Modelo en VHDL del microprocesador PowerPC 604 Primera edición
230
0
0
Texto completo
(2) INSTITUTO TECNOLÓGICO Y DE ESTUDIOS SUPERIORES DE MONTERREY CAMPUS MONTERREY PROGRAMA DE GRADUADOS EN COMPUTACIÓN, INFORMACIÓN Y COMUNICACIONES. MODELO EN VHDL DEL MICROPROCESADOR POWERPC 604. TESIS PRESENTADA COMO REQUISITO PARCIAL PARA OBTENER EL GRADO DE: MAESTRO EN CIENCIAS EN INGENIERÍA ELECTRÓNICA ESPECIALIDAD EN SISTEMAS ELECTRÓNICOS ERASTO VIDALES HERNANDEZ MAYO, 1999.
(3) INSTITUTO TECNOLÓGICO Y DE ESTUDIOS SUPERIORES DE MONTERREY CAMPUS MONTERREY PROGRAMA DE GRADUADOS EN COMPUTACIÓN, INFORMACIÓN Y COMUNICACIONES. MODELO EN VHDL DEL MICROPROCESADOR POWERPC 604. TESIS PRESENTADO COMO REQUISITO PARCIAL PARA OBTENER EL GRADO DE: MAESTRO EN CIENCIAS INGENIERÍA ELECTRÓNICA ESPECIALIDAD SISTEMAS ELECTRÓNICOS ERASTO VIDALES HERNANDEZ. MAYO, 1999.
(4) INSTITUTO TECNOLÓGICO Y DE ESTUDIOS SUPERIORES DE MONTERREY CAMPUS MONTERREY PROGRAMA DE GRADUADOS EN COMPUTACIÓN, INFORMACIÓN Y COMUNICACIONES Los miembros del comité de tesis recomendamos que la presente tesis del Ing. Erasto Vidales Hernandez sea aceptada como requisito parcial para obtener el grado académico de Maestro en Ciencias en:. Ingeniería Electrónica Especialidad en Sistemas Electrónicos Comité de Tesis. Director del Programa de Graduados en Computación, Información y Comunicaciones. Mayo, 1999.
(5) Agradecimientos. Al Instituto Tecnológico y de Estudios Superiores de Monterrey por preparar un programa de graduados altamente competitivo y acorde con la tecnología actual. Al Consejo Nacional de Ciencia y Tecnología (CONACYT) por permitirme realizar mis estudios de maestría y apoyar la investigación en México. Al Ph.D. Ignacio Celis por confiarme este proyecto y por todo su apoyo, interés y motivación para la realización de esta investigación. A mis sinodales Ph.D. Patricia Hinojosa y Ph.D. Alfonso Avila por el tiempo que dedicaron para la revisión de esta tesis y sus acertados comentarios. A los Maestros en Ciencias Antonio Arredondo, Nicólas Cruz y Sergio Saldaña de la academia de Ingeniería Electrónica del Instituto Tecnológico de Nuevo Laredo por preparme para mi vida profesional. A mis compañeros y amigos que de una u otra manera me brindaron su apoyo y amistad en especial: Luis I. Martinez, Jose Luis de la Fuente, Paulo Lara y Pedro Garduza. A mis padres Ing. Erasto Vidales Flores y Q.F.B. María Delfina Hernandez de Vidales por que a pesar de las dificultades y del tiempo creyeron en mi, a mis hermanos Arturo y Esther el mejor equipo que uno puede tener. A mi esposa Melissa que compartió conmigo todas las noches de desvelo y estuvo conmigo en toda esta aventura. Gracias por tus dibujos amor y por Priscila ese regalo que Dios nos dio. Señor Jesús muchas gracias..
(6) “Bendice, alma mía, al Señor, y bendiga todo mi ser su santo nombre. Bendice, alma mía, al Señor, y no olvides ninguno de sus beneficios.” Salmo 1O3:1-~. A mi esposa Melissa, tu amor es la inspiración de mi vida..... A mis padres, por todo el apoyo y cariño que me han dado..... A mis hermanos, por que se que siempre puedo contar con ellos.....
(7) RESUMEN El rendimiento de los procesadores ha aumentado considerablemente gracias a la tecnología en el diseño electrónico (VLSI) y a la complejidad de los procesadores. El objetivo de esta investigación es el desarrollo en VHDL de un modelo fiel del microprocesador PowerPC 604, se entiende por modelo fiel a que se comporta exactamente igual (ciclo a ciclo de reloj) que el procesador comercial. El modelo contiene las etapas del pipeline del procesador las cuales son fetch, decode, dispatch, ejecución, completamiento y write back. Para realizar dicho modelo fue necesario recabar información del funcionamiento del procesador de acuerdo a los documentos que son proporcionados por el fabricante. Además, fue necesario el estudio de: las definiciones básicas de las arquitecturas cornputacionales, filosofía y principios de diseño RISC y la arquitectura PowerPC. El PowerPC 604 es un microprocesador de 32 bits, RISC, superescalar, con un pipeline de seis etapas, algoritmo Tomasulo y predicción dinámica de saltos; además este procesador es capaz de leer y emitir a ejecución hasta cuatro instrucciones por ciclo de reloj. El modelo desarrollado en esta investigación podrá ser utilizado con fines académicos en materias relacionadas con arquitecturas computacionales avanzadas, sistemas digitales avanzados, computo de alto rendimiento y materias afines a microprocesadores. Además, el modelo desarrollado es sintetizable y podrá ser utilizado como benchmark de herramientas de síntesis e incluso podría ser implementado en silicio. La arquitectura de este modelo es una arquitectura abierta la cual puede ser modificada con cierta facilidad para investigar o desarrollar otro tipo de arquitectura computacional Esta tesis pretende dejar las puertas abiertas al desarrollo de diferentes arquitecturas basadas a partir del modelo desarrollado, el cual puede ser utilizado como esqueleto en la investigación de otras arquitecturas. -.
(8) Índice General. Índice de Figuras. y. Índice de Tablas. vii. Capítulo 1 Introducción y Motivación 1.1 Alcance de la. Thsis 1.2 VHDL 1.2.1 Orígenes del VHDL 1.2.2 El Lenguaje VHDL 1.3 Organización de. la Tesis Capítulo 2 Arquitectura Computacional 2.1 Generalidades 2.2 Perspectiva Histórica 2.3 Organización y Arquitectura 2.4 Evolución del Pentium y el PowerPC 2.4.1 Pentium 2.4.2 PowerPC 2.4.3 Velocidad del IVlicroprocesador 2.4.4 Balance en el Rendimiento Capítulo 3 Arquitectura RISC 3.1 Tipos de Arquitectura 3.2 Arquitectura CISC 3.2.1 Por qué CiSC 3.2.2 Lim:itaciones de Rendimiento en la Arquitectura CISC 3.3 Arquitectura RISC 34 Conceptos RISC 3.5 Principios de Diseño RISC 3.6 Ventajas y l)ebventa,jas de la Arquitectura RISC. 1 1 2 2 3 3. .. 5 5 5 6 7 7 S 10 10 13 13 14 15 17 17 18 18 20.
(9) ÍNDICE GENERAL 3.6.1 3.7. 3.8. Ventajas de la Arquitectura RISC. 3,6.2 Desventajas de la Arquitectura RISC Optiinización en el Diseño de Procesadores 3.7.1. Pipeline 3.7.2 Superpipeline 3.7.3 Superescalar Problemas del Pipeline 3.8.1 Riesgos por la Dependencia de Datos 3.8.2 Alternativas para Evitar los Riesgos de Control 353 Solución. para Riesgos 11)01 Depende:nc.ias de i)atos 3.8.4 Programación Diiiámnica. 20 20 22 22 25 25 26 26 26 27 28. Capítulo 4 Arquitectura PowerPC 4.1 Antecedentes 4.2 Microprocesadores PowerPC 4.3 Arquitectura del PowerPC 601 4.4 Arquitectura del PowerPC 603 4.5 Arquitectura. del PowerPC 604 4.6 Arquitectura del PowerPC 740/750. 31 31 32 35 36 38 40. Capítulo 5 Microprocesador PowerPC 604 5.1 Introducción 5.2 Descripción General y Pipeline 5.3 Estados del Pipeline 5.4 Unidades de I\’Ianejo de Memoria 5.5 Llnidade.s Principales 5.5.1 Cache 5.5.2 Fetch 5.5.3 Unidades de Decode y Dispatch 5.5.4 Unidades independientes de Ejecución 5.5.5 Umijdad de Coriiplet.ainieiito 5.6 Registros. 43 43 43 45 46 47 47 48 51 52 56 57. Capítulo 6 Fetch y Decode 6.1 Introducción 6.2 Fetch 6.2.1 Módulo Memoria. de Instrucciones 6.2.2 Módulo Fetch 6.3 Decode. 59 59 59 60 61 62.
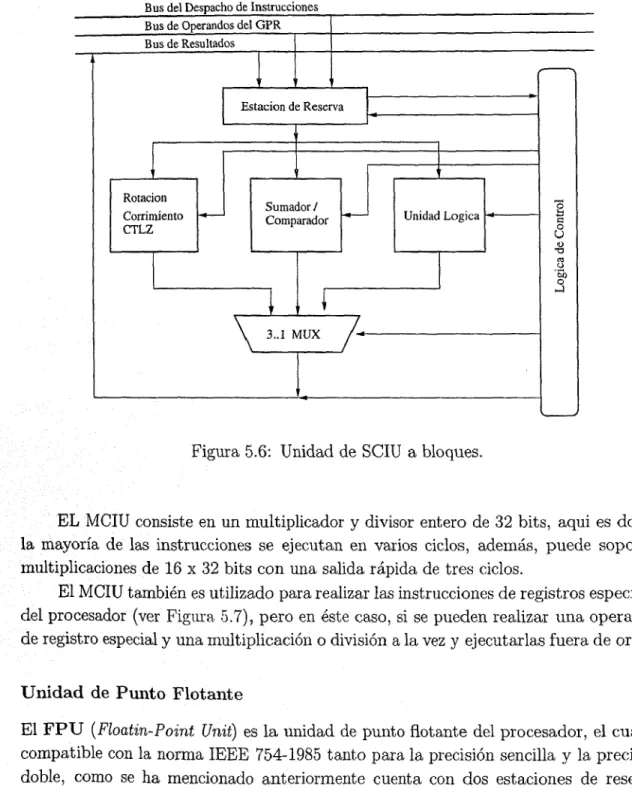
(10) ÍNDICE GENERAL 6.3.1 6.3.2 6.3.3. iii. Actualización de los Registros Decodi.ficación de Instrucciones Interacción con Dispatch. 63 65 66. Capítulo 7 Dispatch 7.1 Introducción 7.2 Actualización de los Registros 7.3 Interacción. con otras Unidades 7.3.1 Interacción con el Bufer de Reordeni 7.3.2 Interacción con el Bufer de Remiorxibre 7.3.3 Interacción coii la Etapa de Ejecución 7.3.4 Interacción con el GPR 7.3.5 Selección de Operandos. 69 69 69 71 71 75 77 78 79. Capítulo 8 Registros 8.1 Introducción 8.2 GPR 8.2.1 Actualización de los Registros 8.2.2 Interacciómi con otras Unidades 8.3 El Bufer de Renombre 8.3.1 Registros del Bufer de Renombre 8.3.2 Interacción con otras Unidades 8.4 El Bufer de R.eorden 8.4.1 Actualización de Registros 8.4.2 Interacción con otras Unidades. 83 83 83 85 87 89 91 95 98 98 101. Capítulo 9 Etapa de Ejecución 9.1 Introducción 9.2 Estaciones (le Reserva 9.3 Bus de Resultados y ALU 9.4 SCIU 9.4.1 Estaciones de Reserva de SCIU 9.4.2 ALU de SCIU 9.4.3 Unidades SCIU1 y SCIU2 9.5 MCJU 9.5.1 Estaciones de Reserva de MCIU 9.5.2 ALU de MCIU 9.6 LSU. 105 105 106 111 112 113 115 116 116 119 119 121. .. .. ..
(11) iv. ÍNDICE GENERAL. Capítulo 10 Síntesis del PowerPC 604 10.1 Introducción 10.2 Archivos en VHDL 10.3 Síntesis. 123 123 123 125. Capítulo 11 Conclusiones 11.1 Problemática 11.2 Aportación 11.3 Futuras Investigaciones. 131 131 132 133. Apéndice A Código VHDL A. 1 Librerias del Modelo A.2 Hardware del Modelo desarrollado A.3 Archivo porwerpc.vhd A.4 Listados. 135 135 135 136 136. Bibliografía. 213. Vita. 215.
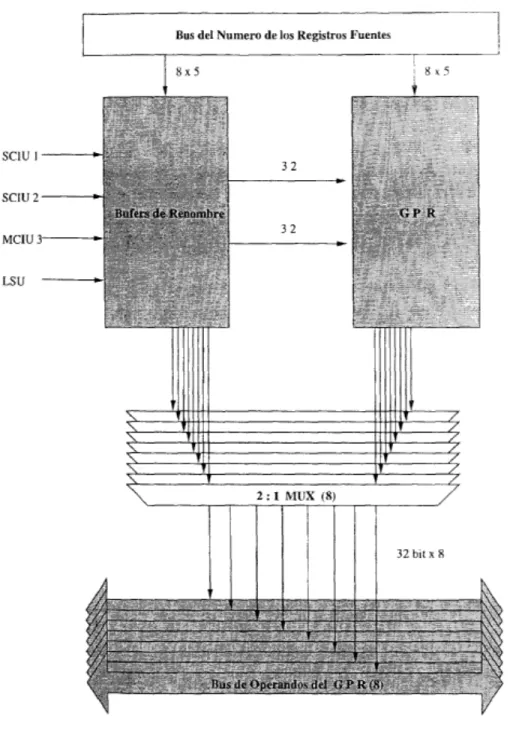
(12) Índice de Figuras. 2.1 2.2. Genealogía del PowerPC. Evolución de la DR.AMs y del procesador. 9 11. 3.1 3.2 3.3 3.4 3.5. Características de algunos procesadores Funcionamiento ideal de urn procesador cori pipeline Pipeline interrumpido por interrupciones o saltos condicionales Técnica de Scoreboard Técnica de Toimiasulo. 21 23 24 29 30. 4.1 4.2 4.3 4.4 4.5. Arquitectura del PowerPC 601 Diagrama a bloques de la arquitectura del PowerPC 603 Diagrarria a bloques de la arquitectura del PowerPC 604. Buses del PowerPC 604 Arquitectura. del PowerPC 750. 35 37 39 40 42. 5.1 5.2 5.3 5.4 5.5 56 5.7 5.8 5.9. Pipeline del PowerPC 604 Diagrama a bloques del PowerPC 604 Unidad de Manejo de Memoria del PowerPC 604 Fetch del PowerPC 604 Buses del PowerPC 604 Unidad de SCIU a bloques Unidad (le MCIU a bloques Unidad de FPU a bloques GPR del PowerPC 604. 6.1 6.2 6.3 6.4 6.5. Modelo de la Memoria de Instrucciones Módulo fetch de la etapa Fetch Etapa ele Fetch F~tapa1)ecode Buses que intervienen en la actualización de DEQ y. .. .. .. .. 44 45 47 50 53 54 55 56 58 61 62 62 63 63.
(13) vi. ÍNDICE DE FIGURAS 7.1 7.2 7.3 7.4 7.5. Conexión de la etapa Dispatch con el Bufer de Reordeii Conexión de la etapa I)is~atchcori el Bufer de Renombre Tiempos de Instrucciones El Dispatch Conexión de la etapa Dispatch cori el GPR Tiempos de Instrucciones Selección de Operanidos. 8.1 8.2 8.3 8.4 8.5 8.6 8.7 8.8 8.9 8.10. Buses del registro de (latos del GPR El GPR y su relación con otras etapas Tiempos de instrucciones Uso del Bufer de Renombre Buses del registro de datos del Bufer de Renombre Buses del registro de control del Bufer de Renombre Registros internos del Bufer de Renombre El J3ufer de Renombre y su relación cori otras etapas Registros (le orden del Bufer de Reorden Registros internos del Bufer de Reorden Conexión de los Registros del procesador cori las demás etapas. 86 89 90 93 94 95 97 99 100 104. 9.1 9.2 9.3 9.4 9.5 9.6. Tiempos de Instrucciones Uso de las Estaciones de Reserva Diagraina a bloques de la Estación de Reserva 1 Unidad de ejecución SCIU Las unidades SCIU y su conexión con otras etapas Unidad de ejecución MCTU La unidad MCIU y su conexión con otras etapas. 107 111 113 117 119 120. -. -. -. -. 10.1 Porcentaje de áreas del. modelo desarrollado 10.2 Distintas áreas del modelo desarrollarlo. 73 76 78 79 80. 127 129.
(14) Índice de Tablas. 4.1. Tabla comparativa de la famniilia PowerPC. 34. 6.1 6.2 6.3 6.4. Buses Buses Buses Buses. 60 60 64 65. 7.1 7.2 7.3 7.4 7.5 7.6. Buses del registro del Dispatch Buses de los registros DISQ y su conexión con otras etapas Características de los buses de la etapa de Dispatch (Prinnera Parte). Características de los buses de la etapa de Dispatch (Segunda Parte).. Buses de la etapa de Dispatch y su conexión con otras etapas Cairipos del Bus DisJLTo..ROB. 8.1 8.2 8.3 8.4 8.5 8.6 8.7 8.8 8.9 8.10 8.11. Buses del GPR Buses del GPR y su conexión cori otras etapas o unidades (le ejecución. Canipos de cada línea del bus WB_Lines Campos del registro de control y del bus DispComitroLGpr Buses del Bufer de Renombre Buses de R,EB y su conexión con otras etapas o unidades de ejecución. Campos del registro de control y del bus DispControl_Ren Campos del Bufer de Reordemr Registros internos del Bufer de Reorden Buses de entrada y salida al ROB su conexión con otras etapas .Bi.ises del Bufer (le Reordeir.. 84 85 86 86 92 93 94 99 100 101 102. 9.1 9.2 9.3 9.4 9.5. Campos de la Estación de Reserva Características de los buses de la Estación de Reserva Subcampos del campo InfoJns y del bus JnsToDisp Campos del bus de resultados Result_Lines l3uscs (le la unidad de ejecución SCIU. 109 110 112 113 114. (le de de de. l.a etapa la etapa la etapa la etapa. de de de de. Fetch y si.i conexión con otra.s etapas Fetch Decode Decode y su conexión con otras etapas. .. .. vii. .. 70 70 72 73 74 76.
(15) viII. ÍNDICE DE TABLAS 9.6 9.7 9.8 9.9. Buses de SCIU y su conexión con otras etapas Buses de la unidad de ejecución MCIU BUSeS de MCIU y su conexión corn otras etapas Duración de las instrucciones de MCIU por ciclos de reloj. 114 118 118 120. 10.1 10.2 10.3 10.4 10.5. Línneas de código de los archivos VI-IDL Archivos en VHDL y tiempo de síntesis Área de componentes del modelo en VHDL en micras Tiempos de Rutas Críticas en ns (ix10~seg.) Número de Flip Flops generados por archivos. 124 125 126 128 128.
(16) Capítulo. 1. Introducción y Motivación. 1,1. Alcance de la Tesis. El objetivo de esta investigación es el desarrollo en VHDL de un modelo fiel del microprocesador PowerPC 604, El modelo desarrollado contiene las etapas del pipeline del procesador las cuales son fetch, decode, dispatch, ejecución, cornpletarniento y write back. De la etapa de ejecución fueron desarrolladas las unidades SCIU y MCIU, además, los registros principales de este procesador GPR., bufer de renombre y hufer de reorden. Las unidades que no fueron implantadas son las de carga/almacenamiento y la parte concerniente a punto flotante (esta investigación abarca solamente el funcionamiento básico de la arquitectura del PowerPC 604) tampoco fueron incluidos los registros especiales, así como también las unidades de manejo de memoria. Para realizar dicho modelo fue necesario recabar información del funcionamiento del procesador de acuerdo a los documentos que son proporcionados por el fabricante. El modelo se desarrolló de acuerdo al pipeline del procesador, es decir, desde la etapa de captura de instrucciones hasta la etapa donde la instrucción es terminada. Cada etapa fue evaluada y simulada de acuerdo al comportamiento del procesador real. Después de que cada etapa era evaluada individualmente, está era conectada a las etapas que ya fueron probadas previamente. Este modelo podrá ser utilizado con fines académicos en materias relacionadas con arquitecturas computacionales avanzadas, sistemas digitales avanzados, computo de alto rendimiento y materias afines a microprocesadores. Además, el modelo desarrollado es sintetizable y podrá ser utilizado como benchmark de herramientas de síntesis, incluso podría ser implantado en silicio. Además esta investigación pretende motivar el desarrollo en VHDL de diferentes procesadores, para el estudio de arquitecturas conniputacioniales.. 1.
(17) 2. 1.2 1.2.1. CAPÍTULO 1. INTRODUCCIÓN Y MOTIVACIÓN. VHDL Orígenes del VHDL. En la búsqueda de una herramienta estandar para diseño y documentación para el programa VHSIC (Very High Speed Integrated Circuits), el Departanienito de Defensa de los Estados Unidos apoyó en el verano de 1981 a un grupo de trabajo en lenguajes descriptores de hardware en Woods Hole, Massachusets. Este grupo de trabajo fue creado por el Instituto de Análisis de Defensa (IDA Institute of Defense Analisys) para estudiar varios métodos de descripción de hardware, esto fue por la necesidad de tener un lenguaje estandar. Debido a que el programa VHSIC se encontraba bajo las restricciones de la Regulación Internacional de Estados Unidos de Trafico de Armas (ITAR United States International Traffic and Arms), el componente VHDL de este programa inicialmente también se encontraba bajo estas restricciones. En 1983, el Departamento de Defensa estableció los requerimientos para el estandar VHSIC Hardware Description Language (VHDL), basada en las recomendaciones del grupo de trabajo de Woods Hole. El contrato para el desarrollo del VHDL incluyendo el software y su ambiente de desarrollo fue ganado por las compañias IBM, Texas Instruments e Intermetrics. En este mismo año las especificaciones del lenguaje ya no estaban bajo las restricciones del ITAR, pero estas restricciones continuaban aplicandose por el gobierno en el software desarrollado. El VHDL 2.0 fue liberado solamente seis meses después de que el proyecto había comenzado, sin embargo, esta version permitia solamente las instrucciones concurrentes y dejaba entrever la capacidad de realizar descripcion de hardware de manera secuencial, en corto tiempo esta se volvio parte de las caracteristicas del lenguaje El lenguaje fue significativamente mejorado en version VHDL 6 0 liberada en Diciembre de 1984 El desarrollo de las herramientas basadas en VHDL tambien comenzo en 1984 En 1985, las restricciones del ITAR fueron removidas del VHDL y del software relacionado con el El Manual de Referencia del Lenguaje VHDL 7 2 (LRM) de derechos reservados fue transferido a là IEEE para su estandarizacion y desarrollo Esto fue el inicio del desarrollo del Manual de Referencia del Lenguaje VHDL IEEE 1076/A (LRM Language Reference Manual) el cual fue liberado en Mayo de 1987 Un año mas tarde la version B del LRM fue desarrollado y aprovado por REVCOM (Coinmite de estandars de là IEEE) El VHDL 1076-1987 formalmente se convirtio en un lenguaje descriptor de hardware de la IEEE en Diciembre de 1987 En el 1993 fue revisado nuevamente este estandar por la IEEE de acuerdo a las normas de la IEEE, en 1998 se realizó la última revisión del estandar. Todos los estandares de la IEEE se deben de revisar cada 5 años [12]..
(18) 1.3. ORGANIZACIÓN DE LA TESIS. 1.2.2. 3. El Lenguaje VHDL. El VHDL es un lenguaje descriptor de hardware que satisface los requerimientos de 1983 del Departamento de Defensa. La experiencia de investigadores y de otros usarios con el VHDL desde que éste se convirtió en un estandar de la IEEE en 1987 indican que este lenguaje es suficientemente rico para el diseño y descripción de los sistemas digitales de la actualidad. Como originalmente fue descrito en los requerimientos originales, el VHDL es un lenguaje descriptor de hardware con un fuerte énfasis en la concurrencia. El lenguaje puede soportar descripción jerárquica de hardware desde un sistema digital hasta una compuerta lógica e incluso hasta nivel interruptor. Como es esperado el VHDL, proveé herramientas para la especificaciones de diseño y configuración. El diseño de un sistema lógico en VHDL está definida en la declaración de la entidad (entity declaration) la cual es asociada a una arquitectura (architecture body). La declaración de la entidad, específica la interfaz del sistema digital y es utilizada por las arquitecturas de entidades de niveles de jerarquía superior. La arquitectura describe la operación o funcionamiento del sistema digital y su interconexión con otros sistemas digitales de menor jerarquía, tanto la entidad como la arquitectura son la base del VHDL, además, las librerias del sistema o en su caso del lenguaje mismo son conocidas como packages. El VHDL es un lenguaje el cual puede utilizarse tanto como lenguaje de simulación, lenguaje de síntesis, lenguaje de documentación y como lenguaje para la creación de modelos de sistemas digitales; como es el caso en esta tesis [12}.. 1.3. Organización de la Tesis. Esta tesis esta dividida en dos partes, la primera parte de esta tesis esta comprendida del Capítulo 2 al Capítulo 5 y abarca desde el inicio del microprocesador hasta la arquitectura del PowerPC 604. La segunda parte habla del modelo creado en VHDL. En el Capítulo 2 se plantea la definición de arquitectura computacional, la perspectiva histórica del microprocesador hasta llegar a la evolución del Pentium y el PowerPC. El Capítulo 3 señala la diferencia existente entre la arquitectura CISC y la RISC, las limitaciones de cada una de estas; ademnás de los conceptos básicos de la arquitectura RISC, métodos empleados en el desarrollo de la misma así como también, su problemática actual y su soluciones. En el CapíI nb 4 se realiza una semblanza de lo que han sido el desarrollo de los procesadores de la familia PowerPC, su origen y sus nuevos miembros. En el Capítulo 5 se da una descripcióni de las unidades que conforman al PowerPC 604, registros y su organización todo de esto de acuerdo a los manuales exis-.
(19) 4. CAPÍTULO 1. INTRODUCCIÓN Y MOTIVACIÓN. tentes del procesador comercial. El Capítulo 6 aborda lo que es el modelo creado para la realización de esta tesis, en este capítulo se abordan las etapas fetch y decode de acuerdo al modelo desarrollado en esta investigación. En el Capítulo 7 se expone el funcionamiento de la etapa dispatch y de las consideraciones que está necesita tomar para el envio de instrucciones a ejecución. El Capítulo 8 muestra el funcionamiento de los registros que son utilizados por el procesador. En el Capítulo 9 se expone el funcionamiento de la etapa de ejecución del procesador. En el Capítulo 10 se dan los resultados de la síntesis realizada al modelo en VHDL del procesador. El Capítulo 11 presenta las conclusiones de esta investigación y propone nuevas investigaciones para desarrollar con este modelo o utilizando a este modelo como herramienta..
(20) Capítulo 2. Arquitectura Computacional. 2.1. Generalidades. Los microprocesadores han evolucionado el uso de las computadoras en todos los niveles de la sociedad. Estamos llegando rapidamente al punto donde todo aparato en la cocina y todo juguete de un niño podrá tener internamente un microprocesador sofisticado En los años recientes la tecnología de los microprocesadores ha avanzado hasta el punto de que los niveles de rendimiento de los microprocesadores rivalizan con las supercomputadoras. Dos importantes sucesos han conducido al incremento en el uso de los microprocesadores. Primero, la introducción de la computadora personal IBM PC la cual llevó al uso extendido de las computadoras personales, basados en los microprocesadores de la familia Intel. Segundo, el número de compañias que han comercializado estaciones de trabajo basados en los microprocesadores. Esto ha popularizado la noción en círculos de ingeniería de que es más efectivo tener una estación (le trabajo razonablemente potente en tu escritorio que una pequeña parte de una supercomnputadora.. 2.2. Perspectiva Histórica. El microprocesador es resultado del comienzo de la tecnología de circuitos integrados y de la arquitectura computacional [16] Con el desarrollo de LSI, los circuitos integrados personalizados fueron ampliamente utilizados. Los circuitos integrados personalizados son especialmente diseñados para una aplicación particular de esta manera se hace más eficiente el uso de un gran número de transistores fabricados en un solo circuito integrado. Sin embargo, el costo de desarrollo de un circuito integrado es alto, excepto para aplicaciones de alto volumen. Antes de la introducción del microprocesador, no estaba claro cual era el estandar de un circuito integrado (a no ser que se tratara de un circuito de memoria) en el se 5.
(21) 6. CAPÍTULO 2. ARQUITECTURA COMPUTACIONAL. utilizaban cientos de compuertas y fuera de propósito general para poder tener un gran mercado. El nacimiento del microprocesador vino cuando Intel diseñó un conjunto de circuitos personalizados para un cliente que estaba construyendo calculadoras. El diseño original era muy complejo y a los diseñadores de Intel se les ocurrió que las minicomputadoras tenían todas las capacidades necesarias y su arquitectura era más sencilla, para realizar dicha función. El conjunto de circuitos integrados fueron diseñados con un programa de computadora almacenado, el cual podría ser personalizado con un programa para realizar las funciones deseadas, Cuando el cliente declinó en comprar el conjunto de circuitos integrados por que eran muy lentos, Intel lo introdujo al mercado como la familia 4004, siendo el nacimiento del microprocesador. Los diseñadores de Intel estaban buscando la manera de reducir el número de componentes requeridos para construir una minicomnputadora, el microprocesador vino a ser la solución a ese problema. Sin embargo, aunque los microprocesadores realizan la función de la unidad de central de procesamiento de una computadora (CPU), su intención original no fue ser un bloque de computadora. El microproceador fue diseñado para reducir el número de componentes de la lógica digital, en el cual las interconexiones determinaban la función.. 2.3. Organización y Arquitectura. En la descripción de sistemas computacionales, existe unia distinción usual entre arquitectura computacional y organizacion computacional [17] Si bien, es dificil dar una definicion exacta para estos terminos, existe un consenso acerca de las areas que cubre cada una de ellas La arquitectura computacional se refiere aquellos atributos del sistema visibles al programador Organizacion computacional se refiere a las unidades operacionales y sus interconexiones que realizan las especificaciones de la arquitectura computacional Ejemplos de los atributos de la arquitectura computacional incluyen el conjunto de instrucciones, el numero de bits utilizados para representar varios tipos de datos (por ejemplo numeros, caracteres, etc) mecanismos de entrada y de salida, y tecnicas para el direccionamiento de memoria Los atributos de organizacion computacional incluyen aquellos detalles de hardware transparentes al programador como son las señales de control, interfaces entre la computadora y los periféricos, además de la tecnólogia de memoria usada. Historicamente y aún hoy en día, la distinción entre arquitectura computacional y organización computacional ha sido importante. Muchos fabricantes de computadoras.
(22) 2.4. EVOLUCIÓN DEL PENTIUM Y EL POWERPC. 7. ofrecen una familia de modelos de computadoras, todas ellas con las misma arquitectura pero, con diferencias en su organización. Consecuentemente, los diferentes modelos de computadora en la familia tienen diferentes precios y características de rendimiento. Además, una arquitectura puede sobrevivir varios años, pero una organización cambia con la tecnología.. 2.4. Evolución del Pentium y el PowerPC. El Pentium representa el resultado de décadas de diseño en base a un complejo conjunto de instrucciones computacionales (CISCs). Este incorpora principios de diseño sofisticados que unicamente fueron encontrados en MainFrames, Supercomputadoras y Servidores. Estos son un ejemplo excelente del diseño CISC. El PowerPC es un descendiente directo del primer sistema RISC, del IBM 801 y es uno de los más poderosos y mejor diseñados sistemas basados en arquitectura RISC del mercado. 2.4.1. Pentium. Intel ha ocupado el lugar número uno de los fabricantes de microprocesadores por décadas, una posición que parece no perderá. La evolución de sus microprocesadores como líderes es un buen indicador de la evolución de la tecnología comnputacional. El Pentium III es ahora la nueva estrella de la línea de productos Intel. Algo interesante de notar es que, así como, los procesadores se han vuelto veloces también ahora son mucho más complejos, Intel acostumbraba desarrollar microprocesadores uno tras otro cada cuatro años. Pero ahora debido al Pentium el desarrollo de microprocesadores se ha venido realizando cada tres años y con sus nuevos procesadores Pentium III Intel espera mantener a sus rivales en la línea. Estos son algunas de las relevancias de la evolución de los productos de la línea Intel: • 4004: Este fue el primer microprocesador del mundo de 4 bits, con una capacidad de direccionamiento de 640 bytes. • 8080: El primer procesador de propósito general del mundo de 8 bits. • 8086: Más poderoso que su predecesor, procesador (le 16 bits, con bus de datos de 16 bit y registros de 16 bits. El 8086 podía soportar una instrucción de cache o una pila que pudieran hacer el Prefetch de algunas instrucciones antes de ser ejecutadas..
(23) 8. CAPÍTULO 2. ARQUITECTURA COMPUTACIONAL • 80286: Este es una extensión del 8086 con la capacidad de direccionar a 16 MByte de memoria en lugar de solamente un MByte. • 80386: Primer procesador de 32 bits que tuvo un mayor rediseño de su arquitectura con respecto a sus predecesores. Con una arquitectura de 32 bits el 80386 rivalizó en complejidad y potencia a las mini computadoras y mainframes que fueron introducidos pocos años atrás. • 80486: El 80486 introdujo el uso de tecnología más sofisticada y poderosa de cache, así como también pipeline. • Pentium: Con el Pentium Intel introdujo el uso de técnicas superescalares, dos pipelines, lo cual permite ejecución de multiples instrucciones en paralelo. • El Pentium II continúa moviendose dentro de la organización superescalar con 2 pipelines comenzada con el Pentium con el uso agresivo de técnicas de predicción de saltos, análisis de flujo de datos y ejecución especulativa. Este procesador convierte las instrucciones a instrucciones más sencillas (microoperaciones) y después utilza el algoritmo Tomasulo.. 2.4.2. PowerPC. En 1975, el proyecto de minicomputadora 801 de IBM fue la pionera de muchos de los conceptos de la arquitectura RISC. El 801 junto con el procesador de Berkeley RISC I iniciaron el movimiento RISC El 801, sin embargo, fue un simple prototipo que trataba de mostrar los conceptos de diseño El exito del 801 motivo a IBM a desarrollar comercialmente una estacion de trabajo RISC, la RT PC La RT PC introducida en 1986, adapto los conceptos de la arquitectura del 801 a este producto La RT PC no tuvo exito comercial y tuvo muchos uvales que tenian un rendimiento igual o mejor En 1990, IBM produjo un tercer sistema el cual tema parte de la arquitectura del 801 y la RT PC, conocido como el sistema RISC System/6000 el cual era una maquina RISC superescalar equiparable a una estacion de trabajo de alto rendimiento, poco tiempo despues de esta introduccion IBM comenzo a llamarle POWER a este tipo de arquitectura. En 1994 IBM entro en una alianza con Motorola (creador de los microprocesadores de la serie 68000), y Apple, el cual, utilizaba los procesadores de Motorola en sus computadoras Macintosh Esta alianza fue realizada para el diseño de una serie de computadoras que implementarían la arquitectura del microprocesador PowerPC. Esta arquitectura es derivada de la arquitectura POWER de IBM (ver Figura 2.1)..
(24) 2.4. EVOLUCIÓN DEL PENTIUM Y EL POWERPC. 9. Figura 2.1: Genealogía del PowerPC.. Hasta ahora se han introducido cuatro miembros de la familia PowerPC, todos estos procesadores son de 32 bits: • PowerPC 601 : El propósito del PowerPC 601 fue abrir en el mercado un lugar para la arquitectura PowerPC tan pronto como fuera posible. • PowerPC 603: Se diseñó para utilizarse en computadoras de escritorio y portátiles, es comparable en rendimiento con el 601, pero coii menor costo y una mejor eficiencia en su implementación. • PowerPC 604: Fue destinado para computadoras de escritorio y para aplicaciones finales de servidores. Este procesador aplica técnicas de diseño superescalar avanzada para alcanzar un mejor rendimiento. • PowerPC 740/750: Son los diseños más recientes de la arquitectura PowerPC, los cuales emplean un nuevo y avanzado diseño, además, de proveer un alto rendimiento mientras utilizan una fracción de potencia que la mayoría de los procesadores disponibles..
(25) 10. CAPÍTULO 2. ARQUITECTURA COMPUTACIONAL. 2.4.3. Velocidad del Microprocesador. Un ejecutivo de Intel, Gordon Moore, a mediados de 1960, mencionó que reduciendo el tamaño de las líneas que forman los circuitos de transistores en un pedazo de SilIcio en un 10% los fabricantes de circuitos integrados podrian dar una nueva generacion de circuitos integrados cada tres años con cuatro veces más transistores. En circuitos de memoria, las memorias aleatorias de acceso dinámico (DRAIVI) han cuadruplicado su capacidad cada tres años. En los microprocesadores la adición de nuevos circuitos y la velocidad a la que estos pueden trabajar han venido reduciendo la distancia entre ellos así como su rendimiento ha venido aumentando cada tres años y esto ha sucedido desde que Intel lanzó al mercado su familia X86 en 1979. Mientras que los fabricantes de circuitos integrados están aprendiendo como fabricar circuitos integrados de mayor densidad, los diseñadores de microprocesadores han estado trabajando en como desarrollar técnicas para agilizar el procesador, algunas técnicas que se utilizan en los procesadores contemporaneos son: • Predicción de saltos: El procesador al encontrar saltos predice si van a ser tomados o no. Si el procesador adivina el salto, éste podrá hacer un Prefetch de las instrucciones siguientes en el bufer, estás mmiantendrán al procesador ocupado. Si adivinó que no, el procesador realiza un fetch de la dirección correcta. • Ejecución fuera de orden: El procesador analiza cuales instrucciones son dependientes del resultado de otras o de datos de ejecución para crear y optimizar la secuencia de instrucciones. Esto se realiza mediante la calendarización de las instrucciones para que estas sean ejecutadas cuando esten listas, independientemente del orden original del programa • Ejecucion especulativa Utilizando la tecmca de prediccion de saltos y de ejecucion fuera de orden, algunos procesadores especulan sobre la ejecucion de mnstruccioiies reteniendo los resultados en locaciones temporales, esto habilita al procesador a mantenerlo ocupado tanto como sea posible por la ejecucion de instrucciones que este pudiera necesitar Estas y otras técnicas sofisticadas han creado procesadores más poderosos para poder explotar la velocidad del procesador. 2.4.4. Balance en el Rendimiento. Mientras que el rendimiento del procesador se ha basado en la frecuencia en la que éste puede trabajar, existen aún otros factores que no se han tomado en cuenta para mejorar.
(26) 2.4. EVOLUCIÓN DEL PENTIUM Y EL POWERPC. 11. el rendimiento. Por eso la necesidad de observar los métodos de diseño para balancear que el rendimiento del procesador no solo dependa de su velocidad, sino también de su arquitectura. Muchos de los problemas de hoy en día en el rendimiento de los procesadores es la interfaz entre el procesador y la memoria principal. Mientras que la velocidad del micropocesador y la capacidad de memoria ó capacidad de almacenamiento han crecido rapidamente, la velocidad por la cual los datos pueden ser transferidos entre la memoria principal y el procesador se ha quedado atrás (ver Figura 2.2). La interfaz entre el procesador y la memoria principal es el camino más crucial de la computadora porque es el responsable del flujo constante de instrucciones y datos. Si la memoria o el bus de datos fallan por un instante el procesador permanecerá en un estado de espera y un tiempo valioso de procesamiento será perdido.. Hay muchas maneras en la que la arquitectura del sistema puede atacar éste problema todas ellas son reflejadas en los diseños contemporáneos de computadoras por ejemplo: • Aumentar el ancho del bus de datos. • Cambiando la interfaz de DRAM para hacerla más eficiente, incluyendo un cache u otro esquema de bufer en el integrado de la DRAM. • Reduciendo la frecuencia de los accesos a memoria por la incorporación de coinplejas estructuras de cache entre el procesador. Esto incluye la incorporación de.
(27) 12. CAPÍTULO 2. ARQUITECTURA COMPUTACIONAL uno o más caches en el integrado del procesador, así como, también un integrado de cache cerca del procesador..
(28) Capítulo 3. Arquitectura RISC. 3.1. Tipos de Arquitectura. En la búsqueda para mejorar el rendimiento de los microprocesadores han llevado a la investigación de alternativas en el el diseño de arquitecturas. Una de estas alterantivas están basadas en nuevos conceptos para el diseño de microprocesadores cuya arquitectura es denominada arquitectura RISC (Reduced Instruction Set Computers) que significa computadora de repertorio de instrucciones reducido [2]. En el pasado el conjunto de instrucciones grandes, eran consideradas una ventaja, los fabricantes orgullosamente anunciaban “más de 200 instrucciones distintas”. El estilo de arquitectura RISC regresa a la idea donde un menor número de instrucciones en el diseño de un microprocesador es mejor “menos es más”. La idea que hay detrás de la filosofía de la arquitectura RISC es simplificar y reducir el número de instrucciones, mediante la eliminación de todas aquellas que no son esenciales. Las instrucciones restantes pueden hacer que el microprocesador desde cierto punto de vista no dependa de la frecuencia de la señal de reloj, sirio que dependa de la sencillez de la instrucción. Que las instrucciones no sean esenciales no significan que no sean ejecutadas de vez en cuando, pero estas pueden ser reemplazadas por una secuencia de instrucciones sencillas sin tener un impacto notable en la eficiencia del microprocesador. La observación que inspiró el desarrollo RISC, fue que solo una pequeña parte de un conjunto de instrucciones son las más cormiunmente ejecutadas, además de que un gran número de instrucciones son ejecutadas esporadica.mente. La filosofía original en el diseño de microprocesadores. conocida ahora como filosofía CISC (complex Instruction Set Computers), además de tener uii gran número de instrucciones, hay que hacer notar la complejidad de algunas de ellas. Esta filosofía existe virtualmente en todas las connputadoras personales, incluyendo aquellas hechas por IBM, Apple, Acer, Packard Bell y Compaq entre otras. Estas utilizan microprocesadores Intel o compatibles con el mismo, el motivo por seguir trabajando con arqui13.
(29) 14. CAPÍTULO 3. ARQUITECTURA RISC. tectura CISC es poder conservar la compatibilidad con los procesadores anteriores, es decir, con la familia 80x86. Cabe mencionar, que el Pentium PRO y Pentium II de Intel los cuales son de la familia 80x86 internamente es un procesador RISC. En cambio la filosofía RISC ha sido utilizada primordialmente en estaciones de trabajo. La filosofía RISC diseña generalmente un número mínimo de instrucciones en la cual estas pueden construir instrucciones más complejas; por otra parte la filosofía CISC trata de encontrar instrucciones que puedan simplificar la programación de las operaciones especializadas más frecuentes. La base de la filosofía CISC es proveer un extenso repertorio de instrucciones para cubrir todas las necesidades de propósito especial. En esta aproximación, el costo de estas instrucciones extras parece mínimo “Tu no tienes que usarlas si no las necesitas”. En contraste, la actitud de la filosofía RISC es que estas instrucciones no son lo suficientemente utilizadas para justificar la complejidad extra en la implementación de hardware y esta complejidad tiende a reducir o retrazar las instrucciones más comunmente ejecutadas. En la práctica la línea divisora entre estas dos filosofías no esta muy clara. Por ejemplo, la división de punto flotante es una operación extremadamente complicada que al igual que otras operaciones complicadas pueden ser programadas utilizando instrucciones más simples. Sin embargo, casi todos los procesadores RISC incluyen la división de punto flotante porque en este caso particular está instrucción es lo suficientemente utilizada para justificar su inclusión. Por otra parte, las más sofisticadas instrucciones a nivel de sistema solo aparecen en algunos procesadores CISC, de tal manera, que estas tareas no parecen lo suficientemente importantes para ser universalmente incluidas en los diseños RISC. 32. Arquitectura CISC. Existen tantas familias de microprocesadores CISC como existen familias de microprocesadores RISC [2] Sin embargo, solamente dos familias CISC han dominado el mercado Estas dos familias son la 80x86 de Intel y la familia 680x0 de Motorola, donde solo la familia Intel ha hecho un mayor esfuerzo por mejorar el rendimiento de sus microprocesadores para compertir contra los microprocesadores RISC Ademas de las familias 80x86 y 680x0 existen otras familias las cuales son las siguientes • La familia Z80 de Zilog con el microprocesador Z80000 de 32 bits. • La familia 32000 de National Semiconductor con el microprocesador 32532 de 32 bits..
(30) 3.2. ARQUITECTURA CISC. 15. • La familia 32000 de AT&T con los microprocesadores 32100 y 32200 de 32 bits. • La familia V de NEC Electronics con los microprocesadores V60, V70 y V80 de 32 bits. • La familia 340x0 de Texas Instruments con los microprocesadores 34010 y 34020 de 32 bits. El esfuerzo por mejorar su rendimiento, los microprocesadores CISC han incrementado sus frecuencias de reloj y han incorporado en el corazón de los mismos algunas características típicas de RISC sin sacrificar su compatibilidad en sus programas binarios, como por ejemplo el Pentium PRO, Pentium II y el i960. Los microprocesadores de 32 bits de Intel y Motorola tienen arquitecturas similares que consisten en unidades de fetch interno, decode, ejecución e interfaz de bus. Estas arquitecturas soportan operaciones de pipeline, multitareas (multitasking), esquemas de protección y privilegios, operación con coprocesador y manejador de memoria avanzado. El conjunto de registros de 32 bits cada uno, que tienen los microprocesadores CISC son convenientemente separados en registros para el programa y el sistema. Los registros del programa consisten al menos de registro del contador de programa, registro del apuntador de la pila (stack pointer), el registro de banderas y registros múltiples de datos de propósito general y de direcciones. Estos registros son tipicamente utilizadas por aplicaciones de programa para manipulación y cálculo de datos. Los registros del sistema consisten en registros de tareas, estatus y de interrupción, los cuales son requeridos para soportar las funciones del sistema operativo. 3.2.1. Por qué CISC. Se ha mencionado que los procesadores CISC tienen un rico conjunto de instrucciones, las cuales incluyen un gran número de instrucciones muy complejas. Dos razones principales han motivado la tendencia de crear cada vez un mayor número de instrucciones: 1. El deseo de simplificar los compiladores. 2. El deseo de utilizar menos memoria. Ambas de estas razones fueron desplazadas por el liso de los lenguajes de alto nivel por parte de los programadores; ahora los diseñadores de microprocesadores han intentado desarrollar máquinas que puedan dar un mejor soporte a los lenguajes de alto nivel. La primera razón mencionada, el deseo (le simplifica.r los compiladores, es obvia. La tarea de un compilador, es la de generar la secuencia de instrucciones en lenguaje.
(31) 16. CAPÍTULO 3. ARQUITECTURA RISC. máquina para cada sentencia de un programa de alto nivel. Si hay instrucciones de lenguaje máquina que son desensambladas de las instrucciones de los lenguajes de alto nivel, la tarea es fácil. Esta es la razón que se han estado disputando los innovadores de la tecnolgía RISC. Ellos han encontrado que las instrucciones complejas de máquina son difíciles de explotar, desde que el compilador debe de encontrar aquellos casos en Un programa de alto nivel en donde exactamente estas se tengan que utilizar. La tarea de optimizar el código para minimizar el tamaño, reducir el número de instrucciones, y mejorar el pipeline es mucho más difícil con un conjunto de instruciones complejas; ya que la mayoría de instrucciones en un programa compilado son relativamente las mismas. La otra razón citada es la expectación de que un CISC tiende a que sus programas sean rápidos y pequeños. Examinemos la base de estos dos aspectos. Existen dos ventajas de que los programas sean pequeños. Primero, estos programas ocupan menos espacio en memoria, por lo que aquí tenemos ahorro de éste recurso. Con la memoria de hoy en día la cual se esta volviendo cada vez más barata está deja de ser una ventaja potencial. Lo más importante es que los programas pequeños deberían mejorar el rendimiento de la máquina y esto, podría hacerse de dos maneras. Primero, pocas instrucciones significan pocos bytes de instrucciones para ser capturados y segundo, en un ambiente de paginación de la memoria los programas pequeños ocupan menos páginas de memoria, reduciendo las paginación de memoria virtual. El problema con este razonamiento de un programa CISC es ciertamente más pequeño que su correspondiente programa RISC. En muchos de los casos, el programa CISC expresado eu un lenguaje maquma simbohco sera mas corto (menos instrucciones), pero el número de bits de memoria ocupada no será notablemente pequeño. Hemos notado que los compiladores en CISC tienden a favor de simplificar instrucciones, por lo que, en las instrucciones complejas entran al juego Tambien, desde que existen mas instrucciones en CISC, mas grande es el espacio para lo codigos operacionales para poder producir un mayor numero de instrucciones Finalmente, la arquitectura RISC tiende a enfatizar el uso de registros mas que las referencias de memoria y de esta forma requerir menos bytes de memoria, asi que, la expectacion de que el codigo CISC produce programas pequeños, considerando los puntos anteriores no es una gran ventaja El segundo factor motivante para incrementar el numero de instrucciones complejas es el que la ejecucion de esta instruccion sera rapido Esto parece tener sentido en la operacion de los lenguajes de alta complejidad, ya que, estos ejecutan las instrucciones más rápidas que una sola instrucción de máquina que un conjunto de instrucciones más primitivas. Sin embargo, no es tan simple el uso de estas instrucciones. El control entero de la unidad debe hacerse más complejo y/o el microprograma de control almacenado debe ser más largo para acomodar un rico conjunto de instrucciones. Uno u.
(32) 3.3. ARQUITECTURA RISC. 17. otro factor incrementa el tiempo de ejecución de instrucciones simples. 3.2.2. Limitaciones de Rendimiento en la Arquitectura CISC. Como se ha mencionado anteriormente, la arquitectura de los procesadores CISC tienden a tener un rico conjunto de instrucciones complejas que minimiza el término de instrucción por tarea, es decir, que tienen instrucciones dedicadas a tareas específicas. En el más simple de los casos, consideremos una instrucción de división, si nos concentramos en reducir el término de instrucciones por tarea, tenemos que tener un repertorio de instrucciones complejas, el cual tiende a incrementar el número de ciclos de reloj por instrucción (CPI). Por ejemplo, las instrucciones complejas requieren una codificación compleja que incrementan la complejidad de la decodificación para el conjunto completo de instrucciones. Las instrucciones simples del conjunto de instrucciones complejas comparten este inconveniente.. 3.3. Arquitectura RISC. En un estudio realizado a mediados de los 70 por el equipo de investigación de IBM encontró que el 80% de computación realizada por un programa requiere unicamente el 20% de instrucciones del repertorio de instrucciones de un procesador [4]. Las instrucciones más frecuentes utilizadas son las más sencillas tales como, carga y almacenamiento de un registro y la suma. La investigación y el desarrollo de productos RISC ha venido progresando, una definición común y un conjunto de principios de diseño han venido surgiendo. El terna fundamental del diseño de la arquitectura RISC es la efectividad de la velocidad, por el diseño de más funciones en software con excepción de aquellas características donde su implementación en hardware no repercuta en ganancia de su rendimiento, como se ha demostrado en estudios detallados de lenguajes de programación de alto nivel. Para abordar este tema, los diseñadores de RISC enfatizan “la ejecución cii un solo ciclo”. Donde la velocidad de un ciclo máquina no dependa de la arquitectura, sino que, dependa de la tecnología en el cual la arquitectura es irnplementada, como es la tecnología CMOS. De tal manera que un microprocesador convencional y uno implementado con filosofía RISC tengan la misma limitante en base al tiempo del ciclo de reloj. La diferencia entre estos dos microprocesadores está basada cori respecto al número de ciclos requeridos para realizar una misma instrucción. Donde los procesadores con arquitectura RISC estriban cii la ejecución de una instrucción por ciclo de reloj, es decir, donde su CPI sea igual a uno y esa es la base que hace posible la ganancia de rendimiento en la filosofía RISC [4]..
(33) 18. CAPÍTULO 3. ARQUITECTURA RISC. Debido a la naturaleza de la filosofía RISC, el CPI en un procesador RISC es menor que en un procesador CISC, ya que el método RISC es más simple debido al formato de instrucciones de una medida fija que permite una decodificación por hardware rápida y una gran simplicidad por el uso de su pipeline, también por el reducido acceso a la memoria principal ya que la mayoría de las instrucciones RISC son de tipo de registro a registro.. 3.4. Conceptos RISC. Los conceptos de la arquitectura RISC son presentados a continuación, hay que aclarar que la arquitectura RISC tiene actualmente más instrucciones que la arquitectura CISC: 1. Eliminar todas aquellas instrucciones que no pueden ser ejecutadas en una solo ciclo. Primero simplificar todas aquellas operaciones del ALU, para ejecutarse unicamente desde los registros. Esto probablemente indica que se necesitaran una gran cantidad de registros. Segundo, eliminar todas las instrucciones que no se puedan ejecutar en un solo ciclo. 2. Mover la complejidad del hardware al software. Utilizar el compilador para ordenar el uso de los registros y utilizar el uso del hardware interno para la ejecución de las instrucciones. 3. Con más hardware, se incluyen más intrucciones. Al utilizar más transistores o compuertas e implementar más lógica podemos agregar más instrucciones e incluso mas unidades de ejecucion 4 Facilidad de implementar pipeline El pipeline es mas facil de implementar en la arquitectura RISC. 35. Principios de Diseño RISC. La base de la ganancia de rendimiento en un procesador RISC radica en que su CPI es muy cercano a 1 [1],las siguientes caracteristicas son tipicas de la arquiectura RISC 1 Instrucciones simples Las instrucciones tienen un formato fijo, el tamaño tipico de la instrucción es de 4 bytes. 2. Pocos modos de direccionamlento: Una arquitectura RISC tiene tipicamente menos de 5 modos de direccionamiento. Una instrucción nada más puede tener por operando unsolo modo de direccionamiento..
(34) 3.5. PRINCIPIOS DE DISEÑO RISC. 19. 3. Arquitectura simple de carga/almacenamiento: Muchas instrucciones están basadas en los registros internos y son soportados por los mismos. Las referencias a memoria externa son minimizadas: el acceso a memoria en la transferencia de resultados y operandos es explicitamente hecho por instrucciones de carga y almacenamiento. Es decir, no existen instrucciones de carga/almacenamiento en combinación con operaciones aritméticas, por ejemplo: incrementar una localidad de memoria. Mientras en los procesadores CISC del 30% al 40% de las instrucciones ejecutadas implicitamente o explicitamente son accesos a la memoria de datos y un 20% son operaciones de registro a registro, en los procesadores RISC menos del 20% son cargas y almacenamientos más del 50% son operaciones de registro a registro. 4. Control simple por hardware: Debido a que las instrucciones RISC son simples y de formato corto, la decodificación es más sencilla y esto permite la implementación de mecanismos de control utilizando técnicas de hardware. 5. Buses de instrucción y de datos separados (Arquitectura Iff2arvard): Nuevamente, esta propiedad no es unicamente de los procesadores RISC, pero es más utilizada en los procesadores RISC que en los CISC. Ya que las instrucciones RISC son más simples que las CISC, además, que son capturadas mucho más rápida que las instrucciones CISC, Esto se debe a que exiten buses separados de instrucciones y de datos, de la misma manera en que hay tanto caches de instrucciones corno de datos implementados en el microprocesador. Esta separación también permite reducir el número de CFI por instrucción, además de que permite la captura de instrucciones y la carga/almacenamiento de datos simultaneamente. 6. Gran conjunto de registros: Esto se debe a que los procesadores RISC poseen un gran número de conjuntos de registros utilizables (mucho más que los procesadores CISC) para un rápido acceso de operandos (los cuales son almacenados eu los registros internos más que en la memoria principal), para llamados de subrutina y guardar el estado del procesador durante la atención de los servicios de atención de la misma. Un gran número de registros internos reduce en gran manera los accesos a memoria fuera del circuito integrado. 7. Frecuencia de reloj alta independiente del rendimiento: Por ejemplo; se puede dar el caso de que el procesador Pentium el cual es de arquitectura CISC y trabaja a una frecuencia de 200 MHz. tenga un rendimiento igual a un procesador PowerPC 604 que trabaje a una frecuencia de 120 MHz..
(35) 20. CAPÍTULO 3. ARQUITECTURA RISC 8. Delay slot: La técnica de delay slot no provoca una detención (stall) para esperar la dirección destino de una instrucción de salto, sino que la ejecución de salto es retardada y serán ejecutadas una o más instrucciones después del salto mientras el salto es ejecutado. Esto asume, que el compilador a examinado el programa y lo ha organizado de esa manera para permitir al pipeline del procesador ejecutar instrucciones durante ese tiempo de espera.. Las características 1 y 2 tienen un impacto directo en la decodificación de instrucciones, las características del 3 al 5 tienen un impacto directo en el pipeline del procesador, las características del 6 y 7 le dan una gran ventaja al compilador y las últimas dos repercuten en el rendimiento en general del procesador [5]. En la siguiente Figura 3.1, los primeros ocho procesadores son arquitecturas RISC, los siguientes cinco son procesadores CISC y las últimos dos son procesadores que tienen tanto características RISC como CISC.. 3.6 3.6.1. Ventajas y Desventajas de la Arquitectura RISC Ventajas de la Arquitectura RISC. Reduciendo el número de instrucciones complej as se incrementa la velocidad del procesador, porque la complejidad de las instrucciones reducen la velocidad del mismo. La velocidad del microprocesador es también incrementada por la minimización de los accesos a memoria por la ejecución de instrucciones con operaciones de registro a registro y adaptando técnicas de hardware para el diseño de la sección de control del procesador. También lo sencillo de las instrucciones reducen la complejidad del circuito (lo que permite un diseño simple y veloz) y los requerimientos de area del circuito integrado del microprocesador (lo cual permite implementar en el circuito integrado un mayor numero de funciones, como son las memorias de caches, unidades de manejo de memoria, unidades de punto flotante, etc) [13]. 362. Desventajas de la Arquitectura RISC. Los programas en RISC tienden a ser grandes. El manejo interno de las intrucciones para el manejo del pipeline, cache de instrucciones y el manejo de los delay slots de los saltos deben ser tomados en cuenta y realizados por el compilador (el rendimiento de los procesadores RISC depende en gran manera del diseño del compilador al igual que la arquitectura CISC) [13]..
(36)
(37) 22. CAPÍTULO 3. ARQUITECTURA RISC. Por qué RISC es mejor A continuación tenemos algunos puntos que determinan el por qué la arquitectura RISC es mejor: 1. La trayectoria del conjunto de instrucciones impacta en los ciclos de reloj en un factor de dos a seis instrucciones por ciclos de reloj. 2. La proporción de los ciclos de reloj por instrucción son mucho mejores que una arquitectura no RISC. 3. El precio de la simplificación de instrucciones se paga por el incremento del número de instrucciones necesarias para la realización de una tarea, como se había mencionado anteriormente.. 3.7. Optimización en el Diseño de Procesadores. Existen diversas técnicas de optimización en el diseño de procesadores para poder incrementar el rendimiento en los mismos, esto lo podemos hacer de dos maneras, una de ellas es incrementar la frecuencia de reloj dejando constante el número de CPI’s pero, esto va estar limitada por la tecnología que se utilizó para implementar el procesador en el circuito integrado; la otra manera y la más viable es que a una frecuencia de reloj constante reducir el valor del CPI. Para reducir el promedio de los ciclos de reloj por instrucción significa que debemos introducir algun tipo de paralelismo interno de tal manera de que más de una instrucción pueda ser ejecutada al mismo tiempo, lo cual incrementaría el número de instrucciones que van a ser completadas por segundo [1].. 3.7.1. Pipeline. Esta tecnica surgio de la observacion, puesto que durante la ejecucion de una mnstruccion no se esta utilizando completamente el microprocesador, por lo que el ciclo para realizar una mstruccion puede ser descompuesto en varias partes, donde cada parte le tomara una fraccion de tiempo para completar la instruccion Cada una de estas partes es asignada exclusivamente a una etapa del pipeline y estas van conectadas en serie. Las instrucciones entran al pipeline y son procesadas por cada una de las etapas del pipeline. Cada una de estas etapas del pipeline opera en paralelo y al terminar de realizar la instrucción, cada etapa pone a su salida el resultado de su operación y empieza a realizar la que tiene a su entrada. Debido a que todas las etapas del pipeline operan en paralelo, cada etapa ejecuta una instrucción diferente por cada ciclo de reloj. De manera, que cuando las n-etapas.
(38) 3.7. OPTIMIZACIÓN EN EL DISEÑO DE PROCESADORES. 23. del pipeline están llenas se están ejecutando n instrucciones simultaneamente. El tiempo por instrucción en un microprocesador con pipeline es igual al tiempo por instrucción dividido por el número de etapas de pipeline. Idealmente cuando el pipeline esta lleno se completa una instrucción por ciclo de reloj (CPI=1) si bien, el promedio del CPI es 1, cada ejecución completa de una instrucción (incluyendo fetch, decode, almacenamiento de los resultados, etc) para un pipeline de 5 etapas toma un promedio de 5 ciclos de reloj. Los compiladores son muy importantes para eficientizar el uso del pipeline y para mantenerlo lleno de instrucciones.. El tiempo para mantener el pipeline, lleno se le conoce como período de latencia, después de que éste se encuentra lleno, una nueva instruccióni se ejecutará en cada ciclo de reloj Naturalmente la explicación anterior se refiere a operaciones ideales del pipeline en cada una de las etapas solamente requieren de un ciclo de reloj y las instrucciones son ordenadas para mantener el pipeline lleno. Desafortunadamente la dependencia de datos y los riesgos de control (control hazards); además de la ejecución de los saltos, saltos condicionales, interrupciones presentan varios problemas que rio permiten una. operación ideal del pipeline En la. Figura 3.2 podemos ver el funcionamiento ideal de.
(39) 24. CAPÍTULO 3. ARQUITECTURA RISC. un pipeline, mientras que en la Figura 3.3 observamos que al aparecer una interrupción o un salto condicional las instrucciones que se estaban ejecutando se convierten en instrucciones inválidas, la instrucción Bc es un salto condicional.. El manejo del pipeline se complica si las instrucciones varían en el número de ciclos de reloj, cabe señalar que el manejo del pipeline es más complicado en una arquitectura CISC que en una arquitectura RISC, ya que un compilador no puede ordenar la ejecución de instrucciones para optimizar el flujo de las mismas en un pipeline CISC. Para minimizar los retardos y las interrupciones en el pipeline, los tiempos de ejecucion de las instrucciones deben de ser uniformes Por lo que en el pipeline debe haber Un enfasis especial en dos eventos que pueden afectar el rendimiento del pipeline, estos son los saltos y las interrupciones, ya que despues de un salto o de una interrupcion los datos en las demas etapas del pipeline son invahdos El pipeline debe mantenerse lleno o la ventaja en el rendimiento del pipeline no se vera alcanzado Cuando un salto es encontrado, los datos contenidos en el resto del pipeline son inválidos ya que es necesario calcular la dirección destino efectiva, por lo que el procesador tiene un ciclo de reloj para rellenar el pipeline; por supuesto que esto no es posible, entonces ocurrirá una detención (stall) en el pipeline. Los saltos.
(40) 3.7. OPTIMIZACIÓN EN EL DISEÑO DE PROCESADORES. 25. condicionales complican el problema en el pipeline, ya que la dirección destino efectiva debe ser calculada después o en paralelo de la evaluación de la condición del salto.. 3.7.2. Superpipeline. Habiendo introducido la técnica del pipeline cómo podemos modificar el pipeline para decrementar aún más el CFI y así incrementar su rendimiento? el superpipeline es utilizado efectivamente para ejecutar más de una instrucción por ciclo de reloj, reduciendo asi el CFI. Esto es acompañado por una subdivisión en etapas del pipeline e incrementando la frecuencia del reloj. La subdivisión en etapas del pipeline se puede realizar, ya que existen etapas del pipeline que por sus características se pueden dividir en. dos etapas. Un microprocesador con superpipeline requiere en su diseño un hardware menos complejo que un superescalar, pero, requiere una lógica más rápida para poder operar frecuencias de reloj más rápidas. Aqui es, sin embargo, el punto donde tenemos que decidir, si disminuir la frecuencia de reloj para poder costear la parte de subdividir las etapas del pipeline.. 3.7.3. Superescalar. En las dos técnicas anteriores solo se podía despachar para ejecución una instrucción por ciclo de reloj, los microprocesadores superescalares son diseñados para poder emitir. más de una instrucción por ciclo de reloj, es decir que tienen varias vías ó varios buses entre cada una de las etapas del pipeline, ya que en realidad este procesador es uii pipeline con etapas paralelas. Comparando un procesador superescalar de n-vías con uno de supeipipeline de ir-etapas podremos notar que su rendimiento son similares (asumiendo que tenemos las mismas instrucciones y restricciones). Sin embargo, mientras que la imnplenientacióri en superpipeline requiere de una frecuencia de reloj muy alta, la implernentaciómi superescalar requiere de un hardware mucho más complejo. El rendimiento de los procesadores RISC está determinado por la proporción del número de instrucciones completadas, no por la proporción de instrucciones despachadas a la etapa de ejecución. El superpipeli’ne es difícil de aplicar en arquitecturas CISC, debido al tamaño variable de las instrucciones. En una arquitectura CISC la ejecución de instrucciones está definida por el tamaño de las instrucciones subsecuentes; al referirse al tamaño de una instrucción se refiere al iiúmero de bits necesarios para el código de operación opcode. Los procesadores MIPS R4000 y R8000 utilizan las técnicas de superpipeline, mientras que el R,10000 es un procesador superescalar..
(41) 26. CAPÍTULO 3. ARQUITECTURA RISC. 3.8. Problemas del Pipeline. Hay situaciones, llamadas riesgos (hazards), que impiden que se ejecute la siguiente instrucción del flujo de instrucciones durante su ciclo de reloj designado. Los riesgos reducen el rendimiento de la velocidad ideal lograda por la segmentación. Hay tres clases de riesgos: [3] 1. Riesgos Estructurales surgen de conflictos de los recursos, cuando el hardware no puede soportar todas las combinaciones posibles de instrucciones en ejecuciones simultaneamente. 2. Riesgos por dependencias de Datos surgen cuando una instrucción depende de los resultados de una instrucción anterior, de tal forma que, ambas no podrían ejecutarse de forma simultánea. 3. Riesgos de control. Surgen del pipeline de los saltos ú otras instrucciones que modifiquen el PC.. 3.8.1. Riesgos por la Dependencia de Datos. Los riesgos de dependencias de datos se pueden clasificar de tres maneras: 1. RAW (Lectura despué’s de Escritura (Read after Write)), j trata de leer un registro fuente antes de que sea actualizado por i; asi que j toma el valor anterior. 2 WAR (Escritura despues de Lectura (Write after Read)), j intenta escribir un valor a un registro fuente antes de que este sea leido por i, asi que i toma incorrectamente el nuevo valor 3. WAW (Escritura despues de escritura (Write after Write)), j intenta escribir un operando antes que sea escrito por i Las escrituras al destmo se estan realizando fuera de orden, dejando en el destino el valor escrito por i en lugar del escrito por 3. 382. Alternativas para Evitar los Riesgos de Control. Los riesgos de control pueden provocar mayor perdida de rendimiento, en un procesador con pipeline, que los provocados por la dependencia de datos. Ya que estos modifican el PC y peor aún cuando ios saltos son condicionales. A continuación se mencionan cuatro alternativas para disminuir los riesgos de control con sus ventajas y desventajas:.
(42) 3.8. PROBLEMAS DEL PIPELINE. 27. 1. Stall (detención) hasta conocer la dirección a la cual se va a saltar. • Como desventaja se puede mencionar que siempre perderemos un ciclo de reloj, esto debido, al cálculo de la dirección efectiva a la que se va saltar. • Por otro lado se tiene la ventaja de que es fácil de implementar. 2. Predecir que el salto no será tomado. • Por desventaja tenemos que si el salto es realmente tomado se desecha la instrucción que se está ejecutando. • Por otra parte como ventaja tenemos que no se pierde un ciclo si la predicción es correcta. 3. Predecir que el salto será tomado. • Este tiene como desventaja que se tiene que saber la dirección a donde se va a saltar antes de hacer el fetch. • Al igual que la anterior, éste tiene la ventaja de que no se pierde un ciclo si la predicción fue correcta. 4. Salto retardado (Delayed Branch). e. Este presenta las siguientes características: —. —. —. —. La siguiente instrucción o instrucciones seguidas del salto siempre se ejecutan. El número de instrucciones está dado por el número de ciclos para decidir a que dirección se va a saltar. A la instrucción posterior al salto se le denonnina delayed slot. El compilador tiene que encontrar que instrucciones colocar dentro del delayed slot.. • Como ventaja tenemos que nunca se pierde ciclo de reloj si y solo si el compilador encuentra algo util que ejecutar.. 3.8.3. Solución para Riesgos por Dependencias de Datos. Los riesgos por dependencias de datos pueden provocar un adelantamiento del dato O un stall (detención de la ejecución), indudablemente los stalls son los más frecueiltes, actualmente existen dos soluciones para atender estos riesgos:.
(43) 28. CAPÍTULO 3. ARQUITECTURA RISC 1. Programación Estática (Static Scheduling), donde el compilador reordena las instrucciones para evitar o disminuir el número de stalls. 2. Programación Dinámica (Dynamic Scheduling), donde el hardware reordena las instrucciones. Es decir, si una instrucción no se puede ejecutar, ejeduta la siguiente.. 3.8.4. Programación Dinámica. Dentro de la programación dinámica, donde es el hardware el encargado de reordenar las instrucciones, por lo que para ejecución existen cuatro alternativas: • Ejecución en orden con terminación en orden. • Ejecución en orden con terminación fuera de orden. • Ejecución fuera de orden con terminación en orden. • Ejecución fuera de orden con terminación fuera de orden. Dentro de la programación dinámica existen dos técnicas: • Scoreboard utilizado en el CDC 6600 (1964). • Tomasulo utilizado en el IBM 360/91 (1967).. Scoreboard (Marcador) En la tecnica de programacion dmnamica scoreboard las desiciones se toman de manera centralizada manteniendo un marcador con el estatus tanto de las unidades funcionales como de las instrucciones, ademas, el marcador servira para decidir cuando una instrucción debe ser detenida (ver Figura 3.4). Los RAW provocan que una unidad deje de funcionar, ya que la unidad que va a leer el registro tiene que esperar, a que la otra unidad que ejecutó una instrucción que va modificar dicho registro escriba el nuevo valor del registro..
(44) 3.8. PROBLEMAS DEL PIPELINE. 29. Figura 3.4: Técnica de Scoreboard.. Tornasulo Esta técmca fue desarrollada por R. Tomasulo, el cual cuenta con un sistema de decisión distribuido se tiene además un bus común de datos (CDB) donde los valores que van a guardarse en los registros puedan ser accesados, tienen una unidad funcional dedicada al load/store, realizan un renombramiento de registros para evitar riesgos WAR y WAW y además las unidades de ejecución tiene estaciones de reserva, esto cori el fin de mantener a la.s instrucciones fuera de la cola del despacho mientras esperan a sus respectivos operandos (ver Figura 3.5). El número de registros no es un cuello de botella, los RAW no provocan que una unidad deje de funcionar, ya que cuando una unidad va a modificar un registro primero modifica el registro renombrado..
(45) 30. CAPÍTULO 3. ARQUITECTURA RISC.
Figure




+7




Documento similar
Reglamento (CE) nº 1069/2009 del parlamento Europeo y del Consejo de 21 de octubre de 2009 por el que se establecen las normas sanitarias apli- cables a los subproductos animales y
4.- Másteres del ámbito de la Biología Molecular y Biotecnología (9% de los títulos. Destaca el de Biotecnología Molecular de la UB con un 4% y se incluyen otros
de su infinito amor.. imperio sobre las nubes, que.. desgracias vencidas, se vu elven las calamidades risueñas.. Publicad sus maravillas, sus inumerables beneficios ,
beralidades piadosas de esta envidiable R eyna, que fué grande, no para nuestra miseria, como el insolente Difilo.. Pedro Crisd- logo que est in cwlis
y para evitarla cede una parte de su asignación mensual con destino á rep¡a- rar y continuar esta obra magestuosa, logrando con gran satisfacción suya
Y así, vamos a intentar que nuestros alumnos reflexionen y desarrollen su sentido crítico, vamos a intentar que perciban el medio ambiente como algo propio, vamos a intentar
Este libro intenta aportar al lector una mirada cuestiona- dora al ambiente que se desarrolló en las redes sociales digitales en un escenario de guerra mediática mantenido por
ma~orrales, y de hombres de poco ingeniD». Apoyándose en la asociación que Covarr ubias hace enh:e letras góticas y letras go rdas, el Sr. además de ser así usado en
