UNIVERSIDAD TÉCNICA PARTICULAR DE LOJA
La Universidad Católica de Loja
ÁREA TÉCNICA
TÍTULO DE INGENIERO CIVIL
Implementación de herramientas de modelización estocástica de las
series hidrológicas en el HydroVLab.
TRABAJO DE TITULACIÓN
AUTORA: Alverca Rivas, Aidé Margoth
DIRECTOR: Oñate Valdivieso, Fernando Rodrigo, PhD
LOJA
–
ECUADOR
Esta versión digital, ha sido acreditada bajo la licencia Creative Commons 4.0, CC BY-NY-SA: Reconocimiento-No comercial-Compartir igual; la cual permite copiar, distribuir y comunicar públicamente la obra, mientras se reconozca la autoría original, no se utilice con fines comerciales y se permiten obras derivadas, siempre que mantenga la misma licencia al ser divulgada. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.es
ii
APROBACIÓN DEL DIRECTOR DEL TRABAJO DE TITULACIÓN
Doctor.
Fernando Oñate Valdivieso DOCENTE DE LA TITULACIÓN
De mi consideración:
El presente trabajo de titulación: Implementación de herramientas de modelización estocástica de series hidrológicas en el HydroVLab realizado por Aidé Margoth Alverca Rivas, ha sido orientado y revisado durante su ejecución, por cuanto se aprueba la presentación del mismo.
Loja, abril del 2016
iii
DECLARACIÓN DE AUTORÍA Y CESIÓN DE DERECHOS
“Yo Alverca Rivas Aidé Margoth declaro ser autora del presente trabajo de titulación: Implementación de herramientas de modelización estocástica de series hidrológicas en el HydroVLab, de la Titulación de Ingeniería Civil, siendo PhD. Fernando Rodrigo Oñate Valdivieso director del presente trabajo; y eximo expresamente a la Universidad Técnica Particular de Loja y a sus representantes legales de posibles reclamos o acciones legales. Además certifico que las ideas, conceptos, procedimiento y resultados vertidos en el presente trabajo investigativo, son de mi exclusiva responsabilidad.
Adicionalmente declaro conocer y aceptar la disposición del Art. 88 del Estatuto Orgánico de la Universidad Técnica Particular de Loja que en su parte pertinente
textualmente dice: “Forman parte del patrimonio de la Universidad la propiedad
intelectual de investigaciones, trabajos científicos o técnicos y tesis de grado o trabajos de titulación que se realicen con el apoyo financiero, académico o institucional
(operativo) de la Universidad”.
iv
DEDICATORIA
Dedico este trabajo a:
v
AGRADECIMIENTO
Le agradezco en primer lugar a Dios, el haberme permitido llegar a éste punto de mi
vida. Sin él, dudo que aún estuviera presente en este mundo.
A mis padres y hermano, que siempre han estado apoyándome en los estudios, con sus
palabras de aliento y reproche, las mismas que me han dado ánimos de seguir adelante.
Al Ph. D. Fernando Oñate director de éste trabajo investigativo, por su gran paciencia
que tiende al infinito positivo.
Y a todos mis compañeros, amigos y familiares, que de una u otra manera facilitaron la
culminación de éste trabajo.
A todos ellos, Gracias…
vi
ÍNDICE DE CONTENIDOS
CARÁTULA………i
APROBACIÓN DEL DIRECTOR DEL TRABAJO DE TITULACIÓN ... ii
DECLARACIÓN DE AUTORÍA Y CESIÓN DE DERECHOS ...iii
DEDICATORIA ... iv
AGRADECIMIENTO ... v
ÍNDICE DE CONTENIDOS ... vi
ÍNDICE DE FIGURAS ... viii
ÍNDICE DE TABLAS ... x
RESUMEN ... 1
ABSTRACT... 2
INTRODUCCIÓN ... 3
CAPÍTULO I: ESTADO DEL ARTE ... 5
CAPÍTULO II: MATERIALES Y MÉTODOS ... 7
2.1. Metodología Box-Jenkins. ... 8
2.2. Series de tiempo. ... 8
2.3. Estacionariedad. ... 8
2.3.1. Función de autocorrelación. ... 8
2.3.2. Error estándar. ... 11
2.3.3. t estadístico. ... 11
2.3.4. T. crítico ... 11
2.3.5. Estadístico “d” de Durbin – Watson. ... 11
2.3.6. Prueba de raíz unitaria. ... 12
2.3.7. Transformación de las series no estacionarias... 13
2.4. Estacionalidad. ... 14
2.4.1. Transformación de una serie de tiempo estacional a estacionaria. ... 14
2.5. Modelos Box-Jenkins. ... 16
2.5.1. Autorregresivo – AR (p). ... 16
vii
2.5.3. Autorregresivo de media móvil – ARMA (p, q)... 18
2.5.4. Autorregresivo integrado de media móvil – ARIMA (p, d, q). ... 18
2.5.5. Estacional autorregresivo integrado de media móvil – SARIMA (p, d, q) (P, D, Q). ... 19
2.5.6. Proceso de construcción de los modelos no estacionales. ... 20
2.5.7. Proceso de construcción del modelo estacional SARIMA. ... 22
2.6. Metodología de programación. ... 22
2.6.1. Descripción de las herramientas virtuales. ... 23
2.6.2. Descripción del software utilizado para el desarrollo de las herramientas. . 23
2.6.3. Manuales de uso de cada una de las herramientas. ... 25
2.6.4. Diagramas de flujo. ... 25
CAPÍTULO III: ANÁLISIS DE RESULTADOS ... 33
3.1. Utilización y análisis de las herramientas desarrolladas. ... 34
3.1.1. Autorregresivo – AR (p). ... 34
3.1.2. Media móvil – MA (q). ... 40
3.1.3. Autorregresivo de media móvil – ARMA (p, q)... 44
3.1.4. Autorregresivo integrado de media móvil – ARIMA (p, d, q). ... 47
3.1.5. Estacional autorregresivo integrado de media móvil – SARIMA (p, d, q) (P, D, Q). ... 54
3.2. Comparación de resultados entre cada método desarrollado. ... 60
3.2.1. Pronósticos en los modelos: AR, MA y ARMA. ... 60
3.2.2. Pronósticos en los modelos: ARIMA y SARIMA. ... 63
CONCLUSIONES ... 66
RECOMENDACIONES ... 67
BIBLIOGRAFÍA ... 68
ANEXOS ... 71
Anexo 1. Coeficientes de MacKinonn para el cálculo de los valores de Tau (τ) críticos. ... 72
viii
ÍNDICE DE FIGURAS
Figura 2.1. Metodología de Box – Jenkins. ... 20
Figura 2.2. Lenguaje Visual Basic de la Página Web AR_p.aspx.vb ... 24
Figura 2.3. Lenguaje HTML de la Página Web AR_p.aspx... 25
Figura 2.4. Diagrama de flujo del modelo autorregresivo. ... 26
Figura 2.5. Diagrama de flujo del modelo de media móvil. ... 27
Figura 2.6. Diagrama de flujo del modelo autorregresivo de media móvil. ... 29
Figura 2.7. Diagrama de flujo del modelo autorregresivo integrado de media móvil. .. 31
Figura 2.8. Diagrama de flujo del modelo estacional autorregresivo integrado de media móvil. ... 32
Figura 3.1. Recorte de página del modelo AR del gráfico de la serie. ... 35
Figura 3.2. Recorte de página del modelo AR de los correlogramas. ... 35
Figura 3.3. Recorte de página del modelo AR de la prueba de raíz unitaria. ... 36
Figura 3.4. Recorte de página del modelo AR de las variables del modelo. ... 37
Figura 3.5. Recorte de página del modelo AR del análisis de residuos. ... 37
Figura 3.6. Recorte de página del modelo AR de los pronósticos. ... 38
Figura 3.7. Recorte de página del modelo AR del resultado de la regresión. ... 39
Figura 3.8. Recorte de página del modelo MA de los correlogramas... 40
Figura 3.9. Recorte de página del modelo MA de las variables del modelo. ... 41
Figura 3.10. Recorte de página del modelo MA del análisis de residuos. ... 41
Figura 3.11. Recorte de página del modelo MA de los pronósticos. ... 42
Figura 3.12. Recorte de página del modelo MA del resultado de la regresión. ... 43
Figura 3.13. Recorte de página del modelo ARMA de las variables del modelo. ... 44
Figura 3.14. Recorte de página del modelo ARMA del análisis de residuos. ... 45
Figura 3.15. Recorte de página del modelo ARMA de los pronósticos. ... 45
Figura 3.16. Recorte de página del modelo ARMA del resultado de la regresión. ... 47
Figura 3.17. Recorte de página del modelo ARIMA del gráfico de la serie. ... 48
Figura 3.18. Recorte de página del modelo ARIMA de los correlogramas. ... 48
Figura 3.19. Recorte de página del modelo ARIMA de la prueba de raíz unitaria. ... 49
Figura 3.20. Recorte de página del modelo ARIMA de la serie diferenciada. ... 49
Figura 3.21. Recorte de página del modelo ARIMA de las variables del modelo. ... 50
Figura 3.22. Recorte de página del modelo ARIMA del análisis de residuos. ... 51
Figura 3.23. Recorte de página del modelo ARIMA de los pronósticos. ... 51
Figura 3.24. Recorte de página del modelo ARIMA del resultado de la regresión. ... 53
Figura 3.25. Recorte de página del modelo ARIMA del resultado de la regresión. ... 54
Figura 3.26. Recorte de página del modelo SARIMA del gráfico de la serie. ... 55
ix
x
ÍNDICE DE TABLAS
Tabla 2.1. Cuatro transformaciones de estacionalidad. ... 15
Tabla 2.2. Características de los modelos AR (p). ... 16
Tabla 2.3. Características de los modelos MA (q)... 17
Tabla 2.4. Características de los modelos ARMA (p, q). ... 18
Tabla 3.1. Pronósticos de los modelos AR, MA y ARMA. ... 61
Tabla 3.2. Coeficientes para la evaluación de los modelos: AR, MA y ARMA. ... 62
Tabla 3.3. Pronósticos de los modelos ARIMA y SARIMA para la misma serie de tiempo. ... 63
Tabla 3.4. Coeficientes para la evaluación de los modelos ARIMA y SARIMA. ... 65
Tabla 4.1. Serie diferenciada de la Tabla 4.2 ... 73
Tabla 4.2. Serie de datos de caudal de la estación arenal oyente boquerón. ... 74
Tabla 4.3. Temperatura máxima absoluta del aire a la sombra... 75
Tabla 4.4. Primera diferencia de los datos de la Tabla 4.5 ... 76
Tabla 4.5. Serie de datos reales utilizados para compararlos con los pronósticos (AR, MA, ARMA). ... 77
1 RESUMEN
Conocer los pronósticos de las series de tiempo es de gran importancia en distintas áreas de estudio, ya que ayuda a tomar medidas preventivas o posibles soluciones. Lamentablemente, el cálculo de tales pronósticos sigue un proceso complejo. La metodología desarrollada en la presente investigación es la de Box-Jenkins, la misma que se puede aplicar a cualquier serie de tiempo univariante. La selección del modelo óptimo se simplifica por medio de la programación y se aplica varios test para determinar el modelo más adecuado. Esta metodología se ha implementado en el laboratorio virtual de hidrología HydroVLab utilizando Visual Studio 2010.
En la fase de resultados, se ha podido ver que los datos obtenidos siguen un patrón similar a los observados, y además cumplen con los requerimientos de aceptación. Por lo tanto se consigue pronósticos coherentes.
2 ABSTRACT
Know the forecasts of the time series is of great important in different study areas, this help to take preventive measures or possible solutions. Unfortunately, the calculate of forecasts have a complex process. The methodology developed in this investigation is the Box-Jenkins, the same that can be applied to any univariate time series. The selection of optimal model is simplified with programming and several test is applied to determine the most appropriate model. This methodology has been implemented in the
virtual laboratory of hidrology “HydroVLab” using Visual Studio 2010.
In the phase of results, it has been seen that the data follow a pattern similar to those observed, and also meet the requirements of acceptance. Of this way consistent forecasts is achieved.
3
INTRODUCCIÓN
En Ingeniería Civil, es de suma importancia la estimación de valores de diseño de obras en general. Existen varias metodologías para el efecto como son los modelos determinísticos, causa y efecto o modelos estadísticos. Pero cuando se desea realizar pronóstico a corto o mediano plazo los modelos estocásticos son los de mejor aplicación en casos como: pronósticos de los niveles de un embalse, precipitaciones, caudales, entre otros y evitar posibles tragedias o a su vez tomar medidas preventivas.
En el presente trabajo investigativo, se pretende desarrollar técnicas estocásticas de predicción, para su posterior implementación en el laboratorio virtual de hidrología
“HydroVLab”.
Los objetivos del presente trabajo investigativo son los siguientes:
Implementar herramientas de modelización estocástica de series hidrológicas en el HydroVLab.
Desarrollar metodologías para el modelamiento estocástico de series hidrológicas: Modelos auto regresivos, auto regresivos de medias móviles, de descomposición lineal, multivariados.
Implementar herramientas en el HydroVLab.
Validar las herramientas implementadas.
Para alcanzar los objetivos planteados, se realizó una recopilación de varias metodologías: modelos autorregresivos, de media móvil, autorregresivos de media móvil, autorregresivos integrados de media móvil y estacional autorregresivo integrado de media móvil. Éstas metodologías fueron evaluadas aplicándolas a series de datos reales, para posteriormente realizar su implementación en el HydroVLab, empleando Microsoft Visual Studio 2010.
4
El presente trabajo de fin de titulación, se encuentra organizado en los siguientes capítulos:
Capítulo 1: Breve descripción de los métodos predictivos, utilidad que tienen en diferentes áreas de estudio, algunas investigaciones en las que han sido aplicados.
Capítulo 2: Conceptos básicos, pasos para la construcción de cada uno de los modelos desarrollados, metodología de programación utilizada para la generación de los algoritmos.
Capítulo 3: Análisis y comparación de los resultados obtenidos con cada modelo.
Conclusiones, recomendaciones y anexos que se utilizaron para describir de mejor manera los métodos.
6
Los estadísticos George E. P. Box y Gwilym Jenkins a quienes se atribuye el nombre de esta metodología (Hudak & Liu, 1992-1994), desarrollaron en 1970 una serie de modelos predictivos con el fin de obtener pronósticos que se acerquen lo más posible a la realidad, dejando que los propios datos de la variable nos indiquen sus características (Universidad Autónoma de Madrid, 2004).
Esta metodología consiste en estimar un modelo por medio de tres fases: identificación, estimación y chequeo del diagnóstico, el cual debe dar como resultado pronósticos óptimos (Hudak & Liu, 1992-1994).
En la práctica, se han utilizado ampliamente en distintas áreas de estudio tales como: medicina (Otoom, Alshraideh, López de Ipiña, Bravo, & Hisham, 2015) emplearon el modelo ARIMA para modelar el azúcar en la sangre en tiempo real; en electricidad (Kwangbok, Choongwan, & Taehoon , 2014) se utiliza modelos SARIMA en combinación de modelos de Red Neuronal Artificial (modelo híbrido superior), para calcular el pronóstico del presupuesto anual del costo de energía en instituciones educativas; en economía: (Ghahramani & Thavaneswaran, 2006) se realiza una comparación de los modelos ARMA procesados con errores GARCH y los procesados con mínimos cuadrados, mostrando superioridad los modelados con errores GARCH; también (Shamsuddin & Holmes, 1997) afirma que la exactitud predictiva del modelo ARMA multivariante no es estadísticamente diferente de la del modelo ARMA univariante; Los modelos Box-Jenkins han sido comparados con otros métodos, en algunos casos se afirma la superioridad de los mismos (sobre los modelos basados en Markov (Otoom et al., 2015)) y en otros se los combina para obtener un modelo mejorado( (Ghahramani & Thavaneswaran, 2006), (Gairaa, Khellaf, Messlem, & Chellali, 2016)).
8 2.1. Metodología Box-Jenkins.
En ocasiones es muy difícil o no se conoce las determinantes de la variable que se requiere pronosticar o no se dispone de las variables explicativas, es aquí en donde los modelos Box-Jenkins muestran una superioridad, ya que éstos modelos realizan las predicciones basándose en el pasado de la misma variable (Holton, 2007).
Dentro de la metodología Box-Jenkins existen varias restricciones para las series de tiempo, como por ejemplo la estacionariedad, si la serie es no estacionaria se la debe transformar hasta alcanzar tal condición (Bowerman et al., 2007).
El propósito de Box y Jenkins, es identificar un modelo que describa el conjunto de datos pero con el número mínimo de elementos, es decir obtener una ecuación lo más reducida posible pero que a la vez cumpla los requerimientos para su aceptación (Gujarati & Porter, 2010).
Por ello, en la presente investigación se describen los conceptos básicos y el procedimiento a desarrollar para la construcción de modelos que pertenecen a esta metodología, con el fin de obtener los óptimos para su posterior aplicación en los pronósticos.
2.2. Series de tiempo.
“Los datos de una serie de tiempo son una secuencia de observaciones ordenadas en forma natural con respecto al tiempo” (Holton, 2007).En esta investigación se utiliza la metodología de Box – Jenkins cuya aplicación es especialmente adecuada para series con más de 50 observaciones (Vasileiadou & Vliegenthart, 2013) , cuya variable debe ser univariante.
2.3. Estacionariedad.
La metodología de Box – Jenkins describe series estacionarias, por lo tanto la serie a pronosticar también debe serlo (Bowerman et al. 2007). La estacionariedad ocurre cuando la media y varianza son constantes en el tiempo (Hernández Alonso, 2007).
2.3.1. Función de autocorrelación.
Autocorrelación.
9
las observaciones se mueven juntas con pendiente creciente, y si es negativa de manera decreciente (Autocorrelación, 2007).
Correlograma.
La representación gráfica de los valores de las autocorrelaciones a diferentes rezagos de tiempo se denomina correlograma (Universidad Autónoma de Madrid, 2004).
La extensión del correlograma inicia desde k=1 hasta la longitud del rezago, que se define como un tercio o la cuarta parte de la longitud de la serie de tiempo (Gujarati & Porter, 2010). Se debe calcular el coeficiente de correlación simple y parcial para cada uno de los rezagos.
En esta investigación se considera una longitud de rezago máxima de 40, ya que es suficiente para notar el comportamiento de la serie.
Función de autocorrelación simple (FAC).
Según, (Bowerman, O'Connell, & Koehler, 2007): “Es una lista, o una gráfica de las autocorrelaciones en los desfasamientos k=1,2,…..”.
La autocorrelación simple en el rezago k, denotada por ρk, se define como:
n b t 2 t k n b t k t t k)
z
z
(
)
z
z
)(
z
z
(
Ecuación 1.
Dónde:
)
1
b
n
(
z
z
n b t t
Ecuación 2.
Función de autocorrelación parcial (FACP).
Según, Bowerman et al. (2007): “Es una lista, o una gráfica de las autocorrelaciones
parciales de la muestra en los desfasamientos k=1,2,…..”. La autocorrelación parcial en el rezago k es:
1 kk
10
k 11 j j j , 1 k 1 k 1 j j k j , 1 k k kk
1
si k = 2,3,…. Ecuación 4.Dónde: j k , 1 k kk j , 1 k
kj
para j = 1,2,….., k-1 Ecuación 5.Significancia estadística de las autocorrelaciones.
Es importante conocer en que rezago los coeficientes de autocorrelación son estadísticamente significativos, ya que esto es de gran ayuda para obtener un orden tentativo del modelo (Gujarati & Porter, 2010).
Intervalos de confianza al 95%.
Bartlett (citada en Gujarati & Porter, 2010) demostró que “si una serie de tiempo es
puramente aleatoria, es decir, si es una muestra de ruido blanco, los coeficientes de autocorrelación muestrales ρˆk son aproximadamente ρˆk ~ N (0, 1/n)”
Es decir, los coeficientes de correlación se encuentran normalmente distribuidos, con media cero y varianza igual a 1 sobre el tamaño de la muestra, tales coeficientes se calculan y grafican para saber hasta que rezago son estadísticamente significativos (Gujarati & Porter, 2010).
Considerando las propiedades de la distribución normal, los intervalos de confianza de 95% se calculan con la siguiente ecuación (Gujarati & Porter, 2010):
n
/
1
*
96
.
1
ob
Pr
Ecuación 6.Estadístico “Q” de Ljung-Box
Otra manera de evaluar la significancia estadística de los coeficientes de autocorrelación, es por medio del estadístico de Ljung-Box el cual consiste en una prueba que se utiliza para determinar si una serie es de ruido blanco (Gujarati & Porter, 2010).
En esta investigación, se utiliza el estadístico de Ljung-Box porque sus propiedades son superiores al Q estadístico de Box-Pierce.
m
k
n
)
2
n
(
n
LB
m 1 k 2 k2
11 2.3.2. Error estándar.
El error estándar es la raíz cuadrada de la varianza y se calcula con el fin de medir la precisión de los valores estimados (Gujarati & Porter, 2010).
ianza
var
ee
Ecuación 8.2.3.3. t estadístico.
El t estadístico es la relación que existe entre el coeficiente estimado y su correspondiente error estándar (Gujarati & Porter, 2010).
ee
/
t
Ecuación 9.2.3.4. T. crítico
El estadístico tau (τ) crítico de MacKinnon, se utiliza para evaluar la hipótesis nula dentro del análisis de raíz unitaria. Este estadístico está en función del número de datos de la serie y de ciertos coeficientes ya establecidos, los cuales han sido obtenidos de (MacKinnon, 2010) y se muestran en el Anexo 1.
El valor tau (τ) crítico se evalúa para el 1%, 5% y 10% de probabilidad, y para tres posibles modelos que puede adoptar la serie en estudio (Gujarati & Porter, 2010). Su cálculo se realiza con la siguiente ecuación:
3 3 2 2 1 crítico
T
T
T
.
Ecuación 10.Dónde: T es el número de datos de la serie y,
β son los coeficientes obtenidos del Anexo 1.
2.3.5. Estadístico “d” de Durbin – Watson.
El estadístico de Durbin – Watson, se calcula con el fin de detectar la presencia de autocorrelación en los residuos y de una regresión espuria (Gujarati & Porter, 2010).
T 1 t 2 t T 2 t 2 1 t te
)
e
e
(
12
Dónde: et, es el residual a la observación en el tiempo t. T, es el número de datos de la serie de tiempo.
Si el coeficiente de determinación es mayor a éste estadístico, entonces se tiene una regresión espuria (Gujarati & Porter, 2010).
M. G. Kendall y W. R. Buckland (citada en Gujarati & Porter, 2010), afirman que “la correlación se describe como espuria si es inducida por el método de manejo de datos
y no está presente en la información original.” Por lo tanto, si se realiza la regresión sobre una serie de este tipo, los resultados carecerían de sentido (Gujarati & Porter, 2010).
2.3.6. Prueba de raíz unitaria.
Una manera diferente de determinar la estacionariedad en una serie, es utilizar la prueba de raíz unitaria. Si se presenta una raíz igual a 1 en la ecuación característica del modelo, entonces la serie es no estacionaria caso contrario es estacionaria, además este test sirve para detectar la presencia de una serie explosiva (Bowerman et al. 2007). Se dice que una serie es explosiva cuando tiene un crecimiento desmedido mostrando un comportamiento poco lógico (Universidad Autónoma de Madrid, 2004).
Existen varias pruebas de raíz unitaria, una de las más populares y utilizada en esta investigación es la de Dickey – Fuller, la cual se basa en la siguiente regresión:
t 1 t
t
Y
u
Y
Ecuación 12.Dónde:
(
1
)
1
1
La prueba de Dickey – Fuller se calcula para tres posibles modelos en los cuales se evalúa la hipótesis nula de que δ=0:
Caminata aleatoria:
t 1 t
t
Y
u
Y
Ecuación 13. Caminata aleatoria con deriva:
t 1 t 1
t
Y
u
Y
13
Camina aleatoria con deriva alrededor de una tendencia determinista:
t 1 t 2
1
t
t
Y
u
Y
Ecuación 15.La serie es estacionaria si se rechaza la hipótesis nula, caso contrario no lo es (Bowerman et al., 2007).
Es importante señalar que los valores críticos de la prueba tau para evaluar la hipótesis nula son diferentes para cada uno de los modelos de la prueba DF.
El procedimiento de cálculo es el siguiente: Se estima los coeficientes de los tres posibles modelos de la prueba DF mediante mínimos cuadrados ordinarios (MCO); se divide el coeficiente de Yt-1 entre su error estándar para obtener el estadístico tau (τ) y se calcula el tau crítico de MacKinnon (Gujarati & Porter, 2010).
EL método de mínimos cuadrados ordinarios, es un método bastante conocido dentro de análisis de regresión debido a sus propiedades estadísticas. El objetivo principal de este método, es estimar coeficientes de tal manera que minimicen la suma de errores al cuadrado, para mayor información se recomienda revisar el libro “Econometría 5ta ed.” de los autores: Gujarati & Porter.
Si el valor absoluto del estadístico tau (τ) es mayor al crítico de MacKinnon, se rechaza la hipótesis nula y la serie es estacionaria. Caso contrario, si el valor tau (τ) calculado no supera el tau crítico, se acepta la hipótesis nula y la serie es no estacionaria (Gujarati & Porter, 2010).
Cabe recalcar que si δ>0, el modelo no se considera ya que la serie sería explosiva (Gujarati & Porter, 2010). Además, δ puede tomar únicamente valores menores a 0, debido a que está relacionada directamente con el coeficiente de correlación.
2.3.7. Transformación de las series no estacionarias.
14
A continuación se explica el procedimiento que se ejecuta para realizar la diferenciación:
Dada una serie de tiempo no estacionaria:
y
1,
y
2,...,
y
nse obtiene la primeradiferencia:
z
2
y
2
y
1,
z
3
y
3
y
2,...,
z
n
y
n
y
n1 y se analiza si la nueva serie es o no estacionaria, en caso de no serlo se procede a obtener las segundas diferencias, este proceso se repite hasta llegar a la estacionariedad, así la serie estacionaria se denomina como serie de trabajo. Cabe recalcar que por lo general no se necesita más de dos diferenciaciones (Bowerman et al., 2007).2.4. Estacionalidad.
La estacionalidad se presenta en una serie, cuando ésta se construye con datos registrados trimestral, mensual, semanal, entre otros, y conservan patrones similares de comportamiento (Antunez Irgoin, 2011).
2.4.1. Transformación de una serie de tiempo estacional a estacionaria.
Por lo general una serie de tiempo estacional, tiene una variabilidad considerable respecto a su varianza. Una manera de estabilizar la varianza es por medio del uso de una transformación de pre-diferenciación (Bowerman et al., 2007).
En ésta investigación, se utiliza como transformación de pre-diferenciación la raíz cuadrada, raíz cuarta y los logaritmos naturales de la serie en estudio, se procede a examinar sus respectivas desviaciones estándar, de las cuales se elige la que tiene un valor intermedio. No se escoge la serie con menor valor de desviación para evitar una transformación excesiva (Bowerman et al., 2007).
Es importante recordar, que la desviación estándar es una medida de cuan alejados están los datos de su media aritmética (Murray R., 1997).
Una vez que se estabiliza la varianza, se procede a estabilizar la media con el fin de obtener una serie de tiempo estacionaria, para lo cual se realiza una transformación de estacionalidad (Bowerman et al., 2007).
15
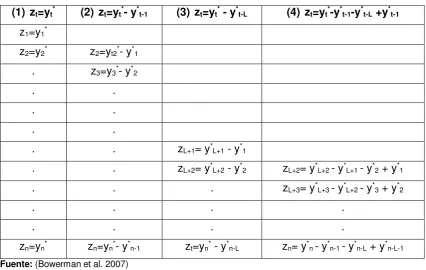
Tabla 2.1. Cuatro transformaciones de estacionalidad.
(1) zt=yt* (2) zt=yt*- y*t-1 (3) zt=yt* - y*t-L (4) zt=yt*-y*t-1-y*t-L +y*t-1 z1=y1*
z2=y2* z2=yt2*- y*1 . z3=y3*- y*2
. .
. .
. .
. . zL+1= y*L+1 - y*1
. . zL+2= y*L+2 - y*2 zL+2= y*L+2 - y*L+1 - y*2 + y*1
. . . zL+3= y*L+3 - y*L+2 - y*3 + y*2
. . . .
. . . .
zn=yn* zn=yn*- y*n-1 zt=yn* - y*n-L zn= y*n - y*n-1 - y*n-L + y*n-L-1
Fuente: (Bowerman et al. 2007)
Elaboración: Elaboración propia
Dónde: L, representa la estacionalidad, por ejemplo: L=4 si se trata de datos trimestrales y L=12 si son mensuales.
Yt*, es la serie luego de la transformación de pre-diferenciación. Zt, es la serie generada con la transformación de estacionalidad.
En la Tabla 2.1, la primera columna representa los valores pre-diferenciados originales, la segunda genera la primera diferencia regular, la tercera produce la primera diferencia estacional y la cuarta muestra la primera diferencia regular y estacional (Bowerman et al., 2007).
Para seleccionar la serie adecuada, se examina la función de autocorrelación simple (FAC) y la función de autocorrelación parcial (FACP) que se obtiene a partir de los valores de Zt, tanto en el nivel no estacional como en el estacional.
Según Bowerman et al. (2007), en el nivel no estacional el comportamiento de la FAC y FACP está descrito en los desfasamientos 1 a (L-3), y en el nivel estacional por desfasamientos iguales a L, 2L, 3L y 4L.
16 2.5. Modelos Box-Jenkins.
La metodología Box-Jenkins, se divide principalmente en: - Modelos autorregresivos (AR).
- Modelos de media móvil (MA).
- Modelos autorregresivos de media móvil (ARMA).
- Modelos autorregresivos integrados de media móvil (ARIMA).
- Modelos estacionales autorregresivos integrados de media móvil (SARIMA). A continuación se presenta la definición y las características de cada uno de los modelos señalados, así como su respectivo proceso de construcción.
2.5.1. Autorregresivo – AR (p).
Se los denomina modelos autorregresivos, porque generan el presente o futuro en función de su propio pasado, donde “p” indica el número de retardos necesarios
(Universidad Autónoma de Madrid, 2008). Se los representa por medio de la siguiente ecuación: t p t p 2 t 2 1 t 1
t
y
y
....
y
a
y
Ecuación 16.Dónde: yt, es la serie de tiempo. δ, es la media del proceso.
at, es un término de error aleatorio.
Φ1, Φ2,….,Φp, son coeficientes desconocidos que relacionan a yt con su pasado.
Algunas de las características principales de este modelo, se muestran en la Tabla 2.2
Tabla 2.2. Características de los modelos AR (p).
TIPO CARACTERÍSTICA
FAC Decrece de manera exponencial, pero sin llegar a anularse.
FACP
Presenta autocorrelaciones parciales diferentes de cero en los desfasamientos 1, 2,…., p, y autocorrelaciones parciales iguales a cero en los demás desfasamientos.
17 Continúa Tabla 2.2
Intercepto δ
(
1
1
2
...
p)
μ=media del proceso.
Pronósticos Tienden a la media del proceso a medida que aumenta la longitud de la predicción.
Fuente: Adaptado de (Bowerman et al., 2007) y (Universidad Autónoma de Madrid, 2008)
Elaboración: Elaboración propia
2.5.2. Media móvil – MA (q).
Los procesos de media móvil son procesos de memoria limitada, se los llama así ya que muestran variación en los pronósticos hasta una longitud de predicción igual a “q”, luego de éste son iguales a su media (Universidad Autónoma de Madrid, 2008).
t q t q 2 t 2 1 t 1
t
a
a
....
a
a
y
Ecuación 17.Dónde: yt, es la serie de tiempo. δ, es la media del proceso.
at, es un término de error aleatorio.
θ1, θ2,…., θp, son coeficientes que relacionan a yt con sus correspondientes errores pasados, los cuales deben ser estadísticamente independientes.
Las características principales de este modelo, se muestran en la Tabla 2.3
Tabla 2.3. Características de los modelos MA (q).
TIPO CARACTERÍSTICA
FAC
Las autocorrelaciones son diferentes de cero en los desfasamientos 1, 2,…., q, e iguales a cero en los demás desfasamientos.
FACP Decrece de manera exponencial, pero sin llegar a anularse. Intercepto δ
μ=media del proceso. Pronósticos
Son iguales a la media del proceso cuando la longitud de la predicción es mayor al orden del modelo (q), esto sucede debido a la memoria limitada que los caracteriza.
Fuente: Adaptado de (Bowerman et al., 2007) y (Universidad Autónoma de Madrid, 2008)
18
2.5.3. Autorregresivo de media móvil – ARMA (p, q).
Los modelos ARMA, son procesos en los que Yt está explicada no solo por sus retardos, sino también por perturbaciones aleatorias, es decir es una combinación de los modelos autorregresivos (AR) y de medias móviles (MA) (Bowerman et al., 2007).
t q t q 2 t 2 1 t 1 p t p 2 t 2 1 t 1
t
y
y
....
y
a
a
....
a
a
y
Ecuación 18.Dónde: yt, es la serie de tiempo.
δ, es la media del proceso.
at, es un término de error aleatorio.
Φ1, Φ2,…., Φp, θ1, θ2,…., θp, son como ya se mencionó: parámetros que relacionan a yt con su pasado y sus errores.
En la Tabla 2.4 se presentan las principales características.
Tabla 2.4. Características de los modelos ARMA (p, q).
TIPO CARACTERÍSTICA
FAC Decrece de manera exponencial, pero sin llegar a anularse. FACP Decrece de manera exponencial, pero sin llegar a anularse. Intercepto δ
(
1
1
2
...
p)
μ=media del proceso.
Pronósticos Después de “q” períodos, los pronósticos se aproximan a la media del proceso conforme aumenta la longitud de predicción.
Fuente: Adaptado de (Bowerman et al., 2007) y (Universidad Autónoma de Madrid, 2008)
Elaboración: Elaboración propia.
2.5.4. Autorregresivo integrado de media móvil – ARIMA (p, d, q).
Como ya se mencionó anteriormente, para utilizar la metodología de Box-Jenkins se requiere que la serie sea estacionaria. Ahora bien, muchas veces ésta condición no se cumple, por lo cual es obligatorio diferenciar la serie, el número de diferencias
necesarias para llegar a la estacionariedad es denotado por “d”, respectivamente “p” y “q” indican el número de retardos y perturbaciones aleatorias (Bowerman et al., 2007).
Se representa con la siguiente ecuación:
t q t q 2 t 2 1 t 1 p t p 2 t 2 1 t 1
t
z
z
....
z
a
a
....
a
a
19
Dónde: zt, es la serie de tiempo diferenciada estacionaria.
δ, es la media del proceso.
at, es un término de error aleatorio.
Φ1, Φ2,…., Φp, θ1, θ2,…., θp, son como ya se mencionó: parámetros que relacionan a zt con su pasado y sus errores.
Una vez que se ha diferenciado la serie obteniendo la nueva serie estacionaria, dicha serie muestra un comportamiento igual al modelo ARMA, razón por la cual no se mencionan las características de este modelo (Gujarati & Porter, 2010).
Es importante aclarar que, los pronósticos ya no se aproximan a la media, sino a una línea recta que inicia de Y (d) con una pendiente igual a la media del proceso Zt, que es la nueva serie diferenciada estacionaria (Universidad Autónoma de Madrid, 2008).
2.5.5. Estacional autorregresivo integrado de media móvil – SARIMA (p, d, q) (P, D, Q).
Este modelo se emplea en series que tienen periodicidad, con períodos estacionales “L”
menores a un año. Con el fin de modelar los patrones de comportamiento presentes en este tipo de series, se considera retardos regulares (1, 2, 3,…) y estacionales (L, 2L,
3L,…) (Bowerman et al., 2007).
Antes de iniciar con el cálculo del modelo en sí, es necesario realizar dos transformaciones: una de pre-diferenciación y otra de estacionalidad, para de esta manera estabilizar tanto la varianza como la media (Bowerman et al., 2007).
El modelo general está descrito por la siguiente ecuación:
PL t L , P L 2 t L , 2 L t L , 1 p t p 2 t 2 1 t 1
t
z
z
....
z
z
z
....
z
z
t QL t L , Q L 2 t L , 2 L t L , 1 q t q 2 t 2 1 t
1a a .... a a a .... a a
Ecuación 20.
Dónde: zt, es la serie transformada estacionaria.
L, 2L, 3L,…, son los desfasamientos estacionales.
20
Q, es el orden de media móvil estacional. q, es el orden de media móvil regular.
L, es el valor de la periodicidad. Por ejemplo: si la serie es mensual L=12, si es trimestral L=4.
Las propiedades de la función de autocorrelación (FAC) y de la autocorrelación parcial (FACP) de este modelo, son análogas a las propiedades de los métodos descritos anteriormente. La diferencia es que se debe tomar en cuenta los desfasamientos estacionales para identificar el orden P y Q (Bowerman et al., 2007).
2.5.6. Proceso de construcción de los modelos no estacionales.
Los modelos no estacionales son: el modelo autorregresivo (AR), de medias móviles (MA), autorregresivo de medias móviles (ARMA) y autorregresivo integrado de medias móviles (ARIMA).
Antes de iniciar con el proceso de construcción, se debe realizar un análisis de estacionariedad con el fin de evitar realizar una regresión espuria, que por lo general aparece en series no estacionarias (Gujarati & Porter, 2010).
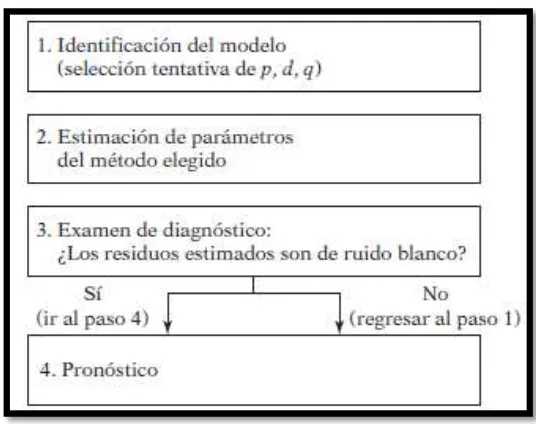
[image:31.595.86.354.527.739.2]Una vez que se afirma que la serie de tiempo a trabajar es estacionaria, se procede a calcular el modelo siguiendo cada una de las fases descritas a continuación. En caso de que el modelo estimado no cumpla con las condiciones establecidas, se debe volver a estimarlo tomando un nuevo orden del modelo (p, d, q), por tal razón la metodología Box-Jenkins es un proceso iterativo (Figura 2.1) (Gujarati & Porter, 2010).
Figura 2.1. Metodología de Box – Jenkins.
21 Identificación.
En la fase de identificación, los datos de la serie se usan para generar la función de autocorrelación simple y parcial (correlograma), con el fin de identificar el orden del modelo y proceder a la estimación del mismo (Universidad Autónoma de Madrid, 2008). Es decir, el objetivo es encontrar un modelo que se ajuste de mejor manera a la serie bajo estudio, tomando los valores más apropiados para p, d y q. En esta fase es importante aplicar el principio de parsimoniapara la selección del modelo más adecuado (Hanke, 2010).
“El principio de parsimonia se refiere a la preferencia por los modelos sencillos por encima de los modelos complejos” (Hanke, 2010).
Estimación.
Una vez identificados los valores de p, d, q, el siguiente paso es determinar los coeficientes de los términos autorregresivos y de medias móviles a incluir en el modelo. Para la estimación se recurre a procedimientos de estimación no lineal, en ésta investigación se ha utilizado el método de mínimos cuadrados no lineales (MCNL) (Bowerman et al., 2007).
El método de mínimos cuadrados no lineales (MCNL), se basa al igual que los mínimos cuadrados ordinarios (MCO) en determinar los valores de los parámetros que reduzcan la suma de residuos al cuadrado. La gran diferencia es que en el caso de MCNL, este proceso se realiza en forma iterativa. Para obtener mayor información del cálculo que se realiza, se sugiere revisar (Chapra & Canale, 2007).
Verificación del modelo.
Una de las maneras más simples de comprobar si el modelo estimado es correcto, es probar que los residuales sean de ruido blanco (Bowerman et al., 2007). Pero también existen otros criterios de evaluación, en este caso se ha considerado además el coeficiente de determinación (R2). Es decir, de todos los modelos estimados se escoge el modelo que tenga el mayor coeficiente de determinación, y que además sus residuos sean de ruido blanco o puramente aleatorio.
22 Predicción.
Ya que se ha obtenido un modelo adecuado y suficiente, se procede a determinar los pronósticos requeridos de la serie de tiempo. Es fundamental recordar si se realizó o no alguna transformación o diferenciación a la serie de tiempo, ya que al momento de
calcular las predicciones se debe “deshacer” tales cambios. Por ejemplo, si la serie de tiempo fue diferenciada una vez, entonces se la debe volver a integrar para obtener el pronóstico correcto (Bowerman et al., 2007).
La metodología de Box y Jenkins, se utiliza con bastante popularidad ya que los pronósticos calculados con los modelos seleccionados son bastante confiables. “Una
razón de la popularidad del proceso de construcción de modelos ARIMA es su éxito en
el pronóstico” (Gujarati & Porter, 2010).
2.5.7. Proceso de construcción del modelo estacional SARIMA.
Para la construcción de un modelo SARIMA, se sigue los siguientes pasos:
- Se realiza una transformación de pre-diferenciación y una de estacionalidad con el fin de obtener la serie de trabajo, tales transformaciones se han descrito en la sección 2.3.1.
- Se obtiene la FAC y FACP de la serie, y se identifica un orden tentativo tanto para p,d,q en el nivel no estacional, y P,D,Q en el nivel estacional.
- Ya que se ha identificado el orden, se procede a calcular el modelo por medio del método de mínimos cuadrados no lineales (MCNL) hasta obtener su convergencia (Bowerman et al., 2007).
- Una vez estimados los parámetros, se evalúa la consistencia del modelo para su posterior aplicación en los pronósticos. Los criterios de evaluación son los mismos que se utiliza en los modelos no estacionales. En caso de cumplir con los requerimientos, el modelo se acepta y se puede pronosticar con el mismo, caso contrario se vuelve a elegir el orden p, d, q y P, D, Q hasta obtener un modelo aceptable.
2.6. Metodología de programación.
23
2.6.1. Descripción de las herramientas virtuales.
La programación de cada uno de los modelos se realizó en Microsoft Visual Studio 2010, con el lenguaje de programación denominado: Visual Basic.
Se puede encontrar los modelos en:
“http://www.hydrovlab.utpl.edu.ec/SIMULACI%C3%93N/pAnalisisEstocastico/tabid/141 /language/es-ES/Default.aspx”
2.6.2. Descripción del software utilizado para el desarrollo de las herramientas.
El software base que se utiliza en la presente investigación es Microsoft Visual Studio 2010. A continuación se presenta una breve descripción de los principales componentes que se utilizaron.
Microsoft Visual Studio 2010.
Es un software completo e ideal para el desarrollo de páginas web, además trabaja con varios lenguajes de programación como: Visual Basic, Visual C#, Visual C++ y Visual F# facilitando la creación de diversos proyectos (MSDN Library, 2001).
“Visual Studio es un conjunto completo de herramientas de desarrollo para la generación de aplicaciones web ASP.NET, Servicios Web XML, aplicaciones de escritorio y
aplicaciones móviles” (MSDN Library, 2001).
Página Web.
Las páginas web en la presente investigación, han sido desarrolladas por medio de asp.net, bajo el lenguaje de programación: Visual Basic. El sitio web al que se enlazan cada uno de los métodos es: http://www.hydrovlab.utpl.edu.ec/.
Es importante saber que para acceder de manera completa a las herramientas virtuales del HYDROVLAB, es necesario registrarse por medio de un usuario y contraseña.
Lenguaje de Visual Basic
24
El código escrito en este lenguaje se encuentra en la ventana que tiene extensión
[image:35.595.88.509.140.446.2]“aspx.vb”. En la Figura 2.2 se muestra un fragmento del código que ha sido desarrollado.
Figura 2.2. Lenguaje Visual Basic de la Página Web AR_p.aspx.vb
Fuente: Elaboración propia.
Lenguaje HTML
25
Figura 2.3. Lenguaje HTML de la Página Web AR_p.aspx
Fuente: Elaboración propia.
Hojas de estilo.
Las hojas de estilo se encuentran predefinidas y contienen el formato del HYDROVLAB, las mismas que trabajan bajo la extensión: “.css”. Estas hojas se cargaron con anterioridad al proyecto, para poderlas aplicar a todos los elementos contenidos dentro de las páginas desarrolladas.
2.6.3. Manuales de uso de cada una de las herramientas.
Se han colocado manuales al inicio de cada una de las páginas, a los cuales se puede
acceder presionando el botón “Descargar manual”, se ha realizado esto con el fin de
brindar mayor comprensión de los métodos y facilidad de uso a los usuarios. 2.6.4. Diagramas de flujo.
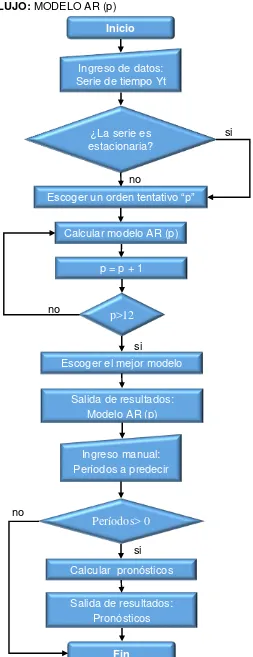
26 DIAGRAMA DE FLUJO: MODELO AR (p)
Figura 2.4. Diagrama de flujo del modelo autorregresivo.
Fuente: Elaboración propia.
Inicio
Fin
Escoger un orden tentativo “p”
¿La serie es estacionaria? Ingreso de datos: Serie de tiempo Yt
p>12
p = p + 1Escoger el mejor modelo
Salida de resultados: Modelo AR (p)
Ingreso manual: Períodos a predecir
Períodos> 0
Calcular pronósticos Calcular modelo AR (p)
Salida de resultados: Pronósticos
si
no
si no
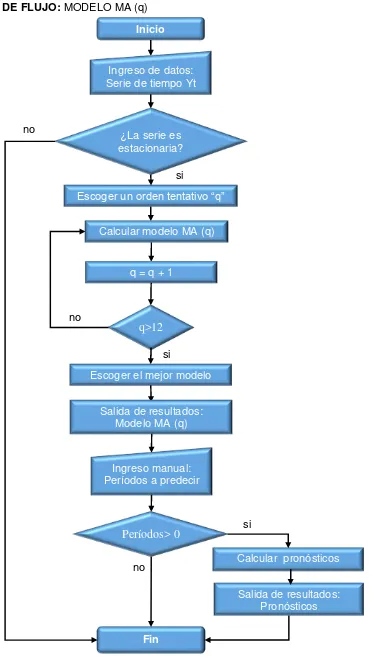
27 DIAGRAMA DE FLUJO: MODELO MA (q)
Figura 2.5. Diagrama de flujo del modelo de media móvil.
Fuente: Elaboración propia.
Inicio
Fin
Escoger un orden tentativo “q”
¿La serie es estacionaria? Ingreso de datos: Serie de tiempo Yt
q>12
q = q + 1Escoger el mejor modelo
Salida de resultados: Modelo MA (q)
Ingreso manual: Períodos a predecir
Períodos> 0
Calcular pronósticos Calcular modelo MA (q)
Salida de resultados: Pronósticos
si
si
si no
no
28 DIAGRAMA DE FLUJO: MODELO ARMA (p, q)
Inicio
p = 0 q = 0 ¿La serie es estacionaria? Ingreso de datos: Serie de tiempo Yt
q>12
q = q + 1p = p + 1 q = 0
Calcular modelo ARMA (p,q)
p > 12
Escoger el mejor modelo
Salida de resultados: Modelo ARMA (p,q)
1
si
si
si no
no
29
Figura 2.6. Diagrama de flujo del modelo autorregresivo de media móvil.
Fuente: Elaboración propia.
Fin
Períodos > 0
Calcular pronósticos
1
Ingreso manual: Períodos a predecir
Salida de resultados Pronósticos
no
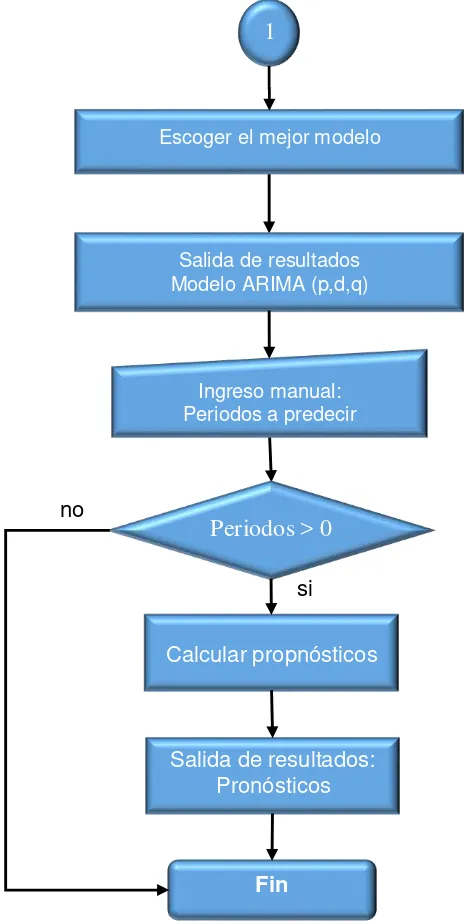
30 DIAGRAMA DE FLUJO: MODELO ARIMA (p, d, q)
Inicio
Diferenciar la serie d = d + 1
¿La serie es estacionaria? Ingreso de datos: Serie de tiempo Yt
d >0
Serie de trabajo = serie original
Serie de trabajo = serie diferenciada
d >12
p=0 q=0
q = q + 1
Calcular modelo ARIMA (p,d,q)
q>12
p >12
p=p+1 q=01
si si si
si
no no
no no
31
Figura 2.7. Diagrama de flujo del modelo autorregresivo integrado de media móvil.
Fuente: Elaboración propia.
1
Escoger el mejor modelo
Salida de resultados Modelo ARIMA (p,d,q)
Ingreso manual: Periodos a predecir
Calcular propnósticos
Periodos > 0
Salida de resultados: Pronósticos
32
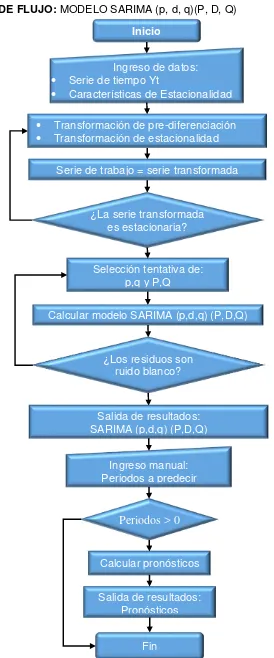
[image:43.595.150.424.68.726.2]DIAGRAMA DE FLUJO: MODELO SARIMA (p, d, q)(P, D, Q)
Figura 2.8. Diagrama de flujo del modelo estacional autorregresivo integrado de media móvil.
Fuente: Elaboración propia.
Inicio
Ingreso de datos:
Serie de tiempo Yt
Características de Estacionalidad
Calcular modelo SARIMA (p,d,q) (P,D,Q) Selección tentativa de:
p,q y P,Q ¿La serie transformada
es estacionaria?
Transformación de pre-diferenciación
Transformación de estacionalidad
Serie de trabajo = serie transformada
¿Los residuos son ruido blanco?
Salida de resultados: SARIMA (p,d,q) (P,D,Q)
Ingreso manual: Periodos a predecir
Periodos > 0
Salida de resultados: Pronósticos Calcular pronósticos
34
3.1. Utilización y análisis de las herramientas desarrolladas.
A continuación se presenta un análisis y una breve descripción de los cálculos realizados en cada uno de los modelos.
Para conocer de una manera más detallada el uso de las herramientas, se recomienda descargar el manual del usuario, el cual se lo puede conseguir al presionar el botón
“DESCARGAR MANUAL” contenido en la página de cada modelo.
3.1.1. Autorregresivo – AR (p).
Para ilustrar el presente método, se utilizó los datos de la Tabla 4.1, Anexo 2, que corresponden a la primera diferencia de los datos de caudal originales (Tabla 4.2, Anexo 2).
Primero se debe realizar un análisis de estacionariedad de la serie actual, para lo cual se procede a examinar: el gráfico, la función de autocorrelación simple (FAC), la función de autocorrelación parcial (FACP) y el test de raíz unitaria de Dickey-Fuller de la serie de tiempo.
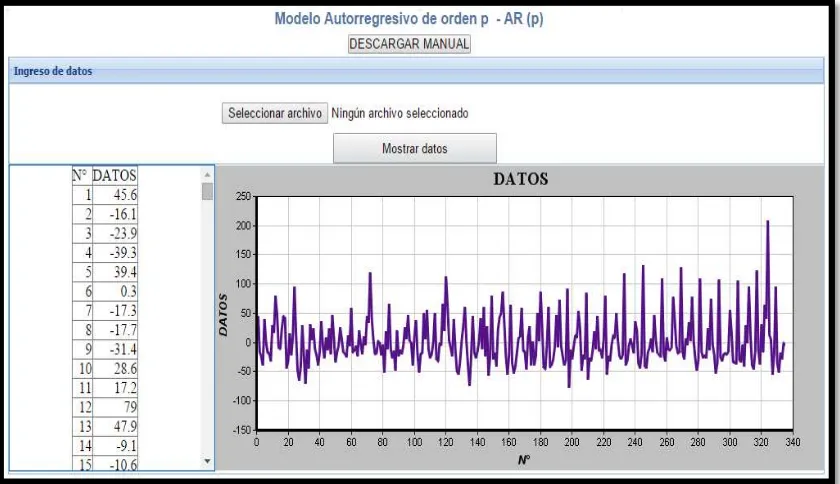
Gráfico de la serie.
“Si al parecer los n valores fluctúan con variación constante respecto de una media constante
μ, entonces es razonable pensar que la serie temporal es estacionaria” (Bowerman et al. 2007).
35
Figura 3.1. Recorte de página del modelo AR del gráfico de la serie.
Fuente: Elaboración propia.
Función de autocorrelación simple y parcial.
En la Figura 3.2 se presenta los valores tanto de la función de autocorrelación simple, como de la parcial, además se muestra sus correspondientes correlogramas para apreciar de una mejor manera el comportamientos de tales funciones.
Figura 3.2. Recorte de página del modelo AR de los correlogramas.
[image:46.595.89.509.88.330.2] [image:46.595.88.512.473.727.2]36
Prueba de raíz unitaria de Dickey-Fuller.
Como un último análisis de estacionariedad se realiza la prueba de Dickey-Fuller, con la cual se determinará de manera contundente si se trata o no de una serie estacionaria.
Como ya se mencionó anteriormente en la sección 2.2.6, la serie es estacionaria si el valor absoluto del estadístico tau (τ) es mayor al crítico de MacKinnon, caso contrario no lo es.
Figura 3.3. Recorte de página del modelo AR de la prueba de raíz unitaria.
Fuente: Elaboración propia.
Se puede ver claramente en la Figura 3.3 que los valores absolutos de estadístico tau “t”
superan a los absolutos críticos de MacKinnon, por lo tanto la serie es estacionaria.
Orden “p” del modelo.
Los correlogramas son bastante útiles a la hora de elegir el orden tentativo del modelo, ya que se está estudiando los modelos autorregresivos se debe examinar la función de autocorrelación parcial. En el gráfico de esta función (Figura 3.2), se puede ver que existen correlaciones significativas en los rezagos: 2, 3, 5, 6, 7, 8, 9, 10, 12 y otros, pero el que sobresale aún más es el rezago 12, por lo tanto el orden tentativo seleccionado es p=12, además éste es el orden máximo que se permite en la programación del modelo.
Estimación del modelo.
Cabe recalcar que en la presente investigación se ha considerado un orden máximo de p=12, ya que la mayoría de series contienen datos mensuales, además si se considera un orden mayor no se cumple con el principio de parsimonia.
37
[image:48.595.90.523.409.673.2]En la Figura 3.4 se presenta el valor de cada variable resultante de la estimación del modelo autorregresivo de orden 12, así como su correspondiente ecuación.
Figura 3.4. Recorte de página del modelo AR de las variables del modelo.
Fuente: Elaboración propia.
Análisis de residuos.
La mayoría de las autocorrelaciones se encuentran dentro de las bandas (Figura 3.5), a excepción de los desfasamientos 1, 2 y 12, a pesar de que se ha considerado estos rezagos en el modelo, lo que significa que los residuos no son puramente aleatorios, pese a ello se continúa con el cálculo a fin de describir el proceso que siguen los modelos autorregresivos.
Figura 3.5. Recorte de página del modelo AR del análisis de residuos.
Fuente: Elaboración propia.
Pronósticos.
38
Se puede ingresar cualquier número de períodos a predecir, pero se recomienda realizar predicciones no mayores a un año, ya que si lo son, las estimaciones tendrían un alto valor de incertidumbre y no serían muy confiables (Hanke, 2010).
En este caso se calcula 36 pronósticos, los valores y su gráfica se puede ver en la Figura 3.6
Figura 3.6. Recorte de página del modelo AR de los pronósticos.
Fuente: Elaboración propia.
A continuación, se detalla el cálculo de 2 pronósticos para los períodos: 336 y 337. Antes de iniciar, se recomienda reemplazar los subíndices de acuerdo a la Ecuación 16.:
yt = 0.7015 + 0.0488 yt-1 + 0.0296 yt-2 - 0.034 yt-3 + 0.0219 yt-4 + 0.1005 yt-5 - 0.1104 yt-6 + 0.0039 yt-7 - 0.0521 yt-8 - 0.1238 yt-9 - 0.1127 yt-10 - 0.0032 yt-11 + 0.7108 yt-12
Seguidamente, se procede al cálculo del pronóstico para los 2 períodos: - Período 336:
La ecuación para el período 336 queda de la siguiente manera:
y336 = 0.7015 + 0.0488 y335 + 0.0296y334 - 0.034y333 + 0.0219 y332 + 0.1005 y331 - 0.1104 y330 + 0.0394 y329 - 0.0521 y328 - 0.1238 y327 - 0.1127 y326 - 0.0032 y325 + 0.7108 y324
Se sustituyen los valores correspondientes de Yt:
y336=0.7015 + 0.0488 (-3.6) + 0.0296 (-1.3) - 0.034 (-27.8) + 0.0219 (-17.4) + 0.1005 (-51.3) - 0.1104 (-36) + 0.0394 (94.6) - 0.0521 (-19.7) - 0.1238 (-53.9) - 0.1127 (5) - 0.0032 (12.9) + 0.7108 (207.4)
Se resuelve los cálculos:
y336 = 0.7015 - 0.1756 - 0.0385 + 0.9452 - 0.3811 - 5.1556 + 3.9744 + 3.7272 + 1.0264 + 6.6728 - 0.5635 - 0.0413 + 147.4199
39 - Período 337:
Para éste período la ecuación es:
y337 = 0.7015 + 0.0488 y336 + 0.0296y335 - 0.034y334 + 0.0219 y333 + 0.1005 y332 - 0.1104 y331 + 0.0394 y330 - 0.0521 y329 - 0.1238 y328 - 0.1127 y327 - 0.0032 y326 + 0.7108 y325
Al reemplazar los valores de Yt, se tiene:
y337=0.7015 + 0.0488 (158.1118) + 0.0296 (-3.6) - 0.034 (-1.3) + 0.0219 (-27.8) + 0.1005 (-17.4) - 0.1104 (-51.3) + 0.0394 (-36) - 0.0521 (-94.6) - 0.1238 (-19.7) - 0.1127 (-53.9) - 0.0032 (5) + 0.7108 (12.9)
Se resuelve los cálculos:
y337 = 0.7015 + 7.7159 - 0.1066 + 0.0442 - 0.6088 - 1.7487 + 5.6635 - 1.4184 - 4.9287 + 2.4389 + 6.0745 - 0.016 + 9.1693
El resultado final es: y337 =22.9806
La diferencia entre el pronóstico aquí calculado y el obtenido con página, se debe al número de decimales.
Finalmente, se genera la regresión del modelo sobre la serie original, en la Figura 3.7 se puede ver que éstas son bastante similares.
Figura 3.7. Recorte de página del modelo AR del resultado de la regresión.
40 3.1.2. Media móvil – MA (q).
Los datos utilizados en este modelo son los mismos del modelo anterior y están en la Tabla 4.1, Anexo 2
Como ya se mencionó anteriormente, el primer paso es realizar un análisis de estacionariedad. Ya que se está trabajando con la misma serie de tiempo, que se conoce es estacionaria, tal análisis se suprime y se pasa directamente a la identificación tentativa de “q”.
Función de autocorrelación simple y parcial.
[image:51.595.88.509.302.535.2]Se muestra los correlogramas de la serie en la Figura 3.2 con el fin de facilitar la selección del orden del modelo.
Figura 3.8. Recorte de página del modelo MA de los correlogramas.
Fuente: Elaboración propia.
Orden “q” del modelo.
Al inspeccionar la función de autocorrelación simple (FAC) en la Figura 3.8, se puede ver que las correlaciones son significativas en los rezagos: 3, 5, ,6 7, 8, 9, 10, 11, 12 y en otros rezagos superiores, pero el que se toma en cuenta para el cálculo es el máximo permitido, por lo tanto el orden tentativo seleccionado es q=12.
Estimación del modelo.
41
En la Figura 3.9 se muestran las variables del modelo de media móvil de orden 12, con su respectivo valor.
Figura 3.9. Recorte de página del modelo MA de las variables del modelo.
Fuente: Elaboración propia.
Análisis de residuos.
[image:52.595.90.510.406.685.2]Una vez más, algunas correlaciones se salen de las bandas de la FAC (Figura 3.10) aunque se ha tomado el orden mayor (q=12), por lo que se sugiere utilizar un modelo más avanzado para tener mayor seguridad en los pronósticos.
Figura 3.10. Recorte de página del modelo MA del análisis de residuos.
42 Pronósticos.
Al igual que en el caso anterior, se calcula 36 pronósticos y sus valores con su gráfica correspondiente se presenta en la Figura 3.11.
Figura 3.11. Recorte de página del modelo MA de los pronósticos.
Fuente: Elaboración propia.
La linealidad que presentan los pronósticos a partir del período 12, se considera normal debido a las propiedades de los modelos de media móvil. Pues como se menciona en la sección 2.5.2,éstos modelos son de memoria limitada ya que presentan variación en los pronósticos
hasta una longitud igual a “q” (Universidad Autónoma de Madrid, 2008), en este caso q=12, luego de éste son iguales a su media.
Para obtener los pronósticos de este modelo, se hace referencia a la Ecuación 17. Además, es necesario tener los residuales resultantes de la regresión.
yt = 1.7252 + 0.0968 at-1 + 0.0060 at-2 - 0.1271 at-3 - 0.0221 at-4 + 0.184 at-5 - 0.1003 at-6 + 0.1065 at-7 - 0.1165 at-8 - 0.1896 at-9 - 0.1922 at-10 - 0.0579 at-11 + 0.6655 at-12
- Período 336:
La ecuación para el período 336 queda de la siguiente manera:
y336 = 1.7252 + 0.0968 a335 + 0.0060 a334 - 0.1271 a333 - 0.0221 a332 + 0.184 a331 - 0.1003 a330 + 0.1065 a329 - 0.1165 a328 - 0.1896 a327 - 0.1922 a326 - 0.0579 a325 + 0.6655 a324
Se sustituyen los valores correspondientes de Yt:
43 Se resuelve las operaciones:
y336 = 1.7252 - 0.8717 - 0.0216 + 0.1293 + 0.2723 - 8.1494 + 1.4895 + 4.1354 + 2.9521 + 2.5880 - 7.9725 + 0.4248 + 99.7585
El resultado final es: y336 =96.4599
- Período 337:
Para el período 337, la ecuación es:
yt337 = 1.7252 + 0.0968 a336 + 0.0060 a335 - 0.1271 a334 - 0.0221 a333 + 0.184 a332 - 0.1003 a331 + 0.1065 a330 - 0.1165 a329 - 0.1896 a328 - 0.1922 a327 - 0.0579 a326 + 0.6655 a325
Al reemplazar los valores de Yt, se tiene:
yt337 = 1.7252 + 0.0968 (0) + 0.0060 (-9.005) - 0.1271 (-3.606) - 0.0221 (-1.017) + 0.184 (-12.32) - 0.1003 (-44.29) + 0.1065 (-14.85) - 0.1165 (38.83) - 0.1896 (-25.34) - 0.1922 (13.65) - 0.0579 (41.48) + 0.6655 (-7.336)
Se resuelve los cálculos:
yt337 = 1.7252 + 0 - 0.0540 + 0.4583 + 0.0225 - 2.2669 + 4.4423 - 1.5815 - 4.5237 + 4.8045 + 2.6235 - 2.4017 - 4.8821
El resultado final es: y337 =-1.6336
Nuevamente, las diferencias entre pronósticos se deben al número de decimales. Finalmente, en la Figura 3.12 se grafica la regresión del modelo sobre la serie original.
Figura 3.12. Recorte de página del modelo MA del resultado de la regresión.
44
3.1.3. Autorregresivo de media móvil – ARMA (p, q).
Al igual que los métodos anteriores, se utiliza los datos de la Tabla 4.1, Anexo 2. De esta serie se conoce que es estacionaria, y por tal razón se pasa directamente a la identificación del modelo.
Orden “p” y “q” del modelo.
Como ya se indicó en la sección 2.4.1.3, las características de los correlogramas resultantes de la FAC y FACP decrecen de una manera bastante similar, por lo que no son de gran ayuda al momento de identificar un orden tentativo tanto para “p” como para “q”.
Estimación del modelo.
Con el objetivo de brindar al usuario el método ARMA más aceptable y considerando que no
se tiene una estimación previa para “p” y “q”, se ha optado por realizar el cálculo de una serie
de modelos que van desde el orden ARMA (0,1) hasta ARMA (12,12).
Es decir, se computa un total de 168 modelos, de los cuales se selecciona el que tenga un mayor coeficiente de determinación y que a su vez, los residuos sean puramente aleatorios. Este procedimiento se realiza en el algoritmo escrito para la automatización del modelo, el cual da como resultado el modelo ARMA (12,7) que se visualiza en la Figura 3.13.
Figura 3.13. Recorte de página del modelo ARMA de las variables del modelo.
Fuente: Elaboración propia.
Análisis de residuos.
45
Figura 3.14. Recorte de página del modelo ARMA del análisis de residuos.
Fuente: Elaboración propia.
Por lo tanto el modelo ARMA (12, 7), se ajusta de una mejor manera a la serie que los antes estimados: AR (12) y MA (12).
Pronósticos.
[image:56.595.91.508.87.351.2]Los 36 períodos proyectados se muestran en la Figura 3.15. En la misma se puede ver que los resultados siguen un patrón similar al de la serie original, lo que indica que el modelo es correcto.
Figura 3.15. Recorte de página del modelo ARMA de los pronósticos.