Propuesta de un servidor Web Apache 2 sobre un Cluster en Linux
65
0
0
Texto completo
(2) Universidad Central “Marta Abreu” de Las Villas Facultad de Ingeniería Eléctrica Dpto. de Telecomunicaciones y Electrónica. TRABAJO DE DIPLOMA “Propuesta de un servidor Web Apache 2 sobre un Cluster en Linux”. Autor: Alberto Hurtado Cuellar. Email: [email protected]. Tutor: Ing. Sandy Bolufé Aguila. Email: [email protected]. “Año 53 de la Revolución” Santa Clara, Cuba 2011.
(3) Hago constar que el presente trabajo de diploma fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de estudios de la especialidad de Ingeniería en Telecomunicaciones y Electrónica, autorizando a que el mismo sea utilizado por la Institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos, ni publicado sin autorización de la Universidad.. Firma del Autor Los abajo firmantes certificamos que el presente trabajo ha sido realizado según acuerdo de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. Firma del Autor. Firma del Jefe de Departamento donde se defiende el trabajo. Firma del Responsable de Información Científico-Técnica.
(4) i. PENSAMIENTO Hay una fuerza motriz más poderosa que el vapor, la electricidad y la energía atómica: "...la voluntad".
(5) ii. DEDICATORIA A mis padres, novia, abuela y seres queridos por su tolerancia y paciencia durante estos años de estudio; ¡lo logramos!.
(6) iii. AGRADECIMIENTOS A Dios, mis suegros, Hendy y tía Denia, por su apoyo en mis años de estudio. A mi amigo Arián y Margarita por su paciencia y ayuda. A Sandy, mi tutor por su esfuerzo y dedicatoria durante esta etapa de tesis. A Mons. Arturo por sus oraciones. A Dionisio, administrador del Nodo Capiro por sus ideas para la confección de mi tesis..
(7) iv. TAREA TÉCNICA. Para lograr los objetivos propuestos en el presente trabajo, la investigación sigue una línea definida por un grupo de tareas, las cuales se muestran a continuación: Revisión bibliográfica de trabajos relacionados con el tema. Evaluación de los Clusters y sus variantes para software libre. Análisis de las diferentes técnicas de balanceo de carga en servidores Web. Determinación de las herramientas de trabajo. Implementación de una variante del servidor Web sobre un Cluster. Confección del informe.. Firma del Autor. Firma del Tutor.
(8) v. RESUMEN. En este trabajo se realiza la implementación de un servidor Web sobre un Cluster en Linux con balanceo de carga. Para esto se realiza un estudio de las principales características que presentan los Cluster de computadoras, se presentan los diferentes algoritmos usados para el balanceo de carga y se explica la importancia que presentan los Cluster hoy en día para utilizarlos en aplicaciones que requieran alto desempeño, alta eficiencia o alta disponibilidad. También se muestra una tabla resumen la cual contempla los software de Cluster de código abierto más utilizados en la actualidad y la justificación de los escogidos para la implementación que se realizó en este trabajo. Por último se describe el proceso de instalación y configuración de todos los software involucrados en la implementación del servidor Web Clusterizado, se realizan varias pruebas para comprobar el correcto funcionamiento del sistema y se analizan los resultados..
(9) vi. TABLA DE CONTENIDOS. PENSAMIENTO.......................................................................................................................i DEDICATORIA ..................................................................................................................... ii AGRADECIMIENTOS .......................................................................................................... iii TAREA TÉCNICA................................................................................................................iv RESUMEN .............................................................................................................................v INTRODUCCIÓN ..................................................................................................................1 CAPÍTULO 1.. Cluster de Computadoras ..........................................................................4. 1.1. Definición de Cluster ...............................................................................................4. 1.2. Características de un Cluster....................................................................................6. 1.3. Clasificación de un Cluster atendiendo a los factores de diseño .............................7. 1.3.1. Acoplamiento....................................................................................................7. 1.3.2. Control ..............................................................................................................8. 1.3.3. Homogeneidad ..................................................................................................8. 1.3.4. Escalabilidad.....................................................................................................9.
(10) vii 1.4. Clasificación de un Cluster atendiendo a su aplicabilidad.......................................9. 1.5. Componentes de un Cluster ...................................................................................11. 1.5.1. Nodos ..............................................................................................................11. 1.5.2. Almacenamiento .............................................................................................12. 1.5.3. Sistemas Operativos........................................................................................13. 1.5.4. Conexiones de red...........................................................................................14. 1.5.4.1. Ethernet...................................................................................................14. 1.5.4.2. Myrinet (Myrinet 2000 y Myri-10G)......................................................15. 1.5.4.3. InfiniBand ...............................................................................................15. 1.5.4.4. SCI (Scalable Coherent Interface) ..........................................................16. 1.5.5. Middleware .....................................................................................................16. 1.5.6. Ambientes de Programación Paralela .............................................................17. 1.6. Balanceo de Carga..................................................................................................17. 1.6.1. Términos fundamentales.................................................................................18. 1.6.2. Tipos de Balanceo de Carga ...........................................................................18. 1.6.3. Algoritmos de Balanceo..................................................................................20. 1.7. Cluster de Alto Rendimiento: Beowulf..................................................................22. 1.7.1. Descripción de un Cluster Beowulf ................................................................22. 1.7.2. Características de un Cluster Beowulf............................................................23. 1.7.3. Clasificación por Clase de Clusters Beowulf .................................................23. 1.8. Software a utilizar en Clusters ...............................................................................24. 1.9. Conclusiones del Capítulo......................................................................................25. CAPÍTULO 2. 2.1. Implementación del servidor Web Clusterizado .....................................26. Hardware y Sistema Operativo utilizado ...............................................................26.
(11) viii 2.2. Topologías de red utilizadas...................................................................................26. 2.3. Software GlusterFS y Fuse.....................................................................................28. 2.3.1. Implementación de GlusterFS y Fuse.............................................................29. 2.3.2. Montando directorio /var/www con GlusterFS ..............................................32. 2.4. Implementación de Apache 2.................................................................................33. 2.5. Implementación DNS.............................................................................................33. 2.5.1. Configurando zonas en el DNS maestro.........................................................34. 2.5.2. Configurando zonas en el DNS esclavo .........................................................36. 2.6. Implementación de HaProxy y Keepalived............................................................37. 2.7. Conclusiones del Capítulo......................................................................................40. CAPÍTULO 3.. Resultados de los Experimentos..............................................................41. 3.1. Pruebas a BIND 9...................................................................................................42. 3.2. Pruebas a HaProxy .................................................................................................45. 3.3. Pruebas a GlusterFS ...............................................................................................48. 3.4. Conclusiones del Capítulo......................................................................................49. CONCLUSIONES Y RECOMENDACIONES ...................................................................50 Conclusiones.....................................................................................................................50 Recomendaciones .............................................................................................................51 REFERENCIAS BIBLIOGRÁFICAS .................................................................................52.
(12) INTRODUCCIÓN. 1. INTRODUCCIÓN. El surgimiento y crecimiento acelerado de las redes de computadoras en los últimos años ha provocado que existan cada vez más usuarios demandando los servicios que estas proveen. Hoy en día tanto en el mundo empresarial, como en el mundo académico, existen diferentes aplicaciones que dada su naturaleza deben proporcionar un servicio ininterrumpido de 24 horas al día, 7 días a la semana. Esta situación ha despertado el interés de crear diferentes alternativas que permitan un mejor rendimiento y una alta disponibilidad para los servicios que se ofrecen en los diferentes ámbitos (Lizárraga, 2002). Los servicios de Cluster se han convertido a lo largo de los años en un elemento esencial para que las organizaciones implementen aplicaciones que se pueden considerar críticas de acuerdo a la gran demanda que presentan por parte de los usuarios. El cómputo con Cluster surge como resultado de la convergencia de varias tendencias actuales que incluyen la disponibilidad de microprocesadores económicos de alto rendimiento y redes de alta velocidad, el desarrollo de herramientas de software para cómputo distribuido de alto rendimiento, así como la creciente necesidad de potencia computacional para aplicaciones que la requieran. La tecnología de Cluster ha evolucionado en apoyo a actividades como las aplicaciones de supercómputo, software de misiones críticas, servidores Proxy, Web, Correo, FTP, comercio electrónico y bases de datos de alto rendimiento (Coar y Bowen, 2007). Un Cluster es un grupo de ordenadores trabajando juntos para ejecutar un conjunto común de aplicaciones y para mostrar un sistema unificado al cliente y a la aplicación. Los equipos están físicamente conectados por cables y a nivel lógico mediante software de Cluster. Este sistema de conexión posibilita la recuperación ante fallos y el balanceo de carga, funciones imposibles de conseguir con un sistema no redundante (un único servidor físico)..
(13) INTRODUCCIÓN. 2. Los Cluster presentan diversas características que hacen que sean viables en el manejo de grandes cantidades de tareas. Tienen como finalidad agrupar el poder de cómputo de los nodos implicados para proporcionar una mayor escalabilidad, disponibilidad y fiabilidad. El desarrollo tecnológico alcanzado actualmente en el mundo hace que la productividad y la rentabilidad de los servicios que se brindan dependan cada vez más del buen funcionamiento de todos los componentes que conforman la red de comunicación. El centro de datos requiere una atención particular porque es aquí donde las aplicaciones y los servidores entran en acción. Acelerar el acceso a los diferentes servicios, eliminar los cuellos de botella, mejorar la seguridad, reducir y balancear las cargas de tráfico, es crucial para gestionar un centro de datos ágil y eficaz (Rodríguez, 2008). Los costos económicos para contar con un servidor profesional que brinde un servicio ininterrumpido de alta calidad se tornan bastantes elevados si se les compara con los costos que implica la implementación de un Cluster de alta disponibilidad, por esta causa la implementación de un servicio sobre un Cluster se presenta como una solución atractiva en escenarios donde es necesario brindar un servicio ininterrumpido para gran cantidad de usuarios con recursos de hardware limitado (Moreno y Calzada, 2010). Por tanto el objetivo de este trabajo es desarrollar un servidor Web Apache2 sobre un Cluster en Linux que permita lograr balanceo de carga. Con vistas a lograr la idea central de la investigación se trazaron los siguientes objetivos específicos: Realizar una revisión bibliográfica sobre los diferentes tipos de Clusters y sus posibles implementaciones en Linux. Valorar las diferentes técnicas que se pudieran emplear para lograr balanceo de carga en un Cluster de servidores Web. Como resultado de esta implementación se debe lograr un servicio Web con balanceo de carga sobre un Cluster en Linux que garantice calidad sobre la demanda de usuarios. Con la implementación del servidor Web Clusterizado se aporta no solo una solución basada en software libre sino también un análisis de los diferentes métodos de balanceo de carga las cuales posibilitan obtener un mejor rendimiento para la aplicación del servicio..
(14) INTRODUCCIÓN. 3. Organización del Informe El informe de la investigación se organiza de la siguiente forma: resumen, introducción, capitulario, conclusiones y recomendaciones, referencias bibliográficas.. Introducción Se realiza una reseña donde se define la necesidad, actualidad e importancia del tema que se aborda y se mencionan los elementos del diseño teórico.. Capítulo I Se realiza un estudio de los aspectos fundamentales que presentan los Cluster de computadoras y se presenta una tabla resumen la cual contempla los software de Cluster de código abierto más utilizados en la actualidad.. Capítulo II Se describe el proceso de implementación de un servidor Web Clusterizado el cual presenta balanceo de carga.. Capítulo III Se realizan una serie de pruebas al servidor Web Clusterizado y se analizan los resultados obtenidos.. Conclusiones Se describen los resultados obtenidos a partir de los objetivos trazados inicialmente..
(15) CAPÍTULO 1. Cluster de Computadoras 4. CAPÍTULO 1. Cluster de Computadoras. Las supercomputadoras han sido las principales herramientas para el procesamiento masivo durante varios años, pero estas son construidas solamente por unos cuantos fabricantes y para un grupo muy reducido de usuarios que necesitan gran potencia de cálculo, como varias empresas, gobiernos y algunas universidades. Existen otros grupos de personas que no pueden hacer frente al costo económico que supone adquirir una máquina de estas características, es aquí donde toma importancia la idea de poder disponer de gran potencia de cálculo, pero a un bajo precio. Así nació el concepto de Cluster, cuando los pioneros de la supercomputación intentaban repartir diferentes procesos entre varias computadoras, para luego poder recoger los resultados que dichos procesos habían de producir. Con un hardware fácil de conseguir (en costo) se tuvo la idea que podrían obtenerse resultados en tiempos muy parecidos a los obtenidos con aquellas máquinas que suponen una mayor inversión, como se ha venido probando desde aquel entonces. 1.1. Definición de Cluster. Cluster (o también castellanizado como clúster) es un término inglés utilizado y estudiado en diferentes áreas técnicas en la actualidad. Su traducción literal es racimo o grupo, básicamente se refiere a todas las entidades que pueden trabajar en conjunto para lograr un fin específico en un algún ámbito (Lizárraga, 2002). Existen diferentes tipos de Cluster, según el área en que se desarrollen: Cluster de empresas Cluster de computadoras Cluster de sistemas de archivos.
(16) CAPÍTULO 1. Cluster de Computadoras 5 Clusters industriales Un Cluster de computadoras es un conjunto de ordenadores que pueden trabajar de manera conjunta y coordinada en la solución de un mismo problema, los cuales se encuentran interconectados entre sí tanto a nivel físico como a nivel lógico. Normalmente a un Cluster también se le considera como un tipo particular de computadora paralela. El término descrito anteriormente puede aplicar tanto a computadoras de alto rendimiento construidas para este propósito como a un grupo de simples computadoras de escritorio (Gómez, 2005).. Figura 1. Cluster de computadoras Un Cluster solo define un grupo de computadoras y estas pueden tener cualquier característica lo único que deben cumplir es tener una interconexión y una interacción para poder realizar alguna tarea en conjunto y sea visto como una única computadora, más potente que las comunes de escritorio. De manera más simple, se puede definir a un Cluster como un grupo de computadoras unidas mediante una red, de tal forma que el conjunto es visto como una sola computadora con grandes prestaciones. Los Clusters son la principal alternativa para el alto desempeño en computación llamado High Performance Computing.
(17) CAPÍTULO 1. Cluster de Computadoras 6 (HPC) y juegan hoy en día un papel importante en la solución de problemas de la ciencia, la ingeniería y hasta del comercio moderno. Un Cluster de computadoras debe presentar combinaciones de los siguientes servicios: Alto rendimiento Alta disponibilidad Balanceo de carga Escalabilidad Para que un Cluster funcione como tal, no basta solo con conectar entre sí los ordenadores, sino que es necesario proveer un sistema de manejo del Cluster, el cual se encargue de interactuar con el usuario y los procesos que corren en él para optimizar el funcionamiento. 1.2. Características de un Cluster. Si se habla de Cluster y de los tipos de Cluster existentes, es necesario mencionar cuales son las cualidades comunes que presentan. Algunas de ellas ya han sido nombradas anteriormente, pero ahora se describirán de una manera más formal (Bookman, 2003). Un Cluster consta de dos o más nodos. Un sólo computador, en ningún caso, puede ser considerado como un Cluster debido a la situación de aislamiento en que se encuentra, puesto que no puede comunicarse y menos, ocupar los recursos de otra máquina. Los nodos de un Cluster deben estar conectados entre sí por, al menos, un canal de comunicación. De no ser así, se produce el efecto de aislamiento anteriormente mencionado. Los Cluster necesitan software de control especializado. Se debe tener presente que el software utilizado es el que determinará el tipo de Cluster que se está implementando. Parte de este software es el encargado de la comunicación entre los componentes del Cluster. El software utilizado puede ser de uno de los siguientes niveles: Software a Nivel de Aplicación: para la utilización de este software se emplean librerías, las cuales son de carácter general y permiten el comportamiento del Cluster como un gran sistema único..
(18) CAPÍTULO 1. Cluster de Computadoras 7 Software a Nivel de Sistema: este tipo de software puede ser una parte del operativo o la totalidad de éste. Este nivel es más complejo, pero la eficiencia que brinda, por norma general, es superior a los de nivel de aplicación. 1.3. Clasificación de un Cluster atendiendo a los factores de diseño. Existen diferentes factores de diseños según los cuales se puede clasificar un Cluster. Entre éstos se encuentran los siguientes (Díaz et al., 2007): Acoplamiento Control Homogeneidad Escalabilidad 1.3.1. Acoplamiento. Una de las características más importantes de un Cluster es el nivel de acoplamiento del mismo. Por acoplamiento del software se entiende la integración que tengan los elementos existentes en cada nodo. Los distintos tipos de acoplamiento son los que se describen a continuación: Escasamente acoplados: una agrupación de computadores está escasamente acoplada si, aún siendo capaz de realizar procesamiento paralelo mediante librerías de paso de mensajes o de memoria compartida, no posee un sistema de instalación y gestión integrado que posibilite una recuperación rápida ante fallos y una gestión centralizada que ahorre tiempo al administrador. Medianamente acoplados: dentro de este grupo se encuentra un software que no necesita un conocimiento tan profundo sobre cuáles son los recursos de los otros nodos que componen el Cluster, pero utiliza el software de otros nodos para realizar aplicaciones de muy bajo nivel. Altamente acoplados: este software se caracteriza por que los elementos que lo componen se interrelacionan unos con otros y posibilitan la mayoría de las funcionalidades del Cluster de manera altamente cooperativa. El acoplamiento más fuerte que se puede dar se produce.
(19) CAPÍTULO 1. Cluster de Computadoras 8 cuando existe sólo una imagen del sistema operativo, la cual está distribuida entre el conjunto de nodos que la compartirán. Este caso es el que se considera como más acoplado, de hecho, no está catalogado como Cluster, sino como sistema operativo distribuido. 1.3.2. Control. Cuando se habla de control de un Cluster, no es más que el modelo de gestión que éste propone. Estos modelos pueden ser de dos tipos: Control centralizado: en este tipo de control existe un nodo maestro desde el cual se realiza la configuración de todo el Cluster. Además ayuda a que la gestión y la administración sean mucho más fáciles de realizar, pero a su vez los hace menos tolerable a los fallos. Control descentralizado: en este tipo de control cada uno de los nodos del Cluster debe ser capaz de administrarse y gestionarse. En este tipo de control se hace más difícil la gestión y la administración, pero como sistema global lo hace más tolerable a fallos. 1.3.3. Homogeneidad. Se entiende por homogeneidad de un Cluster a lo similar que pueden llegar a ser los equipos y recursos que conforman éste. Se clasifican en: Cluster Homogéneos: en este tipo de Cluster todos los nodos que lo componen poseen arquitectura y recursos similares, es decir, no debe existir mucha diferencia entre cada nodo. Cluster Heterogéneos: este tipo de Cluster está formado con nodos en los cuales pueden existir las siguientes diferencias: 1. Tiempos de acceso. 2. Arquitectura. 3. Sistema operativo. 4. Rendimiento de los procesadores o recursos sobre una misma arquitectura. El uso de arquitecturas distintas o distintos sistemas operativos, impone que exista una biblioteca que haga de interfaz..
(20) CAPÍTULO 1. Cluster de Computadoras 9 1.3.4. Escalabilidad. Otro factor de suma importancia que aún no se ha nombrado es el de “Escalabilidad del Cluster”. Escalabilidad es la capacidad de un sistema informático de adaptarse a un número de usuarios cada vez mayor, sin perder calidad en los servicios. En general, se podría definir como la capacidad del sistema informático de cambiar su tamaño o configuración para adaptarse a las circunstancias cambiantes. Por lo tanto, entre más escalable es un sistema, menos costará mejorar el rendimiento, lo cual abarata el coste y, en caso de que un Cluster lo implemente, distribuye más la caída del sistema. 1.4. Clasificación de un Cluster atendiendo a su aplicabilidad. El término Cluster tiene diferentes connotaciones para diferentes grupos de personas. Los tipos de Clusters, establecidos de acuerdo con el uso que se les dé y los servicios que ofrecen, determinan el significado del término para el grupo que lo utiliza. Los Clusters pueden clasificarse según sus características en Clusters de Alto Rendimiento (HPCC – High Performance Computing Clusters), Clusters de Alta Disponibilidad (HA – High Availability) y Clusters de Alta Eficiencia (HT – High Throughput) (Piernas, 2010). Alto Rendimiento: son Clusters en los cuales se ejecutan tareas que requieren de gran capacidad computacional, grandes cantidades de memoria, o ambos aspectos a la vez. El llevar a cabo estas tareas puede comprometer los recursos del Cluster por largos períodos de tiempo. Alta Disponibilidad: son Clusters cuyo objetivo de diseño es el de proveer disponibilidad y confiabilidad. Estos Clusters tratan de brindar la máxima disponibilidad de los servicios que ofrecen. La confiabilidad se provee mediante software que detecta fallos y permite recuperarse frente a los mismos, mientras que en hardware se evita tener un único punto de fallos..
(21) CAPÍTULO 1. Cluster de Computadoras 10. Figura 2. Cluster de Alto Rendimiento Alta Eficiencia: son Clusters cuyo objetivo de diseño es el ejecutar la mayor cantidad de tareas en el menor tiempo posible. Presentan independencia de datos entre las tareas individuales. El retardo entre los nodos del Cluster no es considerado un gran problema.. Figura 3. Cluster de Alta Disponibilidad Los Clusters también se pueden clasificar como Clusters Comerciales (Alta Disponibilidad, Alta Eficiencia) y Clusters Científicos (Alto Rendimiento). A pesar de las discrepancias a.
(22) CAPÍTULO 1. Cluster de Computadoras 11 nivel de requerimientos de las aplicaciones, muchas de las características de las arquitecturas de hardware y software, que están por debajo de las aplicaciones en todos estos Clusters, son las mismas. Más aún, un Cluster de determinado tipo, puede también presentar características de los otros. 1.5. Componentes de un Cluster. En general, un Cluster necesita de varios componentes de software y hardware para poder funcionar. Entre ellos se destacan los siguientes (Gómez, 2005): Nodos Almacenamiento Sistemas Operativos Conexiones de Red Middleware Ambientes de Programación Paralela 1.5.1. Nodos. Pueden ser simples ordenadores, sistemas multi-procesador o estaciones de trabajo (Workstations). En informática, de forma muy general, un nodo es un punto de intersección o unión de varios elementos que confluyen en el mismo lugar. Ahora bien, dentro de la informática la palabra nodo puede referirse a conceptos diferentes según el ámbito en el que nos movamos. En redes de computadoras cada una de las máquinas es un nodo, y si la red es Internet, cada servidor constituye también un nodo. En estructuras de datos dinámicas un nodo es un registro que contiene un dato de interés y al menos un puntero para referenciar (apuntar) a otro nodo. Si la estructura tiene sólo un puntero, la única estructura que se puede construir con él es una lista, si el nodo tiene más de un puntero entonces se pueden construir estructuras más complejas como árboles o grafos. El Cluster puede estar conformado por nodos dedicados o por nodos no dedicados..
(23) CAPÍTULO 1. Cluster de Computadoras 12 En un Cluster con nodos dedicados, los nodos no disponen de teclado, ratón ni monitor y su uso está exclusivamente dedicado a realizar tareas relacionadas con el Cluster. Mientras que, en un Cluster con nodos no dedicados, los nodos disponen de teclado, ratón y monitor y su uso no está exclusivamente dedicado a realizar tareas relacionadas con el Cluster, el Cluster hace uso de los ciclos de reloj que el usuario del computador no está utilizando para realizar sus tareas. Cabe aclarar que a la hora de diseñar un Cluster, los nodos deben tener características similares, es decir, deben guardar cierta similaridad de arquitectura y sistemas operativos, ya que si se conforma un Cluster con nodos totalmente heterogéneos (existe una diferencia grande entre capacidad de procesadores, memoria, disco duro) será ineficiente debido a que el Middleware delegará o asignará todos los procesos al nodo de mayor capacidad de cómputo y solo distribuirá cuando este se encuentre saturado de procesos; por eso es recomendable construir un grupo de ordenadores lo más similares posible. 1.5.2. Almacenamiento. El almacenamiento puede consistir en una NAS (Network Attached Storage), una SAN (Storage Area Network) o almacenamiento interno en el servidor. El protocolo más comúnmente utilizado es NFS (Network File System), sistema de ficheros compartido entre servidor y los nodos. Sin embargo existen sistemas de ficheros específicos para Clusters como Lustre CFS (Cluster File System) y PVFS2 (Parallel Virtual File System). Tecnologías en el soporte del almacenamiento en discos duros: IDE o ATA: velocidades de 33, 66, 100, 133 y 166 MB/s SATA: velocidades de 150, 300 y 600 MB/s SCSI: velocidades de 160, 320, 640 MB/s. Proporciona altos rendimientos. SAS: aún a SATA-II y SCSI. Velocidades de 300 y 600 MB/s Las unidades de cinta DLT (Digital Line Tape) son utilizadas para copias de seguridad por su bajo coste..
(24) CAPÍTULO 1. Cluster de Computadoras 13 NAS es un dispositivo específico dedicado al almacenamiento a través de red (normalmente TCP/IP) que hace uso de un sistema operativo optimizado para dar acceso a través de protocolos CIFS, NFS, FTP o TFTP. Por su parte, DAS (Direct Attached Storage) consiste en conectar unidades externas de almacenamiento SCSI o a una SAN a través de un canal de fibra. 1.5.3. Sistemas Operativos. Un sistema operativo debe ser multiproceso y multiusuario. Otras características deseables son la facilidad de uso y acceso. Un sistema operativo es un programa o conjunto de programas de computadora destinado a permitir una gestión eficaz de sus recursos. Comienza a trabajar cuando se enciende el computador, y gestiona el hardware de la máquina desde los niveles más básicos, permitiendo también la interacción con el usuario. Se puede encontrar normalmente en la mayoría de los aparatos electrónicos que utilicen microprocesadores para funcionar, ya que gracias a estos podemos entender la máquina y que ésta cumpla con sus funciones (teléfonos móviles, reproductores de DVD, radios, computadoras, etc.). GNU/Linux . ABC GNU/Linux. . OpenMosix. . Rocks. . Kerrighed. . Cóndor. . SunGridEngine. Unix . Solaris. . HP-UX. . Aix. Windows.
(25) CAPÍTULO 1. Cluster de Computadoras 14 . NT. . 2000 Server. . 2003 Server. . 2008 Server. Mac OS X . Xgrid. Solaris FreeBSD 1.5.4. Conexiones de red. Los nodos de un Cluster pueden conectarse mediante una simple red Ethernet con placas comunes (adaptadores de red o NICs), o utilizarse tecnologías especiales de alta velocidad como Fast Ethernet, Gigabit Ethernet, Myrinet, InfiniBand, SCI, etc. (Lucke, 2005).. Figura 4. Cluster con conexión de red Fast Ethernet 1.5.4.1 Ethernet Son las redes más utilizadas en la actualidad, debido a su relativo bajo costo. No obstante, su tecnología limita el tamaño de paquete, realizan excesivas comprobaciones de error y sus.
(26) CAPÍTULO 1. Cluster de Computadoras 15 protocolos no son eficientes, y sus velocidades de transmisión pueden limitar el rendimiento de los Clusters. Para aplicaciones con paralelismo de grano grueso puede suponer una solución acertada. La opción más utilizada en la actualidad es Gigabit Ethernet (1 Gbit/s), siendo emergente la solución 10 Gigabit Ethernet (10 Gbit/s). La latencia de estas tecnologías está en torno a los 30-100 μs, dependiendo del protocolo de comunicación empleado. En todo caso, es la red de administración por excelencia, así que aunque no sea la solución de red de altas prestaciones para las comunicaciones, es la red dedicada a las tareas administrativas. 1.5.4.2 Myrinet (Myrinet 2000 y Myri-10G) Su latencia es de 1,3/10 μs y su ancho de Banda de 2/10 Gbps, respectivamente para Myrinet 2000 y Myri-10G. Es la red de baja latencia más utilizada en la actualidad, tanto en Clusters como en MPPs (Massively Parallel Processors) estando presente en más de la mitad de los sistemas del top500. Tiene dos bibliotecas de comunicación a bajo nivel GM y MX. Sobre estas bibliotecas están implementadas MPICH-GM, MPICH-MX, Sockets-GM y Sockets-MX, para aprovechar las excelentes características de Myrinet. Existen también emulaciones IP sobre TCP/IP, IPoGM e IPoMX. 1.5.4.3 InfiniBand Es una red surgida de un estándar desarrollado específicamente para realizar la comunicación en Clusters. Una de sus mayores ventajas es que mediante la agregación de canales (x1, x4 y x12) permite obtener anchos de banda muy elevados. La conexión básica es de 2 Gbps efectivos y con "quad connection" x12 alcanza los 96 Gbps. No obstante, los startups no son muy altos, se sitúan en torno a los 10 μs. Define una conexión entre un nodo de computación y un nodo de I/O (entrada/salida). La conexión va desde un Host Channel Adapter (HCA) hasta un Target Channel Adapter (TCA). Se está usando principalmente para acceder a arreglos de discos SAS..
(27) CAPÍTULO 1. Cluster de Computadoras 16 1.5.4.4 SCI (Scalable Coherent Interface) Su latencia teórica es de 1.43 μs y su ancho de banda de 5333 Mbps bidireccional. Al poder configurarse con topologías de anillo (1D), toro (2D) e hipercubo (3D) sin necesidad de switch, se tiene una red adecuada para Clusters de pequeño y mediano tamaño. Al ser una red de extremadamente baja latencia, presenta ventajas frente a Myrinet en Clusters de pequeño tamaño al tener una topología punto a punto y no ser necesaria la adquisición de un conmutador. El software sobre SCI está menos desarrollado que sobre Myrinet, pero los rendimientos obtenidos son superiores, destacando SCI Sockets (que obtiene startups de 3 microsegundos) y ScaMPI, una biblioteca MPI de elevadas prestaciones. Además, a través del mecanismo de pre-loading (LD_PRELOAD) se puede conseguir que todas las comunicaciones del sistema vayan a través de SCI-SOCKETS (transparencia para el usuario). 1.5.5. Middleware. El Middleware es un software que generalmente actúa entre el sistema operativo y las aplicaciones con la finalidad de proveer a un Cluster lo siguiente: Interfaz única de acceso al sistema: denominada SSI (Single System Image) la cual genera la sensación al usuario de que utiliza un único ordenador muy potente. Herramientas para la optimización y mantenimiento del sistema: migración de procesos, checkpoint-restart (congelar uno o varios procesos, mudarlos de servidor y continuar su funcionamiento en el nuevo host), balanceo de carga, tolerancia a fallos, etc. Escalabilidad: debe poder detectar automáticamente nuevos servidores conectados al Cluster para proceder a su utilización. Existen diversos tipos de Middleware, como por ejemplo: Mosix, OpenMosix, Cóndor, OpenSSI, etc. El Middleware recibe los trabajos entrantes al Cluster y los redistribuye de manera que el proceso se ejecute más rápido y el sistema no sufra sobrecargas en un servidor. Esto se realiza mediante políticas definidas en el sistema (automáticamente o por un administrador).
(28) CAPÍTULO 1. Cluster de Computadoras 17 que le indican dónde y cómo debe distribuir los procesos, por un sistema de monitorización, el cual controla la carga de cada CPU y la cantidad de procesos en él. El Middleware también debe poder migrar procesos entre servidores con distintas finalidades: Balancear la carga: si un servidor está muy cargado de procesos y otro está ocioso, pueden transferirse procesos a este último para liberar de carga al primero y optimizar el funcionamiento. Mantenimiento de servidores: si hay procesos corriendo en un servidor que necesita mantenimiento o una actualización, es posible migrar los procesos a otro servidor y proceder a desconectar del Cluster al primero. Priorización de trabajos: en caso de tener varios procesos corriendo en el Cluster, pero uno de ellos de mayor importancia que los demás, puede migrarse este proceso a los servidores que posean más o mejores recursos para acelerar su procesamiento. 1.5.6. Ambientes de Programación Paralela. Los ambientes de programación paralela permiten implementar algoritmos que hagan uso de recursos compartidos: CPU (Central Processing Unit), memoria, datos y servicios. 1.6. Balanceo de Carga. Un Cluster de balanceo de carga o de cómputo adaptativo está compuesto por uno o más ordenadores (llamados nodos) que actúan como front-end del Cluster, y que se ocupan de repartir las peticiones de servicio que reciba el Cluster, a otros ordenadores del Cluster que forman el back-end de éste. Un tipo concreto de Cluster cuya función es repartir la carga de proceso entre los nodos en lugar de los servicios es el Cluster OpenMosix (Chirinov, 2003). Las características más destacadas de este tipo de Cluster son: Fácil Ampliación. Se puede ampliar su capacidad añadiendo más ordenadores al Cluster..
(29) CAPÍTULO 1. Cluster de Computadoras 18 Robustez. Ante la caída de alguno de los ordenadores del Cluster el servicio se puede ver mermado, pero mientras haya ordenadores en funcionamiento, éstos seguirán dando servicio. 1.6.1. Términos fundamentales. El aspecto del balanceo de carga es bastante importante debido a que en muchas aplicaciones paralelas, como la búsqueda o la optimización, es extraordinariamente difícil predecir el tamaño de las tareas asignadas a cada procesador, de manera que se realice una división de las mismas para que todos mantengan la carga computacional uniforme. Cuando no es uniforme, es decir, hay desbalanceo en la carga, entonces algunos procesadores terminarán permaneciendo inactivos mientras otros todavía están calculando. Frecuentemente todos los procesadores o algunos de ellos necesitan algún sincronismo durante la ejecución del programa, de forma que si no están todos en la misma situación en todo instante entonces algunos de ellos deberán esperar a que otros terminen. El estudio del balanceo de carga es muy importante para poder distribuir de una forma equitativa la carga computacional entre todos los procesadores disponibles y con ello conseguir la máxima velocidad de ejecución. Sin embargo, puede ocurrir que algunos procesadores finalicen sus tareas antes que el resto y queden libres debido a que el trabajo no se haya repartido de una forma equitativa o porque algunos procesadores sean más rápidos que otros, o por ambas situaciones. La situación ideal es que todos los procesadores trabajen de una forma continua sobre las tareas disponibles para conseguir el mínimo tiempo de ejecución. 1.6.2. Tipos de Balanceo de Carga. Existen dos formas de balanceo de carga, balanceo de carga estático y balanceo de carga dinámico (Eugenin, 2005). En el balanceo de carga estático, la distribución de las tareas se realiza al comienzo de la computación, lo cual permite al maestro (nodo principal dentro del Cluster) participar en la computación una vez que haya asignado una fracción del trabajo a cada esclavo (el resto de los nodos de un Cluster). Los nodos esclavos obedecen órdenes del nodo maestro. La asignación de tareas se puede realizar de una sola vez o de manera cíclica..
(30) CAPÍTULO 1. Cluster de Computadoras 19 El balanceo de carga estático tiene serios inconvenientes que lo sitúan en desventaja sobre el balanceo de carga dinámico. Entre ellos cabe destacar los siguientes: Es muy difícil estimar de forma precisa el tiempo de ejecución de todas las partes en las que se divide un programa sin ejecutarlas. Algunos sistemas pueden tener retardos en las comunicaciones que pueden variar bajo diferentes circunstancias, lo que dificulta incorporar la variable retardo de comunicación en el balance de carga estático. A veces los problemas necesitan un número indeterminado de pasos computacionales para alcanzar la solución. El balanceo de carga dinámico es muy útil cuando el número de tareas es mayor que el número de procesadores disponibles o cuando el número de tareas es desconocido al comienzo de la aplicación. Una importante característica del balanceo de carga dinámico es la capacidad que tiene la aplicación de adaptarse a los posibles cambios del sistema, no sólo a la carga de los procesadores sino también a posibles reconfiguraciones de los recursos del sistema. Debido a esta característica, un Cluster puede responder bastante bien cuando se produce el fallo de algún procesador, lo cual simplifica la creación de aplicaciones tolerantes a fallos que sean capaces de sobrevivir cuando se pierde algún esclavo o incluso el maestro. Con el balanceo de carga dinámico todos los inconvenientes que presenta el balanceo de carga estático se tienen en cuenta. Esto es posible porque la división de la carga computacional depende de las tareas que se están ejecutando y no de la estimación del tiempo que pueden tardar en ejecutarse. Aunque el balanceo de carga dinámico lleva consigo una cierta sobrecarga durante la ejecución del programa, resulta una alternativa mucho más eficiente que el balanceo de carga estático. En el balanceo de carga dinámico, las tareas se reparten entre los procesadores durante la ejecución del programa. Dependiendo de dónde y cómo se almacenen y repartan las tareas el balanceo de carga dinámico se divide en: Balanceo de carga dinámico centralizado: se corresponde con la estructura típica de Maestro/Esclavo..
(31) CAPÍTULO 1. Cluster de Computadoras 20 Balanceo de carga dinámico distribuido o descentralizado: se utilizan varios maestros y cada uno controla a un grupo de esclavos. Balanceo de carga dinámico centralizado: el nodo maestro es el que tiene la colección completa de tareas a realizar. Las tareas son enviadas a los nodos esclavos. Cuando un nodo esclavo finaliza una tarea, solicita una nueva al maestro. Esta técnica también se denomina programación por demanda o bolsa de trabajo, y no sólo es aplicable a problemas que tengan tareas de un mismo tamaño. En problemas con tareas de distintos tamaños es mejor repartir primero aquellas que tengan una mayor carga computacional. Si la tarea más compleja se dejase para el final, las tareas más pequeñas serían realizadas por esclavos que después estarían esperando sin hacer nada hasta que alguno completara la tarea más compleja. También se puede utilizar esta técnica para problemas donde el número de tareas pueda variar durante la ejecución. En algunas aplicaciones, especialmente en algoritmos de búsqueda, la ejecución de una tarea puede generar nuevas tareas, aunque al final el número de tareas se debe de reducir a cero para alcanzar la finalización del programa. En este contexto se puede utilizar una cola para mantener las tareas pendientes. Si todas las tareas son del mismo tamaño y de la misma importancia o prioridad, una cola FIFO (First In First Out) puede ser más que suficiente, en otro caso debe analizarse la estructura más adecuada. Balanceo de carga dinámico distribuido o descentralizado: aquí el maestro únicamente puede repartir una tarea a la vez y después de que haya enviado las tareas iniciales sólo podrá responder a nuevas peticiones de una en una. Por tanto, se pueden producir colisiones si varios esclavos solicitan peticiones de tareas de manera simultánea. La estructura centralizada únicamente será recomendable si no hay muchos esclavos y las tareas son intensivas. 1.6.3. Algoritmos de Balanceo. Hay diferentes algoritmos de balanceo habilitados (Rodríguez, 2008): Round Robin (RR): este algoritmo efectúa una conexión por cada equipo del Cluster de forma cíclica. Por ejemplo, si se tiene 3 máquinas en el Cluster (A, B, C), la primera conexión sería a la máquina A, la segunda a la máquina B, la tercera a la máquina C y así sucesivamente..
(32) CAPÍTULO 1. Cluster de Computadoras 21 Weighted Round Robin (WRR): este algoritmo efectúa conexiones por prioridad utilizando el algoritmo anteriormente descrito (Round Robin). Por ejemplo, si se tienen 3 máquinas en el Cluster (A, B, C) y sus prioridades son (4, 3, 2), las conexiones se efectuarían de la siguiente forma: AABACABBC (A como se ve, hace 4 conexiones, B hace 3 conexiones y C hace 2 conexiones, como se puede observar, la secuencia de conexiones sería esa secuencialmente). Least-Connection (LC): este algoritmo efectúa conexiones a la máquina del Cluster con menos conexiones. Weighted Least-Connection (WLC): este algoritmo efectúa conexiones por prioridad de porcentaje, se le da un número a cada servidor del Cluster con el cual se efectúan operaciones para asignar cuántas conexiones van a poder soportar cada equipo hasta pasar al siguiente de la lista de equipos del Cluster. Es una combinación de las ventajas de LeastConnection y Round Robin. Es uno de los modos más utilizados. Locality Based Least-Connection (LBLC): este algoritmo se queda con la dirección de destino (el cliente) y si el servidor en el que está efectuando operaciones se encuentra demasiado cargado, lo destina a otro servidor con menos carga. Se utiliza en los servidores de Cluster con caché. Locality Based Least-Connection with Replication (LBLCR): coge la dirección destino (del cliente) y mira a ver qué servidor está menos cargado, si todos los servidores están cargados espera hasta que pueda meterlo en algún servidor que deje alguna conexión libre y esté menos cargado. Se utiliza en los servidores de Cluster con caché. Destination-Hashing (DH): asigna a la IP de destino un servidor del Cluster específico haciendo un hash de la conexión. Source-Hashing (SH): asigna a la IP de origen un servidor del Cluster específico haciendo un hash de la conexión. Es necesario señalar que la elección del algoritmo de balanceo de carga depende de cada instalación en particular, por tanto es importante estudiar el balance del Cluster cuando se acaba de implementar..
(33) CAPÍTULO 1. Cluster de Computadoras 22 1.7. Cluster de Alto Rendimiento: Beowulf. Beowulf es una tecnología para agrupar computadores basados en el sistema operativo Linux y así poder formar un supercomputador virtual paralelo. En 1994 bajo el patrocinio del proyecto ESS del Centro de la Excelencia en Ciencias de los Datos y de la Información del Espacio (CESDIS), Thomas Sterling y Don Becker crearon el primer Cluster Beowulf con fines de investigación (León, 2004). 1.7.1. Descripción de un Cluster Beowulf. El Cluster Beowulf posee una arquitectura basada en multi-computadores el cual puede ser utilizado para computación paralela. Este sistema consiste de un nodo maestro y uno o más nodos esclavos conectados a través de una red Ethernet u otra topología de red. Está construido con componentes de hardware comunes en el mercado, similar a cualquier computadora capaz de ejecutar Linux, adaptadores de red y Switches Ethernet. Como no contiene elementos especiales, es totalmente reproducible (Abarca y Mellado, 2008).. Figura 5. Cluster Beowulf.
(34) CAPÍTULO 1. Cluster de Computadoras 23 Una de las diferencias principales entre Beowulf y un Cluster de estaciones de trabajo (CoW, Cluster of Workstations) es el hecho de que Beowulf en su funcionamiento se comporta más como una sola máquina y no como un grupo de estaciones de trabajo. En la mayoría de los casos los nodos esclavos no tienen monitores o teclados y son accedidos solamente vía remota o por terminal serial. El nodo maestro controla el Cluster entero y presta servicios de sistemas de archivos a los nodos esclavos. Es también la consola del Cluster y la conexión hacia el mundo exterior. Las máquinas grandes de Beowulf pueden tener más de un nodo maestro, y otros nodos dedicados a diversas tareas específicas, como por ejemplo, consolas o estaciones de supervisión. En la mayoría de los casos los nodos esclavos de un sistema Beowulf son estaciones simples. Los nodos son configurados y controlados por el nodo maestro, y hacen solamente lo que éste le indique. En una configuración de esclavos sin disco duro, estos incluso no saben su dirección IP hasta que el maestro les dice cuál es. 1.7.2. Características de un Cluster Beowulf. Las principales características de un Cluster Beowulf son las que se detallan a continuación: Elevada potencia de cálculo a cambio de un coste muy reducido en comparación con las grandes supercomputadoras. Está basado en Linux y usa PVM (Paralel Virtual Machine) y librerías de paso de mensajes.. Los cambios en el hardware no hacen que cambie el modelo de programación. 1.7.3. Clasificación por Clase de Clusters Beowulf. Clase I: son sistemas compuestos por máquinas cuyos componentes cumplen con la prueba de certificación "Computer Shopper" lo que significa que sus elementos son de uso común, y pueden ser adquiridos muy fácilmente en cualquier tienda distribuidora. De esta manera, estos Clusters no están diseñados para ningún uso ni requerimientos en particular. Clase II: son sistemas compuestos por máquinas cuyos componentes no pasan la prueba de certificación "Computer Shopper" lo que significa que sus componentes no son de uso común y por tanto no pueden encontrarse con la misma facilidad que los componentes de.
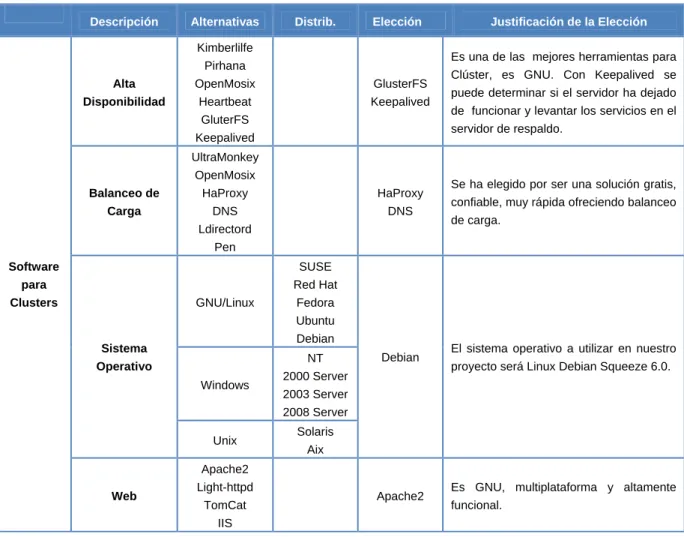
(35) CAPÍTULO 1. Cluster de Computadoras 24 sistemas de la clase anterior. De tal manera, pueden estar diseñados para algún uso o requerimiento en particular. Las máquinas ubicadas en esta categoría pueden presentar un nivel de prestaciones superior a las de la Clase I. Ventajas Clase I: Mayor disponibilidad de software. Reduce la dependencia del fabricante. Soporte de drivers. Basado en estándares (SCSI, Ethernet, etc.) Clase II: Mayor rendimiento. Desventajas Clase I: Rendimiento inferior a Clase II Clase II: Aumento del coste. Dependencia del fabricante. Variedad de drivers. 1.8. Software a utilizar en Clusters. En la Tabla 1 se presenta un resumen de los principales software de código abierto más utilizados hoy en día por la comunidad internacional para realizar un Cluster de Alta Disponibilidad. También se muestran las principales alternativas que existen para lograr balanceo de carga y las diferentes herramientas que permiten brindar un servicio Web. Se debe apreciar que en la Tabla se brinda la elección y justificación del software a utilizar en el trabajo (Eugenin, 2005)..
(36) CAPÍTULO 1. Cluster de Computadoras 25 Tabla 1. Software para Cluster. Descripción. Alternativas. Distrib.. Elección. Kimberlilfe. Justificación de la Elección Es una de las mejores herramientas para. Pirhana Alta. OpenMosix. GlusterFS. Disponibilidad. Heartbeat. Keepalived. GluterFS. Clúster, es GNU. Con Keepalived se puede determinar si el servidor ha dejado de funcionar y levantar los servicios en el servidor de respaldo.. Keepalived UltraMonkey OpenMosix Balanceo de. HaProxy. HaProxy. Carga. DNS. DNS. Ldirectord. Se ha elegido por ser una solución gratis, confiable, muy rápida ofreciendo balanceo de carga.. Pen Software. SUSE. para. Red Hat GNU/Linux. Clusters. Fedora Ubuntu Debian. Sistema. NT. Operativo Windows. Debian. 2000 Server. El sistema operativo a utilizar en nuestro proyecto será Linux Debian Squeeze 6.0.. 2003 Server 2008 Server. Unix. Solaris Aix. Apache2 Web. Light-httpd TomCat. Apache2. Es GNU, multiplataforma y altamente funcional.. IIS. 1.9. Conclusiones del Capítulo. A lo largo de este Capítulo se realiza un estudio de los aspectos fundamentales que presentan los Cluster de computadoras. Principalmente se tratan los siguientes temas: definición de Cluster, principales características, clasificación atendiendo tanto a los factores de diseño como a la aplicabilidad, Cluster Beowulf y algoritmos de balanceo de carga. También se expone la importancia que presentan los Cluster hoy en día y como pueden ser utilizados para aplicaciones que requieran alto desempeño, alta eficiencia o alta disponibilidad. Al final del Capítulo se presenta una tabla resumen la cual contempla los software de Cluster de código abierto más utilizados en la actualidad y la justificación de los escogidos para realizar su implementación en este trabajo..
(37) CAPÍTULO 2. Implementación del servidor Web Clusterizado 26. CAPÍTULO 2. Implementación del servidor Web Clusterizado. En este Capítulo se describe el proceso de implementación de un servidor Web sobre un Cluster en Linux con balanceo de carga. En la implementación se utiliza GlusterFS clienteservidor como software de Cluster y la aplicación Apache 2 para brindar el servicio Web. El balanceo de carga se logra utilizando dos variantes concretas, la primera es a través del DNS y la segunda se realiza con HaProxy. El proceso de implementación descrito en el trabajo parte de considerar que todas las computadoras utilizadas tienen el Sistema Operativo instalado y que las configuraciones de red se encuentran funcionando correctamente. 2.1. Hardware y Sistema Operativo utilizado. Todas las computadoras presentes en la implementación cuentan con un microprocesador Pentium ® CPU 3.00Ghz, 512MB de memoria RAM DDR1, 40GB de disco duro y el sistema operativo Debian GNU/ Linux 6.0.0 _Squeeze_- Official i386. Las direcciones de los repositorios utilizados por el sistema operativo se muestran a continuación: deb http://www.dps.vcl.sld.cu/debian squeeze main contrib non-free deb http://www.dps.vcl.sld.cu/debian-multimedia squeeze main Estas permiten instalar actualizaciones, librerías y paquetes de software necesarios para realizar la implementación. 2.2. Topologías de red utilizadas. Para lograr el balanceo de carga con DNS, en este trabajo, se utiliza la topología de red que se muestra en la Figura 6. Es importante notar que el escenario cuenta con un total de.
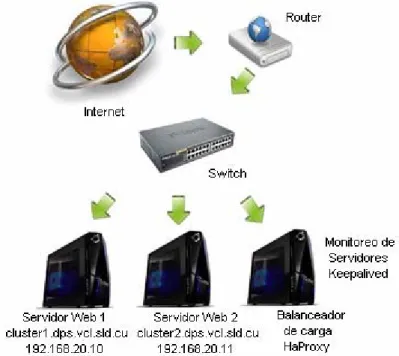
(38) CAPÍTULO 2. Implementación del servidor Web Clusterizado 27 cuatro computadoras conectadas a través de un Switch, dos de ellas se utilizan para instalar el software de Cluster y la aplicación Web, y las otras dos para establecer los balanceadores con DNS en configuración maestro-esclavo. El DNS esclavo tiene como objetivo proporcionar redundancia en la topología de red, así en caso de que falle el balanceador uno este entra en funcionamiento y asume la distribución de las peticiones en el sistema. El balanceo basado en DNS es un proceso en el cual varios servidores pueden compartir la posesión de un recurso y el servidor DNS se encargará de balancear las solicitudes entre ellos. Este balanceo se realiza a través del algoritmo Round Robin el cual funciona respondiendo a las peticiones DNS con una lista de direcciones IP en lugar de una sola (todas ellas deben hospedar el mismo contenido). El orden con el cual las direcciones IP de la lista son retornadas es la base del Round Robin que actúa de forma cíclica.. Figura 6. Topología de red utilizada para el balanceo con DNS En la Figura 7 se muestra la topología de red correspondiente al balanceo de carga con HaProxy, la diferencia que presenta este escenario con el descrito anteriormente es que se utiliza una sola computadora para realizar la distribución de las peticiones en el sistema. En esa computadora se encuentra instalado HaProxy y el software de monitoreo Keepalived..
(39) CAPÍTULO 2. Implementación del servidor Web Clusterizado 28 HAProxy es un software gratuito, con balanceo de carga y que soporta decenas de miles de peticiones. Además de tener un gran rendimiento, permite tener un control de concurrencia, esencial cuando se tienen gran cantidad de peticiones en un sistema (HaProxy, 2010). Keepalived es un software de monitoreo gratuito que se utiliza para censar el funcionamiento de los servidores en una red, este permite detectar cuando un servidor falla y se puede configurar para enviar una notificación por correo electrónico para hacer consciente el administrador del fracaso del servicio (Keepalived, 2010). En este escenario el balanceador de carga HaProxy distribuye todas las solicitudes entrantes entre los dos servidores Apache 2 y al mismo tiempo a través de Keepalived se comprueba la salud de cada uno de ellos. Si uno de los servidores cae (deja de estar en servicio), entonces todas las solicitudes serán automáticamente redirigidas al otro servidor Apache 2.. Figura 7. Topología de red utilizada para el balanceo con HaProxy 2.3. Software GlusterFS y Fuse. GlusterFS constituye un software para Cluster de Alta disponibilidad el cual permite el almacenamiento de archivos distribuidos en un sistema sin un único punto de fallo. Esta herramienta es flexible, de gran alcance, OpenSource y provee replicación sincronizada de archivos sobre la marcha. GlusterFS presenta una versión cliente y otra servidor, con la.
(40) CAPÍTULO 2. Implementación del servidor Web Clusterizado 29 versión servidor se comparte un espacio en una computadora determinada y con la versión cliente se accede sobre la marcha a este espacio a través de FUSE (Gluster, 2008). FUSE, “Filesystem in Userspace” (Sistema de archivos en Espacio de usuario) es un módulo cargable de núcleo para sistemas operativos de computador tipo Unix, que permite a usuarios no privilegiados crear sus propios sistemas de archivos sin necesidad de editar el código del núcleo. Cuando se realiza la ejecución del código del sistema de archivos en el espacio de usuario, el módulo FUSE sólo proporciona un "puente" a la interfaz del núcleo real. 2.3.1. Implementación de GlusterFS y Fuse. El primer paso en el proceso de instalación de GlusterFS y FUSE consiste en establecer la configuración de las computadoras que se van a utilizar para crear el Cluster. A continuación se muestran los nombres y las direcciones IP de cada una de las máquinas. Computadora 1 Hostname: cluster1.dps.vcl.sld.cu IPAddress: 192.168.20.10 Computadora 2 Hostname: cluster2.dps.vcl.sld.cu IPAddress: 192.168.20.11 Una vez establecidas las configuraciones de cada ordenador se procede a instalar ambos software con los comandos siguientes: aptitude install glusterfs-server glusterfs-client y aptitude install fuse-utils. Se debe mencionar que este procedimiento de instalación y las configuraciones que se presentan a lo largo de la sección se realizan exactamente igual en cada una de las computadoras donde se va a montar el Cluster y que en el caso de la instalación del GlusterFS se instala en cada computadora la versión cliente y servidor, esto permite establecer a los dos nodos en una configuración nombrada multi-maestro. A diferencia de las replicaciones maestro-esclavo, las replicaciones multi-maestro permiten la modificación de atributos y objetos en ambas vías facilitando la administración del sistema..
(41) CAPÍTULO 2. Implementación del servidor Web Clusterizado 30 Después que termina el proceso de instalación se deben eliminar los archivos de ejemplos de configuración y crear el directorio de datos para el volumen GlusterFS. Esto se realiza a través de los comandos que se muestran a continuación: > rm –f/etc/glusterfs/*.vol > mkdir /data/export-www Cuando finaliza la operación anterior entonces se crea el archivo de configuración de GlusterFS usando el comando siguiente: > vi /etc/glusterfs/glusterfsd.vol. Figura 8. Contenido del archivo de configuración de GlusterFS.
(42) CAPÍTULO 2. Implementación del servidor Web Clusterizado 31 En la Figura 8 se muestra el contenido del archivo, se debe notar que la línea de código: option directory /data/export-www representa el directorio de replicación, y que las direcciones IP se corresponden con los ordenadores utilizados para implementar el Cluster. Una vez creado el archivo se procede a iniciar el sevicio: > /etc/init.d/glusterfs-server start Ya en esta parte de la implementación se encuentra el servidor de GlusterFS funcionando en ambas computadoras pero falta instalar la versión cliente para permitir que cada ordenador pueda funcionar como maestro y esclavo al mismo tiempo en la comunicación. Para crear el archivo de volumen del cliente y acceder a los GlusterFS Filesystems se utiliza el comando que se muestra a continuación: > vi /etc/glusterfs/glusterfs-www.vol. Figura 9. Contenido del archivo de volumen del cliente.
(43) CAPÍTULO 2. Implementación del servidor Web Clusterizado 32 La Figura 9 presenta el contenido del archivo de volumen del cliente, en la línea de código: option remote-host se colocan las direcciones IP de la computadoras implicadas en la creación del Cluster. 2.3.2. Montando directorio /var/www con GlusterFS. En este punto de la implementación se procede a montar el directorio /var/www con GlusterFS (File System). Se debe mencionar que en este directorio se hospedará la Web. Para poder realizar el montaje primero se debe abrir el archivo fstab a través del comando vi /etc/fstab y agregar la siguiente línea al final: > /etc/glusterfs/glusterfs-www.vol /var/www glusterfs defaults 0 0 Por último se ejecuta el comado: mount -a el cual realiza el proceso de montaje.. Figura 10. Contenido del archivo fstab.
(44) CAPÍTULO 2. Implementación del servidor Web Clusterizado 33 2.4. Implementación de Apache 2. El servidor Apache es un servidor Web HTTP de código abierto para plataformas Unix (GNU/Linux, etc.), Windows, Macintosh y otras, que implementa el protocolo HTTP/1.1 y la noción de sitio virtual. Apache presenta características altamente configurables como bases de datos de autenticación y negociado de contenido, pero fue criticado por la falta de una interfaz gráfica que ayude en su configuración.Apache tiene amplia aceptación en la red desde 1996, es el servidor HTTP más usado. Alcanzó su máxima cuota de mercado en 2005 siendo el servidor empleado en el 70% de los sitios Web en el mundo, sin embargo ha sufrido un descenso en su cuota de mercado en los últimos años.La mayoría de las vulnerabilidades de la seguridad descubiertas tan sólo pueden ser aprovechadas por usuarios locales y no remotamente. Sin embargo, algunas se pueden accionar a distancia en ciertas situaciones. El proceso de instalación de Apache se realiza a través del comado que se muestra a continuación: > aptitude install apache2 2.5. Implementación DNS. Para implementar el DNS en este trabajo se escoge el software BIND 9. El desarrollo de BIND 9 fue realizado con el auspicio conjunto del área comercial y militar. La mayoría de las funcionalidades de este software fueron impulsadas por proveedores de UNIX quienes querían asegurar que BIND se mantuviera competente con la oferta de Microsoft en el sector de soluciones DNS, y las funcionalidades relativas a DNSSEC fueron impulsadas por el ejército de Estados Unidos quien sintió que la seguridad en DNS era importante. BIND (Berkeley Internet Name Domain, anteriormente : Berkeley Internet Name Daemon) es el servidor de DNS más comúnmente usado en Internet, especialmente en sistemas Unix, en los cuales es un Estándar de facto. Para instalar BIND 9 se utiliza la línea de código siguiente:.
(45) CAPÍTULO 2. Implementación del servidor Web Clusterizado 34 > aptitude install bind9 bind9-host bind9utils 2.5.1. Configurando zonas en el DNS maestro. El proceso de configuración de zonas del BIND 9 se comienza editando el archivo “named.conf.local”, aquí se definen parámetros como: nombre de zona, tipo de zona, ruta del archivo donde se encuentran los registros de zonas, envío de notificaciones, transferencia de zonas, etc. En la Figura 11 se muestra la configuración establecida en este trabajo.. Figura 11. Edición del archivo “named.conf.local”.
(46) CAPÍTULO 2. Implementación del servidor Web Clusterizado 35 Después se definen opciones como: directorio, puerto y reenvío en el fichero “named.conf.options”.. Figura 12. Configuración del fichero “named.conf.options” Por último se editan los ficheros de registro de zonas directo e inverso. En ambas zonas se agrega el nombre cluster y se le asignan dos direcciones IP (192.168.20.10 y 192.168.20.11). Esta asignación constituye la esencia del algoritmo de balanceo de carga Round Robin, el cual ante múltiples peticiones devuelve las IP de forma cíclica.. Figura 13. Configuración de los registros zona directa.
(47) CAPÍTULO 2. Implementación del servidor Web Clusterizado 36. Figura 14. Configuración del fichero de registros de zona inverso 2.5.2. Configurando zonas en el DNS esclavo. El mecanismo de configuración de zonas del BIND 9 esclavo solamente se diferencia del procedimiento del maestro explicado anteriormente en que el tipo de zona se declara como esclava indicándosele la IP del BIND 9 maestro.. Figura 15. Configuración de zonas en el DNS esclavo.
(48) CAPÍTULO 2. Implementación del servidor Web Clusterizado 37 2.6. Implementación de HaProxy y Keepalived. El primer paso antes de realizar la instalación de HaProxy y Keepalived consiste en configurar los registros zonas directa e inversa del BIND 9 como se muestra en las Figuras siguientes:. Figura 16. Configuración de los registros zona directa. Figura 17. Configuración de los registros zona inversa.
(49) CAPÍTULO 2. Implementación del servidor Web Clusterizado 38 La instalación del HaProxy se realiza a través del siguiente comando: aptitude install haproxy. Una vez el software instalado se edita el fichero haproxy.cfg que se encuentra en la siguiente dirección: /etc/haproxy/haproxy.cfg. En este fichero se colocan los nombres y las direcciones IP de las dos computadoras donde se encuentran instalados los servidores Apache y además se adiciona la dirección IP de la máquina en la se instaló el HaProxy. La Figura 18 muestra un segmento que representa como queda el fichero después de la edición..
(50) CAPÍTULO 2. Implementación del servidor Web Clusterizado 39 Figura 18. Contenido del fichero haproxy.cfg Es preciso notar que en la línea "listen LoadBalancer 192.168.20.15" se coloca la IP del lugar donde está instalado HaProxy. Y en la línea "stats auth root: 123456" se escribe un usuario y contraseña para poder entrar al gestor de reportes Web que presenta el software. El último paso en la configuración de esta herramienta consiste en editar el archivo haproxy que se encuentra en la dirección /etc/default/haproxy y colocar el valor ENABLED en 1 como aparece en la figura que se presenta a continuación:. Figura 19. Edición del fichero haproxy La instalación de Keepalived se realiza de forma similar, primero se ejecuta aptitude install keepalived, después se agrega la línea net.ipv4.ip_nonlocal_bind=1 al final del fichero sysctl.conf que se encuentra en la siguiente dirección nano /etc/sysctl.conf, acto seguido se ejecuta el comando sysctl -p y por último se modifica el fichero keepalived.conf con la siguiente configuración:. Figura 20. Contenido del fichero keepalived.conf.
(51) CAPÍTULO 2. Implementación del servidor Web Clusterizado 40 Después de todos estos pasos ya se encuentran el HaProxy y el Keepalived instalados y configurados entonces solo falta iniciar los servicios a través de los comandos que se muestran a continuación: > /etc/init.d/keepalived start > /etc/init.d/haproxy start 2.7. Conclusiones del Capítulo. En este Capítulo se describe el proceso de implementación de un servidor Web Clusterizado el cual presenta balanceo de carga. El contenido del Capítulo recoge tanto el hardware utilizado como todos los pasos que se deben seguir para lograr la instalación y la configuración correcta de cada uno de los software. El balanceo se logra por dos vías diferentes, la primera es a través del DNS y la segunda con HaProxy. Cada variante de balanceo lleva implícita una topología de red específica. La configuración de los ficheros de registros zona utilizados en cada variante es de vital importancia porque garantizan un funcionamiento adecuado del sistema..
(52) CAPÍTULO 3. Resultados de los Experimentos 41. CAPÍTULO 3. Resultados de los Experimentos. En este Capítulo se realizan una serie de pruebas al servidor Web Clusterizado y se analizan los resultados obtenidos. Las pruebas consideran los dos mecanismos de balanceo de carga implementados y tienen como objetivo comprobar el correcto funcionamiento del sistema. Para determinar si el servidor Web Clusterizado balancea la carga correctamente se utiliza una herramienta de evaluación de rendimiento de servidores Web nombrada Siege la cual es código abierto y permite simular una alta carga de peticiones. La recolección de las estadísticas resultantes de las pruebas realizadas utilizando el balanceo de carga con DNS se hace a través de un software llamado Webalyzer el cual es capaz de mostrar en forma de tablas y gráficos parámetros relacionados con el uso del los servidores. Las estadísticas del balanceo con HaProxy se recolectan a través del gestor Web que presenta el propio software. Las pruebas realizadas en el trabajo se distribuyen de la siguiente manera: Pruebas a BIND 9: Realizar varias peticiones de servicio Desconectar el DNS Maestro Pruebas a HaProxy: Realizar varias peticiones de servicio Desconectar Servidor Web 2 Pruebas a GlusterFS: Proceso de replicación de archivos.
(53) CAPÍTULO 3. Resultados de los Experimentos 42 3.1. Pruebas a BIND 9. Realizar varias peticiones de servicio En esta prueba se utiliza el software Siege para establecer 300 conexiones paralelas con 50 repeticiones a la dirección http://cluster.dps.vcl.sld.cu/index.php. El comando que permite esta operación se ejecutó dos veces, en la primera ocasión el BIND 9 le asigna la carga al servidor Web 1 (cluster1) y en la segunda al servidor Web 2 (cluster2). En la Figura 21 se muestran los resultados generados por Siege y la estructura del comando utilizado para generar las conexiones.. Figura 21. Resultados generados por Siege En la Figura 22 se muestran las estadísticas recolectadas por el software Webalyzer en el servidor Web 1. Se observa que se producen aproximadamente 15000 accesos lo cual se corresponde con el total de transacciones que se producen en el sistema..
Figure




+7




Outline
Documento similar
Es importante mencionar, que en los últimos 5 años, China ha venido mostrando un gran avance en la industria textil y de la confección, ingresando en mercados como Europa,
Un método de estudio aparte de ser una herramienta muy útil al momento de estudiar también nos ayuda a agilizar nuestra mente y tener una buena memoria para futuro?. Palabras
Entre nosotros anda un escritor de cosas de filología, paisano de Costa, que no deja de tener ingenio y garbo; pero cuyas obras tienen de todo menos de ciencia, y aun
o Si dispone en su establecimiento de alguna silla de ruedas Jazz S50 o 708D cuyo nº de serie figura en el anexo 1 de esta nota informativa, consulte la nota de aviso de la
En cada antecedente debe considerarse como mínimo: Autor, Nombre de la Investigación, año de la investigación, objetivo, metodología de la investigación,
El desarrollo de una conciencia cáritas es esencial para identificar cuando un momento de cuidado se convierte en transpersonal, es necesaria para identificar
El quincenario de los frailes de Filipinas, condena para el Archipiélago los propósitos de nivelación jurídica que para todo territorio español, peninsular o ultramarino, se
Aunque en relación con su volumen de capital al mo- mento de su fundación (1 O millones de pesos) ocupara el segundo lugar entre las empresas manufactureras (el pri-
