Facultad de Estad´ıstica Trabajo de Grado Junio 2017, pp. 1-31
Aproximaci´on Bayesiana de un modelo semiparam´etrico
Cheimi Sayuri Toquica Vargasa
Wilmer Pineda R´ıos.b
Resumen
Los modelos de regresi´on param´etrica tienen como objetivo analizar la relaci´on entre la respuesta y las variables explicativas, esta relaci´on esta dada por una una funci´on de distribuci´on conocida que facilita la estimaci´on de los par´ametros y la interpretaci´on del modelo. Sin embargo, es evidente que pueden existir relaciones complejas o no lineales. En tales circunstancias una posible soluci´on es el uso de polinomios de orden superior, aunque esta pr´actica puede aumentar la complejidad del modelo, y dificultar su interpretaci´on.Por lo tanto, el enfoque param´etrico no provee las he-rramientas necesarias para que el ajuste del modelo sea adecuado. La flexibilidad de los modelos semiparam´etricos permite hacerle frente a tales situaciones, dado que poseen la ventaja de que las variables no necesariamente sigan una distribuci´on de probabilidad te´orica definida, sino que uti-lizan m´etodos que mezclan la estimaci´on de m´axima verosimilitud con t´ecnicas de suavizaci´on.La estimaci´on de regresi´on semiparam´etrica obtenida mediante el suavizado de splines penalizados se puede expresar bajo una estructura de modelos mixtos.Esto facilita los c´alculos de las estimaciones y conduce a una amplia selecci´on de t´ecnicas computacionales para modelos mixtos y bayesianos. Por tal raz´on este trabajo propone la estimaci´on de un modelo semparametrico desde un enfoque Bayesiano utilizando m´etodos computacionales en R, a trav´es de los cuales se comprueba si la estimaci´on bayesiana resulta ser mejor que la estimaci´on cl´asica.
Palabras clave:P-splines, Modelos Mixtos, modelos semiparm´etrico bayesianos.
Abstract
The parametric regression models aim to analyze the Relationship between the response and explanatory variables, this relation is given by a known distribution function that facilitates the estimation of the parameters and the interpretation of the model. However, it is evident that complex or non-linear relations may exist. In such circumstances a possible solution is the use of higher-order polynomials, although this practice may increase the complexity of the model and make it difficult to interpret it. Therefore, the parametric approach does not provide the necessary tools to make the model fit . The flexibility of the semi-parametric models allows them to deal with such situations, since they have the advantage that the variables do not necessarily follow a defined theoretical probability distribution, but use methods that mix the maximum likelihood estimation with smoothing techniques. Of semiparametric regression obtained by the smoothing of penalized splines can be expressed as a structure of mixed models. This facilitates estimation calculations and leads to a wide selection of computational techniques of mixed and Bayesian models. For this reason, this work proposes the estimation of a semiparametric model from a Bayesian approach using computational methods in R, by which it is possible to verify if the Bayesian estimation proves to be better than the classical estimate.
Keywords:P-splines, Mixed Models,Bayesian Semiparametrics.
1. Introducci´
on
Los modelos de regresi´on param´etrica tienen como objetivo analizar la relaci´on entre las variables, y parten de una funci´on de distribuci´on conocida que facilita la estimaci´on de los par´ametros que mejor se ajustan al comportamiento de los datos. Cuando la relaci´on entre las variables es compleja o no lineal, el enfoque param´etrico no provee las herramientas para que el ajuste del modelo sea adecuado, sin embargo es posible obtener un ajuste de los datos mediante modelos polin´omicos
(param´etricos), puesto que a mayor grado del polinomio el ajuste de los datos mejora, no obstante tener un modelo polin´omico de grado elevado puede aumentar la complejidad del modelo, disminuir su precisi´on y dificultar su interpretaci´on.
En estos escenarios es factible que los modelos no param´etricos sean la mejor opci´on para dar soluci´on a esta limitante, dado que su principal ventaja es la flexibilidad que poseen para el ajuste de los datos, lo cual se debe a que la relaci´on entre las variables es determinada por los datos, mientras que en un marco param´etrico la relaci´on es definida por el modelo considerado.
Actualmente existen diversos modelos de regresi´on no param´etricos que permiten modelar dos variables que presenten una relaci´on compleja o no lineal, entre los cuales est´an los m´etodos kernel, regresiones spline, regresiones spline penalizadas, entre otros.
Estos met´odos de suavizamiento y ajuste de datos tienen un papel importante en la actualidad; muchos trabajos y una serie de libros han aparecido (Silverman, 1986; Eubank, 1988; Hastie y Tibshirani, 1990; Hardle ,1990; Wahba, 1990; Wand y Jones, 1993; Verde y Silverman, 1994).
En ocasiones se utiliza el t´ermino “no-param´etrico” para referirse a estos modelos, pero este nombre es solo adecuado si se utilizan modelos tipo kernel ya que el suavizado con splines se hace mediante par´ametros. (Durb´an et al. 2008)
Hay dos grandes enfoques en el tema de modelos de suavizado con splines:
Splines de suavizado (smoothing splines): Los splines de suavizado (ver por ejemplo Green and Silverman (1994)) utilizan tantos par´ametros como observaciones, lo que hace que su implementaci´on no sea eficiente cuando el n´umero de datos es muy elevado.
Splines de regresi´on (regression splines):pueden ser ajustados mediante m´ınimos cuadrados una vez que se han seleccionado el n´umero de nodos, pero la selecci´on de los nodos se hace mediante algoritmos bastante complicados.
Como se menciona en Ruppert (2003), los modelos de regresi´on por splines permiten realizar un ajuste mediante pedazos de curvas polinomiales que son unidos por sus puntos extremos, a los cuales se llaman nodos. Esto permite obtener ajustes adecuados; sin embargo, presenta el inconveniente de ser vulnerables a la cantidad que se emplee y a la ubicaci´on de los mismos con lo cual es posible incurrir en sobre ajustes en el modelo. Una manera de superar este problema es limitar la influencia de los posibles nodos mediante una penalizaci´on, dando origen al modelo de spline penalizado.Los splines con penalizaciones utilizan menos par´ametros que los splines de suavizado, pero la selecci´on de los nodos no es tan determinante como en los splines de regresi´on.
Cuando en un modelo de regresi´on hay componentes param´etricos y no param´etricos, tenemos un “Modelo Semiparametrico” y en particular estos m´etodos permiten la estimaci´on de par´ametros simult´aneamente, sin supuestos espec´ıficos respecto de las formas de las funciones desconocidas.
Como tal, los estimadores semiparam´etricos son menos sensibles a supuestos que los estimadores param´etricos, y son capaces de describir la estructura de los datos de forma m´as clara que estos, Caguari (2009). La modelaci´on semiparam´etrica complementa lo mejor de ambos enfoques para obtener un modelo de regresi´on que describa mejor el comportamiento de los datos, es decir, aque-llas caracter´ısticas de los datos que son adecuadas para la modelaci´on param´etrica son modeladas de esta forma y las componentes no param´etricas son empleadas solo donde sea necesario, Ruppert et al. (2009). Adicionalmente poseen la ventaja de que las variables no necesariamente sigan una distribuci´on de probabilidad te´orica definida sino que utilizan m´etodos que mezclan la estimaci´on de m´axima verosimilitud con t´ecnicas de suavizaci´on.
3
En Ruppert (2003) se puede revisar que el modelo de regresi´on spline penalizado puede ser for-mulado dentro de un marco de modelos lineales mixtos. Esta relaci´on permite poder emplear los programas computacionales donde se han implementado los modelos mixtos. De este modo, los programas desarrollados para la inferencia bayesiana de modelos mixtos pueden ser utilizados para el modelo de regresi´on spline penalizado. En Crainiceanu et al. (2005) se comenta que el modelamiento bayesiano semiparametrico es atractivo debido a que disfruta de la flexibilidad que tienen los modelos no param´etricos para el ajuste de los datos y que, adem´as, posee la inferencia exacta proporcionada por todos los mecanismos desarrollados para la inferencia bayesiana.
Este trabajo propone estimar desde el enfoque bayesiano un modelo de regresi´on semiparametrica mediante P-splines, seg´un la literatura tradada en el estudio Semiparametric Regression realizado por Ruppert, D., Wand, M. P. y Carroll, R. (2003).
La organizaci´on del trabajo es la siguiente. En la secci´on 2 se expone las generalidades de la regresi´on param´etrica. En la secci´on 3 se describe de los m´etodos de suavizamiento no param´etrico y su conexi´on con los modelos mixtos. En la secci´on 4 se encuentran la especificaci´on del modelo semiparam´etrico propuesto desde el enfoque Bayesiano. En la secci´on 5 se presentan la aplicaci´on de modelo propuesto a datos reales. En la seccion 6 se presentan las conclusiones y finalmente en el ap´endice se encuentra el c´odigo computacional del Software estad´ıstico R utilizado en el desarrollo del trabajo.
2. Regresi´
on Lineal Param´
etrica
Es una de las t´ecnicas estad´ısticas m´as antiguas y esta dada por la relaci´on de pares de datos (xi, Yi), i = 1, , , , n. El siguiente modelo de regresi´on lineal simple describe la relaci´on de las
variables
y=β0+β1x+i (1)
Donde β0 y β1 son los par´ametros del modelo y es una variable aleatoria, llamada error, que explica la variabilidad deY que no puede ser explicada con la relaci´on lineal entre x y y. Los errores , se consideran variables aleatorias independientes distribuidas normalmente con media cero y desviaci´on est´andarσ. Esto implica que el valor medio o valor esperado dey, es denotado por
E(Y /x) =β0+β1x (2)
El objetivo principal de esta regresi´on es proporcionar un resumen o una reducci´on de los datos observados con el fin de explorar y presentar la relaci´on entre la variable de dise˜noxy la variable de respuesta y. Por lo tanto al graficar los datos es obvio y natural que se evidencie una linea recta que ratifica esta tendencia y relaci´on. La regresion lineal automatiza este procedimiento y garantiza la comparabilidad de los resultados. El otro objetivo principal de la regresi´on es utilizar el modelo (1) para predicci´on; dado un puntox, obtener una estimaci´on del valor esperado dey. Esta estimaci´on esta dada por la siguiente expressi´on
b
Y =cβ0+cβ1x (3)
2.1. Regresi´
on No Param´
etrica
Por lo general, el an´alisis de Regresi´on lineal implica relacionar una variable de respuesta como una funci´on de al menos una variable explicativa determinista, a trav´es de alguna relaci´on param´etrica. En tales circunstancias, la relaci´on es espec´ıficamente predefinida por el modelo,por lo cual estos modelos son opciones f´aciles en la pr´actica por la simplicidad y la interpretabilidad. Sin embargo, es evidente que pueden existir relaciones m´as complejas entre la respuesta y las variables explicativas, y en tal caso no es viable la utilizacion de estos modelos.
El uso de polinomios de orden superior puede, pero no siempre, dar soluci´on a este proble-ma.Existen en la literatura t´ecnicas m´as flexibles para hacer frente a tales situaciones. La lista de tales t´ecnicas incluye, pero no se limita a, modelos de regresi´on no param´etricos, tales como la estimaci´on a trav´es de Kernel (Azzalini & Bowman 1993), Regresi´on polinomial local(Cleveland & Loader 1996),y suavizado de spline (Silverman 1985) En general, el suavizado de spline puede di-vidirse en tres grandes categor´ıas. En primer lugar, suavizado con splines (ver, por ejemplo, Green y Silverman, 1994) consideran cada una de las observaciones como un punto de nudo. Cuando se utiliza un n´umero fijo de puntos de nudo, y el modelo se ajusta usando m´ınimos cuadrados ordinarios, la segunda categor´ıa conocida como superficies de splines de regresi´on. Junto a los splines de regresi´on, cuando se considera alguna forma de penalizaci´on de los coeficientes de nudo acompa˜nada de una penalizaci´on de rugosidad, se obtiene la tercera clase denominada splines penalizada (por ejemplo, (Eilers & Marx 1996).
Los splines con penalizaciones combinan lo mejor de ambos enfoques: utilizan menos par´ametros que los splines de suavizado, pero la selecci´on de los nodos no es tan determinante como en los splines de regresi´on. Hay tres razones fundamentales para el uso de este tipo de splines:
Son splines de rango bajo, es decir, que el tama˜no de la base utilizada es mucho menor que la dimensi´on de los datos, al contrario de lo que ocurre en el caso de los splines de suavizado donde hay tantos nodos como datos, lo que hace que sea necesario trabajar con matrices de alta dimensi´on. El n´umero de nodos, en el caso de los P-splines, no supera los 40, lo que hace que sean computacionalmente eficientes, sobre todo cuando se trabaja con gran cantidad de datos.
La introducci´on de penalizaciones relaja la importancia de la elecci´on del n´umero y la loca-lizaci´on de los nodos, cuesti´on que es de gran importancia en los splines de rango bajo sin penalizaciones (ver por ejemplo Rice and Wu (2001)).
La correspondencia entre los P-splines y el BLUP en un modelo mixto permite, en algunos casos, utilizar la metodolog´ıa existente en el campo de los modelos mixtos y el uso de software como PROC MIXED en SAS y lme(),gamm () en S-PLUS y R.
Siguiendo a (Durb´an et al. 2008) se ilustrar´a la aplicacion de estas t´ecnicas por medio de la estimaci´on de datos simulados.
2.1.1. Bases y Penalizaciones
Supongamos que tenemos n pares de datos (xi, yi) y estamos interesados en ajustar un modelo no
param´etrico dado por la siguiente expresion:
Yi=f(xi) + ∼N(0, σ2) (4)
donde f(.) es una funci´on suave de los datos. Nos centraremos en el caso simple de datos indepen-dientes, es decir, una sola variable independiente t, con una correspondiente variable dependiente y de naturaleza continua. El prop´osito principal de este ejercicio es mostrar el efecto de algunos de los factores clave asociados al suavizado, a saber, el par´ametro de suavizado y el n´umero de puntos de nudo.
2.1 Regresi´on No Param´etrica 5
1. Utilizar la base para la regresi´on
2. Modificar la funcion de verosimilutud introduciendo una penalizaci´on basada en diferencias entre coeficientes adyacentes.
En el caso de datos normalmente distribuidos tenemos el modelo de regresi´on y=Ba+, donde ,∼ N(0, σ2I) y, B=B(x) es la base de regresi´on construida a partir de x. Para estimar los coeficientes de regresi´on se minimiza la funci´on de m´ınimos cuadrados penalizados:
S(a;y, λ) = (y−Ba)0+ (y−Ba) +λa0P a (5)
Donde P es una matrix que penaliza los coeficientes de forma suave y λ es el param´etro de suavizado. Fijado un valor deλ, minimizar (5) da lugar al sistema de ecuaciones
(B0B+λDD0)ba=B0y (6)
Si λ = 0 se corresponde con las ecuaciones normales de regresi´on de y sobre B. Es importante el hecho de que el tama˜no del sistema de ecuaciones anterior depende del tama˜no de la base y no del n´umero de observaciones. El par´ametroλdetermina la influencia de la penalizaci´on: si es 0, estamos en un caso de regresi´on con B-splines, y siλes muy grande, estar´ıamos ajustando un polinomio de gradop−1 Es sencillo probar que:
ˆ
y=B(B0B+λD0D)−1B0y=Hy (7)
Hno es una matriz de proyecci´on, ya que no es idempotente, pero su forma hace que el m´etodo de suavizado sea lineal. La traza deH corresponde a la dimensi´on del modelo (el n´umero equivalente de par´ametros que estar´ıamos estimando).
2.1.2. Bases y nodos
La base para la regresi´on se puede calcular de muchas maneras, y de hecho hay dos grandes grupos dentro de los estad´ısticos que utilizan los P-splines: los que utilizan las bases polinomios truncados y los que utilizan las bases de B-splines. Adem´as existen otras alternativas como thin plate regression splines; para efectos de este trabajo nos centraremos en B-splines.
Polinomios truncados Supongamos de nuevo que tenemos pares (xi, yi), i= 1, .., n. Para
sim-plificar, vamos a suponer que x est´a en [0,1]. Tomamos k nodos equidistantes en ese intervalo tj= j−k1 j= 2, .., k+ 1. Una base de polinomios truncados de grado pviene dada por:
1, x, x2, ...., xp,
(x−t1)+
p
, ...,
(x−tk)p+
p
(8)
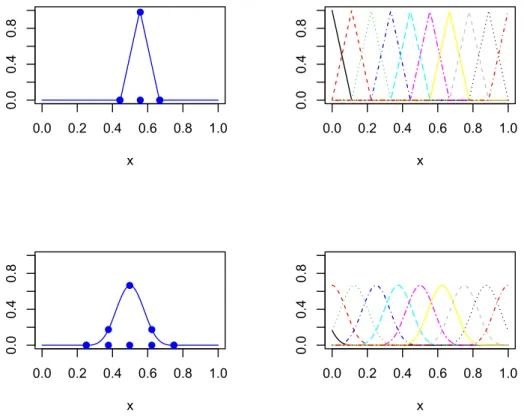
Figura 1: Bases de polinimios truncados de grado 0, 1, 2 y 3
En la figura 1 se observan las bases polin´omicas de grado 0 a grado 3.
2.1.3. B-splines
Las referencias b´asicas son de (Boor 1978) y Dierckx (1993). Un B-spline est´a formado por trozos de polinomios conectados entre si. En general un B-spline de grado p :
1. Consiste enp+ 1 trozos de polinomio de ordenp.
2. Se unen enpnodos interno
3. En los puntos de uni´on las derivadas hasta el ordenp−1 son continuas
4. El B-spline es positivo en el dominio expandido porp+ 2 nodos y 0 en es resto.
5. Excepto en los extremos, se solapa con 2p trozos de polinomios de sus vecinos.
6. Para cada valor de x,p+ 1 B-splines son no nulos.
Los B-splines no “padecen” los efectos de frontera comunes en otros m´etodos de suavizado, como algunos kernels, en los que al extender la curva ajustada fuera del dominio de los datos ´esta tiende hacia cero. De Boor (2001) presenta un algoritmo para el c´alculo de los Bsplines, este algoritmo se puede simplificar f´acilmente en software como MATLAB, S-PLUS y R. (Ver codigo en el apendice)
2.1 Regresi´on No Param´etrica 7
Figura 2: Bases B-spline de grado 1 y 3
2.1.4. Penalizaciones y coeicientes
Supongamos que tenemos una baseB construida con k nodos. Si utilizamos m´ınimos cuadrados para ajustar el modelo, la funci´on objetivo ser´a:
S(a;y) = (y−Ba)0(y−Ba)⇒(B0B)−1B0y (9)
y la curva ajustada ˆf(x) =Bˆadepender´a del tama˜no de la base.Cuanto mayor sea la base menos suave es la curva, cuando el n´umero de nodos coincide con el n´umero de datos obtenemos una curva que interpola los datos. Para solucionar esta situaci´on,O’sullivan (1986) introdujo una penalizaci´on en la segunda derivada de la curva, de modo que la funci´on objetivo pas´o a ser:
S(a;y, λ) = (y−Ba)0(y−Ba) +λ Z
x
(B00a)2dx. (10)
La integral de la segunda derivada de la curva ajustada al cuadrado es una penalizaci´on bastante com´un (es la que se utiliza en los splines de suavizado), sin embargo, no hay nada de particular en la segunda derivada, se puede utilizar derivadas de cualquier orden. novedad que introducen los P-splines es que la penalizaci´oon es discreta y que se penalizan los coeficientes directamente, en vez de penalizar la curva, lo que reduce la dimensionalidad del problema.
Eilers and Marx (1996) utiliza una penalizaci´on basada en la diferencias de orden d entre los coeicientes adyacentes de la bases de B-splines, este tipo de penalizaci´on es m´as flexible ya que es independiente del grado del polinomio utilizado para construir los B-splines. Esta es una buena aproximaci´on discreta a la integral de la d ´esima derivada al cuadrado. La penalizaci´on se a˜nade a la funci´on de m´ınimos cuadrados, dando lugar a una funci´on de m´ınimos cuadrados penalizados,
S(a;y, λ) = (y−Ba)0+ (y−Ba) +λa0Pda⇒ˆa= (B0B+λPd)−1B0y (11)
dondePd = (4d)04d. En general se utiliza d= 2, aunque se puede utilizar ordenes superiores o
inferiores, dependiendo de la variabilidad de la curva y de la cantidad de ruido en los datos. Por ejemplo, una penalizaci´on de orden d= 2 equivale a
Donde
D=
1 −2 1 0 · · · 0 1 −2 1 · · · 0 0 1 −2 · · · ..
. ... ... . ..
En la Figura 2.1.4 se muestra el ajuste de una curva mediante Bsplines sin y con penalizaci´on, se muestran los funciones que forman las bases (las columnas de la matriz B) multiplicadas por los coeficientes, as´ı como los coeficientes (en un circulo), en la parte izquierda vemos como el patr´on err´atico de los coeficientes da lugar a una curva poco suave, en cambio en la parte derecha, cuando se les impone que se pase de un coeficiente a otro de forma suave, la curva tambien lo es. Este gr´afico muestra lo que est´a haciendo la penalizaci´on: fuerza a los coeficientes a que sigan un patr´on suave.
Figura 3: Curva estimada con 20 nodos, sin penalizar los coeficientes (izquierda) y penalizando los coeficientes (derecha).
Se concluye en (Durb´an et al. 2008) Entre las propiedades de los P-splines con bases de B-splines hay que destacar que no tienen efecto de frontera (como le ocurre a los kernels), el efecto de frontera es el que hace que al extender la curva fuera del dominio de x la curva caiga r´apidamente hacia 0, esto no pasa con los P-splines. Adem´as, los P-splines ajustan de forma exacta los polinomios, es decir, si la curva es polin´omica, un P-spline la recuperar´a exactamente. Por ´ultimo, se conservan los momentos, es decir, que la media y la varianza de los valores ajustados ser´a la misma que la de los datos sea cual sea el par´ametro de suavizado, al contrario que los kernels que tienden a aumentar la varianza cuanto mayor es el suavizado.
La selecci´on y localizaci´on de los nodos no est´a hecha de antemano, como en el caso de los smoothing splines, si se elige un n´umero suficientemente grande de nodos es suficiente con elegirlos de forma equidistante; aunque autores como Ruppert (2002) aconsejan elegir los nodosK nodos en losK−quantilesdex, es decir que cada nodotk ser´ıa el cuantilk/(K+ 1)dex. En cuanto al
9
n´umero de nodos =minn40, valores ´unicos de x 4 o
2.1.5. Selecci´on del par´ametro de suavizado
El papel del par´ametro de suavizado en los P-splines, es el mismo que tiene en cualquier otro m´etodo de suavizado: controlar la suavidad de la curva, pero aqu´ı lo que hace es penalizar los coeficientes que est´an muy separados entre s´ı, y cuanto mayor sea λ, m´as se aproximar´an los coeficientes a cero,de modo que siλ→ ∞nos aproximamos a un ajuste polin´omico.Por el contrario, cuando λ→0 estaremos utilizando m´ınimos cuadrados ordinarios. Ahora, al igual que en otros m´etodos de suavizado, hemos de elegir un criterio para seleccionar el par´ametro de suavizado, podemos utilizar AIC, GCV, BIC, etc. Por ejemplo:
GCV =
n
X
n=1
(yi−yˆi)2
n−traza(H);H = (B
0B+λD0)−1)B0 (13)
AIC= 2log
n
X
n=1
(yi−yˆi)2
!
−2log(n) + 2log(traza(H)) (14)
La ventaja de los P-splines es que es mucho m´as r´apido calcular la traza de esa matriz que con otro tipo de suavizadores
3. Regresi´
on Semiparam´
etrica
En t´erminos generales, los m´etodos semiparam´etricos son aproximaciones de medici´on que man-tienen la estructura en un m´etodo emp´ırico que es ´util para la interpretaci´on de los resultados, pero que no se apoya en supuestos espec´ıficos sobre caracter´ısticas que resultan de inter´es se-cundario(Stoker,1991). En particular, los m´etodos semiparam´etricos permiten la estimaci´on de par´ametros y funciones simult´aneamente, sin supuestos espec´ıficos respecto de las formas de las funciones desconocidas. Como tal, los estimadores semiparam´etricos son menos sensibles a su-puestos que los estimadores param´etricos, y son capaces de describir la estructura de los datos de forma m´as clara que estos Caguari (2009).
La modelaci´on semiparametrica permite a un investigador tener lo mejor de ambos enfoques para obtener un modelo de regresi´on que describa mejor el comportamiento de los datos, es decir, aque-llas caracter´ısticas de los datos que son adecuadas para la modelaci´on param´etrica son modeladas de esta forma y las componentes no param´etricas son empleadas solo donde sea necesario, Ruppert et al. (2009).
Dos caracter´ısticas importantes en gran parte de la regresi´on semiparametrica, Ruppert et al. (2009), son:
Emplear la representaci´on del modelo mixto de los splines penalizados Estas brindan varios beneficios: los efectos longitudinales y espaciales pueden ser f´acilmente incorporados en el modelo, el ajuste y la inferencia pueden ser desarrollados dentro de los marcos establecidos de m´axima verosimilitud y mejor predicci´on.
Facilitar la parte de regresi´on no param´etrica utilizando splines penalizados de bajo rango.
yi=m(xi) +i
donde losiN(0, σ) e independientes dexi y m(.)es una funcion suavizada la cual se define
como sugiere Crainiceanu et al. (2005). Es evidente que un modelo de este tipo es una gene-ralizaci´on de un modelo de regresi´on, que indudablemente, tendr´a un coste computacional, pero que permitir´a estimar la funci´on de una forma m´as precisa.
3.1. Modelos Mixtos
Los modelos mixtos son modelos de regresi´on que incorporan efectos aleatorios. Tener un amplio espectro de aplicaciones desde estudios longitudinales hasta an´alisis de supervivencia, tambi´en est´an estrechamente relacionados con el suavizado. El suavizado de splines penali-zado corresponde exactamente a la predicci´on ´optima en un marco de modelo mixto. Esto hace posible el uso de metodolog´ıa del modelo y software para la regresi´on spline penalizada.
Comenzamos con una breve revisi´on de los modelos lineales mixtos, que pueden definirse como:
y=Xβ+Zu+ (15)
As´ı,yes un vector denvariables observables aleatorias,βesp+1 la dimension de efectos fijos, tambi´en conocidos como efectos ”marginales.o”promediados por la poblaci´on”Las matrices modeloX yZpueden ser bastante generales, dependiendo de la aplicaci´on, no especificamos ninguna forma para estas matrices en este momento. K vector dimensional u de efectos aleatorios o sujeto especifico ynerror dimensionalson variables aleatorias no observables, tales que
E=
u
Cov
u
=
G 0
0 R
DondeGyRson matrices positivas de covarianza definida. Normalmente se supone que los efectos aleatorios y el t´ermino de error se distribuyen normalmente.
La estimaci´on de los efectos fijosβ puede realizarse a partir del modelo lineal
y=Xβ+∗ (16)
Donde ∗=Zu+ con Cov(∗) =ZGZ0+R =:V Para una matriz de covarianza dada V Los efectos fijos eval´uan los resultados en
ˆ
β = (X0V−1X)−1X0V−1y (17)
La estimaci´on ˆβse denomina m´ınimos cuadrados generalizados (GLS) y es el mejor estimador lineal no sesgado (BLU E) paraβ.
3.2. La conexi´
on entre splines penalizados y modelos mixtos
La popularidad de las splines penalizadas deriva en parte de su conexi´on con modelos mixtos. Aqu´ı hacemos una breve introducci´on a la sinergia, un componente clave en el uso pr´actico de splines penalizados. Para 1≤j≥T y 1≤k≥KAdoptemos ahora la siguiente notaci´on matricialXj = [1tj]1≤j≥T,zj= [(tj−kk)+],β =β0, β1,b= (b1, ..., bk)0 and= (1, ..., T)
Apilando estas matrices, una debajo de la otra, obtenemos la representaci´on:
y=Xβ+Zu+
3.3 Spline Penalizados como Modelos Mixtos 11
1 σ2
kY −Xβ−Zbk2+λ2 σ2
kb2, λ >0 (18)
Si se utiliza un gran n´umero de puntos de nudo, el modelo puede sobrecargar los datos. Adem´as, el uso de un gran n´umero de nudos aumenta inherentemente la carga computacional. Una forma de eludir este problema es tratar a los coeficientesbk como aleatorios, extra´ıdos
de una distribuci´on normal tal que bk ∼ N(0, σb2) Se ha demostrado que la soluci´on a la
suavidad de spline penalizada que se acaba de describir corresponde al BLUP de un modelo mixto
3.3. Spline Penalizados como Modelos Mixtos
Comparando:
ˆ
y=B(B0B+λD0D)−1B0y=Hy
con
ˆ
y=C(C0R−1C+B)−1C0R−1y
Podemos ver que el ajuste penalizado se puede obtener suponiendo que el coeficiente sea aleatorio. Consideramos el siguiente modelo:
y|u=N ∼(Xβ+Zu, σ2In), U ∼N(0, σ2, IK) (19)
con matricesXQue contienen polinomio y funciones de base polinomialZ,con los resultados anteriores obtenemosR=σ2
In yσ2, IK
ˆ y=C
C0C+σ 2 σ2 u D −1
C0Y (20)
conD=blockdiag(O(p+1)X(p+1), IK−1) As´ı, la relaci´on de varianzas σ2
σ2
u en el marco de mode-los mixtos juega el papel del par´ametro de suavizado λ. Con esto en mente, el suavizado de splines penalizado es equivalente a la estimaci´on de par´ametros en un modelo mixto lineal, que puede llevarse a cabo con cualquier software de modelo mixto est´andar.
Obs´ervese que la inversa de la matriz de penalizaci´on impuesta a los coeficientes de spline tiene que ser una matriz de covarianza apropiada - sim´etrica y positiva definida. Si bien esto no es problem´atico para los polinomios truncados como se muestra arriba (matriz de covarianza es s´olo la identidad), otras funciones de base con las sanciones correspondientes deben ajustarse para ser representados por un modelo mixto lineal.
4. Enfoque Bayesiano Modelo Semiparam´
etrico
posterior de los par´ametros, denotada porπ(β), la cual es obtenida a trav´es de la aplicaci´on del Teorema de Bayes, expresado como (Hoff 2009):
π(β)∝L(β)P β (21)
Basados en la ecuaci´on (21) las funciones de densidad priorP(β) son componente esencial para la obtenci´on de la distribuci´on posterior , de all´ı que dado su naturaleza son inde-pendientes y pueden o no aportar informaci´on al modelo, por tanto seg´un (Hoff 2009) son denominadas: informativas y no informativas. Para el caso particular del plantemiento de la estimaci´on de los par´ametros del modelo se usar´an de funciones prior no informativas que de manera general se denotan como:
β∼N(0, σ2) (22)
donde el hiperpar´ametroσ2>0
Por otro lado, dado que el manejo variables independientes permite el c´alculo de la funci´on de versoimilitud a trav´es de una productoria, nuestra propuesta de modelo pone de mani-fiesto la complejidad que se genera en la obtenci´on de dicha funci´on, ya que se obtienen funciones conjuntas de probabilidad, debido la caracter´ıstica de correlaci´on ya mencionada anteriormente.
Bajo la anterior premisa y haciendo uso de la ecuaci´on (22), la distribuci´on de probabilidad posterior se expresa como:
P(β|Y1, ..., Yk)∝P(Y1, ..., Yk|β)P(β) (23)
dondeπ(β) representa la distribuci´on posterior.
La estimaci´on de dichos par´ametros requiere m´etodos iterativos enmarcados en MCMC tal como lo plantea (Gamerman & Lopes 2006), para lo que hace uso de algoritmos como el Metropolis Hasting y el muestrador de Gibbs, con el ´unico fin de extraer muestras de distribuciones posterior, y observar la convergencia de las cadenas y as´ı la estimaci´on de los par´ametros del modelo.
Antes de mostrar el comportamiento del dichos algoritmos, es necesario recordar que MCMC es una t´ecnica que simula una cadena de Markov cuyos estados siguen una funci´on de pro-babilidad dado un estado de grandes dimensiones tal como lo se˜nala (Hoff 2009). De igual forma, una cadena de Markov es un modelo matem´atico ligado a sistemas estoc´asticos, don-de los estados don-dependon-den don-de las probabilidad don-de transici´on, es decir que el estado actual solo depende de su estado anterior. Seg´un lo expresado por (Koop & Tobias 2007) el m´etodo de Monte Carlo est´a categorizado como un m´etodo no determin´ıstico utilizado para aproximar expresiones matem´aticas complejas de evaluar con exactitud. Donde este m´etodo posee un error absoluto de la estimaci´on, el cual decrece como√1
X central, de all´I que a partir de
varias repeticiones busca reconocer el comportamiento del sistema, destacando que la base de estas simulaciones es ser generadas a apartir de n´umeros aleatorios.
Dado el modelo de semiparametrico:
yi =β0+β1x1i+β2x2i+ k
X
k=1
Ukzk(x2i) ∼N(0, τ−1),1≤n≤ (24)
Donde zk(.) es un conjunto de funciones de base spline El correspondiente modelo mixto
bayesiano puede ser representado por:
y|β, u, τ∼N(Xβ+Zu, τ1) u|τ ∼N(0, τ
−1
u I) (25)
4.1 Intervalos de Confianza 13
dondeτβ, Au, A Son hiperpar´ametros especificados
y= y1 .. . yn , β β0 β1 β2
, u= u1 .. . un X=
1 X11 X21 ..
. ... ... 1 x1n x2n
Z=
z1(x21 · · · zK(x21 ..
. ... ... z1(x2n · · · zK(x2n
β2 no necesita el direccionamiento directo del modelo (27) bajo restricci´on del producto: q(β, u, τu, τ=q(β, u), q(τu, τ)
Conseguimos alrededor de usar el mismo truco que describi´o la secci´on 3.2 (Wand et al. 2011). Esto implica la introducci´on del vectorade datos auxiliarnx1. El establecimiento del dato observado para el igual que 0 y asumiendo un n´umero muy peque˜no para el ajuste, el ajuste del modelo en (29) el esencialmente el resultado que el modelo (27). El modelo actual
y|β, u, τ∼N(Xβ+Zu, τ1) a|β, uτ ∼N
β u , τ1
βI 0
0 τ1
UI (27) , β u
∼N(0, K−1I), β∼N(0, τβ1I), τU|bu∼Gamma(1/2, bu),
bu∼Gamma(1/2,1/A2u), τ|b∼Gamma(1/2, b), b∼Gamma(1/2,1/A2)
4.1. Intervalos de Confianza
En la aproximaci´on bayesiana, la estimaci´on por intervalos se define por una evaluaci´on sim-ple de las distribuciones a posteriori de los par´ametros. Se considera la curva que representa la funci´on de densidad que se obtiene a posteriori, y si el ´area bajo dicha curva entre los valores X e Y es igual a 95 % entonces se puede hablar de que el verdadero valor est´e entre X eY con una probabilidad del 95 %.
4.2. Diagn´
osticos de convergencia
Posterior a la estimacion bayesiana de los par´ametros del modelo, se busca validar las estima-ciones realizadas bajo la convergencia de las cadenas, siendo los diagn´osticos de convergencia la herramienta que cumple con este objetivo. Por tanto, a continuaci´on se presentan tres de los criterios m´as destacados dentro de la literatura :
• Heidelberger and Welch: es un diagn´ostico de control de longitud de ejecuci´on basado en un criterio de precisi´on relativa para la estimaci´on de la media. El ajuste predeterminado corresponde a una precisi´on relativa de dos d´ıgitos significativos. Tambi´en elimina hasta la mitad de la cadena para asegurar que los medios se estimen a partir de una cadena que ha convergido. (P & PD 1981)
• Raftery and Lewis: es un diagn´ostico de control de longitud de ejecuci´on basado en un criterio de exactitud de estimaci´on del cuantil q. Est´a pensado para su uso en una prueba piloto corta de una cadena de Markov. Tambi´en calcula el n´umero de iteraciones de ”quemado”que se descartar´an al principio de la cadena.(Raftery & Lewis 1995)
5. Aplicaci´
on a un modelo de Distribucion de Consumo
Ma-sivo
El modelo en estudio tiene como objetivo establecer la relaci´on entre varaci´on mensual del n´umero de clientes como variable respuesta y el ICC (Indice de Confianza del Consumidor) y los resultados de la variaci´on de ventas mensual del proveedor Papeles Nacionales como variables explicativas.
VARIMP:Variaci´on mensual del n´umero de clientes compradores del proveedor de Papeles Nacionales.(Fuente Distribuidor de consumo masivo ZYS).
VARVENTAS: Variaci´on Porcentual Mensual de ventas del canal Supermercados Indepen-dientes del proveedor Papeles Nacionales. (Fuente Distribuidor de consumo masivo ZYS)
ICC:Indice de confianza del Consumidor. (Fedesarrollo Centro de investigaci´on de Econom´ıa Social)
El ICC se construye a partir de una encuesta denominada Encuesta de Opini´on del Con-sumidor (EOC). Se calcula como un promedio simple de los balances de sus respuestas, es decir, porcentaje de respuestas favorables menos porcentaje de respuestas desfavorables que cuestionan la opini´on de los hogares, tanto de las condiciones actuales como de perspectivas a futuro del pa´ıs.
El ICC re´une cinco componentes, cuyo detalle se expone en el Cuadro 1. Los primeros tres hacen referencia a las expectativas de los hogares a un a˜no vista, mientras que los otros dos hacen alusi´on a la percepci´on de los consumidores acerca de la situaci´on econ´omica actual. Con los tres primeros se construye el ´Indice de Expectativas del Consumidor (IEC) y con los dos restantes el ´Indice de Condiciones Econ´omicas (ICE).
Tabla 1: Componentes del ICC (Balances entre respuestas favorables y desfavorables)
Variable/ Balance % 2015 2016 2017
´Indice de Confianza del Consumidor - ICC Abril Abril Marzo Abril ´Indice de Confianza del Consumidor - ICC 8,2 -13,0 -21,1 -12,8
A. ´Indice de Expectativas del Consumidor - IEC 8,0 -6,3 -18,3 -10,9
¿Dentro de un a˜no a su hogar le estar´a yendo econ´omicamente
mejor? 38,6 26,3 10,5 18,7
Durante los pr´oximos 12 meses vamos a tener buenos tiempos
econ´omicamente -10,0 -31,5 -39,4 -33,6
Dentro de 12 meses, ¿cree usted que las condiciones econ´omicas
del pa´ıs en general estar´an mejores? -4,6 -13,6 -25,9 -17,8
B. ´Indice de Condiciones Econ´omicas - ICE 8,5 -23,1 -25,4 -15,7
¿Cree ud. que a su hogar le est´a yendo econ´omicamente mejor o
peor que hace un a˜no? 4,7 -15,8 -22,1 -17,4
¿Cree ud. que este es un buen momento o un mal momento para que
la gente compre muebles, nevera, lavadora, televisor, y cosas como esas? 12,3 -30,3 -28,8 -14,1
Fuente: Encuesta de Opini´on del Consumidor (EOC) – Fedesarrollo.
5.1 Contexto de las variables 15
5.1. Contexto de las variables
Figura 4: Tendencia Lineal de los indicadores Enero 2016-Abril 2017
En la figura 4 se observa la gr´afica lineal de las variables en estudio donde se evidencia una mejora en la confianza de los consumidores frente al primer trimestre del a˜no se debe a una recuperaci´on importante tanto en la percepci´on acerca de la situaci´on econ´omica del pa´ıs como en la del hogar, despues de la contracci´on economica causada por incremento de impuestos. Los balances para las preguntas relacionadas con la valoraci´on del hogar se ubicaron en terreno levemente positivo y en niveles superiores a los del primer trimestre.
Figura 5: An´alisis univariado VARIMP,ICC,y VARVENTAS
VARIMP Se observa Concentraci´on de los datos el rango de valores negativos entre el -10 y Cero dado por los 4 mes donde se presenta decremento constante del n´umero de clientes. La distribuci´on de los datos no es normal, y es asim´etrica a la derecha
ICCSe evidencia baja dispersi´on en los datos, con una curva de distribuci´on ligeramente positiva fundamentada por la recuperaci´on de la econom´ıa en el a˜no despu´es de la contracci´on econ´omica del pa´ıs causada por el alza de impuestos.se observa un ligera tendencia lineal positiva.
5.2 An´alisis Descriptivo Multivariado 17
5.2. An´
alisis Descriptivo Multivariado
Se presenta un diagrama de dispersi´on entre las covariables y la variable de respuesta VARIMPAC, donde se puede revisar algunas relaciones existentes entre variables.
Figura 6: An´alisis bivariado VARIMP VARVENTAS
En la figura 6 se observa que existe una fuerte relaci´on lineal positiva en cierto modo l´ogica,puesto que un incremento en el n´umero de clientes, genera un incremento autom´atico en el valor de venta.
Figura 7: Gr´afico dispersi´on VARIMP ICC
5.3. Resultados de la estimaci´
on
5.3.1. Resultados de la param´etrica y Semiparam´etrica
Dado que es posible estructurar un modelo con P-splines como un modelo mixto, utilizaremos la funci´on gam(), para esto necesario cargar el paquete mgcv de Wood (2006). Este paquete contiene dos funciones que permiten utilizar P-splines: gam y gamm, la diferencia entre las dos es que la segunda permite elegir el par´ametro de suavizado mediante REML, mientras que la primera es similar a la funci´on escrita por Hastie y Tibshirani, pero permite utilizar splines de rango bajo, y elige el par´ametro de suavizado mediante GCV .
En la siguiente tabla se presenta los valores del Criterio de informaci´on de Akaike(AIC) y Va-lores del criterio de selecci´on de del par´ametro de suavizado para los diferentes modelos que se contemplaron en la escogencia del modelo final.
La diferencia de los modelos de estimaci´on propuestos estan basadas en el n´umero de nodos y tipos de bases.En la primer secci´on con la base thin plate regression splines predeterminada por la funci´on y en la segunda secci´on con bases de splines penalizados.Todos los modelos son estimados sin intercepto, por efecto de validaciones previas.
Tabla 2: Resultados Regresi´on Lineal y Semiparam´etrica
Formula, k=nodos,bs=P Splines VARVENTAS Pr(>—t—) S(ICC) GCV AIC
VARIMP∼-1+ICC+VARVENTAS 0,3232 0,00384** 0,310 119,37 VARIMP∼-1+s(ICC,k=3)+VARVENTAS 0,3234 0,00204** 0,211 133,12 117,41 VARIMP∼-1+s(ICC,k=4)+VARVENTAS 0,2283 0,00747** 0,012* 84,82 109,96 VARIMP∼-1+s(ICC,k=6)+VARVENTAS 0,2393 0,00555** 0,021* 79,81 108,05 VARIMP∼-1+s(ICC,k=7)+VARVENTAS 0,2345 0,00704** 0,023* 81,69 108,48
VARIMP∼-1+s(ICC,bs=”ps”,k=4) +VARVENTAS 0,2382 0,0104* 0,035* 101,89 112,74 VARIMP∼-1+s(ICC,bs=”ps”,k=6)+VARVENTAS 0,2376 0,00648* 0,022* 85,03 108,82 VARIMP∼-1+s(ICC,bs=”ps”,k=7)+VARVENTAS 0,2177 0,017* 0,033* 103,32 111,81
En la tabla 2 se observa en que la estimaci´on del primer modelo mediante regesi´on lineal la variable ICC no es significativa , lo mismo sucede en el segundo modelo semiparam´etrico con 3 nodos, donde la variable ICC se incluye como la parte no parametrica del modelo. En el tercer modelo se utiliza 4 nodos y, se evidencia que la variable ICC es significativa, generando un GCV(84.82) y AIC(109.96) mucho menor comparado con las anteriores calculos lo que indica un mejor ajuste del modelo . En la cuarta estimaci´on se utiliza 6 nodos en este caso se reduce el valor del GCV a (79.1) y del AIC a (108.05), en el quinto modelo se incrementa el n´umero de nodos a 7, no obstante el valor del GCV(84.82) y AIC(109.96) aumenta, por esto confirmamos que el modelo con mejor ajuste es con 6 nodos por tener los GVC y AIC m´as bajos.
5.3 Resultados de la estimaci´on 19
Figura 8: Graficos funci´on no lineal semiparam´etrica
En la figura 8 Se observan las funciones de distribuci´on no lineales de la variable ICC, los tres primeros gr´aficos corresponden al ajuste con bases thin plate regression splines, con el respectivo ajuste seg´un el n´umero de nodos, en esta secci´on se evidencia que el mejor modelo es con 6 nodos.
Los ´ultimos 3 gr´aficos representan las funciones de distribuci´on de la estimaci´on con bases Pspli-nes,y se puede concluir que el modelo con 6 nodos capta con precisi´on el comportamiento de los datos.
5.3.2. Resultados Regresi´on Semiparam´etrica Bayesiana
Esta estimaci´on, se realiza bajo el marco semiparam´etrico bayesiano. Las formas expl´ıcitas de las condicionales no estan provistas, por tanto recurrimos a estimar los par´ametros por medio del paquete BayesGESM v1.3 de Luz Marina Rondon. La funci´on gesm() es utilizado para obtener la inferencia estad´ıstica basada en el enfoque bayesiano para modelos de regresi´on bajo la suposici´on de que los errores aditivos independientes siguen una escala de mezclas de distribuci´on normal. Donde los par´ametros de ubicaci´on y dispersi´on de la distribuci´on de variables de respuesta inclu-yen componentes aditivos no param´etricos descritos por B-splines
Los argumentos para la especificaci´on del modelos son:
Form´ula: La f´ormula del argumento consta de tres partes, a saber: (i) variable de respuesta observada; (Ii) covariables para el par´ametro de localizaci´on que incluye el componente no param´etrico; Y (iii) covariables para el par´ametro de dispersi´on que incluye el componente no param´etrico. Los componentes no param´etricos se pueden especificar utilizando la funci´on bsp () que usa funciones de B Splines es opcional especificar el valor el n´umero de nudos internos. El valor predeterminado es n15. Donde n es el tama˜no de la muestra (O’sullivan
family:Una descripci´on de la distribuci´on de errores que se utilizar´a en el modelo.
burn.in: El n´umero de iteraciones de burn-in para el algoritmo MCMC.
post.sam.s:El tama˜no requerido para la muestra posterior de los par´ametros de inter´es
thin:el intervalo de diluci´on utilizado en la simulaci´on para obtener el tama˜no requerido para la muestra posterior.
Esta funci´on utiliza un algoritmo MCMC eficiente combinando el algoritmo de muestreo Gibbs y el algoritmo Metropolis-Hastings, que se basa principalmente en la capacidad de las B-splines de expresarse linealmente y en el hecho de que la distribuci´on del error del modelo se puede obtener como una mezcla de escala de Distribuciones normales. Suponemos que a priori, los cuatro vectores de par´ametros (componentes param´etricos y no param´etricos en los submodelos de localizaci´on y dispersi´on) son independientes y normalmente distribuidos. Los valores considerados para los hiperpar´ametros permiten una comparaci´on directa de los resultados con los obtenidos bajo el enfoque cl´asico.
Tabla 3: Resultados Regresi´on Semiparam´etrica Bayesiana
Formula,k=nodos, bs=P Splines VARVENTAS C.I.95 % DIC
VARIMP∼ICC+VARVENTAS 0,324 0,1274 0,520 119,692
VARIMP∼bsp(ICC)+VARVENTAS 0,2495 0,0658 0,4382 116,9206 VARIMP∼bsp(ICC,3)+VARVENTAS 0,2515 0,0846 0,419 112,914
VARIMP∼bsp(ICC,4)+VARVENTAS 0,2674 0,061 0,472 115,0631 VARIMP∼bsp(ICC,7)+VARVENTAS 0,3245 0,0286 0,6121 121,0767
En la tabla 3 Se evidencia que al incluir la variable ICC como parte no parem´etrica , se hace significativa y aporta en ajuste del modelo dado que valor de DIC se reduce a (116.92).Por otra parte al especificar 3 nodos, en la f´ormula se obtiene un DIC inferior(112.914), y un intervalo de credibilida m´as preciso. En el modelo 4 y 5 se observa que el DIC aumenta si se incrementa el n´umero de nodos.
5.3 Resultados de la estimaci´on 21
En la figura 9 Se observan las funci´ones de distribuci´on del modelamiento de la relaci´on no lineal de la variable ICC con diferentes n´umeros de nodos. El gr´afico 2 corresponde al modelo elegido k= 3 DIC (112.91)
. Adicional al chequear de los intervalos de credibilidad, y como se menciona en la secci´on teorica se puede hablar de que el verdadero valor del param´etro esta entre 0.0846 y 0.419 con una proba-bilidad del 95 %. Sumado a esto se observa que dentro de este intervalo no esta contenido el ”0”, con lo que se garantiza la existencia de correlaci´on de la variable respuesta.
5.3.3. Diagn´ostico de Heidelberger and Welch
Como se puede observar en la tabla 4 en lo que respecta a las pruebas de convergencia, los valores de probabilidad p en el diagn´ostico de convergencia fueron todos mayores a 0.05, lo que indica que no hay evidencias contra la convergencia. Todos los par´ametros pasaron las pruebas de la mitad de ancho de banda de Heidelberger y Welch y las pruebas estacionarias. En general, los resultados de estas pruebas sugirieron que el n´umero de iteraciones (10000) para las simulaciones MCMC fue suficiente para satisfacer el criterio de convergencia. Por tal raz´on, se concluye que las estimaciones de los par´ametros del modelo est´an dadas bajo cadenas que convergen lo que da fiabilidad a las mismas.
Tabla 4: Diagnosticos de la Cadena
Stationarity start
test iteration p-value
beta 1 passed 1 0.603
alpha 1 1 passed 1 0.640
alpha 1 2 passed 1 0.605
alpha 1 3 passed 1 0.753
alpha 1 4 passed 1 0.762
alpha 1 5 passed 1 0.421
alpha 1 6 passed 1 0.627
tau alpha 1 passed 1 0.803
gamma 1 passed 1 0.105
Halfwidth Mean Halfwidth
beta 1 passed 0.252 0.00164
alpha 1 1 passed -36.613 0.42100
alpha 1 2 passed 56.965 0.35067
alpha 1 3 passed -12.331 0.24981
alpha 1 4 passed 7.346 0.38065
alpha 1 5 passed -4.521 0.33209
alpha 1 6 passed -9.154 0.16042
tau alpha 1 passed 1.641.274 3.883.261
gamma 1 passed 4.218 0.01016
Figura 10: Gr´afico de convergencia y densidad del param´etro VARVENTAS
En la figura 11 se muestra la cadena del valores de la varianza de los componetes del modelo, se evidencia que las estimaciones seleccionadas no presentan tendencia ni estacionalidad y son casi que invariables y constantes entorno a un mismo valor(4.210).
23
(a) Gr´afico Dispersi´on (b) Gr´afico qqnormn
Figura 12: An´alisis de Residuales
En la figura 12 Se considera que los errores presentan baja variabilidad ,la media de los residuales es igual a -0.079 su valor promedio est´a cercano a cero, en este caso los errores negativos son m´as frecuentes que los positivos.
(a) Divergencia Kullback Leiber (b) Divergencia Ji Cuadrado
Figura 13: An´alisis Datos influyentes
En la figura 13 se observa el gr´afico de Divergencia de Kullback- Leibler el cual mide la distancia entre las distribuciones a posterioris con todos los datos y eliminando el i-´esimo dato. Un valor grande de DKL(i) implica mayor influencia de la observaci´on i-´esima en la estimaci´on. Los datos influyentes detectados por DKL corresponden al impacto causado por el incremento de ventas de la 2 feria anual de descuentos que es realizada en Octubre y el notorio decremento en ventas para el siguiente mes dado que los clientes no compran en la misma proporci´on porque tiene un stock alto de inventarios de productos.
6. Conclusiones
En el enfoque cl´asico las bases thin plate regression splines aportan mayor ajuste a los datos tiene un menor AIC comparado con las bases P splines.
Los modelos semiparam´etricos cl´asicos requieren de un mayor n´umero de nodos que los bayesianos, y pueden ser calculados el valor minimo de nodos establecidos para obtener el mejor ajuste. Por otra parte el algoritmo bayesiano es bastante eficiente y aplicable a una amplia variedad de problemas.
la encuesta de comercio minorista, e incluir un factor determinado por las zonas geograficas para aplicar datos longitudinales.
Referencias
Azzalini, A. & Bowman, A. (1993), ‘On the use of nonparametric regression for checking linear relationships’,Journal of the Royal Statistical Society. Series B (Methodological)pp. 549–557.
Boor, D. (1978),A practical guide to splines, Vol. 27, Springer-Verlag New York.
Cleveland, W. S. & Loader, C. (1996), Smoothing by local regression: Principles and methods,in
‘Statistical theory and computational aspects of smoothing’, Springer, pp. 10–49.
Durb´an, M., Lee, D.-J. & Ugarte, M. D. (2008), Splines con penalizaciones (P-splines): teor´ıa y aplicaciones, Universidad P´ublica de Navarra= Nafarroako Unibertsitate Publikoa.
Eilers, P. H. & Marx, B. D. (1996), ‘Flexible smoothing with b-splines and penalties’,Statistical sciencepp. 89–102.
O’sullivan (1986), ‘Automatic smoothing of regression functions in generalized linear models’,
Journal of the American Statistical Association81(393), 96–103.
Ruppert, D., Wand, M. P. & Carroll, R. J. (2003),Semiparametric regression, number 12, Cam-bridge university press.
Silverman, B. W. (1985), ‘Some aspects of the spline smoothing approach to non-parametric regression curve fitting’, Journal of the Royal Statistical Society. Series B (Methodological)
pp. 1–52.
25
7. Ap´
endice C´
odigos R
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ # *Grafica de la funcion no lineal
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
n = 200
x = seq(0,1,length=n)# nemeros secuenciales de 1 hasta 0 # numero de secuencias y = sin(3*pi*x) + 0.5*rnorm(n)
lengths(y)
plot(x,y,pch=1,bty="l",col=12) lines(x,sin(3*pi*x),col=6)
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ # *Polinomios Truncados ejemplo Durban
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
tpoly<-function(x,t,p){
#Polinomios truncados de grado p B=NULL
for(i in 1:length(t)){
B=cbind(B,(x-t[i])^p*(x>t[i]))} B
}
#Tomamos los nodos, por ejemplo, si queremos 10 nodos K=10
knots=seq(0,1,length=(K+2))[-c(1,K+2)] #entonces,
B0=tpoly(x,knots,0) B1=tpoly(x,knots,1) B2=tpoly(x,knots,2) B3=tpoly(x,knots,3) B4=tpoly(x,knots,5)
par(mfrow=c(2,2))
plot(x,B0[,1],type="n",ylim=c(0,1),ylab="")
title("Polinomios truncados de grado 0",cex.main=1) for(i in 1:10){lines(x,B0[,i],col=i,lty=i)}
plot(x,B1[,1],type="n",ylim=c(0,1),ylab="")
title("Polinomios truncados de grado 1",cex.main=1) for(i in 1:10){lines(x,B1[,i],col=i,lty=i)}
plot(x,B2[,1],type="n",ylim=c(0,1),ylab="")
title("Polinomios truncados de grado 2",cex.main=1) for(i in 1:10){lines(x,B2[,i],col=i,lty=i)}
plot(x,B3[,1],type="n",ylim=c(0,1),ylab="")
title("Polinomios truncados de grado 3",cex.main=1) for(i in 1:10){lines(x,B3[,i],col=i,lty=i)}
plot(x,B4[,1],type="n",ylim=c(0,1),ylab="")
title("Polinomios truncados de grado 5",cex.main=1) for(i in 1:10){lines(x,B4[,i],col=i,lty=i)}
plot(x,B5[,1],type="n",ylim=c(0,1),ylab="")
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ # *Bases B-Spline grados 1 y3 con nodos
bspline <- function(x, xl, xr, ndx, bdeg){ dx <- (xr-xl)/ndx
knots <- seq(xl-bdeg*dx, xr+bdeg*dx, by=dx) B <- spline.des(knots,x,bdeg+1,0*x)$design B
}
xl=-0.0000001 xr=1.0000001 bdeg=3 pord=2 ndx=8
B <- bspline(x, xl, xr, ndx, bdeg) BB=bspline(x,xl,xr,ndx=9,1)
par(mfrow=c(2,2))
plot(x,BB[,6],type="l",col=12,ylab="",ylim=c(0,1))
points(x[c(89,112,134)],BB[c(89,112,134),6],col=12,pch=19) points(x[c(89,112,134)],rep(0,3),col=12,pch=19)
plot(x,BB[,1],type="n",ylim=c(0,1),ylab="") for(i in 1:10){lines(x,BB[,i],col=i,lty=i)} plot(x,B[,6],type="l",col=12,ylab="",ylim=c(0,1))
points(x[c(51,76,100,125,150)],B[c(51,76,100,125,150),6],col=12,pch=19) points(x[c(51,76,100,125,150)],rep(0,5),col=12,pch=19)
plot(x,B[,1],type="n",ylim=c(0,1),ylab="") for(i in 1:10){lines(x,B[,i],col=i,lty=i)}
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ # *Coeficientes y penalizaciones
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ n <- 200
x <- seq(0,1,length=n)
y <- sin(3*pi*x) + 0.5*rnorm(n) library(splines)
xl=-0.0000001 xr=1.0000001 bdeg=3 pord=2 ndx=8
bspline2=function(x, xl, xr, ndx, bdeg){ dx <- (xr-xl)/ndx
knots <- seq(xl-bdeg*dx, xr+bdeg*dx, by=dx) B <- spline.des(knots,x,bdeg+1,0*x)$design knots
}
par(mfrow=c(1,2))
plot(x,y,pch=".",cex=3)
27
knots=bspline2(x,xl,xr,ndx=20,3)
points(knots[3:25],a2,col=6,pch=21,cex=2) points(knots[3:25],a2,col=6,pch=20) for(i in 1:ncol(BBB)){
lines(x,BBB[,i]*a2[i])}
d=ncol(BBB)
D=diff(diff(diag(d))) P=t(D)%*%D
a22=solve(t(BBB)%*%BBB+P)%*%t(BBB)%*%y
plot(x,y,pch=".",cex=3)
lines(x,BBB%*%a22,col=4,lwd=2)
points(knots[3:25],a22,col=4,pch=21,cex=2) points(knots[3:25],a22,col=4,pch=20) for(i in 1:ncol(BBB)){
lines(x,BBB[,i]*a22[i])}
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ # *Lambdas
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
n <- 200
x <- seq(0,1,length=n)
y <- sin(3*pi*x) + 0.5*rnorm(n) library(splines)
xl=-0.0000001 xr=1.0000001 bdeg=3 pord=2 ndx=8
bspline2=function(x, xl, xr, ndx, bdeg){ dx <- (xr-xl)/ndx
knots <- seq(xl-bdeg*dx, xr+bdeg*dx, by=dx) B <- spline.des(knots,x,bdeg+1,0*x)$design knots
}
par(mfrow=c(1,2))
plot(x,y,pch=".",cex=3)
BBB=bspline(x,xl,xr,ndx=20,3) a2=solve(t(BBB)%*%BBB)%*%t(BBB)%*%y lines(x,BBB%*%a2,col=6,lwd=2) knots=bspline2(x,xl,xr,ndx=20,3)
points(knots[3:25],a2,col=6,pch=21,cex=2) points(knots[3:25],a2,col=6,pch=20) for(i in 1:ncol(BBB)){
lines(x,BBB[,i]*a2[i])}
d=ncol(BBB)
a22=solve(t(BBB)%*%BBB+P)%*%t(BBB)%*%y
plot(x,y,pch=".",cex=3)
lines(x,BBB%*%a22,col=4,lwd=2)
points(knots[3:25],a22,col=4,pch=21,cex=2) points(knots[3:25],a22,col=4,pch=20) for(i in 1:ncol(BBB)){
lines(x,BBB[,i]*a22[i])}
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ # Estimacion semiparametrica Cl´asica
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ library(foreign)
library(nlme) library(mgcv)
#Regresi´on Lineal
ols.1Panal <- gam(VARIMP ~ -1+ICC+ VARVENTAS, data=Panal) summary(ols.1Panal)
plot(ols.1Panal) AIC(ols.1Panal)
#Regresion Semiparametrica 3 Nodos n/4
gam.1Panal<- gam( VARIMP ~-1+ s(ICC,k=3,m=2)+VARVENTAS, data=Panal) summary(gam.1Panal)
plot(gam.1Panal) AIC(gam.1Panal)
#Regresion Semiparametrica 4 Nodos
gam.2Panal<- gam( VARIMP ~ -1+s(ICC,k=4,m=2)+VARVENTAS,data=Panal) gam.2Panal$deviance
summary(gam.2Panal) gam.2Panal$fit plot(gam.2Panal) AIC(gam.2Panal) predict(gam.2Panal) gam.2Panal$smooth["Xu"]
#Regresion Semiparametrica 6 Nodos
gam.3Panal<- gam( VARIMP ~ -1+s(ICC,k=6)+VARVENTAS, data=Panal) gam.3Panal$deviance
summary(gam.3Panal) gam.vcomp(gam.3Panal) attr(gam.3Panal,"constant") plot(gam.3Panal)
AIC(gam.3Panal) par(mfrow=c(1,1))
#Regresion Semiparametrica 7 Nodos
gam.4Panal<- gam( VARIMP ~ -1+s(ICC,k=7)+VARVENTAS, data=Panal) gam.4Panal$deviance
summary(gam.4Panal) plot(gam.4Panal) AIC(gam.4Panal)
29
#Regresion Semiparametrica p splines 4 Nodos
gam.5Panal<- gam( VARIMP ~ -1+s(ICC,bs="ps",k=4)+VARVENTAS, data=Panal) gam.5Panal$deviance
summary(gam.5Panal) plot(gam.5Panal) AIC(gam.5Panal)
#Regresion Semiparametrica p splines 6 Nodos
gam.6Panal<- gam( VARIMP ~ -1+s(ICC,bs="ps",k=6)+VARVENTAS, data=Panal,method="ML") gam.6Panal$deviance
summary(gam.6Panal) plot(gam.6Panal) AIC(gam.6Panal) gam.vcomp(gam.6Panal)
#Regresion Semiparametrica p splines 7 Nodos
gam.7Panal<- gam( VARIMP ~ s(ICC,bs="ps",k=7)+VARVENTAS, data=Panal) gam.7Panal$deviance
summary(gam.7Panal) AIC(gam.7Panal) plot(gam.7Panal)
#Graficos funcion no parametrica ICC
par(mfrow = c(2, 3))
plot(gam.1Panal,main = "k=3 GCV=133.12 AIC=117.41") plot(gam.2Panal,main = "k=4 GCV=84.82 AIC=109.96")
plot(gam.3Panal,main = "k=6 GCV=79.81 AIC=108.05",col="mediumspringgreen") plot(gam.5Panal,main = "k=4 pspline GCV=101.89 AIC=112.74")
plot(gam.6Panal,main = "k=6 pspline GV=85.03 AIC=108.82",col="mediumspringgreen") plot(gam.7Panal,main = "k=10 pspline GCV=103.32 AIC=111.81")
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ # Estimacion Bayesiana semiparametrica
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
####Modelo Bayesianos library(BayesGESM) library(ssym) library(GIGrvg) library(normalp) library(Formula)
## Bayesiano Lineal
model <- gesm(VARIMP~-1+ICC+VARVENTAS,data=Panal,
burn.in=10000, post.sam.s=10000,thin=10,family="Normal") summary(model)
#bsp.graph.gesm(model,which=1,var="ICC")no hay loc no param´etrico
##Semiparametric
## N´umero de nodos predeterminado
model1 <- gesm(VARIMP~-1+bsp(ICC)+VARVENTAS,data=Panal, burn.in=10000, post.sam.s=10000,thin=10,family="Normal") summary(model1)
bsp.graph.gesm(model1,which=1,var="ICC")
model2 <- gesm(VARIMP~-1+bsp(ICC,3)+VARVENTAS,data=Panal, burn.in=10000, post.sam.s=10000,thin=10,family="Normal") summary(model2)
model2$AIC model2$LMPL
Cadena=(model2$chains) MC2<- as.mcmc(Cadena) heidel.diag(MC2) library(mcmcplots) mcmcplot(MC2) model12$KL
## N´umero de nodos 4
model3 <- gesm(VARIMP~-1+bsp(ICC,4)+VARVENTAS,data=Panal, burn.in=10000, post.sam.s=10000,thin=10,family="Normal")
## N´umero de nodos 7
model4 <- gesm(VARIMP~-1+bsp(ICC,7)+VARVENTAS,data=Panal, burn.in=10000, post.sam.s=10000,thin=10,family="Normal") summary(model4)
# Graficos funcion no lineal comparativos par(mfrow = c(2, 2))
bsp.graph.gesm(model1,which=1,var="ICC",main="DIC=116.92") bsp.graph.gesm(model2,which=1,var="ICC",main="DIC=112.91") bsp.graph.gesm(model3,which=1,var="ICC",main="DIC=115.06") bsp.graph.gesm(model4,which=1,var="ICC",main="DIC=121.06")
mcmcplot(MC2)
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ # Diagnosticos de Modelo Bayesiano semiparametrico #~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ ########## Residual plot
par(mfrow=c(1,2))
plot(model2$res, ylim=c(-2,2), xlab="Index", ylab="", main="Residuals", cex=0.3, type="p", lwd=3)
abline(h=0,lty=3)
qqnorm(model2$res, xlim=c(-2,2), ylim=c(-2,2), xlab="Quantile", ylab="Residuals", cex=0.3, type="p", lwd=3)
abline(0,1,lty=3)
### Graficos residual en terminos de ggplot2 res=model2$res
par(mfrow=c(1,2))
qplot(x=1:15,y=model2$res,main="An´alisis de Residuales")+geom_hline(aes(yintercept=h), color="Blue")
ggplot(data=as.data.frame(qqnorm( res , plot=F)), mapping=aes(x=x, y=y)) + geom_point() + geom_smooth(method="lm", se=FALSE)
mean(model2$res)
31
########## Datos influyentes Influence measures plot
library(ggplot2) par(mfrow=c(1,2))
qplot(x=1:15,y=model2$KL,main="Divergencia de Kullback-Leibler")+xlab("Index")+ylab("")+ geom_hline(aes(yintercept=3*mean(model2$KL)),color="Blue")