ESCUELA SUPERIOR DE INGENIERÍA
MECÁNICA Y ELÉCTRICA
ALGORITMO DE COMPRESIÓN DE IMAGENES DE
ALTA RESOLUCIÓN SIN PÉRDIDAS.
TESIS
QUE PARA OBTENER EL TITULO DE INGENIERO
EN COMUNICACIONES Y ELECTRÓNICA
PRESENTA:
MARIO
SANDOVAL OLIVÉ
ASESOR
DRA. MARIA ELENA ACEVEDO MOSQUEDA
UNIDAD PROFESIONAL '"ADOLFO LÓPEZ MATEOS"
TEMA DE TESIS
QUE PARA OBTENER ELTITtJLO DE INGENIEROEN OOMUNICAOONES y ELECTRÓNICA
POR LA OPCIÓN DE TITULACiÓN
TESIS Y EXAMEN ORAL INDIVIDUAL DEBERA(N) DESARROLLAR
c.-MARIO SANDOVAL OUVE
"ALGORITMO DE COMPRESIÓN DE IMÁGENES DE ALTA RESOLUCIÓN Y POCOS COLORES SIN PÉRDIDAS".
DESARROLLAR UNA ALGORITMO QUE REALICE LA COMPRESIÓN SIN PÉRDIDAS DE INFORMACIÓN, DE IMÁGENES DE ALTA RESOLUCIÓN Y POCOS COLORES, UTILIZANDO EL LENGUAJE DE PROGRAMACIÓN C#.
»
ANÁLISIS DE LOS ALGORITMOS EXISTENTE: COMPRESIÓN SIN PÉRDIDAS YCOMPRESIÓN CON PÉRDIDAS
»
MÉTODO PROPUESTO: COMPRESIÓN RSI (RECORRIDO SOBRE LA IMÁGEN)»
DESARROLLO DEL MÉTODO»
PRUEBASMÉXICO D.F., 10 DE NOVIEMBRE DE 2009
ASESORES
M|セセ|lL@
DRA. MARÍA ELENA ACEVEDO MOSQUEDA.
ESIME Zacatenco
ÍNDICE
Resumen ... III Objetivo general ... IV Objetivos específicos ... IV Hipótesis ... V Justificación ... VI Metodología ... VII
Capítulo 1. Introducción ... 1
La compresión de imágenes ... 1
Compresión sin pérdidas (LOSSLESS) ... 1
Compresión con pérdidas (LOSSY) ... 2
Estado del arte ... 4
Capítulo 2. Métodos de compresión de imágenes ... 7
Teoría de imágenes y colores ... 7
Resolución ... 7
Modelos de color ... 8
Métodos de compresión de imágenes ... 9
Código Huffman... 9
JPEG ... 11
EZW ... 14
SPIHT ... 17
RLE ... 21
LZW ... 23
Capítulo 3. Método de recorridos sobre una imagen ... 25
Método de recorrido sobre una imagen ... 25
ESIME Zacatenco
Desarrollo del software ... 33
Capítulo 4. Pruebas y experimentos realizados ... 41
Conclusiones ... 52
Aplicaciones y trabajo a futuro ... 54
Anexos ... 55
Apéndice A ... 55
Apéndice B ... 57
Apéndice C ... 60
Glosario ... 61
ESIME Zacatenco
RESUMEN
El algoritmo de compresión que se propone en este trabajo de investigación realiza la compresión sin pérdidas de una imagen de alta resolución. Esto surge debido que los algoritmos que se usan en la actualidad presentan detalles que hacen que la compresión realizada no sea 100% eficiente.
Este método se distingue de los actuales por la forma en la que la imagen es guardada. El algoritmo recorre la imagen Pixel por Pixel obteniendo la información de la imagen, que en el proceso de descompresión utiliza para reconstruir una nueva imagen que contiene la información de la imagen original. Así, este algoritmo genera una compresión efectiva, en la cual la imagen obtenida no presenta pérdida de información.
Sin embargo, las imágenes las cuales se pueden implementar este método deben ser de pocos colores, debido a la forma en que la información de la imagen es guardada.
ESIME Zacatenco
OBJETIVO GENERAL
Desarrollar un algoritmo que realice la compresión sin pérdidas de una imagen de alta resolución y pocos colores.
OBJETIVOS ESPECIFICOS
Hacer un estudio de los métodos de compresión actuales.
Describir el método de compresión que se propone.
Implementar este algoritmo con imágenes de alta resolución y pocos colores.
ESIME Zacatenco
HIPOTESIS
ESIME Zacatenco
JUSTIFICACIÓN
En la actualidad, han surgido avances tecnológicos de gran relevancia que ayudan a facilitar la vida del ser humano. Un claro ejemplo de esto es la fotografía digital, en donde las imágenes son capturadas por un sensor electrónico, archivándose en una unidad de memoria. Estas imágenes podemos verlas muy a menudo en cualquier página de Internet, publicación, revistas o incluso como fondo en el escritorio de cualquier computadora, y en el caso de la fotografía profesional, ahorra al fotógrafo mucho tiempo al momento del revelado.
Sin embargo, ocupan demasiado espacio lo cual genera dificultad para su envío, manipulación o utilización. Por esta razón se requieren de métodos de compresión los cuales generen que estas imágenes sean procesadas, ocupando menos espacio y siendo de fácil manejo y transporte.
Este ejemplo nos muestra la importancia de la compresión, ya que sin esta diversos formatos de archivo (como pueden ser archivos de sonidos, archivos de video, etc.) no podrían ser transportados y ser utilizados en diversas aplicaciones de usuario. Sin embargo, estas técnicas de compresión presentan pérdidas, que llegan alterar a la imagen de tal forma que no se pueda recuperar su forma original. Es el precio que se tiene que pagar al utilizar estos métodos: pérdida de información.
Este proyecto de tesis propone el desarrollo de un algoritmo de programación que realice la compresión de imágenes de alta resolución sin que estas presenten pérdidas al momento de su reconstrucción.
ESIME Zacatenco
METODOLOGÍA
El proceso a seguir para el desarrollo de este algoritmo es el que se muestra en el siguiente diagrama:
Figura I. Diagrama de flujo (1).
En el diagrama de flujo (1) se muestra el proceso de compresión de imágenes. Como se puede apreciar, el algoritmo actúa sobre una imagen BMP1, y
mediante una serie de recorridos dentro del vector de almacenamiento, se obtiene como respuesta una imagen comprimida.
Para la construcción de este algoritmo requerimos de un lenguaje de programación con resultados óptimos. Por lo tanto se propone Microsoft Visual C#, debido a que es capaz de manejar imágenes con una capacidad mayor de 24 bits además utilizar pocas líneas de código.
ESIME Zacatenco
CAPÍTULO I
INTRODUCCIÓN
Una imagen (viene del latín "imago", del verbo "imitari" que significa imitar) es una imitación de una figura real. A partir de esta definición, se define la palabra Pixel como la unidad más pequeña de una imagen; proviene de las siglas en inglés PICTURE ELEMENT (elemento de una imagen), y además, en una imagen los píxeles pueden ser más grandes o más pequeños. Mientras más grandes son los píxeles, la imagen se ve más borrosa, mientras más pequeños sean estos, es más nítida y tiene más detalles.
La compresión de imágenes
El principal inconveniente de las imágenes digitales es, sin duda, la cantidad de información que requiere y el tamaño de los archivos que genera. La capacidad de trabajo y de almacenamiento de los sistemas informáticos va en aumento, pero también nos vamos habituando a disponer de mucho más píxeles. De ahí que se mantenga el uso y el interés por la evolución de las técnicas de compresión.
La compresión, en realidad, consiste en sustituir una cadena de datos por otra más corta cuando se guarda un archivo. Ciertos métodos son reversibles ("lossless data compression2", en inglés), porque permiten la reconstrucción exacta del original. Pero con otros, la información original sólo se recupera aproximadamente, ya que se descarta una parte de los datos ("lossy data compression3"), a cambio de relaciones de compresión mucho mayor que este.
Compresión sin pérdidas (LOSSLESS)
Es aquella compresión que permite recuperar exactamente la calidad original de la imagen. La compresión sin pérdida de datos, es utilizada para comprimir
ESIME Zacatenco
archivos o información que contienen datos que no pueden ser degradados o perdidos, como pueden ser documentos de texto, archivos ejecutables, etc.
Se distingue entre sistemas adaptativos, no adaptativos y semiadaptativos, según tengan en cuenta o no las características del archivo a comprimir.
→ Los no adaptativos (se les relacionan con el código Huffman4) establecen a priori una tabla de códigos con las combinaciones de bits que más se repiten estadísticamente. A estas secuencias se asignan códigos cortos, y a otras menos probables claves más largas. El problema que presentan es que un diccionario de claves único tiene resultados muy diferentes en distintos originales.
→ Un sistema es semiadaptativo, si se analiza primero la cadena de datos a comprimir y se crea una tabla a medida. Se logra mayor compresión, pero introduce dos inconvenientes: la pérdida de velocidad al tener que leer el original dos veces, por un lado, y la necesidad de incrustar en el archivo comprimido el índice de claves, por el otro.
→ Entre los métodos adaptativos, el más simple es el Run Lengh Encode (cuyas siglas significan Ejecutar Longitud Codificar) o RLE, que consiste en sustituir series de valores repetidos por una clave con indicador numérico.
Los compresores de uso general más populares utilizan métodos como éste, por eso tardan más en empaquetar los datos que en descomprimirlos.
Compresión con pérdidas (LOSSY)
Se define compresión con pérdidas al tipo de compresión que degrada en mayor o menor medida la calidad de la imagen. Dentro de esta categoría es universalmente conocido por su eficacia el formato JPEG.
ESIME Zacatenco
Sin embargo, los efectos negativos de este método compresión son el empobrecimiento del tono y la nitidez global, que notaríamos más bien en una impresión, y la aparición de artefactos a nivel local visibles sobre todo en pantalla, aunque JPEG sea un formato habitual en Internet.
Los principales sistemas de compresión consideran principalmente los siguientes aspectos:
1. Reducir lo mayor posible la información a transmitir.
2. Reducir el tiempo de enlace o demora.
3. Reducir los costos de conexión.
Estos son los principales objetivos que buscan las diferentes técnicas de compresión pero para lograr estas es necesario que se cumpla lo siguiente:
El código de compresión debe ser lo más compacto posible que el original.
Eliminar toda o casi toda la redundancia existente en la imagen original.
Estos algoritmos hacen uso de las limitaciones de percepción de los sentidos humanos y son utilizados para el audio y video, por ejemplo al comprimir una imagen se puede reducir la información acerca de las variaciones de color debido a que el ojo humano no percibe esas variaciones de color, por lo que se reduce esa información de cambios de color en la imagen original.
ESIME Zacatenco
Figura 1.2. Comparación entre las compresiones con pérdidas y sin pérdidas (lossy y lossless respectivamente). Como podemos observar, en la compresión lossy existen pérdidas de la
información la cual genera que la imagen original no pueda ser recuperada del todo.
ESTADO DEL ARTE
Dentro de la gran variedad de algoritmos para compresión de imágenes existen los siguientes:
ESIME Zacatenco JPEG, JPG: Es la Extensión que corresponde a un tipo de fichero gráfico de mapa de bits. Es un formato comprimido que pierde definición al comprimir: se puede indicar la cantidad de compresión que se desea, pero cuanto más se comprima, mayor pérdida de calidad tiene la imagen.
Para fotografías digitalizadas con 640x480 puntos o más, un nivel de compresión entre 15 y 25 suele ser suficiente para reducir mucho el espacio ocupado por la imagen, pero a la vez que la pérdida de calidad no sea muy apreciable.
EZW. Este método explota las propiedades aportada por la transformada discreta wavelet para obtener resultados satisfactorios en la compresión: un gran porcentaje de coeficientes wavelets próximos a cero y la agrupación de la energía de la imagen.
SPHIT. El tipo de codificación de este algoritmo se basa en la clasificación por orden de bits significativos, resultando ser un método efectivo y económico en el uso de recursos.
RLE. El método de compresión RLE se basa en la repetición de elementos consecutivos. Supone que la imagen se compone de una serie de puntos que son del mismo color. En una imagen que contenga muchas áreas con el mismo color, este método permite obtener un alto nivel de compresión sí que se produzca pérdida de calidad.
ESIME Zacatenco
Algoritmo/
Característica LZW Huffman RLE Aritmética Gzip
Basados en
TDC
Basadas
en
wavelets
Memoria Baja Alta Muy baja Media Baja Media Baja
Tasa de
compresión Media Media Baja - Media Baja - Media Media Media - Alta Alta
Operaciones
complejas No
Construcción
árbol No Punto flotante No Algunos casos
Algunos
casos
Tipo imágenes Colores uniformes Colores uniformes Colores uniformes Tonos continuos Colores uniformes No tan importante Casi cualquier tipo Codificación de regiones de interés (ROI)
NA NA NA NA NA NA Si
Manejo de
errores NA NA NA NA Si NA Si
Con pérdida de
información NA NA NA NA NA Si Si
Sin pérdida de
información Si Si Si Si Si Si Si
ESIME Zacatenco
CAPITULO II
MÉTODOS DE COMPRESIÓN DE IMAGENES
Teoría de imágenes y colores.
→ Resolución.
Las dimensiones en píxeles de las imágenes de mapa de bits son una medida del número de píxeles de altura y anchura de la imagen. La resolución es la precisión del detalle en las imágenes de mapa de bits, que se mide en píxeles por pulgada (PPP). Cuantos más píxeles por pulgada tenga una imagen, mayor es su resolución. En general, las imágenes con mayor resolución producen una calidad de impresión mejor. En la figura 2.1, se muestra la comparación de dos imágenes con diferente resolución.
Figura 2.1. Imagen idéntica con 72ppp (izquierda) y 300ppp (derecha).
ESIME Zacatenco
→ Modelos de color.
Una imagen está representada en una tabla bidimensional en la que una celda es un Pixel. El proceso para representar una imagen digital es crear una tabla de píxeles en la que cada celda contiene un valor. El valor almacenado en cada celda de esta tabla se codifica en un determinado número de bits que determinan el color o la intensidad del Pixel y se lo denomina profundidad de codificación. Existen varios estándares de profundidad de codificación:
Mapa de bits blanco y negro. Si se almacena un bit en cada celda, se pueden definir dos colores: negro o blanco.
Mapa de bits con 16 colores o 16 niveles de gris. Si se almacenan 4 bits en cada celda, se pueden definir 24 intensidades por cada Pixel, es
decir, 16 grados de gris desde el negro al blanco o 16 colores diferentes. Mapa de bits con 256 colores o 256 niveles de gris. Si se almacena 8 bits (equivalente a un byte) en cada celda, se pueden definir 28
intensidades, es decir, 256 grados de gris desde el negro al blanco o 256 colores diferentes.
Mapa de colores de paleta de colores. Se puede definir una paleta de colores, o tabla de colores, con todos los colores que puede contener una imagen, para los cuales hay un índice asociado en cada caso. El número de bits reservados para la codificación de cada índice de la paleta determina el número de colores que pueden utilizarse.
ESIME Zacatenco
"Colores verdaderos" o "Colores reales". Esta representación permite que se represente una imagen al definir cada componente (RGB, acrónimo en inglés de Rojo Verde y Azul). Las imágenes RGB utilizan tres colores o canales para reproducir los colores en la pantalla. Cada Pixel está representado por uno de estos tres componentes, cada uno codificado en un byte, obteniéndose en total 24 bits que pueden definir 224 intensidades que corresponden a 16 millones de colores.
También es posible agregar un cuarto componente, para poder agregar información relacionada con la transparencia o la textura, haciendo que
la imagen sea más “suave”; en este caso cada Pixel estará codificado en
32 bits.
Métodos de compresión de imágenes.
Los métodos de compresión más usados en la actualidad se mencionan a continuación:
→ Código Huffman.
Desarrollo del método. El código Huffman enuncia que la longitud de cada código no es idéntica para todos los símbolos: se asignan códigos cortos a los símbolos utilizados con más frecuencia (los que aparecen más a menudo), mientras que los símbolos menos frecuentes reciben códigos binarios más largos. La expresión Código de Longitud Variable (VLC) se utiliza para indicar este tipo de código porque ningún código es el prefijo de otro. De este modo, la sucesión final de códigos con longitudes variables será en promedio más pequeña que la obtenida con códigos de longitudes constantes.
ESIME Zacatenco
La construcción del árbol se realiza ordenando en primer lugar los símbolos según la frecuencia de aparición. Los dos símbolos con menor frecuencia de aparición se eliminan sucesivamente de la lista y se conectan a un nodo cuyo peso es igual a la suma de la frecuencia de los dos símbolos. El símbolo con menor peso es asignado a la rama 1, el otro a la rama 0 y así sucesivamente, considerando cada nodo formado como un símbolo nuevo, hasta que se obtiene un nodo principal llamado raíz.
El código de cada símbolo corresponde a la sucesión de códigos en el camino, comenzando desde este carácter hasta la raíz. De esta manera, cuanto más dentro del árbol esté el símbolo, más largo será el código.
Como ejemplo, se tiene la oración: "COMMENT_CA_MARHE"; tal como se muestra en la figura 2.2 muestra las frecuencias de aparición de las letras.
M A C E _ H O N T R
3 2 2 2 2 1 1 1 1 1
Figura 2.2. Frecuencia de aparición de las letras del ejemplo citado para explicación del código Huffman.
ESIME Zacatenco
Figura 2.3. Árbol correspondiente al ejemplo del figura 2.1.
Los códigos correspondientes a cada carácter son tales que los códigos para los caracteres más frecuentes son cortos y los correspondientes a los símbolos menos frecuentes son largos. Esto se puede apreciar mejor si se ve la figura 2.4.
M A C E _ H O N T R
00 100 110 010 011 1110 1111 1010 10110 10111
Figura 2.4. Paso final del código Huffman.
Las compresiones basadas en este tipo de código producen buenas proporciones de compresión, en particular, para las imágenes monocromáticas (faxes, por ejemplo). Se utiliza especialmente en las recomendaciones T4 y T5 utilizadas en ITU-T.
Sin embargo, tiene el defecto de que depende del diccionario que se crea para la descompresión de la imagen. Sin este, este método no puede funcionar.
→JPEG.
El Joint Photographic Experts Group (cuyas siglas en inglés significan Grupo
ESIME Zacatenco
compresión más utilizado actualmente para la compresión de imágenes con pérdida. Este método utiliza la transformada discreta del coseno5 (DCT), que se
calcula empleando números enteros, por lo que se aprovecha de algoritmos de computación veloces. El JPEG consigue una compresión ajustable a la calidad de la imagen que se desea reconstruir.
Definición de la transformada discreta del coseno. La imagen de entrada es dividida en bloques de NxN píxeles. El tamaño del bloque se escoge considerando los requisitos de compresión y la calidad de la imagen. En general, a medida que el tamaño del bloque es mayor, la relación de compresión también resulta mayor. Esto se debe a que se utilizan más píxeles para eliminar las redundancias. Pero al aumentar demasiado el tamaño del bloque la suposición de que las características de la imagen se conservan constantes no se cumple, y ocurren algunas degradaciones de la imagen, como bordes sin definir. Los resultados en la experimentación han demostrado que el tamaño del bloque más conveniente es de 8x8 píxeles.
Cuantificación de los coeficientes de la transformada discreta del coseno. Los coeficientes de la transformada son cuantificados en base a un nivel de umbral para obtener el mayor número de ceros posibles. Para la cuantificación se utiliza una matriz de normalización estándar, y se redondean los resultados a números enteros. Este es el proceso donde se produce la pérdida de información. El paso siguiente consiste en reordenar en zigzag la matriz de coeficientes cuantificados. Ver figura 2.5.
5 La transformada de coseno discreta (DCT del inglés
ESIME Zacatenco
Figura 2.5. Recorrido en zig-zag de la matriz de coeficientes cuantificados.
Proceso de codificación. Si se codifica con una longitud variable los coeficientes, la imagen se puede comprimir aún más. El codificador más utilizado es el algoritmo de Huffman, que se encarga de transmitir los coeficientes ordenados. Esto es debido a su facilidad de uso. Para comprimir los símbolos de los datos, el codificador de Huffman crea códigos más cortos para símbolos que se repiten frecuentemente y códigos más largos para símbolos que ocurren con menor frecuencia.
ESIME Zacatenco
Imagen sin comprimir.
Imagen comprimida con JPEG.
Figura 2.6. Ejemplo de compresión de imágenes utilizando el método de JPEG.
→EZW (Embedded Zerotree Wavelet).
Definición. El método de compresión EZW (Wavelet Zerotree Incrustado) fue propuesto por Shapiro en 1993. Este método explota las propiedades aportadas por la DWT6 para obtener resultados satisfactorios en la compresión: un gran
porcentaje de coeficientes wavelets7 próximos a cero y la agrupación de la
energía de la imagen. Este método permite una compresión progresiva conocida como embedded coding (Código Incrustado) de la imagen debido a que cuantos más bits se añadan al resultado de la compresión, más detalles se estarán transmitiendo.
Incrustación. La implementación del EZW se realiza mediante el algoritmo de incrustación definido por Shapiro. El algoritmo de incrustación cuantifica los coeficientes wavelet de la imagen en pasos dados por potencias de dos,
6 La transformada
wavelet (de sus siglas en inglés Discrete Wavelet Transform) es un tipo especial de transformada de Fourier que representa una señal en términos de versiones trasladadas y dilatadas de una onda finita. Ver glosario.
ESIME Zacatenco
reduciéndose progresivamente en sucesivas iteraciones. La primera operación a realizar consiste en calcular el umbral de partida n (primer paso). Para entender esto, ver figura 2.7.
Figura 2.7. Calculo del umbral de partida.
Construcción del mapa de significancias. A continuación, se construye un mapa de significancias (zerotrees8) basado en la búsqueda de los coeficientes mayores o iguales al umbral determinado en el paso anterior. Ver figura 2.8.
Figura 2.8. Búsqueda de los coeficientes mayores o iguales al umbral para la compresión de una imagen usando EZW.
Refinamiento. El siguiente proceso se denomina refinamiento. Consiste en la transmisión de los bits de todos los coeficientes detectados en los pasos previos. Este proceso se repite disminuyendo el umbral hasta alcanzar el umbral cero.
ESIME Zacatenco
Zerotree. La información sobre la significancia de los coeficientes wavelet*
(mapas de significancias) se almacenan en unas estructuras denominadas
zerotrees.
Figura 2.9. Recorrido por la matriz de coeficientes wavelet en diferentes sub-bandas.
La estructura zerotree agrupa los coeficientes de cuatro en cuatro: cada coeficiente tiene cuatro hijos, cada uno los cuales tiene sus propios cuatro hijos y así sucesivamente. Por lo general, los hijos tienen unas magnitudes menores que las de sus padres.
El método EZW aprovecha esta organización basada en el hecho de que los coeficientes wavelet disminuyen a medida que aumenta la escala. Así se puede garantizar que los coeficientes de un quadtree9 son más pequeños que el umbral de estudio, si su padre es más pequeño que el umbral antes mencionado. El EZW transmite el valor de los coeficientes en orden decreciente. El recorrido de la matriz de coeficientes se realiza en zig-zag transmitiendo el n-ésimo bit más significativo en cada pasada.
Para entender mejor el concepto explicado con anterioridad, ver figura 2.10.
9
ESIME Zacatenco
Figura 2.10. Recorrido en zigzag que realiza EZW.
Como se aprecia, al hacer el recorrido en zigzag se etiquetan los coeficientes de la siguiente manera: R, si el coeficiente es menor que el umbral de estudio, I, si el coeficiente es menor que el umbral pero tiene descendientes con valores dentro del rango de estudio (isolated zero), y P, cuando está dentro del rango y es positivo o N si es negativo.
El método de compresión EZW para la compresión de imágenes ofrece unos muy buenos resultados, esto es, altas tasas de compresión con una calidad de imagen aceptable.
Una variación del EZW es el algoritmo de compresión SPIHT, el cual se procede a explicar a continuación.
→SPIHT.
ESIME Zacatenco
Figura 2.11. Coeficientes wavelet organizados en árboles jerárquicos.
Al igual que el EZW, el SPIHT transforma mediante la DWT la imagen a comprimir, y organiza los coeficientes wavelet resultantes en árboles de orientación espacial.
Cuantificación. Los coeficientes wavelet obtenidos mediante la transformada wavelet discreta son valores reales, que se convertirán a enteros mediante una cuantificación. Además, la representación interna del ordenador exige un número finito de bits por coeficiente, lo que supone una cuantificación fina.
Hay que escoger el método más eficaz de cuantificación ya que en este proceso se pierde parte de la información, por corresponder a los métodos de compresión de imágenes con perdidas.
ESIME Zacatenco
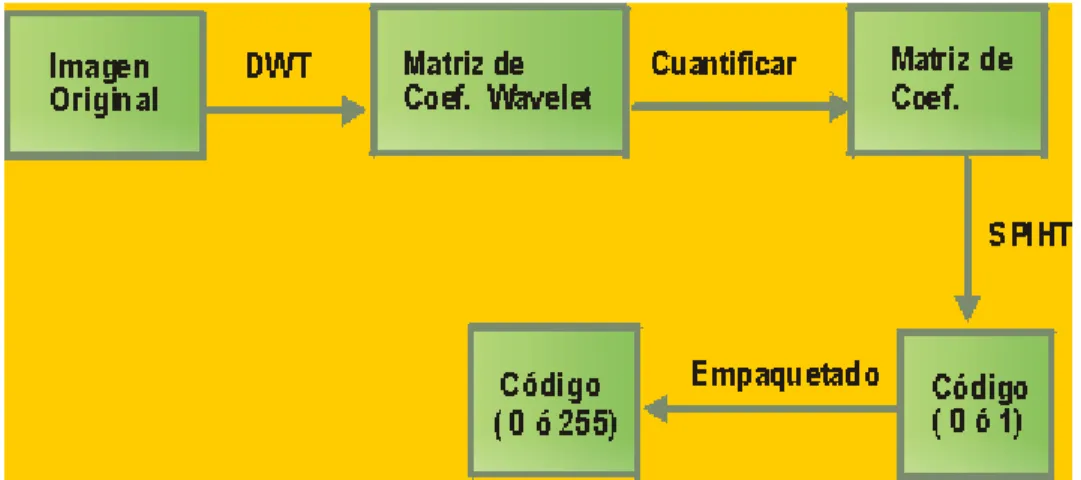
Figura 2.12 Esquema del método de compresión SPIHT.
Proceso de codificación. El primer paso para la codificación consiste en la creación de un mapa de significancia por cada umbral de estudio. Dicho mapa contendrá información sobre si un coeficiente está dentro del umbral de estudio o no. El mapa de significancia se obtiene empleando los árboles de orientación espacial (relación de herencia entre los coeficientes wavelet) y transmitiendo la significancia de hijos a padres.
El primer umbral viene determinado por el bit más significativo del coeficiente mayor en valor absoluto. En las etapas sucesivas basta con decrementar este umbral de uno en uno.
El siguiente paso consiste en la transmisión de bits significativos mediante dos operaciones de ordenación y refinamiento.
ESIME Zacatenco
Inicialización y ordenación. En el paso de inicialización n (el umbral inicial) toma el valor más próximo a una potencia de dos, obtenido de la matriz de coeficientes (el mayor coeficiente en valor absoluto). LSP está vacía, LIP toma las coordenadas de los píxeles de nivel más alto y LIS las coordenadas de los píxeles raíz como tipo A.
La ordenación consiste en verificar si cada entrada de tipo A en LIP es o no significante para el n actual. Si lo es se trasmite un uno, además del signo del Pixel, para luego mover sus coordenadas a LSP. Si no es significativo se trasmite un cero.
A continuación se comprueba la significancia de la descendencia de cada entrada de LIS:
→ Si no se halla una significancia se trasmite un cero, en caso contrario un uno
y, de nuevo, se comprueba la significancia de cada miembro de su descendencia.
→ Si lo es se añade a LSP a la vez que se trasmite su signo, y si no, se añade
a LIP y se transmite un cero.
→ Si ese Pixel dispone de más descendientes (nietos en adelante), se colocan
sus coordenadas al final de LIS y se marca como tipo B.
Por el contrario, si la entrada LIS es de tipo B, se comprueba si tiene descendientes significativos a partir de los nietos (incluidos). Si se confirma se transmite un uno y se añaden sus coordenadas correspondientes al final de LIS marcadas como tipo A. En el caso contrario se transmite un cero y se eliminan sus coordenadas de LIS. Las entradas añadidas a LIS no se tienen en cuenta en la etapa posterior de refinamiento.
ESIME Zacatenco
vuelve al paso de ordenación. El ciclo se repite hasta alcanzar el umbral cero (incluido).
El resultado del algoritmo consiste en un vector compuesto por ceros y unos, que serán empaquetados y almacenados en un fichero con extensión RAW. El número de elementos de este mapa determina el factor de compresión proporcionado por el algoritmo para la imagen dada.
→
RLEDefinición. El método de compresión RLE (Run Length Encoding, a veces escrito RLC por Run Length Coding cuyas siglas significa Código de Manejo de Longitud) es utilizado por muchos formatos de imagen (BMP, PCX, TIFF). Se basa en la repetición de elementos consecutivos.
El principio fundamental consiste en codificar un primer elemento al dar el número de repeticiones de un valor y después el valor que va a repetirse. Por lo tanto, según este principio, como ejemplo, la cadena
“AAAAAHHHHHHHHHHHHHH” cuando está comprimida da como resultado "5A14H". La ganancia de compresión es (19-5) / 19, es decir, aproximadamente 73,7%.
Por otro lado, para la cadena "CORRECTLY", donde hay poca repetición de
caracteres, el resultado de la compresión es “1C1O2R1E1C1T1L1Y”. Por lo
tanto, la compresión genera un costo muy elevado y una ganancia de compresión negativa de (9-16) / 9, es decir, -78%, el cual es un porcentaje pésimo.
ESIME Zacatenco
Si se repiten tres o más elementos consecutivamente, se utiliza el método de compresión RLE.
De lo contrario, se inserta un carácter de control (00) seguido del número de elementos de la cadena no comprimida y después la última.
Si el número de elementos de la cadena es extraño, se agrega el carácter de control (00) al final.
Finalmente, se definen los caracteres de control específicos según el código:
o Un final de línea (00 01). Ver figura 2.13 a.
o El final de la imagen (00 00). Ver figura 2.13 b.
o Un desplazamiento de puntero sobre la imagen de XX columnas e
YY filas en la dirección de lectura (00 02 XX YY). Ver figura 2.13 c.
Por lo tanto, no tiene sentido utilizar la compresión RLE excepto para datos con diversos elementos repetidos de forma consecutiva, en imágenes particulares con áreas grandes y uniformes.
Sin embargo, la ventaja de este método es que es de fácil implementación. Existen alternativas en las que la imagen está codificada en bloques de píxeles, en filas o incluso en zigzag, tal y como se aprecia en la figura 2.13 d.
ESIME Zacatenco
Figura 2.13. Ejemplificación del proceso que realiza la compresión a través de RLE.
→
LZWESIME Zacatenco
Además, funciona en bits y no en bytes, por lo tanto, no depende de la manera en que el procesador codifica información. Es uno de los algoritmos más populares y se utiliza particularmente en formatos TIFF y GIF. Dado que el método de compresión LZW ha sido patentado por Unisys, el que se utiliza en imágenes PNG es el algoritmo LZ77, por el que no se pagan derechos de autor.
Figura 2.14. Comportamiento del algoritmo LZ: # 3 2 significa retroceder tres píxeles y repetir dos; # 12 7 significa retroceder 12 píxeles y repetir siete.
Procedimiento: construcción del diccionario. El diccionario comienza con los 256 valores de la tabla ASCII. El archivo a comprimir se divide en cadenas de bytes (por lo tanto, para las imágenes monocromáticas codificadas en 1 bit, esta compresión no es muy eficaz), cada una de estas cadenas se compara con el diccionario y se agrega si no se encuentra ahí.
Proceso de compresión. El algoritmo pasa por la cadena de información y la codifica. Si una cadena nunca es más corta que la palabra más larga del diccionario, ésta se transmite.
ESIME Zacatenco
CAPITULO III
MÉTODO DE RECORRIDOS SOBRE UNA IMAGEN
Este algoritmo realiza la compresión de una imagen sin presentar pérdidas. Se distingue de los demás métodos en que, la compresión se obtiene de la forma en que los datos de la imagen original son guardados. Así, el algoritmo es capaz de descomprimir la imagen sin que ésta presente pérdida de información. Este método es conocido como recorridos sobre la imagen (RSM).
El principio de funcionamiento de esta técnica, se desglosa a continuación:
→ Obtener los datos de la imagen: dimensiones de la imagen, el número de colores de la imagen, número de píxeles, número de bits por Pixel y los colores de la imagen. Este paso lo ejecuta, haciéndose un escaneo sobre la imagen.
→ Almacenamiento de la información. El algoritmo crea un vector llamado CADENA, el cual sirve como auxiliar para almacenar los datos obtenidos del escaneo hecho sobre la imagen.
→ Archivos *.DAT. La información almacenada en CADENA es guardada en archivos (FILES) con formato en binario (extensión .DAT). Los datos obtenidos se guardan en este formato para ser leídos y procesados por la computadora en el proceso de descompresión.
→ Descompresión. Los archivos en formato binario son leídos por la maquina y acomodados en la forma en la que fueron obtenidos. Sin embargo, dependiendo del tamaño del bit más significativo de cada archivo, será la representación de cada uno de los demás valores almacenado en el.
ESIME Zacatenco
representar al número 15 en binario. Este mismo procedimiento se realiza con los demás archivos.
Debido a la manera en que la información de la imagen es guardada y en la forma en que es colocada sobre la imagen descomprimida, el tamaño de la imagen se reduce considerablemente, no teniendo pérdida alguna.
PROCESO DE COMPRESIÓN POR RSM.
Para iniciar el proceso de compresión, debemos obtener los siguientes datos:
1. Ancho de la imagen.
2. Alto de la imagen.
3. Número de colores.
4. Número de píxeles. Este dato es útil para obtener la información de los colores. En la descompresión se utiliza para situar cada color en la imagen.
5. Número de bits por píxeles. Determina el tamaño en que son representados cada Pixel. Se utiliza en la descompresión.
Este método pretende comprimir imágenes de alta resolución, es decir, deben contener en cada Pixel 24 bits.
Figura 3.1. Número de bits por Pixel para el algoritmo de programación.
ESIME Zacatenco
Figura 3.2. Obtención del número de muestras de un archivo.
Esta fórmula se obtuvo en base al teorema de muestreo y es utilizado comunicaciones para el proceso de compresión de archivos.
Para nuestro ejemplo utilizaremos una variable a la que llamaremos CADENA. Esta variable almacena en archivos con formato en binario la información de la imagen a comprimir. Para discernir cada dato, se incluyen blancos*, cuya
función es separar una variable de otra. En el proceso de conversión de decimal a binario un blanco corresponde a 0000 0000 en 8 bits.
Para indicar la posición de cada color sobre el Pixel, CADENA almacena la información de cada Pixel y realiza comparaciones para determinar a qué color corresponde. Por ejemplo, si CADENA llega a contener “0000”, quiere decir que
el algoritmo identifica a ese color como el negro y le agrega un blanco para distinguir al siguiente color en ser escaneado.
Es así como se identifica cada color de la imagen, y dependiendo del mayor de estos colores será el tamaño en bits de cada dato. Por ejemplo, si 255 es la representación más alta de uno de los colores de la imagen, necesitamos de 8 bits para representar a todos los demás, ya que es la cantidad en bits que se requieren para representar al 255 en binario (1111 1111).
La figura 3.3 muestra un ejemplo sobre la aplicación de este método. Supongamos que esta imagen cuenta con 4 colores.
ESIME Zacatenco
Entonces CADENA almacena:
Ancho ф Alto ф Número de píxeles ф Número de bits por Pixel ф Número de colores.
De estos datos, número de colores ya es conocido. Número de bits por pixel tiene un valor de 24 por ser de una imagen de alta resolución:
CADENA = Ancho ф Alto ф Número de píxeles ф
24DECIMALф 4DECIMAL.
Solo faltan determinar ancho, alto y numero de píxeles, para que la información almacenada en CADENA sea guardada en un archivo con formato *.DAT.
Figura 3.3. Representación de una imagen de alta resolución de pocos colores. Los números del uno al cuatro representan 4 colores diferentes contenidos en esta imagen. Cada celda representa un Pixel, mismo que contiene en su interior 24 bits, esto es por que como se mencionó corresponde a una imagen de alta resolución.
ESIME Zacatenco
Así, tenemos los siguientes valores, tomando en cuenta también que alto x ancho = número de píxeles en la imagen:
CADENA = 512DECIMALф 256DECIMALф 131072DECIMALф 24DECIMALф 4DECIMAL
Para representar a los datos de esta imagen en base binaria, se toma el
número más grande; este corresponde a 131072. Para representar en binario a este número requerimos de 18 bits. Por lo tanto, todos los datos guardados en este archivo, serán de 18 bits.
ESIME Zacatenco
La tabla 3.1 muestra los valores de los datos en base binaria.
Dato 17 16 15 14 13 12 11 10 09 08 07 06 05 04 03 02 01 00
512 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0
256 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0
131072 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
24 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0
4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0
Blanco 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
Tabla 3.1. Conversión de los datos de la imagen. Estos datos se guardan en un archivo llamado DIMESIONES.DAT.
Supóngase que los 4 colores de la imagen sean los que se muestran a continuación:
Color 1 = 0101 1111 0000 1111 0101
Color 2 = 1111 0101 0101 1001 0001
Color 3 = 0000 1101 0111 1101 1011
Color 4 = 1000 0100 0100 1000 0000
Como color 4 es el mayor de los colores, los datos almacenados en CADENA, serán representados con 24 bits. Esta información es guardada en el archivo COLORES.DAT.
NOTA: Este archivo no lleva blancos. Esto se debe a que en DIMENSIONES.DAT se especifica que esta imagen tiene 4 colores, y en este archivo se especifica que se almacenaron datos de 24 bits.
ESIME Zacatenco
1. Color 1 ocupa la posición 0 (ver figura 3.5) Este valor se transforma a base binario y es almacenado en CADENA.
Figura 3.5. Recorrido sobre la imagen.
Después, se detecta la siguiente posición de color 1. En este caso corresponde al lugar 1. La siguiente posición de color 1 es en el lugar 11. Para llegar hasta esa posición se requiere de sumar 9 a la posición en la que estamos. Entonces el valor a almacenar en CADENA no es 11, sino 9, que fue el número que se requirió para llegar hasta esa posición. Se transforma este valor en base binaria y se almacena de nueva cuenta en CADENA.
Este procedimiento se hace sobre la imagen para obtener los incrementos que se utilizaran en la etapa de descompresión, con el fin de ubicar a los colores de la imagen en la misma. El resto de los recorridos se muestran a continuación en base a la figura 3.6.
Posiciones del color 1: 0, 1, 9, 5, 1, 1, 8, 4, 1, 6, 1, 8, 3, 15.
ESIME Zacatenco
Figura 3.6. Recorridos e identificación de la posición de los colores sobre la imagen. Después de localizar la posición del color, observamos que se cuenta desde uno la siguiente localidad.
NOTA: El número mayor de los recorridos debe ser el mayor de los cuatro colores.
Descompresión. La información de los tres archivos creados en la etapa de compresión es concatenada en el vector CADENA para ser procesada por la maquina. De esta forma, se especifica el alto y ancho de la imagen y el número de colores que contiene la misma.
Para colocar cada color sobre la imagen el algoritmo realiza el siguiente procedimiento:
Identifica los colores de la imagen.
ESIME Zacatenco
Dependiendo de los datos almacenados en el archivo RECORRIDOS.DAT, se va incrementando la posición en donde será puesto este color. Ver imagen 3.7.
Este mismo paso se realiza con el resto de los colores, excepto por el ultimo ya que por default, los espacios restantes de la imagen son ocupados por este color.
Figura 3.7. Proceso de descompresión de la imagen mediante RSM.
Esto da como resultado la reconstrucción de la imagen original pero de menor tamaño. El tamaño se determina por la suma de los bits que componen esta imagen.
Desarrollo del software.
ESIME Zacatenco
Se ocuparon 3 Windows form* para elaborar este software. Como primer paso,
se procedió a elaborar una aplicación Windows en el cual se tuvieran tres botones con las siguientes funciones de usuario:
1. Abrir una imagen nueva.
2. Realizar compresión (que será en donde se ejecute el método de recorridos sobre la imagen, explicado en el capítulo anterior).
3. Descomprimir imagen.
En la figura 3.8 se muestran las distribuciones de estos elementos. Como se aprecia, además de los botones que permitirán ejecutar las acciones sobre la imagen, se usaron otras herramientas que el lenguaje C# proporcionaba como son Labels10, TextBoxes11 y un PictureBoxes12, sobre el cual la imagen a abrir se mostrará.
Figura 3.8. Distribución de los componentes gráficos del software de aplicación.
10 Label = representa una etiqueta en Windows. Ver glosario. 11
TextBox = representa un control contenedor de caracteres en Windows. Ver glosario.
ESIME Zacatenco
A continuación, se procederá a explicar a detalle la función de cada uno de los elementos del software.
En la figura 3.9, se aprecian los labels y los textboxes de software. El propósito de los labels sobre el software es de indicar al usuario el campo que describen a los textboxes que tienen a su lado; por el contrario, los textboxes contendrán el dato o resultado de la imagen, de acuerdo a la descripción contenida en los labels.
Figura 3.9. Distribución de labels y textboxes.
La figura 3.10 corresponde a un PictureBox con nombre pic113 (para su fácil uso), sobre el cual se mostrará en pantalla la imagen a comprimir. Como se puede ver, este recuadro está relacionado con el botón con la
etiqueta “ABRIR UNA IMAGEN NUEVA”, ya que al momento de
presionar dicho botón aparece un cuadro de texto, tal y como se aprecia en la figura 3.11, con la cual el usuario selecciona la imagen que desea comprimir.
Para realizar la compresión el usuario sólo debe apretar el botón de
“Realizar Compresión” en el cual, después de apretarlo, el software
ESIME Zacatenco
abrirá una ventana nueva mostrando la carpeta en donde la imagen comprimida se alojará con la extensión del método utilizado.
Figura 3.10. Usos del PictureBox “pic1”.
Figura 3.11. Cuadro de dialogo del botón “ABRIR IMAGEN”.
ESIME Zacatenco
1. Apretar el botón “Realizar compresión”. Esto abrirá una ventana como la
que se ilustra en la figura 3.12, sobre la cual se aprecia un mensaje de texto que nos dice el tiempo estimado que realizará el proceso de compresión.
Figura 3.12. Ventana inicial del proceso de compresión mediante el método RSI.
2. Este proceso consta de 3 pasos:
a. El primer paso consta en llenar la variable “CADENA” con los
datos de la imagen. Esto se puede ver en la figura 3.13.
b. El segundo paso consta de crear el archivo con extensión dat, para construir el archivo con extensión RSI. Ver figura 3.14
ESIME Zacatenco
Figura 3.13.Paso 1 de la compresión de imágenes a través de RSI. Utilización de la variable cadena.
ESIME Zacatenco
Figura 3.14.Paso 3 de la compresión de imágenes a través de RSI. Creación del archivo con extensión RSI.
Una vez que hayamos comprimido una imagen tenemos la opción de descomprimirla a través de nuestro software, y en base a la explicación de la sección anterior. Para descomprimir una imagen, se aprieta el
botón “DESCOMPRIMIR IMAGEN”, el cual mostrará la imagen
ESIME Zacatenco
Figura 3.15. Descompresor de imágenes. Como se puede apreciar posee dos botones: uno para ver la imagen comprimida por este método y otro para guardarla.
ESIME Zacatenco
CAPÍTULO IV
PRUEBAS Y EXPERIMENTOS REALIZADOS
Esta sección pretende hacer mención de las pruebas realizadas por el algoritmo para la compresión de imágenes.
Prueba No. 1.
ESIME Zacatenco
Resultados obtenidos.
Dimensiones de la imagen real: 200 X 200, tamaño: 3,64 Kb, Número de colores: 2385.
ESIME Zacatenco
Prueba No. 2.
Figura 4.2. Compresión de una imagen de alta resolución con 2385 colores.
Resultados obtenidos.
Dimensiones de la imagen real: 200 X 200, tamaño: 3,64 Kb, Número de colores: 2385.
ESIME Zacatenco
Prueba No. 3.
Figura 4.3. Compresión de una imagen de alta resolución con 5 colores.
Resultados obtenidos.
Dimensiones de la imagen real: 300 X 300, tamaño: 263 Kb, Número de colores: 5.
ESIME Zacatenco
Prueba No. 4.
Figura 4.4. Compresión del logotipo de una empresa de comida. Esta imagen tiene 11 colores
Resultados obtenidos.
Dimensiones de la imagen real: 332 X 320, tamaño: 52,6 Kb, Número de colores: 11. Dimensiones de la imagen comprimida: 330 X 320, tamaño: 229 bytes.
ESIME Zacatenco
Prueba No. 5.
Figura 4.5. Compresión de una toma satelital de un lago. Esta imagen contiene 12 colores.
Resultados obtenidos.
Dimensiones de la imagen real: 350 X 624, tamaño: 107 Kb, Número de colores: 12. Dimensiones de la imagen comprimida: 350 X 624, tamaño: 270 bytes.
ESIME Zacatenco
Prueba No. 6.
Figura 4.6. Compresión de una toma satelital del continente americano. Esta imagen contiene 14 colores.
Resultados obtenidos.
Dimensiones de la imagen real: 799 X 543, tamaño: 212 Kb, Número de colores: 14.
ESIME Zacatenco
Prueba No. 7.
Figura 4.7. Compresión de una toma satelital de la ciudad de Villahermosa, Tabasco. Esta imagen contiene 67 colores.
Resultados obtenidos.
Dimensiones de la imagen real: 400 X 345, tamaño: 135 Kb, Número de colores: 67.
ESIME Zacatenco
Prueba No. 8.
Figura 4.8. Compresión de un cuadro artístico. Esta imagen contiene 64 colores. Resultados obtenidos.
Dimensiones de la imagen real: 900 X 637, tamaño: 560 Kb, Número de colores: 64.
ESIME Zacatenco
Prueba No. 9.
Figura 4.9. Compresión de una toma satelital de la ciudad de Irapuato. Esta imagen contiene 567 colores.
Resultados obtenidos.
ESIME Zacatenco Comparaciones.
En la tabla 4.1 se muestra la comparación del método propuesto contra los métodos de compresión más usados en la actualidad.
Figura Numero de colores
Tamaño de la imagen Original
Compresión por método de
recorridos RSI
Compresión por JPEG
Compresión por el Código Huffman
567 184 Kb 934 bytes 22,3 Kb 609 Kb
67 135 Kb 821 bytes 53,0 Kb 64,5 Kb
12 107 Kb 270 bytes 37,9 Kb 28,4 Kb
Tabla 4.1. Tabla comparativa del método de recorridos sobre una imagen vs jpeg y Huffman.
ESIME Zacatenco
CONCLUSIONES
De las imágenes de prueba mostradas en el capitulo anterior concluyo que este algoritmo es útil si se requiere comprimir imágenes de alta resolución pero que posea pocos colores.
La principal razón por la cual este método no puede aplicarse a cualquier imagen es que, como la misma tiene una gran cantidad de colores, los cuales debe obtener su posición exacta, llega un momento en que son tantos datos, tantos valores que la máquina simplemente ya no puede seguir procesando. Es por esta razón que durante las pruebas con la imagen de 2385 colores, no se obtuvo compresión.
Un dato relevante del método es su escaneo. Este paso es de vital importancia, puesto que nos dice realmente cuantos colores posee una imagen, a pesar que ante el ojo humano pareciera tener pocos colores. Esto se corroboro con la misma imagen de la figura 4.3, que a simple vista tiene solo 4 colores, pero mediante el escaneo que el programa realiza sobre la imagen, se determino que el número de colores contenida en la misma era de 2385.
Por lo tanto, concluyo que este método sólo puede aplicarse a imágenes de alta resolución de pocos colores. En caso de querer comprimir imágenes con un número de colores igual o mayor a 2385, se sugiere utilizar otro método de compresión de los ya conocidos.
ESIME Zacatenco
ESIME Zacatenco
APLICACIONES Y TRABAJO A FUTURO.
Como se mencionó al principio de este escrito, la compresión es un proceso muy importante ya que con él se puede manipular y/o transportar archivos cuyo tamaño es muy grande.
En este trabajo se enfocó única y exclusivamente hacia la compresión de imágenes, pero también puede aplicarse a archivos de video, recordando que un archivo de este tipo es un conjunto de imágenes transmitidas en un intervalo de tiempo, que por lo regular resulta ser igual a 24 imágenes por segundo. Cabe mencionar, que también tendría la misma restricción que al comprimir imágenes estáticas: el video debe contener imágenes de alta resolución y de pocos colores para que la compresión sea eficaz.
ESIME Zacatenco
ANEXOS
Apéndice A.
→ David Albert Huffman
David Albert Huffman (1925-1999) nació en Alliance, Ohio. Después de graduarse de la Universidad del Estado de Ohio como ingeniero en electrónica a la edad de 18 años, se unió a la marina. Se recibió como Maestro en Ciencias en ingeniería electrónica en el Estado de Ohio en 1949, y cuatro años más tarde, recibió el título de Doctor en Ciencias en el Instituto Tecnológico de Massachusetts (MIT).
Durante su estancia en el MIT, en 1951, en un curso sobre información teórica, le fue dada la opción de tomar un examen final o un trabajo escrito sobre problemas con codificación de información. Huffman durante meses trabajo arduamente en esto sin resultados hasta que en 1952 propuso un método estadístico que permitía asignar un código binario a los diversos símbolos a comprimir (píxeles o caracteres, por ejemplo). Este método es conocido en la actualidad como CÓDIGO HUFFMAN.
El código de Huffman, también conocido como “codificación Huffman”, puede
ser usado en casi cualquier aplicación, ya que es un sistema válido para la compresión y posterior transmisión de cualquier dato en formato digital, pudiendo aplicarse a faxes, módems, redes de computadoras y televisión.
ESIME Zacatenco
→ Abraham Lempel y Jakob Ziv
Abraham Lempel y Jakob Ziv son los creadores del compresor LZ77, inventado en 1977. Este compresor se utilizó en ese momento para archivar; los formatos ZIP, ARJ y LHA lo utilizan.
ESIME Zacatenco
Apéndice B.
El proceso de compresión consta de los siguientes pasos:
BIBLIOTECAS SUGERIDAS PARA EL PROCESO DE COMPRESIÓN.
System
System Collections Generic System Component Model System Data
System Data Odbc System Drawing System Text
System Windows Forms System IO
System Runtime InteropServices System Collections
VARIABLES A UTILIZAR EN EL PROCESO DE COMPRESIÓN.
Bitmap imagen
int tamaño_de_la_imagen
int ancho_de_la_imagen
int alto_de_la_imagen
int numero_de_pixeles_de_la_imagen
int numero_de_colores
string cadena, colores, resultado
string vector_cadena
ESCANEO SOBRE LA IMAGEN PARA OBTENER EL NUMERO DE COLORES DE LA IMAGEN
ColoresDeLaImagen (Bitmap imagen) {
...
Color col
Int32 bits_
FileInfo (".\\Archivo.DAT");
ESIME Zacatenco
for (Ycontador = 0; Ycontador < image.Height; Ycontador++) {
col = image.GetPixel(Xcontador, Ycontador) cad = col.R.ToString()
bits_ = Convert.ToInt32(cad) }
... }
ALMACENAMIENTO DE LA INFORMACIÓN EN CADENA.
vector_cadena = String.Concat(BaseBinaria(_bits1), BaseBinaria(0),
BaseBinaria(_bits2), BaseBinaria(0), BaseBinaria(_bits_), colores)
SECCIÓN DEL PROGRAMA QUE OBTIENE EL NÚMERO DE BITS, LO COLOCA EN CADENA Y HACE LA CONVERSIÓN A BINARIO PARA LA CREACIÓN DEL RSI.
cad1=Convert.ToString(ancho_de_la_imagen) cad2=Convert.ToString(alto_de_la_imagen)
_bits1 = Convert.ToInt32(cad1) _bits2 = Convert.ToInt32(cad1)
FASE FINAL DE COMPRESIÓN DE LA IMAGEN
ComienzaLosRecorridos() {
_cadena_1 = ReadFromFile(".\\Colores.DAT")
int i=1, j=0
int anterior = 0
while (i < _cadena.Length) {
auxiliar += Convert.ToString(_cadena[i-1]) j = 0
if (auxiliar.Length==NUMERODEBITS) {
ESIME Zacatenco
{
auxiliar += Convert.ToString(_cadena[j])
if (auxiliar.Length==NUMERODEBITS) {
if (auxiliar == auxiliar) {
cadena +=
BaseBinaria24(rec)
anterior = recorrido - anterior
recorrido++ }
else
{
NO LO HACE }
}
j++ }
}
…
FileInfo(".\\Archivo.DAT");
…
ESIME Zacatenco
Apéndice C.
El proceso de descompresión se describe mediante el siguiente algoritmo desglosado:
PARA LA DESCOMPRESIÓN DE IMÁGENES SE CREA UNA NUEVA CLASE Y SE SUGIERE LAS SIGUIENTES BIBLIOTECAS.
System Collections Generic System Component Model System Data
System Drawing
System Drawing Imaging System Media
System Text System IO
System Windows Forms
VARIABLES UTILIZADAS EN ESTE PROCESO.
Bitmap bmp
int ancho, alto
string cadena
DANDO INICIO A ESTE PROCESO SE PROCEDE A ALMACENAR LA INFORMACIÓN DEL ARCHIVO RSI EN LA VARIABLE CADENA Y RECONSTRUIR LA IMAGEN..
cadena = ReadFromFile(".\\Archivo.RSI")
bmp = newBitmap(ancho, alto, PixelFormat FORMATO DE LA IMAGEN); bmpData = bmp.LockBits (ImageLockMode,
bmp.PixelFormat)
UnlockBits (bmpData)
int r = Convert.ToInt32 (aux1) Color rojo
int g = Convert.ToInt32 (aux2) Color verde
int b = Convert.ToInt32 (aux3) Color azul
Color.FromArgb(r, g, b)
ESIME Zacatenco
GLOSARIO
BMP. Es la extensión que corresponde a un tipo de fichero gráfico de mapa de bits (el estándar en Windows). Ver Bitmap.
Bitmap. También conocido como Mapa de Bits es la representación binaria en la cual un bit o conjunto de bits corresponde a alguna parte de un objeto como una imagen o fuente. Se asocia a un tipo o clase de imágenes para ordenador, en las que se almacena información sobre los puntos que las componen y el color de cada punto.
Código Huffman. Método estadístico que permitía asignar un código binario a los diversos símbolos a comprimir (píxeles o caracteres, por ejemplo).
DCT o “Discrete Cosine Transform”. Es una transformada basada en la transformada discreta de Fourier, pero utilizando únicamente números reales.
Formalmente, la transformada de coseno discreta es una función lineal invertible RN -> RN o equivalente una NxN matriz cuadrada. Las variantes más usadas son la DCT-I y la DCT-II. La DCT-III se conoce popularmente como la IDCT(Transformada inversa). Cada uno de estas posibles variaciones es debida a la periodicidad y el tipo de simetría aplicada a las muestras originales.
DCT-I
DCT-II
ESIME Zacatenco DCT-III
DCT-IV
DWT o “Discrete Wavelet Transform”. La Transformada Discreta Wavelet (Discrete Wavelet Transform) es una representación de una señal en base orto normal de valores wavelets infinitos. Todas las transformaciones wavelets pueden ser consideradas formas de representación en tiempo-frecuencia y, por tanto, están relacionadas con el análisis armónico. Las transformadas de wavelets son un caso particular de filtro de respuesta finita al impulso. Esta transformada está definida por la siguiente fórmula:
Esta definición de transformada puede ser descompuesta en las siguientes formulas, con el uso de un filtro pasa altas:
ESIME Zacatenco
public static int[] invoke(int[] input) {
int[] output = new int[input.length];
for (int length = input.length >> 1; ; length >>= 1) { for (int i = 0; i < length; i++) {
int sum = input[i*2]+input[i*2+1];
int difference = input[i*2]-input[i*2+1]; output[i] = sum;
output[length+i] = difference; }
if (length == 1) return output;
System.arraycopy(output, 0, input, 0, length<<1); }
}
Microsoft Visual C#. Lenguaje de programación orientado a objetos, evolución del lenguaje C++, desarrollado por Microsoft.
Label. El control Label se utiliza comúnmente para proporcionar texto descriptivo de otros controles, tales como cuadros de texto. También se pueden utilizar para agregar texto descriptivo de los controles utilizados en un form cread por el usuario..
Lossless. La compresión de datos “Lossless” hace uso de algoritmos de
compresión que permiten que datos de las imágenes o archivos originales puedan ser reconstruidos a partir de datos comprimidos.
Lossy. Se refiere a las técnicas de compresión de datos en la que cierta cantidad de datos de la imagen original se pierden.
ESIME Zacatenco Quadtree. El termino quadtree es utilizado para describir clases de estructuras de datos jerárquicas cuya propiedad común es que están basados en el principio de descomposición recursiva del espacio. En un quadtree, el centro de sus elementos está siempre en un punto. Al insertar un nuevo elemento, el espacio queda divido en cuatro cuadrantes. Al repetir el proceso, el cuadrante se divide de nuevo en cuatro cuadrantes, y así sucesivamente.
Textbox. El control TextBox muestra el texto introducido en tiempo de diseño que pueden ser editados por los usuarios en tiempo de ejecución, o cambiar mediante programación. Normalmente, un control TextBox se utiliza para mostrar una sola línea de texto o permitir que una sola línea de texto que se aporte por el usuario.
Umbral. Es la cantidad mínima de señal que debe estar presente para ser registrada por un sistema.
Wavelet. El término original wavelet, en inglés, ha sido traducido también al castellano como onda. Sin embargo, por su brevedad y mayor semejanza con el paradigma latino, comúnmente se asocia con la palabra ondula, la cual para fines prácticos, es más apropiada esta traducción. Una ondula es una función matemática utilizada para dividir una determinada función o en tiempo continuo de señales en frecuencias diferentes componentes y estudio de cada componente con una resolución que coincide con su magnitud.
Windows form. Al crear un nuevo proyecto de aplicación para Windows, un formulario denominado Form1 se agrega automáticamente al proyecto.
ESIME Zacatenco
ESIME Zacatenco
REFERENCIAS
[1] A. K. Jain, “Fundamentals of digital image processing”, Prentice Hall
International, Englewood Cliffs, 1989.
[2]Cosio Robles Alma Lillian, García Sánchez Miriam, González Fernández
Judith, “Comparación de algoritmos de compresión de imágenes”, Agosto 2004.
[3] “Bitmap property: Height, Physical Dimension, width, raw format and size”,
http://www.java2s.com/Code/CSharp/2D- Graphics / Bitmapproperty Height Physical Dimension width raw formatandsize.htm
[4] “Video e imágenes digitales”, http://es.kioskea.net/video/lumiere.php3
[5] “ZDNet Definition for: Lossless Compression”,
http://images.google.com.mx/imgres
[6] Mike Kitchen, “C# Tutorial” http://en.csharp-online.net/, 2007 – 2008.
[7] Balamurali Balaji, “Conversión of Decimal to any Base (Binary, Octal or
Hexa) and vice-versa (C#)” http://www.codeproject.com/KB/cs/balamurali_balaji. aspx.
[8] Ceballos Sierra Francisco Javier, “Enciclopedia de Microsoft Visual C#”, Alfa omega grupo editor S. A. de C. V., 2006