0 ∧ b > 0. que se aplicará a Leer5DNF , obteniendo: SP Leer13 SP Leer14 SP Leer15 SP Leer16 SP Leer17 SP Leer18 SP Leer19 SP Leer20 SP Leer21. == [Leer5DNF == [Leer5DNF == [Leer5DNF == [Leer5DNF == [Leer5DNF == [Leer5DNF == [Leer5DNF == [Leer5DNF == [Leer5DNF. | longitud ? < 0 ∧ #datos | longitud ? < 0 ∧ #datos | longitud ? < 0 ∧ #datos | longitud ? = 0 ∧ #datos | longitud ? = 0 ∧ #datos | longitud ? = 0 ∧ #datos | longitud ? > 0 ∧ #datos | longitud ? > 0 ∧ #datos | longitud ? > 0 ∧ #datos. < 0] = 0] > 0] < 0] = 0] > 0] < 0] = 0] > 0]. Como para ninguna táctica de testing existe la necesidad de aplicarse a todas las clases de prueba, en este caso se eligirá no hacerlo con la clase Leer1DNF y Leer3DNF ..
(32) CAPÍTULO 3.. EL TESTING BASADO EN ESPECIFICACIONES FORMALES Z. 30. Es importante remarcar que cada clase de prueba está restringida tanto por la condición que aparece explı́citamente como por la dada con la inclusión de esquemas. Por ejemplo, el predicado de Leer7SP es en realidad longitud ? > #datos ∧ datos = {}. Teniendo en cuenta esto, se puede notar que varias de las clases recién listadas tienen predicados contradictorios (son conjunciones equivalentes a false), como es el caso de Leer1SP , Leer5SP , etc. Dado que éstas clases de prueba no están más que definiendo conjuntos vacı́os de casos de prueba, no tienen ninguna utilidad, y se las puede descartar por completo5 , quedando sólo las que se listan a continuación: Leer2SP == [Leer2DNF | 1..longitud ? = {}] Leer3SP == [Leer2DNF | 1..longitud ? = dom datos] Leer4SP == [Leer2DNF | 1..longitud ? 6= {} ∧ 1..longitud ? ⊂ dom datos]. Leer7SP == [Leer4DNF | datos = {}] SP == [Leer DNF | datos 6= {}] Leer12 4 SP == [Leer DNF | longitud ? > 0 ∧ #datos = 0] Leer20 5 SP == [Leer DNF | longitud ? > 0 ∧ #datos > 0] Leer21 5. En esta nueva presentación de las clases de prueba se han simplificado los predicados, omitido aquellas condiciones, generadas por la partición estándar, que puedan deducirse de las que ya introducen los esquemas incluidos en las clases. Por ejemplo, no se ha hecho explı́cito que datos 6= {} en Leer2SP , Leer3SP y Leer4SP porque esto se deduce de la condición #datos > 0 proveniente del predicado de Leer2DNF . Se puede observar aquı́ que las clases de prueba que se obtuvieron con la aplicación de la táctica de Particiones Estándar especifican formas más particulares de ejecutar el programa. Como muestra de esto, vale considerar que la alternativa funcional que se especifica en Leer2DNF se dividió en: Se quiere leer una cantidad de bytes que no sobrepasa el tamaño del archivo, el cual no está vacı́o y no tiene permiso de acceso prohibido... y esa cantidad de bytes a leer es nula. Se quiere leer una cantidad de bytes que no sobrepasa el tamaño del archivo, el cual no está vacı́o y no tiene permiso de acceso prohibido... y esa cantidad de bytes es igual al tamaño del archivo. Es decir, se quiere leer completamente un archivo no vacı́o y que no tiene permiso de acceso prohibido. Se quiere leer una cantidad de bytes que no sobrepasa el tamaño del archivo, el cual no está vacı́o y no tiene permiso de acceso prohibido... y esa cantidad de bytes es menor al tamaño del archivo. Es decir, se quiere leer una porción de un archivo no vacı́o y que no tiene permiso de acceso prohibido. Es evidente que de esta manera se pondrá a prueba el programa en las tres situaciones, mientras que con el enfoque anterior algunas de ellas podrı́an no haberse tenido en cuenta. 5. A esta acción de eliminar las clases de prueba vacı́as se la llama poda del árbol de pruebas, y no está soportada por el prototipo actual de Fastest..
Figure


+7



Outline
Particiones Est´ andar (SP)
Selecci´ on de casos de prueba abstractos
Estilos arquitect´ onicos empleados
Tecnolog´ıa utilizada
El subsistema de Invocaci´ on Impl´ıcita
Aplicando el patr´ on de dise˜ no Visitor a los AST
Los m´ odulos del lado del servidor
Gu´ıa para introducir cambios en la herramienta
Agregar t´ acticas de testing
Conclusiones y trabajo futuro
Documento similar
Cedulario se inicia a mediados del siglo XVIL, por sus propias cédulas puede advertirse que no estaba totalmente conquistada la Nueva Gali- cia, ya que a fines del siglo xvn y en
No había pasado un día desde mi solemne entrada cuando, para que el recuerdo me sirviera de advertencia, alguien se encargó de decirme que sobre aquellas losas habían rodado
Después de una descripción muy rápida de la optimización así como los problemas en los sistemas de fabricación, se presenta la integración de dos herramientas existentes
[r]
SVP, EXECUTIVE CREATIVE DIRECTOR JACK MORTON
Social Media, Email Marketing, Workflows, Smart CTA’s, Video Marketing. Blog, Social Media, SEO, SEM, Mobile Marketing,
Habiendo organizado un movimiento revolucionario en Valencia a principios de 1929 y persistido en las reuniones conspirativo-constitucionalistas desde entonces —cierto que a aquellas
The part I assessment is coordinated involving all MSCs and led by the RMS who prepares a draft assessment report, sends the request for information (RFI) with considerations,
