Marco de trabajo para estandarizar campos tipo cadena
65
0
0
Texto completo
(2) Hago constar que el presente trabajo fue realizado en la Universidad Central Marta Abreu de Las Villas como parte de la culminación de los estudios de la especialidad de Ciencias de la Computación, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad.. ____________________________ Firma de los autores. Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. _________________________. __________________________. Firma de los tutores. Firma del jefe del Seminario.
(3) PENSAMIENTO. "Eli, Eli, ¿lama sabactani?" Mateo 27:46.
(4) DEDICATORIA. A mi hijo Kenier Iván, lo mejor que me ha pasado en la vida. A mi esposa Ivonne Chavez, por aguantarme todas mis malacrianzas. A mis padres biológicos: Matilde, Elías y Ángel, por la educación que me han brindado todos estos años. A mis otros padres: Maria Elena y Luis Felipe, por la gran ayuda que me han brindado y acogerme como su hijo pródigo. A mi hermano: Ángel. A mis amigos(hermanos), Anyer Castillo, Mario Pupo y Asley Arbolaes, siempre estuvieron cuando los necesité..
(5) AGRADECIMIENTOS. Les agradezco de todo corazón a todas las personas que colaboraron de forma científica, material y emocional a realizar este trabajo. A mis padres, a mi esposa, a mi hijo. A todos mis amigos que me han ayudado, los nuevos, los viejos (los voy a extrañar). A Niemelys Bingas Manso, gracias por tu ayuda. A mis tutores Dr. Ramiro Pérez y Msc. Beatriz López por la asesoría prestada..
(6) RESUMEN. En los Sistemas de bases de datos frecuentemente se introducen errores tipográficos en los datos, lo cual en principio puede traer graves consecuencias en las respuestas a solicitudes que se hagan sobre la información; pero esto puede tener aún mayor incidencia si las bases de datos de los sistemas operacionales son fuentes de Almacenes de datos, pues la presencia de estos valores erróneos puede influir negativamente en el proceso de toma de decisiones. Estos errores y otros, producto de malas transcripciones o al entrar los datos hacen que la misma información sea representada de formas diferentes. En la limpieza de datos el paso de estandarizar la información conduce a la eliminación de estos problemas y constituye un importante paso en el proceso de limpieza. En este trabajo se expone un marco de trabajo para realizar la estandarización, se describen las fases de análisis y diseño de la herramienta que implementa este marco de trabajo, así como los algoritmos utilizados para llevar a cabo este proceso..
(7) ABSTRACT. In Database Systems often are introduced typographical errors in the data, which in principle can have grave consequences on responses to requests that are made on information, but this can have even greater impact if the databases of operational systems are sources of datawarehouses, since the presence of these erroneous values may adversely affect the decision-making process. These errors and others, the product of bad transcripts or to enter data make the same information is represented in different ways. In data cleaning the step to standardize the information leads to the elimination of these problems and it is an important step in the cleaning process. This paper presents a framework for conducting the standardization, describes the stages of analysis and design tool that implements this framework, as well as the algorithms used to carry out this process..
(8) ÍNDICE INTRODUCCIÓN ............................................................................................................. 1 CAPÍTULO I La estandarización en el proceso de Limpieza de Datos. ........................... 4 1.1 Estandarización. Definiciones................................................................................... 4 1.2 Estandarización en la Limpieza de Datos. ................................................................ 6 1.3 Marco de trabajo. ..................................................................................................... 7 1.3.1 Elegir tabla y campo .......................................................................................... 7 1.3.2 Sustitución previa. ……………………………………………………………. 8 1.3.3 Clusterización…………………………………………………………………..9 1.3.3.1 K-Medoides………………………………………………………………10 1.3.3.2 Distancia de Edición de Levenshtein…………………………………….13 1.3.3.3 Extensión de la Distancia de Levenshtein………………………………..14 1.3.3.4 Proceso de clusterización. Ejemplo……………………………………....16 1.3.4 Sustitución post-cluster………………………………………………………21 CAPÍTULO II Análisis y diseño de la herramienta “Marco de Trabajo para estandarizar campos tipo cadenas”........................................................................................................ 23 2.1 Modelado del sistema……………………………………………………………..23 2.1.1 Diagrama de casos de uso…………………………………………………….24 2.1.2 Tabla de eventos……………………………………………………………...26 2.1.3 Diagrama de Actividad……………………………………………………….30 2.1.4 Diagramas de clases…………………………………………………………..33 2.2 Características computacionales de la herramienta “Marco de trabajo para la estandarización de datos tipo cadenas”…………………………………………….46 CAPÍTULO III. MANUAL DE USUARIO. ................................................................... 47 3.1. Requerimientos del software................................................................................. 47 3.2. Descripción de la herramienta y sus funcionalidades. .......................................... 47 3.3. Ambiente de trabajo.............................................................................................. 47 3.3.1 Conexión con la Base de Datos. Seleccionar tabla y campo………………….47 3.3.2 Sustitución previa……………………………………………………………..50 3.3.3 Edición de las categorías y las sustituciones………………………………….51 3.3.4 Clusterización y sustitución post-cluster……………………………………..52 3.4. Áreas de aplicación ............................................................................................... 54 CONCLUSIONES ............................................................................................................ 55 RECOMENDACIONES................................................................................................... 56 REFERENCIAS BIBLIOGRÁFICAS.............................................................................. 57.
(9) INTRODUCCIÓN. La limpieza de datos es un proceso que consiste en aplicar una serie de tratamientos a los datos con el objetivo de eliminar los errores para obtener datos más fiables, que nos aporten información más consistente, y que nos faciliten su utilización en procesos posteriores. El proceso de limpieza de datos tiene varias fases, etapas. Según Kimball este proceso consta de 6 pasos: División (elementizing), Estandarización (standardizing), Verificación (verifying),. Comparación. (matching),. Retroalimentación. (house. holding). y. Documentación (documenting) (Kimball R., 1996). Estandarizar consiste en establecer una forma única de poner la información en algunos elementos en que esta puede aparecer de distintas formas. En los sistemas de información en muchas ocasiones se realizan esfuerzos por lograr datos estandarizados, por ejemplo cuando se utilizan máscaras para la entrada de datos o cuando se utilizan componentes de las interfaces visuales que restringen la información a entrar a determinados elementos. Pero hay muchos casos en que la entrada de dato se deja “abierta” pues la naturaleza del dato no permite hacer cosas como las anteriores, o porque no hay posibilidades de máscaras o porque hay muchas posibilidades a entrar y hace que las listas, cuadros combinados, etc. sean inoperantes. Algunos ejemplos pueden ser cuando se capta el nombre de entidades (tanto de personas, como de organizaciones, organismos, etc.). En todos estos casos la entrada del dato depende mucho de la persona que realiza el proceso de captura de la información y aún cuando la copie de un documento escrito puede (porque el sistema se lo permite) hacer la captura de acuerdo a sus propios criterios. Por ejemplo en el documento puede aparece “González” y escribirse “Glez” como abreviatura de este apellido. En estos casos el proceso de estandarización es sumamente importante porque permite que las búsquedas que se realicen sean más sencillas de hacer, pues no hay que tener en 1.
(10) cuenta la posibilidad de una gama amplia de elementos distintos. Además si el proceso de limpieza se realiza para la carga de un almacén de datos que ayudará luego en la toma de decisiones, entonces es aún más necesario pues las estadísticas, los reportes etc, pueden tornarse excesivamente complicados y separar elementos que realmente son los mismos. Problema: La no existencia de un software que permita la ejecución del marco de trabajo para la estandarización de campos tipo cadena. Este proyecto tiene como objetivo general: Realizar el análisis, diseño e implementación de un software que permita la estandarización de campos tipo cadena en el proceso de limpieza de datos. Y como objetivos específicos: -. Comprender los diferentes pasos del marco de trabajo definido para la estandarización.. -. Algoritmizar los diferentes pasos del marco de trabajo.. -. Realizar el análisis y diseño el software.. Preguntas de Investigación. ¿Será posible algoritmizar los diferentes pasos del proceso de estandarización? ¿Qué algoritmo de clusterización será conveniente usar en el marco de trabajo? Justificación de la investigación. La estandarización es un proceso importante en el proceso de la limpieza de datos, pues con este proceso se garantiza que la información obtenida sea fiable, que la información que aporte sea consistente y así facilitar su utilización para procesos posteriores. El trabajo se ha estructurado en tres capítulos:. 2.
(11) Capítulo 1. La estandarización en el proceso de limpieza de datos. Se presentan las características generales del problema, los pasos de la limpieza de datos, específicamente la estandarización y se explican los diferentes pasos del marco de trabajo propuesto, así como los algoritmos utilizados para llevar a cabo el proceso de estandarización. Capítulo 2. Análisis y diseño de la herramienta “Marco de trabajo para la estandarización de campos tipo cadena”. Se presenta el diseño y las características generales de la implementación del software. Capítulo 3. Manual de usuario. Se muestra información de cómo debe ser usado el software.. 3.
(12) CAPÍTULO I LA ESTANDARIZACIÓN EN EL PROCESO DE LIMPIEZA DE DATOS.. 1.1 Estandarización. Definiciones. La normalización o estandarización es la redacción y aprobación de normas que se establecen para garantizar el acoplamiento de elementos construidos independientemente, así como garantizar el repuesto en caso de ser necesario, garantizar la calidad de los elementos fabricados y la seguridad de funcionamiento. (Wikipedia, 2008) La normalización es el proceso de elaboración, aplicación y mejora de las normas que se aplican a distintas actividades científicas, industriales o económicas con el fin de ordenarlas y mejorarlas. Según el diccionario de la Real Academia Española (Diccionario, 2001), normalizar: 1. tr. Regularizar o poner en orden lo que no lo estaba. 2. tr. Hacer que algo se estabilice en la normalidad. Normalizar políticamente. 3. tr. Tipificar (ajustar a un tipo o norma). La asociación estadounidense para pruebas de materiales (ASTM), define la normalización como el proceso de formular y aplicar reglas para una aproximación ordenada a una actividad específica para el beneficio y con la cooperación de todos los involucrados.. 4.
(13) Según la ISO (International Organization for Standarization) la normalización es la actividad que tiene por objeto establecer, ante problemas reales o potenciales, disposiciones destinadas a usos comunes y repetidos, con el fin de obtener un nivel de ordenamiento óptimo en un contexto dado, que puede ser tecnológico, político o económico. La normalización persigue fundamentalmente tres objetivos: •. Simplificación: Se trata de reducir los modelos quedándose únicamente con los más necesarios.. •. Unificación: Para permitir la intercambiabilidad a nivel internacional.. •. Especificación: Se persigue evitar errores de identificación creando un lenguaje claro y preciso. En el mundo de los datos, un estándar es un modelo al cual todos los objetos de la misma clase deben responder. Cuando se habla del proceso de estandarización se habla del proceso con el cual se logra que los datos de un determinado atributo estén conformados de acuerdo a un formato o estándar preestablecido. Este estándar debe ser definido por la organización responsable del dato. Dicha organización debe tener autoridad para lograr que dichos formatos sean utilizados por todos los elementos de la entidad. (Loshin D., 2006) En el momento de confeccionar los sistemas de información de la organización deben asumirse estos formatos y en la medida de lo posible los analistas de sistemas deben velar porque esto se haga. Se puede lograr un alto uso de estándares desde la propia creación de la base de datos, si se incluyen reglas de integridad en los diferentes atributos que permitan solo los valores que cumplan con los estándares establecidos. Por ejemplo si al definir el atributo “sexo” se utiliza la restricción de solo permitir los caracteres “M” o “F” se está logrando que no pueda aparecer otra letra en dicho atributo; o si al definir el atributo “estado civil” se restringe los valores a “soltero”, “casado”, “viudo” no se permitiría crear o considerar otros estados civiles no permitidos por la organización. 5.
(14) El otro momento importante en la estandarización de los datos es el momento de diseñar e implementar la entrada de datos. Los lenguajes de programación hoy en día dan suficientes posibilidades para lograr datos altamente estandarizados. Por ejemplo el uso de máscara en la entrada de datos está presente en las componentes visuales de la mayoría de los lenguajes de programación. Incluso algunos gestores de datos permiten el uso de máscaras en la definición de los atributos de una tabla (elemento no presente en el SQL, pero incorporado en la práctica). Además del uso de la máscara hay otras componentes que permiten la estandarización de los datos, entre otras por ejemplo el uso de listas, cuadros combinados, cajas de chequeo, etc. Todos estos controles permiten que se brinde a la persona que introduce datos la posibilidad de escoger de entre algunos valores (los permitidos por la organización) y “fabricar” nuevos. Esto hace que los datos de los atributos asociados a estos controles cumplan el estándar definido. Además de controles propiamente dichos hay otras técnicas que también pueden ayudar al proceso de estandarización, como lo son la notificación en la entrada de datos de alguna manera de lo que se desea. Por ejemplo si se captura el peso de una persona, debe indicarse en el propio formulario de captura la unidad de medida en que se desea capturar el peso. Esta es una fuente de conflictos importante en los datos numéricos. O por ejemplo, si se desea capturar una fecha debe quedar claro la forma de introducirla (día, mes, año, o alguna otra variante). 1.2 Estandarización en la Limpieza de Datos. A pesar de los esfuerzos que se puedan hacer en las etapas de análisis y diseño de los sistemas informativos de una organización, es muy difícil lograr la estandarización de los datos, en muchos casos por la ausencia de estándares para cada uno de los datos, por la no definición de los mismos, o porque la propia naturaleza de los datos impiden crearlos. Cuando se tiene una ausencia de estándares la captura de datos se hace de una forma “libre”, habitualmente se presenta un control que permite escribir prácticamente cualquier cosa. (López Porrero B. and Pérez Vázquez R., 2007). 6.
(15) El problema se agrava cuando la organización cuenta con sistemas de información que se implementaron sin tener en cuenta los estándares establecidos y es necesario utilizar la información que contienen en la toma de decisiones. Por estas razones aparece como una etapa en el proceso de limpieza de datos la estandarización, de manera de lograr uniformidad en los datos. 1.3 Marco de trabajo. La estandarización de datos es un proceso complejo, y se han tenido en cuenta en el presente trabajo solo los datos de tipo texto. El marco de trabajo que se propone cuenta de las siguientes etapas (López Porrero B. and Pérez Vázquez R., 2007): 1. Elegir tabla y campo. 2. Sustitución previa. 3. Clusterización. 4. Sustitución post-cluster. Se explican a continuación cada una de las etapas. 1.3.1. Elegir tabla y campo.. Es un paso trivial, es necesario encontrar el atributo que se quiere estandarizar. Para esto se le brinda la posibilidad al usuario de escoger el origen de la base de datos, la tabla, y de ésta, el campo al cual se le quiere realizar el proceso de estandarización. Después de tener fijado el objetivo, hay que comprobar la naturaleza tipo texto del mismo. Además es necesario determinar que el atributo no es una dirección, pues este tipo de atributo tendrá un tratamiento particular que no se tratará en este trabajo.. 7.
(16) 1.3.2. Sustitución previa.. Se ha comprobado que uno de los problemas fundamentales que presentan los campos textuales que pueden ser entrados de forma “libre” en un sistema informativo es la utilización de algún tipo de abreviatura, apócopes, que puede incluso no ser los mismos a lo largo de los datos. Por ejemplo, para “resolución 73” se encuentran “res 73”, “resol 73”, “resol 73”, “resol #73”, etc. Otro ejemplo pudieran ser los apellidos, para “Fernández” es común encontrar “fdez” “fern”, “fndez”, etc. Se propone que en este paso se sustituyan este tipo de abreviaturas, apócopes, etc. Estas sustituciones serán almacenadas en un documento XML, que tenga dos etiquetas fundamentales: “qué cambiar”, “por quién cambiar”. Este documento contendrá inicialmente algunos cambios comunes, establecidos por la experiencia de los analistas, y puede ser enriquecido a lo largo del tiempo. Además, es importante que en determinados casos se pueda decidir no utilizar alguno de los cambios propuestos en el documento. La utilización de un documento XML viene dado por el hecho de no depender de un sistema operativo específico, ni de un gestor de datos específicos de tal manera que dicho documento sean transportable fácilmente.. 8.
(17) Este documento XML sigue el siguiente esquema: <?xml version="1.0" encoding="utf-8"?> <XML> <sutitucion> < quien>fdez</quien> < pque>fernandez</pque> </sutitucion> <sutitucion> < quien>glez</quien> < pque>gonzalez</pque> </sutitucion> </XML> 1.3.3. Clusterización.. Para realizar la clusterización del atributo se utiliza el método de los k-medoides, introducido por Kaufman y Rousseeuw (Kaufman L. and Rousseeuw P. J., 1990), en el cual la distancia de dos elementos se determina utilizando una extensión de la distancia de edición de Levenshtein (ver subepígrafe 1.3.3.3), de tal manera que se tenga en cuenta la distancia en el teclado de los diferentes caracteres. El conjunto de datos sería particionado en subconjuntos de artículos con valores similares en el atributo texto. Esto haría que el examen de los datos para determinar su posible unificación no habría que hacerlo sobre el total de los datos, sino sobre aquellos que pertenecen a un cluster determinado, aliviando el trabajo de la limpieza. 9.
(18) 1.3.3.1. K-Medoides.. El algoritmo que usamos en PAM (Partitioning Around Medoids) consta de dos fases. En la primera fase, llamada BUILD, es obtenida una clusterización inicial por la selección sucesiva de k objetos representativos. El primer objeto es aquel cuya suma de su distancia al resto de los objetos es tan pequeña como sea posible. Este objeto se ubica como centro del conjunto de objetos. Subsecuentemente, en cada paso otros objetos son seleccionados. La selección de este objeto como centro es la que permite hacer decrecer la función objetivo tanto como sea posible. Los pasos que se muestran a continuación ilustran como encontrar este objeto: 1. Considerar un objeto ‘i’ el cual no ha sido seleccionado aún. 2. Considerar un objeto ‘j’ no seleccionado y calcular la diferencia entre su distancia Dj con el objeto más similar seleccionado previamente, y la distancia d(j,i) con el objeto ‘i’. 3. Si la diferencia es positiva, el objeto ‘j’ puede contribuir a la decisión para seleccionar el objeto ‘i’. Por lo tanto calcular:. C ji = max( D j − d ( j , i ),0) 4. Calcular la ganancia total obtenida por seleccionar el objeto ‘i’:. ∑C. ji. j. 5. Elegir un objeto ‘i’ no seleccionado aún tal que. maximice ∑ C ji i. j. 10.
(19) Este proceso continúa mientras hayan sido encontrados ‘k’ objetos. En la segunda fase del algoritmo, llamado SWAP, se intenta mejorar el conjunto de objetos representativos y, por tanto también mejorar el conjunto de clusters obtenido. Esto se hace considerando todos los pares de objetos (i,h), para los que el objeto ‘i’ ha sido seleccionado y el objeto ‘h’ no. Se determina qué efecto se obtiene sobre el valor de la agrupación, cuando un intercambio se lleva a cabo, es decir, cuando el objeto ‘i’ ya no es seleccionado como un representante, sino el objeto ‘h’. El valor de una agrupación representada por ‘k’ objetos representativos se define como la suma de diferencias entre cada objeto y el objeto representativo más similar. Para calcular el efecto de un intercambio entre ‘i’ y ‘h’ en el valor de un cluster, a continuación, los pasos 1 y 2 muestran como se lleva a cabo este cálculo: 1. Considerar un objeto ‘j’ no seleccionado y calcular su contribución. C jih. al. intercambio. a. Si ‘j’ es más distante de ‘i’ y ‘h’ que de la unidad de otros objetos representativos, hacer. C jih = 0. b. Si ‘j’ no es aún más lejos de ‘i’ que de otro objeto representativo seleccionado. ( d ( j , i ) = D j ) , deben ser consideradas dos situaciones:. b1. ‘j’ es más cercano a ‘h’ que al segundo objeto representativo mas cercano. d ( j , h) < E j. donde E j es. la disimilitud entre ‘j’ y el segundo objeto similar más representativo. En este caso la contribución del objeto ‘j’ al intercambio entre los objetos ‘i’ y ‘h’ es:. C jih = d ( j , h) − d ( j , i ). 11.
(20) b2. ‘j’ es al menos tan distante de ‘h’ como cercano del segundo objeto más representativo. d ( j , h) ≥ E j. en este. caso la contribución del objeto ‘j’ a el intercambio es. C jih = E j − D j . Se debe observar que en la situación b1 la contribución. Cjih. puede tomar. valores positivos o negativos dependiendo de la posición relativa de los objetos ‘j’, ‘h’, e ‘i’. Solo si el objeto ‘j’ está más cercano a ‘i’ que a ‘h’ la contribución es positiva, esto indica que el intercambio no es favorable desde el punto de vista del objeto ‘j’. En la otra vía, en la situación b2, la contribución es siempre positiva, por esto, no es ventajoso remplazar ‘i’ por un objeto ‘h’ más lejano de ‘j’ que del segundo objeto representativo más cercano. c. ’j’ es más distante del objeto ‘i’ que de al menos uno de los otros objetos representativos, pero más cercano a ‘h’ que a cualquier objeto representativo. En este caso la contribución de ‘j’ al intercambio es:. C jih = d ( j , h) − D j 2. Calcular el resultado total de un intercambio por adición de contribuciones. Cjih:. Tih = ∑ C jih j. En los próximos pasos se decide si se lleva a cabo un intercambio: 3. Seleccionar el par (i,h) que:. minimiceTih i,h. 12.
(21) 4. Si el mínimo de. Tih es negativo, el intercambio se lleva a cabo y el algoritmo. regresa al paso 1. Si el mínimo de. Tih. es positivo o 0(cero), el valor del objetivo. no es disminuido por el intercambio y el algoritmo se detiene. 1.3.3.2 Distancia de Edición de Levenshtein. En la literatura es posible encontrar muchas formas de calcular la distancia de edición. El científico ruso Levenshtein (Levenshtein, 1966) fue el primero que definió la distancia de edición en los siguientes términos: “la distancia entre dos cadenas es la cantidad de inserciones, eliminaciones y reemplazos que son necesarios para transformar una cadena en la otra”. Luego se extendió este concepto y a cada una de estas operaciones se le dio un costo en particular (Ukkonen E., 1983), se considera que para la distancia de Levenshtein las tres operaciones tienen un costo unitario. También se amplió el concepto introduciendo una nueva operación que es el intercambio de dos caracteres (la permutación), este intercambio puede ser de caracteres adyacentes o no. En este trabajo se expone una extensión de la distancia de edición en la cual el costo de cada transformación no es la misma. Una distancia de edición es una correspondencia entre un par de cadenas s y t y un número real r. Un valor pequeño de r indica una mayor similitud entre ambas cadenas. La distancia de Levenshtein, en particular, asigna un costo unitario a todas las operaciones de edición (inserción, eliminación, reemplazo). Por ejemplo: 1. s= Alfredo y t=Alfreto, entonces d(s,t)=1 porque es necesario reemplazar la “d” por la “t” para transformar Alfredo en Alfreto. 2. s=Amor y t = Hamor entonces d(s,t)=1 porque es necesario insertar el carácter “H” en s para transformarla en t. 3. s=Rogelio y t=Rojelios, entonces d(s,t)=2 porque es necesario cambiar el carácter “g” por el “j” e insertar el carácter “s” para transformar la cadena s en t.. 13.
(22) En esta distancia cada transformación tiene costo unitario. Se denominarán a los costos de las operaciones CD (costo de la operación de eliminación), CI (costo de la operación de inserción), CS (costo de la operación de sustitución). 1.3.3.3. Extensión de la Distancia de Levenshtein.. Una de las razones de la existencia de datos “sucios” en una base de datos es la escritura incorrecta en el momento de entrar los datos. Esta escritura incorrecta se puede producir por muchas razones: . errores ortográficos (en español, por ejemplo se cambia frecuentemente la “b” por “v”, “s” por “c” o viceversa, se omite la letra “h”, etc).. . errores cuando son tecleados los datos, por oprimir teclas incorrectamente (por ejemplo si es necesario teclear la letra “a” puede ser oprimida la letra “q” porque ambas están cercanas en el teclado.. . errores de sonido (alguien dice “maría” y la persona que está entrando lo datos oye “manía”, también es frecuente que por sonido se omitan sonidos como “s” y “r” al final de las palabras.. La idea fundamental de la extensión que se propone es en este sentido: el costo de todos los reemplazos, inserciones y eliminaciones no son iguales. Esta idea aparece en la literatura (Xiaomin W., 2003), (Ukkonen E., 1983) pero no de la forma en que se abordan en el presente trabajo. En una primera propuesta solamente se trabajará con la operación de reemplazo y es hecha en la siguiente dirección: Sea G un grafo no dirigido G=(V, A, Γ) V es el conjunto de nodos, A es el conjunto de aristas y Γ una función que a asigna a un conjunto formado por dos vértices una arista dada.. 14.
(23) Cada nodo en el grafo es una tecla del teclado y existe una arista entre dos nodos si ellos son vecinos en el teclado. La siguiente figura muestra una parte de dicho grafo:. que representa la parte izquierda de un teclado “qwerty”. Entonces el costo de una operación de sustitución CS es definida como: la distancia del camino más corto entre los nodos, por lo tanto en el caso de caracteres que son adyacentes el costo de la operación es uno, en otros caso el costo es mayor que uno. Esta proposición hace que dos cadenas estén más cercas si la sustitución ocurre entre caracteres cercanos en el teclado. Es importante en la utilización de la distancia así definida el peso que se dé a las operaciones de inserción y eliminación. Si ambas mantienen costo (CD = CI = 1), entonces cuando se quiera sustituir un carácter por otro que no esté adyacente será mejor (menos costosa) hacer una eliminación y una inserción. Por ejemplo: Sean CD = CI = 1 y el costo de la sustitución como se ha dicho anteriormente. Para a) s=Pascual t=Pascyal. 15.
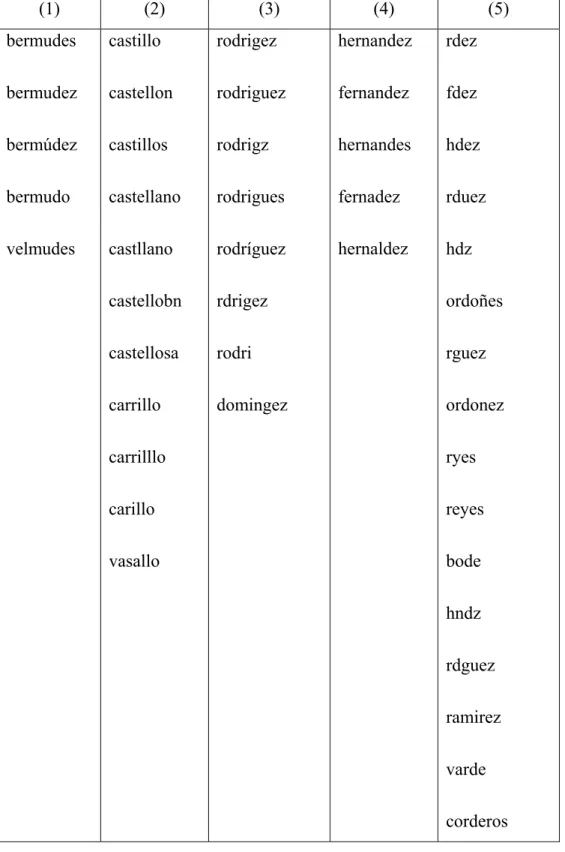
(24) d(s,t)=1 porque el cambio de “u” por “y” tiene peso 1, son teclas vecinas. b) s=Pascual t=Pascaal d(s,t)=2, porque el cambio de “u” por “a” tiene costo 6 (distancia entre las teclas), pero como se busca el mínimo en lugar de una sustitución se haría la eliminación de un carácter (“u”) y la inserción de otro (“a”), lo que hace que la distancia sea 2. Esta situación se puede variar si se toman otros pesos para las operaciones de inserción y eliminación, por ejemplo si se toman de tal forma que la suma de ellos sea menor que la mayor distancia del teclado, siempre se efectuará la operación de sustitución en lugar de una eliminación y una inserción. c) CD = CI = 5 s=Pascual t=Pascyal d(s,t) = 6 que es el costo del cambio de “u” por “y”, es menos costoso que eliminar “u” (costo 5) e insertar “y” (costo 5) que tendría un costo de 10. Si se desea tener en cuenta la operación de intercambio (permutar dos caracteres contiguos) se demuestra en (Ukkonen E., 1983) que el peso de esta operación CT debe cumplir que 2CT ≥ CI + CD. 1.3.3.4 Proceso de clusterización. Ejemplo. En este trabajo se refiere a un ejemplo en que se hizo el proceso de clusterización al atributo “apellido” de una base de datos real, y se obtuvieron, entre otros, los clústeres que se muestran en la siguiente tabla:. 16.
(25) (1). (2). (3). (4). (5). bermudes. castillo. rodrigez. hernandez. rdez. bermudez. castellon. rodriguez. fernandez. fdez. bermúdez. castillos. rodrigz. hernandes. hdez. bermudo. castellano. rodrigues. fernadez. rduez. velmudes. castllano. rodríguez. hernaldez. hdz. castellobn. rdrigez. ordoñes. castellosa. rodri. rguez. carrillo. domingez. ordonez. carrilllo. ryes. carillo. reyes. vasallo. bode hndz rdguez ramirez varde corderos. Tabla 1: Ejemplos del cluster obtenidos. 17.
(26) Este proceso se hizo sin realizar el paso previo de sustitución. Al realizar dicho paso con las sustituciones que se muestran a continuación y volver a ejecutar el algoritmo de clusterización se observa como el cluster numerado como el 5 prácticamente desaparece pues ya no existen las abreviaturas que allí aparecían. Qué sustituir. Por quien. Fdez. Fernández. Glez. González. Hdez. Hernández. Mtnez. Martínez. Rguez. Rodríguez. Rdguez. Rodríguez. Tabla 2: Sustituciones realizadas en los apellidos Lo cual da una idea de la importancia del paso, pues las abreviaturas mal ubicadas se eliminaron y los clústeres reflejan de una manera más real los apellidos semejantes. Otro ejemplo, es la utilización de este paso en el estudio del atributo “causa de baja”, de una base de datos de la ONAT Municipal de Ranchuelo, al hacerlo se obtuvieron entre otros los siguientes clusters: Elementos del Cluster 4 reparación del motor. 0.447. reeparación del motor. 0.446. reoaración del motor. 0.380. reparación del vehículo. 0.274. reparación del equipo. 0.266. reparación del equipo y pintura 0.201 18.
(27) reparación del coche. 0.188. titular suspendido por reparación del motor 0.082 reparación media 0.036 por suspensión del titular. -0.153. Elementos del Cluster 5 chapistería y pintura 0.808 chapistería y pintura 0.785 chapisteria y pintura 0.774 chapistería. 0.283. Elementos del Cluster 10 certificadpm del titular. 0.403. certificado del titular. 0.395. certiticado médico del titular. 0.384. certificado médico del titular. 0.375. suspendido el titular. 0.218. Elementos del Cluster 11 problemas con el equipo. 0.500. problemas con el equino. 0.479. por presentar problemas con el equipo 0.364. 19.
(28) problemas con el animal. 0.106. Elementos del Cluster 12 enfermedad del equino. 0.511. enfermdad del equino. 0.452. enfermedad del animal. 0.419. enfermedad del caballo. 0.344. por enfermedad del titular. 0.146. enfermedad del titular. 0.102. por presentar enfermedad el equino 0.058 muerte del equino. -0.027. Elementos del Cluster 21 resolucion 73 2005 art.36. 0.815. resolucion 73 05 art.36. 0.792. resolucion 73 2005 arti.36. 0.791. resolucion 73 2005 art .36. 0.790. resolución 73 2005 art.36. 0.781. resolucion 73 art.36. 0.746. resolucion 73art.36. 0.720. por resolucion 73 2005 art.36 0.707. 20.
(29) resolucion 73artic.36. 0.672. resolucion 23arti.36. 0.619. resolucion 86 2002. 0.432. También se puede observar que se ha logrado reunir cadenas semejantes, que se refieren a la misma causa, y que sin un proceso de estandarización no permitiría ningún tipo de estadística fiable. El método de los k-medoides también brinda un valor que indica el grado de pertenencia de un elemento al cluster. Este valor se mueve entre -1 y 1, mientras más cerca de 1 esté el valor el sentido de pertenencia es mayor. Como se observa en el ejemplo anterior los valores todos son positivos, excepto el valor del ítem “muerte del equino” del cluster 12 y “por suspensión del titular” del cluster 4 lo que indica una débil pertenencia a sus respectivos clusters, si se analiza el resto de los elementos se ve perfectamente que estos ítems no están asociados al resto. Este valor se puede utilizar al hacer el análisis de cada uno de los clusters. 1.3.4 Sustitución post-cluster. En este paso se escogen en los respectivos clusters hechos en el paso anterior las cadenas que serán sustituidas y por cuál serán sustituidas. Los usuarios tienen la posibilidad de escoger por cada cluster, cuáles son las cadenas que quiere sustituir y por qué lo quiere sustituir. Estas sustituciones se reflejan en la base de datos original, o sea, permite al usuario que las correcciones hechas, se reflejen en la base de datos. El proceso ahora se reduce a la cantidad de clusters definidos, pues en cada uno de ellos se encuentran las cadenas más semejantes. Es necesario determinar las sustituciones a realizar. Este proceso se propone, por el momento, que se haga de forma interactiva entre analista y sistema.. 21.
(30) Por ejemplo en el caso de las “causas” ejemplos de sustituciones pudieran ser: resolucion 73 2005 art.36. por. resolución 73 del 2005, articulo 36. resolucion 73 05 art.36. por. resolución 73 del 2005, articulo 36. resolucion 73 2005 arti.36. por. resolución 73 del 2005, articulo 36. resolucion 73 2005 art .36. por. resolución 73 del 2005, articulo 36. resolución 73 2005 art.36. por. resolución 73 del 2005, articulo 36. resolucion 73 art.36. por. resolución 73 del 2005, articulo 36. resolucion 73art.36. por. resolución 73 del 2005, articulo 36. por resolucion 73 2005 art.36. por. resolución 73 del 2005, articulo 36. resolucion 73artic.36. por. resolución 73 del 2005, articulo 36. resolucion 23arti.36. por. resolución 73 del 2005, articulo 36. 22.
(31) CAPÍTULO II ANÁLISIS Y DISEÑO DE LA HERRAMIENTA “MARCO DE TRABAJO. PARA. ESTANDARIZAR CAMPOS TIPO CADENAS”. En este capítulo desarrollamos el análisis y diseño de la herramienta que proponemos: “Marco de trabajo para la estandarización de campos tipo cadena”, que nos permita conocer una descripción más detallada del problema, así como las herramientas computacionales utilizadas para el desarrollo del mismo. 2.1. Modelado del sistema.. En la modelación del sistema se utilizó la notación UML 1, Lenguaje de Modelado Unificado, que es un lenguaje gráfico para visualizar, especificar y documentar cada una de las partes que comprende el desarrollo del software, además éste prescribe un conjunto de notaciones y diagramas estándares para modelar sistemas orientados a objetos y describe la semántica esencial de lo que estos diagramas y símbolos significan. UML ofrece varios diagramas que permiten modelar sistemas (Jacobson I. et al., 2004): . Diagramas de Casos de Uso para modelar los procesos de negocio.. . Diagramas de Estado para modelar el comportamiento de los objetos en el sistema.. . Diagramas de Clases para modelar la estructura estática de las clases en el sistema.. 1. Siglas en inglés de Unified Modeling Language. 23.
(32) 2.1.1. Diagrama de casos de uso.. Figura 2.1 Casos de uso para el actor analista.. Figura 2.2 Especificación del caso de uso Conectar a la BD.. 24.
(33) Figura 2.3 Especificación del caso de uso Estandarizar campos.. Figura 2.4 Especificación del caso de uso Editar Categorías.. En la herramienta que se presenta, identificamos 3 casos de usos, Conectar a la BD, Estandarizar Campos y Editar Categorías, y un actor, que es el Analista. A continuación describimos los casos de uso para este actor. 1. Conectar a la BD: este caso de uso es el encargado de realizar la conexión a la base de datos. El actor del sistema es el responsable de seleccionar el proveedor (SQL y ACCESS), la base de datos y la tabla y el campo a la cual desea conectarse. 25.
(34) a. SQL: El actor escoge el proveedor SQL. i. Elegir tabla y campo: Elige la tabla y el campo al cual conectarse. ii. Conectar: Se lleva a cabo la conexión a la base de datos seleccionada. b. ACCESS: El actor escoge el proveedor ACCESS. i. Elegir tabla y campo: Elige la tabla y el campo al cual conectarse. ii. Conectar: Se lleva a cabo la conexión a la base de datos. 2. Estandarizar Campos: este caso de uso es el encargado de realizar la estandarización del campo seleccionado, como precondiciones tiene que el actor primeramente debe haber realizado una conexión a alguna base de datos. a. Sustitución previa: El actor realiza la sustitución previa del campo seleccionado. b. Clusterización: Se realiza la clusterización del campo seleccionado. c. Sustitución post-cluster: Se realiza la sustitución post-cluster del campo al cual se le hizo la clusterización. 3. Editar categorías: Una categoría es un posible grupo de sustituciones que se relacionan por un criterio específico. El actor realiza la edición de las categorías que le permiten realizar la sustitución previa. a. Agregar: El actor agrega una nueva categoría o una nueva sustitución a una categoría seleccionada. b. Editar: El actor edita una categoría y el valor de una sustitución seleccionada. c. Eliminar: El actor elimina una categoría y las sustituciones seleccionadas. 2.1.2. Tabla de eventos.. La Tabla de eventos muestra la secuencia de acciones que pueden causar la transición del objeto de un estado a otro en cada una de las ventanas de la aplicación y la respuesta que recibe del sistema al ejecutarse cada una de estas acciones.. 26.
(35) Ventana principal ¿Qué hace el actor?. ¿Qué hace el sistema?. 1. Seleccionar en el menú Archivo la. 1. Abrir la ventana de conexión a la BD.. opción Nueva Conexión. 2. Seleccionar en el menú Edición la. 2. Abrir la ventana. opción Categorías.. Agregar/Editar/Eliminar categorías.. 3. Seleccionar en el menú Edición la. 3. Abrir la ventana de Sustituciones. opción Sustituciones previas.. Previas.. 4. Seleccionar en el menú Ver la opción. 4. Abrir la ventana Clusters.. Clusters. 5. Seleccionar en el menú Ayuda: Acerca. 5. Abrir la ventana Acerca de... que brinda. de…. información sobre la herramienta.. Ventana Conexión a la BD. ¿Qué hace el actor?. ¿Qué hace el sistema?. 1. Escoger el proveedor (SQL, ACCESS). 1. Habilitar los controles para que el actor Si escoge SQL, introduce el servidor y la teclee el nombre del servidor y la base de base de datos a la cual conectarse. Si datos para la conexión. escoge ACCESS, introduce el camino completo donde esta la BD mdb.. Habilitar el control para entrar el camino completo de la BD o el botón de búsqueda.. 2. Presionar el botón Conectar.. 2.. Chequear. si. ha. sido. entrado. correctamente la base de datos y realiza la conexión. En la lista desplegable “tabla”, aparecen las tablas de la base de datos seleccionada. 3. Escoger una tabla.. 3. Desplegar la lista de “Campos” donde aparecen. los. campos. de. la. tabla. seleccionada.. 27.
(36) 4. Presionar el botón Sust_Previa.. 4. Abrir la ventana “Sustitución previa”.. 5. Presionar el botón cancelar.. 5. Cerrar la ventana “conectar”.. Ventana Agregar/Editar/Eliminar Categorías. ¿Qué hace el actor?. ¿Qué hace el sistema?. 1. Seleccionar una categoría. 1. Llenar la lista de chequeo con las categorías pertenecientes a la categoría seleccionada.. 2. Presionar el botón Agregar.. 2. Preguntar si lo que se quiere agregar es una nueva categoría o una sustitución.. 3. Escoger categoría.. 3. Desplegar la ventana para agregar una nueva categoría.. 4. Escoger sustitución.. 4. Desplegar la ventana para agregar una nueva sustitución.. 5. Presionar botón Editar.. 5. Preguntar si lo que se quiere editar una categoría o una sustitución.. 6. Escoger categoría.. 6. Desplegar la ventana para editar la categoría seleccionada.. 7. Escoger sustitución.. 7. Desplegar la ventana para Editar la sustitución.. 8. Presionar el botón Eliminar.. 8. Preguntar si lo que se quiere eliminar es una categoría o una sustitución.. 9. Escoger categoría.. 9. Eliminar la categoría seleccionada.. 10. Escoger sustitución.. 10. Eliminar la sustitución seleccionada.. 28.
(37) 11. Presionar el botón cerrar.. 11. Cerrar la ventana Agregar/Editar/Eliminar Categorías.. Ventana Sustitución previa. ¿Qué hace el actor? 1. Elegir una categoría.. ¿Qué hace el sistema? 1. Desplegar en la lista de chequeo las categorías existentes.. 2. Seleccionar sustituciones previas. 3. Presionar el botón Sust_Prev.. 2. Realizar las sustituciones previas en la BD.. Ventana Clusters. ¿Qué hace el actor?. ¿Qué hace el sistema?. 1. Presionar el botón Clusterizar.. 1. Mostrar los clusters en la lista de chequeo.. 2. Presionar los botones de. 2. Mover por los clusters hacia delante o. desplazamiento > o <.. hacia detrás, respectivamente.. 3. Seleccionar una cadena correcta.. 3. Mover la cadena correcta hacia el cuadro de edición “Cadena correcta”.. 4. Seleccionar las cadenas erróneas.. 4. Mover las cadenas erróneas la lista “Cadenas erróneas”.. 5. Presionar el botón Sust. Postcluster.. 5. Realizar la sustitución post-cluster en la BD de los valores erróneos por el valor verdadero seleccionado.. 6. Presionar el botón Cerrar.. 6. Cerrar la ventana Clusters.. 29.
(38) 2.1.3. Diagrama de Actividad.. Los diagramas de actividad proporcionan una forma de modelar el flujo de la información dentro de un proceso. Son típicamente usados para modelar la secuencia de actividades en un proceso. Un diagrama de actividad es considerado un caso especial de una máquina de estado en la cual la mayor parte de los estados son actividades y la mayor parte de las transiciones son implícitamente provocadas por la finalización de las acciones en las actividades. Los diagramas de actividad de las Figuras 2.5, 2.6, 2.7 y 2.8 muestran la secuencia lógica para un correcto uso de la herramienta.. Figura 2.5 Diagrama de actividad para conectarse a la base de datos.. 30.
(39) Figura 2.6 Diagrama de actividad para estandarizar campos. 31.
(40) Figura 2.7 Diagrama de actividad para editar categorías.. Figura 2.8 Diagrama de Actividad para realizar sustituciones 32.
(41) 2.1.4. Diagramas de clases.. El Diagrama de Clases es el diagrama principal de diseño y análisis para un sistema. En él, la estructura de clases del sistema se especifica con relaciones entre clases y estructuras de herencia. Durante el análisis del sistema, el diagrama se desarrolla buscando una solución ideal. Durante el diseño, se usa el mismo diagrama, y se modifica para satisfacer los detalles de las implementaciones.. 33.
(42) Figura 2.8 Diagrama de clases.. 34.
(43) Las clases fundamentales que conforman el sistema junto con sus principales atributos y métodos, se relacionan a continuación: 1. TPrincipal Esta clase es la encargada de manejar todas las demás clases del sistema. Atributos: . CurDir: String; Æ En este atributo se almacena el directorio actual del sistema.. . Conected:bolean;Æ Si “Conected” toma valor true, es que se ha establecido una conexión a una base de datos. Por otra parte, si “Conected” es false, es que no se ha establecido ninguna conexión aún.. . Selected_Table: String; Æ En este atributo, cuando se realiza una conexión a una base de datos, se almacena el nombre de la tabla seleccionada.. . Selected_Field : String; Æ En este atributo, cuando se realiza una conexión a una base de datos y se ha escogido una tabla, se almacena el campo seleccionado.. Métodos: . procedure FormCreate(Sender: TObject);Æ En este método se inicializan los atributos.. . procedure Coneccinc1Click(Sender: TObject);Æ Este método es el encargado de mostrar la ventana Conexión .. . procedure CerrarAltF41Click(Sender: TObject);Æ Este método cierra la aplicación.. . procedure AcercadeMTECTCClick(Sender: TObject); Æ Muestra la ventana Acerca de MTECTC.. . procedure. XML1Click(Sender:. TObject);Æ. Muestra. la. ventana. Categoría_Edicion. . procedure Sustitucionesprevias1Click(Sender: TObject);Æ Si se ha realizado una conexión, muestra la ventana Categoría.. 35.
(44) . procedure. Clusters1Click(Sender:. TObject);Æ. Muestra. la. ventana. Clusters_View. 2. TCategoría. Atributos: . XML_Dir. : String;Æ En este atributo se almacena el directorio donde están. los XML que contienen las sustituciones. . Categoria_XML_lista_Valores_Que : TStringList;Æ En este atributo se almacenan los valores que se van a sustituir, de la categoría seleccionada.. . Categoria_XML_lista_Valores_PQue : TStringList;Æ En este atributo se almacenan los valores por los cuales se van a sustituir, de la categoría seleccionada.. Métodos: . procedure Cancelar_ButtonClick(Sender: TObject);Æ Este método cierra la ventana Categoría, cancelando la acción realizada.. . procedure FormCreate(Sender: TObject);Æ Se inicializan todos los componentes y las variables.. . procedure Categoria_ComboBoxChange(Sender: TObject);Æ Este método llena lista de chequeo con las sustituciones correspondientes a la categoría seleccionada.. . procedure Sust_Prev_ButtonClick(Sender: TObject);Æ Este método realiza la sustitución previa en la base de datos con las sustituciones seleccionadas.. 3. TConexión. Atributos: . DB_List, Table_List, Field_List : TStringList;Æ En estos atributos se almacena, la lista de bases de datos, de tablas y campos respectivamente.. 36.
(45) . Selected_Table, Selected_Field, filename : String;Æ En estos campos se almacena la tabla y el campo seleccionado respectivamente, en “filename” se almacena el camino de la base de datos .mdb, en caso que el proveedor seleccionado sea ACCESS.. Métodos: . procedure Cancel_ButtonClick(Sender: TObject); Æ Cierra la ventana Conexión, sin realizar la acción anterior.. . procedure FormCreate(Sender: TObject);Æ Se inicializan todos los componentes y las variables.. . procedure Coneccion_ButtonClick(Sender: TObject);Æ Se realiza la conexión a la base de datos.. . procedure Sust_Previa_ButtonClick(Sender: TObject);Æ Visualiza la ventana Categoría.. 4. TCateg_Sust. Atributos: . es_categ : boolean;Æ Este atributo si su valor es verdadero, quiere decir, que se seleccionó la opción categoría, si su valor es false, entonces se ha seleccionado la opción sustitución.. Métodos: . procedure Cancelar_ButtonClick(Sender: TObject);Æ Cierra la ventana.. . procedure FormCreate(Sender: TObject);Æ Inicializa los componentes y el atributo.. . procedure Aceptar_ButtonClick(Sender: TObject);Æ De acuerdo con la opción seleccionada, le da un valor al atributo es_categ.. 37.
(46) 5. TCategoria_Edicion. Atributos: . Categoria_Edicion_XML_Dir : String;Æ Se almacena el camino del directorio donde están las categorías.. . Categoria_Edicion_XML_lista_Valores_Que : TStringList;Æ En este atributo se almacenan los valores que se van a sustituir, de la categoría seleccionada.. . Categoria_Edicion_XML_lista_Valores_PQue. :. TStringListÆ. En. este. atributo se almacenan los valores por los cuales se van a sustituir, de la categoría seleccionada. Métodos: . procedure Cerrar_ButtonClick(Sender: TObject);Æ Cierra la ventana Categoria_Edicion.. . procedure FormCreate(Sender: TObject);Æ Inicializa los componentes y los atributo.. . procedure Agregar_ButtonClick(Sender: TObject);Æ Despliega la ventana Categ_Sust y dependiendo de la opción seleccionada, se agrega una nueva categoría o una sustitución.. . procedure Eliminar_ButtonClick(Sender: TObject);Æ Despliega la ventana Categ_Sust, y dependiendo de la opción seleccionada, elimina una categoría o una sustitución.. . procedure Categoria_Edicion_ComboBoxChange(Sender: TObject);Æ Se invoca al método Llenar_Categoria_Edicion_ComboBox.. . procedure Editar_ButtonClick(Sender: TObject);Æ Despliega la ventana Categ_Sust y dependiendo de la opción seleccionada, edita la categoría o la sustitución seleccionada.. . procedure Llenar_Categoria_Edicion_ComboBox(Sender: TObject);Æ Llena lista de chequeo con las sustituciones correspondientes a la categoría seleccionada.. 38.
(47) 6. TClusters_View. Métodos: . procedure FormCreate(Sender: TObject);Æ Se inicializan los componentes.. . procedure Cluster_View_Cancelar_ButtonClick(Sender: TObject);Æ Cierra la ventana Clusters_View.. . procedure Cluster_View_Button_Valor_VerdaderoClick(Sender: TObject);Æ Pasa un valor seleccionado en la lista de chequeo ubicada a la izquierda de la ventana para el cuadro de edición, seleccionándolo como la cadena correcta.. . Procedure. Cluster_View_Button_Agregar_V_ErroneosClick(Sender:. TObject);Æ Pasa las cadenas erróneas(los valores que se quieren sustituir por la cadena correcta) para el componente lista ubicado a la derecha de la ventana. . procedure Cluster_View_Button_Eliminar_V_ErroneosClick(. Sender:. TObject);Æ Elimina un valor de la lista que contiene las cadenas erróneas. . procedure Cluster_View_Button_atrasClick(Sender: TObject);Æ Se desplaza para el cluster anterior, llenando la lista de chequeo con los valores de ese cluster.. . procedure Cluster_View_Button_AdelanteClick(Sender: TObject);Æ Se desplaza para el próximo cluster, llenando la lista de chequeo con los valores de ese cluster.. . procedure Cluster_View_Button_ClusterizarClick(Sender: TObject);Æ Se realiza la clusterización, se llena la lista de chequeo con el primer cluster.. . procedure. Cluster_View_Button_Sust_Post_ClusterClick(Sender:. TObject);Æ Se realiza la sustitución post-cluster con los valores seleccionados como cadena correcta y las cadenas erróneas.. 39.
(48) 7. TNueva_Sust Atributos: . que, pque. : String;Æ Almacenan el valor que se quiere sustituir y el valor. por el cual se quiere sustituir respectivamente, en el caso de la adición de una nueva sustitución o la edición de una sustitución. . ok : boolean;Æ si el valor es true quiere decir que se han llenado los campos del “que” y el “por qué” sustituir, de lo contrario, uno o ambos campos están vacíos.. Métodos: . procedure Cancelar_ButtonClick(Sender: TObject);Æ Cierra la ventana Nueva_Sust.. . procedure FormCreate(Sender: TObject);Æ Inicializa los componentes y los atributos.. . procedure Aceptar_ButtonClick(Sender: TObject);Æ Llena los atributos “que” y “pque” con los valores no vacíos de los cuadros de edición correspondientes.. 8. TNueva_Categoria. Atributos: . nueva_categoria : String;Æ Almacena el nombre de la nueva categoría que se quiere agregar o editar.. . ok : boolean;Æ si el valor es true quiere decir que se ha llenado el campo del nombre de la categoría, de lo contrario, el campo está vacío.. Métodos: . procedure Cancelar_ButtonClick(Sender: TObject);Æ Cierra la ventana Nueva_Categoria.. 40.
(49) . procedure FormCreate(Sender: TObject);Æ Inicializa lo componentes y los atributos.. . procedure Aceptar_ButtonClick(Sender: TObject);Æ. Llena el atributo. Nueva_categoria con el valor del cuadro de edición correspondiente. 9.. TInstance.. Atributos: . value : String;Æ Contiene el valor de cadena.. . sil : Double;Æ Coeficiente de silueta del elemento.. . cv. : Integer;Æ Número del cluster más cercano, distinto al cual pertenece la. instancia Métodos: . constructor Instance(nv : String);Æ Inicializa el valor del atributo value.. . function Getvalue(): String;Æ Devuelve el valor del atributo value.. . procedure SetValue(nv : String);Æ Pone en el atributo value el valor pasado por parámetros.. . function GetSil(): Double;Æ devuelve el valor del valor del coeficiente de silueta. . procedure SetSil(sil : Double);Æ Asigna el valor del coeficiente de silueta. . function CompateTo(o : TInstance): Integer;Æ Compara el valor del atributo Sil con el Sil de otra instancia pasada por parámetros, devuelve -1 si el valor del Sil es menor que el valor del Sil pasado por parámetro, 0 si son iguales y 1 si el valor del Sil es mayor que el Sil pasado por parámetro.. . function Getcv(): Integer;Æ Devuelve el valor del atributo cv.. . procedure Setcv(cv :Integer);Æ Asigna el valor del atributo cv.. 41.
(50) 10. TCluster. Atributos: . ds. : TStringDataSet;Æ Una lista de TInstance, que representan los. elementos del cluster. . medoide : TInstance;Æ una instancia de TInstance, el medoide del cluster.. . laster, l : boolean;Æ Si el valor de laster es true, quiere decir que es el último. L puede tomar valores true y false.. Métodos: . constructor Cluster(nds: TStringdataSet; nm : TInstance);Æ inicializa los valores de los atributos ds y de medoide.. . function GetStringDataSet(): TStringDataSet;Æ Devuelve el atributo ds que es una instancia de un StringDataSet.. . function GetMonoide(): TInstance;Æ Devuelve el atributo medoide, que es una instancia de TInstance;. . function Size(): Integer;Æ Devuelve la cantidad de elementos del cluster.. . function Diameter(dm : TLevenstDistance): Double;Æ Calcula la máxima distancia entre los elementos del cluster, a la cual se llama diámetro del cluster.. . function AverageDissim(dm : TLevenstDistance): DoubleÆ Calcula el promedio de las distancias entre los elementos del cluster.. . function MaxDissim(dm : TLevenstDistance): Double;Æ Calcula la máxima disimilitud entre las instancias de los elementos del cluster.. . function IsL(): boolean;Æ Devuelve el valor de L.. . procedure SetL(l : boolean);Æ Asigna el valor que se le pasa por parámetros a l.. . function IsLaster(): boolean;Æ Devuelve el valor de laster.. . procedure SetLaster(laster : boolean);Æ Pone el valor que se le pasa por parámetro en el atributo Laster.. 42.
(51) . procedure AddElement(e : pointerTInstance);Æ Agrega un elemento al cluster.. . procedure RemoveElement(e : pointerTInstance);Æ Elimina un elemento del cluster.. 11.. TKMedoids.. Atributos: . dm : TLevenstDistance;Æ Atributo de tipo TLevenstDistance;. . number_of_Clusters : Integer;Æ Cantidad de clusters.. Métodos: . constructor. KMedoidsR1(number_of_Clusters. :. Integer;. dm. :. TLevenstDistance);Æ Inicializa los valores de los atributos. . function executeClustering(data : TStringDataSet): TPartition;Æ algoritmo PAM, se realizan las dos fases del algoritmo, BUILD y SWAP.. . function assign(medoids : ArrInstance; data : TStringDataSet): ArrInteger;Æ crea los clusters a partir de los medoides determinados, determina la distancia de cada elemento a los medoides determinados y lo asocia al medoide más cercano.. . function distancias(data : TStringDataSet): ArrDouble;Æ determina las distancias entre todos los elementos. La forma más natural de organizarlas es mediante una matriz, pero por ser simétrica se organiza como un arreglo lineal de manera de economizar espacio en memoria.. . function meet(l : Integer; j : Integer): Integer;Æ conocido los índices donde se almacenan dos cadenas devuelve el índice en que habría que buscar en el arreglo lineal de distancia.. . function mayor(d : ArrDouble): double;Æ Devuelve el mayor elemento de un arreglo de double.. 12.. TStringDataSet.. 43.
(52) Atributos: . instances : TList;Æ Una lista de TInstance.. Métodos: . constructor StringDataSet();Æ Crea e inicializa el atributo instance.. . function AddInstance(instance : TInstance):boolean;Æ Agrega una instancia a la lista de instancias y devuelve true si se agregó con éxito.. . function Getindex(i : Tinstance):Integer;Æ Devuelve el índice de una instancia pasada por parámetros.. . function GetInstance(index : Integer):Tinstance;Æ Devuelve una instancia de TInstance, conocida su posición.. . function size(): Integer;Æ Devuelve la cantidad de elementos de la lista de TInstance.. . procedure removeInstance(e : Tinstance);Æ Elimina la instancia indicada de la lista.. . procedure SortBySil();Æ Ordena la lista de Instancias, siguiendo el criterio del coeficiente de Silueta.. 13.. TLevenstDistance.. Atributos: . wi, wd, wc, ws : Integer;Æ Pesos de la inserción, eliminación, modificación e intercambio, respectivamente.. . fix : boolean;Æ Si toma valor true, se toma en cuenta el teclado, si toma valor false, no se toma en cuenta.. . d. : array of array of Integer;Æ Matriz de enteros que se utiliza para. calcular la distancia entre dos cadenas.. 44.
(53) Métodos: . constructor LevenstDistance(nwi : Integer; nwd : Integer; nwc : Integer; nws : Integer; nfix: boolean);Æ inicializa los valores de los atributos.. . function CalculateDistance(ss: TInstance; tt : TInstance): Integer;Æ calcula la distancia de edición entre dos cadenas de caracteres, utilizando la distancia de Levenshtein modificada.. . function BuscaGrafo(a: Char; b: Char): Integer;Æ Busca la distancia que hay desde el carácter ‘a’ al ‘b’ pasados por parámetros, en la matriz de distancias entre teclas.. 14.. TPartition.. Atributos: . clusters : ArrClusters;Æ Arreglo de clusters.. . dm. . sc. : TLevenstDistance;Æ Atributo de tipo TLevenstDistance. : Double;Æ Coeficiente de silueta de la partición.. Métodos: . constructor Partition(clusters : ArrClusters; dm : TLevenstDistance);Æ Inicializa los atributos.. . procedure PrintToFile();Æ Encargado de visualizar los clusters.. . procedure SetAllLaster();Æ Determina todos los valores de los Laster.. . procedure SetAllL();ÆDetermina todos los valores de los L.. . procedure SetSilHouttes();Æ Determina los coeficientes de silueta de cada elemento y de la partición.. 45.
(54) 2.2 Características computacionales de la herramienta “Marco de trabajo para la estandarización de datos tipo cadenas”. El sistema fue desarrollado en el ambiente de programación Borland Delphi creándose una aplicación para Windows en lenguaje Pascal y haciendo uso de las facilidades que éste brinda en la programación orientada a objeto. Además se utilizó el lenguaje SQL para algunas consultas y actualizaciones en las tablas de las bases de datos en distintos gestores: SQL y Access.. 46.
(55) CAPÍTULO III. MANUAL DE USUARIO.. Este capítulo está dedicado a la descripción del manual de usuario de la herramienta, mostrando la información de cómo proceder en la interfaz visual y hacer las acciones deseadas. 3.1. Requerimientos del software. El sistema está implementado en Delphi y realiza la conexión con las bases de datos (SQL Server, Access) utilizando la tecnología ADO 2. 3.2. Descripción de la herramienta y sus funcionalidades. La herramienta se ha concebido para la estandarización de campos tipos cadena en los gestores de bases de datos: SQL Server y Access. Para la implementación de la conexión a la Bases de Datos (BD) de tipo Access y SQL Server se usó la componente ADO que brinda Delphi. 3.3. Ambiente de trabajo. El ambiente de trabajo de la herramienta implementada es muy sencillo, posibilitando un buen desenvolvimiento en la ejecución y utilización del mismo, y permitiendo a su vez que el usuario realice la limpieza de sus datos en un corto período de tiempo. 3.3.1. Conexión con la Base de Datos. Seleccionar tabla y campo. La ejecución se inicia con una ventana como la mostrada en la figura 3.1, que contiene el menú inicial de la aplicación. Si se desea hacer la conexión a la base de datos se elige la opción de menú Archivo/Nuevo/Conexión como se muestra en la figura 3.2. 2. Siglas en inglés de ActiveX Data Objects. 47.
(56) Figura 3.1 Ventana principal del sistema.. Figura 3.2 Ventana principal del sistema y menú conexión. Al hacer la elección del menú se muestra una ventana (figuras 3.3, 3.4) en la que se brindan los datos de la conexión.. 48.
(57) Figura 3.3 Ventana de conexión, con SQL Server escogido como proveedor.. Figura 3.4 Ventana de conexión, con ACCESS escogido como proveedor. Para conectarse a la base de datos es necesario, en el caso de SQL Server, que se defina el servidor y la base de datos a la cual conectarse; en caso de ACCESS, se busca una base de datos .mdb.. 49.
(58) Luego de realizar la conexión en el cuadro desplegable “Tabla”, aparecen las tablas relacionadas con la base de datos a la que se hizo la conexión; al escoger una tabla, en la lista “Campos”, aparecen los campos relacionados con la tabla seleccionada. 3.3.2. Sustitución previa. Después de realizada la conexión se pueden realizar las sustituciones previas en el campo elegido. Para hacer las sustituciones previas se puede partir de la propia ventana de conexión a través del botón de presión “Sust_Previa” o a través de la opción de menú Editar/Sustituciones Previas. En cualquiera de los dos casos se muestra la ventana de la figura 3.5. Al escoger la categoría (definidas en el capítulo 2) deseada en la lista desplegable superior se muestran las sustituciones definidas para esta categoría.. Figura 3.5 Ventana Categorías.. 50.
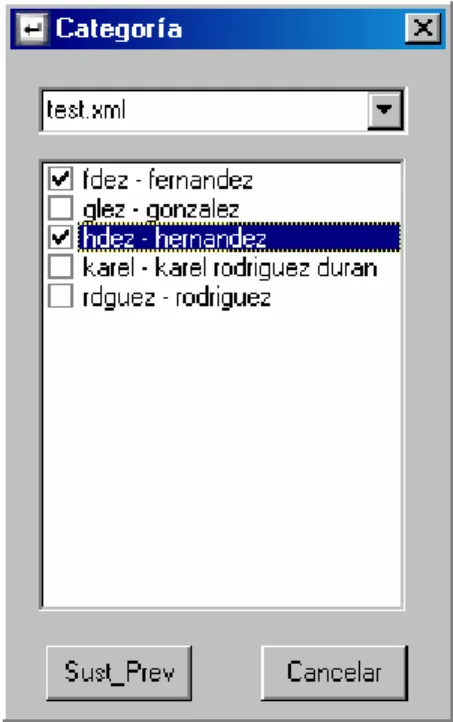
(59) 3.3.3. Edición de las categorías y las sustituciones. Las categorías y las sustituciones pueden ser editadas, de forma que el analista que realiza el proceso de estandarización pueda añadir/eliminar/editar categorías, o para una categoría determinada pueda editar las sustituciones definidas. Para realizar estas acciones se utiliza el menú Editar/Categorías, como se muestra en la figura 3.6. Figura 3.6 Acceso a la edición de categorías y sustituciones. Al elegir esta opción se muestra una ventana (figura 3.7, izquierda) en la cual se elige una categoría determinada y se pueden hacer las acciones que se indican en los botones de presión. Como ya se ha elegido una categoría y aparecen las sustituciones correspondientes siempre se pregunta al analista si se desea trabajar con la categoría o las sustituciones (figura 3.7 derecha).. 51.
(60) Figura 3.7 Ventana de Edición de Categorías y la ventana Categoría o Sustitución. Como se explicó en el primer capítulo estas sustituciones son almacenadas en ficheros XML. 3.3.4. Clusterización y sustitución post-cluster. Luego de realizar las sustituciones se puede formar los cluster de manera que se logre el objetivo de estandarizar el campo de texto con que se trabaja. Para realizar la clusterización se utiliza la opción del menú Ver/Clusters, como indica la figura 3.8. 52.
(61) Figura 3.8 Ventana principal con el menú Ver, desde el cual se puede acceder a la ventana Clusters. Al escoger dicha opción se muestra la ventana representada en la figura 3.9.. . Figura 3.9 Ventana Clusters. Desde esta ventana se realiza la clusterización, presionando el botón Clusterizar, previamente se debe haber entrado en el cuadro de edición de la parte izquierda superior, la cantidad de cluster que se desean obtener. Luego de realizarse la misma, se pueden ver. 53.
(62) los clusters en la parte izquierda de la ventana, y se puede lograr el desplazamiento entre estos clusters, por los botones que están encima del botón Clusterizar. Después de hacer la clusterización, se puede realizar la sustitución post-cluster, se escoge la cadena correcta, y las cadenas erróneas, y al presionar el botón “Sust. PostCluster”, se realiza la sustitución post-cluster en la tabla de la base de datos a la cual se realizó la conexión en la ventana de Conexión. Si la cadena correcta no apareciera en el cluster puede ser entrada en el cuadro de texto correspondiente a la misma. 3.4. Áreas de aplicación La herramienta puede ser usada en cualquier centro siempre y cuando se utilicen bases de datos en Access o SQL Server cuyos datos requieran de un proceso de limpieza, por errores tipográficos en alguno de sus campos.. 54.
(63) CONCLUSIONES. Como resultado del trabajo realizado en esta investigación se logró profundizar en las características del proceso de estandarización de datos tipo cadena en la limpieza de datos lográndose: -. Realizar el análisis, diseño e implementación de una herramienta que permite la estandarización de campos tipo cadena en la limpieza de datos.. -. Algoritmizar todos los pasos del marco de trabajo propuesto.. -. Realizar algunas pruebas con bases de datos reales que mostraron que utilización. la. del algoritmo PAM con la distancia de Levenshtein modificada,. produce resultados favorables. En general se cumplieron los objetivos propuestos en el trabajo.. 55.
(64) RECOMENDACIONES. Como trabajo posterior se recomienda evaluar el uso de otros algoritmos que modifican el algoritmo de clusterización original utilizado en esta tesis para comparar los resultados.. 56.
Figure



+7





Documento similar
Pero antes hay que responder a una encuesta (puedes intentar saltarte este paso, a veces funciona). ¡Haz clic aquí!.. En el segundo punto, hay que seleccionar “Sección de titulaciones
El contar con el financiamiento institucional a través de las cátedras ha significado para los grupos de profesores, el poder centrarse en estudios sobre áreas de interés
Cedulario se inicia a mediados del siglo XVIL, por sus propias cédulas puede advertirse que no estaba totalmente conquistada la Nueva Gali- cia, ya que a fines del siglo xvn y en
[r]
SVP, EXECUTIVE CREATIVE DIRECTOR JACK MORTON
Social Media, Email Marketing, Workflows, Smart CTA’s, Video Marketing. Blog, Social Media, SEO, SEM, Mobile Marketing,
Las necesidades de una sociedad campesina cada vez más numerosa por una parte y las solicitaciones comerciales de la economía urbana más o menos sentidas en los campos por otra
DS N° 012-2014-TR Registro Único de Información sobre accidentes de trabajo, incidentes peligrosos y enfermedades ocupacionales y modificación del art.110º del Reglamento de la Ley
