Automatización del Proceso de Identificación de Sistemas
79
0
0
Texto completo
(2) INSTITUTO TECNOLÓGICO Y DE ESTUDIOS DE CAMPUS MONTERREY PROGRAMA DE GRADUADOS DE LA DIVISIÓN DE COMPUTACION, INFORMACION Y COMUNICACIONES. AUTOMATIZACIÓN DEL PROCESO DE IDENTIFICACIÓN DE SISTEMAS TESIS. PRESENTADA COMO REQUISITO PARCÍAÍ. PARA OBTENER EL GRADO ACADÉMICO DE MAESTRO EN CIENCIAS CON ESPECIALIDAD EN AUTOMATIZACIÓN: INGENIERÍA DE CONTROL. POR ING. QUETZAL GARCÍA GARCÍA. DICIEMBRE DE 2000.
(3) Automatización del Proceso de Identificación de Sistemas. por Ing. Quetzal García García. Tesis Presentada al Programa de Graduados en Computación, Información y Comunicaciones del. Instituto Tecnológico y de Estudios Superiores de Monterrey, Campus Monterrey como requisito parcial para obtener el grado académico de Maestro en Ciencias. Instituto Tecnológico y de Estudios Superiores de Monterrey Campus Monterrey Monterrey, N.L. Diciembre de 2000.
(4) Instituto Tecnológico y de Estudios Superiores de Monterrey Campus Monterrey División de Computación, Información y Comunicaciones Programa de Graduados en Computación, Información y Comunicaciones Los miembros del comité de tesis recomendamos que la presente tesis de Quetzal García García sea aceptada como requisito parcial para obtener el grado académico de Maestro en Ciencias, especialidad en: Automatización: Ingeniería de Control Comité de tesis:. Dr. Jorge Limón Robles Asesor de la tesis. Dr. José de Jesús Rodríguez Ortiz Sinodal. Dr. Carlos Scheel Mayenberger Director del Programa de Graduados en Computación, Información y Comunicaciones. Diciembre de 2000.
(5) A mis padres y hermano. A Lucía..
(6) Reconocimientos Al Dr. Jorge Limón Robles por su constante apoyo y por los conocimientos brindados que contribuyeron a la realización de esta tesis. Al Dr. Ricardo A. Ramirez Mendoza por los valiosos conocimientos aportados durante estos años y por sus contribuciones a esta tesis. Al Dr. José de Jesús Rodríguez por sus aportaciones como sinodal de esta tesis y como director de la maestría. A Lucía Adame por sus consejos y correcciones. Al Lic. Francisco Rodríguez por su continuo apoyo y confianza.. iv.
(7) Automatización del Proceso de Identificación de Sistemas Quetzal García García, M. C. Instituto Tecnológico y de Estudios Superiores de Monterrey, 2000 Asesor de la tesis: Dr. Jorge Limón Robles. Las técnicas de Control Automático de las cuales mejor desempeño se obtiene requieren de un modelo matemático del proceso razonablemente preciso. Al proceso de obtener y validar el modelo a partir de datos experimentales se le conoce como identificación. Desde hace ya varios años existen métodos de identificación basados en el principio de mínimos cuadrados, cuya eficacia es ampliamente reconocida; sin embargo son procesos iterativos que requieren de un experto que tome las decisiones clave. En esta tesis se propone una metodología para automatizar el proceso de identificación completo, en forma tal que pueda ser ejecutado en una computadora (o en un dispositivo basado en microprocesador) prescindiendo del experto. La metodología es evaluada identificando varios modelos teóricos con diferentes características; en todos ellos el modelo encontrado es satisfactorio. En la mayoría el orden coincide con el del modelo teórico; en algunos otros, el modelo es simplificado sin efecto significativo en la precisión, en forma semejante a como lo hace un experto para balancear precisión y simplicidad (parsimonia). Finalmente, la metodología es utilizada para identificar un modelo real..
(8) índice General Reconocimientos. iv. Resumen. v. índice de Figuras. viii. índice de Tablas. x. Capítulo 1 Introducción 1.1 Antecedentes 1.2 Objetivo 1.3 Contenido. 1 1 3 3. Capítulo 2 Marco Teórico 2.1 Identificación por mínimos cuadrados 2.2 Prueba RBS 2.3 Prueba del Relevador 2.4 Validación del modelo identificado 2.5 Proceso manual de identificación 2.6 Identificación en lazo cerrado. 5 5 9 10 11 14 16. Capítulo 3 Algoritmo propuesto 3.1 Método de Identificación 3.2 Señal de prueba basado en el relevador 3.3 Señal de prueba basado en RBS acotada 3.4 Método de identificación modificado. 18 18 23 25 28. Capítulo 4 Implementación computacional 4.1 Panel Principal 4.2 Ajuste de parámetros 4.3 Identificación. 32 32 33 35. Capítulo 5 Resultados 37 5.1 Modelos de Prueba 37 5.2 Resultados de la identificación con señal del relevador 40 5.3 Resultados de la identificación con señal de entrada RBS acotada42. vi.
(9) 5.4 Efecto del tiempo de muestreo 5.1 Proceso real 5.1 Conclusiones. 56 58 62. Capítulo 6 Conclusiones 6.1 Trabajos Futuros. 63 64. Bibliografía. 65. Vita. 67. vii.
(10) y. índice de Figuras 2.1 Problema Genérico 2.2 Modelo Específico 2.3 RBS típica 2.4 Implementación del relevador 2.5 Relevador con histéresis 2.6 Proceso de identificación manual. 5 5 10 11 11 16. 3.1 Diagrama de flujo para la búsqueda del modelo del proceso 3.2 Entrada producida por el relevador 3.3 Salida del proceso con el relevador 3.4 Entrada del proceso con señal RBS no acotada 3.5 Salida del proceso con señal RBS no acotada 3.6 Entrada de una señal RBS acotada 3.7 Salida limitada por el efecto de la RBS acotada 3.8 Diagrama de flujo del algoritmo modificado. 23 24 25 26 26 27 28 31. 4.1 4.2 4.3 4.4 4.5. 33 34 35 35 36. Panel principal Parámetros del proceso Parámetros del relevador Parámetros de señal RBS acotada Panel de identificación. 5.1 Correlaciones para el modelo P5(z- 1 } con entrada del relevador 5.2 Correlaciones para el modelo P5(Z-I) con entrada RBS acotada 5.3 Correlaciones para el modelo P5(z~1) con estructura correcta 5.4 Correlaciones obtenidas para el modelo H1(z~ 1 } 5.5 Correlaciones obtenidas para el modelo H2(z~l) 5.6 Correlaciones obtenidas para el modelo H3(z~l) 5.7 Correlaciones obtenidas para el modelo H4(z~ 1 } 5.8 Correlaciones obtenidas para el modelo H5(z~ 1 } 5.9 Correlaciones obtenidas para el modelo H6(z~1} 5.10 Correlaciones obtenidas para el modelo H7(Z~1) 5.11 Correlaciones obtenidas para el modelo H8(Z~I) 5.12 Correlaciones obtenidas para el modelo H9(z~l). viii. 42 45 45 46 46 47 48 49 50 50 51 52.
(11) 5.13 5.14 5.15 5.16. 5.17 5.18 5.19 5.20 5.21 5.22 5.23. Diagramas Diagramas Diagramas Diagramas. de de de de. Bode Bode Bode Bode. para para para para. los modelos H3(z l}real y H3(z-1)encontrado • 53 los modelos H 5 , ( z ~ l } r e a l y H 5 (z~ l )encontrado • 54 los modelos H6 (z- 1 ) real y H6(z~ l )encontrado .54 los modelos H9(z~ l )real y H9(z~ l }encontrado .55. Respuesta a entrada escalón del modelo H1(Z~I) 57 Respuesta a entrada escalón modelo de 2do orden con (=0.5 y wn=457 Proceso de temperatura 59 Diagrama de bloques del proceso de temperatura 59 Entrada al proceso de temperatura 60 Salida del proceso de temperatura 60 Correlaciones obtenidas para el proceso real 61. ix.
(12) Índice de Tablas 3.1 Orden de búsqueda. 21. 5.1 Relación tiempo muerto y constante de tiempo 37 5.2 Resultados de la identificación con relevador y d = O 40 5.3 Resultados de la identificación con relevador y d = 2 41 5.4 Resultados de la identificación con entrada RBS acotada y d = 0 43 5.5 Resultados de la identificación con entrada RBS acotada y d = 2 . . . . 44 5.6 Resultados de la identificación para el modelo H1(Z~I) 45 5.7 Resultados de la identificación para el modelo H2(z~ 1 } 46 5.8 Resultados de la identificación para el modelo H3(z~ 1 } 47 5.9 Resultados de la identificación para el modelo H4(z-1) 48 5.10 Resultados de la identificación para el modelo H5(z~1) 48 5.11 Resultados de la identificación para el modelo H6(Z~1) 49 5.12 Resultados de la identificación para el modelo H7(Z~1) 50 5.13 Resultados de la identificación para el modelo H8(z~1) 51 l 5.14 Resultados de la identificación para el modelo H9(z~ ) 51 5.15 Desviación estándar de los errores y desviación estándar de la salida 52 5.16 Resultados de la identificación para H(z~1} 58 5.17 Parámetros estimados del proceso real 61 5.18 Parámetros estimados con un modelo de segundo orden 61. X.
(13) Capítulo 1 1. Introducción 1.1. Antecendentes. En general, la necesidad de mantener las variables (temperatura, nivel, presión etc.) de un proceso dentro de un rango de operación específico, es uno de los objetivos de las empresas, para así asegurar que su producto cumpla con los estándares de calidad deseados o lograr ciertas características en el producto terminado. Esta necesidad lleva a la construcción o desarrollo de sistemas que permitan regular las variables del proceso; es aquí donde surge la necesidad de implementar los sistemas de control. El diseño de un sistema de control consiste en especificar los valores deseados de las variables a controlar, tener un método adecuado para el diseño del controlador y finalmente conocer la dinámica del modelo del sistema o proceso que describa las relaciones entre la señal de control y la salida del proceso (la variable a controlar). Esta última parte del diseño del sistema de control es primordial y muchas veces en la industria no se le da la suficiente importancia, tal vez por una falta de conocimiento de parte del operador, además de que requiere de tiempo y experiencia. La falta de una adecuada identificación lleva a un pobre diseño del sistema de control. Mientras más se conozca el sistema o proceso mejor se podrá diseñar el controlador, y a la vez se pueden utilizar controladores más sofisticados que permitan un mejor desempeño. La identificación es utilizada en una gran variedad de disiciplinas, ya que ésta nos permite obtener un modelo del mundo que nos rodea y así poder encontrar y probar soluciones que en un determinado momento serían difíciles de implementar en la realidad o predecir resultados sin necesidad de realizar el expermimento. La identificación nos proporciona un modelo del proceso; sin embargo existen diferentes tipos de modelos, por ejemplo los obtenidos por medio de las leyes físicas o químicas. Estos modelos usualmente son muy complicados para poder ser utilizados en el diseño de un controlador. Otro tipo de modelo es un modelo lineal genérico, que es más fácil de obtener. Se tienen también modelos en el dominio de la frecuencia, por mencionar algunos. Para propósitos de control, por identificación se entenderá como la determinación del modelo dinámico del sistema a partir de datos (mediciones) de entrada/salida. Para lograr este tipo de identificación se deberán seguir tres. 1.
(14) pasos básicos: a)obtención de los datos. Para obtener los datos que se utilizarán en la identificación, se deberá diseñar un experimento en el que se especifique el tipo de entrada que se va a realizar (escalón, rampa, RBS, PRBS, etc.), el tiempo de duración de la prueba, y se considerarán las restricciones a las que está sometido el proceso, b) Proponer una serie de modelos. La elección del modelo se hace en base a un conocimiento previo o pre-identificación que puede consistir en una aproximación matemática del proceso, o se puede proponer un modelo lineal genérico en el que los parámetros a identificar no representan estrictamente a una variable real. Este tipo de modelo es el más utilizado en el control digital, c) Elegir una regla (criterio) de prueba para determinar el modelo más adecuado con lo datos obtenidos. Este último punto es básicamente el método de identificación, y depende del desempeño del modelo al tratar de reproducir los datos obtenidos. Una vez obtenido el modelo se debe pasar a una etapa de validación del modelo, que consiste básicamente en verificar si el modelo resultante es suficientemente bueno para el propósito que fue obtenido. Si éste no cumple con las características deseadas el modelo será rechazado; si éste satisface las características deseadas se podrá tomar como base para el desarrollo del sistema de control. Sin embargo el modelo obtenido nunca deberá aceptarse como la representación real y definitiva del sistema o proceso en estudio, sino como la mejor aproximación obtenida que cumple con los requerimientos que nos interesan. Los trabajos sobre identificación son extensos: Box and Jenkins (1970), Eykhoff(1974), Soderstrom and Stoica (1989), Ljung (1987). El procedimiento mencionado muestra la complejidad que implica identificar un proceso, por lo que la automatización de esta metodología ahorra tiempo y esfuerzo, además de que proporciona una herramienta valiosa al momento de diseñar un sistema de control, proporcionando al usuario un modelo que puede ser utilizado como base para la configuración de un controlador. Los esfuerzos de automatizar este procedimiento son variados; uno muy conocido y aplicado en la industria es la autosintonía por el método del relevador, introducida inicialmente por Astrom and Hágglund (1984). Esta técnica es fácil de implementar pero está diseñada para identificar primordialmente modelos de primer orden. El proceso debe estar completamente estable para iniciar la prueba y se obtienen parámetros que corresponden a procesos continuos. Así pues la necesidad de desarrollar un sistema que identifique procesos de orden mayor, que pueda ser aplicada en cualquier momento y que obtenga directamente un modelo discreto es básica. Los modelos que mejor cumplen con las características antes mencionadas 2.
(15) son los modelos paramétricos, donde el problema de identificación se centra en encontrar el vector de parámetros del modelo. La forma de encontrar tal vector de parámetros conduce a métodos como los mínimos cuadrados, máxima verosimilitud o variable instrumental. El más sencillo de implementar es el primero de ellos, y su uso no sólo se limita al área de control; sus primeras aplicaciones se remontan a principios del siglo XIX y desde entonces se utiliza frecuentemente en muchas aplicaciones con buenos resultados. El aprovechar esta herramienta para hacer accesible un programa de identificación automática a un operador con un conocimiento mínimo sobre sistemas de control es el objetivo de esta tesis. 1.2. Objetivo. Desarrollar un programa computacional que de manera automática aplique una señal de prueba e identifique el proceso deseado. Específicamente: • Implementar un generador de funciones que permita elegir una señal de prueba para aplicarla a un proceso de manera automática. • Recopilar la información obtenida al realizar la prueba y acondicionarla para ser usada en la identificación. • Generar un algoritmo que seleccione el mejor modelo discreto que represente al proceso con los datos obtenidos y que encuentre los parámetros de éste por medio del método de mínimos cuadrados. Probar el algoritmo en simulaciones con diferentes modelos dinámicos y con distintas entradas. Finalmente evaluar el programa en un proceso de temperatura real. 1.3. Contenido. En el Capítulo 2 de esta tesis se introduce el concepto de identificación por mínimos cuadrados. En ese mismo capítulo se presentan las bases de las diferentes señales de prueba que se utilizarán para evaluar el algoritmo, como son el método del relevador y la prueba RBS. Se hace una presentación de los principales problemas que tiene el identificar un proceso en lazo cerrado y se documenta la teoría necesaria para poder validar la selección de un modelo. En el Capítulo 3 se describe la metodología necesaria para poder automatizar la aplicación de la señal 3.
(16) de entrada, y las características que deben tener estas señales para ser usadas en la identificación, Se muestra cómo la prueba del relevador no es óptima al momento de utilizar mínimos cuadrados. Además se propone una modificación a la prueba RBS acotando la amplitud de la salida. Dentro de este capítulo se presenta el algoritmo que permite evaluar cada uno de los modelos y que toma la decisión de cuál es el que mejor se ajusta a los datos obtenidos. En el Capítulo 4 se muestra la interfaz gráfica en la que se hicieron las simulaciones y que se uso para interactuar con el proceso real. El Capítulo 5 presenta los resultados de cada una de las pruebas realizadas tanto en simulación como en un proceso real, analizándose los problemas resultantes en cada uno de los experimentos. Finalmente en el Capítulo 6 se presentan las conclusiones de la investigación y las mejoras que se podrían presentar en trabajos futuros.. 4.
(17) Capítulo 2 2. Marco Teórico 2.1. Identificación por Mínimos Cuadrados. En el ámbito industrial es difícil y costoso experimentar con el proceso. Es por ello deseable tener un método de identificación que no requiera de señales de entrada especiales. Muchos de los métodos clásicos dependen de una entrada específica como una señal senoidal o un impulso. Otras técnicas pueden utilizar casi cualquier tipo de entrada a expensas de aumentar las operaciones necesarias para obtener resultados. Es éste el caso de los mínimos cuadrados. Mínimos cuadrados es un método muy simple y fácil de comprender basado en la minimización de la suma de los cuadrados del error y su uso desde sus primeras aplicaciones ha sido extenso. Supongamos que tenemos un proceso que queremos controlar, pero para poder hacer esto se necesita conocerlo. Consideremos pues un problema como el que se muestra en la Figura 2.1, en donde podemos aplicar una entrada controlada a nuestro proceso y registramos la salida.. salida. entrada. Figura 2.1 Problema Genérico. En la Figura 2.2 se presenta el mismo experimento pero utilizando la nomenclatura que normalmente se utiliza en control, donde el proceso se muestra como una función de transferencia.. uCt). nb ,-d b1z~ 1 + b2z~ 2 + ... + bnbz1 + alz- 1 + a2z' 2 + ...+ anaz~ n a. Figura 2.2 Modelo específico. 5. y(0.
(18) La representación del proceso puede ser a través de un modelo lineal; de manera genérica se pude proponer:. y(t). _d. biz~l + 62z-2 + ... + bnbz-nb l + aíz-1 + a2z-2 + ... + anaz ~na. u(t) esto es equivalente a. + ... + anayk-na = biuk-i-d + b2uk^2-d + ••• + bnbuk-nb-d la k-esima salida se puede despejar como = -ai2/fc-i - a2yk-2 - ••• - anayk-na + biuk-i-d + b2uk^2_d + ••• + bnbuk-nb-d para hacerlo de forma más compacta se definen los vectores. -y(t-l) u(t-l-d). -y(t-2). ... -y(t - na). u(t-2-d). T' r 6 = [ 0,1 a2... ana bi. ... u(t-nb-d). i b2... bnb J. en donde 0 (í) se le conoce como el vector de mediciones y 0 como el vector de parámetros reales. Llegando a y ( t ) = <t>T(t - 1)6. (2.2). El problema consiste en encontrar el valor real de ese vector de parámetros. Supongamos un vector de parámetros estimados O . La salida estimada y ( t ) en función de ese vector de parámetros estaría dada por (2.3). se puede entonces definir un error de estimación e(i) como la salida real menos la salida estimada:. e(f) = y ( t ) - y ( t ). (2.4). Si se desea, se puede obtener la predicción de la salida para cada instante de tiempo como 6.
(19) y(t. (2.5). y(N) = ^(N en donde N es el número de datos obtenidos. Se puede definir un vector de salidas estimadas:. y(t) Y =. y(N) De la misma manera los vectores de mediciones se pueden engloblar en una sola matriz:. Por lo que el sistema queda finalmente como. Y =. (2.6). El error dado por 2.4 de cada una de las estimaciones con respecto al valor real se representará por el vector e , y queda definido como. e =Y - Y. (2.7). El método de mínimos cuadrados, como su nombre lo indica, minimiza un criterio cuadrático basado en este error, y está dado por: J(é) = eTe. Debemos encontrar el vector de parámetros estimados 9 que minimice este error, es decir: min J (0) = 7. (2.8).
(20) Sustituyendo e por 2.7 se obtiene. = (y -y} T (Y -Y Remplazando Y por 2.6 se tiene:. Desarrollando,. Minimizando J con respecto a 6* : dJ(ff) r , —V^ = -2*Ty + 2^TT^9 = O 30 por lo que se obtiene. Se tiene entonces que el vector 9 que minimiza el criterio especificado en 2.8 está dado por: tfT#tfIY. 0=. (2.9). Se llega pues a la conclusión de que a partir de todos los datos obtenidos en un experimento se puede encontrar un vector de parámetros que minimiza el error de estimación. Basta con formar la matriz ^ y el vector Y. La ecuación 2.9 se le conoce como estimador de mínimos cuadrados. El principal problema que se presenta al tratar de implementar esta ecuación es que se debe de invertir una matriz que contiene todos los datos de entrada y salida registrados durante el experimento y que ésta es invertible si la entrada del proceso es suficientemente rica en frecuencias (excitación persistente). Algunas propiedades estadísticas del estimador de mínimos cuadrados se pueden obtener considerando que existe un ruido blanco no correlacionado que afecte las mediciones contenidas en \&. Recordando que el ruido blanco tiene media cero y varianza a1 , las propiedades son:. 8.
(21) 1. El estimador de mínimos cuadrados es insesgado, E6 = 0. A mayor número de datos se tendrá una mejor estimación. 2. La varianza del estimador es igual a Var(9) — a2 (fyTfy) . Sin embargo una característica del ruido es que no se conoce, por lo que a2 tampoco es conocida, por lo que se debe estimar. 3. Un estimador insesgado de a2 es a2 = ~~~ , donde n representa el número de parámetros na 4- nb . Una demostración de estas propiedades se puede encentra en Johansson (1987) . 2.2. Prueba RBS. En la identificación, el tipo de señal de entrada es muy importante. Algunos métodos dependen de que la secuencia sea muy específica y otros tienen un buen desempeño con casi cualquier entrada. Los mínimos cuadrados tienen como una limitante que la señal de entrada excite lo suficiente al proceso para asegurar que la matriz í'7^ sea invertible. Una señal que cumple con estas características y que es de fácil implementación es la prueba RBS. La RBS (Random Binary Sequence) es una señal que puede tomar sólo dos valores: u(t) =ui,u2. donde u\ y u-¿ son niveles permisibles de entrada. La decisión de qué valor tomará la manipulación es aleatoria. Si se define una variable aleatoria rand que pueda tomar un valor entre O y 1, la manipulación en cada instante de muestreo estaría dada por: = v. '. f Ul rand < 0.5 \Ui rand > 0.5. '. Gráficamente se tendría una señal como la que se muestra en la Figura 2.3. 9.
(22) u(t). u2. Figura 2.3 RBS típica. La selección del valor que puede tomar u(t) depende del proceso, y debe de ser lo suficientemente grande para que se distinga del ruido; mientras mayor sea la diferencia mejor será la estimación, respetando siempre los limites de operación del proceso. Al mismo tiempo mientras más tiempo dure la prueba se obtendrán mejores estimados. 2.3. Prueba del relevador. El método del relevador surge como una propuesta por Astrom (1984) para sintonizar automáticamente controladores PID. La idea básica consiste en proporcionar un método que de manera sencilla proporcione un estimado de la ganancia crítica y la frecuencia crítica. Las ventajas que presenta esta prueba con respecto a otras, como la prueba RBS y la PRBS, es que proporciona una señal que mantendrá al proceso dentro de un rango de operación; ademas no se deja en ningún momento al proceso en lazo abierto. Esta prueba se utiliza en la mayoría de los controladores que contemplan autosintonía dentro de sus características. La prueba del relevador consiste básicamente en sustituir el controlador por un relevador; así el proceso quedará con un control que puede considerarse onoff. La propuesta se muestra en la Figura 2.4; la ecuación del relevador es la siguiente: e >O e <O. u(t) =. 10. (2.11).
(23) 7\_,. JT*. L_. ya). u(t),. -1. Figura 2.4 Implementación del relevador Este comportamiento producirá una salida periódica y estable del proceso. El hecho de que la decisión del valor de la manipulación dependa del cruce por cero del error, causa problemas cuando se tienen procesos con ruido, ya que éste puede hacer que el relevador cambie su valor de una manera irregular. Por esto al relevador se le agrega una histéresis, de manera que el relevador cambiará el valor de la manipulación por el error real y no por causa del ruido. La ecuación 2.11 se convierte en u(t) =. MI, e > h u?, e < —h. (2.12). U(t). -h Uj. Figura 2.5 Relevador con histéresis. El uso típico del relevador es para la autosintonía del controlador; sin embargo se pueden aprovechar las características de estabilidad que proporciona el relevador para ser utilizado como un señal de entrada, para identificar el proceso por medio de los mínimos cuadrados. 2.4. Validación del modelo identificado. Mínimos cuadrados se basa en que el error de predicción dado por 2.4 es debido a un ruido blanco. Si es así el estimador de mínimos cuadrados obtendrá un vector de parámetros O insesgados, además de que el modelo será la mejor aproximación 11.
(24) de la salida de la planta puesto que minimiza la varianza del error de predicción. Por otro lado, si el error es ruido blanco, este ruido no está correlacionado con ninguna otra variable del proceso, por lo que todas las correlaciones entre la entrada y la salida de la planta están representadas por el modelo identificado y lo que no está representado no depende de la entrada aplicada. El principio de validación del modelo es como sigue: • si la estructura de la planta y el ruido es elegida adecuadamente. • si el método de identificación es adecuado para la estructura elegida. • si el orden de los polinomios y el valor de d representados en 2.1 es escogido correctamente. entonces el error de predicción 2.7 tiende a ser ruido blanco lo que lleva a: lim E [e(i)e(t - i}}= O. i = ±l,±2,..7V. í—>oo. La implementación de este principio consta de los siguientes pasos: 1. Creación del archivo que contenga los datos de entrada/salida. 2. Obtención y creación de un archivo con los errores de predicción. 3. Prueba de no-correlación del error con las entradas/salidas. Prueba de no-correlación. Se define la covarianza entre dos vectores (x, z] de la siguiente manera: 1 Cov(x, z} = —. N. Por ejemplo, para el vector de errores dado por 2.7, se obtiene su varianza (ya que la covarianza de un vector con respecto a sí mismo es la varianza) como: 1 N al = Cov(e, e) = — ^(e, - e)2 /v • ¿=i. Entonces, para cualquier par de vectores se calcula su correlación como: 12.
(25) . . Cov(x,z) p ( x , z ) = -^-^. .. . (2.13). Vx&z. Donde la correlación da una medida de la dependencia lineal de los datos y es un valor que varía entre -1 y 1. Si el error de estimación (2.7) es debido únicamente a ruido blanco (situación teórica) y el número de datos es grande (N —» oo) , entonces: p(e,z) = Q. (2.14). En donde z puede ser el vector de entradas o salidas. Sin embargo, éste nunca es el caso ya que e(t) contiene errores en el orden del modelo, no-linealidades, ruido no Gaussiano. y el número de datos no puede ser muy grande. Una regla práctica de validación usada extensivamente en aplicaciones es: (2.15) Esta regla proviene de que el ruido blanco tiene una distribución Gaussiana con una media cero y una desviación estándar a= T/Ñ. El intervalo de confianza considerado en la ecuación 2.15 es de un 3% en una prueba de hipótesis para una distribución Gaussiana. Si p(e, z) sigue una distribución normal, hay sólo una probabilidad del 1.5% de que p(e, z) sea mayor 2.17/^/Ñ o menor que —2.17/^/Ñ . Si un valor calculado cae fuera de ese rango, la hipótesis de la independencia de los datos debe ser rechazada. Tomando en cuenta el efecto de ruido no Gaussiano y el error de modelado, por simplicidad, la validación se hace prácticamente en base a Landau(1990) |p(e,z)|<0.2. (2.16). Para su implementación computacional la ecuación 2.13 se puede desarrollar como: N. p(x,z) = N. E ¿=i 13.
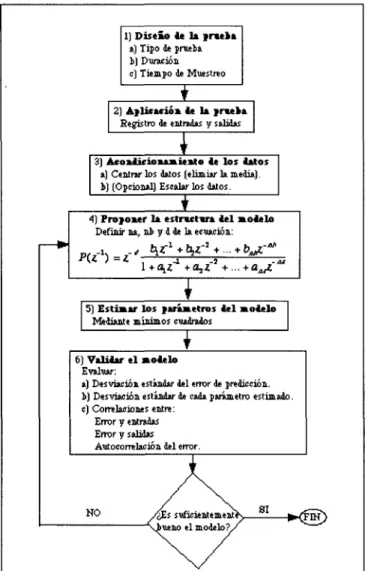
(26) que se puede reescribir como: TV. p(x,z) =. 1 V- T j\¡ 2—i ^i,%i i=l. / hv. \ I/ 2. TV. E( xi ) ~. X. ÍCZ. y/2. N. í. 2. 1. )-¿2. y finalmente: N. TV. N. N E z¿2i - E x, E N. De esta manera se ahorra trabajo computacional. 2.5. Proceso manual de identificación. La integración de las secciones anteriores en un proceso iterativo hasta obtener un modelo satisfactorio del sistema se le conoce como el proceso de identificación. Este proceso se puede dividir en seis pasos que son: 1. Diseño de la prueba Este paso consiste en seleccionar el tipo de prueba a utilizar para la identificación del proceso. Se debe de elegir su duración, la amplitud de la señal y el tiempo de muestreo. Se recomienda que sea rica en frecuencias de manera que estimule mejor al proceso; que sea independiente de la salida del proceso de manera que no se obtenga un sesgo en los parámetros encontrados y que sea binaria. Usualmente se utiliza una señal RBS (Random Binary Sequence) o PRBS (Pseudo Random Binary Sequence). 2. Aplicación de la prueba Aqui se debe de introducir al proceso la señal seleccionada y registrar los datos de entrada y salida del proceso para su posterior utilización. 3. Acondicionamiento de los datos. 14. se puede considerar aceptable..
(27) Dentro de este paso se deben de centrar los datos registrados, esto se logra restando la media de los datos obtenidos o restando el valor de estado estable de cada variable, para poder trabajar con valores de desviación. También se puede hacer un escalamiento de los datos para homogeneizar sus valores, esto se logra dividiendo cada dato entre la desviación estándar del vector de entradas o salidas, de esta manera se evita que algunos parámetros se identifiquen con mayor precisión que otros. 4. Proponer estructura del modelo Aqui se debe de elegir una estructura a identificar, ya que ésta es necesaria para realizar la identificación por mínimos cuadrados. Se recomienda comenzar con un orden pequeño (primer orden sin tiempo muerto) e ir aumentándolo (o disminurlo) si es necesario, dependiendo de los resultados obtenidos en la validación. 5. Estimar parámetros del modelo Se aplica el método de identificación, en este caso mínimos cuadrados. Para poder aplicar los mínimos cuadrados se deben ordenar los datos y formar matrices y vectores de acuerdo a la estructura seleccionada. 6. Validar el modelo En este paso se verificará si el modelo propuesto es aceptado como un modelo suficientemente bueno para el propósito deseado. Esto se logra obteniendo la desviación estándar del error de predicción y comparándola con la desviación estándar de la salida; si es mucho más pequeña es una buena señal de que el modelo puede ser el correcto. Se obtienen las desviaciones estándar de cada parámetro estimado, esta deberá ser al menos dos veces más pequeña que el parámetro, de manera que este sea significativo, de lo contrario probablemente pueda ser suprimido de la estructura. También se obtienen las correlaciones entre el error y el vector de entradas, entre el errror y el vector de salidas y entre el error mismo (autocorrelación); si los valores de estas correlaciones son pequeños (< 0.15 — 0.12), el modelo se puede considerar aceptable. 7. Por último si el modelo es suficientemente bueno de acuerdo a los resultados de la validación, se termina el proceso, de lo contrario se debe de regresar al punto número 4, hasta obtener un modelo aceptable. 15.
(28) En la Figura 2.6 se muestra un diagrama que resume los pasos anteriores. Para hacer todo este proceso es normalmente necesaria la ayuda de un experto que tome las decisiones y es precisamente lo que se trata de automatizar en esta tesis. 1) Diieio ie la fruta a) Tipo de prueba 1) Duración c) Tiempo de Muestreo. i. r. 2] Af licacióa ie la jraeka Registro de entradas y salidas. \ 3) Acokiíeioiamieato ie los iatos a) Centrar tos datos (elimiar la media). 1) (Opcional) Escalar los datos.. 1r. 4) Pro)oaer la esrrwtwa iel mótelo Definir na, ni y d de la ecuación: __ ^ t\£ +. i^z +... + 0^ -2. -AT. ' 5) Estimar los f arámetros leí mótelo Mediante mínimos cuadrados 1 6) Valuar el mótelo Evaluar: a) Desviación estándar del error de predicción, i) Desviación estándar de cada parámetro estimado, c) Correlaciones entre: Error y entradas Error y salidas Autocorrelación del error.. NO. /¿ísswf iiii.Tii.miTX /, 1 modelo?/. SI. ^(fnr). \/. Figura 2.6 Proceso de identificación manual. 2.6. Identificación en lazo cerrado. La identificación en lazo cerrado es necesaria en los procesos reales, ya que identificar en lazo abierto puede ser inestable. Sin embargo al momento de 16.
(29) retroalimentar la salida se establece una relación entre las variables y por lo tanto la correlación se verá afectada. Un ejemplo muy sencillo de cómo la retroalimentación afecta la identificación se presenta a continuación. Considere el modelo: aiy(t - 1) = blU(t - 1) + e(t) Si el controlador tiene la siguiente forma: u(t) = -ky(t) que es un controlador proporcional, la predicción de la salida sería y ( t ) = -aiy(t - 1) + blU(t - 1) = (-fciA: - ai)j/(í - 1) por lo que cualquier combinación de valores de ai y 61 tal que sea igual a ái+ kb\ producirán la misma predicción, por lo que el modelo no puede ser identificado. Una manera de combatir este problema es agregando un valor fijo de referencia distinto de cero y ello permitirá al método de identificación distinguir el efecto de uno u otro parámetro.. 17.
(30) Capítulo 3 3. Algoritmo Propuesto Se propone un algoritmo que consta de 2 partes básicas para lograr una identificación automática de procesos tanto de la estructura como de los parámetros que ajusten mejor esa estructura. El modelo encontrado será representado por una función de transferencia discreta, representada de manera genérica por la ecuación 2.1 . La primera parte de este sistema es la más importante ya que es la que determina los valores de na y nb así como el tiempo muerto d y los valores del vector de parámetros 9 para el modelo encontrado. La segunda parte del sistema permite elegir la entrada de prueba que se utilizará para hacer la identificación. Las señales posibles son una entrada dada por un relevador representado por la ecuación 2.12, que mantiene al proceso en lazo cerrado y que asegura estabilidad en la salida. La otra es una señal RBS con una modificación que permite mantener al sistema en los límites de operación deseados pero con una mayor riqueza de información en la entrada. 3.1. Método de Identificación. El procedimiento aquí propuesto consiste en un algoritmo que organiza los datos de manera que éstos puedan ser utilizados para hacer repetidamente la identificación por mínimos cuadrados, modificando la estructura del proceso en cada iteración. Los datos se deben ordenar en la matriz ^, pero para poder crear esta matriz se necesita fijar el modelo a identificar es decir, los valores de na, nb. yd. Selección del tipo de modelo a identificar. El primer problema a solucionar es encontrar el modelo que servirá para poder iniciar la búsqueda de los parámetros na, nb y d. Partiendo de un modelo continuo representado como un cociente de polinomios de la forma. .... = n. 1. ™Para cualquier modelo físico (realizable) el modelo dado por 3.1 tendrá la condición de que el polinomio del numerador es de menor o igual orden que el polinomio del denominador, esto es m < n. 18.
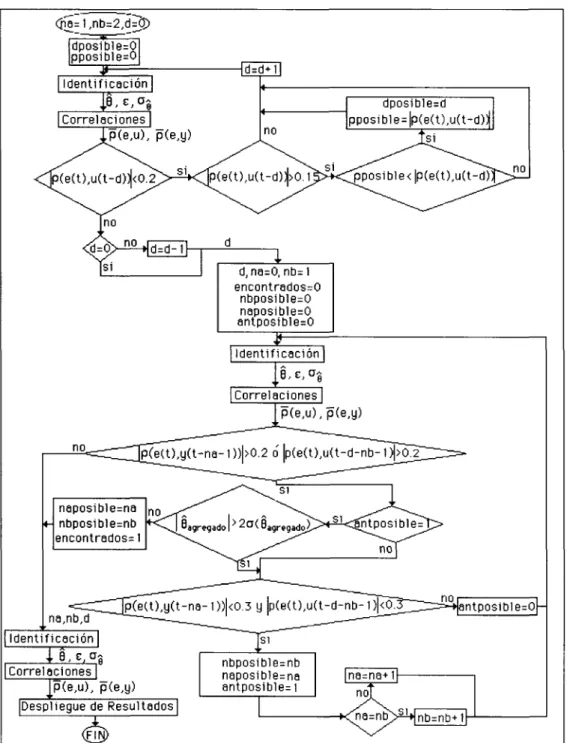
(31) Es conocido que la ecuación 3.1 puede ser expandida en fracciones parciales. Dependiendo de las características del denominador, la función G(s) se puede reescribir como:. G(*) = -%pi • S °- 2p • 2. • SCn -p. n. cuando los polos de la función 3.1 sean diferentes (reales o complejos). Si los polos son iguales (suponiendo que tengamos un polo repetido tres veces) G(s) se puede escribir como:. Cualquiera que sea el caso, las fracciones resultantes son fáciles de discretizar. En la discretización mediante transformada Z se debe de incluir un retenedor de orden cero de la forma:. X(s) =. 1 — e~sT. (3.2). o. y se debe tomar en cuenta que el proceso puede tener un tiempo muerto, representado por e~tos. Utilizando la propiedad de linealidad de la transformada Z, el retendor de orden cero y el tiempo muerto que pueda tener el sistema, se obtiene un modelo discreto de la forma: 1. 2. nb. p(y>-l\ — ~~d bíz- +b2z- +...+bnhzr(z ) - z 1+aiZ-i+a2Z-2+_+anaZ-na. , <na < S no S na +, -il. /o o\. (ó.á). Este será el modelo que se tratará de identificar. Determinación del retraso del proceso El algoritmo comienza por buscar el retraso que tiene el proceso por lo que se debe partir de un modelo inicial. Se sabe que un modelo de primer orden con tiempo muerto (modelo que representa a muchos procesos) está definido por: G. Ke~tos. « = ^TT. Al ser discretizado con un tiempo de muestreo T, se convierte en:. 19. (3 4. '>.
(32) -. (3-5). cuando el tiempo de muestreo T no es un múltiplo exacto de ÍQ- Así que inicialmente ésta será la estructura que utilizará el algoritmo para iniciar la búsqueda del retraso (d). Comenzamos por el menor retraso posible, es decir, un proceso en el que el tiempo muerto es una fracción de tiempo de muestreo, d = 0. Así, nuestra estructura inicial estará definida por na = 1, nb = 2, d = O, por lo que la ecuación 3.5 se convierte en: I. "~1"""'!. (3.6). El algoritmo parte de este modelo y encuentra el valor del retraso. En el capítulo anterior se habló sobre la validación del modelo en base a las correlaciones entre el vector de errores y los vectores de entrada/salida. Esta teoría será utilizada para encontrar el retraso y posteriormente el orden del modelo. El procedimiento para determinar el retraso consiste en proponer el modelo inicial y suponer que los posibles errores sean debidos a ruido blanco no correlacionado. Esto nos permite aplicar la regla de validación dada en 2.16. La implementación de este criterio se basa en el siguiente razonamiento: la estructura inicial 3.6 se puede reescribir corno: y(t) = -aiy(t - 1) + M(¿ - 1) + b2u(t - 2) la salida estimada para este modelo sería: y(t] = -áiy(t - 1) + biu(t - 1) + b2u(t - 2) + e(t). (3.7). donde el error e(i) sería debido únicamente a un ruido blanco no correlacionado. Si éste fuera el caso, la correlación entre el error y la entrada sería muy cercano a cero (2.14). De no ser así, el error tendría una componente debido al error de modelado al no incluir este parámetro. Por ejemplo, en el modelo de la ecuación 3.7, si se supusiera un modelo con una d = 1 se tendría: y(í) = -aiy(t - 1) + b2u(t - 2) + b3u(t - 3) + e(t) Esto haría que el efecto de u(t — 1) representado por 61 se acumule en e(í), por lo tanto la correlación entre e(t) y u(t — 1) será mayor al valor límite dado en 2.16 por lo tanto se puede concluir que el retraso es menor, esto es, d = 0.. 20.
(33) Partiendo del modelo inicial 3.6, para encontrar el valor del retraso se siguen los siguientes pasos: 1. Se hace la identificación por mínimos cuadrados con el modelo propuesto aplicando la ecuación 2.9. Con esto se obtiene el vector de parámetros estimados 9 y el vector de errores e. 2. Se obtienen los valores de correlación entre el error e(t) y la entrada u(t). 3. Se aplica el criterio de validación para determinar si el valor del retraso d es correcto; específicamente: \p(e(t),u(t-d))\. <0.2. 4. Si el criterio arriba mencionado se cumple, se incrementa el valor del retraso d = d + I y se regresa al paso número 1. Por el contrario, si la condición no se cumple, el valor del retraso es igual a d = d — 1 y termina la búsqueda del retraso. Determinación del orden del modelo. Una vez que se tiene el valor del retraso se pasa a una búsqueda sistemática del orden del modelo. La manera de encontrarlo es aumentar progresivamente el orden y observando las correlaciones. Un factor muy importante a considerar es que el valor de nb será mayor o igual al valor de na, ya que una gran variedad de modelos tienen esta característica, como ya se explicó en la sección de selección del modelo. Para este algoritmo se tendrá entonces la restricción siguiente: na < nb < na + 1. (3.8). Esto se puede visualizar mejor en la Tabla 3.1, donde se muestra el orden en el que se buscará la estructura.. Tabla 3.1 Orden de búsqueda. 21.
(34) En cada caso se debe hacer la identificación por mínimos cuadrados y aplicar el criterio 2.16. De manera específica, para encontrar na se parte del modelo más básico posible, que es cuando na = O y nb = 1, pero con el retraso d encontrado anteriormente. Esto nos lleva a un modelo inicial dado por:. Este modelo implica que la salida únicamente depende de la entrada inmediata anterior. Una vez que se tiene este modelo, se siguen los pasos siguientes: 1. Se hace la identificación por mínimos cuadrados y se obtienen tanto el error como los parámetros estimados. 2. Se obtienen los valores de las correlaciones entre el vector de errores y los vectores de entrada/salida. 3. Se compara el valor de las correlaciones con el criterio de validación. Específicamente: \p(e(t),y(t-na-l)\. > 0.2. \p(e(t), u(t -nb-d-l)\ > 0.2 4. Si estas condiciones se cumplen, aún no se encuentran los valores adecuados de na y nb, por lo que se verifica la condición 3.8, para incrementar el valor correspondiente de na o nb y regresar al paso 1. Si no se cumplen los criterios significa que se encontró el valor correcto de na, nb y la búsqueda termina. En la Figura 3.1 se muestra un diagrama de flujo que representa el procedimiento de búsqueda antes descrito.. 22.
(35) Identificación. 8,E [Correlaciones | I p(e,u), p(e,y). encontrados=1 lna,nb,d * i Identificación [Correlaciones | |p(e,u)T p(e,y) I Despliegue de Resultados!. Figura 3.1 Diagrama de flujo para la búsqueda del modelo del proceso. 3.2. Señal de prueba basado en el relevador. Se propone utilizar el relevador como un generador de funciones para obtener los datos de entrada/salida. Esta propuesta está basada en las características de estabilidad que proporciona esta prueba. Se puede ver en la Figura 3.3 la salida de un proceso donde se comprueba que ésta se mantiene oscilando 23.
(36) establemente. Los únicos parámetros que se deben de especificar para lograr una salida estable son la amplitud del relevador y la histéresis; sin embargo, estos parámetros no son difíciles de elegir. La amplitud del relevador debe ser suficientemente grande para obtener una variación en la salida del proceso que sea distinguible del ruido. La histéresis debe ser mayor que la amplitud media del ruido, por lo que se propone una señal de entrada dada por la ecuación 2.12. A pesar de que la identificación se haría en lazo cerrado, el uso del relevador como controlador posiblemente atenué el efecto de retroalimentar la salida. Un riesgo que se corre al utilizar este tipo de entrada radica en la periodicidad de la respuesta; esto puede producir que al momento de formar la matriz \P se tengan renglones iguales, por lo que la matriz no sería invertible. Otro posible problema derivado de la periodicidad de la salida es que entre dos valores de u(t) no se pueda distinguir su efecto en la salida.. Entrada Relevador 2 =r 2. i. .. 1. 1 S 11 .. ^ ** w 3. n5 ^ -. °' nu. i ii. -ns u. o - . — 1I —1 ^ 1-y ~¿. ~. -^> ^ ¿.¿J. -. 1 fi \ \. L. 6. i. ' ¿.. 21. 1. Tiempo. Figura 3.2 Entrada producida por el relevador.. 24. 1. 6.
(37) Salida con Relevador. Tiempo. Figura 3.3 Salida del proceso con relevador. 3.3. Señal de prueba basado en RBS acotada. Esta señal tiene la ventaja de que disminuye la correlación entre la salida y el error, ya que el proceso se encuentra en lazo abierto. Además presenta una mayor excitación para el proceso ya que esta señal, así como la salida del proceso, no serán periódicas, por lo que cumplirá mejor con la condición de excitación persistente requerida para que los mínimos cuadrados converjan al valor del parámetro real. Sin embargo se corre el riesgo de que el sistema salga de los límites de operación.. 25.
(38) Entrada RBS No Acotada 2.Í. 2 1. C g. o. i i i ii. -1. -1.5 -2.5. Tiempo. Figura 3.4 Entrada del proceso con señal RBS no acotada.. Salida con RBS No Acotada 19-i. s~-\ / \ / \ ^ / \ / \t \. 1n S . 6 . 4 . +* w 2 . 9 0 . _o . 1. 4. .. 6. .. /V É. ^. /1. X 1 É. "> 1. °É. 3 A. /AÉ^^. \. Tiempo. Figura 3.5 Salida del proceso con señal RBS no acotada. Por lo cual se propone acotar el valor máximo de la salida para que éste se mantenga en los límites deseados. Así que se propone una modificación a la prueba RBS dada por 2.10. Esta modificación consiste en poner un nivel 26.
(39) límite superior e inferior a la salida del proceso: mientras la salida del proceso se encuentre dentro de estos límites, la manipulación será determinada por la ecuación 2.10; si la salida llega a uno de los límites establecidos entonces la manipulación toma el valor que regrese a la salida dentro de lo límites establecidos. La ecuación que rige este comportamiento sería: rana < 0.5 , „ _ rand > 0.5 u2. u(t). ,,. , .. mínimo < - y(t) u\ i < - máximo y(t) > máximo y (i) < mínimo. (3.9). Para esta prueba se deben proporcionar los límites (mínimo, máximo) en los que se desea mantener la salida del proceso y el valor que tomará la manipulación en cada tiempo de muestreo.. Entrada RBS Acotada 2.5 1.5. « 0.5 T I I I t l l. -0.5 -1 -1.5 -2 -2.5. -31-. Tiempo. Figura 3.6 Entrada de una señal RBS acotada. 27.
(40) Salida con RBS Acotada. 4. 2. . .. t ¿-. 4. /\ /. j». 0 n£ W Si f. A. 1. 6. .. -£. • 0. \. /. 1 1 1 1 1 1 "•*-_' i * y v/ 1 y ' ' ' ' ' ' ' ' ' ' ' V ' ' ' ' ' \ ' ' ' ' ' ' f. \. 1/1. ^. 21. \16. 2/. /. \AA. ". \ / \7. .. 31 \. '. 36 /. \. /. V/. Tiempo. Figura 3.7 Salida limitada por el efecto de la RBS acotada. En el siguiente capítulo se mostrará el programa computacional que implementa este algoritmo. 3.4. Método de identificación modificado Búsqueda del retraso. El hecho de tener una regla binaria en la toma de decisión sobre la validez de un modelo puede causar problemas por la cantidad de factores que influyen (ruido no blanco, perturbaciones, dinámicas no modeladas, efecto del tiempo de muestreo, errores de redondeo) sobre las correlaciones, a pesar de que esta decisión esté bien fundamentada. Por lo anterior se propone hacer una modificación sencilla pero importante al método de identificación. Tal modificación consiste en flexibilizar la regla de validación para encontrar el retraso, ya que un error en la identificación de este parámetro nos puede conducir a un modelo equivocado. Así, se propone una banda de factibilidad para el valor de la correlación entre el error y la entrada para encontrar el valor del retraso. El límite superior de esta banda es 0.20 y el límite inferior es 0.15. De manera que si se cumple 0.15 < \p(e(t),u(t-d))\. 28. <0.2. (3.10).
(41) \p(e(t), u(t — d))\ se guarda en un registo temporal, y se sigue incrementando el valor del retraso (d). Si se encuentra un valor mayor a 0.2 se determina que se encontró el valor del retraso, y si el valor se encuentra en la banda definida por 3.10 y es mayor al registro temporal anterior, éste se convierte en el nuevo valor del registro. Si se tiene un valor de retraso mayor a 5 entonces se toma el valor del registro como referencia para decidir el valor del retraso del modelo. Así se asegura que se encontrará un retraso para el modelo y que este retraso será lo más aproximado posible al retraso del proceso real, el límite de 0.15 se eligió en base a una recomendación de Landau (1990). Búsqueda del orden del modelo Al igual que en la determinación del retraso, en la búsqueda del orden del modelo se propone una flexibilización a la regla de validación y una regla adicional para comprobar la validez de un parámetro. Esta modificación consiste en la posibilidad de considerar aceptable un modelo que no cumple estrictamente con la regla de validación dada por 2.16, siempre y cuando se compruebe que al aumentar el orden del modelo no se encuentra una estructura completamente correcta y que tampoco se aprecie una considerable mejoría en la identificación del modelo. De esta manera se introduce un nuevo elemento de validación consistente en analizar el valor de los parámetros con respecto a su desviación estándar. Estadísticamente hablando, si el valor del parámetro que se desea validar es mayor que 2 veces su desviación estándar, se puede asegurar que en el 95% de los casos el valor del parámetro es correcto, asumiendo una distribución normal. Es decir, la regla de validación para determinar si un parámetro es significativo es > 2 (je. (3.11). Específicamente el nuevo algoritmo realiza los siguientes pasos: 1. Parte de la misma estructura inicial na=0, nb=l y d. Obtiene el valor de los parámetros mediante mínimos cuadrados así como la desviación de cada parámetro y las correlaciones. 2. Comprueba si el modelo propuesto cumple con la regla de validación 2.16. Si es válido se termina la búsqueda, de lo contrario se verifica si el valor de las correlaciones no es mayor que 0.3; es decir: 0.2 < \p(e(t), y(t - na - 1)| < 0.3. 29.
(42) 0.2 < \p(e(t), u(t-nb-d-l}\< 0.3 3. Si la estructura propuesta cumple con el nuevo criterio establecido en el punto 2 entonces se le considera como un modelo probable, pero se pasa a la siguiente estructura. 4. Al proponer la siguiente estructura, se verifica si ésta no cumple con 2.16. Si cumple, la nueva estructura es la correcta. De lo contrario se verifica si el parámetro agregado con respecto a la estructura anterior es significativo 3.11. Si no lo es, la estructura anterior se considera un modelo aceptable y termina la búsqueda. Si el nuevo parámetro es significativo, la nueva estructura se valida con la regla dada en el punto 2; si la cumple éste pasa a ser el nuevo modelo problable y se regresa al punto 3. La Figura 3.8 muesta un diagrama de flujo que muestra el algoritmo con sus modificaciones.. 30.
(43) <Jía= 1 ,nb=2,d? dposible=C ppos1ble=( Identificación dposible=d pposible = |p(e(t),u(t-d))l. lTe,P8 [Correlaciones |. encontrados=0 nbposible=0 naposible=0 antposible=0. ntposible=o}-. Correlaciones p(e,u), p(e,y) [Despliegue de Resultados|. nbposible=nb naposible=na antposible=l. Figura 3.8 Diagrama de flujo del algoritmo modificado.. 31.
(44) Capítulo 4 4. Implementación computacional El software en el cual se implemento el algoritmo de identificación es Lab Windows® de National Instruments. Esta aplicación tiene la facilidad de crear una interfaz gráfica con paneles, indicadores, interruptores, gráficos, textos, barra de opciones, entre otros, que permiten visualizar y modificar fácilmente los parámetros que se definan. Además tiene la capacidad de ligar la interfaz hacia un código en ANSÍ C; con esto se pueden programar rutinas o procesar la información con ayuda de las librerías que contiene de tal manera que se convierte en una herf^~\ ramienta adecuada para el área de control en general. Con Lab Windows® se pueden hacer simulaciones o se pueden implementar directamente sistemas de control o de medición en un proceso real mediante sus rutinas de adquisición de datos. Con ayuda de este softaware se realizó el sistema de identificación. Se llevaron a cabo las pruebas en los diferentes modelos y en el proceso real, por lo que a continuación se presenta la interfaz con el usuario. 4.1. Panel Principal Ésta es la ventana principal del programa (Figura 4.1); desde ella se puede accesar a las demás ventanas que se tienen en el programa. En este panel se pueden modificar los principales parámetros del proceso como son: • Seleccionar entre control manual o automático. Si se selecciona control manual, el proceso queda en lazo abierto y se debe ingresar manualmente la manipulación, Si se selecciona automático se puede modificar la referencia. • Elegir simulación o proceso real. Si se elige simulación se debe especificar la función de transferencia del proceso a simular. Si se desea trabajar con un proceso real se manda la manipulación a la tarjeta de adquisición de datos y se toma la salida real del proceso. • Elegir el tipo de señal de entrada a utilizar. Puede ser la señal de tipo relevador o la señal RBS acotada.. 32.
(45) • Manipular o visualizar la manipulación, referencia y salida del proceso. La visualización se hace directamente en la gráfica que se encuentra en este panel principal; las variables se distinguirán por colores. • Iniciar la ejecución del programa. Con esto se comienza a capturar datos de entrada/salida del proceso así como a enviar la entrada o la referencia al proceso ya sea real o simulado. • Borrar los datos capturados. Esto borra todos los datos capturados de entrada/salida y coloca los valores de la variables principales en sus valores de inicio. Se pasa automáticamente a control manual. 8RARCAD£VAÍ IABLES PRINCIPALES. tao-. i "° >. RELEWlOOB). "". -mo-. BBS AKiKKte). 0. 49. Tiempo. Srfínl de Entrada HtltVáüüR-g. I. 5<H ' -• 3. • :í-í<r z*"~j~r'¡ TI 1H r ~. CDM. REFERENCIA. RESPUESTA. 0.00 N. no. ^. ^000. ¡. ¡. ••^. _ji. ¡j TIMER. •. t. INICIAR ) I. • • • • • aORRAH). Figura 4.1 Panel principal. Desde este panel se tiene el acceso a los siguientes paneles. 4.2. Ajuste de parámetros. Dentro de esta sección se determinan los siguientes parámetros: • Parámetros del proceso. En caso de ser una simulación se debe especificar la función de transferencia, de la forma descrita en la ecuación 3.3.. 33.
(46) 1. | PARÁMETROS DEL PROCESO. rri'? ~*- \. i ~t~£z i z. .d ;§)2J. ~i~cJ2 2. Retraso. • • • -í* Mti¿. ruido ^ JO. 01. .al ;^JO. 00000000 :•':> a2 ^JO. 00000000 :. "ri* 3 2. ¡I. máximo. B1 ^0.00000000 j b2 q 0.00000000. .:„„. ,. a3 ;| ¡0.00000000. b3 ^JO.OOOOOOOO. »r. .a4 j|)o.oooooooo. b4 fjo.oooooooo. áS ígjO. 00000000. bS = JO. 00000000. Tiempo de Muestre (s). •qji.oo. 1. DK |. Figura 4.2 Parámetros del proceso. Señal de prueba. Ésta se puede seleccionar entre: RBS acotada especificando la amplitud de la manipulación, así como los límites en los que se desea mantener el proceso. Relevador: en este caso se tendrá que elegir la amplitud del relevador y el valor de la histéresis.. 34.
(47) VALORES DEL RELEVADOR I. uor d. AMPLITUD :||i3Ü.ÜO HISIERESIS. . .—•. I I. Figura 4.3 Parámetros del relevador. RBS ACOTADA Amplitud!. no.oo Desv. Maséna de la salidaj. IHGO. Figura 4.4 Parámetros de señal RBS acotada. 4.3. Identificación. En esta ventana, se puede elegir entre la identificación automática y la identificación manual. En el caso de la identificación automática el programa comenzará a buscar la estructura más adecuada con los datos capturados durante la prueba y los valores de los parámetros que ajusten esa estructura, desplegándolos 35.
(48) al momento de terminar la identificación. Se muestran también las correlaciones entre el error y la salida/entrada del modelo elegido. En el caso de identificación manual se deben introducir los valores de na, nb y d. El programa hará la identificación y desplegará los parámetros encontrados, así como los valores de las correlaciones entre el error y la entrada/salida. Si el resultado no es satisfactorio se varían los parámetros na, nb y d y se vuelve a hacer la identificación. En este panel se despliega también para cada identificación el valor de la desviación estándar del error de cada parámetro, así como la desviación del error total del modelo encontrado. "»ÜoJ Pwámetrtw EttNnadoi. *llJ. Desviación Parámetro*. * Í2j Parámetros Estmados. Desviación Parámetros. SI ooooooooo |. ¿ai 'OOOOOOOOOE+OÍ. "bl 0.00000000. d*b1 O.OOOOOOOOE+O). &2,'o.oooooooo |. dá2 ¡O.OOOOOOÓOE+O. "b2. ,0.00000000. d"b2 <O.OOOOOOOOE+OJ. 63 -o. oooooooo |. da3 :o.ooooooooE+oj. A. b3 ooooooooo. d"b3 O.OOOOOOOOE+OJ. é4 'o.oooooooo [. d&4 'O.OOOOOOOOE+O. ^M 000000000 t. d'bl o.oooogt:iggE*o|. S5 UOOOOOOOO. d&5 '0 OOOOOOOOE+Oi. "bS 0.00000000 ~ |. d"b5 O.OÓOOOOOOE+O|. |. Desviación del Enof. de O.OOOOOOOOE+O CXlfiRELAQON (&ji). CORRElACION((Mj) fi'o» ü Í ¿ M « » . M * _ ^ í ^ ~ i l i í i t t ' _ .. 2,ízíL & ,. n'í. s:. S:n y • £ •• "' :. • "^. •'* '^'< 'y-. »to,. 415-. ^J--'-\:-;:ví«|J. ^rJlieptífe^-f ' 2. 3. 4. 10. Automática. S. B. 7. 8. . i- í ':. % • '? ", '. '. •1.03. 9. T. 2. *. /. ,. :.. 'á ;.' ;•;;. ?. {-;. ^ í< |7. ;5 ,'. '•' 'i T . *>, í-! „ _ „ _ _ -•'.. .-„ ,-•„ '• ' ' '. ' ^í. í¡K-t#~~~^ÍK~~ SS - - - * - » ft o^ ^|íii,^ü l w l Jí¿¿^.£M^ w . w .^. W M .i h , 1. '" ';•. '; •i. ' •'• '•> '•'•'• k. . J-. •• '",••'• '. fí. - '• '' • *; "• ' •. Sl2llE£.2l¡ll£l_¡,2¿.... 0. '„ '- § ;" :¿ § .. •S ft . :. • * 1 1 ^ i 'i •' *::- * & 1 1 í ^ :;: = 9. «I H '- •• "* * W ''A 'íí v •• - v 1 k Vi- 'if '••. :>,',. nft-. • f f-. ;,. _. t. "''•. ' » '. .,. ;• -"J.tt.A *j,',j "f\'¿\':, : ¿,. . (*;'" l i l i f 1 t 3. 4. IDENTIFICAR |. 5. 6. 7. 3. 9. SAUR ]. Figura 4.5 Panel de identificación. Los resultados obtenidos con este programa se mostrarán en el capítulo 5.. 36.
(49) Capítulo 5 5. Resultados Para probar el desempeño del algoritmo propuesto se eligieron modelos de primer y segundo orden. Los casos de primer orden utilizados se determinaron de manera que hubiera una representación de varias dinámicas basadas en la relación del tiempo muerto y la constante de tiempo ^. En los modelos de segundo orden se seleccionaron tres casos subamortiguados y seis casos sobreamortiguados con diferentes tiempos muertos. En los modelos de primer orden se utilizó entrada de relevador y RBS acotada, y en los casos de segundo orden se introdujo RBS acotada. 5.1. Modelos de prueba. Partiendo de la discretización de un modelo continuo de primer orden con ganancia unitaria y tiempo muerto G(s) = ^^ , con un retenedor de orden cero, considerando que en el caso más general el tiempo muerto se puede escribir como ¿o = dT + /, en donde d es la parte entera de ^ y / la parte fraccionaria, y definiendo m = I — £ se llega a: A. en donde. T. /. T. -v —1. I. T\. í,. .v — 2. T. 61 = (1 - e-mr),bt = (e-^r - e") y a, = -e~r.. Considerando un tiempo de muestreo T = 1 para todos los modelos y tomando las siguientes relaciones entre el tiempo muerto y la constante de tiempo: ío. T. tu. 1. 100 10 2. 0.01 0.1 0.5. 1 1. T. Tabla 5.1 Relación tiempo muerto y constante de tiempo. Seleccionando además dos tipos de tiempos muertos fraccionarios (0.75 y 0.25) para cada relación, se obtienen seis modelos discretos que son: 37.
(50) 0.0025Z-1 + 0.0075Z-1 1 - 0.99Z-1 0.0075Z-1 + 0.0025Z-1 1 - 0.99Z-1 1N. )=. 0.025Z-1 + 0.075Z-1. 0.075Z-1 +0.025Z- 1. 1. +0.08Z-1 1 — 0.6z 1 Si a cada uno de estos modelos se les agrega un retraso d = 2, se tienen en total 12 modelos diferentes. En lo sucesivo para hacer referencia a alguno de estos modelos solamente se denotará por Pi(z~1) con i = 1,2...12. Para la selección de las dinámicas de segundo orden se parte de un modelo continuo con la siguiente estructura general:. en donde un es la frecuencia natural no amortiguada, £ es el coeficiente de amortiguamiento y Í0 el tiempo muerto. Se eligió un caso subamortiguado en donde £ = 0.5 y un = 0.4 con tiempos muertos t0 = 1,1.3 y 1.8, con lo que se obtienen tres modelos: _j. _ a 0.07z 1 + U.UDZ ^Z '~Z 1- 1.54Z-1 +0.67z- 2 38.
(51) _! 0.035Z-1 + 0.09z-2 + O. l-1.54*-i+0.67z-' + 0.038z-3 i + 0.67,-2 Y dos casos sobreamortiguados de forma general:. con TI, T2 = [1, 20], y TI, T2 = [4, 4]. Tomando tres diferentes tiempos muertos = 1, 1.3 y 1.8 se tienen seis modelos más:. 5Z. !. ~Z. _lQ.QQ97z-1 + 0.02Z"2 + O.. 0.022z ~. 2. 1- 1.32Z"1 +0.35z- 2 _! 0.027Z-1 + 0.022z-2. 1. + 0.0342-2 + O. l-1.56z-i+0.6(k- 2 1. + 0.0342"2 + 0.014z-3. que en adelante se hará referencia como HÍ(Z l] con i = 1,1,..., 9. Una vez definidos los diferentes casos de estudio se probó el algoritmo con las diferentes entradas definidas por las ecuaciones (2.12) y (3.9).. 39.
(52) 5.2. Resultados de la identificación con señal del relevador Inicialmente se probaron los modelos de primer orden con una señal de relevador para tratar de aprovechar las ventajas de estabilidad que proporciona esta señal. Considerando un relevador con una amplitud de 30, una histéresis de 0.2 y con un ruido con desviación máxima de 0.1, los resultados fueron los siguientes para 128 datos:. d=0 %error e 9 V. real 2.02 ai -0.99 -0.9699 0.00227 9.04 bi 0.0025 2.14 0.00733 b2 0.0075 1.2 -0.99 -1.0019 a\ 0.00738 1.57 bi 0.0075 0.00232 7.01 bi 0.0025 -0.9182 2.02 ai -0.9 0.025 0.0259 3.9 bi 0.075 0.0753 0.53 b* ai 2.92 -0.9 -0.926 0.075 0.0755 0.73 bi 0.0247 0.86 b2 0.025 NA ai -0.6 no encontrado 0.12 no encontrado NA bi no encontrado NA 0.28 b2 ai -0.6 -0.601 0.26 0.31 0.31 0.01 bi 0.08 0.0798 0.19 b2 Tabla 5.2 Resultados de la identificación con relevador y d = 0. Se puede apreciar en la tabla que en la mayoría de los casos el algoritmo funciona de manera correcta. Los valores estimados de los parámetros tienden a los valores reales, excepto en el caso del modelo P$(z~1^. en donde el ciclo de identificación no logró encontrar una combinación de parámetros adecuada que cumpliera con los criterios establecidos. Específicamente el problema consistió en que la regla para encontrar el retraso d, nunca se cumplió, es decir \p(e(i), u(t — d))| nunca fue mayor a 0.2, y por lo tanto no se encontró el valor del retraso y en consecuencia tampoco los valores de na y nb. Para evitar este 40.
(53) posible problema en identificaciones posteriores se propuso una regla más flexible reflejada en el algoritmo modificado. Para un retraso d=2, se realizó la misma prueba con los siguientes resultados:. d =2 V. real e %error -0.9997 0.98 ai -0.99 3.21 bi 0.0025 0.00258 2.13 b2 0.0075 0.00734 ai -0.99 -1.0059 1.6 2.23 bi 0.0075 0.00766 10.3 b2 0.0025 0.00224 -0.9002 ai -0.9 0.03 0.0250 0.23 bi 0.025 0.0749 0.04 b? 0.075 ai -1.0648 -0.9 22.9 bi 0.075 -0.0100 113.44 0.0766 206.7 h 0.025 ai -0.6 -0.6000 0.01 0.12 0.1200 0.003 bi 0.28 0.2799 0.008 bz ai -0.6 -1.1139 85.65 0.0334 0.31 89.19 bi 0.08 0.2877 259.63 bi tados de la ic entificación con relevador y d — 2 Tabla 5.3 Resa. e. Al igual que en las pruebas anteriores, la mayoría de los casos fueron identificados satisfactoriamente, a excepción los modelos PIO(Z~I) y Pi 2 (z^ 2 ), en donde se puede ver que se encontraron valores estimados para los parámetros, pero estos tienen un error no debido al método de mínimos cuadrados, sino al efecto de que no se encontró el valor del retraso adecuado. El valor que el algoritmo determinó como el óptimo, de acuerdo al criterio establecido y al algoritmo propuesto incialmente, fue de d = 0. Es decir, el valor de \p(e(t), u(t — d}}\ superó 0.2 con d = 0; por tanto el algoritmo determinó que éste era el retraso del proceso real, llevando a una estructura incorrecta y por tanto los parámetros presentan un error muy grande. Sin embargo esta correlación mayor a 0.2 es producida por el tipo de señal de entrada utilizada (relevador), la cual al ser una identificación en 41.
(54) lazo cerrado afecta el valor de la correlación. Esto se puede verificar al revisar las correlaciones obtenidas con este tipo de señal de entrada al momento de ir aumentando progresivamente el orden de la estructura para determinar cuál es la correcta, como lo muestra la Figura 5.1, donde se muestran las correlaciones correspondientes a la identificación del proceso P^(z~1} cuando na = 1, nb = 1 CQRBEUW3QN (fcj>). CORRElAdQNfe-u) l.ü-. i.uQ.B-. M. «^. '•^. '. f i e_ •Jv. 'V. Há-. ;. ¿. n •> u,¿-. -. í. 4. -". :". n •3-. .•. rt A-. •0.6•0.8- m •1.0). -;-. W. ••. •. MI. •M. I. 2. 3. ',?'. 4. 5. f. t. 6. 7. 1. 8. '<•. -na. -1.0-. ÉM. i. a. _n A J1C« F* H. Figura 5.1 Correlaciones para el modelo P5(z. l. ,•: •í. ~¿í. *:-,. *•/. 3. 4. i 5. *. -í. "&. /r. '% I. 2. ;. '.!• ¿? '%. tm. t). 9. '.^. \-«-. !. m f.. mm. •0.2-. *£ «m. M.. :i.. íi'. ',;T. í,. •4. n A-. !?. m. .«. «1 í. 6. 7. *. {. i 9. ) con entrada del relevador. Se puede observar una periodicidad en las correlaciones, y esto se explica por la periodicidad tanto de la entrada como de la salida del proceso producida por el relevador. Esto llevó a proponer una señal de entrada diferente, una señal que no fuera periódica y que mantuviera la salida del proceso acotada; de esto surge la señal RBS acotada, que no es periódica y por tanto tiene mayor información y estimula mejor al proceso. Los resultados se dan a continuación. 5.3. Resultados de la identificación con señal de entrada RBS acotada Modelos de Primer orden. Para identificar con la señal RBS acotada se utilizó un valor de amplitud de 10 y un valor de desviación a la salida permisible de 5. Se probaron nuevamente los doce modelos de primer orden tomando 128 datos, obteniendo los siguientes resultados:. 42.
(55) e ai bi í>2. ai. bi bi ai bi 62 ai. bi b-2 ai bi h ai bi bi Tabla 5.4 Resultados de la. d =0 9 %error V. real 1.22 -0.99 -1.0021 0.0025 0.00266 6.43 1.62 0.0075 0.00737 0.24 -0.99 -0.9875 0.0075 0.00754 0.61 0.0025 0.00231 7.48 -0.9014 0.15 -0.9 0.32 0.025 0.02508 0.075 0.07505 0.06 -0.9 -0.9008 0.09 0.075 0.07512 0.17 0.82 0.025 0.02479 -0.6 -0.5999 0.01 0.12 0.04 0.1200 0.2800 0.01 0.28 0.04 -0.6 -0.5997 0.02 0.3100 0.31 0.08 0.0800 0.05 identificación con entrada RBS acotada y d — O .. Se puede observar que los parámetros estimados son más cercanos a los valores reales; esto se explica por la mayor riqueza de información que se obtiene al utilizar la señal RBS acotada en lugar del relevador y como en casos en los que la identificación había fallado anteriormente (con la entrada del relevador), en esta ocasión fueron acertados, por que la estructura del modelo fue elegida adecuadamente por el algoritmo. Se realizó la misma prueba pero ahora para los procesos con un retraso d — 2 y éstos fueron los resultados:. 43.
(56) 9 a\ bi b2 ai bi b2 ai bi ¿>2. ai bi b2 ai bi b2 ai bi b2 Tabla 5.5 Resultados. d =2 9 V. real %error -0.9921 0.21 -0.99 2.69 0.0025 0.00256 0.0075 0.00777 3.6 -0.9921 0.21 -0.99 0.0075 0.00756 0.89 0.0025 0.00275 10.3 -0.9007 -0.9 0.08 0.025 0.0250 0.19 0.075 0.0753 0.46 -0.9010 0.12 -0.9 0.075 0.0751 0.20 0.0249 0.22 0.025 -0.6 -0.6000 0.01 0.12 0.1199 0.02 0.28 0.2799 0.01 -0.5998 0.02 -0.6 0.02 0.31 0.3099 0.0799 0.08 0.05 de la identificación con entrada RBS y d = 2.. En todos los casos evaluados con los resultados mostrados en las Tablas 5.4 y 5.5 se encontró la estructura correcta del modelo real y en consecuencia los valores de los parámetros estimados fueron cercanos al valor real. Las correlaciones obtenidas son menos periódicas para las mismas condiciones (na = l,nb = 1 y d = 0) que las obtenidas con la entrada del relevador, como se muestra en la Figura 5.2. Esto se debe a que el sistema está en lazo abierto, y así se cumplen de mejor manera los criterios de validación.. 44.
(57) CORRELACIÓN (e-j>J. CGRR£LACIQN(<H*) i.u-. .í. rj. '~i. <t. ;. \ t. nc». 7 í. u -a4•0.6- ^. .í. •í. s. •ty'. J='i. .!.. •í'. <J. i. 5. #\. ?. ;!.. f *. * s^ $?: te í. •;,; í.. ?!' 5. ÍH \. ,'•. X. i. \; -¿. ,„ **. ™ •! "fi K.. -1.0-. v.. i.utt80.6-. 1 '?.. -:. % ''. 3. 'V. ¿fc. 'ff.. ?•• "« *•. !*, -?- í *í «§. & í;-. 5. ?'. ,"•>. HW. 0.2-. •^ -¿. IM ,. MH). '• \. * í. * $. %>. a. \t. •%'. ¡". 4. ^. •. 'f. 1'. 1. ñ. ¿. i. -1.0-. f. é. 3. | '. f1. 1. í. :-i-. Y* m >., •? 3 -% ": "t. ''•. MI ;^ "^. *. í. e. _. f. •' ,". •; • ''í;. ^ ''*§ É| i¡ 9 «. 1. Figura 5.2 Correlaciones para el proceso P$(z *) con entrada RBS acotada. Cuando el modelo encontrado corresponde al modelo real, las correlaciones son mucho más limpias, como lo muestra la Figura 5.3, en donde se presentan las correlaciones obtenidas para el mismo modelo P$(z~1} pero con la estructura correcta. Para todos los demás modelos se obtienen correlaciones similares a la mostrada, cuando la estructura que encuentra es el algorimto es correcta. CORRELACIÓN (e^. CORREUdONÍíHj). I.O-TO.S. Figura 5.3 Correlaciones para el proceso P$(z. ) con estructura correcta.. Modelos de Segundo Orden. Para los modelos de segundo orden con entrada RBS acotada se obtuvieron resultados no tan precisos; sin embargo, éstos son satisfactorios. Específicamente se muestran los resultados para cada modelo en las tablas 5.6-5.14 y las correlaciones finales se muestran en las figuras 5.4-5.13.. e ai a-2 bi b?. V. real V. estimado d real d encontrado 1 1 -1.54 -1.5393 0.6694 0.67 0.07 0.0696 0.06 0.0600 45.
Figure



+7





Documento similar
Abstract: This paper reviews the dialogue and controversies between the paratexts of a corpus of collections of short novels –and romances– publi- shed from 1624 to 1637:
E Clamades andaua sienpre sobre el caua- 11o de madera, y en poco tienpo fue tan lexos, que el no sabia en donde estaña; pero el tomo muy gran esfuergo en si, y pensó yendo assi
SVP, EXECUTIVE CREATIVE DIRECTOR JACK MORTON
Social Media, Email Marketing, Workflows, Smart CTA’s, Video Marketing. Blog, Social Media, SEO, SEM, Mobile Marketing,
Por lo tanto, en base a su perfil de eficacia y seguridad, ofatumumab debe considerarse una alternativa de tratamiento para pacientes con EMRR o EMSP con enfermedad activa
The part I assessment is coordinated involving all MSCs and led by the RMS who prepares a draft assessment report, sends the request for information (RFI) with considerations,
o Si dispone en su establecimiento de alguna silla de ruedas Jazz S50 o 708D cuyo nº de serie figura en el anexo 1 de esta nota informativa, consulte la nota de aviso de la
Las manifestaciones musicales y su organización institucional a lo largo de los siglos XVI al XVIII son aspectos poco conocidos de la cultura alicantina. Analizar el alcance y
