Instituto Tecnológico y de Estudios Superiores de Monterrey
Campus Monterrey
Monterrey, Nuevo León a
", en los sucesivo LA OBRA, en virtud de lo cual autorizo a el Instituto Tecnológico y de Estudios Superiores de Monterrey (EL INSTITUTO) para que efectúe la divulgación, publicación, comunicación pública, distribución y reproducción, así como la digitalización de la misma, con fines académicos o propios al objeto de EL INSTITUTO.
El Instituto se compromete a respetar en todo momento mi autoría y a otorgarme el crédito correspondiente en todas las actividades mencionadas anteriormente de la obra.
De la misma manera, desligo de toda responsabilidad a EL INSTITUTO por cualquier violación a los derechos de autor y propiedad intelectual que cometa el suscrito frente a terceros.
de 200
Lic. Arturo Azuara Flores:
Director de Asesoría Legal del Sistema
Clusterización en redes Ad Hoc de gran escala-Edición Única
Title Clusterización en redes Ad Hoc de gran escala-Edición Única
Authors Eulogio Fabián Ocura Camacho
Affiliation ITESM-Campus Monterrey
Issue Date 2005-12-01
Item type Tesis
Rights Open Access
Downloaded 19-Jan-2017 13:25:27
Instituto Tecnol´
ogico y de Estudios Superiores de
Monterrey
Campus Monterrey
Divisi´
on de Tecnolog´ıas de Informaci´
on y Electr´
onica
Programa de Graduados
Clusterizaci´
on en redes Ad Hoc de gran escala
Tesis
Presentada como requisito parcial para obtener el grado de
Maestr´ıa en Ciencias en Ingenier´ıa Electr´
onica
.con especialidad en Telecomunicaciones
.Eulogio Fabi´
an Ocura Camacho
c
Clusterizaci´
on en redes Ad Hoc de gran escala
por
Ing. Eulogio Fabi´
an Ocura Camacho
Tesis
Presentada al Programa de Graduados de la
Divisi´on de Tecnolog´ıas de Informaci´on y Electr´onica
como requisito parcial para obtener el grado acad´emico de
Maestro en Ciencias
especialidad en
Telecomunicaciones
Instituto Tecnol´
ogico y de Estudios Superiores de Monterrey
Campus Monterrey
Instituto Tecnol´
ogico y de Estudios Superiores de
Monterrey
Campus Monterrey
Divisi´
on de Tecnolog´ıas de Informaci´
on y Electr´
onica
Programa de Graduados
Los miembros del comit´e de tesis recomendamos que la presente tesis de Eulogio Fabi´an Ocura Camacho sea aceptada como requisito parcial para obtener el grado acad´emico de
Maestro en Ciencias, especialidad en:
Telecomunicaciones
Comit´
e de tesis:
Dr. Cesar Vargas Rosales Asesor de la tesis
Dr. Jos´e Ram´on Rodr´ıguez Cruz Sinodal
Dr. Jorge Carlos Mex Perera Sinodal
Dr. David Garza Salazar Director del Programa de Graduados
Reconocimientos
A mi esposa Silvia que ha sido la base de mi determinaci´on por continuar estudiando, quien me ha proporcionado su amor, su confianza, su esfuerzo y comprensi´on.
A mi madre Rosa Mar´ıa que ha servido como ejemplo y me ha brindado su apoyo en todo momento, sin esperar nunca una retribuci´on a cambio y dispuesta siempre a darlo todo por el bienestar de sus hijos.
A mi hermano Jos´e Mart´ın y su esposa Mar´ıa Magdalena, a mis hermanos Gilberto, Horacio y Marbila con quienes estar´e siempre en deuda por todo lo que me han apoyado a lo largo de mi vida, por haberme proporcionarme techo, alimento y apoyo econ´omico en los momentos de crisis padecidos.
A mi t´ıo Miguel y a su familia por el apoyo y la confianza brindada.
A todos los compa˜neros de la maestr´ıa que me acompa˜naron y apoyaron durante mi estancia en el Tecnol´ogico, especialmente a Hilda, Brenda, Elo, Eric, Oziel, Paco, To˜no, Pepe, Jere, Victor, Fernando, Michel, Hugo, Javier y Mario.
Al Dr. Cesar Vargas por guiarme en el desarrollo de mi tema de investigaci´on. Al Dr. Carlos Mex y Dr. Ram´on Rodr´ıguez por aceptar ser mis sinodales. A mis suegros Juan y Guillerma por el apoyo recibido y la confianza brindada.
Pero sobre todo gracias a Dios por bendecirme de esta forma.
Eulogio Fabi´
an Ocura Camacho
Clusterizaci´
on en redes Ad Hoc de gran escala
Eulogio Fabi´an Ocura Camacho, M.C.
Instituto Tecnol´ogico y de Estudios Superiores de Monterrey, 2005
Asesor de la tesis: Dr. Cesar Vargas Rosales
Una red Ad Hoc es conocida por su propiedad de auto organizarse y ser adaptable, lo que significa que una red puede ser formada y modificada rapidamente sin necesidad de sis-temas administrativos. El t´ermino Ad Hoc significa que puede tomar formas diversas en un escenario determinado e implica que un dispositivo de este tipo puede ser m´ovil, permanecer independiente o solitario o bien conectado a una red especifica.
Los algoritmos de clusterizaci´on tienen como funci´on agrupar a los nodos con funda-mento en una o varias caracter´ısticas particulares, y sirven de base para poder efectuar una medici´on del desempe˜no que se tiene en una red. No obstante estos algoritmos aun no han sido plenamente aplicados a redes de gran escala, donde la densidad de los nodos y su movil-idad afectan de forma diferente. Estos algoritmos carecen de alternativas para el ajuste de par´ametros que les permitan manipular la estructura de los grupos formados, de tal manera que puedan variar las condiciones establecidas o resultantes del algoritmo de clusterizaci´on. Permitiendoles de esta forma tener mayor control sobre los escenarios que se establezcan y contar con una herramienta que les proporcione la capacidad de adecuarse a las necesidades que se presenten en una determinada topolog´ıa.
El objetivo de esta investigaci´on no es la de crear un algoritmo de clusterizaci´on, sino m´as bien establecer una forma natural de agrupaci´on de los nodos mediante una distribuci´on geogr´afica basada en la posici´on que tiene cada uno de ellos respecto al resto de los nodos creados y al alcance que tiene en base a su radio de cobertura.
´Indice general
Reconocimientos VI
Resumen VII
´Indice de cuadros X
´Indice de figuras XI
Cap´ıtulo 1. Introducci´on 1
1.1. Justificaci´on . . . 1
1.2. Objetivo . . . 2
1.3. Contribuci´on . . . 3
1.4. Organizaci´on . . . 3
Cap´ıtulo 2. Antecedentes 4 2.1. Redes Inal´ambricas Ad Hoc . . . 4
2.2. Algoritmos de clusterizaci´on . . . 6
2.2.1. Access Based Clustering Protocol (ABCP). . . 7
2.2.2. Cluster Based Routing Protocol (CBRP) . . . 9
2.2.3. The Zone Routing Protocol (ZRP) . . . 12
2.2.4. The cluster (α, t) framework . . . 12
2.2.5. Algoritmos de Control de la Topolog´ıa de la Red . . . 15
Cap´ıtulo 3. Descripci´on del Modelo 17 3.1. Generaci´on del Escenario . . . 17
3.2. Algoritmo de clusterizaci´on . . . 21
3.2.1. Clusterizaci´on B´asica o Normal . . . 22
3.2.2. Integraci´on de clusters . . . 28
3.2.3. Cuantificaci´on del Algoritmo . . . 29
Cap´ıtulo 4. Resultados Num´ericos 32 4.1. Simulaci´on . . . 32
4.1.2. An´alisis de Resultados . . . 36 4.1.3. Niveles Convenientes de Nodos Gateway . . . 52 4.1.4. Cuantificaci´on del Manejo de la Informaci´on de la Red . . . 56
Cap´ıtulo 5. Conclusiones e Investigaciones Futuras 61
5.1. Conclusiones Generales . . . 61 5.2. Investigaciones Futuras . . . 62
Bibliograf´ıa 63
´Indice de cuadros
3.1. Ejemplos de c´alculo del posicionamiento de dos nodos en la red. . . 23
4.1. Caracter´ısticas generales del escenario . . . 33 4.2. Escenarios utilizados para cada una de las λ. . . 34 4.3. Radios de cobertura utilizados en las simulaciones en base al n´umero de nodos
generados . . . 36 4.4. Resultados obtenidos para los escenarios generados con λ= 50 y Υ de 30, 40
y 50 % . . . 38 4.5. Resultados obtenidos para los escenarios generados con λ = 50 y Υ de 60 y
70 % . . . 39 4.6. Resultados obtenidos para los escenarios generados con λ = 600 y Υ de 30,
40 y 50 % . . . 40 4.7. Resultados obtenidos para los escenarios generados con λ = 600 y Υ de 60 y
70 % . . . 41 4.8. Radios de cobertura y porcentaje de integraci´on utilizados en las simulaciones
en base al n´umero de nodos generados . . . 53 4.9. Tabla para establecer el valor adecuado del porcentaje de nodos gateway que
es la base para determinar el radio de cobertura y porcentaje de integraci´on convenientes para un valor de λ. . . 54 4.10. Costos por manejo de la informaci´on de la red para escenarios generados con
λ = 50 aplicando las dos fases del algoritmo. . . 57 4.11. Costos por manejo de la informaci´on de la red para escenarios generados con
´Indice de figuras
2.1. Ejemplo de una red Ad Hoc con 5 nodos mostrando su radio de cobertura y
las conexiones entre ellos. . . 6
2.2. Diagrama del estado de transici´on de un nodo en el protocolo ABCP. . . 8
2.3. Descubrimiento de clusters adyacentes . . . 11
3.1. Generaci´on de nodos con α=50x10−6 en un ´area de 1000 x 1000 m . . . 18
3.2. Escenario donde se muestran los enlaces entre los nodos bas´andose en su radio de cobertura. . . 19
3.3. Determinaci´on del nodo l´ıder del cluster. . . 24
3.4. Formaci´on del cluster y revisi´on de nodos a dos saltos del l´ıder. . . 25
3.5. Revisi´on de nodos a tres saltos del l´ıder. . . 26
3.6. Conformaci´on final de los cluster. . . 26
3.7. Algoritmo de clusterizaci´on. . . 27
3.8. Algoritmo de integraci´on. . . 30
4.1. Escenario donde se muestran los enlaces entre los nodos bas´andose en un radio de cobertura de 150 metros para λ= 50. . . 34
4.2. Escenario donde se muestran los enlaces entre los nodos bas´andose en un radio de cobertura de 175 metros para λ= 50. . . 35
4.3. Escenario donde se muestran los enlaces entre los nodos bas´andose en un radio de cobertura de 200 metros para λ= 50. . . 35
4.4. Gr´afica del promedio de clusters formados en la red para λ= 50. . . 43
4.5. Gr´afica del promedio de nodos por clusters en la red para λ= 50. . . 44
4.6. Gr´afica del promedio de nodos gateways existentes en la red para λ= 50. . . 45
4.7. Gr´afica del promedio de clusters formados en la red para λ= 600. . . 46
4.8. Gr´afica del promedio de nodos por clusters en la red para λ= 600. . . 47
4.9. Gr´afica del promedio de nodos gateways existentes en la red para λ= 600. . 48
4.10. Gr´afica del promedio de clusters formados en la red paraλ= 300. . . 49
4.11. Gr´afica del promedio de nodos por clusters en la red para λ= 300. . . 50
4.13. Ejemplo de como se selecciona el radio de cobertura y porcentaje m´aximo de integraci´on conveniente para el caso de λ = 300 teniendo como fundamento un 60 % promedio de nodos gateways. . . 55 4.14. Gr´afica que muestra el efecto que tiene la aplicaci´on del algoritmo en su
segun-da fase sobre los costos por manejo de la informaci´on de la red para escenarios generados con λ= 50. . . 58 4.15. Gr´afica que muestra el efecto que tiene la aplicaci´on del algoritmo en su
Cap´ıtulo 1
Introducci´
on
Los or´ıgenes de las redes m´oviles inal´ambricas se remontan a los a˜nos 70. Obteni´endose los primeros resultados satisfactorios de comunicaci´on inal´ambrica en una red local en una f´abrica suiza. Desde entonces, la investigaci´on y desarrollo de medios y dispositivos que ha-cen posible las redes de esta naturaleza han experimentado un desarrollo muy notable.
Uno de los puntos que ha permitido la solidificaci´on de esta tecnolog´ıa se debe, en gran medida, a las ventajas con respecto a la movilidad para los usuarios en relaci´on con las redes al´ambricas convencionales. Siempre resulta c´omodo sentirse con la libertad de desplazarse sabiendo que se tiene la oportunidad de seguir conectado. Resulta obvio que existen algunos factores que limitan el ´optimo funcionamiento de un sistema inal´ambrico, como lo es la dis-tancia o radio de cobertura del usuario determinado por la potencia de transmisi´on de su equipo y la interferencia causada por causas naturales o artificiales.
Existen dos tipos de redes inal´ambricas, las convencionales que requieren alg´un tipo de infraestructura de red fija y una forma centralizada de administraci´on, y las redes que no tienen ninguna infraestructura definida, llamadas redes M´oviles Ad-Hoc, que consisten en nodos inal´ambricos que poseen movilidad y pueden crear redes din´amicas entre ellos sin la necesidad de utilizar una infraestructura o soporte administrativo,[1].
1.1.
Justificaci´
on
Una forma de evaluar la eficacia de los algoritmos de clusterizaci´on consiste en la medi-ci´on del n´umero promedio de grupos creados, la proporci´on promedio de nodos gateway o frontera, y el tama˜no promedio del cluster.
Sin embargo estos algoritmos carecen de alternativas para el ajuste de par´ametros que les permitan manipular la estructura de los grupos formados, de tal manera que puedan vari-ar las condiciones establecidas o resultantes del algoritmo de clusterizaci´on. Permiti´endoles de esta forma tener mayor control sobre los escenarios que se establezcan y contar con una herramienta que les proporcione la capacidad de adecuarse a las necesidades que se presenten en una determinada topolog´ıa.
1.2.
Objetivo
Cuando una red est´a formada por nodos solitarios que representan cada uno a un clus-ter, se presenta entonces una gran carga para cada uno de ellos y para la red en general debido al alto requerimiento de ruteo externo que se presenta, dado que el n´umero de no-dos frontera o gateway es muy elevado. Por otra parte si se forma uno o no-dos clusters muy grandes (megaclusters), sucede algo muy similar, si bien la cantidad de nodos gateway se reduce notablemente inclusive puede llegar a desaparecer, se tiene ahora el problema de que la carga es al interior del clusters lo que se se conoce como ruteo interno. Por estos motivos consideramos oportuno que los nodos lleguen a agruparse (formar clusters) de forma tal que el n´umero de nodos solitarios sea reducido y a si mismo se evite lo m´as posible la existencia de megaclusters.
El objetivo de esta investigaci´on no es la de crear un algoritmo de clusterizaci´on, sino m´as bien establecer una forma natural de agrupaci´on de los nodos mediante una distribuci´on geogr´afica basada en la posici´on que tiene cada uno de ellos respecto al resto de los nodos creados y al alcance que tiene en base a su radio de cobertura.
1.3.
Contribuci´
on
La contribuci´on principal de este trabajo es el establecimiento de una segunda fase del algoritmo de clusterizaci´on para permitirle, a trav´es de par´ametros de control como potencia de transmisi´on y otros que ser´an introducidos, manipular la organizaci´on de la red, afectando elementos claves tales como: total de clusters formados, n´umero de nodos por cluster y total de nodos gateway existentes.
1.4.
Organizaci´
on
Cap´ıtulo 2
Antecedentes
En este cap´ıtulo se aborda el concepto de las redes Ad Hoc, algunas de sus caracter´ısti-cas y propiedades m´as significativas. As´ı como una explicaci´on concisa del termino cluster y algunos de los algoritmos de clusterizaci´on m´as comunes existentes.
2.1.
Redes Inal´
ambricas Ad Hoc
Las redes inal´ambricas Ad Hoc est´an formadas por usuarios m´oviles que disponen de acceso a servicios de informaci´on de la misma y tienen capacidad de comunicarse entre si desde cualquier lugar donde se encuentren. La caracter´ıstica que las identifica es que carecen de infraestructura definida, por lo que la red es totalmente m´ovil, y por ello los usuarios se mueven de forma independiente unos de los otros, llegando los nodos a auto organizarse y auto administrarse. Cualquier dispositivo que cuente con un microprocesador es un nodo potencial en una red Ad Hoc. Incluyendo tel´efonos m´oviles, veh´ıculos de motor, estaciones de informaci´on en carreteras, sat´elites, PDA’s, computadoras de escritorio y port´atiles, [10].
Las aplicaciones para redes Ad Hoc son variadas, pudiendo mencionar el ´area militar, en zonas de desastres, en el sector comercial debido a la miniaturizaci´on de los dispositivos electr´onicos, su proliferaci´on y el creciente deseo de las personas por estar conectadas todo el tiempo.
Un dispositivo Ad hoc no solamente detecta la conectividad con nodos o dispositivos cercanos (vecinos), si no que puede identificar el tipo de dispositivo que es (laptop, Internet mobile phone, palmtop, etc.) y sus correspondientes caracter´ısticas.
Si bien el termino Ad Hoc implica movilidad, los nodos o dispositivos en una red de estas caracter´ısticas pueden no siempre estar en movimiento y permanecer estacionarios, los cuales tendr´an la capacidad de detectar la presencia de otros nodos o equipos y la habilidad de establecer comunicaci´on con ellos cuando as´ı sea requerido.
La comunicaci´on en una red Ad hoc inal´ambrica puede presentarse en formas diversas, una de ellas es cuando dos nodos se contactan en forma directa por un periodo de tiempo determinado hasta que la comunicaci´on llega a su fin, o bien uno de los nodos se mueve de tal forma que queda fuera del ´area de cobertura del otro. Esta forma es conocida como comunicaci´on punto a punto.
Una segunda forma es cuando dos o m´as nodos se comunican entre ellos y est´an for-mando parte de un grupo o cluster. Este escenarios se conoce como comunicaci´on remoto a remoto, [11].
Un ejemplo sencillo de una red ad hoc la podemos ver en la Figura 2.1 donde se observa el radio de cobertura de 5 nodos y el enlace que existe entre ellos. Si bien los nodos no pueden alcanzarse entre si en primera instancia dado que su radio de cobertura no se los permite, si pueden estar en contacto con todos a trav´es de los nodos que si est´an dentro de su cobertura. Cuando un nodo se en encuentra dentro del radio de cobertura de otro nodo, se dice que es su nodo vecino o bien que lo puede alcanzar a un salto. Al observar la Figura 2.1 se puede observar por ejemplo que los nodos 2 y 5 son vecinos del nodo 1, o sea los puede alcanzar a un salto, mientras que el nodo 3 est´a a dos saltos del nodo 1 y el nodo 4 est´a a 3 saltos.
Figura 2.1: Ejemplo de una red Ad Hoc con 5 nodos mostrando su radio de cobertura y las conexiones entre ellos.
Un cluster consiste de un grupo de usuarios o nodos con caracter´ısticas espec´ıficas donde uno de ellos es elegido como l´ıder del grupo . El resto se les conoce como miembros del clus-ter o nodos ordinarios, y existen adem´as los nodos gateway o fronclus-tera, que se encuentran dentro del rango de comunicaci´on de 2 o m´as lideres de grupo, y son utilizados por ellos para comunicarse con clusters adyacentes.
El nodo l´ıder es quien posee la mayor informaci´on relacionada con la conformaci´on del cluster (cuantos nodos forman el cluster, su identificaci´on, cuales son nodos ordinarios, cuales son gateways, a cuales clusters se conectan los nodos gateway, etc).
2.2.
Algoritmos de clusterizaci´
on
Una red Ad Hoc, al no depender de alg´un tipo de infraestructura para efectuar la co-municaci´on entre usuarios, los nodos se encuentran regularmente dispersos, motivo por el cual regularmente estos nodos no tienen una comunicaci´on directa con otros nodos, raz´on por la cual es necesario utilizar nodos intermediarios a fin de poder alcanzar al nodo que se desee.
Estas son algunas de las razones por las que se han propuesto algoritmos de clusteri-zaci´on para el control en este tipo de redes de comunicaci´on. De los cuales podemos mencionar como ejemplo a los siguientes:
Access Based Clustering Protocol (ABCP), [6].
Cluster Based Routing Protocol (CBRP), [8].
The Zone Routing Protocol (ZRP), [4].
The cluster (α, t) framework, [10].
2.2.1.
Access Based Clustering Protocol
(ABCP).
Existen b´asicamente dos criterios para agrupar los nodos en una red de usuarios m´oviles. Uno es el basado en su identificaci´on ( ID ) y el otro en el rango del nodo (node degree) el cual est´a relacionado con el n´umero de enlaces directos que tiene. El nodo con m´as bajo ID o el nodo con mayor rango respectivamente son seleccionados para ser nodos l´ıder del cluster. Estudios realizados han demostrado que una estructura de clusterizaci´on basada en el ID es m´as estable, resultando en un manejo menor de mensajes de actualizaci´on de-spu´es que un nodo ha cambiado de posici´on. Sin embargo el criterio basado en el rango de los nodos es muy conveniente cuando los nodos est´an geogr´aficamente distribuidos en grupos.
La clusterizaci´on basada en ruteo puede hacer que una red grande aparente ser m´as peque˜na, y m´as importante aun, puede hacer que una topolog´ıa muy din´amica aparente serlo mucho menos. Por consecuencia el objetivo fundamental del ABCP es crear una estructura de cluster estable que se pueda desarrollar r´apidamente y no requiera de un conjunto de mantenimiento elevado, [6].
El ABCP define el formato de cada mensaje, describe la forma en que debe responder un nodo cuando recibe un mensaje, especifica como un nodo manejara los errores y cualquier condici´on anormal. Permite a la red cambiar incluso cuando la formaci´on de clusters este en progreso.
Figura 2.2: Diagrama del estado de transici´on de un nodo en el protocolo ABCP.
En el caso de un nodo ordinario, tres situaciones propician que env´ıe un mensaje de Request To Join (RTJ):
1.- Un nodo en una red ad hoc enciende su radio y se convierte en un reci´en llegado a la red.
2.- Un nodo detecta que su enlace con el l´ıder del cluster es d´ebil.
3.- Un mensaje de desconexi´on de su l´ıder es recibido.
Bajo cualquiera de estas circunstancias un nodo ordinario difunde un mensaje RTJ, fija su reloj y espera por la respuesta de los lideres de clusters vecinos. Tomara el primero que recibe y enviara un mensaje de uni´on con su ID para informar al nodo l´ıder. Si pasado el tiempo establecido no recibe mensajes de bienvenida el nodo enviara mensajes hello para intentar convertirse en nodo l´ıder. En la Figura 2.2 se muestra el bosquejo de este compor-tamiento.
2.2.2.
Cluster Based Routing Protocol
(CBRP)
Es un protocolo de ruteo dise˜nado para el uso en red Ad Hoc m´ovil. Dentro de sus caracter´ısticas principales se puede mencionar:
1.- Operaci´on plenamente distribuida.
2.- Menor inundaci´on de tr´afico (flooding) durante el proceso din´amico de descubrir rutas.
3.- Utilizaci´on expl´ıcita de los enlaces unidireccionales que de otra forma no ser´ıan uti-lizados.
4.- El rompimiento de rutas puede ser reparado localmente sin la necesidad de un re-descubrimiento de rutas.
5.- Rutas sub´optimas pueden ser reducidas a medida que son utilizadas.
Datos conceptuales
Tabla de vecinos:
Se utiliza para probar el estado de los enlaces y la formaci´on de clusters. Cada entrada de datos contiene,[8]:
1.- La identificaci´on del vecino con el que tiene conexi´on.
2.- El tipo de nodo que es.
3.- El estado del enlace ( bidireccional o unidireccional ).
Tabla de clusters adyacentes:
1.- La identificaci´on del l´ıder del cluster vecino.
2.- El nodo gateway que alcanza el l´ıder del cluster vecino.
3.- El estado del enlace entre el nodo gateway y el cluster vecino (bidireccional o uni-direccional).
Operaci´on del protocolo
La operaci´on del CBRP es enteramente distribuida. Los componentes principales son: La formaci´on del cluster, el descubrimiento de clusters adyacentes y el ruteo.
Formaci´on de clusters:
Todos los nodos inician en un estado indeciso. Cuando un l´ıder de cluster recibe un mensaje hello de alguno de los nodos indecisos, enviara de forma inmediata un mensaje de bienvenida. Cuando el nodo indeciso recibe el mensaje de un nodo l´ıder indicando que existe un enlace bidireccional entre ambos, aborta su reloj de estado indeciso y establece su estado como miembro del cluster, [8].
Dentro de las reglas para cambiar el nodo l´ıder, se tiene que ning´un nodo que no sea l´ıder de cluster puede cambiar el estado de un nodo l´ıder existente. Sin embargo si dos nodos lideres se aproximan y permanecen as´ı por un per´ıodo de tiempo prolongado entonces uno de ello deber´a perder su estado de nodo l´ıder, [3].
Descubrimiento de clusters adyacentes:
Se dice que dos clusters son bidireccionales si existe un nodo en uno de los clusters que tiene un enlace bidireccional con un nodo del otro cluster. Como se muestra en la Figura 2.3.
El objetivo es encontrar todos los clusters que tienen un enlace bidireccional, para este prop´osito cada nodo mantiene una tabla de clusters adyacentes (TCA) que guarda la infor-maci´on de todos los nodos lideres vecinos, [8].
Ruteo:
Figura 2.3: Descubrimiento de clusters adyacentes
debido a la movilidad de los nodos, una ruta fuente puede volverse menos ´optimo con el paso del tiempo y debe ser reducida cuando sea posible. Cuando un nodo descubre que un enlace entre el y su siguiente nodo en la ruta no est´a disponible env´ıa un paquete de error de ruta (ERR) y lo env´ıa de regreso al origen del paquete para notificar la falla en el enlace, [3].
Despu´es de que un nodo ha detectado una falla en la ruta y env´ıa el paquete ERR, tratara de salvar el paquete de la mejor manera que le sea posible, utilizando para ello su propia informaci´on:
1.- Revisa si el nodo que sigue despu´es del que perdi´o el enlace puede ser alcanzado a trav´es de otro nodo que no se encuentra en la ruta de origen, buscando en su tabla de ruteo a los nodos que est´an a 2 saltos.
2.- Revisa si el nodo con el que se perdi´o el enlace puede ser alcanzado a trav´es de otro nodo buscando en su tabla de ruteo a los nodos que est´an a 2 saltos.
2.2.3.
The Zone Routing Protocol
(ZRP)
Es un protocolo h´ıbrido mezcla de dos diferentes protocolos de ruteo, uno proactivo y otro reactivo. Puede ser definido por cada nodo individual y est´a organizado de forma aut´onoma. Cada nodo solo cuida de su propia zona de ruteo. Un nodo mantiene de forma proactiva rutas a los destinos dentro de un vecindario local, el cual se le conoce como la zona de ruteo. M´as precisamente, el ruteo de un nodo est´a definido como una colecci´on de nodos cuya distancia m´ınima en saltos desde el nodo en cuesti´on no es mayor que el par´ametro referido como el radio de zona. Debido a que la zona de ruteo est´a definida por nodo, la zona de ruteo de los nodos del vecindario se traslapan, [2].
ZRP es uno de los m´as apropiados protocolos para las redes inal´ambricas reconfig-urables, debido a que inicia el procedimiento para determinar las rutas sobre demanda con un costo de b´usqueda limitado y provee un eficiente y r´apido descubrimiento de las rutas al integrar las dos clase radicalmente diferentes de protocolos de ruteo tradicional, [5].
Este protocolo permite a los nodos de manera individual identificar los cambios en las condiciones de la red d´andole un conocimiento limitado del comportamiento de la misma.
La zona de ruteo comprende unos pocos nodos dentro de uno, dos o m´as saltos desde donde el nodo central es formado. Dentro de esta zona una tabla de manejo basada en el pro-tocolo de ruteo es utilizada. Un tema relacionado es el de las actualizaciones en la topolog´ıa de la red. Para que un protocolo de ruteo sea eficiente, los cambios en la topolog´ıa de la red deben tener solamente efectos locales. ZRP limita la propagaci´on de la informaci´on al vecindario donde se efectu´o el cambio solamente, provocando con ello que se limite el costo de la actualizaci´on de la topolog´ıa, [3].
Una de las principales desventajas del ZRP se relaciona con la selecci´on de rutas en la red con los suficientes recursos para los par´ametros requeridos de los est´andares de cal-idad de servicio (QoS), y el alcanzar una eficiencia global en la utilizaci´on de los recursos, [2].
2.2.4.
The cluster (
α, t
) framework
pueden mantenerse en la disponibilidad de las rutas de los destinos del cluster en un inter-valo de tiempo especifico. El (α, t) framework puede ser adem´as utilizado como base para el desarrollo de esquemas adaptivos para garant´ıas de probabilidad de calidad de servicios (QoS) en redes ad hoc, [10].
Un m´as realistico uso es el de proveer alg´un tipo de garant´ıa de calidad de servicio man-teniendo las fallas en las conexiones por debajo de un umbral preestablecido y asegurarse con una probabilidad alta que un nivel m´ınimo de ancho de banda estar´a siempre disponible para las conexiones en curso.
La idea b´asica del (α, t) framework es la de particionar la red en grupos de nodos (clusters) que sean mutuamente alcanzables dentro de las rutas internas del cluster y que se esperan est´en disponibles por un periodo de tiempot con una probabilidad α. Los efectos de estos par´ametros est´an directamente relacionados, haciendo dif´ıcil obtener valores ´optimos. Para valores grandes de t implica una mayor estabilidad en el cluster y reduce los requer-imientos computacionales de mantenimiento del cluster. Sin embargo pueden provocar la reducci´on el la disponibilidad de rutas entre los nodos de un cluster para patrones de igual movilidad, lo que hace una condici´on dif´ıcil para alcanzar el l´ımite menor requerido de α. Por consecuencia valores grandes de t tienden a dar como resultado clusters m´as peque˜nos dando como resultado un ruteo m´as ´optimo. La funci´on de t es por consiguiente manejar el tama˜no del cluster el cual controla el balance entre ruteo ´optimo y eficiente, [10].
En un ambiente altamente din´amico el algoritmo debe ser distribuido, operar de forma as´ıncrona y requerir una m´ınima coordinaci´on entre los nodos. Los clusters basados en el algoritmo (α, t) son entidades que son creadas, expandidas, contra´ıdas y eventualmente ter-minadas basados en la informaci´on de ruteo que es mantenido en un un conjunto de nodos m´oviles cooperativos.
La fortaleza de algoritmo (α, t) consiste en que no requiere de una coordinaci´on de nodos de alcance largo cuando se inicia la actividad de clusterizaci´on. Su funci´on es la de modular las acciones del algoritmo de ruteo intracluster con un filtrado efectivo de su visi´on de la red. El algoritmo es simple, eficiente y capaz de auto iniciarse.
Propiedades del algoritmo (α, t)
1.- Activaci´on del nodo:
El objetivo primario de un nodo es descubrir un nodo adyacente y unirse a su cluster. El nodo deber´a estar continuamente revisando a cada uno de sus vecinos hasta que encuentre un cluster que sea propicio para su integraci´on. Si no llega a encontrarlo entonces creara su propio cluster, el cual ser´a denominado como cluster hu´erfano o solitario, y esperara por otra oportunidad para agruparse con otros nodos.
2.- Activaci´on del enlace:
La activaci´on de enlaces propicia que un nodo solitario intente unirse a un cluster. Para poder recibir informaci´on de la topolog´ıa del cluster de su nuevo vecino, el nodo solitario debe resetear su identificaci´on de cluster (CID) para indicar su estado de no clusterizado. Una vez que recibe la informaci´on del cluster el nodo solitario eval´ua la opci´on de unirse al cluster o regresar a su estado de cluster hu´erfano.
3.- Falla del enlace:
El objetivo de que un nodo detecte una falla en el enlace es para determinar si ha provocado una perdida en las rutas del cluster hacia sus destinos. Primeramente cada nodo debe evaluar la disponibilidad de cada ruta de los destinos restantes del cluster en su tabla de ruteo. Despu´es cada nodo env´ıa informaci´on previniendo sobre la falla del enlace a los destinos del cluster restantes. Si un nodo detecta que un destino se ha vuelto inalcanzable entonces asume que el destinatario se ha desactivado o bien ha abandonado el cluster. Lo que propicia que el destinatario sea removido de la tabla de ruteo y no sea considerado en posteriores evaluaciones de rutas. Si un nodo detecta que otro nodo perteneciente al cluster se encuentra conectado pero no es alcanzable a trav´es del algoritmo (α, t) entonces dejara voluntariamente el cluster, [10].
4.- Expiraci´on del reloj α:
5.- Desactivaci´on del nodo α:
Comprende cuatro eventos relacionados denominados: desactivaci´on elegante, falla re-pentina, desconexi´on del cluster y salida voluntaria del cluster. En el caso de una desacti-vaci´on elegante o salida voluntaria del cluster, el nodo anuncia su salida diseminando una actualizaci´on de la topolog´ıa a todos los nodos en el cluster indicando la ruptura de sus enlaces incidentes.
Si un nodo se desconecta de un cluster debido a la movilidad o por una falla repentina, la reacci´on del resto de los nodos depender´a de la secuencia especificada para lograr la con-vergencia del cluster. Un nodo puede reconocer que ha sido desconectado del cluster al no tener rutas de conexi´on con el conjunto de nodos que forman el cluster. Entonces se convierte en nodo solitario y procede con las reglas previamente mencionadas.
Sin embargo existe una situaci´on poco conveniente y es que cuando un nodo se de-sconecta por falla repentina o bien por la movilidad existente, no todos los nodos restantes del cluster pueden ser capaces de determinar inmediatamente que el nodo ha dejado de ser alcanzable e intentaran revaluar sus rutas (α, t) en tal caso esos nodos determinaran que el destinatario no es alcanzable via una ruta (α, t) y consecuentemente ellos dejaran voluntari-amente el cluster,[10].
2.2.5.
Algoritmos de Control de la Topolog´ıa de la Red
Los algoritmos de clusterizaci´on existentes est´an dise˜nados para organizar o administrar un escenario determinado en una red, pero no est´an provistos de las propiedades o carac-ter´ısticas adecuadas para permitirles que lleguen a tener un control sobre la topolog´ıa de la misma.
Estos algoritmos de clusterizaci´on siguen un procedimiento particular que los caracter-iza, y hacen que su funci´on principal sea realizada en forma conveniente, como son los casos de los algoritmos que reci´en acabamos de explicar. Sin embargo ninguno de ellos dispone de una herramienta que les permita adaptarse a las necesidades que se pudieran presentar en la red, teniendo de esta forma la alternativa de controlar la topolog´ıa establecida.
prin-cipalmente a que su funci´on est´a encaminada fundamentalmente en la organizaci´on o bien administraci´on de los escenarios establecidos, pero no van m´as all´a de su proceso. Su fun-cionamiento tiene como objetivo la creaci´on de grupos de nodos o clusters tratando de que en la red se presenten situaciones favorables como lo son: la reutilizaci´on espacial de los re-cursos para incrementar la capacidad del sistema, la actualizaci´on jer´arquica de la topolog´ıa ( cuando un nodo se mueve, solo se requiere que los nodos que se encuentren dentro del mismo cluster actualicen su topolog´ıa y no todo el sistema ) y la reducci´on de la generaci´on y propagaci´on de la informaci´on de ruteo.
En base a esto existe un sin fin de literatura que explica al detalle las diversas inves-tigaciones que se est´an haciendo o se han realizado en este campo. No ha sido posible sin embargo, encontrar casos donde se haga menci´on de la utilizaci´on de una fase que realice la tarea de controlar alguna variable b´asica en el proceso que permita a su vez modificar la topolog´ıa de la red con la finalidad de tener alternativas para que el sistema pueda adaptarse a alguna situaci´on especifica.
Cap´ıtulo 3
Descripci´
on del Modelo
En esta secci´on se propone un modelo para evaluar el efecto que tiene la clusterizaci´on en una red ad hoc de gran escala. Se muestra la forma en que se generan los escenarios a estudiar as´ı como la manera en que se efect´ua la agrupaci´on de los nodos (clusters), como se realiza la integraci´on de los clusters m´as peque˜nos a otros de mayor tama˜no y los principales par´ametros que son estudiados.
3.1.
Generaci´
on del Escenario
Para la creaci´on del escenario se tuvo en consideraci´on algunos par´ametros b´asicos como lo son:
1.- El ´area del escenario: se tomo una superficie cuadrada de 1000 metros por lado, lo que por consecuencia hace un ´area de 1 000 000m2
.
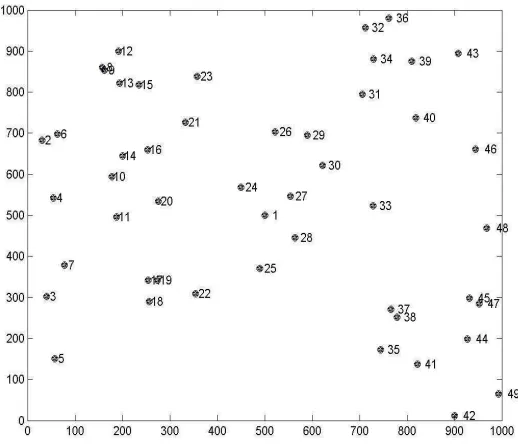
2.- Generaci´on de los nodos: para la generaci´on de los nodos en los diversos esce-narios realizados, se sigui´o una distribuci´on de Poisson espacial,[9], con α como el n´umero promedio de nodos por unidad de ´area o densidad de nodos. En la Figura 3.1 se puede apreciar un escenario utilizando un valor deα = 50x10−6 nodos por metro cuadrado, lo que equivale a un valor promedio de 50 nodos.
Figura 3.1: Generaci´on de nodos conα=50x10−6 en un ´area de 1000 x 1000 m
4.-Tama˜no te´orico del cluster: Establece el tama˜no que en teor´ıa deber´an tener en promedio los clusters que se forman en la red. Haciendo uso de tres variables.
1). ´Area del escenario (AE), que comprende la superficie en donde se efect´uan las sim-ulaciones. En nuestro caso el ´area del escenario es de 1 000 000 m2
.
2). El porcentaje de relaci´on (ζ) es un valor que indica el porcentaje de nodos que puede ser capaz de manejar un nodo determinado en su tabla de ruteo, equivalente a un porcentaje del valor promedio de nodos que se tiene en la red. Lo establecimos en 15 % debido a que consideramos que es un nivel apropiado para el an´alisis. La raz´on de esta propuesta es que un n´umero mayor al orden del 40 % del promedio de nodos en la red o m´as representar´ıa una tendencia a formar dos o tres megaclusters, inclusive la posibilidad de un solo cluster (al superar el 90 %), lo cual no es apropiado.
Figura 3.2: Escenario donde se muestran los enlaces entre los nodos bas´andose en su radio de cobertura.
3) Promedio de nodos generados por unidad de ´area (α),se utilizaron valores de 50, 75, 100, 150, 200, 250, 300, 400, 500 y 600 millon´esimas.
para calcular el tama˜no te´orico de un cluster se utiliza la Ecuaci´on 3.1.
T T C = (AE)(α)(ζ). (3.1)
Se hace uso de la funci´on cielo para redondear el n´umero al d´ıgito superior, a fin de tener mayor holgura.
Cabe mencionar que esta formaci´on de clusters, no es el objetivo de la investigaci´on, pero al ser fundamental el tener una forma de agrupar los nodos, se determino seguir un pro-cedimiento sencillo en lugar de aplicar alguno de los ya creados. Sin embargo es conveniente enfatizar que cualquier algoritmo que realice la agrupaci´on de los nodos en la red es factible de ser utilizado, sin importar cuales condicionantes utiliza para efectuar el agrupamiento.
Cada cluster puede estar conformado de tres tipos de nodos: Nodo l´ıder, nodo ordi-nario y nodo gateway (frontera). El nodo l´ıder como se ha mencionado es la base del cluster, es el que tiene la informaci´on de como est´a conformado el cluster y toma las decisiones convenientes cuando se requiera. El nodo ordinario forma parte del cluster pero no realiza ninguna funci´on en espec´ıfico y el nodo gateway es el que tiene conexi´on con al menos un nodo perteneciente a un cluster diferente al suyo, por lo que es utilizado como puente para establecer comunicaci´on con otros nodos en la red.
6.- Integraci´on de clusters: una vez que los clusters estuvieron formados se procede a efectuar una integraci´on de los clusters de tama˜no menor a aquellos que sean sus vecinos y sean de mayor tama˜no a ellos.
En este criterio se utilizan dos variables: El tama˜no te´orico del cluster (TTC) y el por-centaje m´aximo de integraci´on (Υ).
El TTC se explico en el inciso 4, y b´asicamente consiste en el tama˜no que en teor´ıa tendr´an en promedio los clusters que se forman en la red.
El Υ corresponde al porcentaje mayor permitido a un cluster para que pueda ser con-siderado como factible a ser integrado a otro cluster de mayor tama˜no. Esto es, es el nivel superior que se tiene de referencia para aplicar la segunda fase de nuestro algoritmo y com-prende valores de 30,40, 50, 60 o 70 %.
Este rango para Υ se determino tomando como valor principal al 50 %, despu´es consid-eramos conveniente que un rango del 20 % m´aximo inferior y superior resultar´ıa significativo dado que a un nivel cercano superior al 80 % la gran mayor´ıa o literalmente todos los clusters caer´ıan en ese rango y ser´ıan susceptibles de integrarse a otro cluster, con lo cual se dar´ıa la posibilidad de megaclusters.
Ambas situaciones nos motivaron a utilizar un valor de 20 puntos por encima y debajo del 50 %, debido a que no se acerca demasiado a los extremos, que como ya se ha mencionado representan una situaci´on que no es favorable que se presente.
La Ecuaci´on 3.2 indica la forma en que se realiza el c´alculo del nivel que ser´a la referencia para los clusters que son susceptibles de ser integrados (CI).
CI = (T T C)(Υ). (3.2)
En todos los casos, se determina primeramente cuales son los clusters que tiene de vecinos y que superan el tama˜no m´aximo de integraci´on. Despu´es se verifica cual de ellos tiene menor n´umero de nodos para que se integre a ´el el cluster m´as peque˜no previamente seleccionado.
6.- Par´ametros de medici´on de clusters: Dentro de los par´ametros que se tienen para medir el comportamiento de la red Ad Hoc se tiene al n´umero de clusters creados, al n´umero de nodos por cluster y al n´umero de nodos gateway. Todos estos par´ametros en condiciones antes y despu´es de aplicar la segunda fase del algoritmo (fase de integraci´on).
3.2.
Algoritmo de clusterizaci´
on
El proceso de clusterizaci´on comprende dos etapas: La clusterizaci´on b´asica o normal y la integraci´on de clusters. En la primera se tiene el agrupamiento de los nodos bas´andose en el n´umero de nodos vecinos que tiene cada nodo, el cual est´a regido por su radio de cobertura y como condicionante se tiene al tama˜no te´orico del cluster.
3.2.1.
Clusterizaci´
on B´
asica o Normal
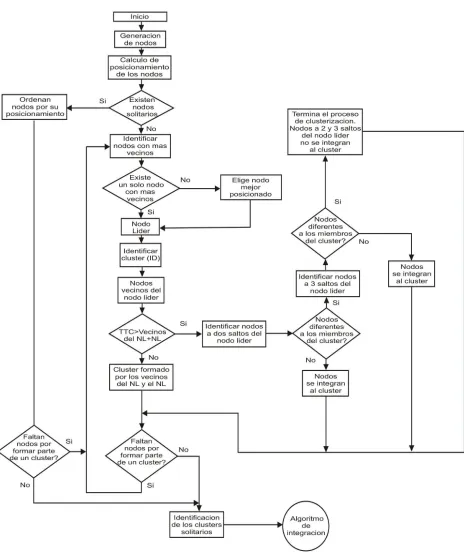
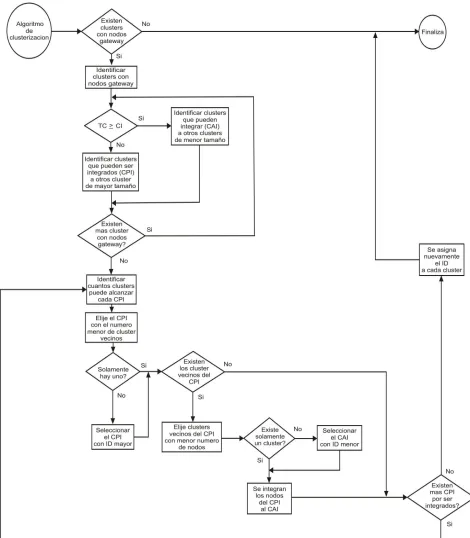
EL diagrama del procedimiento de Clusterizaci´on B´asica o Normal se muestra en la Figura 3.7, donde se indica en forma gr´afica los pasos que se siguen para la agrupaci´on de los nodos en clusters, comprendido b´asicamente por las siguientes etapas:
1.- Para iniciar la clusterizaci´on se verifica primeramente cuales nodos no tienen veci-nos (nodos a un salto), para identificarlos como clusters unitarios o bien nodos solitarios o hu´erfanos. Los cuales formar´an cada uno su propio cluster y tendr´an el n´umero de identifi-caci´on (ID) mayor. Cabe mencionar que entre m´as grande sea el ID representa que el nodo l´ıder tiene una posici´on menos relevante respecto al resto de nodos l´ıder o mejor dicho entre m´as peque˜no sea el ID significa que el nodo l´ıder del cluster est´a mejor posicionado respecto al resto de los nodos.
El t´ermino mejor posicionado hace referencia a la distancia que hay entre un nodo y el resto de los nodos en el escenario, para ello se calcula esta distancia utilizando
dij =
q
(x−h)2
+ (y−k)2
.
entre todos los nodos generados sabiendo que cada nodoi tiene coordenadas (h,k) y el resto de los nodos j est´an ubicados en las coordenadas (x,y). [7] Despu´es se hace una sumatoria para cada uno de ellos obteni´endose un valor que permitir´a determinar el posicionamiento de cada nodo. Entre m´as peque˜no sea este valor representara que el nodo tiene un mejor posicionamiento.
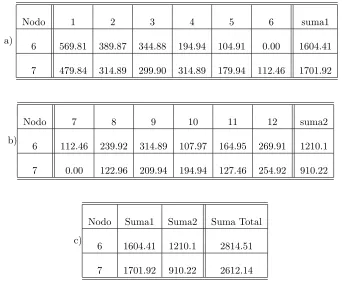
Como ejemplo tenemos el Cuadro 3.1 a y b, donde se muestran los casos de los nodos 6 y 7 que son los que m´as nodos vecinos tienen bas´andonos a su vez en la Figura 3.3. Se puede apreciar las distancias que existen con respecto al resto de los nodos de la red y la suma total de estas distancias, la cual es en nuestro caso el indicativo de posicionamiento de cada nodo.
El Cuadro 3.1 c muestra el resultado de esta suma y nos indica que al tener el nodo 7 un valor m´as bajo, este nodo es el mejor posicionado.
Cuadro 3.1: Ejemplos de c´alculo del posicionamiento de dos nodos en la red.
a)
Nodo 1 2 3 4 5 6 suma1
6 569.81 389.87 344.88 194.94 104.91 0.00 1604.41
7 479.84 314.89 299.90 314.89 179.94 112.46 1701.92
b)
Nodo 7 8 9 10 11 12 suma2
6 112.46 239.92 314.89 107.97 164.95 269.91 1210.1
7 0.00 122.96 209.94 194.94 127.46 254.92 910.22
c)
Nodo Suma1 Suma2 Suma Total
6 1604.41 1210.1 2814.51
Figura 3.3: Determinaci´on del nodo l´ıder del cluster.
donde el nodo 7 es el nodo con mejor posicionamiento, lo cual fue descrito en el inciso (1), y por lo tanto es el nodo l´ıder del cluster (NL).
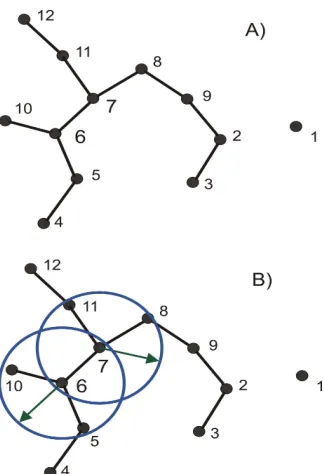
3.- Una vez que el cluster tiene su nodo l´ıder, el paso que prosigue es identificar nue-vamente todos los nodos que est´an dentro de su ´area de cobertura ( nodos a un salto ) los cuales pasan a integrar el cluster de forma directa. En la Figura 3.4-A se observan los nodos que forman parte del cluster identificados con un cuadrado.
4.- En este punto se hace una comparaci´on para ver si el tama˜no te´orico del cluster (TTC) es menor al n´umero de nodos que integran el cluster, de ser as´ı, el algoritmo ya no busca m´as nodos que sean factibles de integrar el cluster y se mantiene solamente con los nodos que est´en a un solo salto del l´ıder. Despu´es se vuelve a efectuar el paso n´umero 2 en busca de otro nodo l´ıder para formar el cluster siguiente.
Figura 3.4: Formaci´on del cluster y revisi´on de nodos a dos saltos del l´ıder.
Una vez identificados se verifica si estos nodos que est´an a dos saltos del l´ıder (nodos 5,9,10 y 12 de la Figura 3.4-B) tienen a su vez nodos vecinos diferentes a los integrantes del cluster, de no ser as´ı se procede a integrarlos al cluster. En la Figura podemos apreciar a los nodos 10 y 12 que se convierten en miembros del cluster.
6.- Si los nodos que est´an a dos saltos del l´ıder tienen nodos vecinos diferentes a los integrantes del cluster (nodos 5 y 9 Figura 3.5), los cuales vienen a ubicarse a 3 saltos del nodo l´ıder, se procede a determinar si estos nodos tienen a su vez nodos vecinos diferentes a los nodos del cluster. De no ser as´ı ambos nodos (el que se encuentra a dos saltos y su vecino) se agregan al cluster existente (nodos 5 y 4).
7.- En caso de que los nodos que est´an a 3 saltos del l´ıder tengan al menos un nodo vecino diferente a los miembros del cluster, (nodo 2) entonces el algoritmo de clusterizaci´on concluye en esa rama y tanto el nodo que se encuentra a dos saltos del l´ıder (nodo 9) y su vecino (nodo 2) no se incluye en el cluster.
Figura 3.5: Revisi´on de nodos a tres saltos del l´ıder.
3.2.2.
Integraci´
on de clusters
EL diagrama del procedimiento de Integraci´on de clusters se muestra en la Figura 3.8, donde se explica gr´aficamente la forma en que este fase es realizada, conformada b´asicamente por las siguientes etapas:
Como se menciono anteriormente, una vez que los clusters se han formado, se procede a ser una revisi´on de los mismos para determinar cuales son factibles de ser integrados a un cluster de dimensiones mayores.
1.- Primeramente se revisa cuales clusters tienen nodos gateway o frontera lo cual nos indica que tiene al menos un cluster de vecino.
2.- Despu´es de identificar los clusters que tienen nodos gateway se identifica a los cluster cuyo tama˜no cumple con los requisitos para ser incorporado a otro cluster, para ello se hace uso de la Ecuaci´on 3.2 donde el Υ puede corresponder al 30,40, 50, 60 o 70 %. Identificandose los clusters cuyo tama˜no es menor o igual al CI.
3.- Una vez que se ha hecho la identificaci´on, se procede a investigar cuantos clusters alcanza cada uno de ellos y se selecciona el que alcance el menor n´umero. Si existen dos o m´as clusters en estas circunstancias se elige al cluster con el ID m´as alto.
4.- Cuando se tiene al cluster que alcanza el menor n´umero de clusters o en su defecto con mayor ID, se revisan sus clusters vecinos y se elige aquel cuyo tama˜no sea menor, si existen dos o m´as clusters se selecciona el que tenga el ID menor y entonces cada uno de los nodos es integrado al cluster vecino. Cuando solo se tiene un solo cluster vecino pues la integraci´on se hace de forma inmediata.
5.- Despu´es que un cluster ha sido integrado se procede a eliminar su n´umero de identi-ficaci´on con la finalidad de que ya no participe en el procedimiento posterior de integraci´on dado que podr´ıa ser factible que otro cluster lo seleccionara para integrarse a ´el.
7.- Finalmente se hace una nueva identificaci´on de los clusters recorriendo el ID que se ten´ıa de acuerdo al espacio que dejaron los clusters que se integraron, es decir si los clusters 3 y 4 fueron incorporados a otro cluster, entonces los cluster 5 y 6 pasan a ser ahora los clusters 3 y 4 respectivamente.
3.2.3.
Cuantificaci´
on del Algoritmo
Al aplicar nuestro algoritmo comprendido en dos fases, se tiene una reducci´on de el-ementos fundamentales en la conformaci´on de una red, tales como el porcentaje de nodos gateway, el total de clusters formados y el tama˜no de estos clusters.
Sabemos que como resultado de la aplicaci´on de la primera fase del algoritmo se forman en la red un determinado n´umero de clusters que denominaremos (NC), los cuales tienen en promedio un n´umero de nodos representado por (NnC) y existe un valor de nodos gateway indicado por (TnG).
Tenemos que cada nodo dentro de un cluster en espec´ıfico maneja en sus tablas de ru-teo (NnC-1) nodos, de forma similar un nodo gateway es capaz de manejar (TnG-1) nodos gateway. Por cada nodo que est´a en el interior de un cluster su costo es representado por (cni) mientras que para un nodo gateway su costo se identifica como (cng).
De esta forma podemos decir que el costo de manejo de informaci´on de un nodo (cin) est´a dado por
cin= (cni)(N nC −1)
y por su parte para conocer el costo de manejo de informaci´on de un cluster (ciC) se multipli-ca elcin por el n´umero de nodos que forman el cluster (NnC). Lo cual estar´ıa representado por
ciC = (cin)(N nC)
o lo que es lo mismo
ciC = (cni)(N nC−1)(N nC)
finalmente para obtener el costo de manejo de informaci´on de los cluster en la red (cicR), basta con multiplicar el ciC por el n´umero de cluster formados NC.
ciCR= (ciCR)(N C)
Por otra parte un nodo gateway tiene dos funciones, es un nodo que esta en el interior de un cluster y es tambi´en nodo de enlace, por tal motivo su costo de manejo de informaci´on es realmente la suma de dos costos, el del nodo interno y del gateway.
Cada nodo gateway maneja (TnG-1) nodos gateway, su costo es representado como
ciG= (cng)(T nG−1)
al ser tambi´en un nodo interno, maneja (NnC-1) nodos y su costo est´a dado por
cin= (cni)(N nC −1)
por lo que el costo de manejo de informaci´on de los nodos gateway en la red es la suma de estos dos valores multiplicado por el total de nodos gateway existentes en la red
ciGR= [(cng)(T nG−1) + (cni)(N nC−1)](T nG) (3.4)
De lo anterior podemos deducir que el costo del manejo de la informaci´on de la red (ciR) est´a dada por la suma del costo de manejo de informaci´on de los cluster en la red m´as el costo de manejo de informaci´on de los nodos gateway en la red. Represent´andose como
ciR=ciCR+ciGR
o bien
ciR= [(cni)(N nC−1)(N nC)(N C)] + [(cng)(T nG−1) + (cni)(N nC−1)](T nG) (3.5)
Cap´ıtulo 4
Resultados Num´
ericos
En este cap´ıtulo se muestran los resultados matem´aticos obtenidos en la simulaci´on aplicando el algoritmo de clusterizaci´on descrito en el capitulo 3 a una red ad hoc, el cual consiste b´asicamente en dos etapas: En la primera se selecciona el nodo que tenga m´as nodos vecinos, de existir dos o m´as nodos con estas caracter´ısticas se toma el nodo que este mejor posicionado, es decir el que tenga menor distancia en relaci´on a todos los nodos de la red y es entonces declarado nodo l´ıder el cual procede a formar su cluster en base a sus nodos vecinos.
En la segunda etapa, se hace uso de un porcentaje m´aximo de integraci´on (Υ), el cual es utilizado en la segunda fase del algoritmo de integraci´on, para determinar el tama˜no m´aximo de los clusters que pueden ser integrados. Esta comprendido por valores de porcentaje de 30, 40, 50, 60 y 70 los cuales se multiplican por el tama˜no te´orico de cluster (TTC) que a su vez comprende el 15 % del total de nodos generados en la simulaci´on. En base al factor de integraci´on se seleccionan los cluster cuyo tama˜no permite sean integrados a un cluster de mayor tama˜no.
El comportamiento del algoritmo es mostrado a trav´es de gr´aficas y tablas, a fin de comprender de una mejor manera el efecto que se tiene en la red.
4.1.
Simulaci´
on
Cuadro 4.1: Caracter´ısticas generales del escenario
Dimensiones del escenario 1000 m x 1000 m
´
Area del escenariom2 1 000 000
Poblaci´on esperada 50, 75, 100, 150, 200, 250
de nodos (λ) 300, 400, 500 y 600
Radio de cobertura (m) 75,100,125,150,175 y 200
% m´aximo de integraci´on 30, 40, 50, 60 y 70
4.1.1.
Escenarios
Se estableci´o realizar varios escenarios por cada uno de los tama˜nos de poblaci´on de nodos (Cuadro 4.2), esto con la finalidad de tener una base m´as s´olida de resultados mane-jando valores promedio de los par´ametros que est´an siendo observados como lo son: total de nodos en escenario, total de clusters formados, n´umero de nodos solitarios, n´umero de nodos por cluster y total de nodos gateway en la red. Para ello se realizaron 5 escenarios para los valores de lambda de 50 a 250, de 4 escenarios para lambda 300 y 400 y de 3 escenarios para lambda de 500 y 600.
En cada uno de estos escenarios se generaban nodos bas´andose en una distribuci´on de poisson espacial. La Figura 4.1 representa el primer escenario con λ = 50 y radio de cober-tura de 150 metros. Despu´es se procedi´o a disminuir o aumentar el radio de cobercober-tura de los nodos seg´un la densidad que se tuviera.
Para el caso del escenario de 50 nodos se elevo a 175 metros mostr´andose en la Figura 4.2 la afectaci´on que tuvo en los enlaces de los nodos dentro del mismo escenario.
Cuadro 4.2: Escenarios utilizados para cada una de las λ.
λ Escenarios Total de Nodos Generados (N)
1 2 3 4 5
50 5 49 54 52 53 51
75 5 86 69 84 67 63
100 5 110 121 91 85 85
150 5 157 162 146 143 150
200 5 197 199 182 200 179
250 5 243 238 236 246 266
300 4 310 277 312 323 –
400 4 423 376 374 398 –
500 3 519 507 513 – –
600 3 621 579 626 – –
Figura 4.2: Escenario donde se muestran los enlaces entre los nodos bas´andose en un radio de cobertura de 175 metros para λ= 50.
[image:49.612.202.455.431.639.2]Cuadro 4.3: Radios de cobertura utilizados en las simulaciones en base al n´umero de nodos generados
Densidad de Poblaci´on (N) Radios de Cobertura
N <100 150,175y 200 mts
100≤N ≤250 125,150 y 175 mts
250< N ≤400 100,125 y 150 mts
400< N ≤600 75,100 y 125 mts
Cabe mencionar que el radio de cobertura de 200 metros solo se aplica cuando existe una poblaci´on menor a 100 nodos, despu´es de ello el rango de cobertura empieza a bajar hasta llegar a un m´ınimo de 75 metros para una poblaci´on mayor a 400 nodos. Esta variaci´on de los radios de cobertura se muestra en el Cuadro 4.3.
4.1.2.
An´
alisis de Resultados
Un ejemplo de los resultados obtenidos podemos apreciarlos en los cuadros 4.4 y 4.5 para una densidad baja (λ= 50). Mientras que en los cuadros 4.6 y 4.7 se tiene una densidad alta, (λ= 600).
Estos casos son nuestros umbrales, 50 es nuestra densidad de poblaci´on m´as baja mien-tras que 600 es la densidad mayor que utilizamos en las simulaciones. En las tablas podemos apreciar el contraste que existe entre ellas.
Cada tabla muestra los siguientes par´ametros:
Porcentaje M´aximo de integraci´on, que como se ha explicado tiene la funci´on de de-terminar cuales clusters pueden ser integrados a otros de mayor tama˜no.
Total de nodos generados, es el n´umero de nodos que se crean en cada escenario, utilizando una distribuci´on de poisson espacial.
Total de nodos solitarios, es el n´umero de nodos que no tienen conexi´on con otros nodos, por lo cual est´an aislados en la red.
% de nodos solitarios, es la relaci´on que existe entre el n´umero de nodos solitarios y el total de nodos generados.
Total de clusters situaci´on normal, consiste en el n´umero de clusters formados al aplicar la primera fase del algoritmo de clusterizaci´on.
Total de clusters integrando, es el n´umero de clusters formados al aplicar la segunda fase del algoritmo de clusterizaci´on, consistente en integrar los clusters m´as peque˜nos a otros de mayor tama˜no.
Promedio de nodos por cluster situaci´on normal, es el n´umero de nodos que en prome-dio forman cada uno de los clusters resultantes de la primera fase del algoritmo de clusterizaci´on.
Promedio de nodos por cluster integrando, es el n´umero de nodos que en promedio forman cada uno de los clusters resultantes de la segunda fase del algoritmo de clus-terizaci´on.
% promedio de nodos gateway situaci´on normal, es el n´umero promedio que indica la relaci´on entre los nodos gateway o frontera que existen en la red y el total de nodos generados en la misma, al aplicar la primera fase del algoritmo de clusterizaci´on.
% promedio de nodos gateway integrando, es el n´umero promedio que indica la relaci´on entre los nodos gateway o frontera que existen en la red y el total de nodos generados en la misma, al aplicar la segunda fase del algoritmo de clusterizaci´on.
Cuadro 4.4: Resultados obtenidos para los escenarios generados conλ = 50 y Υ de 30, 40 y 50 %
% m´aximo
de integraci´on 30 % 40 % 50 %
Radio de
cobertura (mts) 150 175 200 150 175 200 150 175 200
Total de nodos
generados (N) 51.80 51.80 51.80
Total de nodos
solitarios (NS) 2.60 1.00 0.40 2.60 1.00 0.40 2.60 1.00 0.40
% de nodos
solitarios (NS) 4.99 1.89 0.76 4.99 1.89 0.76 4.99 1.89 0.76
Total de cluster
situaci´on normal 12.60 9.60 8.60 12.60 9.60 8.60 12.60 9.60 8.60
Total de cluster
integrando 11.60 9.20 7.20 10.40 7.60 6.40 10.00 7.20 5.80
Promedio de nodos
por cluster 4.15 5.54 6.20 4.15 5.54 6.20 4.15 5.54 6.20
situaci´on normal Promedio de nodos
por cluster 4.51 5.74 7.30 5.13 6.97 8.22 5.38 7.35 9.05
integrando % promedio de
nodos gateway 31.17 44.39 59.61 31.17 44.39 59.61 31.17 44.39 59.61
situaci´on normal % promedio de
nodos gateway 26.24 43.63 50.65 17.70 35.97 46.75 16.06 31.63 43.53
Cuadro 4.5: Resultados obtenidos para los escenarios generados conλ= 50 y Υ de 60 y 70 %
% m´aximo
de integraci´on 60 % 70 %
Radio de
cobertura (mts) 150 175 200 150 175 125
Total de nodos
generados (N) 51.80 51.80
Total de nodos
solitarios (NS) 2.60 1.00 0.40 2.60 1.00 0.40
% de nodos
solitarios (NS) 4.99 1.89 0.76 4.99 1.89 0.76
Total de cluster
situaci´on normal 12.60 9.60 8.60 12.60 9.60 8.60
Total de cluster
integrando 9.60 6.60 5.40 9.20 6.00 5.00
Promedio de nodos
por cluster 4.15 5.54 6.20 4.15 5.54 6.20
situaci´on normal Promedio de nodos
por cluster 5.63 8.20 9.81 5.80 9.03 10.52
integrando % promedio de
nodos gateway 31.17 44.39 59.61 31.17 44.39 59.61
situaci´on normal % promedio de
nodos gateway 12.96 28.84 40.83 10.27 24.58 40.09
Cuadro 4.6: Resultados obtenidos para los escenarios generados con λ = 600 y Υ de 30, 40 y 50 %
% m´aximo
de integraci´on 30 % 40 % 50 %
Radio de
cobertura (mts) 75 100 125 75 100 125 75 100 125
Total de nodos
generados (N) 608.67 608.67 608.67
Total de nodos
solitarios (NS) 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
% de nodos
solitarios (NS) 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Total de cluster
situaci´on normal 38.33 26.33 23.33 38.33 26.33 23.33 38.33 26.33 23.33
Total de cluster
integrando 11.33 12.33 13.33 8.33 9.67 9.67 6.33 7.67 8.33
Promedio de nodos
por cluster 16.11 23.11 26.15 16.11 23.11 26.15 16.11 23.11 26.15
situaci´on normal Promedio de nodos
por cluster 54.76 49.52 45.67 74.35 63.41 63.79 99.78 79.53 74.35
integrando % promedio de
nodos gateway 74.85 87.44 91.59 74.85 87.44 91.59 74.85 87.44 91.59
situaci´on normal % promedio de
nodos gateway 46.98 80.29 90.08 40.26 73.58 82.47 37.83 70.18 80.58
Cuadro 4.7: Resultados obtenidos para los escenarios generados con λ = 600 y Υ de 60 y 70 %
% m´aximo
de integraci´on 60 % 70 %
Radio de
cobertura (mts) 125 150 175 125 150 175
Total de nodos
generados (N) 151.60 151.60
Total de nodos
solitarios (NS) 0.00 0.00 0.00 0.00 0.00 0.00
% de nodos
solitarios (NS) 0.00 0.00 0.00 0.00 0.00 0.00
Total de cluster
situaci´on normal 38.33 26.33 23.33 38.33 26.33 23.33
Total de cluster
integrando 5.33 6.67 7.33 5.00 5.33 5.67
Promedio de nodos
por cluster 16.11 23.11 26.15 16.11 23.11 26.15
situaci´on normal Promedio de nodos
por cluster 119.55 91.88 84.13 129.99 114.83 109.90
integrando % promedio de
nodos gateway 74.85 87.44 91.59 74.85 87.44 91.59
situaci´on normal % promedio de
nodos gateway 34.15 66.86 77.39 29.78 59.55 70.34
Las figuras 4.4, 4.5 y 4.6 muestran el efecto que se tiene al modificar estos par´ametros para el caso de un escenario con λ= 50.
Se puede apreciar en la Figura 4.4 como a medida que el radio de cobertura se aumen-ta, se tiene una reducci´on en el n´umero de clusters formados, el mismo efecto se presenta cuando se incrementa el porcentaje m´aximo de integraci´on dentro de un radio de cobertura establecido. Al tener una densidad de poblaci´on baja, la reducci´on se observa gradual. El caso inverso lo podemos observar en la Figura 4.5 donde se tiene un incremento en la canti-dad de nodos que forman un cluster a medida que se aumenta el radio de cobertura al igual que el porcentaje de integraci´on.
Por otra parte, la Figura 4.6 nos muestra un caso diferente y es que a medida que el radio de cobertura es incrementado el porcentaje de nodos gateway en la red, como resultado de la aplicaci´on del algoritmo de clusterizaci´on en su fase normal, se ve tambi´en incrementado. No obstante se observa como a medida que se aumenta el porcentaje de integraci´on dentro de un radio de cobertura determinado, este porcentaje de nodos gateway se va reduciendo de forma gradual.
Estos mismos efectos tambi´en se presentan en los escenarios con una densidad de poblaci´on alta, situaci´on que se muestra en las figuras 4.7, 4.8 y 4.9 para densidades de poblaci´on de 600 nodos.
Podemos observar como la reducci´on en el promedio de clusters formados en la red se da de forma m´as pronunciada para escenario de altas densidades (Figura 4.7) e igual sucede con el incremento que se presenta en el n´umero de nodos que forman un cluster (Figura 4.8).
4.1.3.
Niveles Convenientes de Nodos Gateway
Una desventaja muy marcada que tiene un nodo frontera o gateway es que al requerirse-le constantemente sus funciones, tiene menos tiempo para reposar, en comparaci´on con los nodos ordinarios, y por lo mismo, consumen mayor energ´ıa.
El que existan muchos nodos gateway o frontera, no tiene mucho sentido ya que se puede obligar al sistema a una complejidad en configuraciones, software y hardware. Uno de los puntos donde m´as repercute es en el ancho de banda, dado que al tener demasiados nodos frontera, actualizando constantemente su informaci´on de las tablas de ruteo correspondientes y continuamente estar en contacto con su respectivo nodo l´ıder y los nodos frontera que est´an a su alcance, requiere de mayor capacidad de la red.
Por otra parte el que exista una cantidad reducida de nodos gateway tambi´en representa un inconveniente, dado que puede estar indicando que no se tenga la conectividad adecuada entre los nodos de la red.
Por estas circunstancias, hemos propuesto un nivel de nodos gateway adecuado el cual es un valor heur´ıstico y que comprende un m´ınimo del 40 % y un m´aximo de 60 % de nodos frontera. En base a esto podemos aplicar nuestro algoritmo de tal forma que se pueda ma-nipular el radio de cobertura o el porcentaje m´aximo de integraci´on y a trav´es de ello poder obtener el valor adecuado de nodos gateway.
Bas´andonos en los resultados que se obtuvieron, se estableci´o un rango con valores heur´ısticos que nos indican un valor confiable tanto del radio de cobertura como del por-centaje m´aximo de integraci´on, lo cual se puede apreciar en el Cuadro 4.8.
Para la realizaci´on del Cuadro 4.8 se sigui´o el siguiente procedimiento: Se tomo el valor m´as alto de nodos gateway obtenido de la simulaci´on al aplicar las dos fases del algoritmo y se sumo al valor m´as bajo para despu´es sacar su promedio. Los resultados m´aximos y m´ınimos de nodos gateway se muestran en el Cuadro 4.9.
Cuadro 4.8: Radios de cobertura y porcentaje de integraci´on utilizados en las simulaciones en base al n´umero de nodos generados
Densidad de Poblaci´on Clusterizar
(N)
Radio Cobertura % Integraci´on
N ≤50 200 70 %
50< N <100 175 40 %
100≤N <200 150 60 %
200≤N <300 125 50 %
300≤N <400 100 30 %
400≤N <600 100 60 %
N = 600 100 70 %
Por ejemplo, en el Cuadro 4.9 se tiene para la lambda 50 un valor promedio de 34.94 % de nodos gateway, al redondear nos dar´ıa 35 y no habr´ıa necesidad de hacer ajuste, sin em-bargo este resultado est´a por debajo del m´ınimo establecido, situaci´on por lo cual se toma como valor adecuado al 40 % que es el l´ımite m´as cercano.
Por otra parte se tiene para la lambda 200 un valor promedio de 66.71 % de nodos gateway, al redondear tendr´ıamos 67 y al hacer el ajuste nos da 65, sin embargo este resul-tado tambi´en se encuentra fuera del rango establecido, solo que ahora por encima del l´ımite m´aximo, por tal motivo se elige al 60 % por ser el l´ımite m´as cercano.
Este valor del porcentaje de nodos gateway es fundamental para determinar el radio de cobertura y el porcentaje de integraci´on convenientes, para ello se toma dicho valor y se busca en las tablas que se obtuvieron para la lambda correspondiente y se selecciona el valor que m´as se aproxime.
Cuadro 4.9: Tabla para establecer el valor adecuado del porcentaje de nodos gateway que es la base para determinar el radio de cobertura y porcentaje de integraci´on convenientes para un valor de λ.
Lambda % Nodos Gateway Promedio Valor Clusterizar
% Adecuado
Mayor Menor Cobertura (mts) % Integraci´on
50 59.61 10.27 39.94 40 200 70 %
75 70.53 30.32 50.43 50 175 40 %
100 73.37 18.66 46.02 45 150 50 %
150 84.26 33.75 59.01 55 150 60 %
200 87.52 45.89 66.71 60 150 70 %
250 94.07 49.33 71.70 60 125 50 %
300 91.06 32.44 61.75 60 100 30 %
400 96.37 55.56 75.97 60 100 60 %
500 91.82 30.21 61.02 60 100 60 %
600 91.59 29.78 60.69 60 100 70 %
Resulta obvio que el valor m´as pr´oximo es el que comprende el radio de cobertura de 100 metros y porcentaje de integraci´on de 30 %, correspondiendo a 59.10 %. situaci´on que deriva en la elecci´on estos par´ametros.
De igual forma se realiza este procedimiento para cada uno de los valores de las lambda correspondientes, logrando de esta forma complementar el Cuadro 4.9.
Una situaci´on que pudimos apreciar es que a medida que la densidad de poblaci´on se incrementa, tambi´en lo hace el n´umero promedio de nodos que integran un cluster, esto como resultado de la condici´on de utilizar el 15 % del total de nodos generados.