Implementación de un sistema para controlar una silla de ruedas eléctrica utilizando redes neuronales y reconocimiento de patrones de voz
110
0
0
Texto completo
(2) DEDICATORIA. Dedicado a mis queridos padres, que son el motivo de todos mis esfuerzos. Gloria Chalco Monroy.
(3) AGRADECIMIENTOS. Mi agradecimiento a la Universidad Nacional de San Agustín de Arequipa, institución en la cual estudio y me brindo la oportunidad de desarrollo personal y profesional en la carrera de ingeniería de sistemas.. Al Dr. Luis Alfaro Casas Docente de Ingeniería de sistemas de la UNSA Por brindarme sus conocimientos en Inteligencia Artificial e inculcarme a la investigación y desarrollo profesional.. En especial a mis padres que son el motor de mi vida y a mi hermano por su constante apoyo y comprensión.. A todos ellos,. MUCHAS GRACIAS.. 1.
(4) RESUMEN. Por lo general una persona tetrapléjica aún puede hacer uso de su voz, a través de la cual solicita asistencia en sus actividades; es por ello que se propone el presente modelo ‘IMPLEMENTACION DE UN SISTEMA PARA CONTROLAR UNA SILLA DE RUEDAS ELECTRICA UTILIZANDO REDES NEURONALES Y RECONOCIMIENTO DE PATRONES DE VOZ’, el cual pueda darle cierto nivel de independencia y mejor calidad de vida a las personas. La característica básica de este modelo consiste en el reconocimiento de órdenes vocales, las cuales serán analizadas por una red neuronal, éstas luego, son procesadas por un agente inteligente que analizará su estado, y además transmitirá esta orden a la interfaz de la silla de ruedas. Adicionalmente, y para validación del módulo se presentará un simulador donde se pueda apreciar, visualmente y en pantalla, las órdenes ejecutadas. Así tal modelo, intérprete de órdenes de voz pueda ser complementado por una interfaz electrónica, en un trabajo futuro, para ser aplicado en el control de una silla de ruedas eléctrica real.. 2.
(5) ABSTRACT Usually a quadriplegic person can still make use of his voice, through which requests assistance in their activities, that is why this model is proposed ‘IMPLEMENTATION OF A SYSTEM FOR CONTROLLING AN ELECTRIC WHEELCHAIR USING NEURONAL NETWORKS AND RECOGNITION OF VOICE PATTERNS', which can give certain level of independence and quality of life for people. The basic feature of this model is the recognition of voice commands, which will be analyzed by a neural network, they then are processed by an intelligent agent to examine its state, and also transmit the order to interface Wheelchair. Additionally, module validation will be presented a simulator where you can see, visually displayed, the orders executed. So this model interpreted voice commands can be complemented by an electronic interface in a future work, to be applied in the control of a real electric wheelchair.. 3.
(6) INDICE DE CONTENIDOS Contenido. Pág.. Agradecimientos. 1. Resumen. 2. Abstract. 3. Índice de figuras. 7. Índice de tablas. 8. Siglas. 10. CAPITULO 1: DESCRIPCION GENERAL 1.1 Título. 12. 1.2 Descripción. 12. 1.3 Formulación del Problema. 13. 1.4 Objetivo General. 13. 1.4.1 Objetivos Específicos. 13. 1.5 Justificación. 14. 1.6 Limitaciones. 14. 1.7 Hipótesis. 15. 1.8 Definición del problema. 15. CAPITULO 2: MARCO TEORICO 2.1 Revisión Histórica. 20. 2.2 Estado del arte. 21. 2.3 Interfaces. 23. 2.3.1 Tecnologías de interfaces de voz. 24. 2.3.2 Tipos de interfaces. 25. 2.3.3 Ergonomía para interfaces. 27. 2.3.4 Usabilidad para interfaces. 31. 4.
(7) 2.4 Técnicas de diseño. 33. 2.4.1Distancia de Alineamiento Temporal (DTW). 34. 2.4.2Modelos ocultos de Markov. 37. 2.4.3Redes Neuronales. 38. 2.4.3.1 Redes neuronales biológicas y redes neuronales. 39. artificiales 2.4.3.2 Elementos de la red neuronal artificial. 41. 2.4.3.3 Perceptrón multicapa. 42. 2.4.3.4 Entrenamiento de una red neuronal artificial. 45. 2.4.3.5 Red Backpropagation. 46. 2.4.4Reconocimiento de Patrones de voz. 49. 2.5 Vector de características. 50. 2.6 Agentes. 50. 2.6.1 Propiedades de los Agentes. 50. 2.6.2 Modelización de Agentes: AUML. 52. CAPITULO 3: METODOLOGIA 3.1 Metodología. 55. 3.1.1Vocabulario. 55. 3.1.2 Pre procesamiento de la señal. 56. 3.1.3 Extractor de características. 58. 3.1.4 Red Neuronal. 59. 3.1.5 Agente. 61. 3.2 Análisis del Agente Reactivo. 63. 3.2.1 Reglas. 64. CAPITULO 4: IMPLEMENTACION 4.1 Implementación. 66. 5.
(8) 4.2 Entrada de Audio. 67. 4.3 Procesamiento de la señal. 67. 4.4 Simulación. 68. 4.5 Aplicación. 68. 4.5.1 Red Neuronal. 68. 4.5.2 Vector de características. 71. 4.5.3 Detector de actividad de voz. 72. 4.6 Resultados obtenidos. 73. 4.7 Análisis de pruebas. 78. CONCLUSIONES. 79. RECOMENDACIONES. 80. BIBLIOGRAFÍA. 81. ANEXOS. 89. 6.
(9) INDICE DE FIGURAS. Contenido. Pág.. Fig. 1. Modelo genérico de comunicación para Reconocimiento del Habla.. 22. Fig. 2: Alineamiento temporal entre la "Referencia" y la "Palabra a reconocer”.. 36. Fig. 3:Modelo de Markov con 'n' estados. 38. Fig. 4: Modelo de una RNA. 39. Fig. 5: Neurona. Red Neuronal. 44. Fig. 6: Red Neuronal Multicapa. 44. Fig. 7: Arquitectura de una RNA Backpropagation. 48. Fig. 8: Reconocimiento de patrones de voz. 49. Fig. 9. Modelo propuesto. 55. Fig. 10. Digitalización de la palabra “derecha”. 57. Fig. 11. Energía respecto al tiempo, para la palabra “derecha”. 57. Fig. 12. Extractor de características de una palabra.. 59. Fig. 13. Diagrama de Estados del Agente.. 61. Fig. 14. Acción del Agente ante un estimulo del ambiente.. 62. Fig. 15. Acción del Agente ante un estimulo del ambiente. 62. Fig. 16. Acción del Agente ante un estimulo del ambiente y análisis.. 63. Fig. 17. Modulo de la Aplicación: Red Neuronal. 68. Fig. 18. Ventana de Simulación.. 70. Fig. 19. Modulo de la Aplicación: Vector de Características. 71. Fig. 20. Modulo de la Aplicación: Detector de Actividad de Voz.. 72. Fig. 21. Grafica de resultados obtenidos en cada prueba.. 77. Fig. 22. Grafica de resultados obtenidos en el resumen de pruebas.. 78. Fig. 23. Diagrama de componentes.. 102. Fig. 24. Diagrama de Casos de Uso.. 103. Fig. 25. Diagrama de Clases. 108. Fig. 26. Diagrama de Clases AUML del Agente. 108. 7.
(10) INDICE DE TABLAS Contenido. Pág.. Tabla 1. Comparación entre neuronas biológicas y neuronas artificiales. 41. Tabla 2. Reglas del Agente. 64. Tabla 3. Resultados de Prueba 1. 73. Tabla 4. Resultados de Prueba 2. 74. Tabla 5. Resultados de Prueba 3. 75. Tabla 6. Resultados de Prueba 4. 76. Tabla 7. Resultados de Prueba 5. 77. Tabla 8. Resultados del análisis de Pruebas. 78. Tabla 9. Requisito General: Control de una silla de ruedas. 89. Tabla 10. Requisito General: Detección de voz. 89. Tabla 11. Requisito General: Reconocimiento de palabras. 90. Tabla 12. Requisito General: Extracción de características. 90. Tabla 13 Requisito General: Red neuronal. 90. Tabla 14 Requisito General: Activación de estados. 91. Tabla 15. Requisito General: Agente Reactivo. 91. Tabla 16. Requisito Funcional: Señal de audio. 91. Tabla 17. Requisito Funcional: procesamiento de señal. 92. Tabla 18. Requisito Funcional: actividad de voz. 92. Tabla 19. Requisito Funcional: vector de características. 92. Tabla 20. Requisito Funcional: librería FANN. 93. Tabla 21. Requisito Funcional: Red neuronal multicapa. 93. Tabla 22. Requisito Funcional: entrenamiento de la red neuronal. 93. Tabla 23. Requisito Funcional: reportes sobre aprendizaje de la red. 94. Tabla 24. Requisito Funcional: ejecución de órdenes. 94. Tabla 25. Requisito Funcional: salida FANN. 94. Tabla 26. Requisito Funcional: simulador de órdenes. 95. 8.
(11) Tabla 27. Requisito Funcional: vector de características. 95. Tabla 28. Requisito Funcional: interfaz del detector de voz. 95. Tabla 29. Requisito No Funcional: parámetros de la señal de audio. 96. Tabla 30. Requisito No Funcional: parámetros de la red neuronal. 96. Tabla 31. Requisito No Funcional: interfaces. 97. Tabla 32. Requisito No Funcional: micrófono. 97. Tabla 33. Requisito No Funcional: tiempo de respuesta. 98. Tabla 34. Requisito No Funcional: librería FANN. 98. Tabla 35. Requisito No Funcional: error deseado. 99. Tabla 36. Requisito No Funcional: iteraciones. 99. Tabla 37. Requisito No Funcional: contador de órdenes. 99. Tabla 38. Requisito No Funcional: plataforma. 100. Tabla 39. Requisito No Funcional: entorno de desarrollo integrado. 100. Tabla 40. Requisito No Funcional: librerías. 100. Tabla 41. Requisito No Funcional: procesamiento de la señal de audio. 101. Tabla 42. Caso de uso: configurar red. 103. Tabla 43. Caso de uso: configurar DAV y agente. 104. Tabla 44. Caso de uso: generar vectores. 104. Tabla 45. Caso de uso: grabar vectores. 105. Tabla 46. Caso de uso: entrenar red. 105. Tabla 47. Caso de uso: iniciar escucha. 106. Tabla 48. Caso de uso: parar. 106. Tabla 49. Caso de uso: girar. 107. Tabla 50. Caso de uso: retroceder. 107. Tabla 51. Caso de uso: avanzar. 107. 9.
(12) SIGLAS NOTACION. SIGNIFICADO. HMM. Modelos Ocultos de Markov. DTMF. Detección de tonos. ASR. Reconocimiento de voz. TTS. Síntesis de voz. SV. Verificación del hablante. GUI. Interfaces gráficas del usuario. DTW. Distancia de Alineamiento Temporal. RNA. Red Neuronal Artificial. UML. lenguaje unificado de modelado. DAV. Detector de actividad de voz. FANN. Red Neuronal Artificial Multicapa. IDE. Entorno de desarrollo integrado. 10.
(13) CAPÍTULO I DESCRIPCION GENERAL. 11.
(14) IMPLEMENTACION DE UN SISTEMA PARA CONTROLAR UNA SILLA DE RUEDAS ELECTRICA UTILIZANDO REDES NEURONALES Y RECONOCIMIENTO DE PATRONES DE VOZ. CAPÍTULO I 1.1. TÍTULO IMPLEMENTACION DE UN SISTEMA PARA CONTROLAR UNA SILLA. DE. RUEDAS. ELECTRICA. UTILIZANDO. REDES. NEURONALES Y RECONOCIMIENTO DE PATRONES DE VOZ. 1.2. DESCRIPCIÓN Una persona que haya perdido capacidad de movimiento en brazos y piernas por daño en su médula espinal, por lo general queda confinada al uso de una silla de ruedas y es dependiente de una persona que pueda asistirla en sus necesidades básicas, como su desplazamiento, entre otras. Por lo general una persona tetrapléjica aún puede hacer uso de su voz, a través de la cual solicita asistencia en sus actividades; es por ello que se propone el presente modelo ‘IMPLEMENTACION DE UN SISTEMA PARA CONTROLAR UNA SILLA DE RUEDAS ELECTRICA UTILIZANDO REDES NEURONALES Y RECONOCIMIENTO DE PATRONES DE VOZ’, que le dé cierto nivel de independencia y mejor calidad de vida a las personas que han quedado incapacitadas. La característica básica de este modelo consiste en el reconocimiento de órdenes vocales, las cuales serán analizadas por una red neuronal, éstas, luego, son procesadas por un agente inteligente que analizará su estado y. 12.
(15) según algunas reglas preestablecidas, adoptará la orden final, y finalmente transmitirá esta orden a la interfaz de la silla de ruedas. El alcance para esta propuesta llega hasta la implementación de un módulo que pueda entregar las órdenes a través de estados, que puedan ser leídos por un módulo eléctrico/electrónico y transferidos al servomecanismo de la silla. Adicionalmente, y para validación del módulo se presentará un simulador donde se pueda apreciar, visualmente y en pantalla, las órdenes ejecutadas.. 1.3. FORMULACION DEL PROBLEMA ¿Cómo realizar el control de una silla de ruedas eléctrica, utilizando la voz? Hoy en día existen en el mercado opciones de sillas de ruedas, con limitaciones en la interfaz que implican el uso de comandos táctiles que en muchos casos por las dificultades motoras severas que el usuario demanda, como la tetraplejia, existe la necesidad de adaptar el movimiento de la silla de ruedas con temas de precisión usando redes neuronales y agentes con reconocimiento de patrones de voz.. 1.4. OBJETIVO GENERAL Proponer la Implementación de un sistema de interfaz para el control de una silla de ruedas eléctrica, basado en técnicas de inteligencia artificial (redes neuronales y reconocimiento de patrones de voz). 13.
(16) 1.4.1.. OBJETIVOS ESPECIFICOS Lograr desarrollar un sistema para el control de una silla de ruedas eléctrica mediante reconocimiento de patrones de voz Desarrollar el sistema de manera efectiva mediante técnicas de inteligencia artificial como redes neuronales y agentes. Implementar distintas interfaces de control para este sistema, que permitan adecuarse para el usuario con dificultades motoras como la tetraplejia, haciendo uso de su voz mediante la interacción con el dispositivo de audio interconectado al sistema.. 1.5. JUSTIFICACIÓN. El uso de la Inteligencia artificial mediante técnicas como las redes neuronales y agentes para reconocer patrones de voz proporciona una herramienta que puede ser utilizada para resolver el problema de personas tetrapléjicas, permitiéndoles controlar dispositivos a través de órdenes vocales sencillas y de esta manera mejorar su calidad de vida.. Los atributos de este sistema facilitan a la movilidad de un importante porcentaje de la población que sufre algún tipo de discapacidad física mediante el uso de la tecnología que es el objetivo de este trabajo centrando el esfuerzo en las personas tetrapléjicas, las cuales no pueden realizar movimiento físico para controlar un joystick, sin embargo pueden usar su voz para controlar la silla de ruedas y de esta manera mantener cierto nivel de independencia.. 14.
(17) 1.6. LIMITACIONES Este Sistema esta destinado para personas tetrapléjicas que están confinadas al uso de una silla de ruedas para su desplazamiento y que puedan hacer el uso de su voz.. 1.7. HIPÓTESIS Un sistema podrá controlar una silla de ruedas eléctrica utilizando la voz, el cual mejorará la calidad de vida de personas tetrapléjicas, el sistema será implementado mediante el uso de redes neuronales y agentes con patrones de reconocimiento de voz.. 1.8. DEFINICIÓN DEL PROBLEMA El reconocimiento del habla parece tan natural y sencillo para las personas que se pensó que podía ser fácilmente realizado por las máquinas. Sin embargo, cuando se empezó a profundizar en el tema, se comprobó que esto no es así. De hecho, es un tema que se ha revelado más complicado que la producción automática de voz. A través de la historia se conoce que las primeras y rudimentarias máquinas parlantes aparecieron en la segunda mitad del siglo XVIII, mientras que los primeros intentos en máquinas capaces de reconocer la voz no aparecieron hasta principios del siglo XX, con la máquina de Flower, capaz de escribir el alfabeto fonográfico pronunciado por una persona. Para entender la complejidad del Reconocimiento del Habla veremos cinco factores determinantes señalados por Fandiño [1]:. 15.
(18) El texto es fundamental para la comprensión y desarrollo del resto del trabajo a. El Locutor: Es quizás el aspecto que introduce mayor variabilidad en la forma de onda entrante, y por tanto requiere que el sistema de reconocimiento sea altamente robusto. Una persona no pronuncia siempre de la misma forma, debido a distintas situaciones físicas y psicológicas (es la llamada variabilidad intra-locutor). Existe además gran variedad entre distintos locutores (hombres, mujeres, niños), diferencias según la edad o la región de origen (variabilidad interlocutor).. b. La Forma De Hablar: El hombre pronuncia las palabras de una forma continua, y debido a la inercia de los órganos articulatorios, que no pueden moverse instantáneamente, se producen efectos coarticulatorios. Ello, unido a las variaciones introducidas por la prosodia, hace que una palabra al principio de una frase sea diferente que cuando se dice en medio, o que sea diferente dependiendo de que es lo que le procede o le sigue. Un reconocedor es relativamente sencillo si sólo tiene que reconocer una palabra dicha de forma aislada (reconocedor de palabras aisladas) y es más complejo si debe reconocer las palabras de una frase, pero introduciendo una pausa entre cada dos de ellas (habla conectada). El sistema más complicado es aquel que debe funcionar reconociendo habla continua, que es la forma natural de hablar.. c. El Vocabulario: Se conoce el vocabulario como el número de palabras diferentes que debe reconocer el sistema. Mientras mayor es el número de palabras más difícil es el reconocedor, por dos motivos. El primero porque al aumentar el número de palabras es más fácil que aparezcan palabras parecidas entre sí, y el segundo porque el tiempo de tratamiento aumenta al aumentar el número de palabras con las que. 16.
(19) debe comparar. Una solución posible a este problema sería el utilizar unidades lingüísticas inferiores a la palabra (alófonos, sílabas, etc.) que en principio tienen un número limitado, e inferior al de posibles palabras. Sin embargo, la dificultad de reconocer estas unidades es aun mayor debido a que su duración es muy corta, la frontera entre dos unidades sucesivas es muy difícil de establecer y los efectos coarticulatorios son mucho más fuertes que entre palabras.. d. La Gramática: Es el conjunto de reglas que limita el número de combinaciones permitidas de las palabras del vocabulario. En general la existencia de una gramática en un reconocedor ayuda a mejorar la tasa de reconocimiento, al eliminar ambigüedades y puede ayudar a disminuir la necesidad de cálculo, al limitar el número de palabras en una determinada fase del reconocimiento ("perplejidad" de la gramática). En sistemas de palabras aisladas en los que no existe una gramática en el sentido estricto del término, se puede entender por tal el número de palabras a reconocer. Si, por ejemplo, el sistema debe reconocer un número telefónico urbano, la gramática de este sistema dice que el vocabulario son los diez dígitos, y debe reconocer un conjunto de siete dígitos, de forma que si el sistema reconoce más o menos, es que hay algún error.. e. El Entorno Físico: El entorno físico es una parte tan importante como las anteriores para definir el reconocedor. No es lo mismo un sistema que funciona en un ambiente poco ruidoso, como puede ser el consultorio de un médico, o el que tiene que funcionar en un automóvil o en una fábrica. 0 por ejemplo, el que debe de funcionar a través de la línea telefónica, con la consiguiente reducción de banda o el que recibe la voz a través de un micrófono, que tiene mayor ancho de banda que la línea telefónica.. 17.
(20) Para completar el análisis del reconocimiento del habla es necesario conocer los tres niveles importantes que nos menciona Austin [2]: Creo que, si no lo pongo literalmente, puede perder vigor o claridad. Acto Locutivo: es el que realizamos por el simple hecho de "decir algo“. En este acto se consideran el aspecto fónico, el gramatical y semántico Acto Ilocutivo: es la finalidad concreta del acto de habla, donde hay que determinar de qué manera estamos usando el enunciado. Acto Perlocutivo: es el que se realiza por haber dicho algo, y se refiere a los efectos producidos. Además de tener en cuenta la clasificación que Austin [2] presenta sobre los actos del habla: Actos asertivos o expositivos: el hablante niega, asevera o corrige algo. Actos directivos: el hablante influye al oyente a ejecutar una acción. Actos compromisorios: el hablante asume un compromiso. Actos expresivos: el hablante expresa sus emociones. Actos declarativos: el hablante pretende cambiar el estado de las cosas. De las premisas antes mencionadas se puede decir que es mucho más sencillo que un sistema funcione para un determinado locutor y que este lo haya entrenado previamente (se dice que el sistema es dependiente del locutor), a que un sistema funcione para cualquier locutor (sistema independiente del locutor).. 18.
(21) CAPÍTULO II MARCO TEORICO. 19.
(22) CAPÍTULO II. MARCO TEÓRICO. 2.1. REVISIÓN HISTÓRICA El objetivo de la tecnología de reconocimiento de voz, según Séller [3], es el de “crear máquinas que puedan recibir información hablada y actuar de forma apropiada de acuerdo con esta información”. Los Sistemas de Reconocimiento de Voz (Automatic Speech recognition, ASR), [3] – [5]; intentan hacer que una computadora reconozca, con un 100% de exactitud, todas las palabras que puedan ser entendidas por cualquier persona, independientemente del tamaño del vocabulario, ruidos presentes, características propias del locutor y preferentemente en tiempo real. Este tema ha sido bastante abordado en la última década, motivada por la enorme cantidad de posibles aplicaciones comerciales de esta tecnología, por ejemplo, ver [6]. Una concepción e implementación de este tipo de software está en fase de maduración, pero el problema de reconocimiento aún se considera abierto y sujeto a nuevos abordajes para su solución. En [7] se explica como aplicaciones comerciales están haciendo grandes investigaciones y experimentando una rápida popularización. A partir de los 90’s, se han reportado muchos proyectos de investigación en el desarrollo de sistemas de identificación de palabras clave (Word Spotting) para aplicaciones donde la detección de unas cuantas palabras es suficiente para realizar una transacción. Las aplicaciones más comunes que se han desarrollado son: servicios de operador automático, servicios de sección amarilla y servicios de asistencia, como se demuestra en [8].. 20.
(23) 2.2. ESTADO DEL ARTE Teniendo en cuenta los conceptos previos como base para la realización de este trabajo, podríamos afirmar que, el principal objetivo del Reconocimiento de Habla es proporcionar una adecuada interacción entre el hombre y la máquina a través de las órdenes habladas. De esta manera los resultados que esta tecnología brinde deberán estar en contraste con teclados, paneles, ratones, etc. Las principales características que diferencian a los sistemas basados en Reconocimiento del Habla frente a otras alternativas, son: “La naturalidad que supone utilizar el habla en las operaciones de comando y control, y la precisión y robustez en la comunicación para diferentes usuarios y diferentes entornos”, como sostiene [1]. El estado actual de la investigación en Reconocimiento del Habla nos muestra excelentes resultados de sistemas trabajando en entornos controlados de laboratorio. Sin embargo, una aplicación real de esta tecnología exige un funcionamiento en el mundo real donde el grado de dificultad de los problemas es un orden de mayor magnitud. Para la búsqueda de una aplicación real, en la Fig. 1 se muestra el modelo genérico de comunicación que el Reconocimiento del Habla propone para el diálogo hombre-máquina para un caso de acceso a una base de datos.. 21.
(24) USUARIO. ESTILO DE HABLA. RECONOCIMIENTO DE PATRONES DE UNIDADES LINGÜÍSTICAS. INTERFAZ DE COMUNICACIÓN. INFORMACIÓN DE LA BASE DE DATOS. . Fig. 1.. Modelo genérico de comunicación para Reconocimiento del Habla. Fuente: Fandiño, D. (2005). Recuperado de: Estado del arte en el reconocimiento Automático de voz.. En la propuesta de Aviles [9] sobre una silla de ruedas multifuncional se da la idea para tomar el camino inicial de este trabajo donde se pueden extraer las características electromecánicas de una silla de ruedas. Para complementar la idea del presente modelo propuesto, en el trabajo de Gutiérrez [10] presenta algunos dispositivos de control para personas con discapacidad, y la forma de interactuar con ellos, y cómo responden estos a las órdenes proporcionadas. De esta manera, teniendo en cuenta que, el principio utilizado para el modelo propuesto, es el reconocimiento de órdenes por voz, por lo tanto, es necesario conocer diferentes procedimientos para su utilización en aplicaciones de voz, en este trabajo y los siguientes, encontramos diferentes maneras de extracción de características y la manera de reconocerlas para su interpretación en dichas aplicaciones. Tenemos, por ejemplo, Cadenas Ocultas de Markov, análisis por frecuencia, amplitud y. 22.
(25) tiempo, se aplican también Transformadas Rápidas de Fourier entre otras, como se demuestra claramente en [11]. Además de la revisión de técnicas de procesado y representación de la señal de voz para el reconocimiento del habla en ambientes ruidosos para la implementación de este sistema, por ejemplo, ver [12]. Así como también la selección de características usando HMM para la identificación de patologías de voz, explicada en [13]. Para el desarrollo del sistema es necesario el uso de la extracción de características en tiempo-frecuencia de residuos de fonemas sonoros para el reconocimiento de voz, como se muestra en [14]. Además de conocer sobre los fundamentos del reconocimiento automático de la voz y algoritmos de extracción de características, detallado en [15]. En la implementación del sistema las principales técnicas a usarse son las redes neuronales artificiales [16] y agentes, donde según Baltimore [17] se tienen diferentes tipos de agentes, los cuales servirán de base para el modelo propuesto, además de realizar un buen diseño y presentación de las interfaces para el sistema siguiendo métodos adecuados para su desarrollo, por ejemplo, ver [18].. 2.3. INTERFACES Para la implementación del sistema se debe tener en cuenta lo que indica [18] “Es necesario profundizar en los aspectos cognitivos del ser humano, para definir modelos de interfaces adaptadas a las necesidades individuales y sociales. Las interfaces son los dispositivos de contacto entre un usuario y una máquina”. Bajo la idea de que los sistemas informáticos establecen la interacción entre usuario-máquina-usuario, se considera que el diseño de las interfaces influye en el proceso de comunicación interactiva y es importante conocer. 23.
(26) las técnicas de diseño para la interfaz del sistema. Las cuales serán descritas a continuación:. 2.3.1. Tecnologías de interfaces de voz De acuerdo a [18] se tiene la siguiente clasificación: El texto en forma literal es fundamental para la comprensión y desarrollo del trabajo a) Detección de tonos (DTMF): El usuario oye una voz que le da las instrucciones y pulsa el teclado del terminal para escoger las opciones. El sistema reconoce la opción dada por el usuario a partir del tono pulsado. b) Reconocimiento de voz (ASR): El usuario oye una voz que le da las instrucciones y responde con la voz para escoger las opciones. El sistema reconoce lo que dice el usuario. c) Síntesis de voz (TTS): La voz que oye el usuario no está pregrabada, es voz sintetizada. útil para dar respuestas con valores variables. d) Verificación de la persona que habla (SV): Es la vertiente biométrica del reconocimiento de voz que permite reconocer a la persona a través de las características de su voz. Además se considera que es necesario conocer e identificar los diferentes tipos de interfaces para el presente trabajo.. 24.
(27) 2.3.2. Tipos de Interfaces Donde [18] también menciona los tipos de interfaces entre las cuales se halla las orientadas a discapacidades, que son de primordial conocimiento para este trabajo: Considero que si no se pone el texto literalmente, puede perder claridad para la comprensión necesaria de los conceptos.. a) Interfaces gráficas o GUI’s: Las interfaces gráficas o GUI (del inglés Graphical User Interfaces) son un tipo de interfaces que permiten la interacción del usuario con la máquina mediante objetos gráficos, métodos visuales e iconos para representar la información. b) Interfaces web: Habitualmente, utilizamos la web mediante el ratón, teclado y monitor, pero en el caso de personas con discapacidades, se complementan con los siguientes métodos: - Personas con ceguera total: Con sintetizadores de voz que leen la pantalla o líneas Braille, una interfaz de salida que traduce las letras al lenguaje en relieve Braille. - Personas con deficiencias visuales: Hacen servir monitores especiales que amplían la pantalla o crean contrastes para resaltar las letras. - Personas con limitaciones motrices: Utilizan sistemas de reconocimiento de voz que hacen la función del teclado o del ratón. - Personas con sordera: Alternativas textuales a los contenidos multimedia sonoros.. 25.
(28) c) Interfaces de voz: obedecen las órdenes mediante la voz, que permite hacer operaciones para realizar una petición. d) Interfaces táctiles: con el desarrollo de nuevos sistemas operativos, más visuales y manejables, surgieron las pantallas táctiles, reduciendo el coste y haciendo más fácil la navegación. e) Interfaces de atención del usuario: los aplicados a controlar la mirada hacia los productos de una zona comercial. f) Orientadas a discapacidades: Escribir en un ordenador, navegar por Internet, leer un texto en pantalla o mover el ratón son actividades sencillas y rutinarias para la mayoría, pero existen personas que padecen alguna discapacidad que limita su acceso a estas herramientas. Interfaces para ciegos: tanto la maquinaria como el programa, es totalmente adaptado. En el apartado de dispositivos de entrada se crearon los teclados con Braille, que pueden ser mixtos, entre Braille y tradicional, o teclados de Braille por funciones. Como dispositivos de entrada y salida tenemos los sistemas de reconocimiento de voz, los sintetizadores de voz y los procesadores de texto para ciegos. Interfaces para sordos: programas donde un terminal convierte la voz en texto y al revés, llamada por vibración o visual del teléfono móvil.. Interfaces para parapléjicos: La primera interfaz que apareció fue una combinación entre pantalla táctil y un puntero que hacía de ratón que la persona movía con la boca; aunque era poco ágil para el usuario, fue el precursor de investigaciones con formas parecidas, como la del Instituto Fraunhover en Alemania, que ha desarrollado un sistema de. 26.
(29) movimiento de punteros que puede interactuar con la máquina mediante la mirada, haciendo movimientos con los ojos para validar una acción, como cerrar una ventana o abrirla. Actualmente, los sistemas informáticos para parapléjicos se focalizan en la interactuación total mediante la voz, tanto de entrada como de salida del PC. Estudios de automatización de la voz desarrollados en cursos de idiomas interactivos, donde se valora la pronunciación del usuario y se puede establecer una conversación, han ayudado a avanzar en el diseño de interfaces para personas afectadas de paraplejia. g) Orientadas a la realidad virtual: realidad paralela a la real, Estos sistemas se basan en el denominado paradigma de la “realidad aumentada”. h) Orientadas a entornos industriales: sirven para controlar los procesos productivos de la maquinaria y otras forman parte de estos mismos procesos, proporcionando información a los trabajadores o como medio de interacción. i) Orientadas al ocio y a los juegos: Son diversas las interfaces de interacción con el usuario que los juegos proporcionan, como por ejemplo los joysticks, volants, joypads, etc. j) Orientadas a la educación: La docencia virtual utiliza interfaces multimodales para impartir contenidos docentes a los estudiantes.. 2.3.3. Ergonomía para interfaces En este trabajo es necesario puntualizar en el tema de la ergonomía ya que está dirigido a la interacción del usuario con el sistema, puesto que la ergonomía es el estudio de todas las. 27.
(30) actividades humanas (capacidades y limitaciones) relacionadas con el conocimiento y el procesamiento de la información que influyen o están influidas por el diseño de máquinas y objetos que usan las personas, relacionados con procesos de trabajo y entornos con los que interactúan. Es necesario tomar en cuenta los aspectos y principios que considera [21] respecto a la ergonomía, para un buen diseño de las interfaces que se implementará en el sistema, los cuales se mencionan a continuación: Considero relevante citar literalmente el texto para una completa comprensión.. Aspectos considerados por la ergonomía Organización de los controles y pantallas para permitir una acción rápida del usuario, que debe poder acceder a todos los controles y ver toda la información sin mover excesivamente el cuerpo: Información más importante situada a la altura de los ojos, colocación espaciada de los controles y prevención de los reflejos. Entorno físico de la interacción Aspectos de salud: posición física, tiempo de permanencia ante el ordenador, temperatura, radiación de las pantallas, Uso del color, los diferentes colores deben ser distinguibles en la presentación de información Percepción visual y auditiva y diseño de soportes de información Percepción y efectos del contexto en la codificación de estímulos. 28.
(31) Atención, ejecución en doble tarea y compatibilidad estímulo Respuesta Carga mental, vigilancia y asignación de funciones Aprendizaje, ejecución habilidosa Memoria y sus limitaciones en la ejecución de tareas complejas Lenguaje, lectura y comunicación hombre Ordenador Resolución de problemas, razonamiento y procesos de control. Principios de la ergonomía a) Principios de procesamiento: Adquirir o percibir información (que entra por los sentidos o que es activada a partir de la memoria permanente o a largo plazo) mediante su reelaboración a través de una serie de transformaciones y estrategias tales como los procesos de codificación. Retener la información mediante estrategias de retención, tales como la repetición o repaso en la memoria a corto plazo, selección de información mediante procesos atencionales que también "administran" la capacidad limitada de procesamiento del sistema, etc. Por último, la información será recuperada para su uso mediante otros procesos.. 29.
(32) b) Principios de representación:: Los usuarios desarrollan conocimiento y comprensión de un sistema aprendiendo, experimentando y usándolo. Este conocimiento se refiere a: cómo usar el sistema en cada momento y qué hacer con sistemas no familiares o situaciones inesperadas Las personas usan estas construcciones internas o “teorías” implícitas de algún aspecto del mundo exterior que les permite hacer inferencias o predicciones para cada tarea o interacción con cada interfaz o producto. c) Principios de limitación de capacidad de procesamiento: El sistema cognitivo tiene una capacidad limitada para procesar información debido a limitaciones estructurales (por ejemplo, de los almacenes de memoria o de los sistemas sensoriales, etc.) que impiden o dificultan el procesamiento de estimulación excesiva. Habrá eficacia o sobre carga mental (mental workload) según sea: La dificultad de la tarea y el nivel de conocimientos, experiencia y/o práctica.. Principios psicológicos generales en el diseño de interfaces: Visibilidad: "Con solo mirar, el usuario puede decir cuál es el estado del dispositivo y las opciones de la acción". Un buen modelo conceptual: El diseñador proporciona al usuario un buen modelo conceptual, coherente en la exposición. 30.
(33) de las operaciones y los resultados y con una imagen del sistema coherente y pertinente. Buena topografía: Que sea "posible determinar las relaciones entre los actos y los resultados, entre los mandos y sus efectos, y entre el estado del sistema y lo que es visible". Retroalimentación: El usuario recibe una retroalimentación completa y constante acerca de los resultados de sus actos.. 2.3.4. Usabilidad para interfaces En este trabajo, además de lograr tener un buen diseño de interfaces a través de la ergonomía, se tendrá en cuenta conceptos de usabilidad que permitirá brindarle calidad al sistema. Según [22] se tiene que “La usabilidad es el grado con el que es fácil de usar un producto o sistema. La evaluación de usabilidad es el proceso de tener a los usuarios interactuando con el sistema para identificar defectos de ergonomía cognitiva en el diseño pasados por alto por los diseñadores”. Respecto a las visiones y variables señaladas por [22] se especifican de la siguiente manera: Considero que, si no cito el texto literalmente, puede perder vigor o claridad. Visiones sobre la usabilidad: Orientación al producto, como una forma de medir términos de atributos ergonómicos del producto. Orientación al usuario, como una medida en términos del esfuerzo mental y de actitud del usuario frente al producto.. 31.
(34) El rendimiento del usuario, que establece relación con la medida de cómo el usuario interactúa con el producto, poniendo el énfasis en cómo de fácil es el producto de usar y cuál es su aceptabilidad en el sentido de ser usado en el mundo real.. Variables de medición: Facilidad de aprendizaje (learnability). El sistema debe ser fácil de aprender de modo que el usuario pueda rápidamente empezar a funcionar con él. Efectividad. Que se logren los objetivos finales del sistema con la máxima precisión posible. Eficiencia. Utilizar la menor cantidad de recursos/esfuerzo por parte del usuario para conseguir dichos objetivos desde que ha aprendido el sistema. Facilidad de recuerdo (memorabilidad). El sistema debe ser fácil de recordar de forma que un usuario casual sea capaz de volver al sistema después de algún periodo de no usarlo sin tener que aprender algo otra vez. Errores. El sistema debe tener una baja tasa de error y si se cometen errores, los usuarios los deben poder rectificar. Errores catastróficos no deben ocurrir. Satisfacción. El sistema debe ser agradable de usar, de modo que los usuarios estén subjetivamente satisfechos de usarlos, que les guste.. 32.
(35) 2.4. TÉCNICAS DE DISEÑO Para el desarrollo del presente trabajo se van a analizar a continuación cuatro técnicas distintas que se utilizan o se han utilizado para el diseño de reconocedores de habla. De ahora en adelante se llamará "palabra" a la unidad básica en la que se base el reconocedor (en la realidad pueden ser sílabas, demisilabas, fonemas, morfemas, palabras, conjuntos de palabras etc.). Estas técnicas son: Técnicas topológicas: Dynamic Time Warping (DTW), basado en el cálculo y comparación de distancias. Técnicas probabilísticas: Modelos ocultos de Markov (HMM), que son modelos generativos de las palabras del vocabulario. Redes neuronales. Sistemas basados en el conocimiento: reconocedores por reglas o sistemas expertos.. A lo que [31] explica que: “En los cuatro casos se puede hablar de una fase de entrenamiento (cálculo de los patrones de referencia, cálculo de los parámetros de los modelos de Markov, entrenamiento de las redes neuronales o creación de estructuras de datos para los sistemas expertos) y de otra fase de reconocimiento propiamente dicho. Y también en los cuatro casos el primer proceso necesario es la parametrización o transformación de la forma de onda de la señal entrante en un conjunto de parámetros o características adecuadas a cada reconocedor”. Es por eso que en este trabajo, se debe conocer el funcionamiento de las técnicas mencionadas anteriormente para la implementación del sistema, las cuales se desarrollaran a detalle a continuación:. 33.
(36) 2.4.1. Distancia de Alineamiento Temporal (Dynamic Time Warping) De acuerdo al análisis sobre esta técnica, Fandiño [1] nos señala que los sistemas de reconocimiento basados en DTW ((Dynamic Time Warping) funcionan de la siguiente manera: El texto es fundamental para la comprensión y desarrollo del resto del trabajo. Primero se parametriza la señal de voz a reconocer; para ello se divide en pequeñas ventanas de análisis (unos 20 mseg), y sobre cada una de esas ventanas se realiza un proceso de análisis que extrae un conjunto de parámetros (que pueden ser acústicos o coeficientes espectrales). Ese conjunto o vector de parámetros se puede ver como un punto en un espacio n-dimensional. El conjunto de todas las ventanas de análisis se convertirá así en una secuencia de puntos en ese espacio, y esa secuencia de puntos es lo que se llama "patrón" o “plantilla". El sistema reconocedor dispone de un conjunto de patrones de "referencia" que se hayan calculado en la fase de entrenamiento, y que representan al conjunto de palabras del vocabulario que el sistema puede reconocer. De esta forma, una vez obtenida la plantilla de la palabra, la tarea del reconocedor consiste en compararla con todos los patrones de referencia que el sistema tiene, calculando la "distancia" que la separa de las referencias, y elegir como palabra reconocida aquella cuya plantilla de referencia de la menor distancia en la comparación.. 34.
(37) Normalmente esas distancias se calcularían como la suma: m. n. X Y d. i1. XY. ij. ij. 0.5 2. j1. Ecuación 1: cálculo de distancias. Donde X es la plantilla de entrada, formada por m vectores de dimensión n, e Y es la referencia, también formada por m vectores de dimensión n. El problema surge cuando X e Y tienen distinto número de vectores (lo cual se deberá a la distinta duración de la pronunciación de las palabras X e Y): ¿Qué hacer con los vectores que sobran del patrón más largo?. Las técnicas de programación dinámica resuelven este problema: si X tiene m2 vectores e Y tiene m2 vectores, lo que se hace es "deformar" el eje de tiempos, estirándolo o encogiéndolo a voluntad para alinear ambos patrones de forma que vectores que representen sonidos iguales (o lo más parecidos posible) queden enfrentados a la hora de calcular las distancias. Así la distancia entre las dos plantillas se calcula siguiendo estos pasos: a) Se calcula la matriz de distancias locales d(i,j) entre cada vector i del patrón de entrada X y cada vector j del de referencia Y, obteniendo una matriz de dimensiones [ml x m2].. b) Se calcula la matriz de distancias acumuladas g(i,j), utilizando las distancias locales d(i,j) según la formula recursiva: g(i,j) = d(i,j) t mintg(i-l,j), g(i- I ,j- I ), g(i,j-l) Ecuación 2: matriz de distancias acumuladas. 35.
(38) c) Es decir, la distancia acumulada entre dos vectores es la suma entre su distancia local y la distancia acumulada mínima de los puntos vecinos anteriores en el tiempo. d) La distancia total entre X e Y es la distancia acumulada entre los últimos vectores de ambas plantillas: g(m1,m2). La Fig. 2. muestra cómo podría quedar la alineación entre dos patrones de longitudes m1 y m2 ("Referencia" y "Palabra a reconocer”). Fig. 2. Alineamiento temporal entre la "Referencia" y la "Palabra a reconocer” Fuente: Fandiño, D. (2005). Recuperado de: “Estado del arte en el reconocimiento Automático de voz.”. El algoritmo que se acaba de describir es una versión muy simple de DTW. Con una tasa elevada de reconocimiento que va por encima del 98%.. 36.
(39) 2.4.2. Modelos ocultos de Markov Para el reconocimiento de voz en este trabajo se verá otro enfoque alternativo donde [35] nos indica que “Al de medir distancias entre patrones (enfoque topográfico) es el de adoptar un modelo estadístico (paramétrico) para cada una de las palabras del vocabulario de reconocimiento, como son los modelos ocultos de Markov (HMM, del ingles 'Hidden Markov Models')”. Hay que tener en cuenta que [41] escribió su teoría de que “Un HMM se puede ver como una máquina de estados finitos en que el siguiente estado depende únicamente del estado actual, y asociado a cada transición entre estados se produce un vector de observaciones o parámetros (correspondiente a un punto del espacio n-dimensional del que se hablaba en el apartado anterior)”. Se puede así decir que un modelo de Markov lleva asociados dos procesos: uno oculto (no observable directamente) correspondiente a las transiciones entre estados, y otro observable (y directamente relacionado con el primero), cuyas realizaciones son los vectores de parámetros que se producen desde cada estado y que forman la plantilla a reconocer. La Fig. 3. representa un modelo con 'n' estados en el que desde cada estado sólo se permiten tres tipos de transición: al propio estado, al estado vecino y a dos estados más allá (este tipo de saltos que da recogido en una matriz de transiciones tridiagonal).. 37.
(40) a11. a22. a33. a23. a12 Q1. ann. Q2. an-1,n Q3. a13. Qn. a24. a11 a12 0 a22 A ........... an-2,n. a13 0 a23 a24. 0 0. 0 0. .............................. ............ 0. 0. 0. 0. 0 1. Fig. 3. Modelo de Markov con 'n' estados Fuente: Oropeza, J. (2000), Recuperado de: “Reconocimiento de voz, codificación predictiva lineal y Cadenas Ocultas de Markov”.. En cuanto a la generación de puntos de la plantilla, en estos modelos se asume que el primer vector de observaciones se produce desde el primer estado, y el último se emite desde el último estado. Teniendo en cuenta que la secuencia de estados es la parte oculta del modelo: se conocen los vectores de parámetros, pero no desde que estado se han producido. Viendo de esta manera los parámetros que se aplicarán al sistema que se va a implementar.. 2.4.3. Redes neuronales Este sistema de reconocimiento de voz basado en redes neuronales artificiales estará desarrollado mediante la interconexión de un conjunto de unidades de proceso (o neuronas) en paralelo (de forma similar que en la mente humana), obtener. 38.
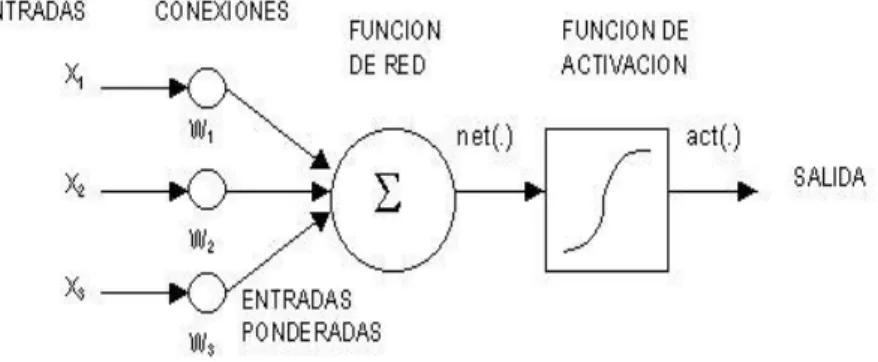
(41) prestaciones de reconocimiento similares a las humanas, tanto en tiempo de respuesta como en tasa de error. Esa forma de interconexión de las unidades de proceso es especialmente útil en aplicaciones que requieren una gran potencia de cálculo para evaluar varias hipótesis en paralelo, como sucede en los problemas de reconocimiento de audio. Para entender mejor esto, se verá la comparación entre RNA y Redes biológicas. 2.4.3.1.. Redes. neuronales. biológicas. y. redes. neuronales artificiales De acuerdo a [47] donde señala que: “Las neuronas artificiales son modelos que tratan de simular el comportamiento de las neuronas biológicas. Cada neurona se representa como una unidad de proceso que forma parte de una entidad mayor, la red neuronal”.. Fig. 4. Modelo de una RNA Fuente: Vemuri, V. (1990). Recuperado de: “Artificial Neural Networks: Theoretical Concepts Computer Society Press”. Como puede verse en la Fig. 4, dicha unidad de proceso consta de una serie de Entradas Xi, que equivalen a las dendritas de donde reciben la estimulación, ponderadas. 39.
(42) por unos pesos Wi , que representan como los impulsos entrantes son evaluados y se combinan con la función de red que nos dará el nivel de potencial de la neurona. La salida de la función de red es evaluada en la función de activación que da lugar a la salida de la unidad de proceso. La neurona artificial se comporta como la neurona biológica pero de una forma muy simplificada. Por las entradas Xi llegan unos valores que pueden ser enteros, reales o binarios. Estos valores equivalen a las señales que enviarían otras neuronas a la nuestra a través de las dendritas. Los pesos que hay en las sinapsis Wi, equivaldrían en la neurona biológica a los mecanismos que existen en las sinapsis para transmitir la señal. De forma que la unión de estos valores (Xi y Wi) equivalen a las señales químicas inhibitorias y excitadoras que se dan en las sinapsis y que inducen a la neurona a cambiar su comportamiento. Estos valores son la entrada de la función de ponderación o red que convierte estos valores en uno solo llamado típicamente el potencial que en la neurona biológica equivaldría al total de las señales que le llegan a la neurona por sus dendritas. La función de ponderación suele ser una la suma ponderada de las entradas y los pesos sinápticos. La salida de función de ponderación llega a la función de activación que transforma este valor en otro en el dominio que trabajen las salidas de las neuronas. Suele ser una función no lineal como la función paso o sigmoidea aunque también se usa funciones lineales.. 40.
(43) TABLA 1. COMPARACIÓN ENTRE NEURONAS BIOLÓGICAS Y NEURONAS ARTIFICIALES. Fuente: Vemuri, V. (1990). Recuperado de: “Artificial Neural Networks: Theoretical Concepts Computer Society Press”. 2.4.3.2. Elementos de la red neuronal artificial Según Diederich [55] en las redes neuronales artificiales se pueden identificar los elementos a continuación: Es necesario colocar el texto para el desarrollo del trabajo. Pesos sinápticos (wij): ligas de conexión entre los datos de entrada y el sumador. Si estas son positivas entonces son excitatorias, de lo contrario son inhibitorias. Sumador: concentra la información como una combinación lineal de los pesos sinápticos y de la entrada. Conocido como la regla de propagación de. 41.
(44) la suma ponderada de las entradas multiplicadas por los pesos. Umbral: disminuye la entrada (obtenida en el sumador) a la función de la función de activación. Función de activación: limita la amplitud de la respuesta de la neurona al intervalo [0; 1] o [-1; 1]. La forma en que las neuronas se conectan entre si define la topología de la red, y se puede decir que el tipo de problemas que una red neuronal particular soluciona de forma eficiente, depende de la topología de la red, del tipo de neuronas que la forman, y la forma concreta en que se entrena la red. En base a esto, Harston [57], indica que: “El algoritmo particular de entrenamiento dependerá de la estructura interna de las neuronas, pero, en cualquier caso, el entrenamiento se llevara a cabo a partir de una base de datos etiquetada”, de esta manera, como sucedía con los modelos de Markov, será un proceso iterativo en el que se modifican los parámetros de la red para que ante un conjunto determinado de estímulos (plantillas), produzca una respuesta determinada: la palabra del vocabulario representada por esas plantillas.. 2.4.3.3. Perceptrón Multicapa En [58] se explica que “Es una red neuronal artificial formada por multicapas, esto le permite resolver problemas que no son linealmente separables lo cual es la principal limitación del perceptrón (también llamado perceptrón simple)”.. 42.
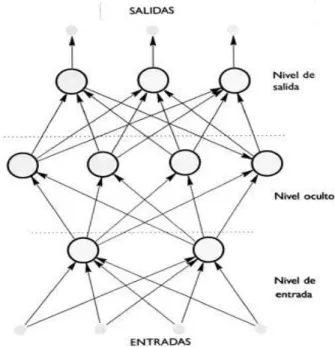
(45) En este sistema se estará trabajando con la red neuronal multicapa para el reconocimiento automático del habla, también llamada "perceptrón multicapa". La Fig. 5 muestra su topología: las neuronas se disponen por "capas". Capa de entrada: las neuronas de la capa de entrada, reciben los datos que se proporcionan a la RNA para que los procese. Opera directamente sobre los vectores de observación o puntos de las plantillas. Capas ocultas: estas capas introducen grados de libertad adicionales en la RNA. El número de ellas puede depender del tipo de red que estemos considerando. Este tipo de capas realiza gran parte del procesamiento. Capa de salida: Esta capa proporciona la respuesta de la red neuronal. Apunta la palabra reconocida. Cada capa está compuesta por varias unidades de proceso, que se conectan con la siguiente capa por una serie de enlaces a los que se da un cierto peso especifico wij.. 43.
(46) Fig. 5. Neurona. Red Neuronal Fuente: Rojas, R. (2006). Recuperado de: “Diseño y desarrollo de prototipo de sistema de traducción instantánea de habla y transmisión en tiempo real, sobre el protocolo RTP utilizando tecnologías de reconocimiento de voz”. Fig. 6. Red Neuronal multicapa Fuente: Rojas, R. (2006). Recuperado de: “Diseño y desarrollo de prototipo de sistema de traducción instantánea de habla y transmisión en tiempo real, sobre el protocolo RTP utilizando tecnologías de reconocimiento de voz”. 44.
(47) 2.4.3.4. Entrenamiento de una red neuronal artificial. Tal como explica [61], para el entrenamiento de una RNA podemos distinguir dos fases o modos de operación: a). Fase de aprendizaje o entrenamiento, la red es entrenada para realizar un determinado tipo de procesamiento.. b). Fase de operación o ejecución, donde la red es utilizada para llevar a cabo la tarea para la cual fue entrenada.. Una vez seleccionada el tipo de neurona artificial que se utilizará en una red neuronal y determinada su topología es necesario entrenarla para que la red pueda ser utilizada. Partiendo de un conjunto de pesos sinápticos aleatorio, el proceso de aprendizaje busca un conjunto de pesos que permitan a la red desarrollar correctamente una determinada tarea. Durante el proceso de aprendizaje se va refinando iterativamente la solución hasta alcanzar un nivel de operación suficientemente bueno.. Además [63] señala que el proceso de aprendizaje se divide en tres grandes grupos de acuerdo a sus características: Es relevante poner literalmente el texto para la compresión de los conceptos de modo exacto.. 45.
(48) 1. Aprendizaje supervisado. Se presenta a la red un. conjunto de patrones de entrada junto con la salida esperada. Los pesos se van modificando de manera proporcional al error que se produce entre la salida real de la red y la salida esperada. 2. Aprendizaje no supervisado. Se presenta a la red un. conjunto de patrones de entrada. No hay información disponible sobre la salida esperada. El proceso de entrenamiento en este caso deberá ajustar sus pesos en base a la correlación existente entre los datos de entrada. 3. Aprendizaje por refuerzo. Este tipo de aprendizaje. se ubica entre medio de los dos anteriores. Se le presenta a la red un conjunto de patrones de entrada y se le indica a la red si la salida obtenida es o no correcta. Sin embargo, no se le proporciona el valor de la salida esperada. Este tipo de aprendizaje es muy útil en aquellos casos en que se desconoce cuál es la salida exacta que debe proporcionar la red.. 2.4.3.5. Red Backpropagation El método backpropagation (propagación del error hacia atrás) formalizado por Rumelhart [52], para que una red neuronal aprendiera la asociación que existe entre los patrones de entrada y las clases correspondientes, utilizando varios niveles de neuronas. Es necesario conocer un análisis detallado del sistema de entrenamiento mediante back-propagation para el. 46.
(49) desarrollo del presente trabajo, para lo cual según [66] se detalla a continuación en qué consiste: Es importante colocar textualmente este proceso para el aprendizaje. Empezar con unos pesos sinápticos cualquiera (generalmente elegidos al azar). Introducir unos datos de entrada (en la capa de entradas) elegidos al azar entre los datos de entrada que se van a usar para el entrenamiento. Dejar que la red genere un vector de datos de salida (propagación hacia delante). Comparar la salida generada por la red con la salida deseada. La diferencia obtenida entre la salida generada y la deseada (denominada error) se usa para ajustar los pesos sinápticos de las neuronas de la capa de salidas. El error se propaga hacia atrás (back-propagation), hacia la capa de neuronas anterior, y se usa para ajustar los pesos sinápticos en esta capa. Se continua propagando el error hacia atrás y ajustando los pesos hasta que se alcance la capa de entradas. Este proceso se repetirá con los diferentes datos de entrenamiento.. 47.
(50) Fig.7. Arquitectura de una red neuronal Artificial Backpropagation Fuente: Trujillano J. (2005). Recuperado de: “Artificial neuronal networks in. Intensive Medicine”. En la Fig. 7 se puede apreciar la arquitectura y a su vez la importancia de la red backpropagation donde [70] señala que “consiste en su capacidad de auto adaptar los pesos de las neuronas de las capas intermedias para aprender la relación que existe ente un conjunto de patrones de entrada y sus salidas correspondientes. Es importante la capacidad de generalización, facilidad de dar salidas satisfactorias a entradas que el sistema no ha visto nunca en su fase de entrenamiento”. La red debe encontrar una representación interna que le permita generar las salidas deseadas cuando se le dan entradas de entrenamiento, y que pueda aplicar, a entradas no presentadas durante la etapa de aprendizaje para clasificarlas.. 48.
(51) 2.4.4. RECONOCIMIENTO DE PATRONES DE VOZ Para el desarrollo de este sistema se debe tener en cuenta de manera exacta los conceptos de reconocimiento de patrones, donde se hace referencia específicamente al que consiste en el reconocimiento de patrones de señales. Los patrones se obtienen a partir de los procesos de segmentación, extracción de características y descripción donde cada objeto queda representado por una colección de descriptores. En base a esto, en [74] se puede encontrar que el sistema de reconocimiento debe asignar a cada objeto su categoría o clase (conjunto de entidades que comparten alguna característica que las diferencia del resto), siguiendo los procesos de Adquisición de datos, extracción de características y toma de decisiones. Para clasificar una señal por de sus características, como sonidos dependiendo de las frecuencias.. Fig. 8. Reconocimiento de patrones de voz Fuente: (2012). Recuperado de: https://iagrupo7.wordpress.com/2012/04/. La Fig. 8. Muestra el modelo de un sistema completo de reconocimiento de patrones de voz, incluye un sensor que recoja fielmente los elementos del universo a ser clasificado, un mecanismo de extracción de características cuyo propósito es extraer la información útil, eliminando la información redundante e irrelevante, y finalmente una etapa de toma de decisiones en la cual se asigna a la categoría apropiada los patrones de clase desconocida a priori.. 49.
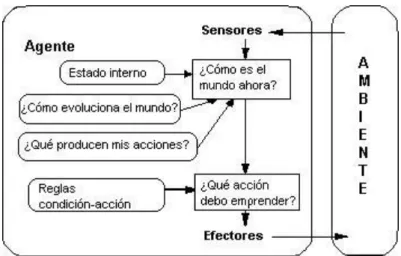
(52) 2.5. VECTOR DE CARACTERÍSTICAS La parametrización de la voz cumple un doble objetivo: primero, busca reducir la cantidad de información redundante de la señal de voz y, segundo, facilitar la tarea de reconocimiento y tratamiento de la misma, conceptos de vital importancia para el desarrollo del presente trabajo. Como sostiene [82], uno de los más utilizados es la parametrización cepstral en la escala Mel (MFCC Mel Frequency Cepstral Coefficients), adicionándole los parámetros transicionales: Delta (velocidad) y DeltaDelta (aceleración). Adicionando también la energía de la trama y sus derivadas primera y segunda.. 2.6. AGENTES Los Agentes serán utilizados en el sistema para delegarles una o varias tareas que debe llevar a cabo el reconocimiento de las órdenes habladas. Para lo cual se debe tener en cuenta las propiedades de los agentes, que [86] presenta a continuación:. 2.6.1. Propiedades de los agentes El texto es fundamental para la comprensión y desarrollo del resto del trabajo Continuidad Temporal: se considera un agente un proceso sin fin, ejecutándose continuamente y desarrollando su función. Autonomía: un agente es completamente autónomo si es capaz de actuar basándose en su experiencia, sin la intervención de un ser humano u otro agente. El agente es capaz de continuar aunque el entorno cambie severamente, o cuando el agente percibe el entorno.. 50.
(53) Sociabilidad: este atributo permite a un agente comunicar con otros agentes o incluso con otras entidades. Racionalidad: el agente siempre realiza lo correcto a partir de los datos que percibe del entorno. Reactividad: un agente actúa como resultado de cambios en su entorno. En este caso, un agente percibe el entorno y esos cambios dirigen el comportamiento del agente. Pro-actividad: un agente es pro-activo cuando es capaz de controlar sus propios objetivos a pesar de cambios en el entorno. Esta definición no contradice la de re-actividad. El comportamiento del agente es resultado de dos tipos de comportamientos, el comportamiento receptivo y el comportamiento de descubrimiento. En un comportamiento receptivo, el agente es guiado por el entorno. El comportamiento de descubrimiento aúna procesos internos del agente para obtener ´ sus propios objetivos. El agente debe tener un grado de comportamiento receptivo (atributo de reactividad) y un grado de comportamiento de descubrimiento (atributo de proactividad). Adaptatividad: está relacionado con el aprendizaje que un agente es capaz de realizar y si puede cambiar su comportamiento basándose en ese aprendizaje. Movilidad: capacidad de un agente de trasladarse a través de una red telemática. Veracidad: asunción de que un agente no comunica información falsa a propósito. Benevolencia: asunción de que un agente está dispuesto a ayudar a otros agentes que lo solicitan, si esto no entra en conflicto con sus propios objetivos.. 51.
(54) 2.6.2. Modelización de agentes: AUML AUML no es en sí una metodología o un método sino que se centra más en intentar adaptar herramientas de desarrollo ya existentes y que están teniendo éxito para aplicaciones industriales reales, tratando de orientarlas hacia el campo de los agentes. El desarrollo a nivel industrial de la tecnología de agentes requiere técnicas que reduzcan el riesgo inherente en toda nueva tecnología. Existen dos maneras de reducir el riesgo, según expone [88]: “Presentar la nueva tecnología como una extensión incremental de métodos ya conocidos y probados; y Proveer herramientas de ingeniería explicitas que den soporte a métodos aceptados por la industria de desarrollo de tecnología”. Un agente se puede ver como una extensión del concepto de objeto activo, mostrando a la vez autonomía dinámica (habilidad de empezar algo sin una invocación externa) y autonomía determinística (habilidad para revocar o modificar peticiones), como indica Wooldridge [92]. La visión que se presenta de un agente lleva a explorar extensiones de UML para poder acoplarse a los requisitos que necesita un agente. El resultado de esto es AUML. AUML sintetiza el creciente interés por disponer de metodologías de desarrollo orientadas a agentes con la gran aceptación obtenida por UML.. 52.
(55) De acuerdo a [97] se debe cumplir con los siguientes requisitos para un correcto modelado: Es necesario citarlos literalmente, ya que en caso contrario el texto podría perder claridad. Capturar la dependencia causal entre las escenas; Definir los mecanismos de sincronización de las escenas; Establecer los mecanismos de paralelismo de las escenas Administrar la identidad de los participantes Definir y validar los requerimientos en base a las capacidades de los participantes o Establecer convenciones de interacción. Facilitar la interacción efectiva. Lograr la satisfacción de objetivos Definir puntos de elección que permita a los roles dejar una escena y elegir qué actividad realizará a continuación Establecer la políticas de flujo de los roles entre las diversas escenas.. 53.
(56) CAPÍTULO III METODOLOGIA. 54.
(57) CAPITULO III 3.1. METODOLOGIA El modelo propuesto para el desarrollo del sistema, comprende las siguientes etapas:. Pre procesamiento. Extractor de características. Red Neuronal. Agente de estados. voz. Fig. 9. Modelo propuesto Fuente: propia. En la Fig. 9, se puede observar que se utilizará la técnica de redes neuronales, para el reconocimiento de voz. El modelo utilizará órdenes vocales y deberá ser capaz de activar y/o desactivar estados, que podrían servir de entrada para una interfaz electrónica, para el control de una silla de ruedas electrónica. Esto implica órdenes que el modelo deberá ser capaz de reconocer, las que se verán a continuación.. 3.1.1. Vocabulario Las palabras sugeridas para el modelo son: Avanzar Activa los estados correspondientes para hacer mover la silla hacia delante.. 55.
(58) Retroceder Activa los estados correspondientes para hacer mover la silla hacia atrás. Derecha Activa los estados correspondientes para hacer girar la silla a la derecha, el ángulo del giro debería ser tratado en la interfaz electrónica. Izquierda Activa los estados correspondientes para hacer girar la silla a la izquierda, el ángulo del giro debería ser tratado en la interfaz electrónica. Detener Activa los estados correspondientes para detener la silla.. 3.1.2. Pre procesamiento de la señal La etapa de pre procesamiento comprende un Detector de Actividad de Voz, mediante el detector de actividad de voz del usuario se realiza una estimación de si hay señal de voz en cuyo caso se prepara una transmisión de vectores de características a la siguiente etapa. En caso contrario no realiza ninguna transmisión. El funcionamiento del DAV se explica por medio de tres posibles estados (DOWN, RISING y DROPPING) en los cuales se entra según sea el valor de la energía (E) de la trama actual, y circundantes. En la Fig. 10, se muestra la señal correspondiente a la palabra derecha y la Fig. 11, representa un ejemplo en el que se muestra la Energía de cada trama respecto al tiempo.. 56.
(59) 0.8 0.6 0.4 0.2. 0 -0.2 -0.4 -0.6 -0.8. -10. 2000. 4000. 6000. 8000. 10000. 12000. 14000. Fig. 10. Digitalización de la palabra “derecha” Fuente: Propia. Fig. 11. Energía respecto al tiempo, para la palabra “derecha” Fuente: Propia. Normalmente el estado del DAV es DOWN, es decir, que no hay voz y sí ruido. En cada muestreo de la señal se va revisando continuamente el valor actual de Energía de la señal de voz. Cuando el frame actual supera un valor (LIMIT1) bastante alto con respecto al ruido de fondo se considera que hay voz y se pasa al estado RISING (que hay voz elevada).. 57.
(60) En el estado RISING se van transmitiendo tramas a medida que van llegando. En este estado estará hasta que la curva decrezca y se pase el límite LIMIT2. Entonces se pasa al estado DROPPING (que está desapareciendo la señal de voz). Al entrar en este estado se espera varias tramas (QUEUEWAIT=10) antes de terminar y volver al estado DOWN indicando que la palabra ha finalizado. La utilidad de la espera final es prevenir que el DAV piense erróneamente que ha terminado la palabra por el simple hecho de que se desvanezca la señal durante unos milisegundos como por ejemplo ocurre en la ”c” de la palabra derecha.. 3.1.3. Extractor de características El extractor de características del modelo propuesto implica la forma de onda de la palabra a reconocer, y su espectro de frecuencias, obteniendo un vector de 256 valores (128 para la forma de onda - energía - y 128 para el espectro de frecuencias): El extractor de características recibe los datos por cada muestra de señal enventanada y los almacena y procesa finalmente, para obtener el vector de características, como se puede observar en la Fig.12.. 58.
(61) Fig. 12. Extractor de características de una palabra. Fuente: Propia. 3.1.4. Red Neuronal Se utiliza la librería FANN (Fast Artificial Neural Network), la que permite crear una red neuronal. Las características de esta librería son: Librería de Red Neuronal Artificial Multicapa, en C Entrenamiento por Backpropagation (RPROP, Quickprop, Batch, Incremental) Fácil de usar(crear, entrenar y correr una RNA (ANN) con 3 llamadas a funciones) Hasta 150 veces más rápida que cualquier otra librería Versátil (es posible ajustar muchos parámetros ‘al vuelo’) Muy bien documentada Multiplataforma Multiples funciones de activación implementadas Framework para el manejo de datos de entrenamiento. 59.
(62) CONFIGURACIÓN. Para el desarrollo del sistema se utiliza la siguiente configuración: Tasa de aprendizaje: 0.7 - especifica cuán agresivo debe ser el entrenamiento, este valor se determina experimentalmente Número de capas: 3 - Topología multicapa. Número de entradas: 256 - Para recibir el vector de características. Neuronas por capa oculta: 64 - La cantidad de neuronas en esta capa ha sido determinada experimentalmente.. Número de salidas: 5 Error deseado: 0.0015 Número de iteraciones máximo: 500. 60.
(63) 3.1.5. Agente. Es necesario contar con la ayuda de un agente, que permita determinar el nivel de confianza del resultado entregado por la red neuronal, además de un autómata, con el que se controlará los datos de la interfase para el control electrónico de la silla de ruedas, como se puede ver de manera gráfica en la Fig. 13. No se implementa la interfase electrónica por no ser objetivo de este proyecto, sin embargo, los datos para el control del mismo pueden ser enviados a través del puerto paralelo. ‘izquierda’. S1 ‘derecha’ ‘avanzar’ ‘detener’ ‘izquierda’. S0 ‘derecha’ ‘detener’ ‘retroceder’ ‘derecha’. S2. ‘izquierda Fig. 13. Diagrama de Estados del Agente. Fuente: Propia. 61.
(64) En términos generales, el agente establecerá la acción a tomar, de acuerdo a los estados actuales de su ambiente, en este caso, la interfaz a la silla de ruedas. Podemos representarlo en forma genérica con la acción del agente ante un estimulo del ambiente como se ve en la Fig.14; o ante un estimulo del ambiente y otros factores representado en la Fig. 15; o también ante un estimulo del ambiente y análisis tal como se observa en la Fig. 16.. Fig. 14. Acción del Agente ante un estimulo del ambiente. Fuente: (2010) Recuperado de: http://razonartificial.com/2010/08/agentesinteligentes. Fig. 15. Acción del Agente ante un estimulo del ambiente y otros factores. Fuente: (2010) Recuperado de: http://razonartificial.com/2010/08/agentesinteligentes. 62.
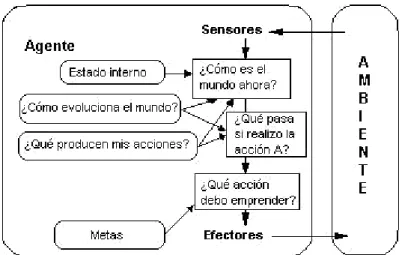
(65) Fig. 16. Acción del Agente ante un estimulo del ambiente y análisis. Fuente: (2010) Recuperado de: http://razonartificial.com/2010/08/agentesinteligentes. 3.2. ANALISIS DEL AGENTE REACTIVO El agente utilizado se encuentra clasificado dentro de los agentes de estímulo/respuesta, pues utiliza un autómata de estados finitos que le permitirá, de acuerdo al estado actual y las entradas que le proporciona la red neuronal, conseguir su siguiente estado, el cual debe ser coherente con el conjunto de reglas establecidas para el funcionamiento de la silla de ruedas.. 63.
Figure


+7



Outline
Documento similar
Como medida de precaución, puesto que talidomida se encuentra en el semen, todos los pacientes varones deben usar preservativos durante el tratamiento, durante la interrupción
Abstract: This paper reviews the dialogue and controversies between the paratexts of a corpus of collections of short novels –and romances– publi- shed from 1624 to 1637:
entorno algoritmo.
por unidad de tiempo (throughput) en estado estacionario de las transiciones.. de una red de Petri
Habiendo organizado un movimiento revolucionario en Valencia a principios de 1929 y persistido en las reuniones conspirativo-constitucionalistas desde entonces —cierto que a aquellas
The part I assessment is coordinated involving all MSCs and led by the RMS who prepares a draft assessment report, sends the request for information (RFI) with considerations,
o Si dispone en su establecimiento de alguna silla de ruedas Jazz S50 o 708D cuyo nº de serie figura en el anexo 1 de esta nota informativa, consulte la nota de aviso de la
Las manifestaciones musicales y su organización institucional a lo largo de los siglos XVI al XVIII son aspectos poco conocidos de la cultura alicantina. Analizar el alcance y
