Implementación de una Normalización Esférica en un Esquema Biométrico para la Generación de Claves Criptográficas Basadas en Voz Utilizando SVM Edición Única
93
0
0
Texto completo
(2) c Victor Hugo Trujillo Rodrı́guez, 2006 °.
(3) Implementación de una Normalización Esférica en un Esquema Biométrico para la Generación de Claves Criptográficas basadas en Voz utilizando SVM por. Lic. Victor Hugo Trujillo Rodrı́guez. Tesis Presentada al Programa de Graduados de la Escuela de Tecnologı́as de Información y Electrónica como requisito parcial para obtener el grado académico de. Maestro en Ciencias especialidad en. Telecomunicaciones. Instituto Tecnológico y de Estudios Superiores de Monterrey Campus Monterrey Mayo de 2006.
(4) Instituto Tecnológico y de Estudios Superiores de Monterrey Campus Monterrey Escuela de Tecnologı́as de Información y Electrónica Programa de Graduados. Los miembros del comité de tesis recomendamos que la presente tesis de Victor Hugo Trujillo Rodrı́guez sea aceptada como requisito parcial para obtener el grado académico de Maestro en Ciencias, especialidad en: Telecomunicaciones. Comité de tesis:. Jorge Carlos Mex Perera,Ph.D. Asesor de la tesis. Juan Arturo Nolazco Flores,Ph.D.. José Ramón Rodrı́guez Cruz,Ph.D.. Sinodal. Sinodal. David Garza Salazar,Ph.D. Director del Programa de Graduados. Mayo de 2006.
(5) Este trabajo de investigación esta dedicado con todo mi amor a mis padres Isabel Rodrı́guez Morales y Gaudencio Trujillo Vera, a mis hermanos Denice Trujillo Rodrı́guez y Ricardo Trujillo Rodrı́guez. Gracias por su amor, apoyo y confianza..
(6) Reconocimientos A la Cátedra de Seguridad Informática por el apoyo y crecimiento profesional que me ofreció durante mis estudios y la elaboración de éste proyecto de investigación. De manera especial a mi asesor de tesis el Dr.Jorge Carlos Mex Perera por su tiempo y dedicación para la realización de éste trabajo de tesis, a Paola Garcı́a Perera por su magnı́fica amistad, compañerismo y trabajo en equipo, al Dr. Juan Arturo Nolazco Flores por sus excelentes comentarios y aportaciones, y al Dr. José Ramón Rodrı́guez Cruz por su apoyo e importante participación como sinodal. A todos los profesores del Centro de Electrónica y Telecomunicaciones por fomentar la investigación como herramienta fundamental en mi desarrollo académico. A Elodia Sánchez Mendoza por su amor y apoyo incondicional a lo largo de mis estudios de posgrado. Te amo princesa.. Victor Hugo Trujillo Rodrı́guez Instituto Tecnológico y de Estudios Superiores de Monterrey Mayo 2006. vi.
(7) Implementación de una Normalización Esférica en un Esquema Biométrico para la Generación de Claves Criptográficas basadas en Voz utilizando SVM. Victor Hugo Trujillo Rodrı́guez, M.C. Instituto Tecnológico y de Estudios Superiores de Monterrey, 2006. Asesor de la tesis: Jorge Carlos Mex Perera,Ph.D.. El presente proyecto de tesis está dirigido al área de seguridad basada en caracterı́sticas Biométricas. La meta es mejorar el desempeño de un sistema de generación de claves criptográficas basadas en la señal de voz y la oraciones que dicen los usuarios aplicando un método novedoso llamado Normalización Esférica. Trabajar con voz tiene algunas ventajas debido a que es una caracterı́stica natural de comunicación, por lo que todos estamos familiarizados con ella, y por la flexibilidad que puede ofrecer al usuario si desea cambiar su clave, ya que al cambiar la frase inevitablemente cambia la vocalización del mismo y de ésta manera es posible generar un número infinito de claves criptográficas. En el presente trabajo se analiza la implementación de una técnica de Reconocimiento Automático de Voz y la técnica de Máquinas de Vectores de Soporte (SVM) para la generación de claves criptográficas. Posteriormente se propone la aplicación de la técnica llamada Normalización Esférica , la cual permite mejorar el desempeño de SVM en procesos de clasificación. La técnica de Normalización Esférica propuesta consiste en mapear los datos de entrada en el espacio caractéristico a la superficie de una hiperesfera unitaria para esparcir los datos y de esta manera facilitar al clasificador el trazo de los hiperplanos óptimos de separación. La implementación de ésta técnica permite mejorar el performance del sistema generador de claves criptográficas en un 8.11 % para el caso de 10 usuarios, 8.18 % y 6.38 % para el caso de 20 y 30 usuarios, lo cual demuestra su efectividad..
(8) Índice general. Reconocimientos. VI. Resumen. VII. Índice de cuadros. X. Índice de figuras Capı́tulo 1. Introducción 1.1. Objetivo . . . . . . . 1.2. Justificación . . . . . 1.3. Contribución . . . . 1.4. Organización . . . .. XI. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. Capı́tulo 2. Antecedentes 2.1. Biometrı́a y sus Aplicaciones . . . . . . . . . . . 2.1.1. Ventajas y Desventajas de la Biometrı́a . 2.1.2. Caracterı́sticas de un Sistema Biométrico 2.1.3. Sistemas Biométricos Actuales . . . . . . 2.1.4. La Voz como Rasgo Biométrico . . . . . 2.2. Reconocimiento Automático de Voz . . . . . . . 2.2.1. Caracterı́sticas de un Sistema RAH . . . 2.2.2. Problemas Propios del RAH . . . . . . . 2.3. Máquinas de Vectores de Soporte (SVM) . . . . 2.3.1. SVM para Clasificación Lineal . . . . . . 2.3.2. SVM para Clasificación NO Lineal . . . 2.3.3. Aplicaciones de SVM . . . . . . . . . . . 2.4. Trabajo Previo . . . . . . . . . . . . . . . . . .. viii. . . . .. . . . . . . . . . . . . .. . . . .. . . . . . . . . . . . . .. . . . .. . . . . . . . . . . . . .. . . . .. . . . . . . . . . . . . .. . . . .. . . . . . . . . . . . . .. . . . .. . . . . . . . . . . . . .. . . . .. . . . . . . . . . . . . .. . . . .. . . . . . . . . . . . . .. . . . .. . . . . . . . . . . . . .. . . . .. . . . . . . . . . . . . .. . . . .. . . . . . . . . . . . . .. . . . .. . . . . . . . . . . . . .. . . . .. . . . . . . . . . . . . .. . . . .. . . . . . . . . . . . . .. . . . .. . . . . . . . . . . . . .. . . . .. 1 3 3 4 4. . . . . . . . . . . . . .. 5 5 6 7 8 9 11 13 14 14 18 18 21 22.
(9) Capı́tulo 3. Métodologı́a Utilizada para la Generación de Claves cas Implementando una Normalización Esférica 3.1. Reconocimiento Automático de Voz . . . . . . . . . . . . . . . . 3.1.1. Preprocesamiento . . . . . . . . . . . . . . . . . . . . . . 3.1.2. Modelación Acústica . . . . . . . . . . . . . . . . . . . . 3.2. Generación de Atributos . . . . . . . . . . . . . . . . . . . . . . 3.3. Clasificación con SVM . . . . . . . . . . . . . . . . . . . . . . . 3.3.1. Fase de Entrenamiento de la SVM . . . . . . . . . . . . . 3.3.2. Fase de Prueba de la SVM . . . . . . . . . . . . . . . . . 3.3.3. Uso de Funciones Kernel . . . . . . . . . . . . . . . . . . 3.4. Normalización Esférica . . . . . . . . . . . . . . . . . . . . . . . 3.4.1. Justificación de la Normalización Esférica . . . . . . . . . Capı́tulo 4. Herramientas para la Simulación, Experimentos Numéricos 4.1. Herramientas para la Simulación . . . . . . . . . . . . . . . . . 4.1.1. Base de Datos YOHO . . . . . . . . . . . . . . . . . . 4.1.2. HTK-Hidden Markov Model Toolkit . . . . . . . . . . 4.1.3. SVMlight . . . . . . . . . . . . . . . . . . . . . . . . . . 4.2. Experimentos y Resultados Numéricos . . . . . . . . . . . . . 4.2.1. Resultados Obtenidos con Vectores de 39 Dimensiones 4.2.2. Resultados Obtenidos con Vectores de 63 Dimensiones 4.2.3. Comparación y Análisis de Resultados . . . . . . . . . 4.2.4. Porcentaje Promedio de Error en la Clave . . . . . . .. Criptográfi. . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. 24 25 26 27 31 32 34 35 36 37 44. y Resultados . . . . . . . . .. 47 47 47 48 48 49 52 55 58 61. Capı́tulo 5. Conclusiones y Trabajo Futuro 5.1. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.2. Trabajo Futuro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 66 66 67. Apéndice A. Modelos Ocultos de Markov-HMM. 69. Apéndice B. Herramientas de Simulación B.1. Base de Datos YOHO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B.2. HTK-Hidden Markov Model Toolkit . . . . . . . . . . . . . . . . . . . . . . . B.3. SVMlight . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 71 71 72 74. Glosario. 78. Bibliografı́a. 79. ix. . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. . . . . . . . . ..
(10) Índice de cuadros. 2.1. Fonemas del idioma inglés utilizados para un sistema tı́pico de lenguaje hablado. 11 2.2. Funciones Kernel para SVM . . . . . . . . . . . . . . . . . . . . . . . . . . . 21 4.1. Resultados para 10,20 y 30 usuarios usando kernel rbf g=0.003 c=9 . . . . . 4.2. Resultados para 10,20 y 30 usuarios con kernel polinomial c=9 s=0.5 r=1 d=5 4.3. Resultados para 10,20 y 30 usuarios con kernel polinomial y Normalización Esférica c=9 s=0.5 r=1 d=13 . . . . . . . . . . . . . . . . . . . . . . . . . . 4.4. Resultados para 10,20 y 30 usuarios usando kernel rbf g=0.001 c=9 . . . . . 4.5. Resultados para 10,20 y 30 usuarios con kernel polinomial c=9 s=0.5 r=1 d=3 4.6. Resultados para 10,20 y 30 usuarios con kernel polinomial y Normalización Esférica c=9 s=0.5 r=1 d=20 . . . . . . . . . . . . . . . . . . . . . . . . . . 4.7. Comparación de Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.8. Tiempo aproximado de procesamiento usando vectores de 39 dimensiones . . 4.9. Tiempo aproximado de procesamiento usando vectores de 63 dimensiones . .. x. 52 53 54 55 56 57 59 60 60.
(11) Índice de figuras. 2.1. 2.2. 2.3. 2.4.. Secuencia de Voz y sus Observaciones . . Componentes de un Sistema RAH tı́pico. Clasificación Binaria en SVM . . . . . . Clasificación NO lineal en SVM . . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. 12 13 16 19. 3.1. Esquema General del Sistema . . . . . . . . . 3.2. Preprocesamiento de la señal de Voz . . . . . 3.3. Principio de Modelación Acústica . . . . . . . 3.4. Etapas del HMM . . . . . . . . . . . . . . . . 3.5. Modelo Oculto de Markov para la palabra one 3.6. Cálculo del hiperplano óptimo . . . . . . . . . 3.7. Normalización Esférica . . . . . . . . . . . . . 3.8. Proyección ortográfica . . . . . . . . . . . . . 3.9. Proyección estereográfica . . . . . . . . . . . . 3.10. Proyección gnomónica . . . . . . . . . . . . . 3.11. Ejemplo de Normalización Esférica en 2D . . . 3.12. Inducción de la frontera de decisión . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. 25 27 28 30 31 35 38 39 40 41 43 46. Reescritura de Dptrain y Dptest en formato SVM . . . . . . . . . . . . . . . . . Estructura de las Simulaciones . . . . . . . . . . . . . . . . . . . . . . . . . . Resultados para 10 usuarios utilizando el kernel rbf . . . . . . . . . . . . . . Resultados para 10 usuarios utilizando el kernel polinomial . . . . . . . . . . Resultados para 10 usuarios utilizando el kernel polinomial con Norma Esférica Resultados para 10 usuarios con vectores de 63 dimensiones y kernel RBF . . Resultados para 10 usuarios con vectores de 63 dimensiones y kernel polinomial Resultados para 10 usuarios con vectores de 63 dimensiones y kernel polinomial con Norma Esférica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.9. Comparación de Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.10. Probabilidad de Ocurrencia de los Fonemas en YOHO . . . . . . . . . . . . . 4.11. Porcentaje de error en una clave considerando 10 usuarios . . . . . . . . . . 4.12. Porcentaje de error en una clave considerando 20 usuarios . . . . . . . . . . 4.1. 4.2. 4.3. 4.4. 4.5. 4.6. 4.7. 4.8.. xi. 50 51 52 53 54 55 56 57 58 62 63 64.
(12) 4.13. Porcentaje de error en la clave considerando 30 usuarios. . . . . . . . . . . .. 65. A.1. Anatomı́a de un Modelo Oculto de Markov de 6 estados . . . . . . . . . . . .. 70. B.1. Estructura de Software de SVM. light. . . . . . . . . . . . . . . . . . . . . . . .. xii. 74.
(13) Capı́tulo 1 Introducción Si bien la Criptografı́a es una ciencia que tiene sus orı́genes desde los principios de la humanidad, esta no ha dejado de existir. El hombre se las ha ingeniado desde hace mucho tiempo para garantizar el secreto de sus comunicaciones privadas e información importante. La existencia de la criptografı́a aparece ya en las tablas cuneiformes y los papiros. Desde el Antiguo Egipto hasta el mundo actual de internet, los criptogramas han sido protagonistas de varios sucesos históricos. En la actualidad, la gran influencia que las telecomunicaciones tienen en todos los aspectos de la cotidianidad ha hecho que las comunicaciones seguras cobren particular importancia. En los procesos de almacenamiento y transmisión de la información normalmente aparece el problema de la seguridad. Todos deseamos el acceso seguro a nuestros documentos, y sistemas sensibles, pero la inconveniencia y las limitaciones técnicas de las medidas de seguridad electrónicas tradicionales tienen puntos débiles. Las contraseñas, de donde se originan las claves criptográficas convencionales, son la forma más clásica y sencilla para la identificación, sin embargo relacionan la identidad con el conocimiento y memoria del usuario: Si una persona sabe la contraseña, puede acceder al sistema. El problema es que una contraseña no tiene relación alguna con su identidad real. Las contraseñas pueden ser robadas y manipuladas por otras personas dando por resultado que la información quede abierta también a otras personas. Por lo tanto no hay manera infalible de hacer sistemas protegidos por contraseñas totalmente seguros de la intrusión desautorizada, y tampoco hay manera para que los sistemas basados en contraseñas determinen la identidad del usuario con certeza absoluta. En el área de seguridad, existen investigaciones dirigidas a la creación de nuevas técnicas para la generación de claves criptográficas confiables, desde los métodos convencionales basados en contraseñas hasta los más complejos como los basados en caracterı́sticas biométricas. La tecnologı́a biométrica utiliza caracterı́sticas fisiológicas mensurables (huella dactilar, iris, rasgos de la cara, voz, entre otras) para determinar nuestras identidades. Aunque 1.
(14) parecen extraı́das de pelı́culas futuristas, lo cierto es que estas tecnologı́as son muy reales y ahora en dia comienzan a tomar gran auge en diversas aplicaciones de seguridad. Durante los últimos años, la industria de la biometrı́a ha madurado y la investigación de las tecnologı́as biométricas orientada al mercado empresarial y de la seguridad cuenta con un aumento exponencial. Dado que todos los seres humanos tenemos caracterı́sticas fisiológicas únicas que nos diferencian, la medición biométrica se puede considerar como el método ideal de identificación humana. El sistema analizado en éste proyecto de tesis trabaja con la señal de voz debido a que es una caracterı́stica fı́sica moldeable que cumple con las necesidades para la generación de claves critograficas ya que ofrece una serie de cualidades y atributos que permiten generar una clave digital eficientemente. Las ventajas de usarla son múltiples, entre las más importantes se encuentran: la autenticación de la voz es una tecnologı́a versátil, difı́cilmente intrusiva ya que el sistema podrı́a proporcionar un texto aleatorio a repetir por el usuario y de éste modo excluye cualquier posibilidad de acceso fraudulento por medio de grabaciones, es fácil de utilizar por ser un proceso natural y por consiguiente es bien aceptada por los usuarios. El propósito del presente proyecto de tesis es mejorar el desempeño de un sistema que genera claves criptográficas teniendo la frase y la señal de voz del usuario. Más adelante se analizará la implementación en dicho sistema de una técnica dominante para el reconocimiento automático de voz basada en Modelos Ocultos de Markov, que captura el sonido de la voz ası́ como los comportamientos lingüı́sticos para finalmente encontrar la transcripción de lo que dijo cada usuario y los inicios y finales de cada fonema en la articulación pronunciada por el mismo. Posteriormente las medias resultantes del modelo y los inicios y finales de cada fonema son procesados para crear conjuntos de vectores que corresponden al mismo fonema. En el proceso para generar la clave se requiere que cada uno de los conjuntos de atributos divididos en fonemas puedan ser particionados de manera que a algunos usuarios les corresponda la clase 1 y a otros la clase -1, siendo éstas clases los bits de la clave para cada usuario. Para lograrlo, se aplica una potente técnica de clasificación llamada Máquina de Vectores de Soporte (SVM, por sus siglas en inglés), es en ésta estapa donde se concentró nuestra atención para mejorar el desempeño del sistema. El modelo más sencillo e intuitivo de SVM es ideado para la resolución de problemas de clasificación lineal en donde la solución proporcionada es aquella en la que se clasifican linealmente todas las muestras disponibles colocando en el espacio de entrada un hiperplano de separación lo más lejos posible de todas ellas. Las muestras más próximas al hiperplano óptimo de separación son conocidas como muestras crı́ticas o “vectores de soporte”, que es lo que da nombre a la SVM.. 2.
(15) No obstante, los mejores resultados se obtienen usando el modelo de SVM no lineal, cuyo funcionamiento se basa en las llamadas funciones kernel, de las cuales se implementaron y analizaron las siguientes: función kernel Lineal, Sigmoidal, RBF y Polinomial. Para finalizar se propone la aplicación de una técnica novedosa al kernel Polinomial llamada Normalización Esférica , la cual permite mejorar el desempeño de SVM en el proceso de clasificación y de ésta manera se logra rebasar los resultados obtenidos con los kernels convencionales.. 1.1.. Objetivo. El objetivo principal del esquema estudiado es obtener claves criptográficas a partir de los atributos intrı́nsecos de la voz de los usuarios utlizando SVM. El propósito es garantizar que el porcentaje de error esperado en una clave criptográfica generada para un usuario sea el menor posible a la hora de reproducirse. Por lo que el objetivo especı́fico en éste trabajo de investigación es encontrar un conjunto adecuado de planos que puedan particionar significativamente el manejo de los datos y dar como resultado la clave criptográfica de manera óptima, lo cual está intimamente relacionado con el tipo de función kernel a utilizar para entrenar las Máquinas de Vectores de Soporte (SVM).. 1.2.. Justificación. El objetivo primordial de la implementación de SVM en el esquema de generación de claves criptográficas analizado, es la clasificación binaria de vectores provenientes de la señal de voz de los usuarios para generar las claves. Las Máquinas de Vectores de Soporte (SVM) son máquinas lineales con una enorme riqueza de representación, ya que es las soluciones no se construyen en el espacio de entrada, sino en un espacio de mayor dimensionalidad, el espacio caracterı́stico, donde es posible que una función lineal simple sea suficiente para resolver el problema de clasificación. Adicionalmente, la forma de la función solución es tal que la transformación no interviene directamente sino que se encuentra implı́cita a través de funciones denominadas Kernels. De acuerdo a lo anterior podemos decir que, un ingrediente fundamental de la implementación de SVM en el sistema es la noción del kernel que se va a usar, es decir, la tarea principal de aplicar SVM es la elección del kernel. La selección de diferentes funciones kernel producirá diferentes SVM’s y por lo tanto diferentes resultados en cada realización. En SVM existen diferentes kernels tales como el Lineal, Polinomial, RBF y Sigmoidal, de los cuales los más utilizados en problemas de clasificación son RBF y Polinomial. Sin embargo, una desventaja significativa de aplicar dicha función kernel polinomial es el problema de escalabilidad por lo que surge el interés de explorar la implementación de una técnica novedosa 3.
(16) llamada Normalización Esférica, que permite mejorar el desempeño del sistema generador de claves criptográficas utilizando una Máquina de Vectores de Soporte entrenada con un kernel Polinomial.. 1.3.. Contribución. En el esquema biométrico para la Generación de Claves Criptográficas basadas en Voz utilizando SVM se propone la implementación de un técnica innovadora llamada Normalización Esférica, la cual permite optimizar los resultados arrojados en la clasificación realizada por SVM con kernel Polinomial y de ésta manera se logra superar la precisión alcanzada utilizando cualquiera de los kernels convencionales para la generación de la clave. Ésta técnica posibilita esparcir los datos de entrada sobre la superficie de una hiperesfera unitaria y de ésta forma se consigue que SVM mejore su desempeño al trazar los hiperplanos de separación cuando se realiza la etapa de clasificación.. 1.4.. Organización. El documento de tesis está organizado como sigue: en el siguiente capı́tulo se presentan conceptos básicos para entender el contenido de la tesis, los cuales incluyen principalmente conocimientos de biometrı́a y sus aplicaciones, reconocimiento automático de voz y sus caracterı́sticas y por último una explicación a fondo de las bases y funcionamiento de SVM, en donde se concentró mayor parte de atención en éste trabajo de tesis. Los capı́tulos 3 y 4 son la parte fundamental de éste documento de tesis debido a que en ellos se puede observar la contribución del proyecto. En ellos presenta el trabajo de investigación realizado, la implementación y experimentación, y los resultados obtenidos y analizados. En el capı́tulo 3 se explica a detalle el esquema de generación de claves criptográficas analizado, se hace principal ènfasis en el trabajo desarrollado con SVM y la aplicación de la técnica de Normalización Esférica propuesta para optimizar los resultados. El capı́tulo 4 contiene una descripción detallada de las herramientas utilizadas para llevar a cabo las simulaciones, el análisis y comparación de resultados y finalmente un estudio del error esperado en una clave criptográfica generada. Para finalizar, el capı́tulo 5 presenta las conclusiones derivadas de la investigación realizada y posteriormente se discute la posible dirección que podrı́a tomar el proyecto como trabajo futuro.. 4.
(17) Capı́tulo 2 Antecedentes Con la evolución de las tecnologı́as asociadas a la información, nuestra sociedad está cada dı́a más conectada electrónicamente. Labores que tradicionalmente eran realizadas por seres humanos son, gracias a las mejoras tecnológicas, realizadas por sistemas automatizados. Dentro de la amplia gama de posibles actividades que pueden automatizarse, aquella relacionada con la capacidad para establecer la identidad de los individuos ha cobrado importancia y como consecuencia directa, la biometrı́a se ha transformado en un área emergente. La seguridad en una empresa ya no tiene que depender exclusivamente de contraseñas, guardias o simples candados. La investigación avanzada se está orientando al desarrollo de sistemas automatizadas para el reconocimiento de personas a partir de sus caracterı́sticas fı́sicas. Entenderemos por sistema biométrico a un sistema automático que realiza labores de biometrı́a [1]. Es decir, un sistema que fundamenta sus decisiones de reconocimiento mediante una caracterı́stica personal que puede ser reconocida o verificada de manera automatizada. Estos sistemas incluyen un dispositivo de captación que en segundos obtiene una muestra biométrica de la persona y la compara con una base de datos, donde se analiza si corresponde o no a la identidad de la persona en cuestión. En éste capitulo son descritas algunas de las caracterı́sticas más importantes de estos sistemas, ası́ como conceptos básicos necesarios para entender el objetivo de este proyecto de tesis.. 2.1.. Biometrı́a y sus Aplicaciones. El concepto biometrı́a proviene de las palabras bio (vida) y metrı́a (medida), lo que significa que todo equipo biométrico mide e identifica alguna caracterı́stica propia de la persona [2]. Todos los seres humanos tenemos caracterı́sticas morfológicas únicas que nos diferencian. Por tanto, la medición biométrica se puede considerar como el método ideal de identificación humana. La biometrı́a es una tecnologı́a de seguridad, que consiste en la verificación automática de la identidad, basada en el reconocimiento de caracterı́sticas biológicas, sico-. 5.
(18) logı́as o conductuales de la persona, como por ejemplo, la huella dactilar, el iris, la mano, el sonido de la voz, la forma del rostro, entre otras. Los orı́genes de la biometrı́a se remontan a los años setenta, cuando la empresa NEC comienza a trabajar junto al Federal Bureau of Investigation (FBI) en algunos estudios de como automatizar biométricamente algunas caracterı́sticas del ser humano. De esa forma se comienzan a desarrollar una serie de algoritmos matemáticos con la finalidad de representar, por ejemplo, una huella dactilar. La tecnologı́a de identificación de personas mediante impresiones dactilares tiene su origen en el estudio de la criminalı́stica y surge como una necesidad de apoyo técnico hacia las policı́as para resolver casos. En cuanto a los tipos de biometrı́as existen dos. Si se lleva a cabo una identificación en base a la anatomı́a de la persona, esto es biometrı́a estática, y si es a partir de su comportamiento, se le denomina biometrı́a dinámica [1]. La primera, apunta a las huellas dactilares, la geometrı́a de la mano, la termografı́a, el iris, las venas del dorso de la mana o el reconocimiento facial. En el caso de la dinámica, estudia el comportamiento del individuo, por medio de la voz, la forma de caminar y el análisis gestual, entre otras. Una tercera variante es la biometrı́a informática, que consiste en la suma de técnicas estadı́sticas y de inteligencia artificial, en la autentificación automática de las personas en este tipo de sistemas de seguridad. Lo anterior, apunta a identificar a los individuos que operan en una red para salvaguardar la seguridad de la misma. Actualmente se están estudiando diferentes softwares basados en biometrı́a desde distintas áreas con el objetivo de llegar a utilizar el cuerpo humano como un DNI digital, midiendo su anatomı́a y comportamiento, lo que se transformarı́a en un salto definitivo para esta tecnologı́a, ya que la información biométrica de la persona será incluida en un chip que portara el mismo para acceder, por ejemplo, a procesos informáticos o lugares restringidos.. 2.1.1.. Ventajas y Desventajas de la Biometrı́a. EI buen nivel de aceptación de los dispositivos biométricos y las proyecciones que se realizan para el futuro, ya estan dando los primeros frutos en el mundo. La biometrı́a tiene ventajas evidentes en comparación con otros sistemas de seguridad. No se puede perder o robar, como sucede actualmente con las tarjetas de crédito. No se puede olvidar o adivinar como sucede con una contraseña. En este sentido, uno de los sectores que más se ha preocupado por la seguridad, para evitar fraudes y perjuicios monetarios es el rubro financiero. Bancos importantes e instituciones han comenzado a implementar sistemas de reconocimiento manual y del iris, para hacer frente a las grandes perdidas debidas en parte a la poca seguridad que presentan los sistemas utilizados hasta ahora [1]. 6.
(19) Las Biométricas proveen un mayor grado de seguridad que los métodos de autentificación tradicionales, esto significa que el sistema es accesible solamente a usuarios autorizados y se mantiene protegido de cualquier persona no autorizada. En teorı́a una contraseña es memorizado por una sola persona, es difı́cil de adivinar y nunca es compartido. Sin embargo en la práctica la gente constantemente viola estas espectativas ya que las contraseñas y los PINs son a veces fáciles de descubrir. Muchos usuarios seleccionan palabras o números obvios como contraseña, asi que personas no autorizadas tienen la capacidad de romper con la seguridad del sistema. En contraste, los datos bimométricos no pueden ser adivinados o robados de la misma forma que una contraseña o PIN [2]. En cuanto a las transacciones electrónicas de todo tipo, la biometrı́a tiene mucho para ofrecer, ya que si bien contraseñas, criptografı́a y firma digital han impulsado en buena medida el desarrollo del comercio electrónico, no dejan de depender de una clave secreta que siempre puede ser robada. Como la biometrı́a permite establecer que una persona es quien dice ser, funciona como el complemento ideal de esos tres sistemas, en un verdadero “trabajo en equipo”para garantizar la mayor seguridad posible [3]. Aunque pareciera que la biometrı́a es la panacea para todos los problemas, tenemos que señalar que existen también algunas desventajas, como por ejemplo: “darse de alta”no es siempre tan sencillo, ya que no es inmediato y hay que obtener más de una muestra de la biométrica a usar, además de que depende del cambio constante de nuestra fisionomı́a. Aún contando con estas desventajas, estos sistemas presentan importantes mejoras respecto a los sistemas tradicionales de autenticación y resultan muy ventajosos para las empresas implantar sistemas de este tipo, ya que podemos decir que, gracias al empleo de la tecnologı́a biométrica, el acceso a una área restringida, a una Red o a un Sistema Computacional no dependerá de algo que sabemos o que tenemos y que nos pueden copiar o robar sino dependerá de lo que “somos”.. 2.1.2.. Caracterı́sticas de un Sistema Biométrico. Las caracterı́sticas básicas que un sistema biométrico para identificación personal debe cumplir pueden expresarse mediante las restricciones que deben ser satisfechas [2]. Ellas apuntan, básicamente, a la obtención de un sistema biométrico con utilidad práctica y son las siguientes: 1. El desempeño, que se refiere a la exactitud, la rapidez y la robustez alcanzada en la identificación, además de los recursos invertidos y el efecto de factores ambientales y operacionales. El objetivo de esta restricción es comprobar si el sistema posee una exactitud y rapidez aceptable con un requerimiento de recursos razonable. 7.
(20) 2. La aceptabilidad, que indica el grado en que la gente está dispuesta a aceptar un sistema biométrico en su vida diaria. Es claro que el sistema no debe representar peligro alguno para los usuarios y debe inspirar“confianza” a los mismos. Factores psicológicos pueden afectar esta última caracterı́stica. Por ejemplo, el reconocimiento de una retina, que requiere un contacto cercano de la persona con el dispositivo de reconocimiento, puede desconcertar a ciertos individuos debido al hecho de tener su ojo sin protección frente a un “aparato”. 3. La fiabilidad, que refleja cuán difı́cil es burlar al sistema. El sistema biométrico debe reconocer caracterı́sticas de una persona viva, pues es posible crear dedos de látex, grabaciones digitales de voz, prótesis de ojos, etc. Algunos sistemas incorporan métodos para determinar si la caracterı́stica bajo estudio corresponde o no a la de una persona viva. Los métodos empleados son ingeniosos y usualmente más simples de lo que uno podrı́a imaginar. Por ejemplo, un sistema basado en el reconocimiento del iris revisa patrones caracterı́sticos en las manchas de éste, un sistema infrarrojo para chequear las venas de la mano detecta flujos de sangre caliente y lectores de ultrasonido para huellas dactilares revisan estructuras subcutáneas de los dedos.. 2.1.3.. Sistemas Biométricos Actuales. En la actualidad existen sistemas biométricos que basan su acción en el reconocimiento de diversas caracterı́sticas. Las técnicas más conocidas son diez y están basadas en los siguientes indicadores biométricos: ADN, huella dactilar, iris, retina, termograma facial, venas, rostro, firma digital, geometrı́a de la mano y voz. Cada rasgo biométrico posee propiedades comparativas, las cuales deben tenerse en consideración al momento de decidir que técnica se va a utilizar en una aplicación especı́fica. Existen dos modos fundamentales de funcionamiento para un sistema de reconocimiento basado en caracterı́sticas biométricas: verificación e identificación. En el primer caso, el sistema biométrico pide, “es esta persona quien dice ser compara este registro con el que está en un medio externo, por lo general una tarjeta lectora o simplemente una contraseña. La verificación es conocida como 1:1 (Uno a Uno). En el segundo, el sistema biométrico pregunta “quién es esta persona establece si existe un expediente biométrico, y, si es ası́ la identidad de la persona registrada que muestra es aceptada. La identificación es también llamada 1:N (Uno a muchos). 2. 2. Como podemos observar, un número extenso de biométricas han sido propuestas para la implementación en sistemas de autentificación personal y generación de claves criptográficas. En el caso del esquema analizado, se trabaja con voz por diferentes razones. En primera, 8.
(21) todos estamos familiarizados con ese medio de comunicación, lo cual lo hace ideal para diferentes aplicaciones. En segundo lugar, trabajos recientes sobre verificación de voz han demostrado que la voz es una biométrica efectiva en distinción de usuarios. Otra razón, es el hecho de que cuando un usuario cambia su contraseña hablada, inevitablemente cambia la vocalización del mismo. Ası́ a diferencia de otras biométricas estáticas (huellas digitales, Iris, retina, etc), es concebible que un usuario pueda tener arbitrariamente diferentes e ilimitadas llaves a claves del tiempo.. 2.1.4.. La Voz como Rasgo Biométrico. La voz es simplemente una onda acústica que es radiada por el aparato bucal humano cuando se genera aire en los pulmones y el flujo del aire resultante es perturbado por alguna abertura del tracto vocal. Cada persona tiene caracterı́sticas bucales únicas, de tal manera que frecuentemente somos capaces de reconocer una persona solamente por su voz. Estas caracterı́sticas están relacionadas directamente con la fisiologı́a de cada ser humano, tales caracterı́sticas son: la edad, el sexo, la altura, el peso, la estructura de las cuerdas vocales, las cavidades oral y nasal, los dientes y labios [9]. Debido a la estructura fisiológica del tracto vocal y el hecho que todos los seres humanos “sonamos”diferente, se puede afirmar que existe una cantidad significativa de información fonética en la señal de voz [9]. Clasificación de los Sonidos La producción de sonidos de voz puede se clasificada en distintas clases de acuerdo a su modo de exitación [9]: 1. Por la acción de las cuerdas vocales: Sonidos sonoros, cuando vibran Sonidos sordos, en caso contrario. 2. En función de las cavidades implicadas: Sonidos orales o bucales. Sonidos nasales. 3. Por el modo de articulación, según se produzca la restricción del flujo de aire al atravesar el tracto vocal. Sonidos abiertos 9.
(22) Sonidos medio cerrados. Sonidos cerrados. 4. Por el lugar de articulación, en el que atendemos al lugar de máximo estrechamiento del tracto vocal. En el contexto de la producción de voz, las frecuencias resonantes del tracto bucal son llamadas formantes. Estas frecuancias dependen de la forma y dimensión del tracto bucal. El primer formante f1 es la frecuencia resonante más baja, la cual cae en el rango de 250 a 900 Hz. El segundo formante f2 tiene un rango más amplio que va desde 600 hasta 3600 Hz. Los formantes subsiguienes f3 , f4 y f5 están presentes en la señal de voz, pero sin embargo únicamente los formantes f1 y f2 (y algunas veces f3 ) son usualmente suficientes para identificar sonidos individuales que son representados por las letras del alfabeto, conocidos como fonemas. Caracterı́sticas de los Fonemas El término fonema es usado para denotar cualquiera de las unidades mı́nimas de lenguaje hablado (articulado) en un lenguaje que puede servir para distinguir una palabra de otra. Convencionalmente se usa el término fono para denotar la realización acústica de un fonema [8]. Es mejor tratar cada realización como un fonema diferente. El Cuadro 2.1 muestra una lista de algunos de los fonemas utilizados en el inglés americano [7]. El conjunto de fonemas podrá diferir en la realización entre hablantes individuales. Pero los fonemas siempre funcionarán sistemáticamente para diferenciar significados en las palabras, asi como el fonema /p/ señala la palabra del inglés pat (palmada), opuesto a bat (murciélago), de sonido similar. El contraste entre este par de palabras es /p/ contra /b/ [7]. Como seleccionar la unidad mı́nima básica para representar información acústica y fonética de un lenguaje es una cuestión importante al momento de diseñar un sistema de reconocimiento. En muchos idiomas, las palabras son tı́picamente consideradas como el principal portador de significado. Los modelos de palabras son precisos si existen suficientes datos disponibles, por lo tanto, son entrenables sólo para tareas pequeñas. Generalmente no son generalizables. Alternativamente, existen aproximadamente sólo 50 fonemas en el idioma inglés, y pueden ser lo suficientemente entrenados con unos cuantos cientos de enunciados. Al contrario de los modelos de palabras, los modelos fonéticos no tienen problema de entrenamiento. Más aún, por naturaleza también son independientes del vocabulario y pueden ser entrenados en una tarea y probados en otra. Ası́, los fonemas son más entrenables y generalizables. 10.
(23) Cuadro 2.1: Fonemas del idioma inglés utilizados para un sistema tı́pico de lenguaje hablado.. 2.2.. Fonema. Ejemplo de Palabra. iy ih ae aa ah ao ay ax ey eh er ow aw oy uh uw b p d t th .... feel fill at father cut dog bite ago tape pet turn tone our coin book tool big put dig talk thin .... Reconocimiento Automático de Voz. El reconocimiento automático de voz o habla (RAH) es una disciplina que se encarga de la concepción y realización de sistemas que convierten señales acústicas procedentes de un locutor humano en categorı́as lingüı́sticas de un universo dado. En los sistemas de reconocimiento de voz se intenta modular las caracterı́sticas de los usuarios y decidir si el usuario es quien dice ser. Existen muchas ventajas de el uso del reconocimiento de voz en un sistema biométrico, alguna de ellas son: Considerada un tecnologı́a biométrica “natural”. 11.
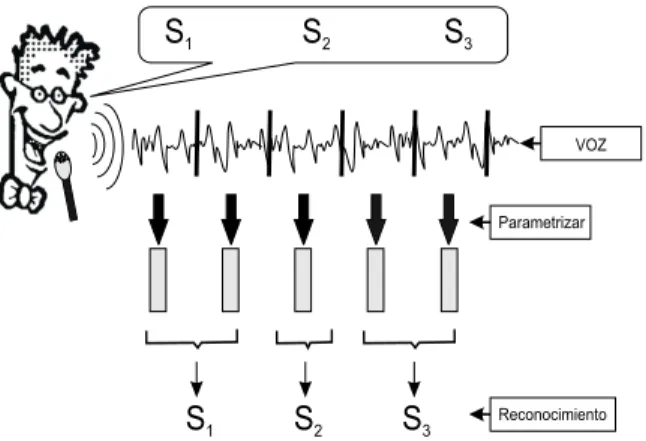
(24) Provee ojos y manos libres para su utilización. Confiabilidad. Flexibilidad. Ahorro de tiempo en la información de entrada. La tecnologı́a RAH se ha basado primordialmente en la técnica llamada “Modelos Ocultos de Markov” o HMM por sus siglas en inglés (Hidden Markov Model); se antepone la palabra ocultos debido a que los modelos deben inferirse o deducirse a través de observaciones de la salida de voz, no de cualquier representación interna de producción de voz [26]. La teorı́a básica sobre HMMs se encuentra en forma detallada al final del documento en el Apendice A. La técnica HMM modula el habla estimando la probabilidad de cada fonema en regiones continuas, pequeñas, dentro de la señal de voz. Los estados pueden verse como correspondiendo aproximadamente a eventos acústicos. En un modelo de palabra, por ejemplo, los primeros estados representan fonemas iniciales de la palabra y los últimos estados los fonemas finales. Los Modelos Ocultos de Markov nos permiten modelar tanto la variabilidad espectral utilizando una distribución de probabilidad en los vectores de salida ası́ como también la variabilidad temporal con la probabilidad de transición entre los estados de la cadena de Markov. La Figura 2.1 muestra una secuencia de voz con sus correspondientes observaciones, estas observaciones contienen, cada una de ellas toda la información de la señal de voz como puede ser por ejemplo el ”Pitch”, el frame, etc.. O1. O2. O3. O4. .............. On. Figura 2.1: Secuencia de Voz y sus Observaciones. 12.
(25) 2.2.1.. Caracterı́sticas de un Sistema RAH. La estructura general de los sistemas de RAH tiene esencialmente tres módulos o etapas, Figura 2.2 [8], las cuales se describen a continuación: 1. Procesamiento o análisis del habla (en inglés se conoce como front-end): en esta etapa se realiza algún tipo de análisis de la señal de voz en términos de la evolución temporal de parámetros espectrales (previa conversión analógica/digital de la señal). Esto tiene por función hacer más evidentes las caracterı́sticas necesarias para la etapa siguiente y a veces también limpiar y reducir la dimensión de los patrones para facilitar su clasificación. 2. Clasificación de unidades fonéticas o modelo acústico: esta etapa clasifica o identifica los segmentos de voz ya procesados con sı́mbolos fonéticos (fonemas, dı́fonos o sı́labas). A veces se puede asociar una probabilidad con este sı́mbolo fonético, lo que permite ampliar la información presentada al siguiente módulo. 3. Análisis en función de reglas del lenguaje o modelo del lenguaje: en esta última etapa se pueden aprovechar las reglas utilizadas en la codificación del mensaje contenido en la señal para mejorar el desempeño del sistema y producir una transcripción adecuada. Aquı́ se utilizan otras fuentes de conocimiento como la ortográfica, la sintáctica, la prosódica, la semántica o la pragmática.. Datos de Entrenamiento. Entrenamiento/Adaptación Modelos S1. a22. a33. S2. S3. Adaptación de Datos. Extracción de Características. HMM S6. Modelos Léxicos y de Lenguaje. Secuencia de Palabras Búsqueda de Viterbi. Análisis Espectral. Figura 2.2: Componentes de un Sistema RAH tı́pico. . Los modelos acústicos incluyen la representación del conocimiento acerca de la acústica, fonética, variables ambientales, diferencias de género y dialecto entre los hablantes, etc. Los modelos de lenguaje se refieren al conocimiento del sistema de lo que constituye una posible palabra, que palabras son posibles de ocurrir y en que secuencia. La semántica y las 13.
(26) funciones relacionadas a alguna operación que un usuario quiera realizar también pueden ser necesarias para el modelo de lenguaje. Existe mucha incertidumbre en el área dirigida al RAH, asociada con las caracterı́sticas del hablante, la velocidad y el estilo de hablar, el reconocimiento de segmentos básicos del habla, palabras posibles, palabras parecidas, palabras desconocidas, variación gramática, interferencia de ruido, acento no nativo, etc.. 2.2.2.. Problemas Propios del RAH. Los principales problemas que dificultan el reconocimiento automático del habla son los siguientes: No existe separador, ni silencios entre palabras, análogos a los espacios en el lenguaje escrito. Un alto grado de variabilidad del individuo causado por el modo de hablar (acento regional, con resfriado, etc.) y por el género del locutor. Cada fonema es modificado por su contexto cercano, esto es; cada sonido elemental es afectado por el fonema que le antecede y por el que le sigue, este efecto es conocido como coarticulación. Además, se tienen modificaciones en los fonemas debido a un contexto más amplio, tal como el lugar que ocupa en la oración. La señal de voz lleva diferentes tipos de información, tales como: el sexo e identidad de la persona, humor, etc. No tienen reglas fijas para formalizar la información en los diferentes niveles de codificación de voz.. 2.3.. Máquinas de Vectores de Soporte (SVM). SVM es una técnica de aprendizaje que utiliza fundamentos estadı́sticos para realizar tareas de clasificación y regresión. Las Máquinas de Vectores de Soporte (SVM) fueron ideadas originalmente para la resolución de problemas de clasificación binarios en los que las clases eran linealmente separables (Vapnik y Lerner, 1965). Por este motivo se conocı́a también como hiperplano óptimo de decisión ya que la solución proporcionada es aquella en la que se clasifican correctamente todas las muestras disponibles, colocando el hiperplano de separación lo más lejos posible de todas ellas [10]. Las muestras más próximas al hiperplano óptimo de separación son conocidas como muestras crı́ticas o “vectores soporte”, que es lo 14.
(27) que da nombre a la SVM. Las máquinas de vectores de soporte pertenecen a la familia de los clasificadores lineales puesto que se encargan de inducir separadores lineales o hiperplanos en espacios de caracterı́sticas de muy alta dimensionalidad [10]. A continuación exponemos un ejemplo sencillo para explicar brevemente cuál es el objetivo que se pretende conseguir con la utilización de la SVM. En una fábrica de tornillos se sabe que una pieza buena es aquella que tiene una longitud entre 4 y 6 cm y una pieza no válida es aquella que está por debajo de 4 cm o es mayor de 6 cm. Por otra parte, se tienen una serie de caracterı́sticas de las piezas, como la forma del tornillo, el peso y el color. Ası́ pues, se dispone de una serie de piezas etiquetadas como ((buenas)) y otra serie como ((malas)). Estas muestras sirven para entrenar la SVM. Una vez terminado este proceso y hallados una serie de parámetros, lo que se pretende es que al introducir en la máquina un conjunto de datos nuevos (en este caso tornillos), ver cómo generaliza; es decir, comprobar si se cometen errores o se clasifican bien las muestras dentro de su respectiva clase (2 clases: pieza válida o no). Para explicar las bases del funcionamiento de SVM en primer lugar, recordemos que todo hiperplano es un espacio D-dimensional, RD , se puede expresar como h(x) = hw, xi + b, donde w ∈ RD es el vector ortgonal al hiperplano, b ∈ R y h·, ·i expresa el producto escalar habitual en R. Visto como un clasificador binario, la regla de clasificación se puede expresar como: f (x) = signo(h(x)), donde la función signo se define como: (. signo(x) =. +1 si x > 0 −1 si x < 0. En terminologı́a de de clasificación, las x ∈ RD son representaciones vectoriales de los ejemplos, con una componente real por cada atributo, el vector w se suele denominar “vector de pesos”. Este vector contiene un peso para cada atributo indicando su importancia o contribución en la regla de clasificación. Finalmente, b suele denominarse sesgo (bias) y define el umbral de decisión [11]. Dado un conjunto binario (es decir, con dos clases) de datos linealmente separables, existen diversos algoritmos para construir hiperplanos (w, b) que los clasifiquen correctamente. Podemos citar como ejemplo: Perceptron, Widrow-Hoff, Exponentiated-Gradient, Sleeping Experts, etc. A pesar de que esté garantizada la convergencia de todos ellos hacia un hiperplano solución, las particularidades de cada algoritmo de aprendizaje pueden conducirnos a soluciones ligeramente distintas, puesto que puede haber varios hiperplanos que separen correctamente el conjunto de ejemplos. Suponiendo que el conjunto de ejemplos es ligeramente separable, ¿cual es el mejor hiperplano separador en términos de generalización? La idea que hay detrás de las SVM de margen máximo consiste en seleccionar el hiperplano separador que está a la misma distancia 15.
(28) que los ejemplos más cercanos de cada clase. De manera equivalente, es el hiperplano que maximiza la distancia mı́nima (o margen geométrico) entre los ejemplares del conjunto de datos y el hiperplano. Intuitivamente, este hiperplano está situado en la posición más neutra posible con respecto a las clases representadas por el conjunto de datos, sin estar sesgado, por ejemplo, hacia la clase más númerosa. Además, sólo considera los puntos que estan en las fronteras de la región de decisión, que es la zona donde puede haber dudas sobre a que clase pertenece un ejemplo (son los denominados vectores de soporte). En la Figura 2.3 se presenta geométricamente este hiperplano equidistante para el caso bidimensional. Este sesgo inductivo de aprendizaje consistente en maximizar el margen se justifica dentro de la teorı́a de aprendizaje estadı́stico [10]. La mejor función f para llevar a cabo la clasificación será aquella con la esperanza del error de clasificación más baja, aquella con la que obtenga el mı́nimo riesgo real, riesgo esperado o simplemente riesgo: Z. R(ζ) =. 1 |y − f (x, ζ)|dP (x, y), 2. ζ = parámetros de SVM. (2.1). 2 llwll. +1 -1. Vectores de Soporte. + w ·x. +1 b= -1 b= + x w·. Figura 2.3: Clasificación Binaria en SVM Parece una forma secilla de calcular el error medio real, pero normalmente no tenemos ni siquiera una estimación de la forma de P (x, y). La densidad de probabilidad P (x, y) es desconocida, por lo que la función de riesgo no puede minimizarse de forma directa empleando la expresión 2.1. Debe encontrarse una estimación de la expresión f lo más próxima posible a la de mı́nimo riesgo. Para ello se parte de un conjunto de muestras de entrenamiento, junto con las propiedades de la familia de funciones F entre las que se busca f .. 16.
(29) El riesgo empı́rico se define como la tasa de error medio en el conjunto de entrenamiento para un número finito y fijo de observaciones: Remp (ζ) =. N 1 X |yi − f (xi , ζ)| 2N i=1. (2.2). Nótese que es este caso no aparece ninguna distribución de probabilidad. Remp (ζ) es un número fijo para una opción determinada de ζ y para un particular conjunto de entrenamiento {xi , yi }. A la cantidad 1 |yi − f (xi , ζ)| 2N. (2.3). se le denomina pérdida. El riesgo empı́rico puede emplearse para tabular el riesgo, sobre la distribución P (x, y), con una probabilidad de 1 − ρ, 0 ≤ ρ ≤ 1: s. R(ζ) ≤ Remp (ζ) +. h(log(2N/h) + 1) − log(ρ/4) N. (2.4). donde N es el número de observaciones y h es un entero, no negativo, conocido como la dimensión Vapnik Chervonenkis (VC) y es una medida de la idea de capacidad mencionada al principio de la sección. A la parte derecha de la desigualdad se le llama cota del riesgo y al segundo término de la cota del riesgo se le llama confianza VC. La teorı́a de Vapnik sobre la reducción del riesgo y la dimensión VC indica que reduciendo el riesgo empı́rico también se reduce el riesgo sobre la distribución P (x, y) [26]. Para encontrar f que minimice el riesgo el objetivo se convierte en encontrar un subconjunto del conjunto de funciones que minimice la cota del riesgo. Para ello se divide la clase completa de funciones en subconjuntos anidados. Para cada conjunto se debe poder calcular h o, al menos, establecer una cota de su valor. La minimización estructural del riesgo consiste en encontrar el subconjunto de funciones que minimiza la cota del error actual. De esta manera se toma aquella máquina entrenada de la serie con menor valor para la suma del riesgo empı́rico y la confianza VC. A nivel algorı́tmico, el aprendizaje de las SVM representa un problema de optimización con restricciones que se puede resolver usando técnnicas de programación cuadrática (QP). La convexidad garantiza una solución única (esto supone una ventaja con respecto al modelo clásico de redes neuronales) y las implementaciones actuales permiten una eficiencia razonable para problemas reales con miles de ejemplos y atributos. 17.
(30) 2.3.1.. SVM para Clasificación Lineal. SVM lineal con márgen máximo (maximal margin linear SVM) es el modelo más sencillo e intuitivo de SVM, aunque también el que tiene condiciones de aplicabilidad más restringidas, puesto que parte de la hipótesis de que el conjunto de datos es linealmente separable en el espacio de entrada [12]. Supongamos que el conjunto es de datos es linealmente separable en el espacio de entrada. Es decir, sin hacer ninguna transformación de los datos, los ejemplos pueden ser separados por un hiperplano de manera que en cada lado del mismo sólo hay ejemplos de una clase. En términos matemáticos, es equivalente a decir que existe un hiperplano h : X → R tal que h(x) > 0 para los ejemplos de la clase +1 y h(x) < 0 para los ejemplos de la clase −1. De manera más concisa, h cumple que yi · h(xi ) > 0 para todo i entre 1 y N , es decir, para todos los ejemplos. Formulación Original de SVM Recordemos que la idea que hay detrás de las SVM consiste en seleccionar el hiperplano separador que está a la misma distancia de los ejemplos más cercanos de cada clase (Ver Figura ??) [10]. Es muy fácil ver que la distancia de un vector x a un hiperplano h, definido por (w, b) como h(x) = hw, bi + b, viene dada por la fórmula dist(h, x) = |h(x)|/kwk, donde kwk es la norma en RD asociada al producto escalar (es decir, kwk2 = hw, wi). Ası́ pues, el hiperplano equidistante a dos clases es el que maximiza el valor mı́nimo de dist(h, x) en el conjunto de datos. Además, dados dos puntos z1 y z2 equidistantes a un hiperplano, se cumple que b = −(hw, z1 i + hw, z2 i)/2. Como el conjunto es linealmente separable, podemos reescalar w y b de manera que la distancia de los vectores más cercanos al hiperplano sea 1/kwk (al multiplicar w y b por una constante, la distancia no varı́a). Como consecuencia, los vectores z más cercanos tendrán |h(z)| = 1, mientras que para el resto |h(z)| ≥ 1. De manera que el problema de encontrar el hiperplano equidistante a dos clases se reduce a encontrar la solución del siguiente problema de optimización con restricciones: Maximizar sujeto a:. 2.3.2.. yi (hw, xi i + b) ≥ 1. donde. 1 kwk 1≤i≤N. SVM para Clasificación NO Lineal. SVM lineal con margen máximo tiene dos restricciones importantes [11]. En primer lugar, el clasificador resultante es lineal. Es bien conocido que la mejor manera de representar 18.
(31) muchos problemas no es un modo lineal, como se muestra en forma gráfica en la Figura 2.4. En segundo lugar, necesita que el conjunto de datos sea linealmente separable, cosa que no tiene porque ser cierta o fácil de conseguir. En la Figura 2.4 se puede ver un conjunto de datos que no es linealmente separable, en el que SVM lineal con margen máximo no es la mejor solución. SVM no lineal con margen máximo en el espacio de caracterı́sticas se basa en la idea de hacer una transformación no lineal del espacio de entrada a un espacio dotado de un producto escalar. En este espacio se pueden aplicar los mismos razonamientos que para la SVM lineal con margen máximo. Dicho de otro modo, supongamos que existe una transformación no lineal del espacio de entrada a un cierto espacio de caracterı́sticas =: φ : RD → = x → φ(x) dotado de un producto esclar hφ(x), φ(y)i (= es un espacio de Hilbert). Si el conjunto de datos es linealmente separable en = (con los hiperplanos definidos a partir del producto escalar correspondiente), entonces SVM con margen máximo en el espacio de caracterı́sticas se puede obtener sustituyendo en el SVM lineal con margen máximo hx, yi por hφ(x), φ(y)i.. ?. pe ma. o. Kern el. +1 -1. Figura 2.4: Clasificación NO lineal en SVM. 19.
(32) La dimensión del espacio de caracterı́sticas necesaria para poder separar el conjunto de datos puede ser arbitrariamente grande. pero al aumentar la dimensión de = también se incrementa el tiempo de cómputo de cualquier algoritmo que calcule el producto escalar operando directamente con las componentes de φ(x). Por ejemplo, supongamos que queremos transformar imágenes de 16x16 puntos al espacio de monomios de orden 5 de los 256 puntos de la imagen. La dimensión de este espacio serı́a 1010 , lo cual serı́a muy costoso en cuanto a tiempo de procesamiento. Afortunadamente, para ciertos espacios de caracterı́sticas y ciertas transformaciones existe una forma muy efectiva de calcular el producto escalar usando las denominadas funciones kernel [10]. Una función kernel o simplemente kernel, es una función K : X × X → R, tal que K(x, y) = hφ(x), φ(y)i, donde φ es una transformación de X en un cierto espacio de Hilbert =. Es decir, el producto escalar se puede calcular usando la función kernel, quedando implı́cita la transformación del espacio de entrada al espacio de caracterı́sticas. Por ejemplo supongamos que definimos la siguiente transformación φ de R2 en el espacio de √ caracterı́sticas R3 : φ(x1 , x2 ) = (x1 , x2 ) = (x21 , 2x1 x2 , x22 ). Entonces, el producto escalar hφ(x), φ(y)i se puede reformular como: √ √ hφ(x), φ(y)i = (x21 , 2x1 x2 , x22 ) · (y12 , 2y1 y2 , y22 )T = ((x1 , x2 ) · (y1 , y2 )T )2 = hx, yi2. Por tanto, la función kernel K(x, y) = hx, yi2 permite calcular el producto escalar hφ(x), φ(y)i en el espacio de caracterı́sticas sin necesidad de utilizar la transformación φ. Funciones Kernel Como se ha visto en este sección, el aprendizaje de separadores no lineales con SVM se consigue mediante una transformación no lineal del espacio de atributos de entrada (input space) a un espacio de caracterı́sticas (feature space) de dimensionalidad mucho mayor y donde sı́ es posible separar linealmente los ejemplos [12]. El uso de las denominadas funciones kernel, que calculan el producto escalar de dos vectores en el espacio de caracterı́sticas, permite trabajar de manera eficiente en el espacio de caracterı́sticas sin necesidad de calcular explı́citamente las transformaciones de los ejemplos de aprendizaje. Una de las grandes ventajas de las funciones kernel es que su aplicación no está limitada a ejemplos de tipo vectorial sino que son aplicables a prácticamente cualquier tipo de representación. Las funciones kernel de propósito general más comúnmente utilizadas en RD se presentan en el Cuadro 2.2. 20.
(33) Cuadro 2.2: Funciones Kernel para SVM Tipo de Kernel Polinomial RBF Sigmoidal Multicuadrática inversa. Fórmula. Parámetros d. (hx,³ yi + c) ´ 2 exp −kx−yk γ tanh(shx, yi + r) √ 1 2 2 kx−yk +c. c ∈ R, d ∈ ℵ γ>0 s, r ∈ R c≥0. El aprendizaje en espacios de caracterı́sticas vı́a transformaciones no lineales por medio de funciones kernel no es exclusiva del paradigma SVM. Aunque se suele asociar los métodos basados en funciones kernel con las SVM, al ser su ejemplo más paradigmático y más avanzado, hay muchos otros algorı́tmos en donde se puede hacer uso de funciones kernel para permitir el aprendizaje de funciones no lineales. Éste es el caso, por ejemplo, del perceptrón, de los discriminantes de Fisher, del análisis de componentes principales, etc. Un requisito básico para aplicar con éxito SVM a un problema real es la elección de una función kernel adecuada, que debe reflejar el conocimiento a priori sobre el problema. El desarrollo de funciones kernel para estructuras no vectoriales es actualmente una importante área de investigación con aplicación en dominios como el procesamiento del lenguaje natural y la biometrı́a.. 2.3.3.. Aplicaciones de SVM. Como ya se ha dicho a lo largo de esta sección, SVM se ha aplicado con éxito a numerosos problemas reales pertenecientes a áreas como la recuperación de información, reconocimiento y clasificación de imágenes, ánalisis de biosecuencias, reconocimiento de escritura, etc. Aparte de la solidez teórica de los modelos, el éxito empı́rico ha sido tal que algunos autores sugieren que SVM podrı́a desplazar a las redes neuronales en una gran variedad de campos. La aplicación de SVM a problemas de clasificación multiclase se suele plantear mediante los esquemas habituales de binarización, en donde el problema multiclase se convierte en varios problemas binarios [12] . Sin embargo, existen también variantes más elegantes de SVM donde una modificación de la función objetivo permite obtener simultáneamente el cálculo de un clasificador multiclase. Estas variantes han demostrado ser experimentalmente competitivas en términos de calidad con respecto a los esquemas de binarización. Joachims [31] sugiere que SVM es muy adecuado para problemas del tipo de Clasificación de Documentos. En este tipo de problemas el número de dimensiones es muy elevado y 21.
(34) cada ejemplo tiene una codificación muy dispersa. En problemas donde se dispone de pocos ejemplos, SVM presenta ventajas con respecto a otros métodos basados en maximización del margen. Desde el punto de vista práctico, el hecho de enfretarnos a un problema con miles de ejemplos de aprendizaje y miles de atributos no debe detenernos a la hora de usar SVM. Este proyecto es un ejemplo del buen desempeño que SVM puede alcanzar en problemas reales, en donde la dimensión de los vectores es considerablemente grande.. 2.4.. Trabajo Previo. Se ha mencionado a lo largo de este capı́tulo que la autentificación mediante biométricas se refiere a la verificación de individuos basada en caracterı́siticas fı́sicas y de comportamiento. La idea básica de generar claves criptográficas a partir de estas caracterı́sticas es que la componente biométrica lleve acabo el proceso de autentificación, mientras que un sistema genérico criptográfico pueda manipular otros componentes para realizar el proceso de encriptado. Existen hasta la fecha un número relativamente reducido de investigaciones dirigidas al área de generación de llaves criptográficas a partir de biométricas. Algunos de los trabajos realizados serán mencionados a continuación. Soutar [13] propone un sistema basado en la lectura de huellas digitales. El algoritmo genera una clave criptográfica a partir de la imágen de la huella dactilar del usuario. Usando en la fase de entrenamiento diversas imágenes (por lo general 5), el sistema primero crea una función filtro de correlación H(u) con dos componentes importantes ( magnitud y fase). El criterio de diseño de esta función comprende propiedades de tolerancia a la distorsión y discriminabilidad. El sistema produce una salida c0 (x), la cual se obtiene por la convolución y correlación de las huellas digitales de entrenamiento con H(u). Una clave criptográfica k0 de N-bits (tı́picamente 128 bits) es producida a partir de la salida c0 (x) usando un código corrector de errores (con el objetivo de tolerar cierta variación en las muestras leidas de la biométrica en la fase de autentificación). El principal problema de este algoritmo propuesto es que no garantiza buena seguridad. Los autores no explican en forma detallada la cantidad de entropia que es perdida en cada fase del algoritmo que proponen. Davida [15],[14] propone un algoritmo basado en la lectura del iris de una persona. En su propuesta consideran la representación binaria de la textura del iris, llamada ”Iris Code”, la cual tiene 2048 bits de longitud. El sistema calcula la distancia Hamming entre los datos de entrada y la base construida durante la fase de entrenamiento, después realiza una comparación para determinar si las muestras pertenecen a la misma persona. Los autores asumen que solo el 10 % de los 2048 bits (204 bits) del IrisCode pueden cambiar durante el escaneo de diferentes muestras del mismo iris, lo cual restringe de manera significativa el error que 22.
(35) puede ocurrir al realizar diferentes lecturas de la mima biométrica. Juels y Wattenberg [16] proponen un concepto llamado ‘‘fuzzy comitmment”, que generaliza y mejora los métodos de Davida para tolerar mayor variación en las caracterı́sticas biométricas y proveer mayor seguridad en un sistema. Monrose [17],[18] muestra un método para generar claves criptográficas a partir de la voz. Dicho método consta principalmente de dos fases. En la primera fase se analizan rasgos de la señal de voz para formar lo que Monrose nombra como “Descriptor de caracterı́sticas” (feature descriptor). La tarea de estos descriptores es separar o diferenciar a un usuario de otro, en el sentido que los descriptores producidos por un mismo usuario son lo suficientemente similares como para producir la misma llave criptográfica. La segunda fase consta de recuperar a partir de una tabla T elementos relacionados con los descriptores de caracterı́sticas para poder completar y reconstruir la llave criptográfica. Monrose describe una evaluación empı́rica para mostrar el buen desempeño de la técnica propuesta usando 250 articulaciones grabadas por 50 Usuarios. A diferencia de este método en nuestro proyecto se propone una forma más flexible de crear una llave criptográfica a partir de la voz usando SVM.. 23.
(36) Capı́tulo 3 Métodologı́a Utilizada para la Generación de Claves Criptográficas Implementando una Normalización Esférica El propósito general del esquema presentado en la Figura 3.1 es la generación de una clave criptográfica para un usuario basada en su señal de voz y la oración que dice, y posteriormente poder generar repetidamente en forma exacta la clave que ha sido asignada para cada usuario cuando articule la misma frase. Por lo tanto, si se tiene el conjunto de articulaciones de cada uno de los usuarios representadas por sus rasgos caracterı́sticos y divididas en fonemas, el desafı́o principal del presente proyecto de tesis es encontrar un clasificador capaz de particionar los rasgos de tal manera que produzcan la misma clave para el mismo usuario y claves distintas para diferentes usuarios en forma precisa. En el esquema se puede apreciar que el proceso de generación de claves criptográficas consta de dos etapas importantes: Fase de Entrenamiento: consiste en tomar muestras de articulaciones correspondientes a cada uno de los usuarios para entrenar el sistema con el fin de obtener el mejor desempeño posible. Fase de Prueba: es menos compleja que la anterior, en ella se evalua el sistema analizando la precisión obtenida al generar la clave después de haber sido entrenado con ciertos parámetros. La estructura está conformada por diferentes bloques, cada uno de ellos representan el procedimiento a seguir para la obtención la clave criptográfica. Los primeros dos están relacionados con la técnica de reconocimiento automático de voz analizada e implementada en [19] para la obtención de caracterı́sticas. Los últimos bloques corresponden a la técnica 24.
(37) SVM utilizada para realizar el proceso de clasificación. Por último, se tienen dos bloques intermedios, uno llamado generación de atributos, el cual permite hacer una conexión entre las dos técnicas anteriores [19], y el bloque llamado Normalización Esférica, el cual apunta a la aplicación propuesta de una técnica novedosa que permite mejorar el desempeño de SVM al realizar las tareas de clasificación binaria de los vectores que representan a cada uno de los fonemas pronunciados por el usuario para formar la clave. Con el propósito de obtener un mejor entendimiento del esquema, a continuación se analizará en forma detallada cada uno de los bloques correspondientes al reconocimiento automático de voz y a la generación de atributos que conforman el sistema para poder generar la clave critográfica basada en la señal de voz del locutor. Posteriormente se explica en forma detallada el trabajo realizado con SVM y sobre todo la implementación propuesta de la Normalización Esférica, la cual permite mejorar el desempeño del sistema.. Fase de Prueba. Rij Señal de Voz de Prueba. Preprocesamiento. u. Reconocimiento Automatico. Generacion de Atributos. NORMALIZACION ESFERICA. Dp prueba. Clasificador SVM Prueba. CLAVE. Modelo SVM Dp Entrenamiento. Parametros del Modelo HMM. Clasificador SVM Entrenamiento. Asignación Aleatoria. Señal de Voz de Entrenamiento. Preprocesamiento. KERNEL. Entrenamiento. Fase de Entrenamiento. Figura 3.1: Esquema General del Sistema. 3.1.. Reconocimiento Automático de Voz. El objetivo principal del Reconocimiento Automático de voz (RAH) en el sistema es encontrar la transcripción precisa de lo que dice cada usuario y los inicios y finales de cada fonema en cada articulación. El reconocimiento de voz es una tarea compleja que requiere del uso de varias disciplinas y varias etapas para poder finalmente lograr el objetivo de transformar una señal de voz a una forma de representación entendible por alguna máquina.. 25.
(38) 3.1.1.. Preprocesamiento. La señal de voz está compuesta de una secuencia de excitación combinada con la respuesta de impulso del modelo del sistema vocal [7]. El objetivo del preprocesamiento de la señal de voz en el sistema es convertir la forma de onda de la voz a algún tipo de representación paramétrica. La voz es dinámica o variante con respecto al tiempo, pero por otro lado, durante el habla lenta, la forma del tracto vocal y el tipo de excitación pueden estar sin alterarse en duraciones de hasta 200 ms [7]; sin embargo, cambian en promedio más rápidamente debido a que la duración promedio de los fonemas es alrededor de los 80 ms. No obstante el análisis de voz asume que las propiedades de la señal cambian relativamente lento con el tiempo. Esto permite la examinación de una ventana de voz corta en tiempo para extraer parámetros que se mantengan fijos para la duración de la ventana. Entonces, para modelar parámetros dinámicos, se divide la señal en ventanas sucesivas o cuadros de análisis, de forma que los parámetros calculados sean suficientes para seguir cambios relevantes. Ventaneo se define como la multiplicación de la señal de voz s(n) por una ventana w(n), los cuales producen un conjunto de muestras de voz x(n) ponderado por la forma de la ventana [9]. w(n) puede tener duración infinita, pero ventanas más prácticas tienen longitud finita para simplificar el cómputo. La ventana más común es la ventana Hamming que tiene la forma: 2πn w(n) = 0,54 − 0,46 cos( ), 0 ≤ n ≤ N − 1 N −1 Para fines prácticos es común hacerle a la señal un pre-énfasis aplicándole la ecuación en diferencias de primer orden mostrada a continuación: Sn0 = Sn − ksn−1. (3.1). donde k es el coeficiente de pre-énfasis que debe estar entre 0 y 1. Una vez que la señal de voz ha sido ventaneada, se aplica el método de análisis más popular para reconocimiento autómático de voz llamado “Análisis Mel Cepstral”, el cual usa el cepstrum con un eje de frecuencia no lineal siguiendo la escala Mel o Bark. Los coeficientes cepstrales de frecuencia mel cn (MFCC’s) dan una representación alternativa para espectros de voz que incorporan algunos aspectos de audición.. 26.
(39) Básicamente para obtener los MFCC’s, después de que la señal de voz es dividida en pequeños fragmentos, un espectro S de magnitud DFT de cada cuadro de voz es deformado en frecuencia (para seguir la escala bark o de banda crı́tica) y en amplitud (escala logarı́tmica). Entonces se usa un banco de filtro para suavizar el espectro escalado. Finalmente, se aplica la transformada discreta de coseno DCT para eliminar la correlación entre los componentes, dando como resultado un vector de 13 dimensiones, donde cada dimensión corresponde a un parámetro. Después se calcula la derivada en el tiempo 4 y la aceleración en el tiempo 44 para acentuar las caracterı́sticas dinámicas de la voz en el tiempo, dando como resultado un vector de 39 dimensiones formado por los 12 MFFC’s mas un coeficiente de energı́a, 13 componentes resultantes de 4 y 13 de 44, el esquema de este preprocesamiento se muestra en la Figura 3.2 [19]. La primera y segunda derivada con respecto al tiempo de los coeficientes cepstrales indican la tasa a la cual los coeficientes cepstrales cambian. Se ha demostrado que aumentando la primera y segunda derivada a los coeficientes cepstrales mejora la precisión en los sistemas de reconocimiento de voz. Voz Trama. Ventaneo. Ventana. DFT. Log10. .. Banco de Filtros. MFCC. a1. a39. Figura 3.2: Preprocesamiento de la señal de Voz. 3.1.2.. Modelación Acústica. En el reconocimiento de voz generalmente se asume que la señal de voz es una realización de un mensaje codificado como una secuencia de sı́mbolos (ver Figura 3.3). En éste caso, las observaciones se presentan como señales continuas. Debido a eso, es ventajoso usar HMMs con densidades continuas para modelar la representación de dichas señales. Las densidades tı́picamente usadas son las gausianas y una simple función gausiana no es adecuada, por lo que una suma cargada de gausianas es conveniente.. 27.
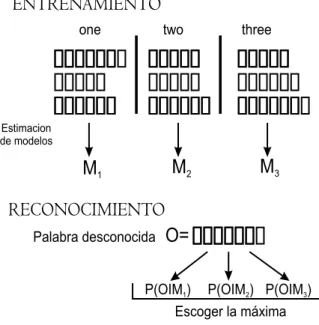
(40) S1. S2. S3. VOZ. Parametrizar. S1. S2. S3. Reconocimiento. Figura 3.3: Principio de Modelación Acústica El reconocedor de voz basado en HMM del sistema emplea dos etapas para realizar su propósito, el entrenamiento de los modelos y el reconocimiento de los mismos. En el caso del entrenamiento lo que se quiere es representar a través del modelo más apropiado una palabra. Para esto se tiene un conjunto de caracterı́sticas obtenidas a partir de pronunciaciones de las frases especialmente para entrenamiento y que han sido obtenidas previamente por la etapa de pre-procesamiento explicado anteriormente. El reconocimiento resulta ser menos complejo, y el objetivo es deducir, a partir de los modelos creados previamente para cada palabra del vocabulario, cual de estos corresponde mejor o tiene la probabilidad más alta de correspondencia a una secuencia de observación, como es el caso de la señal de entrada, pasada anteriormente por la etapa de pre-procesamiento. Reconocimiento de HMM El objetivo principal del HMM en el reconocimiento de voz es dado un conjunto de datos acústicos M = m1 , m2 , ..., mk , encontrar un conjunto de secuencia de observación de palabras O = o1 , o2 , ..., on , de forma que la probabilidad P (O|M ) sea máxima. Lo que nos da la regla de Bayes: P (O|M ) =. P (M |O) · P (O) P (M ). (3.2). donde: P (M |O) es un modelo acústico (HMMs), P (O) es un modelo de lenguaje y P (M ) es una constante para una oración completa. Como hemos visto hasta este momento, con la ayuda de la etapa de preprocesamiento de voz, podemos representar la voz como un conjunto de observaciones, con lo que usamos 28.
Figure




+7



Documento similar
Para recibir todos los números de referencia en un solo correo electrónico, es necesario que las solicitudes estén cumplimentadas y sean todos los datos válidos, incluido el
La determinación molecular es esencial para continuar optimizando el abordaje del cáncer de pulmón, por lo que es necesaria su inclusión en la cartera de servicios del Sistema
trañables para él: el campo, la vida del labriego, otra vez el tiempo, insinuando ahora una novedad: la distinción del tiempo pleno, el tiempo-vida, y el tiempo
Habiendo organizado un movimiento revolucionario en Valencia a principios de 1929 y persistido en las reuniones conspirativo-constitucionalistas desde entonces —cierto que a aquellas
Por lo tanto, en base a su perfil de eficacia y seguridad, ofatumumab debe considerarse una alternativa de tratamiento para pacientes con EMRR o EMSP con enfermedad activa
The part I assessment is coordinated involving all MSCs and led by the RMS who prepares a draft assessment report, sends the request for information (RFI) with considerations,
La siguiente y última ampliación en la Sala de Millones fue a finales de los años sesenta cuando Carlos III habilitó la sexta plaza para las ciudades con voto en Cortes de
Ciaurriz quien, durante su primer arlo de estancia en Loyola 40 , catalogó sus fondos siguiendo la división previa a la que nos hemos referido; y si esta labor fue de
